25 KiB
You might want to know this — the landscape around CVSS v4.0 is rapidly shifting, and the time is now to treat it as a first-class citizen in vulnerability-management workflows.

🔎 What is CVSS v4.0 — and why it matters now
- CVSS is the standard framework for scoring software/hardware/firmware vulnerabilities, producing a 0–10 numeric severity score. (Wikipedia)
- On November 1 2023, the maintainers FIRST published version 4.0, replacing older 3.x/2.0 lines. (FIRST)
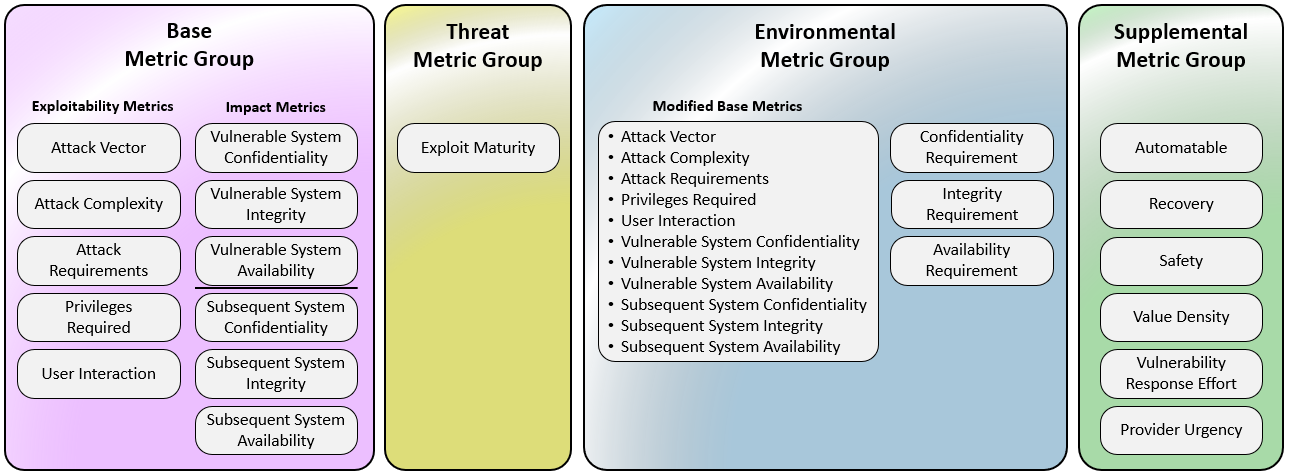
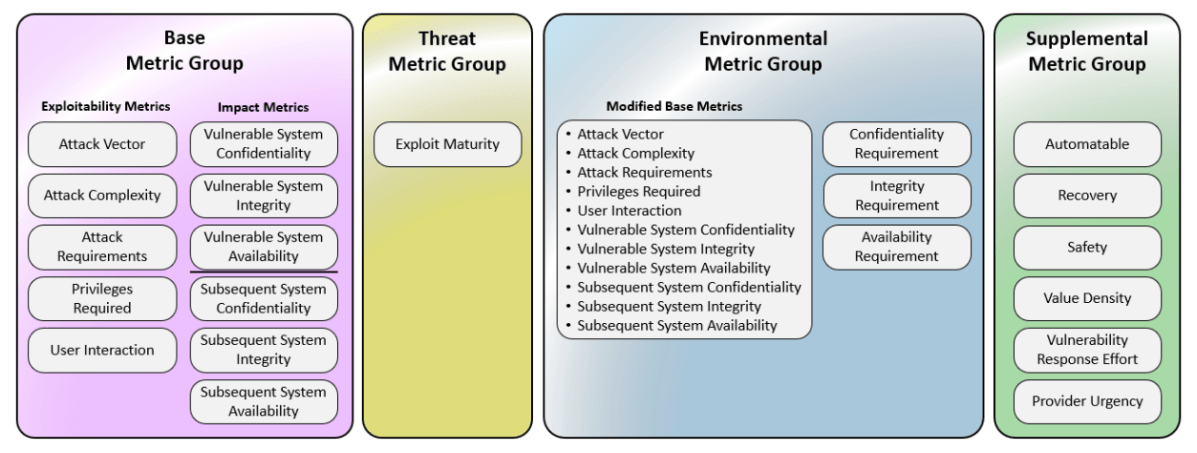
- v4.0 expands the standard to four metric groups: Base, Threat, Environmental, and a new Supplemental — enabling far more granular, context-aware scoring. (Checkmarx)
🧩 What Changed in v4.0 Compared to 3.x
-
The old “Temporal” metrics are renamed to Threat metrics; new Base metric Attack Requirements (AT) was added. v4.0 also refines User Interaction (UI) into more nuanced values (e.g., Passive vs Active). (FIRST)
-
The old “Scope” metric was removed, replaced by distinct impact metrics on the vulnerable system (VC/VI/VA) vs subsequent systems (SC/SI/SA), clarifying real-world risk propagation. (FIRST)
-
The Supplemental metric group adds flags like “Safety,” “Automatable,” “Recovery,” “Value Density,” “Provider Urgency,” etc. — providing extra context that doesn’t alter the numeric score but helps decision-making. (FIRST)
-
As a result, the scoring nomenclature also changes: instead of a single “CVSS score,” v4.0 supports combinations like CVSS-B (Base only), CVSS-BT (Base + Threat), CVSS-BE, or CVSS-BTE (Base + Threat + Environmental). (FIRST)
✅ Industry Adoption Is Underway — Not In The Future, Now
-
The National Vulnerability Database (NVD) — maintained by NIST — officially supports CVSS v4.0 as of June 2024. (NVD)
-
The major code-host & vulnerability platform GitHub Security Advisories began exposing CVSS v4.0 fields in September 2024. (The GitHub Blog)
-
On the ecosystem and vendor side: Microsoft Defender Vulnerability Management updated to prefer CVSS v4 in March 2025. (TECHCOMMUNITY.MICROSOFT.COM)
-
According to Snyk Open Source, all new advisories now come with both CVSS v4.0 and v3.1 assessments — with v4.0 becoming the default for evaluating severity. (Snyk Updates)
-
