559 lines
19 KiB
Mathematica
559 lines
19 KiB
Mathematica
You might find this interesting — there’s a new paper, ReachCheck, that describes a breakthrough in call‑graph reachability analysis for IDEs that could be exactly what you need for Stella’s third‑party library precomputations and incremental call‑stack explainers. ([LiLin's HomePage][1])
|
||
|
||

|
||
|
||
|
||
|
||
|
||
|
||
## 🔍 What ReachCheck does
|
||
|
||
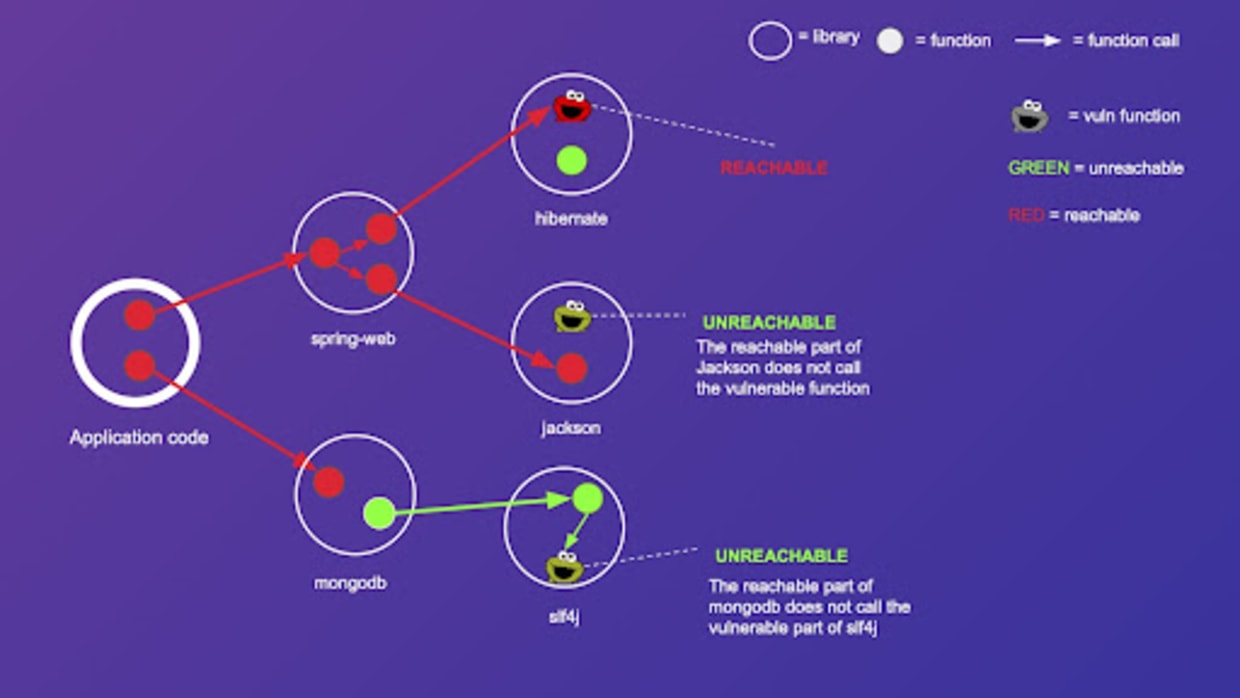
* ReachCheck builds a *compositional, library‑aware call‑graph summary*: it pre‑summarizes third‑party library reachability (offline), then merges those summaries on‑demand with your application code. ([LiLin's HomePage][1])
|
||
* It relies on a matrix‑based representation of call graphs + fast matrix multiplication to compute transitive closures. That lets it answer “can method A reach method B (possibly via library calls)?” queries extremely quickly. ([Chengpeng Wang][2])
|
||
|
||
## ⚡ Impressive Efficiency Gains
|
||
|
||
In experiments over real‑world codebases, ReachCheck outperformed online traversal and classic summary‑based or graph algorithms by **2–4 orders of magnitude**. ([LiLin's HomePage][1])
|
||
|
||
* For example: some comparisons showed speedups of 80×, 238×, even up to 4369× vs older techniques. ([LiLin's HomePage][1])
|
||
* Downstream tasks — like dependency‑conflict detection or vulnerability (CVE) risk detection — completed in **sub‑second times** (0.35 s, 0.61 s in reported cases). ([LiLin's HomePage][1])
|
||
|
||
## ✅ Why this aligns with Stella’s Architecture Goals
|
||
|
||
Given your plans for Stella Ops — especially around **pre‑computing third‑party libs**, **deterministic/replayable scans**, and **explainable call‑stack / dependency tracing** — ReachCheck fits like a glove:
|
||
|
||
* You could **precompute summaries** for every third‑party library once, store them, and reuse them across scans.
