consolidation of some of the modules, localization fixes, product advisories work, qa work
This commit is contained in:
@@ -0,0 +1,129 @@
|
||||
Here’s a compact, auditor‑first UX concept you can drop into Stella to make “inspect → verify → export” fast, reproducible, and trustable—plus the KPIs to prove it works.
|
||||
|
||||
# 1) Call‑stack Visualizations (for binary/runtime findings)
|
||||
|
||||
**Why it matters:** Auditors need to see *how* a vulnerable code path actually executes, not just that a package is present.
|
||||
|
||||
**Mini‑layout (wireframe):**
|
||||
|
||||
```
|
||||
┌──────────────────┬──────────────────────────────┬───────────────────────┐
|
||||
│ Call Stack │ Source / Binary View │ Replay Controls │
|
||||
│ (frames + conf.) │ (symbol map, line peek) │ seed | start | stdout │
|
||||
│ fnA() [92%] │ > src/foo/bar.c:214 │ [▶︎ Replay] [⟳ Reset] │
|
||||
│ └ fnB() [88%] │ mov eax,... ; sym: do_io │ Last run: ok (2.1s) │
|
||||
│ └ fnC() [71%] │ ... │ Artifact: trace.dsee │
|
||||
└──────────────────┴──────────────────────────────┴───────────────────────┘
|
||||
```
|
||||
|
||||
**Key interactions**
|
||||
|
||||
* Frames show confidence chips (e.g., 92%) from trace/symbol resolution.
|
||||
* Clicking a frame jumps the code pane to the exact line/symbol.
|
||||
* “Replay” re‑executes deterministic seed, captures stdout/stderr, and emits a DSSE‑signed trace artifact.
|
||||
|
||||
**KPIs**
|
||||
|
||||
* `replay_success_ratio ≥ 95%`
|
||||
* `symbol_coverage_pct ≥ 90%`
|
||||
|
||||
---
|
||||
|
||||
# 2) Explainability Trails (tie every claim to signed evidence)
|
||||
|
||||
**Why it matters:** Auditors must traverse from a “finding” to the **specific** proof you used, in the **exact** order.
|
||||
|
||||
**Mini‑layout (wireframe):**
|
||||
|
||||
```
|
||||
┌──────────────────────────────── Trail (breadcrumbs) ────────────────────────────────┐
|
||||
│ Finding ▸ Evidence (DSSE id: 0xABCD) ▸ Replay Log ▸ Analyst Notes │
|
||||
└────────────────────────────────────────────────────────────────────────────────────┘
|
||||
┌────────────── Timeline (factors over time) ───────────────┐
|
||||
│ CVSS 7.2 → 7.5 | EPSS 0.19 → 0.31 | Reachability: gated │
|
||||
└───────────────────────────────────────────────────────────┘
|
||||
┌────────────── Export ──────────────┐
|
||||
│ [ Download DSSE Envelope ] [ Rekor Tile ] │
|
||||
└────────────────────────────────────┘
|
||||
```
|
||||
|
||||
**Key interactions**
|
||||
|
||||
* Breadcrumbs are clickable, each node opens the canonical, signed artifact.
|
||||
* Factor timeline shows how CVSS/EPSS/reachability changed across evidence updates.
|
||||
* “Export” yields a DSSE bundle + transparency‑log (Rekor‑style) inclusion proof.
|
||||
|
||||
**KPIs**
|
||||
|
||||
* `signed_evidence_downloads ≤ 1 click`
|
||||
* `auditor_recompute_time ≤ 3s` (canonical verify of bundle)
|
||||
|
||||
---
|
||||
|
||||
# 3) Signed‑score Explainers (deterministic, verifiable scoring)
|
||||
|
||||
**Why it matters:** Replace “mystery badges” with a **signed, reproducible** score and the inputs that produced it.
|
||||
|
||||
**Mini‑layout (wireframe):**
|
||||
|
||||
```
|
||||
┌ Score Ribbon ───────────────────────────────────────────────┐
|
||||
│ Score: 7.2 [DSSE‑signed] [Verify] [Inputs ▾] │
|
||||
└─────────────────────────────────────────────────────────────┘
|
||||
Chips (collapsible):
|
||||
[Base CVSS: 6.8 ▸ open inputs] [EPSS: 0.31 ▸ open inputs]
|
||||
[Reachability: exposed ▸ open inputs] [Compensating Controls: 2 ▸ open]
|
||||
```
|
||||
|
||||
**Key interactions**
|
||||
|
||||
* Each factor chip opens the canonical inputs (files, logs, attestations) used.
|
||||
* “Verify” runs local deterministic recompute and signature check.
|
||||
|
||||
**KPIs**
|
||||
|
||||
* `signed_score_verify_time ≤ 3000 ms`
|
||||
* `deterministic_repeatability = 100%` (same inputs ⇒ identical score)
|
||||
|
||||
---
|
||||
|
||||
## How these three pieces fit the auditor loop
|
||||
|
||||
1. **Inspect** actual execution (call‑stack + source view).
|
||||
2. **Verify** with one‑click canonical checks (Explainability Trail + Signed Score).
|
||||
3. **Export** DSSE bundles + log tiles as audit artifacts.
|
||||
|
||||
---
|
||||
|
||||
## Minimal event/telemetry you’ll want (to back the KPIs)
|
||||
|
||||
* Replay runs: started/ended, exit code, artifact hash, symbol coverage %.
|
||||
* Evidence fetches: path, DSSE envelope hash, verify duration.
|
||||
* Score verify: input hashes, runtime (ms), match/nomatch flag.
|
||||
|
||||
---
|
||||
|
||||
## Quick implementation notes (Stella modules)
|
||||
|
||||
* **EvidenceLocker**: store trace files, symbol maps, DSSE envelopes, Rekor tiles.
|
||||
* **Attestor**: sign replay traces and score manifests; expose `/verify` for ≤3s target.
|
||||
* **AdvisoryAI**: render Explainability Trail; compute factor timelines; wire to provenance.
|
||||
* **ReleaseOrchestrator/Doctor**: provide deterministic seeds and environment captures for replays.
|
||||
|
||||
---
|
||||
|
||||
## “Done means measured”: acceptance checklist
|
||||
|
||||
* [ ] 100 replay samples across 10 projects → `replay_success_ratio ≥ 95%`
|
||||
* [ ] Symbolizer test corpus → `symbol_coverage_pct ≥ 90%`
|
||||
* [ ] “Open inputs” for every score factor returns DSSE‑verifiable files in ≤3s
|
||||
* [ ] Score recompute matches signed result 100% on CI (cold cache + warm cache)
|
||||
* [ ] Single‑click export yields bundle (≤5 MB typical) + verifiable Rekor tile
|
||||
|
||||
---
|
||||
|
||||
If you want, I can turn this into:
|
||||
|
||||
* Playwright tests for each KPI,
|
||||
* a tiny DSSE schema for **ScoreManifest v1**, and
|
||||
* React/ASCII mocks upgraded to full Figma‑ready specs.
|
||||
@@ -0,0 +1,162 @@
|
||||
Here’s a crisp plan that turns a big strategy into shippable work, with clear KPIs and sequencing so you can schedule sprints instead of debating them.
|
||||
|
||||
---
|
||||
|
||||
# Why this matters (quick primer)
|
||||
|
||||
You’re building a release‑control plane with evidence‑based security. These five “moats” are concrete assets that compound over time:
|
||||
|
||||
* **CSFG:** a graph that fingerprints call stacks to match incidents fast.
|
||||
* **Marketplace:** curated symbol packs & test harnesses that boost coverage and create network effects.
|
||||
* **PSDI:** precomputed semantic delta index for sub‑second (or near) binary delta verification.
|
||||
* **FRVF:** cached “micro‑witnesses” to rapidly re‑verify incidents.
|
||||
* **FBPE:** federated provenance exchange + usage reputation across vendors.
|
||||
|
||||
Below I give: (1) a 6‑sprint MVP plan for **Marketplace + FRVF**, then (2) a 6‑quarter roadmap to phase **CSFG → PSDI → FBPE**. All items come with acceptance criteria you can wire into your CI dashboards.
|
||||
|
||||
---
|
||||
|
||||
# 6 sprints (2‑week sprints) → Marketplace + FRVF MVP
|
||||
|
||||
**Global MVP exit criteria (after Sprint 6)**
|
||||
|
||||
* Marketplace: **≥500 symbol bundles** hosted; **median symbol_lookup_latency ≤ 50 ms**; **contributor_retention ≥ 30%** at 1 quarter; initial licensing flows live.
|
||||
* FRVF: deterministic micro‑witness capture & sandbox replay with **replay_success_ratio ≥ 0.95** on seeded incidents; **avg verify_time ≤ 30 s** for cached proofs.
|
||||
|
||||
### Sprint 1 — Foundations & APIs
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Repo layout, contributor manifest spec (symbol pack schema, license tag, checksum).
|
||||
* Upload API (signed, size/format validated), storage backend, basic search (by toolchain, arch, version).
|
||||
* FRVF
|
||||
|
||||
* “Micro‑witness” schema (inputs, seeds, env, toolchain digest, artifact IDs).
|
||||
* Deterministic runner scaffold (container/Snap/OCI capsule), seed capture hooks.
|
||||
**Demos/KPIs:** 50 internal symbol packs; witness capsule recorded & replayed locally.
|
||||
|
||||
### Sprint 2 — Curation & Replay Harness
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Maintainer review workflow, reputation seed (download count, maintainer trust score), basic UI.
|
||||
* FRVF
|
||||
|
||||
* Replay harness v1 (controlled sandbox, resource caps), initial cache layer for verify results.
|
||||
**KPIs:** ingest 150 curated packs; **replay_success_ratio ≥ 0.90** on 10 seeded incidents.
|
||||
|
||||
### Sprint 3 — Auth, Licensing, & Privacy
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Account system (OIDC), EULA/license templates, entitlement checks, signed pack index.
|
||||
* FRVF
|
||||
|
||||
* Privacy controls (PII scrubbing in logs), redaction policy, provenance pointers (DSSE).
|
||||
**KPIs:** 300 packs live; end‑to‑end paid/private pack smoke test; FRVF logs pass redaction checks.
|
||||
|
||||
### Sprint 4 — Performance & Observability
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Index acceleration (in‑memory key paths), CDN for pack metadata, **p50 lookup ≤ 50 ms**.
|
||||
* FRVF
|
||||
|
||||
* Cached micro‑witness store; verify pipeline parallelism; per‑incident SLOs & dashboards.
|
||||
**KPIs:** p50 lookup ≤ 50 ms; **avg verify_time ≤ 30 s** on cached proofs.
|
||||
|
||||
### Sprint 5 — Contributor Flywheel & Incident Bundles
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Contributor portal (stats, badges), auto‑compat checks vs toolchains; abuse/gaming guardrails.
|
||||
* FRVF
|
||||
|
||||
* “Incident bundle” artifact: witness + symbol pointers + minimal replay script; export/import.
|
||||
**KPIs:** **≥500 packs** total; 10 external contributors; publish 10 incident bundles.
|
||||
|
||||
### Sprint 6 — Hardening & MVP Gate
|
||||
|
||||
* Marketplace
|
||||
|
||||
* Billing hooks (plan entitlements), takedown & dispute workflow, audit logs.