Several vendor-facing security / vulnerability-management products have signaled or started integrating v4.0 (though rollout is still ongoing) — consistent with the broader industry shift. (Rapid7 Discuss)
🎯 What This Means for Your Approach (Given What You’re Building)
Because you’re architecting a supply-chain / container / SCA-aware scanning stack (as with your StellaOps plans), this shift matters:
- Granular scoring — v4.0’s more detailed metrics help differentiate between a “theoretical high-impact but low-likelihood” flaw versus a “realistic immediate threat.”
- Context-aware risk — using Threat + Environmental + Supplemental metrics lets you layer real-world usage context (e.g. container deployment environment, exposure profile, exploit maturity, safety implications).
- Auditability & traceability — storing full vector strings, metric breakdowns (Base/Threat/Environmental/Supplemental), computed scores (CVSS-B, BT, BE, BTE), timestamp, scorer/source URL — plus legacy v3.1 vector — gives you a full provenance trail. That aligns with your ambition to build a “proof-of-integrity graph” and supply-chain-compliance ledger.
🧠 Caveats & What To Watch Out For
- Although v4.0 is supported by core infrastructures (NVD, GitHub, Microsoft, Snyk, etc.), not all existing CVEs have v4.0 assessments yet. Many older entries still carry only v3.x scores. (NVD)
- v4.0’s increased granularity brings increased complexity — more metric fields to collect, store, and evaluate. Without consistent population of Threat, Environmental or Supplemental fields, many scores could default back to “base only,” limiting the advantage over v3.1. (Checkmarx)
- A purely numeric score remains a partial view of risk — v4.0 improves it, but still does not compute exploitation likelihood. Combining CVSS with external data (e.g. exploit intelligence, usage context, threat modeling) remains critical. (CrowdStrike)
Given your goals — supply-chain compliance, auditability, multi-tool integration — adopting CVSS v4.0 now (or planning for it) is absolutely the right move.
If you like, I can check as of late 2025 which major container/SCA tools (like grype, Trivy, Aqua, GitLab, etc.) already support v4.0 — this may help you decide how quickly to bake v4 support into StellaOps.