|
||
* On-demand analysis becomes **lightweight and near instantaneous**, which supports incremental, fast feedback (e.g. in IDE or CI/CD).
|
||
* Combining with your planned **Proof‑of‑Integrity Graph** and **AI-assisted explainers**, call‑graph queries (e.g. “does our code reach this vulnerable library method?”) become efficient enough to embed in runtime or build‑time workflows.
|
||
|
||
If you like — I can fetch the paper’s **limitations** section (hard cases, unsoundness/tradeoffs) so you can assess whether ReachCheck’s assumptions align with your threat‑model for Stella.
|
||
|
||
[1]: https://matafeiyanll.github.io/paper/TOSEM-2025.pdf?utm_source=chatgpt.com "ReachCheck: Compositional Library-Aware Call Graph ..."
|
||
[2]: https://chengpeng-wang.github.io/publications/TOSEM2025.pdf?utm_source=chatgpt.com "ReachCheck: Compositional Library-Aware Call Graph ..."
|
||
Right, if the variation space explodes, you do **not** want a full all-pairs precompute. The usual pattern is:
|
||
|
||
* Precompute and store only the **underlying graph/index** once per artifact.
|
||
* Answer reachability **on demand per query** (per “call”).
|
||
* **Cache query results** (and maybe the discovered path) keyed by a small, deterministic tuple.
|
||
|
||
Let me outline how I’d shape this for Stella Ops.
|
||
|
||
---
|
||
|
||
## 1. Separate “graph build” from “reachability query”
|
||
|
||
Instead of “precompute all paths”, you:
|
||
|
||
1. **Once per artifact (image / repo / package):**
|
||
|
||
* Build a compact call graph (nodes = functions/methods, edges = calls).
|
||
* Persist it in a deterministic format:
|
||
|
||
* E.g. `callgraph.{language}.{artifact_hash}.bin`.
|
||
* Think of this as “static index” – it is stable for all queries on that artifact.
|
||
|
||
2. **For each reachability query (once per call):**
|
||
|
||
* Input: `(artifact_hash, source_symbol, target_symbol, query_context)`
|
||
* Load call graph (or retrieve from in-memory cache).
|
||
* Run a **bounded graph search**:
|
||
|
||
* BFS / bidirectional BFS / A* on the call graph.
|
||
* Return:
|
||
|
||
* `reachable: bool`
|
||
* `path: [symbol1, symbol2, ...]` (canonical shortest path)
|
||
* maybe some “explanation metadata” (callsite locations, files/lines).
|
||
|
||
No all-pairs transitive closure. Just efficient search on a pre-indexed graph.
|
||
|
||
---
|
||
|
||
## 2. Caching “once per query” – but done smartly
|
||
|
||
Your idea “do it once per call and maybe cache the result” is exactly the right middle ground. The key is to define what the cache key is.
|
||
|
||
### 2.1. Suggested cache key
|
||
|
||
For Stella, something like:
|
||
|
||
```text
|
||
Key = (
|
||
artifact_digest, // container image / repo hash
|
||
language, // java, dotnet, go, etc.
|
||
source_symbol_id, // normalized symbol id (e.g. method handle)
|
||
target_symbol_id, // same
|
||
context_flags_hash // OS/arch, feature flags, framework env etc (optional)
|
||
)
|
||
```
|
||
|
||
Value:
|
||
|
||
```text
|
||
Value = {
|
||
reachable: bool,
|
||
path: [symbol_id...], // empty if not reachable
|
||
computed_at_version: graph_version_id
|
||
}
|
||
```
|
||
|
||
Where `graph_version_id` increments if you change the call-graph builder, so you can invalidate stale cache entries across releases.
|
||
|
||
### 2.2. Cache scopes
|
||
|
||
You can have layered caches:
|
||
|
||
1. **In-scan in-memory cache (per scanner run):**
|
||
|
||
* Lives only for the current scan.
