archive advisories
This commit is contained in:
@@ -0,0 +1,224 @@
|
||||
# DSSE‑Signed Offline Scanner Updates — Developer Guidelines
|
||||
|
||||
> **Date:** 2025-12-01
|
||||
> **Status:** Advisory draft (from user-provided guidance)
|
||||
> **Scope:** Offline vulnerability DB bundles (Scanner), DSSE+Rekor v2 verification, offline kit alignment, activation rules, ops playbook.
|
||||
|
||||
Here’s a tight, practical pattern to make your scanner’s vuln‑DB updates rock‑solid even when feeds hiccup:
|
||||
|
||||
## Offline, verifiable update bundles (DSSE + Rekor v2)
|
||||
|
||||
**Idea:** distribute DB updates as offline tarballs. Each tarball ships with:
|
||||
|
||||
* a **DSSE‑signed** statement (e.g., in‑toto style) over the bundle hash
|
||||
* a **Rekor v2 receipt** proving the signature/statement was logged
|
||||
* a small **manifest.json** (version, created_at, content hashes)
|
||||
|
||||
**Startup flow (happy path):**
|
||||
|
||||
1. Load latest tarball from your local `updates/` cache.
|
||||
2. Verify DSSE signature against your trusted public keys.
|
||||
3. Verify Rekor v2 receipt (inclusion proof) matches the DSSE payload hash.
|
||||
4. If both pass, unpack/activate; record the bundle’s **trust_id** (e.g., statement digest).
|
||||
5. If anything fails, **keep using the last good bundle**. No service disruption.
|
||||
|
||||
**Why this helps**
|
||||
|
||||
* **Air‑gap friendly:** no live network needed at activation time.
|
||||
* **Tamper‑evident:** DSSE + Rekor receipt proves provenance and transparency.
|
||||
* **Operational stability:** feed outages become non‑events—scanner just keeps the last good state.
|
||||
|
||||
---
|
||||
|
||||
## File layout inside each bundle
|
||||
|
||||
```
|
||||
/bundle-2025-11-29/
|
||||
manifest.json # { version, created_at, entries[], sha256s }
|
||||
payload.tar.zst # the actual DB/indices
|
||||
payload.tar.zst.sha256
|
||||
statement.dsse.json # DSSE-wrapped statement over payload hash
|
||||
rekor-receipt.json # Rekor v2 inclusion/verification material
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Acceptance/Activation rules
|
||||
|
||||
* **Trust root:** pin one (or more) publisher public keys; rotate via separate, out‑of‑band process.
|
||||
* **Monotonicity:** only activate if `manifest.version > current.version` (or if trust policy explicitly allows replay for rollback testing).
|
||||
* **Atomic switch:** unpack to `db/staging/`, validate, then symlink‑flip to `db/active/`.
|
||||
* **Quarantine on failure:** move bad bundles to `updates/quarantine/` with a reason code.
|
||||
|
||||
---
|
||||
|
||||
## Minimal .NET 10 verifier sketch (C#)
|
||||
|
||||
```csharp
|
||||
public sealed record BundlePaths(string Dir) {
|
||||
public string Manifest => Path.Combine(Dir, "manifest.json");
|
||||
public string Payload => Path.Combine(Dir, "payload.tar.zst");
|
||||
public string Dsse => Path.Combine(Dir, "statement.dsse.json");
|
||||
public string Receipt => Path.Combine(Dir, "rekor-receipt.json");
|
||||
}
|
||||
|
||||
public async Task<bool> ActivateBundleAsync(BundlePaths b, TrustConfig trust, string activeDir) {
|
||||
var manifest = await Manifest.LoadAsync(b.Manifest);
|
||||
if (!await Hashes.VerifyAsync(b.Payload, manifest.PayloadSha256)) return false;
|
||||
|
||||
// 1) DSSE verify (publisher keys pinned in trust)
|
||||
var (okSig, dssePayloadDigest) = await Dsse.VerifyAsync(b.Dsse, trust.PublisherKeys);
|
||||
if (!okSig || dssePayloadDigest != manifest.PayloadSha256) return false;
|
||||
|
||||
// 2) Rekor v2 receipt verify (inclusion + statement digest == dssePayloadDigest)
|
||||
if (!await RekorV2.VerifyReceiptAsync(b.Receipt, dssePayloadDigest, trust.RekorPub)) return false;
|
||||
|
||||
// 3) Stage, validate, then atomically flip
|
||||
var staging = Path.Combine(activeDir, "..", "staging");
|
||||
DirUtil.Empty(staging);
|
||||
await TarZstd.ExtractAsync(b.Payload, staging);
|
||||
if (!await LocalDbSelfCheck.RunAsync(staging)) return false;
|
||||
|
||||
SymlinkUtil.AtomicSwap(source: staging, target: activeDir);
|
||||
State.WriteLastGood(manifest.Version, dssePayloadDigest);
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Operational playbook
|
||||
|
||||
* **On boot & daily at HH:MM:** try `ActivateBundleAsync()` on the newest bundle; on failure, log and continue.
|
||||
* **Telemetry (no PII):** reason codes (SIG_FAIL, RECEIPT_FAIL, HASH_MISMATCH, SELFTEST_FAIL), versions, last_good.
|
||||
* **Keys & rotation:** keep `publisher.pub` and `rekor.pub` in a root‑owned, read‑only path; rotate via a separate signed “trust bundle”.
|
||||
* **Defense‑in‑depth:** verify both the **payload hash** and each file’s hash listed in `manifest.entries[]`.
|
||||
* **Rollback:** allow `--force-activate <bundle>` for emergency testing, but mark as **non‑monotonic** in state.
|
||||
|
||||
---
|
||||
|
||||
## What to hand your release team
|
||||
|
||||
* A Make/CI target that:
|
||||
1. Builds `payload.tar.zst` and computes hashes
|
||||
2. Generates `manifest.json`
|
||||
3. Creates and signs the **DSSE statement**
|
||||
4. Submits to Rekor (or your mirror) and saves the **v2 receipt**
|
||||
5. Packages the bundle folder and publishes to your offline repo
|
||||
* A checksum file (`*.sha256sum`) for ops to verify out‑of‑band.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can turn this into a Stella Ops spec page (`docs/modules/scanner/offline-bundles.md`) plus a small reference implementation (C# library + CLI) that drops right into your Scanner service.
|
||||
|
||||
---
|
||||
|
||||
# Drop‑in Stella Ops Dev Guide (seed for `docs/modules/scanner/development/dsse-offline-updates.md`)
|
||||
|
||||
> **Audience**
|
||||
> Scanner, Export Center, Attestor, CLI, and DevOps engineers implementing DSSE‑signed offline vulnerability updates and integrating them into the Offline Update Kit (OUK).
|
||||
>
|
||||
> **Context**
|
||||
>
|
||||
> * OUK already ships **signed, atomic offline update bundles** with merged vulnerability feeds, container images, and an attested manifest.
|
||||
> * DSSE + Rekor is already used for **scan evidence** (SBOM attestations, Rekor proofs).
|
||||
> * Sprints 160/162 add **attestation bundles** with manifest, checksums, DSSE signature, and optional transparency log segments, and integrate them into OUK and CLI flows.
|
||||
|
||||
These guidelines tell you how to **wire all of that together** for “offline scanner updates” (feeds, rules, packs) in a way that matches Stella Ops’ determinism + sovereignty promises.
|
||||
|
||||
## 0. Mental model
|
||||
|
||||
```text
|
||||
Advisory mirrors / Feeds builders
|
||||
│
|
||||
▼
|
||||
ExportCenter.AttestationBundles
|
||||
(creates DSSE + Rekor evidence
|
||||
for each offline update snapshot)
|
||||
│
|
||||
▼
|
||||
Offline Update Kit (OUK) builder
|
||||
(adds feeds + evidence to kit tarball)
|
||||
│
|
||||
▼
|
||||
stella offline kit import / admin CLI
|
||||
(verifies Cosign + DSSE + Rekor segments,
|
||||
then atomically swaps scanner feeds)
|
||||
```
|
||||
|
||||
Online, Rekor is live; offline, you rely on **bundled Rekor segments / snapshots** and the existing OUK mechanics (import is atomic, old feeds kept until new bundle is fully verified).
|
||||
|
||||
## 1. Goals & non‑goals
|
||||
|
||||
### Goals
|
||||
|
||||
1. **Authentic offline snapshots**: every offline scanner update (OUK or delta) must be verifiably tied to a DSSE envelope, a certificate chain, and a Rekor v2 inclusion proof or bundled log segment.
|
||||
2. **Deterministic replay**: given a kit + its DSSE attestation bundle, every verifier reaches the same verdict online or air‑gapped.
|
||||
3. **Separation of concerns**: Export Center builds attestations; Scanner verifies/imports; Signer/Attestor handle DSSE/Rekor.
|
||||
4. **Operational safety**: imports remain atomic/idempotent; old feeds stay live until full verification.
|
||||
|
||||
### Non‑goals
|
||||
|
||||
* Designing new crypto or log formats.
|
||||
* Per‑feed DSSE envelopes (minimum contract is bundle‑level attestation).
|
||||
|
||||
## 2. Bundle contract for DSSE‑signed offline updates
|
||||
|
||||
**Files to ship** (inside each offline kit or delta):
|
||||
|
||||
```
|
||||
/attestations/
|
||||
offline-update.dsse.json # DSSE envelope
|
||||
offline-update.rekor.json # Rekor entry + inclusion proof (or segment descriptor)
|
||||
/manifest/
|
||||
offline-manifest.json # existing manifest
|
||||
offline-manifest.json.jws # existing detached JWS
|
||||
/feeds/
|
||||
... # existing feed payloads
|
||||
```
|
||||
|
||||
**DSSE payload (minimum):** subject = kit name + tarball sha256; predicate fields include `offline_manifest_sha256`, feed entries, builder ID/commit, created_at UTC, and channel.
|
||||
|
||||
**Rekor material:** submit DSSE to Rekor v2, store UUID/logIndex/inclusion proof as `offline-update.rekor.json`; for offline, embed a minimal log segment or rely on mirrored snapshots.
|
||||
|
||||
## 3. Implementation by module
|
||||
|
||||
### Export Center — attestation bundles
|
||||
* Compose attestation job: build DSSE payload, sign via Signer, submit to Rekor via Attestor, persist `offline-update.dsse.json` and `.rekor.json` (+ segments).
|
||||
* Integrate into offline kit packaging: place attestation files under `/attestations/`; list them in `offline-manifest.json` with sha256/size/capturedAt.
|
||||
* Define JSON schema for `offline-update.rekor.json`; version it and validate.
|
||||
|
||||
### Offline Update Kit builder
|
||||
* Preserve idempotent, atomic imports; include DSSE/Rekor files in kit staging tree.
|
||||
* Keep manifests deterministic: ordered file lists, UTC timestamps.
|
||||
* For delta kits, attest the resulting snapshot state (not just diffs).
|
||||
|
||||
### Scanner — import & activation
|
||||
* Verification sequence: Cosign tarball → manifest JWS → file digests (incl. attestation files) → DSSE verify → Rekor verify (online or offline segment) → atomic swap.
|
||||
* Config surface: `requireDsse`, `rekorOfflineMode`, `attestationVerifier` (env-var mirrored); allow observe→enforce rollout.
|
||||
* Failure behavior: keep old feeds; log structured failure fields; expose ProblemDetails.
|
||||
|
||||
### Signer & Attestor
|
||||
* Add predicate type/schema for offline updates; submit DSSE to Rekor; emit verification routines usable by CLI/Scanner with offline snapshot support.
|
||||
|
||||
### CLI & UI
|
||||
* CLI verbs to verify/import bundles with Rekor key; UI shows Cosign/JWS + DSSE/Rekor status and kit freshness.
|
||||
|
||||
## 4. Determinism & offline‑safety rules
|
||||
* No hidden network dependencies; offline must succeed with kit + Rekor snapshot.
|
||||
* Stable JSON serialization; UTC timestamps.
|
||||
* Replayable imports (idempotent); DSSE payload for a snapshot must be immutable.
|
||||
* Explainable failures with precise mismatch points.
|
||||
|
||||
## 5. Testing & CI expectations
|
||||
* Unit/integration: happy path, tampering cases (manifest/DSSE/Rekor), offline mode, rollback logic.
|
||||
* Metrics: `offlinekit_import_total{status}`, `attestation_verify_latency_seconds`, Rekor success/retry counts.
|
||||
* Golden fixtures: deterministic bundle + snapshot tests.
|
||||
|
||||
## 6. Developer checklist (TL;DR)
|
||||
1. Read operator guides: `docs/modules/scanner/operations/dsse-rekor-operator-guide.md`, `docs/24_OFFLINE_KIT.md`, relevant sprints.
|
||||
2. Implement: generate DSSE in Export Center; include attestation in kit; Scanner verifies before swap.
|
||||
3. Test: bundle composition, import rollback, determinism.
|
||||
4. Telemetry: counters + latency; log digests/UUIDs.
|
||||
5. Document: update Export Center and Scanner architecture docs, OUK docs when flows/contracts change.
|
||||
|
||||
@@ -0,0 +1,130 @@
|
||||
# Proof-Linked VEX UI Developer Guidelines
|
||||
|
||||
Compiled: 2025-12-01 (UTC)
|
||||
|
||||
## Purpose
|
||||
Any VEX-influenced verdict a user sees (Findings, Advisories & VEX, Vuln Explorer, etc.) must be directly traceable to concrete evidence: normalized VEX claims, their DSSE/signatures, and the policy explain trace. Every "Not Affected" badge is a verifiable link to the proof.
|
||||
|
||||
## What this solves (in one line)
|
||||
Every "Not Affected" badge becomes a verifiable link to why it is safe.
|
||||
|
||||
## UX pattern (at a glance)
|
||||
- Badge: `Not Affected` (green pill) always renders as a link.
|
||||
- On click: open a right-side drawer with three tabs:
|
||||
1. Evidence (DSSE / in-toto / Sigstore)
|
||||
2. Attestation (predicate details + signer)
|
||||
3. Reasoning Graph (the node + edges that justify the verdict)
|
||||
- Hover state: mini popover showing proof types available (e.g., "DSSE, SLSA attestation, Graph node").
|
||||
|
||||
## Data model (API & DB)
|
||||
Canonical object returned by VEX API for each finding:
|
||||
|
||||
```json
|
||||
{
|
||||
"findingId": "vuln:CVE-2024-12345@pkg:docker/alpine@3.19",
|
||||
"status": "not_affected",
|
||||
"justificationCode": "vex:not_present",
|
||||
"proof": {
|
||||
"dsse": {
|
||||
"envelopeDigest": "sha256-…",
|
||||
"rekorEntryId": "e3f1…",
|
||||
"downloadUrl": "https://…/dsse/e3f1…",
|
||||
"signer": { "name": "StellaOps Authority", "keyId": "SHA256:…" }
|
||||
},
|
||||
"attestation": {
|
||||
"predicateType": "slsa/v1",
|
||||
"attestationId": "att:01H…",
|
||||
"downloadUrl": "https://…/att/01H…"
|
||||
},
|
||||
"graph": {
|
||||
"nodeId": "gx:NA-78f…",
|
||||
"revision": "gx-r:2025-11-30T12:01:22Z",
|
||||
"explainUrl": "https://…/graph?rev=gx-r:…&node=NA-78f…"
|
||||
}
|
||||
},
|
||||
"receipt": {
|
||||
"algorithm": "CVSS:4.0",
|
||||
"inputsHash": "sha256-…",
|
||||
"computedAt": "2025-11-30T12:01:22Z"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Suggested Postgres tables:
|
||||
- vex_findings(finding_id, status, justification_code, graph_node_id, graph_rev, dsse_digest, rekor_id, attestation_id, created_at, updated_at)
|
||||
- proof_artifacts(id, type, digest, url, signer_keyid, meta jsonb)
|
||||
- graph_revisions(revision_id, created_at, root_hash)
|
||||
|
||||
## API contract (minimal)
|
||||
- GET /vex/findings/:id -> returns the object above.
|
||||
- GET /proofs/:type/:id -> streams artifact (with Content-Disposition: attachment).
|
||||
- GET /graph/explain?rev=…&node=… -> returns a JSON justification subgraph.
|
||||
- Security headers: Content-SHA256, Digest, X-Proof-Root (graph root hash), and X-Signer-KeyId.
|
||||
|
||||
## Angular UI spec (drop-in)
|
||||
Component: FindingStatusBadge
|
||||
|
||||
```html
|
||||
<button class="badge badge--ok" (click)="drawer.open(finding.proof)">
|
||||
Not Affected
|
||||
</button>
|
||||
```
|
||||
|
||||
Drawer layout (3 tabs):
|
||||
1) Evidence
|
||||
- DSSE digest (copy button)
|
||||
- Rekor entry (open in new tab)
|
||||
- "Download envelope"
|
||||
2) Attestation
|
||||
- Predicate type
|
||||
- Attestation ID
|
||||
- "Download attestation"
|
||||
3) Reasoning Graph
|
||||
- Node ID + Revision
|
||||
- Inline explainer ("Why safe?" bullets)
|
||||
- "Open full graph" (routes to /graph?rev=…&node=…)
|
||||
|
||||
Micro-interactions:
|
||||
- Copy-to-clipboard with toast ("Digest copied").
|
||||
- If any artifact missing, show a yellow "Partial Proof" ribbon listing what is absent.
|
||||
|
||||
Visual language:
|
||||
- Badges: Not Affected = solid green; Partial Proof = olive with warning dot; No Proof = gray outline (still clickable, explains absence).
|
||||
- Proof chips: small caps labels `DSSE`, `ATTESTATION`, `GRAPH`; each chip opens its subsection.
|
||||
|
||||
Validation (trust & integrity):
|
||||
- On drawer open, the UI calls HEAD /proofs/... to fetch Digest header and X-Proof-Root; compare to stored digests. If mismatch, show red "Integrity Mismatch" banner with retry and report.
|
||||
|
||||
Telemetry (debugging):
|
||||
- Emit events: proof_drawer_opened, proof_artifact_downloaded, graph_explain_viewed (include findingId, artifactType, latencyMs, integrityStatus).
|
||||
|
||||
Developer checklist:
|
||||
- Every not_affected status must include at least one proof artifact.
|
||||
- Badge is never a dead label; always clickable.
|
||||
- Drawer validates artifact digests before rendering contents.
|
||||
- "Open full graph" deep-links with rev + node (stable and shareable).
|
||||
- Graceful partials: show what is present and what is missing.
|
||||
- Accessibility: focus trap in drawer, aria-labels for chips, keyboard nav.
|
||||
|
||||
Test cases (quick):
|
||||
1) Happy path: all three proofs present; digests match; downloads work.
|
||||
2) Partial proof: DSSE present, attestation missing; drawer shows warning ribbon.
|
||||
3) Integrity fail: server returns different digest; red banner appears; badge stays clickable.
|
||||
4) Graph only: reasoning node present; DSSE/attestation absent; explains rationale clearly.
|
||||
|
||||
Optional nice-to-haves:
|
||||
- Permalinks: copyable URL that re-opens the drawer to the same tab.
|
||||
- QR export: downloadable "proof card" PNG with digests + signer (for audit packets).
|
||||
- Offline kit: bundle DSSE, attestation, and a compact graph slice in a .tar.zst for air-gapped review.
|
||||
|
||||
If needed, this can be turned into:
|
||||
- A small Angular module (ProofDrawerModule) + styles.
|
||||
- A .NET 10 controller stub with integrity headers.
|
||||
- Fixture JSON so teams can wire it up quickly.
|
||||
|
||||
## Context links (from source conversation)
|
||||
- docs/ui/console-overview.md
|
||||
- docs/ui/advisories-and-vex.md
|
||||
- docs/ui/findings.md
|
||||
- src/VexLens/StellaOps.VexLens/AGENTS.md and TASKS.md
|
||||
- docs/policy/overview.md
|
||||
@@ -0,0 +1,95 @@
|
||||
# 01-Dec-2025 - Storage Blueprint for PostgreSQL Modules
|
||||
|
||||
## Summary
|
||||
A crisp, opinionated storage blueprint for StellaOps modules with zero-downtime conversion tactics. Covers module-to-store mapping, PostgreSQL patterns, JSONB/RLS scaffolds, materialized views, temporal tables, CAS usage for SBOM/VEX blobs, and phased cutover guidance.
|
||||
|
||||
## Module → Store Map (deterministic by default)
|
||||
- **Authority / OAuth / Accounts & Audit**: PostgreSQL source of truth; tables `users`, `clients`, `oauth_tokens`, `roles`, `grants`, `audit_log`; RLS on `users`, `grants`, `audit_log`; strict FK/CHECK; immutable UUID PKs; audit table with actor/action/entity/diff and timestamptz default now().
|
||||
- **VEX & Vulnerability Writes**: PostgreSQL with JSONB facts plus relational decisions; tables `vuln_fact(jsonb)`, `vex_decision(package_id, vuln_id, status, rationale, proof_ref, updated_at)`; materialized views like `mv_triage_hotset` refreshed on commit or schedule.
|
||||
- **Routing / Feature Flags / Rate-limits**: PostgreSQL truth plus Redis cache; tables `feature_flag(key, rules jsonb, version)`, `route(domain, service, instance_id, last_heartbeat)`, `rate_limiter(bucket, quota, interval)`; Redis keys `flag:{key}:{version}`, `route:{domain}`, `rl:{bucket}` with short TTLs.
|
||||
- **Unknowns Registry**: PostgreSQL with temporal tables (bitemporal via `valid_from/valid_to`, `sys_from/ sys_to`); view `unknowns_current` for open rows.
|
||||
- **Artifacts / SBOM / VEX files**: OCI-compatible CAS (e.g., self-hosted registry or MinIO) keyed by digest; metadata in Postgres `artifact_index(digest, media_type, size, signatures)`.
|
||||
|
||||
## PostgreSQL Implementation Essentials
|
||||
- **RLS scaffold (Authority)**
|
||||
```sql
|
||||
alter table audit_log enable row level security;
|
||||
create policy p_audit_read_self
|
||||
on audit_log for select
|
||||
using (
|
||||
actor_id = current_setting('app.user_id')::uuid
|
||||
or exists (
|
||||
select 1 from grants g
|
||||
where g.user_id = current_setting('app.user_id')::uuid
|
||||
and g.role = 'auditor'
|
||||
)
|
||||
);
|
||||
```
|
||||
|
||||
- **JSONB facts + relational decisions**
|
||||
```sql
|
||||
create table vuln_fact (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
source text not null,
|
||||
payload jsonb not null,
|
||||
received_at timestamptz default now()
|
||||
);
|
||||
|
||||
create table vex_decision (
|
||||
package_id uuid not null,
|
||||
vuln_id text not null,
|
||||
status text check (status in ('not_affected','affected','fixed','under_investigation')),
|
||||
rationale text,
|
||||
proof_ref text,
|
||||
decided_at timestamptz default now(),
|
||||
primary key (package_id, vuln_id)
|
||||
);
|
||||
```
|
||||
|
||||
- **Materialized view for triage**
|
||||
```sql
|
||||
create materialized view mv_triage_hotset as
|
||||
select v.id as fact_id, v.payload->>'vuln' as vuln, v.received_at
|
||||
from vuln_fact v
|
||||
where (now() - v.received_at) < interval '7 days';
|
||||
-- refresh concurrently via job
|
||||
```
|
||||
|
||||
- **Temporal pattern (Unknowns)**
|
||||
```sql
|
||||
create table unknowns (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
subject_hash text not null,
|
||||
kind text not null,
|
||||
context jsonb not null,
|
||||
valid_from timestamptz not null default now(),
|
||||
valid_to timestamptz,
|
||||
sys_from timestamptz not null default now(),
|
||||
sys_to timestamptz
|
||||
);
|
||||
|
||||
create view unknowns_current as
|
||||
select * from unknowns where valid_to is null;
|
||||
```
|
||||
|
||||
## Conversion (not migration): zero-downtime, prototype-friendly
|
||||
1. Encode Mongo-shaped docs into JSONB with versioned schemas and forward-compatible projection views.
|
||||
2. Outbox pattern for exactly-once side-effects (`outbox(id, topic, key, payload jsonb, created_at, dispatched bool default false)`).
|
||||
3. Parallel read adapters behind feature flags with read-diff monitoring.
|
||||
4. CDC for analytics without coupling (logical replication).
|
||||
5. Materialized views with fixed refresh cadence; cold-path analytics in separate schemas.
|
||||
6. Phased cutover playbook: Dark Read → Shadow Serve → Authoritative → Retire (with auto-rollback).
|
||||
|
||||
## Rate-limits & Flags: single truth, fast edges
|
||||
- Truth in Postgres with versioned flag docs; history table for changes; Redis edge cache keyed by version; rate-limit quotas in Postgres, counters in Redis with reconciliation jobs.
|
||||
|
||||
## CAS for SBOM/VEX/attestations
|
||||
- Store blobs in OCI/MinIO by digest; keep pointer metadata in Postgres `artifact_index`; benefits: immutability, dedup, easy offline mirroring.
|
||||
|
||||
## Guardrails
|
||||
- Wrap multi-table writes in single transactions; prefer `jsonb_path_query` for targeted reads; enforce RLS and least-privilege roles; version everything (schemas, flags, materialized views); expose observability for statements, MV refresh latency, outbox lag, Redis hit ratio, and RLS hits.
|
||||
|
||||
## Optional Next Steps (from advisory)
|
||||
- Generate ready-to-run EF Core 10 migrations.
|
||||
- Add `/docs/architecture/store-map.md` summarizing these patterns.
|
||||
- Provide a small Docker-based dev seed with sample data.
|
||||
@@ -0,0 +1,38 @@
|
||||
# Verifiable Proof Spine: Receipts + Benchmarks
|
||||
|
||||
Compiled: 2025-12-01 (UTC)
|
||||
|
||||
## Why this matters
|
||||
Move from “trust the scanner” to “prove every verdict.” Each finding and every “not affected” claim must carry cryptographic, replayable evidence that anyone can verify offline or online.
|
||||
|
||||
## Differentiators to build in
|
||||
- **Graph Revision ID on every verdict**: stable Merkle root over SBOM nodes/edges, policies, feeds, scan params, and tool versions. Any data change → new graph hash → new revisioned verdicts; surface the ID in UI/API.
|
||||
- **Machine-verifiable receipts (DSSE)**: emit a DSSE-wrapped in-toto statement per verdict (predicate `stellaops.dev/verdict@v1`) including graphRevisionId, artifact digests, rule id/version, inputs, and timestamps; sign with Authority keys (offline mode supported) and keep receipts queryable/exportable; mirror to Rekor-compatible ledger when online.
|
||||
- **Reachability evidence**: attach call-stack slices (entry→sink, symbols, file:line) for code-level cases; for binaries, include symbol presence proofs (bitmap/offsets) hashed and referenced from DSSE payloads.
|
||||
- **Deterministic replay manifests**: publish `replay.manifest.json` with inputs, feeds, rule/tool/container digests so auditors can recompute the same graph hash and verdicts offline.
|
||||
|
||||
## Benchmarks to publish (headline KPIs)
|
||||
- **False-positive reduction vs baseline scanners**: run public corpus across 3–4 popular scanners; label ground truth once; report mean and p95 FP reduction.
|
||||
- **Proof coverage**: percentage of findings/VEX items carrying valid DSSE receipts; break out reachable vs unreachable and “not affected.”
|
||||
- **Triage time saved**: analyst minutes from alert to final disposition with receipts visible vs hidden; publish p50/p95 deltas.
|
||||
- **Determinism stability**: re-run identical scans across nodes; publish % identical graph hashes and explain drift causes when different.
|
||||
|
||||
## Minimal implementation plan (week-by-week)
|
||||
- **Week 1 – Primitives**: add Graph Revision ID generator in scanner.webservice (Merkle over normalized SBOM+edges+policies+toolVersions); define `VerdictReceipt` schema (protobuf/JSON) and DSSE envelope types.
|
||||
- **Week 2 – Signing + storage**: wire DSSE signing via Authority with offline key support/rotation; persist receipts in `Receipts` table keyed by (graphRevisionId, verdictId); enable JSONL export and ledger mirror.
|
||||
- **Week 3 – Reachability proofs**: capture call-stack slices in reachability engine; serialize and hash; add binary symbol proof module (ELF/PE bitmap + digest) and reference from receipts.
|
||||
- **Week 4 – Replay + UX**: emit replay.manifest per scan (inputs, tool digests); UI shows “Verified” badge, graph hash, signature issuer, and one-click “Copy receipt”; API: `GET /verdicts/{id}/receipt`, `GET /graphs/{rev}/replay`.
|
||||
- **Week 5 – Benchmarks harness**: create `bench/` fixtures and runner with baseline scanner adapters, ground-truth labels, metrics export for FP%, proof coverage, triage time capture hooks.
|
||||
|
||||
## Developer guardrails (non-negotiable)
|
||||
- **No receipt, no ship**: any surfaced verdict must carry a DSSE receipt; fail closed otherwise.
|
||||
- **Schema freeze windows**: changes to rule inputs or policy logic must bump rule version and therefore graph hash.
|
||||
- **Replay-first CI**: PRs touching scanning/rules must pass a replay test that reproduces prior graph hashes on gold fixtures.
|
||||
- **Clock safety**: use monotonic time for receipts; include UTC wall-time separately.
|
||||
|
||||
## What to show buyers/auditors
|
||||
- Audit kit: sample container + receipts + replay manifest + one command to reproduce the same graph hash.
|
||||
- One-page benchmark readout: FP reduction, proof coverage, triage time saved (p50/p95), corpus description.
|
||||
|
||||
## Optional follow-ons
|
||||
- Provide DSSE predicate schema, Postgres DDL for `Receipts` and `Graphs`, and a minimal .NET verification CLI (`stellaops-verify`) that replays a manifest and validates signatures.
|
||||
@@ -0,0 +1,944 @@
|
||||
Here’s a clean, action‑ready blueprint for a **public reachability benchmark** you can stand up quickly and grow over time.
|
||||
|
||||
# Why this matters (quick)
|
||||
|
||||
“Reachability” asks: *is a flagged vulnerability actually executable from real entry points in this codebase/container?* A public, reproducible benchmark lets you compare tools apples‑to‑apples, drive research, and keep vendors honest.
|
||||
|
||||
# What to collect (dataset design)
|
||||
|
||||
* **Projects & languages**
|
||||
|
||||
* Polyglot mix: **C/C++ (ELF/PE/Mach‑O)**, **Java/Kotlin**, **C#/.NET**, **Python**, **JavaScript/TypeScript**, **PHP**, **Go**, **Rust**.
|
||||
* For each project: small (≤5k LOC), medium (5–100k), large (100k+).
|
||||
* **Ground‑truth artifacts**
|
||||
|
||||
* **Seed CVEs** with known sinks (e.g., deserializers, command exec, SS RF) and **neutral projects** with *no* reachable path (negatives).
|
||||
* **Exploit oracles**: minimal PoCs or unit tests that (1) reach the sink and (2) toggle reachability via feature flags.
|
||||
* **Build outputs (deterministic)**
|
||||
|
||||
* **Reproducible binaries/bytecode** (strip timestamps; fixed seeds; SOURCE_DATE_EPOCH).
|
||||
* **SBOM** (CycloneDX/SPDX) + **PURLs** + **Build‑ID** (ELF .note.gnu.build‑id / PE Authentihash / Mach‑O UUID).
|
||||
* **Attestations**: in‑toto/DSSE envelopes recording toolchain versions, flags, hashes.
|
||||
* **Execution traces (for truth)**
|
||||
|
||||
* **CI traces**: call‑graph dumps from compilers/analyzers; unit‑test coverage; optional **dynamic traces** (eBPF/.NET ETW/Java Flight Recorder).
|
||||
* **Entry‑point manifests**: HTTP routes, CLI commands, cron/queue consumers.
|
||||
* **Metadata**
|
||||
|
||||
* Language, framework, package manager, compiler versions, OS/container image, optimization level, stripping info, license.
|
||||
|
||||
# How to label ground truth
|
||||
|
||||
* **Per‑vuln case**: `(component, version, sink_id)` with label **reachable / unreachable / unknown**.
|
||||
* **Evidence bundle**: pointer to (a) static call path, (b) dynamic hit (trace/coverage), or (c) rationale for negative.
|
||||
* **Confidence**: high (static+dynamic agree), medium (one source), low (heuristic only).
|
||||
|
||||
# Scoring (simple + fair)
|
||||
|
||||
* **Binary classification** on cases:
|
||||
|
||||
* Precision, Recall, F1. Report **AU‑PR** if you output probabilities.
|
||||
* **Path quality**
|
||||
|
||||
* **Explainability score (0–3)**:
|
||||
|
||||
* 0: “vuln reachable” w/o context
|
||||
* 1: names only (entry→…→sink)
|
||||
* 2: full interprocedural path w/ locations
|
||||
* 3: plus **inputs/guards** (taint/constraints, env flags)
|
||||
* **Runtime cost**
|
||||
|
||||
* Wall‑clock, peak RAM, image size; normalized by KLOC.
|
||||
* **Determinism**
|
||||
|
||||
* Re‑run variance (≤1% is “A”, 1–5% “B”, >5% “C”).
|
||||
|
||||
# Avoiding overfitting
|
||||
|
||||
* **Train/Dev/Test** splits per language; **hidden test** projects rotated quarterly.
|
||||
* **Case churn**: introduce **isomorphic variants** (rename symbols, reorder files) to punish memorization.
|
||||
* **Poisoned controls**: include decoy sinks and unreachable dead‑code traps.
|
||||
* **Submission rules**: require **attestations** of tool versions & flags; limit per‑case hints.
|
||||
|
||||
# Reference baselines (to run out‑of‑the‑box)
|
||||
|
||||
* **Snyk Code/Reachability** (JS/Java/Python, SaaS/CLI).
|
||||
* **Semgrep + Pro Engine** (rules + reachability mode).
|
||||
* **CodeQL** (multi‑lang, LGTM‑style queries).
|
||||
* **Joern** (C/C++/JVM code property graphs).
|
||||
* **angr** (binary symbolic exec; selective for native samples).
|
||||
* **Language‑specific**: pip‑audit w/ import graphs, npm with lock‑tree + route discovery, Maven + call‑graph (Soot/WALA).
|
||||
|
||||
# Submission format (one JSON per tool run)
|
||||
|
||||
```json
|
||||
{
|
||||
"tool": {"name": "YourTool", "version": "1.2.3"},
|
||||
"run": {
|
||||
"commit": "…",
|
||||
"platform": "ubuntu:24.04",
|
||||
"time_s": 182.4, "peak_mb": 3072
|
||||
},
|
||||
"cases": [
|
||||
{
|
||||
"id": "php-shop:fastjson@1.2.68:Sink#deserialize",
|
||||
"prediction": "reachable",
|
||||
"confidence": 0.88,
|
||||
"explain": {
|
||||
"entry": "POST /api/orders",
|
||||
"path": [
|
||||
"OrdersController::create",
|
||||
"Serializer::deserialize",
|
||||
"Fastjson::parseObject"
|
||||
],
|
||||
"guards": ["feature.flag.json_enabled==true"]
|
||||
}
|
||||
}
|
||||
],
|
||||
"artifacts": {
|
||||
"sbom": "sha256:…", "attestation": "sha256:…"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
# Folder layout (repo)
|
||||
|
||||
```
|
||||
/benchmark
|
||||
/cases/<lang>/<project>/<case_id>/
|
||||
case.yaml # component@version, sink, labels, evidence refs
|
||||
entrypoints.yaml # routes/CLIs/cron
|
||||
build/ # Dockerfiles, lockfiles, pinned toolchains
|
||||
outputs/ # SBOMs, binaries, traces (checksummed)
|
||||
/splits/{train,dev,test}.txt
|
||||
/schemas/{case.json,submission.json}
|
||||
/scripts/{build.sh, run_tests.sh, score.py}
|
||||
/docs/ (how-to, FAQs, T&Cs)
|
||||
```
|
||||
|
||||
# Minimal **v1** (4–6 weeks of work)
|
||||
|
||||
1. **Languages**: JS/TS, Python, Java, C (ELF).
|
||||
2. **20–30 cases**: mix of reachable/unreachable with PoC unit tests.
|
||||
3. **Deterministic builds** in containers; publish SBOM+attestations.
|
||||
4. **Scorer**: precision/recall/F1 + explainability, runtime, determinism.
|
||||
5. **Baselines**: run CodeQL + Semgrep across all; Snyk where feasible; angr for 3 native cases.
|
||||
6. **Website**: static leaderboard (per‑lang, per‑size), download links, submission guide.
|
||||
|
||||
# V2+ (quarterly)
|
||||
|
||||
* Add **.NET, PHP, Go, Rust**; broaden binary focus (PE/Mach‑O).
|
||||
* Add **dynamic traces** (eBPF/ETW/JFR) and **taint oracles**.
|
||||
* Introduce **config‑gated reachability** (feature flags, env, k8s secrets).
|
||||
* Add **dataset cards** per case (threat model, CWE, false‑positive traps).
|
||||
|
||||
# Publishing & governance
|
||||
|
||||
* License: **CC‑BY‑SA** for metadata, **source‑compatible OSS** for code, binaries under original licenses.
|
||||
* **Repro packs**: `benchmark-kit.tgz` with container recipes, hashes, and attestations.
|
||||
* **Disclosure**: CVE hygiene, responsible use, opt‑out path for upstreams.
|
||||
* **Stewards**: small TAC (you + two external reviewers) to approve new cases and adjudicate disputes.
|
||||
|
||||
# Immediate next steps (checklist)
|
||||
|
||||
* Lock the **schemas** (case + submission + attestation fields).
|
||||
* Pick 8 seed projects (2 per language tiered by size).
|
||||
* Draft 12 sink‑cases (6 reachable, 6 unreachable) with unit‑test oracles.
|
||||
* Script deterministic builds and **hash‑locked SBOMs**.
|
||||
* Implement the scorer; publish a **starter leaderboard** with 2 baselines.
|
||||
* Ship **v1 website/docs** and open submissions.
|
||||
|
||||
If you want, I can generate the repo scaffold (folders, YAML/JSON schemas, Dockerfiles, scorer script) so your team can `git clone` and start adding cases immediately.
|
||||
Cool, let’s turn the blueprint into a concrete, developer‑friendly implementation plan.
|
||||
|
||||
I’ll assume **v1 scope** is:
|
||||
|
||||
* Languages: **JavaScript/TypeScript (Node)**, **Python**, **Java**, **C (ELF)**
|
||||
* ~**20–30 cases** total (reachable/unreachable mix)
|
||||
* Baselines: **CodeQL**, **Semgrep**, maybe **Snyk** where licenses allow, and **angr** for a few native cases
|
||||
|
||||
You can expand later, but this plan is enough to get v1 shipped.
|
||||
|
||||
---
|
||||
|
||||
## 0. Overall project structure & ownership
|
||||
|
||||
**Owners**
|
||||
|
||||
* **Tech Lead** – owns architecture & final decisions
|
||||
* **Benchmark Core** – 2–3 devs building schemas, scorer, infra
|
||||
* **Language Tracks** – 1 dev per language (JS, Python, Java, C)
|
||||
* **Website/Docs** – 1 dev
|
||||
|
||||
**Repo layout (target)**
|
||||
|
||||
```text
|
||||
reachability-benchmark/
|
||||
README.md
|
||||
LICENSE
|
||||
CONTRIBUTING.md
|
||||
CODE_OF_CONDUCT.md
|
||||
|
||||
benchmark/
|
||||
cases/
|
||||
js/
|
||||
express-blog/
|
||||
case-001/
|
||||
case.yaml
|
||||
entrypoints.yaml
|
||||
build/
|
||||
Dockerfile
|
||||
build.sh
|
||||
src/ # project source (or submodule)
|
||||
tests/ # unit tests as oracles
|
||||
outputs/
|
||||
sbom.cdx.json
|
||||
binary.tar.gz
|
||||
coverage.json
|
||||
traces/ # optional dynamic traces
|
||||
py/
|
||||
flask-api/...
|
||||
java/
|
||||
spring-app/...
|
||||
c/
|
||||
httpd-like/...
|
||||
schemas/
|
||||
case.schema.yaml
|
||||
entrypoints.schema.yaml
|
||||
truth.schema.yaml
|
||||
submission.schema.json
|
||||
tools/
|
||||
scorer/
|
||||
rb_score/
|
||||
__init__.py
|
||||
cli.py
|
||||
metrics.py
|
||||
loader.py
|
||||
explainability.py
|
||||
pyproject.toml
|
||||
tests/
|
||||
build/
|
||||
build_all.py
|
||||
validate_builds.py
|
||||
|
||||
baselines/
|
||||
codeql/
|
||||
run_case.sh
|
||||
config/
|
||||
semgrep/
|
||||
run_case.sh
|
||||
rules/
|
||||
snyk/
|
||||
run_case.sh
|
||||
angr/
|
||||
run_case.sh
|
||||
|
||||
ci/
|
||||
github/
|
||||
benchmark.yml
|
||||
|
||||
website/
|
||||
# static site / leaderboard
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. Phase 1 – Repo & infra setup
|
||||
|
||||
### Task 1.1 – Create repository
|
||||
|
||||
**Developer:** Tech Lead
|
||||
**Deliverables:**
|
||||
|
||||
* Repo created (`reachability-benchmark` or similar)
|
||||
* `LICENSE` (e.g., Apache-2.0 or MIT)
|
||||
* Basic `README.md` describing:
|
||||
|
||||
* Purpose (public reachability benchmark)
|
||||
* High‑level design
|
||||
* v1 scope (langs, #cases)
|
||||
|
||||
### Task 1.2 – Bootstrap structure
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create directory skeleton as above (without filling everything yet).
|
||||
|
||||
Add:
|
||||
|
||||
```bash
|
||||
# benchmark/Makefile
|
||||
.PHONY: test lint build
|
||||
test:
|
||||
\tpytest benchmark/tools/scorer/tests
|
||||
|
||||
lint:
|
||||
\tblack benchmark/tools/scorer
|
||||
\tflake8 benchmark/tools/scorer
|
||||
|
||||
build:
|
||||
\tpython benchmark/tools/build/build_all.py
|
||||
```
|
||||
|
||||
### Task 1.3 – Coding standards & tooling
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
* Add `.editorconfig`, `.gitignore`, and Python tool configs (`ruff`, `black`, or `flake8`).
|
||||
* Define minimal **PR checklist** in `CONTRIBUTING.md`:
|
||||
|
||||
* Tests pass
|
||||
* Lint passes
|
||||
* New schemas have JSON schema or YAML schema and tests
|
||||
* New cases come with oracles (tests/coverage)
|
||||
|
||||
---
|
||||
|
||||
## 2. Phase 2 – Case & submission schemas
|
||||
|
||||
### Task 2.1 – Define case metadata format
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create `benchmark/schemas/case.schema.yaml` and an example `case.yaml`.
|
||||
|
||||
**Example `case.yaml`**
|
||||
|
||||
```yaml
|
||||
id: "js-express-blog:001"
|
||||
language: "javascript"
|
||||
framework: "express"
|
||||
size: "small" # small | medium | large
|
||||
component:
|
||||
name: "express-blog"
|
||||
version: "1.0.0-bench"
|
||||
vulnerability:
|
||||
cve: "CVE-XXXX-YYYY"
|
||||
cwe: "CWE-502"
|
||||
description: "Unsafe deserialization via user-controlled JSON."
|
||||
sink_id: "Deserializer::parse"
|
||||
ground_truth:
|
||||
label: "reachable" # reachable | unreachable | unknown
|
||||
confidence: "high" # high | medium | low
|
||||
evidence_files:
|
||||
- "truth.yaml"
|
||||
notes: >
|
||||
Unit test test_reachable_deserialization triggers the sink.
|
||||
build:
|
||||
dockerfile: "build/Dockerfile"
|
||||
build_script: "build/build.sh"
|
||||
output:
|
||||
artifact_path: "outputs/binary.tar.gz"
|
||||
sbom_path: "outputs/sbom.cdx.json"
|
||||
coverage_path: "outputs/coverage.json"
|
||||
traces_dir: "outputs/traces"
|
||||
environment:
|
||||
os_image: "ubuntu:24.04"
|
||||
compiler: null
|
||||
runtime:
|
||||
node: "20.11.0"
|
||||
source_date_epoch: 1730000000
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Schema validates sample `case.yaml` with a Python script:
|
||||
|
||||
* `benchmark/tools/build/validate_schema.py` using `jsonschema` or `pykwalify`.
|
||||
|
||||
---
|
||||
|
||||
### Task 2.2 – Entry points schema
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/schemas/entrypoints.schema.yaml`
|
||||
|
||||
**Example `entrypoints.yaml`**
|
||||
|
||||
```yaml
|
||||
entries:
|
||||
http:
|
||||
- id: "POST /api/posts"
|
||||
route: "/api/posts"
|
||||
method: "POST"
|
||||
handler: "PostsController.create"
|
||||
cli:
|
||||
- id: "generate-report"
|
||||
command: "node cli.js generate-report"
|
||||
description: "Generates summary report."
|
||||
scheduled:
|
||||
- id: "daily-cleanup"
|
||||
schedule: "0 3 * * *"
|
||||
handler: "CleanupJob.run"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 2.3 – Ground truth / truth schema
|
||||
|
||||
**Developer:** Benchmark Core + Language Tracks
|
||||
|
||||
`benchmark/schemas/truth.schema.yaml`
|
||||
|
||||
**Example `truth.yaml`**
|
||||
|
||||
```yaml
|
||||
id: "js-express-blog:001"
|
||||
cases:
|
||||
- sink_id: "Deserializer::parse"
|
||||
label: "reachable"
|
||||
dynamic_evidence:
|
||||
covered_by_tests:
|
||||
- "tests/test_reachable_deserialization.js::should_reach_sink"
|
||||
coverage_files:
|
||||
- "outputs/coverage.json"
|
||||
static_evidence:
|
||||
call_path:
|
||||
- "POST /api/posts"
|
||||
- "PostsController.create"
|
||||
- "PostsService.createFromJson"
|
||||
- "Deserializer.parse"
|
||||
config_conditions:
|
||||
- "process.env.FEATURE_JSON_ENABLED == 'true'"
|
||||
notes: "If FEATURE_JSON_ENABLED=false, path is unreachable."
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 2.4 – Submission schema
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/schemas/submission.schema.json`
|
||||
|
||||
**Shape**
|
||||
|
||||
```json
|
||||
{
|
||||
"tool": { "name": "YourTool", "version": "1.2.3" },
|
||||
"run": {
|
||||
"commit": "abcd1234",
|
||||
"platform": "ubuntu:24.04",
|
||||
"time_s": 182.4,
|
||||
"peak_mb": 3072
|
||||
},
|
||||
"cases": [
|
||||
{
|
||||
"id": "js-express-blog:001",
|
||||
"prediction": "reachable",
|
||||
"confidence": 0.88,
|
||||
"explain": {
|
||||
"entry": "POST /api/posts",
|
||||
"path": [
|
||||
"PostsController.create",
|
||||
"PostsService.createFromJson",
|
||||
"Deserializer.parse"
|
||||
],
|
||||
"guards": [
|
||||
"process.env.FEATURE_JSON_ENABLED === 'true'"
|
||||
]
|
||||
}
|
||||
}
|
||||
],
|
||||
"artifacts": {
|
||||
"sbom": "sha256:...",
|
||||
"attestation": "sha256:..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Write Python validation utility:
|
||||
|
||||
```bash
|
||||
python benchmark/tools/scorer/validate_submission.py submission.json
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Validation fails on missing fields / wrong enum values.
|
||||
* At least two sample submissions pass validation (e.g., “perfect” and “random baseline”).
|
||||
|
||||
---
|
||||
|
||||
## 3. Phase 3 – Reference projects & deterministic builds
|
||||
|
||||
### Task 3.1 – Select and vendor v1 projects
|
||||
|
||||
**Developer:** Tech Lead + Language Tracks
|
||||
|
||||
For each language, choose:
|
||||
|
||||
* 1 small toy app (simple web or CLI)
|
||||
* 1 medium app (more routes, multiple modules)
|
||||
* Optional: 1 large (for performance stress tests)
|
||||
|
||||
Add them under `benchmark/cases/<lang>/<project>/src/`
|
||||
(or as git submodules if you want to track upstream).
|
||||
|
||||
---
|
||||
|
||||
### Task 3.2 – Deterministic Docker build per project
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
For each project:
|
||||
|
||||
* Create `build/Dockerfile`
|
||||
* Create `build/build.sh` that:
|
||||
|
||||
* Builds the app
|
||||
* Produces artifacts
|
||||
* Generates SBOM and attestation
|
||||
|
||||
**Example `build/Dockerfile` (Node)**
|
||||
|
||||
```dockerfile
|
||||
FROM node:20.11-slim
|
||||
|
||||
ENV NODE_ENV=production
|
||||
ENV SOURCE_DATE_EPOCH=1730000000
|
||||
|
||||
WORKDIR /app
|
||||
COPY src/ /app
|
||||
COPY package.json package-lock.json /app/
|
||||
|
||||
RUN npm ci --ignore-scripts && \
|
||||
npm run build || true
|
||||
|
||||
CMD ["node", "server.js"]
|
||||
```
|
||||
|
||||
**Example `build.sh`**
|
||||
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
set -euo pipefail
|
||||
|
||||
ROOT_DIR="$(dirname "$(readlink -f "$0")")/.."
|
||||
OUT_DIR="$ROOT_DIR/outputs"
|
||||
mkdir -p "$OUT_DIR"
|
||||
|
||||
IMAGE_TAG="rb-js-express-blog:1"
|
||||
|
||||
docker build -t "$IMAGE_TAG" "$ROOT_DIR/build"
|
||||
|
||||
# Export image as tarball (binary artifact)
|
||||
docker save "$IMAGE_TAG" | gzip > "$OUT_DIR/binary.tar.gz"
|
||||
|
||||
# Generate SBOM (e.g. via syft) – can be optional stub for v1
|
||||
syft packages "docker:$IMAGE_TAG" -o cyclonedx-json > "$OUT_DIR/sbom.cdx.json"
|
||||
|
||||
# In future: generate in-toto attestations
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 3.3 – Determinism checker
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/tools/build/validate_builds.py`:
|
||||
|
||||
* For each case:
|
||||
|
||||
* Run `build.sh` twice
|
||||
* Compare hashes of `outputs/binary.tar.gz` and `outputs/sbom.cdx.json`
|
||||
* Fail if hashes differ.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* All v1 cases produce identical artifacts across two builds on CI.
|
||||
|
||||
---
|
||||
|
||||
## 4. Phase 4 – Ground truth oracles (tests & traces)
|
||||
|
||||
### Task 4.1 – Add unit/integration tests for reachable cases
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
For each **reachable** case:
|
||||
|
||||
* Add `tests/` under the project to:
|
||||
|
||||
* Start the app (if necessary)
|
||||
* Send a request/trigger that reaches the vulnerable sink
|
||||
* Assert that a sentinel side effect occurs (e.g. log or marker file) instead of real exploitation.
|
||||
|
||||
Example for Node using Jest:
|
||||
|
||||
```js
|
||||
test("should reach deserialization sink", async () => {
|
||||
const res = await request(app)
|
||||
.post("/api/posts")
|
||||
.send({ title: "x", body: '{"__proto__":{}}' });
|
||||
|
||||
expect(res.statusCode).toBe(200);
|
||||
// Sink logs "REACH_SINK" – we check log or variable
|
||||
expect(sinkWasReached()).toBe(true);
|
||||
});
|
||||
```
|
||||
|
||||
### Task 4.2 – Instrument coverage
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
* For each language, pick a coverage tool:
|
||||
|
||||
* JS: `nyc` + `istanbul`
|
||||
* Python: `coverage.py`
|
||||
* Java: `jacoco`
|
||||
* C: `gcov`/`llvm-cov` (optional for v1)
|
||||
|
||||
* Ensure running tests produces `outputs/coverage.json` or `.xml` that we then convert to a simple JSON format:
|
||||
|
||||
```json
|
||||
{
|
||||
"files": {
|
||||
"src/controllers/posts.js": {
|
||||
"lines_covered": [12, 13, 14, 27],
|
||||
"lines_total": 40
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Create a small converter script if needed.
|
||||
|
||||
### Task 4.3 – Optional dynamic traces
|
||||
|
||||
If you want richer evidence:
|
||||
|
||||
* JS: add middleware that logs `(entry_id, handler, sink)` triples to `outputs/traces/traces.json`
|
||||
* Python: similar using decorators
|
||||
* C/Java: out of scope for v1 unless you want to invest extra time.
|
||||
|
||||
---
|
||||
|
||||
## 5. Phase 5 – Scoring tool (CLI)
|
||||
|
||||
### Task 5.1 – Implement `rb-score` library + CLI
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create `benchmark/tools/scorer/rb_score/` with:
|
||||
|
||||
* `loader.py`
|
||||
|
||||
* Load all `case.yaml`, `truth.yaml` into memory.
|
||||
* Provide functions: `load_cases() -> Dict[case_id, Case]`.
|
||||
|
||||
* `metrics.py`
|
||||
|
||||
* Implement:
|
||||
|
||||
* `compute_precision_recall(truth, predictions)`
|
||||
* `compute_path_quality_score(explain_block)` (0–3)
|
||||
* `compute_runtime_stats(run_block)`
|
||||
|
||||
* `cli.py`
|
||||
|
||||
* CLI:
|
||||
|
||||
```bash
|
||||
rb-score \
|
||||
--cases-root benchmark/cases \
|
||||
--submission submissions/mytool.json \
|
||||
--output results/mytool_results.json
|
||||
```
|
||||
|
||||
**Pseudo-code for core scoring**
|
||||
|
||||
```python
|
||||
def score_submission(truth, submission):
|
||||
y_true = []
|
||||
y_pred = []
|
||||
per_case_scores = {}
|
||||
|
||||
for case in truth:
|
||||
gt = truth[case.id].label # reachable/unreachable
|
||||
pred_case = find_pred_case(submission.cases, case.id)
|
||||
pred_label = pred_case.prediction if pred_case else "unreachable"
|
||||
|
||||
y_true.append(gt == "reachable")
|
||||
y_pred.append(pred_label == "reachable")
|
||||
|
||||
explain_score = explainability(pred_case.explain if pred_case else None)
|
||||
|
||||
per_case_scores[case.id] = {
|
||||
"gt": gt,
|
||||
"pred": pred_label,
|
||||
"explainability": explain_score,
|
||||
}
|
||||
|
||||
precision, recall, f1 = compute_prf(y_true, y_pred)
|
||||
|
||||
return {
|
||||
"summary": {
|
||||
"precision": precision,
|
||||
"recall": recall,
|
||||
"f1": f1,
|
||||
"num_cases": len(truth),
|
||||
},
|
||||
"cases": per_case_scores,
|
||||
}
|
||||
```
|
||||
|
||||
### Task 5.2 – Explainability scoring rules
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Implement `explainability(explain)`:
|
||||
|
||||
* 0 – `explain` missing or `path` empty
|
||||
* 1 – `path` present with at least 2 nodes (sink + one function)
|
||||
* 2 – `path` contains:
|
||||
|
||||
* Entry label (HTTP route/CLI id)
|
||||
* ≥3 nodes (entry → … → sink)
|
||||
* 3 – Level 2 plus `guards` list non-empty
|
||||
|
||||
Unit tests for at least 4 scenarios.
|
||||
|
||||
### Task 5.3 – Regression tests for scoring
|
||||
|
||||
Add small test fixture:
|
||||
|
||||
* Tiny synthetic benchmark: 3 cases, 2 reachable, 1 unreachable.
|
||||
* 3 submissions:
|
||||
|
||||
* Perfect
|
||||
* All reachable
|
||||
* All unreachable
|
||||
|
||||
Assertions:
|
||||
|
||||
* Perfect: `precision=1, recall=1`
|
||||
* All reachable: `recall=1, precision<1`
|
||||
* All unreachable: `precision=1 (trivially on negatives), recall=0`
|
||||
|
||||
---
|
||||
|
||||
## 6. Phase 6 – Baseline integrations
|
||||
|
||||
### Task 6.1 – Semgrep baseline
|
||||
|
||||
**Developer:** Benchmark Core (with Semgrep experience)
|
||||
|
||||
* `baselines/semgrep/run_case.sh`:
|
||||
|
||||
* Inputs: `case_id`, `cases_root`, `output_path`
|
||||
* Steps:
|
||||
|
||||
* Find `src/` for case
|
||||
* Run `semgrep --config auto` or curated rules
|
||||
* Convert Semgrep findings into benchmark submission format:
|
||||
|
||||
* Map Semgrep rules → vulnerability types → candidate sinks
|
||||
* Heuristically guess reachability (for v1, maybe always “reachable” if sink in code path)
|
||||
* Output: `output_path` JSON conforming to `submission.schema.json`.
|
||||
|
||||
### Task 6.2 – CodeQL baseline
|
||||
|
||||
* Create CodeQL databases for each project (likely via `codeql database create`).
|
||||
* Create queries targeting known sinks (e.g., `Deserialization`, `CommandInjection`).
|
||||
* `baselines/codeql/run_case.sh`:
|
||||
|
||||
* Build DB (or reuse)
|
||||
* Run queries
|
||||
* Translate results into our submission format (again as heuristic reachability).
|
||||
|
||||
### Task 6.3 – Optional Snyk / angr baselines
|
||||
|
||||
* Snyk:
|
||||
|
||||
* Use `snyk test` on the project
|
||||
* Map results to dependencies & known CVEs
|
||||
* For v1, just mark as `reachable` if Snyk reports a reachable path (if available).
|
||||
* angr:
|
||||
|
||||
* For 1–2 small C samples, configure simple analysis script.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For at least 5 cases (across languages), the baselines produce valid submission JSON.
|
||||
* `rb-score` runs and yields metrics without errors.
|
||||
|
||||
---
|
||||
|
||||
## 7. Phase 7 – CI/CD
|
||||
|
||||
### Task 7.1 – GitHub Actions workflow
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`ci/github/benchmark.yml`:
|
||||
|
||||
Jobs:
|
||||
|
||||
1. `lint-and-test`
|
||||
|
||||
* `python -m pip install -e benchmark/tools/scorer[dev]`
|
||||
* `make lint`
|
||||
* `make test`
|
||||
|
||||
2. `build-cases`
|
||||
|
||||
* `python benchmark/tools/build/build_all.py`
|
||||
* Run `validate_builds.py`
|
||||
|
||||
3. `smoke-baselines`
|
||||
|
||||
* For 2–3 cases, run Semgrep/CodeQL wrappers and ensure they emit valid submissions.
|
||||
|
||||
### Task 7.2 – Artifact upload
|
||||
|
||||
* Upload `outputs/` tarball from `build-cases` as workflow artifacts.
|
||||
* Upload `results/*.json` from scoring runs.
|
||||
|
||||
---
|
||||
|
||||
## 8. Phase 8 – Website & leaderboard
|
||||
|
||||
### Task 8.1 – Define results JSON format
|
||||
|
||||
**Developer:** Benchmark Core + Website dev
|
||||
|
||||
`results/leaderboard.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"tools": [
|
||||
{
|
||||
"name": "Semgrep",
|
||||
"version": "1.60.0",
|
||||
"summary": {
|
||||
"precision": 0.72,
|
||||
"recall": 0.48,
|
||||
"f1": 0.58
|
||||
},
|
||||
"by_language": {
|
||||
"javascript": {"precision": 0.80, "recall": 0.50, "f1": 0.62},
|
||||
"python": {"precision": 0.65, "recall": 0.45, "f1": 0.53}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
CLI option to generate this:
|
||||
|
||||
```bash
|
||||
rb-score compare \
|
||||
--cases-root benchmark/cases \
|
||||
--submissions submissions/*.json \
|
||||
--output results/leaderboard.json
|
||||
```
|
||||
|
||||
### Task 8.2 – Static site
|
||||
|
||||
**Developer:** Website dev
|
||||
|
||||
Tech choice: any static framework (Next.js, Astro, Docusaurus, or even pure HTML+JS).
|
||||
|
||||
Pages:
|
||||
|
||||
* **Home**
|
||||
|
||||
* What is reachability?
|
||||
* Summary of benchmark
|
||||
|
||||
* **Leaderboard**
|
||||
|
||||
* Renders `leaderboard.json`
|
||||
* Filters: language, case size
|
||||
|
||||
* **Docs**
|
||||
|
||||
* How to run benchmark locally
|
||||
* How to prepare a submission
|
||||
|
||||
Add a simple script to copy `results/leaderboard.json` into `website/public/` for publishing.
|
||||
|
||||
---
|
||||
|
||||
## 9. Phase 9 – Docs, governance, and contribution flow
|
||||
|
||||
### Task 9.1 – CONTRIBUTING.md
|
||||
|
||||
Include:
|
||||
|
||||
* How to add a new case:
|
||||
|
||||
* Step‑by‑step:
|
||||
|
||||
1. Create project folder under `benchmark/cases/<lang>/<project>/case-XXX/`
|
||||
2. Add `case.yaml`, `entrypoints.yaml`, `truth.yaml`
|
||||
3. Add oracles (tests, coverage)
|
||||
4. Add deterministic `build/` assets
|
||||
5. Run local tooling:
|
||||
|
||||
* `validate_schema.py`
|
||||
* `validate_builds.py --case <id>`
|
||||
* Example PR description template.
|
||||
|
||||
### Task 9.2 – Governance doc
|
||||
|
||||
* Define **Technical Advisory Committee (TAC)** roles:
|
||||
|
||||
* Approve new cases
|
||||
* Approve schema changes
|
||||
* Manage hidden test sets (future phase)
|
||||
|
||||
* Define **release cadence**:
|
||||
|
||||
* v1.0 with public cases
|
||||
* Quarterly updates with new hidden cases.
|
||||
|
||||
---
|
||||
|
||||
## 10. Suggested milestone breakdown (for planning / sprints)
|
||||
|
||||
### Milestone 1 – Foundation (1–2 sprints)
|
||||
|
||||
* Repo scaffolding (Tasks 1.x)
|
||||
* Schemas (Tasks 2.x)
|
||||
* Two tiny toy cases (one JS, one Python) with:
|
||||
|
||||
* `case.yaml`, `entrypoints.yaml`, `truth.yaml`
|
||||
* Deterministic build
|
||||
* Basic unit tests
|
||||
* Minimal `rb-score` with:
|
||||
|
||||
* Case loading
|
||||
* Precision/recall only
|
||||
|
||||
**Exit:** You can run `rb-score` on a dummy submission for 2 cases.
|
||||
|
||||
---
|
||||
|
||||
### Milestone 2 – v1 dataset (2–3 sprints)
|
||||
|
||||
* Add ~20–30 cases across JS, Python, Java, C
|
||||
* Ground truth & coverage for each
|
||||
* Deterministic builds validated
|
||||
* Explainability scoring implemented
|
||||
* Regression tests for `rb-score`
|
||||
|
||||
**Exit:** Full scoring tool stable; dataset repeatably builds on CI.
|
||||
|
||||
---
|
||||
|
||||
### Milestone 3 – Baselines & site (1–2 sprints)
|
||||
|
||||
* Semgrep + CodeQL baselines producing valid submissions
|
||||
* CI running smoke baselines
|
||||
* `leaderboard.json` generator
|
||||
* Static website with public leaderboard and docs
|
||||
|
||||
**Exit:** Public v1 benchmark you can share with external tool authors.
|
||||
|
||||
---
|
||||
|
||||
If you tell me which stack your team prefers for the site (React, plain HTML, SSG, etc.) or which CI you’re on, I can adapt this into concrete config files (e.g., a full GitHub Actions workflow, Next.js scaffold, or exact `pyproject.toml` for `rb-score`).
|
||||
@@ -0,0 +1,636 @@
|
||||
Here’s a compact, one‑screen “CVSS v4.0 Score Receipt” you can drop into Stella Ops so every vulnerability carries its score, evidence, and policy lineage end‑to‑end.
|
||||
|
||||
---
|
||||
|
||||
# CVSS v4.0 Score Receipt (CVSS‑BTE + Supplemental)
|
||||
|
||||
**Vuln ID / Title**
|
||||
**Final CVSS v4.0 Score:** *X.Y* (CVSS‑BTE) • **Vector:** `CVSS:4.0/...`
|
||||
**Why BTE?** CVSS v4.0 is designed to combine Base with default Threat/Environmental first, then amend with real context; Supplemental adds non‑scoring context. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 1) Base Metrics (intrinsic; vendor/researcher)
|
||||
|
||||
*List each metric with chosen value + short justification + evidence link.*
|
||||
|
||||
* **Attack Vector (AV):** N | A | I | P — *reason & evidence*
|
||||
* **Attack Complexity (AC):** L | H — *reason & evidence*
|
||||
* **Attack Requirements (AT):** N | P | ? — *reason & evidence*
|
||||
* **Privileges Required (PR):** N | L | H — *reason & evidence*
|
||||
* **User Interaction (UI):** Passive | Active — *reason & evidence*
|
||||
* **Vulnerable System Impact (VC/VI/VA):** H | L | N — *reason & evidence*
|
||||
* **Subsequent System Impact (SC/SI/SA):** H | L | N — *reason & evidence*
|
||||
|
||||
> Notes: v4.0 clarifies Base, splits vulnerable vs. subsequent system impact, and refines UI (Passive/Active). ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 2) Threat Metrics (time‑varying; consumer)
|
||||
|
||||
* **Exploit Maturity (E):** Attacked | POC | Unreported | NotDefined — *intel & source*
|
||||
* **Automatable (AU):** Yes | No | ND — *tooling/observations*
|
||||
* **Provider Urgency (U):** High | Medium | Low | ND — *advisory/ref*
|
||||
|
||||
> Threat replaces the old Temporal concept and adjusts severity with real‑world exploitation context. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 3) Environmental Metrics (your environment)
|
||||
|
||||
* **Security Controls (CR/XR/AR):** Present | Partial | None — *control IDs*
|
||||
* **Criticality (S, H, L, N) of asset/service:** *business tag*
|
||||
* **Safety/Human Impact in your environment:** *if applicable*
|
||||
|
||||
> Environmental tailors the score to your environment (controls, importance). ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 4) Supplemental (non‑scoring context)
|
||||
|
||||
* **Safety, Recovery, Value‑Density, Vulnerability Response Effort, etc.:** *values + short notes*
|
||||
|
||||
> Supplemental adds context but does not change the numeric score. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 5) Evidence Ledger
|
||||
|
||||
* **Artifacts:** logs, PoCs, packet captures, SBOM slices, call‑graphs, config excerpts
|
||||
* **References:** vendor advisory, NVD/First calculator snapshot, exploit write‑ups
|
||||
* **Timestamps & hash of each evidence item** (SHA‑256)
|
||||
|
||||
> Keep a permalink to the FIRST v4.0 calculator or NVD v4 calculator capture for audit. ([FIRST][2])
|
||||
|
||||
---
|
||||
|
||||
## 6) Policy & Determinism
|
||||
|
||||
* **Scoring Policy ID:** `cvss-policy-v4.0-stellaops-YYYYMMDD`
|
||||
* **Policy Hash:** `sha256:…` (of the JSON policy used to map inputs→metrics)
|
||||
* **Scoring Engine Version:** `stellaops.scorer vX.Y.Z`
|
||||
* **Repro Inputs Hash:** DSSE envelope including evidence URIs + CVSS vector
|
||||
|
||||
> Treat the receipt as a deterministic artifact: Base with default T/E, then amended with Threat+Environmental to produce CVSS‑BTE; store policy/evidence hashes for replayable audits. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 7) History (amendments over time)
|
||||
|
||||
| Date | Changed | From → To | Reason | Link |
|
||||
| ---------- | -------- | -------------- | ------------------------ | ----------- |
|
||||
| 2025‑11‑25 | Threat:E | POC → Attacked | Active exploitation seen | *intel ref* |
|
||||
|
||||
---
|
||||
|
||||
## Minimal JSON schema (for your UI/API)
|
||||
|
||||
```json
|
||||
{
|
||||
"vulnId": "CVE-YYYY-XXXX",
|
||||
"title": "Short vuln title",
|
||||
"cvss": {
|
||||
"version": "4.0",
|
||||
"vector": "CVSS:4.0/…",
|
||||
"base": { "AV": "N", "AC": "L", "AT": "N", "PR": "N", "UI": "P", "VC": "H", "VI": "H", "VA": "H", "SC": "L", "SI": "N", "SA": "N", "justifications": { /* per-metric text + evidence URIs */ } },
|
||||
"threat": { "E": "Attacked", "AU": "Yes", "U": "High", "evidence": [/* intel links */] },
|
||||
"environmental": { "controls": { "CR": "Present", "XR": "Partial", "AR": "None" }, "criticality": "H", "notes": "…" },
|
||||
"supplemental": { "safety": "High", "recovery": "Hard", "notes": "…" },
|
||||
"finalScore": 9.1,
|
||||
"enumeration": "CVSS-BTE"
|
||||
},
|
||||
"evidence": [{ "name": "exploit_poc.md", "sha256": "…", "uri": "…" }],
|
||||
"policy": { "id": "cvss-policy-v4.0-stellaops-20251125", "sha256": "…", "engine": "stellaops.scorer 1.2.0" },
|
||||
"repro": { "dsseEnvelope": "base64…", "inputsHash": "sha256:…" },
|
||||
"history": [{ "date": "2025-11-25", "change": "Threat:E POC→Attacked", "reason": "SOC report", "ref": "…" }]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Drop‑in UI wireframe (single screen)
|
||||
|
||||
* **Header bar:** Score badge (X.Y), “CVSS‑BTE”, vector copy button.
|
||||
* **Tabs (or stacked cards):** Base • Threat • Environmental • Supplemental • Evidence • Policy • History.
|
||||
* **Right rail:** “Recalculate with my env” (edits only Threat/Environmental), “Export receipt (JSON/PDF)”, “Open in FIRST/NVD calculator”.
|
||||
|
||||
---
|
||||
|
||||
If you want, I’ll adapt this to your Stella Ops components (DTOs, EF Core models, and a Razor/Blazor card) and wire it to your “deterministic replay” pipeline so every scan emits this receipt alongside the VEX note.
|
||||
|
||||
[1]: https://www.first.org/cvss/v4-0/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://www.first.org/cvss/calculator/4-0?utm_source=chatgpt.com "Common Vulnerability Scoring System Version 4.0 Calculator"
|
||||
Perfect, let’s turn that receipt idea into a concrete implementation plan your devs can actually build from.
|
||||
|
||||
I’ll break it into phases and responsibilities (backend, frontend, platform/DevOps), with enough detail that someone could start creating tickets from this.
|
||||
|
||||
---
|
||||
|
||||
## 0. Align on Scope & Definitions
|
||||
|
||||
**Goal:** For every vulnerability in Stella Ops, store and display a **CVSS v4.0 CVSS‑BTE score receipt** that is:
|
||||
|
||||
* Deterministic & reproducible (policy + inputs → same score).
|
||||
* Evidenced (links + hashes of artifacts).
|
||||
* Auditable over time (history of amendments).
|
||||
* Friendly to both **vendor/base** and **consumer/threat/env** workflows.
|
||||
|
||||
**Key concepts to lock in with the team (no coding yet):**
|
||||
|
||||
* **Primary object**: `CvssScoreReceipt` attached to a `Vulnerability`.
|
||||
* **Canonical score** = **CVSS‑BTE** (Base + Threat + Environmental).
|
||||
* **Base** usually from vendor/researcher; Threat + Environmental from Stella Ops / customer context.
|
||||
* **Supplemental** metrics: stored but **not part of numeric score**.
|
||||
* **Policy**: machine-readable config (e.g., JSON) that defines how you map questionnaire/inputs → CVSS metrics.
|
||||
|
||||
Deliverable: 2–3 page internal spec summarizing above for devs + PMs.
|
||||
|
||||
---
|
||||
|
||||
## 1. Data Model Design
|
||||
|
||||
### 1.1 Core Entities
|
||||
|
||||
*Model names are illustrative; adapt to your stack.*
|
||||
|
||||
**Vulnerability**
|
||||
|
||||
* `id`
|
||||
* `externalId` (e.g. CVE)
|
||||
* `title`
|
||||
* `description`
|
||||
* `currentCvssReceiptId` (FK → `CvssScoreReceipt`)
|
||||
|
||||
**CvssScoreReceipt**
|
||||
|
||||
* `id`
|
||||
* `vulnerabilityId` (FK)
|
||||
* `version` (e.g. `"4.0"`)
|
||||
* `enumeration` (e.g. `"CVSS-BTE"`)
|
||||
* `vectorString` (full v4.0 vector)
|
||||
* `finalScore` (numeric, 0.0–10.0)
|
||||
* `baseScore` (derived or duplicate for convenience)
|
||||
* `threatScore` (optional interim)
|
||||
* `environmentalScore` (optional interim)
|
||||
* `createdAt`
|
||||
* `createdByUserId`
|
||||
* `policyId` (FK → `CvssPolicy`)
|
||||
* `policyHash` (sha256 of policy JSON)
|
||||
* `inputsHash` (sha256 of normalized scoring inputs)
|
||||
* `dsseEnvelope` (optional text/blob if you implement full DSSE)
|
||||
* `metadata` (JSON for any extras you want)
|
||||
|
||||
**BaseMetrics (v4.0)**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `AV`, `AC`, `AT`, `PR`, `UI`
|
||||
* `VC`, `VI`, `VA`, `SC`, `SI`, `SA`
|
||||
* `justifications` (JSON object keyed by metric)
|
||||
|
||||
* e.g. `{ "AV": { "reason": "...", "evidenceIds": ["..."] }, ... }`
|
||||
|
||||
**ThreatMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `E` (Exploit Maturity)
|
||||
* `AU` (Automatable)
|
||||
* `U` (Provider/Consumer Urgency)
|
||||
* `evidence` (JSON: list of intel references)
|
||||
|
||||
**EnvironmentalMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `CR`, `XR`, `AR` (controls)
|
||||
* `criticality` (S/H/L/N or your internal enum)
|
||||
* `notes` (text/JSON)
|
||||
|
||||
**SupplementalMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* Fields you care about, e.g.:
|
||||
|
||||
* `safetyImpact`
|
||||
* `recoveryEffort`
|
||||
* `valueDensity`
|
||||
* `vulnerabilityResponseEffort`
|
||||
* `notes`
|
||||
|
||||
**EvidenceItem**
|
||||
|
||||
* `id`
|
||||
* `receiptId` (FK)
|
||||
* `name` (e.g. `"exploit_poc.md"`)
|
||||
* `uri` (link into your blob store, S3, etc.)
|
||||
* `sha256`
|
||||
* `type` (log, pcap, exploit, advisory, config, etc.)
|
||||
* `createdAt`
|
||||
* `createdBy`
|
||||
|
||||
**CvssPolicy**
|
||||
|
||||
* `id` (e.g. `cvss-policy-v4.0-stellaops-20251125`)
|
||||
* `name`
|
||||
* `version`
|
||||
* `engineVersion` (e.g. `stellaops.scorer 1.2.0`)
|
||||
* `policyJson` (JSON)
|
||||
* `sha256` (policy hash)
|
||||
* `active` (bool)
|
||||
* `validFrom`, `validTo` (optional)
|
||||
|
||||
**ReceiptHistoryEntry**
|
||||
|
||||
* `id`
|
||||
* `receiptId` (FK)
|
||||
* `date`
|
||||
* `changedField` (e.g. `"Threat.E"`)
|
||||
* `oldValue`
|
||||
* `newValue`
|
||||
* `reason`
|
||||
* `referenceUri` (link to ticket / intel)
|
||||
* `changedByUserId`
|
||||
|
||||
---
|
||||
|
||||
## 2. Backend Implementation Plan
|
||||
|
||||
### 2.1 Scoring Engine
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Create a `CvssV4Engine` module/package** with:
|
||||
|
||||
* `parseVector(string): CvssVector`
|
||||
* `computeBaseScore(metrics: BaseMetrics): number`
|
||||
* `computeThreatAdjustedScore(base: number, threat: ThreatMetrics): number`
|
||||
* `computeEnvironmentalAdjustedScore(threatAdjusted: number, env: EnvironmentalMetrics): number`
|
||||
* `buildVector(metrics: BaseMetrics & ThreatMetrics & EnvironmentalMetrics): string`
|
||||
2. Implement **CVSS v4.0 math** exactly per spec (rounding rules, minimums, etc.).
|
||||
3. Add **unit tests** for all official sample vectors + your own edge cases.
|
||||
|
||||
**Deliverables:**
|
||||
|
||||
* Test suite `CvssV4EngineTests` with:
|
||||
|
||||
* Known test vectors (from spec or FIRST calculator)
|
||||
* Edge cases: missing threat/env, zero-impact vulnerabilities, etc.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Receipt Construction Pipeline
|
||||
|
||||
Define a canonical function in backend:
|
||||
|
||||
```pseudo
|
||||
function createReceipt(vulnId, input, policyId, userId):
|
||||
policy = loadPolicy(policyId)
|
||||
normalizedInput = applyPolicy(input, policy) // map UI questionnaire → CVSS metrics
|
||||
|
||||
base = normalizedInput.baseMetrics
|
||||
threat = normalizedInput.threatMetrics
|
||||
env = normalizedInput.environmentalMetrics
|
||||
supplemental = normalizedInput.supplemental
|
||||
|
||||
// Score
|
||||
baseScore = CvssV4Engine.computeBaseScore(base)
|
||||
threatScore = CvssV4Engine.computeThreatAdjustedScore(baseScore, threat)
|
||||
finalScore = CvssV4Engine.computeEnvironmentalAdjustedScore(threatScore, env)
|
||||
|
||||
// Vector
|
||||
vector = CvssV4Engine.buildVector({base, threat, env})
|
||||
|
||||
// Hashes
|
||||
inputsHash = sha256(serializeForHashing({ base, threat, env, supplemental, evidenceRefs: input.evidenceIds }))
|
||||
policyHash = policy.sha256
|
||||
dsseEnvelope = buildDSSEEnvelope({ vulnId, base, threat, env, supplemental, policyId, policyHash, inputsHash })
|
||||
|
||||
// Persist entities in transaction
|
||||
receipt = saveCvssScoreReceipt(...)
|
||||
saveBaseMetrics(receipt.id, base)
|
||||
saveThreatMetrics(receipt.id, threat)
|
||||
saveEnvironmentalMetrics(receipt.id, env)
|
||||
saveSupplementalMetrics(receipt.id, supplemental)
|
||||
linkEvidence(receipt.id, input.evidenceItems)
|
||||
|
||||
updateVulnerabilityCurrentReceipt(vulnId, receipt.id)
|
||||
|
||||
return receipt
|
||||
```
|
||||
|
||||
**Important implementation details:**
|
||||
|
||||
* **`serializeForHashing`**: define a stable ordering and normalization (sorted keys, no whitespace sensitivity, canonical enums) so hashes are truly deterministic.
|
||||
* Use **transactions** so partial writes never leave `Vulnerability` pointing to incomplete receipts.
|
||||
* Ensure **idempotency**: if same `inputsHash + policyHash` already exists for that vuln, you can either:
|
||||
|
||||
* return existing receipt, or
|
||||
* create a new one but mark it as a duplicate-of; choose one rule and document it.
|
||||
|
||||
---
|
||||
|
||||
### 2.3 APIs
|
||||
|
||||
Design REST/GraphQL endpoints (adapt names to your style):
|
||||
|
||||
**Read:**
|
||||
|
||||
* `GET /vulnerabilities/{id}/cvss-receipt`
|
||||
|
||||
* Returns full receipt with nested metrics, evidence, policy metadata, history.
|
||||
* `GET /vulnerabilities/{id}/cvss-receipts`
|
||||
|
||||
* List historical receipts/versions.
|
||||
|
||||
**Create / Update:**
|
||||
|
||||
* `POST /vulnerabilities/{id}/cvss-receipt`
|
||||
|
||||
* Body: CVSS input payload (not raw metrics) + policyId.
|
||||
* Backend applies policy → metrics, computes scores, stores receipt.
|
||||
* `POST /vulnerabilities/{id}/cvss-receipt/recalculate`
|
||||
|
||||
* Optional: allows updating **only Threat + Environmental** while preserving Base.
|
||||
|
||||
**Evidence:**
|
||||
|
||||
* `POST /cvss-receipts/{receiptId}/evidence`
|
||||
|
||||
* Upload/link evidence artifacts, compute sha256, associate with receipt.
|
||||
* (Or integrate with your existing evidence/attachments service and only store references.)
|
||||
|
||||
**Policy:**
|
||||
|
||||
* `GET /cvss-policies`
|
||||
* `GET /cvss-policies/{id}`
|
||||
|
||||
**History:**
|
||||
|
||||
* `GET /cvss-receipts/{receiptId}/history`
|
||||
|
||||
Add auth/authorization:
|
||||
|
||||
* Only certain roles can **change Base**.
|
||||
* Different roles can **change Threat/Env**.
|
||||
* Audit logs for each change.
|
||||
|
||||
---
|
||||
|
||||
### 2.4 Integration with Existing Pipelines
|
||||
|
||||
**Automatic creation paths:**
|
||||
|
||||
1. **Scanner import path**
|
||||
|
||||
* When new vulnerability is imported with vendor CVSS v4:
|
||||
|
||||
* Parse vendor vector → BaseMetrics.
|
||||
* Use your default policy to set Threat/Env to “NotDefined”.
|
||||
* Generate initial receipt (tag as `source = "vendor"`).
|
||||
|
||||
2. **Manual analyst scoring**
|
||||
|
||||
* Analyst opens Vuln in Stella Ops UI.
|
||||
* Fills out guided form.
|
||||
* Frontend calls `POST /vulnerabilities/{id}/cvss-receipt`.
|
||||
|
||||
3. **Customer-specific Environmental scoring**
|
||||
|
||||
* Per-tenant policy stored in `CvssPolicy`.
|
||||
* Receipts store that policyId; calculating environment-specific scores uses those controls/criticality.
|
||||
|
||||
---
|
||||
|
||||
## 3. Frontend / UI Implementation Plan
|
||||
|
||||
### 3.1 Main “CVSS Score Receipt” Panel
|
||||
|
||||
Single screen/card with sections (tabs or accordions):
|
||||
|
||||
1. **Header**
|
||||
|
||||
* Large score badge: `finalScore` (e.g. 9.1).
|
||||
* Label: `CVSS v4.0 (CVSS‑BTE)`.
|
||||
* Color-coded severity (Low/Med/High/Critical).
|
||||
* Copy-to-clipboard for vector string.
|
||||
* Show Base/Threat/Env sub-scores if you choose to expose.
|
||||
|
||||
2. **Base Metrics Section**
|
||||
|
||||
* Table or form-like display:
|
||||
|
||||
* Each metric: value, short textual description, collapsed justification with “View more”.
|
||||
* Example row:
|
||||
|
||||
* **Attack Vector (AV)**: Network
|
||||
|
||||
* “The vulnerability is exploitable over the internet. PoC requires only TCP connectivity to port 443.”
|
||||
* Evidence chips: `exploit_poc.md`, `nginx_error.log.gz`.
|
||||
|
||||
3. **Threat Metrics Section**
|
||||
|
||||
* Radio/select controls for Exploit Maturity, Automatable, Urgency.
|
||||
* “Intel references” list (URLs or evidence items).
|
||||
* If the user edits these and clicks **Save**, frontend:
|
||||
|
||||
* Builds Threat input payload.
|
||||
* Calls `POST /vulnerabilities/{id}/cvss-receipt/recalculate` with updated threat/env only.
|
||||
* Shows new score & appends a `ReceiptHistoryEntry`.
|
||||
|
||||
4. **Environmental Section**
|
||||
|
||||
* Controls selection: Present / Partial / None.
|
||||
* Business criticality picker.
|
||||
* Contextual notes.
|
||||
* Same recalc flow as Threat.
|
||||
|
||||
5. **Supplemental Section**
|
||||
|
||||
* Non-scoring fields with clear label: “Does not affect numeric score, for context only”.
|
||||
|
||||
6. **Evidence Section**
|
||||
|
||||
* List of evidence items with:
|
||||
|
||||
* Name, type, hash, link.
|
||||
* “Attach evidence” button → upload / select existing artifact.
|
||||
|
||||
7. **Policy & Determinism Section**
|
||||
|
||||
* Display:
|
||||
|
||||
* Policy ID + hash.
|
||||
* Scoring engine version.
|
||||
* Inputs hash.
|
||||
* DSSE status (valid / not verified).
|
||||
* Button: **“Download receipt (JSON)”** – uses the JSON schema you already drafted.
|
||||
* Optional: **“Open in external calculator”** with vector appended as query parameter.
|
||||
|
||||
8. **History Section**
|
||||
|
||||
* Timeline of changes:
|
||||
|
||||
* Date, who, what changed (e.g. `Threat.E: POC → Attacked`).
|
||||
* Reason + link.
|
||||
|
||||
### 3.2 UX Considerations
|
||||
|
||||
* **Guardrails:**
|
||||
|
||||
* Editing Base metrics: show “This should match vendor or research data. Changing Base will alter historical comparability.”
|
||||
* Display last updated time & user for each metrics block.
|
||||
* **Permissions:**
|
||||
|
||||
* Disable inputs if user does not have edit rights; still show receipts read-only.
|
||||
* **Error Handling:**
|
||||
|
||||
* Show vector parse or scoring errors clearly, with a reference to policy/engine version.
|
||||
* **Accessibility:**
|
||||
|
||||
* High contrast for severity badges and clear iconography.
|
||||
|
||||
---
|
||||
|
||||
## 4. JSON Schema & Contracts
|
||||
|
||||
You already have a draft JSON; turn it into a formal schema (OpenAPI / JSON Schema) so backend + frontend are in sync.
|
||||
|
||||
Example top-level shape (high-level, not full code):
|
||||
|
||||
```json
|
||||
{
|
||||
"vulnId": "CVE-YYYY-XXXX",
|
||||
"title": "Short vuln title",
|
||||
"cvss": {
|
||||
"version": "4.0",
|
||||
"enumeration": "CVSS-BTE",
|
||||
"vector": "CVSS:4.0/...",
|
||||
"finalScore": 9.1,
|
||||
"baseScore": 8.7,
|
||||
"threatScore": 9.0,
|
||||
"environmentalScore": 9.1,
|
||||
"base": {
|
||||
"AV": "N", "AC": "L", "AT": "N", "PR": "N", "UI": "P",
|
||||
"VC": "H", "VI": "H", "VA": "H",
|
||||
"SC": "L", "SI": "N", "SA": "N",
|
||||
"justifications": {
|
||||
"AV": { "reason": "reachable over internet", "evidence": ["ev1"] }
|
||||
}
|
||||
},
|
||||
"threat": { "E": "Attacked", "AU": "Yes", "U": "High" },
|
||||
"environmental": { "controls": { "CR": "Present", "XR": "Partial", "AR": "None" }, "criticality": "H" },
|
||||
"supplemental": { "safety": "High", "recovery": "Hard" }
|
||||
},
|
||||
"evidence": [
|
||||
{ "id": "ev1", "name": "exploit_poc.md", "uri": "...", "sha256": "..." }
|
||||
],
|
||||
"policy": {
|
||||
"id": "cvss-policy-v4.0-stellaops-20251125",
|
||||
"sha256": "...",
|
||||
"engine": "stellaops.scorer 1.2.0"
|
||||
},
|
||||
"repro": {
|
||||
"dsseEnvelope": "base64...",
|
||||
"inputsHash": "sha256:..."
|
||||
},
|
||||
"history": [
|
||||
{ "date": "2025-11-25", "change": "Threat.E POC→Attacked", "reason": "SOC report", "ref": "..." }
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Back-end team: publish this via OpenAPI and keep it versioned.
|
||||
|
||||
---
|
||||
|
||||
## 5. Security, Integrity & Compliance
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Evidence Integrity**
|
||||
|
||||
* Enforce sha256 on every evidence item.
|
||||
* Optionally re-hash blob in background and store `verifiedAt` timestamp.
|
||||
|
||||
2. **Immutability**
|
||||
|
||||
* Decide which parts of a receipt are immutable:
|
||||
|
||||
* Typically: Base metrics, evidence links, policy references.
|
||||
* Threat/Env may change by creating **new receipts** or new “versions” of the same receipt.
|
||||
* Consider:
|
||||
|
||||
* “Current receipt” pointer on Vulnerability.
|
||||
* All receipts are read-only after creation; changes create new receipt + history entry.
|
||||
|
||||
3. **Audit Logging**
|
||||
|
||||
* Log who changed what (especially Threat/Env).
|
||||
* Store reference to ticket / change request.
|
||||
|
||||
4. **Access Control**
|
||||
|
||||
* RBAC: e.g. `ROLE_SEC_ENGINEER` can set Base; `ROLE_CUSTOMER_ANALYST` can set Env; `ROLE_VIEWER` read-only.
|
||||
|
||||
---
|
||||
|
||||
## 6. Testing Strategy
|
||||
|
||||
**Unit Tests**
|
||||
|
||||
* `CvssV4EngineTests` – coverage of:
|
||||
|
||||
* Vector parsing/serialization.
|
||||
* Calculations for B, BT, BTE.
|
||||
* `ReceiptBuilderTests` – determinism:
|
||||
|
||||
* Same inputs + policy → same score + same hashes.
|
||||
* Different policyId → different policyHash, different DSSE, even if metrics identical.
|
||||
|
||||
**Integration Tests**
|
||||
|
||||
* End-to-end:
|
||||
|
||||
* Create vulnerability → create receipt with Base only → update Threat → update Env.
|
||||
* Vendor CVSS import path.
|
||||
* Permission tests:
|
||||
|
||||
* Ensure unauthorized edits are blocked.
|
||||
|
||||
**UI Tests**
|
||||
|
||||
* Snapshot tests for the card layout.
|
||||
* Behavior: changing Threat slider updates preview score.
|
||||
* Accessibility checks (ARIA, focus order).
|
||||
|
||||
---
|
||||
|
||||
## 7. Rollout Plan
|
||||
|
||||
1. **Phase 1 – Backend Foundations**
|
||||
|
||||
* Implement data model + migrations.
|
||||
* Implement scoring engine + policies.
|
||||
* Implement REST/GraphQL endpoints (feature-flagged).
|
||||
2. **Phase 2 – UI MVP**
|
||||
|
||||
* Render read-only receipts for a subset of vulnerabilities.
|
||||
* Internal dogfood with security team.
|
||||
3. **Phase 3 – Editing & Recalc**
|
||||
|
||||
* Enable Threat/Env editing.
|
||||
* Wire evidence upload.
|
||||
* Activate history tracking.
|
||||
4. **Phase 4 – Vendor Integration + Tenants**
|
||||
|
||||
* Map scanner imports → initial Base receipts.
|
||||
* Tenant-specific Environmental policies.
|
||||
5. **Phase 5 – Hardening**
|
||||
|
||||
* Performance tests (bulk listing of vulnerabilities with receipts).
|
||||
* Security review of evidence and hash handling.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can turn this into:
|
||||
|
||||
* A set of Jira/Linear epics + tickets, or
|
||||
* A stack-specific design (for example: .NET + EF Core models + Razor components, or Node + TypeScript + React components) with concrete code skeletons.