Good request. I checked — support for CVSS v4.0 is being gradually adopted in major vulnerability-tracking and container/SCA tools, but it is not yet ubiquitous. Here’s what’s clear today (late 2025), plus what remains uncertain — from a neutral fact-based perspective.
✅ What we know: CVSS 4.0 is gaining traction
- GitHub Advisory Database — widely used for open source vulnerability advisories — now supports CVSS v4.0 (in addition to older v3.1). (GitHub Docs)
- The maintainers of the standard, FIRST, define CVSS 4.0 as full suite of metric groups (Base, Threat, Environmental, Supplemental), giving more precise, environment-aware severity scoring. (first.org)
- Some high-profile CVEs (e.g. Trivy-related CVE-2024-35192) already contain CVSS v4.0 vector strings in their official NVD entries, indicating that the community is reporting vulnerabilities under the new standard. (nvd.nist.gov)
🔎 What modern container/SCA tools do — mixed readiness
-
Trivy remains one of the most popular open-source scanners for containers, VMs, filesystems, language dependencies, and Kubernetes environments. (GitHub)
-
Documentation and tool descriptions for Trivy (and its ecosystem integrations) emphasize detection of CVEs, generation of SBOMs, license/compliance scanning, IaC misconfigurations, secrets, etc. (Chainguard Academy)
-
However — I did not find explicit public documentation confirming that Trivy (or other major SCA/container scanners) fully parse, store, and expose CVSS v4.0 metrics (Base, Threat, Environmental, Supplemental) across all output formats.
- Many vulnerability-scanning tools still default to older scoring (e.g. CVSS v3.x) because much of the existing CVE ecosystem remains populated with v3.x data.
- Some vulnerabilities (even recent ones) may carry v4.0 vectors, but if the scanning tool or its database backend does not yet support v4.0, the output may degrade to “severity level” (Low/Medium/High/Critical) or rely on legacy score — losing some of the finer granularity.
-
A recent academic evaluation of the “VEX tool space” for container-scanning highlighted low consistency across different scanners, suggesting divergent capabilities and output semantics. (arxiv.org)
⚠ What remains uncertain / risk factors
- Lack of uniform adoption: Many older CVEs still carry only CVSS v2 or v3.x scores; full re-scoring with v4.0 is non-trivial and may lag. Without upstream v4 scoring, scanner support is moot.
- Tools may partially support v4.0: Even if a scanner identifies a v4-vector, it may not support all metric groups (e.g. Threat, Environmental, Supplemental) — or may ignore them in summary output.
- Output format issues: For compliance, audit, or traceability (as you plan for with your “proof-of-integrity graph”), you need vector strings, not just severity labels. If scanners only emit severity labels or old-school base scores, you lose auditability.
- Inconsistency among scanners: As shown in recent comparative research, different tools may disagree on which vulnerabilities they detect — and by extension, which CVEs get v4.0 scoring in their data. (arxiv.org)
🎯 What this means for your build (e.g. Stella Ops)
- You should design Stella Ops to natively support CVSS v4.0 vectors — store them as structured data (vector string + separate metric fields) rather than just severity label or numeric base score. That preserves maximum fidelity and auditability.
- Continue to ingest from sources that publish v4.0 data (e.g. GitHub Advisory Database, NVD entries already tagged with v4 vector).
- For scanners (e.g. Trivy) that lack confirmed v4 output support — treat them as legacy feed, and supplement with heuristics or external metadata fetch to reconstruct full context where possible (or fallback to v3.x with clear marking).
- Account for inconsistency among scanners: treat scan output as advisory — use cross-tool correlation, SBOM provenance tracking, and your planned “proof-of-integrity graph” to triangulate real risk rather than trust a single tool.
✅ Final Assessment — “Yes, but partial”
CVSS 4.0 is supported in key vulnerability/advisory databases and appearing in real CVE entries, but full support across container/SCA scanning tools remains uneven. For a forward-looking, compliance- and audit-oriented platform like Stella Ops, it is rational and recommended to adopt v4.0 as primary internal standard, while building fallback paths for legacy data.
If you like — I can run a small 2025-era snapshot of 7–10 top container / SCA tools (open source + commercial) and tabulate which of them already publish full CVSS v4.0 output (vectors + all metric groups). That gives you a practical compatibility map for Stella Ops architecture.