|
||||
* FRVF
|
||||
|
||||
* Determinism checks (variance = 0 across N replays), failure triage UI, limits & quotas.
|
||||
**MVP gate:** replay_success_ratio ≥ 0.95; contributor_retention early proxy ≥ 30% (opt‑in waitlist); security review passed.
|
||||
|
||||
---
|
||||
|
||||
# 6‑quarter roadmap (18 months) — CSFG → PSDI → FBPE
|
||||
|
||||
## Q1: MVP ship & seed customers (Sprints 1‑6 above)
|
||||
|
||||
* **Ship Marketplace + FRVF MVP**; start paid pilots for incident‑response retainers.
|
||||
* Instrument KPI baselines.
|
||||
|
||||
## Q2: CSFG foundations (graph + normalizer)
|
||||
|
||||
* Build **canonical frame normalizer** (unifies frames across ABIs/optimizations).
|
||||
* Ingest **1 000 curated traces**; expose **match API** with **median_latency ≤ 200 ms**.
|
||||
* **Acceptance:** stack_precision ≥ 0.90, stack_recall ≥ 0.85 on seeded corpus.
|
||||
* **Synergy:** Marketplace boosts symbol_coverage → better CSFG precision.
|
||||
|
||||
## Q3: PSDI prototype (delta proofs)
|
||||
|
||||
* Normalize IR for **top 10 OSS toolchains** (e.g., GCC/Clang/MSVC/Go/Rust/Java/.NET).
|
||||
* Generate **delta index**; verify 80% of deltas **≤ 5 s** (p95 ≤ 30 s).
|
||||
* **Synergy:** FRVF uses PSDI to accelerate verify loops; offer “fast‑patch acceptance” SLA.
|
||||
|
||||
## Q4: CSFG + PSDI scale‑out
|
||||
|
||||
* CSFG: continuous contribution APIs, enterprise private graphs; privacy/anonymization.
|
||||
* PSDI: sharding, freshness strategies; client libraries.
|
||||
* **Commercial:** add paid SLAs for “verified delta” and “stack match coverage”.
|
||||
|
||||
## Q5: FBPE federation (seed network)
|
||||
|
||||
* Implement **federation protocol**, basic **usage reputation**, private peering with 3 partners.
|
||||
* **Acceptance:** cross_verify_success_ratio ≥ 0.95; provenance_query p50 ≤ 250 ms.
|
||||
* **GTM:** joint reference customers, procurement preference for federation members.
|
||||
|
||||
## Q6: Federation scale & governance
|
||||
|
||||
* Multi‑tenant federation, credits/rewards for contribution, governance & legal guardrails.
|
||||
* Enterprise private graphs + hardened privacy controls across all moats.
|
||||
* **North‑star KPIs:** participating_node_growth ≥ 50% QoQ; incident **time‑to‑verify ↓ 60%** vs baseline.
|
||||
|
||||
---
|
||||
|
||||
# Roles, squads, and effort bands
|
||||
|
||||
* **Squad A (Marketplace + FRVF)** — 1 PM, 1 EM, 4–5 engineers.
|
||||
|
||||
* Effort bands: Marketplace **4–8 eng‑months**, FRVF **4–9 eng‑months**.
|
||||
* **Research Engine (CSFG + PSDI)** — 1 research‑lead, 3–4 engineers (compilers/IR/graph).
|
||||
|
||||
* CSFG **9–18 eng‑months**, PSDI **6–12 eng‑months**.
|
||||
* **FBPE** — starts Q5 with 3–4 engineers (protocols, privacy, governance) **6–12 eng‑months**.
|
||||
|
||||
---
|
||||
|
||||
# Risks & mitigations (short)
|
||||
|
||||
* **Symbol/IP licensing disputes** → strict license tags, contributor contracts, takedown SLAs.
|
||||
* **Poisoning/PII leakage** → validation pipelines, redaction, attestation on submissions.
|
||||
* **Determinism gaps** → constrained capsules, toolchain snapshotting, seed pinning.
|
||||
* **Index freshness cost (PSDI)** → tiered sharding + recency heuristics.
|
||||