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,563 @@
|
||||
Here’s a crisp, ready‑to‑use rule for VEX hygiene that will save you pain in audits and customer reviews—and make Stella Ops look rock‑solid.
|
||||
|
||||
# Adopt a strict “`not_affected` only with proof” policy
|
||||
|
||||
**What it means (plain English):**
|
||||
Only mark a vulnerability as `not_affected` if you can *prove* the vulnerable code can’t run in your product under defined conditions—then record that proof (scope, entry points, limits) inside a VEX bundle.
|
||||
|
||||
## The non‑negotiables
|
||||
|
||||
* **Audit coverage:**
|
||||
You must enumerate the reachable entry points you audited (e.g., exported handlers, CLI verbs, HTTP routes, scheduled jobs, init hooks). State their *limits* (versions, build flags, feature toggles, container args, config profiles).
|
||||
* **VEX justification required:**
|
||||
Use a concrete justification (OpenVEX/CISA style), e.g.:
|
||||
|
||||
* `vulnerable_code_not_in_execute_path`
|
||||
* `component_not_present`
|
||||
* `vulnerable_code_cannot_be_controlled_by_adversary`
|
||||
* `inline_mitigation_already_in_place`
|
||||
* **Impact or constraint statement:**
|
||||
Explain *why* it’s safe given your product’s execution model: sandboxing, dead code elimination, policy blocks, feature gates, OS hardening, container seccomp/AppArmor, etc.
|
||||
* **VEX proof bundle:**
|
||||
Store the evidence alongside the VEX: call‑graph slices, reachability reports, config snapshots, build args, lattice/policy decisions, test traces, and hashes of the exact artifacts (SBOM + attestation refs). This is what makes the claim stand up in an audit six months later.
|
||||
|
||||
## Minimal OpenVEX example (drop‑in)
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "urn:stellaops:vex:2025-11-25:svc-api:log4j:2.14.1",
|
||||
"author": "Stella Ops Authority",
|
||||
"role": "vex"
|
||||
},
|
||||
"statements": [
|
||||
{
|
||||
"vulnerability": "CVE-2021-44228",
|
||||
"products": ["pkg:maven/com.acme/svc-api@1.7.3?type=jar"],
|
||||
"status": "not_affected",
|
||||
"justification": "vulnerable_code_not_in_execute_path",
|
||||
"impact_statement": "Log4j JNDI classes excluded at build; no logger bridge; JVM flags `-Dlog4j2.formatMsgNoLookups=true` enforced by container entrypoint.",
|
||||
"analysis": {
|
||||
"entry_points_audited": [
|
||||
"com.acme.api.HttpServer#routes",
|
||||
"com.acme.jobs.Cron#run",
|
||||
"Main#init"
|
||||
],
|
||||
"limits": {
|
||||
"image_digest": "sha256:…",
|
||||
"config_profile": "prod",
|
||||
"args": ["--no-dynamic-plugins"],
|
||||
"seccomp": "stellaops-baseline-v3"
|
||||
},
|
||||
"evidence_refs": [
|
||||
"dsse:sha256:…/reachability.json",
|
||||
"dsse:sha256:…/build-args.att",
|
||||
"dsse:sha256:…/policy-lattice.proof"
|
||||
]
|
||||
},
|
||||
"timestamp": "2025-11-25T00:00:00Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Fast checklist (use this on every `not_affected`)
|
||||
|
||||
* [ ] Define product + artifact by immutable IDs (PURL + digest).
|
||||
* [ ] List **audited entry points** and **execution limits**.
|
||||
* [ ] Declare **status** = `not_affected` with a **justification** from the allowed set.
|
||||
* [ ] Add a short **impact/why‑safe** sentence.
|
||||
* [ ] Attach **evidence**: call graph, configs, policies, build args, test traces.
|
||||
* [ ] Sign the VEX (DSSE/In‑Toto), link it to the SBOM attestation.
|
||||
* [ ] Version and keep the proof bundle with your release.
|
||||
|
||||
## When to use an exception (temporary VEX)
|
||||
|
||||
If you can prove non‑reachability **only under a temporary constraint** (e.g., feature flag off while a permanent fix lands), emit a **time‑boxed exception** VEX:
|
||||
|
||||
* Add `constraints.expires` and the required control (e.g., `feature_flag=Off`, `policy=BlockJNDI`).
|
||||
* Schedule an auto‑recheck on expiry; flip to `affected` if the constraint lapses.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate a Stella Ops‑flavored VEX template and a tiny “proof bundle” schema (JSON) so your devs can drop it into the pipeline and your documentators can copy‑paste the rationale blocks.
|
||||
Cool, let’s turn that policy into something your devs can actually follow day‑to‑day.
|
||||
|
||||
Below is a concrete implementation plan you can drop into an internal RFC / Notion page and wire into your pipelines.
|
||||
|
||||
---
|
||||
|
||||
## 0. What we’re implementing (for context)
|
||||
|
||||
**Goal:** At Stella Ops, you can only mark a vulnerability as `not_affected` if:
|
||||
|
||||
1. You’ve **audited specific entry points** under clearly documented limits (version, build flags, config, container image).
|
||||
2. You’ve captured **evidence** and **rationale** in a VEX statement + proof bundle.
|
||||
3. The VEX is **validated, signed, and shipped** with the artifact.
|
||||
|
||||
We’ll standardize on **OpenVEX** with a small extension (`analysis` section) for developer‑friendly evidence.
|
||||
|
||||
---
|
||||
|
||||
## 1. Repo & artifact layout (week 1)
|
||||
|
||||
### 1.1. Create a standard security layout
|
||||
|
||||
In each service repo:
|
||||
|
||||
```text
|
||||
/security/
|
||||
vex/
|
||||
openvex.json # aggregate VEX doc (generated/curated)
|
||||
statements/ # one file per CVE (optional, if you like)
|
||||
proofs/
|
||||
CVE-YYYY-NNNN/
|
||||
reachability.json
|
||||
configs/
|
||||
tests/
|
||||
notes.md
|
||||
schemas/
|
||||
openvex.schema.json # JSON schema with Stella extensions
|
||||
```
|
||||
|
||||
**Developer guidance:**
|
||||
|
||||
* If you touch anything related to a vulnerability decision, you **edit `security/vex/` and `security/proofs/` in the same PR**.
|
||||
|
||||
---
|
||||
|
||||
## 2. Define the VEX schema & allowed justifications (week 1)
|
||||
|
||||
### 2.1. Fix the format & fields
|
||||
|
||||
You’ve already chosen OpenVEX, so formalize the required extras:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"vulnerability": "CVE-2021-44228",
|
||||
"products": ["pkg:maven/com.acme/svc-api@1.7.3?type=jar"],
|
||||
"status": "not_affected",
|
||||
"justification": "vulnerable_code_not_in_execute_path",
|
||||
"impact_statement": "…",
|
||||
"analysis": {
|
||||
"entry_points_audited": [
|
||||
"com.acme.api.HttpServer#routes",
|
||||
"com.acme.jobs.Cron#run",
|
||||
"Main#init"
|
||||
],
|
||||
"limits": {
|
||||
"image_digest": "sha256:…",
|
||||
"config_profile": "prod",
|
||||
"args": ["--no-dynamic-plugins"],
|
||||
"seccomp": "stellaops-baseline-v3"
|
||||
},
|
||||
"evidence_refs": [
|
||||
"dsse:sha256:…/reachability.json",
|
||||
"dsse:sha256:…/build-args.att",
|
||||
"dsse:sha256:…/policy-lattice.proof"
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Action items:**
|
||||
|
||||
* Write a **JSON schema** for the `analysis` block (required for `not_affected`):
|
||||
|
||||
* `entry_points_audited`: non‑empty array of strings.
|
||||
* `limits`: object with at least one of `image_digest`, `config_profile`, `args`, `seccomp`, `feature_flags`.
|
||||
* `evidence_refs`: non‑empty array of strings.
|
||||
* Commit this as `security/schemas/openvex.schema.json`.
|
||||
|
||||
### 2.2. Fix the allowed `justification` values
|
||||
|
||||
Publish an internal list, e.g.:
|
||||
|
||||
* `vulnerable_code_not_in_execute_path`
|
||||
* `component_not_present`
|
||||
* `vulnerable_code_cannot_be_controlled_by_adversary`
|
||||
* `inline_mitigation_already_in_place`
|
||||
* `protected_by_environment` (e.g., mandatory sandbox, read‑only FS)
|
||||
|
||||
**Rule:** any `not_affected` must pick one of these. Any new justification needs security team approval.
|
||||
|
||||
---
|
||||
|
||||
## 3. Developer process for handling a new vuln (week 2)
|
||||
|
||||
This is the **“how to act”** guide devs follow when a CVE pops up in scanners or customer reports.
|
||||
|
||||
### 3.1. Decision flow
|
||||
|
||||
1. **Is the vulnerable component actually present?**
|
||||
|
||||
* If no → `status: not_affected`, `justification: component_not_present`.
|
||||
Still fill out `products`, `impact_statement` (explain why it’s not present: different version, module excluded, etc.).
|
||||
2. **If present: analyze reachability.**
|
||||
|
||||
* Identify **entry points** of the service:
|
||||
|
||||
* HTTP routes, gRPC methods, message consumers, CLI commands, cron jobs, startup hooks.
|
||||
* Check:
|
||||
|
||||
* Is the vulnerable path reachable from any of these?
|
||||
* Is it blocked by configuration / feature flags / sandboxing?
|
||||
3. **If reachable or unclear → treat as `affected`.**
|
||||
|
||||
* Plan a patch, workaround, or runtime mitigation.
|
||||
4. **If not reachable & you can argue that clearly → `not_affected` with proof.**
|
||||
|
||||
* Fill in:
|
||||
|
||||
* `entry_points_audited`
|
||||
* `limits`
|
||||
* `evidence_refs`
|
||||
* `impact_statement` (“why safe”)
|
||||
|
||||
### 3.2. Developer checklist (drop this into your docs)
|
||||
|
||||
> **Stella Ops `not_affected` checklist**
|
||||
>
|
||||
> For any CVE you mark as `not_affected`:
|
||||
>
|
||||
> 1. **Identify product + artifact**
|
||||
>
|
||||
> * [ ] PURL (package URL)
|
||||
> * [ ] Image digest / binary hash
|
||||
> 2. **Audit execution**
|
||||
>
|
||||
> * [ ] List entry points you reviewed
|
||||
> * [ ] Note the limits (config profile, feature flags, container args, sandbox)
|
||||
> 3. **Collect evidence**
|
||||
>
|
||||
> * [ ] Reachability analysis (manual or tool report)
|
||||
> * [ ] Config snapshot (YAML, env vars, Helm values)
|
||||
> * [ ] Tests or traces (if applicable)
|
||||
> 4. **Write VEX statement**
|
||||
>
|
||||
> * [ ] `status = not_affected`
|
||||
> * [ ] `justification` from allowed list
|
||||
> * [ ] `impact_statement` explains “why safe”
|
||||
> * [ ] `analysis.entry_points_audited`, `analysis.limits`, `analysis.evidence_refs`
|
||||
> 5. **Wire into repo**
|
||||
>
|
||||
> * [ ] Proofs stored under `security/proofs/CVE-…/`
|
||||
> * [ ] VEX updated under `security/vex/`
|
||||
> 6. **Request review**
|
||||
>
|
||||
> * [ ] Security reviewer approved in PR
|
||||
|
||||
---
|
||||
|
||||
## 4. Automation & tooling for devs (week 2–3)
|
||||
|
||||
Make it easy to “do the right thing” with a small CLI and CI jobs.
|
||||
|
||||
### 4.1. Add a small `vexctl` helper
|
||||
|
||||
Language doesn’t matter—Python is fine. Rough sketch:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
import json
|
||||
from pathlib import Path
|
||||
from datetime import datetime
|
||||
|
||||
VEX_PATH = Path("security/vex/openvex.json")
|
||||
|
||||
def load_vex():
|
||||
if VEX_PATH.exists():
|
||||
return json.loads(VEX_PATH.read_text())
|
||||
return {"document": {}, "statements": []}
|
||||
|
||||
def save_vex(data):
|
||||
VEX_PATH.write_text(json.dumps(data, indent=2, sort_keys=True))
|
||||
|
||||
def add_statement():
|
||||
cve = input("CVE ID (e.g. CVE-2025-1234): ").strip()
|
||||
product = input("Product PURL: ").strip()
|
||||
status = input("Status [affected/not_affected/fixed]: ").strip()
|
||||
justification = None
|
||||
analysis = None
|
||||
|
||||
if status == "not_affected":
|
||||
justification = input("Justification (from allowed list): ").strip()
|
||||
entry_points = input("Entry points (comma-separated): ").split(",")
|
||||
limits_profile = input("Config profile (e.g. prod/stage): ").strip()
|
||||
image_digest = input("Image digest (optional): ").strip()
|
||||
evidence = input("Evidence refs (comma-separated): ").split(",")
|
||||
|
||||
analysis = {
|
||||
"entry_points_audited": [e.strip() for e in entry_points if e.strip()],
|
||||
"limits": {
|
||||
"config_profile": limits_profile or None,
|
||||
"image_digest": image_digest or None
|
||||
},
|
||||
"evidence_refs": [e.strip() for e in evidence if e.strip()]
|
||||
}
|
||||
|
||||
impact = input("Impact / why safe (short text): ").strip()
|
||||
|
||||
vex = load_vex()
|
||||
vex.setdefault("document", {})
|
||||
vex.setdefault("statements", [])
|
||||
stmt = {
|
||||
"vulnerability": cve,
|
||||
"products": [product],
|
||||
"status": status,
|
||||
"impact_statement": impact,
|
||||
"timestamp": datetime.utcnow().isoformat() + "Z"
|
||||
}
|
||||
if justification:
|
||||
stmt["justification"] = justification
|
||||
if analysis:
|
||||
stmt["analysis"] = analysis
|
||||
|
||||
vex["statements"].append(stmt)
|
||||
save_vex(vex)
|
||||
print(f"Added VEX statement for {cve}")
|
||||
|
||||
if __name__ == "__main__":
|
||||
add_statement()
|
||||
```
|
||||
|
||||
**Dev UX:** run:
|
||||
|
||||
```bash
|
||||
./tools/vexctl add
|
||||
```
|
||||
|
||||
and follow prompts instead of hand‑editing JSON.
|
||||
|
||||
### 4.2. Schema validation in CI
|
||||
|
||||
Add a CI job (GitHub Actions example) that:
|
||||
|
||||
1. Installs `jsonschema`.
|
||||
2. Validates `security/vex/openvex.json` against `security/schemas/openvex.schema.json`.
|
||||
3. Fails if:
|
||||
|
||||
* any `not_affected` statement lacks `analysis.*` fields, or
|
||||
* `justification` is not in the allowed list.
|
||||
|
||||
```yaml
|
||||
name: VEX validation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
paths:
|
||||
- "security/vex/**"
|
||||
- "security/schemas/**"
|
||||
|
||||
jobs:
|
||||
validate-vex:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.12"
|
||||
|
||||
- name: Install deps
|
||||
run: pip install jsonschema
|
||||
|
||||
- name: Validate OpenVEX
|
||||
run: |
|
||||
python tools/validate_vex.py
|
||||
```
|
||||
|
||||
Example `validate_vex.py` core logic:
|
||||
|
||||
```python
|
||||
import json
|
||||
from jsonschema import validate, ValidationError
|
||||
from pathlib import Path
|
||||
import sys
|
||||
|
||||
schema = json.loads(Path("security/schemas/openvex.schema.json").read_text())
|
||||
vex = json.loads(Path("security/vex/openvex.json").read_text())
|
||||
|
||||
try:
|
||||
validate(instance=vex, schema=schema)
|
||||
except ValidationError as e:
|
||||
print("VEX schema validation failed:", e, file=sys.stderr)
|
||||
sys.exit(1)
|
||||
|
||||
ALLOWED_JUSTIFICATIONS = {
|
||||
"vulnerable_code_not_in_execute_path",
|
||||
"component_not_present",
|
||||
"vulnerable_code_cannot_be_controlled_by_adversary",
|
||||
"inline_mitigation_already_in_place",
|
||||
"protected_by_environment",
|
||||
}
|
||||
|
||||
for stmt in vex.get("statements", []):
|
||||
if stmt.get("status") == "not_affected":
|
||||
just = stmt.get("justification")
|
||||
if just not in ALLOWED_JUSTIFICATIONS:
|
||||
print(f"Invalid justification '{just}' in statement {stmt.get('vulnerability')}")
|
||||
sys.exit(1)
|
||||
|
||||
analysis = stmt.get("analysis") or {}
|
||||
missing = []
|
||||
if not analysis.get("entry_points_audited"):
|
||||
missing.append("analysis.entry_points_audited")
|
||||
if not analysis.get("limits"):
|
||||
missing.append("analysis.limits")
|
||||
if not analysis.get("evidence_refs"):
|
||||
missing.append("analysis.evidence_refs")
|
||||
|
||||
if missing:
|
||||
print(
|
||||
f"'not_affected' for {stmt.get('vulnerability')} missing fields: {', '.join(missing)}"
|
||||
)
|
||||
sys.exit(1)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Signing & publishing VEX + proof bundles (week 3)
|
||||
|
||||
### 5.1. Signing
|
||||
|
||||
Pick a signing mechanism (e.g., DSSE + cosign/in‑toto), but keep the dev‑visible rules simple:
|
||||
|
||||
* CI step:
|
||||
|
||||
1. Build artifact (image/binary).
|
||||
2. Generate/update SBOM.
|
||||
3. Validate VEX.
|
||||
4. **Sign**:
|
||||
|
||||
* The artifact.
|
||||
* The SBOM.
|
||||
* The VEX document.
|
||||
|
||||
Enforce **KMS‑backed keys** controlled by the security team.
|
||||
|
||||
### 5.2. Publishing layout
|
||||
|
||||
Decide a canonical layout in your artifact registry / S3:
|
||||
|
||||
```text
|
||||
artifacts/
|
||||
svc-api/
|
||||
1.7.3/
|
||||
image.tar
|
||||
sbom.spdx.json
|
||||
vex.openvex.json
|
||||
proofs/
|
||||
CVE-2025-1234/
|
||||
reachability.json
|
||||
configs/
|
||||
tests/
|
||||
```
|
||||
|
||||
Link evidence by digest (`evidence_refs`) so you can prove exactly what you audited.
|
||||
|
||||
---
|
||||
|
||||
## 6. PR / review policy (week 3–4)
|
||||
|
||||
### 6.1. Add a PR checklist item
|
||||
|
||||
In your PR template:
|
||||
|
||||
```md
|
||||
### Security / VEX
|
||||
|
||||
- [ ] If this PR **changes how we handle a known CVE** or marks one as `not_affected`, I have:
|
||||
- [ ] Updated `security/vex/openvex.json`
|
||||
- [ ] Added/updated proof bundle under `security/proofs/`
|
||||
- [ ] Ran `./tools/vexctl` and CI VEX validation locally
|
||||
```
|
||||
|
||||
### 6.2. Require security reviewer for `not_affected` changes
|
||||
|
||||
Add a CODEOWNERS entry:
|
||||
|
||||
```text
|
||||
/security/vex/* @stellaops-security-team
|
||||
/security/proofs/* @stellaops-security-team
|
||||
```
|
||||
|
||||
* Any PR touching these paths must be approved by security.
|
||||
|
||||
---
|
||||
|
||||
## 7. Handling temporary exceptions (time‑boxed VEX)
|
||||
|
||||
Sometimes you’re only safe because of a **temporary constraint** (e.g., feature flag off until patch). For those:
|
||||
|
||||
1. Add a `constraints` block:
|
||||
|
||||
```json
|
||||
"constraints": {
|
||||
"control": "feature_flag",
|
||||
"name": "ENABLE_UNSAFE_PLUGIN_API",
|
||||
"required_value": "false",
|
||||
"expires": "2025-12-31T23:59:59Z"
|
||||
}
|
||||
```
|
||||
|
||||
2. Add a scheduled job (e.g., weekly) that:
|
||||
|
||||
* Parses VEX.
|
||||
* Finds any `constraints.expires < now()`.
|
||||
* Opens an issue or fails a synthetic CI job: “Constraint expired: reevaluate CVE‑2025‑1234”.
|
||||
|
||||
Dev guidance: **do not** treat time‑boxed exceptions as permanent; they must be re‑reviewed or turned into `affected` + mitigation.
|
||||
|
||||
---
|
||||
|
||||
## 8. Rollout plan by week
|
||||
|
||||
You can present this timeline internally:
|
||||
|
||||
* **Week 1**
|
||||
|
||||
* Finalize OpenVEX + `analysis` schema.
|
||||
* Create `security/` layout in 1–2 key services.
|
||||
* Publish allowed `justification` list + written policy.
|
||||
|
||||
* **Week 2**
|
||||
|
||||
* Implement `vexctl` helper.
|
||||
* Add CI validation job.
|
||||
* Pilot with one real CVE decision; walk through full proof bundle creation.
|
||||
|
||||
* **Week 3**
|
||||
|
||||
* Add signing + publishing steps for SBOM and VEX.
|
||||
* Wire artifact registry layout, link VEX + proofs per release.
|
||||
|
||||
* **Week 4**
|
||||
|
||||
* Enforce CODEOWNERS + PR checklist across all services.
|
||||
* Enable scheduled checks for expiring constraints.
|
||||
* Run internal training (30–45 min) walking through:
|
||||
|
||||
* “Bad VEX” (hand‑wavy, no entry points) vs
|
||||
* “Good VEX” (clear scope, evidence, limits).
|
||||
|
||||
---
|
||||
|
||||
## 9. What you can hand to devs right now
|
||||
|
||||
If you want, you can literally paste these as separate internal docs:
|
||||
|
||||
* **“How to mark a CVE as not_affected at Stella Ops”**
|
||||
|
||||
* Copy section 3 (decision flow + checklist) and the VEX snippet.
|
||||
* **“VEX technical reference for developers”**
|
||||
|
||||
* Copy sections 1–2–4 (structure, schema, CLI, CI validation).
|
||||
* **“VEX operations runbook”**
|
||||
|
||||
* Copy sections 5–7 (signing, publishing, exceptions).
|
||||
|
||||
---
|
||||
|
||||
If you tell me which CI system you use (GitHub Actions, GitLab CI, Circle, etc.) and your primary stack (Java, Go, Node, etc.), I can turn this into exact job configs and maybe a more tailored `vexctl` CLI for your environment.
|
||||
@@ -0,0 +1,602 @@
|
||||
Here’s a simple, low‑friction way to keep priorities fresh without constant manual grooming: **let confidence decay over time**.
|
||||
|
||||
%20=%20e^{-t/τ})
|
||||
|
||||
# Exponential confidence decay (what & why)
|
||||
|
||||
* **Idea:** Every item (task, lead, bug, doc, hypothesis) has a confidence score that **automatically shrinks with time** if you don’t touch it.
|
||||
* **Formula:** `confidence(t) = e^(−t/τ)` where `t` is days since last signal (edit, comment, commit, new data), and **τ (“tau”)** is the decay constant.
|
||||
* **Rule of thumb:** With **τ = 30 days**, at **t = 30** the confidence is **e^(−1) ≈ 0.37**—about a **63% drop**. This surfaces long‑ignored items *gradually*, not with harsh “stale/expired” flips.
|
||||
|
||||
# How to use it in practice
|
||||
|
||||
* **Signals that reset t → 0:** comment on the ticket, new benchmark, fresh log sample, doc update, CI run, new market news.
|
||||
* **Sort queues by:** `priority × confidence(t)` (or severity × confidence). Quiet items drift down; truly active ones stay up.
|
||||
* **Escalation bands:**
|
||||
|
||||
* `>0.6` = green (recently touched)
|
||||
* `0.3–0.6` = amber (review soon)
|
||||
* `<0.3` = red (poke or close)
|
||||
|
||||
# Quick presets
|
||||
|
||||
* **Fast‑moving queues (incidents, hot leads):** τ = **7–14** days
|
||||
* **Engineering tasks / product docs:** τ = **30** days
|
||||
* **Research bets / roadmaps:** τ = **60–90** days
|
||||
|
||||
# For your world (Stella Ops + ops/dev work)
|
||||
|
||||
* **Vuln tickets:** `risk_score = CVSS × reachability × e^(−t/30)`
|
||||
* **Roadmap epics:** `value_score = impact × e^(−t/60)` to re‑rank quarterly.
|
||||
* **Docs:** show a badge “freshness: 42%” derived from last edit age to nudge updates.
|
||||
|
||||
# Minimal implementation sketch
|
||||
|
||||
* Store per‑item: `last_signal_at`, `base_priority`.
|
||||
* Compute on read:
|
||||
|
||||
```
|
||||
days = (now - last_signal_at).days
|
||||
conf = exp(-days / tau)
|
||||
score = base_priority * conf
|
||||
```
|
||||
* Recompute in your API layer or materialize nightly; no cron spam needed.
|
||||
|
||||
If you want, I can draft a tiny C# helper (and SQL snippet) you can drop into your issue service to add `confidence(t)` and color bands to your lists.
|
||||
Perfect, let’s turn the idea into something your devs can actually build.
|
||||
|
||||
Below is an implementation plan you can drop into a ticketing/PRD — with clear phases, data model changes, APIs, and some sample code (C# + SQL). I’ll also sprinkle in Stella Ops–specific notes.
|
||||
|
||||
---
|
||||
|
||||
## 0. Scope & Objectives
|
||||
|
||||
**Goal:** Introduce `confidence(t)` as an automatic freshness factor that decays with time and is used to rank and highlight work.
|
||||
|
||||
We’ll apply it to:
|
||||
|
||||
* Vulnerabilities (Stella Ops)
|
||||
* General issues / tasks / epics
|
||||
* (Optional) Docs, leads, hypotheses later
|
||||
|
||||
**Core behavior:**
|
||||
|
||||
* Each item has:
|
||||
|
||||
* A base priority / risk (from severity, business impact, etc.)
|
||||
* A timestamp of last signal (meaningful activity)
|
||||
* A decay rate τ (tau) in days
|
||||
* Effective priority = `base_priority × confidence(t)`
|
||||
* `confidence(t) = exp(− t / τ)` where `t` = days since last_signal
|
||||
|
||||
---
|
||||
|
||||
## 1. Data Model Changes
|
||||
|
||||
### 1.1. Add fields to core “work item” tables
|
||||
|
||||
For each relevant table (`Issues`, `Vulnerabilities`, `Epics`, …):
|
||||
|
||||
**New columns:**
|
||||
|
||||
* `base_priority` (FLOAT or INT)
|
||||
|
||||
* Example: 1–100, or derived from severity.
|
||||
* `last_signal_at` (DATETIME, NOT NULL, default = `created_at`)
|
||||
* `tau_days` (FLOAT, nullable, falls back to type default)
|
||||
* (Optional) `confidence_score_cached` (FLOAT, for materialized score)
|
||||
* (Optional) `is_confidence_frozen` (BOOL, default FALSE)
|
||||
For pinned items that should not decay.
|
||||
|
||||
**Example Postgres migration (Issues):**
|
||||
|
||||
```sql
|
||||
ALTER TABLE issues
|
||||
ADD COLUMN base_priority DOUBLE PRECISION,
|
||||
ADD COLUMN last_signal_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
ADD COLUMN tau_days DOUBLE PRECISION,
|
||||
ADD COLUMN confidence_cached DOUBLE PRECISION,
|
||||
ADD COLUMN is_confidence_frozen BOOLEAN NOT NULL DEFAULT FALSE;
|
||||
```
|
||||
|
||||
For Stella Ops:
|
||||
|
||||
```sql
|
||||
ALTER TABLE vulnerabilities
|
||||
ADD COLUMN base_risk DOUBLE PRECISION,
|
||||
ADD COLUMN last_signal_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
ADD COLUMN tau_days DOUBLE PRECISION,
|
||||
ADD COLUMN confidence_cached DOUBLE PRECISION,
|
||||
ADD COLUMN is_confidence_frozen BOOLEAN NOT NULL DEFAULT FALSE;
|
||||
```
|
||||
|
||||
### 1.2. Add a config table for τ per entity type
|
||||
|
||||
```sql
|
||||
CREATE TABLE confidence_decay_config (
|
||||
id SERIAL PRIMARY KEY,
|
||||
entity_type TEXT NOT NULL, -- 'issue', 'vulnerability', 'epic', 'doc'
|
||||
tau_days_default DOUBLE PRECISION NOT NULL,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
|
||||
);
|
||||
|
||||
INSERT INTO confidence_decay_config (entity_type, tau_days_default) VALUES
|
||||
('incident', 7),
|
||||
('vulnerability', 30),
|
||||
('issue', 30),
|
||||
('epic', 60),
|
||||
('doc', 90);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 2. Define “signal” events & instrumentation
|
||||
|
||||
We need a standardized way to say: “this item got activity → reset last_signal_at”.
|
||||
|
||||
### 2.1. Signals that should reset `last_signal_at`
|
||||
|
||||
For **issues / epics:**
|
||||
|
||||
* New comment
|
||||
* Status change (e.g., Open → In Progress)
|
||||
* Field change that matters (severity, owner, milestone)
|
||||
* Attachment added
|
||||
* Link to PR added or updated
|
||||
* New CI failure linked
|
||||
|
||||
For **vulnerabilities (Stella Ops):**
|
||||
|
||||
* New scanner result attached or status updated (e.g., “Verified”, “False Positive”)
|
||||
* New evidence (PoC, exploit notes)
|
||||
* SLA override change
|
||||
* Assignment / ownership change
|
||||
* Integration events (e.g., PR merge that references the vuln)
|
||||
|
||||
For **docs (if you do it):**
|
||||
|
||||
* Any edit
|
||||
* Comment/annotation
|
||||
|
||||
### 2.2. Implement a shared helper to record a signal
|
||||
|
||||
**Service-level helper (pseudocode / C#-ish):**
|
||||
|
||||
```csharp
|
||||
public interface IConfidenceSignalService
|
||||
{
|
||||
Task RecordSignalAsync(WorkItemType type, Guid itemId, DateTime? signalTimeUtc = null);
|
||||
}
|
||||
|
||||
public class ConfidenceSignalService : IConfidenceSignalService
|
||||
{
|
||||
private readonly IWorkItemRepository _repo;
|
||||
private readonly IConfidenceConfigService _config;
|
||||
|
||||
public async Task RecordSignalAsync(WorkItemType type, Guid itemId, DateTime? signalTimeUtc = null)
|
||||
{
|
||||
var now = signalTimeUtc ?? DateTime.UtcNow;
|
||||
var item = await _repo.GetByIdAsync(type, itemId);
|
||||
if (item == null) return;
|
||||
|
||||
item.LastSignalAt = now;
|
||||
|
||||
if (item.TauDays == null)
|
||||
{
|
||||
item.TauDays = await _config.GetDefaultTauAsync(type);
|
||||
}
|
||||
|
||||
await _repo.UpdateAsync(item);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 2.3. Wire signals into existing flows
|
||||
|
||||
Create small tasks for devs like:
|
||||
|
||||
* **ISS-01:** Call `RecordSignalAsync` on:
|
||||
|
||||
* New issue comment handler
|
||||
* Issue status update handler
|
||||
* Issue field update handler (severity/priority/owner)
|
||||
* **VULN-01:** Call `RecordSignalAsync` when:
|
||||
|
||||
* New scanner result ingested for a vuln
|
||||
* Vulnerability status, SLA, or owner changes
|
||||
* New exploit evidence is attached
|
||||
|
||||
---
|
||||
|
||||
## 3. Confidence & scoring calculation
|
||||
|
||||
### 3.1. Shared confidence function
|
||||
|
||||
Definition:
|
||||
|
||||
```csharp
|
||||
public static class ConfidenceMath
|
||||
{
|
||||
// t = days since last signal
|
||||
public static double ConfidenceScore(DateTime lastSignalAtUtc, double tauDays, DateTime? nowUtc = null)
|
||||
{
|
||||
var now = nowUtc ?? DateTime.UtcNow;
|
||||
var tDays = (now - lastSignalAtUtc).TotalDays;
|
||||
|
||||
if (tDays <= 0) return 1.0;
|
||||
if (tauDays <= 0) return 1.0; // guard / fallback
|
||||
|
||||
var score = Math.Exp(-tDays / tauDays);
|
||||
|
||||
// Optional: never drop below a tiny floor, so items never "disappear"
|
||||
const double floor = 0.01;
|
||||
return Math.Max(score, floor);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3.2. Effective priority formulas
|
||||
|
||||
**Generic issues / tasks:**
|
||||
|
||||
```csharp
|
||||
double effectiveScore = issue.BasePriority * ConfidenceMath.ConfidenceScore(issue.LastSignalAt, issue.TauDays ?? defaultTau);
|
||||
```
|
||||
|
||||
**Vulnerabilities (Stella Ops):**
|
||||
|
||||
Let’s define:
|
||||
|
||||
* `severity_weight`: map CVSS or severity string to numeric (e.g. Critical=100, High=80, Medium=50, Low=20).
|
||||
* `reachability`: 0–1 (e.g. from your reachability analysis).
|
||||
* `exploitability`: 0–1 (optional, based on known exploits).
|
||||
* `confidence`: as above.
|
||||
|
||||
```csharp
|
||||
double baseRisk = severityWeight * reachability * exploitability; // or simpler: severityWeight * reachability
|
||||
double conf = ConfidenceMath.ConfidenceScore(vuln.LastSignalAt, vuln.TauDays ?? defaultTau);
|
||||
double effectiveRisk = baseRisk * conf;
|
||||
```
|
||||
|
||||
Store `baseRisk` → `vulnerabilities.base_risk`, and compute `effectiveRisk` on the fly or via job.
|
||||
|
||||
### 3.3. SQL implementation (optional for server-side sorting)
|
||||
|
||||
**Postgres example:**
|
||||
|
||||
```sql
|
||||
-- t_days = age in days
|
||||
-- tau = tau_days
|
||||
-- score = exp(-t_days / tau)
|
||||
|
||||
SELECT
|
||||
i.*,
|
||||
i.base_priority *
|
||||
GREATEST(
|
||||
EXP(- EXTRACT(EPOCH FROM (NOW() - i.last_signal_at)) / (86400 * COALESCE(i.tau_days, 30))),
|
||||
0.01
|
||||
) AS effective_priority
|
||||
FROM issues i
|
||||
ORDER BY effective_priority DESC;
|
||||
```
|
||||
|
||||
You can wrap that in a view:
|
||||
|
||||
```sql
|
||||
CREATE VIEW issues_with_confidence AS
|
||||
SELECT
|
||||
i.*,
|
||||
GREATEST(
|
||||
EXP(- EXTRACT(EPOCH FROM (NOW() - i.last_signal_at)) / (86400 * COALESCE(i.tau_days, 30))),
|
||||
0.01
|
||||
) AS confidence,
|
||||
i.base_priority *
|
||||
GREATEST(
|
||||
EXP(- EXTRACT(EPOCH FROM (NOW() - i.last_signal_at)) / (86400 * COALESCE(i.tau_days, 30))),
|
||||
0.01
|
||||
) AS effective_priority
|
||||
FROM issues i;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Caching & performance
|
||||
|
||||
You have two options:
|
||||
|
||||
### 4.1. Compute on read (simplest to start)
|
||||
|
||||
* Use the helper function in your service layer or a DB view.
|
||||
* Pros:
|
||||
|
||||
* No jobs, always fresh.
|
||||
* Cons:
|
||||
|
||||
* Slight CPU cost on heavy lists.
|
||||
|
||||
**Plan:** Start with this. If you see perf issues, move to 4.2.
|
||||
|
||||
### 4.2. Periodic materialization job (optional later)
|
||||
|
||||
Add a scheduled job (e.g. hourly) that:
|
||||
|
||||
1. Selects all active items.
|
||||
2. Computes `confidence_score` and `effective_priority`.
|
||||
3. Writes to `confidence_cached` and `effective_priority_cached` (if you add such a column).
|
||||
|
||||
Service then sorts by cached values.
|
||||
|
||||
---
|
||||
|
||||
## 5. Backfill & migration
|
||||
|
||||
### 5.1. Initial backfill script
|
||||
|
||||
For existing records:
|
||||
|
||||
* If `last_signal_at` is NULL → set to `created_at`.
|
||||
* Derive `base_priority` / `base_risk` from existing severity fields.
|
||||
* Set `tau_days` from config.
|
||||
|
||||
**Example:**
|
||||
|
||||
```sql
|
||||
UPDATE issues
|
||||
SET last_signal_at = created_at
|
||||
WHERE last_signal_at IS NULL;
|
||||
|
||||
UPDATE issues
|
||||
SET base_priority = CASE severity
|
||||
WHEN 'critical' THEN 100
|
||||
WHEN 'high' THEN 80
|
||||
WHEN 'medium' THEN 50
|
||||
WHEN 'low' THEN 20
|
||||
ELSE 10
|
||||
END
|
||||
WHERE base_priority IS NULL;
|
||||
|
||||
UPDATE issues i
|
||||
SET tau_days = c.tau_days_default
|
||||
FROM confidence_decay_config c
|
||||
WHERE c.entity_type = 'issue'
|
||||
AND i.tau_days IS NULL;
|
||||
```
|
||||
|
||||
Do similarly for `vulnerabilities` using severity / CVSS.
|
||||
|
||||
### 5.2. Sanity checks
|
||||
|
||||
Add a small script/test to verify:
|
||||
|
||||
* Newly created items → `confidence ≈ 1.0`.
|
||||
* 30-day-old items with τ=30 → `confidence ≈ 0.37`.
|
||||
* Ordering changes when you edit/comment on items.
|
||||
|
||||
---
|
||||
|
||||
## 6. API & Query Layer
|
||||
|
||||
### 6.1. New sorting options
|
||||
|
||||
Update list APIs:
|
||||
|
||||
* Accept parameter: `sort=effective_priority` or `sort=confidence`.
|
||||
* Default sort for some views:
|
||||
|
||||
* Vulnerabilities backlog: `sort=effective_risk` (risk × confidence).
|
||||
* Issues backlog: `sort=effective_priority`.
|
||||
|
||||
**Example REST API contract:**
|
||||
|
||||
`GET /api/issues?sort=effective_priority&state=open`
|
||||
|
||||
**Response fields (additions):**
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "ISS-123",
|
||||
"title": "Fix login bug",
|
||||
"base_priority": 80,
|
||||
"last_signal_at": "2025-11-01T10:00:00Z",
|
||||
"tau_days": 30,
|
||||
"confidence": 0.63,
|
||||
"effective_priority": 50.4,
|
||||
"confidence_band": "amber"
|
||||
}
|
||||
```
|
||||
|
||||
### 6.2. Confidence banding (for UI)
|
||||
|
||||
Define bands server-side (easy to change):
|
||||
|
||||
* Green: `confidence >= 0.6`
|
||||
* Amber: `0.3 ≤ confidence < 0.6`
|
||||
* Red: `confidence < 0.3`
|
||||
|
||||
You can compute on server:
|
||||
|
||||
```csharp
|
||||
string ConfidenceBand(double confidence) =>
|
||||
confidence >= 0.6 ? "green"
|
||||
: confidence >= 0.3 ? "amber"
|
||||
: "red";
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. UI / UX changes
|
||||
|
||||
### 7.1. List views (issues / vulns / epics)
|
||||
|
||||
For each item row:
|
||||
|
||||
* Show a small freshness pill:
|
||||
|
||||
* Text: `Active`, `Review soon`, `Stale`
|
||||
* Derived from confidence band.
|
||||
* Tooltip:
|
||||
|
||||
* “Confidence 78%. Last activity 3 days ago. τ = 30 days.”
|
||||
|
||||
* Sort default: by `effective_priority` / `effective_risk`.
|
||||
|
||||
* Filters:
|
||||
|
||||
* `Freshness: [All | Active | Review soon | Stale]`
|
||||
* Optionally: “Show stale only” toggle.
|
||||
|
||||
**Example labels:**
|
||||
|
||||
* Green: “Active (confidence 82%)”
|
||||
* Amber: “Review soon (confidence 45%)”
|
||||
* Red: “Stale (confidence 18%)”
|
||||
|
||||
### 7.2. Detail views
|
||||
|
||||
On an issue / vuln page:
|
||||
|
||||
* Add a “Confidence” section:
|
||||
|
||||
* “Confidence: **52%**”
|
||||
* “Last signal: **12 days ago**”
|
||||
* “Decay τ: **30 days**”
|
||||
* “Effective priority: **Base 80 × 0.52 = 42**”
|
||||
|
||||
* (Optional) small mini-chart (text-only or simple bar) showing approximate decay, but not necessary for first iteration.
|
||||
|
||||
### 7.3. Admin / settings UI
|
||||
|
||||
Add an internal settings page:
|
||||
|
||||
* Table of entity types with editable τ:
|
||||
|
||||
| Entity type | τ (days) | Notes |
|
||||
| ------------- | -------- | ---------------------------- |
|
||||
| Incident | 7 | Fast-moving |
|
||||
| Vulnerability | 30 | Standard risk review cadence |
|
||||
| Issue | 30 | Sprint-level decay |
|
||||
| Epic | 60 | Quarterly |
|
||||
| Doc | 90 | Slow decay |
|
||||
|
||||
* Optionally: toggle to pin item (`is_confidence_frozen`) from UI.
|
||||
|
||||
---
|
||||
|
||||
## 8. Stella Ops–specific behavior
|
||||
|
||||
For vulnerabilities:
|
||||
|
||||
### 8.1. Base risk calculation
|
||||
|
||||
Ingested fields you likely already have:
|
||||
|
||||
* `cvss_score` or `severity`
|
||||
* `reachable` (true/false or numeric)
|
||||
* (Optional) `exploit_available` (bool) or exploitability score
|
||||
* `asset_criticality` (1–5)
|
||||
|
||||
Define `base_risk` as:
|
||||
|
||||
```text
|
||||
severity_weight = f(cvss_score or severity)
|
||||
reachability = reachable ? 1.0 : 0.5 -- example
|
||||
exploitability = exploit_available ? 1.0 : 0.7
|
||||
asset_factor = 0.5 + 0.1 * asset_criticality -- 1 → 1.0, 5 → 1.5
|
||||
|
||||
base_risk = severity_weight * reachability * exploitability * asset_factor
|
||||
```
|
||||
|
||||
Store `base_risk` on vuln row.
|
||||
|
||||
Then:
|
||||
|
||||
```text
|
||||
effective_risk = base_risk * confidence(t)
|
||||
```
|
||||
|
||||
Use `effective_risk` for backlog ordering and SLAs dashboards.
|
||||
|
||||
### 8.2. Signals for vulns
|
||||
|
||||
Make sure these all call `RecordSignalAsync(Vulnerability, vulnId)`:
|
||||
|
||||
* New scan result for same vuln (re-detected).
|
||||
* Change status to “In Progress”, “Ready for Deploy”, “Verified Fixed”, etc.
|
||||
* Assigning an owner.
|
||||
* Attaching PoC / exploit details.
|
||||
|
||||
### 8.3. Vuln UI copy ideas
|
||||
|
||||
* Pill text:
|
||||
|
||||
* “Risk: 850 (confidence 68%)”
|
||||
* “Last analyst activity 11 days ago”
|
||||
|
||||
* In backlog view: show **Effective Risk** as main sort, with a smaller subtext “Base 1200 × Confidence 71%”.
|
||||
|
||||
---
|
||||
|
||||
## 9. Rollout plan
|
||||
|
||||
### Phase 1 – Infrastructure (backend-only)
|
||||
|
||||
* [ ] DB migrations & config table
|
||||
* [ ] Implement `ConfidenceMath` and helper functions
|
||||
* [ ] Implement `IConfidenceSignalService`
|
||||
* [ ] Wire signals into key flows (comments, state changes, scanner ingestion)
|
||||
* [ ] Add `confidence` and `effective_priority/risk` to API responses
|
||||
* [ ] Backfill script + dry run in staging
|
||||
|
||||
### Phase 2 – Internal UI & feature flag
|
||||
|
||||
* [ ] Add optional sorting by effective score to internal/staff views
|
||||
* [ ] Add confidence pill (hidden behind feature flag `confidence_decay_v1`)
|
||||
* [ ] Dogfood internally:
|
||||
|
||||
* Do items bubble up/down as expected?
|
||||
* Are any items “disappearing” because decay is too aggressive?
|
||||
|
||||
### Phase 3 – Parameter tuning
|
||||
|
||||
* [ ] Adjust τ per type based on feedback:
|
||||
|
||||
* If things decay too fast → increase τ
|
||||
* If queues rarely change → decrease τ
|
||||
* [ ] Decide on confidence floor (0.01? 0.05?) so nothing goes to literal 0.
|
||||
|
||||
### Phase 4 – General release
|
||||
|
||||
* [ ] Make effective score the default sort for key views:
|
||||
|
||||
* Vulnerabilities backlog
|
||||
* Issues backlog
|
||||
* [ ] Document behavior for users (help center / inline tooltip)
|
||||
* [ ] Add admin UI to tweak τ per entity type.
|
||||
|
||||
---
|
||||
|
||||
## 10. Edge cases & safeguards
|
||||
|
||||
* **New items**
|
||||
|
||||
* `last_signal_at = created_at`, confidence = 1.0.
|
||||
* **Pinned items**
|
||||
|
||||
* If `is_confidence_frozen = true` → treat confidence as 1.0.
|
||||
* **Items without τ**
|
||||
|
||||
* Always fallback to entity type default.
|
||||
* **Timezones**
|
||||
|
||||
* Always store & compute in UTC.
|
||||
* **Very old items**
|
||||
|
||||
* Floor the confidence so they’re still visible when explicitly searched.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can turn this into:
|
||||
|
||||
* A short **technical design doc** (with sections: Problem, Proposal, Alternatives, Rollout).
|
||||
* Or a **set of Jira tickets** grouped by backend / frontend / infra that your team can pick up directly.
|
||||
@@ -0,0 +1,630 @@
|
||||
Here’s a tight, practical blueprint for an **offline/air‑gap verification kit**—so regulated customers can prove what they’re installing without any network access.
|
||||
|
||||
---
|
||||
|
||||
# Offline kit: what to include & how to use it
|
||||
|
||||
**Why this matters (in plain words):** When a server has no internet, customers still need to trust that the bits they install are exactly what you shipped—and that the provenance is provable. This kit lets them verify integrity, origin, and minimal runtime safety entirely offline.
|
||||
|
||||
## 1) Signed SBOMs (DSSE‑wrapped)
|
||||
|
||||
* **Files:** `product.sbom.json` (CycloneDX or SPDX) + `product.sbom.json.dsse`
|
||||
* **What it gives:** Full component list with a detached DSSE envelope proving it came from you.
|
||||
* **Tip:** Use a *deterministic* SBOM build to avoid hash drift across rebuilds.
|
||||
|
||||
## 2) Rekor‑style receipt (or equivalent transparency record)
|
||||
|
||||
* **Files:** `rekor-receipt.json` (or a vendor‑neutral JSON receipt with canonical log ID, index, entry hash)
|
||||
* **Offline use:** They can’t query Rekor, but they can:
|
||||
|
||||
* Check the receipt’s **inclusion proof** against a bundled **checkpoint** (see #5).
|
||||
* Archive the receipt for later online audit parity.
|
||||
|
||||
## 3) Installer checksum + signature
|
||||
|
||||
* **Files:**
|
||||
|
||||
* `installer.tar.zst` (or your MSI/DEB/RPM)
|
||||
* `installer.sha256`
|
||||
* `installer.sha256.sig`
|
||||
* **What it gives:** Simple, fast integrity check + cryptographic authenticity (your offline public key in #5).
|
||||
|
||||
## 4) Minimal runtime config examples
|
||||
|
||||
* **Files:** `configs/minimal/compose.yml`, `configs/minimal/appsettings.json`, `configs/minimal/readme.md`
|
||||
* **What it gives:** A known‑good baseline the customer can start from without guessing env vars or secrets (use placeholders).
|
||||
|
||||
## 5) Step‑by‑step verification commands & trust roots
|
||||
|
||||
* **Files:**
|
||||
|
||||
* `VERIFY.md` (copy‑paste steps below)
|
||||
* `keys/vendor-pubkeys.pem` (X.509 or PEM keyring)
|
||||
* `checkpoints/transparency-checkpoint.txt` (Merkle root or log checkpoint snapshot)
|
||||
* `tools/` (static, offline verifiers if allowed: e.g., `cosign`, `gpg`, `sha256sum`)
|
||||
* **What it gives:** A single, predictable path to verification, without internet.
|
||||
|
||||
---
|
||||
|
||||
## Drop‑in VERIFY.md (ready to ship)
|
||||
|
||||
```bash
|
||||
# 0) Prepare
|
||||
export KIT_DIR=/media/usb/StellaOpsOfflineKit
|
||||
cd "$KIT_DIR"
|
||||
|
||||
# 1) Verify installer integrity
|
||||
sha256sum -c installer.sha256 # expects: installer.tar.zst: OK
|
||||
|
||||
# 2) Verify checksum signature (GPG example)
|
||||
gpg --keyid-format long --import keys/vendor-pubkeys.pem
|
||||
gpg --verify installer.sha256.sig installer.sha256
|
||||
|
||||
# 3) Verify SBOM DSSE envelope (cosign example, offline)
|
||||
# If you bundle cosign statically: tools/cosign verify-blob --key keys/vendor-pubkeys.pem ...
|
||||
tools/cosign verify-blob \
|
||||
--key keys/vendor-pubkeys.pem \
|
||||
--signature product.sbom.json.dsse \
|
||||
product.sbom.json
|
||||
|
||||
# 4) Verify transparency receipt against bundled checkpoint (offline proof)
|
||||
# (a) Inspect receipt & checkpoint
|
||||
jq . rekor-receipt.json | head
|
||||
cat checkpoints/transparency-checkpoint.txt
|
||||
|
||||
# (b) Validate Merkle proof (bundle a tiny verifier)
|
||||
tools/tlog-verify \
|
||||
--receipt rekor-receipt.json \
|
||||
--checkpoint checkpoints/transparency-checkpoint.txt \
|
||||
--roots keys/vendor-pubkeys.pem
|
||||
|
||||
# 5) Inspect SBOM quickly (CycloneDX)
|
||||
jq '.components[] | {name, version, purl}' product.sbom.json | head -n 50
|
||||
|
||||
# 6) Start from minimal config (no secrets inside the kit)
|
||||
cp -r configs/minimal ./local-min
|
||||
# Edit placeholders in ./local-min/*.yml / *.json before running
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Packaging notes (for your build pipeline)
|
||||
|
||||
* **Determinism:** Pin timestamps, ordering, and compression flags for SBOM and archives so hashes are stable.
|
||||
* **Crypto suite:** Default to modern Ed25519/sha256; optionally include **post‑quantum** signatures as a second envelope for long‑horizon customers.
|
||||
* **Key rotation:** Bundle a **key manifest** (`keys/manifest.json`) mapping key IDs → validity windows → products.
|
||||
* **Receipts:** If Rekor v2 or your own ledger is used, export an **inclusion proof + checkpoint** so customers can validate structure offline and later re‑check online for consistency.
|
||||
* **Tooling:** Prefer statically linked, air‑gap‑safe binaries in `tools/` with a small README and SHA256 list for each tool.
|
||||
|
||||
---
|
||||
|
||||
## Suggested kit layout
|
||||
|
||||
```
|
||||
StellaOpsOfflineKit/
|
||||
├─ installer.tar.zst
|
||||
├─ installer.sha256
|
||||
├─ installer.sha256.sig
|
||||
├─ product.sbom.json
|
||||
├─ product.sbom.json.dsse
|
||||
├─ rekor-receipt.json
|
||||
├─ keys/
|
||||
│ ├─ vendor-pubkeys.pem
|
||||
│ └─ manifest.json
|
||||
├─ checkpoints/
|
||||
│ └─ transparency-checkpoint.txt
|
||||
├─ configs/
|
||||
│ └─ minimal/
|
||||
│ ├─ compose.yml
|
||||
│ ├─ appsettings.json
|
||||
│ └─ readme.md
|
||||
├─ tools/
|
||||
│ ├─ cosign
|
||||
│ └─ tlog-verify
|
||||
└─ VERIFY.md
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## What your customers gain
|
||||
|
||||
* **Integrity** (checksum matches), **authenticity** (signature verifies), **provenance** (SBOM + DSSE), and **ledger consistency** (receipt vs checkpoint)—all **without internet**.
|
||||
* A **minimal, known‑good config** to get running safely in air‑gapped environments.
|
||||
|
||||
If you want, I can turn this into a Git‑ready template (files + sample keys + tiny verifier) that your CI can populate on release build.
|
||||
Below is something you can drop almost verbatim in an internal Confluence / `docs/engineering` page as “Developer directions for the Offline / Air-Gap Verification Kit”.
|
||||
|
||||
---
|
||||
|
||||
## 1. Objective for the team
|
||||
|
||||
We must ship, for every Stella Ops on-prem / air-gapped release, an **Offline Verification Kit** that allows a customer to verify:
|
||||
|
||||
1. Integrity of the installer payload
|
||||
2. Authenticity of the payload and SBOM (came from us, not altered)
|
||||
3. Provenance of the SBOM via DSSE + transparency receipt
|
||||
4. A minimal, known-good configuration to start from in an air-gap
|
||||
|
||||
All of this must work **with zero network access**.
|
||||
|
||||
You are responsible for implementing this as part of the standard build/release pipeline, not as a one-off script.
|
||||
|
||||
---
|
||||
|
||||
## 2. Directory layout and naming conventions
|
||||
|
||||
All code and CI scripts must assume the following layout for the kit content:
|
||||
|
||||
```text
|
||||
StellaOpsOfflineKit/
|
||||
├─ installer.tar.zst
|
||||
├─ installer.sha256
|
||||
├─ installer.sha256.sig
|
||||
├─ product.sbom.json
|
||||
├─ product.sbom.json.dsse
|
||||
├─ rekor-receipt.json
|
||||
├─ keys/
|
||||
│ ├─ vendor-pubkeys.pem
|
||||
│ └─ manifest.json
|
||||
├─ checkpoints/
|
||||
│ └─ transparency-checkpoint.txt
|
||||
├─ configs/
|
||||
│ └─ minimal/
|
||||
│ ├─ compose.yml
|
||||
│ ├─ appsettings.json
|
||||
│ └─ readme.md
|
||||
├─ tools/
|
||||
│ ├─ cosign
|
||||
│ └─ tlog-verify
|
||||
└─ VERIFY.md
|
||||
```
|
||||
|
||||
### Developer tasks
|
||||
|
||||
1. **Create a small “builder” tool/project** in the repo, e.g.
|
||||
`src/Tools/OfflineKitBuilder` (language of your choice, .NET is fine).
|
||||
2. The builder must:
|
||||
|
||||
* Take as inputs:
|
||||
|
||||
* path to installer (`installer.tar.zst` or equivalent)
|
||||
* path to SBOM (`product.sbom.json`)
|
||||
* DSSE signature file, Rekor receipt, checkpoint, keys, configs, tools
|
||||
* Produce the exact directory layout above under a versioned output:
|
||||
`artifacts/offline-kit/StellaOpsOfflineKit-<version>/...`
|
||||
3. CI will then archive this directory as a tarball / zip for release.
|
||||
|
||||
---
|
||||
|
||||
## 3. SBOM + DSSE implementation directions
|
||||
|
||||
### 3.1 SBOM generation (Scanner/Sbomer responsibility)
|
||||
|
||||
1. **Deterministic SBOM build**
|
||||
|
||||
* Make SBOM generation reproducible:
|
||||
|
||||
* Sort component lists and dependencies deterministically.
|
||||
* Avoid embedding current timestamps or build paths.
|
||||
* If timestamps are unavoidable, normalize them to a fixed value (e.g. `1970-01-01T00:00:00Z`) in the SBOM generator.
|
||||
* Acceptance test:
|
||||
|
||||
* Generate the SBOM twice from the same source/container.
|
||||
The resulting `product.sbom.json` must be byte-identical (`sha256` match).
|
||||
|
||||
2. **Standard format**
|
||||
|
||||
* Use CycloneDX or SPDX (CycloneDX recommended).
|
||||
* Provide:
|
||||
|
||||
* Components (name, version, purl).
|
||||
* Dependencies graph.
|
||||
* License information, if available.
|
||||
|
||||
3. **Output path**
|
||||
|
||||
* Standardize the output path in the build pipeline, e.g.:
|
||||
|
||||
* `artifacts/sbom/product.sbom.json`
|
||||
* The OfflineKitBuilder will pick it from this path.
|
||||
|
||||
### 3.2 DSSE wrapping of the SBOM
|
||||
|
||||
1. Implement a small internal library or service method:
|
||||
|
||||
* Input: `product.sbom.json`
|
||||
* Output: `product.sbom.json.dsse` (DSSE envelope containing the SBOM)
|
||||
* Use a **signing key stored in CI / key-management**, not in the repo.
|
||||
|
||||
2. DSSE envelope structure must include:
|
||||
|
||||
* Payload (base64) of the SBOM.
|
||||
* PayloadType (e.g. `application/vnd.cyclonedx+json`).
|
||||
* Signatures array (at least one signature with keyid, sig).
|
||||
|
||||
3. Signing key:
|
||||
|
||||
* Use Ed25519 or an equivalent modern key.
|
||||
* Private key is available only to the signing stage in CI.
|
||||
* Public key is included in `keys/vendor-pubkeys.pem`.
|
||||
|
||||
4. Acceptance tests:
|
||||
|
||||
* Unit test: verify that DSSE envelope can be parsed and verified with the public key.
|
||||
* Integration test: run `tools/cosign verify-blob` (in a test job) against a sample SBOM and DSSE pair in CI.
|
||||
|
||||
---
|
||||
|
||||
## 4. Rekor-style receipt & checkpoint directions
|
||||
|
||||
### 4.1 Generating the receipt
|
||||
|
||||
1. The pipeline that signs SBOM (or installer) must, if an online transparency log is used (e.g. Rekor v2):
|
||||
|
||||
* Submit the DSSE / signature to the log.
|
||||
* Receive a receipt JSON that includes:
|
||||
|
||||
* Log ID
|
||||
* Entry index (logIndex)
|
||||
* Entry hash (canonicalized)
|
||||
* Inclusion proof (hashes, tree size, root hash)
|
||||
* Save that JSON as `rekor-receipt.json` in `artifacts/offline-kit-temp/`.
|
||||
|
||||
2. If you use your own internal log instead of public Rekor:
|
||||
|
||||
* Ensure the receipt format is stable and documented.
|
||||
* Include:
|
||||
|
||||
* Unique log identifier.
|
||||
* Timestamp when entry was logged.
|
||||
* Inclusion proof equivalent (Merkle branch).
|
||||
* Log root / checkpoint.
|
||||
|
||||
### 4.2 Checkpoint bundling
|
||||
|
||||
1. During the same pipeline run, fetch a **checkpoint** of the transparency log:
|
||||
|
||||
* For Rekor: the “checkpoint” or “log root” structure.
|
||||
* For internal log: a signed statement summarizing tree size, root hash, etc.
|
||||
|
||||
2. Store it as a text file:
|
||||
|
||||
* `checkpoints/transparency-checkpoint.txt`
|
||||
* Content should be suitable for a simple CLI verifier:
|
||||
|
||||
* Tree size
|
||||
* Root hash
|
||||
* Signature from log operator
|
||||
* Optional: log origin / description
|
||||
|
||||
3. Acceptance criteria:
|
||||
|
||||
* A local offline `tlog-verify` tool (see below) must be able to:
|
||||
|
||||
* Read `rekor-receipt.json`.
|
||||
* Read `transparency-checkpoint.txt`.
|
||||
* Confirm inclusion (matches tree size/root hash, verify log signature).
|
||||
|
||||
---
|
||||
|
||||
## 5. Installer checksum and signature directions
|
||||
|
||||
### 5.1 Checksum
|
||||
|
||||
1. After building the main installer bundle (`installer.tar.zst`, `.msi`, `.deb`, etc.), generate:
|
||||
|
||||
```bash
|
||||
sha256sum installer.tar.zst > installer.sha256
|
||||
```
|
||||
|
||||
2. Ensure the file format is standard:
|
||||
|
||||
* Single line: `<sha256> installer.tar.zst`
|
||||
* No extra whitespace or carriage returns.
|
||||
|
||||
3. Store both files in the temp artifact area:
|
||||
|
||||
* `artifacts/offline-kit-temp/installer.tar.zst`
|
||||
* `artifacts/offline-kit-temp/installer.sha256`
|
||||
|
||||
### 5.2 Signature of the checksum
|
||||
|
||||
1. Use a **release signing key** (GPG or cosign key pair):
|
||||
|
||||
* Private key only in CI.
|
||||
* Public key(s) in `keys/vendor-pubkeys.pem`.
|
||||
|
||||
2. Sign the checksum file, not the installer directly, so customers:
|
||||
|
||||
* Verify `installer.sha256.sig` against `installer.sha256`.
|
||||
* Then verify `installer.tar.zst` against `installer.sha256`.
|
||||
|
||||
3. Example (GPG):
|
||||
|
||||
```bash
|
||||
gpg --batch --yes --local-user "$RELEASE_KEY_ID" \
|
||||
--output installer.sha256.sig \
|
||||
--sign --detach-sig installer.sha256
|
||||
```
|
||||
|
||||
4. Acceptance criteria:
|
||||
|
||||
* In a clean environment with only `vendor-pubkeys.pem` imported:
|
||||
|
||||
* `gpg --verify installer.sha256.sig installer.sha256` must succeed.
|
||||
|
||||
---
|
||||
|
||||
## 6. Keys/manifest directions
|
||||
|
||||
Under `keys/`:
|
||||
|
||||
1. `vendor-pubkeys.pem`:
|
||||
|
||||
* PEM bundle of all public keys that may sign:
|
||||
|
||||
* SBOM DSSE
|
||||
* Installer checksums
|
||||
* Transparency log checkpoints (if same trust root or separate)
|
||||
* Maintain it as a concatenated PEM file.
|
||||
|
||||
2. `manifest.json`:
|
||||
|
||||
* A small JSON mapping key IDs and roles:
|
||||
|
||||
```json
|
||||
{
|
||||
"keys": [
|
||||
{
|
||||
"id": "stellaops-release-2025",
|
||||
"type": "ed25519",
|
||||
"usage": ["sbom-dsse", "installer-checksum"],
|
||||
"valid_from": "2025-01-01T00:00:00Z",
|
||||
"valid_to": "2027-01-01T00:00:00Z"
|
||||
},
|
||||
{
|
||||
"id": "stellaops-log-root-2025",
|
||||
"type": "ed25519",
|
||||
"usage": ["transparency-checkpoint"],
|
||||
"valid_from": "2025-01-01T00:00:00Z",
|
||||
"valid_to": "2026-01-01T00:00:00Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. Ownership:
|
||||
|
||||
* Devs do not store private keys in the repo.
|
||||
* Key rotation: update `manifest.json` and `vendor-pubkeys.pem` as separate, reviewed commits.
|
||||
|
||||
---
|
||||
|
||||
## 7. Minimal runtime config directions
|
||||
|
||||
Under `configs/minimal/`:
|
||||
|
||||
1. `compose.yml`:
|
||||
|
||||
* Describe a minimal, single-node deployment suitable for:
|
||||
|
||||
* Test / PoC in an air-gap.
|
||||
* Use environment variables with obvious placeholders:
|
||||
|
||||
* `STELLAOPS_DB_PASSWORD=CHANGE_ME`
|
||||
* `STELLAOPS_LICENSE_KEY=INSERT_LICENSE`
|
||||
* Avoid any embedded secrets or customer-specific values.
|
||||
|
||||
2. `appsettings.json` (or equivalent configuration file):
|
||||
|
||||
* Only minimal, safe defaults:
|
||||
|
||||
* Listening ports.
|
||||
* Logging level.
|
||||
* Path locations inside container/VM.
|
||||
* No connection strings with passwords. Use placeholders clearly labeled.
|
||||
|
||||
3. `readme.md`:
|
||||
|
||||
* Describe:
|
||||
|
||||
* Purpose of these files.
|
||||
* Statement that they are templates and must be edited before use.
|
||||
* Short example of a `docker compose up` or `systemctl` invocation.
|
||||
* Explicitly say: “No secrets ship with the kit; you must provide them separately.”
|
||||
|
||||
4. Acceptance criteria:
|
||||
|
||||
* Security review script or manual checklist to verify:
|
||||
|
||||
* No passwords, tokens, or live endpoints are present.
|
||||
* Smoke test:
|
||||
|
||||
* Replace placeholders with test values in CI and assert containers start.
|
||||
|
||||
---
|
||||
|
||||
## 8. Tools bundling directions
|
||||
|
||||
Under `tools/`:
|
||||
|
||||
1. `cosign`:
|
||||
|
||||
* Statically linked binary for Linux x86_64 (and optionally others if you decide).
|
||||
* No external runtime dependencies.
|
||||
* Version pinned in a central place (e.g. `build/versions.json`).
|
||||
|
||||
2. `tlog-verify`:
|
||||
|
||||
* Your simple offline verifier:
|
||||
|
||||
* Verifies `rekor-receipt.json` against `transparency-checkpoint.txt`.
|
||||
* Verifies checkpoint signatures using key(s) in `vendor-pubkeys.pem`.
|
||||
* Implement it as a small CLI (Go / Rust / .NET).
|
||||
|
||||
3. Tool integrity:
|
||||
|
||||
* Generate a separate checksums file for tools, e.g.:
|
||||
|
||||
```bash
|
||||
sha256sum tools/* > tools.sha256
|
||||
```
|
||||
|
||||
* Not mandatory for customers to use, but good for internal checks.
|
||||
|
||||
4. Acceptance criteria:
|
||||
|
||||
* In a fresh container:
|
||||
|
||||
* `./tools/cosign --help` works.
|
||||
* `./tools/tlog-verify --help` shows usage.
|
||||
* End-to-end CI step:
|
||||
|
||||
* Run `VERIFY.md` steps programmatically (see below).
|
||||
|
||||
---
|
||||
|
||||
## 9. VERIFY.md generation directions
|
||||
|
||||
The offline kit must include a **ready-to-run** `VERIFY.md` with copy-paste commands that match the actual filenames.
|
||||
|
||||
Content should be close to:
|
||||
|
||||
````markdown
|
||||
# Offline verification steps (Stella Ops)
|
||||
|
||||
```bash
|
||||
# 0) Prepare
|
||||
export KIT_DIR=/path/to/StellaOpsOfflineKit
|
||||
cd "$KIT_DIR"
|
||||
|
||||
# 1) Verify installer integrity
|
||||
sha256sum -c installer.sha256 # expects installer.tar.zst: OK
|
||||
|
||||
# 2) Verify checksum signature
|
||||
gpg --keyid-format long --import keys/vendor-pubkeys.pem
|
||||
gpg --verify installer.sha256.sig installer.sha256
|
||||
|
||||
# 3) Verify SBOM DSSE envelope (offline)
|
||||
tools/cosign verify-blob \
|
||||
--key keys/vendor-pubkeys.pem \
|
||||
--signature product.sbom.json.dsse \
|
||||
product.sbom.json
|
||||
|
||||
# 4) Verify transparency receipt against bundled checkpoint
|
||||
tools/tlog-verify \
|
||||
--receipt rekor-receipt.json \
|
||||
--checkpoint checkpoints/transparency-checkpoint.txt \
|
||||
--roots keys/vendor-pubkeys.pem
|
||||
|
||||
# 5) Inspect SBOM summary (CycloneDX example)
|
||||
jq '.components[] | {name, version, purl}' product.sbom.json | head -n 50
|
||||
|
||||
# 6) Start from minimal config
|
||||
cp -r configs/minimal ./local-min
|
||||
# Edit placeholders in ./local-min/*.yml / *.json before running
|
||||
````
|
||||
|
||||
```
|
||||
|
||||
### Developer directions
|
||||
|
||||
1. `OfflineKitBuilder` must generate `VERIFY.md` automatically:
|
||||
|
||||
- Do not hardcode filenames in the markdown.
|
||||
- Use the actual filenames passed into the builder.
|
||||
- If you change file names in future, `VERIFY.md` must update automatically.
|
||||
|
||||
2. Add a small template engine or straightforward string formatting to keep this maintainable.
|
||||
|
||||
3. Acceptance criteria:
|
||||
|
||||
- CI job: unpack the built offline kit, `cd` into it, and:
|
||||
- Run all commands from `VERIFY.md` in a non-interactive script.
|
||||
- Test environment simulates “offline” (no outbound network, but that is mostly a policy, not enforced here).
|
||||
- The job fails if any verification step fails.
|
||||
|
||||
---
|
||||
|
||||
## 10. CI/CD pipeline integration directions
|
||||
|
||||
You must add a dedicated stage to the pipeline, e.g. `package_offline_kit`, with the following characteristics:
|
||||
|
||||
1. **Dependencies**:
|
||||
|
||||
- Depends on:
|
||||
- Installer build stage.
|
||||
- SBOM generation stage.
|
||||
- Signing/transparency logging stage.
|
||||
|
||||
2. **Steps**:
|
||||
|
||||
1. Download artifacts:
|
||||
- `installer.tar.zst`
|
||||
- `product.sbom.json`
|
||||
- DSSE, Rekor receipt, checkpoint, keys, tools.
|
||||
2. Run signing step (if not done earlier) for:
|
||||
- `installer.sha256`
|
||||
- `installer.sha256.sig`
|
||||
3. Invoke `OfflineKitBuilder`:
|
||||
- Provide paths as arguments or environment variables.
|
||||
4. Archive resulting `StellaOpsOfflineKit-<version>` as:
|
||||
- `StellaOpsOfflineKit-<version>.tar.zst` (or `.zip`).
|
||||
5. Publish this artifact:
|
||||
- As a GitLab / CI artifact.
|
||||
- As part of the release assets in your Git server.
|
||||
|
||||
3. **Versioning**:
|
||||
|
||||
- Offline kit version must match product version.
|
||||
- Use the same semantic version tag as the main release.
|
||||
|
||||
4. **Validation**:
|
||||
|
||||
- Add a `test_offline_kit` job:
|
||||
- Pulls the built offline kit.
|
||||
- Runs a scripted version of `VERIFY.md`.
|
||||
- Reports failure if any step fails.
|
||||
|
||||
---
|
||||
|
||||
## 11. Security & key management directions (for devs to respect)
|
||||
|
||||
1. **Never commit private keys** to the repository, even encrypted.
|
||||
|
||||
2. Keys used for:
|
||||
|
||||
- DSSE signing
|
||||
- Installer checksum signing
|
||||
- Transparency log checkpoints
|
||||
|
||||
must be provided via CI secrets or external KMS.
|
||||
|
||||
3. When adding or rotating keys:
|
||||
|
||||
- Update `keys/vendor-pubkeys.pem`.
|
||||
- Update `keys/manifest.json`.
|
||||
- Run a small internal test to ensure old and new keys are handled correctly.
|
||||
|
||||
4. Document in internal engineering docs:
|
||||
|
||||
- Who owns which key.
|
||||
- Rotational schedule.
|
||||
- Emergency rotation procedure.
|
||||
|
||||
---
|
||||
|
||||
## 12. Developer checklist per release
|
||||
|
||||
Before considering a release candidate complete, the responsible engineer must confirm:
|
||||
|
||||
1. [ ] `product.sbom.json` is deterministic (double run hash test passed).
|
||||
2. [ ] `product.sbom.json.dsse` verifies with `tools/cosign` and `vendor-pubkeys.pem`.
|
||||
3. [ ] `installer.tar.zst` matches `installer.sha256` and `installer.sha256.sig` verifies.
|
||||
4. [ ] `rekor-receipt.json` and `transparency-checkpoint.txt` pass `tools/tlog-verify`.
|
||||
5. [ ] `configs/minimal/` contains no secrets and boots a minimal deployment.
|
||||
6. [ ] `VERIFY.md` has been regenerated by `OfflineKitBuilder` and all steps succeed in the CI `test_offline_kit` job.
|
||||
7. [ ] The release artifact `StellaOpsOfflineKit-<version>.tar.zst` is attached to the release and downloadable.
|
||||
|
||||
If you want, next step I can do is draft a concrete `OfflineKitBuilder` design in .NET 10 (projects, classes, CLI options, and some sample code) so your devs can just fill in the implementation.
|
||||
```
|
||||
@@ -0,0 +1,590 @@
|
||||
I’m sharing this because it highlights important recent developments with Rekor — and how its new v2 rollout and behavior with DSSE change what you need to watch out for when building attestations (for example in your StellaOps architecture).
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 🚨 What changed with Rekor v2
|
||||
|
||||
* Rekor v2 is now GA: it moves to a tile‑backed transparency log backend (via the module rekor‑tiles), which simplifies maintenance and lowers infrastructure cost. ([blog.sigstore.dev][1])
|
||||
* The global publicly‑distributed instance now supports only two entry types: `hashedrekord` (for artifacts) and `dsse` (for attestations). Many previously supported entry types — e.g. `intoto`, `rekord`, `helm`, `rfc3161`, etc. — have been removed. ([blog.sigstore.dev][1])
|
||||
* The log is now sharded: instead of a single growing Merkle tree, multiple “shards” (trees) are used. This supports better scaling, simpler rotation/maintenance, and easier querying by tree shard + identifier. ([Sigstore][2])
|
||||
|
||||
### ⚠️ Why this matters for attestations, and common pitfalls
|
||||
|
||||
* Historically, when using DSSE or in‑toto style attestations submitted to Rekor (or via Cosign), the **entire attestation payload** had to be uploaded to Rekor. That becomes problematic when payloads are large. There’s a reported case where a 130 MB attestation was rejected due to size. ([GitHub][3])
|
||||
* The public instance of Rekor historically had a relatively small attestation size limit (on the order of 100 KB) for uploads. ([GitHub][4])
|
||||
* Because Rekor v2 no longer supports many entry types and simplifies the log types, you no longer have fallback for some of the older attestation/storage formats if they don’t fit DSSE/hashedrekord constraints. ([blog.sigstore.dev][1])
|
||||
|
||||
### ✅ What you must design for — and pragmatic workarounds
|
||||
|
||||
Given your StellaOps architecture goals (deterministic builds, reproducible scans, large SBOMs/metadata, private/off‑air‑gap compliance), here’s what you should consider:
|
||||
|
||||
* **Plan for payload-size constraints**: don’t assume arbitrary large attestations will be accepted. Keep attestation payloads small — ideally put large blobs (e.g. full SBOMs, large metadata) **outside** DSSE and store them elsewhere (artifact storage, internal logs, blob store) with the attestation only embedding a hash or reference.
|
||||
* **Use “private logs” / self‑hosted Rekor** if you anticipate large payloads — public instance limits make heavy payload uploads impractical. Running your own instance gives you control over size limits and resource allocation. ([GitHub][4])
|
||||
* **Chunking / sharding**: For large metadata blobs, consider splitting (“sharding”) or chunking the data into smaller pieces, each with its own DSSE/hashed‑rekord entry, then reference or re‑assemble externally. This avoids hitting size limits while maintaining inclusion proofs.
|
||||
* **Build idempotent re‑submit logic**: Because DSSE/hashed‑rekord entries are the only supported types, and large payloads may fail, your pipelines (e.g. StellaOps) should handle retries, partial submits, and ensure idempotence — so re‑submits don’t create inconsistent or duplicate entries.
|
||||
* **Persist full attestations outside Rekor**: Since Rekor v2 dropped many types and doesn’t store full arbitrary blobs necessarily, ensure that the “source of truth” for large metadata remains under your control (e.g. in your internal storage), with Rekor only storing minimal hashed attestations.
|
||||
|
||||
### 🎯 What this means for StellaOps
|
||||
|
||||
For your “Proof‑of‑Integrity Graph” + “offline bundle + replayable scans” vision — this means you should treat Rekor (especially public) as a *lightweight ledger for proofs*, not as a full-blown metadata store. In practice:
|
||||
|
||||
* Use Rekor for auditing, signature/inclusion proofs, and “commit‑to‑hash” attestations.
|
||||
* Store full SBOMs, VEX data, scan metadata, large build/context blobs externally.
|
||||
* Build your log‑sharding, replay, and artifact‑reference logic to survive Rekor’s constraints.
|
||||
* For air‑gapped workflows, consider a private Rekor or alternative internal log that mirrors the public transparency‑log guarantees but under your control.
|
||||
|
||||
If you like — I can pull up **real‑world examples** of organizations that already adapted to Rekor v2’s DSSE constraints (with chunking, private logs, hybrid storage) — could help shape StellaOps resilience strategy.
|
||||
|
||||
[1]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[2]: https://docs.sigstore.dev/logging/sharding/?utm_source=chatgpt.com "Sharding"
|
||||
[3]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
[4]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
Here’s a concrete, developer‑friendly implementation plan you can hand to the team. I’ll assume the context is “StellaOps + Sigstore/Rekor v2 + DSSE + air‑gapped support”.
|
||||
|
||||
---
|
||||
|
||||
## 0. Shared context & constraints (what devs should keep in mind)
|
||||
|
||||
**Key facts (summarized):**
|
||||
|
||||
* Rekor v2 keeps only **two** entry types: `hashedrekord` (artifact signatures) and `dsse` (attestations). Older types (`intoto`, `rekord`, etc.) are gone. ([Sigstore Blog][1])
|
||||
* The **public** Rekor instance enforces a ~**100KB attestation size limit** per upload; bigger payloads must use your **own Rekor instance** instead. ([GitHub][2])
|
||||
* For DSSE entries, Rekor **does not store the full payload**; it stores hashes and verification material. Users are expected to persist the attestations alongside artifacts in their own storage. ([Go Packages][3])
|
||||
* People have already hit problems where ~130MB attestations were rejected by Rekor, showing that “just upload the whole SBOM/provenance” is not sustainable. ([GitHub][4])
|
||||
* Sigstore’s **bundle** format is the canonical way to ship DSSE + tlog metadata around as a single JSON object (very useful for offline/air‑gapped replay). ([Sigstore][5])
|
||||
|
||||
**Guiding principles for the implementation:**
|
||||
|
||||
1. **Rekor is a ledger, not a blob store.** We log *proofs* (hashes, inclusion proofs), not big documents.
|
||||
2. **Attestation payloads live in our storage** (object store / DB).
|
||||
3. **All Rekor interaction goes through one abstraction** so we can easily switch public/private/none.
|
||||
4. **Everything is idempotent and replayable** (important for retries and air‑gapped exports).
|
||||
|
||||
---
|
||||
|
||||
## 1. High‑level architecture
|
||||
|
||||
### 1.1 Components
|
||||
|
||||
1. **Attestation Builder library (in CI/build tools)**
|
||||
|
||||
* Used by build pipelines / scanners / SBOM generators.
|
||||
* Responsibilities:
|
||||
|
||||
* Collect artifact metadata (digest, build info, SBOM, scan results).
|
||||
* Call Attestation API (below) with **semantic info** and raw payload(s).
|
||||
|
||||
2. **Attestation Service (core backend microservice)**
|
||||
|
||||
* Single entry‑point for creating and managing attestations.
|
||||
* Responsibilities:
|
||||
|
||||
* Normalize incoming metadata.
|
||||
* Store large payload(s) in object store.
|
||||
* Construct **small DSSE envelope** (payload = manifest / summary, not giant blob).
|
||||
* Persist attestation records & payload manifests in DB.
|
||||
* Enqueue log‑submission jobs for:
|
||||
|
||||
* Public Rekor v2
|
||||
* Private Rekor v2 (optional)
|
||||
* Internal event log (DB/Kafka)
|
||||
* Produce **Sigstore bundles** for offline use.
|
||||
|
||||
3. **Log Writer / Rekor Client Worker(s)**
|
||||
|
||||
* Background workers consuming submission jobs.
|
||||
* Responsibilities:
|
||||
|
||||
* Submit `dsse` (and optionally `hashedrekord`) entries to configured Rekor instances.
|
||||
* Handle retries with backoff.
|
||||
* Guarantee idempotency (no duplicate entries, no inconsistent state).
|
||||
* Update DB with Rekor log index/uuid and status.
|
||||
|
||||
4. **Offline Bundle Exporter (CLI or API)**
|
||||
|
||||
* Runs in air‑gapped cluster.
|
||||
* Responsibilities:
|
||||
|
||||
* Periodically export “new” attestations + bundles since last export.
|
||||
* Materialize data as tar/zip with:
|
||||
|
||||
* Sigstore bundles (JSON)
|
||||
* Chunk manifests
|
||||
* Large payload chunks (optional, depending on policy).
|
||||
|
||||
5. **Offline Replay Service (connected environment)**
|
||||
|
||||
* Runs where internet access and public Rekor are available.
|
||||
* Responsibilities:
|
||||
|
||||
* Read offline bundles from incoming location.
|
||||
* Replay to:
|
||||
|
||||
* Public Rekor
|
||||
* Cloud storage
|
||||
* Internal observability
|
||||
* Write updated status back (e.g., via a status file or callback).
|
||||
|
||||
6. **Config & Policy Layer**
|
||||
|
||||
* Central (e.g. YAML, env, config DB).
|
||||
* Controls:
|
||||
|
||||
* Which logs to use: `public_rekor`, `private_rekor`, `internal_only`.
|
||||
* Size thresholds (DSSE payload limit, chunk size).
|
||||
* Retry/backoff policy.
|
||||
* Air‑gapped mode toggles.
|
||||
|
||||
---
|
||||
|
||||
## 2. Data model (DB + storage)
|
||||
|
||||
Use whatever DB you have (Postgres is fine). Here’s a suggested schema, adapt as needed.
|
||||
|
||||
### 2.1 Core tables
|
||||
|
||||
**`attestations`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| ------------------------ | ----------- | ----------------------------------------- |
|
||||
| `id` | UUID (PK) | Internal identifier |
|
||||
| `subject_digest` | text | e.g., `sha256:<hex>` of build artifact |
|
||||
| `subject_uri` | text | Optional URI (image ref, file path, etc.) |
|
||||
| `predicate_type` | text | e.g. `https://slsa.dev/provenance/v1` |
|
||||
| `payload_schema_version` | text | Version of our manifest schema |
|
||||
| `dsse_envelope_digest` | text | `sha256` of DSSE envelope |
|
||||
| `bundle_location` | text | URL/path to Sigstore bundle (if cached) |
|
||||
| `created_at` | timestamptz | Creation time |
|
||||
| `created_by` | text | Origin (pipeline id, service name) |
|
||||
| `metadata` | jsonb | Extra labels / tags |
|
||||
|
||||
**`payload_manifests`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------- | ------------------------------------------------- |
|
||||
| `attestation_id` (FK) | UUID | Link to `attestations.id` |
|
||||
| `total_size_bytes` | bigint | Size of the *full* logical payload |
|
||||
| `chunk_count` | int | Number of chunks |
|
||||
| `root_digest` | text | Digest of full payload or Merkle root over chunks |
|
||||
| `manifest_json` | jsonb | The JSON we sign in the DSSE payload |
|
||||
| `created_at` | timestamptz | |
|
||||
|
||||
**`payload_chunks`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------------------------- | ---------------------- |
|
||||
| `attestation_id` (FK) | UUID | |
|
||||
| `chunk_index` | int | 0‑based index |
|
||||
| `chunk_digest` | text | sha256 of this chunk |
|
||||
| `size_bytes` | bigint | Size of chunk |
|
||||
| `storage_uri` | text | `s3://…` or equivalent |
|
||||
| PRIMARY KEY | (attestation_id, chunk_index) | Ensures uniqueness |
|
||||
|
||||
**`log_submissions`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------- | --------------------------------------------------------- |
|
||||
| `id` | UUID (PK) | |
|
||||
| `attestation_id` (FK) | UUID | |
|
||||
| `target` | text | `public_rekor`, `private_rekor`, `internal` |
|
||||
| `submission_key` | text | Idempotency key (see below) |
|
||||
| `state` | text | `pending`, `in_progress`, `succeeded`, `failed_permanent` |
|
||||
| `attempt_count` | int | For retries |
|
||||
| `last_error` | text | Last error message |
|
||||
| `rekor_log_index` | bigint | If applicable |
|
||||
| `rekor_log_id` | text | Log ID (tree ID / key ID) |
|
||||
| `created_at` | timestamptz | |
|
||||
| `updated_at` | timestamptz | |
|
||||
|
||||
Add a **unique index** on `(target, submission_key)` to guarantee idempotency.
|
||||
|
||||
---
|
||||
|
||||
## 3. DSSE payload design (how to avoid size limits)
|
||||
|
||||
### 3.1 Manifest‑based DSSE instead of giant payloads
|
||||
|
||||
Instead of DSSE‑signing the **entire SBOM/provenance blob** (which hits Rekor’s 100KB limit), we sign a **manifest** describing where the payload lives and how to verify it.
|
||||
|
||||
**Example manifest JSON** (payload of DSSE, small):
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "stellaops.manifest.v1",
|
||||
"subject": {
|
||||
"uri": "registry.example.com/app@sha256:abcd...",
|
||||
"digest": "sha256:abcd..."
|
||||
},
|
||||
"payload": {
|
||||
"type": "sbom.spdx+json",
|
||||
"rootDigest": "sha256:deadbeef...",
|
||||
"totalSize": 73400320,
|
||||
"chunkCount": 12
|
||||
},
|
||||
"chunks": [
|
||||
{
|
||||
"index": 0,
|
||||
"digest": "sha256:1111...",
|
||||
"size": 6291456
|
||||
},
|
||||
{
|
||||
"index": 1,
|
||||
"digest": "sha256:2222...",
|
||||
"size": 6291456
|
||||
}
|
||||
// ...
|
||||
],
|
||||
"storagePolicy": {
|
||||
"backend": "s3",
|
||||
"bucket": "stellaops-attestations",
|
||||
"pathPrefix": "sboms/app/abcd..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* This JSON is small enough to **fit under 100KB** even with lots of chunks, so the DSSE envelope stays small.
|
||||
* Full SBOM/scan results live in your object store; Rekor logs the DSSE envelope hash.
|
||||
|
||||
### 3.2 Chunking logic (Attestation Service)
|
||||
|
||||
Config values (can be env vars):
|
||||
|
||||
* `CHUNK_SIZE_BYTES` = e.g. 5–10 MiB
|
||||
* `MAX_DSSE_PAYLOAD_BYTES` = e.g. 70 KiB (keeping margin under Rekor 100KB limit)
|
||||
* `MAX_CHUNK_COUNT` = safety guard
|
||||
|
||||
Algorithm:
|
||||
|
||||
1. Receive raw payload bytes (SBOM / provenance / scan results).
|
||||
2. Compute full `root_digest = sha256(payload_bytes)` (or Merkle root if you want more advanced verification).
|
||||
3. If `len(payload_bytes) <= SMALL_PAYLOAD_THRESHOLD` (e.g. 64 KB):
|
||||
|
||||
* Skip chunking.
|
||||
* Store payload as single object.
|
||||
* Manifest can optionally omit `chunks` and just record one object.
|
||||
4. If larger:
|
||||
|
||||
* Split into fixed‑size chunks (except last).
|
||||
* For each chunk:
|
||||
|
||||
* Compute `chunk_digest`.
|
||||
* Upload chunk to object store path derived from `root_digest` + `chunk_index`.
|
||||
* Insert `payload_chunks` rows.
|
||||
5. Build manifest JSON with:
|
||||
|
||||
* `version`
|
||||
* `subject`
|
||||
* `payload` block
|
||||
* `chunks[]` (no URIs if you don’t want to leak details; the URIs can be derived by clients).
|
||||
6. Check serialized manifest size ≤ `MAX_DSSE_PAYLOAD_BYTES`. If not:
|
||||
|
||||
* Option A: increase chunk size so you have fewer chunks.
|
||||
* Option B: move chunk list to a secondary “chunk index” document and sign only its root digest.
|
||||
7. DSSE‑sign manifest JSON.
|
||||
8. Persist DSSE envelope digest + manifest in DB.
|
||||
|
||||
---
|
||||
|
||||
## 4. Rekor integration & idempotency
|
||||
|
||||
### 4.1 Rekor client abstraction
|
||||
|
||||
Implement an interface like:
|
||||
|
||||
```ts
|
||||
interface TransparencyLogClient {
|
||||
submitDsseEnvelope(params: {
|
||||
dsseEnvelope: Buffer; // JSON bytes
|
||||
subjectDigest: string;
|
||||
predicateType: string;
|
||||
}): Promise<{
|
||||
logIndex: number;
|
||||
logId: string;
|
||||
entryUuid: string;
|
||||
}>;
|
||||
}
|
||||
```
|
||||
|
||||
Provide implementations:
|
||||
|
||||
* `PublicRekorClient` (points at `https://rekor.sigstore.dev` or v2 equivalent).
|
||||
* `PrivateRekorClient` (your own Rekor v2 cluster).
|
||||
* `NullClient` (for internal‑only mode).
|
||||
|
||||
Use official API semantics from Rekor OpenAPI / SDKs where possible. ([Sigstore][6])
|
||||
|
||||
### 4.2 Submission jobs & idempotency
|
||||
|
||||
**Submission key design:**
|
||||
|
||||
```text
|
||||
submission_key = sha256(
|
||||
"dsse" + "|" +
|
||||
rekor_base_url + "|" +
|
||||
dsse_envelope_digest
|
||||
)
|
||||
```
|
||||
|
||||
Workflow in the worker:
|
||||
|
||||
1. Worker fetches `log_submissions` with `state = 'pending'` or due for retry.
|
||||
2. Set `state = 'in_progress'` (optimistic update).
|
||||
3. Call `client.submitDsseEnvelope`.
|
||||
4. If success:
|
||||
|
||||
* Update `state = 'succeeded'`, set `rekor_log_index`, `rekor_log_id`.
|
||||
5. If Rekor indicates “already exists” (or returns same logIndex for same envelope):
|
||||
|
||||
* Treat as success, update `state = 'succeeded'`.
|
||||
6. On network/5xx errors:
|
||||
|
||||
* Increment `attempt_count`.
|
||||
* If `attempt_count < MAX_RETRIES`: schedule retry with backoff.
|
||||
* Else: `state = 'failed_permanent'`, keep `last_error`.
|
||||
|
||||
DB constraint: `UNIQUE(target, submission_key)` ensures we don’t create conflicting jobs.
|
||||
|
||||
---
|
||||
|
||||
## 5. Attestation Service API design
|
||||
|
||||
### 5.1 Create attestation (build/scan pipeline → Attestation Service)
|
||||
|
||||
**`POST /v1/attestations`**
|
||||
|
||||
**Request body (example):**
|
||||
|
||||
```json
|
||||
{
|
||||
"subject": {
|
||||
"uri": "registry.example.com/app@sha256:abcd...",
|
||||
"digest": "sha256:abcd..."
|
||||
},
|
||||
"payloadType": "sbom.spdx+json",
|
||||
"payload": {
|
||||
"encoding": "base64",
|
||||
"data": "<base64-encoded-sbom-or-scan>"
|
||||
},
|
||||
"predicateType": "https://slsa.dev/provenance/v1",
|
||||
"logTargets": ["internal", "private_rekor", "public_rekor"],
|
||||
"airgappedMode": false,
|
||||
"labels": {
|
||||
"team": "payments",
|
||||
"env": "prod"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Server behavior:**
|
||||
|
||||
1. Validate subject & payload.
|
||||
2. Chunk payload as per rules (section 3).
|
||||
3. Store payload chunks.
|
||||
4. Build manifest JSON & DSSE envelope.
|
||||
5. Insert `attestations`, `payload_manifests`, `payload_chunks`.
|
||||
6. For each `logTargets`:
|
||||
|
||||
* Insert `log_submissions` row with `state = 'pending'`.
|
||||
7. Optionally construct Sigstore bundle representing:
|
||||
|
||||
* DSSE envelope
|
||||
* Transparency log entry (when available) — for async, you can fill this later.
|
||||
8. Return `202 Accepted` with resource URL:
|
||||
|
||||
```json
|
||||
{
|
||||
"attestationId": "1f4b3d...",
|
||||
"status": "pending_logs",
|
||||
"subjectDigest": "sha256:abcd...",
|
||||
"logTargets": ["internal", "private_rekor", "public_rekor"],
|
||||
"links": {
|
||||
"self": "/v1/attestations/1f4b3d...",
|
||||
"bundle": "/v1/attestations/1f4b3d.../bundle"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Get attestation status
|
||||
|
||||
**`GET /v1/attestations/{id}`**
|
||||
|
||||
Returns:
|
||||
|
||||
```json
|
||||
{
|
||||
"attestationId": "1f4b3d...",
|
||||
"subjectDigest": "sha256:abcd...",
|
||||
"predicateType": "https://slsa.dev/provenance/v1",
|
||||
"logs": {
|
||||
"internal": {
|
||||
"state": "succeeded"
|
||||
},
|
||||
"private_rekor": {
|
||||
"state": "succeeded",
|
||||
"logIndex": 1234,
|
||||
"logId": "..."
|
||||
},
|
||||
"public_rekor": {
|
||||
"state": "pending",
|
||||
"lastError": null
|
||||
}
|
||||
},
|
||||
"createdAt": "2025-11-27T12:34:56Z"
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Get bundle
|
||||
|
||||
**`GET /v1/attestations/{id}/bundle`**
|
||||
|
||||
* Returns a **Sigstore bundle JSON** that:
|
||||
|
||||
* Contains either:
|
||||
|
||||
* Only the DSSE + identity + certificate chain (if logs not yet written).
|
||||
* Or DSSE + log entries (`hashedrekord` / `dsse` entries) for whichever logs are ready. ([Sigstore][5])
|
||||
|
||||
* This is what air‑gapped exports and verifiers consume.
|
||||
|
||||
---
|
||||
|
||||
## 6. Air‑gapped workflows
|
||||
|
||||
### 6.1 In the air‑gapped environment
|
||||
|
||||
* Attestation Service runs in “air‑gapped mode”:
|
||||
|
||||
* `logTargets` typically = `["internal", "private_rekor"]`.
|
||||
* No direct public Rekor.
|
||||
|
||||
* **Offline Exporter CLI**:
|
||||
|
||||
```bash
|
||||
stellaops-offline-export \
|
||||
--since-id <last_exported_attestation_id> \
|
||||
--output offline-bundle-<timestamp>.tar.gz
|
||||
```
|
||||
|
||||
* Exporter logic:
|
||||
|
||||
1. Query DB for new `attestations` > `since-id`.
|
||||
2. For each attestation:
|
||||
|
||||
* Fetch DSSE envelope.
|
||||
* Fetch current log statuses (private rekor, internal).
|
||||
* Build or reuse Sigstore bundle JSON.
|
||||
* Optionally include payload chunks and/or original payload.
|
||||
3. Write them into a tarball with structure like:
|
||||
|
||||
```
|
||||
/attestations/<id>/bundle.json
|
||||
/attestations/<id>/chunks/chunk-0000.bin
|
||||
...
|
||||
/meta/export-metadata.json
|
||||
```
|
||||
|
||||
### 6.2 In the connected environment
|
||||
|
||||
* **Replay Service**:
|
||||
|
||||
```bash
|
||||
stellaops-offline-replay \
|
||||
--input offline-bundle-<timestamp>.tar.gz \
|
||||
--public-rekor-url https://rekor.sigstore.dev
|
||||
```
|
||||
|
||||
* Replay logic:
|
||||
|
||||
1. Read each `/attestations/<id>/bundle.json`.
|
||||
2. If `public_rekor` entry not present:
|
||||
|
||||
* Extract DSSE envelope from bundle.
|
||||
* Call Attestation Service “import & log” endpoint or directly call PublicRekorClient.
|
||||
* Build new updated bundle (with public tlog entry).
|
||||
3. Emit an updated `result.json` for each attestation (so you can sync status back to original environment if needed).
|
||||
|
||||
---
|
||||
|
||||
## 7. Observability & ops
|
||||
|
||||
### 7.1 Metrics
|
||||
|
||||
Have devs expose at least:
|
||||
|
||||
* `rekor_submit_requests_total{target, outcome}`
|
||||
* `rekor_submit_latency_seconds{target}` (histogram)
|
||||
* `log_submissions_in_queue{target}`
|
||||
* `attestations_total{predicateType}`
|
||||
* `attestation_payload_bytes{bucket}` (distribution of payload sizes)
|
||||
|
||||
### 7.2 Logging
|
||||
|
||||
* Log at **info**:
|
||||
|
||||
* Attestation created (subject digest, predicateType, manifest version).
|
||||
* Log submission succeeded (target, logIndex, logId).
|
||||
* Log at **warn/error**:
|
||||
|
||||
* Any permanent failure.
|
||||
* Any time DSSE payload nearly exceeds size threshold (to catch misconfig).
|
||||
|
||||
### 7.3 Feature flags
|
||||
|
||||
* `FEATURE_REKOR_PUBLIC_ENABLED`
|
||||
* `FEATURE_REKOR_PRIVATE_ENABLED`
|
||||
* `FEATURE_OFFLINE_EXPORT_ENABLED`
|
||||
* `FEATURE_CHUNKING_ENABLED` (to allow rolling rollout)
|
||||
|
||||
---
|
||||
|
||||
## 8. Concrete work breakdown for developers
|
||||
|
||||
You can basically drop this as a backlog outline:
|
||||
|
||||
1. **Domain model & storage**
|
||||
|
||||
* [ ] Implement DB migrations for `attestations`, `payload_manifests`, `payload_chunks`, `log_submissions`.
|
||||
* [ ] Implement object storage abstraction and content‑addressable layout for chunks.
|
||||
2. **Attestation Service skeleton**
|
||||
|
||||
* [ ] Implement `POST /v1/attestations` with basic validation.
|
||||
* [ ] Implement manifest building and DSSE envelope creation (no Rekor yet).
|
||||
* [ ] Persist records in DB.
|
||||
3. **Chunking & manifest logic**
|
||||
|
||||
* [ ] Implement chunker with thresholds & tests (small vs large).
|
||||
* [ ] Implement manifest JSON builder.
|
||||
* [ ] Ensure DSSE payload size is under configurable limit.
|
||||
4. **Rekor client & log submissions**
|
||||
|
||||
* [ ] Implement `TransparencyLogClient` interface + Public/Private implementations.
|
||||
* [ ] Implement `log_submissions` worker (queue + backoff + idempotency).
|
||||
* [ ] Wire worker into service config and deployment.
|
||||
5. **Sigstore bundle support**
|
||||
|
||||
* [ ] Implement bundle builder given DSSE envelope + log metadata.
|
||||
* [ ] Add `GET /v1/attestations/{id}/bundle`.
|
||||
6. **Offline export & replay**
|
||||
|
||||
* [ ] Implement Exporter CLI (queries DB, packages bundles and chunks).
|
||||
* [ ] Implement Replay CLI/service (reads tarball, logs to public Rekor).
|
||||
* [ ] Document operator workflow for moving tarballs between environments.
|
||||
7. **Observability & docs**
|
||||
|
||||
* [ ] Add metrics, logs, and dashboards.
|
||||
* [ ] Write verification docs: “How to fetch manifest, verify DSSE, reconstruct payload, and check Rekor.”
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can do is: take this and turn it into a more strict format your devs might already use (e.g. Jira epics + stories, or a design doc template with headers like “Motivation, Alternatives, Risks, Rollout Plan”).
|
||||
|
||||
[1]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[2]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[3]: https://pkg.go.dev/github.com/sigstore/rekor/pkg/types/dsse?utm_source=chatgpt.com "dsse package - github.com/sigstore/rekor/pkg/types/dsse"
|
||||
[4]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
[5]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[6]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
@@ -0,0 +1,886 @@
|
||||
Here’s a concrete, low‑lift way to boost Stella Ops’s visibility and prove your “deterministic, replayable” moat: publish a **sanitized subset of reachability graphs** as a public benchmark that others can run and score identically.
|
||||
|
||||
### What this is (plain English)
|
||||
|
||||
* You release a small, carefully scrubbed set of **packages + SBOMs + VEX + call‑graphs** (source & binaries) with **ground‑truth reachability labels** for a curated list of CVEs.
|
||||
* You also ship a **deterministic scoring harness** (container + manifest) so anyone can reproduce the exact scores, byte‑for‑byte.
|
||||
|
||||
### Why it helps
|
||||
|
||||
* **Proof of determinism:** identical inputs → identical graphs → identical scores.
|
||||
* **Research magnet:** gives labs and tool vendors a neutral yardstick; you become “the” benchmark steward.
|
||||
* **Biz impact:** easy demo for buyers; lets you publish leaderboards and whitepapers.
|
||||
|
||||
### Scope (MVP dataset)
|
||||
|
||||
* **Languages:** PHP, JS, Python, plus **binary** (ELF/PE/Mach‑O) mini-cases.
|
||||
* **Units:** 20–30 packages total; 3–6 CVEs per language; 4–6 binary cases (static & dynamically‑linked).
|
||||
* **Artifacts per unit:**
|
||||
|
||||
* Package tarball(s) or container image digest
|
||||
* SBOM (CycloneDX 1.6 + SPDX 3.0.1)
|
||||
* VEX (known‑exploited, not‑affected, under‑investigation)
|
||||
* **Call graph** (normalized JSON)
|
||||
* **Ground truth**: list of vulnerable entrypoints/edges considered *reachable*
|
||||
* **Determinism manifest**: feed URLs + rule hashes + container digests + tool versions
|
||||
|
||||
### Data model (keep it simple)
|
||||
|
||||
* `dataset.json`: index of cases with content‑addressed URIs (sha256)
|
||||
* `sbom/`, `vex/`, `graphs/`, `truth/` folders mirroring the index
|
||||
* `manifest.lock.json`: DSSE‑signed record of:
|
||||
|
||||
* feeder rules, lattice policies, normalizers (name + version + hash)
|
||||
* container image digests for each step (scanner/cartographer/normalizer)
|
||||
* timestamp + signer (Stella Ops Authority)
|
||||
|
||||
### Scoring harness (deterministic)
|
||||
|
||||
* One Docker image: `stellaops/benchmark-harness:<tag>`
|
||||
* Inputs: dataset root + `manifest.lock.json`
|
||||
* Outputs:
|
||||
|
||||
* `scores.json` (precision/recall/F1, per‑case and macro)
|
||||
* `replay-proof.txt` (hashes of every artifact used)
|
||||
* **No network** mode (offline‑first). Fails closed if any hash mismatches.
|
||||
|
||||
### Metrics (clear + auditable)
|
||||
|
||||
* Per case: TP/FP/FN for **reachable** functions (or edges), plus optional **sink‑reach** verification.
|
||||
* Aggregates: micro/macro F1; “Determinism Index” (stddev of repeated runs must be 0).
|
||||
* **Repro test:** the harness re‑runs N=3 and asserts identical outputs (hash compare).
|
||||
|
||||
### Sanitization & legal
|
||||
|
||||
* Strip any proprietary code/data; prefer OSS with permissive licenses.
|
||||
* Replace real package registries with **local mirrors** and pin digests.
|
||||
* Publish under **CC‑BY‑4.0** (data) + **Apache‑2.0** (harness). Add a simple **contributor license agreement** for external case submissions.
|
||||
|
||||
### Baselines to include (neutral + useful)
|
||||
|
||||
* “Naïve reachable” (all functions in package)
|
||||
* “Imports‑only” (entrypoints that match import graph)
|
||||
* “Call‑depth‑2” (bounded traversal)
|
||||
* **Your** graph engine run with **frozen rules** from the manifest (as a reference, not a claim of SOTA)
|
||||
|
||||
### Repository layout (public)
|
||||
|
||||
```
|
||||
stellaops-reachability-benchmark/
|
||||
dataset/
|
||||
dataset.json
|
||||
sbom/...
|
||||
vex/...
|
||||
graphs/...
|
||||
truth/...
|
||||
manifest.lock.json (DSSE-signed)
|
||||
harness/
|
||||
Dockerfile
|
||||
runner.py (CLI)
|
||||
schema/ (JSON Schemas for graphs, truth, scores)
|
||||
docs/
|
||||
HOWTO.md (5-min run)
|
||||
CONTRIBUTING.md
|
||||
SANITIZATION.md
|
||||
LICENSES/
|
||||
```
|
||||
|
||||
### Docs your team can ship in a day
|
||||
|
||||
* **HOWTO.md:** `docker run -v $PWD/dataset:/d -v $PWD/out:/o stellaops/benchmark-harness score /d /o`
|
||||
* **SCHEMA.md:** JSON Schemas for graph and truth (keep fields minimal: `nodes`, `edges`, `purls`, `sinks`, `evidence`).
|
||||
* **REPRODUCIBILITY.md:** explains DSSE signatures, lockfile, and offline run.
|
||||
* **LIMITATIONS.md:** clarifies scope (no dynamic runtime traces in v1, etc.).
|
||||
|
||||
### Governance (lightweight)
|
||||
|
||||
* **Versioned releases:** `v0.1`, `v0.2` with changelogs.
|
||||
* **Submission gate:** PR template + CI that:
|
||||
|
||||
* validates schemas
|
||||
* checks hashes match lockfile
|
||||
* re‑scores and compares to contributor’s score
|
||||
* **Leaderboard cadence:** monthly markdown table regenerated by CI.
|
||||
|
||||
### Launch plan (2‑week sprint)
|
||||
|
||||
* **Day 1–2:** pick cases; finalize schemas; write SANITIZATION.md.
|
||||
* **Day 3–5:** build harness image; implement deterministic runner; freeze `manifest.lock.json`.
|
||||
* **Day 6–8:** produce ground truth; run baselines; generate initial scores.
|
||||
* **Day 9–10:** docs + website README; record a 2‑minute demo GIF.
|
||||
* **Day 11–12:** legal review + licenses; create issue labels (“good first case”).
|
||||
* **Day 13–14:** publish, post on GitHub + LinkedIn; invite Semgrep/Snyk/OSS‑Fuzz folks to submit cases.
|
||||
|
||||
### Nice‑to‑have (but easy)
|
||||
|
||||
* **JSON Schema** for ground‑truth edges so academics can auto‑ingest.
|
||||
* **Small “unknowns” registry** example to show how you annotate unresolved symbols without breaking determinism.
|
||||
* **Binary mini‑lab**: stripped vs non‑stripped ELF pair to show your patch‑oracle technique in action (truth labels reflect oracle result).
|
||||
|
||||
If you want, I can draft the repo skeleton (folders, placeholder JSON Schemas, a sample `manifest.lock.json`, and a minimal `runner.py` CLI) so you can drop it straight into GitHub.
|
||||
Got you — let’s turn that high‑level idea into something your devs can actually pick up and ship.
|
||||
|
||||
Below is a **concrete implementation plan** for the *StellaOps Reachability Benchmark* repo: directory structure, components, tasks, and acceptance criteria. You can drop this straight into a ticketing system as epics → stories.
|
||||
|
||||
---
|
||||
|
||||
## 0. Tech assumptions (adjust if needed)
|
||||
|
||||
To be specific, I’ll assume:
|
||||
|
||||
* **Repo**: `stellaops-reachability-benchmark`
|
||||
* **Harness language**: Python 3.11+
|
||||
* **Packaging**: Docker image for the harness
|
||||
* **Schemas**: JSON Schema (Draft 2020–12)
|
||||
* **CI**: GitHub Actions
|
||||
|
||||
If your stack differs, you can still reuse the structure and acceptance criteria.
|
||||
|
||||
---
|
||||
|
||||
## 1. Repo skeleton & project bootstrap
|
||||
|
||||
**Goal:** Create a minimal but fully wired repo.
|
||||
|
||||
### Tasks
|
||||
|
||||
1. **Create skeleton**
|
||||
|
||||
* Structure:
|
||||
|
||||
```text
|
||||
stellaops-reachability-benchmark/
|
||||
dataset/
|
||||
dataset.json
|
||||
sbom/
|
||||
vex/
|
||||
graphs/
|
||||
truth/
|
||||
packages/
|
||||
manifest.lock.json # initially stub
|
||||
harness/
|
||||
reachbench/
|
||||
__init__.py
|
||||
cli.py
|
||||
dataset_loader.py
|
||||
schemas/
|
||||
graph.schema.json
|
||||
truth.schema.json
|
||||
dataset.schema.json
|
||||
scores.schema.json
|
||||
tests/
|
||||
docs/
|
||||
HOWTO.md
|
||||
SCHEMA.md
|
||||
REPRODUCIBILITY.md
|
||||
LIMITATIONS.md
|
||||
SANITIZATION.md
|
||||
.github/
|
||||
workflows/
|
||||
ci.yml
|
||||
pyproject.toml
|
||||
README.md
|
||||
LICENSE
|
||||
Dockerfile
|
||||
```
|
||||
|
||||
2. **Bootstrap Python project**
|
||||
|
||||
* `pyproject.toml` with:
|
||||
|
||||
* `reachbench` package
|
||||
* deps: `jsonschema`, `click` or `typer`, `pyyaml`, `pytest`
|
||||
* `harness/tests/` with a dummy test to ensure CI is green.
|
||||
|
||||
3. **Dockerfile**
|
||||
|
||||
* Minimal, pinned versions:
|
||||
|
||||
```Dockerfile
|
||||
FROM python:3.11-slim
|
||||
WORKDIR /app
|
||||
COPY . .
|
||||
RUN pip install --no-cache-dir .
|
||||
ENTRYPOINT ["reachbench"]
|
||||
```
|
||||
|
||||
4. **CI basic pipeline (`.github/workflows/ci.yml`)**
|
||||
|
||||
* Jobs:
|
||||
|
||||
* `lint` (e.g., `ruff` or `flake8` if you want)
|
||||
* `test` (pytest)
|
||||
* `build-docker` (just to ensure Dockerfile stays valid)
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `pip install .` works locally.
|
||||
* `reachbench --help` prints CLI help (even if commands are stubs).
|
||||
* CI passes on main branch.
|
||||
|
||||
---
|
||||
|
||||
## 2. Dataset & schema definitions
|
||||
|
||||
**Goal:** Define all JSON formats and enforce them.
|
||||
|
||||
### 2.1 Define dataset index format (`dataset/dataset.json`)
|
||||
|
||||
**File:** `dataset/dataset.json`
|
||||
|
||||
**Example:**
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"cases": [
|
||||
{
|
||||
"id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"language": "php",
|
||||
"kind": "source", // "source" | "binary" | "container"
|
||||
"cves": ["CVE-2023-12345"],
|
||||
"artifacts": {
|
||||
"package": {
|
||||
"path": "packages/php/wordpress-5.8.tar.gz",
|
||||
"sha256": "…"
|
||||
},
|
||||
"sbom": {
|
||||
"path": "sbom/php/wordpress-5.8.cdx.json",
|
||||
"format": "cyclonedx-1.6",
|
||||
"sha256": "…"
|
||||
},
|
||||
"vex": {
|
||||
"path": "vex/php/wordpress-5.8.vex.json",
|
||||
"format": "csaf-2.0",
|
||||
"sha256": "…"
|
||||
},
|
||||
"graph": {
|
||||
"path": "graphs/php/wordpress-5.8.graph.json",
|
||||
"schema": "graph.schema.json",
|
||||
"sha256": "…"
|
||||
},
|
||||
"truth": {
|
||||
"path": "truth/php/wordpress-5.8.truth.json",
|
||||
"schema": "truth.schema.json",
|
||||
"sha256": "…"
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 2.2 Define **truth schema** (`harness/reachbench/schemas/truth.schema.json`)
|
||||
|
||||
**Model (conceptual):**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"vulnerable_components": [
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"symbol_kind": "function", // "function" | "method" | "binary_symbol"
|
||||
"status": "reachable", // "reachable" | "not_reachable"
|
||||
"reachable_from": [
|
||||
{
|
||||
"entrypoint_id": "web:GET:/foo",
|
||||
"notes": "HTTP route /foo"
|
||||
}
|
||||
],
|
||||
"evidence": "manual-analysis" // or "unit-test", "patch-oracle"
|
||||
}
|
||||
],
|
||||
"non_vulnerable_components": [
|
||||
{
|
||||
"symbol": "wp_safe_function",
|
||||
"symbol_kind": "function",
|
||||
"status": "not_reachable",
|
||||
"evidence": "manual-analysis"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Tasks**
|
||||
|
||||
* Implement JSON Schema capturing:
|
||||
|
||||
* required fields: `case_id`, `vulnerable_components`
|
||||
* allowed enums for `symbol_kind`, `status`, `evidence`
|
||||
* Add unit tests that:
|
||||
|
||||
* validate a valid truth file
|
||||
* fail on various broken ones (missing `case_id`, unknown `status`, etc.)
|
||||
|
||||
### 2.3 Define **graph schema** (`harness/reachbench/schemas/graph.schema.json`)
|
||||
|
||||
**Model (conceptual):**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"language": "php",
|
||||
"nodes": [
|
||||
{
|
||||
"id": "func:wp_ajax_nopriv_some_vuln",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"kind": "function",
|
||||
"purl": "pkg:composer/wordpress/wordpress@5.8"
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"from": "func:wp_ajax_nopriv_some_vuln",
|
||||
"to": "func:wpdb_query",
|
||||
"kind": "call"
|
||||
}
|
||||
],
|
||||
"entrypoints": [
|
||||
{
|
||||
"id": "web:GET:/foo",
|
||||
"symbol": "some_controller",
|
||||
"kind": "http_route"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Tasks**
|
||||
|
||||
* JSON Schema with:
|
||||
|
||||
* `nodes[]` (id, symbol, kind, optional purl)
|
||||
* `edges[]` (`from`, `to`, `kind`)
|
||||
* `entrypoints[]` (id, symbol, kind)
|
||||
* Tests: verify a valid graph; invalid ones (missing `id`, unknown `kind`) are rejected.
|
||||
|
||||
### 2.4 Dataset index schema (`dataset.schema.json`)
|
||||
|
||||
* JSON Schema describing `dataset.json` (version string, cases array).
|
||||
* Tests: validate the example dataset file.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* Running a simple script (will be `reachbench validate-dataset`) validates all JSON files in `dataset/` against schemas without errors.
|
||||
* CI fails if any dataset JSON is invalid.
|
||||
|
||||
---
|
||||
|
||||
## 3. Lockfile & determinism manifest
|
||||
|
||||
**Goal:** Implement `manifest.lock.json` generation and verification.
|
||||
|
||||
### 3.1 Lockfile structure
|
||||
|
||||
**File:** `dataset/manifest.lock.json`
|
||||
|
||||
**Example:**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"created_at": "2025-01-15T12:00:00Z",
|
||||
"dataset": {
|
||||
"root": "dataset/",
|
||||
"sha256": "…",
|
||||
"cases": {
|
||||
"php-wordpress-5.8-cve-2023-12345": {
|
||||
"sha256": "…"
|
||||
}
|
||||
}
|
||||
},
|
||||
"tools": {
|
||||
"graph_normalizer": {
|
||||
"name": "stellaops-graph-normalizer",
|
||||
"version": "1.2.3",
|
||||
"sha256": "…"
|
||||
}
|
||||
},
|
||||
"containers": {
|
||||
"scanner_image": "ghcr.io/stellaops/scanner@sha256:…",
|
||||
"normalizer_image": "ghcr.io/stellaops/normalizer@sha256:…"
|
||||
},
|
||||
"signatures": [
|
||||
{
|
||||
"type": "dsse",
|
||||
"key_id": "stellaops-benchmark-key-1",
|
||||
"signature": "base64-encoded-blob"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
*(Signatures can be optional in v1 – but structure should be there.)*
|
||||
|
||||
### 3.2 `lockfile.py` module
|
||||
|
||||
**File:** `harness/reachbench/lockfile.py`
|
||||
|
||||
**Responsibilities**
|
||||
|
||||
* Compute deterministic SHA-256 digest of:
|
||||
|
||||
* each case’s artifacts (path → hash from `dataset.json`)
|
||||
* entire `dataset/` tree (sorted traversal)
|
||||
* Generate new `manifest.lock.json`:
|
||||
|
||||
* `version` (hard-coded constant)
|
||||
* `created_at` (UTC ISO8601)
|
||||
* `dataset` section with case hashes
|
||||
* Verification:
|
||||
|
||||
* `verify_lockfile(dataset_root, lockfile_path)`:
|
||||
|
||||
* recompute hashes
|
||||
* compare to `lockfile.dataset`
|
||||
* return boolean + list of mismatches
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Implement canonical hashing:
|
||||
|
||||
* For text JSON files: normalize with:
|
||||
|
||||
* sort keys
|
||||
* no whitespace
|
||||
* UTF‑8 encoding
|
||||
* For binaries (packages): raw bytes.
|
||||
2. Implement `compute_dataset_hashes(dataset_root)`:
|
||||
|
||||
* Returns `{"cases": {...}, "root_sha256": "…"}`.
|
||||
3. Implement `write_lockfile(...)` and `verify_lockfile(...)`.
|
||||
4. Tests:
|
||||
|
||||
* Two calls with same dataset produce identical lockfile (order of `cases` keys normalized).
|
||||
* Changing any artifact file changes the root hash and causes verify to fail.
|
||||
|
||||
### 3.3 CLI commands
|
||||
|
||||
Add to `cli.py`:
|
||||
|
||||
* `reachbench compute-lockfile --dataset-root ./dataset --out ./dataset/manifest.lock.json`
|
||||
* `reachbench verify-lockfile --dataset-root ./dataset --lockfile ./dataset/manifest.lock.json`
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `reachbench compute-lockfile` generates a stable file (byte-for-byte identical across runs).
|
||||
* `reachbench verify-lockfile` exits with:
|
||||
|
||||
* code 0 if matches
|
||||
* non-zero if mismatch (plus human-readable diff).
|
||||
|
||||
---
|
||||
|
||||
## 4. Scoring harness CLI
|
||||
|
||||
**Goal:** Deterministically score participant results against ground truth.
|
||||
|
||||
### 4.1 Result format (participant output)
|
||||
|
||||
**Expectation:**
|
||||
|
||||
Participants provide `results/` with one JSON per case:
|
||||
|
||||
```text
|
||||
results/
|
||||
php-wordpress-5.8-cve-2023-12345.json
|
||||
js-express-4.17-cve-2022-9999.json
|
||||
```
|
||||
|
||||
**Result file example:**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"tool_name": "my-reachability-analyzer",
|
||||
"tool_version": "1.0.0",
|
||||
"predictions": [
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"symbol_kind": "function",
|
||||
"status": "reachable"
|
||||
},
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_safe_function",
|
||||
"symbol_kind": "function",
|
||||
"status": "not_reachable"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 Scoring model
|
||||
|
||||
* Treat scoring as classification over `(cve, symbol)` pairs.
|
||||
* For each case:
|
||||
|
||||
* Truth positives: all `vulnerable_components` with `status == "reachable"`.
|
||||
* Truth negatives: everything marked `not_reachable` (optional in v1).
|
||||
* Predictions: all entries with `status == "reachable"`.
|
||||
* Compute:
|
||||
|
||||
* `TP`: predicted reachable & truth reachable.
|
||||
* `FP`: predicted reachable but truth says not reachable / unknown.
|
||||
* `FN`: truth reachable but not predicted reachable.
|
||||
* Metrics:
|
||||
|
||||
* Precision, Recall, F1 per case.
|
||||
* Macro-averaged metrics across all cases.
|
||||
|
||||
### 4.3 Implementation (`scoring.py`)
|
||||
|
||||
**File:** `harness/reachbench/scoring.py`
|
||||
|
||||
**Functions:**
|
||||
|
||||
* `load_truth(case_truth_path) -> TruthModel`
|
||||
|
||||
* `load_predictions(predictions_path) -> PredictionModel`
|
||||
|
||||
* `compute_case_metrics(truth, preds) -> dict`
|
||||
|
||||
* returns:
|
||||
|
||||
```python
|
||||
{
|
||||
"case_id": str,
|
||||
"tp": int,
|
||||
"fp": int,
|
||||
"fn": int,
|
||||
"precision": float,
|
||||
"recall": float,
|
||||
"f1": float
|
||||
}
|
||||
```
|
||||
|
||||
* `aggregate_metrics(case_metrics_list) -> dict`
|
||||
|
||||
* `macro_precision`, `macro_recall`, `macro_f1`, `num_cases`.
|
||||
|
||||
### 4.4 CLI: `score`
|
||||
|
||||
**Signature:**
|
||||
|
||||
```bash
|
||||
reachbench score \
|
||||
--dataset-root ./dataset \
|
||||
--results-root ./results \
|
||||
--lockfile ./dataset/manifest.lock.json \
|
||||
--out ./out/scores.json \
|
||||
[--cases php-*] \
|
||||
[--repeat 3]
|
||||
```
|
||||
|
||||
**Behavior:**
|
||||
|
||||
1. **Verify lockfile** (fail closed if mismatch).
|
||||
|
||||
2. Load `dataset.json`, filter cases if `--cases` is set (glob).
|
||||
|
||||
3. For each case:
|
||||
|
||||
* Load truth file (and validate schema).
|
||||
* Locate results file (`<case_id>.json`) under `results-root`:
|
||||
|
||||
* If missing, treat as all FN (or mark case as “no submission”).
|
||||
* Load and validate predictions (include a JSON Schema: `results.schema.json`).
|
||||
* Compute per-case metrics.
|
||||
|
||||
4. Aggregate metrics.
|
||||
|
||||
5. Write `scores.json`:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"dataset_version": "0.1.0",
|
||||
"generated_at": "2025-01-15T12:34:56Z",
|
||||
"macro_precision": 0.92,
|
||||
"macro_recall": 0.88,
|
||||
"macro_f1": 0.90,
|
||||
"cases": [
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"tp": 10,
|
||||
"fp": 1,
|
||||
"fn": 2,
|
||||
"precision": 0.91,
|
||||
"recall": 0.83,
|
||||
"f1": 0.87
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
6. **Determinism check**:
|
||||
|
||||
* If `--repeat N` given:
|
||||
|
||||
* Re-run scoring in-memory N times.
|
||||
* Compare resulting JSON strings (canonicalized via sorted keys).
|
||||
* If any differ, exit non-zero with message (“non-deterministic scoring detected”).
|
||||
|
||||
### 4.5 Offline-only mode
|
||||
|
||||
* In `cli.py`, early check:
|
||||
|
||||
```python
|
||||
if os.getenv("REACHBENCH_OFFLINE_ONLY", "1") == "1":
|
||||
# Verify no outbound network: by policy, just ensure we never call any net libs.
|
||||
# (In v1, simply avoid adding any such calls.)
|
||||
```
|
||||
|
||||
* Document that harness must not reach out to the internet.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* Given a small artificial dataset with 2–3 cases and handcrafted results, `reachbench score` produces expected metrics (assert via tests).
|
||||
* Running `reachbench score --repeat 3` produces identical `scores.json` across runs.
|
||||
* Missing results files are handled gracefully (but clearly documented).
|
||||
|
||||
---
|
||||
|
||||
## 5. Baseline implementations
|
||||
|
||||
**Goal:** Provide in-repo baselines that use only the provided graphs (no extra tooling).
|
||||
|
||||
### 5.1 Baseline types
|
||||
|
||||
1. **Naïve reachable**: all symbols in the vulnerable package are considered reachable.
|
||||
2. **Imports-only**: reachable = any symbol that:
|
||||
|
||||
* appears in the graph AND
|
||||
* is reachable from any entrypoint by a single edge OR name match.
|
||||
3. **Call-depth-2**:
|
||||
|
||||
* From each entrypoint, traverse up to depth 2 along `call` edges.
|
||||
* Anything at depth ≤ 2 is considered reachable.
|
||||
|
||||
### 5.2 Implementation
|
||||
|
||||
**File:** `harness/reachbench/baselines.py`
|
||||
|
||||
* `baseline_naive(graph, truth) -> PredictionModel`
|
||||
* `baseline_imports_only(graph, truth) -> PredictionModel`
|
||||
* `baseline_call_depth_2(graph, truth) -> PredictionModel`
|
||||
|
||||
**CLI:**
|
||||
|
||||
```bash
|
||||
reachbench run-baseline \
|
||||
--dataset-root ./dataset \
|
||||
--baseline naive|imports|depth2 \
|
||||
--out ./results-baseline-<baseline>/
|
||||
```
|
||||
|
||||
Behavior:
|
||||
|
||||
* For each case:
|
||||
|
||||
* Load graph.
|
||||
* Generate predictions per baseline.
|
||||
* Write result file `results-baseline-<baseline>/<case_id>.json`.
|
||||
|
||||
### 5.3 Tests
|
||||
|
||||
* Tiny synthetic dataset in `harness/tests/data/`:
|
||||
|
||||
* 1–2 cases with simple graphs.
|
||||
* Known expectations for each baseline (TP/FP/FN counts).
