3.9 KiB
I’m sharing this because the current state of scanner triage and trace UIs exposes the very disconnects you’ve been targeting — tools are great at finding issues, but the paths from vulnerability to proven context are still too brittle for reliable triage and automated workflows.

Scanner tools like Snyk are adding reachability analysis to help prioritize vulnerabilities by whether application code can call the affected functions — effectively analyzing call graphs to determine reachable CVEs. This uses static program analysis and AI heuristics to map paths from your app into vulnerability code, though it still acknowledges limitations where static paths aren’t fully known. (Snyk Docs) Enterprise scanners such as JFrog Xray extend SCA into binaries and SBOMs, performing deep artifact scans and ingesting SBOM data (e.g., CycloneDX) to detect vulnerabilities and license risks — and they’re integrated into build and CI/CD lifecycles. (JFrog)
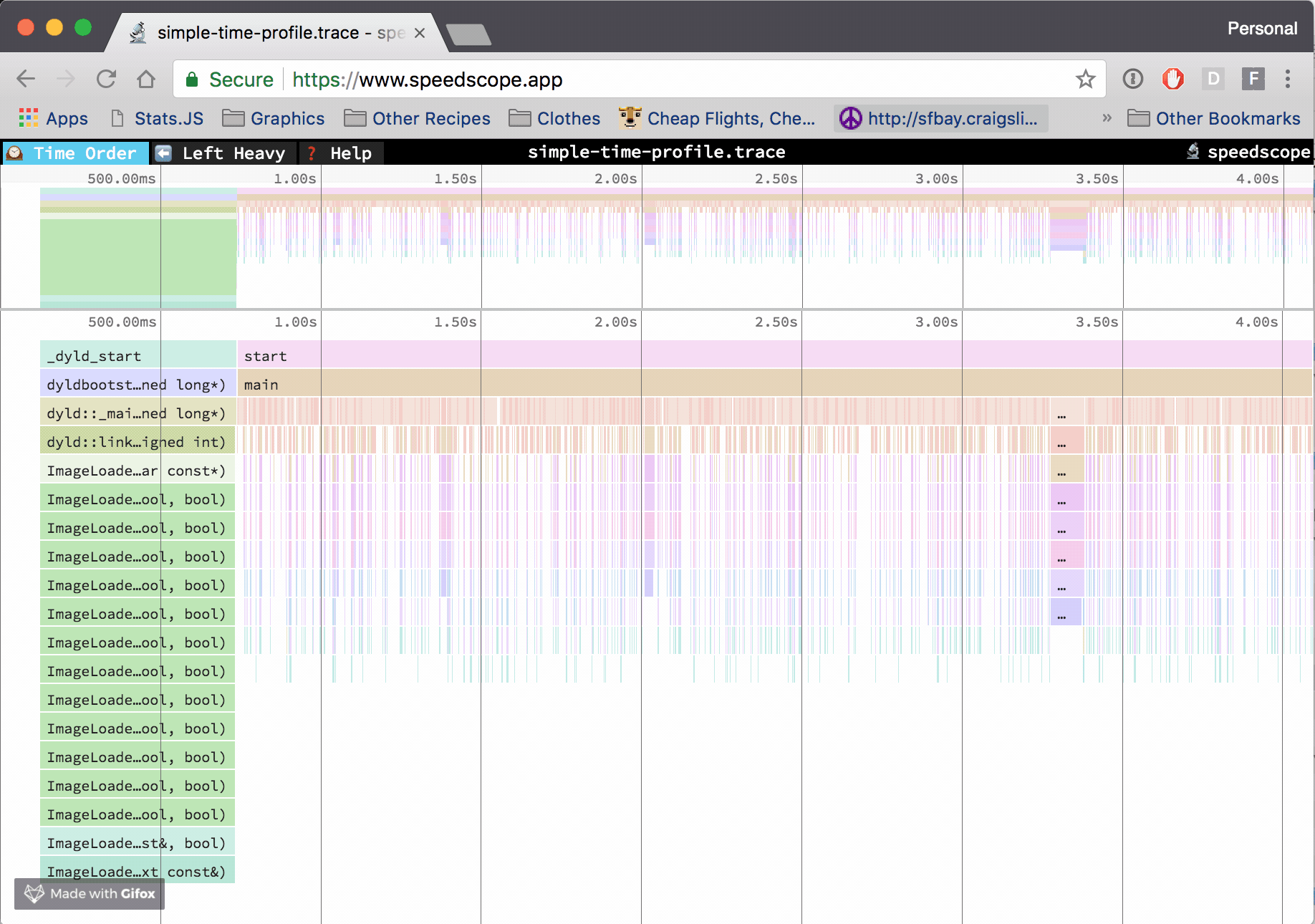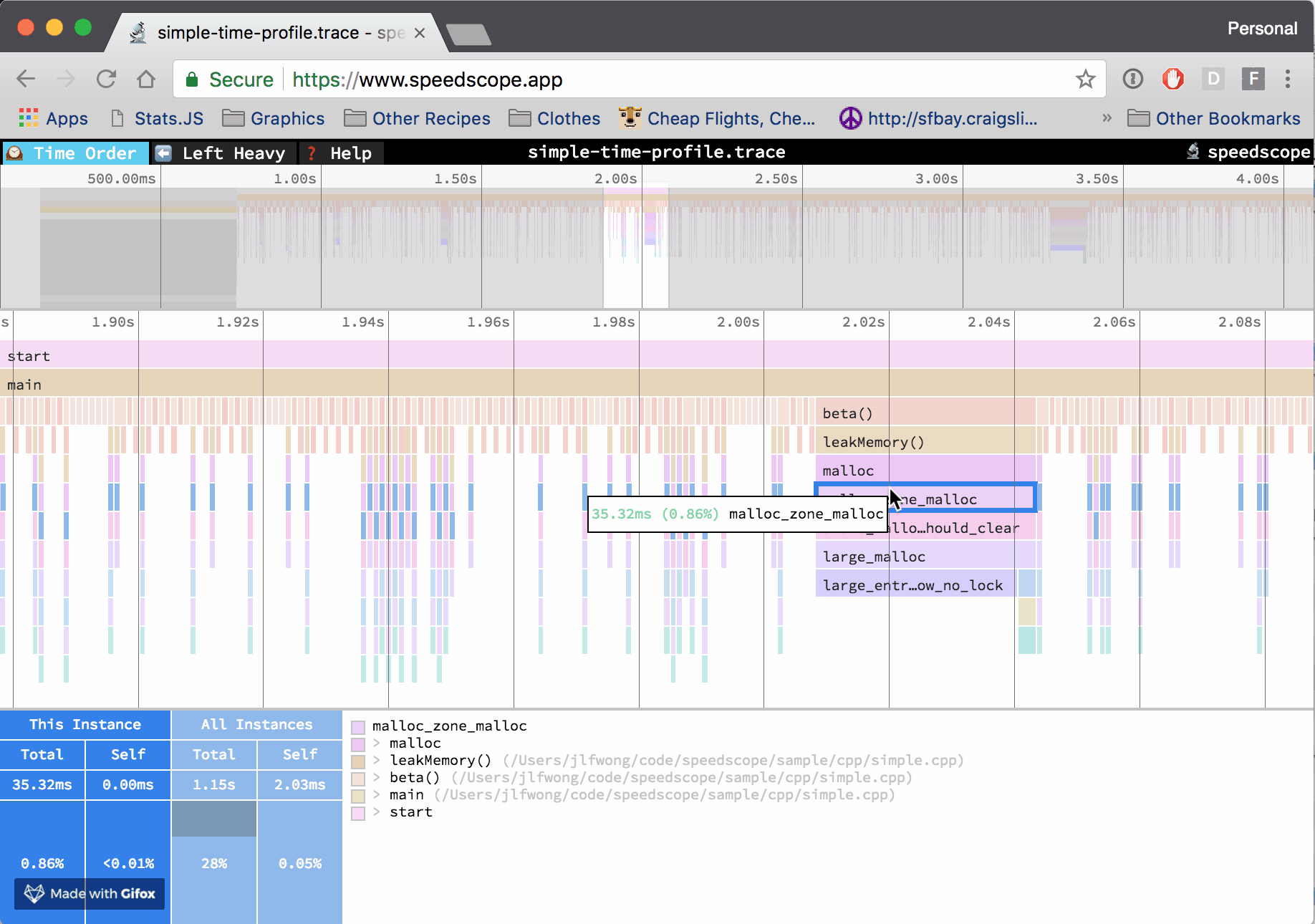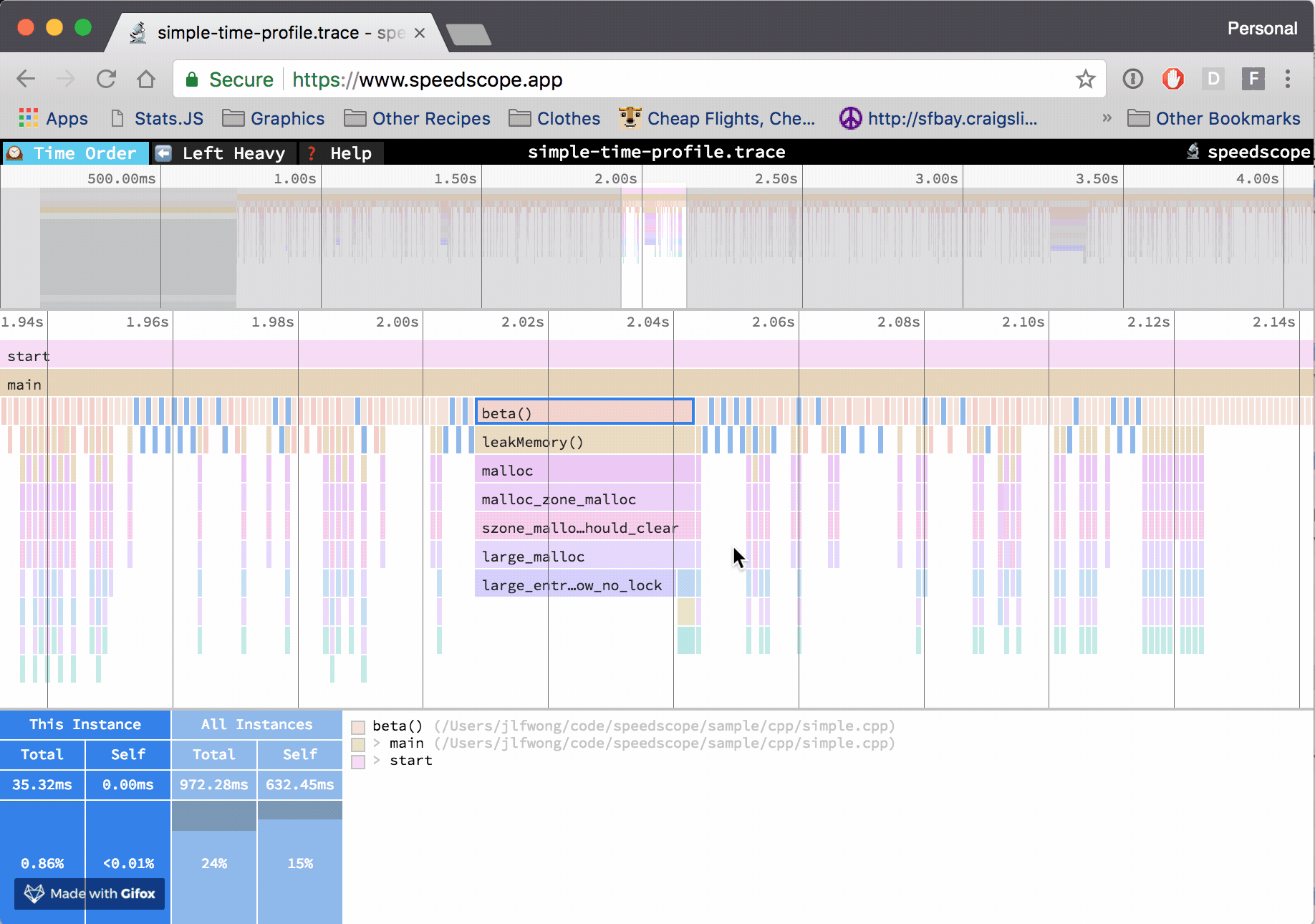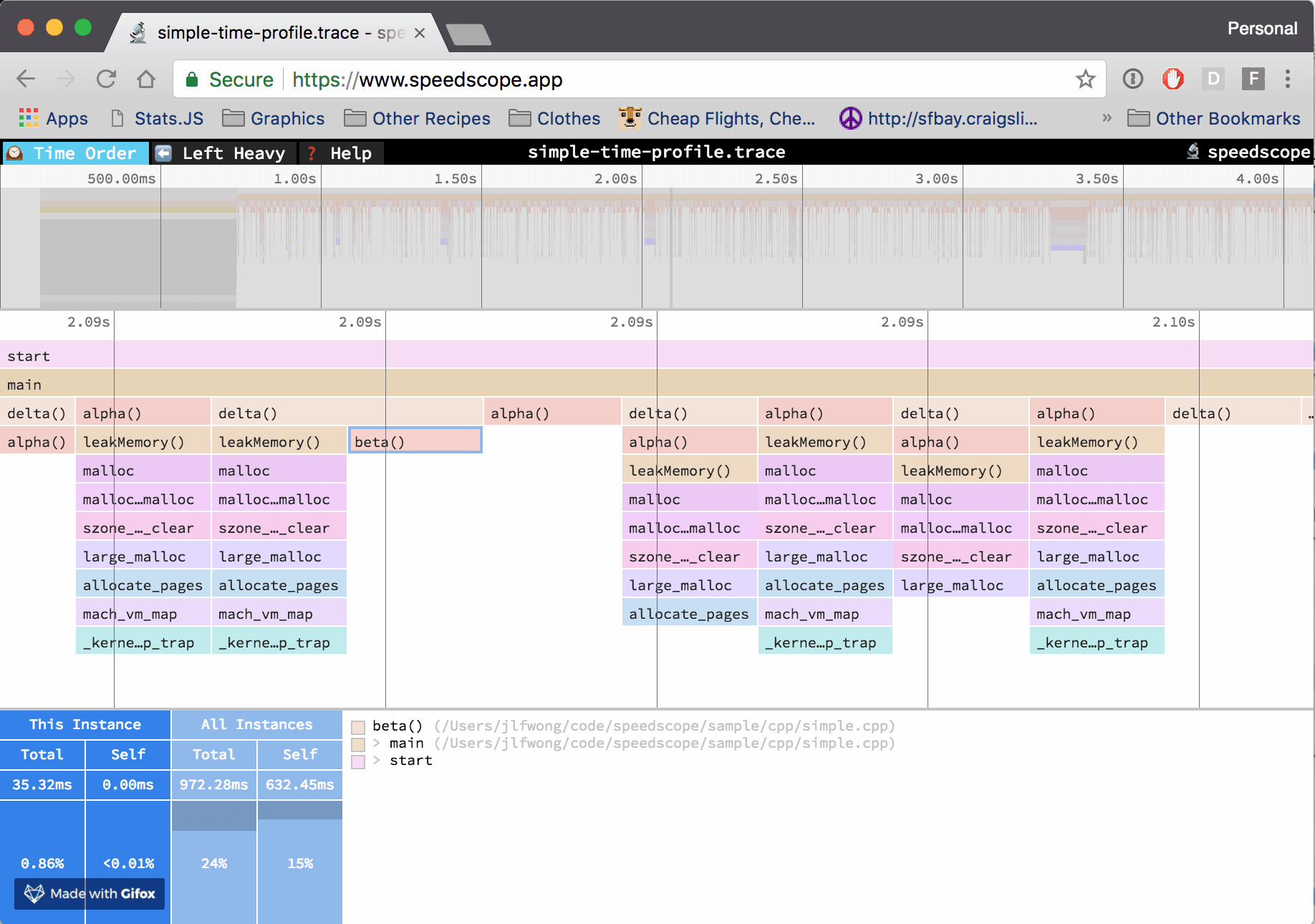
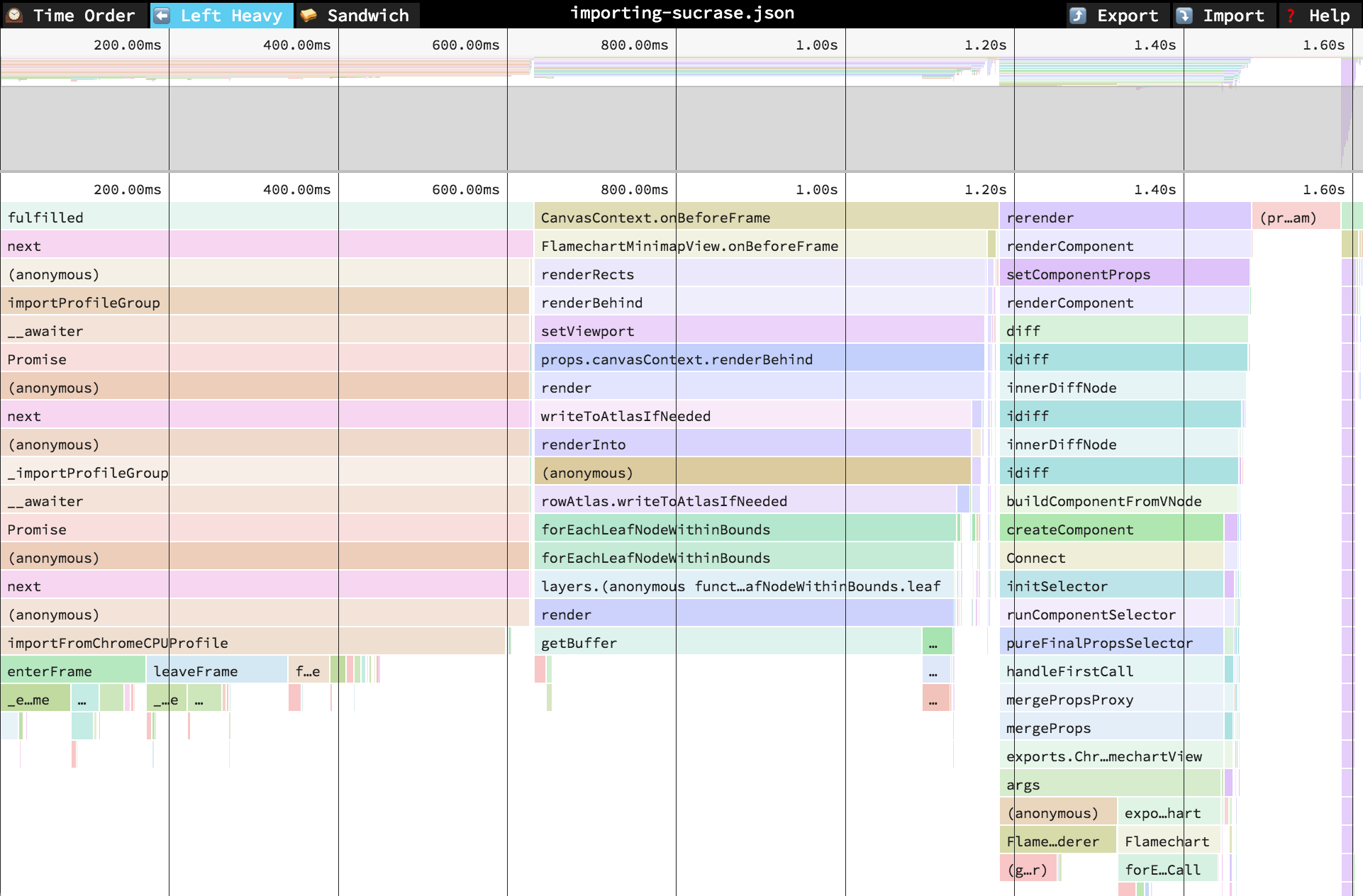