Below is something you can drop into an internal design doc and hand straight to engineering.
1. Objectives (what “done” looks like)
Developers should aim for:
-
First‑class CVSS v4.0 support
-
Version‑aware, lossless storage
- Preserve original vector strings and raw metrics for both v3.x and v4.0.
- Do not down‑convert v4.0 to v3.x or blend them into a single number.
-
Clear separation of concerns
- CVSS = standardized “severity” input, not your internal “risk score.” (first.org)
- Threat / Environmental / Supplemental metrics feed your risk model, but are stored distinctly.
2. Data model & schema
2.1 Core CVSS entity
For each vulnerability finding (CVE or tool‑specific ID), you should support multiple CVSS assessments over time and from different sources.
Table: cvss_assessments (or equivalent)
Required columns:
id(PK)vuln_id(FK to CVE/finding table)version('2.0' | '3.0' | '3.1' | '4.0')vector_string(full textual vector, e.g.CVSS:4.0/AV:N/AC:L/...)score(numeric, 0.0–10.0)score_type('CVSS-B' | 'CVSS-BT' | 'CVSS-BE' | 'CVSS-BTE') (first.org)severity_band('None' | 'Low' | 'Medium' | 'High' | 'Critical') per official v4 qualitative scale. (first.org)source('NVD' | 'GitHub' | 'Vendor' | 'Internal' | 'Scanner:<name>' | ...)assessed_at(timestamp)assessed_by(user/system id)
2.2 Structured metrics (JSON or separate tables)
Store metrics machine‑readably, not just in the string:
{
"base": {
"AV": "N", // Attack Vector
"AC": "L", // Attack Complexity
"AT": "N", // Attack Requirements
"PR": "N", // Privileges Required
"UI": "N", // User Interaction: N, P, A in v4.0
"VC": "H",
"VI": "H",
"VA": "H",
"SC": "H",
"SI": "H",
"SA": "H"
},
"threat": {
"E": "A" // Exploit Maturity
},
"environmental": {
"CR": "H", // Confidentiality Requirement
"IR": "H",
"AR": "H",
// plus modified versions of base metrics, per spec
"MAV": "N",
"MAC": "L",
"MPR": "N",
"MUI": "N",
"MVC": "H",
"MVI": "H",
"MVA": "H",
"MSC": "H",
"MSI": "H",
"MSA": "H"
},
"supplemental": {
"S": "S", // Safety
"AU": "Y", // Automatable (v4.0 uses AU in the spec) :contentReference[oaicite:5]{index=5}
"U": "H", // Provider Urgency
"R": "H", // Recovery
"V": "H", // Value Density
"RE": "H" // Vulnerability Response Effort
}
}
Implementation guidance:
- Use a JSON column or dedicated tables (
cvss_base_metrics,cvss_threat_metrics, etc.) depending on how heavily you will query by metric. - Always persist both
vector_stringand parsed metrics; treat parsing as a reversible transformation.
3. Parsing & ingestion
3.1 Recognizing and parsing vectors
Develop a parser library (or adopt an existing well‑maintained one) with these properties:
-
Recognizes prefixes:
CVSS:2.0,CVSS:3.0,CVSS:3.1,CVSS:4.0. (Wikipedia) -
Validates all metric abbreviations and values for the given version.
-
Returns:
versionmetricsobject (structured as above)score(recalculated from metrics, not blindly trusted)score_type(B / BT / BE / BTE inferred from which metric groups are defined). (first.org)
Error handling:
-
If the vector is syntactically invalid:
- Store it as
vector_string_invalid. - Mark assessment as
status = 'invalid'. - Do not drop the vulnerability; log and alert.
- Store it as
-
If metrics are missing for Threat / Environmental / Supplemental:
- Treat them as “Not Defined” per spec, defaulting them in calculations. (first.org)
3.2 Integrating with external feeds
For each source (NVD, GitHub Advisory Database, vendor advisories, scanner outputs):
-
Normalize:
- If numeric score + vector provided: always trust the vector, not the numeric; recompute score internally and compare for sanity.
- If only numeric score provided (no vector): store, but mark
vector_string = nullandis_partial = true.