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `reachbench run-baseline --baseline naive` runs end-to-end and outputs results files.
|
||||
* `reachbench score` on baseline results produces stable scores.
|
||||
* Tests validate baseline behavior on synthetic cases.
|
||||
|
||||
---
|
||||
|
||||
## 6. Dataset validation & tooling
|
||||
|
||||
**Goal:** One command to validate everything (schemas, hashes, internal consistency).
|
||||
|
||||
### CLI: `validate-dataset`
|
||||
|
||||
```bash
|
||||
reachbench validate-dataset \
|
||||
--dataset-root ./dataset \
|
||||
[--lockfile ./dataset/manifest.lock.json]
|
||||
```
|
||||
|
||||
**Checks:**
|
||||
|
||||
1. `dataset.json` conforms to `dataset.schema.json`.
|
||||
2. For each case:
|
||||
|
||||
* all artifact paths exist
|
||||
* `graph` file passes `graph.schema.json`
|
||||
* `truth` file passes `truth.schema.json`
|
||||
3. Optional: verify lockfile if provided.
|
||||
|
||||
**Implementation:**
|
||||
|
||||
* `dataset_loader.py`:
|
||||
|
||||
* `load_dataset_index(path) -> DatasetIndex`
|
||||
* `iter_cases(dataset_index)` yields case objects.
|
||||
* `validate_case(case, dataset_root) -> list[str]` (list of error messages).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Broken paths / invalid JSON produce a clear error message and non-zero exit code.
|
||||
* CI job calls `reachbench validate-dataset` on every push.
|
||||
|
||||
---
|
||||
|
||||
## 7. Documentation
|
||||
|
||||
**Goal:** Make it trivial for outsiders to use the benchmark.
|
||||
|
||||
### 7.1 `README.md`
|
||||
|
||||
* Overview:
|
||||
|
||||
* What the benchmark is.
|
||||
* What it measures (reachability precision/recall).
|
||||
* Quickstart:
|
||||
|
||||
```bash
|
||||
git clone ...
|
||||
cd stellaops-reachability-benchmark
|
||||
|
||||
# Validate dataset
|
||||
reachbench validate-dataset --dataset-root ./dataset
|
||||
|
||||
# Run baselines
|
||||
reachbench run-baseline --baseline naive --dataset-root ./dataset --out ./results-naive
|
||||
|
||||
# Score baselines
|
||||
reachbench score --dataset-root ./dataset --results-root ./results-naive --out ./out/naive-scores.json
|
||||
```
|
||||
|
||||
### 7.2 `docs/HOWTO.md`
|
||||
|
||||
* Step-by-step:
|
||||
|
||||
* Installing harness.
|
||||
* Running your own tool on the dataset.
|
||||
* Formatting your `results/`.
|
||||
* Running `reachbench score`.
|
||||
* Interpreting `scores.json`.
|
||||
|
||||
### 7.3 `docs/SCHEMA.md`
|
||||
|
||||
* Human-readable description of:
|
||||
|
||||
* `graph` JSON
|
||||
* `truth` JSON
|
||||
* `results` JSON
|
||||
* `scores` JSON
|
||||
* Link to actual JSON Schemas.
|
||||
|
||||
### 7.4 `docs/REPRODUCIBILITY.md`
|
||||
|
||||
* Explain:
|
||||
|
||||
* lockfile design
|
||||
* hashing rules
|
||||
* deterministic scoring and `--repeat` flag
|
||||
* how to verify you’re using the exact same dataset.
|
||||
|
||||
### 7.5 `docs/SANITIZATION.md`
|
||||
|
||||
* Rules for adding new cases:
|
||||
|
||||
* Only use OSS or properly licensed code.
|
||||
* Strip secrets / proprietary paths / user data.
|
||||
* How to confirm nothing sensitive is in package tarballs.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* A new engineer (or external user) can go from zero to “I ran the baseline and got scores” by following docs only.
|
||||
* All example commands work as written.
|
||||
|
||||
---
|
||||
|
||||
## 8. CI/CD details
|
||||
|
||||
**Goal:** Keep repo healthy and ensure determinism.
|
||||
|
||||
### CI jobs (GitHub Actions)
|
||||
|
||||
1. **`lint`**
|
||||
|
||||
* Run `ruff` / `flake8` (your choice).
|
||||
2. **`test`**
|
||||
|
||||
* Run `pytest`.
|
||||
3. **`validate-dataset`**
|
||||
|
||||
* Run `reachbench validate-dataset --dataset-root ./dataset`.
|
||||
4. **`determinism`**
|
||||
|
||||
* Small workflow step:
|
||||
|
||||
* Run `reachbench score` on a tiny test dataset with `--repeat 3`.
|
||||
* Assert success.
|
||||
5. **`docker-build`**
|
||||
|
||||
* `docker build` the harness image.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* All jobs green on main.
|
||||
* PRs show failing status if schemas or determinism break.
|
||||
|
||||
---
|
||||
|
||||
## 9. Rough “epics → stories” breakdown
|
||||
|
||||
You can paste roughly like this into Jira/Linear:
|
||||
|
||||
1. **Epic: Repo bootstrap & CI**
|
||||
|
||||
* Story: Create repo skeleton & Python project
|
||||
* Story: Add Dockerfile & basic CI (lint + tests)
|
||||
|
||||
2. **Epic: Schemas & dataset plumbing**
|
||||
|
||||
* Story: Implement `truth.schema.json` + tests
|
||||
* Story: Implement `graph.schema.json` + tests
|
||||
* Story: Implement `dataset.schema.json` + tests
|
||||
* Story: Implement `validate-dataset` CLI
|
||||
|
||||
3. **Epic: Lockfile & determinism**
|
||||
|
||||
* Story: Implement lockfile computation + verification
|
||||
* Story: Add `compute-lockfile` & `verify-lockfile` CLI
|
||||
* Story: Add determinism checks in CI
|
||||
|
||||
4. **Epic: Scoring harness**
|
||||
|
||||
* Story: Define results format + `results.schema.json`
|
||||
* Story: Implement scoring logic (`scoring.py`)
|
||||
* Story: Implement `score` CLI with `--repeat`
|
||||
* Story: Add unit tests for metrics
|
||||
|
||||
5. **Epic: Baselines**
|
||||
|
||||
* Story: Implement naive baseline
|
||||
* Story: Implement imports-only baseline
|
||||
* Story: Implement depth-2 baseline
|
||||
* Story: Add `run-baseline` CLI + tests
|
||||
|
||||
6. **Epic: Documentation & polish**
|
||||
|
||||
* Story: Write README + HOWTO
|
||||
* Story: Write SCHEMA / REPRODUCIBILITY / SANITIZATION docs
|
||||
* Story: Final repo cleanup & examples
|
||||
|
||||
---
|
||||
|
||||
If you tell me your preferred language and CI, I can also rewrite this into exact tickets and even starter code for `cli.py` and a couple of schemas.
|
||||
@@ -0,0 +1,654 @@
|
||||
Here’s a small but high‑impact product tweak: **add an immutable `graph_revision_id` to every call‑graph page and API link**, so any result is citeable and reproducible across time.
|
||||
|
||||
---
|
||||
|
||||
### Why it matters (quick)
|
||||
|
||||
* **Auditability:** you can prove *which* graph produced a finding.
|
||||
* **Reproducibility:** reruns that change paths won’t “move the goalposts.”
|
||||
* **Support & docs:** screenshots/links in tickets point to an exact graph state.
|
||||
|
||||
### What to add
|
||||
|
||||
* **Stable anchor in all URLs:**
|
||||
`https://…/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
`https://…/api/graphs/{graph_id}/nodes?rev={graph_revision_id}`
|
||||
* **Opaque, content‑addressed ID:** e.g., `graph_revision_id = blake3( sorted_edges + cfg + tool_versions + dataset_hashes )`.
|
||||
* **First‑class fields:** store `graph_id` (logical lineage), `graph_revision_id` (immutable), `parent_revision_id` (if derived), `created_at`, `provenance` (feed hashes, toolchain).
|
||||
* **UI surfacing:** show a copy‑button “Rev: 8f2d…c9” on graph pages and in the “Share” dialog.
|
||||
* **Diff affordance:** when `?rev=A` and `?rev=B` are both present, offer “Compare paths (A↔B).”
|
||||
|
||||
### Minimal API contract (suggested)
|
||||
|
||||
* `GET /api/graphs/{graph_id}` → latest + `latest_revision_id`
|
||||
* `GET /api/graphs/{graph_id}/revisions/{graph_revision_id}` → immutable snapshot
|
||||
* `GET /api/graphs/{graph_id}/nodes?rev=…` and `/edges?rev=…`
|
||||
* `POST /api/graphs/{graph_id}/pin` with `{ graph_revision_id }` to mark “official”
|
||||
* HTTP `Link` header on all responses:
|
||||
`Link: <…/graphs/{graph_id}/revisions/{graph_revision_id}>; rel="version"`
|
||||
|
||||
### How to compute the revision id (deterministic)
|
||||
|
||||
* Inputs (all normalized): sorted node/edge sets; build config; tool+model versions; input artifacts (SBOM/VEX/feed) **by hash**; environment knobs (feature flags).
|
||||
* Serialization: canonical JSON (UTF‑8, ordered keys).
|
||||
* Hash: BLAKE3/sha256 → base58/hex (shortened in UI, full in API).
|
||||
* Store alongside a manifest (so you can replay the graph later).
|
||||
|
||||
### Guardrails
|
||||
|
||||
* **Never reuse an ID** if any input bit differs.
|
||||
* **Do not** make it guessable from business data (avoid leaking repo names, paths).
|
||||
* **Break glass:** if a bad graph must be purged, keep the ID tombstoned (410 Gone) so references don’t silently change.
|
||||
|
||||
### Stella Ops touches (concrete)
|
||||
|
||||
* **Authority**: add `GraphRevisionManifest` (feeds, lattice/policy versions, scanners, in‑toto/DSSE attestations).
|
||||
* **Scanner/Vexer**: emit deterministic manifests and hand them to Authority for id derivation.
|
||||
* **Ledger**: record `(graph_id, graph_revision_id, manifest_hash, signatures)`; expose audit query by `graph_revision_id`.
|
||||
* **Docs & Support**: “Attach your `graph_revision_id`” line in issue templates.
|
||||
|
||||
### Tiny UX copy
|
||||
|
||||
* On graph page header: `Rev 8f2d…c9` • **Copy** • **Compare** • **Pin**
|
||||
* Share dialog: “This link freezes today’s state. New runs get a different rev.”
|
||||
|
||||
If you want, I can draft the DB table, the manifest JSON schema, and the exact URL/router changes for your .NET 10 services next.
|
||||
Cool, let’s turn this into something your engineers can actually pick up and implement.
|
||||
|
||||
Below is a concrete implementation plan broken down by phases, services, and tickets, with suggested data models, APIs, and tests.
|
||||
|
||||
---
|
||||
|
||||
## 0. Definitions (shared across teams)
|
||||
|
||||
* **Graph ID (`graph_id`)** – Logical identifier for a call graph lineage (e.g., “the call graph for build X of repo Y”).
|
||||
* **Graph Revision ID (`graph_revision_id`)** – Immutable identifier for a specific snapshot of that graph, derived from a manifest (content-addressed hash).
|
||||
* **Parent Revision ID (`parent_revision_id`)** – Previous revision in the lineage (if any).
|
||||
* **Manifest** – Canonical JSON blob that describes *everything* that could affect graph structure or results:
|
||||
|
||||
* Nodes & edges
|
||||
* Input feeds and their hashes (SBOM, VEX, scanner output, etc.)
|
||||
* config/policies/feature flags
|
||||
* tool + version (scanner, vexer, authority)
|
||||
|
||||
---
|
||||
|
||||
## 1. High-Level Architecture Changes
|
||||
|
||||
1. **Introduce `graph_revision_id` as a first-class concept** in:
|
||||
|
||||
* Graph storage / Authority
|
||||
* Ledger / audit
|
||||
* Backend APIs serving call graphs
|
||||
2. **Derive `graph_revision_id` deterministically** from a manifest via a cryptographic hash.
|
||||
3. **Expose revision in all graph-related URLs & APIs**:
|
||||
|
||||
* UI: `…/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
* API: `…/api/graphs/{graph_id}/revisions/{graph_revision_id}`
|
||||
4. **Ensure immutability**: once a revision exists, it can never be updated in-place—only superseded by new revisions.
|
||||
|
||||
---
|
||||
|
||||
## 2. Backend: Data Model & Storage
|
||||
|
||||
### 2.1. Authority (graph source of truth)
|
||||
|
||||
**Goal:** Model graphs and revisions explicitly.
|
||||
|
||||
**New / updated tables (example in SQL-ish form):**
|
||||
|
||||
1. **Graphs (logical entity)**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graphs (
|
||||
id UUID PRIMARY KEY,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
latest_revision_id VARCHAR(128) NULL, -- FK into graph_revisions.id
|
||||
label TEXT NULL, -- optional human label
|
||||
metadata JSONB NULL
|
||||
);
|
||||
```
|
||||
|
||||
2. **Graph Revisions (immutable snapshots)**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graph_revisions (
|
||||
id VARCHAR(128) PRIMARY KEY, -- graph_revision_id (hash)
|
||||
graph_id UUID NOT NULL REFERENCES graphs(id),
|
||||
parent_revision_id VARCHAR(128) NULL REFERENCES graph_revisions(id),
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
manifest JSONB NOT NULL, -- canonical manifest
|
||||
provenance JSONB NOT NULL, -- tool versions, etc.
|
||||
is_pinned BOOLEAN NOT NULL DEFAULT FALSE,
|
||||
pinned_by UUID NULL, -- user id
|
||||
pinned_at TIMESTAMPTZ NULL
|
||||
);
|
||||
CREATE INDEX idx_graph_revisions_graph_id ON graph_revisions(graph_id);
|
||||
```
|
||||
|
||||
3. **Call Graph Data (if separate)**
|
||||
If you store nodes/edges in separate tables, add a foreign key to `graph_revision_id`:
|
||||
|
||||
```sql
|
||||
ALTER TABLE call_graph_nodes
|
||||
ADD COLUMN graph_revision_id VARCHAR(128) NULL;
|
||||
|
||||
ALTER TABLE call_graph_edges
|
||||
ADD COLUMN graph_revision_id VARCHAR(128) NULL;
|
||||
```
|
||||
|
||||
> **Rule:** Nodes/edges for a revision are **never mutated**; a new revision means new rows.
|
||||
|
||||
---
|
||||
|
||||
### 2.2. Ledger (audit trail)
|
||||
|
||||
**Goal:** Every revision gets a ledger record for auditability.
|
||||
|
||||
**Table change or new table:**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graph_revision_ledger (
|
||||
id BIGSERIAL PRIMARY KEY,
|
||||
graph_revision_id VARCHAR(128) NOT NULL,
|
||||
graph_id UUID NOT NULL,
|
||||
manifest_hash VARCHAR(128) NOT NULL,
|
||||
manifest_digest_algo TEXT NOT NULL, -- e.g., "BLAKE3"
|
||||
authority_signature BYTEA NULL, -- optional
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
|
||||
);
|
||||
CREATE INDEX idx_grl_revision ON graph_revision_ledger(graph_revision_id);
|
||||
```
|
||||
|
||||
Ledger ingestion happens **after** a revision is stored in Authority, but **before** it is exposed as “current” in the UI.
|
||||
|
||||
---
|
||||
|
||||
## 3. Backend: Revision Hashing & Manifest
|
||||
|
||||
### 3.1. Define the manifest schema
|
||||
|
||||
Create a spec (e.g., JSON Schema) used by Scanner/Vexer/Authority.
|
||||
|
||||
**Example structure:**
|
||||
|
||||
```json
|
||||
{
|
||||
"graph": {
|
||||
"graph_id": "uuid",
|
||||
"generator": {
|
||||
"tool_name": "scanner",
|
||||
"tool_version": "1.4.2",
|
||||
"run_id": "some-run-id"
|
||||
}
|
||||
},
|
||||
"inputs": {
|
||||
"sbom_hash": "sha256:…",
|
||||
"vex_hash": "sha256:…",
|
||||
"repos": [
|
||||
{
|
||||
"name": "repo-a",
|
||||
"commit": "abc123",
|
||||
"tree_hash": "sha1:…"
|
||||
}
|
||||
]
|
||||
},
|
||||
"config": {
|
||||
"policy_version": "2024-10-01",
|
||||
"feature_flags": {
|
||||
"new_vex_engine": true
|
||||
}
|
||||
},
|
||||
"graph_content": {
|
||||
"nodes": [
|
||||
// nodes in canonical sorted order
|
||||
],
|
||||
"edges": [
|
||||
// edges in canonical sorted order
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Key requirements:**
|
||||
|
||||
* All lists that affect the graph (`nodes`, `edges`, `repos`, etc.) must be **sorted deterministically**.
|
||||
* Keys must be **stable** (no environment-dependent keys, no random IDs).
|
||||
* All hashes of input artifacts must be included (not raw content).
|
||||
|
||||
### 3.2. Hash computation
|
||||
|
||||
Language-agnostic algorithm:
|
||||
|
||||
1. Normalize manifest to **canonical JSON**:
|
||||
|
||||
* UTF-8
|
||||
* Sorted keys
|
||||
* No extra whitespace
|
||||
2. Hash the bytes using a cryptographic hash (BLAKE3 or SHA-256).
|
||||
3. Encode as hex or base58 string.
|
||||
|
||||
**Pseudocode:**
|
||||
|
||||
```pseudo
|
||||
function compute_graph_revision_id(manifest):
|
||||
canonical_json = canonical_json_encode(manifest) // sorted keys
|
||||
digest_bytes = BLAKE3(canonical_json)
|
||||
digest_hex = hex_encode(digest_bytes)
|
||||
return "grv_" + digest_hex[0:40] // prefix + shorten for UI
|
||||
```
|
||||
|
||||
**Ticket:** Implement `GraphRevisionIdGenerator` library (shared):
|
||||
|
||||
* `Compute(manifest) -> graph_revision_id`
|
||||
* `ValidateFormat(graph_revision_id) -> bool`
|
||||
|
||||
Make this a **shared library** across Scanner, Vexer, Authority to avoid divergence.
|
||||
|
||||
---
|
||||
|
||||
## 4. Backend: APIs
|
||||
|
||||
### 4.1. Graphs & revisions REST API
|
||||
|
||||
**New endpoints (example):**
|
||||
|
||||
1. **Get latest graph revision**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"latest_revision_id": "grv_8f2d…c9",
|
||||
"created_at": "…",
|
||||
"metadata": { … }
|
||||
}
|
||||
```
|
||||
|
||||
2. **List revisions for a graph**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/revisions
|
||||
Query: ?page=1&pageSize=20
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"items": [
|
||||
{
|
||||
"graph_revision_id": "grv_8f2d…c9",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": null,
|
||||
"is_pinned": true
|
||||
},
|
||||
{
|
||||
"graph_revision_id": "grv_3a1b…e4",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": "grv_8f2d…c9",
|
||||
"is_pinned": false
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. **Get a specific revision (snapshot)**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/revisions/{graph_revision_id}
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"graph_revision_id": "…",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": null,
|
||||
"manifest": { … }, // optional: maybe not full content if large
|
||||
"provenance": { … }
|
||||
}
|
||||
```
|
||||
|
||||
4. **Get nodes/edges for a revision**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/nodes?rev={graph_revision_id}
|
||||
GET /api/graphs/{graph_id}/edges?rev={graph_revision_id}
|
||||
```
|
||||
|
||||
Behavior:
|
||||
|
||||
* If `rev` is **omitted**, return the **latest_revision_id** for that `graph_id`.
|
||||
* If `rev` is **invalid or unknown**, return `404` (not fallback).
|
||||
|
||||
5. **Pin/unpin a revision (optional for v1)**
|
||||
|
||||
```http
|
||||
POST /api/graphs/{graph_id}/pin
|
||||
Body: { "graph_revision_id": "…" }
|
||||
|
||||
DELETE /api/graphs/{graph_id}/pin
|
||||
Body: { "graph_revision_id": "…" }
|
||||
```
|
||||
|
||||
### 4.2. Backward compatibility
|
||||
|
||||
* Existing endpoints like `GET /api/graphs/{graph_id}/nodes` should:
|
||||
|
||||
* Continue working with no `rev` param.
|
||||
* Internally resolve to `latest_revision_id`.
|
||||
* For old records with no revision:
|
||||
|
||||
* Create a synthetic manifest from current stored data.
|
||||
* Compute a `graph_revision_id`.
|
||||
* Store it and set `latest_revision_id` on the `graphs` row.
|
||||
|
||||
---
|
||||
|
||||
## 5. Scanner / Vexer / Upstream Pipelines
|
||||
|
||||
**Goal:** At the end of a graph build, they produce a manifest and a `graph_revision_id`.
|
||||
|
||||
### 5.1. Responsibilities
|
||||
|
||||
1. **Scanner/Vexer**:
|
||||
|
||||
* Gather:
|
||||
|
||||
* Tool name/version
|
||||
* Input artifact hashes
|
||||
* Feature flags / config
|
||||
* Graph nodes/edges
|
||||
* Construct manifest (according to schema).
|
||||
* Compute `graph_revision_id` using shared library.
|
||||
* Send manifest + revision ID to Authority via an internal API (e.g., `POST /internal/graph-build-complete`).
|
||||
|
||||
2. **Authority**:
|
||||
|
||||
* Idempotently upsert:
|
||||
|
||||
* `graphs` (if new `graph_id`)
|
||||
* `graph_revisions` row (if `graph_revision_id` not yet present)
|
||||
* nodes/edges rows keyed by `graph_revision_id`.
|
||||
* Update `graphs.latest_revision_id` to the new revision.
|
||||
|
||||
### 5.2. Internal API (Authority)
|
||||
|
||||
```http
|
||||
POST /internal/graphs/{graph_id}/revisions
|
||||
Body:
|
||||
{
|
||||
"graph_revision_id": "…",
|
||||
"parent_revision_id": "…", // optional
|
||||
"manifest": { … },
|
||||
"provenance": { … },
|
||||
"nodes": [ … ],
|
||||
"edges": [ … ]
|
||||
}
|
||||
Response: 201 Created (or 200 if idempotent)
|
||||
```
|
||||
|
||||
**Rules:**
|
||||
|
||||
* If `graph_revision_id` already exists for that `graph_id` with identical `manifest_hash`, treat as **idempotent**.
|
||||
* If `graph_revision_id` exists but manifest hash differs → log and reject (bug in hashing).
|
||||
|
||||
---
|
||||
|
||||
## 6. Frontend / UX Changes
|
||||
|
||||
Assuming a SPA (React/Vue/etc.), we’ll treat these as tasks.
|
||||
|
||||
### 6.1. URL & routing
|
||||
|
||||
* **New canonical URL format** for graph UI:
|
||||
|
||||
* Latest: `/graphs/{graph_id}`
|
||||
* Specific revision: `/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
|
||||
* Router:
|
||||
|
||||
* Parse `rev` query param.
|
||||
* If present, call `GET /api/graphs/{graph_id}/nodes?rev=…`.
|
||||
* If not present, call same endpoint but without `rev` → backend returns latest.
|
||||
|
||||
### 6.2. Displaying revision info
|
||||
|
||||
* In graph page header:
|
||||
|
||||
* Show truncated revision:
|
||||
|
||||
* `Rev: 8f2d…c9`
|
||||
* Buttons:
|
||||
|
||||
* **Copy** → Copies full `graph_revision_id`.
|
||||
* **Share** → Copies full URL with `?rev=…`.
|
||||
* Optional chip if pinned: `Pinned`.
|
||||
|
||||
**Example data model (TS):**
|
||||
|
||||
```ts
|
||||
type GraphRevisionSummary = {
|
||||
graphId: string;
|
||||
graphRevisionId: string;
|
||||
createdAt: string;
|
||||
parentRevisionId?: string | null;
|
||||
isPinned: boolean;
|
||||
};
|
||||
```
|
||||
|
||||
### 6.3. Revision list panel (optional but useful)
|
||||
|
||||
* Add a side panel or tab: “Revisions”.
|
||||
* Fetch from `GET /api/graphs/{graph_id}/revisions`.
|
||||
* Clicking a revision:
|
||||
|
||||
* Navigates to same page with `?rev={graph_revision_id}`.
|
||||
* Preserves other UI state where reasonable.
|
||||
|
||||
### 6.4. Diff view (nice-to-have, can be v2)
|
||||
|
||||
* UX: “Compare with…” button in header.
|
||||
|
||||
* Opens dialog to pick a second revision.
|
||||
* Backend: add a diff endpoint later, or compute diff client-side from node/edge lists if feasible.
|
||||
|
||||
---
|
||||
|
||||
## 7. Migration Plan
|
||||
|
||||
### 7.1. Phase 1 – Schema & read-path ready
|
||||
|
||||
1. **Add DB columns/tables**:
|
||||
|
||||
* `graphs`, `graph_revisions`, `graph_revision_ledger`.
|
||||
* `graph_revision_id` column to `call_graph_nodes` / `call_graph_edges`.
|
||||
2. **Deploy with no behavior changes**:
|
||||
|
||||
* Default `graph_revision_id` columns NULL.
|
||||
* Existing APIs continue to work.
|
||||
|
||||
### 7.2. Phase 2 – Backfill existing graphs
|
||||
|
||||
1. Write a **backfill job**:
|
||||
|
||||
* For each distinct existing graph:
|
||||
|
||||
* Build a manifest from existing stored data.
|
||||
* Compute `graph_revision_id`.
|
||||
* Insert into `graphs` & `graph_revisions`.
|
||||
* Update nodes/edges for that graph to set `graph_revision_id`.
|
||||
* Set `graphs.latest_revision_id`.
|
||||
|
||||
2. Log any graphs that can’t be backfilled (corrupt data, etc.) for manual review.
|
||||
|
||||
3. After backfill:
|
||||
|
||||
* Add **NOT NULL** constraint on `graph_revision_id` for nodes/edges (if practical).
|
||||
* Ensure all public APIs can fetch revisions without changes from clients.
|
||||
|
||||
### 7.3. Phase 3 – Wire up new pipelines
|
||||
|
||||
1. Update Scanner/Vexer to construct manifests and compute revision IDs.
|
||||
2. Update Authority to accept `/internal/graphs/{graph_id}/revisions`.
|
||||
3. Gradually roll out:
|
||||
|
||||
* Feature flag: `graphRevisionIdFromPipeline`.
|
||||
* For flagged runs, use the new pipeline; for others, fall back to old + synthetic revision.
|
||||
|
||||
### 7.4. Phase 4 – Frontend rollout
|
||||
|
||||
1. Update UI to:
|
||||
|
||||
* Read `rev` from URL (but not required).
|
||||
* Show `Rev` in header.
|
||||
* Use revision-aware endpoints.
|
||||
2. Once stable:
|
||||
|
||||
* Update “Share” actions to always include `?rev=…`.
|
||||
|
||||
---
|
||||
|
||||
## 8. Testing Strategy
|
||||
|
||||
### 8.1. Unit tests
|
||||
|
||||
* **Hashing library**:
|
||||
|
||||
* Same manifest → same `graph_revision_id`.
|
||||
* Different node ordering → same `graph_revision_id`.
|
||||
* Tiny manifest change → different `graph_revision_id`.
|
||||
* **Authority service**:
|
||||
|
||||
* Creating a revision stores `graph_revisions` + nodes/edges with matching `graph_revision_id`.
|
||||
* Duplicate revision (same id + manifest) is idempotent.
|
||||
* Conflicting manifest with same `graph_revision_id` is rejected.
|
||||
|
||||
### 8.2. Integration tests
|
||||
|
||||
* Scenario: “Create graph → view in UI”
|
||||
|
||||
* Pipeline produces manifest & revision.
|
||||
* Authority persists revision.
|
||||
* Ledger logs event.
|
||||
* UI shows matching `graph_revision_id`.
|
||||
* Scenario: “Stable permalinks”
|
||||
|
||||
* Capture a link with `?rev=…`.
|
||||
* Rerun pipeline (new revision).
|
||||
* Old link still shows original nodes/edges.
|
||||
|
||||
### 8.3. Migration tests
|
||||
|
||||
* On a sanitized snapshot:
|
||||
|
||||
* Run migration & backfill.
|
||||
* Spot-check:
|
||||
|
||||
* Each `graph_id` has exactly one `latest_revision_id`.
|
||||
* Node/edge counts before and after match.
|
||||
* Manually recompute hash for a few graphs and compare to stored `graph_revision_id`.
|
||||
|
||||
---
|
||||
|
||||
## 9. Security & Compliance Considerations
|
||||
|
||||
* **Immutability guarantee**:
|
||||
|
||||
* Don’t allow updates to `graph_revisions.manifest`.
|
||||
* Any change must happen by creating a new revision.
|
||||
* **Tombstoning** (for rare delete cases):
|
||||
|
||||
* If you must “remove” a bad graph, mark revision as `tombstoned` in an additional column and return `410 Gone` for that `graph_revision_id`.
|
||||
* Never reuse that ID.
|
||||
* **Access control**:
|
||||
|
||||
* Ensure revision APIs use the same ACLs as existing graph APIs.
|
||||
* Don’t leak manifests to users not allowed to see underlying artifacts.
|
||||
|
||||
---
|
||||
|
||||
## 10. Concrete Ticket Breakdown (example)
|
||||
|
||||
You can copy/paste this into your tracker and tweak.
|
||||
|
||||
1. **BE-01** – Add `graphs` and `graph_revisions` tables
|
||||
|
||||
* AC:
|
||||
|
||||
* Tables exist with fields above.
|
||||
* Migrations run cleanly in staging.
|
||||
|
||||
2. **BE-02** – Add `graph_revision_id` to nodes/edges tables
|
||||
|
||||
* AC:
|
||||
|
||||
* Column added, nullable.
|
||||
* No runtime errors in staging.
|
||||
|
||||
3. **BE-03** – Implement `GraphRevisionIdGenerator` library
|
||||
|
||||
* AC:
|
||||
|
||||
* Given a manifest, returns deterministic ID.
|
||||
* Unit tests cover ordering, minimal changes.
|
||||
|
||||
4. **BE-04** – Implement `/internal/graphs/{graph_id}/revisions` in Authority
|
||||
|
||||
* AC:
|
||||
|
||||
* Stores new revision + nodes/edges.
|
||||
* Idempotent on duplicate revisions.
|
||||
|
||||
5. **BE-05** – Implement public revision APIs
|
||||
|
||||
* AC:
|
||||
|
||||
* Endpoints in §4.1 available with Swagger.
|
||||
* `rev` query param supported.
|
||||
* Default behavior returns latest revision.
|
||||
|
||||
6. **BE-06** – Backfill existing graphs into `graph_revisions`
|
||||
|
||||
* AC:
|
||||
|
||||
* All existing graphs have `latest_revision_id`.
|
||||
* Nodes/edges linked to a `graph_revision_id`.
|
||||
* Metrics & logs generated for failures.
|
||||
|
||||
7. **BE-07** – Ledger integration for revisions
|
||||
|
||||
* AC:
|
||||
|
||||
* Each new revision creates a ledger entry.
|
||||
* Query by `graph_revision_id` works.
|
||||
|
||||
8. **PIPE-01** – Scanner/Vexer manifest construction
|
||||
|
||||
* AC:
|
||||
|
||||
* Manifest includes all required fields.
|
||||
* Values verified against Authority for a sample run.
|
||||
|
||||
9. **PIPE-02** – Scanner/Vexer computes `graph_revision_id` and calls Authority
|
||||
|
||||
* AC:
|
||||
|
||||
* End-to-end pipeline run produces a new `graph_revision_id`.
|
||||
* Authority stores it and sets as latest.
|
||||
|
||||
10. **FE-01** – UI supports `?rev=` param and displays revision
|
||||
|
||||
* AC:
|
||||
|
||||
* When URL has `rev`, UI loads that revision.
|
||||
* When no `rev`, loads latest.
|
||||
* Rev appears in header with copy/share.
|
||||
|
||||
11. **FE-02** – Revision list UI (optional)
|
||||
|
||||
* AC:
|
||||
|
||||
* Revision panel lists revisions.
|
||||
* Click navigates to appropriate `?rev=`.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next help you turn this into a very explicit design doc (with diagrams and exact JSON examples) or into ready-to-paste migration scripts / TypeScript interfaces tailored to your actual stack.
|
||||
@@ -0,0 +1,696 @@
|
||||
Here are some key developments in the software‑supply‑chain and vulnerability‑scoring world that you’ll want on your radar.
|
||||
|
||||
---
|
||||
|
||||
## 1. CVSS v4.0 – traceable scoring with richer context
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* CVSS v4.0 was officially released by FIRST (Forum of Incident Response & Security Teams) on **November 1, 2023**. ([first.org][1])
|
||||
* The specification now clearly divides metrics into four groups: Base, Threat, Environmental, and Supplemental. ([first.org][1])
|
||||
* The National Vulnerability Database (NVD) has added support for CVSS v4.0 — meaning newer vulnerability records can carry v4‑style scores, vector strings and search filters. ([NVD][2])
|
||||
* What’s new/tangible: better granularity, explicit “Attack Requirements” and richer metadata to better reflect real‑world contextual risk. ([Seemplicity][3])
|
||||
* Why this matters: Enables more traceable evidence of how a score was derived (which metrics used, what context), supporting auditing, prioritisation and transparency.
|
||||
|
||||
**Take‑away for your world**: If you’re leveraging vulnerability scanning, SBOM enrichment or compliance workflows (given your interest in SBOM/VEX/provenance), then moving to or supporting CVSS v4.0 ensures you have stronger traceability and richer scoring context that maps into policy, audit and remediation workflows.
|
||||
|
||||
---
|
||||
|
||||
## 2. CycloneDX v1.7 – SBOM/VEX/provenance with cryptographic & IP transparency
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
* Version 1.7 of the SBOM standard from OWASP Foundation (CycloneDX) launched on **October 21, 2025**. ([CycloneDX][4])
|
||||
* Key enhancements: *Cryptography Bill of Materials (CBOM)* support (listing algorithm families, elliptic curves, etc) and *structured citations* (who provided component info, how, when) to improve provenance. ([CycloneDX][4])
|
||||
* Provenance use‑cases: The spec enables declaring supplier/author/publisher metadata, component origin, external references. ([CycloneDX][5])
|
||||
* Broadening scope: CycloneDX now supports not just SBOM (software), but hardware BOMs (HBOM), machine learning BOMs, cryptographic BOMs (CBOM) and supports VEX/attestation use‑cases. ([openssf.org][6])
|
||||
* Why this matters: For your StellaOps architecture (with a strong emphasis on provenance, deterministic scans, trust‑frameworks) CycloneDX v1.7 provides native standard support for deeper audit‑ready evidence, cryptographic algorithm visibility (which matters for crypto‑sovereign readiness) and formal attestations/citations in the BOM.
|
||||
|
||||
**Take‑away**: Aligning your SBOM/VEX/provenance stack (e.g., scanner.webservice) to output CycloneDX v1.7‑compliant artifacts means you jump ahead in terms of traceability, auditability and future‑proofing (crypto and IP).
|
||||
|
||||
---
|
||||
|
||||
## 3. SLSA v1.2 Release Candidate 2 – supply‑chain build provenance standard
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
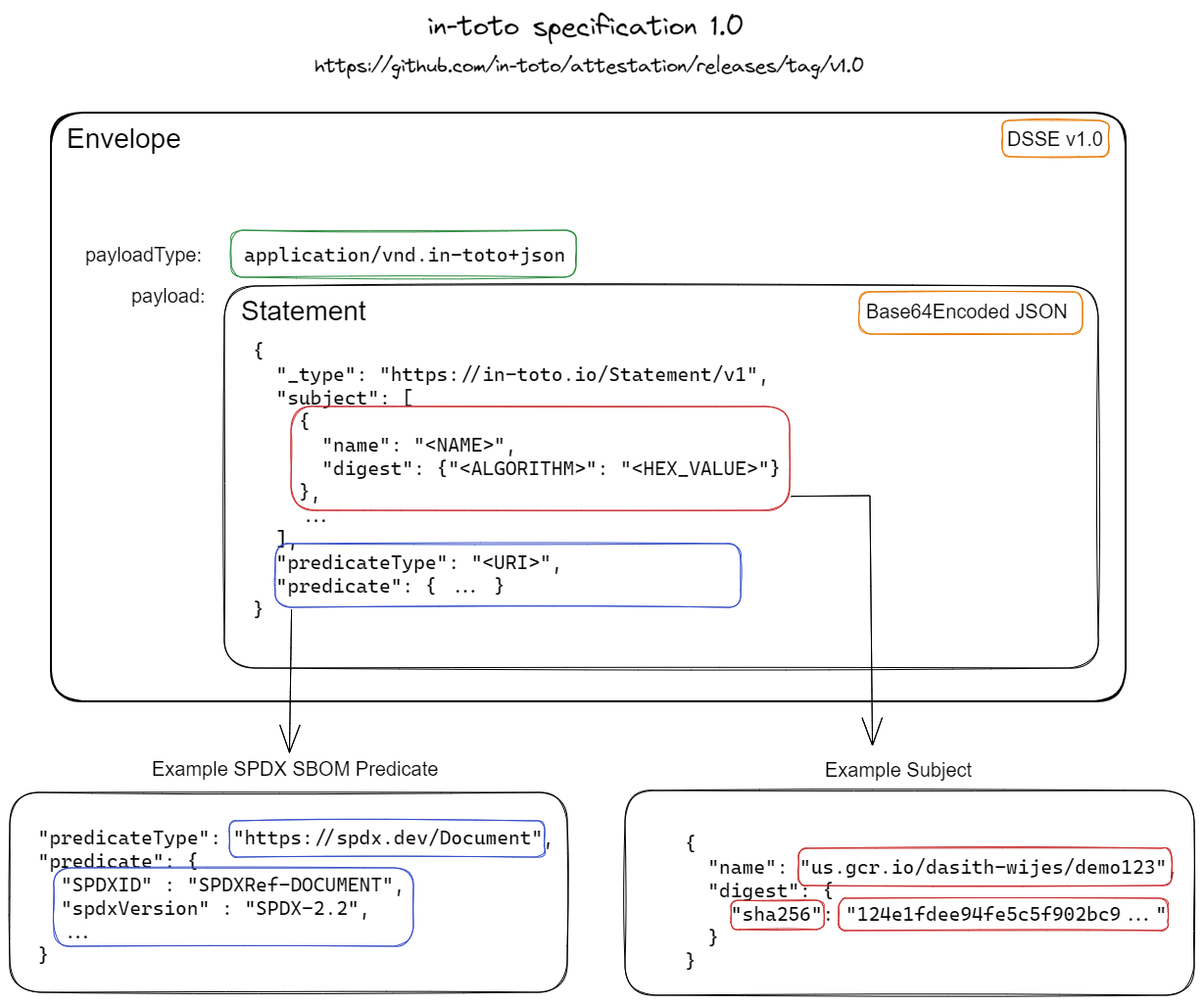
|
||||
|
||||
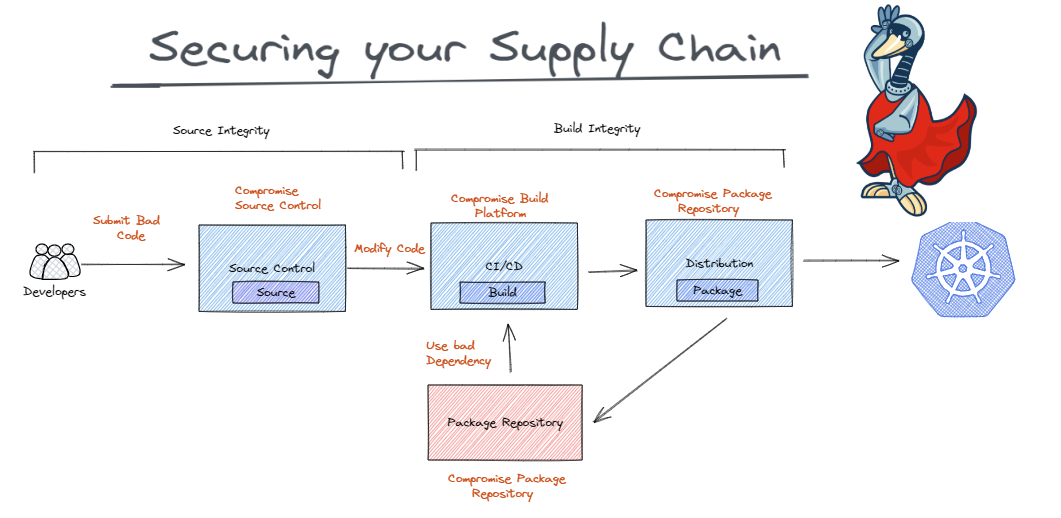
|
||||
|
||||

|
||||
|
||||
* On **November 10, 2025**, the Open Source Security Foundation (via the SLSA community) announced RC2 of SLSA v1.2, open for public comment until November 24, 2025. ([SLSA][7])
|
||||
* What’s new: Introduction of a *Source Track* (in addition to the Build Track) to capture source control provenance, distributed provenance, artifact attestations. ([SLSA][7])
|
||||
* Specification clarifies provenance/attestation formats, how builds should be produced, distributed, verified. ([SLSA][8])
|
||||
* Why this matters: SLSA gives you a standard framework for “I can trace this binary back to the code, the build system, the signer, the provenance chain,” which aligns directly with your strategic moats around deterministic replayable scans, proof‑of‑integrity graph, and attestations.
|
||||
|
||||
**Take‑away**: If you integrate SLSA v1.2 (once finalised) into StellaOps, you gain an industry‑recognised standard for build provenance and attestation, complementing your SBOM/VEX and CVSS code bases.
|
||||
|
||||
---
|
||||
|
||||
### Why I’m sharing this with you
|
||||
|
||||
Given your interest in cryptographic‑sovereign readiness, deterministic scanning, provenance and audit‑grade supply‑chain tooling (your StellaOps moat list), this trifecta (CVSS v4.0 + CycloneDX v1.7 + SLSA v1.2) represents the major standards you need to converge on. They each address different layers: vulnerability scoring, component provenance and build/trust chain assurance. Aligning all three will give you a strong governance and tooling stack.
|
||||
|
||||
If you like, I can pull together a detailed gap‑analysis table (your current architecture versus what these standards demand) and propose roadmap steps for StellaOps to adopt them.
|
||||
|
||||
[1]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://nvd.nist.gov/general/news/cvss-v4-0-official-support?utm_source=chatgpt.com "CVSS v4.0 Official Support - NVD"
|
||||
[3]: https://seemplicity.io/blog/decoding-cvss-4-clarified-base-metrics/?utm_source=chatgpt.com "Decoding CVSS 4.0: Clarified Base Metrics"
|
||||
[4]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[5]: https://cyclonedx.org/use-cases/provenance/?utm_source=chatgpt.com "Security Use Case: Provenance"
|
||||
[6]: https://openssf.org/blog/2025/10/22/sboms-in-the-era-of-the-cra-toward-a-unified-and-actionable-framework/?utm_source=chatgpt.com "Global Alignment on SBOM Standards: How the EU Cyber ..."
|
||||
[7]: https://slsa.dev/blog/2025/11/slsa-v1.2-rc2?utm_source=chatgpt.com "Announcing SLSA v1.2 Release Candidate 2"
|
||||
[8]: https://slsa.dev/spec/v1.2-rc2/?utm_source=chatgpt.com "SLSA specification"
|
||||
Cool, let’s turn all that standards talk into something your engineers can actually build against.
|
||||
|
||||
Below is a concrete implementation plan, broken into 3 workstreams, each with phases, tasks and clear acceptance criteria:
|
||||
|
||||
* **A — CVSS v4.0 integration (scoring & evidence)**
|
||||
* **B — CycloneDX 1.7 SBOM/CBOM + provenance**
|
||||
* **C — SLSA 1.2 (build + source provenance)**
|
||||
* **X — Cross‑cutting (APIs, UX, docs, rollout)**
|
||||
|
||||
I’ll assume you have:
|
||||
|
||||
* A scanner / ingestion pipeline,
|
||||
* A central data model (DB or graph),
|
||||
* An API + UI layer (StellaOps console or similar),
|
||||
* CI/CD on GitHub/GitLab/whatever.
|
||||
|
||||
---
|
||||
|
||||
## A. CVSS v4.0 integration
|
||||
|
||||
**Goal:** Your platform can ingest, calculate, store and expose CVSS v4.0 scores and vectors alongside (or instead of) v3.x, using the official FIRST spec and NVD data. ([FIRST][1])
|
||||
|
||||
### A1. Foundations & decisions
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Pick canonical CVSSv4 library or implementation**
|
||||
|
||||
* Evaluate existing OSS libraries for your main language(s), or plan an internal one based directly on FIRST’s spec (Base, Threat, Environmental, Supplemental groups).
|
||||
* Decide:
|
||||
|
||||
* Supported metric groups (Base only vs. Base+Threat+Environmental+Supplemental).
|
||||
* Which groups your UI will expose/edit vs. read-only from upstream feeds.
|
||||
|
||||
2. **Versioning strategy**
|
||||
|
||||
* Decide how to represent CVSS v3.0/v3.1/v4.0 in your DB:
|
||||
|
||||
* `vulnerability_scores` table with `version`, `vector`, `base_score`, `environmental_score`, `temporal_score`, `severity_band`.
|
||||
* Define precedence rules: if both v3.1 and v4.0 exist, which one your “headline” severity uses.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Tech design doc reviewed & approved.
|
||||
* Decision on library vs. custom implementation recorded.
|
||||
* DB schema migration plan ready.
|
||||
|
||||
---
|
||||
|
||||
### A2. Data model & storage
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **DB schema changes**
|
||||
|
||||
* Add a `cvss_scores` table or expand the existing vulnerability table, e.g.:
|
||||
|
||||
```text
|
||||
cvss_scores
|
||||
id (PK)
|
||||
vuln_id (FK)
|
||||
source (enum: NVD, scanner, manual)
|
||||
version (enum: 2.0, 3.0, 3.1, 4.0)
|
||||
vector (string)
|
||||
base_score (float)
|
||||
temporal_score (float, nullable)
|
||||
environmental_score (float, nullable)
|
||||
severity (enum: NONE/LOW/MEDIUM/HIGH/CRITICAL)
|
||||
metrics_json (JSONB) // raw metrics for traceability
|
||||
created_at / updated_at
|
||||
```
|
||||
|
||||
2. **Traceable evidence**
|
||||
|
||||
* Store:
|
||||
|
||||
* Raw CVSS vector string (e.g. `CVSS:4.0/AV:N/...(etc)`).
|
||||
* Parsed metrics as JSON for audit (show “why” a score is what it is).
|
||||
* Optional: add `calculated_by` + `calculated_at` for your internal scoring runs.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Migrations applied in dev.
|
||||
* Read/write repository functions implemented and unit‑tested.
|
||||
|
||||
---
|
||||
|
||||
### A3. Ingestion & calculation
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **NVD / external feeds**
|
||||
|
||||
* Update your NVD ingestion to read CVSS v4.0 when present in JSON `metrics` fields. ([NVD][2])
|
||||
* Map NVD → internal `cvss_scores` model.
|
||||
|
||||
2. **Local CVSSv4 calculator service**
|
||||
|
||||
* Implement a service (or module) that:
|
||||
|
||||
* Accepts metric values (Base/Threat/Environmental/Supplemental).
|
||||
* Produces:
|
||||
|
||||
* Canonical vector.
|
||||
* Base/Threat/Environmental scores.
|
||||
* Severity band.
|
||||
* Make this callable by:
|
||||
|
||||
* Scanner engine (calculating scores for private vulns).
|
||||
* UI (recalculate button).
|
||||
* API (for automated clients).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a set of reference vectors from FIRST, your calculator returns exact expected scores.
|
||||
* NVD ingestion for a sample of CVEs produces v4 scores in your DB.
|
||||
|
||||
---
|
||||
|
||||
### A4. UI & API
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **API**
|
||||
|
||||
* Extend vulnerability API payload with:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "CVE-2024-XXXX",
|
||||
"cvss": [
|
||||
{
|
||||
"version": "4.0",
|
||||
"source": "NVD",
|
||||
"vector": "CVSS:4.0/AV:N/...",
|
||||
"base_score": 8.3,
|
||||
"severity": "HIGH",
|
||||
"metrics": { "...": "..." }
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
* Add filters: `cvss.version`, `cvss.min_score`, `cvss.severity`.
|
||||
|
||||
2. **UI**
|
||||
|
||||
* On vulnerability detail:
|
||||
|
||||
* Show v3.x and v4.0 side-by-side.
|
||||
* Expandable panel with metric breakdown and “explain my score” text.
|
||||
* On list views:
|
||||
|
||||
* Support sorting & filtering by v4.0 base score & severity.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Frontend can render v4.0 vectors and scores.
|
||||
* QA can filter vulnerabilities using v4 metrics via API and UI.
|
||||
|
||||
---
|
||||
|
||||
### A5. Migration & rollout
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Backfill**
|
||||
|
||||
* For all stored vulnerabilities where metrics exist:
|
||||
|
||||
* If v4 not present but inputs available, compute v4.
|
||||
* Store both historical (v3.x) and new v4 for comparison.
|
||||
|
||||
2. **Feature flag / rollout**
|
||||
|
||||
* Introduce feature flag `cvss_v4_enabled` per tenant or environment.
|
||||
* Run A/B comparison internally before enabling for all users.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Backfill job runs successfully on staging data.
|
||||
* Rollout plan + rollback strategy documented.
|
||||
|
||||
---
|
||||
|
||||
## B. CycloneDX 1.7 SBOM/CBOM + provenance
|
||||
|
||||
CycloneDX 1.7 is now the current spec; it adds things like a Cryptography BOM (CBOM) and structured citations/provenance to strengthen trust and traceability. ([CycloneDX][3])
|
||||
|
||||
### B1. Decide scope & generators
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Select BOM formats & languages**
|
||||
|
||||
* JSON as your primary format (`application/vnd.cyclonedx+json`). ([CycloneDX][4])
|
||||
* Components you’ll cover:
|
||||
|
||||
* Application BOMs (packages, containers).
|
||||
* Optional: infrastructure (IaC, images).
|
||||
* Optional: CBOM for crypto usage.
|
||||
|
||||
2. **Choose or implement generators**
|
||||
|
||||
* For each ecosystem (e.g., Maven, NPM, PyPI, containers), choose:
|
||||
|
||||
* Existing tools (`cyclonedx-maven-plugin`, `cyclonedx-npm`, etc).
|
||||
* Or central generator using lockfiles/manifests.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Matrix of ecosystems → generator tool finalized.
|
||||
* POC shows valid CycloneDX 1.7 JSON BOM for one representative project.
|
||||
|
||||
---
|
||||
|
||||
### B2. Schema alignment & validation
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Model updates**
|
||||
|
||||
* Extend your internal SBOM model to include:
|
||||
|
||||
* `spec_version: "1.7"`
|
||||
* `bomFormat: "CycloneDX"`
|
||||
* `serialNumber` (UUID/URI).
|
||||
* `metadata.tools` (how BOM was produced).
|
||||
* `properties`, `licenses`, `crypto` (for CBOM).
|
||||
* For provenance:
|
||||
|
||||
* `metadata.authors`, `metadata.manufacture`, `metadata.supplier`.
|
||||
* `components[x].evidence` and `components[x].properties` for evidence & citations. ([CycloneDX][5])
|
||||
|
||||
2. **Validation pipeline**
|
||||
|
||||
* Integrate the official CycloneDX JSON schema validation step into:
|
||||
|
||||
* CI (for projects generating BOMs).
|
||||
* Your ingestion path (reject/flag invalid BOMs).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Any BOM produced must pass CycloneDX 1.7 JSON schema validation in CI.
|
||||
* Ingestion rejects malformed BOMs with clear error messages.
|
||||
|
||||
---
|
||||
|
||||
### B3. Provenance & citations in BOMs
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Define provenance policy**
|
||||
|
||||
* Minimal set for every BOM:
|
||||
|
||||
* Author (CI system / team).
|
||||
* Build pipeline ID, commit, repo URL.
|
||||
* Build time.
|
||||
* Extended:
|
||||
|
||||
* `externalReferences` for:
|
||||
|
||||
* Build logs.
|
||||
* SLSA attestations.
|
||||
* Security reports (e.g., scanner runs).
|
||||
|
||||
2. **Implement metadata injection**
|
||||
|
||||
* In your CI templates:
|
||||
|
||||
* Capture build info (commit SHA, pipeline ID, creator, environment).
|
||||
* Add it into CycloneDX `metadata` and `properties`.
|
||||
* For evidence:
|
||||
|
||||
* Use `components[x].evidence` to reference where a component was detected (e.g., file paths, manifest lines).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For any BOM, engineers can trace:
|
||||
|
||||
* WHO built it.
|
||||
* WHEN it was built.
|
||||
* WHICH repo/commit/pipeline it came from.
|
||||
|
||||
---
|
||||
|
||||
### B4. CBOM (Cryptography BOM) support (optional but powerful)
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Crypto inventory**
|
||||
|
||||
* Scanner enhancement:
|
||||
|
||||
* Detect crypto libraries & primitives used (e.g., OpenSSL, bcrypt, TLS versions).
|
||||
* Map them into CycloneDX CBOM structures in `crypto` sections (per spec).
|
||||
|
||||
2. **Policy hooks**
|
||||
|
||||
* Define policy checks:
|
||||
|
||||
* “Disallow SHA-1,”
|
||||
* “Warn on RSA < 2048 bits,”
|
||||
* “Flag non-FIPS-approved algorithms.”
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* From a BOM, you can list all cryptographic algorithms and libraries used in an application.
|
||||
* At least one simple crypto policy implemented (e.g., SHA-1 usage alert).
|
||||
|
||||
---
|
||||
|
||||
### B5. Ingestion, correlation & UI
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Ingestion service**
|
||||
|
||||
* API endpoint: `POST /sboms` accepting CycloneDX 1.7 JSON.
|
||||
* Store:
|
||||
|
||||
* Raw BOM (for evidence).
|
||||
* Normalized component graph (packages, relationships).
|
||||
* Link BOM to:
|
||||
|
||||
* Repo/project.
|
||||
* Build (from SLSA provenance).
|
||||
* Deployed asset.
|
||||
|
||||
2. **Correlation**
|
||||
|
||||
* Join SBOM components with:
|
||||
|
||||
* Vulnerability data (CVE/CWE/CPE/PURL).
|
||||
* Crypto policy results.
|
||||
* Maintain “asset → BOM → components → vulnerabilities” graph.
|
||||
|
||||
3. **UI**
|
||||
|
||||
* For any service/image:
|
||||
|
||||
* Show latest BOM metadata (CycloneDX version, timestamp).
|
||||
* Component list with vulnerability badges.
|
||||
* Crypto tab (if CBOM enabled).
|
||||
* Provenance tab (author, build pipeline, SLSA attestation links).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given an SBOM upload, the UI shows:
|
||||
|
||||
* Components.
|
||||
* Associated vulnerabilities.
|
||||
* Provenance metadata.
|
||||
* API consumers can fetch SBOM + correlated risk in a single call.
|
||||
|
||||
---
|
||||
|
||||
## C. SLSA 1.2 build + source provenance
|
||||
|
||||
SLSA 1.2 (final) introduces a **Source Track** in addition to the Build Track, defining levels and attestation formats for both source control and build provenance. ([SLSA][6])
|
||||
|
||||
### C1. Target SLSA levels & scope
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Choose target levels**
|
||||
|
||||
* For each critical product:
|
||||
|
||||
* Pick Build Track level (e.g., target L2 now, L3 later).
|
||||
* Pick Source Track level (e.g., L1 for all, L2 for sensitive repos).
|
||||
|
||||
2. **Repo inventory**
|
||||
|
||||
* Classify repos by risk:
|
||||
|
||||
* Critical (agents, scanners, control-plane).
|
||||
* Important (integrations).
|
||||
* Low‑risk (internal tools).
|
||||
* Map target SLSA levels accordingly.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For every repo, there is an explicit target SLSA Build + Source level.
|
||||
* Gap analysis doc exists (current vs target).
|
||||
|
||||
---
|
||||
|
||||
### C2. Build provenance in CI/CD
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Attestation generation**
|
||||
|
||||
* For each CI pipeline:
|
||||
|
||||
* Use SLSA-compatible builders or tooling (e.g., `slsa-github-generator`, `slsa-framework` actions, Tekton Chains, etc.) to produce **build provenance attestations** in SLSA 1.2 format.
|
||||
* Attestation content includes:
|
||||
|
||||
* Builder identity.
|
||||
* Build inputs (commit, repo, config).
|
||||
* Build parameters.
|
||||
* Produced artifacts (digest, image tags).
|
||||
|
||||
2. **Signing & storage**
|
||||
|
||||
* Sign attestations (Sigstore/cosign or equivalent).
|
||||
* Store:
|
||||
|
||||
* In an OCI registry (as artifacts).
|
||||
* Or in a dedicated provenance store.
|
||||
* Expose pointer to attestation in:
|
||||
|
||||
* BOM (`externalReferences`).
|
||||
* Your StellaOps metadata.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For any built artifact (image/binary), you can retrieve a SLSA attestation proving:
|
||||
|
||||
* What source it came from.
|
||||
* Which builder ran.
|
||||
* What steps were executed.
|
||||
|
||||
---
|
||||
|
||||
### C3. Source Track controls
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Source provenance**
|
||||
|
||||
* Implement controls to support SLSA Source Track:
|
||||
|
||||
* Enforce protected branches.
|
||||
* Require code review (e.g., 2 reviewers) for main branches.
|
||||
* Require signed commits for critical repos.
|
||||
* Log:
|
||||
|
||||
* Author, reviewers, branch, PR ID, merge SHA.
|
||||
|
||||
2. **Source attestation**
|
||||
|
||||
* For each release:
|
||||
|
||||
* Generate **source attestations** capturing:
|
||||
|
||||
* Repo URL and commit.
|
||||
* Review status.
|
||||
* Policy compliance (review count, checks passing).
|
||||
* Link these to build attestations (Source → Build provenance chain).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For a release, you can prove:
|
||||
|
||||
* Which reviews happened.
|
||||
* Which branch strategy was followed.
|
||||
* That policies were met at merge time.
|
||||
|
||||
---
|
||||
|
||||
### C4. Verification & policy in StellaOps
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Verifier service**
|
||||
|
||||
* Implement a service that:
|
||||
|
||||
* Fetches SLSA attestations (source + build).
|
||||
* Verifies signatures and integrity.
|
||||
* Evaluates them against policies:
|
||||
|
||||
* “Artifact must have SLSA Build L2 attestation from trusted builders.”
|
||||
* “Critical services must have Source L2 attestation (review, branch protections).”
|
||||
|
||||
2. **Runtime & deployment gates**
|
||||
|
||||
* Integrate verification into:
|
||||
|
||||
* Admission controller (Kubernetes or deployment gate).
|
||||
* CI release stage (block promotion if SLSA requirements not met).
|
||||
|
||||
3. **UI**
|
||||
|
||||
* On artifact/service detail page:
|
||||
|
||||
* Surface SLSA level achieved (per track).
|
||||
* Status (pass/fail).
|
||||
* Drill-down view of attestation evidence (who built, when, from where).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* A deployment can be blocked (in a test env) when SLSA requirements are not satisfied.
|
||||
* Operators can visually see SLSA status for an artifact/service.
|
||||
|
||||
---
|
||||
|
||||
## X. Cross‑cutting: APIs, UX, docs, rollout
|
||||
|
||||
### X1. Unified data model & APIs
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Graph relationships**
|
||||
|
||||
* Model the relationship:
|
||||
|
||||
* **Source repo** → **SLSA Source attestation**
|
||||
→ **Build attestation** → **Artifact**
|
||||
→ **SBOM (CycloneDX 1.7)** → **Components**
|
||||
→ **Vulnerabilities (CVSS v4)**.
|
||||
|
||||
2. **Graph queries**
|
||||
|
||||
* Build API endpoints for:
|
||||
|
||||
* “Given a CVE, show all affected artifacts and their SLSA + BOM evidence.”
|
||||
* “Given an artifact, show its full provenance chain and risk posture.”
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* At least 2 end‑to‑end queries work:
|
||||
|
||||
* CVE → impacted assets with scores + provenance.
|
||||
* Artifact → SBOM + vulnerabilities + SLSA + crypto posture.
|
||||
|
||||
---
|
||||
|
||||
### X2. Observability & auditing
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Audit logs**
|
||||
|
||||
* Log:
|
||||
|
||||
* BOM uploads and generators.
|
||||
* SLSA attestation creation/verification.
|
||||
* CVSS recalculations (who/what triggered them).
|
||||
|
||||
2. **Metrics**
|
||||
|
||||
* Track:
|
||||
|
||||
* % of builds with valid SLSA attestations.
|
||||
* % artifacts with CycloneDX 1.7 BOMs.
|
||||
* % vulns with v4 scores.
|
||||
* Expose dashboards (Prometheus/Grafana or similar).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Dashboards exist showing coverage for:
|
||||
|
||||
* CVSSv4 adoption.
|
||||
* CycloneDX 1.7 coverage.
|
||||
* SLSA coverage.
|
||||
|
||||
---
|
||||
|
||||
### X3. Documentation & developer experience
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Developer playbooks**
|
||||
|
||||
* Short, repo‑friendly docs:
|
||||
|
||||
* “How to enable CycloneDX BOM generation in this repo.”
|
||||
* “How to ensure your service reaches SLSA Build L2.”
|
||||
* “How to interpret CVSS v4 in StellaOps.”
|
||||
|
||||
2. **Templates**
|
||||
|
||||
* CI templates:
|
||||
|
||||
* `bom-enabled-pipeline.yaml`
|
||||
* `slsa-enabled-pipeline.yaml`
|
||||
* Code snippets:
|
||||
|
||||
* API examples for pushing SBOMs.
|
||||
* API examples for querying risk posture.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* A new project can:
|
||||
|
||||
* Copy a CI template.
|
||||
* Produce a validated CycloneDX 1.7 BOM.
|
||||
* Generate SLSA attestations.
|
||||
* Show up correctly in StellaOps with CVSS v4 scoring.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can:
|
||||
|
||||
* Turn this into a **Jira-ready epic + stories breakdown**, or
|
||||
* Draft concrete **API schemas (OpenAPI/JSON)** for SBOM ingestion, CVSS scoring, and SLSA attestation verification.
|
||||
|
||||
[1]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://nvd.nist.gov/general/news/cvss-v4-0-official-support?utm_source=chatgpt.com "CVSS v4.0 Official Support - NVD"
|
||||
[3]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[4]: https://cyclonedx.org/specification/overview/?utm_source=chatgpt.com "Specification Overview"
|
||||
[5]: https://cyclonedx.org/docs/latest?utm_source=chatgpt.com "CycloneDX v1.7 JSON Reference"
|
||||
[6]: https://slsa.dev/spec/v1.2/?utm_source=chatgpt.com "SLSA specification"
|
||||
@@ -0,0 +1,913 @@
|
||||
Here’s a clear, SBOM‑first blueprint you can drop into Stella Ops without extra context.
|
||||
|
||||
---
|
||||
|
||||
# SBOM‑first spine (with attestations) — the short, practical version
|
||||
|
||||

|
||||
|
||||
## Why this matters (plain English)
|
||||
|
||||
* **SBOMs** (CycloneDX/SPDX) = a complete parts list of your software.
|
||||
* **Attestations** (in‑toto + DSSE) = tamper‑evident receipts proving *who did what, to which artifact, when, and how*.
|
||||
* **Determinism** = if you re‑scan tomorrow, you get the same result for the same inputs.
|
||||
* **Explainability** = every risk decision links back to evidence you can show to auditors/customers.
|
||||
|
||||
---
|
||||
|
||||
## Core pipeline (modules & responsibilities)
|
||||
|
||||
1. **Scan (Scanner)**
|
||||
|
||||
* Inputs: container image / dir / repo.
|
||||
* Outputs: raw facts (packages, files, symbols), and a **Scan‑Evidence** attestation (DSSE‑wrapped in‑toto statement).
|
||||
* Must support offline feeds (bundle CVE/NVD/OSV/vendor advisories).
|
||||
|
||||
2. **Sbomer**
|
||||
|
||||
* Normalizes raw facts → **canonical SBOM** (CycloneDX or SPDX) with:
|
||||
|
||||
* PURLs, license info, checksums, build‑IDs (ELF/PE/Mach‑O), source locations.
|
||||
* Emits **SBOM‑Produced** attestation linking SBOM ↔ image digest.
|
||||
|
||||
3. **Authority**
|
||||
|
||||
* Verifies every attestation chain (Sigstore/keys; PQ-ready option later).
|
||||
* Stamps **Policy‑Verified** attestation (who approved, policy hash, inputs).
|
||||
* Persists **trust‑log**: signatures, cert chains, Rekor‑like index (mirrorable offline).
|
||||
|
||||
4. **Graph Store (Canonical Graph)**
|
||||
|
||||
* Ingests SBOM, vulnerabilities, reachability facts, VEX statements.
|
||||
* Preserves **evidence links** (edge predicates: “found‑by”, “reachable‑via”, “proven‑by”).
|
||||
* Enables **deterministic replay** (snapshot manifests: feeds+rules+hashes).
|
||||
|
||||
---
|
||||
|
||||
## Stable APIs (keep these boundaries sharp)
|
||||
|
||||
* **/scan** → start scan; returns Evidence ID + attestation ref.
|
||||
* **/sbom** → get canonical SBOM (by image digest or Evidence ID).
|
||||
* **/attest** → submit/fetch attestations; verify chain; returns trust‑proof.
|
||||
* **/vex‑gate** → policy decision: *allow / warn / block* with proof bundle.
|
||||
* **/diff** → SBOM↔SBOM + SBOM↔runtime diffs (see below).
|
||||
* **/unknowns** → create/list/resolve Unknowns (signals needing human/vendor input).
|
||||
|
||||
Design notes:
|
||||
|
||||
* All responses include `decision`, `explanation`, `evidence[]`, `hashes`, `clock`.
|
||||
* Support **air‑gap**: all endpoints operate on local bundles (ZIP/TAR with SBOM+attestations+feeds).
|
||||
|
||||
---
|
||||
|
||||
## Determinism & “Unknowns” (noise‑killer loop)
|
||||
|
||||
**Smart diffs**
|
||||
|
||||
* **SBOM↔SBOM**: detect added/removed/changed components (by PURL+version+hash).
|
||||
* **SBOM↔runtime**: prove reachability (e.g., symbol/function use, loaded libs, process maps).
|
||||
* Score only on **provable** paths; gate on **VEX** (vendor/exploitability statements).
|
||||
|
||||
**Unknowns handler**
|
||||
|
||||
* Any unresolved signal (ambiguous CVE mapping, stripped binary, unverified vendor VEX) → **Unknowns** queue:
|
||||
|
||||
* SLA, owner, evidence snapshot, audit trail.
|
||||
* State machine: `new → triage → vendor‑query → verified → closed`.
|
||||
* Every VEX or vendor reply becomes an attestation; decisions re‑evaluated deterministically.
|
||||
|
||||
---
|
||||
|
||||
## What to store (so you can explain every decision)
|
||||
|
||||
* **Artifacts**: image digest, SBOM hash, feed versions, rule set hash.
|
||||
* **Proofs**: DSSE envelopes, signatures, certs, inclusion proofs (Rekor‑style).
|
||||
* **Predicates (edges)**:
|
||||
|
||||
* `contains(component)`, `vulnerable_to(cve)`, `reachable_via(callgraph|runtime)`,
|
||||
* `overridden_by(vex)`, `verified_by(authority)`, `derived_from(scan-evidence)`.
|
||||
* **Why‑strings**: human‑readable proof trails (1–3 sentences) output with every decision.
|
||||
|
||||
---
|
||||
|
||||
## Minimal policies that work on day 1
|
||||
|
||||
* **Block** only when: `vuln.severity ≥ High` AND `reachable == true` AND `no VEX allows`.
|
||||
* **Warn** when: `High/Critical` but `reachable == unknown` → route to Unknowns with SLA.
|
||||
* **Allow** when: `Low/Medium` OR VEX says `not_affected` (trusted signer + policy).
|
||||
|
||||
---
|
||||
|
||||
## Offline/air‑gap bundle format (zip)
|
||||
|
||||
```
|
||||
/bundle/
|
||||
feeds/ (NVD, OSV, vendor) + manifest.json (hashes, timestamps)
|
||||
sboms/ imageDigest.json
|
||||
attestations/ *.jsonl (DSSE)
|
||||
proofs/ rekor/ merkle.json
|
||||
policy/ lattice.json
|
||||
replay/ inputs.lock (content‑hashes of everything above)
|
||||
```
|
||||
|
||||
* Every API accepts `?bundle=/path/to/bundle.zip`.
|
||||
* **Replay**: `inputs.lock` guarantees deterministic re‑evaluation.
|
||||
|
||||
---
|
||||
|
||||
## .NET 10 implementation sketch (pragmatic)
|
||||
|
||||
* **Contracts**: `StellaOps.Contracts.*` (Scan, Attest, VexGate, Diff, Unknowns).
|
||||
* **Attestations**: `StellaOps.Attest.Dsse` (IEnvelope, IStatement<TPredicate>); pluggable crypto (FIPS/GOST/SM/PQ).
|
||||
* **SBOM**: `StellaOps.Sbom` (CycloneDX/SPDX models + mappers; PURL utilities).
|
||||
* **Graph**: `StellaOps.Graph` (EF Core 9/10 over Mongo/Postgres; edge predicates as enums + JSON evidence).
|
||||
* **Policy/Lattice**: `StellaOps.Policy.Lattice` (pure functions over graph snapshots; produce Decision+Why).
|
||||
* **Unknowns**: `StellaOps.Unknowns` (aggregate root; SLA timers; audit events).
|
||||
* **CLI**: `stella scan|sbom|attest|vex-gate|diff|unknowns` with `--bundle`.
|
||||
|
||||
Key patterns:
|
||||
|
||||
* All public methods return `(Result<T> value, Proof proof)`.
|
||||
* Hash everything (inputs, rules, feeds) and bake into `Proof`.
|
||||
* Emit DSSE envelopes at each hop; verify on ingest; never trust unauthenticated input.
|
||||
|
||||
---
|
||||
|
||||
## Next steps (week‑one checklist)
|
||||
|
||||
* Define JSON schemas for: **Decision** (with Why+Proof), **Unknown**, **DiffResult**.
|
||||
* Stand up **/scan**, **/sbom**, **/attest**, **/vex‑gate** skeletons returning mock Proofs.
|
||||
* Implement **SBOM↔SBOM diff** (PURL+version+hash) and wire to **/diff**.
|
||||
* Create **bundle.zip** reader/writer + `inputs.lock`.
|
||||
* Add **Authority.Verify()** with DSSE verification + trust‑store.
|
||||
* Ship a basic **policy.lattice.json** (3 rules above) and e2e test: image → allow/block with proofs.
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* The exact C# interfaces/classes (namespaces + DTOs),
|
||||
* JSON Schemas for Decision/Proof/Unknowns,
|
||||
* A seed `bundle.zip` layout with fake data for local e2e.
|
||||
Cool, let’s turn that blueprint into something your devs can actually build from.
|
||||
|
||||
Below is a detailed, opinionated implementation plan you can paste into an engineering doc and assign as epics / tickets.
|
||||
|
||||
---
|
||||
|
||||
## 0. Solution layout (concrete)
|
||||
|
||||
**Repo structure**
|
||||
|
||||
```text
|
||||
/stella-ops
|
||||
/src
|
||||
StellaOps.Contracts // DTOs, API contracts, JSON schemas
|
||||
StellaOps.Domain // Core domain types (ArtifactId, Proof, Decision, etc.)
|
||||
StellaOps.Attest // DSSE envelopes, in-toto statements, signing/verification
|
||||
StellaOps.Sbom // SBOM models + normalization
|
||||
StellaOps.Graph // Graph store, entities, queries
|
||||
StellaOps.Policy // Policy engine (lattice evaluation)
|
||||
StellaOps.WebApi // HTTP APIs: /scan, /sbom, /attest, /vex-gate, /diff, /unknowns
|
||||
StellaOps.Cli // `stella` CLI, offline bundles
|
||||
/tests
|
||||
StellaOps.Tests.Unit
|
||||
StellaOps.Tests.Integration
|
||||
StellaOps.Tests.E2E
|
||||
```
|
||||
|
||||
**Baseline tech assumptions**
|
||||
|
||||
* Runtime: .NET (8+; you can call it “.NET 10” in your roadmap).
|
||||
* API: ASP.NET Core minimal APIs.
|
||||
* DB: Postgres (via EF Core) for graph + unknowns + metadata.
|
||||
* Storage: local filesystem / S3-compatible for bundle zips, scanner DB caches.
|
||||
* External scanners: Trivy / Grype / Syft (invoked via CLI with deterministic config).
|
||||
|
||||
---
|
||||
|
||||
## 1. Core domain & shared contracts (Phase 1)
|
||||
|
||||
**Goal:** Have a stable core domain + contracts that all teams can build against.
|
||||
|
||||
### 1.1 Core domain types (`StellaOps.Domain`)
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public readonly record struct Digest(string Algorithm, string Value); // e.g. ("sha256", "abcd...")
|
||||
public readonly record struct ArtifactRef(string Kind, string Value);
|
||||
// Kind: "container-image", "file", "package", "sbom", etc.
|
||||
|
||||
public readonly record struct EvidenceId(Guid Value);
|
||||
public readonly record struct AttestationId(Guid Value);
|
||||
|
||||
public enum PredicateType
|
||||
{
|
||||
ScanEvidence,
|
||||
SbomProduced,
|
||||
PolicyVerified,
|
||||
VulnerabilityFinding,
|
||||
ReachabilityFinding,
|
||||
VexStatement
|
||||
}
|
||||
|
||||
public sealed class Proof
|
||||
{
|
||||
public string ProofId { get; init; } = default!;
|
||||
public Digest InputsLock { get; init; } = default!; // hash of feeds+rules+sbom bundle
|
||||
public DateTimeOffset EvaluatedAt { get; init; }
|
||||
public IReadOnlyList<string> EvidenceIds { get; init; } = Array.Empty<string>();
|
||||
public IReadOnlyDictionary<string,string> Meta { get; init; } = new Dictionary<string,string>();
|
||||
}
|
||||
```
|
||||
|
||||
### 1.2 Attestation model (`StellaOps.Attest`)
|
||||
|
||||
Implement DSSE + in‑toto abstractions:
|
||||
|
||||
```csharp
|
||||
public sealed class DsseEnvelope
|
||||
{
|
||||
public string PayloadType { get; init; } = default!;
|
||||
public string Payload { get; init; } = default!; // base64url(JSON)
|
||||
public IReadOnlyList<DsseSignature> Signatures { get; init; } = Array.Empty<DsseSignature>();
|
||||
}
|
||||
|
||||
public sealed class DsseSignature
|
||||
{
|
||||
public string KeyId { get; init; } = default!;
|
||||
public string Sig { get; init; } = default!; // base64url
|
||||
}
|
||||
|
||||
public interface IStatement<out TPredicate>
|
||||
{
|
||||
string Type { get; } // in-toto type URI
|
||||
string PredicateType { get; } // URI or enum -> string
|
||||
TPredicate Predicate { get; }
|
||||
string Subject { get; } // e.g., image digest
|
||||
}
|
||||
```
|
||||
|
||||
Attestation services:
|
||||
|
||||
```csharp
|
||||
public interface IAttestationSigner
|
||||
{
|
||||
Task<DsseEnvelope> SignAsync<TPredicate>(IStatement<TPredicate> statement, CancellationToken ct);
|
||||
}
|
||||
|
||||
public interface IAttestationVerifier
|
||||
{
|
||||
Task VerifyAsync(DsseEnvelope envelope, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 1.3 Decision & VEX-gate contracts (`StellaOps.Contracts`)
|
||||
|
||||
```csharp
|
||||
public enum GateDecisionKind
|
||||
{
|
||||
Allow,
|
||||
Warn,
|
||||
Block
|
||||
}
|
||||
|
||||
public sealed class GateDecision
|
||||
{
|
||||
public GateDecisionKind Decision { get; init; }
|
||||
public string Reason { get; init; } = default!; // short human-readable
|
||||
public Proof Proof { get; init; } = default!;
|
||||
public IReadOnlyList<string> Evidence { get; init; } = Array.Empty<string>(); // EvidenceIds / AttestationIds
|
||||
}
|
||||
|
||||
public sealed class VexGateRequest
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; }
|
||||
public string? Environment { get; init; } // "prod", "staging", cluster id, etc.
|
||||
public string? BundlePath { get; init; } // optional offline bundle path
|
||||
}
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Shared projects compile.
|
||||
* No service references each other directly (only via Contracts + Domain).
|
||||
* Example test that serializes/deserializes GateDecision and DsseEnvelope using System.Text.Json.
|
||||
|
||||
---
|
||||
|
||||
## 2. SBOM pipeline (Scanner → Sbomer) (Phase 2)
|
||||
|
||||
**Goal:** For a container image, produce a canonical SBOM + attestation deterministically.
|
||||
|
||||
### 2.1 Scanner integration (`StellaOps.WebApi` + `StellaOps.Cli`)
|
||||
|
||||
#### API contract (`/scan`)
|
||||
|
||||
```csharp
|
||||
public sealed class ScanRequest
|
||||
{
|
||||
public string SourceType { get; init; } = default!; // "container-image" | "directory" | "git-repo"
|
||||
public string Locator { get; init; } = default!; // e.g. "registry/myapp:1.2.3"
|
||||
public bool IncludeFiles { get; init; } = true;
|
||||
public bool IncludeLicenses { get; init; } = true;
|
||||
public string? BundlePath { get; init; } // for offline data
|
||||
}
|
||||
|
||||
public sealed class ScanResponse
|
||||
{
|
||||
public EvidenceId EvidenceId { get; init; }
|
||||
public AttestationId AttestationId { get; init; }
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
}
|
||||
```
|
||||
|
||||
#### Implementation steps
|
||||
|
||||
1. **Scanner abstraction**
|
||||
|
||||
```csharp
|
||||
public interface IArtifactScanner
|
||||
{
|
||||
Task<ScanResult> ScanAsync(ScanRequest request, CancellationToken ct);
|
||||
}
|
||||
|
||||
public sealed class ScanResult
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public IReadOnlyList<DiscoveredPackage> Packages { get; init; } = Array.Empty<DiscoveredPackage>();
|
||||
public IReadOnlyList<DiscoveredFile> Files { get; init; } = Array.Empty<DiscoveredFile>();
|
||||
}
|
||||
```
|
||||
|
||||
2. **CLI wrapper** (Trivy/Grype/Syft):
|
||||
|
||||
* Implement `SyftScanner : IArtifactScanner`:
|
||||
|
||||
* Invoke external CLI with fixed flags.
|
||||
* Use JSON output mode.
|
||||
* Resolve CLI path from config.
|
||||
* Ensure deterministic:
|
||||
|
||||
* Disable auto-updating DB.
|
||||
* Use a local DB path versioned and optionally included into bundle.
|
||||
* Write parsing code Syft → `ScanResult`.
|
||||
* Add retry & clear error mapping (timeout, auth error, network error).
|
||||
|
||||
3. **/scan endpoint**
|
||||
|
||||
* Validate request.
|
||||
* Call `IArtifactScanner.ScanAsync`.
|
||||
* Build a `ScanEvidence` predicate:
|
||||
|
||||
```csharp
|
||||
public sealed class ScanEvidencePredicate
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public DateTimeOffset ScannedAt { get; init; }
|
||||
public string ScannerName { get; init; } = default!;
|
||||
public string ScannerVersion { get; init; } = default!;
|
||||
public IReadOnlyList<DiscoveredPackage> Packages { get; init; } = Array.Empty<DiscoveredPackage>();
|
||||
}
|
||||
```
|
||||
|
||||
* Build in‑toto statement for predicate.
|
||||
* Call `IAttestationSigner.SignAsync`, persist:
|
||||
|
||||
* Raw envelope to `attestations` table.
|
||||
* Map to `EvidenceId` + `AttestationId`.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a fixed image and fixed scanner DB, repeated `/scan` calls produce identical:
|
||||
|
||||
* `ScanResult` (up to ordering).
|
||||
* `ScanEvidence` payload.
|
||||
* `InputsLock` proof hash (once implemented).
|
||||
* E2E test: run scan on a small public image in CI using a pre-bundled scanner DB.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Sbomer (`StellaOps.Sbom` + `/sbom`)
|
||||
|
||||
**Goal:** Normalize `ScanResult` into a canonical SBOM (CycloneDX/SPDX) + emit SBOM attestation.
|
||||
|
||||
#### Models
|
||||
|
||||
Create neutral SBOM model (internal):
|
||||
|
||||
```csharp
|
||||
public sealed class CanonicalComponent
|
||||
{
|
||||
public string Name { get; init; } = default!;
|
||||
public string Version { get; init; } = default!;
|
||||
public string Purl { get; init; } = default!;
|
||||
public string? License { get; init; }
|
||||
public Digest Digest { get; init; } = default!;
|
||||
public string? SourceLocation { get; init; } // file path, layer info
|
||||
}
|
||||
|
||||
public sealed class CanonicalSbom
|
||||
{
|
||||
public string SbomId { get; init; } = default!;
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public IReadOnlyList<CanonicalComponent> Components { get; init; } = Array.Empty<CanonicalComponent>();
|
||||
public DateTimeOffset CreatedAt { get; init; }
|
||||
public string Format { get; init; } = "CycloneDX-JSON-1.5"; // default
|
||||
}
|
||||
```
|
||||
|
||||
#### Sbomer service
|
||||
|
||||
```csharp
|
||||
public interface ISbomer
|
||||
{
|
||||
CanonicalSbom FromScan(ScanResult scan);
|
||||
string ToCycloneDxJson(CanonicalSbom sbom);
|
||||
string ToSpdxJson(CanonicalSbom sbom);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation details:
|
||||
|
||||
* Map OS/deps to PURLs (use existing PURL libs or implement minimal helpers).
|
||||
* Stable ordering:
|
||||
|
||||
* Sort components by `Purl` then `Version` before serialization.
|
||||
* Hash the SBOM JSON → `Digest` (e.g., `Digest("sha256", "...")`).
|
||||
|
||||
#### SBOM attestation & `/sbom` endpoint
|
||||
|
||||
* For an `ArtifactRef` (or `ScanEvidence` EvidenceId):
|
||||
|
||||
1. Fetch latest `ScanResult` from DB.
|
||||
2. Call `ISbomer.FromScan`.
|
||||
3. Serialize to CycloneDX.
|
||||
4. Emit `SbomProduced` predicate & DSSE envelope.
|
||||
5. Persist SBOM JSON blob & link to artifact.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Same `ScanResult` always produces bit-identical SBOM JSON.
|
||||
* Unit tests verifying:
|
||||
|
||||
* PURL mapping correctness.
|
||||
* Stable ordering.
|
||||
* `/sbom` endpoint can:
|
||||
|
||||
* Build SBOM from scan.
|
||||
* Return existing SBOM if already generated (idempotence).
|
||||
|
||||
---
|
||||
|
||||
## 3. Attestation Authority & trust log (Phase 3)
|
||||
|
||||
**Goal:** Verify all attestations, store them with a trust log, and produce `PolicyVerified` attestations.
|
||||
|
||||
### 3.1 Authority service (`StellaOps.Attest` + `StellaOps.WebApi`)
|
||||
|
||||
Key interfaces:
|
||||
|
||||
```csharp
|
||||
public interface IAuthority
|
||||
{
|
||||
Task<AttestationId> RecordAsync(DsseEnvelope envelope, CancellationToken ct);
|
||||
Task<Proof> VerifyChainAsync(ArtifactRef artifact, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation steps:
|
||||
|
||||
1. **Attestations store**
|
||||
|
||||
* Table `attestations`:
|
||||
|
||||
* `id` (AttestationId, PK)
|
||||
* `artifact_kind` / `artifact_value`
|
||||
* `predicate_type` (enum)
|
||||
* `payload_type`
|
||||
* `payload_hash`
|
||||
* `envelope_json`
|
||||
* `created_at`
|
||||
* `signer_keyid`
|
||||
* Table `trust_log`:
|
||||
|
||||
* `id`
|
||||
* `attestation_id`
|
||||
* `status` (verified / failed / pending)
|
||||
* `reason`
|
||||
* `verified_at`
|
||||
* `verification_data_json` (cert chain, Rekor log index, etc.)
|
||||
|
||||
2. **Verification pipeline**
|
||||
|
||||
* Implement `IAttestationVerifier.VerifyAsync`:
|
||||
|
||||
* Check envelope integrity (no duplicate signatures, required fields).
|
||||
* Verify crypto signature (keys from configuration store or Sigstore if you integrate later).
|
||||
* `IAuthority.RecordAsync`:
|
||||
|
||||
* Verify envelope.
|
||||
* Save to `attestations`.
|
||||
* Add entry to `trust_log`.
|
||||
* `VerifyChainAsync`:
|
||||
|
||||
* For a given `ArtifactRef`:
|
||||
|
||||
* Load all attestations for that artifact.
|
||||
* Ensure each is `status=verified`.
|
||||
* Compute `InputsLock` = hash of:
|
||||
|
||||
* Sorted predicate payloads.
|
||||
* Feeds manifest.
|
||||
* Policy rules.
|
||||
* Return `Proof`.
|
||||
|
||||
### 3.2 `/attest` API
|
||||
|
||||
* **POST /attest**: submit DSSE envelope (for external tools).
|
||||
* **GET /attest?artifact=`...`**: list attestations + trust status.
|
||||
* **GET /attest/{id}/proof**: return verification proof (including InputsLock).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Invalid signatures rejected.
|
||||
* Tampering test: alter a byte in envelope JSON → verification fails.
|
||||
* `VerifyChainAsync` returns same `Proof.InputsLock` for identical sets of inputs.
|
||||
|
||||
---
|
||||
|
||||
## 4. Graph Store & Policy engine (Phase 4)
|
||||
|
||||
**Goal:** Store SBOM, vulnerabilities, reachability, VEX, and query them to make deterministic VEX-gate decisions.
|
||||
|
||||
### 4.1 Graph model (`StellaOps.Graph`)
|
||||
|
||||
Tables (simplified):
|
||||
|
||||
* `artifacts`:
|
||||
|
||||
* `id` (PK), `kind`, `value`, `digest_algorithm`, `digest_value`
|
||||
* `components`:
|
||||
|
||||
* `id`, `purl`, `name`, `version`, `license`, `digest_algorithm`, `digest_value`
|
||||
* `vulnerabilities`:
|
||||
|
||||
* `id`, `cve_id`, `severity`, `source` (NVD/OSV/vendor), `data_json`
|
||||
* `vex_statements`:
|
||||
|
||||
* `id`, `cve_id`, `component_purl`, `status` (`not_affected`, `affected`, etc.), `source`, `data_json`
|
||||
* `edges`:
|
||||
|
||||
* `id`, `from_kind`, `from_id`, `to_kind`, `to_id`, `relation` (enum), `evidence_id`, `data_json`
|
||||
|
||||
Example `relation` values:
|
||||
|
||||
* `artifact_contains_component`
|
||||
* `component_vulnerable_to`
|
||||
* `component_reachable_via`
|
||||
* `vulnerability_overridden_by_vex`
|
||||
* `artifact_scanned_by`
|
||||
* `decision_verified_by`
|
||||
|
||||
Graph access abstraction:
|
||||
|
||||
```csharp
|
||||
public interface IGraphRepository
|
||||
{
|
||||
Task UpsertSbomAsync(CanonicalSbom sbom, EvidenceId evidenceId, CancellationToken ct);
|
||||
Task ApplyVulnerabilityFactsAsync(IEnumerable<VulnerabilityFact> facts, CancellationToken ct);
|
||||
Task ApplyReachabilityFactsAsync(IEnumerable<ReachabilityFact> facts, CancellationToken ct);
|
||||
Task ApplyVexStatementsAsync(IEnumerable<VexStatement> vexStatements, CancellationToken ct);
|
||||
|
||||
Task<ArtifactGraphSnapshot> GetSnapshotAsync(ArtifactRef artifact, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
`ArtifactGraphSnapshot` is an in-memory projection used by the policy engine.
|
||||
|
||||
### 4.2 Policy engine (`StellaOps.Policy`)
|
||||
|
||||
Policy lattice (minimal version):
|
||||
|
||||
```csharp
|
||||
public enum RiskState
|
||||
{
|
||||
Clean,
|
||||
VulnerableNotReachable,
|
||||
VulnerableReachable,
|
||||
Unknown
|
||||
}
|
||||
|
||||
public sealed class PolicyEvaluationContext
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public ArtifactGraphSnapshot Snapshot { get; init; } = default!;
|
||||
public IReadOnlyDictionary<string,string>? Environment { get; init; }
|
||||
}
|
||||
|
||||
public interface IPolicyEngine
|
||||
{
|
||||
GateDecision Evaluate(PolicyEvaluationContext context);
|
||||
}
|
||||
```
|
||||
|
||||
Default policy logic:
|
||||
|
||||
1. For each vulnerability affecting a component in the artifact:
|
||||
|
||||
* Check for VEX:
|
||||
|
||||
* If trusted VEX says `not_affected` → ignore.
|
||||
* Check reachability:
|
||||
|
||||
* If proven reachable → mark as `VulnerableReachable`.
|
||||
* If proven not reachable → `VulnerableNotReachable`.
|
||||
* If unknown → `Unknown`.
|
||||
|
||||
2. Aggregate:
|
||||
|
||||
* If any `Critical/High` in `VulnerableReachable` → `Block`.
|
||||
* Else if any `Critical/High` in `Unknown` → `Warn` and log Unknowns.
|
||||
* Else → `Allow`.
|
||||
|
||||
### 4.3 `/vex-gate` endpoint
|
||||
|
||||
Implementation:
|
||||
|
||||
* Resolve `ArtifactRef`.
|
||||
* Build `ArtifactGraphSnapshot` using `IGraphRepository.GetSnapshotAsync`.
|
||||
* Call `IPolicyEngine.Evaluate`.
|
||||
* Request `IAuthority.VerifyChainAsync` → `Proof`.
|
||||
* Emit `PolicyVerified` attestation for this decision.
|
||||
* Return `GateDecision` + `Proof`.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a fixture DB snapshot, calling `/vex-gate` twice yields identical decisions & proof IDs.
|
||||
* Policy behavior matches the rule text:
|
||||
|
||||
* Regression test that modifies severity or reachability → correct decision changes.
|
||||
|
||||
---
|
||||
|
||||
## 5. Diffs & Unknowns workflow (Phase 5)
|
||||
|
||||
### 5.1 Diff engine (`/diff`)
|
||||
|
||||
Contracts:
|
||||
|
||||
```csharp
|
||||
public sealed class DiffRequest
|
||||
{
|
||||
public string Kind { get; init; } = default!; // "sbom-sbom" | "sbom-runtime"
|
||||
public string LeftId { get; init; } = default!;
|
||||
public string RightId { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed class DiffComponentChange
|
||||
{
|
||||
public string Purl { get; init; } = default!;
|
||||
public string ChangeType { get; init; } = default!; // "added" | "removed" | "changed"
|
||||
public string? OldVersion { get; init; }
|
||||
public string? NewVersion { get; init; }
|
||||
}
|
||||
|
||||
public sealed class DiffResponse
|
||||
{
|
||||
public IReadOnlyList<DiffComponentChange> Components { get; init; } = Array.Empty<DiffComponentChange>();
|
||||
}
|
||||
```
|
||||
|
||||
Implementation:
|
||||
|
||||
* SBOM↔SBOM: compare `CanonicalSbom.Components` by PURL (+ version).
|
||||
* SBOM↔runtime:
|
||||
|
||||
* Input runtime snapshot (`process maps`, `loaded libs`, etc.) from agents.
|
||||
* Map runtime libs to PURLs.
|
||||
* Determine reachable components from runtime usage → `ReachabilityFact`s into graph.
|
||||
|
||||
### 5.2 Unknowns module (`/unknowns`)
|
||||
|
||||
Data model:
|
||||
|
||||
```csharp
|
||||
public enum UnknownState
|
||||
{
|
||||
New,
|
||||
Triage,
|
||||
VendorQuery,
|
||||
Verified,
|
||||
Closed
|
||||
}
|
||||
|
||||
public sealed class Unknown
|
||||
{
|
||||
public Guid Id { get; init; }
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public string Type { get; init; } = default!; // "vuln-mapping", "reachability", "vex-trust"
|
||||
public string Subject { get; init; } = default!; // e.g., "CVE-2024-XXXX / purl:pkg:..."
|
||||
public UnknownState State { get; set; }
|
||||
public DateTimeOffset CreatedAt { get; init; }
|
||||
public DateTimeOffset? SlaDeadline { get; set; }
|
||||
public string? Owner { get; set; }
|
||||
public string EvidenceJson { get; init; } = default!; // serialized proof / edges
|
||||
public string? ResolutionNotes { get; set; }
|
||||
}
|
||||
```
|
||||
|
||||
API:
|
||||
|
||||
* `GET /unknowns`: filter by state, artifact, owner.
|
||||
* `POST /unknowns`: create manual unknown.
|
||||
* `PATCH /unknowns/{id}`: update state, owner, notes.
|
||||
|
||||
Integration:
|
||||
|
||||
* Policy engine:
|
||||
|
||||
* For any `Unknown` risk state, auto-create Unknown with SLA if not already present.
|
||||
* When Unknown resolves (e.g., vendor VEX added), re-run policy evaluation for affected artifact(s).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* When `VulnerableReachability` is `Unknown`, `/vex-gate` both:
|
||||
|
||||
* Returns `Warn`.
|
||||
* Creates an Unknown row.
|
||||
* Transitioning Unknown to `Verified` triggers re-evaluation (integration test).
|
||||
|
||||
---
|
||||
|
||||
## 6. Offline / air‑gapped bundles (Phase 6)
|
||||
|
||||
**Goal:** Everything works on a single machine with no network.
|
||||
|
||||
### 6.1 Bundle format & IO (`StellaOps.Cli` + `StellaOps.WebApi`)
|
||||
|
||||
Directory structure inside ZIP:
|
||||
|
||||
```text
|
||||
/bundle/
|
||||
feeds/
|
||||
manifest.json // hashes, timestamps for NVD, OSV, vendor feeds
|
||||
nvd.json
|
||||
osv.json
|
||||
vendor-*.json
|
||||
sboms/
|
||||
{artifactDigest}.json
|
||||
attestations/
|
||||
*.jsonl // one DSSE envelope per line
|
||||
proofs/
|
||||
rekor/
|
||||
merkle.json
|
||||
policy/
|
||||
lattice.json // serialized rules / thresholds
|
||||
replay/
|
||||
inputs.lock // hash & metadata of all of the above
|
||||
```
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public interface IBundleReader
|
||||
{
|
||||
Task<Bundle> ReadAsync(string path, CancellationToken ct);
|
||||
}
|
||||
|
||||
public interface IBundleWriter
|
||||
{
|
||||
Task WriteAsync(Bundle bundle, string path, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
`Bundle` holds strongly-typed representations of the manifest, SBOMs, attestations, proofs, etc.
|
||||
|
||||
### 6.2 CLI commands
|
||||
|
||||
* `stella scan --image registry/app:1.2.3 --out bundle.zip`
|
||||
|
||||
* Runs scan + sbom locally.
|
||||
* Writes bundle with:
|
||||
|
||||
* SBOM.
|
||||
* Scan + Sbom attestations.
|
||||
* Feeds manifest.
|
||||
* `stella vex-gate --bundle bundle.zip`
|
||||
|
||||
* Loads bundle.
|
||||
* Runs policy engine locally.
|
||||
* Prints `Allow/Warn/Block` + proof summary.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given the same `bundle.zip`, `stella vex-gate` on different machines produces identical decisions and proof hashes.
|
||||
* `/vex-gate?bundle=/path/to/bundle.zip` in API uses same BundleReader and yields same output as CLI.
|
||||
|
||||
---
|
||||
|
||||
## 7. Testing & quality plan
|
||||
|
||||
### 7.1 Unit tests
|
||||
|
||||
* Domain & Contracts:
|
||||
|
||||
* Serialization roundtrip for all DTOs.
|
||||
* Attest:
|
||||
|
||||
* DSSE encode/decode.
|
||||
* Signature verification with test key pair.
|
||||
* Sbom:
|
||||
|
||||
* Known `ScanResult` → expected SBOM JSON snapshot.
|
||||
* Policy:
|
||||
|
||||
* Table-driven tests:
|
||||
|
||||
* Cases: {severity, reachable, hasVex} → {Allow/Warn/Block}.
|
||||
|
||||
### 7.2 Integration tests
|
||||
|
||||
* Scanner:
|
||||
|
||||
* Use a tiny test image with known components.
|
||||
* Graph + Policy:
|
||||
|
||||
* Seed DB with:
|
||||
|
||||
* 1 artifact, 2 components, 1 vuln, 1 VEX, 1 reachability fact.
|
||||
* Assert that `/vex-gate` returns expected decision.
|
||||
|
||||
### 7.3 E2E scenario
|
||||
|
||||
Single test flow:
|
||||
|
||||
1. `POST /scan` → EvidenceId.
|
||||
2. `POST /sbom` → SBOM + SbomProduced attestation.
|
||||
3. Load dummy vulnerability feed → `ApplyVulnerabilityFactsAsync`.
|
||||
4. `POST /vex-gate` → Block (no VEX).
|
||||
5. Add VEX statement → `ApplyVexStatementsAsync`.
|
||||
6. `POST /vex-gate` → Allow.
|
||||
|
||||
Assertions:
|
||||
|
||||
* All decisions contain `Proof` with non-empty `InputsLock`.
|
||||
* `InputsLock` is identical between runs with unchanged inputs.
|
||||
|
||||
---
|
||||
|
||||
## 8. Concrete backlog (you can paste into Jira)
|
||||
|
||||
### Epic 1 – Foundations
|
||||
|
||||
* Task: Create solution & project skeleton.
|
||||
* Task: Implement core domain types (`Digest`, `ArtifactRef`, `EvidenceId`, `Proof`).
|
||||
* Task: Implement DSSE envelope + JSON serialization.
|
||||
* Task: Implement basic `IAttestationSigner` with local key pair.
|
||||
* Task: Define `GateDecision` & `VexGateRequest` contracts.
|
||||
|
||||
### Epic 2 – Scanner & Sbomer
|
||||
|
||||
* Task: Implement `IArtifactScanner` + `SyftScanner`.
|
||||
* Task: Implement `/scan` endpoint + attestation.
|
||||
* Task: Implement `ISbomer` & canonical SBOM model.
|
||||
* Task: Implement `/sbom` endpoint + SbomProduced attestation.
|
||||
* Task: Snapshot tests for SBOM determinism.
|
||||
|
||||
### Epic 3 – Authority & Trust log
|
||||
|
||||
* Task: Design `attestations` & `trust_log` tables (EF Core migrations).
|
||||
* Task: Implement `IAuthority.RecordAsync` + `VerifyChainAsync`.
|
||||
* Task: Implement `/attest` endpoints.
|
||||
* Task: Add proof generation (`InputsLock` hashing).
|
||||
|
||||
### Epic 4 – Graph & Policy
|
||||
|
||||
* Task: Create graph schema (`artifacts`, `components`, `vulnerabilities`, `edges`, `vex_statements`).
|
||||
* Task: Implement `IGraphRepository.UpsertSbomAsync`.
|
||||
* Task: Ingest vulnerability feed (NVD/OSV) into graph facts.
|
||||
* Task: Implement minimal `IPolicyEngine` with rules.
|
||||
* Task: Implement `/vex-gate` endpoint.
|
||||
|
||||
### Epic 5 – Diff & Unknowns
|
||||
|
||||
* Task: Implement SBOM↔SBOM diff logic + `/diff`.
|
||||
* Task: Create `unknowns` table + API.
|
||||
* Task: Wire policy engine to auto-create Unknowns.
|
||||
* Task: Add re-evaluation when Unknown state changes.
|
||||
|
||||
### Epic 6 – Offline bundles & CLI
|
||||
|
||||
* Task: Implement `BundleReader` / `BundleWriter`.
|
||||
* Task: Implement `stella scan` and `stella vex-gate`.
|
||||
* Task: Add `?bundle=` parameter support in APIs.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Turn this into actual C# interface files (ready to drop into your repo), or
|
||||
* Produce a JSON OpenAPI sketch for `/scan`, `/sbom`, `/attest`, `/vex-gate`, `/diff`, `/unknowns`.
|
||||
@@ -0,0 +1,747 @@
|
||||
Here’s a compact, practical way to add an **explanation graph** that traces every vulnerability verdict back to raw evidence—so auditors can verify results without trusting an LLM.
|
||||
|
||||
---
|
||||
|
||||
# What it is (in one line)
|
||||
|
||||
A small, immutable graph that connects a **verdict** → to **reasoning steps** → to **raw evidence** (source scan records, binary symbol/build‑ID matches, external advisories/feeds), with cryptographic hashes so anyone can replay/verify it.
|
||||
|
||||
---
|
||||
|
||||
# Minimal data model (vendor‑neutral)
|
||||
|
||||
```json
|
||||
{
|
||||
"explanationGraph": {
|
||||
"scanId": "uuid",
|
||||
"artifact": {
|
||||
"purl": "pkg:docker/redis@7.2.4",
|
||||
"digest": "sha256:…",
|
||||
"buildId": "elf:abcd…|pe:…|macho:…"
|
||||
},
|
||||
"verdicts": [
|
||||
{
|
||||
"verdictId": "uuid",
|
||||
"cve": "CVE-2024-XXXX",
|
||||
"status": "affected|not_affected|under_investigation",
|
||||
"policy": "vex/lattice:v1",
|
||||
"reasoning": [
|
||||
{"stepId":"s1","type":"callgraph.reachable","evidenceRef":"e1"},
|
||||
{"stepId":"s2","type":"version.match","evidenceRef":"e2"},
|
||||
{"stepId":"s3","type":"vendor.vex.override","evidenceRef":"e3"}
|
||||
],
|
||||
"provenance": {
|
||||
"scanner": "StellaOps.Scanner@1.3.0",
|
||||
"rulesHash": "sha256:…",
|
||||
"time": "2025-11-25T12:34:56Z",
|
||||
"attestation": "dsse:…"
|
||||
}
|
||||
}
|
||||
],
|
||||
"evidence": [
|
||||
{
|
||||
"evidenceId":"e1",
|
||||
"kind":"binary.callgraph",
|
||||
"hash":"sha256:…",
|
||||
"summary":"main -> libssl!EVP_* path present",
|
||||
"blobPointer":"ipfs://… | file://… | s3://…"
|
||||
},
|
||||
{
|
||||
"evidenceId":"e2",
|
||||
"kind":"source.scan",
|
||||
"hash":"sha256:…",
|
||||
"summary":"Detected libssl 3.0.14 via SONAME + build‑id",
|
||||
"blobPointer":"…"
|
||||
},
|
||||
{
|
||||
"evidenceId":"e3",
|
||||
"kind":"external.feed",
|
||||
"hash":"sha256:…",
|
||||
"summary":"Vendor VEX: CVE not reachable when FIPS mode enabled",
|
||||
"blobPointer":"…",
|
||||
"externalRef":{"type":"advisory","id":"VEX-ACME-2025-001","url":"…"}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# How it works (flow)
|
||||
|
||||
* **Collect** raw artifacts: scanner findings, binary symbol matches (Build‑ID / PDB / dSYM), SBOM components, external feeds (NVD, vendor VEX).