While these tools excel at surface detection and prioritization based on static context, they don’t yet bridge the gap into live, low‑latency trace or call‑stack verified evidence the way observability UIs (Perfetto/Jaeger/Speedscope) do for performance and distributed traces. Those UIs let engineers visually inspect call stacks, timelines, and flamegraphs with tight symbol binding — something scanner consoles rarely provide in an actionable, signed form.
The contrast is clear in practice:
-
Scanner flows (Snyk, Anchore/Grype, Xray, Wiz, Prisma Cloud) focus on detection and risk scoring, integrated with SBOMs and CI/CD. They stop short of reliable runtime evidence playback or signed call‑stack histories that can prove exploitability or triage decisions with cryptographic confidence. (echo.ai)
-
Trace / profiling UIs (Perfetto, Speedscope flamegraphs, Jaeger distributed tracing) provide interactive timelines with symbol resolution and execution context — the exact sort of evidence you’d want when determining if a reported issue truly matters in a given run. Yet scanners don’t emit this form of trace data, and observability tools aren’t wired into vulnerability pipelines by default.
That explains why your proposed targets — provenance aggregation, minimal repro anchoring, reachability/trace fusion, and in‑console timelines — are hitting core gaps in the ecosystem: current solutions optimize detection and prioritization, not evidence-backed, low‑latency verification in triage. In other words, we have deep scanning engines and deep tracing UIs — but not a cohesive, signed pipeline that ties them together in real time with actionable context.
The ecosystem today gives us strong static analysis and SBOM‑focused tools, but not the runtime replay/verified call‑stack context that would close the loop on triage confidence in high‑velocity CICD environments.