* **Federation trust bootstrapping** → start with private peering & reputation primitives.
|
||||
|
||||
---
|
||||
|
||||
# What to wire into your dashboards (KPI set)
|
||||
|
||||
* Marketplace: symbol_coverage_pct uplift (target **≥ 20% in 90 days** for pilots), p50 lookup latency, contributor_retention, dispute rate.
|
||||
* FRVF: replay_success_ratio, verify_time_ms, deterministic_score_variance.
|
||||
* CSFG: stack_precision / stack_recall, median_match_latency.
|
||||
* PSDI: median/p95 delta_proof_verification_time, delta_entropy calibration.
|
||||
* FBPE: participating_node_growth, cross_verify_success_ratio, provenance_query_latency.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate the **six sprint tickets** (per sprint: epics → stories → tasks), plus a **lightweight schema pack** (symbol pack manifest, micro‑witness JSON, CSFG frame normalizer rules) ready to drop into your Stella Ops repo structure.
|
||||
@@ -0,0 +1,42 @@
|
||||
I’m sharing this because the current state of runtime security, VEX maturity, and SBOM/attestation tooling is *actively shaping how buyers prioritize verifiable evidence over vendor claims* — and the latest product releases and community discussions show real gaps you should be tracking.
|
||||
|
||||
When vendors talk about **runtime protection and exploitability insights**, the focus is increasingly on live telemetry, threat detection, and *actionable blocking*, but the specifics vary in documentation and implementation.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
**1) Runtime exploitation & blocking — vendors pushing real-time, but evidence varies**
|
||||
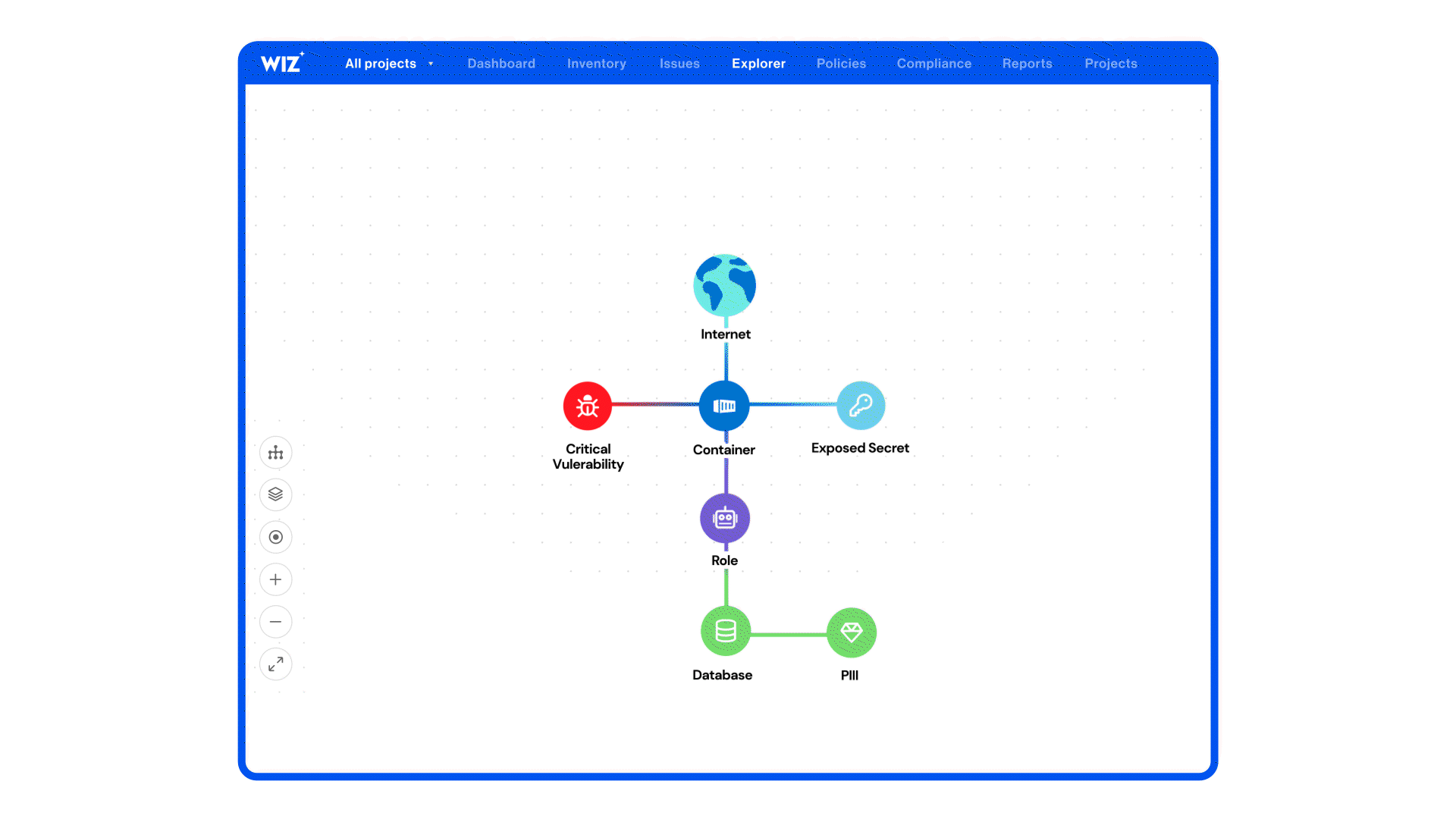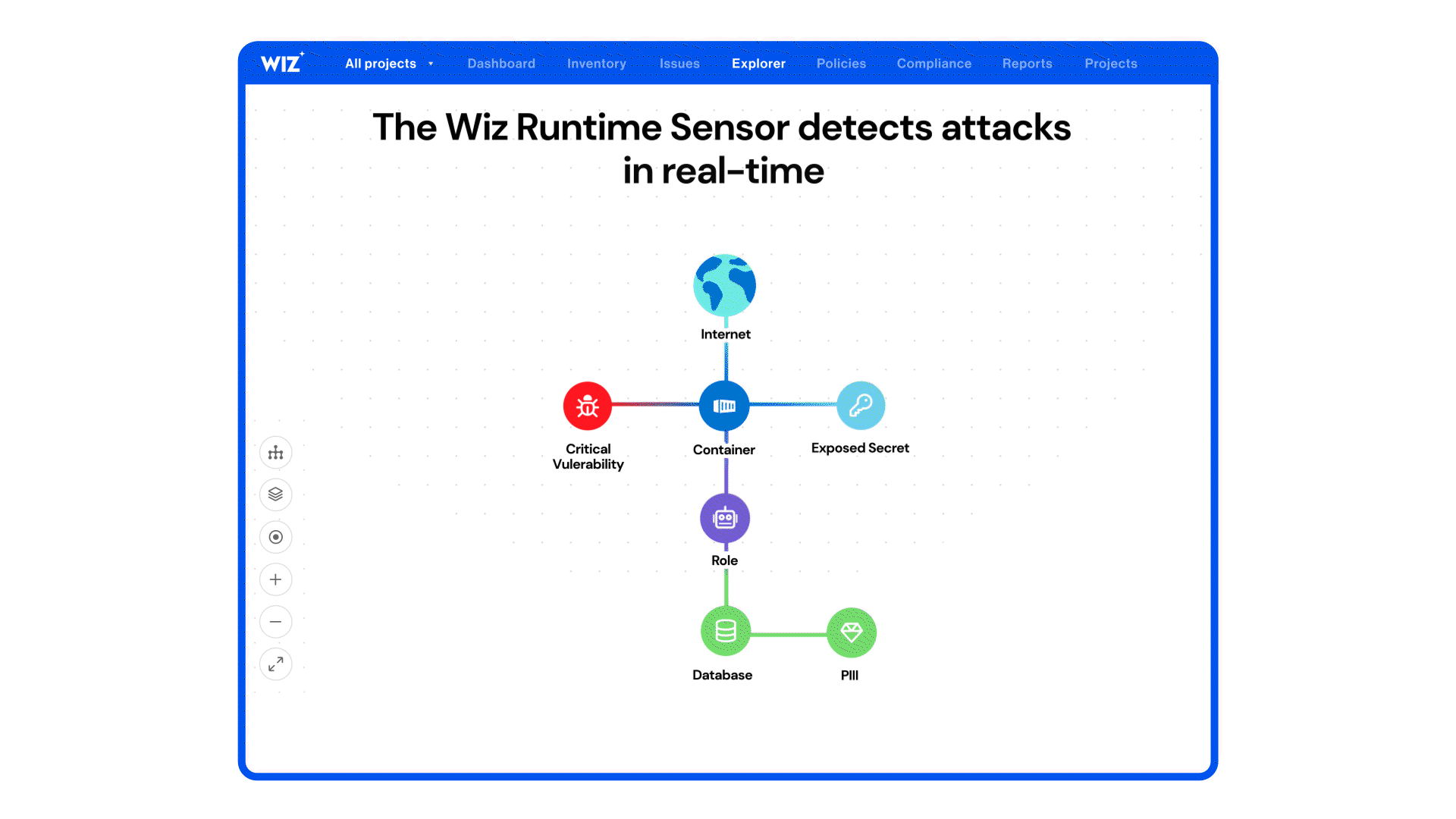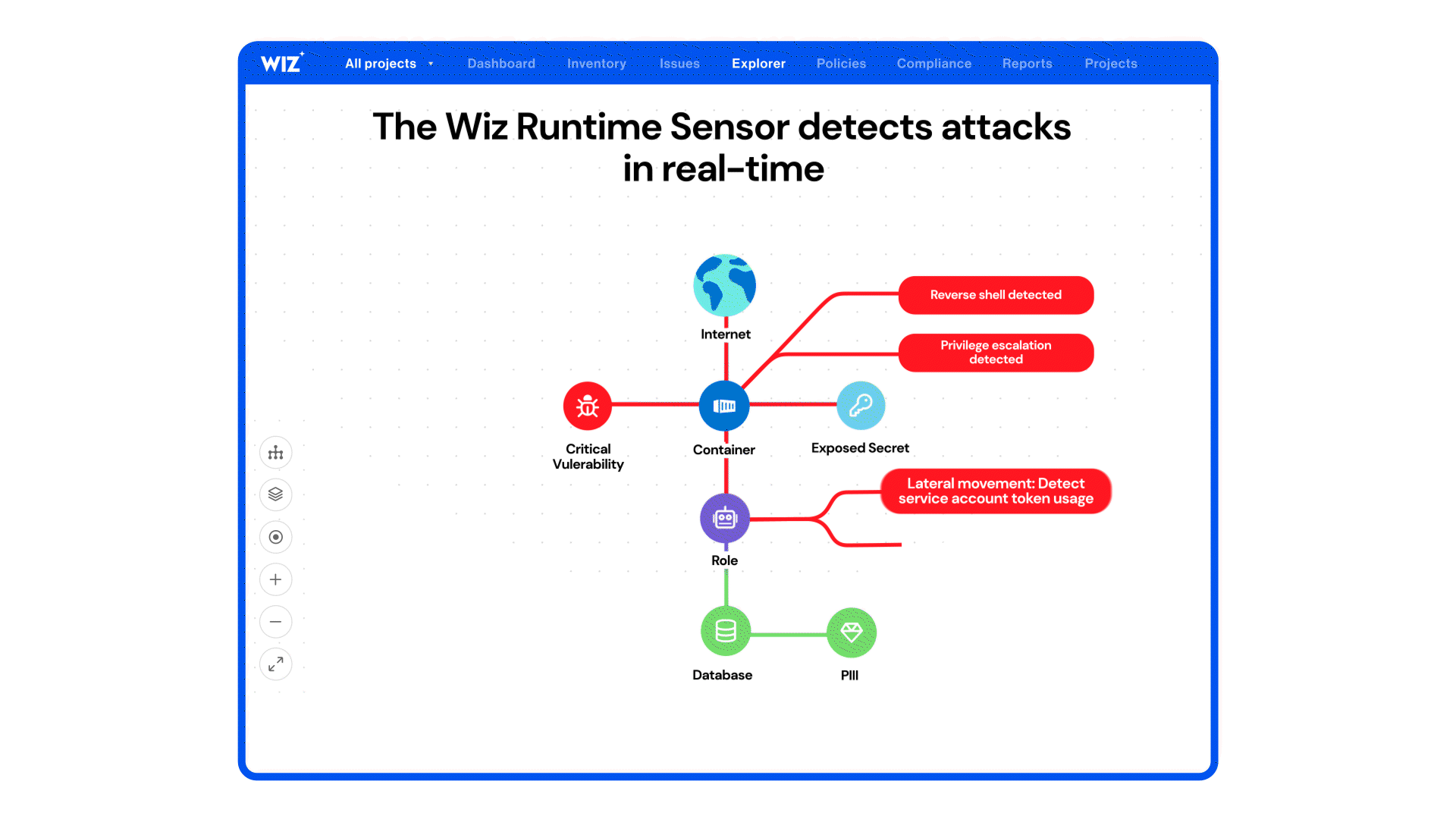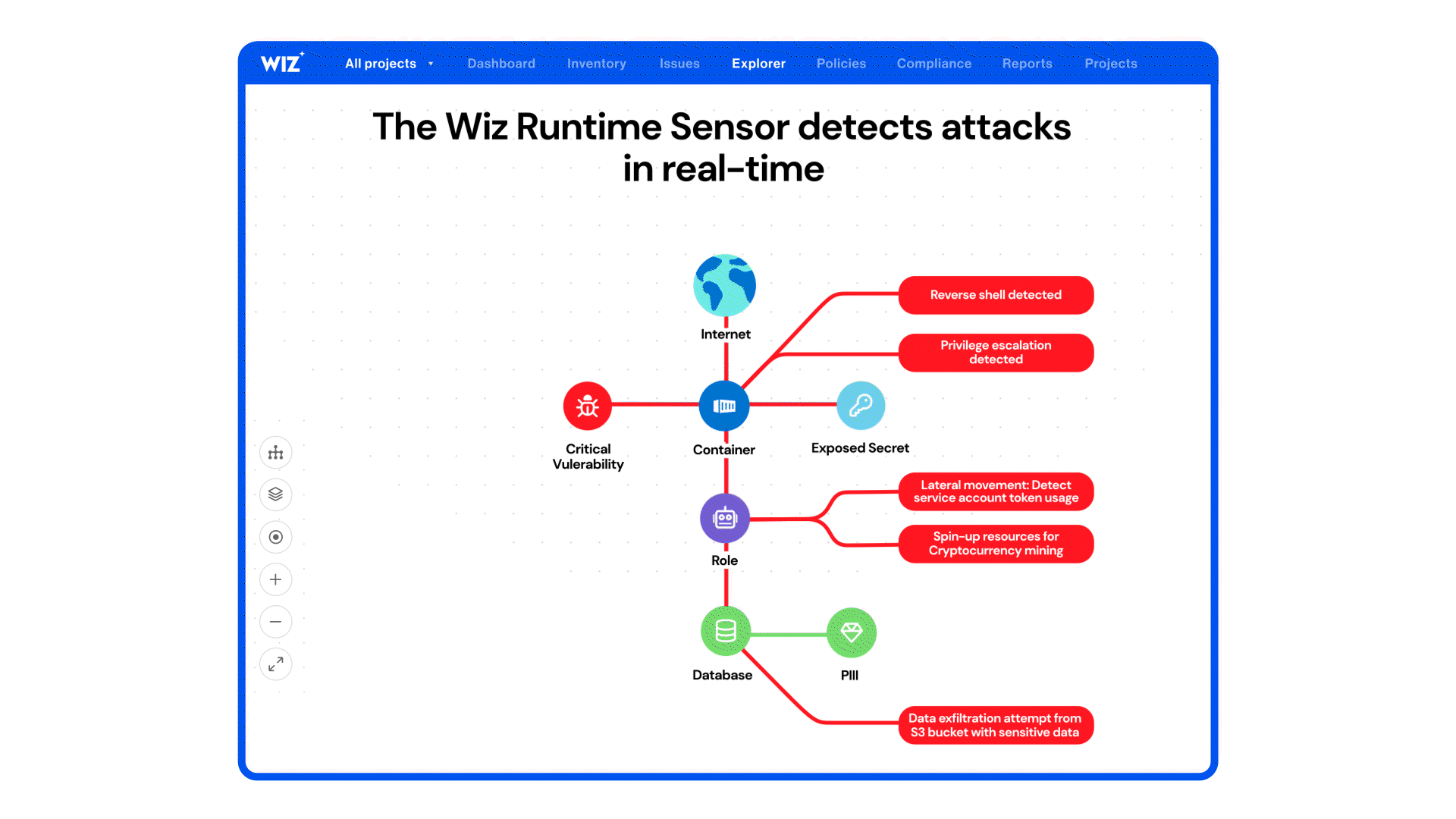
Wiz’s runtime sensor for Windows and cloud-native workloads is positioned around *real‑time threat detection, execution context, and blocking* of suspicious behaviors across containers, VMs, and hybrid environments — framing runtime as a *last line of defense* with hybrid file integrity monitoring and automated responses. ([wiz.io][1])
|
||||
Sysdig’s recent release notes focus on *runtime vulnerability scanning, “in‑use” spotlighting of active vulnerabilities,* and enhancements like cloud response actions in their threat detection feed, but explicit exploitability blocking is handled via policy/risk mechanisms rather than a singular “block here” narrative. ([Sysdig Documentation][2])
|
||||
|
||||
This reinforces a practical buyer theme: *raw runtime telemetry + reproducible blocking artifacts* matter more than UI screenshots alone when evaluating exploitability claims.
|
||||
|
||||
**2) VEX / OpenVEX tooling is still “experimental” in major scanners**
|
||||
Trivy’s documentation still labels VEX support as **experimental**, outlining only basic filtering based on SBOM and VEX documents. ([Trivy][3])
|
||||
Real community issues — like Trivy not suppressing multiple VEX statements for the same CVE when PURLs differ, or tools ignoring OpenVEX at ingestion time — highlight *edge‑case gaps* in practical suppression workflows. ([GitHub][4])
|
||||
|
||||
For procurement, that means *test vectors and compliance scripts* should include VEX corner cases vendors rarely document.