|
||
* No eviction needed, deterministic, very simple.
|
||
* Great when a UX asks the same or similar question repeatedly.
|
||
|
||
2. **Local persistent cache (per node / per deployment):**
|
||
|
||
* E.g. Postgres / RocksDB with the key above.
|
||
* Useful if:
|
||
|
||
* The same artifact is scanned repeatedly (typical for CI and policy checks).
|
||
* The same CVEs / sinks get queried often.
|
||
|
||
You can keep the persistent cache optional so air-gapped/offline deployments can decide whether they want this extra optimization.
|
||
|
||
---
|
||
|
||
## 3. Why this works even with many variations
|
||
|
||
You are right: there are “too many variations” if you think in terms of:
|
||
|
||
* All entrypoints × all sinks
|
||
* All frameworks × all environment conditions
|
||
|
||
But note:
|
||
|
||
* You are **not** computing all combinations.
|
||
* You only compute **those actually asked by:**
|
||
|
||
* The UX (“show me path from `vuln_method` to `Controller.Foo`”).
|
||
* The policy engine (“prove whether this HTTP handler can reach this vulnerable method”).
|
||
|
||
So the number of **distinct, real queries** is usually far smaller than the combinatorial space.
|
||
|
||
And for each such query, a graph search on a typical microservice-size codebase is usually cheap (tens of milliseconds) if:
|
||
|
||
* The call graph is kept in memory (or memory-mapped).
|
||
* You keep a compact node/edge representation (integer IDs, adjacency lists).
|
||
|
||
---
|
||
|
||
## 4. Implementation details you might care about
|
||
|
||
### 4.1. On-demand graph search
|
||
|
||
Per language you can stay with simple, predictable algorithms:
|
||
|
||
* **BFS / Dijkstra / bidirectional BFS** on a directed graph.
|
||
* For large graphs, **bidirectional search** is usually the best “bang for the buck”.
|
||
|
||
You can encapsulate this in a small “Reachability Engine” module with a uniform API:
|
||
|
||
```csharp
|
||
ReachabilityResult CheckReachability(
|
||
ArtifactId artifact,
|
||
string language,
|
||
SymbolId from,
|
||
SymbolId to,
|
||
ReachabilityContext ctx);
|
||
```
|
||
|
||
Internally it:
|
||
|
||
1. Looks up `callgraph(artifact, language)`.
|
||
2. Checks in-memory cache for the key `(artifact, lang, from, to, ctxhash)`.
|
||
3. If miss:
|
||
|
||
* Does bidirectional BFS.
|
||
* Stores result (reachable, canonical path) into cache.
|
||
4. Returns result.
|
||
|
||
### 4.2. Determinism
|
||
|
||
For Stella’s deterministic / replayable scans, you want:
|
||
|
||
* **Deterministic traversal order** inside the BFS:
|
||
|
||
* Sort adjacency lists once when building the graph.
|
||
* Then BFS always visits neighbors in the same order.
|
||
* **Canonical path**:
|
||
|
||
* Always store/report the lexicographically minimal shortest path, or “first discovered shortest path” with deterministic adjacency sorting.
|
||
|
||
For your **replay bundles**, you simply store:
|
||
|
||
* The original graph (or a hash referencing it).
|
||
* The list of queries and their results (including the paths).
|
||
* Optionally, the cache is re-derivable from those query logs.
|
||
|
||
You do not need to store the whole cache; you just need enough to replay.
|
||
|
||
---
|
||
|
||
## 5. When you still might want precomputation (but limited)
|
||
|
||
You might selectively precompute for:
|
||
|
||
* **Hot sinks**:
|
||
|
||
* e.g. `Runtime.exec`, `ProcessBuilder.start`, dangerous deserialization APIs, SQL exec functions.
|
||
* **Framework entrypoints**:
|
||
|
||
* HTTP controllers, message handlers, scheduled tasks.
|
||
|
||
For those, you can precompute or at least **pre-index outgoing/incoming cones**:
|
||
|
||
* E.g. build “forward cones” of dangerous sinks:
|
||
|
||
* From each sink, compute reachable callers up to some depth and store only that summary.
|
||
* Or “backward cones” from hot entrypoints.
|
||
|
||
This is much cheaper than all-pairs and helps common queries (CVE affecting a known sink) to be answered almost instantly.