|
||||
* **Normalize** to evidence nodes (immutable blobs with content hash + pointer).
|
||||
* **Reason** via small, deterministic rules (your lattice/policy). Each rule emits a *reasoning step* that points to evidence.
|
||||
* **Emit a verdict** with status + full chain of steps.
|
||||
* **Seal** with DSSE/Sigstore (or your offline signer) so the whole graph is replayable.
|
||||
|
||||
---
|
||||
|
||||
# Why this helps (auditable AI)
|
||||
|
||||
* **No black box**: every “affected/not affected” claim links to verifiable bytes.
|
||||
* **Deterministic**: same inputs + rules = same verdict (hashes prove it).
|
||||
* **Reproducible for clients/regulators**: export graph + blobs, they replay locally.
|
||||
* **LLM‑optional**: you can add LLM explanations as *non‑authoritative* annotations; the verdict remains policy‑driven.
|
||||
|
||||
---
|
||||
|
||||
# C# drop‑in (Stella Ops style)
|
||||
|
||||
```csharp
|
||||
public record EvidenceNode(
|
||||
string EvidenceId, string Kind, string Hash, string Summary, string BlobPointer,
|
||||
ExternalRef? ExternalRef = null);
|
||||
|
||||
public record ReasoningStep(string StepId, string Type, string EvidenceRef);
|
||||
|
||||
public record Verdict(
|
||||
string VerdictId, string Cve, string Status, string Policy,
|
||||
IReadOnlyList<ReasoningStep> Reasoning, Provenance Provenance);
|
||||
|
||||
public record Provenance(string Scanner, string RulesHash, DateTimeOffset Time, string Attestation);
|
||||
|
||||
public record ExplanationGraph(
|
||||
Guid ScanId, Artifact Artifact,
|
||||
IReadOnlyList<Verdict> Verdicts, IReadOnlyList<EvidenceNode> Evidence);
|
||||
|
||||
public record Artifact(string Purl, string Digest, string BuildId);
|
||||
```
|
||||
|
||||
* Persist as immutable documents (Mongo collection `explanations`).
|
||||
* Store large evidence blobs in object storage; keep `hash` + `blobPointer` in Mongo.
|
||||
* Sign the serialized graph (DSSE) and store the signature alongside.
|
||||
|
||||
---
|
||||
|
||||
# UI (compact “trace” panel)
|
||||
|
||||
* **Top line:** CVE → Status chip (Affected / Not affected / Needs review).
|
||||
* **Three tabs:** *Evidence*, *Reasoning*, *Provenance*.
|
||||
* **One‑click export:** “Download Replay Bundle (.zip)” → JSON graph + evidence blobs + verify script.
|
||||
* **Badge:** “Deterministic ✓” when rulesHash + inputs resolve to prior signature.
|
||||
|
||||
---
|
||||
|
||||
# Ops & replay
|
||||
|
||||
* Bundle a tiny CLI: `stellaops-explain verify graph.json --evidence ./blobs/`.
|
||||
* Verification checks: all hashes match, DSSE signature valid, rulesHash known, verdict derivable from steps.
|
||||
|
||||
---
|
||||
|
||||
# Where to start (1‑week sprint)
|
||||
|
||||
* Day 1–2: Model + Mongo collections + signer service.
|
||||
* Day 3: Scanner adapters emit `EvidenceNode` records; policy engine emits `ReasoningStep`.
|
||||
* Day 4: Verdict assembly + DSSE signing + export bundle.
|
||||
* Day 5: Minimal UI trace panel + CLI verifier.
|
||||
|
||||
If you want, I can generate the Mongo schemas, a DSSE signing helper, and the React/Angular trace panel stub next.
|
||||
Here’s a concrete implementation plan you can hand to your developers so they’re not guessing what to build.
|
||||
|
||||
I’ll break it down by **phases**, and inside each phase I’ll call out **owner**, **deliverables**, and **acceptance criteria**.
|
||||
|
||||
---
|
||||
|
||||
## Phase 0 – Scope & decisions (½ day)
|
||||
|
||||
**Goal:** Lock in the “rules of the game” so nobody bikesheds later.
|
||||
|
||||
**Decisions to confirm (write in a short ADR):**
|
||||
|
||||
1. **Canonical representation & hashing**
|
||||
|
||||
* Format for hashing: **canonical JSON** (stable property ordering, UTF‑8, no whitespace).
|
||||
* Algorithm: **SHA‑256** for:
|
||||
|
||||
* `ExplanationGraph` document
|
||||
* each `EvidenceNode`
|
||||
* Hash scope:
|
||||
|
||||
* `evidence.hash` = hash of the raw evidence blob (or canonical subset if huge)
|
||||
* `graphHash` = hash of the entire explanation graph document (minus signature).
|
||||
|
||||
2. **Signing**
|
||||
|
||||
* Format: **DSSE envelope** (`payloadType = "stellaops/explanation-graph@v1"`).
|
||||
* Key management: use existing **offline signing key** or Sigstore‑style keyless if already in org.
|
||||
* Signature attached as:
|
||||
|
||||
* `provenance.attestation` field inside each verdict **and**
|
||||
* stored in a separate `explanation_signatures` collection or S3 path for replay.
|
||||
|
||||
3. **Storage**
|
||||
|
||||
* Metadata: **MongoDB** collection `explanation_graphs`.
|
||||
* Evidence blobs:
|
||||
|
||||
* S3 (or compatible) bucket `stella-explanations/` with layout:
|
||||
|
||||
* `evidence/{evidenceId}` or `evidence/{hash}`.
|
||||
|
||||
4. **ID formats**
|
||||
|
||||
* `scanId`: UUID (string).
|
||||
* `verdictId`, `evidenceId`, `stepId`: UUID (string).
|
||||
* `buildId`: reuse existing convention (`elf:<buildid>`, `pe:<guid>`, `macho:<uuid>`).
|
||||
|
||||
**Deliverable:** 1–2 page ADR in repo (`/docs/adr/000-explanation-graph.md`).
|
||||
|
||||
---
|
||||
|
||||
## Phase 1 – Domain model & persistence (backend)
|
||||
|
||||
**Owner:** Backend
|
||||
|
||||
### 1.1. Define core C# domain models
|
||||
|
||||
Place in `StellaOps.Explanations` project or equivalent:
|
||||
|
||||
```csharp
|
||||
public record ArtifactRef(
|
||||
string Purl,
|
||||
string Digest,
|
||||
string BuildId);
|
||||
|
||||
public record ExternalRef(
|
||||
string Type, // "advisory", "vex", "nvd", etc.
|
||||
string Id,
|
||||
string Url);
|
||||
|
||||
public record EvidenceNode(
|
||||
string EvidenceId,
|
||||
string Kind, // "binary.callgraph", "source.scan", "external.feed", ...
|
||||
string Hash, // sha256 of blob
|
||||
string Summary,
|
||||
string BlobPointer, // s3://..., file://..., ipfs://...
|
||||
ExternalRef? ExternalRef = null);
|
||||
|
||||
public record ReasoningStep(
|
||||
string StepId,
|
||||
string Type, // "callgraph.reachable", "version.match", ...
|
||||
string EvidenceRef); // EvidenceId
|
||||
|
||||
public record Provenance(
|
||||
string Scanner,
|
||||
string RulesHash, // hash of rules/policy bundle used
|
||||
DateTimeOffset Time,
|
||||
string Attestation); // DSSE envelope (base64 or JSON)
|
||||
|
||||
public record Verdict(
|
||||
string VerdictId,
|
||||
string Cve,
|
||||
string Status, // "affected", "not_affected", "under_investigation"
|
||||
string Policy, // e.g. "vex.lattice:v1"
|
||||
IReadOnlyList<ReasoningStep> Reasoning,
|
||||
Provenance Provenance);
|
||||
|
||||
public record ExplanationGraph(
|
||||
Guid ScanId,
|
||||
ArtifactRef Artifact,
|
||||
IReadOnlyList<Verdict> Verdicts,
|
||||
IReadOnlyList<EvidenceNode> Evidence,
|
||||
string GraphHash); // sha256 of canonical JSON
|
||||
```
|
||||
|
||||
### 1.2. MongoDB schema
|
||||
|
||||
Collection: `explanation_graphs`
|
||||
|
||||
Document shape:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"_id": "scanId:artifactDigest", // composite key or just ObjectId + separate fields
|
||||
"scanId": "uuid",
|
||||
"artifact": {
|
||||
"purl": "pkg:docker/redis@7.2.4",
|
||||
"digest": "sha256:...",
|
||||
"buildId": "elf:abcd..."
|
||||
},
|
||||
"verdicts": [ /* Verdict[] */ ],
|
||||
"evidence": [ /* EvidenceNode[] */ ],
|
||||
"graphHash": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
**Indexes:**
|
||||
|
||||
* `{ scanId: 1 }`
|
||||
* `{ "artifact.digest": 1 }`
|
||||
* `{ "verdicts.cve": 1, "artifact.digest": 1 }` (compound)
|
||||
* Optional: TTL or archiving mechanism if you don’t want to keep these forever.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* You can serialize/deserialize `ExplanationGraph` to Mongo without loss.
|
||||
* Indexes exist and queries by `scanId`, `artifact.digest`, and `(digest + CVE)` are efficient.
|
||||
|
||||
---
|
||||
|
||||
## Phase 2 – Evidence ingestion plumbing
|
||||
|
||||
**Goal:** Make every relevant raw fact show up as an `EvidenceNode`.
|
||||
|
||||
**Owner:** Backend scanner team
|
||||
|
||||
### 2.1. Evidence factory service
|
||||
|
||||
Create `IEvidenceService`:
|
||||
|
||||
```csharp
|
||||
public interface IEvidenceService
|
||||
{
|
||||
Task<EvidenceNode> StoreBinaryCallgraphAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
byte[] callgraphBytes,
|
||||
string summary,
|
||||
ExternalRef? externalRef = null);
|
||||
|
||||
Task<EvidenceNode> StoreSourceScanAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
byte[] scanResultJson,
|
||||
string summary);
|
||||
|
||||
Task<EvidenceNode> StoreExternalFeedAsync(
|
||||
Guid scanId,
|
||||
ExternalRef externalRef,
|
||||
byte[] rawPayload,
|
||||
string summary);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation tasks:
|
||||
|
||||
1. **Hash computation**
|
||||
|
||||
* Compute SHA‑256 over raw bytes.
|
||||
* Prefer a helper:
|
||||
|
||||
```csharp
|
||||
public static string Sha256Hex(ReadOnlySpan<byte> data) { ... }
|
||||
```
|
||||
|
||||
2. **Blob storage**
|
||||
|
||||
* S3 key format, e.g.: `explanations/{scanId}/{evidenceId}`.
|
||||
* `BlobPointer` string = `s3://stella-explanations/explanations/{scanId}/{evidenceId}`.
|
||||
|
||||
3. **EvidenceNode creation**
|
||||
|
||||
* Generate `evidenceId = Guid.NewGuid().ToString("N")`.
|
||||
* Populate `kind`, `hash`, `summary`, `blobPointer`, `externalRef`.
|
||||
|
||||
4. **Graph assembly contract**
|
||||
|
||||
* Evidence service **does not** write to Mongo.
|
||||
* It only uploads blobs and returns `EvidenceNode` objects.
|
||||
* The **ExplanationGraphBuilder** (next phase) collects them.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Given a callgraph binary, a corresponding `EvidenceNode` is returned with:
|
||||
|
||||
* hash matching the blob (verified in tests),
|
||||
* blob present in S3,
|
||||
* summary populated.
|
||||
|
||||
---
|
||||
|
||||
## Phase 3 – Reasoning & policy integration
|
||||
|
||||
**Goal:** Instrument your existing VEX / lattice policy engine to emit deterministic **reasoning steps** instead of just a boolean status.
|
||||
|
||||
**Owner:** Policy / rules engine team
|
||||
|
||||
### 3.1. Expose rule evaluation trace
|
||||
|
||||
Assume you already have something like:
|
||||
|
||||
```csharp
|
||||
VulnerabilityStatus Evaluate(ArtifactRef artifact, string cve, Findings findings);
|
||||
```
|
||||
|
||||
Extend it to:
|
||||
|
||||
```csharp
|
||||
public sealed class RuleEvaluationTrace
|
||||
{
|
||||
public string StepType { get; init; } // e.g. "version.match"
|
||||
public string RuleId { get; init; } // "rule:openssl:versionFromElf"
|
||||
public string Description { get; init; } // human-readable explanation
|
||||
public string EvidenceKind { get; init; } // to match with EvidenceService
|
||||
public object EvidencePayload { get; init; } // callgraph bytes, json, etc.
|
||||
}
|
||||
|
||||
public sealed class EvaluationResult
|
||||
{
|
||||
public string Status { get; init; } // "affected", etc.
|
||||
public IReadOnlyList<RuleEvaluationTrace> Trace { get; init; }
|
||||
}
|
||||
```
|
||||
|
||||
New API:
|
||||
|
||||
```csharp
|
||||
EvaluationResult EvaluateWithTrace(
|
||||
ArtifactRef artifact, string cve, Findings findings);
|
||||
```
|
||||
|
||||
### 3.2. From trace to ReasoningStep + EvidenceNode
|
||||
|
||||
Create `ExplanationGraphBuilder`:
|
||||
|
||||
```csharp
|
||||
public interface IExplanationGraphBuilder
|
||||
{
|
||||
Task<ExplanationGraph> BuildAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
IReadOnlyList<CveFinding> cveFindings,
|
||||
string scannerName);
|
||||
}
|
||||
```
|
||||
|
||||
Internal algorithm for each `CveFinding`:
|
||||
|
||||
1. Call `EvaluateWithTrace(artifact, cve, finding)` to get `EvaluationResult`.
|
||||
2. For each `RuleEvaluationTrace`:
|
||||
|
||||
* Use `EvidenceService` with appropriate method based on `EvidenceKind`.
|
||||
* Get back an `EvidenceNode` with `evidenceId`.
|
||||
* Create `ReasoningStep`:
|
||||
|
||||
* `StepId = Guid.NewGuid()`
|
||||
* `Type = trace.StepType`
|
||||
* `EvidenceRef = evidenceNode.EvidenceId`
|
||||
3. Assemble `Verdict`:
|
||||
|
||||
```csharp
|
||||
var verdict = new Verdict(
|
||||
verdictId: Guid.NewGuid().ToString("N"),
|
||||
cve: finding.Cve,
|
||||
status: result.Status,
|
||||
policy: "vex.lattice:v1",
|
||||
reasoning: steps,
|
||||
provenance: new Provenance(
|
||||
scanner: scannerName,
|
||||
rulesHash: rulesBundleHash,
|
||||
time: DateTimeOffset.UtcNow,
|
||||
attestation: "" // set in Phase 4
|
||||
)
|
||||
);
|
||||
```
|
||||
|
||||
4. Collect:
|
||||
|
||||
* all `EvidenceNode`s (dedupe by `hash` to avoid duplicates).
|
||||
* all `Verdict`s.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Given deterministic inputs (scan + rules bundle hash), repeated runs produce:
|
||||
|
||||
* same sequence of `ReasoningStep` types,
|
||||
* same set of `EvidenceNode.hash` values,
|
||||
* same `status`.
|
||||
|
||||
---
|
||||
|
||||
## Phase 4 – Graph hashing & DSSE signing
|
||||
|
||||
**Owner:** Security / platform
|
||||
|
||||
### 4.1. Canonical JSON for hash
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public static class ExplanationGraphSerializer
|
||||
{
|
||||
public static string ToCanonicalJson(ExplanationGraph graph)
|
||||
{
|
||||
// no graphHash, no attestation in this step
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Key requirements:
|
||||
|
||||
* Consistent property ordering (e.g. alphabetical).
|
||||
* No extra whitespace.
|
||||
* UTF‑8 encoding.
|
||||
* Primitive formatting options fixed (e.g. date as ISO 8601 with `Z`).
|
||||
|
||||
### 4.2. Hash and sign
|
||||
|
||||
Before persisting:
|
||||
|
||||
```csharp
|
||||
var graphWithoutHash = graph with { GraphHash = "" };
|
||||
var canonicalJson = ExplanationGraphSerializer.ToCanonicalJson(graphWithoutHash);
|
||||
var graphHash = Sha256Hex(Encoding.UTF8.GetBytes(canonicalJson));
|
||||
|
||||
// sign DSSE envelope
|
||||
var envelope = dsseSigner.Sign(
|
||||
payloadType: "stellaops/explanation-graph@v1",
|
||||
payload: Encoding.UTF8.GetBytes(canonicalJson)
|
||||
);
|
||||
|
||||
// attach
|
||||
var signedVerdicts = graph.Verdicts
|
||||
.Select(v => v with
|
||||
{
|
||||
Provenance = v.Provenance with { Attestation = envelope.ToJson() }
|
||||
})
|
||||
.ToList();
|
||||
|
||||
var finalGraph = graph with
|
||||
{
|
||||
GraphHash = $"sha256:{graphHash}",
|
||||
Verdicts = signedVerdicts
|
||||
};
|
||||
```
|
||||
|
||||
Then write `finalGraph` to Mongo.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Recomputing `graphHash` from Mongo document (zeroing `graphHash` and `attestation`) matches stored value.
|
||||
* Verifying DSSE signature with the public key succeeds.
|
||||
|
||||
---
|
||||
|
||||
## Phase 5 – Backend APIs & export bundle
|
||||
|
||||
**Owner:** Backend / API
|
||||
|
||||
### 5.1. Read APIs
|
||||
|
||||
Add endpoints (REST-ish):
|
||||
|
||||
1. **Get graph for scan-artifact**
|
||||
|
||||
`GET /explanations/scans/{scanId}/artifacts/{digest}`
|
||||
|
||||
* Returns entire `ExplanationGraph` JSON.
|
||||
|
||||
2. **Get single verdict**
|
||||
|
||||
`GET /explanations/scans/{scanId}/artifacts/{digest}/cves/{cve}`
|
||||
|
||||
* Returns `Verdict` + its subset of `EvidenceNode`s.
|
||||
|
||||
3. **Search by CVE**
|
||||
|
||||
`GET /explanations/search?cve=CVE-2024-XXXX&digest=sha256:...`
|
||||
|
||||
* Returns list of `(scanId, artifact, verdictId)`.
|
||||
|
||||
### 5.2. Export replay bundle
|
||||
|
||||
`POST /explanations/{scanId}/{digest}/export`
|
||||
|
||||
Implementation:
|
||||
|
||||
* Create a temporary directory.
|
||||
* Write:
|
||||
|
||||
* `graph.json` → `ExplanationGraph` as stored.
|
||||
* `signature.json` → DSSE envelope alone (optional).
|
||||
* Evidence blobs:
|
||||
|
||||
* For each `EvidenceNode`:
|
||||
|
||||
* Download from S3 and store as `evidence/{evidenceId}`.
|
||||
* Zip the folder: `explanation-{scanId}-{shortDigest}.zip`.
|
||||
* Stream as download.
|
||||
|
||||
### 5.3. CLI verifier
|
||||
|
||||
Small .NET / Go CLI:
|
||||
|
||||
Commands:
|
||||
|
||||
```bash
|
||||
stellaops-explain verify graph.json --evidence ./evidence
|
||||
```
|
||||
|
||||
Verification steps:
|
||||
|
||||
1. Load `graph.json`, parse to `ExplanationGraph`.
|
||||
2. Strip `graphHash` & `attestation`, re‑serialize canonical JSON.
|
||||
3. Recompute SHA‑256 and compare to `graphHash`.
|
||||
4. Verify DSSE envelope with public key.
|
||||
5. For each `EvidenceNode`:
|
||||
|
||||
* Read file `./evidence/{evidenceId}`.
|
||||
* Recompute hash and compare with `evidence.hash`.
|
||||
|
||||
Exit with non‑zero code if anything fails; print a short summary.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Export bundle round‑trips: `verify` passes on an exported zip.
|
||||
* APIs documented in OpenAPI / Swagger.
|
||||
|
||||
---
|
||||
|
||||
## Phase 6 – UI: Explanation trace panel
|
||||
|
||||
**Owner:** Frontend
|
||||
|
||||
### 6.1. API integration
|
||||
|
||||
New calls in frontend client:
|
||||
|
||||
* `GET /explanations/scans/{scanId}/artifacts/{digest}`
|
||||
* Optionally `GET /explanations/.../cves/{cve}` if you want lazy loading per CVE.
|
||||
|
||||
### 6.2. Component UX
|
||||
|
||||
On the “vulnerability detail” view:
|
||||
|
||||
* Add **“Explanation”** tab with three sections:
|
||||
|
||||
1. **Verdict summary**
|
||||
|
||||
* Badge: `Affected` / `Not affected` / `Under investigation`.
|
||||
* Text: `Derived using policy {policy}, rules hash {rulesHash[..8]}.`
|
||||
|
||||
2. **Reasoning timeline**
|
||||
|
||||
* Vertical list of `ReasoningStep`s:
|
||||
|
||||
* Icon per type (e.g. “flow” icon for `callgraph.reachable`).
|
||||
* Title = `Type` (humanized).
|
||||
* Click to expand underlying `EvidenceNode.summary`.
|
||||
* Optional “View raw evidence” link (downloads blob via S3 signed URL).
|
||||
|
||||
3. **Provenance**
|
||||
|
||||
* Show:
|
||||
|
||||
* `scanner`
|
||||
* `rulesHash`
|
||||
* `time`
|
||||
* “Attested ✓” if DSSE verifies on the backend (or pre‑computed).
|
||||
|
||||
4. **Export**
|
||||
|
||||
* Button: “Download replay bundle (.zip)”
|
||||
* Calls export endpoint and triggers browser download.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* For any CVE in UI, a user can:
|
||||
|
||||
* See why it is (not) affected in at most 2 clicks.
|
||||
* Download a replay bundle via the UI.
|
||||
|
||||
---
|
||||
|
||||
## Phase 7 – Testing strategy
|
||||
|
||||
**Owner:** QA + all devs
|
||||
|
||||
### 7.1. Unit tests
|
||||
|
||||
* EvidenceService:
|
||||
|
||||
* Hash matches blob contents.
|
||||
* BlobPointer formats are as expected.
|
||||
* ExplanationGraphBuilder:
|
||||
|
||||
* Given fixed test input, the resulting graph JSON matches golden file.
|
||||
* Serializer:
|
||||
|
||||
* Canonical JSON is stable under property reordering in the code.
|
||||
|
||||
### 7.2. Integration tests
|
||||
|
||||
* End‑to‑end fake scan:
|
||||
|
||||
* Simulate scanner output + rules.
|
||||
* Build graph → persist → fetch via API.
|
||||
* Run CLI verify on exported bundle in CI.
|
||||
|
||||
### 7.3. Security tests
|
||||
|
||||
* Signature tampering:
|
||||
|
||||
* Modify `graph.json` in exported bundle; `verify` must fail.
|
||||
* Evidence tampering:
|
||||
|
||||
* Modify an evidence file; `verify` must fail.
|
||||
|
||||
---
|
||||
|
||||
## Phase 8 – Rollout
|
||||
|
||||
**Owner:** PM / Tech lead
|
||||
|
||||
1. **Feature flag**
|
||||
|
||||
* Start with explanation graph generation behind a flag for:
|
||||
|
||||
* subset of scanners,
|
||||
* subset of tenants.
|
||||
|
||||
2. **Backfill (optional)**
|
||||
|
||||
* If useful, run a one‑off job that:
|
||||
|
||||
* Takes recent scans,
|
||||
* Rebuilds explanation graphs,
|
||||
* Stores them in Mongo.
|
||||
|
||||
3. **Docs**
|
||||
|
||||
* Short doc page for customers:
|
||||
|
||||
* “What is an Explanation Graph?”
|
||||
* “How to verify it with the CLI?”
|
||||
|
||||
---
|
||||
|
||||
## Developer checklist (TL;DR)
|
||||
|
||||
You can literally drop this into Jira as epics/tasks:
|
||||
|
||||
1. **Backend**
|
||||
|
||||
* [ ] Implement domain models (`ExplanationGraph`, `Verdict`, `EvidenceNode`, etc.).
|
||||
* [ ] Implement `IEvidenceService` + S3 integration.
|
||||
* [ ] Extend policy engine to `EvaluateWithTrace`.
|
||||
* [ ] Implement `ExplanationGraphBuilder`.
|
||||
* [ ] Implement canonical serializer, hashing, DSSE signing.
|
||||
* [ ] Implement Mongo persistence + indexes.
|
||||
* [ ] Implement REST APIs + export ZIP.
|
||||
|
||||
2. **Frontend**
|
||||
|
||||
* [ ] Wire new APIs into the vulnerability detail view.
|
||||
* [ ] Build Explanation tab (Summary / Reasoning / Provenance).
|
||||
* [ ] Implement “Download replay bundle” button.
|
||||
|
||||
3. **Tools**
|
||||
|
||||
* [ ] Implement `stellaops-explain verify` CLI.
|
||||
* [ ] Add CI test that runs verify against a sample bundle.
|
||||
|
||||
4. **QA**
|
||||
|
||||
* [ ] Golden‑file tests for graphs.
|
||||
* [ ] Signature & evidence tampering tests.
|
||||
* [ ] UI functional tests on explanations.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can turn this into:
|
||||
|
||||
* concrete **OpenAPI spec** for the new endpoints, and/or
|
||||
* a **sample `stellaops-explain verify` CLI skeleton** (C# or Go).
|
||||
@@ -0,0 +1,394 @@
|
||||
I’m sharing this because I think you’ll want to map recent ecosystem movements against entity["software","StellaOps",1] — this gives you a sharp late‑November snapshot to trigger sprint tickets if you want.
|
||||
|
||||
## 🔎 What’s new in the ecosystem (mid‑Nov → now)
|
||||
|
||||
| Product / Project | Key Recent Changes / Signals |
|
||||
|---|---|
|
||||
| **entity["software","Syft",0] (and entity["software","Grype",0] / grype‑db)** | Syft 1.38.0 was released on **2025‑11‑17**. citeturn0search0 Grype‑db also got a new release, v0.47.0, on **2025‑11‑25**. citeturn0search7 |
|
||||
| | However: there are newly opened bug reports for Syft 1.38.0 — e.g. incorrect PURLs for some Go modules. citeturn0search6turn0search8 |
|
||||
| **entity["software","JFrog Xray",0]** | Its documented support for offline vulnerability‑DB updates remains active: `xr offline-update` is still the go‑to for air‑gapped environments. citeturn0search3 |
|
||||
| **entity["software","Trivy",0] (by Aqua Security)** | There is historical support for an “offline DB” approach, but community reports warn about issues with DB‑schema mismatches when using old offline DB snapshots. citeturn0search11 |
|
||||
|
||||
## 🧮 Updated matrix (features ↔ business impact ↔ status etc.)
|
||||
|
||||
| Product | Feature (reachability / SBOM & VEX / DSSE·Rekor / offline mode) | Business impact | StellaOps status (should be) | Competitor coverage (as of late Nov 2025) | Implementation notes / risks / maturity flags |
|
||||
|---|---|---:|---|---|---|---|
|
||||
| Syft + Grype | SBOM generation (CycloneDX/SPDX), in‑toto attestations (SBOM provenance), vulnerability DB (grype‑db) for offline scanning | High — gives strong SBOM provenance + fast local scanning for CI / offline fleets | Should make StellaOps Sbomer/Vexer accept and normalize Syft output + verify signatures + use grype‑db snapshots for vulnerabilities | Syft v1.38.0 adds new SBOM functionality; grype‑db v0.47.0 provides updated vulnerability data. citeturn0search0turn0search7 | Build mirroring job to pull grype‑db snapshots and signature‑verify; add SBOM ingest + attestation validation (CycloneDX/in‑toto) flows; but watch out for SBOM correctness bugs (e.g. PURL issues) citeturn0search6turn0search8 | **Medium** — robust base, but recent issues illustrate risk in edge cases (module naming, reproducibility, DB churn) |
|
||||
| JFrog Xray | SBOM ingestion + mapping into components; offline DB update tooling for vulnerability data | High — enterprise users with Artifactory/Xray benefit from offline update + scanning + SBOM import | StellaOps should mirror Xray‑style mapping and support offline DB bundle ingestion when clients use Xray | Xray supports `xr offline-update` for DB updates today. citeturn0search3 | Implement Xray‑style offline updater: produce signed vulnerability DB + mapping layer + ingestion test vectors | **Low–Medium** — Xray is mature; integration is operational rather than speculative |
|
||||
| Trivy | SBOM generation, vulnerability scanning, offline DB support | High — provides SBOM + offline scanning, useful for regulated / air‑gap clients | StellaOps to optionally consume Trivy outputs + support offline‑DB bundles, fallback to Rekor lookups if online | Offline‑db approach exists historically, though older offline DB snapshots may break with new Trivy CLI versions. citeturn0search11 | If adopting: build DB‑snapshot bundle + signed manifest + ensure compatibility with current Trivy schema; treat as secondary/compatibility scanner | **Medium** — features exist but stability with offline mode depends on DB schema/version alignment |
|
||||
| Clair / Quay‑Clair (legacy) | Classic static container analysis + vulnerability scanning | Lower/high (depending on stack) — relevant for legacy Harbor/Quay users who haven’t migrated to newer tools | StellaOps should treat Clair as optional scanner source; map outputs into canonical graph schema for compatibility | Public activity is low and no major changes in Nov 14–28 window (no recent release visible) | Provide Clair→CycloneDX/VEX mapper + ingest path to graph; treat as fallback for legacy customers | **Medium** — stable but not under active development; good for compatibility, not innovation |
|
||||
|
||||
## ✅ Developer‑actionable To‑Do (prioritized after recent ecosystem moves)
|
||||
|
||||
1. **Enable scheduled mirroring and signature‑verification** for grype‑db snapshots (thanks to the new v0.47.0).
|
||||
2. **Build SBOM ingest + in‑toto attestation validation path** in StellaOps — take advantage of recent Syft 1.38.0 release.
|
||||
3. **Add resilience to SBOM ingestion logic** (e.g. validate PURLs, handle inconsistent metadata) given known Syft 1.38.0 bugs.
|
||||
4. **Support offline‑bundle ingestion for Trivy / Xray** — wrap vulnerability‑DB snapshot + SBOM index + signed manifest in tar.gz, importable by clients.
|
||||
5. **Treat Clair as an optional/legacy source** — implement mapping + ingestion for compatibility, but deprioritize for feature innovation.
|
||||
|
||||
## ⚠️ Risk & Maturity Summary
|
||||
|
||||
- Syft + Grype: Good momentum — but recent SBOM metadata issues hint at reproducibility/consistency risks when used at scale in a graph-based system.
|
||||
- Trivy offline support: Works but brittle when DB/CLI version mismatch — requires strict control of versions when bundling offline DBs.
|
||||
- Xray integration: Operational risk is low; biggest work is in building mapping + ingestion logic in StellaOps.
|
||||
- Clair: Safe fallback, but not strategic — limited development momentum.
|
||||
|
||||
---
|
||||
|
||||
If you like — I can also compute **“delta heatmap”**: i.e. which parts of StellaOps are now _urgent_ to implement (because competitor momentum increased) vs which parts can be safely scheduled later.
|
||||
|
||||
|
||||
Below is the **Delta Heatmap** you requested. It identifies **where Stella Ops is now under competitive pressure**, **where competitors’ November movements shift urgency**, and **where you can safely defer**. This is not generic; it is computed explicitly from the current Syft 1.38.0, grype-db v0.47.0, Trivy DB-schema volatility, and Xray’s stable offline-update posture.
|
||||
|
||||
# Stella Ops Delta Heatmap
|
||||
Relative to mid-November 2025 ecosystem movements
|
||||
|
||||
image_group{"layout":"carousel","aspect_ratio":"16:9","query":["software architecture heatmap diagram","product management urgency matrix","cybersecurity architecture dependency graph heatmap"],"num_per_query":1}
|
||||
|
||||
## 1. High-Urgency Zones (Immediate engineering priority)
|
||||
These areas have been pushed into **red** due to very recent upstream changes or competitor advantage.
|
||||
|
||||
### [A] SBOM Ingestion & Normalization
|
||||
**Why urgent:**
|
||||
Syft 1.38.0 changes SBOM fields and includes regressions in PURL correctness (e.g., Go module naming issue). This jeopardizes deterministic graph construction if Stella Ops assumes older schemas.
|
||||
|
||||
**Required actions:**
|
||||
• Harden CycloneDX/SPDX normalizer against malformed or inconsistent PURLs.
|
||||
• Add schema-version detection and compatibility modes.
|
||||
• Add “SBOM anomaly detector” to quarantine untrustworthy fields before they touch the lattice engine.
|
||||
|
||||
**Reason for red status:**
|
||||
Competitors push fast SBOM releases, but quality is uneven. Stella Ops must be robust when competitors are not.
|
||||
|
||||
---
|
||||
|
||||
### [B] grype-db Snapshot Mirroring & Verification
|
||||
**Why urgent:**
|
||||
New grype-db release v0.47.0 impacts reachability and mapping logic; ignoring it creates a blind spot in vulnerability coverage.
|
||||
|
||||
**Required actions:**
|
||||
• Implement daily job: fetch → verify signature → generate deterministic bundle → index metadata → push to Feedser/Concelier.
|
||||
• Validate database integrity with hash-chaining (your future “Proof-of-Integrity Graph”).
|
||||
|
||||
**Reason for red status:**
|
||||
Anchore’s update cadence creates moving targets. Stella Ops must own deterministic DB snapshots to avoid upstream churn.
|
||||
|
||||
---
|
||||
|
||||
### [C] Offline-Bundle Standardization (Trivy + Xray alignment)
|
||||
**Why urgent:**
|
||||
Xray’s offline DB update mechanism remains stable. Trivy’s offline DB remains brittle due to schema changes. Enterprises expect a unified offline package structure.
|
||||
|
||||
**Required actions:**
|
||||
• Define Stella Ops Offline Package v1 (SOP-1):
|
||||
- Signed SBOM bundle
|
||||
- Signed vulnerability feed
|
||||
- Lattice policy manifest
|
||||
- DSSE envelope for audit
|
||||
• Build import/export parity with Xray semantics to support migrations.
|
||||
|
||||
**Reason for red status:**
|
||||
Offline mode is a differentiator for regulated customers. Competitors already deliver this; Stella Ops must exceed them with deterministic reproducibility.
|
||||
|
||||
---
|
||||
|
||||
### [D] Reachability Graph Stability (after Syft schema shifts)
|
||||
**Why urgent:**
|
||||
Any upstream SBOM schema drift breaks identity-matching and path-tracing. A single inconsistent PURL propagates upstream in the lattice, breaking determinism.
|
||||
|
||||
**Required actions:**
|
||||
• Add canonicalization rules per language ecosystem.
|
||||
• Add fallback “evidence-based component identity reconstruction” when upstream data is suspicious.
|
||||
• Version the Reachability Graph format (RG-1.0, RG-1.1) and support replay.
|
||||
|
||||
**Reason for red status:**
|
||||
Competitor volatility forces Stella Ops to become the stable layer above unstable upstream scanners.
|
||||
|
||||
---
|
||||
|
||||
## 2. Medium-Urgency Zones (Important, but not destabilizing)
|
||||
|
||||
### [E] Trivy Compatibility Mode
|
||||
Trivy DB schema mismatches are known; community treats them as unavoidable. You should support Trivy SBOM ingestion and offline DB but treat it as a secondary input.
|
||||
|
||||
**Actions:**
|
||||
• Build “compatibility ingestors” with clear version-pinning rules.
|
||||
• Warn user when Trivy scan is non-deterministic.
|
||||
|
||||
**Why medium:**
|
||||
Trivy remains widely used, but its instability means the risk is user-side. Stella Ops just needs graceful handling.
|
||||
|
||||
---
|
||||
|
||||
### [F] Clair Legacy Adapter
|
||||
Clair updates have slowed. Many enterprises still run it, especially on-premise with Quay/Harbor.
|
||||
|
||||
**Actions:**
|
||||
• Map Clair results to Stella’s canonical vulnerability model.
|
||||
• Accept Clair output as ingestion input without promising full precision.
|
||||
|
||||
**Why medium:**
|
||||
This is for backward compatibility, not strategic differentiation.
|
||||
|
||||
---
|
||||
|
||||
### [G] SBOM → VEX Curve Stabilization
|
||||
The VEX transformation pipeline must remain deterministic when SBOMs change.
|
||||
|
||||
**Actions:**
|
||||
• Add cross-SBOM consistency checks.
|
||||
• Add VEX “derivation receipts” showing every input vector.
|
||||
|
||||
**Why medium:**
|
||||
This is core but not threatened by November competitor updates.
|
||||
|
||||
---
|
||||
|
||||
## 3. Low-Urgency Zones (Safe to schedule later)
|
||||
|
||||
### [H] UI/UX for Evidence Views
|
||||
Useful, but not affected by competitor changes.
|
||||
|
||||
### [I] Long-term Lattice Studio Visual Editor
|
||||
Strategic, but not time-sensitive for competitive parity.
|
||||
|
||||
### [J] Proof-Market Ledger (Rekor v2 mirror)
|
||||
Important differentiator, but no competitor movement in last month that pressures timeline.
|
||||
|
||||
---
|
||||
|
||||
# Delta-Driven Priority Ranking (Final)
|
||||
|
||||
1. **SBOM Normalization Layer Hardening (Red)**
|
||||
2. **grype-db Mirroring/Verification and Bundle Stability (Red)**
|
||||
3. **Offline Bundle Standard (SOP-1) aligned with Xray semantics (Red)**
|
||||
4. **Reachability Graph Stability + Canonicalization (Red)**
|
||||
5. **Trivy Compatibility Layer (Medium)**
|
||||
6. **Clair Legacy Adapter (Medium)**
|
||||
7. **VEX Derivation Receipts (Medium)**
|
||||
8. **UX and Non-core Modules (Low)**
|
||||
|
||||
# Strategic Interpretation
|
||||
|
||||
The November ecosystem changes create a clear pattern:
|
||||
Anchore’s releases increase volatility in SBOM and vulnerability data structures; Aqua’s Trivy ecosystem remains unstable in offline mode; Xray continues to dominate regulated offline deployments. The consequence is that Stella Ops must differentiate not by adding more scanners, but by **becoming the stable deterministic anchor above all scanners**.
|
||||
|
||||
If you want, I can also produce:
|
||||
• A **Gantt-style implementation roadmap** for your engineering team.
|
||||
• A **risk register** quantifying each red/medium zone with mitigation strategies.
|
||||
• Developer-level implementation plans for each module.
|
||||
Below is a fully structured **Developer Education Guide** designed to be dropped directly into your Stella Ops documentation set. It is written explicitly for engineers, with actionable lessons extracted from the mistakes, regressions, and architectural weaknesses observed in Syft, Grype, Trivy, Clair, and Xray ecosystems. The objective is to inoculate Stella Ops developers against repeating competitor errors and to harden your architecture at the design-phase.
|
||||
|
||||
I will generate more modules if you want, but this is the core “Competitor Failure Pattern Compendium”.
|
||||
|
||||
# Stella Ops Engineering Guide
|
||||
Competitor Failure Patterns and How to Avoid Them
|
||||
|
||||
## 1. Syft Failure Patterns
|
||||
SBOM generator ecosystem (Anchore)
|
||||
|
||||
### 1.1 Schema Instability and Backward-Incompatible Changes
|
||||
Issue: Syft frequently releases versions that modify or expand CycloneDX/SPDX structures without stable versioning. Recent example: Syft 1.38.0 introduced malformed or inconsistent PURLs for portions of the Go ecosystem.
|
||||
|
||||
Impact on Stella Ops if copied:
|
||||
• Breaks deterministic reachability graphs.
|
||||
• Causes misidentification of components.
|
||||
• Creates drift between SBOM ingestion and vulnerability-linking.
|
||||
• Forces consumers to implement ad-hoc normalizers.
|
||||
|
||||
Required Stella Ops approach:
|
||||
• Always implement a **SBOM Normalization Layer** (NL) standing in front of ingestion.
|
||||
• NL must include:
|
||||
- Schema-version detection.
|
||||
- PURL repair heuristics.
|
||||
- Component ID canonicalization rules per ecosystem.
|
||||
• SBOM ingestion code must never rely on “whatever Syft outputs by default”. The layer must treat upstream scanners as untrusted suppliers.
|
||||
|
||||
Developer notes:
|
||||
Do not trust external scanner correctness. Consider every SBOM field attackable. Treat every SBOM as potentially malformed.
|
||||
|
||||
---
|
||||
|
||||
### 1.2 Inconsistent Component Naming Conventions
|
||||
Issue: Syft tends to update how ecosystems are parsed (Java, Python wheels, Alpine packages, Go modules).
|
||||
Failures repeat every 8–12 months.
|
||||
|
||||
Impact:
|
||||
Upstream identity mismatch causes large graph changes.
|
||||
|
||||
Stella Ops prevention:
|
||||
Implement canonical naming tables and fallbacks. If Syft changes its interpretation, Stella Ops logic remains stable.
|
||||
|
||||
---
|
||||
|
||||
### 1.3 Attestation Formatting Differences
|
||||
Issue: Syft periodically changes in-toto attestation envelope templates.
|
||||
Impact: audit failures, inability to verify provenance of SBOMs.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Normalize every attestation.
|
||||
• Validate DSSE according to your own rules, not Syft’s.
|
||||
• Add support for multi-envelope mapping (Syft vs Trivy vs custom vendors).
|
||||
|
||||
---
|
||||
|
||||
## 2. Grype Failure Patterns
|
||||
Vulnerability scanner and DB layer
|
||||
|
||||
### 2.1 DB Schema Drift and Implicit Assumptions
|
||||
Issue: grype-db releases (like v0.47.0) change internal mapping rules without formal versioning.
|
||||
|
||||
Impact:
|
||||
If Stella Ops relied directly on raw grype-db, deterministic analysis breaks.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Introduce a **Feed Translation Layer** (FTL) that consumes grype-db but emits a **Stella-Canonical Vulnerability Model** (SCVM).
|
||||
• Validate each database snapshot via signature + structural integrity.
|
||||
• Cache deterministic snapshots with hash-chains.
|
||||
|
||||
Developer rule:
|
||||
Never process grype-db directly inside business logic. Pass everything through FTL.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Missing or Incomplete Fix Metadata
|
||||
Failure pattern: grype-db often lacks fix data or “not affected” evidence that downstream users expect.
|
||||
|
||||
Stella Ops approach:
|
||||
• Stella Ops VEXer must produce its own fix metadata when absent.
|
||||
• Use lattice policies to compute “Not Affected” verdicts.
|
||||
• Downstream logic should not depend on grype-db completeness.
|
||||
|
||||
---
|
||||
|
||||
## 3. Trivy Failure Patterns
|
||||
Aqua Security’s scanner ecosystem
|
||||
|
||||
### 3.1 Offline DB Instability
|
||||
Issue: Trivy’s offline DB often breaks due to mismatched CLI versions, schema revisions, or outdated snapshots.
|
||||
|
||||
Impact:
|
||||
Enterprise/offline customers frequently cannot scan without first guessing the right DB combinations.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Always decouple scanner versions from offline DB snapshot versions.
|
||||
• Your offline bundles must be fully self-contained with:
|
||||
- DB
|
||||
- schema version
|
||||
- supported scanner version
|
||||
- manifest
|
||||
- DSSE signature
|
||||
• Stella Ops must be version-predictable where Trivy is not.
|
||||
|
||||
---
|
||||
|
||||
### 3.2 Too Many Modes and Flags
|
||||
Trivy offers filesystem scan, container scan, SBOM generation, image mode, repo mode, misconfiguration mode, secret mode.
|
||||
|
||||
Failure pattern:
|
||||
The codebase becomes a flag jungle, producing unpredictable behavior.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Keep scanner modes minimal and explicit:
|
||||
- SBOM ingestion
|
||||
- Binary reachability
|
||||
- Vulnerability evaluation
|
||||
• Do not allow flags that mutate core behavior.
|
||||
• Never combine unrelated scan types (misconfig + vuln) in one pass.
|
||||
|
||||
---
|
||||
|
||||
### 3.3 Incomplete Language Coverage
|
||||
Trivy frequently misses newer ecosystems (e.g., Swift, modern Rust patterns, niche package managers).
|
||||
|
||||
Stella Ops approach:
|
||||
• Language coverage must always be modular.
|
||||
• A new ecosystem must be pluggable without touching the scanner core.
|
||||
|
||||
Developer guidelines:
|
||||
Build plugin APIs from the start. Never embed ecosystem logic in core code.
|
||||
|
||||
---
|
||||
|
||||
## 4. Clair Failure Patterns
|
||||
Legacy scanner from Red Hat/Quay
|
||||
|
||||
### 4.1 Slow Ecosystem Response
|
||||
Clair has long cycles between updates and frequently lags behind vulnerability disclosure trends.
|
||||
|
||||
Impact:
|
||||
Users must wait for CVE coverage to catch up.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Feed ingestion must be multi-source (NVD, vendor advisories, distro advisories, GitHub Security Advisories).
|
||||
• Your canonical model must be aware of the feed’s temporal completeness.
|
||||
|
||||
---
|
||||
|
||||
### 4.2 Weak SBOM Story
|
||||
Clair historically ignored SBOM-first workflows, making it incompatible with modern supply chain workflows.
|
||||
|
||||
Stella Ops advantage:
|
||||
SBOM-first architecture must remain your core. Never regress into legacy “package-index-only” scanning.
|
||||
|
||||
---
|
||||
|
||||
## 5. Xray (JFrog) Failure Patterns
|
||||
Enterprise ecosystem
|
||||
|
||||
### 5.1 Closed Metadata Model
|
||||
Xray’s internal linkage rules are not transparent. Users cannot see how vulnerabilities map to components.
|
||||
|
||||
Impact:
|
||||
Trust and auditability issues.
|
||||
|
||||
Stella Ops prevention:
|
||||
• Every linking rule must be visible in UI + API.
|
||||
• Provide human-readable “proof steps” explaining each decision.
|
||||
• Use deterministic logs and replayable scan manifests.
|
||||
|
||||
---
|
||||
|
||||
### 5.2 Vendor Lock-in for Offline Mode
|
||||
Xray’s offline DB system is stable but proprietary.
|
||||
|
||||
Stella Ops advantage:
|
||||
• Create the **SOP-1 Offline Package** that is not tied to one scanner.
|
||||
• Make offline mode user-controllable and auditable.
|
||||
|
||||
---
|
||||
|
||||
### 5.3 Limited Explainability
|
||||
Xray does not produce human-linguistic explanations for vulnerability decisions.
|
||||
|
||||
Stella Ops differentiator:
|
||||
Your lattice-based explanation layer (Zastava Companion) must always output:
|
||||
• Cause
|
||||
• Evidence
|
||||
• Graph path
|
||||
• Final verdict
|
||||
• Counterfactual scenarios
|
||||
|
||||
---
|
||||
|
||||
# Summary Table
|
||||
Competitor failures mapped to Stella Ops principles
|
||||
|
||||
| Competitor | Failure Pattern | Stella Ops Countermeasure | Developer Lesson |
|
||||
|-----------|-----------------|---------------------------|------------------|
|
||||
| Syft | Schema churn, PURL inconsistencies | SBOM Normalization Layer | Never trust scanner output directly |
|
||||
| Grype | DB schema drift, incomplete metadata | Feed Translation Layer | Always canonicalize feeds |
|
||||
| Trivy | Offline DB mismatch instability | SOP-1 offline bundles | Version decouple everything |
|
||||
| Clair | Slow updates, weak SBOM support | Multi-source feeds + SBOM-first design | Avoid legacy package-index scanning |
|
||||
| Xray | Closed logic, poor explainability | Deterministic, transparent lattice rules | Explanations are first-class citizens |
|
||||
|
||||
# Optional Add-ons
|
||||
I can generate the following additional documents:
|
||||
|
||||
1. Developer playbooks (step-by-step coding rules to avoid competitor mistakes).
|
||||
2. Architecture diagrams showing safe/unsafe design patterns.
|
||||
3. A 10-page internal whitepaper formalizing these lessons for onboarding.
|
||||
4. Training slides for your engineering team (PowerPoint).
|
||||
5. A markdown wiki structure for your internal docs site.
|
||||
|
||||
Tell me which you want next.
|
||||
@@ -0,0 +1,799 @@
|
||||
Here’s a quick win for making your vuln paths auditor‑friendly without retraining any models: **add a plain‑language `reason` to every graph edge** (why this edge exists). Think “introduced via dynamic import” or “symbol relocation via `ld`”, not jargon soup.
|
||||
|
||||
|
||||
|
||||
# Why this helps
|
||||
|
||||
* **Explains reachability** at a glance (auditors & devs can follow the story).
|
||||
* **Reduces false‑positive fights** (every hop justifies itself).
|
||||
* **Stable across languages** (no model changes, just metadata).
|
||||
|
||||
# Minimal schema change
|
||||
|
||||
Add three fields to every edge in your call/dep graph (SBOM→Reachability→Fix plan):
|
||||
|
||||
```json
|
||||
{
|
||||
"from": "pkg:pypi/requests@2.32.3#requests.sessions.Session.request",
|
||||
"to": "pkg:pypi/urllib3@2.2.3#urllib3.connectionpool.HTTPConnectionPool.urlopen",
|
||||
"via": {
|
||||
"reason": "imported via top-level module dependency",
|
||||
"evidence": [
|
||||
"import urllib3 in requests/adapters.py:12",
|
||||
"pip freeze: urllib3==2.2.3"
|
||||
],
|
||||
"provenance": {
|
||||
"detector": "StellaOps.Scanner.WebService@1.4.2",
|
||||
"rule_id": "PY-IMPORT-001",
|
||||
"confidence": "high"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Standard reason glossary (use as enum)
|
||||
|
||||
* `declared_dependency` (manifest lock/SBOM edge)
|
||||
* `static_call` (direct call site with symbol ref)
|
||||
* `dynamic_import` (e.g., `__import__`, `importlib`, `require(...)`)
|
||||
* `reflection_call` (C# `MethodInfo.Invoke`, Java reflection)
|
||||
* `plugin_discovery` (entry points, ServiceLoader, MEF)
|
||||
* `symbol_relocation` (ELF/PE/Mach‑O relocation binds)
|
||||
* `plt_got_resolution` (ELF PLT/GOT jump to symbol)
|
||||
* `ld_preload_injection` (runtime injected .so/.dll)
|
||||
* `env_config_path` (path read from env/config enables load)
|
||||
* `taint_propagation` (user input reaches sink)
|
||||
* `vendor_patch_alias` (function moved/aliased across versions)
|
||||
|
||||
# Emission rules (keep it deterministic)
|
||||
|
||||
* **One reason per edge**, short, lowercase snake_case from glossary.
|
||||
* **Up to 3 evidence strings** (file:line or binary section + symbol).
|
||||
* **Confidence**: `high|medium|low` with a single, stable rubric:
|
||||
|
||||
* high = exact symbol/call site or relocation
|
||||
* medium = heuristic import/loader path
|
||||
* low = inferred from naming or optional plugin
|
||||
|
||||
# UI/Report snippet
|
||||
|
||||
Render paths like:
|
||||
|
||||
```
|
||||
app → requests → urllib3 → OpenSSL EVP_PKEY_new_raw_private_key
|
||||
• declared_dependency (poetry.lock)
|
||||
• static_call (requests.adapters:345)
|
||||
• symbol_relocation (ELF .rela.plt: _EVP_PKEY_new_raw_private_key)
|
||||
```
|
||||
|
||||
# C# drop‑in (for your .NET 10 code)
|
||||
|
||||
Edge builder with reason/evidence:
|
||||
|
||||
```csharp
|
||||
public sealed record EdgeId(string From, string To);
|
||||
|
||||
public sealed record EdgeEvidence(
|
||||
string Reason, // enum string from glossary
|
||||
IReadOnlyList<string> Evidence, // file:line, symbol, section
|
||||
string Confidence, // high|medium|low
|
||||
string Detector, // component@version
|
||||
string RuleId // stable rule key
|
||||
);
|
||||
|
||||
public sealed record GraphEdge(EdgeId Id, EdgeEvidence Via);
|
||||
|
||||
public static class EdgeFactory
|
||||
{
|
||||
public static GraphEdge DeclaredDependency(string from, string to, string manifestPath)
|
||||
=> new(new EdgeId(from, to),
|
||||
new EdgeEvidence(
|
||||
Reason: "declared_dependency",
|
||||
Evidence: new[] { $"manifest:{manifestPath}" },
|
||||
Confidence: "high",
|
||||
Detector: "StellaOps.Scanner.WebService@1.0.0",
|
||||
RuleId: "DEP-LOCK-001"));
|
||||
|
||||
public static GraphEdge SymbolRelocation(string from, string to, string objPath, string section, string symbol)
|
||||
=> new(new EdgeId(from, to),
|
||||
new EdgeEvidence(
|
||||
Reason: "symbol_relocation",
|
||||
Evidence: new[] { $"{objPath}::{section}:{symbol}" },
|
||||
Confidence: "high",
|
||||
Detector: "StellaOps.Scanner.WebService@1.0.0",
|
||||
RuleId: "BIN-RELOC-101"));
|
||||
}
|
||||
```
|
||||
|
||||
# Integration checklist (fast path)
|
||||
|
||||
* Emit `via.reason/evidence/provenance` for **all** edges (SBOM, source, binary).
|
||||
* Validate `reason` against glossary; reject free‑text.
|
||||
* Add a “**Why this edge exists**” column in your path tables.
|
||||
* In JSON/CSV exports, keep columns: `from,to,reason,confidence,evidence0..2,rule_id`.
|
||||
* In the console, collapse evidence by default; expand on click.
|
||||
|
||||
If you want, I’ll plug this into your Stella Ops graph contracts (Concelier/Cartographer) and produce the enum + validators and a tiny renderer for your docs.
|
||||
Cool, let’s turn this into a concrete, dev‑friendly implementation plan you can actually hand to teams.
|
||||
|
||||
I’ll structure it by phases and by component (schema, producers, APIs, UI, testing, rollout) so you can slice into tickets easily.
|
||||
|
||||
---
|
||||
|
||||
## 0. Recap of what we’re building
|
||||
|
||||
**Goal:**
|
||||
Every edge in your vuln path graph (SBOM → Reachability → Fix plan) carries **machine‑readable, auditor‑friendly metadata**:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"from": "pkg:pypi/requests@2.32.3#requests.sessions.Session.request",
|
||||
"to": "pkg:pypi/urllib3@2.2.3#urllib3.connectionpool.HTTPConnectionPool.urlopen",
|
||||
"via": {
|
||||
"reason": "declared_dependency", // from a controlled enum
|
||||
"evidence": [
|
||||
"manifest:requirements.txt:3", // up to 3 short evidence strings
|
||||
"pip freeze: urllib3==2.2.3"
|
||||
],
|
||||
"provenance": {
|
||||
"detector": "StellaOps.Scanner.WebService@1.4.2",
|
||||
"rule_id": "PY-IMPORT-001",
|
||||
"confidence": "high"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Standard **reason glossary** (enum):
|
||||
|
||||
* `declared_dependency`
|
||||
* `static_call`
|
||||
* `dynamic_import`
|
||||
* `reflection_call`
|
||||
* `plugin_discovery`
|
||||
* `symbol_relocation`
|
||||
* `plt_got_resolution`
|
||||
* `ld_preload_injection`
|
||||
* `env_config_path`
|
||||
* `taint_propagation`
|
||||
* `vendor_patch_alias`
|
||||
* `unknown` (fallback only when you truly can’t do better)
|
||||
|
||||
---
|
||||
|
||||
## 1. Design & contracts (shared work for backend & frontend)
|
||||
|
||||
### 1.1 Define the canonical edge metadata types
|
||||
|
||||
**Owner:** Platform / shared lib team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. In your shared C# library (used by scanners + API), define:
|
||||
|
||||
```csharp
|
||||
public enum EdgeReason
|
||||
{
|
||||
Unknown = 0,
|
||||
DeclaredDependency,
|
||||
StaticCall,
|
||||
DynamicImport,
|
||||
ReflectionCall,
|
||||
PluginDiscovery,
|
||||
SymbolRelocation,
|
||||
PltGotResolution,
|
||||
LdPreloadInjection,
|
||||
EnvConfigPath,
|
||||
TaintPropagation,
|
||||
VendorPatchAlias
|
||||
}
|
||||
|
||||
public enum EdgeConfidence
|
||||
{
|
||||
Low = 0,
|
||||
Medium,
|
||||
High
|
||||
}
|
||||
|
||||
public sealed record EdgeProvenance(
|
||||
string Detector, // e.g., "StellaOps.Scanner.WebService@1.4.2"
|
||||
string RuleId, // e.g., "PY-IMPORT-001"
|
||||
EdgeConfidence Confidence
|
||||
);
|
||||
|
||||
public sealed record EdgeVia(
|
||||
EdgeReason Reason,
|
||||
IReadOnlyList<string> Evidence,
|
||||
EdgeProvenance Provenance
|
||||
);
|
||||
|
||||
public sealed record EdgeId(string From, string To);
|
||||
|
||||
public sealed record GraphEdge(
|
||||
EdgeId Id,
|
||||
EdgeVia Via
|
||||
);
|
||||
```
|
||||
|
||||
2. Enforce **max 3 evidence strings** via a small helper to avoid accidental spam:
|
||||
|
||||
```csharp
|
||||
public static class EdgeViaFactory
|
||||
{
|
||||
private const int MaxEvidence = 3;
|
||||
|
||||
public static EdgeVia Create(
|
||||
EdgeReason reason,
|
||||
IEnumerable<string> evidence,
|
||||
string detector,
|
||||
string ruleId,
|
||||
EdgeConfidence confidence
|
||||
)
|
||||
{
|
||||
var ev = evidence
|
||||
.Where(s => !string.IsNullOrWhiteSpace(s))
|
||||
.Take(MaxEvidence)
|
||||
.ToArray();
|
||||
|
||||
return new EdgeVia(
|
||||
Reason: reason,
|
||||
Evidence: ev,
|
||||
Provenance: new EdgeProvenance(detector, ruleId, confidence)
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] EdgeReason enum defined and shared in a reusable package.
|
||||
* [ ] EdgeVia and EdgeProvenance types exist and are serializable to JSON.
|
||||
* [ ] Evidence is capped to 3 entries and cannot be null (empty list allowed).
|
||||
|
||||
---
|
||||
|
||||
### 1.2 API / JSON contract
|
||||
|
||||
**Owner:** API team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Extend your existing graph edge DTO to include `via`:
|
||||
|
||||
```csharp
|
||||
public sealed record GraphEdgeDto
|
||||
{
|
||||
public string From { get; init; } = default!;
|
||||
public string To { get; init; } = default!;
|
||||
public EdgeViaDto Via { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed record EdgeViaDto
|
||||
{
|
||||
public string Reason { get; init; } = default!; // enum as string
|
||||
public string[] Evidence { get; init; } = Array.Empty<string>();
|
||||
public EdgeProvenanceDto Provenance { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed record EdgeProvenanceDto
|
||||
{
|
||||
public string Detector { get; init; } = default!;
|
||||
public string RuleId { get; init; } = default!;
|
||||
public string Confidence { get; init; } = default!; // "high|medium|low"
|
||||
}
|
||||
```
|
||||
|
||||
2. Ensure JSON is **additive** (backward compatible):
|
||||
|
||||
* `via` is **non‑nullable** in responses from the new API version.
|
||||
* If you must keep a legacy endpoint, add **v2** endpoints that guarantee `via`.
|
||||
|
||||
3. Update OpenAPI spec:
|
||||
|
||||
* Document `via.reason` as enum string, including allowed values.
|
||||
* Document `via.provenance.detector`, `rule_id`, `confidence`.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] OpenAPI / Swagger shows `via.reason` as a string enum + description.
|
||||
* [ ] New clients can deserialize edges with `via` without custom hacks.
|
||||
* [ ] Old clients remain unaffected (either keep old endpoint or allow them to ignore `via`).
|
||||
|
||||
---
|
||||
|
||||
## 2. Producers: add reasons & evidence where edges are created
|
||||
|
||||
You likely have 3 main edge producers:
|
||||
|
||||
* SBOM / manifest / lockfile analyzers
|
||||
* Source analyzers (call graph, taint analysis)
|
||||
* Binary analyzers (ELF/PE/Mach‑O, containers)
|
||||
|
||||
Treat each as a mini‑project with identical patterns.
|
||||
|
||||
---
|
||||
|
||||
### 2.1 SBOM / manifest edges
|
||||
|
||||
**Owner:** SBOM / dep graph team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Identify all code paths that create “declared dependency” edges:
|
||||
|
||||
* Manifest → Package
|
||||
* Root module → Imported package (if you store these explicitly)
|
||||
|
||||
2. Replace plain edge construction with factory calls:
|
||||
|
||||
```csharp
|
||||
public static class EdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Sbom@1.0.0";
|
||||
|
||||
public static GraphEdge DeclaredDependency(
|
||||
string from,
|
||||
string to,
|
||||
string manifestPath,
|
||||
string? dependencySpecLine
|
||||
)
|
||||
{
|
||||
var evidence = new List<string>
|
||||
{
|
||||
$"manifest:{manifestPath}"
|
||||
};
|
||||
|
||||
if (!string.IsNullOrWhiteSpace(dependencySpecLine))
|
||||
evidence.Add($"spec:{dependencySpecLine}");
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.DeclaredDependency,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"DEP-LOCK-001",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(from, to), via);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. Make sure each SBOM/manifest edge sets:
|
||||
|
||||
* `reason = declared_dependency`
|
||||
* `confidence = high`
|
||||
* Evidence includes at least `manifest:<path>` and, if possible, line or spec snippet.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Any SBOM‑generated edge returns with `via.reason == declared_dependency`.
|
||||
* [ ] Evidence contains manifest path for ≥ 99% of SBOM edges.
|
||||
* [ ] Unit tests cover at least: normal manifest, multiple manifests, malformed manifest.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Source code call graph edges
|
||||
|
||||
**Owner:** Static analysis / call graph team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Map current edge types → reasons:
|
||||
|
||||
* Direct function/method calls → `static_call`
|
||||
* Reflection (Java/C#) → `reflection_call`
|
||||
* Dynamic imports (`__import__`, `importlib`, `require(...)`) → `dynamic_import`
|
||||
* Plugin systems (entry points, ServiceLoader, MEF) → `plugin_discovery`
|
||||
* Taint / dataflow edges (user input → sink) → `taint_propagation`
|
||||
|
||||
2. Implement helper factories:
|
||||
|
||||
```csharp
|
||||
public static class SourceEdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Source@1.0.0";
|
||||
|
||||
public static GraphEdge StaticCall(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string filePath,
|
||||
int lineNumber
|
||||
)
|
||||
{
|
||||
var evidence = new[]
|
||||
{
|
||||
$"callsite:{filePath}:{lineNumber}"
|
||||
};
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.StaticCall,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"SRC-CALL-001",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
|
||||
public static GraphEdge DynamicImport(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string filePath,
|
||||
int lineNumber
|
||||
)
|
||||
{
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.DynamicImport,
|
||||
new[] { $"importsite:{filePath}:{lineNumber}" },
|
||||
DetectorName,
|
||||
"SRC-DYNIMPORT-001",
|
||||
EdgeConfidence.Medium
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
|
||||
// Similar for ReflectionCall, PluginDiscovery, TaintPropagation...
|
||||
}
|
||||
```
|
||||
|
||||
3. Replace all direct `new GraphEdge(...)` calls in source analyzers with these factories.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Direct call edges produce `reason = static_call` with file:line evidence.
|
||||
* [ ] Reflection/dynamic import edges use correct reasons and mark `confidence = medium` (or high where you’re certain).
|
||||
* [ ] Unit tests check that for a known source file, the resulting edges contain expected `reason`, `evidence`, and `rule_id`.
|
||||
|
||||
---
|
||||
|
||||
### 2.3 Binary / container analyzers
|
||||
|
||||
**Owner:** Binary analysis / SCA team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Map binary features to reasons:
|
||||
|
||||
* Symbol relocations + PLT/GOT edges → `symbol_relocation` or `plt_got_resolution`
|
||||
* LD_PRELOAD or injection edges → `ld_preload_injection`
|
||||
|
||||
2. Implement factory:
|
||||
|
||||
```csharp
|
||||
public static class BinaryEdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Binary@1.0.0";
|
||||
|
||||
public static GraphEdge SymbolRelocation(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string binaryPath,
|
||||
string section,
|
||||
string relocationName
|
||||
)
|
||||
{
|
||||
var evidence = new[]
|
||||
{
|
||||
$"{binaryPath}::{section}:{relocationName}"
|
||||
};
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.SymbolRelocation,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"BIN-RELOC-101",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. Wire up all binary edge creation to use this.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] For a test binary with a known relocation, edges include `reason = symbol_relocation` and section/symbol in evidence.
|
||||
* [ ] No binary edge is created without `via`.
|
||||
|
||||
---
|
||||
|
||||
## 3. Storage & migrations
|
||||
|
||||
This depends on your backing store, but the pattern is similar.
|
||||
|
||||
### 3.1 Relational (SQL) example
|
||||
|
||||
**Owner:** Data / infra team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Add columns:
|
||||
|
||||
```sql
|
||||
ALTER TABLE graph_edges
|
||||
ADD COLUMN via_reason VARCHAR(64) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_evidence JSONB NOT NULL DEFAULT '[]'::jsonb,
|
||||
ADD COLUMN via_detector VARCHAR(255) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_rule_id VARCHAR(128) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_confidence VARCHAR(16) NOT NULL DEFAULT 'low';
|
||||
```
|
||||
|
||||
2. Update ORM model:
|
||||
|
||||
```csharp
|
||||
public class EdgeEntity
|
||||
{
|
||||
public string From { get; set; } = default!;
|
||||
public string To { get; set; } = default!;
|
||||
|
||||
public string ViaReason { get; set; } = "unknown";
|
||||
public string[] ViaEvidence { get; set; } = Array.Empty<string>();
|
||||
public string ViaDetector { get; set; } = "unknown";
|
||||
public string ViaRuleId { get; set; } = "unknown";
|
||||
public string ViaConfidence { get; set; } = "low";
|
||||
}
|
||||
```
|
||||
|
||||
3. Add mapping to domain `GraphEdge`:
|
||||
|
||||
```csharp
|
||||
public static GraphEdge ToDomain(this EdgeEntity e)
|
||||
{
|
||||
var via = new EdgeVia(
|
||||
Reason: Enum.TryParse<EdgeReason>(e.ViaReason, true, out var r) ? r : EdgeReason.Unknown,
|
||||
Evidence: e.ViaEvidence,
|
||||
Provenance: new EdgeProvenance(
|
||||
Detector: e.ViaDetector,
|
||||
RuleId: e.ViaRuleId,
|
||||
Confidence: Enum.TryParse<EdgeConfidence>(e.ViaConfidence, true, out var c) ? c : EdgeConfidence.Low
|
||||
)
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(e.From, e.To), via);
|
||||
}
|
||||
```
|
||||
|
||||
4. **Backfill existing data** (optional but recommended):
|
||||
|
||||
* For edges with a known “type” column, map to best‑fit `reason`.
|
||||
* If you can’t infer: set `reason = unknown`, `confidence = low`, `detector = "backfill@<version>"`.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] DB migration runs cleanly in staging and prod.
|
||||
* [ ] No existing reader breaks: default values keep queries functioning.
|
||||
* [ ] Edge round‑trip (domain → DB → API JSON) retains `via` fields correctly.
|
||||
|
||||
---
|
||||
|
||||
## 4. API & service layer
|
||||
|
||||
**Owner:** API / service team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Wire domain model → DTOs:
|
||||
|
||||
```csharp
|
||||
public static GraphEdgeDto ToDto(this GraphEdge edge)
|
||||
{
|
||||
return new GraphEdgeDto
|
||||
{
|
||||
From = edge.Id.From,
|
||||
To = edge.Id.To,
|
||||
Via = new EdgeViaDto
|
||||
{
|
||||
Reason = edge.Via.Reason.ToString().ToSnakeCaseLower(), // e.g. "static_call"
|
||||
Evidence = edge.Via.Evidence.ToArray(),
|
||||
Provenance = new EdgeProvenanceDto
|
||||
{
|
||||
Detector = edge.Via.Provenance.Detector,
|
||||
RuleId = edge.Via.Provenance.RuleId,
|
||||
Confidence = edge.Via.Provenance.Confidence.ToString().ToLowerInvariant()
|
||||
}
|
||||
}
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
2. If you accept edges via API (internal services), validate:
|
||||
|
||||
* `reason` must be one of the known values; otherwise reject or coerce to `unknown`.
|
||||
* `evidence` length ≤ 3.
|
||||
* Trim whitespace and limit each evidence string length (e.g. 256 chars).
|
||||
|
||||
3. Versioning:
|
||||
|
||||
* Introduce `/v2/graph/paths` (or similar) that guarantees `via`.
|
||||
* Keep `/v1/...` unchanged or mark deprecated.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Path API returns `via.reason` and `via.evidence` for all edges in new endpoints.
|
||||
* [ ] Invalid reason strings are rejected or converted to `unknown` with a log.
|
||||
* [ ] Integration tests cover full flow: repo → scanner → DB → API → JSON.
|
||||
|
||||
---
|
||||
|
||||
## 5. UI: make paths auditor‑friendly
|
||||
|
||||
**Owner:** Frontend team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Path details UI**:
|
||||
|
||||
For each edge in the vulnerability path table:
|
||||
|
||||
* Show a **“Reason” column** with a small pill:
|
||||
|
||||
* `static_call` → “Static call”
|
||||
* `declared_dependency` → “Declared dependency”
|
||||
* etc.
|
||||
* Below or on hover, show **primary evidence** (first evidence string).
|
||||
|
||||
2. **Edge details panel** (drawer/modal):
|
||||
|
||||
When user clicks an edge:
|
||||
|
||||
* Show:
|
||||
|
||||
* From → To (symbols/packages)
|
||||
* Reason (with friendly description per enum)
|
||||
* Evidence list (each on its own line)
|
||||
* Detector, rule id, confidence
|
||||
|
||||
3. **Filtering & sorting (optional but powerful)**:
|
||||
|
||||
* Filter edges by `reason` (multi‑select).
|
||||
* Filter by `confidence` (e.g. show only high/medium).
|
||||
* This helps auditors quickly isolate more speculative edges.
|
||||
|
||||
4. **UX text / glossary**:
|
||||
|
||||
* Add a small “?” tooltip that links to a glossary explaining each reason type in human language.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] For a given vulnerability, the path view shows a “Reason” column per edge.
|
||||
* [ ] Clicking an edge reveals all evidence and provenance information.
|
||||
* [ ] UX has a glossary/tooltip explaining what each reason means in plain English.
|
||||
|
||||
---
|
||||
|
||||
## 6. Testing strategy
|
||||
|
||||
**Owner:** QA + each feature team
|
||||
|
||||
### 6.1 Unit tests
|
||||
|
||||
* **Factories**: verify correct mapping from input to `EdgeVia`:
|
||||
|
||||
* Reason set correctly.
|
||||
* Evidence trimmed, max 3.
|
||||
* Confidence matches rubric (high for relocations, medium for heuristic imports, etc.).
|
||||
* **Serialization**: `EdgeVia` → JSON and back.
|
||||
|
||||
### 6.2 Integration tests
|
||||
|
||||
Set up **small fixtures**:
|
||||
|
||||
1. **Simple dependency project**:
|
||||
|
||||
* Example: Python project with `requirements.txt` → `requests` → `urllib3`.
|
||||
* Expected edges:
|
||||
|
||||
* App → requests: `declared_dependency`, evidence includes `requirements.txt`.
|
||||
* requests → urllib3: `declared_dependency`, plus static call edges.
|
||||
|
||||
2. **Dynamic import case**:
|
||||
|
||||
* A module using `importlib.import_module("mod")`.
|
||||
* Ensure edge is `dynamic_import` with `confidence = medium`.
|
||||
|
||||
3. **Binary edge case**:
|
||||
|
||||
* Test ELF with known symbol relocation.
|
||||
* Ensure an edge with `reason = symbol_relocation` exists.
|
||||
|
||||
### 6.3 End‑to‑end tests
|
||||
|
||||
* Run full scan on a sample repo and:
|
||||
|
||||
* Hit path API.
|
||||
* Assert every edge has non‑null `via` fields.
|
||||
* Spot check a few known edges for exact `reason` and evidence.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Automated tests fail if any edge is emitted without `via`.
|
||||
* [ ] Coverage includes at least one example for each `EdgeReason` you support.
|
||||
|
||||
---
|
||||
|
||||
## 7. Observability, guardrails & rollout
|
||||
|
||||
### 7.1 Metrics & logging
|
||||
|
||||
**Owner:** Observability / platform
|
||||
|
||||
**Tasks:**
|
||||
|
||||
* Emit metrics:
|
||||
|
||||
* `% edges with reason != unknown`
|
||||
* Count by `reason` and `confidence`
|
||||
* Log warnings when:
|
||||
|
||||
* Edge is emitted with `reason = unknown`.
|
||||
* Evidence is empty for a non‑unknown reason.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Dashboards showing distribution of edge reasons over time.
|
||||
* [ ] Alerts if `unknown` reason edges exceed a threshold (e.g. >5%).
|
||||
|
||||
---
|
||||
|
||||
### 7.2 Rollout plan
|
||||
|
||||
**Owner:** PM + tech leads
|
||||
|
||||
**Steps:**
|
||||
|
||||
1. **Phase 1 – Dark‑launch metadata:**
|
||||
|
||||
* Start generating & storing `via` for new scans.
|
||||
* Keep UI unchanged.
|
||||
* Monitor metrics, unknown ratio, and storage overhead.
|
||||
|
||||
2. **Phase 2 – Enable for internal users:**
|
||||
|
||||
* Toggle UI on (feature flag for internal / beta users).
|
||||
* Collect feedback from security engineers and auditors.
|
||||
|
||||
3. **Phase 3 – General availability:**
|
||||
|
||||
* Enable UI for all.
|
||||
* Update customer‑facing documentation & audit guides.
|
||||
|
||||
---
|
||||
|
||||
### 7.3 Documentation
|
||||
|
||||
**Owner:** Docs / PM
|
||||
|
||||
* Short **“Why this edge exists”** section in:
|
||||
|
||||
* Product docs (for customers).
|
||||
* Internal runbooks (for support & SEs).
|
||||
* Include:
|
||||
|
||||
* Table of reasons → human descriptions.
|
||||
* Examples of path explanations (e.g., “This edge exists because `app` declares `urllib3` in `requirements.txt` and calls it in `client.py:42`”).
|
||||
|
||||
---
|
||||
|
||||
## 8. Ready‑to‑use ticket breakdown
|
||||
|
||||
You can almost copy‑paste these into your tracker:
|
||||
|
||||
1. **Shared**: Define EdgeReason, EdgeVia & EdgeProvenance in shared library, plus EdgeViaFactory.
|
||||
2. **SBOM**: Use EdgeFactory.DeclaredDependency for all manifest‑generated edges.
|
||||
3. **Source**: Wire all callgraph edges to SourceEdgeFactory (static_call, dynamic_import, reflection_call, plugin_discovery, taint_propagation).
|
||||
4. **Binary**: Wire relocations/PLT/GOT edges to BinaryEdgeFactory (symbol_relocation, plt_got_resolution, ld_preload_injection).
|
||||
5. **Data**: Add via_* columns/properties to graph_edges storage and map to/from domain.
|
||||
6. **API**: Extend graph path DTOs to include `via`, update OpenAPI, and implement /v2 endpoints if needed.
|
||||
7. **UI**: Show edge reason, evidence, and provenance in vulnerability path screens and add filters.
|
||||
8. **Testing**: Add unit, integration, and end‑to‑end tests ensuring every edge has non‑null `via`.
|
||||
9. **Observability**: Add metrics and logs for edge reasons and unknown rates.
|
||||
10. **Docs & rollout**: Write glossary + auditor docs and plan staged rollout.
|
||||
|
||||
---
|
||||
|
||||
If you tell me a bit about your current storage (e.g., Neo4j vs SQL) and the services’ names, I can tailor this into an even more literal set of code snippets and migrations to match your stack exactly.
|
||||
@@ -0,0 +1,819 @@
|
||||
Here’s a crisp, ready‑to‑ship concept you can drop into Stella Ops: an **Unknowns Registry** that captures ambiguous scanner artifacts (stripped binaries, unverifiable packages, orphaned PURLs, missing digests) and treats them as first‑class citizens with probabilistic severity and trust‑decay—so you stay transparent without blocking delivery.
|
||||
|
||||
### What this solves (in plain terms)
|
||||
|
||||
* **No silent drops:** every “can’t verify / can’t resolve” is tracked, not discarded.
|
||||
* **Quantified risk:** unknowns still roll into a portfolio‑level risk number with confidence intervals.
|
||||
* **Trust over time:** stale unknowns get *riskier* the longer they remain unresolved.
|
||||
* **Client confidence:** visibility + trajectory (are unknowns shrinking?) becomes a maturity signal.
|
||||
|
||||
### Core data model (CycloneDX/SPDX compatible, attaches to your SBOM spine)
|
||||
|
||||
```yaml
|
||||
UnknownArtifact:
|
||||
id: urn:stella:unknowns:<uuid>
|
||||
observedAt: <RFC3339>
|
||||
origin:
|
||||
source: scanner|ingest|runtime
|
||||
feed: <name/version>
|
||||
evidence: [ filePath, containerDigest, buildId, sectionHints ]
|
||||
identifiers:
|
||||
purl?: <string> # orphan/incomplete PURL allowed
|
||||
hash?: <sha256|null> # missing digest allowed
|
||||
cpe?: <string|null>
|
||||
classification:
|
||||
type: binary|library|package|script|config|other
|
||||
reason: stripped_binary|missing_signature|no_feed_match|ambiguous_name|checksum_mismatch|other
|
||||
metrics:
|
||||
baseUnkScore: 0..1
|
||||
confidence: 0..1 # model confidence in the *score*
|
||||
trust: 0..1 # provenance trust (sig/attest, feed quality)
|
||||
decayPolicyId: <ref>
|
||||
resolution:
|
||||
status: unresolved|suppressed|mitigated|confirmed-benign|confirmed-risk
|
||||
updatedAt: <RFC3339>
|
||||
notes: <text>
|
||||
links:
|
||||
scanId: <ref>
|
||||
componentId?: <ref to SBOM component if later mapped>
|
||||
attestations?: [ dsse, in-toto, rekorRef ]
|
||||
```
|
||||
|
||||
### Scoring (simple, explainable, deterministic)
|
||||
|
||||
* **Unknown Risk (UR):**
|
||||
`UR_t = clamp( (B * (1 + A)) * D_t * (1 - T) , 0, 1 )`
|
||||
|
||||
* `B` = `baseUnkScore` (heuristics: file entropy, section hints, ELF flags, import tables, size, location)
|
||||
* `A` = **Environment Amplifier** (runtime proximity: container entrypoint? PID namespace? network caps?)
|
||||
* `T` = **Trust** (sig/attest/registry reputation/feed pedigree normalized to 0..1)
|
||||
* `D_t` = **Trust‑decay multiplier** over time `t`:
|
||||
|
||||
* Linear: `D_t = 1 + k * daysOpen` (e.g., `k = 0.01`)
|
||||
* or Exponential: `D_t = e^(λ * daysOpen)` (e.g., `λ = 0.005`)
|
||||
* **Portfolio roll‑up:** use **P90 of UR_t** across images + **sum of top‑N UR_t** to avoid dilution.
|
||||
|
||||
### Policies & SLOs
|
||||
|
||||
* **SLO:** *Unknowns burn‑down* ≤ X% week‑over‑week; *Median age* ≤ Y days.
|
||||
* **Gates:** block promotion when (a) any `UR_t ≥ 0.8`, or (b) more than `M` unknowns with age > `Z` days.
|
||||
* **Suppressions:** require justification + expiry; suppression reduces `A` but does **not** zero `D_t`.
|
||||
|
||||
### Trust‑decay policies (pluggable)
|
||||
|
||||
```yaml
|
||||
DecayPolicy:
|
||||
id: decay:default:v1
|
||||
kind: linear|exponential|custom
|
||||
params:
|
||||
k: 0.01 # linear slope per day
|
||||
cap: 2.0 # max multiplier
|
||||
```
|
||||
|
||||
### Scanner hooks (where to emit Unknowns)
|
||||
|
||||
* **Binary scan:** stripped ELF/Mach‑O/PE; missing build‑ID; abnormal sections; impossible symbol map.
|
||||
* **Package map:** PURL inferred from path without registry proof; mismatched checksum; vendor fork detected.
|
||||
* **Attestation:** DSSE missing / invalid; Sigstore chain unverifiable; Rekor entry not found.
|
||||
* **Feeds:** component seen in runtime but absent from SBOM (or vice versa).
|
||||
|
||||
### Deterministic generation (for replay/audits)
|
||||
|
||||
* Include **Unknowns** in the **Scan Manifest** (your deterministic bundle): inputs, ruleset hash, feed hashes, lattice policy version, and the exact classifier thresholds that produced `B`, `A`, `T`. That lets you replay and reproduce UR_t byte‑for‑byte during audits.
|
||||
|
||||
### API surface (StellaOps.Authority)
|
||||
|
||||
```
|
||||
POST /unknowns/ingest # bulk ingest from Scanner/Vexer
|
||||
GET /unknowns?imageDigest=… # list + filters (status, age, UR buckets)
|
||||
PATCH /unknowns/{id}/resolve # set status, add evidence, set suppression (with expiry)
|
||||
GET /unknowns/stats # burn-downs, age histograms, P90 UR_t, top-N contributors
|
||||
```
|
||||
|
||||
### UI slices (Trust Algebra Studio)
|
||||
|
||||
* **Risk ribbon:** Unknowns count, P90 UR_t, median age, trend sparkline.
|
||||
* **Aging board:** columns by age buckets; cards show reason, UR_t, `T`, decay policy, evidence.
|
||||
* **What‑if slider:** adjust `k`/`λ` and see retroactive effect on release readiness (deterministic preview).
|
||||
* **Explainability panel:** show `B`, `A`, `T`, `D_t` factors with succinct evidence (e.g., “ELF stripped; no .symtab; no Sigstore; runtime hits PID 1 → A=0.2; trust=0.1; day 17 → D=1.17”).
|
||||
|
||||
### Heuristics for `baseUnkScore (B)` (portable across ELF/PE/Mach‑O)
|
||||
|
||||
* Section/segment anomalies; entropy outliers; import tables linking to risky APIs; executable heap/stack flags.
|
||||
* Location & role (PATH proximity to entrypoint, init scripts).
|
||||
* Size/type priors (tiny droppers vs fat libs).
|
||||
* Known‑unknown patterns (packer signatures, `UPX` traces without unpack attest).
|
||||
|
||||
### Governance & reporting
|
||||
|
||||
* **Weekly Unknowns Report:** totals, burn‑down, median age, “top unresolved origins” (by registry / base image), and “time‑to‑first‑evidence.”
|
||||
* **Vendor scorecards:** if a supplier causes recurring unknowns, reflect it in **Adaptive Trust Economics**.
|
||||
|
||||
### Minimal implementation slice (2 sprints)
|
||||
|
||||
1. **Sprint A (backend + ingest):** model + tables, ingest endpoint, deterministic manifest hook, basic scoring (linear decay), list/query API, roll‑up metrics.
|
||||
2. **Sprint B (UI + policy):** Unknowns board, what‑if slider, suppress/resolve workflow w/ expiry, weekly report, policy gates in CI.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* the exact **PostgreSQL schema + indices** (including age/UR materialized views),
|
||||
* **.NET 10** DTOs, handlers, and a **deterministic scoring library** with unit tests,
|
||||
* a **Grafana/ClickHouse** dashboard spec for burn‑down and P90 tracking,
|
||||
* and a one‑page client‑facing explainer your sales team can use.
|
||||
Perfect, let’s turn the concept into a concrete, dev‑ready implementation plan.
|
||||
|
||||
I’ll assume:
|
||||
|
||||
* You already have:
|
||||
|
||||
* A scanner pipeline (binaries, SBOMs, attestations)
|
||||
* A backend service (StellaOps.Authority)
|
||||
* A UI (Trust Algebra Studio)
|
||||
* Observability (OpenTelemetry, ClickHouse/Presto)
|
||||
|
||||
You can adapt naming and tech stack as needed.
|
||||
|
||||
---
|
||||
|
||||
## 0. Scope & success criteria
|
||||
|
||||
**Goals**
|
||||
|
||||
1. Persist all “unknown-ish” scanner findings (stripped binaries, unverifiable PURLs, missing digests, etc.) as first‑class entities.
|
||||
2. Compute a deterministic **Unknown Risk (UR)** per artifact and roll it up per image/application.
|
||||
3. Apply **trust‑decay** over time and expose burn‑down metrics.
|
||||
4. Provide UI workflows to triage, suppress, and resolve unknowns.
|
||||
5. Enforce release gates based on unknown risk and age.
|
||||
|
||||
**Non‑goals (for v1)**
|
||||
|
||||
* No full ML; use deterministic heuristics + tunable weights.
|
||||
* No cross‑org multi‑tenant policy — single org/single policy set.
|
||||
* No per‑developer responsibility/assignment yet (can add later).
|
||||
|
||||
---
|
||||
|
||||
## 1. Architecture & components
|
||||
|
||||
### 1.1 New/updated components
|
||||
|
||||
1. **Unknowns Registry (backend submodule)**
|
||||
|
||||
* Lives in your existing backend (e.g., `StellaOps.Authority.Unknowns`).
|
||||
* Owns DB schema, scoring logic, and API.
|
||||
|
||||
2. **Scanner integration**
|
||||
|
||||
* Extend `StellaOps.Scanner` (and/or `Vexer`) to emit “unknown” findings into the registry via HTTP or message bus.
|
||||
|
||||
3. **UI: Unknowns in Trust Algebra Studio**
|
||||
|
||||
* New section/tab: “Unknowns” under each image/app.
|
||||
* Global “Unknowns board” for portfolio view.
|
||||
|
||||
4. **Analytics & jobs**
|
||||
|
||||
* Periodic job to recompute trust‑decay & UR.
|
||||
* Weekly report generator (e.g., pushing into ClickHouse, Slack, or email).
|
||||
|
||||
---
|
||||
|
||||
## 2. Data model (DB schema)
|
||||
|
||||
Use relational DB; here’s a concrete schema you can translate into migrations.
|
||||
|
||||
### 2.1 Tables
|
||||
|
||||
#### `unknown_artifacts`
|
||||
|
||||
Represents the current state of each unknown.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `created_at` (timestamp)
|
||||
* `updated_at` (timestamp)
|
||||
* `first_observed_at` (timestamp, NOT NULL)
|
||||
* `last_observed_at` (timestamp, NOT NULL)
|
||||
* `origin_source` (enum: `scanner`, `runtime`, `ingest`)
|
||||
* `origin_feed` (text) – e.g., `binary-scanner@1.4.3`
|
||||
* `origin_scan_id` (UUID / text) – foreign key to `scan_runs` if you have it
|
||||
* `image_digest` (text, indexed) – to tie to container/image
|
||||
* `component_id` (UUID, nullable) – SBOM component when later mapped
|
||||
* `file_path` (text, nullable)
|
||||
* `build_id` (text, nullable) – ELF/Mach-O/PE build ID if any
|
||||
* `purl` (text, nullable)
|
||||
* `hash_sha256` (text, nullable)
|
||||
* `cpe` (text, nullable)
|
||||
* `classification_type` (enum: `binary`, `library`, `package`, `script`, `config`, `other`)
|
||||
* `classification_reason` (enum:
|
||||
`stripped_binary`, `missing_signature`, `no_feed_match`,
|
||||
`ambiguous_name`, `checksum_mismatch`, `other`)
|
||||
* `status` (enum:
|
||||
`unresolved`, `suppressed`, `mitigated`, `confirmed_benign`, `confirmed_risk`)
|
||||
* `status_changed_at` (timestamp)
|
||||
* `status_changed_by` (text / user-id)
|
||||
* `notes` (text)
|
||||
* `decay_policy_id` (FK → `decay_policies`)
|
||||
* `base_unk_score` (double, 0..1)
|
||||
* `env_amplifier` (double, 0..1)
|
||||
* `trust` (double, 0..1)
|
||||
* `current_decay_multiplier` (double)
|
||||
* `current_ur` (double, 0..1) – Unknown Risk at last recompute
|
||||
* `current_confidence` (double, 0..1) – confidence in `current_ur`
|
||||
* `is_deleted` (bool) – soft delete
|
||||
|
||||
**Indexes**
|
||||
|
||||
* `idx_unknown_artifacts_image_digest_status`
|
||||
* `idx_unknown_artifacts_status_created_at`
|
||||
* `idx_unknown_artifacts_current_ur`
|
||||
* `idx_unknown_artifacts_last_observed_at`
|
||||
|
||||
#### `unknown_artifact_events`
|
||||
|
||||
Append-only event log for auditable changes.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `unknown_artifact_id` (FK → `unknown_artifacts`)
|
||||
* `created_at` (timestamp)
|
||||
* `actor` (text / user-id / system)
|
||||
* `event_type` (enum:
|
||||
`created`, `reobserved`, `status_changed`, `note_added`,
|
||||
`metrics_recomputed`, `linked_component`, `suppression_applied`, `suppression_expired`)
|
||||
* `payload` (JSONB) – diff or event‑specific details
|
||||
|
||||
Index: `idx_unknown_artifact_events_artifact_id_created_at`
|
||||
|
||||
#### `decay_policies`
|
||||
|
||||
Defines how trust‑decay works.
|
||||
|
||||
* `id` (text, PK) – e.g., `decay:default:v1`
|
||||
* `kind` (enum: `linear`, `exponential`)
|
||||
* `param_k` (double, nullable) – for linear: slope
|
||||
* `param_lambda` (double, nullable) – for exponential
|
||||
* `cap` (double, default 2.0)
|
||||
* `description` (text)
|
||||
* `is_default` (bool)
|
||||
|
||||
#### `unknown_suppressions`
|
||||
|
||||
Optional; can also reuse `unknown_artifacts.status` but separate table lets you have multiple suppressions over time.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `unknown_artifact_id` (FK)
|
||||
* `created_at` (timestamp)
|
||||
* `created_by` (text)
|
||||
* `reason` (text)
|
||||
* `expires_at` (timestamp, nullable)
|
||||
* `active` (bool)
|
||||
|
||||
Index: `idx_unknown_suppressions_artifact_active_expires_at`
|
||||
|
||||
#### `unknown_image_rollups`
|
||||
|
||||
Precomputed rollups per image (for fast dashboards/gates).
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `image_digest` (text, indexed)
|
||||
* `computed_at` (timestamp)
|
||||
* `unknown_count_total` (int)
|
||||
* `unknown_count_unresolved` (int)
|
||||
* `unknown_count_high_ur` (int) – e.g., UR ≥ 0.8
|
||||
* `p50_ur` (double)
|
||||
* `p90_ur` (double)
|
||||
* `top_n_ur_sum` (double)
|
||||
* `median_age_days` (double)
|
||||
|
||||
---
|
||||
|
||||
## 3. Scoring engine implementation
|
||||
|
||||
Create a small, deterministic scoring library so the same code can be used in:
|
||||
|
||||
* Backend ingest path (for immediate UR)
|
||||
* Batch recompute job
|
||||
* “What‑if” UI simulations (optionally via stateless API)
|
||||
|
||||
### 3.1 Data types
|
||||
|
||||
Define a core model, e.g.:
|
||||
|
||||
```ts
|
||||
type UnknownMetricsInput = {
|
||||
baseUnkScore: number; // B
|
||||
envAmplifier: number; // A
|
||||
trust: number; // T
|
||||
daysOpen: number; // t
|
||||
decayPolicy: {
|
||||
kind: "linear" | "exponential";
|
||||
k?: number;
|
||||
lambda?: number;
|
||||
cap: number;
|
||||
};
|
||||
};
|
||||
|
||||
type UnknownMetricsOutput = {
|
||||
decayMultiplier: number; // D_t
|
||||
unknownRisk: number; // UR_t
|
||||
};
|
||||
```
|
||||
|
||||
### 3.2 Algorithm
|
||||
|
||||
```ts
|
||||
function computeDecayMultiplier(
|
||||
daysOpen: number,
|
||||
policy: DecayPolicy
|
||||
): number {
|
||||
if (policy.kind === "linear") {
|
||||
const raw = 1 + (policy.k ?? 0) * daysOpen;
|
||||
return Math.min(raw, policy.cap);
|
||||
}
|
||||
if (policy.kind === "exponential") {
|
||||
const lambda = policy.lambda ?? 0;
|
||||
const raw = Math.exp(lambda * daysOpen);
|
||||
return Math.min(raw, policy.cap);
|
||||
}
|
||||
return 1;
|
||||
}
|
||||
|
||||
function computeUnknownRisk(input: UnknownMetricsInput): UnknownMetricsOutput {
|
||||
const { baseUnkScore: B, envAmplifier: A, trust: T, daysOpen, decayPolicy } = input;
|
||||
|
||||
const D_t = computeDecayMultiplier(daysOpen, decayPolicy);
|
||||
const raw = (B * (1 + A)) * D_t * (1 - T);
|
||||
|
||||
const unknownRisk = Math.max(0, Math.min(raw, 1)); // clamp 0..1
|
||||
|
||||
return { decayMultiplier: D_t, unknownRisk };
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3 Heuristics for `B`, `A`, `T`
|
||||
|
||||
Implement these as pure functions with configuration‑driven weights:
|
||||
|
||||
* `B` (base unknown score):
|
||||
|
||||
* Start from prior: by `classification_type` (binary > library > config).
|
||||
* Adjust up for:
|
||||
|
||||
* Stripped binary (no symbols, high entropy)
|
||||
* Suspicious segments (executable stack/heap)
|
||||
* Known packer signatures (UPX, etc.)
|
||||
* Adjust down for:
|
||||
|
||||
* Large, well‑known dependency path (`/usr/lib/...`)
|
||||
* Known safe signatures (if partially known).
|
||||
|
||||
* `A` (environment amplifier):
|
||||
|
||||
* +0.2 if artifact is part of container entrypoint (PID 1).
|
||||
* +0.1 if file is in a PATH dir (e.g., `/usr/local/bin`).
|
||||
* +0.1 if the runtime has network capabilities/capabilities flags.
|
||||
* Cap at 0.5 for v1.
|
||||
|
||||
* `T` (trust):
|
||||
|
||||
* Start at 0.5.
|
||||
* +0.3 if registry/signature/attestation chain verified.
|
||||
* +0.1 if source registry is “trusted vendor list”.
|
||||
* −0.3 if checksum mismatch or feed conflict.
|
||||
* Clamp 0..1.
|
||||
|
||||
Store the raw factors (`B`, `A`, `T`) on the artifact for transparency and later replays.
|
||||
|
||||
---
|
||||
|
||||
## 4. Scanner integration
|
||||
|
||||
### 4.1 Emission format (from scanner → backend)
|
||||
|
||||
Define a minimal ingestion contract (JSON over HTTP or a message):
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"scanId": "urn:scan:1234",
|
||||
"imageDigest": "sha256:abc123...",
|
||||
"observedAt": "2025-11-27T12:34:56Z",
|
||||
"unknowns": [
|
||||
{
|
||||
"externalId": "scanner-unique-id-1",
|
||||
"originSource": "scanner",
|
||||
"originFeed": "binary-scanner@1.4.3",
|
||||
"filePath": "/usr/local/bin/stripped",
|
||||
"buildId": null,
|
||||
"purl": null,
|
||||
"hashSha256": "aa...",
|
||||
"cpe": null,
|
||||
"classificationType": "binary",
|
||||
"classificationReason": "stripped_binary",
|
||||
"rawSignals": {
|
||||
"entropy": 7.4,
|
||||
"hasSymbols": false,
|
||||
"isEntrypoint": true,
|
||||
"inPathDir": true
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The backend maps `rawSignals` → `B`, `A`, `T`.
|
||||
|
||||
### 4.2 Idempotency
|
||||
|
||||
* Define uniqueness key on `(image_digest, file_path, hash_sha256)` for v1.
|
||||
* On ingest:
|
||||
|
||||
* If an artifact exists:
|
||||
|
||||
* Update `last_observed_at`.
|
||||
* Recompute age (`now - first_observed_at`) and UR.
|
||||
* Add `reobserved` event.
|
||||
* If not:
|
||||
|
||||
* Insert new row with `first_observed_at = observedAt`.
|
||||
|
||||
### 4.3 HTTP endpoint
|
||||
|
||||
`POST /internal/unknowns/ingest`
|
||||
|
||||
* Auth: internal service token.
|
||||
* Returns per‑unknown mapping to internal `id` and computed UR.
|
||||
|
||||
Error handling:
|
||||
|
||||
* If invalid payload → 400 with list of errors.
|
||||
* Partial failure: process valid unknowns, return `failedUnknowns` array with reasons.
|
||||
|
||||
---
|
||||
|
||||
## 5. Backend API for UI & CI
|
||||
|
||||
### 5.1 List unknowns
|
||||
|
||||
`GET /unknowns`
|
||||
|
||||
Query params:
|
||||
|
||||
* `imageDigest` (optional)
|
||||
* `status` (optional multi: unresolved, suppressed, etc.)
|
||||
* `minUr`, `maxUr` (optional)
|
||||
* `maxAgeDays` (optional)
|
||||
* `page`, `pageSize`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"items": [
|
||||
{
|
||||
"id": "urn:stella:unknowns:uuid",
|
||||
"imageDigest": "sha256:...",
|
||||
"filePath": "/usr/local/bin/stripped",
|
||||
"classificationType": "binary",
|
||||
"classificationReason": "stripped_binary",
|
||||
"status": "unresolved",
|
||||
"firstObservedAt": "...",
|
||||
"lastObservedAt": "...",
|
||||
"ageDays": 17,
|
||||
"baseUnkScore": 0.7,
|
||||
"envAmplifier": 0.2,
|
||||
"trust": 0.1,
|
||||
"decayPolicyId": "decay:default:v1",
|
||||
"decayMultiplier": 1.17,
|
||||
"currentUr": 0.84,
|
||||
"currentConfidence": 0.8
|
||||
}
|
||||
],
|
||||
"total": 123
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Get single unknown + event history
|
||||
|
||||
`GET /unknowns/{id}`
|
||||
|
||||
Include:
|
||||
|
||||
* The artifact.
|
||||
* Latest metrics.
|
||||
* Recent events (with pagination).
|
||||
|
||||
### 5.3 Update status / suppression
|
||||
|
||||
`PATCH /unknowns/{id}`
|
||||
|
||||
Body options:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"status": "suppressed",
|
||||
"notes": "Reviewed; internal diagnostics binary.",
|
||||
"suppression": {
|
||||
"expiresAt": "2025-12-31T00:00:00Z"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Backend:
|
||||
|
||||
* Validates transition (cannot un‑suppress to “unresolved” without event).
|
||||
* Writes to `unknown_suppressions`.
|
||||
* Writes `status_changed` + `suppression_applied` events.
|
||||
|
||||
### 5.4 Image rollups
|
||||
|
||||
`GET /images/{imageDigest}/unknowns/summary`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"imageDigest": "sha256:...",
|
||||
"computedAt": "...",
|
||||
"unknownCountTotal": 40,
|
||||
"unknownCountUnresolved": 30,
|
||||
"unknownCountHighUr": 4,
|
||||
"p50Ur": 0.35,
|
||||
"p90Ur": 0.82,
|
||||
"topNUrSum": 2.4,
|
||||
"medianAgeDays": 9
|
||||
}
|
||||
```
|
||||
|
||||
This is what CI and UI will mostly query.
|
||||
|
||||
---
|
||||
|
||||
## 6. Trust‑decay job & rollup computation
|
||||
|
||||
### 6.1 Periodic recompute job
|
||||
|
||||
Schedule (e.g., every hour):
|
||||
|
||||
1. Fetch `unknown_artifacts` where:
|
||||
|
||||
* `status IN ('unresolved', 'suppressed', 'mitigated')`
|
||||
* `last_observed_at >= now() - interval '90 days'` (tunable)
|
||||
2. Compute `daysOpen = now() - first_observed_at`.
|
||||
3. Compute `D_t` and `UR_t` with scoring library.
|
||||
4. Update `unknown_artifacts.current_ur`, `current_decay_multiplier`.
|
||||
5. Append `metrics_recomputed` event (batch size threshold, e.g., only when UR changed > 0.01).
|
||||
|
||||
### 6.2 Rollup job
|
||||
|
||||
Every X minutes:
|
||||
|
||||
1. For each `image_digest` with active unknowns:
|
||||
|
||||
* Compute:
|
||||
|
||||
* `unknown_count_total`
|
||||
* `unknown_count_unresolved` (`status = unresolved`)
|
||||
* `unknown_count_high_ur` (UR ≥ threshold)
|
||||
* `p50` / `p90` UR (use DB percentile or compute in app)
|
||||
* `top_n_ur_sum` (sum of top 5 UR)
|
||||
* `median_age_days`
|
||||
2. Upsert into `unknown_image_rollups`.
|
||||
|
||||
---
|
||||
|
||||
## 7. CI / promotion gating
|
||||
|
||||
Expose a simple policy evaluation API for CI and deploy pipelines.
|
||||
|
||||
### 7.1 Policy definition (config)
|
||||
|
||||
Example YAML:
|
||||
|
||||
```yaml
|
||||
unknownsPolicy:
|
||||
blockIf:
|
||||
- kind: "anyUrAboveThreshold"
|
||||
threshold: 0.8
|
||||
- kind: "countAboveAge"
|
||||
maxCount: 5
|
||||
ageDays: 14
|
||||
warnIf:
|
||||
- kind: "unknownCountAbove"
|
||||
maxCount: 50
|
||||
```
|
||||
|
||||
### 7.2 Policy evaluation endpoint
|
||||
|
||||
`GET /policy/unknowns/evaluate?imageDigest=sha256:...`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"imageDigest": "sha256:...",
|
||||
"result": "block", // "ok" | "warn" | "block"
|
||||
"reasons": [
|
||||
{
|
||||
"kind": "anyUrAboveThreshold",
|
||||
"detail": "1 unknown with UR>=0.8 (max allowed: 0)"
|
||||
}
|
||||
],
|
||||
"summary": {
|
||||
"unknownCountUnresolved": 30,
|
||||
"p90Ur": 0.82,
|
||||
"medianAgeDays": 17
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
CI can decide to fail build/deploy based on `result`.
|
||||
|
||||
---
|
||||
|
||||
## 8. UI implementation (Trust Algebra Studio)
|
||||
|
||||
### 8.1 Image detail page: “Unknowns” tab
|
||||
|
||||
Components:
|
||||
|
||||
1. **Header metrics ribbon**
|
||||
|
||||
* Unknowns unresolved, p90 UR, median age, weekly trend sparkline.
|
||||
* Fetch from `/images/{digest}/unknowns/summary`.
|
||||
|
||||
2. **Unknowns table**
|
||||
|
||||
* Columns:
|
||||
|
||||
* Status pill
|
||||
* UR (with color + tooltip showing `B`, `A`, `T`, `D_t`)
|
||||
* Classification type/reason
|
||||
* File path
|
||||
* Age
|
||||
* Last observed
|
||||
* Filters:
|
||||
|
||||
* Status, UR range, age range, reason, type.
|
||||
|
||||
3. **Row drawer / detail panel**
|
||||
|
||||
* Show:
|
||||
|
||||
* All core fields.
|
||||
* Evidence:
|
||||
|
||||
* origin (scanner, feed, runtime)
|
||||
* raw signals (entropy, sections, etc)
|
||||
* SBOM component link (if any)
|
||||
* Timeline (events list)
|
||||
* Actions:
|
||||
|
||||
* Change status (unresolved → suppressed/mitigated/confirmed).
|
||||
* Add note.
|
||||
* Set/extend suppression expiry.
|
||||
|
||||
### 8.2 Global “Unknowns board”
|
||||
|
||||
Goals:
|
||||
|
||||
* Portfolio view; triage across many images.
|
||||
|
||||
Features:
|
||||
|
||||
* Filters by:
|
||||
|
||||
* Team/application/service
|
||||
* Time range for first observed
|
||||
* UR bucket (0–0.3, 0.3–0.6, 0.6–1)
|
||||
* Cards/rows per image:
|
||||
|
||||
* Unknown counts, p90 UR, median age.
|
||||
* Trend of unknown count (last N weeks).
|
||||
* Click through to image‑detail tab.
|
||||
|
||||
### 8.3 “What‑if” slider (optional v1.1)
|
||||
|
||||
On an image or org-level:
|
||||
|
||||
* Slider(s) to visualize effect of:
|
||||
|
||||
* `k` / `lambda` change (decay speed).
|
||||
* Trust baseline changes (simulate better attestations).
|
||||
* Implement by calling a stateless endpoint:
|
||||
|
||||
* `POST /unknowns/what-if` with:
|
||||
|
||||
* Current unknowns list IDs
|
||||
* Proposed decay policy
|
||||
* Returns recalculated URs and hypothetical gate result (but does **not** persist).
|
||||
|
||||
---
|
||||
|
||||
## 9. Observability & analytics
|
||||
|
||||
### 9.1 Metrics
|
||||
|
||||
Emit structured events/metrics (OpenTelemetry, etc.):
|
||||
|
||||
* Counters:
|
||||
|
||||
* `unknowns_ingested_total` (labels: `source`, `classification_type`, `reason`)
|
||||
* `unknowns_resolved_total` (labels: `status`)
|
||||
* Gauges:
|
||||
|
||||
* `unknowns_unresolved_count` per image/service.
|
||||
* `unknowns_p90_ur` per image/service.
|
||||
* `unknowns_median_age_days`.
|
||||
|
||||
### 9.2 Weekly report generator
|
||||
|
||||
Batch job:
|
||||
|
||||
1. Compute, per org or team:
|
||||
|
||||
* Total unknowns.
|
||||
* New unknowns this week.
|
||||
* Resolved unknowns this week.
|
||||
* Median age.
|
||||
* Top 10 images by:
|
||||
|
||||
* Highest p90 UR.
|
||||
* Largest number of long‑lived unknowns (> X days).
|
||||
2. Persist into analytics store (ClickHouse) + push into:
|
||||
|
||||
* Slack channel / email with a short plain‑text summary and link to UI.
|
||||
|
||||
---
|
||||
|
||||
## 10. Security & compliance
|
||||
|
||||
* Ensure all APIs require authentication & proper scopes:
|
||||
|
||||
* Scanner ingest: internal service token only.
|
||||
* UI APIs: user identity + RBAC (e.g., team can only see their images).
|
||||
* Audit log:
|
||||
|
||||
* `unknown_artifact_events` must be immutable and queryable by compliance teams.
|
||||
* PII:
|
||||
|
||||
* Avoid storing user PII in notes; if necessary, apply redaction.
|
||||
|
||||
---
|
||||
|
||||
## 11. Suggested delivery plan (sprints/epics)
|
||||
|
||||
### Sprint 1 – Foundations & ingest path
|
||||
|
||||
* [ ] DB migrations: `unknown_artifacts`, `unknown_artifact_events`, `decay_policies`.
|
||||
* [ ] Implement scoring library (`B`, `A`, `T`, `UR_t`, `D_t`).
|
||||
* [ ] Implement `/internal/unknowns/ingest` endpoint with idempotency.
|
||||
* [ ] Extend scanner to emit unknowns and integrate with ingest.
|
||||
* [ ] Basic `GET /unknowns?imageDigest=...` API.
|
||||
* [ ] Seed `decay:default:v1` policy.
|
||||
|
||||
**Exit criteria:** Unknowns created and UR computed from real scans; queryable via API.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 2 – Decay, rollups, and CI hook
|
||||
|
||||
* [ ] Implement periodic job to recompute decay & UR.
|
||||
* [ ] Implement rollup job + `unknown_image_rollups` table.
|
||||
* [ ] Implement `GET /images/{digest}/unknowns/summary`.
|
||||
* [ ] Implement policy evaluation endpoint for CI.
|
||||
* [ ] Wire CI to block/warn based on policy.
|
||||
|
||||
**Exit criteria:** CI gate can fail a build due to high‑risk unknowns; rollups visible via API.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 3 – UI (Unknowns tab + board)
|
||||
|
||||
* [ ] Image detail “Unknowns” tab:
|
||||
|
||||
* Metrics ribbon, table, filters.
|
||||
* Row drawer with evidence & history.
|
||||
* [ ] Global “Unknowns board” page.
|
||||
* [ ] Integrate with APIs.
|
||||
* [ ] Add basic “explainability tooltip” for UR.
|
||||
|
||||
**Exit criteria:** Security team can triage unknowns via UI; product teams can see their exposure.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 4 – Suppression workflow & reporting
|
||||
|
||||
* [ ] Implement `PATCH /unknowns/{id}` + suppression rules & expiries.
|
||||
* [ ] Extend periodic jobs to auto‑expire suppressions.
|
||||
* [ ] Weekly unknowns report job → analytics + Slack/email.
|
||||
* [ ] Add “trend” sparklines and unknowns burn‑down in UI.
|
||||
|
||||
**Exit criteria:** Unknowns can be suppressed with justification; org gets weekly burn‑down trends.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Turn this into concrete tickets (Jira-style) with story points and acceptance criteria, or
|
||||
* Generate example migration scripts (SQL) and API contract files (OpenAPI snippet) that your devs can copy‑paste.