|
||||
|
||||
**3) Signing and attestation practices are evolving but not yet commodity**
|
||||
Industry guidance (e.g., the emerging VeriSBOM research) emphasizes *cryptographically verifiable SBOM assertions using zero‑knowledge proofs*, selective disclosure, and trustless validation.
|
||||
Meanwhile, projects like Chainguard and cosign are promoting SBOM signing recipes and Rekor logs as artifacts, but the *evidence of vendor support (signed DSSE envelopes + inclusion proofs) isn’t broadly published in recent release notes.*
|
||||
|
||||
**Why this matters right now**
|
||||
|
||||
* Runtime claims without *signed evidence or API artifacts* leave buyers unable to prove exploitability coverage in audits.
|
||||
* VEX tooling is improving but still fails on real-world suppression edge cases.
|
||||
* Attestation infrastructure (DSSE + Rekor) is available; what’s missing is *standardized published artifacts* vendors can point to in procurement benchmarks.
|
||||
|
||||
You’re seeing exactly where **procurement acceptance criteria can force conversion of vendor claims into verifiable artifacts** rather than promises. This matters when evaluating CNAPP/CWPP platforms and asking vendors for reproducible evidence — not just UI screenshots or blog posts.
|
||||
|
||||
If you want, I can point you to specific RFCs, SBOM/VEX test cases, and trivy/Grype output examples showing these gaps in action.
|
||||
|
||||
[1]: https://www.wiz.io/blog/wiz-runtime-sensor-for-your-windows-environment?utm_source=chatgpt.com "Cloud-native Security for your Windows environment"
|
||||
[2]: https://docs.sysdig.com/en/release-notes/saas-sysdig-secure-release-notes/?utm_source=chatgpt.com "SaaS: Sysdig Secure Release Notes"
|
||||
[3]: https://trivy.dev/docs/v0.51/supply-chain/vex/?utm_source=chatgpt.com "VEX"
|
||||
[4]: https://github.com/aquasecurity/trivy/discussions/7885?utm_source=chatgpt.com "CycloneDX VEX: Trivy fails to suppress all findings when ..."
|
||||
@@ -0,0 +1,134 @@
|
||||
Here’s a compact, plug‑and‑play blueprint for making **“unknown” a first‑class, auditable state** in your VEX pipeline (fits Stella Ops nicely).
|
||||
|
||||
# Why this matters (quick)
|
||||
|
||||
VEX (OpenVEX/CSAF) often forces binary “affected/not_affected.” In practice, evidence is missing, conflicting, or stale. Treating **unknown** as a deliberate, signed, and replayable decision keeps you compliant (CRA/NIS2/DORA) and operationally honest.
|
||||
|
||||
# Lifecycle & precedence
|
||||
|
||||
```
|
||||
unvalidated
|
||||
→ evidence_ingested
|
||||
→ proof_anchored
|
||||
→ merge_candidate
|
||||
→ merged_outcome { affected | not_affected | unknown }
|
||||
→ scored
|
||||
→ triage
|
||||
```
|
||||
|
||||
* **Default unknown at ingest** if anything is missing/ambiguous.
|
||||
* **Precedence:** latest valid timestamp wins; hard tie → **lexicographic source_id** tie‑break.
|
||||
* Carry a **provenance bundle** with every hop: `{source_id, timestamp, proof_hash}`.
|
||||
* Every **merged outcome** and **score** is **DSSE‑wrapped** and **Rekor‑anchored**.
|
||||
|
||||
# Four readiness gates (fail fast)
|
||||
|
||||
1. **ingest_validation**
|
||||
|
||||
* Schema‑valid OpenVEX/CSAF + DSSE envelope present.
|
||||
* Reject → `unvalidated` (record reasons).
|
||||
|
||||
2. **proof_anchor**
|
||||
|
||||
* Rekor entry (UUID) + inclusion proof persisted.
|
||||
* Reject if no inclusion proof or log not reachable (offline mode: queue + mark `unknown`).
|
||||
|
||||
3. **merge_precheck**
|
||||
|
||||
* Deterministic timestamp precedence; evidence sufficiency (at least one attestation + SBOM ref).
|
||||
* Reject if conflicts unresolved → stay at `proof_anchored` and set target outcome `unknown`.
|
||||
|
||||
4. **scoring_precondition**
|
||||
|
||||
* `replay_success_ratio` (e.g., ≥0.95) on verification of DSSE/rekor bundles + provenance presence.
|
||||
* Reject if below threshold or provenance gaps → do not score; outcome remains `unknown`.
|
||||
|
||||
# Deterministic merge rules
|
||||
|
||||
* Normalize identifiers (CVE, package PURL, image digest).
|
||||
* Collapse equivalent justifications (OpenVEX) and product trees (CSAF).
|
||||
* If any required justification absent or conflicting → **merged_outcome = unknown** with rationale snapshot.
|
||||
* Merge is **idempotent**: same inputs → byte‑identical output and provenance trace.
|
||||
|
||||
# API surface (minimal)
|
||||
|
||||
```
|
||||
POST /v1/vex/ingest
|
||||
Body: DSSE-envelope { payload: OpenVEX|CSAF, signatures:[] }
|
||||
Resp: { state: "evidence_ingested"|"unvalidated", provenance_bundle, rekor_hint? }
|
||||
|
||||
POST /v1/vex/merge
|
||||
Body: { product_ref, candidates:[{openvex_or_csaf_ref, provenance_bundle}], strategy:"timestamp_lexi_tiebreak" }
|
||||
Resp: { merged_outcome, provenance_trace[], dsse_signed_merged }
|
||||
|
||||
POST /v1/score
|
||||
Body: { merged_outcome_ref, policy_id, replay_window }
|
||||
Resp: { signed_score_dsse, replay_verification:{ratio, failures[]}, gate_passed:boolean }
|
||||
|
||||
GET /v1/triage?outcome=unknown
|
||||
Resp: [{ product_ref, vuln_id, last_timestamp, missing_evidence[], next_actions[] }]
|
||||
```
|
||||
|
||||
# Evidence & storage
|
||||
|
||||
* **EvidenceLocker** (your module) keeps: raw docs, DSSE envelopes, Rekor inclusion proofs, SBOM/attestation refs, provenance bundles.
|
||||
* Hash all decision artifacts; store `{artifact_hash → Rekor UUID}` map.
|
||||
* Offline/air‑gap: stage to local transparency log; when online, **bridge** to Rekor and backfill inclusion proofs.
|
||||
|
||||
# Scoring model (example)
|
||||
|
||||
* Base score source (e.g., CVSS/CVSS‑SR).
|
||||
* Dampener if outcome=`unknown`: apply policy (e.g., cap at 6.9 or bump to triage queue).
|
||||
* Require `replay_success_ratio ≥ threshold` and `provenance.complete=true` before emitting scores.
|
||||
|
||||
# Acceptance tests (must‑pass)
|
||||
|
||||
1. **missing_evidence_defaults_unknown**
|
||||
|
||||
* Ingest CSAF missing justification → merged outcome is `unknown` with rationale.
|
||||
|
||||
2. **dsse_anchor_presence**
|
||||
|
||||
* Attempt score without Rekor inclusion → gate fails.
|
||||
|
||||
3. **timestamp_precedence_tiebreak**
|
||||
|
||||
* Two equal timestamps from different sources → lexicographic `source_id` decides, deterministic.
|
||||
|
||||
4. **merge_idempotence**
|
||||
|
||||
* Re‑run merge with same inputs → identical `dsse_signed_merged` hash.
|
||||
|
||||
5. **scoring_gate_replay_success**
|
||||
|
||||
* Corrupt one signature in replay set → `replay_success_ratio` drops; scoring blocked.
|
||||
|
||||
# CLI hints (nice DX)
|
||||
|
||||
```
|
||||
stella vex ingest --file advisories/openvex.json --sign key.pem --rekor-url $REKOR
|
||||
stella vex merge --product my/image:sha256:… --inputs dir:./evidence
|
||||
stella score --policy default --replay-window 30d
|
||||
stella triage --outcome unknown --limit 50
|
||||
```
|
||||
|
||||
# UI touchpoints (lean)
|
||||
|
||||
* **Evidence Ingest**: file drop (OpenVEX/CSAF), DSSE status, Rekor anchor badge.
|
||||
* **Merge Review**: side‑by‑side justifications, conflicts, deterministic decision summary.
|
||||
* **Scoring Gate**: replay bar (ratio), provenance checklist.
|
||||
* **Triage (unknown)**: prioritized queue with “missing evidence” chips and one‑click requests.
|
||||
|
||||
# Drop‑in for Stella Ops modules
|
||||
|
||||
* **Concelier**: orchestrates gates.
|
||||
* **Attestor**: DSSE wrap/verify.
|
||||
* **EvidenceLocker**: storage + provenance.
|
||||
* **AdvisoryAI**: explanation/triage suggestions (surfacing unknowns first).
|
||||
* **ReleaseOrchestrator**: policy “block if unknown>0 and critical path”.
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* a ready OpenAPI spec for the 4 endpoints,
|
||||
* the DSSE/Rekor wiring stubs (C#) and a minimal SQLite/Postgres schema,
|
||||
* a Playwright test suite implementing the five acceptance tests.
|
||||
@@ -0,0 +1,21 @@
|
||||
You’re seeing three converging waves in modern security and DevOps — **runtime‑oriented defenses**, **supply‑chain transparency and attestation**, and **composable toolchains that scale with CI/CD** — because the threat landscape has shifted toward live environments, AI‑driven execution, and complex open‑source stacks, and the ecosystem has responded with focused platforms and standards that make these problems tractable at scale.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
Across the market and research, **runtime protection platforms** emphasize *real‑time telemetry, context enrichment, and proactive intervention* — they don’t just passively collect logs, they fuse execution signals with identity, cloud events, and behavioral analytics to identify and stop threats as workloads actually run (not just at build time). This is why modern CNAPP/CDR offerings correlate telemetry across endpoints, cloud, and identity to generate low‑latency detections and dynamic policy enforcement. ([CrowdStrike][1])
|
||||
|
||||
At the same time, **SBOMs and attestation frameworks like SLSA** are establishing *verifiable supply‑chain transparency* — listing every component and dependency with metadata, signing them, and enabling downstream tools to check integrity and compliance throughout the artifact lifecycle. There’s even cutting‑edge work on *verifiable SBOM sharing* that uses cryptographic proofs to expose only what third parties need to see without leaking proprietary details. ([wiz.io][2])
|
||||
|
||||
Finally, the ecosystem of **modular, open toolchains** — SBOM generators, fast scanners, delta‑aware engines, and CI/CD integrations — lets teams assemble automated pipelines that produce inventory, scan for vulnerabilities, prioritize changes, and enforce policies before and after deployment. Popular combos like Syft + Grype or Trivy illustrate how these components can be stitched into existing DevOps workflows. ([ox.security][3])
|
||||
|
||||
**What’s key across all patterns is protecting any workload, anywhere — at runtime — by blending deep visibility, cryptographically anchored supply‑chain integrity, and composable automation that works inside modern CI/CD lifecycles.**
|
||||
|
||||
[1]: https://www.crowdstrike.com/en-us/press-releases/crowdstrike-to-acquire-seraphic-security/?utm_source=chatgpt.com "CrowdStrike to Acquire Seraphic, Turning Any Browser into ..."