|
||
|
||
---
|
||
|
||
## 6. How this maps to your multi-language priority (Java, JS, Python, Go, C/C++, .NET)
|
||
|
||
The strategy is language-agnostic:
|
||
|
||
* Each language plugin produces:
|
||
|
||
* `CallGraphNodes` (with stable `SymbolId`s).
|
||
* `CallGraphEdges`.
|
||
* The reachability engine is shared; only symbol encoding / mapping is language-specific.
|
||
|
||
The “once per call, then cache” strategy stays identical:
|
||
|
||
1. Normalize `(from_symbol, to_symbol)` into internal IDs.
|
||
2. Run search.
|
||
3. Cache.
|
||
|
||
---
|
||
|
||
## 7. Concrete recommendation for Stella Ops
|
||
|
||
If I distill it into a decision:
|
||
|
||
* Do **not** precompute all reachability; it will not scale.
|
||
* Do **precompute and store only the call graph** per artifact.
|
||
* Implement a **deterministic, on-demand reachability engine** with:
|
||
|
||
* In-scan in-memory cache (mandatory).
|
||
* Optional persisted cache (per deployment).
|
||
* Add the query log + results to your **deterministic scan manifest** so each answer is replayable.
|
||
|
||
If you like, next step I can sketch a small C# interface and data model for `StellaOps.Reachability` (nodes, edges, cache keys, and the main `CheckReachability` entrypoint) that your agents can implement directly.
|
||
Below is a distilled and expanded articulation of **Stella Ops’ competitive advantages**, followed by **deep, developer-oriented guidelines** for implementing them consistently across all modules (Scanner, Sbomer, Authority, Vexer, Concelier, Excitors, Scheduler, Feedser, Gateway, UI).
|
||
|
||
The intention is to give you both the **strategic narrative** and the **engineering discipline** to ensure Stella retains a fundamental moat versus all classical scanners.
|
||
|
||
---
|
||
|
||
# Stella Ops: Expanded Advantages
|
||
|
||
Structured in a way that a developer or architect can immediately translate into code, data models, policies, and UX surfaces.
|
||
|
||
## 1. Deterministic Security Engine
|
||
|
||
**Advantage:** Modern vulnerability scanners produce non-deterministic results: changing feeds, inconsistent call-graphs, transient metadata. Stella Ops produces **replayable evidence**.
|
||
|
||
### What this means for developers
|
||
|
||
* Every scan must produce a **Manifest of Deterministic Inputs**:
|
||
|
||
* Feed versions, rule versions, SBOM versions, VEX versions.
|
||
* Hashes of each input.
|
||
* The scan output must be fully reproducible with no external network calls.
|
||
* Every module must support a **Replay Mode**:
|
||
|
||
* Inputs only from the manifest bundle.
|
||
* Deterministic ordering of graph traversals, vulnerability matches, and path results.
|
||
* No module may fetch anything non-pinned or non-hashed.
|
||
|
||
**Outcome:** An auditor can verify the exact same result years later.
|
||
|
||
---
|
||
|
||
## 2. Proof-Linked SBOM → VEX Chain
|
||
|
||
**Advantage:** Stella generates **cryptographically signed evidence graphs**, not just raw SBOMs and JSON VEX files.
|
||
|
||
### Developer requirements
|
||
|
||
* Always produce **DSSE attestations** for SBOM, reachability, and call-graph outputs.
|
||
* The Authority service maintains a **Proof Ledger** linking:
|
||
|
||
* SBOM digest → Reachability digest → VEX reduction digest → Final policy decision.
|
||
* Each reduction step records:
|
||
|
||
* Rule ID, lattice rule, inputs digests, output digest, timestamp, signer.
|
||
|
||
**Outcome:** A customer can present a *chain of proof*, not a PDF.
|
||
|
||
---
|
||
|
||
## 3. Compositional Reachability Engine
|
||
|
||
**Advantage:** Stella calculates call-stack reachability **on demand**, with deterministic caching and pre-summarized third-party libraries.
|
||
|
||
### Developer requirements
|
||
|
||
* Store only the **call graph** per artifact.
|
||
* Provide an engine API:
|
||
|
||
```csharp
|
||
ReachabilityResult Query(ArtifactId a, SymbolId from, SymbolId to, Context ctx);
|
||
```
|
||
* Ensure deterministic BFS/bidirectional BFS with sorted adjacency lists.