-
Preserve
sourceandsource_reference(e.g., NVD URL, GHSA ID) for audit.
4. Scoring engine
4.1 Core functions
Implement pure, deterministic functions:
Cvss4Result computeCvss4Score(Cvss4Metrics metrics)Cvss3Result computeCvss3Score(Cvss3Metrics metrics)
Where Cvss4Result includes:
score(0.0–10.0, properly rounded per spec; one decimal place) (first.org)score_type(CVSS-B/CVSS-BT/CVSS-BE/CVSS-BTE)severity_band(None/Low/Medium/High/Critical)
Implementation notes:
- Use the equations from section 8 of the CVSS v4.0 spec; do not invent your own approximations. (first.org)
- Ensure rounding and severity bands exactly match official calculators (run golden tests).
4.2 Nomenclature & flags
-
Always tag scores with the nomenclature:
CVSS-B,CVSS-BT,CVSS-BE, orCVSS-BTE. (first.org) -
Default behavior:
- If Threat/Environmental metrics are not explicitly provided, treat them as “Not Defined” (defaults), and still label the score
CVSS-B. - Only use
CVSS-BT/CVSS-BE/CVSS-BTEwhen non‑default values are present.
- If Threat/Environmental metrics are not explicitly provided, treat them as “Not Defined” (defaults), and still label the score
4.3 Strict separation from “risk”
-
Do not overload CVSS as a risk score. The spec is explicit that base scores measure severity, not risk. (first.org)
-
Implement a separate risk model (e.g.,
risk_score0–100) that uses:- CVSS (v3/v4) as one input
- Asset criticality
- Compensating controls
- Business context
- Threat intel signals
5. Threat & Environmental automation
You want developers to wire CVSS v4.0 to real‑world intel and asset data.
5.1 Threat metrics (Exploit Maturity, E)
Threat metrics in v4.0 are largely about Exploit Maturity (E). (first.org)
Implementation guidelines:
-
Define a mapping from your threat intel signals to E values:
E:X– Not Defined (no data)E:U– UnreportedE:P– Proof‑of‑concept onlyE:F– FunctionalE:A– Active exploitation
-
Data sources:
- Threat intel feeds (CISA KEV, vendor threat bulletins, commercial feeds)
- Public PoC trackers (exploit DB, GitHub PoC repositories)
-
Automation:
- Nightly job updates Threat metrics per vuln based on latest intel.
- Recompute
CVSS-BT/CVSS-BTEand store new assessments withassessed_attimestamp.
5.2 Environmental metrics
Environmental metrics adjust severity to a specific environment. (first.org)
Implementation guidelines:
-
Link
vuln_idto asset(s) via your CMDB / asset inventory. -
For each asset, maintain:
- CIA requirements:
CR,IR,AR(Low / Medium / High) - Key controls: e.g., network segmentation, WAF, EDR, backups, etc.
- CIA requirements:
-
Map asset metadata to Environmental metrics:
- For high‑critical systems, set
CR/IR/AR = H. - For heavily segmented systems, adjust Modified Attack Vector or Impact metrics accordingly.
- For high‑critical systems, set
-
Provide:
- A default environment profile (for generic scoring).
- Per‑asset or per‑asset‑group overrides.
6. Supplemental metrics handling
Supplemental metrics do not affect the CVSS score formula but provide critical context: Safety (S), Automatable (AU), Provider Urgency (U), Recovery (R), Value Density (V), Response Effort (RE). (first.org)
Guidelines:
-
Always parse and store them for v4.0 vectors.
-
Provide an internal risk model that can optionally:
-
Up‑weight vulns with:
S = Safety-criticalAU = True(fully automatable exploitation)V = High(many assets affected)
-
Down‑weight vulns with very high Response Effort (RE) when there is low business impact.
-
-
Make Supplemental metrics explicitly visible in the UI as “context flags,” not hidden inside a numeric score.
7. Backward compatibility with CVSS v3.x
You will be living in a dual world for a while.
Guidelines:
-
Store v3.x assessments as‑is
version = '3.1'or'3.0'vector_string,score,severity_band(using v3 scale).
-
Never treat v3.x and v4.0 scores as directly comparable
- 7.5 in v3.x ≠ 7.5 in v4.0.