|
||||
[2]: https://www.wiz.io/academy/application-security/top-open-source-sbom-tools?utm_source=chatgpt.com "The Top 11 Open-Source SBOM Tools"
|
||||
[3]: https://www.ox.security/blog/sbom-tools/?utm_source=chatgpt.com "Top 5 SBOM Tools for Securing the Software Supply Chain"
|
||||
@@ -0,0 +1,32 @@
|
||||
I’m sharing this because the building blocks you’re spec’ing — vulnerability characteristics, probability models, canonical hashing, and secure signing — are all *real, published standards and data sources* that can be directly referenced when you’re implementing or validating a deterministic portfolio of risk scores.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
At the core of what you’re tying together:
|
||||
|
||||
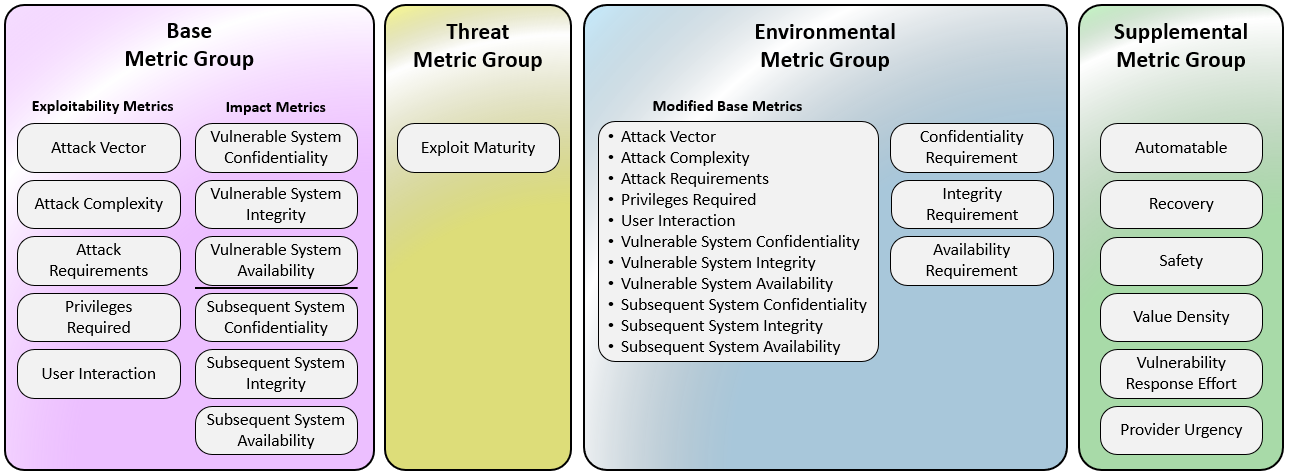
**• CVSS v4.0** defines how to mathematically derive a base score from vulnerability attributes (attack vector, impact, etc.) in a standardized way. v4.0 was formalized with its own specification and scoring methodology that returns 0–10 values based on those metrics. ([first.org][1])
|
||||
|
||||
**• EPSS (Exploit Prediction Scoring System)** generates a probability that a given vulnerability will be *exploited in the wild* — a complementary input to severity scores like CVSS. It’s updated from historical exploit data and uses machine‑learning models to assign likelihoods between 0 and 1 that a CVE will be exploited within a time window. ([Splunk][2])
|
||||
|
||||
**• JSON Canonicalization Scheme (RFC 8785)** provides a *deterministic representation* of JSON data for hashing and signing. It defines how whitespace, object order, and number formats must be normalized so that repeated canonicalization yields identical outputs for the same logical payload — a prerequisite for reproducible fingerprints. ([RFC Editor][3])
|
||||
|
||||
These standards, taken together, support building a deterministic scoring pipeline that:
|
||||
|
||||
* **normalizes inputs** (CVSS vectors, EPSS probabilities, tri‑state VEX outcomes) based on published metrics and schemas;
|
||||
* **applies arithmetic and normalization rules** with clear rounding/quantization policies;
|
||||
* **serializes and canonicalizes** the scoring output into a reproducible byte sequence;
|
||||
* **hashes and signs** the canonical JSON payload to produce verifiable artifacts.
|
||||
|
||||
Established specifications like CVSS and JCS ensure that any implementation that *recreates their canonical form and numeric results* can be verified independently by recomputing hashes and signature checks, which is exactly what a robust, deterministic scoring spec would require. ([first.org][1])
|
||||
|
||||
If you’re incorporating EPSS data into that score, be aware that EPSS scores are probabilistic predictions that change over time — typically published daily — and the snapshot date must be included in your deterministic inputs so that different runs with the same snapshot yield identical results. ([Splunk][2])
|
||||
|
||||
[1]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://www.splunk.com/en_us/blog/learn/epss-exploit-prediction-scoring-system.html?utm_source=chatgpt.com "Exploit Prediction Scoring System (EPSS): How It Works ..."
|
||||
[3]: https://www.rfc-editor.org/rfc/rfc8785.pdf?utm_source=chatgpt.com "RFC 8785: JSON Canonicalization Scheme (JCS)"
|
||||
@@ -0,0 +1,53 @@
|
||||
I’m sharing this because there’s a **growing research and open‑source ecosystem around *auditable, semantic‑aware diffing of software artifacts*** — a blend of chunk‑level delta encoding, binary semantic similarity, and provenance that your excerpt hints at so strongly.
|
||||
|
||||
---
|
||||
|
||||
### Cutting‑edge methods for semantic and content‑defined diffing
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
At least two distinct veins of research are relevant:
|
||||
|
||||
**1. Advanced content‑defined chunking with strict guarantees** — beyond classic Rabin‑based CDC
|
||||
A very recent algorithm called **Chonkers** offers a new way to do CDC such that **chunk sizes stay bounded and local edits only minimally shift boundaries**, something older approaches like standard anchor or rolling‑hash CDC can’t promise. It achieves this with a layered construction and priority‑based merging to get provable bounds on both *size* and *locality*, with potential for better deduplication and delta accuracy. ([arXiv][1])
|
||||
|
||||
* Rabin and anchor methods remain useful for simple CDC, but are often unpredictable under adversarial inputs.
|
||||
* Chonkers introduces new primitives that could underpin more stable delta manifests like what your spec describes, hence why it’s being cited in contexts of **auditable smart diffing**. ([arXiv][1])
|
||||
|
||||
**2. Binary semantic similarity via graph‑based diffing** — beyond byte or text diff tools
|
||||
There’s active research on **semantic graph diffing**, where control‑flow / semantic graphs are compared instead of plain bytes or instruction streams. One referenced technique called *SemDiff* extracts key semantic behaviors from binaries, builds a graph, and then quantifies similarity. ([arXiv][2])
|
||||
|
||||
* This aligns with “function‑level matching → semantic graph diff → normalized IR hash” workflows your spec outlines.
|
||||
* The idea is that *different compilations or minor reordering won’t break a semantic match*, meaning you get more robust detection of real behavioral change. ([arXiv][2])
|
||||
|
||||
A widely used **open‑source diffing tool** in the binary analysis space is **Diaphora**, a plugin for IDA Pro that does graph and control‑flow diffing with heuristics and similarity scoring. ([GitHub][3])
|
||||
|
||||
* While not designed for automation at CI scale, it’s a strong practical reference for function‑level matching heuristics.
|
||||
* Automated pipelines often export Diaphora data to *sqlite* and then do custom post‑processing. ([Orange Cyberdefense][4])
|
||||
|
||||
---
|
||||
|
||||
### Why all this matters for your delta + provenance model
|
||||
|
||||
Across CDC research like Chonkers and semantics‑based binary diffing, three themes consistently emerge:
|
||||
|
||||
* **Deterministic chunk boundaries** help generate reproducible “delta manifests” that can be hashed and signed reliably — vital for verifiers.
|
||||
* **Semantic matching** (beyond raw content) lets you reason about *behavioral* changes instead of just byte changes.
|
||||
* **Provenance integration** (e.g., attestations + canonicalization) provides end‑to‑end auditability from source → build → diff → verification.
|
||||
|
||||
These research directions give concrete primitives and trade‑offs for the knobs in your smart‑diff spec, from CDC params to semantic graph confidence scoring — and they’re grounded in **current state‑of‑the‑art academic + OSS tooling**. ([arXiv][1])
|
||||
|
||||
---
|
||||
|
||||
If you want, I can drill into *each research paper/tool* and extract the key algorithmic insights that map directly to your schema (e.g., how SemDiff’s graph hashing aligns with your function_change_impact score), or show where standard Rust/LLVM + CDC libraries already implement pieces of this.
|
||||
|
||||
[1]: https://arxiv.org/abs/2509.11121?utm_source=chatgpt.com "The Chonkers Algorithm: Content-Defined Chunking with Strict Guarantees on Size and Locality"
|
||||
[2]: https://arxiv.org/abs/2308.01463?utm_source=chatgpt.com "SemDiff: Binary Similarity Detection by Diffing Key-Semantics Graphs"
|
||||
[3]: https://github.com/joxeankoret/diaphora?utm_source=chatgpt.com "Diaphora - program diffing tool"
|
||||
[4]: https://www.orangecyberdefense.com/global/blog/research/introduction-to-binary-diffing-part-2?utm_source=chatgpt.com "Introduction to Binary Diffing – Part 2"
|
||||
@@ -0,0 +1,171 @@
|
||||
Here’s a compact, practical design for a **smart‑difference scanner** that produces tiny, verifiable binary deltas and plugs cleanly into a release/provenance workflow—explained from the ground up.
|
||||
|
||||
---
|
||||
|
||||
# What this thing does (in plain words)
|
||||
|
||||
It compares two software artifacts (containers, packages, binaries), computes the *smallest safe update* between them, and emits both:
|
||||
|
||||
* a **delta** (what to apply),
|
||||
* and **proof** (why it’s safe and who built it).
|
||||
|
||||
You get faster rollouts, smaller downloads, and auditable provenance—plus a built‑in rollback that’s just as verifiable.
|
||||
|
||||
---
|
||||
|
||||
# Core idea
|
||||
|
||||
1. **Content‑defined chunking (CDC)**
|
||||
Split files into variable‑size chunks using Rabin/CDC, so similar regions line up even if bytes shift. Build a **Merkle DAG** over the chunks.
|
||||
2. **Deterministic delta ops**
|
||||
Delta = ordered ops: `COPY <chunk-id>` or `ADD <chunk-bytes>`. No “magic heuristics”; same inputs → same delta.
|
||||
3. **Function‑level diffs (executables only)**
|
||||
For ELF/PE, disassemble and compare by symbol/function to highlight *semantic* changes (added/removed/modified functions), but still ship chunk‑level ops for patching.
|
||||
4. **Verification & attestation**
|
||||
Every delta links to attestations (SLSA/DSSE/cosign/Rekor) so a verifier can check builder identity, materials, and inclusion proofs **offline**.