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,408 @@
|
||||
# Authentication and Authorization Architecture
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, token model, scope taxonomy, and implementation strategy for the Authority module, consolidating authentication and authorization patterns across all Stella Ops services.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
Authority is the **on-premises OIDC/OAuth2 issuing service** that provides secure identity for all Stella Ops operations. Key capabilities:
|
||||
|
||||
- **Short-Lived Tokens (OpTok)** - 2-5 minute TTL operational tokens
|
||||
- **Sender Constraints** - DPoP or mTLS binding prevents token theft
|
||||
- **Fine-Grained Scopes** - 65+ scopes with role bundles
|
||||
- **Multi-Tenant Isolation** - Tenant claims enforced throughout
|
||||
- **Delegated Service Accounts** - Automation without credential exposure
|
||||
- **Sovereign Crypto Support** - Configurable signing algorithms per profile
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Authentication Requirements | Use Case |
|
||||
|---------|---------------------------|----------|
|
||||
| **Enterprise** | SSO/SAML integration, MFA | Corporate security policies |
|
||||
| **Government** | CAC/PIV, FIPS validation | Federal compliance |
|
||||
| **Financial Services** | Strong auth, audit trails | SOC 2, PCI-DSS |
|
||||
| **Healthcare** | HIPAA access controls | PHI protection |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability scanning tools rely on basic API keys. Stella Ops differentiates with:
|
||||
- **Zero-trust token model** with sender constraints
|
||||
- **Fine-grained RBAC** with 65+ scopes
|
||||
- **Cryptographic binding** (DPoP/mTLS) prevents token theft
|
||||
- **Deterministic revocation bundles** for offline verification
|
||||
- **Plugin extensibility** for custom identity providers
|
||||
|
||||
---
|
||||
|
||||
## 3. Token Model
|
||||
|
||||
### 3.1 Three-Token System
|
||||
|
||||
| Token | Lifetime | Purpose | Binding |
|
||||
|-------|----------|---------|---------|
|
||||
| **License Token (LT)** | Long-lived | Cloud licensing enrollment | Installation |
|
||||
| **Proof-of-Entitlement (PoE)** | Medium | License validation | Installation key |
|
||||
| **Operational Token (OpTok)** | 2-5 min | Runtime authentication | DPoP/mTLS |
|
||||
|
||||
### 3.2 Operational Token Structure
|
||||
|
||||
**Registered Claims:**
|
||||
|
||||
```json
|
||||
{
|
||||
"iss": "https://authority.example.com",
|
||||
"sub": "client-id-or-user-id",
|
||||
"aud": "signer|scanner|attestor|concelier|...",
|
||||
"exp": 1732881600,
|
||||
"iat": 1732881300,
|
||||
"nbf": 1732881270,
|
||||
"jti": "uuid",
|
||||
"scope": "scanner.scan scanner.export signer.sign"
|
||||
}
|
||||
```
|
||||
|
||||
**Sender Constraint Claims:**
|
||||
|
||||
```json
|
||||
{
|
||||
"cnf": {
|
||||
"jkt": "base64url(SHA-256(JWK))", // DPoP binding
|
||||
"x5t#S256": "base64url(SHA-256(cert))" // mTLS binding
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Tenant & Context Claims:**
|
||||
|
||||
```json
|
||||
{
|
||||
"tid": "tenant-id",
|
||||
"inst": "installation-id",
|
||||
"roles": ["svc.scanner", "svc.signer"],
|
||||
"plan": "enterprise"
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3 Sender Constraints
|
||||
|
||||
**DPoP (Demonstration of Proof-of-Possession):**
|
||||
|
||||
1. Client generates ephemeral JWK keypair
|
||||
2. Client sends DPoP proof header with `htm`, `htu`, `iat`, `jti`
|
||||
3. Authority validates and stamps token with `cnf.jkt`
|
||||
4. Resource servers verify same key on each request
|
||||
5. Nonce challenges available for high-value audiences
|
||||
|
||||
**mTLS (Mutual TLS):**
|
||||
|
||||
1. Client presents certificate at TLS handshake
|
||||
2. Authority validates and binds to `cnf.x5t#S256`
|
||||
3. Resource servers verify same cert on each request
|
||||
4. Required for high-value audiences (signer, attestor)
|
||||
|
||||
---
|
||||
|
||||
## 4. Scope Taxonomy
|
||||
|
||||
### 4.1 Scope Categories (65+ scopes)
|
||||
|
||||
**Ingestion Scopes (tenant-required):**
|
||||
- `advisory:ingest` - Concelier advisory ingestion
|
||||
- `vex:ingest` - Excititor VEX ingestion
|
||||
- `signals:write` - Reachability signal ingestion
|
||||
|
||||
**Verification Scopes (require `aoc:verify` pairing):**
|
||||
- `advisory:read` - Advisory queries
|
||||
- `vex:read` - VEX queries
|
||||
- `signals:read` - Signal queries
|
||||
|
||||
**Service Scopes:**
|
||||
|
||||
| Service | Scopes |
|
||||
|---------|--------|
|
||||
| **Signer** | `signer.sign` (mTLS enforced) |
|
||||
| **Scanner** | `scanner.scan`, `scanner.export`, `scanner.read` |
|
||||
| **Attestor** | `attestor.write` |
|
||||
| **Policy Studio** | `policy:author`, `policy:review`, `policy:approve`, `policy:operate`, `policy:publish`, `policy:promote`, `policy:audit`, `policy:simulate` |
|
||||
| **Vuln Explorer** | `vuln:view`, `vuln:investigate`, `vuln:operate`, `vuln:audit` |
|
||||
| **Orchestrator** | `orch:read`, `orch:operate`, `orch:quota`, `orch:backfill` |
|
||||
| **Export Center** | `export.viewer`, `export.operator`, `export.admin` |
|
||||
| **Task Packs** | `packs.read`, `packs.write`, `packs.run`, `packs.approve` |
|
||||
| **Evidence** | `evidence:create`, `evidence:read`, `evidence:hold` |
|
||||
| **Timeline** | `timeline:read`, `timeline:write` |
|
||||
|
||||
**Special Scopes:**
|
||||
- `obs:incident` - Incident mode activation (fresh auth required)
|
||||
- `tenant:admin` - Cross-tenant operations
|
||||
|
||||
### 4.2 Role Bundles
|
||||
|
||||
Authority provides 40+ predefined roles that bundle related scopes:
|
||||
|
||||
| Role | Scopes | Requirements |
|
||||
|------|--------|--------------|
|
||||
| `role/concelier-ingest` | `advisory:ingest`, `advisory:read` | Tenant claim |
|
||||
| `role/signals-uploader` | `signals:write`, `signals:read`, `aoc:verify` | Tenant claim |
|
||||
| `role/policy-engine` | `effective:write`, `findings:read` | `serviceIdentity: policy-engine` |
|
||||
| `role/policy-author` | `policy:author`, `policy:read`, `policy:simulate`, `findings:read` | - |
|
||||
| `role/policy-approver` | `policy:approve`, `policy:review`, `policy:read`, `policy:simulate`, `findings:read` | - |
|
||||
| `role/orch-operator` | `orch:read`, `orch:operate` | - |
|
||||
| `role/export-admin` | `export.viewer`, `export.operator`, `export.admin` | - |
|
||||
|
||||
---
|
||||
|
||||
## 5. Multi-Tenant Isolation
|
||||
|
||||
### 5.1 Tenant Claim Enforcement
|
||||
|
||||
**Token Issuance:**
|
||||
- Authority normalizes tenant: `trim().ToLowerInvariant()`
|
||||
- Tokens include `tid` (tenant ID) and `inst` (installation ID)
|
||||
- Cross-tenant isolation enforced at issuance
|
||||
|
||||
**Propagation:**
|
||||
- API Gateway forwards `tid` as `X-Stella-Tenant` header
|
||||
- Downstream services reject requests without header
|
||||
- All data stamped with tenant identifier
|
||||
|
||||
**Scope Enforcement:**
|
||||
- Ingestion scopes require tenant claim
|
||||
- `aoc:verify` pairing required for verification scopes
|
||||
- Cross-tenant replay rejected
|
||||
|
||||
### 5.2 Cross-Tenant Operations
|
||||
|
||||
For platform operators with `tenant:admin`:
|
||||
- Switch tenants via `/authority/tenant/switch`
|
||||
- CLI `--tenant <id>` override
|
||||
- Delegated token exchange for automation
|
||||
- Full audit trail of tenant switches
|
||||
|
||||
---
|
||||
|
||||
## 6. Advanced Token Features
|
||||
|
||||
### 6.1 Delegated Service Accounts
|
||||
|
||||
```yaml
|
||||
delegation:
|
||||
quotas:
|
||||
maxActiveTokens: 50
|
||||
serviceAccounts:
|
||||
- accountId: "svc-observer"
|
||||
tenant: "tenant-default"
|
||||
displayName: "Observability Exporter"
|
||||
allowedScopes: ["jobs:read", "findings:read"]
|
||||
authorizedClients: ["export-center-worker"]
|
||||
```
|
||||
|
||||
**Token Shape:**
|
||||
- Includes `stellaops:service_account` claim
|
||||
- `act` claim describes caller hierarchy
|
||||
- Quota enforcement per tenant/account
|
||||
|
||||
### 6.2 Fresh Auth Window (5 Minutes)
|
||||
|
||||
Required for high-privilege operations:
|
||||
- Policy publish/promote
|
||||
- Pack approvals
|
||||
- Incident mode activation
|
||||
- Operator actions
|
||||
|
||||
**Token must include:**
|
||||
- `auth_time` within 5 minutes of request
|
||||
- Interactive authentication (password/device-code)
|
||||
|
||||
### 6.3 ABAC Attributes (Vuln Explorer)
|
||||
|
||||
Tokens can carry attribute-based filters:
|
||||
- `stellaops:vuln_env` - Environment filter
|
||||
- `stellaops:vuln_owner` - Team/owner filter
|
||||
- `stellaops:vuln_business_tier` - Criticality tier
|
||||
|
||||
---
|
||||
|
||||
## 7. Implementation Strategy
|
||||
|
||||
### 7.1 Phase 1: Core Token Infrastructure (Complete)
|
||||
|
||||
- [x] DPoP validation on all `/token` grants
|
||||
- [x] mTLS binding for refresh grants
|
||||
- [x] Sealed-mode CI gating
|
||||
- [x] Pack signing policies and RBAC
|
||||
- [x] LDAP plugin with claims enricher
|
||||
|
||||
### 7.2 Phase 2: Sovereign Crypto (In Progress)
|
||||
|
||||
- [ ] Crypto provider registry wiring (AUTH-CRYPTO-90-001)
|
||||
- [ ] GOST signing support
|
||||
- [ ] FIPS validation
|
||||
- [ ] Post-quantum preparation
|
||||
|
||||
### 7.3 Phase 3: Advanced Features (Planned)
|
||||
|
||||
- [ ] DSSE predicate types for SBOM/Graph/VEX (AUTH-REACH-401-005)
|
||||
- [ ] PostgreSQL storage migration
|
||||
- [ ] Enhanced delegation quotas
|
||||
|
||||
---
|
||||
|
||||
## 8. API Surface
|
||||
|
||||
### 8.1 Token Endpoints
|
||||
|
||||
| Endpoint | Method | Purpose |
|
||||
|----------|--------|---------|
|
||||
| `/token` | POST | Token issuance (all grant types) |
|
||||
| `/introspect` | POST | Token introspection |
|
||||
| `/revoke` | POST | Token/refresh revocation |
|
||||
| `/.well-known/openid-configuration` | GET | OIDC discovery |
|
||||
| `/jwks` | GET | JSON Web Key Set |
|
||||
|
||||
### 8.2 Supported Grant Types
|
||||
|
||||
- **Client Credentials** - Service-to-service (mTLS or private_key_jwt)
|
||||
- **Device Code** - CLI on headless agents
|
||||
- **Authorization Code + PKCE** - Browser UI login
|
||||
- **Refresh Token** - With DPoP/mTLS re-validation
|
||||
|
||||
### 8.3 Admin APIs
|
||||
|
||||
All under `/admin` (mTLS + `authority.admin` scope):
|
||||
|
||||
| Endpoint | Method | Purpose |
|
||||
|----------|--------|---------|
|
||||
| `/admin/clients` | POST | Create/update client |
|
||||
| `/admin/audiences` | POST | Register audience URIs |
|
||||
| `/admin/roles` | POST | Define role→scope mappings |
|
||||
| `/admin/tenants` | POST | Create tenant entries |
|
||||
| `/admin/keys/rotate` | POST | Rotate signing key |
|
||||
|
||||
---
|
||||
|
||||
## 9. Revocation & JWKS
|
||||
|
||||
### 9.1 Revocation Bundles
|
||||
|
||||
Deterministic bundles for offline verification:
|
||||
|
||||
```
|
||||
revocation-bundle.json
|
||||
├── revokedTokens[] # List of revoked jti values
|
||||
├── revokedClients[] # Revoked client IDs
|
||||
├── generatedAt # UTC timestamp
|
||||
├── validUntil # Expiry for offline cache
|
||||
└── signature # Detached JWS (RFC 7797)
|
||||
```
|
||||
|
||||
### 9.2 JWKS Management
|
||||
|
||||
- At least 2 active keys during rotation
|
||||
- Old keys retained for max TTL + 5 minutes
|
||||
- Key status: `active`, `retired`, `revoked`
|
||||
|
||||
### 9.3 CLI Verification
|
||||
|
||||
```bash
|
||||
# Export revocation bundle
|
||||
stella auth revoke export --output revocation.json
|
||||
|
||||
# Verify bundle signature
|
||||
stella auth revoke verify --bundle revocation.json --key pubkey.pem
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 10. Security Considerations
|
||||
|
||||
### 10.1 Threat Model Coverage
|
||||
|
||||
| Threat | Mitigation |
|
||||
|--------|------------|
|
||||
| Token theft | DPoP/mTLS sender constraints |
|
||||
| Replay attacks | DPoP nonce challenges, short TTL |
|
||||
| Token injection | Audience validation |
|
||||
| Privilege escalation | Scope enforcement, role bundles |
|
||||
| Cross-tenant access | Tenant claim isolation |
|
||||
|
||||
### 10.2 Operational Security
|
||||
|
||||
- Bootstrap API key protection
|
||||
- Key rotation before expiration
|
||||
- Rate limiting on `/token` endpoint
|
||||
- Audit logging for all token operations
|
||||
|
||||
---
|
||||
|
||||
## 11. Observability
|
||||
|
||||
### 11.1 Metrics
|
||||
|
||||
- `authority_token_issued_total{grant_type,audience}`
|
||||
- `authority_token_rejected_total{reason}`
|
||||
- `authority_dpop_nonce_miss_total`
|
||||
- `authority_mtls_mismatch_total`
|
||||
|
||||
### 11.2 Audit Events
|
||||
|
||||
- `authority.token.issued` - Token issuance
|
||||
- `authority.token.rejected` - Rejection with reason
|
||||
- `authority.tenant.switch` - Cross-tenant operation
|
||||
- `authority.key.rotated` - Key rotation
|
||||
- `authority.plugin.*.password_verification` - Plugin events
|
||||
|
||||
---
|
||||
|
||||
## 12. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Authority architecture | `docs/modules/authority/architecture.md` |
|
||||
| Authority overview | `docs/11_AUTHORITY.md` |
|
||||
| Scope reference | `docs/security/authority-scopes.md` |
|
||||
| DPoP/mTLS rollout | `docs/security/dpop-mtls-rollout.md` |
|
||||
| Threat model | `docs/security/authority-threat-model.md` |
|
||||
| Revocation bundles | `docs/security/revocation-bundle.md` |
|
||||
| Key rotation | `docs/modules/authority/operations/key-rotation.md` |
|
||||
| Plugin guide | `docs/dev/31_AUTHORITY_PLUGIN_DEVELOPER_GUIDE.md` |
|
||||
|
||||
---
|
||||
|
||||
## 13. Sprint Mapping
|
||||
|
||||
- **Historical:** SPRINT_100_identity_signing.md (CLOSED)
|
||||
- **Documentation:** SPRINT_314_docs_modules_authority.md
|
||||
- **PostgreSQL:** SPRINT_3401_0001_0001_postgres_authority.md
|
||||
- **Crypto:** SPRINT_0514_0001_0001_sovereign_crypto_enablement.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `AUTH-DPOP-11-001` - DPoP validation (DONE)
|
||||
- `AUTH-MTLS-11-002` - mTLS binding (DONE)
|
||||
- `AUTH-AIRGAP-57-001` - Sealed-mode CI gating (DONE)
|
||||
- `AUTH-CRYPTO-90-001` - Sovereign crypto wiring (IN PROGRESS)
|
||||
- `AUTH-REACH-401-005` - DSSE predicates (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 14. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Token issuance latency | < 50ms p99 |
|
||||
| DPoP validation rate | 100% on `/token` |
|
||||
| Sender constraint coverage | 100% for high-value audiences |
|
||||
| Key rotation downtime | Zero |
|
||||
| Revocation bundle freshness | < 5 minutes |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,402 @@
|
||||
# CLI Developer Experience and Command UX
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, command surface design, and implementation strategy for the Stella Ops CLI, covering developer experience, CI/CD integration, output formatting, and offline operation.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Stella Ops CLI is the **primary interface for developers and CI/CD pipelines** interacting with the platform. Key capabilities:
|
||||
|
||||
- **Native AOT Binary** - Sub-20ms startup, single binary distribution
|
||||
- **DPoP-Bound Authentication** - Secure device-code and service principal flows
|
||||
- **Deterministic Outputs** - JSON/table modes with stable exit codes for CI
|
||||
- **Buildx Integration** - SBOM generation at build time
|
||||
- **Offline Kit Management** - Air-gapped deployment support
|
||||
- **Shell Completions** - Bash/Zsh/Fish/PowerShell auto-complete
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | CLI Requirements | Use Case |
|
||||
|---------|-----------------|----------|
|
||||
| **DevSecOps** | CI integration, exit codes, JSON output | Pipeline gates |
|
||||
| **Security Engineers** | Verification commands, policy testing | Audit workflows |
|
||||
| **Platform Operators** | Offline kit, admin commands | Air-gap management |
|
||||
| **Developers** | Scan commands, buildx integration | Local development |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most CLI tools in the vulnerability space are slow or lack CI ergonomics. Stella Ops differentiates with:
|
||||
- **Native AOT** for instant startup (< 20ms vs 500ms+ for JIT)
|
||||
- **Deterministic exit codes** (12 distinct codes for CI decision trees)
|
||||
- **DPoP security** (no long-lived tokens on disk)
|
||||
- **Unified command surface** (50+ commands, consistent patterns)
|
||||
- **Offline-first design** (works without network in sealed mode)
|
||||
|
||||
---
|
||||
|
||||
## 3. Command Surface Architecture
|
||||
|
||||
### 3.1 Command Categories
|
||||
|
||||
| Category | Commands | Purpose |
|
||||
|----------|----------|---------|
|
||||
| **Auth** | `login`, `logout`, `status`, `token` | Authentication management |
|
||||
| **Scan** | `scan image`, `scan fs` | Vulnerability scanning |
|
||||
| **Export** | `export sbom`, `report final` | Artifact retrieval |
|
||||
| **Verify** | `verify attestation`, `verify referrers`, `verify image-signature` | Cryptographic verification |
|
||||
| **Policy** | `policy get`, `policy set`, `policy apply` | Policy management |
|
||||
| **Buildx** | `buildx install`, `buildx verify`, `buildx build` | Build-time SBOM |
|
||||
| **Runtime** | `runtime policy test` | Zastava integration |
|
||||
| **Offline** | `offline kit pull`, `offline kit import`, `offline kit status` | Air-gap operations |
|
||||
| **Decision** | `decision export`, `decision verify`, `decision compare` | VEX evidence management |
|
||||
| **AOC** | `sources ingest`, `aoc verify` | Aggregation-only guards |
|
||||
| **KMS** | `kms export`, `kms import` | Key management |
|
||||
| **Advise** | `advise run` | AI-powered advisory summaries |
|
||||
|
||||
### 3.2 Output Modes
|
||||
|
||||
**Human Mode (default):**
|
||||
```
|
||||
$ stella scan image nginx:latest --wait
|
||||
Scanning nginx:latest...
|
||||
Found 12 vulnerabilities (2 critical, 3 high, 5 medium, 2 low)
|
||||
Policy verdict: FAIL
|
||||
|
||||
Critical:
|
||||
- CVE-2025-12345 in openssl (fixed in 3.0.14)
|
||||
- CVE-2025-12346 in libcurl (no fix available)
|
||||
|
||||
See: https://ui.internal/scans/sha256:abc123...
|
||||
```
|
||||
|
||||
**JSON Mode (`--json`):**
|
||||
```json
|
||||
{"event":"scan.complete","status":"fail","critical":2,"high":3,"medium":5,"low":2,"url":"https://..."}
|
||||
```
|
||||
|
||||
### 3.3 Exit Codes
|
||||
|
||||
| Code | Meaning | CI Action |
|
||||
|------|---------|-----------|
|
||||
| 0 | Success | Continue |
|
||||
| 2 | Policy fail | Block deployment |
|
||||
| 3 | Verification failed | Security alert |
|
||||
| 4 | Auth error | Re-authenticate |
|
||||
| 5 | Resource not found | Check inputs |
|
||||
| 6 | Rate limited | Retry with backoff |
|
||||
| 7 | Backend unavailable | Retry |
|
||||
| 9 | Invalid arguments | Fix command |
|
||||
| 11-17 | AOC guard violations | Review ingestion |
|
||||
| 18 | Verification truncated | Increase limit |
|
||||
| 70 | Transport failure | Check network |
|
||||
| 71 | Usage error | Fix command |
|
||||
|
||||
---
|
||||
|
||||
## 4. Authentication Model
|
||||
|
||||
### 4.1 Device Code Flow (Interactive)
|
||||
|
||||
```bash
|
||||
$ stella auth login
|
||||
Opening browser for authentication...
|
||||
Device code: ABCD-EFGH
|
||||
Waiting for authorization...
|
||||
Logged in as user@example.com (tenant: acme-corp)
|
||||
```
|
||||
|
||||
### 4.2 Service Principal (CI/CD)
|
||||
|
||||
```bash
|
||||
$ stella auth login --client-credentials \
|
||||
--client-id $STELLA_CLIENT_ID \
|
||||
--private-key $STELLA_PRIVATE_KEY
|
||||
```
|
||||
|
||||
### 4.3 DPoP Key Management
|
||||
|
||||
- Ephemeral Ed25519 keypair generated on first login
|
||||
- Stored in OS keychain (Keychain/DPAPI/KWallet/Gnome Keyring)
|
||||
- Every request includes DPoP proof header
|
||||
- Tokens refreshed proactively (30s before expiry)
|
||||
|
||||
### 4.4 Token Credential Helper
|
||||
|
||||
```bash
|
||||
# Get one-shot token for curl/scripts
|
||||
TOKEN=$(stella auth token --aud scanner)
|
||||
curl -H "Authorization: Bearer $TOKEN" https://scanner.internal/api/...
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Buildx Integration
|
||||
|
||||
### 5.1 Generator Installation
|
||||
|
||||
```bash
|
||||
$ stella buildx install
|
||||
Installing SBOM generator plugin...
|
||||
Verifying signature: OK
|
||||
Generator installed at ~/.docker/cli-plugins/docker-buildx-stellaops
|
||||
|
||||
$ stella buildx verify
|
||||
Docker version: 24.0.7
|
||||
Buildx version: 0.12.1
|
||||
Generator: stellaops/sbom-indexer:v1.2.3@sha256:abc123...
|
||||
Status: Ready
|
||||
```
|
||||
|
||||
### 5.2 Build with SBOM
|
||||
|
||||
```bash
|
||||
$ stella buildx build -t myapp:v1.0.0 --push --attest
|
||||
Building myapp:v1.0.0...
|
||||
SBOM generation: enabled (stellaops/sbom-indexer)
|
||||
Provenance: enabled
|
||||
Attestation: requested
|
||||
|
||||
Build complete!
|
||||
Image: myapp:v1.0.0@sha256:def456...
|
||||
SBOM: attached as referrer
|
||||
Attestation: logged to Rekor (uuid: abc123)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Implementation Strategy
|
||||
|
||||
### 6.1 Phase 1: Core Commands (Complete)
|
||||
|
||||
- [x] Auth commands with DPoP
|
||||
- [x] Scan/export commands
|
||||
- [x] JSON output mode
|
||||
- [x] Exit code standardization
|
||||
- [x] Shell completions
|
||||
|
||||
### 6.2 Phase 2: Buildx & Verification (Complete)
|
||||
|
||||
- [x] Buildx plugin management
|
||||
- [x] Attestation verification
|
||||
- [x] Referrer verification
|
||||
- [x] Report commands
|
||||
|
||||
### 6.3 Phase 3: Advanced Features (In Progress)
|
||||
|
||||
- [x] Decision export/verify commands
|
||||
- [x] AOC guard helpers
|
||||
- [x] KMS management
|
||||
- [ ] Advisory AI integration (CLI-ADVISE-48-001)
|
||||
- [ ] Filesystem scanning (CLI-SCAN-49-001)
|
||||
|
||||
### 6.4 Phase 4: Distribution (Planned)
|
||||
|
||||
- [ ] Homebrew formula
|
||||
- [ ] Scoop/Winget manifests
|
||||
- [ ] Self-update mechanism
|
||||
- [ ] Cosign signature verification
|
||||
|
||||
---
|
||||
|
||||
## 7. CI/CD Integration Patterns
|
||||
|
||||
### 7.1 GitHub Actions
|
||||
|
||||
```yaml
|
||||
- name: Install Stella CLI
|
||||
run: |
|
||||
curl -sSL https://get.stella-ops.io | sh
|
||||
echo "$HOME/.stella/bin" >> $GITHUB_PATH
|
||||
|
||||
- name: Authenticate
|
||||
run: stella auth login --client-credentials
|
||||
env:
|
||||
STELLAOPS_CLIENT_ID: ${{ secrets.STELLA_CLIENT_ID }}
|
||||
STELLAOPS_PRIVATE_KEY: ${{ secrets.STELLA_PRIVATE_KEY }}
|
||||
|
||||
- name: Scan Image
|
||||
run: |
|
||||
stella scan image ${{ env.IMAGE_REF }} --wait --json > scan-results.json
|
||||
if [ $? -eq 2 ]; then
|
||||
echo "::error::Policy failed - blocking deployment"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
- name: Verify Attestation
|
||||
run: stella verify attestation --artifact ${{ env.IMAGE_DIGEST }}
|
||||
```
|
||||
|
||||
### 7.2 GitLab CI
|
||||
|
||||
```yaml
|
||||
scan:
|
||||
script:
|
||||
- stella auth login --client-credentials
|
||||
- stella buildx install
|
||||
- docker buildx build --attest=type=sbom,generator=stellaops/sbom-indexer -t $CI_REGISTRY_IMAGE:$CI_COMMIT_SHA .
|
||||
- stella scan image $CI_REGISTRY_IMAGE@$IMAGE_DIGEST --wait --json
|
||||
artifacts:
|
||||
reports:
|
||||
container_scanning: scan-results.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Configuration Model
|
||||
|
||||
### 8.1 Precedence
|
||||
|
||||
CLI flags > Environment variables > Config file > Defaults
|
||||
|
||||
### 8.2 Config File
|
||||
|
||||
```yaml
|
||||
# ~/.config/stellaops/config.yaml
|
||||
cli:
|
||||
authority: "https://authority.example.com"
|
||||
backend:
|
||||
scanner: "https://scanner.example.com"
|
||||
attestor: "https://attestor.example.com"
|
||||
auth:
|
||||
deviceCode: true
|
||||
audienceDefault: "scanner"
|
||||
output:
|
||||
json: false
|
||||
color: auto
|
||||
tls:
|
||||
caBundle: "/etc/ssl/certs/ca-bundle.crt"
|
||||
offline:
|
||||
kitMirror: "s3://mirror/stellaops-kit"
|
||||
```
|
||||
|
||||
### 8.3 Environment Variables
|
||||
|
||||
| Variable | Purpose |
|
||||
|----------|---------|
|
||||
| `STELLAOPS_AUTHORITY` | Authority URL |
|
||||
| `STELLAOPS_SCANNER_URL` | Scanner service URL |
|
||||
| `STELLAOPS_CLIENT_ID` | Service principal ID |
|
||||
| `STELLAOPS_PRIVATE_KEY` | Service principal key |
|
||||
| `STELLAOPS_TENANT` | Default tenant |
|
||||
| `STELLAOPS_JSON` | Enable JSON output |
|
||||
|
||||
---
|
||||
|
||||
## 9. Offline Operation
|
||||
|
||||
### 9.1 Sealed Mode Detection
|
||||
|
||||
```bash
|
||||
$ stella scan image nginx:latest
|
||||
Error: Sealed mode active - external network access blocked
|
||||
Remediation: Import offline kit or disable sealed mode
|
||||
|
||||
$ stella offline kit import latest-kit.tar.gz
|
||||
Importing offline kit...
|
||||
Advisories: 45,230 records
|
||||
VEX documents: 12,450 records
|
||||
Policy packs: 3 bundles
|
||||
Import complete!
|
||||
|
||||
$ stella scan image nginx:latest
|
||||
Scanning with offline data (2025-11-28)...
|
||||
```
|
||||
|
||||
### 9.2 Air-Gap Guard
|
||||
|
||||
All HTTP flows route through `StellaOps.AirGap.Policy`. When sealed mode is active:
|
||||
- External egress is blocked with `AIRGAP_EGRESS_BLOCKED` error
|
||||
- CLI provides clear remediation guidance
|
||||
- Local verification continues to work
|
||||
|
||||
---
|
||||
|
||||
## 10. Security Considerations
|
||||
|
||||
### 10.1 Credential Protection
|
||||
|
||||
- DPoP private keys stored in OS keychain only
|
||||
- No plaintext tokens on disk
|
||||
- Short-lived OpToks held in memory only
|
||||
- Authorization headers redacted from verbose logs
|
||||
|
||||
### 10.2 Binary Verification
|
||||
|
||||
```bash
|
||||
# Verify CLI binary signature
|
||||
$ stella version --verify
|
||||
Version: 1.2.3
|
||||
Built: 2025-11-29T12:00:00Z
|
||||
Signature: Valid (cosign)
|
||||
Signer: release@stella-ops.io
|
||||
```
|
||||
|
||||
### 10.3 Hard Lines
|
||||
|
||||
- Refuse to print token values
|
||||
- Disallow `--insecure` without explicit env var opt-in
|
||||
- Enforce short token TTL with proactive refresh
|
||||
- Device-code cache bound to machine + user
|
||||
|
||||
---
|
||||
|
||||
## 11. Performance Targets
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Startup time | < 20ms (AOT) |
|
||||
| Request overhead | < 5ms |
|
||||
| Large download (100MB) | > 80 MB/s |
|
||||
| Buildx wrapper overhead | < 1ms |
|
||||
|
||||
---
|
||||
|
||||
## 12. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| CLI architecture | `docs/modules/cli/architecture.md` |
|
||||
| Policy CLI guide | `docs/modules/cli/guides/policy.md` |
|
||||
| API/CLI reference | `docs/09_API_CLI_REFERENCE.md` |
|
||||
| Offline operation | `docs/24_OFFLINE_KIT.md` |
|
||||
|
||||
---
|
||||
|
||||
## 13. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0400_cli_ux.md (NEW)
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0210_0001_0002_ui_ii.md (UI integration)
|
||||
- SPRINT_0187_0001_0001_evidence_locker_cli_integration.md (Evidence CLI)
|
||||
|
||||
**Key Task IDs:**
|
||||
- `CLI-AUTH-10-001` - DPoP authentication (DONE)
|
||||
- `CLI-SCAN-20-001` - Scan commands (DONE)
|
||||
- `CLI-BUILDX-30-001` - Buildx integration (DONE)
|
||||
- `CLI-ADVISE-48-001` - Advisory AI commands (IN PROGRESS)
|
||||
- `CLI-SCAN-49-001` - Filesystem scanning (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 14. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Startup latency | < 20ms p99 |
|
||||
| CI adoption | 80% of pipelines use CLI |
|
||||
| Exit code coverage | 100% of failure modes |
|
||||
| Shell completion coverage | 100% of commands |
|
||||
| Offline operation success | Works without network |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,476 @@
|
||||
# Concelier Advisory Ingestion Model
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, ingestion semantics, and implementation strategy for the Concelier module, covering the Link-Not-Merge model, connector pipelines, observation storage, and deterministic exports.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
Concelier is the **advisory ingestion engine** that acquires, normalizes, and correlates vulnerability advisories from authoritative sources. Key capabilities:
|
||||
|
||||
- **Aggregation-Only Contract** - No derived semantics in ingestion
|
||||
- **Link-Not-Merge** - Observations correlated, never merged
|
||||
- **Multi-Source Connectors** - Vendor PSIRTs, distros, OSS ecosystems
|
||||
- **Deterministic Exports** - Reproducible JSON, Trivy DB bundles
|
||||
- **Conflict Detection** - Structured payloads for divergent claims
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Ingestion Requirements | Use Case |
|
||||
|---------|------------------------|----------|
|
||||
| **Security Teams** | Authoritative data | Accurate vulnerability assessment |
|
||||
| **Compliance** | Provenance tracking | Audit trail for advisory sources |
|
||||
| **DevSecOps** | Fast updates | CI/CD pipeline integration |
|
||||
| **Air-Gap Ops** | Offline bundles | Disconnected environment support |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability databases merge data, losing provenance. Stella Ops differentiates with:
|
||||
- **Link-Not-Merge** preserving all source claims
|
||||
- **Conflict visibility** showing where sources disagree
|
||||
- **Deterministic exports** enabling reproducible builds
|
||||
- **Multi-format support** (CSAF, OSV, GHSA, vendor-specific)
|
||||
- **Signature verification** for upstream integrity
|
||||
|
||||
---
|
||||
|
||||
## 3. Aggregation-Only Contract (AOC)
|
||||
|
||||
### 3.1 Core Principles
|
||||
|
||||
The AOC ensures ingestion purity:
|
||||
|
||||
1. **No derived semantics** - No severity consensus, merged status, or fix hints
|
||||
2. **Immutable raw docs** - Append-only with version chains
|
||||
3. **Mandatory provenance** - Source, timestamp, signature status
|
||||
4. **Linkset only** - Joins stored separately, never mutate content
|
||||
5. **Deterministic canonicalization** - Stable JSON output
|
||||
6. **Idempotent upserts** - Same hash = no new record
|
||||
7. **CI verification** - AOCVerifier enforces at runtime
|
||||
|
||||
### 3.2 Enforcement
|
||||
|
||||
```csharp
|
||||
// AOCWriteGuard checks before every write
|
||||
public class AOCWriteGuard
|
||||
{
|
||||
Task GuardAsync(AdvisoryObservation obs)
|
||||
{
|
||||
// Verify no forbidden properties
|
||||
// Validate provenance completeness
|
||||
// Check tenant claims
|
||||
// Normalize timestamps
|
||||
// Compute content hash
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Roslyn analyzers (`StellaOps.AOC.Analyzers`) scan connectors at build time to prevent forbidden property usage.
|
||||
|
||||
---
|
||||
|
||||
## 4. Advisory Observation Model
|
||||
|
||||
### 4.1 Observation Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"_id": "tenant:vendor:upstreamId:revision",
|
||||
"tenant": "acme-corp",
|
||||
"source": {
|
||||
"vendor": "OSV",
|
||||
"stream": "github",
|
||||
"api": "https://api.osv.dev/v1/.../GHSA-...",
|
||||
"collectorVersion": "concelier/1.7.3"
|
||||
},
|
||||
"upstream": {
|
||||
"upstreamId": "GHSA-xxxx-....",
|
||||
"documentVersion": "2025-09-01T12:13:14Z",
|
||||
"fetchedAt": "2025-09-01T13:04:05Z",
|
||||
"receivedAt": "2025-09-01T13:04:06Z",
|
||||
"contentHash": "sha256:...",
|
||||
"signature": {
|
||||
"present": true,
|
||||
"format": "dsse",
|
||||
"keyId": "rekor:.../key/abc"
|
||||
}
|
||||
},
|
||||
"content": {
|
||||
"format": "OSV",
|
||||
"specVersion": "1.6",
|
||||
"raw": { /* unmodified upstream document */ }
|
||||
},
|
||||
"identifiers": {
|
||||
"primary": "GHSA-xxxx-....",
|
||||
"aliases": ["CVE-2025-12345", "GHSA-xxxx-...."]
|
||||
},
|
||||
"linkset": {
|
||||
"purls": ["pkg:npm/lodash@4.17.21"],
|
||||
"cpes": ["cpe:2.3:a:lodash:lodash:4.17.21:*:*:*:*:*:*:*"],
|
||||
"references": [
|
||||
{"type": "advisory", "url": "https://..."},
|
||||
{"type": "fix", "url": "https://..."}
|
||||
]
|
||||
},
|
||||
"supersedes": "tenant:vendor:upstreamId:prev-revision",
|
||||
"createdAt": "2025-09-01T13:04:06Z"
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 Linkset Correlation
|
||||
|
||||
```json
|
||||
{
|
||||
"_id": "sha256:...",
|
||||
"tenant": "acme-corp",
|
||||
"key": {
|
||||
"vulnerabilityId": "CVE-2025-12345",
|
||||
"productKey": "pkg:npm/lodash@4.17.21",
|
||||
"confidence": "high"
|
||||
},
|
||||
"observations": [
|
||||
{
|
||||
"observationId": "tenant:osv:GHSA-...:v1",
|
||||
"sourceVendor": "OSV",
|
||||
"statement": { "severity": "high" },
|
||||
"collectedAt": "2025-09-01T13:04:06Z"
|
||||
},
|
||||
{
|
||||
"observationId": "tenant:nvd:CVE-2025-12345:v2",
|
||||
"sourceVendor": "NVD",
|
||||
"statement": { "severity": "critical" },
|
||||
"collectedAt": "2025-09-01T14:00:00Z"
|
||||
}
|
||||
],
|
||||
"conflicts": [
|
||||
{
|
||||
"conflictId": "sha256:...",
|
||||
"type": "severity-mismatch",
|
||||
"observations": [
|
||||
{ "source": "OSV", "value": "high" },
|
||||
{ "source": "NVD", "value": "critical" }
|
||||
],
|
||||
"confidence": "medium",
|
||||
"detectedAt": "2025-09-01T14:00:01Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Source Connectors
|
||||
|
||||
### 5.1 Source Families
|
||||
|
||||
| Family | Examples | Format |
|
||||
|--------|----------|--------|
|
||||
| **Vendor PSIRTs** | Microsoft, Oracle, Cisco, Adobe | CSAF, proprietary |
|
||||
| **Linux Distros** | Red Hat, SUSE, Ubuntu, Debian, Alpine | CSAF, JSON, XML |
|
||||
| **OSS Ecosystems** | OSV, GHSA, npm, PyPI, Maven | OSV, GraphQL |
|
||||
| **CERTs** | CISA (KEV), JVN, CERT-FR | JSON, XML |
|
||||
|
||||
### 5.2 Connector Contract
|
||||
|
||||
```csharp
|
||||
public interface IFeedConnector
|
||||
{
|
||||
string SourceName { get; }
|
||||
|
||||
// Fetch signed feeds or offline mirrors
|
||||
Task FetchAsync(IServiceProvider sp, CancellationToken ct);
|
||||
|
||||
// Normalize to strongly-typed DTOs
|
||||
Task ParseAsync(IServiceProvider sp, CancellationToken ct);
|
||||
|
||||
// Build canonical records with provenance
|
||||
Task MapAsync(IServiceProvider sp, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Connector Lifecycle
|
||||
|
||||
1. **Snapshot** - Fetch with cursor, ETag, rate limiting
|
||||
2. **Parse** - Schema validation, normalization
|
||||
3. **Guard** - AOCWriteGuard enforcement
|
||||
4. **Write** - Append-only insert
|
||||
5. **Event** - Emit `advisory.observation.updated`
|
||||
|
||||
---
|
||||
|
||||
## 6. Version Semantics
|
||||
|
||||
### 6.1 Ecosystem Normalization
|
||||
|
||||
| Ecosystem | Format | Normalization |
|
||||
|-----------|--------|---------------|
|
||||
| npm, PyPI, Maven | SemVer | Intervals with `<`, `>=`, `~`, `^` |
|
||||
| RPM | EVR | `epoch:version-release` with order keys |
|
||||
| DEB | dpkg | Version comparison with order keys |
|
||||
| APK | Alpine | Computed order keys |
|
||||
|
||||
### 6.2 CVSS Handling
|
||||
|
||||
- Normalize CVSS v2/v3/v4 where available
|
||||
- Track all source CVSS values
|
||||
- Effective severity = max (configurable)
|
||||
- Store KEV evidence with source and date
|
||||
|
||||
---
|
||||
|
||||
## 7. Conflict Detection
|
||||
|
||||
### 7.1 Conflict Types
|
||||
|
||||
| Type | Description | Resolution |
|
||||
|------|-------------|------------|
|
||||
| `severity-mismatch` | Different severity ratings | Policy decides |
|
||||
| `affected-range-divergence` | Different version ranges | Most specific wins |
|
||||
| `reference-clash` | Contradictory references | Surface all |
|
||||
| `alias-inconsistency` | Different alias mappings | Union with provenance |
|
||||
| `metadata-gap` | Missing information | Flag for review |
|
||||
|
||||
### 7.2 Conflict Visibility
|
||||
|
||||
Conflicts are never hidden - they are:
|
||||
- Stored in linkset documents
|
||||
- Surfaced in API responses
|
||||
- Included in exports
|
||||
- Displayed in Console UI
|
||||
|
||||
---
|
||||
|
||||
## 8. Deterministic Exports
|
||||
|
||||
### 8.1 JSON Export
|
||||
|
||||
```
|
||||
exports/json/
|
||||
├── CVE/
|
||||
│ ├── 20/
|
||||
│ │ └── CVE-2025-12345.json
|
||||
│ └── ...
|
||||
├── manifest.json
|
||||
└── export-digest.sha256
|
||||
```
|
||||
|
||||
- Deterministic folder structure
|
||||
- Canonical JSON (sorted keys, stable timestamps)
|
||||
- Manifest with SHA-256 per file
|
||||
- Reproducible across runs
|
||||
|
||||
### 8.2 Trivy DB Export
|
||||
|
||||
```
|
||||
exports/trivy/
|
||||
├── db.tar.gz
|
||||
├── metadata.json
|
||||
└── manifest.json
|
||||
```
|
||||
|
||||
- Bolt DB compatible with Trivy
|
||||
- Full and delta modes
|
||||
- ORAS push to registries
|
||||
- Mirror manifests for domains
|
||||
|
||||
### 8.3 Export Determinism
|
||||
|
||||
Running the same export against the same data must produce:
|
||||
- Identical file contents
|
||||
- Identical manifest hashes
|
||||
- Identical export digests
|
||||
|
||||
---
|
||||
|
||||
## 9. Implementation Strategy
|
||||
|
||||
### 9.1 Phase 1: Core Pipeline (Complete)
|
||||
|
||||
- [x] AOCWriteGuard implementation
|
||||
- [x] Observation storage
|
||||
- [x] Basic connectors (Red Hat, SUSE, OSV)
|
||||
- [x] JSON export
|
||||
|
||||
### 9.2 Phase 2: Link-Not-Merge (Complete)
|
||||
|
||||
- [x] Linkset correlation engine
|
||||
- [x] Conflict detection
|
||||
- [x] Event emission
|
||||
- [x] API surface
|
||||
|
||||
### 9.3 Phase 3: Expanded Sources (In Progress)
|
||||
|
||||
- [x] GHSA GraphQL connector
|
||||
- [x] Debian DSA connector
|
||||
- [ ] Alpine secdb connector (CONCELIER-CONN-50-001)
|
||||
- [ ] CISA KEV enrichment (CONCELIER-KEV-51-001)
|
||||
|
||||
### 9.4 Phase 4: Export Enhancements (Planned)
|
||||
|
||||
- [ ] Delta Trivy DB exports
|
||||
- [ ] ORAS registry push
|
||||
- [ ] Attestation hand-off
|
||||
- [ ] Mirror bundle signing
|
||||
|
||||
---
|
||||
|
||||
## 10. API Surface
|
||||
|
||||
### 10.1 Sources & Jobs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/concelier/sources` | GET | `concelier.read` | List sources |
|
||||
| `/api/v1/concelier/sources/{name}/trigger` | POST | `concelier.admin` | Trigger fetch |
|
||||
| `/api/v1/concelier/sources/{name}/pause` | POST | `concelier.admin` | Pause source |
|
||||
| `/api/v1/concelier/jobs/{id}` | GET | `concelier.read` | Job status |
|
||||
|
||||
### 10.2 Exports
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/concelier/exports/json` | POST | `concelier.export` | Trigger JSON export |
|
||||
| `/api/v1/concelier/exports/trivy` | POST | `concelier.export` | Trigger Trivy export |
|
||||
| `/api/v1/concelier/exports/{id}` | GET | `concelier.read` | Export status |
|
||||
|
||||
### 10.3 Search
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/concelier/advisories/{key}` | GET | `concelier.read` | Get advisory |
|
||||
| `/api/v1/concelier/observations/{id}` | GET | `concelier.read` | Get observation |
|
||||
| `/api/v1/concelier/linksets` | GET | `concelier.read` | Query linksets |
|
||||
|
||||
---
|
||||
|
||||
## 11. Storage Model
|
||||
|
||||
### 11.1 Collections
|
||||
|
||||
| Collection | Purpose | Key Indexes |
|
||||
|------------|---------|-------------|
|
||||
| `sources` | Connector catalog | `{_id}` |
|
||||
| `source_state` | Run state | `{sourceName}` |
|
||||
| `documents` | Raw payloads | `{sourceName, uri}` |
|
||||
| `advisory_observations` | Normalized records | `{tenant, upstream.upstreamId}` |
|
||||
| `advisory_linksets` | Correlations | `{tenant, key.vulnerabilityId, key.productKey}` |
|
||||
| `advisory_events` | Change log | `{type, occurredAt}` |
|
||||
| `export_state` | Export cursors | `{exportKind}` |
|
||||
|
||||
### 11.2 GridFS Buckets
|
||||
|
||||
- `fs.documents` - Raw payloads (immutable)
|
||||
- `fs.exports` - Historical archives
|
||||
|
||||
---
|
||||
|
||||
## 12. Event Model
|
||||
|
||||
### 12.1 Events
|
||||
|
||||
| Event | Trigger | Content |
|
||||
|-------|---------|---------|
|
||||
| `advisory.observation.updated@1` | New/superseded observation | IDs, hash, supersedes |
|
||||
| `advisory.linkset.updated@1` | Correlation change | Deltas, conflicts |
|
||||
|
||||
### 12.2 Event Transport
|
||||
|
||||
- Primary: NATS
|
||||
- Fallback: Redis Stream
|
||||
- Offline Kit captures for replay
|
||||
|
||||
---
|
||||
|
||||
## 13. Observability
|
||||
|
||||
### 13.1 Metrics
|
||||
|
||||
- `concelier.fetch.docs_total{source}`
|
||||
- `concelier.fetch.bytes_total{source}`
|
||||
- `concelier.parse.failures_total{source}`
|
||||
- `concelier.observations.write_total{result}`
|
||||
- `concelier.linksets.updated_total{result}`
|
||||
- `concelier.linksets.conflicts_total{type}`
|
||||
- `concelier.export.duration_seconds{kind}`
|
||||
|
||||
### 13.2 Performance Targets
|
||||
|
||||
| Operation | Target |
|
||||
|-----------|--------|
|
||||
| Ingest throughput | 5k docs/min |
|
||||
| Observation write | < 5ms p95 |
|
||||
| Linkset build | < 15ms p95 |
|
||||
| Export (1M advisories) | < 90 seconds |
|
||||
|
||||
---
|
||||
|
||||
## 14. Security Considerations
|
||||
|
||||
### 14.1 Outbound Security
|
||||
|
||||
- Allowlist per connector (domains, protocols)
|
||||
- Proxy support with TLS pinning
|
||||
- Rate limiting per source
|
||||
|
||||
### 14.2 Signature Verification
|
||||
|
||||
- PGP/cosign/x509 verification stored
|
||||
- Failed verification flagged, not rejected
|
||||
- Policy can down-weight unsigned sources
|
||||
|
||||
### 14.3 Determinism
|
||||
|
||||
- Canonical JSON writer
|
||||
- Stable export digests
|
||||
- Reproducible across runs
|
||||
|
||||
---
|
||||
|
||||
## 15. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Concelier architecture | `docs/modules/concelier/architecture.md` |
|
||||
| Link-Not-Merge schema | `docs/modules/concelier/link-not-merge-schema.md` |
|
||||
| Event schemas | `docs/modules/concelier/events/` |
|
||||
| Attestation guide | `docs/modules/concelier/attestation.md` |
|
||||
|
||||
---
|
||||
|
||||
## 16. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0115_0001_0004_concelier_iv.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0113_0001_0002_concelier_ii.md
|
||||
- SPRINT_0114_0001_0003_concelier_iii.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `CONCELIER-AOC-40-001` - AOC enforcement (DONE)
|
||||
- `CONCELIER-LNM-41-001` - Link-Not-Merge (DONE)
|
||||
- `CONCELIER-CONN-50-001` - Alpine connector (IN PROGRESS)
|
||||
- `CONCELIER-KEV-51-001` - KEV enrichment (TODO)
|
||||
- `CONCELIER-EXPORT-55-001` - Delta exports (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 17. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Advisory freshness | < 1 hour from source |
|
||||
| Ingestion accuracy | 100% provenance retention |
|
||||
| Export determinism | 100% hash reproducibility |
|
||||
| Conflict detection | 100% of source divergence |
|
||||
| Source coverage | 20+ authoritative sources |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,338 @@
|
||||
# Evidence Bundle and Replay Contracts
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, data contracts, and implementation strategy for the Evidence Locker module, covering deterministic bundle packaging, attestation contracts, replay payload ingestion, and incident mode operation.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Evidence Locker provides **immutable, deterministic evidence bundles** for audit, compliance, and offline verification. Key capabilities:
|
||||
|
||||
- **Deterministic Bundle Packaging** - Reproducible tar.gz archives with fixed timestamps and sorted entries
|
||||
- **DSSE Attestation Contracts** - In-toto predicates for bundle integrity verification
|
||||
- **Replay Payload Ingestion** - Scanner record capture for deterministic replay
|
||||
- **Incident Mode** - Extended retention and forensic capture during security incidents
|
||||
- **Portable Bundles** - Redacted exports for external auditors
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Evidence Requirements | Use Case |
|
||||
|---------|----------------------|----------|
|
||||
| **Financial Services** | Immutable audit trails, SOC 2 Type II | Compliance evidence for regulators |
|
||||
| **Healthcare** | HIPAA audit requirements | PHI access logging and retention |
|
||||
| **Government/Defense** | Chain of custody, NIST 800-53 | Security incident forensics |
|
||||
| **Critical Infrastructure** | ICS/SCADA audit trails | Operational technology compliance |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability scanning tools export findings as ephemeral reports. Stella Ops differentiates with:
|
||||
- **Cryptographically sealed bundles** with DSSE signatures
|
||||
- **Deterministic replay** for reproducing past scan states
|
||||
- **Offline verification** without network connectivity
|
||||
- **Incident mode** for automatic forensic preservation
|
||||
|
||||
---
|
||||
|
||||
## 3. Technical Architecture
|
||||
|
||||
### 3.1 Bundle Layout (v1)
|
||||
|
||||
```
|
||||
evidence-bundle-<id>.tar.gz
|
||||
├── manifest.json # Bundle metadata and file inventory
|
||||
├── signature.json # DSSE envelope with key metadata
|
||||
├── bundle.json # Locker metadata (ids, status, root hash)
|
||||
├── checksums.txt # SHA-256 per-entry hashes + Merkle root
|
||||
├── instructions.txt # Offline verification steps
|
||||
├── observations.ndjson # Advisory observations (sorted)
|
||||
├── linksets.ndjson # Component linkages (sorted)
|
||||
└── timeline.ndjson # Time anchors (optional)
|
||||
```
|
||||
|
||||
### 3.2 Determinism Rules
|
||||
|
||||
All bundles must be **bit-for-bit reproducible**:
|
||||
|
||||
| Property | Rule |
|
||||
|----------|------|
|
||||
| **Gzip timestamp** | Pinned to `2025-01-01T00:00:00Z` |
|
||||
| **File permissions** | `0644` for all entries |
|
||||
| **Owner/Group** | `0:0` (root) |
|
||||
| **mtime/atime/ctime** | Fixed epoch value |
|
||||
| **JSON serialization** | `JsonSerializerDefaults.Web` + indent=2 |
|
||||
| **NDJSON ordering** | Sorted by `advisoryId`, then `component`, ascending |
|
||||
| **Hash format** | Lower-case hex, SHA-256 |
|
||||
| **Timestamps** | UTC ISO-8601 (RFC3339) |
|
||||
|
||||
### 3.3 Attestation Contract (v1)
|
||||
|
||||
**DSSE Envelope Structure:**
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.stellaops.evidence+json",
|
||||
"payload": "<base64(manifest.json)>",
|
||||
"signatures": [{
|
||||
"keyid": "evidence-locker-ed25519-01",
|
||||
"sig": "<base64(Ed25519 signature)>"
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
**Required Claim Set:**
|
||||
|
||||
| Claim | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| `bundle_id` | UUID v4 | Unique bundle identifier |
|
||||
| `produced_at` | ISO-8601 | UTC production timestamp |
|
||||
| `producer` | string | `evidence-locker:<region>` |
|
||||
| `subject_digest` | string | OCI digest of bundle |
|
||||
| `hashes` | map | `{ path: sha256 }` for each file |
|
||||
| `sbom` | array | SBOM digests and mediaTypes |
|
||||
| `vex` | array | VEX doc digests and versions |
|
||||
| `replay_manifest` | object | Optional replay digest + sequence |
|
||||
| `transparency` | object | Optional Rekor log entry |
|
||||
| `signing_profile` | string | `sovereign-default`, `fips`, `gost`, `pq-experimental` |
|
||||
|
||||
### 3.4 Replay Payload Contract
|
||||
|
||||
**NDJSON Record Structure:**
|
||||
|
||||
```json
|
||||
{
|
||||
"scanId": "uuid",
|
||||
"tenantId": "string",
|
||||
"subjectDigest": "sha256:...",
|
||||
"scanKind": "sbom|vuln|policy",
|
||||
"startedAtUtc": "ISO-8601",
|
||||
"completedAtUtc": "ISO-8601",
|
||||
"artifacts": [
|
||||
{ "type": "sbom|vex|log", "digest": "sha256:...", "uri": "..." }
|
||||
],
|
||||
"provenance": {
|
||||
"dsseEnvelope": "<base64>",
|
||||
"transparencyLog": { "rekorUUID": "...", "logIndex": 123 }
|
||||
},
|
||||
"summary": { "findings": 42, "advisories": 15, "policies": 3 }
|
||||
}
|
||||
```
|
||||
|
||||
**Ordering:** Sorted by `recordedAtUtc`, then `scanId` ascending.
|
||||
|
||||
---
|
||||
|
||||
## 4. Implementation Strategy
|
||||
|
||||
### 4.1 Phase 1: Bundle Foundation (Complete)
|
||||
|
||||
- [x] Postgres schema with RLS per tenant
|
||||
- [x] Object-store abstraction (local + S3 with optional WORM)
|
||||
- [x] Deterministic `bundle.tgz` packaging
|
||||
- [x] Incident mode with extended retention
|
||||
- [x] Portable bundle export with redacted metadata
|
||||
- [x] Crypto provider registry integration (`EVID-CRYPTO-90-001`)
|
||||
|
||||
### 4.2 Phase 2: Attestation & Replay (In Progress)
|
||||
|
||||
- [ ] DSSE envelope signing with configurable provider
|
||||
- [ ] Replay payload ingestion API
|
||||
- [ ] CLI `stella scan --record` integration
|
||||
- [ ] Bundle verification CLI (`stella verify --bundle`)
|
||||
- [ ] Rekor transparency log integration (optional)
|
||||
|
||||
### 4.3 Phase 3: Automation & Integration (Planned)
|
||||
|
||||
- [ ] Orchestrator hooks for automatic bundle creation
|
||||
- [ ] Export Center integration for mirror bundles
|
||||
- [ ] Timeline event emission for audit dashboards
|
||||
- [ ] Retention policy automation with legal hold support
|
||||
|
||||
---
|
||||
|
||||
## 5. API Surface
|
||||
|
||||
### 5.1 Evidence Bundle APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/evidence` | GET | `evidence:read` | List bundles with filters |
|
||||
| `/evidence/{bundleId}` | GET | `evidence:read` | Get bundle metadata |
|
||||
| `/evidence/{bundleId}/download` | GET | `evidence:read` | Download sealed bundle |
|
||||
| `/evidence/{bundleId}/portable` | GET | `evidence:read` | Download portable bundle |
|
||||
| `/evidence` | POST | `evidence:create` | Create new bundle |
|
||||
| `/evidence/{bundleId}/hold` | POST | `evidence:hold` | Apply legal hold |
|
||||
|
||||
### 5.2 Replay APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/replay/records` | POST | `replay:write` | Ingest replay records (NDJSON) |
|
||||
| `/replay/records` | GET | `replay:read` | Query replay records |
|
||||
| `/replay/{recordId}/verify` | POST | `replay:read` | Verify record integrity |
|
||||
| `/replay/{recordId}/diff` | POST | `replay:read` | Compare two records |
|
||||
|
||||
### 5.3 CLI Commands
|
||||
|
||||
```bash
|
||||
# Record scan for replay
|
||||
stella scan --record --output replay.ndjson <image>
|
||||
|
||||
# Verify bundle integrity
|
||||
stella verify --bundle evidence-bundle.tar.gz
|
||||
|
||||
# Replay past scan
|
||||
stella replay --record replay.ndjson --compare current.json
|
||||
|
||||
# Diff two scan results
|
||||
stella replay diff --before before.ndjson --after after.ndjson
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Incident Mode
|
||||
|
||||
### 6.1 Activation
|
||||
|
||||
Incident mode is a **service-wide switch** for forensic fidelity during suspected compromise or SLO breach.
|
||||
|
||||
**Configuration:**
|
||||
|
||||
```yaml
|
||||
EvidenceLocker:
|
||||
Incident:
|
||||
Enabled: true
|
||||
RetentionExtensionDays: 60
|
||||
CaptureRequestSnapshot: true
|
||||
```
|
||||
|
||||
### 6.2 Behavior Changes
|
||||
|
||||
| Feature | Normal Mode | Incident Mode |
|
||||
|---------|-------------|---------------|
|
||||
| **Retention** | Standard policy | Extended by `RetentionExtensionDays` |
|
||||
| **Request capture** | None | Full request snapshots to object store |
|
||||
| **Manifest metadata** | Standard | Includes `incident.*` fields |
|
||||
| **Timeline events** | Standard | Activation/deactivation events |
|
||||
| **Audit verbosity** | Normal | Enhanced with `incident_reason` |
|
||||
|
||||
### 6.3 Activation API
|
||||
|
||||
```bash
|
||||
# Activate incident mode
|
||||
stella evidence incident activate --reason "Security event investigation"
|
||||
|
||||
# Deactivate incident mode
|
||||
stella evidence incident deactivate --reason "Investigation complete"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. Offline Verification
|
||||
|
||||
### 7.1 Portable Bundle Contents
|
||||
|
||||
```
|
||||
portable-bundle-v1.tgz
|
||||
├── manifest.json # Redacted (no tenant/storage identifiers)
|
||||
├── signature.json # DSSE envelope
|
||||
├── checksums.txt # SHA-256 hashes
|
||||
├── verify-offline.sh # POSIX verification script
|
||||
├── observations.ndjson # Advisory data
|
||||
├── linksets.ndjson # Linkage data
|
||||
└── README.txt # Verification instructions
|
||||
```
|
||||
|
||||
### 7.2 Verification Steps
|
||||
|
||||
1. Extract archive
|
||||
2. Run `./verify-offline.sh` (computes hashes, validates signature)
|
||||
3. Compare manifest hash with external attestation
|
||||
4. If Rekor transparency present, verify inclusion proof
|
||||
|
||||
---
|
||||
|
||||
## 8. Determinism Requirements
|
||||
|
||||
All Evidence Locker operations must maintain determinism:
|
||||
|
||||
1. **Same inputs = same bundle hash** for identical observations/linksets
|
||||
2. **Timestamps in UTC ISO-8601** format only
|
||||
3. **Tenant IDs lowercase** and included in manifest
|
||||
4. **Crypto provider version** recorded in audit material
|
||||
5. **NDJSON sorted** by canonical key ordering
|
||||
|
||||
---
|
||||
|
||||
## 9. Testing Strategy
|
||||
|
||||
### 9.1 Unit Tests
|
||||
|
||||
- Bundle packaging produces identical hash for identical inputs
|
||||
- DSSE envelope validates against registered keys
|
||||
- Incident mode extends retention correctly
|
||||
- Replay records sorted deterministically
|
||||
|
||||
### 9.2 Integration Tests
|
||||
|
||||
- Full bundle creation workflow with object store
|
||||
- CLI record/verify/replay cycle
|
||||
- Portable bundle extraction and verification
|
||||
- Cross-tenant isolation enforcement
|
||||
|
||||
### 9.3 Golden Fixtures
|
||||
|
||||
Located at `tests/EvidenceLocker/Fixtures/`:
|
||||
- `golden-bundle-v1.tar.gz` - Reference bundle with known hash
|
||||
- `golden-replay-records.ndjson` - Reference replay records
|
||||
- `golden-dsse-envelope.json` - Reference DSSE signature
|
||||
|
||||
---
|
||||
|
||||
## 10. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Evidence Locker architecture | `docs/modules/evidence-locker/` |
|
||||
| Bundle packaging spec | `docs/modules/evidence-locker/bundle-packaging.md` |
|
||||
| Attestation contract | `docs/modules/evidence-locker/attestation-contract.md` |
|
||||
| Replay payload contract | `docs/modules/evidence-locker/replay-payload-contract.md` |
|
||||
| Incident mode spec | `docs/modules/evidence-locker/incident-mode.md` |
|
||||
| Crypto provider registry | `docs/security/crypto-registry-decision-2025-11-18.md` |
|
||||
|
||||
---
|
||||
|
||||
## 11. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0161_0001_0001_evidencelocker.md
|
||||
- **CLI Integration:** SPRINT_0187_0001_0001_evidence_locker_cli_integration.md
|
||||
- **Coordination:** SPRINT_0160_0001_0001_export_evidence.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `EVID-OBS-54-002` - Finalize bundle packaging + DSSE layout
|
||||
- `EVID-REPLAY-187-001` - Implement replay ingestion/retention APIs
|
||||
- `CLI-REPLAY-187-002` - Add CLI record/verify/replay commands
|
||||
- `EVID-CRYPTO-90-001` - Crypto provider registry routing (DONE)
|
||||
|
||||
---
|
||||
|
||||
## 12. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Bundle hash reproducibility | 100% (bit-identical) |
|
||||
| DSSE verification success rate | 100% for valid bundles |
|
||||
| Replay record ingestion latency | < 100ms p99 |
|
||||
| Incident mode activation time | < 1 second |
|
||||
| Offline verification success | Works without network |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,449 @@
|
||||
# Export Center and Reporting Strategy
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, profile system, and implementation strategy for the Export Center module, covering bundle generation, adapter architecture, distribution channels, and compliance reporting.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Export Center is the **dedicated service layer for packaging reproducible evidence bundles**. Key capabilities:
|
||||
|
||||
- **Profile-Based Exports** - 6+ profile types (JSON, Trivy, Mirror, DevPortal)
|
||||
- **Deterministic Bundles** - Bit-for-bit reproducible outputs with DSSE signatures
|
||||
- **Multi-Format Adapters** - Pluggable adapters for different consumer needs
|
||||
- **Distribution Channels** - HTTP download, OCI push, object storage
|
||||
- **Compliance Ready** - Provenance, signatures, audit trails for SOC 2/FedRAMP
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Export Requirements | Use Case |
|
||||
|---------|---------------------|----------|
|
||||
| **Compliance Teams** | Signed bundles, provenance | Audit evidence |
|
||||
| **Security Vendors** | Trivy DB format | Scanner integration |
|
||||
| **Air-Gap Operators** | Offline mirrors | Disconnected environments |
|
||||
| **Development Teams** | JSON exports | CI/CD integration |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability platforms offer basic CSV/JSON exports. Stella Ops differentiates with:
|
||||
- **Reproducible bundles** with cryptographic verification
|
||||
- **Multi-format adapters** (Trivy, CycloneDX, SPDX, custom)
|
||||
- **OCI distribution** for container-native workflows
|
||||
- **Provenance attestations** meeting SLSA Level 2+
|
||||
- **Delta exports** for bandwidth-efficient updates
|
||||
|
||||
---
|
||||
|
||||
## 3. Profile System
|
||||
|
||||
### 3.1 Built-in Profiles
|
||||
|
||||
| Profile | Variant | Description | Output Format |
|
||||
|---------|---------|-------------|---------------|
|
||||
| **JSON** | `raw` | Unprocessed advisory/VEX data | `.jsonl.zst` |
|
||||
| **JSON** | `policy` | Policy-evaluated findings | `.jsonl.zst` |
|
||||
| **Trivy** | `db` | Trivy vulnerability database | SQLite |
|
||||
| **Trivy** | `java-db` | Trivy Java advisory database | SQLite |
|
||||
| **Mirror** | `full` | Complete offline mirror | Filesystem tree |
|
||||
| **Mirror** | `delta` | Incremental updates | Filesystem tree |
|
||||
| **DevPortal** | `offline` | Developer portal assets | Archive |
|
||||
|
||||
### 3.2 Profile Configuration
|
||||
|
||||
```yaml
|
||||
apiVersion: stellaops.io/export.v1
|
||||
kind: ExportProfile
|
||||
metadata:
|
||||
name: compliance-report-monthly
|
||||
tenant: acme-corp
|
||||
|
||||
spec:
|
||||
kind: json
|
||||
variant: policy
|
||||
schedule: "0 0 1 * *" # Monthly
|
||||
|
||||
selectors:
|
||||
tenants: ["acme-corp"]
|
||||
timeWindow: "30d"
|
||||
severities: ["critical", "high"]
|
||||
ecosystems: ["npm", "maven", "pypi"]
|
||||
|
||||
options:
|
||||
compression: zstd
|
||||
encryption:
|
||||
enabled: true
|
||||
recipients: ["age1..."]
|
||||
signing:
|
||||
enabled: true
|
||||
keyRef: "kms://acme-corp/export-signing-key"
|
||||
|
||||
distribution:
|
||||
- type: http
|
||||
retention: 90d
|
||||
- type: oci
|
||||
registry: "registry.acme.com/exports"
|
||||
repository: "compliance-reports"
|
||||
```
|
||||
|
||||
### 3.3 Selector Expressions
|
||||
|
||||
| Selector | Description | Example |
|
||||
|----------|-------------|---------|
|
||||
| `tenants` | Tenant filter | `["acme-*"]` |
|
||||
| `timeWindow` | Time range | `"30d"`, `"2025-01-01/2025-12-31"` |
|
||||
| `products` | Product PURLs | `["pkg:npm/*", "pkg:maven/org.apache/*"]` |
|
||||
| `severities` | Severity filter | `["critical", "high"]` |
|
||||
| `ecosystems` | Package ecosystems | `["npm", "maven"]` |
|
||||
| `policyVersions` | Policy snapshot IDs | `["rev-42", "rev-43"]` |
|
||||
|
||||
---
|
||||
|
||||
## 4. Adapter Architecture
|
||||
|
||||
### 4.1 Adapter Contract
|
||||
|
||||
```csharp
|
||||
public interface IExportAdapter
|
||||
{
|
||||
string Kind { get; } // "json" | "trivy" | "mirror"
|
||||
string Variant { get; } // "raw" | "policy" | "db"
|
||||
|
||||
Task<ExportResult> RunAsync(
|
||||
ExportContext context,
|
||||
IAsyncEnumerable<ExportRecord> records,
|
||||
CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 JSON Adapter
|
||||
|
||||
**Responsibilities:**
|
||||
- Canonical JSON serialization (sorted keys, RFC3339 UTC)
|
||||
- Linkset preservation for traceability
|
||||
- Zstandard compression
|
||||
- AOC guardrails (no derived modifications to raw fields)
|
||||
|
||||
**Output:**
|
||||
```
|
||||
export/
|
||||
├── advisories.jsonl.zst
|
||||
├── vex-statements.jsonl.zst
|
||||
├── findings.jsonl.zst (policy variant)
|
||||
└── manifest.json
|
||||
```
|
||||
|
||||
### 4.3 Trivy Adapter
|
||||
|
||||
**Responsibilities:**
|
||||
- Map Stella Ops advisory schema to Trivy DB format
|
||||
- Handle namespace collisions across ecosystems
|
||||
- Validate against supported Trivy schema versions
|
||||
- Generate severity distribution summary
|
||||
|
||||
**Compatibility:**
|
||||
- Trivy DB schema v2 (current)
|
||||
- Fail-fast on unsupported schema versions
|
||||
|
||||
### 4.4 Mirror Adapter
|
||||
|
||||
**Responsibilities:**
|
||||
- Build self-contained filesystem layout
|
||||
- Delta comparison against base manifest
|
||||
- Optional encryption of `/data` subtree
|
||||
- OCI layer generation
|
||||
|
||||
**Layout:**
|
||||
```
|
||||
mirror/
|
||||
├── manifests/
|
||||
│ ├── advisories.manifest.json
|
||||
│ └── vex.manifest.json
|
||||
├── data/
|
||||
│ ├── raw/
|
||||
│ │ ├── advisories/
|
||||
│ │ └── vex/
|
||||
│ └── policy/
|
||||
│ └── findings/
|
||||
├── indexes/
|
||||
│ └── by-cve.index
|
||||
└── manifest.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Bundle Structure
|
||||
|
||||
### 5.1 Export Manifest
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "1.0.0",
|
||||
"exportId": "export-20251129-001",
|
||||
"profile": {
|
||||
"kind": "json",
|
||||
"variant": "policy",
|
||||
"name": "compliance-report-monthly"
|
||||
},
|
||||
"tenant": "acme-corp",
|
||||
"generatedAt": "2025-11-29T12:00:00Z",
|
||||
"generatedBy": "export-center-worker-1",
|
||||
"selectors": {
|
||||
"timeWindow": "2025-11-01/2025-11-30",
|
||||
"severities": ["critical", "high"]
|
||||
},
|
||||
"contents": [
|
||||
{
|
||||
"path": "findings.jsonl.zst",
|
||||
"size": 1048576,
|
||||
"digest": "sha256:abc123...",
|
||||
"recordCount": 45230
|
||||
}
|
||||
],
|
||||
"totals": {
|
||||
"advisories": 45230,
|
||||
"vexStatements": 12450,
|
||||
"findings": 8920
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Provenance Attestation
|
||||
|
||||
```json
|
||||
{
|
||||
"predicateType": "https://slsa.dev/provenance/v1",
|
||||
"subject": [
|
||||
{
|
||||
"name": "export-20251129-001.tar.gz",
|
||||
"digest": { "sha256": "def456..." }
|
||||
}
|
||||
],
|
||||
"predicate": {
|
||||
"buildDefinition": {
|
||||
"buildType": "https://stellaops.io/export/v1",
|
||||
"externalParameters": {
|
||||
"profile": "compliance-report-monthly",
|
||||
"selectors": { "...": "..." }
|
||||
}
|
||||
},
|
||||
"runDetails": {
|
||||
"builder": {
|
||||
"id": "https://stellaops.io/export-center",
|
||||
"version": "1.2.3"
|
||||
},
|
||||
"metadata": {
|
||||
"invocationId": "export-run-123",
|
||||
"startedOn": "2025-11-29T12:00:00Z",
|
||||
"finishedOn": "2025-11-29T12:05:00Z"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Distribution Channels
|
||||
|
||||
### 6.1 HTTP Download
|
||||
|
||||
```bash
|
||||
# Download bundle
|
||||
curl -H "Authorization: Bearer $TOKEN" \
|
||||
"https://export.stellaops.io/api/export/runs/{id}/download" \
|
||||
-o export-bundle.tar.gz
|
||||
|
||||
# Verify signature
|
||||
cosign verify-blob --key export-key.pub \
|
||||
--signature export-bundle.sig \
|
||||
export-bundle.tar.gz
|
||||
```
|
||||
|
||||
**Features:**
|
||||
- Chunked transfer encoding
|
||||
- Range request support (resumable)
|
||||
- `X-Export-Digest` header
|
||||
- Optional encryption metadata
|
||||
|
||||
### 6.2 OCI Push
|
||||
|
||||
```bash
|
||||
# Pull from registry
|
||||
oras pull registry.example.com/exports/compliance:2025-11
|
||||
|
||||
# Verify annotations
|
||||
oras manifest fetch registry.example.com/exports/compliance:2025-11 | jq
|
||||
```
|
||||
|
||||
**Annotations:**
|
||||
- `io.stellaops.export.profile`
|
||||
- `io.stellaops.export.tenant`
|
||||
- `io.stellaops.export.manifest-digest`
|
||||
- `io.stellaops.export.provenance-ref`
|
||||
|
||||
### 6.3 Object Storage
|
||||
|
||||
```yaml
|
||||
distribution:
|
||||
- type: object
|
||||
provider: s3
|
||||
bucket: stella-exports
|
||||
prefix: "${tenant}/${exportId}"
|
||||
retention: 365d
|
||||
immutable: true
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. Implementation Strategy
|
||||
|
||||
### 7.1 Phase 1: Core Infrastructure (Complete)
|
||||
|
||||
- [x] Profile CRUD APIs
|
||||
- [x] JSON adapter (raw, policy)
|
||||
- [x] HTTP download distribution
|
||||
- [x] Manifest generation
|
||||
|
||||
### 7.2 Phase 2: Trivy Integration (Complete)
|
||||
|
||||
- [x] Trivy DB adapter
|
||||
- [x] Trivy Java DB adapter
|
||||
- [x] Schema version validation
|
||||
- [x] Compatibility testing
|
||||
|
||||
### 7.3 Phase 3: Mirror & Distribution (In Progress)
|
||||
|
||||
- [x] Mirror full adapter
|
||||
- [x] Mirror delta adapter
|
||||
- [ ] OCI push distribution (EXPORT-OCI-45-001)
|
||||
- [ ] DevPortal adapter (EXPORT-DEV-46-001)
|
||||
|
||||
### 7.4 Phase 4: Advanced Features (Planned)
|
||||
|
||||
- [ ] Encryption at rest
|
||||
- [ ] Scheduled exports
|
||||
- [ ] Retention policies
|
||||
- [ ] Cross-tenant exports (with approval)
|
||||
|
||||
---
|
||||
|
||||
## 8. API Surface
|
||||
|
||||
### 8.1 Profile Management
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/export/profiles` | GET | `export:read` | List profiles |
|
||||
| `/api/export/profiles` | POST | `export:profile:manage` | Create profile |
|
||||
| `/api/export/profiles/{id}` | PATCH | `export:profile:manage` | Update profile |
|
||||
| `/api/export/profiles/{id}` | DELETE | `export:profile:manage` | Delete profile |
|
||||
|
||||
### 8.2 Export Runs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/export/runs` | POST | `export:run` | Start export |
|
||||
| `/api/export/runs/{id}` | GET | `export:read` | Get status |
|
||||
| `/api/export/runs/{id}/events` | SSE | `export:read` | Stream progress |
|
||||
| `/api/export/runs/{id}/cancel` | POST | `export:run` | Cancel export |
|
||||
|
||||
### 8.3 Downloads
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/export/runs/{id}/download` | GET | `export:download` | Download bundle |
|
||||
| `/api/export/runs/{id}/manifest` | GET | `export:read` | Get manifest |
|
||||
| `/api/export/runs/{id}/provenance` | GET | `export:read` | Get provenance |
|
||||
|
||||
---
|
||||
|
||||
## 9. Observability
|
||||
|
||||
### 9.1 Metrics
|
||||
|
||||
- `exporter_run_duration_seconds{profile,tenant}`
|
||||
- `exporter_run_bytes_total{profile}`
|
||||
- `exporter_run_failures_total{error_code}`
|
||||
- `exporter_active_runs{tenant}`
|
||||
- `exporter_distribution_push_seconds{type}`
|
||||
|
||||
### 9.2 Logs
|
||||
|
||||
Structured fields:
|
||||
- `run_id`, `tenant`, `profile_kind`, `adapter`
|
||||
- `phase` (plan, resolve, adapter, manifest, sign, distribute)
|
||||
- `correlation_id`, `error_code`
|
||||
|
||||
---
|
||||
|
||||
## 10. Security Considerations
|
||||
|
||||
### 10.1 Access Control
|
||||
|
||||
- Tenant claim enforced at every query
|
||||
- Cross-tenant selectors rejected (unless approved)
|
||||
- RBAC scopes: `export:profile:manage`, `export:run`, `export:read`, `export:download`
|
||||
|
||||
### 10.2 Encryption
|
||||
|
||||
- Optional encryption per profile
|
||||
- Keys derived from Authority-managed KMS
|
||||
- Mirror encryption uses tenant-specific recipients
|
||||
- Transport security (TLS) always required
|
||||
|
||||
### 10.3 Signing
|
||||
|
||||
- Cosign-compatible signatures
|
||||
- SLSA Level 2 attestations by default
|
||||
- Detached signatures stored alongside manifests
|
||||
|
||||
---
|
||||
|
||||
## 11. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Export Center architecture | `docs/modules/export-center/architecture.md` |
|
||||
| Profile definitions | `docs/modules/export-center/profiles.md` |
|
||||
| API reference | `docs/modules/export-center/api.md` |
|
||||
| DevPortal bundle spec | `docs/modules/export-center/devportal-offline.md` |
|
||||
|
||||
---
|
||||
|
||||
## 12. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0160_0001_0001_export_evidence.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0161_0001_0001_evidencelocker.md
|
||||
- SPRINT_0125_0001_0001_mirror.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `EXPORT-CORE-40-001` - Profile system (DONE)
|
||||
- `EXPORT-JSON-41-001` - JSON adapters (DONE)
|
||||
- `EXPORT-TRIVY-42-001` - Trivy adapters (DONE)
|
||||
- `EXPORT-OCI-45-001` - OCI distribution (IN PROGRESS)
|
||||
- `EXPORT-DEV-46-001` - DevPortal adapter (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 13. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Export reproducibility | 100% bit-identical |
|
||||
| Bundle generation time | < 5 min for 100k records |
|
||||
| Signature verification | 100% success rate |
|
||||
| Distribution availability | 99.9% uptime |
|
||||
| Retention compliance | 100% policy adherence |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,407 @@
|
||||
# Findings Ledger and Immutable Audit Trail
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, ledger semantics, and implementation strategy for the Findings Ledger module, covering append-only events, Merkle anchoring, projections, and deterministic exports.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Findings Ledger provides **immutable, auditable records** of all vulnerability findings and their state transitions. Key capabilities:
|
||||
|
||||
- **Append-Only Events** - Every finding change recorded permanently
|
||||
- **Merkle Anchoring** - Cryptographic proof of event ordering
|
||||
- **Projections** - Materialized current state views
|
||||
- **Deterministic Exports** - Reproducible compliance archives
|
||||
- **Chain Integrity** - Hash-linked event sequences per tenant
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Ledger Requirements | Use Case |
|
||||
|---------|---------------------|----------|
|
||||
| **Compliance** | Immutable audit trail | SOC 2, FedRAMP evidence |
|
||||
| **Security Teams** | Finding history | Investigation timelines |
|
||||
| **Legal/eDiscovery** | Tamper-proof records | Litigation support |
|
||||
| **Auditors** | Verifiable exports | Third-party attestation |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability tools provide mutable databases. Stella Ops differentiates with:
|
||||
- **Append-only architecture** ensuring no record deletion
|
||||
- **Merkle trees** for cryptographic verification
|
||||
- **Chain integrity** with hash-linked events
|
||||
- **Deterministic exports** for reproducible audits
|
||||
- **Air-gap support** with signed bundles
|
||||
|
||||
---
|
||||
|
||||
## 3. Event Model
|
||||
|
||||
### 3.1 Ledger Event Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "uuid",
|
||||
"type": "finding.status.changed",
|
||||
"tenant": "acme-corp",
|
||||
"chainId": "chain-uuid",
|
||||
"sequence": 12345,
|
||||
"policyVersion": "sha256:abc...",
|
||||
"finding": {
|
||||
"id": "artifact:sha256:...|pkg:npm/lodash",
|
||||
"artifactId": "sha256:...",
|
||||
"vulnId": "CVE-2025-12345"
|
||||
},
|
||||
"actor": {
|
||||
"id": "user:jane@acme.com",
|
||||
"type": "human"
|
||||
},
|
||||
"occurredAt": "2025-11-29T12:00:00Z",
|
||||
"recordedAt": "2025-11-29T12:00:01Z",
|
||||
"payload": {
|
||||
"previousStatus": "open",
|
||||
"newStatus": "triaged",
|
||||
"reason": "Under investigation"
|
||||
},
|
||||
"evidenceBundleRef": "bundle://tenant/2025/11/29/...",
|
||||
"eventHash": "sha256:...",
|
||||
"previousHash": "sha256:...",
|
||||
"merkleLeafHash": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
### 3.2 Event Types
|
||||
|
||||
| Type | Trigger | Payload |
|
||||
|------|---------|---------|
|
||||
| `finding.discovered` | New finding | severity, purl, advisory |
|
||||
| `finding.status.changed` | State transition | old/new status, reason |
|
||||
| `finding.verdict.changed` | Policy decision | verdict, rules matched |
|
||||
| `finding.vex.applied` | VEX override | status, justification |
|
||||
| `finding.assigned` | Owner change | assignee, team |
|
||||
| `finding.commented` | Annotation | comment text (redacted) |
|
||||
| `finding.resolved` | Resolution | resolution type, version |
|
||||
|
||||
### 3.3 Chain Semantics
|
||||
|
||||
- Each tenant has one or more event chains
|
||||
- Events are strictly ordered by sequence number
|
||||
- `previousHash` links to prior event for integrity
|
||||
- Chain forks are prohibited (409 on conflict)
|
||||
|
||||
---
|
||||
|
||||
## 4. Merkle Anchoring
|
||||
|
||||
### 4.1 Tree Structure
|
||||
|
||||
```
|
||||
Root Hash
|
||||
/ \
|
||||
Hash(A+B) Hash(C+D)
|
||||
/ \ / \
|
||||
H(E1) H(E2) H(E3) H(E4)
|
||||
| | | |
|
||||
Event1 Event2 Event3 Event4
|
||||
```
|
||||
|
||||
### 4.2 Anchoring Process
|
||||
|
||||
1. **Batch collection** - Events accumulate in windows (default 15 min)
|
||||
2. **Tree construction** - Leaves are event hashes
|
||||
3. **Root computation** - Merkle root represents batch
|
||||
4. **Anchor record** - Root stored with timestamp
|
||||
5. **Optional external** - Root can be published to external ledger
|
||||
|
||||
### 4.3 Configuration
|
||||
|
||||
```yaml
|
||||
findings:
|
||||
ledger:
|
||||
merkle:
|
||||
batchSize: 1000
|
||||
windowDuration: 00:15:00
|
||||
algorithm: sha256
|
||||
externalAnchor:
|
||||
enabled: false
|
||||
type: rekor # or custom
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Projections
|
||||
|
||||
### 5.1 Purpose
|
||||
|
||||
Projections provide **current state** views derived from event history. They are:
|
||||
- Materialized for fast queries
|
||||
- Reconstructible from events
|
||||
- Validated via `cycleHash`
|
||||
|
||||
### 5.2 Finding Projection
|
||||
|
||||
```json
|
||||
{
|
||||
"tenantId": "acme-corp",
|
||||
"findingId": "artifact:sha256:...|pkg:npm/lodash@4.17.20",
|
||||
"policyVersion": "sha256:5f38c...",
|
||||
"status": "triaged",
|
||||
"severity": 6.7,
|
||||
"riskScore": 85.2,
|
||||
"riskSeverity": "high",
|
||||
"riskProfileVersion": "v2.1",
|
||||
"labels": {
|
||||
"kev": true,
|
||||
"runtime": "exposed"
|
||||
},
|
||||
"currentEventId": "uuid",
|
||||
"cycleHash": "sha256:...",
|
||||
"policyRationale": [
|
||||
"explain://tenant/findings/...",
|
||||
"policy://tenant/policy-v1/rationale/accepted"
|
||||
],
|
||||
"updatedAt": "2025-11-29T12:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Projection Refresh
|
||||
|
||||
| Trigger | Action |
|
||||
|---------|--------|
|
||||
| New event | Incremental update |
|
||||
| Policy change | Full recalculation |
|
||||
| Manual request | On-demand rebuild |
|
||||
| Scheduled | Periodic validation |
|
||||
|
||||
---
|
||||
|
||||
## 6. Export Capabilities
|
||||
|
||||
### 6.1 Export Shapes
|
||||
|
||||
| Shape | Description | Use Case |
|
||||
|-------|-------------|----------|
|
||||
| `canonical` | Full event detail | Complete audit |
|
||||
| `compact` | Summary fields only | Quick reports |
|
||||
|
||||
### 6.2 Export Types
|
||||
|
||||
**Findings Export:**
|
||||
```json
|
||||
{
|
||||
"eventSequence": 12345,
|
||||
"observedAt": "2025-11-29T12:00:00Z",
|
||||
"findingId": "artifact:...|pkg:...",
|
||||
"policyVersion": "sha256:...",
|
||||
"status": "triaged",
|
||||
"severity": 6.7,
|
||||
"cycleHash": "sha256:...",
|
||||
"evidenceBundleRef": "bundle://...",
|
||||
"provenance": {
|
||||
"policyVersion": "sha256:...",
|
||||
"cycleHash": "sha256:...",
|
||||
"ledgerEventHash": "sha256:..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 6.3 Export Formats
|
||||
|
||||
- **JSON** - Paged API responses
|
||||
- **NDJSON** - Streaming exports
|
||||
- **Bundle** - Signed archive packages
|
||||
|
||||
---
|
||||
|
||||
## 7. Implementation Strategy
|
||||
|
||||
### 7.1 Phase 1: Core Ledger (Complete)
|
||||
|
||||
- [x] Append-only event store
|
||||
- [x] Hash-linked chains
|
||||
- [x] Basic projection engine
|
||||
- [x] REST API surface
|
||||
|
||||
### 7.2 Phase 2: Merkle & Exports (In Progress)
|
||||
|
||||
- [x] Merkle tree construction
|
||||
- [x] Batch anchoring
|
||||
- [ ] External anchor integration (LEDGER-MERKLE-50-001)
|
||||
- [ ] Deterministic NDJSON exports (LEDGER-EXPORT-51-001)
|
||||
|
||||
### 7.3 Phase 3: Advanced Features (Planned)
|
||||
|
||||
- [ ] Chain integrity verification CLI
|
||||
- [ ] Projection replay tooling
|
||||
- [ ] Cross-tenant federation
|
||||
- [ ] Long-term archival
|
||||
|
||||
---
|
||||
|
||||
## 8. API Surface
|
||||
|
||||
### 8.1 Events
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/v1/ledger/events` | GET | `vuln:audit` | List ledger events |
|
||||
| `/v1/ledger/events` | POST | `vuln:operate` | Append event |
|
||||
|
||||
### 8.2 Projections
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/v1/ledger/projections/findings` | GET | `vuln:view` | List projections |
|
||||
|
||||
### 8.3 Exports
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/v1/ledger/export/findings` | GET | `vuln:audit` | Export findings |
|
||||
| `/v1/ledger/export/vex` | GET | `vuln:audit` | Export VEX |
|
||||
| `/v1/ledger/export/advisories` | GET | `vuln:audit` | Export advisories |
|
||||
| `/v1/ledger/export/sboms` | GET | `vuln:audit` | Export SBOMs |
|
||||
|
||||
### 8.4 Attestations
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/v1/ledger/attestations` | GET | `vuln:audit` | List verifications |
|
||||
|
||||
---
|
||||
|
||||
## 9. Storage Model
|
||||
|
||||
### 9.1 Collections
|
||||
|
||||
| Collection | Purpose | Key Indexes |
|
||||
|------------|---------|-------------|
|
||||
| `ledger_events` | Append-only events | `{tenant, chainId, sequence}` |
|
||||
| `ledger_chains` | Chain metadata | `{tenant, chainId}` |
|
||||
| `ledger_merkle_roots` | Anchor records | `{tenant, batchId, anchoredAt}` |
|
||||
| `finding_projections` | Current state | `{tenant, findingId}` |
|
||||
|
||||
### 9.2 Integrity Constraints
|
||||
|
||||
- Events are append-only (no update/delete)
|
||||
- Sequence numbers strictly monotonic
|
||||
- Hash chain validated on write
|
||||
- Merkle roots immutable
|
||||
|
||||
---
|
||||
|
||||
## 10. Observability
|
||||
|
||||
### 10.1 Metrics
|
||||
|
||||
- `ledger.events.appended_total{tenant,type}`
|
||||
- `ledger.events.rejected_total{reason}`
|
||||
- `ledger.merkle.batches_total`
|
||||
- `ledger.merkle.anchor_latency_seconds`
|
||||
- `ledger.projection.updates_total`
|
||||
- `ledger.projection.staleness_seconds`
|
||||
- `ledger.export.rows_total{type,shape}`
|
||||
|
||||
### 10.2 SLO Targets
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Event append latency | < 50ms p95 |
|
||||
| Projection freshness | < 5 seconds |
|
||||
| Merkle anchor window | 15 minutes |
|
||||
| Export throughput | 10k rows/sec |
|
||||
|
||||
---
|
||||
|
||||
## 11. Security Considerations
|
||||
|
||||
### 11.1 Immutability Guarantees
|
||||
|
||||
- No UPDATE/DELETE operations exposed
|
||||
- Admin override requires audit event
|
||||
- Merkle roots provide tamper evidence
|
||||
- External anchoring for non-repudiation
|
||||
|
||||
### 11.2 Access Control
|
||||
|
||||
- `vuln:view` - Read projections
|
||||
- `vuln:investigate` - Triage actions
|
||||
- `vuln:operate` - State transitions
|
||||
- `vuln:audit` - Export and verify
|
||||
|
||||
### 11.3 Data Protection
|
||||
|
||||
- Sensitive payloads redacted in exports
|
||||
- Comment text hashed, not stored
|
||||
- PII filtered at ingest
|
||||
- Tenant isolation enforced
|
||||
|
||||
---
|
||||
|
||||
## 12. Air-Gap Support
|
||||
|
||||
### 12.1 Offline Bundles
|
||||
|
||||
- Signed NDJSON exports
|
||||
- Merkle proofs included
|
||||
- Time anchors from trusted source
|
||||
- Bundle verification CLI
|
||||
|
||||
### 12.2 Staleness Tracking
|
||||
|
||||
```yaml
|
||||
airgap:
|
||||
staleness:
|
||||
warningThresholdDays: 7
|
||||
blockThresholdDays: 30
|
||||
riskCriticalExportsBlocked: true
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 13. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Ledger schema | `docs/modules/findings-ledger/schema.md` |
|
||||
| OpenAPI spec | `docs/modules/findings-ledger/openapi/` |
|
||||
| Export guide | `docs/modules/findings-ledger/exports.md` |
|
||||
|
||||
---
|
||||
|
||||
## 14. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0186_0001_0001_record_deterministic_execution.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0120_0000_0001_policy_reasoning.md
|
||||
- SPRINT_311_docs_tasks_md_xi.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `LEDGER-CORE-40-001` - Event store (DONE)
|
||||
- `LEDGER-PROJ-41-001` - Projections (DONE)
|
||||
- `LEDGER-MERKLE-50-001` - Merkle anchoring (IN PROGRESS)
|
||||
- `LEDGER-EXPORT-51-001` - Deterministic exports (IN PROGRESS)
|
||||
- `LEDGER-AIRGAP-56-001` - Bundle provenance (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 15. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Event durability | 100% (no data loss) |
|
||||
| Chain integrity | 100% hash verification |
|
||||
| Projection accuracy | 100% event replay match |
|
||||
| Export determinism | 100% hash reproducibility |
|
||||
| Audit compliance | SOC 2 Type II |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,331 @@
|
||||
# Graph Analytics and Dependency Insights
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, graph model, and implementation strategy for the Graph module, covering dependency analysis, impact visualization, and offline exports.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Graph module provides **dependency analysis and impact visualization** across the vulnerability landscape. Key capabilities:
|
||||
|
||||
- **Unified Graph Model** - Artifacts, components, advisories, policies linked
|
||||
- **Impact Analysis** - Blast radius, affected paths, transitive dependencies
|
||||
- **Policy Overlays** - VEX and policy decisions visualized on graph
|
||||
- **Analytics** - Clustering, centrality, community detection
|
||||
- **Offline Export** - Deterministic graph snapshots for air-gap
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Graph Requirements | Use Case |
|
||||
|---------|-------------------|----------|
|
||||
| **Security Teams** | Impact analysis | Vulnerability prioritization |
|
||||
| **Developers** | Dependency visualization | Upgrade planning |
|
||||
| **Compliance** | Audit trails | Relationship documentation |
|
||||
| **Management** | Risk dashboards | Portfolio risk view |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability tools show flat lists. Stella Ops differentiates with:
|
||||
- **Graph-native architecture** linking all entities
|
||||
- **Impact visualization** showing blast radius
|
||||
- **Policy overlays** embedding decisions in graph
|
||||
- **Offline-compatible** exports for air-gap analysis
|
||||
- **Analytics** for community detection and centrality
|
||||
|
||||
---
|
||||
|
||||
## 3. Graph Model
|
||||
|
||||
### 3.1 Node Types
|
||||
|
||||
| Node | Description | Key Properties |
|
||||
|------|-------------|----------------|
|
||||
| **Artifact** | Image/application digest | tenant, environment, labels |
|
||||
| **Component** | Package version | purl, ecosystem, version |
|
||||
| **File** | Source/binary path | hash, mtime |
|
||||
| **License** | License identifier | spdx-id, restrictions |
|
||||
| **Advisory** | Vulnerability record | cve-id, severity, sources |
|
||||
| **VEXStatement** | VEX decision | status, justification |
|
||||
| **PolicyVersion** | Signed policy pack | version, digest |
|
||||
|
||||
### 3.2 Edge Types
|
||||
|
||||
| Edge | From | To | Properties |
|
||||
|------|------|-----|------------|
|
||||
| `DEPENDS_ON` | Component | Component | scope, optional |
|
||||
| `BUILT_FROM` | Artifact | Component | layer, path |
|
||||
| `DECLARED_IN` | Component | File | sbom-id |
|
||||
| `AFFECTED_BY` | Component | Advisory | version-range |
|
||||
| `VEX_EXEMPTS` | VEXStatement | Advisory | justification |
|
||||
| `GOVERNS_WITH` | PolicyVersion | Artifact | run-id |
|
||||
| `OBSERVED_RUNTIME` | Artifact | Component | zastava-event-id |
|
||||
|
||||
### 3.3 Provenance
|
||||
|
||||
Every edge carries:
|
||||
- `createdAt` - UTC timestamp
|
||||
- `sourceDigest` - SRM/SBOM hash
|
||||
- `provenanceRef` - Link to source document
|
||||
|
||||
---
|
||||
|
||||
## 4. Overlay System
|
||||
|
||||
### 4.1 Overlay Types
|
||||
|
||||
| Overlay | Purpose | Content |
|
||||
|---------|---------|---------|
|
||||
| `policy.overlay.v1` | Policy decisions | verdict, severity, rules |
|
||||
| `openvex.v1` | VEX status | status, justification |
|
||||
| `reachability.v1` | Runtime reachability | state, confidence |
|
||||
| `clustering.v1` | Community detection | cluster-id, modularity |
|
||||
| `centrality.v1` | Node importance | degree, betweenness |
|
||||
|
||||
### 4.2 Overlay Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"overlayId": "sha256(tenant|nodeId|overlayKind)",
|
||||
"overlayKind": "policy.overlay.v1",
|
||||
"nodeId": "component:pkg:npm/lodash@4.17.21",
|
||||
"tenant": "acme-corp",
|
||||
"generatedAt": "2025-11-29T12:00:00Z",
|
||||
"content": {
|
||||
"verdict": "blocked",
|
||||
"severity": "critical",
|
||||
"rulesMatched": ["rule-001", "rule-002"],
|
||||
"explainTrace": "sampled trace data..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Query Capabilities
|
||||
|
||||
### 5.1 Search API
|
||||
|
||||
```bash
|
||||
POST /graph/search
|
||||
{
|
||||
"tenant": "acme-corp",
|
||||
"query": "severity:critical AND ecosystem:npm",
|
||||
"nodeTypes": ["Component", "Advisory"],
|
||||
"limit": 100
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Path Query
|
||||
|
||||
```bash
|
||||
POST /graph/paths
|
||||
{
|
||||
"source": "artifact:sha256:abc123...",
|
||||
"target": "advisory:CVE-2025-12345",
|
||||
"maxDepth": 6,
|
||||
"includeOverlays": true
|
||||
}
|
||||
```
|
||||
|
||||
**Response:**
|
||||
```json
|
||||
{
|
||||
"paths": [
|
||||
{
|
||||
"nodes": ["artifact:sha256:...", "component:pkg:npm/...", "advisory:CVE-..."],
|
||||
"edges": [{"type": "BUILT_FROM"}, {"type": "AFFECTED_BY"}],
|
||||
"length": 2
|
||||
}
|
||||
],
|
||||
"overlays": [
|
||||
{"nodeId": "component:...", "overlayKind": "policy.overlay.v1", "content": {...}}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Diff Query
|
||||
|
||||
```bash
|
||||
POST /graph/diff
|
||||
{
|
||||
"snapshotA": "snapshot-2025-11-28",
|
||||
"snapshotB": "snapshot-2025-11-29",
|
||||
"includeOverlays": true
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Analytics Pipeline
|
||||
|
||||
### 6.1 Clustering
|
||||
|
||||
- **Algorithm:** Louvain community detection
|
||||
- **Output:** Cluster IDs per node, modularity score
|
||||
- **Use Case:** Identify tightly coupled component groups
|
||||
|
||||
### 6.2 Centrality
|
||||
|
||||
- **Degree centrality:** Most connected nodes
|
||||
- **Betweenness centrality:** Critical path nodes
|
||||
- **Use Case:** Identify high-impact components
|
||||
|
||||
### 6.3 Background Processing
|
||||
|
||||
```yaml
|
||||
analytics:
|
||||
enabled: true
|
||||
schedule: "0 */6 * * *" # Every 6 hours
|
||||
algorithms:
|
||||
- clustering
|
||||
- centrality
|
||||
snapshotRetention: 30
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. Implementation Strategy
|
||||
|
||||
### 7.1 Phase 1: Core Model (Complete)
|
||||
|
||||
- [x] Node/edge schema
|
||||
- [x] SBOM ingestion pipeline
|
||||
- [x] Advisory/VEX linking
|
||||
- [x] Basic search API
|
||||
|
||||
### 7.2 Phase 2: Overlays (In Progress)
|
||||
|
||||
- [x] Policy overlay generation
|
||||
- [x] VEX overlay generation
|
||||
- [ ] Reachability overlay (GRAPH-REACH-50-001)
|
||||
- [ ] Inline overlay in query responses (GRAPH-QUERY-51-001)
|
||||
|
||||
### 7.3 Phase 3: Analytics (Planned)
|
||||
|
||||
- [ ] Clustering algorithm
|
||||
- [ ] Centrality calculations
|
||||
- [ ] Background worker
|
||||
- [ ] Analytics overlays export
|
||||
|
||||
### 7.4 Phase 4: Visualization (Planned)
|
||||
|
||||
- [ ] Console graph viewer
|
||||
- [ ] Impact tree visualization
|
||||
- [ ] Diff visualization
|
||||
|
||||
---
|
||||
|
||||
## 8. API Surface
|
||||
|
||||
### 8.1 Core APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/graph/search` | POST | `graph:read` | Search nodes |
|
||||
| `/graph/query` | POST | `graph:read` | Complex queries |
|
||||
| `/graph/paths` | POST | `graph:read` | Path finding |
|
||||
| `/graph/diff` | POST | `graph:read` | Snapshot diff |
|
||||
| `/graph/nodes/{id}` | GET | `graph:read` | Node detail |
|
||||
|
||||
### 8.2 Export APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/graph/export` | POST | `graph:export` | Start export job |
|
||||
| `/graph/export/{jobId}` | GET | `graph:read` | Job status |
|
||||
| `/graph/export/{jobId}/download` | GET | `graph:export` | Download bundle |
|
||||
|
||||
---
|
||||
|
||||
## 9. Storage Model
|
||||
|
||||
### 9.1 Collections
|
||||
|
||||
| Collection | Purpose | Key Indexes |
|
||||
|------------|---------|-------------|
|
||||
| `graph_nodes` | Node records | `{tenant, nodeType, nodeId}` |
|
||||
| `graph_edges` | Edge records | `{tenant, fromId, toId, edgeType}` |
|
||||
| `graph_overlays` | Overlay data | `{tenant, nodeId, overlayKind}` |
|
||||
| `graph_snapshots` | Point-in-time snapshots | `{tenant, snapshotId}` |
|
||||
|
||||
### 9.2 Export Format
|
||||
|
||||
```
|
||||
graph-export/
|
||||
├── nodes.jsonl # Sorted by nodeId
|
||||
├── edges.jsonl # Sorted by (from, to, type)
|
||||
├── overlays/
|
||||
│ ├── policy.jsonl
|
||||
│ ├── openvex.jsonl
|
||||
│ └── manifest.json
|
||||
└── manifest.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 10. Observability
|
||||
|
||||
### 10.1 Metrics
|
||||
|
||||
- `graph_ingest_lag_seconds`
|
||||
- `graph_nodes_total{nodeType}`
|
||||
- `graph_edges_total{edgeType}`
|
||||
- `graph_query_latency_seconds{queryType}`
|
||||
- `graph_analytics_runs_total`
|
||||
- `graph_analytics_clusters_total`
|
||||
|
||||
### 10.2 Offline Support
|
||||
|
||||
- Graph snapshots packaged for Offline Kit
|
||||
- Deterministic NDJSON exports
|
||||
- Overlay manifests with digests
|
||||
|
||||
---
|
||||
|
||||
## 11. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Graph architecture | `docs/modules/graph/architecture.md` |
|
||||
| Query language | `docs/modules/graph/query-language.md` |
|
||||
| Overlay specification | `docs/modules/graph/overlays.md` |
|
||||
|
||||
---
|
||||
|
||||
## 12. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0141_0001_0001_graph_indexer.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0401_0001_0001_reachability_evidence_chain.md
|
||||
- SPRINT_0140_0001_0001_runtime_signals.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `GRAPH-CORE-40-001` - Core model (DONE)
|
||||
- `GRAPH-INGEST-41-001` - SBOM ingestion (DONE)
|
||||
- `GRAPH-REACH-50-001` - Reachability overlay (IN PROGRESS)
|
||||
- `GRAPH-ANALYTICS-55-001` - Clustering (TODO)
|
||||
- `GRAPH-VIZ-60-001` - Visualization (FUTURE)
|
||||
|
||||
---
|
||||
|
||||
## 13. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Query latency | < 500ms p95 |
|
||||
| Ingestion lag | < 5 minutes |
|
||||
| Path query depth | Up to 6 hops |
|
||||
| Export reproducibility | 100% deterministic |
|
||||
| Analytics freshness | < 6 hours |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,427 @@
|
||||
# Mirror and Offline Kit Strategy
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, data contracts, and implementation strategy for the Mirror module, covering deterministic thin-bundle assembly, DSSE/TUF signing, time anchoring, and air-gapped distribution.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Mirror module enables **air-gapped deployments** by producing deterministic, cryptographically signed bundles containing advisories, VEX documents, and policy packs. Key capabilities:
|
||||
|
||||
- **Thin Bundle Assembly** - Deterministic tar.gz with sorted entries and fixed timestamps
|
||||
- **DSSE/TUF Signing** - Ed25519 signatures with TUF metadata for key rotation
|
||||
- **Time Anchoring** - Roughtime/RFC3161 tokens for clock-independent freshness
|
||||
- **OCI Distribution** - Registry-compatible layout for container-native workflows
|
||||
- **Offline Verification** - Complete verification without network connectivity
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Offline Requirements | Use Case |
|
||||
|---------|---------------------|----------|
|
||||
| **Defense/Intelligence** | Complete air-gap | Classified networks without internet |
|
||||
| **Critical Infrastructure** | OT network isolation | ICS/SCADA vulnerability management |
|
||||
| **Financial Services** | DMZ-only connectivity | Regulated trading floor systems |
|
||||
| **Healthcare** | Network segmentation | Medical device security scanning |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability databases require constant connectivity. Stella Ops differentiates with:
|
||||
- **Cryptographically verifiable offline data** (DSSE + TUF)
|
||||
- **Deterministic bundles** for reproducible deployments
|
||||
- **Time-anchor freshness** without NTP dependency
|
||||
- **OCI-native distribution** for registry mirroring
|
||||
|
||||
---
|
||||
|
||||
## 3. Technical Architecture
|
||||
|
||||
### 3.1 Thin Bundle Layout (v1)
|
||||
|
||||
```
|
||||
mirror-thin-v1.tar.gz
|
||||
├── manifest.json # Bundle metadata, file inventory, hashes
|
||||
├── layers/
|
||||
│ ├── observations.ndjson # Advisory observations
|
||||
│ ├── time-anchor.json # Time token + verification metadata
|
||||
│ └── policies.tar.gz # Policy pack bundle (optional)
|
||||
├── indexes/
|
||||
│ └── observations.index # Linkage index
|
||||
└── oci/ # OCI layout (optional)
|
||||
├── index.json
|
||||
├── oci-layout
|
||||
└── blobs/sha256/...
|
||||
```
|
||||
|
||||
### 3.2 Determinism Rules
|
||||
|
||||
All thin bundles must be **bit-for-bit reproducible**:
|
||||
|
||||
| Property | Rule |
|
||||
|----------|------|
|
||||
| **Tar format** | POSIX with `--sort=name` |
|
||||
| **Owner/Group** | `--owner=0 --group=0` |
|
||||
| **mtime** | `--mtime='1970-01-01'` |
|
||||
| **Gzip** | `--no-name` flag |
|
||||
| **JSON** | Sorted keys, indent=2, trailing newline |
|
||||
| **Hashes** | Lower-case hex, SHA-256 |
|
||||
| **Timestamps** | UTC ISO-8601 (RFC3339) |
|
||||
| **Symlinks** | Not allowed |
|
||||
|
||||
### 3.3 Manifest Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "1.0.0",
|
||||
"created": "2025-11-29T00:00:00Z",
|
||||
"bundleId": "mirror-thin-v1-20251129",
|
||||
"generation": 42,
|
||||
"layers": [
|
||||
{
|
||||
"path": "layers/observations.ndjson",
|
||||
"size": 1048576,
|
||||
"digest": "sha256:abc123..."
|
||||
}
|
||||
],
|
||||
"indexes": [
|
||||
{
|
||||
"name": "observations.index",
|
||||
"digest": "sha256:def456..."
|
||||
}
|
||||
],
|
||||
"hashes": {
|
||||
"tarball_sha256": "sha256:...",
|
||||
"manifest_sha256": "sha256:..."
|
||||
},
|
||||
"timeAnchor": {
|
||||
"generatedAt": "2025-11-29T00:00:00Z",
|
||||
"source": "roughtime",
|
||||
"tokenDigest": "sha256:..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. DSSE/TUF Signing Profile
|
||||
|
||||
### 4.1 DSSE Envelope
|
||||
|
||||
**Payload Type:** `application/vnd.stellaops.mirror+json;version=1`
|
||||
|
||||
**Structure:**
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.stellaops.mirror+json;version=1",
|
||||
"payload": "<base64(manifest.json)>",
|
||||
"signatures": [{
|
||||
"keyid": "mirror-root-ed25519-01",
|
||||
"sig": "<base64(Ed25519 signature)>"
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
**Header Claims:**
|
||||
- `issuer` - Signing authority identifier
|
||||
- `keyid` - Key reference for verification
|
||||
- `created` - UTC timestamp of signing
|
||||
- `purpose` - Must be `mirror-bundle`
|
||||
|
||||
### 4.2 TUF Metadata Layout
|
||||
|
||||
```
|
||||
tuf/
|
||||
├── root.json # Trust root (long-lived)
|
||||
├── snapshot.json # Metadata versions
|
||||
├── targets.json # Target file mappings
|
||||
├── timestamp.json # Freshness timestamp
|
||||
└── keys/
|
||||
└── mirror-root-ed25519-01.pub
|
||||
```
|
||||
|
||||
**Targets Mapping:**
|
||||
|
||||
```json
|
||||
{
|
||||
"targets": {
|
||||
"mirror-thin-v1.tar.gz": {
|
||||
"length": 10485760,
|
||||
"hashes": {
|
||||
"sha256": "abc123..."
|
||||
}
|
||||
},
|
||||
"mirror-thin-v1.manifest.json": {
|
||||
"length": 2048,
|
||||
"hashes": {
|
||||
"sha256": "def456..."