- For dashboards and filters, compare inside a version, or map both to coarse severity bands.
-
Do not auto‑convert v3 vectors to v4 vectors
- Mapping is not lossless; misleading conversions are worse than clearly labeled legacy scores.
-
UI and API
- Always show
versionandscore_typenext to the numeric score. - For API clients, include structured metrics so downstream systems can migrate at their own pace.
- Always show
8. UI/UX guidelines
Give your designers and frontend devs explicit behaviors.
-
On vulnerability detail pages:
-
Show:
CVSS v4.0 (CVSS-BTE) 9.1 – Critical- Version and score type are always visible.
-
Provide a toggle or tab:
- “View raw vector,” expanding to show all metrics grouped: Base / Threat / Environmental / Supplemental.
-
-
For lists and dashboards:
-
Use severity bands (None / Low / Medium / High / Critical) as primary visual grouping.
-
For mixed environments:
- Show two columns if available:
CVSS v4.0andCVSS v3.1.
- Show two columns if available:
-
-
For analysts:
- Provide a built‑in calculator UI that lets them adjust Threat / Environmental metrics and immediately see updated
CVSS-BT/BE/BTE.
- Provide a built‑in calculator UI that lets them adjust Threat / Environmental metrics and immediately see updated
9. Testing & validation
Define a clean test strategy before implementation.
-
Golden test cases
-
Use official FIRST examples and calculators (v4.0 spec & user guide) as ground truth. (first.org)
-
Build a small public corpus:
- 20–50 CVEs with published v4.0 vectors and scores (from NVD / vendors) and confirm byte‑for‑byte matches.
-
-
Round‑trip tests
-
vector_string -> parse -> metrics -> compute -> vector_string- Ensure you can reconstruct the same canonical vector.
-
-
Regression tests
-
Add tests for:
- Missing Threat / Environmental metrics (defaults).
- Invalid vectors (fail gracefully, log, do not crash pipelines).
- Mixed v3/v4 data in the same views.
-
-
Performance
- CVSS computations are cheap, but in bulk (e.g., 1M+ findings) avoid per‑request recalculation; cache computed results per
(vuln_id, metrics_hash).
- CVSS computations are cheap, but in bulk (e.g., 1M+ findings) avoid per‑request recalculation; cache computed results per
10. Rollout / migration plan (high level)
What you can ask engineering to follow:
-
Phase 1 – Data model & parsing
- Add schema changes for
cvss_assessments. - Implement v4.0 parser and scorer, with full unit tests.
- Add schema changes for
-
Phase 2 – Ingestion
- Update NVD / GitHub / vendor importers to capture v4 vectors when present.
- Backfill existing data with
version= v3.x or v2.0 as appropriate.
-
Phase 3 – UI & API
- Expose versioned CVSS data and vector strings.
- Mark all legacy places that assumed “CVSS = single number” and refactor to be version‑aware.
-
Phase 4 – Threat & Environmental automation
- Wire in threat intel feeds and asset metadata.
- Start generating
CVSS-BT/CVSS-BTEscores for key asset groups.
-
Phase 5 – Risk model integration
- Use CVSS (v3/v4), plus Supplemental metrics, plus your own business logic to output a platform‑specific risk score.
11. Developer checklist (condensed)
You can literally put this as a checklist in Jira/Notion:
-
Schema updated to store:
version,vector_string,score,score_type,severity_band,source, timestamps.- Structured Base / Threat / Environmental / Supplemental metrics.
-
Parser for
CVSS:4.0/...with validation and graceful error handling. -
Scoring engine for v4.0 using official equations; golden tests against FIRST calculator.
-
Support for v3.x preserved; no cross‑version conversion.
-
UI shows version and score type; exposes vector and metrics.
-
Threat intel mapping to Exploit Maturity (E) implemented.
-
Environmental mapping from asset metadata implemented (even if initially basic).
-
Supplemental metrics parsed, stored, and surfaced.
-
Risk scoring logic separated from raw CVSS.
-
Regression tests + performance tests in CI.
If you tell me what your current schema and pipeline look like (tables, services, scanners in use), I can produce a concrete migration diff (DDL and service‑level changes) tailored to your stack.