|
||||
|
||||
---
|
||||
|
||||
# Supported inputs
|
||||
|
||||
* **Blobs**: OCI layers, .deb/.rpm payloads, zip/jar/war
|
||||
* **Binaries**: ELF/PE segments (per‑section CDC first, then optional symbol compare)
|
||||
|
||||
---
|
||||
|
||||
# Artifacts the scanner emits
|
||||
|
||||
**`delta-manifest.json` (deterministic):**
|
||||
|
||||
* `base_digest`, `target_digest`, `artifact_type`
|
||||
* `changed_chunks[]` (ids, byte ranges)
|
||||
* `ops[]` (COPY/ADD sequence)
|
||||
* `functions_changed` (added/removed/modified counts; top symbols)
|
||||
* `materials_delta` (new/removed deps & digests)
|
||||
* `attestations[]` (DSSE/cosign refs, Rekor log pointers or embedded CT tile)
|
||||
* `score_inputs` (pre‑computed metrics to keep scoring reproducible)
|
||||
|
||||
The actual **delta payload** is a compact binary: header + op stream + ADD byte blobs.
|
||||
|
||||
---
|
||||
|
||||
# How verification works (offline‑first)
|
||||
|
||||
* **Content addressability**: chunk ids are hashes; COPY ops verify by recomputing.
|
||||
* **Attestations**: DSSE/cosign bundle includes builder identity and `materials[]` digests. Rekor inclusion proof (or embedded tile fragment) lets verifiers reassemble the transparency chain without the Internet.
|
||||
* **Policy**: if SLSA predicate present and policy threshold met → “green”; else fall back to vendor signature + content checks and mark **provenance gaps**.
|
||||
|
||||
---
|
||||
|
||||
# Risk scoring (explainable)
|
||||
|
||||
Compute a single `delta_risk` from:
|
||||
|
||||
* `provenance_completeness` (SLSA level, DSSE validity, Rekor inclusion)
|
||||
* `delta_entropy` (how many new bytes vs copies; unexpected high entropy is riskier)
|
||||
* `new_deps_count` (materials delta)
|
||||
* `signed_attestation_validity` (key/trust chain freshness)
|
||||
* `function_change_impact` (count/criticality of changed symbols)
|
||||
|
||||
Expose the **breakdown** directly in UI so reviewers see *why* the score is what it is.
|
||||
|
||||
---
|
||||
|
||||
# Rollback that’s actually safe
|
||||
|
||||
* Rollback is just “apply delta going to previous artifact” **plus** a **signed rollback attestation** anchored in the transparency log.
|
||||
* Verifier refuses rollbacks without matching provenance or if the computed rollback delta doesn’t reproduce the earlier artifact’s digest.
|
||||
|
||||
---
|
||||
|
||||
# Minimal internal data structures (sketch)
|
||||
|
||||
```txt
|
||||
Chunk {
|
||||
id: sha256(bytes),
|
||||
size: u32,
|
||||
merkle: sha256(left||right)
|
||||
}
|
||||
|
||||
DeltaOp = COPY {chunk_id} | ADD {len, bytes}
|
||||
|
||||
DeltaManifest {
|
||||
base_digest, target_digest, artifact_type,
|
||||
ops[], changed_chunks[],
|
||||
functions_changed: {added[], removed[], modified[]},
|
||||
materials_delta: {added[], removed[]},
|
||||
attestations: {dsse_bundle_ref, rekor_inclusion[]},
|
||||
score_inputs: {provenance, entropy, deps, attestation_validity, fn_impact}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# Pipeline (end‑to‑end)
|
||||
|
||||
1. **Ingest** base & target → normalize (strip nondeterministic metadata; preserve signatures).
|
||||
2. **CDC pass** → chunk map → Merkle DAGs.
|
||||
3. **Delta construction** (greedy minimal ADDs, prefer COPY of identical chunk ids).
|
||||
4. **(Executables)** symbol table → lightweight disassembly → function map diff.
|
||||
5. **Attestation linkage** → attach DSSE bundle refs + Rekor proofs.
|
||||
6. **Scoring** → deterministic `delta_risk` + breakdown.
|
||||
7. **Emit** `delta.manifest` + `delta.bin`.
|
||||
|
||||
---
|
||||
|
||||
# UI: what reviewers see
|
||||
|
||||
* **Top changed functions** (name, section, size delta, call‑fanout hint)
|
||||
* **Provenance panel** (SLSA level, DSSE signer, Rekor entry—click to open)
|
||||
* **Delta anatomy** (COPY/ADD ratio, entropy, bytes added)
|
||||
* **Dependencies delta** (new/removed materials with digests)
|
||||
* **“Apply” / “Rollback”** buttons gated by policy & attestation validity
|
||||
|
||||
---
|
||||
|
||||
# How this fits your Stella Ops stack (drop‑in plan)
|
||||
|
||||
* **Module**: add `DeltaScanner` service under Evidence/Attestor boundary.
|
||||
* **Air‑gap**: store DSSE bundles and Rekor tile fragments alongside artifacts in EvidenceLocker.
|
||||
* **SBOM/VEX**: on delta, also diff SBOM nodes and attach a *delta‑SBOM* for impacted components; feed VEX evaluation to **AdvisoryAI** for surfaced risk notes.
|
||||
* **Release gates**: block promotion if `delta_risk > threshold` or `provenance_completeness < policy`.
|
||||
* **CLI**: `stella delta create|verify|apply|rollback --base A --target B --policy policy.yaml`.
|
||||
|
||||
---
|
||||
|
||||
# Implementation notes (concise)
|
||||
|
||||
* **CDC**: Rabin fingerprinting window 48–64B; average chunk 4–16 KiB; rolling mask yields boundaries.
|
||||
* **Hashing**: BLAKE3 for speed; SHA‑256 for interop (store both if needed).
|
||||
* **Disassembly**: Capstone/llvm‑objdump (ELF/PE), symbol map fallback if stripped.
|
||||
* **Determinism**: fix chunk params, hash orderings, and traversal; sort tables prior to emit.
|
||||
* **Security**: validate all COPY targets exist in base; cap ADD size; verify DSSE before score.
|
||||
|
||||
---
|
||||
|
||||
# Deliverables you can ship quickly
|
||||
|
||||
* `delta-scanner` lib (CDC + DAG + ops)
|
||||
* `delta-verify` (attestations, Rekor proof check offline)
|
||||
* `delta-score` (pure function over `delta-manifest`)
|
||||
* UI panels: Delta, Provenance, Risk (reuse Stella’s style system)
|
||||
* CI job: create delta + attach DSSE + upload to EvidenceLocker
|
||||
|
||||
---
|
||||
|
||||
# Test matrix (essentials)
|
||||
|
||||
* Small edit in large file (ADD minimal)
|
||||
* Repacked zip with same payload (COPY dominates)
|
||||
* Stripped vs non‑stripped ELF (function compare graceful)
|
||||
* Added dependency layer in OCI (materials_delta flagged)
|
||||
* Missing SLSA but valid vendor sig (gap recorded, lower score)
|
||||
* Rollback with/without signed rollback attestation (accept/deny)
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* a ready‑to‑commit **Go/.NET** reference implementation skeleton,
|
||||
* a **policy.yaml** template with thresholds,
|
||||
* and **UI wireframes** (ASCII + Mermaid) for the three panels.
|
||||
@@ -0,0 +1,128 @@
|
||||
Here’s a compact, practical pattern for making runtime traces auditable end‑to‑end—so every stack frame ties back to a signed build and can be replayed deterministically.
|
||||
|
||||
# Why this matters (in plain terms)
|
||||
|
||||
When something crashes or behaves oddly, you want to prove **which code** actually ran, **who built it**, **with what flags**, and **replay it**. The pattern below links: **trace → symbol bundle → build artifact → signed provenance**, and stores small “replay harness” contracts so auditors (or future you) can reproduce the run.
|
||||
|
||||
---
|
||||
|
||||
## 1) Join model: trace → symbols → artifacts → provenance
|
||||
|
||||
Use content‑addressed keys that already exist in your toolchain:
|
||||
|
||||
* Frames: instruction pointer (IP), build‑id
|
||||
* Symbols: symbol bundle hash (e.g., `sha256` of PDB/dSYM/ELF DWARF bundle)
|
||||
* Artifacts: release image/object `sha256`, compiler, flags, commit
|
||||
* Provenance: DSSE envelope + Rekor inclusion proof (tile ref)
|
||||
|
||||
**SQL pattern (drop‑in for Postgres):**
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
f.trace_id,
|
||||
f.frame_index,
|
||||
f.ip,
|
||||
f.resolved_symbol,
|
||||
s.sha256 AS symbol_bundle,
|
||||
a.artifact_id,
|
||||
a.builder_commit,
|
||||
a.compiler,
|
||||
a.compiler_flags,
|
||||
a.provenance_dsse
|
||||
FROM frames f
|
||||
JOIN symbol_bundles s
|
||||
ON f.symbol_bundle_sha256 = s.sha256
|
||||
JOIN artifacts a
|
||||
ON s.origin_artifact_sha256 = a.sha256
|
||||
WHERE f.trace_id = $1
|
||||
ORDER BY f.frame_index;
|
||||
```
|
||||
|
||||
This yields a per‑frame audit trail from **IP → symbol → artifact → signed provenance**.
|
||||
|
||||
**Content‑addressed keys you can leverage:**
|
||||
|
||||
* Linux: function blob `sha256`, `build-id` note
|
||||
* Windows: PDB `GUID+Age`
|
||||
* macOS: dSYM `UUID`
|
||||
* OCI: layer/config `sha256`
|
||||
|
||||
---
|
||||
|
||||
## 2) Minimal “replay harness” contract (store per trace/run)
|
||||
|
||||
Keep a tiny JSON alongside the trace row (e.g., `replays.replay_manifest JSONB`). It pins environment, symbols, and evidence pointers:
|
||||
|
||||
```json
|
||||
{
|
||||
"harness_version": "1",
|
||||
"os": "linux|windows|macos",
|
||||
"kernel_version": "5.x|10.x|..",
|
||||
"libc_version": "glibc 2.3.4",
|
||||
"compiler": "gcc 12.1",
|
||||
"compiler_flags": "-g -O2 -fno-omit-frame-pointer",
|
||||
"build_id": "<id>",
|
||||
"symbol_bundle_sha256": "sha256:...",
|
||||
"dsse_envelope": "dsse:...",
|
||||
"rekor_tile_ref": "rekor:...",
|
||||
"sandbox_image_sha256": "sha256:...",
|
||||
"seed": 123456,
|
||||
"run_instructions": "deterministic-run.sh --seed $seed",
|
||||
"verifier_version": "v1.2.3"
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3) Acceptance & auditor checks (automatable)
|
||||
|
||||
1. **Evidence integrity**
|
||||
|
||||
* Verify DSSE (signature + subject)
|
||||
* Verify Rekor inclusion proof matches `rekor_tile_ref`
|
||||
2. **Provenance join completeness**
|
||||
|
||||
* ≥95% of top‑N frames resolve to symbol bundles and linked artifacts
|
||||
3. **Reproducible replay**
|
||||
|
||||
* Harness run achieves `replay_success_ratio ≥ 95%`
|
||||
* For “forensic” policy: bit‑identical final state
|
||||
4. **Chain‑of‑custody**
|
||||
|
||||
* Each join includes signer identity, timestamp, and `insertion_rekor_tile_ref`
|
||||
|
||||
---
|
||||
|
||||
## 4) Operational recommendations (Stella Ops‑ready)
|
||||
|
||||
* **Gate symbol intake**: require SLSA/in‑toto/DSSE attestation before accepting symbol bundles.