|
||
* Cache on:
|
||
|
||
* `(artifact_digest, from_id, to_id, ctx_hash)`.
|
||
* Store optional summaries for:
|
||
|
||
* Hot sinks (deserialization, SQL exec, command exec).
|
||
* Framework entrypoints (HTTP handlers, queues).
|
||
|
||
**Outcome:** Fast and precise evidence, not “best guess” matching.
|
||
|
||
---
|
||
|
||
## 4. Lattice-Based VEX Resolution
|
||
|
||
**Advantage:** A visual “Trust Algebra Studio” where users define how VEX, vendor attestations, runtime info, and internal evidence merge.
|
||
|
||
### Developer requirements
|
||
|
||
* Implement lattice operators as code interfaces:
|
||
|
||
```csharp
|
||
interface ILatticeRule {
|
||
EvidenceState Combine(EvidenceState left, EvidenceState right);
|
||
}
|
||
```
|
||
* Produce canonical merge logs for every decision.
|
||
* Store the final state with:
|
||
|
||
* Trace of merges, reductions, evidence nodes.
|
||
* Ensure monotonic, deterministic ordering of rule evaluation.
|
||
|
||
**Outcome:** Transparent, explainable policy outcomes, not opaque severity scores.
|
||
|
||
---
|
||
|
||
## 5. Quiet-by-Design Vulnerability Triage
|
||
|
||
**Advantage:** Stella only flags what is provable and relevant, unlike noisy scanners.
|
||
|
||
### Developer requirements
|
||
|
||
* Every finding must include:
|
||
|
||
* Evidence chain
|
||
* Reachability path (or absence of one)
|
||
* Provenance
|
||
* Confidence class
|
||
* Findings must be grouped by:
|
||
|
||
* Exploitable
|
||
* Probably exploitable
|
||
* Non-exploitable
|
||
* Unknown (with ranking of unknowns)
|
||
* Unknowns must be ranked by:
|
||
|
||
* Distance to sinks
|
||
* Structural entropy
|
||
* Pattern similarity to vulnerable nodes
|
||
* Missing metadata dimensions
|
||
|
||
**Outcome:** DevOps receives actionable intelligence, not spreadsheet chaos.
|
||
|
||
---
|
||
|
||
## 6. Crypto-Sovereign Readiness
|
||
|
||
**Advantage:** Stella works in any national crypto regime (eIDAS, FIPS, GOST, SM2/3/4, PQC).
|
||
|
||
### Developer requirements
|
||
|
||
* Modular signature providers:
|
||
|
||
```csharp
|
||
ISignatureProvider { Sign(), Verify() }
|
||
```
|
||
* Allow switching signature suite via configuration.
|
||
* Include post-quantum functions (Dilithium/Falcon) for long-term archival.
|
||
|
||
**Outcome:** Sovereign deployments across Europe, Middle East, Asia without compromise.
|
||
|
||
---
|
||
|
||
## 7. Proof-of-Integrity Graph (Runtime → Build Ancestry)
|
||
|
||
**Advantage:** Stella links running containers to provable build origins.
|
||
|
||
### Developer requirements
|
||
|
||
* Each runtime probe generates:
|
||
|
||
* Container digest
|
||
* Build recipe digest
|
||
* Git commit digest
|
||
* SBOM + VEX chain
|
||
* Graph nodes: artifacts; edges: integrity proofs.
|
||
* The final ancestry graph must be persisted and queryable:
|
||
|
||
* “Show me all running containers derived from a compromised artifact.”
|
||
|
||
**Outcome:** Real runtime accountability.
|
||
|
||
---
|
||
|
||
## 8. Adaptive Trust Economics
|
||
|
||
**Advantage:** Vendors earn trust credits; untrustworthy artifacts lose trust weight.
|
||
|
||
### Developer requirements
|
||
|
||
* Trust scoring function must be deterministic and signed.
|
||
* Inputs:
|
||
|
||
* Vendor signature quality
|
||
* Update cadence
|
||
* Vulnerability density
|
||
* Historical reliability
|
||
* SBOM completeness
|
||
* Store trust evolution over time for auditing.