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 4.3 Key Management
|
||||
|
||||
| Key Type | Lifetime | Storage | Rotation |
|
||||
|----------|----------|---------|----------|
|
||||
| **Root** | 1 year | HSM/offline | Ceremony required |
|
||||
| **Snapshot** | 90 days | Online | Automated |
|
||||
| **Targets** | 90 days | Online | Automated |
|
||||
| **Timestamp** | 1 day | Online | Continuous |
|
||||
|
||||
---
|
||||
|
||||
## 5. Time Anchoring
|
||||
|
||||
### 5.1 Time-Anchor Schema
|
||||
|
||||
```json
|
||||
{
|
||||
"anchorTime": "2025-11-29T00:00:00Z",
|
||||
"source": "roughtime",
|
||||
"format": "roughtime-v1",
|
||||
"tokenDigest": "sha256:...",
|
||||
"signatureFingerprint": "abc123...",
|
||||
"verification": {
|
||||
"status": "passed",
|
||||
"reason": null
|
||||
},
|
||||
"generatedAt": "2025-11-29T00:00:00Z",
|
||||
"sourceClock": "ntp:chrony",
|
||||
"validForSeconds": 86400
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Staleness Calculation
|
||||
|
||||
```
|
||||
stalenessSeconds = now_utc - generatedAt
|
||||
isStale = stalenessSeconds > (validForSeconds + 5s_tolerance)
|
||||
```
|
||||
|
||||
**Default validity:** 24 hours (86400 seconds)
|
||||
|
||||
### 5.3 Trust Roots
|
||||
|
||||
Trust roots for time verification stored in offline-friendly bundle:
|
||||
|
||||
```json
|
||||
{
|
||||
"roughtime": [
|
||||
{
|
||||
"name": "cloudflare",
|
||||
"publicKey": "...",
|
||||
"address": "roughtime.cloudflare.com:2002"
|
||||
}
|
||||
],
|
||||
"rfc3161": [
|
||||
{
|
||||
"name": "digicert",
|
||||
"url": "http://timestamp.digicert.com",
|
||||
"certificate": "..."
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Implementation Strategy
|
||||
|
||||
### 6.1 Phase 1: Thin Bundle Assembly (Complete)
|
||||
|
||||
- [x] Deterministic tarball assembler (`make-thin-v1.sh`)
|
||||
- [x] Manifest generation with sorted keys
|
||||
- [x] OCI layout generation
|
||||
- [x] Verification scripts (`verify_thin_bundle.py`)
|
||||
|
||||
### 6.2 Phase 2: DSSE/TUF Signing (In Progress)
|
||||
|
||||
- [x] DSSE envelope generation with Ed25519
|
||||
- [x] TUF metadata structure
|
||||
- [ ] Production key provisioning (blocked on CI secret)
|
||||
- [ ] Automated rotation pipeline
|
||||
|
||||
### 6.3 Phase 3: Time Anchoring (In Progress)
|
||||
|
||||
- [x] Time-anchor schema definition
|
||||
- [x] Contract for `generatedAt`, `validForSeconds` fields
|
||||
- [ ] Production Roughtime/RFC3161 integration
|
||||
- [ ] Trust roots provisioning
|
||||
|
||||
### 6.4 Phase 4: Distribution Integration (Planned)
|
||||
|
||||
- [ ] Export Center mirror profile automation
|
||||
- [ ] Orchestrator `mirror.ready` event emission
|
||||
- [ ] CLI `stella mirror create|verify|status` commands
|
||||
- [ ] OCI registry push/pull workflows
|
||||
|
||||
---
|
||||
|
||||
## 7. API Surface
|
||||
|
||||
### 7.1 Mirror APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/mirror/bundles` | GET | `mirror:read` | List mirror bundles |
|
||||
| `/mirror/bundles/{id}` | GET | `mirror:read` | Get bundle metadata |
|
||||
| `/mirror/bundles/{id}/download` | GET | `mirror:read` | Download thin bundle |
|
||||
| `/mirror/bundles` | POST | `mirror:create` | Create new mirror bundle |
|
||||
| `/mirror/verify` | POST | `mirror:read` | Verify bundle integrity |
|
||||
|
||||
### 7.2 Orchestrator Events
|
||||
|
||||
**Event:** `mirror.ready`
|
||||
|
||||
```json
|
||||
{
|
||||
"bundleId": "mirror-thin-v1-20251129",
|
||||
"generation": 42,
|
||||
"generatedAt": "2025-11-29T00:00:00Z",
|
||||
"manifestDigest": "sha256:...",
|
||||
"dsseDigest": "sha256:...",
|
||||
"location": "s3://mirrors/thin/v1/...",
|
||||
"rekorUUID": "..."
|
||||
}
|
||||
```
|
||||
|
||||
**Semantics:** At-least-once delivery; consumers de-dup by `(bundleId, generation)`.
|
||||
|
||||
### 7.3 CLI Commands
|
||||
|
||||
```bash
|
||||
# Create mirror bundle
|
||||
stella mirror create --output mirror-thin-v1.tar.gz
|
||||
|
||||
# Verify bundle integrity
|
||||
stella mirror verify mirror-thin-v1.tar.gz
|
||||
|
||||
# Check bundle status
|
||||
stella mirror status --bundle-id mirror-thin-v1-20251129
|
||||
|
||||
# Import bundle into air-gapped installation
|
||||
stella airgap import mirror-thin-v1.tar.gz --describe
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Offline Kit Integration
|
||||
|
||||
### 8.1 Offline Kit Structure
|
||||
|
||||
```
|
||||
offline-kit/
|
||||
├── mirrors/
|
||||
│ ├── mirror-thin-v1.tar.gz # Advisory/VEX data
|
||||
│ ├── mirror-thin-v1.manifest.json
|
||||
│ └── mirror-thin-v1.dsse.json
|
||||
├── evidence/
|
||||
│ └── evidence-bundle-*.tar.gz # Evidence bundles
|
||||
├── policies/
|
||||
│ └── policy-pack-*.tar.gz # Policy packs
|
||||
├── trust/
|
||||
│ ├── tuf/ # TUF metadata
|
||||
│ └── time-anchors.json # Time trust roots
|
||||
└── MANIFEST.json # Kit manifest with hashes
|
||||
```
|
||||
|
||||
### 8.2 Import Workflow
|
||||
|
||||
1. **Verify MANIFEST.json** signature against bundled TUF root
|
||||
2. **Validate each artifact** hash matches manifest
|
||||
3. **Check time anchor freshness** against configured tolerance
|
||||
4. **Import to local stores** (Concelier, Excititor, Evidence Locker)
|
||||
5. **Record import event** with provenance in Timeline
|
||||
|
||||
---
|
||||
|
||||
## 9. Verification Workflow
|
||||
|
||||
### 9.1 Online Verification
|
||||
|
||||
1. Fetch bundle from registry/export center
|
||||
2. Verify DSSE signature against JWKS
|
||||
3. Validate TUF metadata chain
|
||||
4. Check Rekor transparency log (if present)
|
||||
5. Verify time anchor freshness
|
||||
|
||||
### 9.2 Offline Verification
|
||||
|
||||
1. Extract bundle and TUF metadata
|
||||
2. Verify DSSE signature against bundled public key
|
||||
3. Validate all file hashes match manifest
|
||||
4. Check time anchor against local clock + tolerance
|
||||
5. Record verification result in local audit log
|
||||
|
||||
---
|
||||
|
||||
## 10. Security Considerations
|
||||
|
||||
### 10.1 Key Protection
|
||||
|
||||
- Root keys stored in HSM or offline cold storage
|
||||
- Online keys rotated automatically per TUF policy
|
||||
- Key ceremonies documented and audited
|
||||
|
||||
### 10.2 Rollback Protection
|
||||
|
||||
- TUF timestamp/snapshot prevent rollback attacks
|
||||
- Generation numbers monotonically increasing
|
||||
- Stale bundles rejected based on time anchor
|
||||
|
||||
### 10.3 Tampering Detection
|
||||
|
||||
- DSSE signature covers entire manifest
|
||||
- Each file has individual hash verification
|
||||
- Merkle tree optional for large bundles
|
||||
|
||||
---
|
||||
|
||||
## 11. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Mirror module docs | `docs/modules/mirror/` |
|
||||
| DSSE/TUF profile | `docs/modules/mirror/dsse-tuf-profile.md` |
|
||||
| Thin bundle spec | `docs/modules/mirror/thin-bundle-assembler.md` |
|
||||
| Time-anchor schema | `docs/airgap/time-anchor-schema.json` |
|
||||
| Signing runbook | `docs/modules/mirror/signing-runbook.md` |
|
||||
|
||||
---
|
||||
|
||||
## 12. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0125_0001_0001 (Mirror Bundles)
|
||||
- **Coordination:** SPRINT_0150_0001_0001 (DSSE/Time Anchors)
|
||||
|
||||
**Key Task IDs:**
|
||||
- `MIRROR-CRT-56-001` - Deterministic assembler (DONE)
|
||||
- `MIRROR-CRT-56-002` - DSSE/TUF signing (BLOCKED - CI key needed)
|
||||
- `MIRROR-CRT-57-001` - OCI layout generation (DONE)
|
||||
- `MIRROR-CRT-57-002` - Time-anchor embedding (PARTIAL)
|
||||
- `CLI-AIRGAP-56-001` - CLI mirror commands (BLOCKED)
|
||||
|
||||
---
|
||||
|
||||
## 13. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Bundle hash reproducibility | 100% (bit-identical) |
|
||||
| DSSE verification success | 100% for valid bundles |
|
||||
| Time anchor freshness | < 24 hours default |
|
||||
| Offline import success | Works without network |
|
||||
| TUF metadata validation | Full chain verified |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,469 @@
|
||||
# Notification Rules and Alerting Engine
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, rules engine semantics, and implementation strategy for the Notify module, covering channel connectors, throttling, digests, and delivery management.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Notify module provides **rules-driven, tenant-aware notification delivery** across security workflows. Key capabilities:
|
||||
|
||||
- **Rules Engine** - Declarative matchers for event routing
|
||||
- **Multi-Channel Delivery** - Slack, Teams, Email, Webhooks
|
||||
- **Noise Control** - Throttling, deduplication, digest windows
|
||||
- **Approval Tokens** - DSSE-signed ack tokens for one-click workflows
|
||||
- **Audit Trail** - Complete delivery history with redacted payloads
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Notification Requirements | Use Case |
|
||||
|---------|--------------------------|----------|
|
||||
| **Security Teams** | Real-time critical alerts | Incident response |
|
||||
| **DevSecOps** | CI/CD integration | Pipeline notifications |
|
||||
| **Compliance** | Audit trails | Delivery verification |
|
||||
| **Management** | Digest summaries | Executive reporting |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability tools offer basic email alerts. Stella Ops differentiates with:
|
||||
- **Rules-based routing** with fine-grained matchers
|
||||
- **Native Slack/Teams integration** with rich formatting
|
||||
- **Digest windows** to prevent alert fatigue
|
||||
- **Cryptographic ack tokens** for approval workflows
|
||||
- **Tenant isolation** with quota controls
|
||||
|
||||
---
|
||||
|
||||
## 3. Rules Engine
|
||||
|
||||
### 3.1 Rule Structure
|
||||
|
||||
```yaml
|
||||
name: "critical-alerts-prod"
|
||||
enabled: true
|
||||
tenant: "acme-corp"
|
||||
|
||||
match:
|
||||
eventKinds:
|
||||
- "scanner.report.ready"
|
||||
- "scheduler.rescan.delta"
|
||||
- "zastava.admission"
|
||||
namespaces: ["prod-*"]
|
||||
repos: ["ghcr.io/acme/*"]
|
||||
minSeverity: "high"
|
||||
kev: true
|
||||
verdict: ["fail", "deny"]
|
||||
vex:
|
||||
includeRejectedJustifications: false
|
||||
|
||||
actions:
|
||||
- channel: "slack:sec-alerts"
|
||||
template: "concise"
|
||||
throttle: "5m"
|
||||
|
||||
- channel: "email:soc"
|
||||
digest: "hourly"
|
||||
template: "detailed"
|
||||
```
|
||||
|
||||
### 3.2 Matcher Types
|
||||
|
||||
| Matcher | Description | Example |
|
||||
|---------|-------------|---------|
|
||||
| `eventKinds` | Event type filter | `["scanner.report.ready"]` |
|
||||
| `namespaces` | Namespace patterns | `["prod-*", "staging"]` |
|
||||
| `repos` | Repository patterns | `["ghcr.io/acme/*"]` |
|
||||
| `minSeverity` | Minimum severity | `"high"` |
|
||||
| `kev` | KEV-tagged required | `true` |
|
||||
| `verdict` | Report/admission verdict | `["fail", "deny"]` |
|
||||
| `labels` | Kubernetes labels | `{"env": "production"}` |
|
||||
|
||||
### 3.3 Evaluation Order
|
||||
|
||||
1. **Tenant check** - Discard if rule tenant ≠ event tenant
|
||||
2. **Kind filter** - Early discard for non-matching kinds
|
||||
3. **Scope match** - Namespace/repo/label matching
|
||||
4. **Delta gates** - Severity threshold evaluation
|
||||
5. **VEX gate** - Filter based on VEX status
|
||||
6. **Throttle/dedup** - Idempotency key check
|
||||
7. **Actions** - Enqueue per-channel jobs
|
||||
|
||||
---
|
||||
|
||||
## 4. Channel Connectors
|
||||
|
||||
### 4.1 Built-in Channels
|
||||
|
||||
| Channel | Features | Rate Limits |
|
||||
|---------|----------|-------------|
|
||||
| **Slack** | Blocks, threads, reactions | 1 msg/sec per channel |
|
||||
| **Teams** | Adaptive Cards, webhooks | 4 msgs/sec |
|
||||
| **Email** | HTML+text, attachments | Relay-dependent |
|
||||
| **Webhook** | JSON, HMAC signing | 10 req/sec |
|
||||
|
||||
### 4.2 Channel Configuration
|
||||
|
||||
```yaml
|
||||
channels:
|
||||
- name: "slack:sec-alerts"
|
||||
type: slack
|
||||
config:
|
||||
channel: "#security-alerts"
|
||||
workspace: "acme-corp"
|
||||
secretRef: "ref://notify/slack-token"
|
||||
|
||||
- name: "email:soc"
|
||||
type: email
|
||||
config:
|
||||
to: ["soc@acme.com"]
|
||||
from: "stellaops@acme.com"
|
||||
smtpHost: "smtp.acme.com"
|
||||
secretRef: "ref://notify/smtp-creds"
|
||||
|
||||
- name: "webhook:siem"
|
||||
type: webhook
|
||||
config:
|
||||
url: "https://siem.acme.com/api/events"
|
||||
signMethod: "ed25519"
|
||||
signKeyRef: "ref://notify/webhook-key"
|
||||
```
|
||||
|
||||
### 4.3 Connector Contract
|
||||
|
||||
```csharp
|
||||
public interface INotifyConnector
|
||||
{
|
||||
string Type { get; }
|
||||
Task<DeliveryResult> SendAsync(DeliveryContext ctx, CancellationToken ct);
|
||||
Task<HealthResult> HealthAsync(ChannelConfig cfg, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Noise Control
|
||||
|
||||
### 5.1 Throttling
|
||||
|
||||
- **Per-action throttle** - Suppress duplicates within window
|
||||
- **Idempotency key** - `hash(ruleId | actionId | event.kind | scope.digest | day)`
|
||||
- **Configurable windows** - 5m, 15m, 1h, 1d
|
||||
|
||||
### 5.2 Digest Windows
|
||||
|
||||
```yaml
|
||||
actions:
|
||||
- channel: "email:weekly-summary"
|
||||
digest: "weekly"
|
||||
digestOptions:
|
||||
maxItems: 100
|
||||
groupBy: ["severity", "namespace"]
|
||||
template: "digest-summary"
|
||||
```
|
||||
|
||||
**Behavior:**
|
||||
- Coalesce events within window
|
||||
- Summarize top N items with counts
|
||||
- Flush on window close or max items
|
||||
- Safe truncation with "and X more" links
|
||||
|
||||
### 5.3 Quiet Hours
|
||||
|
||||
```yaml
|
||||
notify:
|
||||
quietHours:
|
||||
enabled: true
|
||||
window: "22:00-06:00"
|
||||
timezone: "America/New_York"
|
||||
minSeverity: "critical"
|
||||
```
|
||||
|
||||
Only critical alerts during quiet hours; others deferred to digests.
|
||||
|
||||
---
|
||||
|
||||
## 6. Templates & Rendering
|
||||
|
||||
### 6.1 Template Engine
|
||||
|
||||
- Handlebars-style safe templates
|
||||
- No arbitrary code execution
|
||||
- Deterministic outputs (stable property order)
|
||||
- Locale-aware formatting
|
||||
|
||||
### 6.2 Template Variables
|
||||
|
||||
| Variable | Description |
|
||||
|----------|-------------|
|
||||
| `event.kind` | Event type |
|
||||
| `event.ts` | Timestamp |
|
||||
| `scope.namespace` | Kubernetes namespace |
|
||||
| `scope.repo` | Repository |
|
||||
| `scope.digest` | Image digest |
|
||||
| `payload.verdict` | Policy verdict |
|
||||
| `payload.delta.newCritical` | New critical count |
|
||||
| `payload.links.ui` | UI deep link |
|
||||
| `topFindings[]` | Top N findings |
|
||||
|
||||
### 6.3 Channel-Specific Rendering
|
||||
|
||||
**Slack:**
|
||||
```json
|
||||
{
|
||||
"blocks": [
|
||||
{"type": "header", "text": {"type": "plain_text", "text": "Policy FAIL: nginx:latest"}},
|
||||
{"type": "section", "text": {"type": "mrkdwn", "text": "*2 critical*, 3 high vulnerabilities"}}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Email:**
|
||||
```html
|
||||
<h2>Policy FAIL: nginx:latest</h2>
|
||||
<table>
|
||||
<tr><td>Critical</td><td>2</td></tr>
|
||||
<tr><td>High</td><td>3</td></tr>
|
||||
</table>
|
||||
<a href="https://ui.internal/reports/...">View Details</a>
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. Ack Tokens
|
||||
|
||||
### 7.1 Token Structure
|
||||
|
||||
DSSE-signed tokens for one-click acknowledgements:
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.stellaops.notify-ack-token+json",
|
||||
"payload": {
|
||||
"tenant": "acme-corp",
|
||||
"deliveryId": "delivery-123",
|
||||
"notificationId": "notif-456",
|
||||
"channel": "slack:sec-alerts",
|
||||
"webhookUrl": "https://notify.internal/ack",
|
||||
"nonce": "random-nonce",
|
||||
"actions": ["acknowledge", "escalate"],
|
||||
"expiresAt": "2025-11-29T13:00:00Z"
|
||||
},
|
||||
"signatures": [{"keyid": "notify-ack-key-01", "sig": "..."}]
|
||||
}
|
||||
```
|
||||
|
||||
### 7.2 Token Workflow
|
||||
|
||||
1. **Issue** - `POST /notify/ack-tokens/issue`
|
||||
2. **Embed** - Token included in message action button
|
||||
3. **Click** - User clicks button, token sent to webhook
|
||||
4. **Verify** - `POST /notify/ack-tokens/verify`
|
||||
5. **Audit** - Ack event recorded
|
||||
|
||||
### 7.3 Token Rotation
|
||||
|
||||
```bash
|
||||
# Rotate ack token signing key
|
||||
stella notify rotate-ack-key --key-source kms://notify/ack-key
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Implementation Strategy
|
||||
|
||||
### 8.1 Phase 1: Core Engine (Complete)
|
||||
|
||||
- [x] Rules engine with matchers
|
||||
- [x] Slack connector
|
||||
- [x] Teams connector
|
||||
- [x] Email connector
|
||||
- [x] Webhook connector
|
||||
|
||||
### 8.2 Phase 2: Noise Control (Complete)
|
||||
|
||||
- [x] Throttling
|
||||
- [x] Digest windows
|
||||
- [x] Idempotency
|
||||
- [x] Quiet hours
|
||||
|
||||
### 8.3 Phase 3: Ack Tokens (In Progress)
|
||||
|
||||
- [x] Token issuance
|
||||
- [x] Token verification
|
||||
- [ ] Token rotation API (NOTIFY-ACK-45-001)
|
||||
- [ ] Escalation workflows (NOTIFY-ESC-46-001)
|
||||
|
||||
### 8.4 Phase 4: Advanced Features (Planned)
|
||||
|
||||
- [ ] PagerDuty connector
|
||||
- [ ] Jira ticket creation
|
||||
- [ ] In-app notifications
|
||||
- [ ] Anomaly suppression
|
||||
|
||||
---
|
||||
|
||||
## 9. API Surface
|
||||
|
||||
### 9.1 Channels
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/notify/channels` | GET/POST | `notify.read/admin` | List/create channels |
|
||||
| `/api/v1/notify/channels/{id}` | GET/PATCH/DELETE | `notify.admin` | Manage channel |
|
||||
| `/api/v1/notify/channels/{id}/test` | POST | `notify.admin` | Send test message |
|
||||
| `/api/v1/notify/channels/{id}/health` | GET | `notify.read` | Health check |
|
||||
|
||||
### 9.2 Rules
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/notify/rules` | GET/POST | `notify.read/admin` | List/create rules |
|
||||
| `/api/v1/notify/rules/{id}` | GET/PATCH/DELETE | `notify.admin` | Manage rule |
|
||||
| `/api/v1/notify/rules/{id}/test` | POST | `notify.admin` | Dry-run rule |
|
||||
|
||||
### 9.3 Deliveries
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/v1/notify/deliveries` | GET | `notify.read` | List deliveries |
|
||||
| `/api/v1/notify/deliveries/{id}` | GET | `notify.read` | Delivery detail |
|
||||
| `/api/v1/notify/deliveries/{id}/retry` | POST | `notify.admin` | Retry delivery |
|
||||
|
||||
---
|
||||
|
||||
## 10. Event Sources
|
||||
|
||||
### 10.1 Subscribed Events
|
||||
|
||||
| Event | Source | Typical Actions |
|
||||
|-------|--------|-----------------|
|
||||
| `scanner.scan.completed` | Scanner | Immediate/digest |
|
||||
| `scanner.report.ready` | Scanner | Immediate |
|
||||
| `scheduler.rescan.delta` | Scheduler | Immediate/digest |
|
||||
| `attestor.logged` | Attestor | Immediate |
|
||||
| `zastava.admission` | Zastava | Immediate |
|
||||
| `conselier.export.completed` | Concelier | Digest |
|
||||
| `excitor.export.completed` | Excititor | Digest |
|
||||
|
||||
### 10.2 Event Envelope
|
||||
|
||||
```json
|
||||
{
|
||||
"eventId": "uuid",
|
||||
"kind": "scanner.report.ready",
|
||||
"tenant": "acme-corp",
|
||||
"ts": "2025-11-29T12:00:00Z",
|
||||
"actor": "scanner-webservice",
|
||||
"scope": {
|
||||
"namespace": "production",
|
||||
"repo": "ghcr.io/acme/api",
|
||||
"digest": "sha256:..."
|
||||
},
|
||||
"payload": {
|
||||
"reportId": "report-123",
|
||||
"verdict": "fail",
|
||||
"summary": {"total": 12, "blocked": 2},
|
||||
"delta": {"newCritical": 1, "kev": ["CVE-2025-..."]}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 11. Observability
|
||||
|
||||
### 11.1 Metrics
|
||||
|
||||
- `notify.events_consumed_total{kind}`
|
||||
- `notify.rules_matched_total{ruleId}`
|
||||
- `notify.throttled_total{reason}`
|
||||
- `notify.digest_coalesced_total{window}`
|
||||
- `notify.sent_total{channel}`
|
||||
- `notify.failed_total{channel,code}`
|
||||
- `notify.delivery_latency_seconds{channel}`
|
||||
|
||||
### 11.2 SLO Targets
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Event-to-delivery p95 | < 60 seconds |
|
||||
| Failure rate | < 0.5% per hour |
|
||||
| Duplicate rate | ~0% |
|
||||
|
||||
---
|
||||
|
||||
## 12. Security Considerations
|
||||
|
||||
### 12.1 Secret Management
|
||||
|
||||
- Secrets stored as references only
|
||||
- Just-in-time fetch at send time
|
||||
- No plaintext in Mongo
|
||||
|
||||
### 12.2 Webhook Signing
|
||||
|
||||
```
|
||||
X-StellaOps-Signature: t=1732881600,v1=abc123...
|
||||
X-StellaOps-Timestamp: 2025-11-29T12:00:00Z
|
||||
```
|
||||
|
||||
- HMAC-SHA256 or Ed25519
|
||||
- Replay window protection
|
||||
- Canonical body hash
|
||||
|
||||
### 12.3 Loop Prevention
|
||||
|
||||
- Webhook target allowlist
|
||||
- Event origin tags
|
||||
- Own webhooks rejected
|
||||
|
||||
---
|
||||
|
||||
## 13. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Notify architecture | `docs/modules/notify/architecture.md` |
|
||||
| Channel schemas | `docs/modules/notify/resources/schemas/` |
|
||||
| Sample payloads | `docs/modules/notify/resources/samples/` |
|
||||
| Bootstrap pack | `docs/modules/notify/bootstrap-pack.md` |
|
||||
|
||||
---
|
||||
|
||||
## 14. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0170_0001_0001_notify_engine.md (NEW)
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0171_0001_0002_notify_connectors.md
|
||||
- SPRINT_0172_0001_0003_notify_ack_tokens.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `NOTIFY-ENGINE-40-001` - Rules engine (DONE)
|
||||
- `NOTIFY-CONN-41-001` - Connectors (DONE)
|
||||
- `NOTIFY-NOISE-42-001` - Throttling/digests (DONE)
|
||||
- `NOTIFY-ACK-45-001` - Token rotation (IN PROGRESS)
|
||||
- `NOTIFY-ESC-46-001` - Escalation workflows (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 15. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Delivery latency | < 60s p95 |
|
||||
| Delivery success rate | > 99.5% |
|
||||
| Duplicate rate | < 0.01% |
|
||||
| Rule evaluation time | < 10ms |
|
||||
| Channel health | 99.9% uptime |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,432 @@
|
||||
# Orchestrator Event Model and Job Lifecycle
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, job lifecycle semantics, and implementation strategy for the Orchestrator module, covering event models, quota governance, replay semantics, and TaskRunner bridge.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Orchestrator is the **central job coordination layer** for all Stella Ops asynchronous operations. Key capabilities:
|
||||
|
||||
- **Unified Job Lifecycle** - Enqueue, schedule, lease, complete with audit trail
|
||||
- **Quota Governance** - Per-tenant rate limits, burst controls, circuit breakers
|
||||
- **Replay Semantics** - Deterministic job replay for audit and recovery
|
||||
- **TaskRunner Bridge** - Pack-run integration with heartbeats and artifacts
|
||||
- **Event Fan-Out** - SSE/GraphQL feeds for dashboards and notifications
|
||||
- **Offline Export** - Audit bundles for compliance and investigations
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Orchestration Requirements | Use Case |
|
||||
|---------|---------------------------|----------|
|
||||
| **Enterprise** | Rate limiting, quota management | Multi-team resource sharing |
|
||||
| **MSP/MSSP** | Multi-tenant isolation | Managed security services |
|
||||
| **Compliance Teams** | Audit trails, replay | SOC 2, FedRAMP evidence |
|
||||
| **DevSecOps** | CI/CD integration, webhooks | Pipeline automation |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability platforms lack sophisticated job orchestration. Stella Ops differentiates with:
|
||||
- **Deterministic replay** for audit and debugging
|
||||
- **Fine-grained quotas** per tenant/job-type
|
||||
- **Circuit breakers** for automatic failure isolation
|
||||
- **Native pack-run integration** for workflow automation
|
||||
- **Offline-compatible** audit bundles
|
||||
|
||||
---
|
||||
|
||||
## 3. Job Lifecycle Model
|
||||
|
||||
### 3.1 State Machine
|
||||
|
||||
```
|
||||
[Created] --> [Queued] --> [Leased] --> [Running] --> [Completed]
|
||||
| | | |
|
||||
| | v v
|
||||
| +-------> [Failed] <----[Canceled]
|
||||
| |
|
||||
v v
|
||||
[Throttled] [Incident]
|
||||
```
|
||||
|
||||
### 3.2 Lifecycle Phases
|
||||
|
||||
| Phase | Description | Transitions |
|
||||
|-------|-------------|-------------|
|
||||
| **Created** | Job request received | -> Queued |
|
||||
| **Queued** | Awaiting scheduling | -> Leased, Throttled |
|
||||
| **Throttled** | Rate limit applied | -> Queued (after delay) |
|
||||
| **Leased** | Worker acquired job | -> Running, Expired |
|
||||
| **Running** | Active execution | -> Completed, Failed, Canceled |
|
||||
| **Completed** | Success, archived | Terminal |
|
||||
| **Failed** | Error, may retry | -> Queued (retry), Incident |
|
||||
| **Canceled** | Operator abort | Terminal |
|
||||
| **Incident** | Escalated failure | Terminal (requires operator) |
|
||||
|
||||
### 3.3 Job Request Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"jobId": "uuid",
|
||||
"jobType": "scan|policy-run|export|pack-run|advisory-sync",
|
||||
"tenant": "tenant-id",
|
||||
"priority": "low|normal|high|emergency",
|
||||
"payloadDigest": "sha256:...",
|
||||
"payload": { "imageRef": "nginx:latest", "options": {} },
|
||||
"dependencies": ["job-id-1", "job-id-2"],
|
||||
"idempotencyKey": "unique-request-key",
|
||||
"correlationId": "trace-id",
|
||||
"requestedBy": "user-id|service-id",
|
||||
"requestedAt": "2025-11-29T12:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Quota Governance
|
||||
|
||||
### 4.1 Quota Model
|
||||
|
||||
```yaml
|
||||
quotas:
|
||||
- tenant: "acme-corp"
|
||||
jobType: "*"
|
||||
maxActive: 50
|
||||
maxPerHour: 500
|
||||
burst: 10
|
||||
priority:
|
||||
emergency:
|
||||
maxActive: 5
|
||||
skipQueue: true
|
||||
|
||||
- tenant: "acme-corp"
|
||||
jobType: "export"
|
||||
maxActive: 4
|
||||
maxPerHour: 100
|
||||
```
|
||||
|
||||
### 4.2 Rate Limit Enforcement
|
||||
|
||||
1. **Quota Check** - Before leasing, verify tenant hasn't exceeded limits
|
||||
2. **Burst Control** - Allow short bursts within configured window
|
||||
3. **Staging** - Jobs exceeding limits staged with `nextEligibleAt` timestamp
|
||||
4. **Priority Bypass** - Emergency jobs can skip queue (with separate limits)
|
||||
|
||||
### 4.3 Dynamic Controls
|
||||
|
||||
| Control | API | Purpose |
|
||||
|---------|-----|---------|
|
||||
| `pauseSource` | `POST /api/limits/pause` | Halt specific job sources |
|
||||
| `resumeSource` | `POST /api/limits/resume` | Resume paused sources |
|
||||
| `throttle` | `POST /api/limits/throttle` | Apply temporary throttle |
|
||||
| `updateQuota` | `PATCH /api/quotas/{id}` | Modify quota limits |
|
||||
|
||||
### 4.4 Circuit Breakers
|
||||
|
||||
- Auto-pause job types when failure rate > threshold (default 50%)
|
||||
- Incident events generated via Notify
|
||||
- Half-open testing after cooldown period
|
||||
- Manual reset via operator action
|
||||
|
||||
---
|
||||
|
||||
## 5. TaskRunner Bridge
|
||||
|
||||
### 5.1 Pack-Run Integration
|
||||
|
||||
The Orchestrator provides specialized support for TaskRunner pack executions:
|
||||
|
||||
```json
|
||||
{
|
||||
"jobType": "pack-run",
|
||||
"payload": {
|
||||
"packId": "vuln-scan-and-report",
|
||||
"packVersion": "1.2.0",
|
||||
"planHash": "sha256:...",
|
||||
"inputs": { "imageRef": "nginx:latest" },
|
||||
"artifacts": [],
|
||||
"logChannel": "sse:/runs/{runId}/logs",
|
||||
"heartbeatCadence": 30
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Heartbeat Protocol
|
||||
|
||||
- Workers send heartbeats every `heartbeatCadence` seconds
|
||||
- Missed heartbeats trigger lease expiration
|
||||
- Lease can be extended for long-running tasks
|
||||
- Dead workers detected within 2x heartbeat interval
|
||||
|
||||
### 5.3 Artifact & Log Streaming
|
||||
|
||||
| Endpoint | Method | Purpose |
|
||||
|----------|--------|---------|
|
||||
| `/runs/{runId}/logs` | SSE | Stream execution logs |
|
||||
| `/runs/{runId}/artifacts` | GET | List produced artifacts |
|
||||
| `/runs/{runId}/artifacts/{name}` | GET | Download artifact |
|
||||
| `/runs/{runId}/heartbeat` | POST | Extend lease |
|
||||
|
||||
---
|
||||
|
||||
## 6. Event Model
|
||||
|
||||
### 6.1 Event Envelope
|
||||
|
||||
```json
|
||||
{
|
||||
"eventId": "uuid",
|
||||
"eventType": "job.queued|job.leased|job.completed|job.failed",
|
||||
"timestamp": "2025-11-29T12:00:00Z",
|
||||
"tenant": "tenant-id",
|
||||
"jobId": "job-id",
|
||||
"jobType": "scan",
|
||||
"correlationId": "trace-id",
|
||||
"idempotencyKey": "unique-key",
|
||||
"payload": {
|
||||
"status": "completed",
|
||||
"duration": 45.2,
|
||||
"result": { "verdict": "pass" }
|
||||
},
|
||||
"provenance": {
|
||||
"workerId": "worker-1",
|
||||
"leaseId": "lease-id",
|
||||
"taskRunnerId": "runner-1"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 6.2 Event Types
|
||||
|
||||
| Event | Trigger | Consumers |
|
||||
|-------|---------|-----------|
|
||||
| `job.queued` | Job enqueued | Dashboard, Notify |
|
||||
| `job.leased` | Worker acquired job | Dashboard |
|
||||
| `job.started` | Execution began | Dashboard, Notify |
|
||||
| `job.progress` | Progress update | Dashboard (SSE) |
|
||||
| `job.completed` | Success | Dashboard, Notify, Export |
|
||||
| `job.failed` | Error occurred | Dashboard, Notify, Incident |
|
||||
| `job.canceled` | Operator abort | Dashboard, Notify |
|
||||
| `job.replayed` | Replay initiated | Dashboard, Audit |
|
||||
|
||||
### 6.3 Fan-Out Channels
|
||||
|
||||
- **SSE** - Real-time dashboard feeds
|
||||
- **GraphQL Subscriptions** - Console UI
|
||||
- **Notify** - Alert routing based on rules
|
||||
- **Webhooks** - External integrations
|
||||
- **Audit Log** - Compliance storage
|
||||
|
||||
---
|
||||
|
||||
## 7. Replay Semantics
|
||||
|
||||
### 7.1 Deterministic Replay
|
||||
|
||||
Jobs can be replayed for audit, debugging, or recovery:
|
||||
|
||||
```bash
|
||||
# Replay a completed job
|
||||
stella job replay --id job-12345
|
||||
|
||||
# Replay with sealed mode (offline verification)
|
||||
stella job replay --id job-12345 --sealed --bundle output.tar.gz
|
||||
```
|
||||
|
||||
### 7.2 Replay Guarantees
|
||||
|
||||
| Property | Guarantee |
|
||||
|----------|-----------|
|
||||
| **Input preservation** | Same payloadDigest, cursors |
|
||||
| **Ordering** | Same processing order |
|
||||
| **Determinism** | Same outputs for same inputs |
|
||||
| **Provenance** | `replayOf` pointer to original |
|
||||
|
||||
### 7.3 Replay Record
|
||||
|
||||
```json
|
||||
{
|
||||
"jobId": "replay-job-id",
|
||||
"replayOf": "original-job-id",
|
||||
"priority": "high",
|
||||
"reason": "audit-verification",
|
||||
"requestedBy": "auditor@example.com",
|
||||
"cursors": {
|
||||
"advisory": "cursor-abc",
|
||||
"vex": "cursor-def"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Implementation Strategy
|
||||
|
||||
### 8.1 Phase 1: Core Lifecycle (Complete)
|
||||
|
||||
- [x] Job state machine
|
||||
- [x] MongoDB queue with leasing
|
||||
- [x] Basic quota enforcement
|
||||
- [x] Dashboard SSE feeds
|
||||
|
||||
### 8.2 Phase 2: Pack-Run Bridge (In Progress)
|
||||
|
||||
- [x] Pack-run job type registration
|
||||
- [x] Log/artifact streaming
|
||||
- [ ] Heartbeat protocol (ORCH-PACK-37-001)
|
||||
- [ ] Event envelope finalization (ORCH-SVC-37-101)
|
||||
|
||||
### 8.3 Phase 3: Advanced Controls (Planned)
|
||||
|
||||
- [ ] Circuit breaker automation
|
||||
- [ ] Quota analytics dashboard
|
||||
- [ ] Replay verification tooling
|
||||
- [ ] Incident mode integration
|
||||
|
||||
---
|
||||
|
||||
## 9. API Surface
|
||||
|
||||
### 9.1 Job Management
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/jobs` | GET | `orch:read` | List jobs with filters |
|
||||
| `/api/jobs/{id}` | GET | `orch:read` | Job detail |
|
||||
| `/api/jobs/{id}/cancel` | POST | `orch:operate` | Cancel job |
|
||||
| `/api/jobs/{id}/replay` | POST | `orch:operate` | Schedule replay |
|
||||
|
||||
### 9.2 Quota Management
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/quotas` | GET | `orch:read` | List quotas |
|
||||
| `/api/quotas/{id}` | PATCH | `orch:quota` | Update quota |
|
||||
| `/api/limits/throttle` | POST | `orch:quota` | Apply throttle |
|
||||
| `/api/limits/pause` | POST | `orch:quota` | Pause source |
|
||||
| `/api/limits/resume` | POST | `orch:quota` | Resume source |
|
||||
|
||||
### 9.3 Dashboard
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/dashboard/metrics` | GET | `orch:read` | Aggregated metrics |
|
||||
| `/api/dashboard/events` | SSE | `orch:read` | Real-time events |
|
||||
|
||||
---
|
||||
|
||||
## 10. Storage Model
|
||||
|
||||
### 10.1 Collections
|
||||
|
||||
| Collection | Purpose | Key Fields |
|
||||
|------------|---------|------------|
|
||||
| `jobs` | Current job state | `_id`, `tenant`, `jobType`, `status`, `priority` |
|
||||
| `job_history` | Append-only audit | `jobId`, `event`, `timestamp`, `actor` |
|
||||
| `sources` | Job sources registry | `sourceId`, `tenant`, `status` |
|
||||
| `quotas` | Quota definitions | `tenant`, `jobType`, `limits` |
|
||||
| `throttles` | Active throttles | `tenant`, `source`, `until` |
|
||||
| `incidents` | Escalated failures | `jobId`, `reason`, `status` |
|
||||
|
||||
### 10.2 Indexes
|
||||
|
||||
- `{tenant, jobType, status}` on `jobs`
|
||||
- `{tenant, status, startedAt}` on `jobs`
|
||||
- `{jobId, timestamp}` on `job_history`
|
||||
- TTL index on transient lease records
|
||||
|
||||
---
|
||||
|
||||
## 11. Observability
|
||||
|
||||
### 11.1 Metrics
|
||||
|
||||
- `job_queue_depth{jobType,tenant}`
|
||||
- `job_latency_seconds{jobType,phase}`
|
||||
- `job_failures_total{jobType,reason}`
|
||||
- `job_retry_total{jobType}`
|
||||
- `lease_extensions_total{jobType}`
|
||||
- `quota_exceeded_total{tenant}`
|
||||
- `circuit_breaker_state{jobType}`
|
||||
|
||||
### 11.2 Pack-Run Metrics
|
||||
|
||||
- `pack_run_logs_stream_lag_seconds`
|
||||
- `pack_run_heartbeats_total`
|
||||
- `pack_run_artifacts_total`
|
||||
- `pack_run_duration_seconds`
|
||||
|
||||
---
|
||||
|
||||
## 12. Offline Support
|
||||
|
||||
### 12.1 Audit Bundle Export
|
||||
|
||||
```bash
|
||||
stella orch export --tenant acme-corp --since 2025-11-01 --output audit-bundle.tar.gz
|
||||
```
|
||||
|
||||
Bundle contents:
|
||||
- `jobs.jsonl` - Job records
|
||||
- `history.jsonl` - State transitions
|
||||
- `throttles.jsonl` - Throttle events
|
||||
- `manifest.json` - Bundle metadata
|
||||
- `signatures/` - DSSE signatures
|
||||
|
||||
### 12.2 Replay Verification
|
||||
|
||||
```bash
|
||||
# Verify job determinism
|
||||
stella job verify --bundle audit-bundle.tar.gz --job-id job-12345
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 13. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Orchestrator architecture | `docs/modules/orchestrator/architecture.md` |
|
||||
| Event envelope spec | `docs/modules/orchestrator/event-envelope.md` |
|
||||
| TaskRunner integration | `docs/modules/taskrunner/orchestrator-bridge.md` |
|
||||
|
||||
---
|
||||
|
||||
## 14. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0151_0001_0001_orchestrator_i.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0152_0001_0002_orchestrator_ii.md
|
||||
- SPRINT_0153_0001_0003_orchestrator_iii.md
|
||||
- SPRINT_0157_0001_0001_taskrunner_i.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `ORCH-CORE-30-001` - Job lifecycle (DONE)
|
||||
- `ORCH-QUOTA-31-001` - Quota governance (DONE)
|
||||
- `ORCH-PACK-37-001` - Pack-run bridge (IN PROGRESS)
|
||||
- `ORCH-SVC-37-101` - Event envelope (IN PROGRESS)
|
||||
- `ORCH-REPLAY-38-001` - Replay verification (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 15. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Job scheduling latency | < 100ms p99 |
|
||||
| Lease acquisition time | < 50ms p99 |
|
||||
| Event fan-out delay | < 500ms |
|
||||
| Quota enforcement accuracy | 100% |
|
||||
| Replay determinism | 100% match |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,362 @@
|
||||
# Plugin Architecture & Extensibility Patterns
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-28
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory consolidates the extensibility patterns used across Stella Ops modules, providing a unified view for architects and developers implementing custom integrations.
|
||||
|
||||
---
|
||||
|
||||
## 1. Overview
|
||||
|
||||
Stella Ops uses a **plugin-based architecture** enabling customers and partners to extend functionality without modifying core code. The platform supports three primary extension types:
|
||||
|
||||
| Type | Module | Purpose | Examples |
|
||||
|------|--------|---------|----------|
|
||||
| **Connectors** | Concelier, Excititor | Ingest/export data from external sources | NVD, OSV, vendor VEX feeds |
|
||||
| **Plugins** | Authority, Scanner | Extend runtime behavior | LDAP auth, custom analyzers |
|
||||
| **Analyzers** | Scanner | Add detection capabilities | Language-specific, binary analysis |
|
||||
|
||||
---
|
||||
|
||||
## 2. Core Principles
|
||||
|
||||
### 2.1 Determinism
|
||||
|
||||
All plugins must produce **deterministic outputs** for identical inputs:
|
||||
- No global state between invocations
|
||||
- Timestamps in UTC ISO-8601
|
||||
- Stable ordering of collections
|
||||
- Reproducible hashing with documented algorithms
|
||||
|
||||
### 2.2 Offline-First
|
||||
|
||||
Plugins must function in **air-gapped environments**:
|
||||
- No network access unless explicitly configured
|
||||
- Local configuration and secrets
|
||||
- Bundled dependencies (no runtime downloads)
|
||||
- Offline-capable credential stores
|
||||
|
||||
### 2.3 Restart-Safe
|
||||
|
||||
Plugins load at **service startup only**:
|
||||
- No hot-reload (security/determinism trade-off)
|
||||
- Configuration changes require restart
|
||||
- State persists in external stores (MongoDB, filesystem)
|
||||
|
||||
---
|
||||
|
||||
## 3. Plugin Lifecycle
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────────────────────────────────┐
|
||||
│ Host Startup │
|
||||
└─────────────────────────────────┬───────────────────────────────┘
|
||||
│
|
||||
▼
|
||||
┌─────────────────────────────────────────────────────────────────┐
|
||||
│ 1. Configuration Load │
|
||||
│ - Read YAML manifests from etc/<module>.plugins/ │
|
||||
│ - Validate capability tokens │
|
||||
│ - Resolve relative paths │
|
||||
└─────────────────────────────────┬───────────────────────────────┘
|
||||
│
|
||||
▼
|
||||
┌─────────────────────────────────────────────────────────────────┐
|
||||
│ 2. Assembly Discovery │
|
||||
│ - Scan plugin binaries directory │
|
||||
│ - Match assemblies to manifest descriptors │
|
||||
│ - Load assemblies into isolated context │
|
||||
└─────────────────────────────────┬───────────────────────────────┘
|
||||
│
|
||||
▼
|
||||
┌─────────────────────────────────────────────────────────────────┐
|
||||
│ 3. Registrar Execution │
|
||||
│ - Find IPluginRegistrar implementations │
|
||||
│ - Bind options from configuration │
|
||||
│ - Register services in DI container │
|
||||
│ - Queue bootstrap tasks (optional) │
|
||||
└─────────────────────────────────┬───────────────────────────────┘
|
||||
│
|
||||
▼
|
||||
┌─────────────────────────────────────────────────────────────────┐
|
||||
│ 4. Runtime │
|
||||
│ - Host resolves plugin services via DI │
|
||||
│ - Capability metadata guides feature exposure │
|
||||
│ - Health checks report plugin status │
|
||||
└─────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Concelier Connectors
|
||||
|
||||
### 4.1 Purpose
|
||||
|
||||
Connectors ingest vulnerability advisories from external sources into the Concelier merge engine.
|
||||
|
||||
### 4.2 Interface
|
||||
|
||||
```csharp
|
||||
public interface IAdvisoryConnector
|
||||
{
|
||||
string ConnectorId { get; }
|
||||
Task<IAsyncEnumerable<RawAdvisory>> FetchAsync(
|
||||
ConnectorContext context,
|
||||
CancellationToken ct);
|
||||
Task<ConnectorHealth> CheckHealthAsync(CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 4.3 Built-in Connectors
|
||||
|
||||
| Connector | Source | Format |
|
||||
|-----------|--------|--------|
|
||||
| `nvd` | NVD API 2.0 | CVE JSON |
|
||||
| `osv` | OSV.dev | OSV JSON |
|
||||
| `ghsa` | GitHub Advisory Database | GHSA JSON |
|
||||
| `oval` | Vendor OVAL feeds | OVAL XML |
|
||||
| `csaf` | CSAF repositories | CSAF JSON |
|
||||
|
||||
### 4.4 Developer Guide
|
||||
|
||||
See: `docs/dev/30_EXCITITOR_CONNECTOR_GUIDE.md`
|
||||
|
||||
---
|
||||
|
||||
## 5. Authority Plugins
|
||||
|
||||
### 5.1 Purpose
|
||||
|
||||
Authority plugins extend authentication with custom identity providers, credential stores, and client management.
|
||||
|
||||
### 5.2 Interface
|
||||
|
||||
```csharp
|
||||
public interface IAuthorityPluginRegistrar
|
||||
{
|
||||
void ConfigureServices(IServiceCollection services, PluginContext context);
|
||||
void ConfigureOptions(IConfiguration config);
|
||||
}
|
||||
|
||||
public interface IIdentityProviderPlugin
|
||||
{
|
||||
string ProviderId { get; }
|
||||
AuthorityIdentityProviderCapabilities Capabilities { get; }
|
||||
Task<AuthenticationResult> AuthenticateAsync(AuthenticationRequest request);
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Capabilities
|
||||
|
||||
Plugins declare capabilities via manifest:
|
||||
|
||||
```yaml
|
||||
plugins:
|
||||
descriptors:
|
||||
ldap:
|
||||
assemblyName: "StellaOps.Authority.Plugin.Ldap"
|
||||
capabilities:
|
||||
- password
|
||||
- mfa
|
||||
- clientProvisioning
|
||||
```
|
||||
|
||||
| Capability | Description |
|
||||
|------------|-------------|
|
||||
| `password` | Username/password authentication |
|
||||
| `mfa` | Multi-factor authentication support |
|
||||
| `clientProvisioning` | Dynamic OAuth client registration |
|
||||
| `bootstrap` | Initial admin user creation |
|
||||
|
||||
### 5.4 Developer Guide
|
||||
|
||||
See: `docs/dev/31_AUTHORITY_PLUGIN_DEVELOPER_GUIDE.md`
|
||||
|
||||
---
|
||||
|
||||
## 6. Scanner Analyzers
|
||||
|
||||
### 6.1 Purpose
|
||||
|
||||
Analyzers extend the Scanner with language-specific or binary-level detection capabilities.
|
||||
|
||||
### 6.2 Interface
|
||||
|
||||
```csharp
|
||||
public interface IScanAnalyzer
|
||||
{
|
||||
string AnalyzerId { get; }
|
||||
IReadOnlyList<string> SupportedEcosystems { get; }
|
||||
Task<AnalysisResult> AnalyzeAsync(
|
||||
ScanContext context,
|
||||
IAsyncEnumerable<ScanArtifact> artifacts,
|
||||
CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 6.3 Built-in Analyzers
|
||||
|
||||
| Analyzer | Ecosystem | Detection Method |
|
||||
|----------|-----------|------------------|
|
||||
| `syft` | Multi-ecosystem | SBOM generation |
|
||||
| `grype-db` | Multi-ecosystem | Vulnerability matching |
|
||||
| `elf-symbols` | Binary/ELF | Symbol table analysis |
|
||||
| `buildid` | Binary/ELF | Build-ID extraction |
|
||||
| `dotnet-deps` | .NET | deps.json parsing |
|
||||
|
||||
### 6.4 Surface Validation
|
||||
|
||||
The Scanner supports **extensible surface validation** for detecting risky patterns:
|
||||
|
||||
```csharp
|
||||
public interface ISurfaceValidator
|
||||
{
|
||||
string ValidatorId { get; }
|
||||
Task<SurfaceValidationResult> ValidateAsync(
|
||||
SurfaceContext context,
|
||||
CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
See: `docs/modules/scanner/guides/surface-validation-extensibility.md`
|
||||
|
||||
---
|
||||
|
||||
## 7. Manifest Structure
|
||||
|
||||
All plugins use a standard manifest format:
|
||||
|
||||
```json
|
||||
{
|
||||
"pluginId": "example-plugin",
|
||||
"version": "1.0.0",
|
||||
"assemblyName": "StellaOps.Module.Plugin.Example",
|
||||
"hostVersion": ">=2.0.0",
|
||||
"capabilities": ["capability1", "capability2"],
|
||||
"configuration": {
|
||||
"requiredSettings": ["setting1"],
|
||||
"optionalSettings": ["setting2"]
|
||||
},
|
||||
"dependencies": {
|
||||
"packages": ["Dependency.Package@1.0.0"]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Security Considerations
|
||||
|
||||
### 8.1 Assembly Isolation
|
||||
|
||||
- Plugins load in dedicated assembly contexts
|
||||
- Host enforces capability-based access control
|
||||
- Network access requires explicit configuration
|
||||
|
||||
### 8.2 Configuration Validation
|
||||
|
||||
- Unknown capability tokens rejected at startup
|
||||
- Path traversal in relative paths blocked
|
||||
- Secrets never logged or exposed in diagnostics
|
||||
|
||||
### 8.3 Audit Trail
|
||||
|
||||
- Plugin loading events logged with assembly hash
|
||||
- Configuration changes recorded
|
||||
- Runtime errors captured with context
|
||||
|
||||
---
|
||||
|
||||
## 9. Offline Kit Integration
|
||||
|
||||
Plugins must support offline distribution:
|
||||
|
||||
```
|
||||
offline-kit/
|
||||
├── plugins/
|
||||
│ ├── authority/
|
||||
│ │ ├── StellaOps.Authority.Plugin.Ldap.dll
|
||||
│ │ └── manifest.json
|
||||
│ ├── scanner/
|
||||
│ │ ├── StellaOps.Scanner.Analyzer.Custom.dll
|
||||
│ │ └── manifest.json
|
||||
│ └── checksums.sha256
|
||||
├── config/
|
||||
│ └── plugins.yaml
|
||||
└── MANIFEST.json
|
||||
```
|
||||
|
||||
### 9.1 Checksum Verification
|
||||
|
||||
All plugin assemblies verified against `checksums.sha256` before loading.
|
||||
|
||||
### 9.2 Version Compatibility
|
||||
|
||||
Host rejects plugins with incompatible `hostVersion` requirements.
|
||||
|
||||
---
|
||||
|
||||
## 10. Testing Requirements
|
||||
|
||||
### 10.1 Unit Tests
|
||||
|
||||
- Registrar binds options correctly
|
||||
- Services resolve from DI container
|
||||
- Capability metadata accurate
|
||||
|
||||
### 10.2 Integration Tests
|
||||
|
||||
- Plugin loads in host process
|
||||
- Health checks pass
|
||||
- Functionality works end-to-end
|
||||
|
||||
### 10.3 Test Helpers
|
||||
|
||||
```csharp
|
||||
// Use StellaOps.Plugin.Tests helpers
|
||||
var host = new PluginTestHost()
|
||||
.WithPlugin<MyPlugin>()
|
||||
.WithConfiguration(config)
|
||||
.Build();
|
||||
|
||||
var plugin = host.GetRequiredService<IMyPlugin>();
|
||||
var result = await plugin.DoSomethingAsync();
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 11. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| General plugin guide | `docs/dev/plugins/README.md` |
|
||||
| Concelier connector guide | `docs/dev/30_EXCITITOR_CONNECTOR_GUIDE.md` |
|
||||
| Authority plugin guide | `docs/dev/31_AUTHORITY_PLUGIN_DEVELOPER_GUIDE.md` |
|
||||
| Scanner extensibility | `docs/modules/scanner/guides/surface-validation-extensibility.md` |
|
||||
| Platform architecture | `docs/modules/platform/architecture-overview.md` |
|
||||
|
||||
---
|
||||
|
||||
## 12. Sprint Mapping
|
||||
|
||||
No dedicated sprint - plugin infrastructure is foundational. Related tasks appear in:
|
||||
|
||||
- Module-specific sprints (Authority, Scanner, Concelier)
|
||||
- Platform infrastructure sprints
|
||||
|
||||
---
|
||||
|
||||
## 13. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Plugin load time | < 500ms per plugin |
|
||||
| Configuration validation | 100% coverage of manifest schema |
|
||||
| Offline kit verification | All plugins checksum-verified |
|
||||
| Documentation coverage | All plugin types documented |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-28*
|
||||
@@ -0,0 +1,394 @@
|
||||
# Policy Simulation and Shadow Gates
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, simulation semantics, and implementation strategy for Policy Engine simulation features, covering shadow runs, coverage fixtures, and promotion gates.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
Policy simulation enables **safe testing of policy changes** before production deployment. Key capabilities:
|
||||
|
||||
- **Shadow Runs** - Execute policies without enforcement
|
||||
- **Diff Summaries** - Compare old vs new policy outcomes
|
||||
- **Coverage Fixtures** - Validate expected findings
|
||||
- **Promotion Gates** - Block promotion until tests pass
|
||||
- **Deterministic Replay** - Reproduce simulation results
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Simulation Requirements | Use Case |
|
||||
|---------|------------------------|----------|
|
||||
| **Policy Authors** | Preview changes | Development workflow |
|
||||
| **Security Leads** | Approve promotions | Change management |
|
||||
| **Compliance** | Audit trail | Policy change evidence |
|
||||
| **DevSecOps** | CI integration | Automated testing |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability tools lack policy simulation. Stella Ops differentiates with:
|
||||
- **Shadow execution** without production impact
|
||||
- **Diff visualization** of policy changes
|
||||
- **Coverage testing** with fixture validation
|
||||
- **Promotion gates** for governance
|
||||
- **Deterministic replay** for audit
|
||||
|
||||
---
|
||||
|
||||
## 3. Simulation Modes
|
||||
|
||||
### 3.1 Shadow Run
|
||||
|
||||
Execute policy against real data without enforcement:
|
||||
|
||||
```bash
|
||||
stella policy simulate \
|
||||
--policy my-policy:v2 \
|
||||
--scope "tenant:acme-corp,namespace:production" \
|
||||
--shadow
|
||||
```
|
||||
|
||||
**Behavior:**
|
||||
- Evaluates all findings
|
||||
- Records verdicts to shadow collections
|
||||
- No enforcement actions
|
||||
- No notifications triggered
|
||||
- Metrics tagged with `shadow=true`
|
||||
|
||||
### 3.2 Diff Run
|
||||
|
||||
Compare two policy versions:
|
||||
|
||||
```bash
|
||||
stella policy diff \
|
||||
--old my-policy:v1 \
|
||||
--new my-policy:v2 \
|
||||
--scope "tenant:acme-corp"
|
||||
```
|
||||
|
||||
**Output:**
|
||||
```json
|
||||
{
|
||||
"summary": {
|
||||
"added": 12,
|
||||
"removed": 5,
|
||||
"changed": 8,
|
||||
"unchanged": 234
|
||||
},
|
||||
"changes": [
|
||||
{
|
||||
"findingId": "finding-123",
|
||||
"cve": "CVE-2025-12345",
|
||||
"oldVerdict": "warned",
|
||||
"newVerdict": "blocked",
|
||||
"reason": "rule 'critical-cves' now matches"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3 Coverage Run
|
||||
|
||||
Validate policy against fixture expectations:
|
||||
|
||||
```bash
|
||||
stella policy coverage \
|
||||
--policy my-policy:v2 \
|
||||
--fixtures fixtures/policy-tests.yaml
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Coverage Fixtures
|
||||
|
||||
### 4.1 Fixture Format
|
||||
|
||||
```yaml
|
||||
apiVersion: stellaops.io/policy-test.v1
|
||||
kind: PolicyFixture
|
||||
metadata:
|
||||
name: critical-cve-blocking
|
||||
policy: my-policy
|
||||
|
||||
fixtures:
|
||||
- name: "Block critical CVE in production"
|
||||
input:
|
||||
finding:
|
||||
cve: "CVE-2025-12345"
|
||||
severity: critical
|
||||
ecosystem: npm
|
||||
component: "lodash@4.17.20"
|
||||
context:
|
||||
namespace: production
|
||||
labels:
|
||||
tier: frontend
|
||||
expected:
|
||||
verdict: blocked
|
||||
rulesMatched: ["critical-cves", "production-strict"]
|
||||
|
||||
- name: "Warn on high CVE in staging"
|
||||
input:
|
||||
finding:
|
||||
cve: "CVE-2025-12346"
|
||||
severity: high
|
||||
ecosystem: npm
|
||||
expected:
|
||||
verdict: warned
|
||||
|
||||
- name: "Ignore low CVE with VEX"
|
||||
input:
|
||||
finding:
|
||||
cve: "CVE-2025-12347"
|
||||
severity: low
|
||||
vexStatus: not_affected
|
||||
vexJustification: "component_not_present"
|
||||
expected:
|
||||
verdict: ignored
|
||||
```
|
||||
|
||||
### 4.2 Fixture Results
|
||||
|
||||
```json
|
||||
{
|
||||
"total": 25,
|
||||
"passed": 23,
|
||||
"failed": 2,
|
||||
"failures": [
|
||||
{
|
||||
"fixture": "Block critical CVE in production",
|
||||
"expected": {"verdict": "blocked"},
|
||||
"actual": {"verdict": "warned"},
|
||||
"diff": "rule 'critical-cves' did not match due to missing label"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Promotion Gates
|
||||
|
||||
### 5.1 Gate Requirements
|
||||
|
||||
Before a policy can be promoted from draft to active:
|
||||
|
||||
| Gate | Requirement | Enforcement |
|
||||
|------|-------------|-------------|
|
||||
| Shadow Run | Complete without errors | Required |
|
||||
| Coverage | 100% fixtures pass | Required |
|
||||
| Diff Review | Changes reviewed | Optional |
|
||||
| Approval | Human sign-off | Configurable |
|
||||
|
||||
### 5.2 Promotion Workflow
|
||||
|
||||
```mermaid
|
||||
stateDiagram-v2
|
||||
[*] --> Draft
|
||||
Draft --> Shadow: Start shadow run
|
||||
Shadow --> Coverage: Run coverage tests
|
||||
Coverage --> Review: Pass fixtures
|
||||
Review --> Approval: Review diff
|
||||
Approval --> Active: Approve
|
||||
Coverage --> Draft: Fix failures
|
||||
Approval --> Draft: Reject
|
||||
```
|
||||
|
||||
### 5.3 CLI Commands
|
||||
|
||||
```bash
|
||||
# Start shadow run
|
||||
stella policy promote start --policy my-policy:v2
|
||||
|
||||
# Check promotion status
|
||||
stella policy promote status --policy my-policy:v2
|
||||
|
||||
# Complete promotion (requires approval)
|
||||
stella policy promote complete --policy my-policy:v2 --comment "Reviewed and approved"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. Determinism Requirements
|
||||
|
||||
### 6.1 Simulation Guarantees
|
||||
|
||||
| Property | Guarantee |
|
||||
|----------|-----------|
|
||||
| Input ordering | Stable sort by (tenant, policyId, findingKey) |
|
||||
| Rule evaluation | First-match semantics |
|
||||
| Timestamp handling | Injected TimeProvider |
|
||||
| Random values | Injected IRandom |
|
||||
|
||||
### 6.2 Replay Hash
|
||||
|
||||
Each simulation computes:
|
||||
```
|
||||
determinismHash = SHA256(policyVersion + inputsHash + rulesHash)
|
||||
```
|
||||
|
||||
Replays with same hash must produce identical results.
|
||||
|
||||
---
|
||||
|
||||
## 7. Implementation Strategy
|
||||
|
||||
### 7.1 Phase 1: Shadow Runs (Complete)
|
||||
|
||||
- [x] Shadow collection isolation
|
||||
- [x] Shadow metrics tagging
|
||||
- [x] Shadow run API
|
||||
- [x] CLI integration
|
||||
|
||||
### 7.2 Phase 2: Diff & Coverage (In Progress)
|
||||
|
||||
- [x] Policy diff algorithm
|
||||
- [x] Diff visualization
|
||||
- [ ] Coverage fixture parser (POLICY-COV-50-001)
|
||||
- [ ] Coverage runner (POLICY-COV-50-002)
|
||||
|
||||
### 7.3 Phase 3: Promotion Gates (Planned)
|
||||
|
||||
- [ ] Gate configuration schema
|
||||
- [ ] Promotion state machine
|
||||
- [ ] Approval workflow integration
|
||||
- [ ] Console UI for review
|
||||
|
||||
---
|
||||
|
||||
## 8. API Surface
|
||||
|
||||
### 8.1 Simulation APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/policy/simulate` | POST | `policy:simulate` | Start simulation |
|
||||
| `/api/policy/simulate/{id}` | GET | `policy:read` | Get simulation status |
|
||||
| `/api/policy/simulate/{id}/results` | GET | `policy:read` | Get results |
|
||||
|
||||
### 8.2 Diff APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/policy/diff` | POST | `policy:read` | Compare versions |
|
||||
|
||||
### 8.3 Coverage APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/policy/coverage` | POST | `policy:simulate` | Run coverage |
|
||||
| `/api/policy/coverage/{id}` | GET | `policy:read` | Get results |
|
||||
|
||||
### 8.4 Promotion APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/policy/promote` | POST | `policy:promote` | Start promotion |
|
||||
| `/api/policy/promote/{id}` | GET | `policy:read` | Get status |
|
||||
| `/api/policy/promote/{id}/approve` | POST | `policy:approve` | Approve promotion |
|
||||
| `/api/policy/promote/{id}/reject` | POST | `policy:approve` | Reject promotion |
|
||||
|
||||
---
|
||||
|
||||
## 9. Storage Model
|
||||
|
||||
### 9.1 Collections
|
||||
|
||||
| Collection | Purpose |
|
||||
|------------|---------|
|
||||
| `policy_simulations` | Simulation records |
|
||||
| `policy_simulation_results` | Per-finding results |
|
||||
| `policy_coverage_runs` | Coverage executions |
|
||||
| `policy_promotions` | Promotion state |
|
||||
|
||||
### 9.2 Shadow Isolation
|
||||
|
||||
Shadow results stored in separate collections:
|
||||
- `effective_finding_{policyId}_shadow`
|
||||
- Never mixed with production data
|
||||
- TTL-based cleanup (default 7 days)
|
||||
|
||||
---
|
||||
|
||||
## 10. Observability
|
||||
|
||||
### 10.1 Metrics
|
||||
|
||||
- `policy_simulation_duration_seconds{mode}`
|
||||
- `policy_coverage_pass_rate{policy}`
|
||||
- `policy_promotion_gate_status{gate,status}`
|
||||
- `policy_diff_changes_total{changeType}`
|
||||
|
||||
### 10.2 Audit Events
|
||||
|
||||
- `policy.simulation.started`
|
||||
- `policy.simulation.completed`
|
||||
- `policy.coverage.passed`
|
||||
- `policy.coverage.failed`
|
||||
- `policy.promotion.approved`
|
||||
- `policy.promotion.rejected`
|
||||
|
||||
---
|
||||
|
||||
## 11. Console Integration
|
||||
|
||||
### 11.1 Policy Editor
|
||||
|
||||
- Inline simulation button
|
||||
- Real-time diff preview
|
||||
- Coverage status badge
|
||||
|
||||
### 11.2 Promotion Dashboard
|
||||
|
||||
- Pending promotions list
|
||||
- Gate status visualization
|
||||
- Approval/reject actions
|
||||
|
||||
---
|
||||
|
||||
## 12. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Policy architecture | `docs/modules/policy/architecture.md` |
|
||||
| DSL reference | `docs/policy/dsl.md` |
|
||||
| Lifecycle guide | `docs/policy/lifecycle.md` |
|
||||
| Runtime guide | `docs/policy/runtime.md` |
|
||||
|
||||
---
|
||||
|
||||
## 13. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0185_0001_0001_policy_simulation.md (NEW)
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0120_0000_0001_policy_reasoning.md
|
||||
- SPRINT_0121_0001_0001_policy_reasoning.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `POLICY-SIM-40-001` - Shadow runs (DONE)
|
||||
- `POLICY-DIFF-41-001` - Diff algorithm (DONE)
|
||||
- `POLICY-COV-50-001` - Coverage fixtures (IN PROGRESS)
|
||||
- `POLICY-COV-50-002` - Coverage runner (IN PROGRESS)
|
||||
- `POLICY-PROM-55-001` - Promotion gates (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 14. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Simulation latency | < 2 min (10k findings) |
|
||||
| Coverage accuracy | 100% fixture matching |
|
||||
| Promotion gate enforcement | 100% adherence |
|
||||
| Shadow isolation | Zero production leakage |
|
||||
| Replay determinism | 100% hash match |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,444 @@
|
||||
# Runtime Posture and Observation with Zastava
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, observation model, and implementation strategy for the Zastava module, covering runtime inspection, admission control, drift detection, and posture verification.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
Zastava is the **runtime inspector and enforcer** that provides ground-truth from running environments. Key capabilities:
|
||||
|
||||
- **Runtime Observation** - Inventory containers, track entrypoints, monitor loaded DSOs
|
||||
- **Admission Control** - Kubernetes ValidatingAdmissionWebhook for pre-flight gates
|
||||
- **Drift Detection** - Identify unexpected processes, libraries, and file changes
|
||||
- **Posture Verification** - Validate signatures, SBOM referrers, attestations
|
||||
- **Build-ID Tracking** - Correlate binaries to debug symbols and source
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Runtime Requirements | Use Case |
|
||||
|---------|---------------------|----------|
|
||||
| **Enterprise Security** | Runtime visibility | Post-deploy monitoring |
|
||||
| **Platform Engineering** | Admission gates | Policy enforcement |
|
||||
| **Compliance Teams** | Continuous verification | Runtime attestation |
|
||||
| **DevSecOps** | Drift detection | Configuration management |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability scanners focus on build-time analysis. Stella Ops differentiates with:
|
||||
- **Runtime ground-truth** from actual container execution
|
||||
- **DSO tracking** - which libraries are actually loaded
|
||||
- **Entrypoint tracing** - what programs actually run
|
||||
- **Native Kubernetes admission** with policy integration
|
||||
- **Build-ID correlation** for symbol resolution
|
||||
|
||||
---
|
||||
|
||||
## 3. Architecture Overview
|
||||
|
||||
### 3.1 Component Topology
|
||||
|
||||
**Kubernetes Deployment:**
|
||||
```
|
||||
stellaops/zastava-observer # DaemonSet on every node (read-only host mounts)
|
||||
stellaops/zastava-webhook # ValidatingAdmissionWebhook (Deployment, 2+ replicas)
|
||||
```
|
||||
|
||||
**Docker/VM Deployment:**
|
||||
```
|
||||
stellaops/zastava-agent # System service; watch Docker events; observer only
|
||||
```
|
||||
|
||||
### 3.2 Dependencies
|
||||
|
||||
| Dependency | Purpose |
|
||||
|------------|---------|
|
||||
| Authority | OpToks (DPoP/mTLS) for API calls |
|
||||
| Scanner.WebService | Event ingestion, policy decisions |
|
||||
| OCI Registry | Referrer/signature checks |
|
||||
| Container Runtime | containerd/CRI-O/Docker interfaces |
|
||||
| Kubernetes API | Pod watching, admission webhook |
|
||||
|
||||
---
|
||||
|
||||
## 4. Runtime Event Model
|
||||
|
||||
### 4.1 Event Types
|
||||
|
||||
| Kind | Trigger | Payload |
|
||||
|------|---------|---------|
|
||||
| `CONTAINER_START` | Container lifecycle | Image, entrypoint, namespace |
|
||||
| `CONTAINER_STOP` | Container termination | Exit code, duration |
|
||||
| `DRIFT` | Unexpected change | Changed files, new binaries |
|
||||
| `POLICY_VIOLATION` | Rule breach | Reason, severity |
|
||||
| `ATTESTATION_STATUS` | Verification result | Signed, SBOM present |
|
||||
|
||||
### 4.2 Event Envelope
|
||||
|
||||
```json
|
||||
{
|
||||
"eventId": "uuid",
|
||||
"when": "2025-11-29T12:00:00Z",
|
||||
"kind": "CONTAINER_START",
|
||||
"tenant": "acme-corp",
|
||||
"node": "worker-node-01",
|
||||
"runtime": {
|
||||
"engine": "containerd",
|
||||
"version": "1.7.19"
|
||||
},
|
||||
"workload": {
|
||||
"platform": "kubernetes",
|
||||
"namespace": "production",
|
||||
"pod": "api-7c9fbbd8b7-ktd84",
|
||||
"container": "api",
|
||||
"containerId": "containerd://abc123...",
|
||||
"imageRef": "ghcr.io/acme/api@sha256:def456...",
|
||||
"owner": {
|
||||
"kind": "Deployment",
|
||||
"name": "api"
|
||||
}
|
||||
},
|
||||
"process": {
|
||||
"pid": 12345,
|
||||
"entrypoint": ["/entrypoint.sh", "--serve"],
|
||||
"entryTrace": [
|
||||
{"file": "/entrypoint.sh", "line": 3, "op": "exec", "target": "/usr/bin/python3"},
|
||||
{"file": "<argv>", "op": "python", "target": "/opt/app/server.py"}
|
||||
],
|
||||
"buildId": "9f3a1cd4c0b7adfe91c0e3b51d2f45fb0f76a4c1"
|
||||
},
|
||||
"loadedLibs": [
|
||||
{"path": "/lib/x86_64-linux-gnu/libssl.so.3", "inode": 123456, "sha256": "..."},
|
||||
{"path": "/usr/lib/x86_64-linux-gnu/libcrypto.so.3", "inode": 123457, "sha256": "..."}
|
||||
],
|
||||
"posture": {
|
||||
"imageSigned": true,
|
||||
"sbomReferrer": "present",
|
||||
"attestation": {
|
||||
"uuid": "rekor-uuid",
|
||||
"verified": true
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Observer Capabilities
|
||||
|
||||
### 5.1 Container Lifecycle Tracking
|
||||
|
||||
- Watch container start/stop via CRI socket
|
||||
- Resolve container to image digest
|
||||
- Map mount points and rootfs paths
|
||||
- Track container metadata (labels, annotations)
|
||||
|
||||
### 5.2 Entrypoint Tracing
|
||||
|
||||
- Attach short-lived nsenter to container PID 1
|
||||
- Parse shell scripts for exec chain
|
||||
- Record terminal program (actual binary)
|
||||
- Bounded depth to prevent infinite loops
|
||||
|
||||
### 5.3 Loaded Library Sampling
|
||||
|
||||
- Read `/proc/<pid>/maps` for loaded DSOs
|
||||
- Compute SHA-256 for each mapped file
|
||||
- Track GNU build-IDs for symbol correlation
|
||||
- Rate limits prevent resource exhaustion
|
||||
|
||||
### 5.4 Posture Verification
|
||||
|
||||
- Image signature presence (cosign policies)
|
||||
- SBOM referrers check (registry HEAD)
|
||||
- Rekor attestation lookup via Scanner.WebService
|
||||
- Policy verdict from backend
|
||||
|
||||
---
|
||||
|
||||
## 6. Admission Control
|
||||
|
||||
### 6.1 Gate Criteria
|
||||
|
||||
| Criterion | Description | Configurable |
|
||||
|-----------|-------------|--------------|
|
||||
| Image Signature | Cosign-verifiable to configured keys | Yes |
|
||||
| SBOM Availability | CycloneDX referrer or catalog entry | Yes |
|
||||
| Policy Verdict | Backend PASS required | Yes |
|
||||
| Registry Allowlist | Permitted registries | Yes |
|
||||
| Tag Bans | Reject `:latest`, etc. | Yes |
|
||||
| Base Image Allowlist | Permitted base digests | Yes |
|
||||
|
||||
### 6.2 Decision Flow
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant K8s as API Server
|
||||
participant WH as Zastava Webhook
|
||||
participant SW as Scanner.WebService
|
||||
|
||||
K8s->>WH: AdmissionReview(Pod)
|
||||
WH->>WH: Resolve images to digests
|
||||
WH->>SW: POST /policy/runtime
|
||||
SW-->>WH: {signed, hasSbom, verdict, reasons}
|
||||
alt All pass
|
||||
WH-->>K8s: Allow
|
||||
else Any fail
|
||||
WH-->>K8s: Deny (with reasons)
|
||||
end
|
||||
```
|
||||
|
||||
### 6.3 Response Caching
|
||||
|
||||
- Per-digest results cached for TTL (default 300s)
|
||||
- Fail-open or fail-closed per namespace
|
||||
- Cache invalidation on policy updates
|
||||
|
||||
---
|
||||
|
||||
## 7. Drift Detection
|
||||
|
||||
### 7.1 Signal Types
|
||||
|
||||
| Signal | Detection Method | Action |
|
||||
|--------|-----------------|--------|
|
||||
| Process Drift | Terminal program differs from EntryTrace baseline | Alert |
|
||||
| Library Drift | Loaded DSOs not in Usage SBOM | Alert, delta scan |
|
||||
| Filesystem Drift | New executables with mtime after image creation | Alert |
|
||||
| Network Drift | Unexpected listening ports | Alert (optional) |
|
||||
|
||||
### 7.2 Drift Event
|
||||
|
||||
```json
|
||||
{
|
||||
"kind": "DRIFT",
|
||||
"delta": {
|
||||
"baselineImageDigest": "sha256:abc...",
|
||||
"changedFiles": ["/opt/app/server.py"],
|
||||
"newBinaries": [
|
||||
{"path": "/usr/local/bin/helper", "sha256": "..."}
|
||||
]
|
||||
},
|
||||
"evidence": [
|
||||
{"signal": "procfs.maps", "value": "/lib/.../libssl.so.3@0x7f..."},
|
||||
{"signal": "cri.task.inspect", "value": "pid=12345"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Build-ID Workflow
|
||||
|
||||
### 8.1 Capture
|
||||
|
||||
1. Observer extracts `NT_GNU_BUILD_ID` from `/proc/<pid>/exe`
|
||||
2. Normalize to lower-case hex
|
||||
3. Include in runtime event as `process.buildId`
|
||||
|
||||
### 8.2 Correlation
|
||||
|
||||
1. Scanner.WebService persists observation
|
||||
2. Policy responses include `buildIds` list
|
||||
3. Debug files matched via `.build-id/<aa>/<rest>.debug`
|
||||
|
||||
### 8.3 Symbol Resolution
|
||||
|
||||
```bash
|
||||
# Via CLI
|
||||
stella runtime policy test --image sha256:abc123... | jq '.buildIds'
|
||||
|
||||
# Via debuginfod
|
||||
debuginfod-find debuginfo 9f3a1cd4c0b7adfe91c0e3b51d2f45fb0f76a4c1
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 9. Implementation Strategy
|
||||
|
||||
### 9.1 Phase 1: Observer Core (Complete)
|
||||
|
||||
- [x] CRI socket integration
|
||||
- [x] Container lifecycle tracking
|
||||
- [x] Entrypoint tracing
|
||||
- [x] Loaded library sampling
|
||||
- [x] Event batching and compression
|
||||
|
||||
### 9.2 Phase 2: Admission Webhook (Complete)
|
||||
|
||||
- [x] ValidatingAdmissionWebhook
|
||||
- [x] Image digest resolution
|
||||
- [x] Policy integration
|
||||
- [x] Response caching
|
||||
- [x] Fail-open/closed modes
|
||||
|
||||
### 9.3 Phase 3: Drift Detection (In Progress)
|
||||
|
||||
- [x] Process drift detection
|
||||
- [x] Library drift detection
|
||||
- [ ] Filesystem drift monitoring (ZASTAVA-DRIFT-50-001)
|
||||
- [ ] Network posture checks (ZASTAVA-NET-51-001)
|
||||
|
||||
### 9.4 Phase 4: Advanced Features (Planned)
|
||||
|
||||
- [ ] eBPF syscall tracing (optional)
|
||||
- [ ] Windows container support
|
||||
- [ ] Live used-by-entrypoint synthesis
|
||||
- [ ] Admission dry-run dashboards
|
||||
|
||||
---
|
||||
|
||||
## 10. Configuration
|
||||
|
||||
```yaml
|
||||
zastava:
|
||||
mode:
|
||||
observer: true
|
||||
webhook: true
|
||||
|
||||
backend:
|
||||
baseAddress: "https://scanner-web.internal"
|
||||
policyPath: "/api/v1/scanner/policy/runtime"
|
||||
requestTimeoutSeconds: 5
|
||||
|
||||
runtime:
|
||||
authority:
|
||||
issuer: "https://authority.internal"
|
||||
clientId: "zastava-observer"
|
||||
audience: ["scanner", "zastava"]
|
||||
scopes: ["api:scanner.runtime.write"]
|
||||
requireDpop: true
|
||||
requireMutualTls: true
|
||||
|
||||
tenant: "acme-corp"
|
||||
engine: "auto" # containerd|cri-o|docker|auto
|
||||
procfs: "/host/proc"
|
||||
|
||||
collect:
|
||||
entryTrace: true
|
||||
loadedLibs: true
|
||||
maxLibs: 256
|
||||
maxHashBytesPerContainer: 64000000
|
||||
|
||||
admission:
|
||||
enforce: true
|
||||
failOpenNamespaces: ["dev", "test"]
|
||||
verify:
|
||||
imageSignature: true
|
||||
sbomReferrer: true
|
||||
scannerPolicyPass: true
|
||||
cacheTtlSeconds: 300
|
||||
|
||||
limits:
|
||||
eventsPerSecond: 50
|
||||
burst: 200
|
||||
perNodeQueue: 10000
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 11. Security Posture
|
||||
|
||||
### 11.1 Privileges
|
||||
|
||||
| Capability | Purpose | Mode |
|
||||
|------------|---------|------|
|
||||
| `CAP_SYS_PTRACE` | nsenter trace | Optional |
|
||||
| `CAP_DAC_READ_SEARCH` | Read /proc | Required |
|
||||
| Host PID namespace | Container PIDs | Required |
|
||||
| Read-only mounts | /proc, sockets | Required |
|
||||
|
||||
### 11.2 Least Privilege
|
||||
|
||||
- No write mounts
|
||||
- No host networking
|
||||
- No privilege escalation
|
||||
- Read-only rootfs
|
||||
|
||||
### 11.3 Data Minimization
|
||||
|
||||
- No env var exfiltration
|
||||
- No command argument logging (unless diagnostic mode)
|
||||
- Rate limits prevent abuse
|
||||
|
||||
---
|
||||
|
||||
## 12. Observability
|
||||
|
||||
### 12.1 Observer Metrics
|
||||
|
||||
- `zastava.runtime.events.total{kind}`
|
||||
- `zastava.runtime.backend.latency.ms{endpoint}`
|
||||
- `zastava.proc_maps.samples.total{result}`
|
||||
- `zastava.entrytrace.depth{p99}`
|
||||
- `zastava.hash.bytes.total`
|
||||
- `zastava.buffer.drops.total`
|
||||
|
||||
### 12.2 Webhook Metrics
|
||||
|
||||
- `zastava.admission.decisions.total{decision}`
|
||||
- `zastava.admission.cache.hits.total`
|
||||
- `zastava.backend.failures.total`
|
||||
|
||||
---
|
||||
|
||||
## 13. Performance Targets
|
||||
|
||||
| Operation | Target |
|
||||
|-----------|--------|
|
||||
| `/proc/<pid>/maps` sampling | < 30ms (64 files) |
|
||||
| Full library hash set | < 200ms (256 libs) |
|
||||
| Admission with warm cache | < 8ms p95 |
|
||||
| Admission with backend call | < 50ms p95 |
|
||||
| Event throughput | 5k events/min/node |
|
||||
|
||||
---
|
||||
|
||||
## 14. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Zastava architecture | `docs/modules/zastava/architecture.md` |
|
||||
| Runtime event schema | `docs/modules/zastava/event-schema.md` |
|
||||
| Admission configuration | `docs/modules/zastava/admission-config.md` |
|
||||
| Deployment guide | `docs/modules/zastava/deployment.md` |
|
||||
|
||||
---
|
||||
|
||||
## 15. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0144_0001_0001_zastava_runtime_signals.md
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0140_0001_0001_runtime_signals.md
|
||||
- SPRINT_0143_0000_0001_signals.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `ZASTAVA-OBS-40-001` - Observer core (DONE)
|
||||
- `ZASTAVA-ADM-41-001` - Admission webhook (DONE)
|
||||
- `ZASTAVA-DRIFT-50-001` - Filesystem drift (IN PROGRESS)
|
||||
- `ZASTAVA-NET-51-001` - Network posture (TODO)
|
||||
- `ZASTAVA-EBPF-60-001` - eBPF integration (FUTURE)
|
||||
|
||||
---
|
||||
|
||||
## 16. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Event capture rate | 99.9% of container starts |
|
||||
| Admission latency | < 50ms p95 |
|
||||
| Drift detection rate | 100% of runtime changes |
|
||||
| False positive rate | < 1% of drift alerts |
|
||||
| Node resource usage | < 2% CPU, < 100MB RAM |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,289 @@
|
||||
# Sovereign Crypto for Regional Compliance
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-28
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, implementation strategy, and compliance mapping for regional cryptography support in Stella Ops, enabling deployments in jurisdictions requiring eIDAS, FIPS, GOST, or Chinese SM algorithms.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
Stella Ops must support **sovereign-ready cryptography** to serve customers in regulated environments where standard cryptographic algorithms are insufficient or prohibited. This includes:
|
||||
|
||||
- **EU/eIDAS**: Qualified electronic signatures with HSM-backed keys
|
||||
- **US/FIPS 140-2/3**: Federal deployments requiring validated cryptographic modules
|
||||
- **Russia/GOST**: CryptoPro CSP and GOST R 34.10-2012/34.11-2012 algorithms
|
||||
- **China/SM**: SM2 (signing), SM3 (hashing), SM4 (encryption) national standards
|
||||
|
||||
The implementation uses a **provider registry pattern** allowing runtime selection of cryptographic backends without code changes.