|
||||
* **Persist replay contracts**: store the JSON above next to each trace (Postgres JSONB).
|
||||
* **One‑click “Audit bundle” export**: deliver `{trace, symbol_bundles, DSSE envelopes, Rekor tile fragments, replay harness}` as a **content‑addressed** archive for offline/legal review.
|
||||
* **Policies**: make “join completeness” and “replay ratio” first‑class pass/fail gates in EvidenceLocker.
|
||||
|
||||
---
|
||||
|
||||
## 5) Where this plugs into Stella Ops
|
||||
|
||||
* **EvidenceLocker**: stores DSSE, Rekor fragments, and replay manifests.
|
||||
* **Attestor**: validates DSSE + Rekor, stamps chain‑of‑custody.
|
||||
* **ReleaseOrchestrator**: enforces “no symbols without attestation”.
|
||||
* **Doctor**: offers a “Reproduce this crash” action that pulls the harness and runs it in a pinned sandbox.
|
||||
* **AdvisoryAI**: can surface “provenance gaps” and recommend remediation (e.g., missing dSYM, mismatched PDB Age).
|
||||
|
||||
---
|
||||
|
||||
## 6) Quick backlog (bite‑sized tasks)
|
||||
|
||||
* Tables: `frames`, `symbol_bundles`, `artifacts`, `provenance_evidence`, `replays` (JSONB).
|
||||
* Ingestors: symbol bundle hasher; artifact provenance fetcher; Rekor proof cache.
|
||||
* Verifiers: DSSE verify, Rekor inclusion verify, join‑completeness scorer, replay runner.
|
||||
* UI: Trace view with “Audit bundle” download + policy badges (join %, replay %, signer).
|
||||
|
||||
If you want, I can draft the Postgres DDL + a tiny Go/TS service that:
|
||||
|
||||
1. ingests a trace,
|
||||
2. resolves frames against symbols,
|
||||
3. joins to artifacts via `sha256/build-id/PDB GUID+Age/dSYM UUID`,
|
||||
4. verifies DSSE/Rekor,
|
||||
5. emits the replay manifest and an exportable audit bundle.
|
||||
@@ -0,0 +1,163 @@
|
||||
Here’s a compact, end‑to‑end design you can drop into a repo: a **cross‑platform call‑stack analyzer** plus an **offline capture/replay pipeline** with provable symbol provenance—built to behave the same on Linux, Windows, and macOS, and to pass strict CI acceptance tests.
|
||||
|
||||
---
|
||||
|
||||
# What this solves (quick context)
|
||||
|
||||
* **Problem:** stack unwinding differs by OS, binary format, runtime (signals/async/coroutines), and symbol sources—making incident triage noisy and non‑reproducible.
|
||||
* **Goal:** one analyzer that **normalizes unwinding invariants**, **records traces**, **resolves symbols offline**, and **replays** to verify determinism and coverage—useful for Stella Ops evidence capture and air‑gapped flows.
|
||||
|
||||
---
|
||||
|
||||
# Unwinding model (portable)
|
||||
|
||||
* **Primary CFI:** DWARF `.eh_frame` / `.debug_frame` (Linux/macOS), `.pdata` / unwind info (Windows).
|
||||
* **IDs for symbol lookup:**
|
||||
|
||||
* Linux: **ELF build‑id** (`.note.gnu.build-id`)
|
||||
* macOS: **Mach‑O UUID** (dSYM)
|
||||
* Windows: **PDB GUID+Age**
|
||||
* **Fallback chain per frame (strict order, record provenance):**
|
||||
|
||||
1. CFI/CIE lookup (libunwind/LLVM, DIA on Windows, Apple DWARF tools)
|
||||
2. **Frame‑pointer** walk if available
|
||||
3. **Language/runtime helpers** (e.g., Go, Rust, JVM, .NET where present)
|
||||
4. **Heuristic last‑resort** (conservative unwind, stop on ambiguity)
|
||||
* **Async/signal/coroutines:** stitch segments by reading runtime metadata and signal trampolines, then join on saved contexts; tag boundaries so replay can validate.
|
||||
* **Kernel/eBPF contexts (Linux):** optional BTF‑assisted unwind for kernel frames when traces cross user/kernel boundary.
|
||||
|
||||
---
|
||||
|
||||
# Offline symbol bundles (content‑addressed)
|
||||
|
||||
**Required bundle contents (per‑OS id map + index):**
|
||||
|
||||
* **Content‑addressed index** (sha256 keys)
|
||||
* **Per‑OS mapping:**
|
||||
|
||||
* Linux: **build‑id → path/blob**
|
||||
* Windows: **PDB GUID+Age → PDB blob**
|
||||
* macOS: **UUID → dSYM blob**
|
||||
* **`symbol_index.json`** (addr → file:line + function)
|
||||
* **DSSE signature** (+ signer)
|
||||
* **Rekor inclusion proof** or embedded tile fragment (for transparency)
|
||||
|
||||
**Acceptance rules:**
|
||||
|
||||
* `symbol_coverage_pct ≥ 90%` per trace (resolver chain: debuginfod → local bundle → heuristic demangle)
|
||||
* Replay across 5 seeds: `replay_success_ratio ≥ 0.95`
|
||||
* DSSE + Rekor proofs verify **offline**
|
||||
* Platform checks:
|
||||
|
||||
* **ELF build‑id** matches binary note
|
||||
* **PDB GUID+Age** matches module metadata
|
||||
* **dSYM UUID** matches Mach‑O UUID
|
||||
|
||||
---
|
||||
|
||||
# Minimal Postgres schema (ready to run)
|
||||
|
||||
```sql
|
||||
CREATE TABLE traces(
|
||||
trace_id UUID PRIMARY KEY,
|
||||
platform TEXT,
|
||||
captured_at TIMESTAMP,
|
||||
build_id TEXT,
|
||||
symbol_bundle_sha256 TEXT,
|
||||
dsse_ref TEXT
|
||||
);
|
||||
|
||||
CREATE TABLE frames(
|
||||
trace_id UUID REFERENCES traces,
|
||||
frame_index INT,
|
||||
ip BIGINT,
|
||||
module_path TEXT,
|
||||
module_build_id TEXT,
|
||||
resolved_symbol TEXT,
|
||||
symbol_offset BIGINT,
|
||||
resolver TEXT,
|
||||
PRIMARY KEY(trace_id, frame_index)
|
||||
);
|
||||
|
||||
CREATE TABLE symbol_bundles(
|
||||
sha256 TEXT PRIMARY KEY,
|
||||
os TEXT,
|
||||
bundle_blob BYTEA,
|
||||
index_json JSONB,
|
||||
signer TEXT,
|
||||
rekor_tile_ref TEXT
|
||||
);
|
||||
|
||||
CREATE TABLE replays(
|
||||
replay_id UUID PRIMARY KEY,
|
||||
trace_id UUID REFERENCES traces,
|
||||
seed BIGINT,
|
||||
started_at TIMESTAMP,
|
||||
finished_at TIMESTAMP,
|
||||
replay_success_ratio FLOAT,
|
||||
verify_time_ms INT,
|
||||
verifier_version TEXT,
|
||||
notes JSONB
|
||||
);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# Event payloads (wire format)
|
||||
|
||||
```json
|
||||
{"event":"trace.capture","trace_id":"...","platform":"linux","build_id":"<gnu-build-id>","frames":[{"ip":"0x..","module":"/usr/bin/foo","module_build_id":"<id>"}],"symbol_bundle_ref":"sha256:...","dsse_ref":"dsse:..."}
|
||||
|
||||
{"event":"replay.result","replay_id":"...","trace_id":"...","seed":42,"replay_success_ratio":0.98,"symbol_coverage_pct":93,"verify_time_ms":8423}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# Resolver policy (per‑OS, enforced)
|
||||
|
||||
* **Linux:** debuginfod → local bundle (build‑id) → DWARF CFI → FP → heuristic demangle
|
||||
* **Windows:** local bundle (PDB GUID+Age via DIA) → .pdata unwind → FP → demangle
|
||||
* **macOS:** local bundle (dSYM UUID) → DWARF CFI → FP → demangle
|
||||
Record **`resolver`** used on every frame.
|
||||
|
||||
---
|
||||
|
||||
# CI acceptance scripts (tiny but strict)
|
||||
|
||||
* Run capture → resolve → replay across 5 seeds; fail merge if any SLO unmet.
|
||||
* Verify DSSE signature and Rekor inclusion offline.
|
||||
* Assert per‑platform ID matches (build‑id / GUID+Age / UUID).
|
||||
* Emit a short JUnit‑style report plus `% coverage` and `% success`.
|
||||
|
||||
---
|
||||
|
||||
# Implementation notes (drop‑in)
|
||||
|
||||
* Use **libunwind/LLVM** (Linux/macOS), **DIA SDK** (Windows).
|
||||
* Add small shims for **signal trampolines** and **runtime helpers** (Go/Rust/JVM/.NET) when present.
|
||||
* Protobuf or JSON Lines for event logs; gzip + content‑address everything (sha256).
|
||||
* Store **provenance per frame** (`resolver`, source, bundle hash).
|
||||
* Provide a tiny **CLI**:
|
||||
|
||||
* `trace-capture --with-btf --pid ...`
|
||||
* `trace-resolve --bundle sha256:...`
|
||||
* `trace-replay --trace ... --seeds 5`
|
||||
* `trace-verify --bundle sha256:... --dsse --rekor`
|
||||
|
||||
---
|
||||
|
||||
# Why this fits your stack (Stella Ops)
|
||||
|
||||
* **Air‑gap/attestation first:** DSSE, Rekor tile fragments, offline verification—aligns with your evidence model.
|
||||
* **Deterministic evidence:** replayable traces with SLOs → reliable RCA artifacts you can store beside SBOM/VEX.
|
||||
* **Provenance:** per‑frame resolver trail supports auditor queries (“how was this line derived?”).
|
||||
|
||||
---
|
||||
|
||||
# Next steps (ready‑made tasks)
|
||||
|
||||
* Add a **SymbolBundleBuilder** job to produce DSSE‑signed bundles per release.
|
||||
* Integrate **Capture→Resolve→Replay** into CI and gate merges on SLOs above.
|
||||
* Expose a **Stella Ops Evidence card**: coverage%, success ratio, verifier version, and links to frames.
|
||||
|
||||
If you want, I’ll generate a starter repo (CLI skeleton, DSSE/Rekor validators, Postgres migrations, CI workflow, and a tiny sample bundle) so you can try it immediately.
|
||||
@@ -0,0 +1,207 @@
|
||||
Here’s a compact, plug‑and‑play spec for a **Signed Score** ribbon that makes vuln scores deterministic, auditable, and safe to auto‑act on—plus exactly how to wire it into Stella Ops’ evidence and gating flows.