|
||
|
||
**Outcome:** Procurement decisions driven by quantifiable reliability, not guesswork.
|
||
|
||
---
|
||
|
||
# Developers Guidelines for Implementing Those Advantages
|
||
|
||
Here is an actionable, module-by-module guideline set.
|
||
|
||
---
|
||
|
||
# Global Engineering Principles (apply to all modules)
|
||
|
||
1. **Determinism First**
|
||
|
||
* All loops with collections must use sorted structures.
|
||
* All graph algorithms must use canonical neighbor ordering.
|
||
* All outputs must be hash-stable.
|
||
|
||
2. **Evidence Everywhere**
|
||
|
||
* Every decision includes a provenance node.
|
||
* Never return a boolean without a proof trail.
|
||
|
||
3. **Separation of Reduction Steps**
|
||
|
||
* SBOM generation
|
||
* Vulnerability mapping
|
||
* Reachability estimation
|
||
* VEX reduction
|
||
* Policy/Lattice resolution
|
||
must be separate services or separate steps with isolated digests.
|
||
|
||
4. **Offline First**
|
||
|
||
* Feed updates must be packaged and pinned.
|
||
* No live API calls allowed during scanning.
|
||
|
||
5. **Replay Mode Required**
|
||
|
||
* Every service can re-run the scan from recorded evidence without external data.
|
||
|
||
---
|
||
|
||
# Module-Specific Developer Guidelines
|
||
|
||
## Scanner
|
||
|
||
* Perform layered FS exploration deterministically.
|
||
* Load vulnerability datasets from Feedser by digest.
|
||
* For each match, require:
|
||
|
||
* Package evidence
|
||
* Version bound match
|
||
* Full rule trace.
|
||
|
||
## Sbomer
|
||
|
||
* Produce SPDX 3.0.1 + CycloneDX 1.6 simultaneously.
|
||
* Emit DSSE attestations.
|
||
* Guarantee stable ordering of all components.
|
||
|
||
## Reachability Engine
|
||
|
||
* Implement deterministic bidirectional BFS.
|
||
* Add “unknown symbol” ranking heuristics.
|
||
* Cache per `(artifact, from, to, context_hash)`.
|
||
* Store path and evidence.
|
||
|
||
## Vexer / Excitors
|
||
|
||
* Interpret vendor VEX, internal evidence, runtime annotations.
|
||
* Merge using lattice logic.
|
||
* Produce signed reduction logs.
|
||
|
||
## Concelier
|
||
|
||
* Enforces policies using lattice outputs.
|
||
* Must produce a “policy decision record” per artifact.
|
||
* Must include a machine-readable decision DAG.
|
||
|
||
## Feedser
|
||
|
||
* Feeds emitted with version, timestamp, immutable hash.
|
||
* Must support delta updates.
|
||
* Must support full offline installation.
|
||
|
||
## Authority
|
||
|
||
* Stores all proofs in a verifiable ledger.
|
||
* Exposes graph queries:
|
||
|
||
* “Show the exact evidence chain leading to this status.”
|
||
|
||
## Scheduler
|
||
|
||
* Ensures scan runs are reproducible.
|
||
* Logs all parameters.
|
||
* Stores outputs with manifest.
|
||
|
||
## UI / Gateway
|
||
|
||
* No decision without showing the proof chain.
|
||
* Always show:
|
||
|
||
* Path evidence
|
||
* Lattice reasoning
|
||
* Final verdict with confidence class
|
||
|
||
---
|
||
|
||
# Final Deliverable: Stella Ops Advantage Summary for Developers
|
||
|
||
You can give this to your engineers:
|
||
|
||
1. Produce **deterministic, replayable evidence** for every scan.
|
||
2. Store and link SBOM → Reachability → VEX → Policy outputs into a **Proof Ledger**.
|
||
3. Use **compositional reachability** with deterministic caching.
|
||
4. Implement **lattice-based evidence merging**.
|
||
5. Maintain **quiet-by-design triage**: only show evidence-proven risks.
|
||
6. Support **sovereign crypto** including PQC.
|
||
7. Build a **runtime integrity graph** referencing build ancestry.
|
||
8. Maintain **trust economics** for artifacts and vendors.
|
||
9. Everything must be auditable, replayable, signed, and offline-capable.
|
||
|
||
If you want, I can now produce **architectural diagrams**, **module interfaces**, or **a complete AGENTS.md charter** incorporating these guidelines.
|