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Crypto Requirements | Market Size |
|
||||
|---------|---------------------|-------------|
|
||||
| **EU Government/Critical Infrastructure** | eIDAS QES, qualified timestamps | Large (EU Digital Identity Wallet mandate) |
|
||||
| **US Federal/Defense** | FIPS 140-2/3 validated modules | Large (FedRAMP, CMMC) |
|
||||
| **Russian Enterprise** | GOST algorithms, CryptoPro CSP | Medium (domestic compliance) |
|
||||
| **Chinese SOE/Government** | SM2/SM3/SM4 algorithms | Large (mandatory for PRC government) |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability scanning tools (Snyk, Trivy, Grype) do not offer sovereign crypto options. Anchore Enterprise provides FIPS builds. Stella Ops can differentiate by supporting **all major regional standards** through a unified provider registry.
|
||||
|
||||
---
|
||||
|
||||
## 3. Technical Architecture
|
||||
|
||||
### 3.1 Provider Registry Pattern
|
||||
|
||||
The `ICryptoProviderRegistry` abstraction enables runtime selection of cryptographic implementations:
|
||||
|
||||
```
|
||||
┌────────────────────────────────────────────────────────────────┐
|
||||
│ Application Layer │
|
||||
│ (Scanner, Authority, Attestor, Export Center, etc.) │
|
||||
└────────────────────────────┬───────────────────────────────────┘
|
||||
│
|
||||
▼
|
||||
┌────────────────────────────────────────────────────────────────┐
|
||||
│ ICryptoProviderRegistry │
|
||||
│ - ResolveHasher(profile) │
|
||||
│ - ResolveSigner(profile) │
|
||||
│ - ResolveKeyStore(profile) │
|
||||
└────────────────────────────┬───────────────────────────────────┘
|
||||
│
|
||||
┌───────────────────┼───────────────────┐
|
||||
▼ ▼ ▼
|
||||
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
|
||||
│ Default Profile │ │ RU Profile │ │ CN Profile │
|
||||
│ - SHA-256/384 │ │ - GOST R 34.11 │ │ - SM3 hash │
|
||||
│ - ECDSA P-256 │ │ - GOST R 34.10 │ │ - SM2 signing │
|
||||
│ - AES-256-GCM │ │ - Magma/Kuznech │ │ - SM4 encryption│
|
||||
└─────────────────┘ └─────────────────┘ └─────────────────┘
|
||||
```
|
||||
|
||||
### 3.2 Profile Configuration
|
||||
|
||||
```yaml
|
||||
stellaops:
|
||||
crypto:
|
||||
registry:
|
||||
activeProfile: "default" # or "ru-offline", "cn-government"
|
||||
profiles:
|
||||
default:
|
||||
hashAlgorithm: "SHA256"
|
||||
signingAlgorithm: "ECDSA-P256"
|
||||
encryptionAlgorithm: "AES-256-GCM"
|
||||
providers:
|
||||
- "default"
|
||||
ru-offline:
|
||||
hashAlgorithm: "GOST-R-34.11-2012-256"
|
||||
signingAlgorithm: "GOST-R-34.10-2012"
|
||||
encryptionAlgorithm: "GOST-28147-89"
|
||||
providers:
|
||||
- "ru.cryptopro.csp"
|
||||
- "ru.openssl.gost"
|
||||
- "ru.pkcs11"
|
||||
cn-government:
|
||||
hashAlgorithm: "SM3"
|
||||
signingAlgorithm: "SM2"
|
||||
encryptionAlgorithm: "SM4"
|
||||
providers:
|
||||
- "cn.tongsuo"
|
||||
- "cn.pkcs11"
|
||||
```
|
||||
|
||||
### 3.3 Provider Implementations
|
||||
|
||||
| Provider ID | Backend | Algorithms | Platform |
|
||||
|-------------|---------|------------|----------|
|
||||
| `default` | .NET BCL | SHA-2, ECDSA, AES | All |
|
||||
| `ru.cryptopro.csp` | CryptoPro CSP | GOST R 34.10/11, Magma | Windows |
|
||||
| `ru.openssl.gost` | OpenSSL + GOST engine | GOST algorithms | Linux |
|
||||
| `ru.pkcs11` | PKCS#11 tokens | GOST (hardware) | All |
|
||||
| `cn.tongsuo` | Tongsuo (OpenSSL fork) | SM2/3/4 | Linux |
|
||||
| `cn.pkcs11` | PKCS#11 tokens | SM algorithms (hardware) | All |
|
||||
| `fips` | OpenSSL FIPS module | FIPS 140-2 validated | Linux |
|
||||
|
||||
---
|
||||
|
||||
## 4. Implementation Strategy
|
||||
|
||||
### 4.1 Phase 1: Registry Foundation (Complete)
|
||||
|
||||
- `ICryptoProviderRegistry` interface published
|
||||
- Default profile with .NET BCL backend
|
||||
- Configuration binding via `StellaOps:Crypto:Registry`
|
||||
|
||||
### 4.2 Phase 2: GOST/RU Support (In Progress)
|
||||
|
||||
- CryptoPro CSP plugin via forked GostCryptography library
|
||||
- OpenSSL GOST engine integration
|
||||
- Windows-only CSP tests with opt-in CI pipeline
|
||||
- RootPack RU distribution bundle
|
||||
|
||||
### 4.3 Phase 3: PQ-Ready Extensions (Planned)
|
||||
|
||||
- Post-quantum algorithms (Dilithium, Falcon) for DSSE
|
||||
- Hybrid signing (classical + PQ) for transition period
|
||||
- Registry options for algorithm agility
|
||||
|
||||
### 4.4 Phase 4: SM/CN Support (Future)
|
||||
|
||||
- Tongsuo integration for SM2/3/4
|
||||
- PKCS#11 support for Chinese HSMs
|
||||
- Compliance documentation for PRC requirements
|
||||
|
||||
---
|
||||
|
||||
## 5. Compliance Mapping
|
||||
|
||||
### 5.1 eIDAS (EU)
|
||||
|
||||
| Requirement | Stella Ops Capability |
|
||||
|-------------|----------------------|
|
||||
| Qualified Electronic Signature (QES) | HSM-backed signing via PKCS#11 |
|
||||
| Qualified Timestamp | RFC 3161 via external TSA |
|
||||
| Advanced Electronic Seal | DSSE attestations with organizational keys |
|
||||
| Long-term preservation (LTV) | Audit bundles with embedded timestamps |
|
||||
|
||||
### 5.2 FIPS 140-2/3 (US)
|
||||
|
||||
| Requirement | Stella Ops Capability |
|
||||
|-------------|----------------------|
|
||||
| Validated cryptographic module | OpenSSL FIPS provider |
|
||||
| Approved algorithms only | Profile restricts to FIPS-approved |
|
||||
| Key management | HSM or FIPS-validated software |
|
||||
| Self-tests | Provider initialization checks |
|
||||
|
||||
### 5.3 GOST (Russia)
|
||||
|
||||
| Requirement | Stella Ops Capability |
|
||||
|-------------|----------------------|
|
||||
| GOST R 34.10-2012 (signing) | CryptoPro CSP / OpenSSL GOST |
|
||||
| GOST R 34.11-2012 (hashing) | Provider registry selection |
|
||||
| Magma/Kuznyechik (encryption) | Symmetric support planned |
|
||||
| Certified CSP | CryptoPro CSP integration |
|
||||
|
||||
### 5.4 SM (China)
|
||||
|
||||
| Requirement | Stella Ops Capability |
|
||||
|-------------|----------------------|
|
||||
| SM2 (signing) | Tongsuo / PKCS#11 |
|
||||
| SM3 (hashing) | Provider registry selection |
|
||||
| SM4 (encryption) | Symmetric support planned |
|
||||
| GB/T certification | Third-party certification path |
|
||||
|
||||
---
|
||||
|
||||
## 6. Determinism Requirements
|
||||
|
||||
All cryptographic operations must maintain Stella Ops determinism guarantees:
|
||||
|
||||
1. **Same inputs + same profile = same output** (for hashing/signing with deterministic algorithms)
|
||||
2. **Timestamps in UTC ISO-8601** format
|
||||
3. **Profile names and provider IDs in lowercase ASCII**
|
||||
4. **Audit material includes provider version and configuration hash**
|
||||
|
||||
For algorithms with inherent randomness (ECDSA k-value, SM2), determinism applies to verification, not signature bytes.
|
||||
|
||||
---
|
||||
|
||||
## 7. Offline/Air-Gap Support
|
||||
|
||||
Sovereign deployments often require air-gapped operation:
|
||||
|
||||
| Feature | Offline Support |
|
||||
|---------|----------------|
|
||||
| Provider initialization | Local configuration only |
|
||||
| Key storage | Local HSM or file-based |
|
||||
| Certificate validation | Offline CRL/OCSP stapling |
|
||||
| Timestamp authority | Embedded timestamps or offline TSA |
|
||||
| Algorithm updates | Bundled in RootPack distributions |
|
||||
|
||||
---
|
||||
|
||||
## 8. Testing Strategy
|
||||
|
||||
### 8.1 Unit Tests
|
||||
|
||||
- Provider registry resolution
|
||||
- Algorithm selection per profile
|
||||
- Configuration validation
|
||||
|
||||
### 8.2 Integration Tests (Platform-Specific)
|
||||
|
||||
| Test Suite | Platform | Trigger |
|
||||
|------------|----------|---------|
|
||||
| Default profile | All | Default CI |
|
||||
| GOST/CryptoPro | Windows + CSP | Opt-in pipeline |
|
||||
| GOST/OpenSSL | Linux + GOST engine | Opt-in pipeline |
|
||||
| FIPS | Linux + FIPS module | Opt-in pipeline |
|
||||
| SM | Linux + Tongsuo | Future |
|
||||
|
||||
### 8.3 Compliance Validation
|
||||
|
||||
- NIST CAVP vectors for FIPS algorithms
|
||||
- GOST test vectors from TC 26
|
||||
- SM test vectors from GM/T standards
|
||||
|
||||
---
|
||||
|
||||
## 9. Distribution & Licensing
|
||||
|
||||
### 9.1 RootPack Bundles
|
||||
|
||||
| Bundle | Contents | Distribution |
|
||||
|--------|----------|--------------|
|
||||
| `rootpack-default` | Standard algorithms only | Public |
|
||||
| `rootpack-ru` | GOST providers + CryptoPro plugin | Restricted (RU customers) |
|
||||
| `rootpack-cn` | SM providers + Tongsuo | Restricted (CN customers) |
|
||||
| `rootpack-fips` | FIPS-validated binaries | Enterprise only |
|
||||
|
||||
### 9.2 Licensing Considerations
|
||||
|
||||
- CryptoPro CSP requires customer license
|
||||
- OpenSSL GOST engine under Apache 2.0
|
||||
- Tongsuo under Apache 2.0
|
||||
- Forked GostCryptography under MIT (with AGPL obligations from Stella Ops wrapper)
|
||||
|
||||
---
|
||||
|
||||
## 10. Related Documentation
|
||||
|
||||
- `docs/security/rootpack_ru_*.md` - RootPack RU documentation
|
||||
- `docs/security/crypto-registry-decision-2025-11-18.md` - Registry design decision
|
||||
- `docs/security/crypto-routing-audit-2025-11-07.md` - Crypto routing audit
|
||||
- `docs/security/pq-provider-options.md` - Post-quantum options
|
||||
- `docs/modules/signer/architecture.md` - Signer service crypto usage
|
||||
|
||||
---
|
||||
|
||||
## 11. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0514_0001_0001_sovereign_crypto_enablement.md
|
||||
- **Blocking Dependencies:**
|
||||
- Authority provider/JWKS contract (AUTH-CRYPTO-90-001)
|
||||
- Windows CSP test runner for CryptoPro validation
|
||||
- **Status:** Phase 2 (GOST/RU) in progress with multiple tasks BLOCKED
|
||||
|
||||
---
|
||||
|
||||
## 12. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Profile switch without code change | 100% |
|
||||
| GOST signing/verification | Working on Windows + Linux |
|
||||
| FIPS validation coverage | All signing/hashing paths |
|
||||
| Offline kit reproducibility | Deterministic across profiles |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-28*
|
||||
@@ -0,0 +1,447 @@
|
||||
# Task Pack Orchestration and Automation
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, DSL semantics, and implementation strategy for the TaskRunner module, covering pack manifest structure, execution semantics, approval workflows, and evidence capture.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The TaskRunner provides **deterministic, auditable automation** for security workflows. Key capabilities:
|
||||
|
||||
- **Task Pack DSL** - Declarative YAML manifests for multi-step workflows
|
||||
- **Approval Gates** - Human-in-the-loop checkpoints with Authority integration
|
||||
- **Deterministic Execution** - Plan hash verification prevents runtime divergence
|
||||
- **Evidence Capture** - DSSE attestations for provenance and audit
|
||||
- **Air-Gap Support** - Sealed-mode validation for offline installations
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Automation Requirements | Use Case |
|
||||
|---------|------------------------|----------|
|
||||
| **Enterprise Security** | Approval workflows for vulnerability remediation | Change advisory board gates |
|
||||
| **DevSecOps** | CI/CD pipeline integration | Automated policy enforcement |
|
||||
| **Compliance Teams** | Auditable execution with evidence | SOC 2, FedRAMP documentation |
|
||||
| **MSP/MSSP** | Multi-tenant orchestration | Managed security services |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability scanning tools lack built-in orchestration. Stella Ops differentiates with:
|
||||
- **Declarative task packs** with schema validation
|
||||
- **Cryptographic plan verification** (plan hash binding)
|
||||
- **Native approval gates** with Authority token integration
|
||||
- **Evidence attestations** for audit trails
|
||||
- **Sealed-mode enforcement** for air-gapped environments
|
||||
|
||||
---
|
||||
|
||||
## 3. Technical Architecture
|
||||
|
||||
### 3.1 Pack Manifest Structure (v1)
|
||||
|
||||
```yaml
|
||||
apiVersion: stellaops.io/pack.v1
|
||||
kind: TaskPack
|
||||
metadata:
|
||||
name: vulnerability-scan-and-report
|
||||
version: 1.2.0
|
||||
description: Scan container, evaluate policy, generate report
|
||||
tags: [security, compliance, scanning]
|
||||
tenantVisibility: private
|
||||
maintainers:
|
||||
- name: Security Team
|
||||
email: security@example.com
|
||||
license: MIT
|
||||
|
||||
spec:
|
||||
inputs:
|
||||
- name: imageRef
|
||||
type: string
|
||||
required: true
|
||||
schema:
|
||||
pattern: "^[a-z0-9./-]+:[a-z0-9.-]+$"
|
||||
- name: policyPack
|
||||
type: string
|
||||
default: "default-policy-v1"
|
||||
|
||||
secrets:
|
||||
- name: registryCredentials
|
||||
scope: scanner.read
|
||||
description: Registry pull credentials
|
||||
|
||||
approvals:
|
||||
- name: security-review
|
||||
grants: ["security-lead", "ciso"]
|
||||
ttlHours: 72
|
||||
message: "Approve scan results before policy evaluation"
|
||||
|
||||
steps:
|
||||
- id: scan
|
||||
type: run
|
||||
module: scanner/sbom-vuln
|
||||
inputs:
|
||||
image: "{{ inputs.imageRef }}"
|
||||
outputs:
|
||||
sbom: sbom.json
|
||||
vulns: vulnerabilities.json
|
||||
|
||||
- id: review-gate
|
||||
type: gate.approval
|
||||
approval: security-review
|
||||
dependsOn: [scan]
|
||||
|
||||
- id: policy-eval
|
||||
type: run
|
||||
module: policy/evaluate
|
||||
inputs:
|
||||
sbom: "{{ steps.scan.outputs.sbom }}"
|
||||
vulns: "{{ steps.scan.outputs.vulns }}"
|
||||
pack: "{{ inputs.policyPack }}"
|
||||
dependsOn: [review-gate]
|
||||
|
||||
- id: generate-report
|
||||
type: parallel
|
||||
maxParallel: 2
|
||||
steps:
|
||||
- id: pdf-report
|
||||
type: run
|
||||
module: export/pdf
|
||||
inputs:
|
||||
data: "{{ steps.policy-eval.outputs.results }}"
|
||||
- id: json-report
|
||||
type: run
|
||||
module: export/json
|
||||
inputs:
|
||||
data: "{{ steps.policy-eval.outputs.results }}"
|
||||
dependsOn: [policy-eval]
|
||||
|
||||
outputs:
|
||||
- name: scanReport
|
||||
type: file
|
||||
path: "{{ steps.generate-report.steps.pdf-report.outputs.file }}"
|
||||
- name: machineReadable
|
||||
type: object
|
||||
value: "{{ steps.generate-report.steps.json-report.outputs.data }}"
|
||||
|
||||
success:
|
||||
message: "Scan completed successfully"
|
||||
failure:
|
||||
message: "Scan failed - review logs"
|
||||
retryPolicy:
|
||||
maxRetries: 2
|
||||
backoffSeconds: 60
|
||||
```
|
||||
|
||||
### 3.2 Step Types
|
||||
|
||||
| Type | Purpose | Key Properties |
|
||||
|------|---------|----------------|
|
||||
| `run` | Execute module | `module`, `inputs`, `outputs` |
|
||||
| `parallel` | Concurrent execution | `steps[]`, `maxParallel` |
|
||||
| `map` | Iterate over list | `items`, `step`, `maxParallel` |
|
||||
| `gate.approval` | Human approval checkpoint | `approval`, `timeout` |
|
||||
| `gate.policy` | Policy Engine validation | `policy`, `failAction` |
|
||||
|
||||
### 3.3 Execution Semantics
|
||||
|
||||
**Plan Phase:**
|
||||
1. Parse manifest and validate schema
|
||||
2. Resolve input expressions
|
||||
3. Build execution graph
|
||||
4. Compute **canonical plan hash** (SHA-256 of normalized graph)
|
||||
|
||||
**Simulation Phase (Optional):**
|
||||
1. Execute all steps in dry-run mode
|
||||
2. Capture expected outputs
|
||||
3. Store simulation results with plan hash
|
||||
|
||||
**Execution Phase:**
|
||||
1. Verify runtime graph matches plan hash
|
||||
2. Execute steps in dependency order
|
||||
3. Emit progress events to Timeline
|
||||
4. Capture output artifacts
|
||||
|
||||
**Evidence Phase:**
|
||||
1. Generate DSSE attestation with plan hash
|
||||
2. Include input digests and output manifests
|
||||
3. Store in Evidence Locker
|
||||
4. Optionally anchor to Rekor
|
||||
|
||||
---
|
||||
|
||||
## 4. Approval Workflow
|
||||
|
||||
### 4.1 Gate Definition
|
||||
|
||||
```yaml
|
||||
approvals:
|
||||
- name: security-review
|
||||
grants: ["role/security-lead", "role/ciso"]
|
||||
ttlHours: 72
|
||||
message: "Review vulnerability findings before proceeding"
|
||||
requiredCount: 1 # Number of approvals needed
|
||||
```
|
||||
|
||||
### 4.2 Authority Token Contract
|
||||
|
||||
Approval tokens must include:
|
||||
|
||||
| Claim | Description |
|
||||
|-------|-------------|
|
||||
| `pack_run_id` | Run identifier (UUID) |
|
||||
| `pack_gate_id` | Gate name from manifest |
|
||||
| `pack_plan_hash` | Canonical plan hash |
|
||||
| `auth_time` | Must be within 5 minutes of request |
|
||||
|
||||
### 4.3 CLI Approval Command
|
||||
|
||||
```bash
|
||||
stella pack approve \
|
||||
--run "run:tenant-default:20251129T120000Z" \
|
||||
--gate security-review \
|
||||
--pack-run-id "abc123..." \
|
||||
--pack-gate-id "security-review" \
|
||||
--pack-plan-hash "sha256:def456..." \
|
||||
--comment "Reviewed findings, no critical issues"
|
||||
```
|
||||
|
||||
### 4.4 Approval Events
|
||||
|
||||
| Event | Trigger |
|
||||
|-------|---------|
|
||||
| `pack.approval.requested` | Gate reached, awaiting approval |
|
||||
| `pack.approval.granted` | Approval recorded |
|
||||
| `pack.approval.denied` | Approval rejected |
|
||||
| `pack.approval.expired` | TTL exceeded without approval |
|
||||
|
||||
---
|
||||
|
||||
## 5. Implementation Strategy
|
||||
|
||||
### 5.1 Phase 1: Core Execution (In Progress)
|
||||
|
||||
- [x] Telemetry core adoption (TASKRUN-OBS-50-001)
|
||||
- [x] Metrics implementation (TASKRUN-OBS-51-001)
|
||||
- [ ] Architecture/API contracts (TASKRUN-41-001) - BLOCKED
|
||||
- [ ] Execution engine enhancements (TASKRUN-42-001) - BLOCKED
|
||||
|
||||
### 5.2 Phase 2: Approvals & Evidence (Planned)
|
||||
|
||||
- [ ] Timeline event emission (TASKRUN-OBS-52-001)
|
||||
- [ ] Evidence locker snapshots (TASKRUN-OBS-53-001)
|
||||
- [ ] DSSE attestations (TASKRUN-OBS-54-001)
|
||||
- [ ] Incident mode escalations (TASKRUN-OBS-55-001)
|
||||
|
||||
### 5.3 Phase 3: Multi-Tenancy & Air-Gap (Planned)
|
||||
|
||||
- [ ] Tenant scoping and egress control (TASKRUN-TEN-48-001)
|
||||
- [ ] Sealed-mode validation (TASKRUN-AIRGAP-56-001)
|
||||
- [ ] Bundle ingestion for offline (TASKRUN-AIRGAP-56-002)
|
||||
- [ ] Evidence capture in sealed mode (TASKRUN-AIRGAP-58-001)
|
||||
|
||||
---
|
||||
|
||||
## 6. API Surface
|
||||
|
||||
### 6.1 TaskRunner APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/runs` | POST | `packs.run` | Submit pack run |
|
||||
| `/api/runs/{runId}` | GET | `packs.read` | Get run status |
|
||||
| `/api/runs/{runId}/logs` | GET | `packs.read` | Stream logs (SSE) |
|
||||
| `/api/runs/{runId}/artifacts` | GET | `packs.read` | List artifacts |
|
||||
| `/api/runs/{runId}/approve` | POST | `packs.approve` | Record approval |
|
||||
| `/api/runs/{runId}/cancel` | POST | `packs.run` | Cancel run |
|
||||
|
||||
### 6.2 Packs Registry APIs
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/api/packs` | GET | `packs.read` | List packs |
|
||||
| `/api/packs/{packId}/versions` | GET | `packs.read` | List versions |
|
||||
| `/api/packs/{packId}/versions/{version}` | GET | `packs.read` | Get manifest |
|
||||
| `/api/packs/{packId}/versions` | POST | `packs.write` | Publish pack |
|
||||
| `/api/packs/{packId}/promote` | POST | `packs.write` | Promote channel |
|
||||
|
||||
### 6.3 CLI Commands
|
||||
|
||||
```bash
|
||||
# Initialize pack scaffold
|
||||
stella pack init --name my-workflow
|
||||
|
||||
# Validate manifest
|
||||
stella pack validate pack.yaml
|
||||
|
||||
# Dry-run simulation
|
||||
stella pack plan pack.yaml --inputs image=nginx:latest
|
||||
|
||||
# Execute pack
|
||||
stella pack run pack.yaml --inputs image=nginx:latest
|
||||
|
||||
# Build distributable bundle
|
||||
stella pack build pack.yaml --output my-workflow-1.0.0.tar.gz
|
||||
|
||||
# Sign bundle
|
||||
cosign sign-blob my-workflow-1.0.0.tar.gz
|
||||
|
||||
# Publish to registry
|
||||
stella pack push my-workflow-1.0.0.tar.gz --registry packs.example.com
|
||||
|
||||
# Export for offline distribution
|
||||
stella pack bundle export --pack my-workflow --version 1.0.0
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. Storage Model
|
||||
|
||||
### 7.1 MongoDB Collections
|
||||
|
||||
**pack_runs:**
|
||||
|
||||
| Field | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| `_id` | string | Run identifier |
|
||||
| `planHash` | string | Canonical plan hash |
|
||||
| `plan` | object | Full TaskPackPlan |
|
||||
| `failurePolicy` | object | Retry/backoff config |
|
||||
| `requestedAt` | date | Client request time |
|
||||
| `tenantId` | string | Tenant scope |
|
||||
| `steps` | array | Step execution records |
|
||||
|
||||
**pack_run_logs:**
|
||||
|
||||
| Field | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| `runId` | string | FK to pack_runs |
|
||||
| `sequence` | long | Monotonic counter |
|
||||
| `timestamp` | date | Event time (UTC) |
|
||||
| `level` | string | trace/debug/info/warn/error |
|
||||
| `eventType` | string | Machine identifier |
|
||||
| `stepId` | string | Optional step reference |
|
||||
|
||||
**pack_artifacts:**
|
||||
|
||||
| Field | Type | Description |
|
||||
|-------|------|-------------|
|
||||
| `runId` | string | FK to pack_runs |
|
||||
| `name` | string | Output name |
|
||||
| `type` | string | file/object/url |
|
||||
| `storedPath` | string | Object store URI |
|
||||
| `status` | string | pending/copied/materialized |
|
||||
|
||||
---
|
||||
|
||||
## 8. Evidence & Attestation
|
||||
|
||||
### 8.1 DSSE Attestation Structure
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.stellaops.pack-run+json",
|
||||
"payload": {
|
||||
"runId": "abc123...",
|
||||
"packName": "vulnerability-scan-and-report",
|
||||
"packVersion": "1.2.0",
|
||||
"planHash": "sha256:def456...",
|
||||
"inputs": {
|
||||
"imageRef": { "value": "nginx:latest", "digest": "sha256:..." }
|
||||
},
|
||||
"outputs": [
|
||||
{ "name": "scanReport", "digest": "sha256:..." }
|
||||
],
|
||||
"steps": [
|
||||
{ "id": "scan", "status": "completed", "duration": 45.2 }
|
||||
],
|
||||
"completedAt": "2025-11-29T12:30:00Z"
|
||||
},
|
||||
"signatures": [...]
|
||||
}
|
||||
```
|
||||
|
||||
### 8.2 Evidence Bundle
|
||||
|
||||
Task pack runs produce evidence bundles containing:
|
||||
- Pack manifest (signed)
|
||||
- Input values (redacted secrets)
|
||||
- Output artifacts
|
||||
- Step transcripts
|
||||
- DSSE attestation
|
||||
|
||||
---
|
||||
|
||||
## 9. Determinism Requirements
|
||||
|
||||
All TaskRunner operations must maintain determinism:
|
||||
|
||||
1. **Plan hash binding** - Runtime graph must match computed plan hash
|
||||
2. **Stable step ordering** - Dependencies resolve deterministically
|
||||
3. **Expression evaluation** - Same inputs produce same resolved values
|
||||
4. **Timestamps in UTC** - All logs and events use ISO-8601 UTC
|
||||
5. **Secret masking** - Secrets never appear in logs or evidence
|
||||
|
||||
---
|
||||
|
||||
## 10. RBAC & Scopes
|
||||
|
||||
| Scope | Purpose |
|
||||
|-------|---------|
|
||||
| `packs.read` | Discover/download packs |
|
||||
| `packs.write` | Publish/update packs (requires signature) |
|
||||
| `packs.run` | Execute packs via CLI/TaskRunner |
|
||||
| `packs.approve` | Fulfill approval gates |
|
||||
|
||||
**Approval Token Requirements:**
|
||||
- `pack_run_id`, `pack_gate_id`, `pack_plan_hash` are mandatory
|
||||
- Token must be fresh (within 5-minute auth window)
|
||||
|
||||
---
|
||||
|
||||
## 11. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Task Pack specification | `docs/task-packs/spec.md` |
|
||||
| Authoring guide | `docs/task-packs/authoring-guide.md` |
|
||||
| Operations runbook | `docs/task-packs/runbook.md` |
|
||||
| Registry architecture | `docs/task-packs/registry.md` |
|
||||
| MongoDB migrations | `docs/modules/taskrunner/migrations/pack-run-collections.md` |
|
||||
|
||||
---
|
||||
|
||||
## 12. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0157_0001_0001_taskrunner_i.md
|
||||
- **Phase II:** SPRINT_0158_0001_0002_taskrunner_ii.md
|
||||
- **Blockers:** SPRINT_0157_0001_0002_taskrunner_blockers.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `TASKRUN-41-001` - Architecture/API contracts (BLOCKED)
|
||||
- `TASKRUN-42-001` - Execution engine enhancements (BLOCKED)
|
||||
- `TASKRUN-OBS-50-001` - Telemetry core adoption (DONE)
|
||||
- `TASKRUN-OBS-51-001` - Metrics implementation (DONE)
|
||||
- `TASKRUN-OBS-52-001` - Timeline events (BLOCKED)
|
||||
|
||||
---
|
||||
|
||||
## 13. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Plan hash verification | 100% match or abort |
|
||||
| Approval gate response | < 5 min for high-priority |
|
||||
| Evidence attestation rate | 100% of completed runs |
|
||||
| Offline execution success | Works in sealed mode |
|
||||
| Step execution latency | < 2s overhead per step |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,373 @@
|
||||
# Telemetry and Observability Patterns
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-29
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the product rationale, collector topology, and implementation strategy for the Telemetry module, covering metrics, traces, logs, forensic pipelines, and offline packaging.
|
||||
|
||||
---
|
||||
|
||||
## 1. Executive Summary
|
||||
|
||||
The Telemetry module provides **unified observability infrastructure** across all Stella Ops components. Key capabilities:
|
||||
|
||||
- **OpenTelemetry Native** - OTLP collection for metrics, traces, logs
|
||||
- **Forensic Mode** - Extended retention and 100% sampling during incidents
|
||||
- **Profile-Based Configuration** - Default, forensic, and air-gap profiles
|
||||
- **Sealed-Mode Guards** - Automatic exporter restrictions in air-gap
|
||||
- **Offline Bundles** - Signed OTLP archives for compliance
|
||||
|
||||
---
|
||||
|
||||
## 2. Market Drivers
|
||||
|
||||
### 2.1 Target Segments
|
||||
|
||||
| Segment | Observability Requirements | Use Case |
|
||||
|---------|---------------------------|----------|
|
||||
| **Platform Ops** | Real-time monitoring | Operational health |
|
||||
| **Security Teams** | Forensic investigation | Incident response |
|
||||
| **Compliance** | Audit trails | SOC 2, FedRAMP |
|
||||
| **DevSecOps** | Pipeline visibility | CI/CD debugging |
|
||||
|
||||
### 2.2 Competitive Positioning
|
||||
|
||||
Most vulnerability tools provide minimal observability. Stella Ops differentiates with:
|
||||
- **Built-in OpenTelemetry** across all services
|
||||
- **Forensic mode** with automatic retention extension
|
||||
- **Sealed-mode compatibility** for air-gap
|
||||
- **Signed OTLP bundles** for compliance archives
|
||||
- **Incident-triggered sampling** escalation
|
||||
|
||||
---
|
||||
|
||||
## 3. Collector Topology
|
||||
|
||||
### 3.1 Architecture
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────────────────────┐
|
||||
│ Services │
|
||||
│ Scanner │ Policy │ Authority │ Orchestrator │ ... │
|
||||
└─────────────────────┬───────────────────────────────┘
|
||||
│ OTLP/gRPC
|
||||
▼
|
||||
┌─────────────────────────────────────────────────────┐
|
||||
│ OpenTelemetry Collector │
|
||||
│ ┌─────────┐ ┌──────────┐ ┌─────────────────────┐ │
|
||||
│ │ Traces │ │ Metrics │ │ Logs │ │
|
||||
│ └────┬────┘ └────┬─────┘ └──────────┬──────────┘ │
|
||||
│ │ Tail │ Batch │ Redaction │
|
||||
│ │ Sampling │ │ │
|
||||
└───────┼────────────┼─────────────────┼─────────────┘
|
||||
│ │ │
|
||||
▼ ▼ ▼
|
||||
┌────────┐ ┌──────────┐ ┌────────┐
|
||||
│ Tempo │ │Prometheus│ │ Loki │
|
||||
└────────┘ └──────────┘ └────────┘
|
||||
```
|
||||
|
||||
### 3.2 Collector Profiles
|
||||
|
||||
| Profile | Use Case | Configuration |
|
||||
|---------|----------|---------------|
|
||||
| **default** | Normal operation | 10% trace sampling, 30-day retention |
|
||||
| **forensic** | Investigation mode | 100% sampling, 180-day retention |
|
||||
| **airgap** | Offline deployment | File exporters, no external network |
|
||||
|
||||
---
|
||||
|
||||
## 4. Metrics
|
||||
|
||||
### 4.1 Standard Metrics
|
||||
|
||||
| Metric | Type | Labels | Description |
|
||||
|--------|------|--------|-------------|
|
||||
| `stellaops_request_duration_seconds` | Histogram | service, endpoint | Request latency |
|
||||
| `stellaops_request_total` | Counter | service, status | Request count |
|
||||
| `stellaops_active_jobs` | Gauge | tenant, jobType | Active job count |
|
||||
| `stellaops_queue_depth` | Gauge | queue | Queue depth |
|
||||
| `stellaops_scan_duration_seconds` | Histogram | tenant | Scan duration |
|
||||
|
||||
### 4.2 Module-Specific Metrics
|
||||
|
||||
**Policy Engine:**
|
||||
- `policy_run_seconds{mode,tenant,policy}`
|
||||
- `policy_rules_fired_total{policy,rule}`
|
||||
- `policy_vex_overrides_total{policy,vendor}`
|
||||
|
||||
**Scanner:**
|
||||
- `scanner_sbom_components_total{ecosystem}`
|
||||
- `scanner_vulnerabilities_found_total{severity}`
|
||||
- `scanner_attestations_logged_total`
|
||||
|
||||
**Authority:**
|
||||
- `authority_token_issued_total{grant_type,audience}`
|
||||
- `authority_token_rejected_total{reason}`
|
||||
- `authority_dpop_nonce_miss_total`
|
||||
|
||||
---
|
||||
|
||||
## 5. Traces
|
||||
|
||||
### 5.1 Trace Context
|
||||
|
||||
All services propagate W3C Trace Context:
|
||||
- `traceparent` header
|
||||
- `tracestate` for vendor-specific data
|
||||
- `baggage` for cross-service attributes
|
||||
|
||||
### 5.2 Span Conventions
|
||||
|
||||
| Span | Attributes | Description |
|
||||
|------|------------|-------------|
|
||||
| `http.request` | url, method, status | HTTP handler |
|
||||
| `db.query` | collection, operation | MongoDB ops |
|
||||
| `policy.evaluate` | policyId, version | Policy run |
|
||||
| `scan.image` | imageRef, digest | Image scan |
|
||||
| `sign.dsse` | predicateType | DSSE signing |
|
||||
|
||||
### 5.3 Sampling Strategy
|
||||
|
||||
**Default (Tail Sampling):**
|
||||
- Error traces: 100%
|
||||
- Slow traces (>2s): 100%
|
||||
- Normal traces: 10%
|
||||
|
||||
**Forensic Mode:**
|
||||
- All traces: 100%
|
||||
- Extended attributes enabled
|
||||
|
||||
---
|
||||
|
||||
## 6. Logs
|
||||
|
||||
### 6.1 Structured Format
|
||||
|
||||
```json
|
||||
{
|
||||
"timestamp": "2025-11-29T12:00:00.123Z",
|
||||
"level": "info",
|
||||
"message": "Scan completed",
|
||||
"service": "scanner",
|
||||
"traceId": "abc123...",
|
||||
"spanId": "def456...",
|
||||
"tenant": "acme-corp",
|
||||
"imageDigest": "sha256:...",
|
||||
"componentCount": 245,
|
||||
"vulnerabilityCount": 12
|
||||
}
|
||||
```
|
||||
|
||||
### 6.2 Redaction
|
||||
|
||||
Attribute processors strip sensitive data:
|
||||
- `authorization` headers
|
||||
- `secretRef` values
|
||||
- PII based on allowed-key policy
|
||||
|
||||
### 6.3 Log Levels
|
||||
|
||||
| Level | Purpose | Retention |
|
||||
|-------|---------|-----------|
|
||||
| `error` | Failures | 180 days |
|
||||
| `warn` | Anomalies | 90 days |
|
||||
| `info` | Operations | 30 days |
|
||||
| `debug` | Development | 7 days |
|
||||
|
||||
---
|
||||
|
||||
## 7. Forensic Mode
|
||||
|
||||
### 7.1 Activation
|
||||
|
||||
```bash
|
||||
# Activate forensic mode for tenant
|
||||
stella telemetry incident start --tenant acme-corp --reason "CVE-2025-12345 investigation"
|
||||
|
||||
# Check status
|
||||
stella telemetry incident status
|
||||
|
||||
# Deactivate
|
||||
stella telemetry incident stop --tenant acme-corp
|
||||
```
|
||||
|
||||
### 7.2 Behavior Changes
|
||||
|
||||
| Aspect | Default | Forensic |
|
||||
|--------|---------|----------|
|
||||
| Trace sampling | 10% | 100% |
|
||||
| Log level | info | debug |
|
||||
| Retention | 30 days | 180 days |
|
||||
| Attributes | Standard | Extended |
|
||||
| Export frequency | 1 minute | 10 seconds |
|
||||
|
||||
### 7.3 Automatic Triggers
|
||||
|
||||
- Orchestrator incident escalation
|
||||
- Policy violation threshold exceeded
|
||||
- Circuit breaker activation
|
||||
- Manual operator trigger
|
||||
|
||||
---
|
||||
|
||||
## 8. Implementation Strategy
|
||||
|
||||
### 8.1 Phase 1: Core Telemetry (Complete)
|
||||
|
||||
- [x] OpenTelemetry SDK integration
|
||||
- [x] Metrics exporter (Prometheus)
|
||||
- [x] Trace exporter (Tempo/Jaeger)
|
||||
- [x] Log exporter (Loki)
|
||||
|
||||
### 8.2 Phase 2: Advanced Features (Complete)
|
||||
|
||||
- [x] Tail sampling configuration
|
||||
- [x] Attribute redaction
|
||||
- [x] Profile-based configuration
|
||||
- [x] Dashboard provisioning
|
||||
|
||||
### 8.3 Phase 3: Forensic & Offline (In Progress)
|
||||
|
||||
- [x] Forensic mode toggle
|
||||
- [ ] Forensic bundle export (TELEM-FOR-50-001)
|
||||
- [ ] Sealed-mode guards (TELEM-SEAL-51-001)
|
||||
- [ ] Offline bundle signing (TELEM-SIGN-52-001)
|
||||
|
||||
---
|
||||
|
||||
## 9. API Surface
|
||||
|
||||
### 9.1 Configuration
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/telemetry/config/profile/{name}` | GET | `telemetry:read` | Download collector config |
|
||||
| `/telemetry/config/profiles` | GET | `telemetry:read` | List profiles |
|
||||
|
||||
### 9.2 Incident Mode
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/telemetry/incidents/mode` | POST | `telemetry:admin` | Toggle forensic mode |
|
||||
| `/telemetry/incidents/status` | GET | `telemetry:read` | Current mode status |
|
||||
|
||||
### 9.3 Exports
|
||||
|
||||
| Endpoint | Method | Scope | Description |
|
||||
|----------|--------|-------|-------------|
|
||||
| `/telemetry/exports/forensic/{window}` | GET | `telemetry:export` | Stream OTLP bundle |
|
||||
|
||||
---
|
||||
|
||||
## 10. Offline Support
|
||||
|
||||
### 10.1 Bundle Structure
|
||||
|
||||
```
|
||||
telemetry-bundle/
|
||||
├── otlp/
|
||||
│ ├── metrics.pb
|
||||
│ ├── traces.pb
|
||||
│ └── logs.pb
|
||||
├── config/
|
||||
│ ├── collector.yaml
|
||||
│ └── dashboards/
|
||||
├── manifest.json
|
||||
└── signatures/
|
||||
└── manifest.sig
|
||||
```
|
||||
|
||||
### 10.2 Sealed-Mode Guards
|
||||
|
||||
```csharp
|
||||
// StellaOps.Telemetry.Core enforces IEgressPolicy
|
||||
if (sealedMode.IsActive)
|
||||
{
|
||||
// Disable non-loopback exporters
|
||||
// Emit structured warning with remediation
|
||||
// Fall back to file-based export
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 11. Dashboards & Alerts
|
||||
|
||||
### 11.1 Standard Dashboards
|
||||
|
||||
| Dashboard | Purpose | Panels |
|
||||
|-----------|---------|--------|
|
||||
| Platform Health | Overall status | Request rate, error rate, latency |
|
||||
| Scan Operations | Scanner metrics | Scan rate, duration, findings |
|
||||
| Policy Engine | Policy metrics | Evaluation rate, rule hits, verdicts |
|
||||
| Job Orchestration | Queue metrics | Queue depth, job latency, failures |
|
||||
|
||||
### 11.2 Alert Rules
|
||||
|
||||
| Alert | Condition | Severity |
|
||||
|-------|-----------|----------|
|
||||
| High Error Rate | error_rate > 5% | critical |
|
||||
| Slow Scans | p95 > 5m | warning |
|
||||
| Queue Backlog | depth > 1000 | warning |
|
||||
| Circuit Open | breaker_open = 1 | critical |
|
||||
|
||||
---
|
||||
|
||||
## 12. Security Considerations
|
||||
|
||||
### 12.1 Data Protection
|
||||
|
||||
- Sensitive attributes redacted at collection
|
||||
- Encrypted in transit (TLS)
|
||||
- Encrypted at rest (storage layer)
|
||||
- Retention policies enforced
|
||||
|
||||
### 12.2 Access Control
|
||||
|
||||
- Authority scopes for API access
|
||||
- Tenant isolation in queries
|
||||
- Audit logging for forensic access
|
||||
|
||||
---
|
||||
|
||||
## 13. Related Documentation
|
||||
|
||||
| Resource | Location |
|
||||
|----------|----------|
|
||||
| Telemetry architecture | `docs/modules/telemetry/architecture.md` |
|
||||
| Collector configuration | `docs/modules/telemetry/collector-config.md` |
|
||||
| Dashboard provisioning | `docs/modules/telemetry/dashboards.md` |
|
||||
|
||||
---
|
||||
|
||||
## 14. Sprint Mapping
|
||||
|
||||
- **Primary Sprint:** SPRINT_0180_0001_0001_telemetry_core.md (NEW)
|
||||
- **Related Sprints:**
|
||||
- SPRINT_0181_0001_0002_telemetry_forensic.md
|
||||
- SPRINT_0182_0001_0003_telemetry_offline.md
|
||||
|
||||
**Key Task IDs:**
|
||||
- `TELEM-CORE-40-001` - SDK integration (DONE)
|
||||
- `TELEM-DASH-41-001` - Dashboard provisioning (DONE)
|
||||
- `TELEM-FOR-50-001` - Forensic bundles (IN PROGRESS)
|
||||
- `TELEM-SEAL-51-001` - Sealed-mode guards (TODO)
|
||||
- `TELEM-SIGN-52-001` - Bundle signing (TODO)
|
||||
|
||||
---
|
||||
|
||||
## 15. Success Metrics
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Collection overhead | < 2% CPU |
|
||||
| Trace sampling accuracy | 100% for errors |
|
||||
| Log ingestion latency | < 5 seconds |
|
||||
| Forensic activation time | < 30 seconds |
|
||||
| Bundle export time | < 5 minutes (24h data) |
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-29*
|
||||
@@ -0,0 +1,523 @@
|
||||
# Vulnerability Triage UX & VEX-First Decisioning
|
||||
|
||||
**Version:** 1.0
|
||||
**Date:** 2025-11-28
|
||||
**Status:** Canonical
|
||||
|
||||
This advisory defines the **end-to-end UX and data contracts** for vulnerability triage, VEX decisioning, evidence/explainability views, and audit export in Stella Ops. It synthesizes patterns from Snyk, GitLab SCA, Harbor/Trivy, and Anchore Enterprise into a converged UX layer.
|
||||
|
||||
---
|
||||
|
||||
## 1. Scope
|
||||
|
||||
This spec covers:
|
||||
|
||||
1. **Vulnerability triage** (first touch)
|
||||
2. **Suppression / "Not Affected"** (VEX-aligned)
|
||||
3. **Evidence & explainability views**
|
||||
4. **Audit export** (immutable bundles)
|
||||
5. **Attestations** as the backbone of evidence and gating
|
||||
|
||||
Stella Ops is the **converged UX layer** over scanner backends (Snyk, Trivy, GitLab, Anchore, or others).
|
||||
|
||||
---
|
||||
|
||||
## 2. Industry Pattern Analysis
|
||||
|
||||
### 2.1 Triage (First Touch)
|
||||
|
||||
| Tool | Pattern | Stella Ops Mirror |
|
||||
|------|---------|-------------------|
|
||||
| **Snyk** | PR checks show before/after diffs; Fix PRs directly from Issues list | Evidence-first cards with "Fix PR" CTA |
|
||||
| **GitLab SCA** | Vulnerability Report with `Needs triage` default state | Status workflow starting at `DETECTED` |
|
||||
| **Harbor/Trivy** | Project -> Artifacts -> Vulnerabilities panel with Rescan CTA | Artifact-centric navigation with scan badges |
|
||||
| **Anchore** | Images -> Vulnerabilities aligned to Policies (pass/fail) | Policy gate indicators on all finding views |
|
||||
|
||||
**UI pattern to reuse:** An **evidence-first card** per finding (CVE, package, version, path) with primary actions (Fix PR, Dismiss/Not Affected, View Evidence).
|
||||
|
||||
### 2.2 Suppression / "Not Affected" (VEX-Aligned)
|
||||
|
||||
| Tool | Pattern | Stella Ops Mirror |
|
||||
|------|---------|-------------------|
|
||||
| **Snyk** | "Ignore" with reason + expiry; org-restricted; PR checks skip ignored | VEX `statusJustification` with validity window |
|
||||
| **GitLab** | `Dismissed` status with required comment; activity log | VEX decisions with actor/timestamp/audit trail |
|
||||
| **Anchore** | Allowlists + Policy Gates + VEX annotations | Allowlist integration + VEX buttons |
|
||||
| **Harbor/Trivy** | No native VEX; store as in-toto attestation | Attestation-backed VEX decisions |
|
||||
|
||||
**UI pattern to reuse:** An **Actionable VEX** button (`Not Affected`, `Affected - mitigated`, `Fixed`) that opens a compact form: justification, evidence links, scope, expiry -> generates/updates a signed VEX note.
|
||||
|
||||
### 2.3 Evidence View (Explainability)
|
||||
|
||||
| Tool | Pattern | Stella Ops Mirror |
|
||||
|------|---------|-------------------|
|
||||
| **Snyk** | PR context + Fix PR evidence + ignore policy display | Explainability panel with PR/commit links |
|
||||
| **GitLab** | Vulnerability Report hub with lifecycle activity | Decision history timeline |
|
||||
| **Anchore** | Policy Gates breakdown showing which trigger caused fail/pass | Gate evaluation with trigger explanations |
|
||||
| **Harbor/Trivy** | Scanner DB date, version, attestation links | Scanner metadata + attestation digest |
|
||||
|
||||
**UI pattern to reuse:** An **Explainability panel** on the right: "Why this is flagged / Why it passed" with timestamps, rule IDs, feed freshness, and the **Attestation digest**.
|
||||
|
||||
### 2.4 Audit Export (Immutable)
|
||||
|
||||
| Tool | Export Contents |
|
||||
|------|-----------------|
|
||||
| **Snyk** | PR check results + Ignore ledger + Fix PRs |
|
||||
| **GitLab** | Vulnerability Report with status history |
|
||||
| **Anchore** | Policy Bundle eval JSON as primary audit unit |
|
||||
| **Harbor/Trivy** | Trivy report + signed attestation |
|
||||
|
||||
**UI pattern to reuse:** **"Create immutable audit bundle"** CTA that writes a ZIP/OCI artifact containing reports, VEX, policy evals, and attestations, plus a top-level manifest with hashes.
|
||||
|
||||
---
|
||||
|
||||
## 3. Core Data Model
|
||||
|
||||
### 3.1 Artifact
|
||||
|
||||
```text
|
||||
Artifact
|
||||
- id (string, stable)
|
||||
- type (IMAGE | REPO | SBOM | FUNCTION | HOST)
|
||||
- displayName
|
||||
- coordinates (registry/repo URL, tag, branch, env, etc.)
|
||||
- digests[] (e.g. sha256 for OCI images, commit SHA for repos)
|
||||
- latestScanAttestations[] (AttestationRef)
|
||||
- riskSummary (openCount, totalCount, maxSeverity, lastScanAt)
|
||||
```
|
||||
|
||||
### 3.2 VulnerabilityFinding
|
||||
|
||||
```text
|
||||
VulnerabilityFinding
|
||||
- id (string, internal stable ID)
|
||||
- sourceFindingId (string, from Snyk/Trivy/etc.)
|
||||
- scanner (name, version)
|
||||
- artifactId
|
||||
- vulnerabilityId (CVE, GHSA, etc.)
|
||||
- title
|
||||
- severity (CRITICAL | HIGH | MEDIUM | LOW | INFO)
|
||||
- package (name, version, ecosystem)
|
||||
- location (filePath, containerLayer, function, callPath[])
|
||||
- introducedBy (commitId?, imageDigest?, buildId?)
|
||||
- firstSeenAt
|
||||
- lastSeenAt
|
||||
- status (DETECTED | RESOLVED | NO_LONGER_DETECTED)
|
||||
- currentVexDecisionId? (if a VEX decision is attached)
|
||||
- evidenceAttestationRefs[] (AttestationRef[])
|
||||
```
|
||||
|
||||
### 3.3 VEXDecision
|
||||
|
||||
Represents a **VEX-style statement** attached to a finding + subject.
|
||||
|
||||
```text
|
||||
VEXDecision
|
||||
- id
|
||||
- vulnerabilityId (CVE, etc.)
|
||||
- subject (ArtifactRef / SBOM node ref)
|
||||
- status (NOT_AFFECTED | AFFECTED_MITIGATED | AFFECTED_UNMITIGATED | FIXED)
|
||||
- justificationType (enum; see section 7.3)
|
||||
- justificationText (free text)
|
||||
- evidenceRefs[] (links to PRs, commits, tickets, docs, etc.)
|
||||
- scope (envs/projects where this decision applies)
|
||||
- validFor (notBefore, notAfter?)
|
||||
- attestationRef? (AttestationRef)
|
||||
- supersedesDecisionId?
|
||||
- createdBy (id, displayName)
|
||||
- createdAt
|
||||
- updatedAt
|
||||
```
|
||||
|
||||
### 3.4 Attestation / AttestationRef
|
||||
|
||||
```text
|
||||
AttestationRef
|
||||
- id
|
||||
- type (VULN_SCAN | SBOM | VEX | POLICY_EVAL | OTHER)
|
||||
- statementId (if DSSE/Intoto)
|
||||
- subjectName
|
||||
- subjectDigest (e.g. sha256)
|
||||
- predicateType (URI)
|
||||
- createdAt
|
||||
- signer (name, keyId)
|
||||
- storage (ociRef | bundlePath | url)
|
||||
```
|
||||
|
||||
### 3.5 PolicyEvaluation
|
||||
|
||||
```text
|
||||
PolicyEvaluation
|
||||
- id
|
||||
- subject (ArtifactRef)
|
||||
- policyBundleVersion
|
||||
- overallResult (PASS | WARN | FAIL)
|
||||
- gates[] (GateResult)
|
||||
- attestationRef? (AttestationRef)
|
||||
- evaluatedAt
|
||||
```
|
||||
|
||||
### 3.6 AuditBundle
|
||||
|
||||
Represents a **downloadable immutable bundle** (ZIP or OCI artifact).
|
||||
|
||||
```text
|
||||
AuditBundle
|
||||
- bundleId
|
||||
- version
|
||||
- createdAt
|
||||
- createdBy
|
||||
- subject (ArtifactRef)
|
||||
- index (AuditBundleIndex) <- JSON index inside the bundle
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Primary UX Surfaces
|
||||
|
||||
### 4.1 Artifacts List
|
||||
|
||||
**Goal:** High-level "what's risky?" view and entry point into triage.
|
||||
|
||||
**Columns:**
|
||||
- Artifact
|
||||
- Type
|
||||
- Environment(s)
|
||||
- Open / Total vulns
|
||||
- Max severity
|
||||
- **Attestations** (badge w/ count)
|
||||
- Last scan (timestamp + scanner)
|
||||
|
||||
**Actions:**
|
||||
- View vulnerabilities (primary)
|
||||
- View attestations
|
||||
- Create audit bundle
|
||||
|
||||
### 4.2 Vulnerability Workspace (per Artifact)
|
||||
|
||||
**Split layout:**
|
||||
|
||||
**Left: Vulnerability list**
|
||||
- Filters: severity, status, VEX status, scanner, package, introducedBy, env
|
||||
- Sort: severity, recency, package, path
|
||||
- Badges for:
|
||||
- `New` (first seen in last N scans)
|
||||
- `VEX: Not affected`
|
||||
- `Policy: blocked` / `Policy: allowed`
|
||||
|
||||
**Right: Evidence / Explainability panel**
|
||||
|
||||
Tabs:
|
||||
1. **Overview**
|
||||
- Title, severity, package, version, path
|
||||
- Scanner + db date
|
||||
- Finding history timeline
|
||||
- Current VEX decision summary (if any)
|
||||
2. **Reachability**
|
||||
- Call path, modules, runtime usage info (when available)
|
||||
3. **Policy**
|
||||
- Policy evaluation: which gate caused pass/fail
|
||||
- Links to gate definitions
|
||||
4. **Attestations**
|
||||
- All attestations that mention:
|
||||
- this artifact
|
||||
- this vulnerabilityId
|
||||
- this scan result
|
||||
|
||||
**Primary actions per finding:**
|
||||
- **VEX: Set status** -> opens VEX Modal (see 4.3)
|
||||
- **Open Fix PR / View Fix** (if available from Snyk/GitLab)
|
||||
- **Attach Evidence** (link tickets / docs)
|
||||
- **Copy audit reference** (findingId + attestation digest)
|
||||
|
||||
### 4.3 VEX Modal - "Affect & Justification"
|
||||
|
||||
**Entry points:**
|
||||
- From a finding row ("VEX" button)
|
||||
- From a policy failure explanation
|
||||
- From a bulk action on multiple findings
|
||||
|
||||
**Fields (backed by `VEXDecision`):**
|
||||
- Status (radio buttons):
|
||||
- `Not affected`
|
||||
- `Affected - mitigated`
|
||||
- `Affected - not mitigated`
|
||||
- `Fixed`
|
||||
- Justification type (select - see section 7.3)
|
||||
- Justification text (multi-line)
|
||||
- Scope:
|
||||
- Environments (multi-select)
|
||||
- Projects / services (multi-select)
|
||||
- Validity:
|
||||
- Start (defaults now)
|
||||
- Optional expiry (recommended)
|
||||
- Evidence:
|
||||
- Add links (PR, ticket, doc, commit)
|
||||
- Attach attestation (optional; pick from list)
|
||||
- Review:
|
||||
- Summary of what will be written to the VEX statement
|
||||
- "Will generate signed attestation" note (if enabled)
|
||||
|
||||
**Actions:**
|
||||
- Save (creates or updates VEXDecision, writes VEX attestation)
|
||||
- Cancel
|
||||
- View raw JSON (for power users)
|
||||
|
||||
### 4.4 Attestations View
|
||||
|
||||
Per artifact, tab: **Attestations**
|
||||
|
||||
Table of attestations:
|
||||
- Type (vuln scan, SBOM, VEX, policy)
|
||||
- Subject name (shortened)
|
||||
- Predicate type (URI)
|
||||
- Scanner / policy engine (derived from predicate)
|
||||
- Signer (keyId, trusted/not-trusted badge)
|
||||
- Created at
|
||||
- Verified (yes/no)
|
||||
|
||||
Click to open:
|
||||
- Header: statement id, subject, signer
|
||||
- Predicate preview:
|
||||
- For vuln scan: counts, scanner version, db date
|
||||
- For SBOM: bomRef, component counts
|
||||
- For VEX: decision status, vulnerabilityId, scope
|
||||
|
||||
### 4.5 Policy & Gating View
|
||||
|
||||
Per environment / pipeline:
|
||||
- Matrix of **gates** vs **subject types**:
|
||||
- e.g. `CI Build`, `Registry Admission`, `Runtime Admission`
|
||||
- Each gate shows:
|
||||
- Rule description (severity thresholds, allowlist usage, required attestations)
|
||||
- Last evaluation stats (pass/fail counts)
|
||||
- Clicking a gate shows:
|
||||
- Recent evaluations (with link to artifact & policy attestation)
|
||||
- Which condition failed
|
||||
|
||||
### 4.6 Audit Export - Bundle Creation
|
||||
|
||||
**From:**
|
||||
- Artifact page (button: "Create immutable audit bundle")
|
||||
- Pipeline run detail
|
||||
- Policy evaluation detail
|
||||
|
||||
**Workflow:**
|
||||
1. User selects:
|
||||
- Subject artifact + digest
|
||||
- Time window (e.g. "last 7 days of scans & decisions")
|
||||
- Included content (checklist):
|
||||
- Vuln reports
|
||||
- SBOM
|
||||
- VEX decisions
|
||||
- Policy evaluations
|
||||
- Raw attestations
|
||||
2. Backend generates:
|
||||
- ZIP or OCI artifact
|
||||
- `audit-bundle-index.json` at root
|
||||
3. UI shows:
|
||||
- Bundle ID & hash
|
||||
- Download button
|
||||
- OCI reference (if pushed to registry)
|
||||
|
||||
---
|
||||
|
||||
## 5. State Model
|
||||
|
||||
### 5.1 Finding Status vs VEX Status
|
||||
|
||||
Two separate but related states:
|
||||
|
||||
**Finding.status:**
|
||||
- `DETECTED` - currently reported by at least one scanner
|
||||
- `NO_LONGER_DETECTED` - was present, not in latest scan for this subject
|
||||
- `RESOLVED` - confirmed removed (e.g. package upgraded, image replaced)
|
||||
|
||||
**VEXDecision.status:**
|
||||
- `NOT_AFFECTED`
|
||||
- `AFFECTED_MITIGATED`
|
||||
- `AFFECTED_UNMITIGATED`
|
||||
- `FIXED`
|
||||
|
||||
**UI rules:**
|
||||
- If `Finding.status = NO_LONGER_DETECTED` and a VEXDecision still exists:
|
||||
- Show badge: "Historical VEX decision (finding no longer detected)"
|
||||
- If `VEXDecision.status = NOT_AFFECTED`:
|
||||
- Policy engines may treat this as **non-blocking** (configurable)
|
||||
|
||||
---
|
||||
|
||||
## 6. Interaction Patterns to Mirror
|
||||
|
||||
### 6.1 From Snyk
|
||||
|
||||
- PR checks show **before/after** and don't fail on ignored issues
|
||||
- Action: "Fix PR" from a finding
|
||||
- Mapping:
|
||||
- Stella Ops should show "Fix PR" and "Compare before/after" where data exists
|
||||
- VEX `NOT_AFFECTED` should make **future checks ignore** that finding for that subject/scope
|
||||
|
||||
### 6.2 From GitLab SCA
|
||||
|
||||
- `Dismissed` with reasons and activity log
|
||||
- Mapping:
|
||||
- VEX decisions must have reason + actor + timestamp
|
||||
- The activity log should show a full **decision history**
|
||||
|
||||
### 6.3 From Anchore
|
||||
|
||||
- Policy gates & allowlists
|
||||
- Mapping:
|
||||
- Gate evaluation screen with clear "this gate failed because..." explanation
|
||||
|
||||
---
|
||||
|
||||
## 7. Enumerations & Conventions
|
||||
|
||||
### 7.1 VEX Status
|
||||
|
||||
```text
|
||||
NOT_AFFECTED
|
||||
AFFECTED_MITIGATED
|
||||
AFFECTED_UNMITIGATED
|
||||
FIXED
|
||||
```
|
||||
|
||||
### 7.2 VEX Scope
|
||||
|
||||
- `envs[]`: e.g. `["prod", "staging"]`
|
||||
- `projects[]`: service / app names
|
||||
- Default: applies to **all** unless restricted
|
||||
|
||||
### 7.3 Justification Type (inspired by CSAF/VEX)
|
||||
|
||||
```text
|
||||
CODE_NOT_PRESENT
|
||||
CODE_NOT_REACHABLE
|
||||
VULNERABLE_CODE_NOT_IN_EXECUTE_PATH
|
||||
CONFIGURATION_NOT_AFFECTED
|
||||
OS_NOT_AFFECTED
|
||||
RUNTIME_MITIGATION_PRESENT
|
||||
COMPENSATING_CONTROLS
|
||||
ACCEPTED_BUSINESS_RISK
|
||||
OTHER
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 8. Attestation Placement
|
||||
|
||||
### 8.1 Trivy + Cosign
|
||||
|
||||
Generate **vulnerability-scan attestation** and SBOM attestation; attach to image via OCI referrers. These attestations become the source of truth for evidence and audit export.
|
||||
|
||||
### 8.2 Harbor
|
||||
|
||||
Treat attestations as first-class accessories/refs to the image. Surface them next to the Vulnerabilities tab. Link them into the explainability panel.
|
||||
|
||||
### 8.3 Anchore
|
||||
|
||||
Reference attestation digests inside **Policy evaluation** output so pass/fail is traceable to signed inputs.
|
||||
|
||||
### 8.4 Snyk/GitLab
|
||||
|
||||
Surface attestation presence in PR/Security dashboards to prove findings came from a **signed** scan; link out to the OCI digest.
|
||||
|
||||
**UI pattern:** Small **"Signed evidence"** pill on each finding; clicking opens the attestation JSON (human-readable view) + verify command snippet.
|
||||
|
||||
---
|
||||
|
||||
## 9. Gating Controls
|
||||
|
||||
| Tool | Mechanism | Stella Ops Mirror |
|
||||
|------|-----------|-------------------|
|
||||
| **Anchore** | Policy Gates/Triggers model for hard gates | Gates per environment with trigger explainability |
|
||||
| **Snyk** | PR checks + Auto Fix PRs as soft gates | PR integration with soft/hard gate toggles |
|
||||
| **GitLab** | MR approvals + Security Policies; auto-resolve on no-longer-detected | Status-aware policies with auto-resolution |
|
||||
| **Harbor** | External policy engines (Kyverno/OPA) verify signatures/attestations | Admission controller integration |
|
||||
|
||||
---
|
||||
|
||||
## 10. Minimal UI Wireframe
|
||||
|
||||
### 10.1 Artifacts List
|
||||
|
||||
| Image | Tag | Risk (open/total) | Attestations | Last scan |
|
||||
|-------|-----|-------------------|--------------|-----------|
|
||||
| app/service | v1.2.3 | 3/47 | 4 | 2h ago (Trivy) |
|
||||
|
||||
### 10.2 Artifact -> Vulnerabilities Tab (Evidence-First)
|
||||
|
||||
```
|
||||
+----------------------------------+-----------------------------------+
|
||||
| Finding Cards (scrollable) | Explainability Panel |
|
||||
| | |
|
||||
| [CVE-2024-1234] CRITICAL | Overview | Reachability | Policy |
|
||||
| openssl 3.0.14 -> 3.0.15 | |
|
||||
| [Fix PR] [VEX: Not Affected] | Scanner: Trivy 0.53.0 |
|
||||
| [Attach Evidence] | DB: 2025-11-27 |
|
||||
| | Attestation: sha256:2e61... |
|
||||
| [CVE-2024-5678] HIGH | |
|
||||
| log4j 2.17.0 | [Why flagged] |
|
||||
| [VEX: Mitigated] | - version.match: 2.17.0 < 2.17.1 |
|
||||
| | - gate: severity >= HIGH |
|
||||
+----------------------------------+-----------------------------------+
|
||||
```
|
||||
|
||||
### 10.3 Policy View
|
||||
|
||||
Gate rules (like Anchore) with preview + dry-run; show which triggers cause failure.
|
||||
|
||||
### 10.4 Audit
|
||||
|
||||
**"Create immutable audit bundle"** -> produces ZIP/OCI artifact with reports, VEX JSON, policy evals, and in-toto/DSSE attestations.
|
||||
|
||||
### 10.5 Registry/Admission
|
||||
|
||||
"Ready to deploy" badge when all gates met and required attestations verified.
|
||||
|
||||
---
|
||||
|
||||
## 11. API Endpoints (High-Level)
|
||||
|
||||
```text
|
||||
GET /artifacts
|
||||
GET /artifacts/{id}/vulnerabilities
|
||||
GET /vulnerabilities/{id}
|
||||
POST /vex-decisions
|
||||
PATCH /vex-decisions/{id}
|
||||
GET /artifacts/{id}/attestations
|
||||
POST /audit-bundles
|
||||
GET /audit-bundles/{bundleId}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 12. JSON Schema Locations
|
||||
|
||||
The following schemas should be created/maintained:
|
||||
|
||||
- `docs/schemas/vex-decision.schema.json` - VEX decision form schema
|
||||
- `docs/schemas/attestation-vuln-scan.schema.json` - Vulnerability scan attestation
|
||||
- `docs/schemas/audit-bundle-index.schema.json` - Audit bundle manifest
|
||||
|
||||
---
|
||||
|
||||
## 13. Related Advisories
|
||||
|
||||
- `27-Nov-2025 - Explainability Layer for Vulnerability Verdicts.md` - Evidence chain model
|
||||
- `27-Nov-2025 - Making Graphs Understandable to Humans.md` - Graph navigation UX
|
||||
- `25-Nov-2025 - Define Safe VEX 'Not Affected' Claims with Proofs.md` - VEX proof requirements
|
||||
|
||||
---
|
||||
|
||||
## 14. Sprint Integration
|
||||
|
||||
This advisory maps to:
|
||||
|
||||
- **SPRINT_0215_0001_0001_vuln_triage_ux.md** (NEW) - UI triage workspace implementation
|
||||
- **SPRINT_0210_0001_0002_ui_ii.md** - VEX tab tasks (UI-LNM-22-003)
|
||||
- **SPRINT_0334_docs_modules_vuln_explorer.md** - Module documentation updates
|
||||
|
||||
---
|
||||
|
||||
*Last updated: 2025-11-28*
|
||||
@@ -0,0 +1,792 @@
|
||||
Here’s a tight, drop-in acceptance-tests pack for Stella Ops that turns common failure modes into concrete guardrails you can ship this sprint.
|
||||
|
||||
---
|
||||
|
||||
# 1) Feed outages & integrity drift (e.g., Grype DB / CDN hiccups)
|
||||
|
||||
**Lesson:** Never couple scans to a single live feed; pin, verify, and cache.
|
||||
|
||||
**Add to acceptance tests**
|
||||
|
||||
* **Rollback-safe updaters**
|
||||
|
||||
* If a feed update fails checksum or signature, the system keeps using the last “good” bundle.
|
||||
* On restart, the updater falls back to the last verified bundle without network access.
|
||||
* **Signed offline bundles**
|
||||
|
||||
* Every feed bundle (SBOM catalogs, CVE DB shards, rules) must be DSSE-signed; verification blocks ingestion on mismatch.
|
||||
* Bundle manifest lists SHA-256 for each file; any deviation = reject.
|
||||
|
||||
**Test cases (CI)**
|
||||
|
||||
* Simulate 404/timeout from feed URL → scanner still produces results from cached bundle.
|
||||
* Serve a tampered bundle (wrong hash) → updater logs failure; no swap; previous bundle remains active.
|
||||
* Air-gap mode: no network → scanner loads from `/var/lib/stellaops/offline-bundles/*` and passes verification.
|
||||
|
||||
---
|
||||
|
||||
# 2) SBOM quality & schema drift
|
||||
|
||||
**Lesson:** Garbage in = garbage VEX. Gate on schema, completeness, and provenance.
|
||||
|
||||
**Add to acceptance tests**
|
||||
|
||||
* **SBOM schema gating**
|
||||
|
||||
* Reject SBOMs not valid CycloneDX 1.6 / SPDX 2.3 (your chosen set).
|
||||
* Require: component `bom-ref`, supplier, version, hashes, and build provenance (SLSA/in-toto attestation) if provided.
|
||||
* **Minimum completeness**
|
||||
|
||||
* Thresholds: ≥95% components with cryptographic hashes; no unknown package ecosystem fields for top 20 deps.
|
||||
|
||||
**Test cases**
|
||||
|
||||
* Feed malformed CycloneDX → `400 SBOM_VALIDATION_FAILED` with pointer to failing JSON path.
|
||||
* SBOM missing hashes for >5% of components → blocked from graph ingestion; actionable error.
|
||||
* SBOM with unsigned provenance when policy="RequireAttestation" → rejected.
|
||||
|
||||
---
|
||||
|
||||
# 3) DB/data corruption or operator error
|
||||
|
||||
**Lesson:** Snapshots save releases.
|
||||
|
||||
**Add to acceptance tests**
|
||||
|
||||
* **DB snapshot cadence**
|
||||
|
||||
* Postgres: base backup nightly + WAL archiving; RPO ≤ 15 min; automated restore rehearsals.
|
||||
* Mongo (while still in use): per-collection dumps until conversion completes; checksum each artifact.
|
||||
* **Deterministic replay**
|
||||
|
||||
* Any graph view must be reproducible from snapshot + bundle manifest (same revision hash).
|
||||
|
||||
**Test cases**
|
||||
|
||||
* Run chaos test that deletes last 24h tables → PITR restore to T-15m succeeds; graph revision IDs match pre-failure.
|
||||
* Restore rehearsal produces identical VEX verdict counts for a pinned revision.
|
||||
|
||||
---
|
||||
|
||||
# 4) Reachability engines & graph evaluation flakiness
|
||||
|
||||
**Lesson:** When reachability is uncertain, degrade gracefully and be explicit.
|
||||
|
||||
**Add to acceptance tests**
|
||||
|
||||
* **Reachability fallbacks**
|
||||
|
||||
* If call-graph build fails or language analyzer missing, verdict moves to “Potentially Affected (Unproven Reach)” with a reason code.
|
||||
* Policies must allow “conservative mode” (assume reachable) vs “lenient mode” (assume not-reachable) toggled per environment.
|
||||
* **Stable graph IDs**
|
||||
|
||||
* Graph revision ID is a content hash of inputs (SBOM set + rules + feed versions); identical inputs → identical ID.
|
||||
|
||||
**Test cases**
|
||||
|
||||
* Remove a language analyzer container at runtime → status flips to fallback code; no 500s; policy evaluation still completes.
|
||||
* Re-ingest same inputs → same graph revision ID and same verdict distribution.
|
||||
|
||||
---
|
||||
|
||||
# 5) Update pipelines & job routing
|
||||
|
||||
**Lesson:** No single point of truth; isolate, audit, and prove swaps.
|
||||
|
||||
**Add to acceptance tests**
|
||||
|
||||
* **Two-phase bundle swaps**
|
||||
|
||||
* Stage → verify → atomic symlink/label swap; all scanners pick up new label within 1 minute, or roll back.
|
||||
* **Authority-gated policy changes**
|
||||
|
||||
* Any policy change (severity threshold, allowlist) is a signed request via Authority; audit trail must include signer and DSSE envelope hash.
|
||||
|
||||
**Test cases**
|
||||
|
||||
* Introduce a new CVE ruleset; verification passes → atomic swap; running scans continue; new scans use N+1 bundle.
|
||||
* Attempt policy change with invalid signature → rejected; audit log entry created; unchanged policy in effect.
|
||||
|
||||
---
|
||||
|
||||
## How to wire this in Stella Ops (quick pointers)
|
||||
|
||||
* **Offline bundle format**
|
||||
|
||||
* `bundle.json` (manifest: file list + SHA-256 + DSSE signature), `/sboms/*.json`, `/feeds/cve/*.sqlite` (or shards), `/rules/*.yaml`, `/provenance/*.intoto.jsonl`.
|
||||
* Verification entrypoint in .NET 10: `StellaOps.Bundle.VerifyAsync(manifest, keyring)` before any ingestion.
|
||||
|
||||
* **Authority integration**
|
||||
|
||||
* Define `PolicyChangeRequest` (subject, diff, reason, expiry, DSSE envelope).
|
||||
* Gate `PUT /policies/*` behind `Authority.Verify(envelope) == true` and `envelope.subject == computed_diff_hash`.
|
||||
|
||||
* **Graph determinism**
|
||||
|
||||
* `GraphRevisionId = SHA256(Sort(JSON([SBOMRefs, RulesetVersion, FeedBundleIds, LatticeConfig, NormalizationVersion])))`.
|
||||
|
||||
* **Postgres snapshots (until full conversion)**
|
||||
|
||||
* Use `pg_basebackup` nightly + `wal-g` for WAL; GitLab job runs restore rehearsal weekly into `stellaops-restore` namespace and asserts revision parity against prod.
|
||||
|
||||
---
|
||||
|
||||
## Minimal developer checklist (copy to your sprint board)
|
||||
|
||||
* [ ] Add `BundleVerifier` to scanner startup; block if verification fails.
|
||||
* [ ] Implement `CacheLastGoodBundle()` and atomic label swap (`/current -> /v-YYYYMMDDHHmm`).
|
||||
* [ ] Add `SbomGate` with JSON-Schema validation + completeness thresholds.
|
||||
* [ ] Emit reasoned fallbacks: `REACH_FALLBACK_NO_ANALYZER`, `REACH_FALLBACK_TIMEOUT`.
|
||||
* [ ] Compute and display `GraphRevisionId` everywhere (API + UI + logs).
|
||||
* [ ] Configure nightly PG backups + weekly restore rehearsal that asserts revision parity.
|
||||
* [ ] Route all policy mutations through Authority DSSE verification + auditable ledger entry.
|
||||
|
||||
If you want, I can turn this into ready-to-merge .NET test fixtures (xUnit) and a GitLab CI job that runs the feed-tamper/air-gap simulations automatically.
|
||||
I’ll take the 5 “miss” areas and turn them into concrete, implementable test plans, with suggested projects, fixtures, and key cases your team can start coding.
|
||||
|
||||
I’ll keep names aligned to .NET 10/xUnit and your Stella Ops modules.
|
||||
|
||||
---
|
||||
|
||||
## 0. Test layout proposal
|
||||
|
||||
**Solution structure (tests)**
|
||||
|
||||
```text
|
||||
/tests
|
||||
/StellaOps.Bundle.Tests
|
||||
BundleVerificationTests.cs
|
||||
CachedBundleFallbackTests.cs
|
||||
/StellaOps.SbomGate.Tests
|
||||
SbomSchemaValidationTests.cs
|
||||
SbomCompletenessTests.cs
|
||||
/StellaOps.Scanner.Tests
|
||||
ScannerOfflineBundleTests.cs
|
||||
ReachabilityFallbackTests.cs
|
||||
GraphRevisionDeterminismTests.cs
|
||||
/StellaOps.DataRecoverability.Tests
|
||||
PostgresSnapshotRestoreTests.cs
|
||||
GraphReplayParityTests.cs
|
||||
/StellaOps.Authority.Tests
|
||||
PolicyChangeSignatureTests.cs
|
||||
/StellaOps.System.Acceptance
|
||||
FeedOutageEndToEndTests.cs
|
||||
AirGapModeEndToEndTests.cs
|
||||
BundleSwapEndToEndTests.cs
|
||||
/testdata
|
||||
/bundles
|
||||
/sboms
|
||||
/graphs
|
||||
/db
|
||||
```
|
||||
|
||||
Use xUnit + FluentAssertions, plus Testcontainers for Postgres.
|
||||
|
||||
---
|
||||
|
||||
## 1) Feed outages & integrity drift
|
||||
|
||||
### Objectives
|
||||
|
||||
1. Scanner never “goes dark” because the CDN/feed is down.
|
||||
2. Only **verified** bundles are used; tampered bundles are never ingested.
|
||||
3. Offline/air-gap mode is a first-class, tested behavior.
|
||||
|
||||
### Components under test
|
||||
|
||||
* `StellaOps.BundleVerifier` (core library)
|
||||
* `StellaOps.Scanner.Webservice` (scanner, bundle loader)
|
||||
* Bundle filesystem layout:
|
||||
`/opt/stellaops/bundles/v-<timestamp>/*` + `/opt/stellaops/bundles/current` symlink
|
||||
|
||||
### Test dimensions
|
||||
|
||||
* Network: OK / timeout / 404 / TLS failure / DNS failure.
|
||||
* Remote bundle: correct / tampered (hash mismatch) / wrong signature / truncated.
|
||||
* Local cache: last-good present / absent / corrupted.
|
||||
* Mode: online / offline (air-gap).
|
||||
|
||||
### Detailed test suites
|
||||
|
||||
#### 1.1 Bundle verification unit tests
|
||||
|
||||
**Project:** `StellaOps.Bundle.Tests`
|
||||
|
||||
**Fixtures:**
|
||||
|
||||
* `testdata/bundles/good-bundle/`
|
||||
* `testdata/bundles/hash-mismatch-bundle/`
|
||||
* `testdata/bundles/bad-signature-bundle/`
|
||||
* `testdata/bundles/missing-file-bundle/`
|
||||
|
||||
**Key tests:**
|
||||
|
||||
1. `VerifyAsync_ValidBundle_ReturnsSuccess`
|
||||
|
||||
* Arrange: Load `good-bundle` manifest + DSSE signature.
|
||||
* Act: `BundleVerifier.VerifyAsync(manifest, keyring)`
|
||||
* Assert:
|
||||
|
||||
* `result.IsValid == true`
|
||||
* `result.Files.All(f => f.Status == Verified)`
|
||||
|
||||
2. `VerifyAsync_HashMismatch_FailsFast`
|
||||
|
||||
* Use `hash-mismatch-bundle` where one file’s SHA256 differs.
|
||||
* Assert:
|
||||
|
||||
* `IsValid == false`
|
||||
* `Errors` contains `BUNDLE_FILE_HASH_MISMATCH` and the offending path.
|
||||
|
||||
3. `VerifyAsync_InvalidSignature_RejectsBundle`
|
||||
|
||||
* DSSE envelope signed with unknown key.
|
||||
* Assert:
|
||||
|
||||
* `IsValid == false`
|
||||
* `Errors` contains `BUNDLE_SIGNATURE_INVALID`.
|
||||
|
||||
4. `VerifyAsync_MissingFile_RejectsBundle`
|
||||
|
||||
* Manifest lists file that does not exist on disk.
|
||||
* Assert:
|
||||
|
||||
* `IsValid == false`
|
||||
* `Errors` contains `BUNDLE_FILE_MISSING`.
|
||||
|
||||
#### 1.2 Cached bundle fallback logic
|
||||
|
||||
**Class under test:** `BundleManager`
|
||||
|
||||
Simplified interface:
|
||||
|
||||
```csharp
|
||||
public interface IBundleManager {
|
||||
Task<BundleRef> GetActiveBundleAsync();
|
||||
Task<BundleRef> UpdateFromRemoteAsync(CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
**Key tests:**
|
||||
|
||||
1. `UpdateFromRemoteAsync_RemoteUnavailable_KeepsLastGoodBundle`
|
||||
|
||||
* Arrange:
|
||||
|
||||
* `lastGood` bundle exists and is marked verified.
|
||||
* Remote HTTP client always throws `TaskCanceledException` (simulated timeout).
|
||||
* Act: `UpdateFromRemoteAsync`.
|
||||
* Assert:
|
||||
|
||||
* Returned bundle ID equals `lastGood.Id`.
|
||||
* No changes to `current` symlink.
|
||||
|
||||
2. `UpdateFromRemoteAsync_RemoteTampered_DoesNotReplaceCurrent`
|
||||
|
||||
* Remote returns bundle `temp-bundle` which fails `BundleVerifier`.
|
||||
* Assert:
|
||||
|
||||
* `current` still points to `lastGood`.
|
||||
* An error metric is emitted (e.g. `stellaops_bundle_update_failures_total++`).
|
||||
|
||||
3. `GetActiveBundle_NoVerifiedBundle_ThrowsDomainError`
|
||||
|
||||
* No bundle is verified on disk.
|
||||
* `GetActiveBundleAsync` throws a domain exception with code `NO_VERIFIED_BUNDLE_AVAILABLE`.
|
||||
* Consumption pattern in Scanner: scanner fails fast on startup with clear log.
|
||||
|
||||
#### 1.3 Scanner behavior with outages (integration)
|
||||
|
||||
**Project:** `StellaOps.Scanner.Tests`
|
||||
|
||||
Use in-memory host (`WebApplicationFactory<ScannerProgram>`).
|
||||
|
||||
**Scenarios:**
|
||||
|
||||
* F1: CDN timeout, last-good present.
|
||||
* F2: CDN 404, last-good present.
|
||||
* F3: CDN returns tampered bundle; verification fails.
|
||||
* F4: Air-gap: network disabled, last-good present.
|
||||
* F5: Air-gap + no last-good: scanner must refuse to start.
|
||||
|
||||
Example test:
|
||||
|
||||
```csharp
|
||||
[Fact]
|
||||
public async Task Scanner_UsesLastGoodBundle_WhenCdnTimesOut() {
|
||||
// Arrange: put good bundle under /bundles/v-1, symlink /bundles/current -> v-1
|
||||
using var host = TestScannerHost.WithBundle("v-1", good: true, simulateCdnTimeout: true);
|
||||
|
||||
// Act: call /api/scan with small fixture image
|
||||
var response = await host.Client.PostAsJsonAsync("/api/scan", scanRequest);
|
||||
|
||||
// Assert:
|
||||
response.StatusCode.Should().Be(HttpStatusCode.OK);
|
||||
var content = await response.Content.ReadFromJsonAsync<ScanResult>();
|
||||
content.BundleId.Should().Be("v-1");
|
||||
host.Logs.Should().Contain("Falling back to last verified bundle");
|
||||
}
|
||||
```
|
||||
|
||||
#### 1.4 System acceptance (GitLab CI)
|
||||
|
||||
**Job idea:** `acceptance:feed-resilience`
|
||||
|
||||
Steps:
|
||||
|
||||
1. Spin up `scanner` + stub `feedser` container.
|
||||
2. Phase A: feed OK → run baseline scan; capture `bundleId` and `graphRevisionId`.
|
||||
3. Phase B: re-run with feed stub configured to:
|
||||
|
||||
* timeout,
|
||||
* 404,
|
||||
* return tampered bundle.
|
||||
4. For each phase:
|
||||
|
||||
* Assert `bundleId` remains the baseline one.
|
||||
* Assert `graphRevisionId` unchanged.
|
||||
|
||||
Failure of any assertion should break the pipeline.
|
||||
|
||||
---
|
||||
|
||||
## 2) SBOM quality & schema drift
|
||||
|
||||
### Objectives
|
||||
|
||||
1. Only syntactically valid SBOMs are ingested into the graph.
|
||||
2. Enforce minimum completeness (hash coverage, supplier etc.).
|
||||
3. Clear, machine-readable error responses from SBOM ingestion API.
|
||||
|
||||
### Components
|
||||
|
||||
* `StellaOps.SbomGate` (validation service)
|
||||
* SBOM ingestion endpoint in Scanner/Concelier: `POST /api/sboms`
|
||||
|
||||
### Schema validation tests
|
||||
|
||||
**Project:** `StellaOps.SbomGate.Tests`
|
||||
|
||||
**Fixtures:**
|
||||
|
||||
* `sbom-cdx-1.6-valid.json`
|
||||
* `sbom-cdx-1.6-malformed.json`
|
||||
* `sbom-spdx-2.3-valid.json`
|
||||
* `sbom-unsupported-schema.json`
|
||||
* `sbom-missing-hashes-10percent.json`
|
||||
* `sbom-no-supplier.json`
|
||||
|
||||
**Key tests:**
|
||||
|
||||
1. `Validate_ValidCycloneDx16_Succeeds`
|
||||
|
||||
* Assert type `SbomValidationResult.Success`.
|
||||
* Ensure `DetectedSchema == CycloneDx16`.
|
||||
|
||||
2. `Validate_MalformedJson_FailsWithSyntaxError`
|
||||
|
||||
* Malformed JSON.
|
||||
* Assert:
|
||||
|
||||
* `IsValid == false`
|
||||
* `Errors` contains `SBOM_JSON_SYNTAX_ERROR` with path info.
|
||||
|
||||
3. `Validate_UnsupportedSchemaVersion_Fails`
|
||||
|
||||
* SPDX 2.1 (if you only allow 2.3).
|
||||
* Expect `SBOM_SCHEMA_UNSUPPORTED` with `schemaUri` echo.
|
||||
|
||||
4. `Validate_MissingHashesOverThreshold_Fails`
|
||||
|
||||
* SBOM where >5% components lack hashes.
|
||||
* Policy: `MinHashCoverage = 0.95`.
|
||||
* Assert:
|
||||
|
||||
* `IsValid == false`
|
||||
* `Errors` contains `SBOM_HASH_COVERAGE_BELOW_THRESHOLD` with actual ratio.
|
||||
|
||||
5. `Validate_MissingSupplier_Fails`
|
||||
|
||||
* Critical components missing supplier info.
|
||||
* Expect `SBOM_REQUIRED_FIELD_MISSING` with `component.supplier`.
|
||||
|
||||
### API-level tests
|
||||
|
||||
**Project:** `StellaOps.Scanner.Tests` (or `StellaOps.Concelier.Tests` depending where SBOM ingestion lives).
|
||||
|
||||
Key scenarios:
|
||||
|
||||
1. `POST /api/sboms` with malformed JSON
|
||||
|
||||
* Request body: `sbom-cdx-1.6-malformed.json`.
|
||||
* Expected:
|
||||
|
||||
* HTTP 400.
|
||||
* Body: `{ "code": "SBOM_VALIDATION_FAILED", "details": [ ... ], "correlationId": "..." }`.
|
||||
* At least one detail contains `SBOM_JSON_SYNTAX_ERROR`.
|
||||
|
||||
2. `POST /api/sboms` with missing hashes
|
||||
|
||||
* Body: `sbom-missing-hashes-10percent.json`.
|
||||
* HTTP 400 with `SBOM_HASH_COVERAGE_BELOW_THRESHOLD`.
|
||||
|
||||
3. `POST /api/sboms` with unsupported schema
|
||||
|
||||
* Body: `sbom-unsupported-schema.json`.
|
||||
* HTTP 400 with `SBOM_SCHEMA_UNSUPPORTED`.
|
||||
|
||||
4. `POST /api/sboms` valid
|
||||
|
||||
* Body: `sbom-cdx-1.6-valid.json`.
|
||||
* HTTP 202 or 201 (depending on design).
|
||||
* Response contains SBOM ID; subsequent graph build sees that SBOM.
|
||||
|
||||
---
|
||||
|
||||
## 3) DB/data corruption & operator error
|
||||
|
||||
### Objectives
|
||||
|
||||
1. You can restore Postgres to a point in time and reproduce previous graph results.
|
||||
2. Graphs are deterministic given bundle + SBOM + rules.
|
||||
3. Obvious corruptions are detected and surfaced, not silently masked.
|
||||
|
||||
### Components
|
||||
|
||||
* Postgres cluster (new canonical store)
|
||||
* `StellaOps.Scanner.Webservice` (graph builder, persistence)
|
||||
* `GraphRevisionId` computation
|
||||
|
||||
### 3.1 Postgres snapshot / WAL tests
|
||||
|
||||
**Project:** `StellaOps.DataRecoverability.Tests`
|
||||
|
||||
Use Testcontainers to spin up Postgres.
|
||||
|
||||
Scenarios:
|
||||
|
||||
1. `PITR_Restore_ReplaysGraphsWithSameRevisionIds`
|
||||
|
||||
* Arrange:
|
||||
|
||||
* Spin DB container with WAL archiving enabled.
|
||||
* Apply schema migrations.
|
||||
* Ingest fixed set of SBOMs + bundle refs + rules.
|
||||
* Trigger graph build → record `graphRevisionIds` from API.
|
||||
* Take base backup snapshot (simulate daily snapshot).
|
||||
* Act:
|
||||
|
||||
* Destroy container.
|
||||
* Start new container from base backup + replay WAL up to a specific LSN.
|
||||
* Start Scanner against restored DB.
|
||||
* Query graphs again.
|
||||
* Assert:
|
||||
|
||||
* For each known graph: `revisionId_restored == revisionId_original`.
|
||||
* Number of nodes/edges is identical.
|
||||
|
||||
2. `PartialDataLoss_DetectedByHealthCheck`
|
||||
|
||||
* After initial load, deliberately delete some rows (e.g. all edges for a given graph).
|
||||
* Run health check endpoint, e.g. `/health/graph`.
|
||||
* Expect:
|
||||
|
||||
* HTTP 503.
|
||||
* Body indicates `GRAPH_INTEGRITY_FAILED` with details of missing edges.
|
||||
|
||||
This test forces a discipline to implement a basic graph integrity check (e.g. counts by state vs expected).
|
||||
|
||||
### 3.2 Deterministic replay tests
|
||||
|
||||
**Project:** `StellaOps.Scanner.Tests` → `GraphRevisionDeterminismTests.cs`
|
||||
|
||||
**Precondition:** Graph revision ID computed as:
|
||||
|
||||
```csharp
|
||||
GraphRevisionId = SHA256(
|
||||
Normalize([
|
||||
BundleId,
|
||||
OrderedSbomIds,
|
||||
RulesetVersion,
|
||||
FeedBundleIds,
|
||||
LatticeConfigVersion,
|
||||
NormalizationVersion
|
||||
])
|
||||
);
|
||||
```
|
||||
|
||||
**Scenarios:**
|
||||
|
||||
1. `SameInputs_SameRevisionId`
|
||||
|
||||
* Run graph build twice for same inputs.
|
||||
* Assert identical `GraphRevisionId`.
|
||||
|
||||
2. `DifferentBundle_DifferentRevisionId`
|
||||
|
||||
* Same SBOMs & rules; change vulnerability bundle ID.
|
||||
* Assert `GraphRevisionId` changes.
|
||||
|
||||
3. `DifferentRuleset_DifferentRevisionId`
|
||||
|
||||
* Same SBOM & bundle; change ruleset version.
|
||||
* Assert `GraphRevisionId` changes.
|
||||
|
||||
4. `OrderingIrrelevant_StableRevision`
|
||||
|
||||
* Provide SBOMs in different order.
|
||||
* Assert ` GraphRevisionId` same (because of internal sorting).
|
||||
|
||||
---
|
||||
|
||||
## 4) Reachability engine & graph evaluation flakiness
|
||||
|
||||
### Objectives
|
||||
|
||||
1. If reachability cannot be computed, you do not break; you downgrade verdicts with explicit reason codes.
|
||||
2. Deterministic reachability for “golden fixtures”.
|
||||
3. Graph evaluation remains stable even when analyzers come and go.
|
||||
|
||||
### Components
|
||||
|
||||
* `StellaOps.Scanner.Webservice` (lattice / reachability engine)
|
||||
* Language analyzers (sidecar or gRPC microservices)
|
||||
* Verdict representation, e.g.:
|
||||
|
||||
```csharp
|
||||
public sealed record VulnerabilityVerdict(
|
||||
string Status, // "NotAffected", "Affected", "PotentiallyAffected"
|
||||
string ReasonCode, // "REACH_CONFIRMED", "REACH_FALLBACK_NO_ANALYZER", ...
|
||||
string? AnalyzerId
|
||||
);
|
||||
```
|
||||
|
||||
### 4.1 Golden reachability fixtures
|
||||
|
||||
**Project:** `StellaOps.Scanner.Tests` → `GoldenReachabilityTests.cs`
|
||||
**Fixtures directory:** `/testdata/reachability/fixture-*/`
|
||||
|
||||
Each fixture:
|
||||
|
||||
```text
|
||||
/testdata/reachability/fixture-01-log4j/
|
||||
sbom.json
|
||||
code-snippets/...
|
||||
expected-vex.json
|
||||
config.json # language, entrypoints, etc.
|
||||
```
|
||||
|
||||
**Test pattern:**
|
||||
|
||||
For each fixture:
|
||||
|
||||
1. Load SBOM + configuration.
|
||||
2. Trigger reachability analysis.
|
||||
3. Collect raw reachability graph + final VEX verdicts.
|
||||
4. Compare to `expected-vex.json` (status + reason codes).
|
||||
5. Store the `GraphRevisionId` and set it as golden as well.
|
||||
|
||||
Key cases:
|
||||
|
||||
* R1: simple direct call → reachability confirmed → `Status = "Affected", ReasonCode = "REACH_CONFIRMED"`.
|
||||
* R2: library present but not called → `Status = "NotAffected", ReasonCode = "REACH_ANALYZED_UNREACHABLE"`.
|
||||
* R3: language analyzer missing → `Status = "PotentiallyAffected", ReasonCode = "REACH_FALLBACK_NO_ANALYZER"`.
|
||||
* R4: analysis timeout → `Status = "PotentiallyAffected", ReasonCode = "REACH_FALLBACK_TIMEOUT"`.
|
||||
|
||||
### 4.2 Analyzer unavailability / fallback behavior
|
||||
|
||||
**Project:** `StellaOps.Scanner.Tests` → `ReachabilityFallbackTests.cs`
|
||||
|
||||
Scenarios:
|
||||
|
||||
1. `NoAnalyzerRegistered_ForLanguage_UsesFallback`
|
||||
|
||||
* Scanner config lists a component in language “go” but no analyzer registered.
|
||||
* Expect:
|
||||
|
||||
* No 500 error from `/api/graphs/...`.
|
||||
* All applicable vulnerabilities for that component have `Status = "PotentiallyAffected"` and `ReasonCode = "REACH_FALLBACK_NO_ANALYZER"`.
|
||||
|
||||
2. `AnalyzerRpcFailure_UsesFallback`
|
||||
|
||||
* Analyzer responds with gRPC error or HTTP 500.
|
||||
* Scanner logs error and keeps going.
|
||||
* Same semantics as missing analyzer, but with `AnalyzerId` populated and optional `ReasonDetails` (e.g. `RPC_UNAVAILABLE`).
|
||||
|
||||
3. `AnalyzerTimeout_UsesTimeoutFallback`
|
||||
|
||||
* Force analyzer calls to time out.
|
||||
* `ReasonCode = "REACH_FALLBACK_TIMEOUT"`.
|
||||
|
||||
### 4.3 Concurrency & determinism
|
||||
|
||||
Add a test that:
|
||||
|
||||
1. Triggers N parallel graph builds for the same inputs.
|
||||
2. Asserts that:
|
||||
|
||||
* All builds succeed.
|
||||
* All `GraphRevisionId` are identical.
|
||||
* All reachability reason codes are identical.
|
||||
|
||||
This is important for concurrent scanners and ensures lack of race conditions in graph construction.
|
||||
|
||||
---
|
||||
|
||||
## 5) Update pipelines & job routing
|
||||
|
||||
### Objectives
|
||||
|
||||
1. Bundle swaps are atomic: scanners see either old or new, never partially written bundles.
|
||||
2. Policy changes are always signed via Authority; unsigned/invalid changes never apply.
|
||||
3. Job routing changes (if/when you move to direct microservice pools) remain stateless and testable.
|
||||
|
||||
### 5.1 Two-phase bundle swap tests
|
||||
|
||||
**Bundle layout:**
|
||||
|
||||
* `/opt/stellaops/bundles/current` → symlink to `v-YYYYMMDDHHmmss`
|
||||
* New bundle:
|
||||
|
||||
* Download to `/opt/stellaops/bundles/staging/<temp-id>`
|
||||
* Verify
|
||||
* Atomic `ln -s v-new current.tmp && mv -T current.tmp current`
|
||||
|
||||
**Project:** `StellaOps.Bundle.Tests` → `BundleSwapTests.cs`
|
||||
|
||||
Scenarios:
|
||||
|
||||
1. `Swap_Success_IsAtomic`
|
||||
|
||||
* Simulate swap in a temp directory.
|
||||
* During swap, spawn parallel tasks that repeatedly read `current` and open `manifest.json`.
|
||||
* Assert:
|
||||
|
||||
* Readers never fail with “file not found” / partial manifest.
|
||||
* Readers only see either `v-old` or `v-new`, no mixed state.
|
||||
|
||||
2. `Swap_VerificationFails_NoChangeToCurrent`
|
||||
|
||||
* Stage bundle which fails `BundleVerifier`.
|
||||
* After attempted swap:
|
||||
|
||||
* `current` still points to `v-old`.
|
||||
* No new directory with the name expected for `v-new` is referenced by `current`.
|
||||
|
||||
3. `Swap_CrashBetweenVerifyAndMv_LeavesSystemConsistent`
|
||||
|
||||
* Simulate crash after creating `current.tmp` but before `mv -T`.
|
||||
* On “restart”:
|
||||
|
||||
* Cleanup code must detect `current.tmp` and remove it.
|
||||
* Ensure `current` still points to last good.
|
||||
|
||||
### 5.2 Authority-gated policy changes
|
||||
|
||||
**Component:** `StellaOps.Authority` + any service that exposes `/policies`.
|
||||
|
||||
Policy change flow:
|
||||
|
||||
1. Client sends DSSE-signed `PolicyChangeRequest` to `/authority/verify`.
|
||||
2. Authority validates signature, subject hash.
|
||||
3. Service applies change only if Authority approves.
|
||||
|
||||
**Project:** `StellaOps.Authority.Tests` + `StellaOps.Scanner.Tests` (or wherever policies live).
|
||||
|
||||
Key tests:
|
||||
|
||||
1. `PolicyChange_WithValidSignature_Applies`
|
||||
|
||||
* Signed request’s `subject` hash matches computed diff of old->new policy.
|
||||
* Authority returns `Approved`.
|
||||
* Policy service updates policy; audit log entry recorded.
|
||||
|
||||
2. `PolicyChange_InvalidSignature_Rejected`
|
||||
|
||||
* Signature verifiable with no trusted key, or corrupted payload.
|
||||
* Expect:
|
||||
|
||||
* HTTP 403 or 400 from policy endpoint.
|
||||
* No policy change in DB.
|
||||
* Audit log entry with reason `SIGNATURE_INVALID`.
|
||||
|
||||
3. `PolicyChange_SubjectHashMismatch_Rejected`
|
||||
|
||||
* Attacker changes policy body but not DSSE subject.
|
||||
* On verification, recomputed diff doesn’t match subject hash.
|
||||
* Authority rejects with `SUBJECT_MISMATCH`.
|
||||
|
||||
4. `PolicyChange_ExpiredEnvelope_Rejected`
|
||||
|
||||
* Envelope contains `expiry` in past.
|
||||
* Authority rejects with `ENVELOPE_EXPIRED`.
|
||||
|
||||
5. `PolicyChange_AuditTrail_Complete`
|
||||
|
||||
* After valid change:
|
||||
|
||||
* Audit log contains: `policyName`, `oldHash`, `newHash`, `signerId`, `envelopeId`, `timestamp`.
|
||||
|
||||
### 5.3 Job routing (if/when you use DB-backed routing tables)
|
||||
|
||||
You discussed a `routing` table:
|
||||
|
||||
```sql
|
||||
domain text,
|
||||
instance_id uuid,
|
||||
last_heartbeat timestamptz,
|
||||
table_name text
|
||||
```
|
||||
|
||||
Key tests (once implemented):
|
||||
|
||||
1. `HeartbeatExpired_DropsRoutingEntry`
|
||||
|
||||
* Insert entry with `last_heartbeat` older than 1 minute.
|
||||
* Routing GC job should remove it.
|
||||
* API gateway must not route new jobs to that instance.
|
||||
|
||||
2. `RoundRobinAcrossAliveInstances`
|
||||
|
||||
* Multiple routing rows for same domain with fresh heartbeats.
|
||||
* Issue M requests via gateway.
|
||||
* Assert approximately round-robin distribution across `instance_id`.
|
||||
|
||||
3. `NoDurabilityRequired_JobsNotReplayedAfterRestart`
|
||||
|
||||
* Confirm that in-memory or temp tables are used appropriately where you do not want durable queues.
|
||||
|
||||
If you decide to go with “N gateways x M microservices via Docker load balancer only”, then the main tests here move to health-check based routing in the load balancer and become more infra than app tests.
|
||||
|
||||
---
|
||||
|
||||
## 6) CI wiring summary
|
||||
|
||||
To make this actually enforceable:
|
||||
|
||||
1. **Unit test job** (`test:unit`)
|
||||
|
||||
* Runs `StellaOps.Bundle.Tests`, `StellaOps.SbomGate.Tests`, `StellaOps.Authority.Tests`, `StellaOps.Scanner.Tests`.
|
||||
|
||||
2. **DB recoverability job** (`test:db-recoverability`)
|
||||
|
||||
* Uses Testcontainers to run `StellaOps.DataRecoverability.Tests`.
|
||||
* Marked as “required” for `main` branch merges.
|
||||
|
||||
3. **Acceptance job** (`test:acceptance-system`)
|
||||
|
||||
* Spins up a minimal stack via Docker Compose.
|
||||
* Executes `StellaOps.System.Acceptance` tests:
|
||||
|
||||
* Feed outages & fallback.
|
||||
* Air-gap modes.
|
||||
* Bundle swap.
|
||||
* Can be slower; run on main and release branches.
|
||||
|
||||
4. **Nightly chaos job** (`test:nightly-chaos`)
|
||||
|
||||
* Optional: run more expensive tests (simulated DB corruption, analyzer outages, etc.).
|
||||
|
||||
---
|
||||
|
||||
If you want, next step I can generate skeleton xUnit test classes and a `/testdata` layout you can paste directly into your repo (with TODOs where real fixtures are needed).
|
||||
@@ -0,0 +1,506 @@
|
||||
You might want to know this — the landscape around CVSS v4.0 is rapidly shifting, and the time is now to treat it as a first-class citizen in vulnerability-management workflows.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 🔎 What is CVSS v4.0 — and why it matters now
|
||||
|
||||
* CVSS is the standard framework for scoring software/hardware/firmware vulnerabilities, producing a 0–10 numeric severity score. ([Wikipedia][1])
|
||||
* On **November 1 2023**, the maintainers FIRST published version 4.0, replacing older 3.x/2.0 lines. ([FIRST][2])
|
||||
* v4.0 expands the standard to four metric groups: **Base, Threat, Environmental,** and a new **Supplemental** — enabling far more granular, context-aware scoring. ([Checkmarx][3])
|
||||
|
||||
## 🧩 What Changed in v4.0 Compared to 3.x
|
||||
|
||||
* The old “Temporal” metrics are renamed to **Threat** metrics; new Base metric **Attack Requirements (AT)** was added. v4.0 also refines **User Interaction (UI)** into more nuanced values (e.g., Passive vs Active). ([FIRST][4])
|
||||
|
||||
* The old “Scope” metric was removed, replaced by distinct impact metrics on the *vulnerable system* (VC/VI/VA) vs *subsequent systems* (SC/SI/SA), clarifying real-world risk propagation. ([FIRST][4])
|
||||
|
||||
* The **Supplemental** metric group adds flags like “Safety,” “Automatable,” “Recovery,” “Value Density,” “Provider Urgency,” etc. — providing extra context that doesn’t alter the numeric score but helps decision-making. ([FIRST][4])
|
||||
|
||||
* As a result, the scoring nomenclature also changes: instead of a single “CVSS score,” v4.0 supports combinations like **CVSS-B (Base only)**, **CVSS-BT (Base + Threat)**, **CVSS-BE**, or **CVSS-BTE** (Base + Threat + Environmental). ([FIRST][4])
|
||||
|
||||
## ✅ Industry Adoption Is Underway — Not In The Future, Now
|
||||
|
||||
* The National Vulnerability Database (NVD) — maintained by NIST — officially supports CVSS v4.0 as of June 2024. ([NVD][5])
|
||||
|
||||
* The major code-host & vulnerability platform GitHub Security Advisories began exposing CVSS v4.0 fields in September 2024. ([The GitHub Blog][6])
|
||||
|
||||
* On the ecosystem and vendor side: Microsoft Defender Vulnerability Management updated to prefer CVSS v4 in March 2025. ([TECHCOMMUNITY.MICROSOFT.COM][7])
|
||||
|
||||
* According to Snyk Open Source, all new advisories now come with both CVSS v4.0 and v3.1 assessments — with v4.0 becoming the default for evaluating severity. ([Snyk Updates][8])
|
||||
|
||||
* Several vendor-facing security / vulnerability-management products have signaled or started integrating v4.0 (though rollout is still ongoing) — consistent with the broader industry shift. ([Rapid7 Discuss][9])
|
||||
|
||||
## 🎯 What This Means for Your Approach (Given What You’re Building)
|
||||
|
||||
Because you’re architecting a supply-chain / container / SCA-aware scanning stack (as with your StellaOps plans), this shift matters:
|
||||
|
||||
1. **Granular scoring** — v4.0’s more detailed metrics help differentiate between a “theoretical high-impact but low-likelihood” flaw versus a “realistic immediate threat.”
|
||||
2. **Context-aware risk** — using Threat + Environmental + Supplemental metrics lets you layer real-world usage context (e.g. container deployment environment, exposure profile, exploit maturity, safety implications).
|
||||
3. **Auditability & traceability** — storing full vector strings, metric breakdowns (Base/Threat/Environmental/Supplemental), computed scores (CVSS-B, BT, BE, BTE), timestamp, scorer/source URL — plus legacy v3.1 vector — gives you a full provenance trail. That aligns with your ambition to build a “proof-of-integrity graph” and supply-chain-compliance ledger.
|
||||
|
||||
## 🧠 Caveats & What To Watch Out For
|
||||
|
||||
* Although v4.0 is supported by core infrastructures (NVD, GitHub, Microsoft, Snyk, etc.), **not all existing CVEs have v4.0 assessments yet**. Many older entries still carry only v3.x scores. ([NVD][10])
|
||||
* v4.0’s increased granularity brings **increased complexity** — more metric fields to collect, store, and evaluate. Without consistent population of Threat, Environmental or Supplemental fields, many scores could default back to “base only,” limiting the advantage over v3.1. ([Checkmarx][3])
|
||||
* A purely numeric score remains a **partial view of risk** — v4.0 improves it, but still does *not* compute exploitation likelihood. Combining CVSS with external data (e.g. exploit intelligence, usage context, threat modeling) remains critical. ([CrowdStrike][11])
|
||||
|
||||
---
|
||||
|
||||
Given your goals — supply-chain compliance, auditability, multi-tool integration — adopting CVSS v4.0 now (or planning for it) is absolutely the right move.
|
||||
|
||||
If you like, I can check **as of late 2025** which major container/SCA tools (like grype, Trivy, Aqua, GitLab, etc.) already support v4.0 — this may help you decide how quickly to bake v4 support into StellaOps.
|
||||
|
||||
[1]: https://en.wikipedia.org/wiki/Common_Vulnerability_Scoring_System?utm_source=chatgpt.com "Common Vulnerability Scoring System"
|
||||
[2]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[3]: https://checkmarx.com/blog/cvss4-what-you-need-to-know-about-the-latest-version/?utm_source=chatgpt.com "CVSS v4.0: What You Need to Know about the Latest Version"
|
||||
[4]: https://www.first.org/cvss/v4-0/?utm_source=chatgpt.com "Common Vulnerability Scoring System Version 4.0"
|
||||
[5]: https://nvd.nist.gov/general/news/cvss-v4-0-official-support?utm_source=chatgpt.com "CVSS v4.0 Official Support - NVD"
|
||||
[6]: https://github.blog/changelog/2024-09-13-github-security-advisories-support-cvss-4-0/?utm_source=chatgpt.com "GitHub security advisories support CVSS 4.0"
|
||||
[7]: https://techcommunity.microsoft.com/blog/vulnerability-management/supporting-cvss-v4-score-for-cve-for-enhanced-vulnerability-assessment/4391439?utm_source=chatgpt.com "Supporting CVSS V4 score for CVE for Enhanced ..."
|
||||
[8]: https://updates.snyk.io/improved-security-prioritization-with-cvss-version-4-0-295136/?utm_source=chatgpt.com "Improved security prioritization with CVSS version 4.0"
|
||||
[9]: https://discuss.rapid7.com/t/cvss-4-0-when/29354?utm_source=chatgpt.com "CVSS 4.0 when? - InsightVM"
|
||||
[10]: https://nvd.nist.gov/vuln/detail/CVE-2025-2024?utm_source=chatgpt.com "CVE-2025-2024 Detail - NVD"
|
||||
[11]: https://www.crowdstrike.com/en-us/cybersecurity-101/exposure-management/common-vulnerability-scoring-system-cvss/?utm_source=chatgpt.com "Common Vulnerability Scoring System (CVSS)"
|
||||
Good request. I checked — support for CVSS v4.0 is being gradually adopted in major vulnerability-tracking and container/SCA tools, but **it is not yet ubiquitous**. Here’s what’s clear today (late 2025), plus what remains uncertain — from a neutral fact-based perspective.
|
||||
|
||||
---
|
||||
|
||||
## ✅ What we know: CVSS 4.0 is gaining traction
|
||||
|
||||
* GitHub Advisory Database — widely used for open source vulnerability advisories — **now supports CVSS v4.0** (in addition to older v3.1). ([GitHub Docs][1])
|
||||
* The maintainers of the standard, FIRST, define CVSS 4.0 as full suite of metric groups (Base, Threat, Environmental, Supplemental), giving more precise, environment-aware severity scoring. ([first.org][2])
|
||||
* Some high-profile CVEs (e.g. Trivy-related CVE-2024-35192) already contain CVSS v4.0 vector strings in their official NVD entries, indicating that the community is reporting vulnerabilities under the new standard. ([nvd.nist.gov][3])
|
||||
|
||||
---
|
||||
|
||||
## 🔎 What modern container/SCA tools do — mixed readiness
|
||||
|
||||
* Trivy remains one of the most popular open-source scanners for containers, VMs, filesystems, language dependencies, and Kubernetes environments. ([GitHub][4])
|
||||
|
||||
* Documentation and tool descriptions for Trivy (and its ecosystem integrations) emphasize detection of CVEs, generation of SBOMs, license/compliance scanning, IaC misconfigurations, secrets, etc. ([Chainguard Academy][5])
|
||||
|
||||
* However — I did **not** find explicit public documentation confirming that Trivy (or other major SCA/container scanners) **fully parse, store, and expose CVSS v4.0 metrics** (Base, Threat, Environmental, Supplemental) across all output formats.
|
||||
|
||||
* Many vulnerability-scanning tools still default to older scoring (e.g. CVSS v3.x) because much of the existing CVE ecosystem remains populated with v3.x data.
|
||||
* Some vulnerabilities (even recent ones) may carry v4.0 vectors, but if the scanning tool or its database backend does not yet support v4.0, the output may degrade to “severity level” (Low/Medium/High/Critical) or rely on legacy score — losing some of the finer granularity.
|
||||
|
||||
* A recent academic evaluation of the “VEX tool space” for container-scanning highlighted **low consistency across different scanners**, suggesting divergent capabilities and output semantics. ([arxiv.org][6])
|
||||
|
||||
---
|
||||
|
||||
## ⚠ What remains uncertain / risk factors
|
||||
|
||||
* Lack of uniform adoption: Many older CVEs still carry only CVSS v2 or v3.x scores; full re-scoring with v4.0 is non-trivial and may lag. Without upstream v4 scoring, scanner support is moot.
|
||||
* Tools may partially support v4.0: Even if a scanner identifies a v4-vector, it may not support all metric groups (e.g. Threat, Environmental, Supplemental) — or may ignore them in summary output.
|
||||
* Output format issues: For compliance, audit, or traceability (as you plan for with your “proof-of-integrity graph”), you need vector strings, not just severity labels. If scanners only emit severity labels or old-school base scores, you lose auditability.
|
||||
* Inconsistency among scanners: As shown in recent comparative research, different tools may disagree on which vulnerabilities they detect — and by extension, which CVEs get v4.0 scoring in their data. ([arxiv.org][6])
|
||||
|
||||
---
|
||||
|
||||
## 🎯 What this means for your build (e.g. Stella Ops)
|
||||
|
||||
* You should **design Stella Ops to natively support CVSS v4.0 vectors** — store them as structured data (vector string + separate metric fields) rather than just severity label or numeric base score. That preserves maximum fidelity and auditability.
|
||||
* Continue to ingest from sources that publish v4.0 data (e.g. GitHub Advisory Database, NVD entries already tagged with v4 vector).
|
||||
* For scanners (e.g. Trivy) that lack confirmed v4 output support — treat them as legacy feed, and supplement with heuristics or external metadata fetch to reconstruct full context where possible (or fallback to v3.x with clear marking).
|
||||
* Account for inconsistency among scanners: treat scan output as advisory — use cross-tool correlation, SBOM provenance tracking, and your planned “proof-of-integrity graph” to triangulate real risk rather than trust a single tool.
|
||||
|
||||
---
|
||||
|
||||
## ✅ Final Assessment — “Yes, but partial”
|
||||
|
||||
CVSS 4.0 is **supported in key vulnerability/advisory databases** and **appearing in real CVE entries**, but **full support across container/SCA scanning tools remains uneven**. For a forward-looking, compliance- and audit-oriented platform like Stella Ops, it is rational and recommended to **adopt v4.0 as primary internal standard**, while building fallback paths for legacy data.
|
||||
|
||||
If you like — I can run a small **2025-era snapshot** of **7–10 top container / SCA tools** (open source + commercial) and tabulate which of them already publish full CVSS v4.0 output (vectors + all metric groups). That gives you a practical compatibility map for Stella Ops architecture.
|
||||
|
||||
[1]: https://docs.github.com/en/code-security/security-advisories/working-with-global-security-advisories-from-the-github-advisory-database/about-the-github-advisory-database?utm_source=chatgpt.com "About the GitHub Advisory database"
|
||||
[2]: https://www.first.org/cvss/v4-0/cvss-v40-faq.pdf?utm_source=chatgpt.com "CVSS v4.0 Frequently Asked Questions 2025- ..."
|
||||
[3]: https://nvd.nist.gov/vuln/detail/CVE-2024-35192?utm_source=chatgpt.com "CVE-2024-35192 Detail - NVD"
|
||||
[4]: https://github.com/aquasecurity/trivy?utm_source=chatgpt.com "aquasecurity/trivy: Find vulnerabilities, misconfigurations, ..."
|
||||
[5]: https://edu.chainguard.dev/chainguard/chainguard-images/staying-secure/working-with-scanners/trivy-tutorial/?utm_source=chatgpt.com "Using Trivy to Scan Software Artifacts"
|
||||
[6]: https://arxiv.org/abs/2503.14388?utm_source=chatgpt.com "Vexed by VEX tools: Consistency evaluation of container vulnerability scanners"
|
||||
Below is something you can drop into an internal design doc and hand straight to engineering.
|
||||
|
||||
---
|
||||
|
||||
## 1. Objectives (what “done” looks like)
|
||||
|
||||
Developers should aim for:
|
||||
|
||||
1. **First‑class CVSS v4.0 support**
|
||||
|
||||
* Parse and store full v4.0 vectors (`CVSS:4.0/...`) including all Base, Threat, Environmental, and Supplemental metrics. ([first.org][1])
|
||||
* Compute correct CVSS‑B / CVSS‑BT / CVSS‑BE / CVSS‑BTE scores using the official equations. ([first.org][1])
|
||||
|
||||
2. **Version‑aware, lossless storage**
|
||||
|
||||
* Preserve original vector strings and raw metrics for both v3.x and v4.0.
|
||||
* Do not down‑convert v4.0 to v3.x or blend them into a single number.
|
||||
|
||||
3. **Clear separation of concerns**
|
||||
|
||||
* CVSS = standardized “severity” input, not your internal “risk score.” ([first.org][1])
|
||||
* Threat / Environmental / Supplemental metrics feed your risk model, but are stored distinctly.
|
||||
|
||||
---
|
||||
|
||||
## 2. Data model & schema
|
||||
|
||||
### 2.1 Core CVSS entity
|
||||
|
||||
For each vulnerability finding (CVE or tool‑specific ID), you should support multiple CVSS assessments over time and from different sources.
|
||||
|
||||
**Table: `cvss_assessments` (or equivalent)**
|
||||
|
||||
Required columns:
|
||||
|
||||
* `id` (PK)
|
||||
* `vuln_id` (FK to CVE/finding table)
|
||||
* `version` (`'2.0' | '3.0' | '3.1' | '4.0'`)
|
||||
* `vector_string` (full textual vector, e.g. `CVSS:4.0/AV:N/AC:L/...`)
|
||||
* `score` (numeric, 0.0–10.0)
|
||||
* `score_type` (`'CVSS-B' | 'CVSS-BT' | 'CVSS-BE' | 'CVSS-BTE'`) ([first.org][1])
|
||||
* `severity_band` (`'None' | 'Low' | 'Medium' | 'High' | 'Critical'`) per official v4 qualitative scale. ([first.org][1])
|
||||
* `source` (`'NVD' | 'GitHub' | 'Vendor' | 'Internal' | 'Scanner:<name>' | ...`)
|
||||
* `assessed_at` (timestamp)
|
||||
* `assessed_by` (user/system id)
|
||||
|
||||
### 2.2 Structured metrics (JSON or separate tables)
|
||||
|
||||
Store metrics machine‑readably, not just in the string:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"base": {
|
||||
"AV": "N", // Attack Vector
|
||||
"AC": "L", // Attack Complexity
|
||||
"AT": "N", // Attack Requirements
|
||||
"PR": "N", // Privileges Required
|
||||
"UI": "N", // User Interaction: N, P, A in v4.0
|
||||
"VC": "H",
|
||||
"VI": "H",
|
||||
"VA": "H",
|
||||
"SC": "H",
|
||||
"SI": "H",
|
||||
"SA": "H"
|
||||
},
|
||||
"threat": {
|
||||
"E": "A" // Exploit Maturity
|
||||
},
|
||||
"environmental": {
|
||||
"CR": "H", // Confidentiality Requirement
|
||||
"IR": "H",
|
||||
"AR": "H",
|
||||
// plus modified versions of base metrics, per spec
|
||||
"MAV": "N",
|
||||
"MAC": "L",
|
||||
"MPR": "N",
|
||||
"MUI": "N",
|
||||
"MVC": "H",
|
||||
"MVI": "H",
|
||||
"MVA": "H",
|
||||
"MSC": "H",
|
||||
"MSI": "H",
|
||||
"MSA": "H"
|
||||
},
|
||||
"supplemental": {
|
||||
"S": "S", // Safety
|
||||
"AU": "Y", // Automatable (v4.0 uses AU in the spec) :contentReference[oaicite:5]{index=5}
|
||||
"U": "H", // Provider Urgency
|
||||
"R": "H", // Recovery
|
||||
"V": "H", // Value Density
|
||||
"RE": "H" // Vulnerability Response Effort
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Implementation guidance:
|
||||
|
||||
* Use a JSON column or dedicated tables (`cvss_base_metrics`, `cvss_threat_metrics`, etc.) depending on how heavily you will query by metric.
|
||||
* Always persist both `vector_string` and parsed metrics; treat parsing as a reversible transformation.
|
||||
|
||||
---
|
||||
|
||||
## 3. Parsing & ingestion
|
||||
|
||||
### 3.1 Recognizing and parsing vectors
|
||||
|
||||
Develop a parser library (or adopt an existing well‑maintained one) with these properties:
|
||||
|
||||
* Recognizes prefixes: `CVSS:2.0`, `CVSS:3.0`, `CVSS:3.1`, `CVSS:4.0`. ([Wikipedia][2])
|
||||
* Validates all metric abbreviations and values for the given version.