|
||||
|
||||
---
|
||||
|
||||
# What it is (plain words)
|
||||
|
||||
A slim UI ribbon that shows a numeric risk score with a tiny “chevron” to expand details. Every factor (CVSS v4 vector, EPSS probability, call‑stack/confidence) has a **provenance pill** you can click to see the signed, canonical inputs that produced it. A **Verify** button deterministically replays the calculation and surfaces three live badges: verify time, replay success ratio, and symbol‑coverage. If replay confidence is low, remediation is blocked and the ribbon explains *exactly why*, with signed evidence attached.
|
||||
|
||||
---
|
||||
|
||||
# Quick wireframe (ASCII)
|
||||
|
||||
```
|
||||
[ Signed Score: 7.34 ▾ ] [Verify] [Download reproducibility bundle]
|
||||
Badges: [⏱ ≤3000ms] [✔ Replay ≥95%] [Σ Symbols 82%]
|
||||
Factors:
|
||||
• CVSS v4: AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:L/SC:H/… [Provenance]
|
||||
• EPSS: 0.71 (p75) [Provenance]
|
||||
• Confidence: 0.86 (stack depth=4, frames=io/net/crypto) [Provenance]
|
||||
|
||||
If Replay <95%:
|
||||
! Action gating: auto‑remediation blocked (Δconfidence = -0.11)
|
||||
View audit → [signed_score_dsse] [input hashes diff] [seed] [verifier log]
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# UX behavior (concise)
|
||||
|
||||
* **Collapsed state:** shows numeric score + color (e.g., green ≤4, amber 4–7, red >7).
|
||||
* **Expanded state:** lists factor tiles with provenance pills and short tooltips.
|
||||
* **Provenance pill:** opens an overlay with DSSE verification result and the **exact** canonical inputs used.
|
||||
* **Verify action:** runs a seeded, deterministic replay (client or server). Shows badges:
|
||||
|
||||
* `median_verify_time ≤ 3000ms`
|
||||
* `replay_success_ratio ≥ 95%`
|
||||
* `symbol_coverage_pct` (target configurable)
|
||||
* **Evidence Ribbon:** visual tiny glyphs next to each factor:
|
||||
|
||||
* 🔏 signed (DSSE)
|
||||
* ⛓ rekor‑anchored (transparency log)
|
||||
* 🔁 replayed (this session)
|
||||
* **Download reproducibility bundle:** 1‑click zip (DSSE envelope + JCS‑canonicalized input JSON + replay seed + verifier log).
|
||||
|
||||
---
|
||||
|
||||
# Safety gating (what gets blocked, when)
|
||||
|
||||
* If `replay_success_ratio < 0.95`:
|
||||
|
||||
* Block auto‑remediation or mark finding “Needs Triage”.
|
||||
* Show **confidence delta** vs. last verified run.
|
||||
* Expose `signed_score_dsse`, input hash diff, and verifier stdout for audit.
|
||||
* If `median_verify_time > 3000ms`:
|
||||
|
||||
* Allow action, but warn (perf badge turns ⚠).
|
||||
* If `symbol_coverage_pct < target`:
|
||||
|
||||
* Allow only low‑risk operations; require human approve for destructive ops.
|
||||
|
||||
---
|
||||
|
||||
# Data contracts (lean, ready to implement)
|
||||
|
||||
**RibbonScore dto**
|
||||
|
||||
```json
|
||||
{
|
||||
"score": 7.34,
|
||||
"factors": {
|
||||
"cvss_v4": {
|
||||
"vector": "CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:L/SC:H/...",
|
||||
"provenance_ref": "evidence://cvss/123"
|
||||
},
|
||||
"epss": {
|
||||
"prob": 0.71,
|
||||
"percentile": 0.75,
|
||||
"provenance_ref": "evidence://epss/456"
|
||||
},
|
||||
"confidence": {
|
||||
"value": 0.86,
|
||||
"stack_summary": ["io", "net", "crypto"],
|
||||
"depth": 4,
|
||||
"provenance_ref": "evidence://conf/789"
|
||||
}
|
||||
},
|
||||
"verify": {
|
||||
"seed": "base64...",
|
||||
"median_ms": 1840,
|
||||
"success_ratio": 0.97,
|
||||
"symbol_coverage_pct": 82,
|
||||
"bundle_ref": "evidence://bundle/abc"
|
||||
},
|
||||
"badges": {
|
||||
"time_ok": true,
|
||||
"replay_ok": true,
|
||||
"coverage_ok": false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Provenance object (same shape for every factor)**
|
||||
|
||||
```json
|
||||
{
|
||||
"dsse_envelope_ref": "evidence://dsse/…",
|
||||
"rekor_log_index": 1234567,
|
||||
"rekor_integrated_time": "2026-02-20T12:34:56Z",
|
||||
"inputs": {
|
||||
"canonical_json_jcs_ref": "evidence://inputs/…",
|
||||
"sha256": "…",
|
||||
"sha512": "…"
|
||||
},
|
||||
"verification_result": "PASS|FAIL",
|
||||
"verifier_log_ref": "evidence://log/…"
|
||||
}
|
||||
```
|
||||
|
||||
**Repro bundle (zip layout)**
|
||||
|
||||
```
|
||||
/README.txt
|
||||
/dsse/envelope.json (DSSE, MIN-SIGNATURES=1)
|
||||
/inputs/canonical.json (JCS-canonicalized)
|
||||
/replay/seed.txt
|
||||
/replay/verifier.log
|
||||
/checksums/sha256sum.txt
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# Deterministic replay (engine notes)
|
||||
|
||||
* **Inputs**: CVSS vector string, EPSS p(score) snapshot, call‑stack hash/classification, optional reachability graph hash.
|
||||
* **Canonicalization**: JCS (RFC 8785) on the combined input JSON prior to hashing/signing.
|
||||
* **Hashing**: SHA‑256 primary, SHA‑512 secondary (dual for migration).
|
||||
* **Signing**: DSSE envelope (Stella Ops KMS; PQ‑ready key if available).
|
||||
* **Transparency**: Publish DSSE hash to Rekor‑compatible log (air‑gap mode: local mirror queue).
|
||||
* **Replay**: Use the **seed** + exact inputs; record success/failure per step to compute `replay_success_ratio`.
|
||||
|
||||
---
|
||||
|
||||
# API surface (minimal)
|
||||
|
||||
* `POST /evidence/signed-score/compute`
|
||||
|
||||
* Body: canonical inputs (cvss_v4, epss, confidence_evidence, seed?)
|
||||
* Returns: `RibbonScore` + DSSE attestation
|
||||
* `POST /evidence/signed-score/verify`
|
||||
|
||||
* Body: `signed_score_ref` (or full bundle)
|
||||
* Returns: verify metrics + badges + audit refs
|
||||
* `GET /evidence/bundle/:id/download`
|
||||
|
||||
* Returns: zip bundle above
|
||||
* `POST /evidence/signed-score/gate`
|
||||
|
||||
* Body: `signed_score_ref`, policy `{min_replay:0.95, max_ms:3000, min_symbols:80}`
|
||||
* Returns: `allow|block`, reason, deltas
|
||||
|
||||
---
|
||||
|
||||
# UI component API (frontend)
|
||||
|
||||
```ts
|
||||
<SignedScoreRibbon
|
||||
scoreRef="finding:SR-2026-0215-042"
|
||||
onGateDecision={(d) => showActionButtons(d.allow)}
|
||||
policy={{ minReplay:0.95, maxMs:3000, minSymbols:80 }}
|
||||
/>
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# Storage & integration (Stella Ops modules)
|
||||
|
||||
* **EvidenceLocker**: store DSSE, inputs, logs, bundles; expose `evidence://` URIs.
|
||||
* **Attestor**: sign DSSE; push to Rekor (or queue for offline sync).
|
||||
* **AdvisoryAI**: computes EPSS and confidence features; emits canonical inputs.
|
||||
* **Doctor**: consumes gate decision; blocks risky auto‑fix flows.
|
||||
* **ReleaseOrchestrator**: shows ribbon in pipelines; honors gating on promote/patch.
|
||||
|
||||
---
|
||||
|
||||
# Default policies (good starting values)
|
||||
|
||||
* `min_replay_success_ratio = 0.95`
|
||||
* `max_median_verify_ms = 3000`
|
||||
* `min_symbol_coverage_pct = 80`
|
||||
* Auto‑remediation requires all three badges green; else require human approve.
|
||||
|
||||
---
|
||||
|
||||
# Test plan (very short)
|
||||
|
||||
* Golden test vectors (CVSS, EPSS, stacks) → freeze as canonical JSON → sign.
|
||||
* Fuzz seed variation: replay must yield **identical** numeric score.
|
||||
* Flip single input bit → verification must FAIL; UI shows audit diff.
|
||||
* Degraded symbol map → coverage badge amber; gate blocks destructive ops.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* a ready React component scaffold (TS + minimal CSS),
|
||||
* the JSON Schemas for `RibbonScore` and `Provenance`,
|
||||
* and a small .NET or Go verifier that packs the reproducibility bundle.
|
||||
17
docs-archived/product/advisories/ARCHIVE_LOG_20260304.md
Normal file
17
docs-archived/product/advisories/ARCHIVE_LOG_20260304.md
Normal file
@@ -0,0 +1,17 @@
|
||||
# Advisory Archive Log - 2026-03-04
|
||||
|
||||
| Timestamp (UTC) | Source Name | Archived Name |
|
||||
| --- | --- | --- |
|
||||
| 2026-03-04T13:56:05Z | 2026-02-28 - Auditor‑first differentiator mocks.md | 2026-02-28 - Auditor‑first differentiator mocks.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-02-28 - Five concrete moats with measurable milestones.md | 2026-02-28 - Five concrete moats with measurable milestones.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-02-28 -Closing Stella’s top product and roadmap gaps.md | 2026-02-28 -Closing Stella’s top product and roadmap gaps.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-01 - Auditable ‘unknown’ VEX lifecycle design.md | 2026-03-01 - Auditable ‘unknown’ VEX lifecycle design.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-01 - Three dominant vendor architecture patterns.md | 2026-03-01 - Three dominant vendor architecture patterns.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 - Deterministic scoring formula and DSSE vectors.md | 2026-03-04 - Deterministic scoring formula and DSSE vectors.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 - Smart‑diff algorithm knobs and delta_manifest recipe.md | 2026-03-04 - Smart‑diff algorithm knobs and delta_manifest recipe.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 - Smart‑diff and binary provenance chain.md | 2026-03-04 - Smart‑diff and binary provenance chain.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 - Trace‑to‑source lineage and reproducible replay harness.md | 2026-03-04 - Trace‑to‑source lineage and reproducible replay harness.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 - Unified call‑stack analyzer and micro‑witness schema.md | 2026-03-04 - Unified call‑stack analyzer and micro‑witness schema.md |
|
||||
| 2026-03-04T13:56:05Z | 2026-03-04 -Signed‑score explainability UI pattern.md | 2026-03-04 -Signed‑score explainability UI pattern.md |
|
||||
|
||||
Batch note: all advisories from 2026-02-28 through 2026-03-04 were translated into active sprints and archived.
|
||||
Reference in New Issue
Block a user