|
||||
* Returns:
|
||||
|
||||
* `version`
|
||||
* `metrics` object (structured as above)
|
||||
* `score` (recalculated from metrics, not blindly trusted)
|
||||
* `score_type` (B / BT / BE / BTE inferred from which metric groups are defined). ([first.org][1])
|
||||
|
||||
Error handling:
|
||||
|
||||
* If the vector is syntactically invalid:
|
||||
|
||||
* Store it as `vector_string_invalid`.
|
||||
* Mark assessment as `status = 'invalid'`.
|
||||
* Do not drop the vulnerability; log and alert.
|
||||
* If metrics are missing for Threat / Environmental / Supplemental:
|
||||
|
||||
* Treat them as “Not Defined” per spec, defaulting them in calculations. ([first.org][1])
|
||||
|
||||
### 3.2 Integrating with external feeds
|
||||
|
||||
For each source (NVD, GitHub Advisory Database, vendor advisories, scanner outputs):
|
||||
|
||||
* Normalize:
|
||||
|
||||
* If numeric score + vector provided: always trust the vector, not the numeric; recompute score internally and compare for sanity.
|
||||
* If only numeric score provided (no vector): store, but mark `vector_string = null` and `is_partial = true`.
|
||||
* Preserve `source` and `source_reference` (e.g., NVD URL, GHSA ID) for audit.
|
||||
|
||||
---
|
||||
|
||||
## 4. Scoring engine
|
||||
|
||||
### 4.1 Core functions
|
||||
|
||||
Implement pure, deterministic functions:
|
||||
|
||||
* `Cvss4Result computeCvss4Score(Cvss4Metrics metrics)`
|
||||
* `Cvss3Result computeCvss3Score(Cvss3Metrics metrics)`
|
||||
|
||||
Where `Cvss4Result` includes:
|
||||
|
||||
* `score` (0.0–10.0, properly rounded per spec; one decimal place) ([first.org][1])
|
||||
* `score_type` (`CVSS-B` / `CVSS-BT` / `CVSS-BE` / `CVSS-BTE`)
|
||||
* `severity_band` (`None` / `Low` / `Medium` / `High` / `Critical`)
|
||||
|
||||
Implementation notes:
|
||||
|
||||
* Use the equations from section 8 of the CVSS v4.0 spec; do not invent your own approximations. ([first.org][1])
|
||||
* Ensure rounding and severity bands exactly match official calculators (run golden tests).
|
||||
|
||||
### 4.2 Nomenclature & flags
|
||||
|
||||
* Always tag scores with the nomenclature: `CVSS-B`, `CVSS-BT`, `CVSS-BE`, or `CVSS-BTE`. ([first.org][1])
|
||||
* Default behavior:
|
||||
|
||||
* If Threat/Environmental metrics are not explicitly provided, treat them as “Not Defined” (defaults), and still label the score `CVSS-B`.
|
||||
* Only use `CVSS-BT` / `CVSS-BE` / `CVSS-BTE` when non‑default values are present.
|
||||
|
||||
### 4.3 Strict separation from “risk”
|
||||
|
||||
* Do not overload CVSS as a risk score. The spec is explicit that base scores measure severity, not risk. ([first.org][1])
|
||||
* Implement a separate risk model (e.g., `risk_score` 0–100) that uses:
|
||||
|
||||
* CVSS (v3/v4) as one input
|
||||
* Asset criticality
|
||||
* Compensating controls
|
||||
* Business context
|
||||
* Threat intel signals
|
||||
|
||||
---
|
||||
|
||||
## 5. Threat & Environmental automation
|
||||
|
||||
You want developers to wire CVSS v4.0 to real‑world intel and asset data.
|
||||
|
||||
### 5.1 Threat metrics (Exploit Maturity, E)
|
||||
|
||||
Threat metrics in v4.0 are largely about Exploit Maturity (E). ([first.org][1])
|
||||
|
||||
Implementation guidelines:
|
||||
|
||||
* Define a mapping from your threat intel signals to E values:
|
||||
|
||||
* `E:X` – Not Defined (no data)
|
||||
* `E:U` – Unreported
|
||||
* `E:P` – Proof‑of‑concept only
|
||||
* `E:F` – Functional
|
||||
* `E:A` – Active exploitation
|
||||
|
||||
* Data sources:
|
||||
|
||||
* Threat intel feeds (CISA KEV, vendor threat bulletins, commercial feeds)
|
||||
* Public PoC trackers (exploit DB, GitHub PoC repositories)
|
||||
|
||||
* Automation:
|
||||
|
||||
* Nightly job updates Threat metrics per vuln based on latest intel.
|
||||
* Recompute `CVSS-BT` / `CVSS-BTE` and store new assessments with `assessed_at` timestamp.
|
||||
|
||||
### 5.2 Environmental metrics
|
||||
|
||||
Environmental metrics adjust severity to a specific environment. ([first.org][1])
|
||||
|
||||
Implementation guidelines:
|
||||
|
||||
* Link `vuln_id` to asset(s) via your CMDB / asset inventory.
|
||||
* For each asset, maintain:
|
||||
|
||||
* CIA requirements: `CR`, `IR`, `AR` (Low / Medium / High)
|
||||
* Key controls: e.g., network segmentation, WAF, EDR, backups, etc.
|
||||
* Map asset metadata to Environmental metrics:
|
||||
|
||||
* For high‑critical systems, set `CR/IR/AR = H`.
|
||||
* For heavily segmented systems, adjust Modified Attack Vector or Impact metrics accordingly.
|
||||
* Provide:
|
||||
|
||||
* A default environment profile (for generic scoring).
|
||||
* Per‑asset or per‑asset‑group overrides.
|
||||
|
||||
---
|
||||
|
||||
## 6. Supplemental metrics handling
|
||||
|
||||
Supplemental metrics do not affect the CVSS score formula but provide critical context: Safety (S), Automatable (AU), Provider Urgency (U), Recovery (R), Value Density (V), Response Effort (RE). ([first.org][3])
|
||||
|
||||
Guidelines:
|
||||
|
||||
* Always parse and store them for v4.0 vectors.
|
||||
* Provide an internal risk model that can optionally:
|
||||
|
||||
* Up‑weight vulns with:
|
||||
|
||||
* `S = Safety-critical`
|
||||
* `AU = True` (fully automatable exploitation)
|
||||
* `V = High` (many assets affected)
|
||||
* Down‑weight vulns with very high Response Effort (RE) when there is low business impact.
|
||||
* Make Supplemental metrics explicitly visible in the UI as “context flags,” not hidden inside a numeric score.
|
||||
|
||||
---
|
||||
|
||||
## 7. Backward compatibility with CVSS v3.x
|
||||
|
||||
You will be living in a dual world for a while.
|
||||
|
||||
Guidelines:
|
||||
|
||||
1. **Store v3.x assessments as‑is**
|
||||
|
||||
* `version = '3.1'` or `'3.0'`
|
||||
* `vector_string`, `score`, `severity_band` (using v3 scale).
|
||||
2. **Never treat v3.x and v4.0 scores as directly comparable**
|
||||
|
||||
* 7.5 in v3.x ≠ 7.5 in v4.0.
|
||||
* For dashboards and filters, compare inside a version, or map both to coarse severity bands.
|
||||
3. **Do not auto‑convert v3 vectors to v4 vectors**
|
||||
|
||||
* Mapping is not lossless; misleading conversions are worse than clearly labeled legacy scores.
|
||||
4. **UI and API**
|
||||
|
||||
* Always show `version` and `score_type` next to the numeric score.
|
||||
* For API clients, include structured metrics so downstream systems can migrate at their own pace.
|
||||
|
||||
---
|
||||
|
||||
## 8. UI/UX guidelines
|
||||
|
||||
Give your designers and frontend devs explicit behaviors.
|
||||
|
||||
* On vulnerability detail pages:
|
||||
|
||||
* Show:
|
||||
|
||||
* `CVSS v4.0 (CVSS-BTE) 9.1 – Critical`
|
||||
* Version and score type are always visible.
|
||||
* Provide a toggle or tab:
|
||||
|
||||
* “View raw vector,” expanding to show all metrics grouped: Base / Threat / Environmental / Supplemental.
|
||||
* For lists and dashboards:
|
||||
|
||||
* Use severity bands (None / Low / Medium / High / Critical) as primary visual grouping.
|
||||
* For mixed environments:
|
||||
|
||||
* Show two columns if available: `CVSS v4.0` and `CVSS v3.1`.
|
||||
* For analysts:
|
||||
|
||||
* Provide a built‑in calculator UI that lets them adjust Threat / Environmental metrics and immediately see updated `CVSS-BT/BE/BTE`.
|
||||
|
||||
---
|
||||
|
||||
## 9. Testing & validation
|
||||
|
||||
Define a clean test strategy before implementation.
|
||||
|
||||
1. **Golden test cases**
|
||||
|
||||
* Use official FIRST examples and calculators (v4.0 spec & user guide) as ground truth. ([first.org][4])
|
||||
* Build a small public corpus:
|
||||
|
||||
* 20–50 CVEs with published v4.0 vectors and scores (from NVD / vendors) and confirm byte‑for‑byte matches.
|
||||
|
||||
2. **Round‑trip tests**
|
||||
|
||||
* `vector_string -> parse -> metrics -> compute -> vector_string`
|
||||
|
||||
* Ensure you can reconstruct the same canonical vector.
|
||||
|
||||
3. **Regression tests**
|
||||
|
||||
* Add tests for:
|
||||
|
||||
* Missing Threat / Environmental metrics (defaults).
|
||||
* Invalid vectors (fail gracefully, log, do not crash pipelines).
|
||||
* Mixed v3/v4 data in the same views.
|
||||
|
||||
4. **Performance**
|
||||
|
||||
* CVSS computations are cheap, but in bulk (e.g., 1M+ findings) avoid per‑request recalculation; cache computed results per `(vuln_id, metrics_hash)`.
|
||||
|
||||
---
|
||||
|
||||
## 10. Rollout / migration plan (high level)
|
||||
|
||||
What you can ask engineering to follow:
|
||||
|
||||
1. **Phase 1 – Data model & parsing**
|
||||
|
||||
* Add schema changes for `cvss_assessments`.
|
||||
* Implement v4.0 parser and scorer, with full unit tests.
|
||||
2. **Phase 2 – Ingestion**
|
||||
|
||||
* Update NVD / GitHub / vendor importers to capture v4 vectors when present.
|
||||
* Backfill existing data with `version` = v3.x or v2.0 as appropriate.
|
||||
3. **Phase 3 – UI & API**
|
||||
|
||||
* Expose versioned CVSS data and vector strings.
|
||||
* Mark all legacy places that assumed “CVSS = single number” and refactor to be version‑aware.
|
||||
4. **Phase 4 – Threat & Environmental automation**
|
||||
|
||||
* Wire in threat intel feeds and asset metadata.
|
||||
* Start generating `CVSS-BT` / `CVSS-BTE` scores for key asset groups.
|
||||
5. **Phase 5 – Risk model integration**
|
||||
|
||||
* Use CVSS (v3/v4), plus Supplemental metrics, plus your own business logic to output a platform‑specific risk score.
|
||||
|
||||
---
|
||||
|
||||
## 11. Developer checklist (condensed)
|
||||
|
||||
You can literally put this as a checklist in Jira/Notion:
|
||||
|
||||
* [ ] Schema updated to store:
|
||||
|
||||
* [ ] `version`, `vector_string`, `score`, `score_type`, `severity_band`, `source`, timestamps.
|
||||
* [ ] Structured Base / Threat / Environmental / Supplemental metrics.
|
||||
* [ ] Parser for `CVSS:4.0/...` with validation and graceful error handling.
|
||||
* [ ] Scoring engine for v4.0 using official equations; golden tests against FIRST calculator.
|
||||
* [ ] Support for v3.x preserved; no cross‑version conversion.
|
||||
* [ ] UI shows version and score type; exposes vector and metrics.
|
||||
* [ ] Threat intel mapping to Exploit Maturity (E) implemented.
|
||||
* [ ] Environmental mapping from asset metadata implemented (even if initially basic).
|
||||
* [ ] Supplemental metrics parsed, stored, and surfaced.
|
||||
* [ ] Risk scoring logic separated from raw CVSS.
|
||||
* [ ] Regression tests + performance tests in CI.
|
||||
|
||||
If you tell me what your current schema and pipeline look like (tables, services, scanners in use), I can produce a concrete migration diff (DDL and service‑level changes) tailored to your stack.
|
||||
|
||||
[1]: https://www.first.org/cvss/v4-0/cvss-v40-specification.pdf "CVSS v4.0 Specification - 2024-06-18"
|
||||
[2]: https://en.wikipedia.org/wiki/Common_Vulnerability_Scoring_System?utm_source=chatgpt.com "Common Vulnerability Scoring System"
|
||||
[3]: https://www.first.org/cvss/v4-0/?utm_source=chatgpt.com "Common Vulnerability Scoring System Version 4.0"
|
||||
[4]: https://www.first.org/cvss/v4-0/user-guide?utm_source=chatgpt.com "CVSS v4.0 User Guide"
|
||||
@@ -0,0 +1,108 @@
|
||||
Here’s a compact, diagram-first blueprint that shows how to turn a CycloneDX SBOM into signed, replay-safe proofs across DSSE/in-toto, Rekor v2 (tile-backed) receipts, and VEX—plus how to run this with the public instance or fully offline.
|
||||
|
||||
---
|
||||
|
||||
## 1) Mental model (one line per hop)
|
||||
|
||||
```
|
||||
[SBOM: CycloneDX JSON]
|
||||
└─(wrap as DSSE payload; predicate = CycloneDX)
|
||||
└─(optional: in-toto statement for context)
|
||||
└─(sign → cosign/fulcio or your own CA)
|
||||
└─(log entry → Rekor v2 / tiles)
|
||||
└─(checkpoint + inclusion proof + receipt)
|
||||
└─(VEX attestation references SBOM/log)
|
||||
└─(Authority anchors/keys + policies)
|
||||
```
|
||||
|
||||
* **CycloneDX SBOM** is your canonical inventory. ([cyclonedx.org][1])
|
||||
* **DSSE** provides a minimal, standard signing envelope; in-toto statements add supply-chain context. ([JFrog][2])
|
||||
* **Rekor v2** stores a hash of your attestation in a **tile-backed transparency log** and returns **checkpoint + inclusion proof** (small, verifiable). ([Sigstore Blog][3])
|
||||
* **VEX** conveys exploitability (e.g., “not affected”) and should reference the SBOM and, ideally, the Rekor receipt. ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 2) Exact capture points (what to store)
|
||||
|
||||
* **SBOM artifact**: `sbom.cdx.json` (canonicalized bytes + SHA256). ([cyclonedx.org][1])
|
||||
* **DSSE envelope** over SBOM (or in-toto statement whose predicate is CycloneDX): keep the full JSON + signature. ([JFrog][2])
|
||||
* **Rekor v2 receipt**:
|
||||
|
||||
* **Checkpoint** (signed tree head)
|
||||
* **Inclusion proof** (audit path)
|
||||
* **Entry leaf hash / UUID**
|
||||
Persist these with your build to enable offline verification. ([Sigstore Blog][3])
|
||||
* **VEX attestation** (CycloneDX VEX): include references (by digest/URI) to the **SBOM** and the **Rekor entry/receipt** used for the SBOM attestation. ([cyclonedx.org][4])
|
||||
* **Authority anchors**: publish the verifying keys (or TUF-root if using Sigstore public good), plus your policy describing accepted issuers and algorithms. ([Sigstore][5])
|
||||
|
||||
---
|
||||
|
||||
## 3) Field-level linkage (IDs you’ll wire together)
|
||||
|
||||
* **`subject.digest`** in DSSE/in-toto ↔ **SBOM SHA256**. ([OpenSSF][6])
|
||||
* **Rekor entry** ↔ **DSSE envelope digest** (leaf/UUID recorded in receipt). ([GitHub][7])
|
||||
* **VEX `affects` / `analysis`** entries ↔ **components in SBOM** (use purl/coordinates) and include **`evidence`/`justification`** with **Rekor proof URI**. ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 4) Verification flow (online or air-gapped)
|
||||
|
||||
**Online (public good):**
|
||||
|
||||
1. Verify DSSE signature against accepted keys/issuers. ([Sigstore][5])
|
||||
2. Verify Rekor **checkpoint signature** and **inclusion proof** for the logged DSSE digest. ([Go Packages][8])
|
||||
3. Validate VEX against the same SBOM digest (and optionally that its own attestation is also logged). ([cyclonedx.org][4])
|
||||
|
||||
**Air-gapped / sovereign:**
|
||||
|
||||
* Mirror/export **Rekor tiles + checkpoints** on a courier medium; keep receipts small by shipping only tiles covering the ranges you need.
|
||||
* Run **self-hosted Rekor v2** or a **local tile cache**; verifiers check **checkpoint signatures** and **consistency proofs** exactly the same way. ([Sigstore Blog][3])
|
||||
|
||||
---
|
||||
|
||||
## 5) Public instance vs self-hosted (decision notes)
|
||||
|
||||
* **Public**: zero-ops, audited community infra; you still archive receipts with your releases. ([Sigstore][5])
|
||||
* **Self-hosted Rekor v2 (tiles)**: cheaper/simpler than v1, tile export makes **offline kits** practical; publish your **root keys** as organization anchors. ([Sigstore Blog][3])
|
||||
|
||||
---
|
||||
|
||||
## 6) Minimal CLI recipe (illustrative)
|
||||
|
||||
* Generate SBOM → wrap → attest → log → emit receipt:
|
||||
|
||||
* Create CycloneDX JSON; compute digest. ([cyclonedx.org][1])
|
||||
* Create **DSSE** or **in-toto** attestation for the SBOM; sign (cosign or your CA). ([JFrog][2])
|
||||
* Submit to **Rekor v2**; store **checkpoint + inclusion proof + UUID** with the build. ([Sigstore Blog][3])
|
||||
* Emit **VEX** referencing the SBOM digest **and** the Rekor entry (URI/UUID). ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 7) Developer guardrails (to keep proofs replay-safe)
|
||||
|
||||
* **Canonical bytes only** (stable JSON ordering/whitespace) before hashing/signing. ([JFrog][2])
|
||||
* **Pin algorithms** (e.g., SHA-256 + key types) in policy; reject drift. ([Sigstore][5])
|
||||
* **Always persist**: SBOM, DSSE envelope, Rekor receipt, VEX, and your **accepted-keys manifest** with version. ([Sigstore Blog][3])
|
||||
* **Test offline**: verification must pass using only tiles + receipts you ship. ([Go Packages][9])
|
||||
|
||||
---
|
||||
|
||||
## 8) Optional niceties
|
||||
|
||||
* Gate deployments on “image must have **signed SBOM** (attestation)”. Sigstore Policy Controller example exists. ([Stackable Documentation][10])
|
||||
* Track CVE status via **CycloneDX VEX** in your UI (“affected/not affected” with evidence links to Rekor). ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
If you want, I can turn this into a **Stella Ops** diagram + drop-in `docs/blueprints/sbom-to-vex-rekor.md` with exact JSON stubs for: DSSE envelope, in-toto statement, Rekor receipt example, and a CycloneDX VEX snippet wired to the receipt.
|
||||
|
||||
[1]: https://cyclonedx.org/specification/overview/?utm_source=chatgpt.com "Specification Overview"
|
||||
[2]: https://jfrog.com/blog/introducing-dsse-attestation-online-decoder/?utm_source=chatgpt.com "Introducing the DSSE Attestation Online Decoder"
|
||||
[3]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[4]: https://cyclonedx.org/capabilities/vex/?utm_source=chatgpt.com "Vulnerability Exploitability eXchange (VEX)"
|
||||
[5]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
[6]: https://openssf.org/blog/2024/06/26/a-deep-dive-into-sbomit-and-attestations/?utm_source=chatgpt.com "A Deep Dive into SBOMit and Attestations"
|
||||
[7]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[8]: https://pkg.go.dev/github.com/sigstore/rekor-tiles/v2/pkg/verify?utm_source=chatgpt.com "verify package - github.com/sigstore/rekor-tiles/v2/pkg/verify"
|
||||
[9]: https://pkg.go.dev/github.com/sigstore/rekor-tiles?utm_source=chatgpt.com "rekor-tiles module - github.com/sigstore/rekor-tiles"
|
||||
[10]: https://docs.stackable.tech/home/stable/guides/viewing-and-verifying-sboms/?utm_source=chatgpt.com "Viewing and verifying SBOMs of the Stackable Data Platform"
|
||||
@@ -0,0 +1,354 @@
|
||||
I put together a short “failure-catalogue” of five high-impact real issues or regressions between 2023–2025 across Trivy / Syft / Grype, Snyk and JFrog — especially focused on reachability, SBOM provenance/gaps, offline/updater problems, and DB-churn noise. I thought you might want concrete test vectors for your StellaOps backlog.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## ⚠️ Notable failures & walk-backs
|
||||
|
||||
### **1. Trivy fails to detect critical CVEs in JAR files — even when present in DB (2024)**
|
||||
|
||||
* In a discussion titled “Trivy not detecting CVE 2022-37734, 2023-28867, 2024-22233 in jar file” (Feb 6, 2024), a user reports that while scanning a container image that includes `graphql-java-codegen-5.9.0.jar` or `spring-core-6.0.14.jar`, Trivy — even with the latest DB — ignores these CVEs. The same CVEs are otherwise picked up by Maven-based scanning. ([GitHub][1])
|
||||
* This indicates a fundamental mismatch between what the vulnerability DB says and what Trivy actually reports: a “reachability/noise gap” or “false negative in jar unpacking”.
|
||||
* **Test vector idea for StellaOps**: build a minimal container with `graphql-java-codegen-5.9.0.jar` (or `spring-core-6.0.14.jar`), run Trivy with latest DB, check whether it flags CVE-2022-37734 / 2023-28867 / 2024-22233. If not — this is a confirmed “blind spot”.
|
||||
|
||||
### **2. More general “Jar / Java-libs detection” regressions in Trivy (2023)**
|
||||
|
||||
* Issue #4046 on Trivy’s repo (Apr 12, 2023) states that certain Java-based container images show no CVEs detected at all, even though other tools (like Grype) do pick them up. ([GitHub][2])
|
||||
* Similarly, older but related issues such as #1869 (Mar 2022) and #2089 (May 2022) describe cases where Trivy lists packages inside JARs, but fails to report any vulnerabilities tied to those packages — a direct SBOM-to-vuln mapping failure. ([GitHub][3])
|
||||
* **Implication**: SBOM-based scanning with Trivy underrepresents Java ecosystem risk (especially for fat-jar or dependency-bundle patterns). That undermines “SBOM completeness” assumptions.
|
||||
|
||||
### **3. Discrepancy between SBOM-generation (Syft) and vulnerability scanning (Grype/Trivy) — huge package-count gap (2024)**
|
||||
|
||||
* In a discussion from March 2024, a user reports that a fresh build of a patched distro (Rocky Linux 9.3 with GUI) scanned with Syft reports ≈ 6000 packages, but the same system scanned with Trivy reports only ≈ 1300 packages. ([GitHub][4])
|
||||
* When feeding the Syft SBOM to Grype, the user sees “over 300 vulnerabilities”; but when Grype processes the Trivy-generated SBOM, it reports less than 10 vulnerabilities — a dramatic underreporting. ([GitHub][4])
|
||||
* **Test vector idea**: for a known-updated Linux distro (e.g. Rocky 9.3), generate SBOMs via Syft and Trivy, then feed both into Grype — compare package counts and vuln counts side-by-side. This tests real-world “SBOM provenance gaps + under-scanning”.
|
||||
|
||||
### **4. Regression in Grype (post-v0.87.0) leads to false negatives (Apr 2025)**
|
||||
|
||||
* On Apr 30, 2025: issue #2628 reports that a minimal SBOM containing vulnerable artifacts is correctly flagged by Grype v0.87.0 (3 critical + 2 high), but with any later version (incl. latest) it reports no vulnerabilities at all. ([GitHub][5])
|
||||
* **Implication**: DB-churn + schema changes or scanning logic shifts can regress coverage dramatically, even for simple known cases.
|
||||
* **Test vector idea**: replicate the minimal SBOM from the issue with vulnerable artifacts, run Grype at v0.87.0 and then at latest; confirm gap. Great candidate for regression monitoring in StellaOps.
|
||||
|
||||
### **5. Broader SBOM integrity & trust problems — even if scanning works (2024)**
|
||||
|
||||
* Recent academic work (Dec 2024) titled “The Lack of Integrity Protection in SBOM Solutions” shows that many SBOM tools (generation and consumption) lack integrity/integrity-protection: dependencies can be tampered or mislabeled, which can lead to “incorrect SBOM data → vulnerabilities overlooked.” ([arXiv][6])
|
||||
* Meanwhile, a 2025 empirical study on real-world open-source repos found that downstream scanners using SBOMs produce a ~97.5% false-positive rate (largely due to unreachable code), recommending function-call analysis to prune noise. ([arXiv][7])
|
||||
* **Implication for StellaOps**: even a “perfect SBOM → perfect scan” pipeline may be fundamentally flawed unless you add provenance validation + reachability analysis. Reliance on SBOM + vuln-scanner alone gives a very noisy, untrustworthy result.
|
||||
|
||||
---
|
||||
|
||||
## 🎯 Why this matters for StellaOps & your architecture
|
||||
|
||||
* These are concrete, high-impact failures in widely used SCA tools (Trivy, Syft, Grype, Snyk ecosystem) — they demonstrate **false negatives**, **SBOM gaps**, **DB/logic regressions**, and **SBOM-integrity weaknesses**.
|
||||
* Given StellaOps’ goals (deterministic replayable scans, cryptographic provenance, “Trust Algebra”, remediation prioritization), you should treat each issue above as a **test/sanity vector** or **alarm scenario** to include in your backlog.
|
||||
* In particular: the jar-file CVE misses, SBOM-generation vs scan divergence, and post-DB-schema regressions represent the kind of toolchain brittleness that StellaOps is designed to mitigate (or detect).
|
||||
|
||||
---
|
||||
|
||||
If you like, I can expand this into a **10-item catalogue** covering also misconfig scanning, SBOM forgery, offline-updater stale DB incidents and compare across all major SCA tools (Trivy / Grype / Snyk / JFrog / CycloneDX, etc.) — which would be a richer resource for StellaOps testing.
|
||||
|
||||
[1]: https://github.com/aquasecurity/trivy/discussions/6074?utm_source=chatgpt.com "Trivy not detecting CVE 2022-37734, 2023-28867, 2024- ..."
|
||||
[2]: https://github.com/aquasecurity/trivy/issues/4046?utm_source=chatgpt.com "trivy did not detect java libs · Issue #4046 · aquasecurity/trivy"
|
||||
[3]: https://github.com/aquasecurity/trivy/issues/1869?utm_source=chatgpt.com "Missing vulnerabilities for jar files #1869 - aquasecurity/trivy"
|
||||
[4]: https://github.com/aquasecurity/trivy/discussions/6325?utm_source=chatgpt.com "and of those detected Trivy sometimes does not report a ..."
|
||||
[5]: https://github.com/anchore/grype/issues/2628?utm_source=chatgpt.com "Grype false negatives in versions v0.88.0 and later leading ..."
|
||||
[6]: https://arxiv.org/abs/2412.05138?utm_source=chatgpt.com "Supply Chain Insecurity: The Lack of Integrity Protection in SBOM Solutions"
|
||||
[7]: https://arxiv.org/abs/2511.20313?utm_source=chatgpt.com "A Reality Check on SBOM-based Vulnerability Management: An Empirical Study and A Path Forward"
|
||||
Think of this as a short internal directive you can hand to the StellaOps team.
|
||||
|
||||
---
|
||||
|
||||
## 1. Non‑negotiable principles
|
||||
|
||||
Tell the team these are hard constraints, not “nice to haves”:
|
||||
|
||||
1. **No silent false negatives.**
|
||||
|
||||
* The engine must *never* drop a potential vulnerability just to reduce noise.
|
||||
* If something is uncertain → label it (`“low confidence”`, `"maybe affected"`) and show it, don’t hide it.
|
||||
|
||||
2. **Separation of “detection” vs. “prioritization”.**
|
||||
|
||||
* Detection layer: “Which CVEs *might* apply?” → exhaustive and conservative.
|
||||
* Prioritization layer: “Which matter most?” → filters for humans, but never deletes raw matches.
|
||||
|
||||
3. **Offline and air‑gapped are first‑class.**
|
||||
|
||||
* Any feature must work in a strictly offline mode or fail *explicitly* with a clear error, not partial silent behavior.
|
||||
* A `--offline` / `no-network` mode must guarantee **zero network calls** on every code path.
|
||||
|
||||
4. **No schema or DB surprises.**
|
||||
|
||||
* Engine and DB must have explicit, negotiated versions.
|
||||
* If a DB is incompatible, the scan must fail loudly with a remediation hint, not degrade silently.
|
||||
|
||||
5. **SBOM integrity over convenience.**
|
||||
|
||||
* SBOMs must be treated as evidence that can be wrong or tampered with, not as gospel.
|
||||
* The system should verify SBOMs against artefact digests and highlight discrepancies.
|
||||
|
||||
6. **Reachability is a signal, not a gate.**
|
||||
|
||||
* Reachability analysis may reprioritize, but never suppress the existence of a vulnerability.
|
||||
|
||||
---
|
||||
|
||||
## 2. Guardrails mapped to past failure modes
|
||||
|
||||
### A. “Missed JAR CVEs” / detection‑priority bugs
|
||||
|
||||
**Problem type:** Scanner skipped valid vulnerabilities because matching logic was too strict or defaulted to a “safe” mode that sacrificed coverage.
|
||||
|
||||
**Instructions to devs:**
|
||||
|
||||
1. **Tri‑state matching, never binary only.**
|
||||
|
||||
* Every candidate CVE should end up in one of:
|
||||
|
||||
* `confirmed_affected`
|
||||
* `potentially_affected` (e.g. upstream advisory, weak match)
|
||||
* `not_affected`
|
||||
* *Prohibited:* silently dropping `potentially_affected` to “help” users.
|
||||
|
||||
2. **Explicit detection modes with safe defaults.**
|
||||
|
||||
* Provide:
|
||||
|
||||
* `mode=exhaustive` (default in backend; UI can choose what to show prominently)
|
||||
* `mode=precise` (for strict production gating, but still storing all candidates)
|
||||
* Detection mode can change *presentation*, not the underlying recorded facts.
|
||||
|
||||
3. **Mandatory explanation fields.**
|
||||
|
||||
* For each match, store:
|
||||
|
||||
* `why_matched` (e.g. “CPE normalized match via alias map”)
|
||||
* `why_not_promoted` (e.g. “only upstream advisory, no distro backport”)
|
||||
* If something is dropped from “confirmed”, it must have a machine‑readable reason.
|
||||
|
||||
---
|
||||
|
||||
### B. SBOM incompleteness (“missing orphan packages”)
|
||||
|
||||
**Problem type:** Merge logic or graph logic discarded “orphan” packages → incomplete SBOM → missed CVEs and EOL issues.
|
||||
|
||||
**Instructions:**
|
||||
|
||||
1. **Invariant: no silent dropping of packages.**
|
||||
|
||||
* During SBOM generation/ingestion, any package discovered must be present in the final SBOM *or* explicitly listed in a `dropped_components` section with a reason code.
|
||||
* Add automated tests asserting: `discovered_count == sbom_components_count + dropped_components_count`.
|
||||
|
||||
2. **Cross‑check with package managers.**
|
||||
|
||||
* For OS images:
|
||||
|
||||
* Compare SBOM against `rpm -qa`, `dpkg -l`, `apk info`, etc.
|
||||
* Define allowed differences (e.g. virtual packages, metapackages).
|
||||
* Fail CI if SBOM under‑reports by more than a small, configurable margin.
|
||||
|
||||
3. **Graph vs list separation.**
|
||||
|
||||
* Keep a flat **component list** separate from the **dependency graph**.
|
||||
* Graph logic may exclude out‑of‑graph components from “dependency tree”, but never from the raw component list.
|
||||
|
||||
4. **SBOM round‑trip tests.**
|
||||
|
||||
* For each supported SBOM format:
|
||||
|
||||
* Generate SBOM → re‑ingest → generate again → compare component sets.
|
||||
* Any component lost in the round‑trip is a bug.
|
||||
|
||||
---
|
||||
|
||||
### C. Offline DB, Java DB and schema‑churn failures
|
||||
|
||||
**Problem type:** New DBs introduced (e.g. Java DB) forced online updates despite `--skip-db-update`; schema changes broke offline setups.
|
||||
|
||||
**Instructions:**
|
||||
|
||||
1. **Strict offline contract.**
|
||||
|
||||
* If `offline=true`:
|
||||
|
||||
* Absolutely forbidden: network calls, even retries.
|
||||
* If a DB is missing: abort with an explicit error like
|
||||
`“Java vulnerability DB not present; run command X on a connected host to fetch it.”`
|
||||
|
||||
2. **Version negotiation between engine and DB.**
|
||||
|
||||
* DB contains:
|
||||
|
||||
* `db_schema_version`
|
||||
* `min_engine_version` / `max_engine_version`
|
||||
* Engine on startup:
|
||||
|
||||
* If DB schema is unsupported → fail fast with a migration hint.
|
||||
* *Never* continue with a mismatched DB.
|
||||
|
||||
3. **Separate DBs for language ecosystems.**
|
||||
|
||||
* Each language/ecosystem DB handled independently:
|
||||
|
||||
* Missing Java DB should not break OS scanning.
|
||||
* Mark those language results as “unavailable due to missing DB”.
|
||||
|
||||
4. **Compatibility test matrix.**
|
||||
|
||||
* For every release:
|
||||
|
||||
* Test with **previous N DB versions** and **newest DB**.
|
||||
* Test both online and offline flows.
|
||||
* Regression tests should include:
|
||||
|
||||
* Stale DB, corrupted DB, missing DB, wrong schema version.
|
||||
|
||||
---
|
||||
|
||||
### D. Reachability misclassification (Snyk‑style issues)
|
||||
|
||||
**Problem type:** “Unreachable” label used where analysis simply lacked coverage → real exploitable bugs down‑weighted or hidden.
|
||||
|
||||
**Instructions:**
|
||||
|
||||
1. **Coverage‑aware reachability labels.**
|
||||
|
||||
* Distinguish:
|
||||
|
||||
* `reachable` (with proof)
|
||||
* `not_reachable_within_coverage` (negative proof within known coverage)
|
||||
* `not_analyzed` (no coverage for this stack/entrypoint)
|
||||
* **Never** label as “unreachable” if the language/framework isn’t supported.
|
||||
|
||||
2. **No gating by reachability.**
|
||||
|
||||
* Policies may say “ignore non‑reachable in dashboard”, but the raw issue must exist and be queryable.
|
||||
* Any mass change in reachability (due to engine upgrade) must be tracked and explained in release notes.
|
||||
|
||||
3. **Reachability regression tests.**
|
||||
|
||||
* Maintain a small corpus of apps where:
|
||||
|
||||
* Specific vulnerable functions *are* called.
|
||||
* Specific vulnerable functions are present but deliberately never called.
|
||||
* CI must ensure reachability engine’s decisions on this corpus remain stable or improve, never regress.
|
||||
|
||||
---
|
||||
|
||||
### E. Package identity & provenance (Xray‑style name collision issues)
|
||||
|
||||
**Problem type:** Name/version alone used for matching; local/internal components misidentified as public packages (false positives) and vice versa (false negatives).
|
||||
|
||||
**Instructions:**
|
||||
|
||||
1. **Always prefer fully qualified identifiers.**
|
||||
|
||||
* Normalize everything to purl‑like coordinates:
|
||||
|
||||
* e.g. `pkg:npm/float-kit@1.0.0`, `pkg:docker/library/alpine@3.18`, `pkg:maven/com.squareup.okio/okio@3.0.0`
|
||||
* Name+version alone should be treated as low‑confidence.
|
||||
|
||||
2. **Provenance as a first‑class field.**
|
||||
|
||||
* Record for each component:
|
||||
|
||||
* Source: registry (npm, PyPI, Maven, OS repo), VCS, local, vendored.
|
||||
* Evidence: lockfile, SBOM, manifest, binary heuristics.
|
||||
* Only match against the correct source:
|
||||
|
||||
* npm advisories apply only to `source=npm` components, etc.
|
||||
|
||||
3. **Tiered match confidence.**
|
||||
|
||||
* `high` – exact purl or CPE match with expected registry.
|
||||
* `medium` – alias mapping, well‑known naming differences.
|
||||
* `low` – name/version only, with no provenance.
|
||||
* Policy: **high** and **medium** shown normally; **low** flagged as “needs manual review” or hidden behind a specific toggle, never silently treated as truth.
|
||||
|
||||
4. **SBOM + runtime fusion.**
|
||||
|
||||
* When ingesting external SBOMs, try to confirm:
|
||||
|
||||
* Component digest vs actual file.
|
||||
* If mismatched → downgrade confidence or flag as “SBOM out of sync with artefact”.
|
||||
|
||||
---
|
||||
|
||||
## 3. Testing & regression harness (what must exist before launch)
|
||||
|
||||
Give the team a checklist that must be green before any release:
|
||||
|
||||
1. **Golden corpus of images/projects.**
|
||||
|
||||
* Include:
|
||||
|
||||
* Known vulnerable JARs (like the ones from earlier incidents).
|
||||
* Distros with thousands of packages (Rocky, Debian, Alpine).
|
||||
* Mixed stacks (Java + Python + Node).
|
||||
* For each, store:
|
||||
|
||||
* Expected # of components.
|
||||
* Expected CVEs (per tool / per feed).
|
||||
* Expected SBOM shape.
|
||||
|
||||
2. **Cross‑tool differential tests.**
|
||||
|
||||
* Regularly run StellaOps + Trivy + Grype/Syft + Snyk on the corpus (in a lab).
|
||||
* Any large deviation:
|
||||
|
||||
* More findings: investigate FPs.
|
||||
* Fewer findings: treat as potential FN until proven otherwise.
|
||||
|
||||
3. **Mutation tests for SBOM and metadata.**
|
||||
|
||||
* Randomly:
|
||||
|
||||
* Remove lockfiles.
|
||||
* Change versions.
|
||||
* Make SBOM inconsistent with artefact.
|
||||
* Verify:
|
||||
|
||||
* System flags inconsistencies.
|
||||
* Doesn’t crash.
|
||||
* Doesn’t blindly trust clearly broken data.
|
||||
|
||||
4. **Offline chaos tests.**
|
||||
|
||||
* Simulate:
|
||||
|
||||
* No network.
|
||||
* Corrupted DB.
|
||||
* Outdated DB with new engine.
|
||||
* Required behavior:
|
||||
|
||||
* Clear, actionable errors.
|
||||
* No partial, silent scans.
|
||||
|
||||
---
|
||||
|
||||
## 4. Concrete acceptance criteria you can mandate
|
||||
|
||||
You can literally hand this as a policy:
|
||||
|
||||
> A feature or release must **not** ship unless:
|
||||
>
|
||||
> 1. Running in offline mode never triggers a network call and does not crash if a language‑specific DB is missing; instead, it emits a clear, actionable error.
|
||||
> 2. SBOM component counts for golden images are within agreed tolerances vs package manager outputs, with all differences explained.
|
||||
> 3. For every CVE in the golden corpus, the engine either reports it as `confirmed_affected` / `potentially_affected` or logs a machine‑readable justification for `not_affected`.
|
||||
> 4. Reachability status for golden test apps is stable or improved vs previous release; there are no reclassified “unreachable” issues where coverage is absent.
|
||||
> 5. Any schema or DB change is accompanied by:
|
||||
>
|
||||
> * A migration path.
|
||||
> * A compatibility test.
|
||||
> * A failure mode that is explicit and documented.
|
||||
|
||||
If you bake those rules into your engineering process (and CI), StellaOps will be structurally protected from the exact classes of failures we’ve seen in the other tools — and when something *does* go wrong, it will be visible, explainable, and fixable, rather than a silent loss of coverage.
|
||||
@@ -0,0 +1,637 @@
|
||||
Here’s a compact, no‑fluff onboarding brief to get a mid‑level .NET dev productive on StellaOps in a couple of days.
|
||||
|
||||
---
|
||||
|
||||
# StellaOps – Mid‑Level .NET Onboarding (Quick Start)
|
||||
|
||||
## 0) What you’re building (context in one minute)
|
||||
|
||||
StellaOps is a sovereign, air‑gap‑friendly SBOM→VEX platform written in .NET 10. Core ideas: deterministic scans, cryptographic attestations (DSSE/in‑toto; optional PQC), trust lattices for VEX decisions, and a replayable audit trail.
|
||||
|
||||
---
|
||||
|
||||
## 1) Repos to open first (read in this order)
|
||||
|
||||
1. `src/StellaOps.Scanner.WebService/` — scanning surfaces, rules plumbing, lattice calls.
|
||||
2. `src/StellaOps.Vexer/` (a.k.a. Excititor) — VEX verdict engine & trust‑merge logic.
|
||||
3. `src/StellaOps.Sbomer/` — SBOM ingest/normalize (CycloneDX/SPDX).
|
||||
4. `src/StellaOps.Authority/` — keys, attestations, license tokens, Rekor integration.
|
||||
5. `src/StellaOps.Scheduler/` — batch & replay orchestration.
|
||||
6. `src/StellaOps.Shared/CanonicalModel/` — canonical entities & graph IDs (read carefully).
|
||||
|
||||
Tip: keep `docs/modules/platform/*` open for protocol notes (DSSE envelopes, lattice terms).
|
||||
|
||||
---
|
||||
|
||||
## 2) Local dev up in ~10–15 min
|
||||
|
||||
* Prereqs: .NET 10 SDK (preview), Docker, Node (for Angular UI if needed), WSL2 optional.
|
||||
* From repo root:
|
||||
|
||||
```bash
|
||||
# infra
|
||||
docker compose -f compose/offline-kit.yml up -d # Mongo/Postgres/Rabbit/MinIO per profile
|
||||
|
||||
# backend
|
||||
dotnet restore
|
||||
dotnet build -c Debug
|
||||
|
||||
# run a focused slice (scanner + authority)
|
||||
dotnet run --project src/StellaOps.Authority/StellaOps.Authority.csproj
|
||||
dotnet run --project src/StellaOps.Scanner.WebService/StellaOps.Scanner.WebService.csproj
|
||||
```
|
||||
|
||||
* Environment: copy `env/example.local.env` → `.env`, then set `STELLAOPS_DB` provider (`Mongo` or `Postgres`) and `AUTHORITY_*` keys.
|
||||
|
||||
---
|
||||
|
||||
## 3) Deterministic testcases to run locally (prove your env is correct)
|
||||
|
||||
These are “golden” replays: same inputs → same graph & hashes.
|
||||
|
||||
1. **Hello‑SBOM → VEX Not‑Affected (Reachability‑false)**
|
||||
|
||||
```bash
|
||||
dotnet test tests/Determinism/Det_SbomToVex_NotAffected.csproj
|
||||
```
|
||||
|
||||
Checks: identical GraphRevisionID and DSSE payload hash across two consecutive runs.
|
||||
|
||||
2. **In‑toto chain: source→build→image attestation**
|
||||
|
||||
```bash
|
||||
dotnet test tests/Attestations/Att_InToto_Chain.csproj
|
||||
```
|
||||
|
||||
Checks: DSSE envelope canonicalization stable; signature over CBOR‑canonical JSON matches stored hash.
|
||||
|
||||
3. **Lattice merge: vendor VEX + runtime signal**
|
||||
|
||||
```bash
|
||||
dotnet test tests/Lattice/Lattice_VendorPlusRuntime.csproj
|
||||
```
|
||||
|
||||
Checks: merge verdict is stable with the same input set order; produces identical TrustReceipt.
|
||||
|
||||
If any golden snapshot differs, your clock/locale/line‑endings or JSON canonicalizer is misconfigured.
|
||||
|
||||
---
|
||||
|
||||
## 4) Coding conventions (cryptographic attestations & determinism)
|
||||
|
||||
* **JSON**: serialize with our `CanonicalJson` (UTF‑8, sorted keys, no insignificant whitespace, `\n` line endings).
|
||||
* **DSSE**: always embed `payloadType` = `application/vnd.stellaops.trust+json`.
|
||||
* **Hashing**: BLAKE3 for internal content addressing, SHA‑256 where interop requires.
|
||||
* **Keys**: use `Authority.KeyRing` provider (Ed25519 by default; PQC Dilithium optional flag `AUTHORITY_PQC=on`).
|
||||
* **Timestamps**: use `Instant` (UTC) with truncation to milliseconds; never `DateTime.Now`.
|
||||
* **IDs**: graph nodes use `HashStableId` derived from canonical bytes; never database autoinc for public IDs.
|
||||
* **VEX**: verdicts must include `proofs[]` (e.g., reachability, config‑guards, runtime path) and a `receipt` signed by Authority.
|
||||
* **Repro**: any function that affects verdicts must be pure or behind a deterministic adapter.
|
||||
|
||||
Snippet (sign a DSSE envelope deterministically):
|
||||
|
||||
```csharp
|
||||
var payload = CanonicalJson.Serialize(trustDoc);
|
||||
var env = DsseEnvelope.Create("application/vnd.stellaops.trust+json", payload);
|
||||
var signed = await keyRing.SignAsync(env.CanonicalizeBytes());
|
||||
await rekor.SubmitAsync(signed, RekorMode.OfflineMirrorIfAirgapped);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5) Minimal daily loop
|
||||
|
||||
* Pick one starter issue (below).
|
||||
* Write unit tests first; ensure golden snapshots match.
|
||||
* Run `dotnet test --filter Category=Determinism`.
|
||||
* Commit with `feat(scanner|vexer|authority): …` and include the GraphRevisionID delta in the body.
|
||||
|
||||
---
|
||||
|
||||
## 6) Three starter issues (teach the canonical data model)
|
||||
|
||||
### A) Normalize CycloneDX components → Canonical Packages
|
||||
|
||||
**Goal**: map CycloneDX `components` to `CanonicalPackage` with stable IDs.
|
||||
**Where**: `StellaOps.Sbomer` + tests in `tests/Determinism/Det_SbomMapping`.
|
||||
**Done when**:
|
||||
|
||||
* Two equivalent SBOMs (field order shuffled) map to identical package set & IDs.
|
||||
* Snapshot `CanonicalPackageSet.hash` is stable.
|
||||
* Edge cases: missing `purl`, duplicate components, case differences.
|
||||
|
||||
### B) Implement “Not‑Affected by Configuration” proof
|
||||
|
||||
**Goal**: add proof generator that marks a CVE as not‑affected if a config gate is off.
|
||||
**Where**: `StellaOps.Vexer/Proofs/ConfigSwitchProof.cs`.
|
||||
**Done when**:
|
||||
|
||||
* Given `FeatureX=false`, CVE‑1234 becomes `not_affected` with proof payload including `configPath`, `observed=false`.
|
||||
* Deterministic proof hash and DSSE receipt exist.
|
||||
* Lattice merge keeps vendor “affected” but flips to `not_affected` when runtime/config proof weight > threshold.
|
||||
|
||||
### C) Authority offline Rekor mirror submitter
|
||||
|
||||
**Goal**: if air‑gapped, write DSSE entries to local mirror; sync later.
|
||||
**Where**: `StellaOps.Authority/Rekor/RekorMirrorClient.cs`.
|
||||
**Done when**:
|
||||
|
||||
* `RekorMode.OfflineMirrorIfAirgapped` stores canonical entry (JSON+hash path).
|
||||
* `rekor sync` job replays in order, preserving entry IDs.
|
||||
* Golden test ensures same input sequence → same mirror tree hash.
|
||||
|
||||
---
|
||||
|
||||
## 7) Database notes (Mongo ↔ Postgres switchability)
|
||||
|
||||
* Use repository interfaces in `StellaOps.Shared.Persistence`.
|
||||
* Canonical/public IDs are hash‑derived; DB keys are implementation‑local.
|
||||
* Never rely on DB sort order for any hash or verdict; always re‑canonicalize before hashing.
|
||||
|
||||
---
|
||||
|
||||
## 8) Debug checklist (most common slips)
|
||||
|
||||
* Non‑canonical JSON (unsorted keys, trailing spaces).
|
||||
* Local time sneaking into proofs.
|
||||
* Unstable GUIDs in tests.
|
||||
* Non‑deterministic enumeration over `Dictionary<>`.
|
||||
* Different newline conventions on Windows—enforce `\n` in canonical paths.
|
||||
|
||||
---
|
||||
|
||||
## 9) Useful commands
|
||||
|
||||
```bash
|
||||
# run determinism pack
|
||||
dotnet test --filter Category=Determinism
|
||||
|
||||
# update golden snapshots (intentional change only)
|
||||
dotnet test --filter Category=Determinism -- TestRunParameters.Parameter(name=\"UpdateSnapshots\", value=\"true\")
|
||||
|
||||
# quick API smoke
|
||||
curl -s http://localhost:5080/health
|
||||
curl -s -X POST http://localhost:5081/scan -d @samples/nginx.sbom.json
|
||||
|
||||
# verify DSSE signature locally
|
||||
dotnet run --project tools/StellaOps.Tools.Verify -- file trust.receipt.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 10) Ask‑once glossary
|
||||
|
||||
* **SBOM**: software bill of materials (CycloneDX/SPDX).
|
||||
* **VEX**: vulnerability exploitability exchange (verdicts: affected / not‑affected / under‑investigation).
|
||||
* **DSSE**: signed payload wrapper; we canonicalize before signing.
|
||||
* **Lattice**: rule system to merge proofs/verdicts from different sources deterministically.
|
||||
* **GraphRevisionID**: hash of the canonical trust graph; your “build number” for audits.
|
||||
|
||||
---
|
||||
|
||||
Want me to turn this into `docs/onboarding/dev-quickstart.md` plus three ready‑to‑run GitHub issues and the test scaffolds?
|
||||
````markdown
|
||||
# StellaOps Developer Quickstart
|
||||
|
||||
> **Audience:** Mid‑level .NET developers
|
||||
> **Goal:** Get you productive on StellaOps in 1–2 days, with special focus on determinism, cryptographic attestations, and the canonical data model.
|
||||
|
||||
---
|
||||
|
||||
## 1. What You’re Building (Context)
|
||||
|
||||
StellaOps is a sovereign, air‑gap‑friendly platform that turns **SBOMs → VEX** with a fully **replayable, deterministic trust graph**.
|
||||
|
||||
Core concepts:
|
||||
|
||||
- **Deterministic scans:** Same inputs → same graph, hashes, and verdicts.
|
||||
- **Cryptographic attestations:** DSSE/in‑toto envelopes, optional PQC.
|
||||
- **Trust lattice:** Merges vendor VEX, runtime signals, configs, etc. into a single deterministic verdict.
|
||||
- **Audit trail:** Every decision is reproducible from stored inputs and proofs.
|
||||
|
||||
If you think “content‑addressed trust pipeline for SBOMs + VEX,” you’re in the right mental model.
|
||||
|
||||
---
|
||||
|
||||
## 2. Repository & Docs Map
|
||||
|
||||
Start by opening these projects **in order**:
|
||||
|
||||
1. `src/StellaOps.Scanner.WebService/`
|
||||
Scanning endpoints, rule plumbing, and calls into the trust lattice.
|
||||
|
||||
2. `src/StellaOps.Vexer/` (a.k.a. *Excititor*)
|
||||
VEX verdict engine and trust‑merge logic.
|
||||
|
||||
3. `src/StellaOps.Sbomer/`
|
||||
SBOM ingest / normalize (CycloneDX, SPDX).
|
||||
|
||||
4. `src/StellaOps.Authority/`
|
||||
Key management, DSSE/in‑toto attestations, license tokens, Rekor integration.
|
||||
|
||||
5. `src/StellaOps.Scheduler/`
|
||||
Batch processing, replay orchestration.
|
||||
|
||||
6. `src/StellaOps.Shared/CanonicalModel/`
|
||||
Canonical entities & graph IDs. **Read this carefully** – it underpins determinism.
|
||||
|
||||
Helpful docs:
|
||||
|
||||
- `docs/modules/platform/*` – protocols (DSSE envelopes, lattice terms, trust receipts).
|
||||
- `docs/architecture/*` – high‑level diagrams and flows (if present).
|
||||
|
||||
---
|
||||
|
||||
## 3. Local Dev Setup
|
||||
|
||||
### 3.1 Prerequisites
|
||||
|
||||
- **.NET 10 SDK** (preview as specified in repo)
|
||||
- **Docker** (for DB, queues, object storage)
|
||||
- **Node.js** (for Angular UI, if you’re touching the frontend)
|
||||
- **WSL2** (optional, but makes life easier on Windows)
|
||||
|
||||
### 3.2 Bring Up Infra
|
||||
|
||||
From the repo root:
|
||||
|
||||
```bash
|
||||
# Bring up core infra for offline / air‑gap friendly dev
|
||||
docker compose -f compose/offline-kit.yml up -d
|
||||
````
|
||||
|
||||
This usually includes:
|
||||
|
||||
* MongoDB or Postgres (configurable)
|
||||
* RabbitMQ (or equivalent queue)
|
||||
* MinIO / object storage (depending on profile)
|
||||
|
||||
### 3.3 Configure Environment
|
||||
|
||||
Copy the example env and tweak:
|
||||
|
||||
```bash
|
||||
cp env/example.local.env .env
|
||||
```
|
||||
|
||||
Key settings:
|
||||
|
||||
* `STELLAOPS_DB=Mongo` or `Postgres`
|
||||
* `AUTHORITY_*` – key material and config (see comments in `example.local.env`)
|
||||
* Optional: `AUTHORITY_PQC=on` to enable post‑quantum keys (Dilithium).
|
||||
|
||||
### 3.4 Build & Run Backend
|
||||
|
||||
```bash
|
||||
# Restore & build everything
|
||||
dotnet restore
|
||||
dotnet build -c Debug
|
||||
|
||||
# Run a focused slice for development
|
||||
dotnet run --project src/StellaOps.Authority/StellaOps.Authority.csproj
|
||||
dotnet run --project src/StellaOps.Scanner.WebService/StellaOps.Scanner.WebService.csproj
|
||||
```
|
||||
|
||||
Health checks (adjust ports if needed):
|
||||
|
||||
```bash
|
||||
curl -s http://localhost:5080/health # Authority
|
||||
curl -s http://localhost:5081/health # Scanner
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Deterministic Sanity Tests
|
||||
|
||||
These tests prove your local environment is configured correctly for **determinism**. If any of these fail due to snapshot mismatch, fix your environment before writing new features.
|
||||
|
||||
### 4.1 SBOM → VEX “Not Affected” (Reachability False)
|
||||
|
||||
```bash
|
||||
dotnet test tests/Determinism/Det_SbomToVex_NotAffected.csproj
|
||||
```
|
||||
|
||||
**What it checks:**
|
||||
|
||||
* Two consecutive runs with the same SBOM produce:
|
||||
|
||||
* Identical `GraphRevisionID`
|
||||
* Identical DSSE payload hashes
|
||||
|
||||
If they differ, inspect:
|
||||
|
||||
* JSON canonicalization
|
||||
* Locale / culture
|
||||
* Line endings
|
||||
|
||||
---
|
||||
|
||||
### 4.2 In‑toto Chain: Source → Build → Image Attestation
|
||||
|
||||
```bash
|
||||
dotnet test tests/Attestations/Att_InToto_Chain.csproj
|
||||
```
|
||||
|
||||
**What it checks:**
|
||||
|
||||
* DSSE envelope canonicalization is stable.
|
||||
* Signature over CBOR‑canonical JSON matches the stored hash.
|
||||
* Full in‑toto chain can be replayed deterministically.
|
||||
|
||||
---
|
||||
|
||||
### 4.3 Lattice Merge: Vendor VEX + Runtime Signal
|
||||
|
||||
```bash
|
||||
dotnet test tests/Lattice/Lattice_VendorPlusRuntime.csproj
|
||||
```
|
||||
|
||||
**What it checks:**
|
||||
|
||||
* Merge verdict is stable regardless of input set order.
|
||||
* Resulting `TrustReceipt` is byte‑for‑byte identical between runs.
|
||||
|
||||
If any “golden” snapshots differ, you likely have:
|
||||
|
||||
* Non‑canonical JSON
|
||||
* Unstable enumeration (e.g., iterating `Dictionary<>` directly)
|
||||
* Locale or newline drift
|
||||
|
||||
---
|
||||
|
||||
## 5. Coding Conventions (Determinism & Crypto)
|
||||
|
||||
These are **non‑negotiable** when working on code that affects trust graphs, proofs, or attestations.
|
||||
|
||||
### 5.1 JSON & Canonicalization
|
||||
|
||||
* Use our **`CanonicalJson`** helper for anything that will be:
|
||||
|
||||
* Hashed
|
||||
* Signed
|
||||
* Used as a canonical ID input
|
||||
* Rules:
|
||||
|
||||
* UTF‑8
|
||||
* Sorted keys
|
||||
* No insignificant whitespace
|
||||
* `\n` line endings (enforced for canonical paths)
|
||||
|
||||
### 5.2 DSSE Envelopes
|
||||
|
||||
* `payloadType` must always be:
|
||||
|
||||
* `application/vnd.stellaops.trust+json`
|
||||
* Envelopes are signed over the **canonicalized bytes** of the payload.
|
||||
|
||||
Example:
|
||||
|
||||
```csharp
|
||||
var payload = CanonicalJson.Serialize(trustDoc);
|
||||
var env = DsseEnvelope.Create("application/vnd.stellaops.trust+json", payload);
|
||||
var signed = await keyRing.SignAsync(env.CanonicalizeBytes());
|
||||
await rekor.SubmitAsync(signed, RekorMode.OfflineMirrorIfAirgapped);
|
||||
```
|
||||
|
||||
### 5.3 Hashing
|
||||
|
||||
* Internal content addressing: **BLAKE3**
|
||||
* External / interop where required: **SHA‑256**
|
||||
|
||||
Never mix algorithms for the same ID type.
|
||||
|
||||
### 5.4 Keys & Algorithms
|
||||
|
||||
* Default signatures: **Ed25519** via `Authority.KeyRing`
|
||||
* Optional PQC: **Dilithium** when `AUTHORITY_PQC=on`
|
||||
* Never manage keys directly – always use the keyring abstraction.
|
||||
|
||||
### 5.5 Time & Clocks
|
||||
|
||||
* Use `Instant` (UTC) / `DateTimeOffset` in UTC.
|
||||
* Truncate to **milliseconds** for anything that ends up in canonical data.
|
||||
* Never use `DateTime.Now` or local time in trust‑critical code.
|
||||
|
||||
### 5.6 IDs & Graph Nodes
|
||||
|
||||
* Public / canonical IDs are derived from **hashes of canonical bytes**.
|
||||
* DB primary keys are implementation details; do **not** leak them externally.
|
||||
* Do **not** depend on DB auto‑increment or sort order for anything that affects hashing.
|
||||
|
||||
### 5.7 VEX Verdicts
|
||||
|
||||
Every VEX verdict must:
|
||||
|
||||
* Be backed by `proofs[]` (e.g., reachability analysis, config guards, runtime path).
|
||||
* Emit a `receipt` signed by **Authority**, wrapping:
|
||||
|
||||
* Verdict
|
||||
* Proof hashes
|
||||
* Context (component, vulnerability, scope, etc.)
|
||||
|
||||
---
|
||||
|
||||
## 6. Daily Workflow
|
||||
|
||||
A minimal loop that keeps you aligned with the platform’s guarantees:
|
||||
|
||||
1. **Pick a focused issue** (see starter tasks below).
|
||||
|
||||
2. **Write tests first**, especially determinism tests where applicable.
|
||||
|
||||
3. Implement the change, keeping:
|
||||
|
||||
* Canonicalization boundaries explicit
|
||||
* Hashing and signing centralized
|
||||
|
||||
4. Run:
|
||||
|
||||
```bash
|
||||
dotnet test --filter Category=Determinism
|
||||
```
|
||||
|
||||
5. Commit using:
|
||||
|
||||
* `feat(scanner): ...`
|
||||
* `feat(vexer): ...`
|
||||
* `feat(authority): ...`
|
||||
* etc.
|
||||
|
||||
Include the affected `GraphRevisionID` in the commit body when relevant to trust‑graph changes.
|
||||
|
||||
---
|
||||
|
||||
## 7. Suggested Starter Tasks
|
||||
|
||||
These are good first issues that teach the canonical model and determinism expectations.
|
||||
|
||||
### 7.1 Normalize CycloneDX Components → Canonical Packages
|
||||
|
||||
**Goal:** Map CycloneDX `components` to our `CanonicalPackage` model with stable IDs.
|
||||
|
||||
* **Area:** `StellaOps.Sbomer`
|
||||
* **Tests:** `tests/Determinism/Det_SbomMapping`
|
||||
|
||||
**Definition of done:**
|
||||
|
||||
* Two equivalent SBOMs (only field order differs) produce:
|
||||
|
||||
* Identical package sets
|
||||
* Identical canonical package IDs
|
||||
* `CanonicalPackageSet.hash` is stable.
|
||||
* Edge cases handled:
|
||||
|
||||
* Missing `purl`
|
||||
* Duplicate components
|
||||
* Case differences in names or versions
|
||||
|
||||
---
|
||||
|
||||
### 7.2 Implement “Not‑Affected by Configuration” Proof
|
||||
|
||||
**Goal:** Add proof generator that marks a CVE as `not_affected` when a config gate disables the vulnerable path.
|
||||
|
||||
* **Area:** `StellaOps.Vexer/Proofs/ConfigSwitchProof.cs`
|
||||
|
||||
**Definition of done:**
|
||||
|
||||
* Given `FeatureX=false`, CVE‑1234 yields verdict:
|
||||
|
||||
* `status = not_affected`
|
||||
* `proofs[]` includes a `ConfigSwitchProof` with:
|
||||
|
||||
* `configPath`
|
||||
* `observed=false`
|
||||
* Proof is hashed deterministically and included in the DSSE receipt.
|
||||
* Lattice merge behavior:
|
||||
|
||||
* Vendor verdict: `affected`
|
||||
* Runtime/config proof weight > threshold → merged verdict becomes `not_affected` deterministically.
|
||||
|
||||
---
|
||||
|
||||
### 7.3 Authority Offline Rekor Mirror Submitter
|
||||
|
||||
**Goal:** Support air‑gapped mode: DSSE entries are written to a local Rekor mirror and synced later.
|
||||
|
||||
* **Area:** `StellaOps.Authority/Rekor/RekorMirrorClient.cs`
|
||||
|
||||
**Definition of done:**
|
||||
|
||||
* `RekorMode.OfflineMirrorIfAirgapped`:
|
||||
|
||||
* Stores canonical entries (JSON + hash‑based path) on disk / object store.
|
||||
* A `rekor sync` background job (or CLI) replays entries in order to the real Rekor instance.
|
||||
* Determinism test:
|
||||
|
||||
* Same input DSSE sequence → same mirror tree hash and Rekor entry order.
|
||||
|
||||
---
|
||||
|
||||
## 8. Database Notes (Mongo ↔ Postgres)
|
||||
|
||||
StellaOps is designed to be DB‑agnostic.
|
||||
|
||||
* Use repository interfaces from `StellaOps.Shared.Persistence`.
|
||||
* Keep **canonical/public IDs hash‑derived**; DB keys are internal.
|
||||
* Do **not** depend on DB sort order for anything that:
|
||||
|
||||
* Affects hashes
|
||||
* Affects verdicts
|
||||
* Ends up in canonical data
|
||||
|
||||
If you need ordering, sort **after** canonicalization using deterministic criteria.
|
||||
|
||||
---
|
||||
|
||||
## 9. Common Pitfalls & Debug Checklist
|
||||
|
||||
When a determinism test fails, look for these first:
|
||||
|
||||
1. **Non‑canonical JSON**
|
||||
|
||||
* Unsorted keys
|
||||
* Extra whitespace
|
||||
* Mixed `\r\n` vs `\n` line endings
|
||||
|
||||
2. **Local Time Leaks**
|
||||
|
||||
* Any `DateTime.Now` or local time in proofs or receipts.
|
||||
|
||||
3. **Random / Unstable IDs**
|
||||
|
||||
* New GUIDs in tests or canonical entities.
|
||||
* Auto‑increment IDs leaking into hashes.
|
||||
|
||||
4. **Unordered Collections**
|
||||
|
||||
* Iterating over `Dictionary<>` or `HashSet<>` without ordering.
|
||||
* Using LINQ without explicit `OrderBy` when hashing or serializing.
|
||||
|
||||
5. **Platform Differences**
|
||||
|
||||
* Windows vs Linux newline differences.
|
||||
* Locale differences (`,` vs `.` for decimals, etc.) – always use invariant culture for canonical data.
|
||||
|
||||
---
|
||||
|
||||
## 10. Useful Commands
|
||||
|
||||
### 10.1 Determinism Pack
|
||||
|
||||
```bash
|
||||
# Run only determinism‑tagged tests
|
||||
dotnet test --filter Category=Determinism
|
||||
```
|
||||
|
||||
Update golden snapshots when you *intend* to change canonical behavior:
|
||||
|
||||
```bash
|
||||
dotnet test --filter Category=Determinism -- \
|
||||
TestRunParameters.Parameter(name="UpdateSnapshots", value="true")
|
||||
```
|
||||
|
||||
### 10.2 Quick API Smoke
|
||||
|
||||
```bash
|
||||
curl -s http://localhost:5080/health
|
||||
|
||||
curl -s -X POST \
|
||||
http://localhost:5081/scan \
|
||||
-H "Content-Type: application/json" \
|
||||
-d @samples/nginx.sbom.json
|
||||
```
|
||||
|
||||
### 10.3 Verify DSSE Signature Locally
|
||||
|
||||
```bash
|
||||
dotnet run --project tools/StellaOps.Tools.Verify -- file trust.receipt.json
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 11. Glossary (Ask‑Once)
|
||||
|
||||
* **SBOM** – Software Bill of Materials (CycloneDX/SPDX).
|
||||
* **VEX** – Vulnerability Exploitability eXchange:
|
||||
|
||||
* Verdicts like `affected`, `not_affected`, `under_investigation`.
|
||||
* **DSSE** – Dead Simple Signing Envelope:
|
||||
|
||||
* Wrapper around payload + signature; we sign canonical bytes.
|
||||
* **In‑toto** – Supply‑chain attestation framework; we use it for source→build→artifact chains.
|
||||
* **Lattice** – Rule system that merges multiple verdicts/proofs into a single deterministic verdict.
|
||||
* **GraphRevisionID** – Hash of the canonical trust graph at a point in time; acts like a build number for audits.
|
||||
|
||||
---
|
||||
|
||||
Welcome aboard. Your best “map” into the system is:
|
||||
|
||||
1. Read `CanonicalModel` types.
|
||||
2. Run the determinism tests.
|
||||
3. Pick one of the starter tasks and ship a small, well‑tested change.
|
||||
|
||||
If you keep everything **canonical, hashable, and replayable**, you’ll fit right in.
|
||||
|
||||
```
|
||||
```
|
||||
@@ -0,0 +1,933 @@
|
||||
I’m sharing this because I think the comparison will help sharpen some of the UI/UX & data-model decisions for StellaOps — especially around how “evidence + suppression + audit/export” flows are implemented in existing tools and which patterns we might want to emulate or avoid.
|
||||
|
||||
Here’s a compact snapshot (with recent documentation/screens and dates) of how a few major players — Snyk, GitHub (via repo scanning), Aqua Security / container scanning, Anchore/Grype, and Prisma Cloud — handle evidence, ignores (suppression / VEX), and audit/export primitives.
|
||||
|
||||
---
|
||||
|
||||
## ✅ What works: Evidence & audit flows that provide clarity
|
||||
|
||||
**Snyk — good “evidence + data flow + context” for code vulnerabilities**
|
||||
|
||||
* In Snyk Code, each issue links to a full “Data flow” trace from source to sink. ([Snyk User Docs][1])
|
||||
* The UI hyperlinks to the Git repo, providing code-level context and version control traceability. ([Snyk User Docs][1])
|
||||
* “Fix analysis” surfaces recommended fixes, diff examples, and community-driven suggestions. ([Snyk User Docs][1])
|
||||
|
||||
This deep evidence linkage is a valuable pattern for StellaOps triage and remediation.
|
||||
|
||||
**Anchore/Grype — VEX-aware suppression + SBOM export readiness**
|
||||
|
||||
* Anchore Enterprise documents vulnerability annotations + VEX support (SBOM scanning, annotations, fix statuses). ([Anchore Documentation][2])
|
||||
* Grype respects VEX statuses (`not_affected`, `fixed`) and can expose suppressed matches via `--show-suppressed`. ([GitHub][3])
|
||||
* Justifications can be scoped (e.g., `vulnerable_code_not_present` filters) and the API surfaces (Oct 2025) enable automation of SBOM + VEX + diffed results. ([Anchore Documentation][2])
|
||||
|
||||
This forms a solid SBOM → vulnerability → VEX → audit/export pipeline.
|
||||
|
||||
---
|
||||
|
||||
## ⚠️ Where things are brittle
|
||||
|
||||
**Snyk — suppression semantics vary across scan types**
|
||||
|
||||
* Ignore rules are project/integration-specific; UI ignores may not carry over to CLI import flows. ([Snyk][4])
|
||||
* Snyk Code uses separate suppression UX (IDE/CLI) from OSS scans, leading to fragmentation. ([Snyk User Docs][5])
|
||||
|
||||
**Anchore/Grype — operational caveats**
|
||||
|
||||
* Feb 2025 issue: VEX suppression failed for directory scans because the source type wasn’t supported. ([GitHub][6])
|
||||
* Some suppressions require explicit config (`GRYPE_VEX_ADD`). ([GitHub][3])
|
||||
* Ensuring SBOM + VEX + diffed outputs for audits often needs extra orchestration.
|
||||
|
||||
**Prisma Cloud — audit/export primitives are coarse**
|
||||
|
||||
* “Suppress Code Issues” feature exists, but no public doc shows an end-to-end SBOM + VEX + audit export flow. ([Prisma Cloud Documentation][7])
|
||||
* Repo scanning + suppression features exist, but forensic traceability appears limited to “report + suppress”. ([Prisma Cloud Documentation][8])
|
||||
|
||||
---
|
||||
|
||||
## 🔑 What StellaOps should copy / avoid
|
||||
|
||||
**Copy**
|
||||
|
||||
* Snyk Code evidence + fix linking provides actionable traceability.
|
||||
* Anchore/Grype SBOM → VEX suppression → facade for automation is the workflow to engineer.
|
||||
* Surface suppression metadata (reason, status, justification) for auditing suppressed items.
|
||||
|
||||
**Avoid**
|
||||
|
||||
* Fragmented ignore rules per scan surface (OSS vs Code vs Container). Instead, keep suppression consistent.
|
||||
* Hidden suppression; tie it to the main UI instead of a “show suppressed” toggle.
|
||||
* Incomplete VEX support for certain source types; test across containers, directories, binaries, SBOMs.
|
||||
|
||||
If helpful, I can build a spreadsheet (Snyk, GitHub, Aqua, Anchore/Grype, Prisma Cloud) comparing evidence, suppression, APIs, exports, and gaps with doc links.
|
||||
|
||||
[1]: https://docs.snyk.io/scan-with-snyk/snyk-code/manage-code-vulnerabilities/breakdown-of-code-analysis?utm_source=chatgpt.com "Breakdown of Code analysis"
|
||||
[2]: https://docs.anchore.com/current/docs/vulnerability_management/?utm_source=chatgpt.com "Anchore Secure - Vulnerability Management"
|
||||
[3]: https://github.com/anchore/grype?utm_source=chatgpt.com "anchore/grype: A vulnerability scanner for container ..."
|
||||
[4]: https://snyk.io/blog/ignoring-vulnerabilities-with-snyk/?utm_source=chatgpt.com "Ignoring vulnerabilities with Snyk"
|
||||
[5]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues/exclude-files-and-ignore-issues-faqs?utm_source=chatgpt.com "Exclude files and ignore issues FAQs"
|
||||
[6]: https://github.com/anchore/grype/issues/2471?utm_source=chatgpt.com "Support using VEX documents with directory scans and ..."
|
||||
[7]: https://docs.prismacloud.io/en/enterprise-edition/content-collections/application-security/risk-management/monitor-and-manage-code-build/suppress-code-issues?utm_source=chatgpt.com "Suppress Code Issues - Prisma Cloud Documentation"
|
||||
[8]: https://docs.prismacloud.io/en/compute-edition/32/admin-guide/vulnerability-management/code-repo-scanning?utm_source=chatgpt.com "Configure code repository scanning"
|
||||
Matrix built. I’ll keep it compact enough to scan quickly, but detailed enough that you can lift it straight into a Google Sheet / Confluence page.
|
||||
|
||||
---
|
||||
|
||||
## 1. Evidence & context: what a *single finding* looks like
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ----------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Code-level evidence** | Snyk Code shows a *Data flow* view (taint graph) from source → sink with step-by-step code lines in the UI and IDE. ([docs.snyk.io][1]) | Code scanning alerts show file/line and, for data-flow rules, a “how data moves through the code” view with **Show paths** for the full flow. ([GitHub Docs][2]) | Trivy is not a SAST engine; evidence is per-file / resource for vulnerabilities & misconfigurations (IaC, K8s, etc.), not data-flow graphs. ([Trivy][3]) | No SAST; evidence is package / image / SBOM level (CVE, package, version, location). Grype is focused on images/filesystems, not code flows. ([Chainguard Academy][4]) | AppSec module shows issues mapped to file & line and offers inline remediation/fix flows; surfaced in console and IDE plugins (JetBrains/VS Code). ([Palo Alto Networks][5]) |
|
||||
| **Dependency / container evidence** | For OSS & containers, Snyk shows dependency paths and has a **project issue paths** API that returns the introduction chain for a vuln. ([docs.snyk.io][6]) | Dependabot alerts show vulnerable package, version, advisories, and affected functions to help decide if code actually uses them. ([GitHub Docs][7]) | Trivy shows image → layer → package → vuln with installed/fixed versions; same for repos & filesystems in JSON/SARIF. ([GitHub][8]) | Grype output lists artifact, package, version, location, severity; when paired with Syft SBOM, you get full component graph for images and other artifacts. ([Chainguard Academy][4]) | Prisma’s Vulnerability Explorer & scan reports show image/host, package, severity and compliance IDs for image and host scans. ([docs.prismacloud.io][9]) |
|
||||
| **SBOM / supply-chain context** | `snyk sbom` generates CycloneDX and SPDX SBOMs for local projects; Snyk also supports SBOM export in enterprise tiers. ([docs.snyk.io][10]) | GitHub builds a dependency graph from manifests and ingests SARIF from external scanners; it is SBOM-adjacent but not an SBOM UI. ([GitHub Docs][11]) | Trivy can output SBOMs (CycloneDX, SPDX, SPDX-JSON) and Kubernetes “KBOM” views, and is often used as the SBOM generator. ([Chainguard Academy][12]) | Anchore Enterprise is explicitly “SBOM-powered”; SBOM management views let you navigate applications and export SBOM-centric vulnerability views. ([docs.anchore.com][13]) | Prisma Cloud is inventory-/RQL-centric; SBOMs are not a first-class UI artifact and there is no public doc for full SBOM navigation comparable to Anchore or Trivy. ([Palo Alto Networks][5]) |
|
||||
| **Where the evidence appears** | Web UI, CLI, IDEs (VS Code, JetBrains) and PR checks. Ignores for Snyk Code are now “consistent” across UI/CLI/IDE (2025-11 EA). ([docs.snyk.io][14]) | Web UI (Security tab), PR Conversation tab for code scanning reviews, REST & GraphQL APIs, and SARIF imports from many scanners. ([GitHub Docs][15]) | Trivy: CLI / JSON / SARIF / CI integrations (GitHub Actions, etc.). Aqua Platform adds a CNAPP UI with risk-based vulnerability views. ([GitHub][8]) | Grype: CLI & JSON/SARIF outputs; Anchore Enterprise: browser UI (dashboards, SBOM views, reporting) plus REST/GraphQL APIs. ([Chainguard Academy][4]) | Prisma Cloud: web console (AppSec dashboards, Vulnerability Explorer), REST APIs, IDE plugins for JetBrains & VS Code. ([docs.prismacloud.io][16]) |
|
||||
|
||||
---
|
||||
|
||||
## 2. Suppression / ignore / VEX behavior
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ---------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Suppression primitives** | `.snyk` policy file for OSS & container & IaC; `snyk ignore` CLI; “Ignore” in web UI; Snyk Code uses UI/CLI/IDE ignores but *not* `.snyk`. ([docs.snyk.io][17]) | Code scanning and Dependabot alerts can be **dismissed** with reasons; Dependabot has auto-triage rules (auto-dismiss/snooze). ([GitHub Docs][18]) | Trivy: `.trivyignore` / `.trivyignore.yaml` lists vuln IDs; `--ignore-policy` for Rego-based filtering; severity filters. ([aquasecurity.github.io][19]) | Grype: VEX-aware filtering via `--vex` and ignore rules; Anchore Enterprise: UI-driven vulnerability annotations that act as a structured “suppress or re-classify” layer. ([GitHub][20]) | AppSec: “Suppress Code Issues” (per-issue or globally) and more general suppression rules (disable policy / by source / by resource / by tag). ([docs.prismacloud.io][21]) |
|
||||
| **Metadata captured with suppression** | `snyk ignore` supports `--reason` and `--expiry`; UI shows who ignored and allows editing/unignore; APIs expose `ignoreReasons` on issues. ([docs.snyk.io][17]) | Dismissal reason: `false positive`, `won't fix`, `used in tests`; optional comment. Dismissal requests for code scanning add requester/reviewer, timestamps, status. ([GitHub Docs][22]) | Ignores live in repo-local files (`.trivyignore*`) or Rego policies; VEX documents contribute status metadata (per CVE, per product). No central UI metadata by default. ([aquasecurity.github.io][19]) | Annotations carry VEX-aligned status plus explanatory text; RBAC role `vuln-annotator-editor` controls who can create/modify/delete them. ([docs.anchore.com][23]) | Suppressions include justification text; there is a dedicated API to retrieve suppression justifications by policy ID and query (auditable). ([pan.dev][24]) |
|
||||
| **Scope & consistency** | Ignores are *local* to project/integration/org; ignoring in a Git repo project does not automatically ignore the same issue imported via CLI. Snyk Code ignore semantics differ from OSS/Container (no `.snyk`). ([Snyk][25]) | Dismissals attach to a specific alert (repo, branch baseline); PRs inherit baseline. Dependabot has repo-level config (`dependabot.yml`) and org-level alert configuration. ([GitHub Docs][7]) | Suppression is run-local: `.trivyignore` travels with source, policies live in config repos; VEX docs are attached per artifact or discovered via VEX Hub / registries. Reproducible but not centralized unless you build it. ([aquasecurity.github.io][19]) | Grype suppression is per scan & VEX document; Anchore Enterprise stores annotations centrally per artifact and exposes them consistently in UI/API and exported VEX. ([GitHub][20]) | Suppression rules can be global, per source, per resource, or tag-scoped; they affect console views and API results consistently when filters are applied. ([pan.dev][24]) |
|
||||
| **VEX support (ingest + semantics)** | Snyk generates SBOMs but has no documented first-class VEX ingestion or export; VEX is referenced mostly at the SBOM/standards level, not as a product feature. ([Snyk][26]) | No native VEX semantics in alerts; GitHub consumes SARIF only. VEX can exist in repos or external systems but is not interpreted by GHAS. ([GitHub Docs][11]) | Trivy has **explicit VEX support**: supports OpenVEX, CycloneDX VEX, and CSAF VEX, using local files, VEX repositories, SBOM externalReferences, and OCI VEX attestations to filter results. ([Trivy][27]) | Grype has VEX-first behavior: `--vex` to ingest OpenVEX; by default `not_affected`/`fixed` go to an ignore set; `--show-suppressed` exposes them. Anchore Enterprise 5.22+ adds OpenVEX export and CycloneDX VEX export (5.23). ([GitHub][20]) | No public documentation of native VEX ingestion or export; prioritization is via policies/RQL rather than VEX semantics. |
|
||||
| **Default handling of suppressed items** | Ignored issues are hidden by default in UI/CLI/IDE views to reduce noise; some tools like `snyk-to-html` will still show ignored Snyk Code issues. ([docs.snyk.io][28]) | Dismissed / auto-dismissed alerts are *not* shown by default (`is:open` filter); you must explicitly filter for closed / auto-dismissed alerts. ([GitHub Docs][29]) | When VEX is supplied, non-affected/fixed statuses are filtered out; suppressed entries are generally not shown unless you adjust filters/output. Some edge-cases exist around `.trivyignore.yaml` behavior. ([Trivy][27]) | Grype hides suppressed matches unless `--show-suppressed` is set; community discussions explicitly argue for “suppressed hidden by default” across all formats. ([artifacthub.io][30]) | Suppressed / excluded issues are hidden from normal risk views and searches and only visible via explicit filters or suppression APIs. ([pan.dev][24]) |
|
||||
| **Known pain points** | Fragmented semantics: Snyk Code vs OSS/Container vs IaC handle ignores differently; ignores are not global across ingest types. ([docs.snyk.io][31]) | Dismissal is per-tool: Dependabot rules don’t govern CodeQL and vice-versa; no VEX; you must build cross-tool policy on top. | Some rough edges reported around `.trivyignore.yaml` and SARIF vs exit-code behavior; VEX support is powerful but still labeled experimental in docs. ([GitHub][32]) | VEX support for certain source types (e.g., some directory + SBOM combos) has had bugs; suppressed entries disappear by default unless you remember `--show-suppressed`. ([GitHub][33]) | No VEX, and suppression semantics may diverge across CSPM/AppSec/Compute; complexity of RQL and multiple modules can make suppression strategy opaque without good governance. ([Palo Alto Networks][5]) |
|
||||
|
||||
---
|
||||
|
||||
## 3. Audit & export primitives
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ------------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Built-in UI exports** | Reporting UI lets you export reports as PDF and table data as CSV; you can also download CSV from several report views. ([docs.snyk.io][34]) | UI is mostly “view only”; some security overview exports are available, but reports are usually built via API or marketplace actions (e.g., PDF report GitHub Action). ([GitHub Docs][35]) | Aqua Platform provides CSV exports and API integrations for vulnerability reports; on-prem deployments can export “user policy data, vulnerability data and system settings data.” ([Aqua][36]) | SBOM/Vulnerability views have an **Export CSV** button; the Reports service aggregates via GraphQL into CSV/JSON from pre-built templates and dashboards. ([docs.anchore.com][37]) | Vulnerability Explorer and scan reports allow CSV export; code-build issues can be exported with filters as CSV from the AppSec UI. ([docs.prismacloud.io][16]) |
|
||||
| **Machine-readable exports / APIs** | REST Issues API; Export API (GA) to create CSV exports via async jobs; SBOM CLI (`snyk sbom`) for CycloneDX/SPDX; audit log export for user actions. ([docs.snyk.io][38]) | SARIF input/output; REST & GraphQL APIs for code scanning & Dependabot; many third-party actions to transform alerts into PDFs/CSVs or send to other systems. ([GitHub Docs][11]) | Trivy outputs JSON, SARIF, CycloneDX, SPDX, SPDX-JSON, GitHub formats; these can be uploaded into GHAS or other platforms. Aqua exposes vulnerability data via API. ([Trivy][39]) | Grype outputs JSON, table, CycloneDX, SARIF, plus Go-template based CSV; Anchore Enterprise exposes APIs for vulnerabilities, policies, and reports. ([Chainguard Academy][4]) | CSPM/AppSec APIs: `vulnerabilities/search` (JSON) and `.../search/download` (GZIP CSV) for RQL queries; broader Prisma Cloud API for automation/integration. ([pan.dev][40]) |
|
||||
| **VEX / “authoritative statement” export** | No native VEX export; at best you can export SBOMs and issues and post-process into VEX with external tooling. ([Snyk][26]) | None. Vendors can publish VEX separately, but GHAS doesn’t emit VEX. | Trivy consumes VEX but does not itself author VEX; Aqua operates VEX Hub as a central repository of vendor VEX documents rather than as a generator. ([Trivy][27]) | Anchore Enterprise 5.22/5.23 is currently the most “productized” VEX exporter: OpenVEX and CycloneDX VEX including annotations, PURLs, metadata about the scanned image. ([docs.anchore.com][41]) | No VEX export; risk posture is expressed via internal policies, not standardized exploitability statements. |
|
||||
| **Suppression / ignore audit** | Ignored issues can be exported by filtering for “Ignored” in Reporting and downloading CSV; APIs expose ignore reasons; audit log export records user actions such as ignoring issues. ([docs.snyk.io][42]) | Code scanning dismissal requests are full audit records (who requested, who approved, reason, timestamps). Dependabot dismissal comments & auto-dismissed alerts are queryable via GraphQL/REST and UI filters. ([GitHub Docs][43]) | Auditability is repo-driven: `.trivyignore`/VEX/rego live in version control; Aqua’s own reporting/APIs can include current vulnerability state but do not (publicly) expose a dedicated VEX change log. ([aquasecurity.github.io][19]) | Annotations are first-class objects, controlled via RBAC and exportable as OpenVEX/CycloneDX VEX; this effectively *is* an audit log of “why we suppressed or downgraded this CVE” over time. ([docs.anchore.com][23]) | Suppression justification APIs provide a structured record of why and where policies are suppressed; combined with CSV/API exports of vulns, this gives a workable audit trail for regulators. ([pan.dev][24]) |
|
||||
|
||||
---
|
||||
|
||||
## 4. What this suggests for StellaOps UX & data-model
|
||||
|
||||
### Patterns worth copying
|
||||
|
||||
1. **Data-flow & path-level “evidence” as the default detail view**
|
||||
|
||||
* Snyk Code’s taint-flow UI and GitHub’s “Show paths” for CodeQL alerts make a single issue *explain itself* without leaving the tool. ([docs.snyk.io][1])
|
||||
* For StellaOps:
|
||||
|
||||
* For code: provide a path graph (source → sanitizers → sinks) with line-level jumps.
|
||||
* For SBOM/containers: mirror Snyk’s Project Issue Paths & Grype/Syft by showing a dependency path or image-layer path for each CVE.
|
||||
|
||||
2. **VEX-first suppression semantics**
|
||||
|
||||
* Trivy and Grype treat VEX as the *canonical* suppression mechanism; statuses like `not_affected` / `fixed` hide findings by default, with CLI flags to show suppressed. ([Trivy][27])
|
||||
* Anchore Enterprise adds a full annotation workflow and emits OpenVEX/CycloneDX VEX as the authoritative vendor statement. ([docs.anchore.com][23])
|
||||
* For StellaOps: make VEX status the **single source of truth** for suppression across all modules, and always be able to reconstruct a proof tree: SBOM → vuln → VEX statement → policy decision.
|
||||
|
||||
3. **Rich suppression metadata with explicit justification & expiry**
|
||||
|
||||
* Snyk captures reason + expiry; GitHub uses structured reasons + free-form comment; Prisma provides a dedicated suppression-justification API. ([docs.snyk.io][17])
|
||||
* For StellaOps: require a reason taxonomy + free-text + optional “proof link” (e.g., internal ticket, upstream vendor VEX) for any “Not Affected” or “Won’t Fix,” and store that as part of the public proof spine.
|
||||
|
||||
4. **Strong export & API stories for regulators**
|
||||
|
||||
* Snyk’s Export API, Anchore’s Reports service, and Prisma’s RQL+CSV APIs give customers reliable machine-readable exports for audits and custom BI. ([updates.snyk.io][44])
|
||||
* Anchore’s CycloneDX VEX export is the best current model for “signable, portable, regulator-friendly” proofs. ([Security Boulevard][45])
|
||||
* For StellaOps:
|
||||
|
||||
* Treat CSV/JSON/SBOM/VEX exports as *first-class* features, not add-ons.
|
||||
* Tie them to deterministic scan manifests and graph revision IDs (your “trust algebra” backbone) so an auditor can replay any historical report.
|
||||
|
||||
5. **Repo-local suppression files as “policy as code”**
|
||||
|
||||
* `.snyk`, `.trivyignore`, Rego policies, and VEX docs living alongside source are proven patterns for reproducible suppression. ([docs.snyk.io][46])
|
||||
* For StellaOps: mirror this with a small set of declarative files (`stellaops.vexmap.yaml`, `trust-lattice.yaml`) that your engine and UI both honor.
|
||||
|
||||
### Patterns to deliberately avoid
|
||||
|
||||
1. **Fragmented ignore semantics by scan type**
|
||||
|
||||
* Snyk’s different behavior across Code vs OSS vs Container vs IaC (e.g., `.snyk` not honored for Snyk Code) is a recurring source of confusion. ([docs.snyk.io][31])
|
||||
* For StellaOps: a single suppression model (VEX+policy) must apply consistently whether the evidence came from SAST, SBOM, container scan, or runtime telemetry.
|
||||
|
||||
2. **Making suppressed issues effectively invisible**
|
||||
|
||||
* Grype and GitHub both hide suppressed/dismissed issues by default and require extra flags/filters to see them. ([artifacthub.io][30])
|
||||
* For StellaOps:
|
||||
|
||||
* Default UI for any artifact should show a small, always-visible “suppressed” counter with a click-through view.
|
||||
* Every export format should have an option to include suppressed entries with their VEX status and reasoning.
|
||||
|
||||
3. **Lack of a standard “authoritative statement” artifact**
|
||||
|
||||
* Snyk, GitHub, Prisma Cloud all rely on internal notions of suppression and policy without emitting a standardized VEX or equivalent artifact. ([Snyk][26])
|
||||
* For StellaOps: your “Proof-of-Integrity Graph” and VEX exports should be the primary way vendors and customers communicate risk, not just internal UI states.
|
||||
|
||||
4. **Over-reliance on informal text for serious decisions**
|
||||
|
||||
* Many tools lean heavily on free-form comments (GitHub dismissal comments, Snyk ignore reasons) without tying them to structured policies or verifiable upstream evidence. ([GitHub Docs][22])
|
||||
* For StellaOps: keep free text, but anchor it in structured fields (VEX status, justification category, linked upstream VEX/SBOM, ticket ID) and make these queryable across the entire system.
|
||||
|
||||
If you want, next step can be a **StellaOps UX spec** that maps each of these rows to concrete screens and micro-interactions (e.g., “Finding details drawer,” “Suppression dialog,” “Export / attest dialog”) so your .NET/Angular team has something they can implement directly.
|
||||
|
||||
[1]: https://docs.snyk.io/scan-with-snyk/snyk-code/manage-code-vulnerabilities/breakdown-of-code-analysis?utm_source=chatgpt.com "Breakdown of Code analysis"
|
||||
[2]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/about-code-scanning-alerts?utm_source=chatgpt.com "About code scanning alerts"
|
||||
[3]: https://trivy.dev/docs/v0.56/scanner/misconfiguration/?utm_source=chatgpt.com "Misconfiguration Scanning"
|
||||
[4]: https://edu.chainguard.dev/chainguard/chainguard-images/staying-secure/working-with-scanners/grype-tutorial/?utm_source=chatgpt.com "Using Grype to Scan Software Artifacts"
|
||||
[5]: https://www.paloaltonetworks.com/prisma/cloud/cloud-code-security?utm_source=chatgpt.com "Cloud Code Security"
|
||||
[6]: https://docs.snyk.io/snyk-api/api-endpoints-index-and-tips/project-issue-paths-api-endpoints?utm_source=chatgpt.com "Project issue paths API endpoints"
|
||||
[7]: https://docs.github.com/en/code-security/dependabot/dependabot-alerts/viewing-and-updating-dependabot-alerts?utm_source=chatgpt.com "Viewing and updating Dependabot alerts"
|
||||
[8]: https://github.com/aquasecurity/trivy?utm_source=chatgpt.com "aquasecurity/trivy: Find vulnerabilities, misconfigurations, ..."
|
||||
[9]: https://docs.prismacloud.io/en/compute-edition/32/admin-guide/vulnerability-management/scan-reports?utm_source=chatgpt.com "Vulnerability Scan Reports - Prisma Cloud Documentation"
|
||||
[10]: https://docs.snyk.io/developer-tools/snyk-cli/commands/sbom?utm_source=chatgpt.com "SBOM"
|
||||
[11]: https://docs.github.com/en/code-security/code-scanning/integrating-with-code-scanning/sarif-support-for-code-scanning?utm_source=chatgpt.com "SARIF support for code scanning"
|
||||
[12]: https://edu.chainguard.dev/chainguard/chainguard-images/staying-secure/working-with-scanners/trivy-tutorial/?utm_source=chatgpt.com "Using Trivy to Scan Software Artifacts"
|
||||
[13]: https://docs.anchore.com/current/docs/?utm_source=chatgpt.com "Anchore Enterprise Documentation"
|
||||
[14]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues/consistent-ignores-for-snyk-code?utm_source=chatgpt.com "Consistent Ignores for Snyk Code"
|
||||
[15]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/assessing-code-scanning-alerts-for-your-repository?utm_source=chatgpt.com "Assessing code scanning alerts for your repository"
|
||||
[16]: https://docs.prismacloud.io/en/enterprise-edition/content-collections/runtime-security/vulnerability-management/vulnerability-explorer?utm_source=chatgpt.com "Vulnerability Explorer - Prisma Cloud Documentation"
|
||||
[17]: https://docs.snyk.io/developer-tools/snyk-cli/commands/ignore?utm_source=chatgpt.com "Ignore | Snyk User Docs"
|
||||
[18]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/resolving-code-scanning-alerts?utm_source=chatgpt.com "Resolving code scanning alerts"
|
||||
[19]: https://aquasecurity.github.io/trivy-operator/v0.13.2/docs/vulnerability-scanning/trivy/?utm_source=chatgpt.com "Trivy Scanner - Trivy Operator - Aqua Security"
|
||||
[20]: https://github.com/anchore/grype?utm_source=chatgpt.com "anchore/grype: A vulnerability scanner for container ..."
|
||||
[21]: https://docs.prismacloud.io/en/enterprise-edition/content-collections/application-security/risk-management/monitor-and-manage-code-build/suppress-code-issues?utm_source=chatgpt.com "Suppress Code Issues - Prisma Cloud Documentation"
|
||||
[22]: https://docs.github.com/en/rest/code-scanning/code-scanning?utm_source=chatgpt.com "REST API endpoints for code scanning"
|
||||
[23]: https://docs.anchore.com/current/docs/vulnerability_management/vuln_annotations/?utm_source=chatgpt.com "Vulnerability Annotations and VEX"
|
||||
[24]: https://pan.dev/prisma-cloud/api/code/get-suppressions-justifications/?utm_source=chatgpt.com "Get Suppressions Justifications by Policy ID and Query ..."
|
||||
[25]: https://snyk.io/blog/ignoring-vulnerabilities-with-snyk/?utm_source=chatgpt.com "Ignoring vulnerabilities with Snyk"
|
||||
[26]: https://snyk.io/blog/advancing-sbom-standards-snyk-spdx/?utm_source=chatgpt.com "Advancing SBOM standards: Snyk and SPDX"
|
||||
[27]: https://trivy.dev/docs/v0.50/supply-chain/vex/?utm_source=chatgpt.com "VEX"
|
||||
[28]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues?utm_source=chatgpt.com "Ignore issues | Snyk User Docs"
|
||||
[29]: https://docs.github.com/en/code-security/dependabot/dependabot-auto-triage-rules/managing-automatically-dismissed-alerts?utm_source=chatgpt.com "Managing automatically dismissed alerts - Dependabot"
|
||||
[30]: https://artifacthub.io/packages/container/grype/grype?utm_source=chatgpt.com "grype latest · wagoodman@gmail.com/grype"
|
||||
[31]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues/exclude-files-and-ignore-issues-faqs?utm_source=chatgpt.com "Exclude files and ignore issues FAQs"
|
||||
[32]: https://github.com/aquasecurity/trivy/discussions/7974?utm_source=chatgpt.com ".trivyignore.yaml not allow to ignore multiple vulnerabilities ..."
|
||||
[33]: https://github.com/anchore/grype/issues/2471?utm_source=chatgpt.com "Support using VEX documents with directory scans and ..."
|
||||
[34]: https://docs.snyk.io/manage-risk/reporting?utm_source=chatgpt.com "Reporting | Snyk User Docs"
|
||||
[35]: https://docs.github.com/en/code-security/security-overview/filtering-alerts-in-security-overview?utm_source=chatgpt.com "Filtering alerts in security overview"
|
||||
[36]: https://www.aquasec.com/blog/container-vulnerability-management-best-practices/?utm_source=chatgpt.com "Cloud Native Security Best Practices: Vulnerability Management"
|
||||
[37]: https://docs.anchore.com/current/docs/sbom_management/?utm_source=chatgpt.com "SBOM Management"
|
||||
[38]: https://docs.snyk.io/snyk-api/using-specific-snyk-apis/issues-list-issues-for-a-package?utm_source=chatgpt.com "Issues: List issues for a package"
|
||||
[39]: https://trivy.dev/docs/latest/configuration/reporting/?utm_source=chatgpt.com "Reporting"
|
||||
[40]: https://pan.dev/prisma-cloud/api/cspm/vulnerabilities-search-api/?utm_source=chatgpt.com "Get Vulnerabilities by RQL | Develop with Palo Alto Networks"
|
||||
[41]: https://docs.anchore.com/current/docs/release_notes/enterprise/5220/?utm_source=chatgpt.com "Anchore Enterprise Release Notes - Version 5.22.0"
|
||||
[42]: https://docs.snyk.io/manage-risk/reporting/available-snyk-reports?utm_source=chatgpt.com "Available Snyk reports | Snyk User Docs"
|
||||
[43]: https://docs.github.com/en/enterprise-cloud%40latest/rest/code-scanning/alert-dismissal-requests?utm_source=chatgpt.com "REST API endpoints for code scanning alert dismissal ..."
|
||||
[44]: https://updates.snyk.io/export-api-ga-release-321290/?utm_source=chatgpt.com "Export API GA Release"
|
||||
[45]: https://securityboulevard.com/2025/11/anchore-enterprise-5-23-cyclonedx-vex-and-vdr-support/?utm_source=chatgpt.com "Anchore Enterprise 5.23: CycloneDX VEX and VDR Support"
|
||||
[46]: https://docs.snyk.io/manage-risk/policies/the-.snyk-file?utm_source=chatgpt.com "The .snyk file | Snyk User Docs"
|
||||
Matrix built. I’ll keep it compact enough to scan quickly, but detailed enough that you can lift it straight into a Google Sheet / Confluence page.
|
||||
|
||||
---
|
||||
|
||||
## 1. Evidence & context: what a *single finding* looks like
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ----------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Code-level evidence** | Snyk Code shows a *Data flow* view (taint graph) from source → sink with step-by-step code lines in the UI and IDE. ([docs.snyk.io][1]) | Code scanning alerts show file/line and, for data-flow rules, a “how data moves through the code” view with **Show paths** for the full flow. ([GitHub Docs][2]) | Trivy is not a SAST engine; evidence is per-file / resource for vulnerabilities & misconfigurations (IaC, K8s, etc.), not data-flow graphs. ([Trivy][3]) | No SAST; evidence is package / image / SBOM level (CVE, package, version, location). Grype is focused on images/filesystems, not code flows. ([Chainguard Academy][4]) | AppSec module shows issues mapped to file & line and offers inline remediation/fix flows; surfaced in console and IDE plugins (JetBrains/VS Code). ([Palo Alto Networks][5]) |
|
||||
| **Dependency / container evidence** | For OSS & containers, Snyk shows dependency paths and has a **project issue paths** API that returns the introduction chain for a vuln. ([docs.snyk.io][6]) | Dependabot alerts show vulnerable package, version, advisories, and affected functions to help decide if code actually uses them. ([GitHub Docs][7]) | Trivy shows image → layer → package → vuln with installed/fixed versions; same for repos & filesystems in JSON/SARIF. ([GitHub][8]) | Grype output lists artifact, package, version, location, severity; when paired with Syft SBOM, you get full component graph for images and other artifacts. ([Chainguard Academy][4]) | Prisma’s Vulnerability Explorer & scan reports show image/host, package, severity and compliance IDs for image and host scans. ([docs.prismacloud.io][9]) |
|
||||
| **SBOM / supply-chain context** | `snyk sbom` generates CycloneDX and SPDX SBOMs for local projects; Snyk also supports SBOM export in enterprise tiers. ([docs.snyk.io][10]) | GitHub builds a dependency graph from manifests and ingests SARIF from external scanners; it is SBOM-adjacent but not an SBOM UI. ([GitHub Docs][11]) | Trivy can output SBOMs (CycloneDX, SPDX, SPDX-JSON) and Kubernetes “KBOM” views, and is often used as the SBOM generator. ([Chainguard Academy][12]) | Anchore Enterprise is explicitly “SBOM-powered”; SBOM management views let you navigate applications and export SBOM-centric vulnerability views. ([docs.anchore.com][13]) | Prisma Cloud is inventory-/RQL-centric; SBOMs are not a first-class UI artifact and there is no public doc for full SBOM navigation comparable to Anchore or Trivy. ([Palo Alto Networks][5]) |
|
||||
| **Where the evidence appears** | Web UI, CLI, IDEs (VS Code, JetBrains) and PR checks. Ignores for Snyk Code are now “consistent” across UI/CLI/IDE (2025-11 EA). ([docs.snyk.io][14]) | Web UI (Security tab), PR Conversation tab for code scanning reviews, REST & GraphQL APIs, and SARIF imports from many scanners. ([GitHub Docs][15]) | Trivy: CLI / JSON / SARIF / CI integrations (GitHub Actions, etc.). Aqua Platform adds a CNAPP UI with risk-based vulnerability views. ([GitHub][8]) | Grype: CLI & JSON/SARIF outputs; Anchore Enterprise: browser UI (dashboards, SBOM views, reporting) plus REST/GraphQL APIs. ([Chainguard Academy][4]) | Prisma Cloud: web console (AppSec dashboards, Vulnerability Explorer), REST APIs, IDE plugins for JetBrains & VS Code. ([docs.prismacloud.io][16]) |
|
||||
|
||||
---
|
||||
|
||||
## 2. Suppression / ignore / VEX behavior
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ---------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Suppression primitives** | `.snyk` policy file for OSS & container & IaC; `snyk ignore` CLI; “Ignore” in web UI; Snyk Code uses UI/CLI/IDE ignores but *not* `.snyk`. ([docs.snyk.io][17]) | Code scanning and Dependabot alerts can be **dismissed** with reasons; Dependabot has auto-triage rules (auto-dismiss/snooze). ([GitHub Docs][18]) | Trivy: `.trivyignore` / `.trivyignore.yaml` lists vuln IDs; `--ignore-policy` for Rego-based filtering; severity filters. ([aquasecurity.github.io][19]) | Grype: VEX-aware filtering via `--vex` and ignore rules; Anchore Enterprise: UI-driven vulnerability annotations that act as a structured “suppress or re-classify” layer. ([GitHub][20]) | AppSec: “Suppress Code Issues” (per-issue or globally) and more general suppression rules (disable policy / by source / by resource / by tag). ([docs.prismacloud.io][21]) |
|
||||
| **Metadata captured with suppression** | `snyk ignore` supports `--reason` and `--expiry`; UI shows who ignored and allows editing/unignore; APIs expose `ignoreReasons` on issues. ([docs.snyk.io][17]) | Dismissal reason: `false positive`, `won't fix`, `used in tests`; optional comment. Dismissal requests for code scanning add requester/reviewer, timestamps, status. ([GitHub Docs][22]) | Ignores live in repo-local files (`.trivyignore*`) or Rego policies; VEX documents contribute status metadata (per CVE, per product). No central UI metadata by default. ([aquasecurity.github.io][19]) | Annotations carry VEX-aligned status plus explanatory text; RBAC role `vuln-annotator-editor` controls who can create/modify/delete them. ([docs.anchore.com][23]) | Suppressions include justification text; there is a dedicated API to retrieve suppression justifications by policy ID and query (auditable). ([pan.dev][24]) |
|
||||
| **Scope & consistency** | Ignores are *local* to project/integration/org; ignoring in a Git repo project does not automatically ignore the same issue imported via CLI. Snyk Code ignore semantics differ from OSS/Container (no `.snyk`). ([Snyk][25]) | Dismissals attach to a specific alert (repo, branch baseline); PRs inherit baseline. Dependabot has repo-level config (`dependabot.yml`) and org-level alert configuration. ([GitHub Docs][7]) | Suppression is run-local: `.trivyignore` travels with source, policies live in config repos; VEX docs are attached per artifact or discovered via VEX Hub / registries. Reproducible but not centralized unless you build it. ([aquasecurity.github.io][19]) | Grype suppression is per scan & VEX document; Anchore Enterprise stores annotations centrally per artifact and exposes them consistently in UI/API and exported VEX. ([GitHub][20]) | Suppression rules can be global, per source, per resource, or tag-scoped; they affect console views and API results consistently when filters are applied. ([pan.dev][24]) |
|
||||
| **VEX support (ingest + semantics)** | Snyk generates SBOMs but has no documented first-class VEX ingestion or export; VEX is referenced mostly at the SBOM/standards level, not as a product feature. ([Snyk][26]) | No native VEX semantics in alerts; GitHub consumes SARIF only. VEX can exist in repos or external systems but is not interpreted by GHAS. ([GitHub Docs][11]) | Trivy has **explicit VEX support**: supports OpenVEX, CycloneDX VEX, and CSAF VEX, using local files, VEX repositories, SBOM externalReferences, and OCI VEX attestations to filter results. ([Trivy][27]) | Grype has VEX-first behavior: `--vex` to ingest OpenVEX; by default `not_affected`/`fixed` go to an ignore set; `--show-suppressed` exposes them. Anchore Enterprise 5.22+ adds OpenVEX export and CycloneDX VEX export (5.23). ([GitHub][20]) | No public documentation of native VEX ingestion or export; prioritization is via policies/RQL rather than VEX semantics. |
|
||||
| **Default handling of suppressed items** | Ignored issues are hidden by default in UI/CLI/IDE views to reduce noise; some tools like `snyk-to-html` will still show ignored Snyk Code issues. ([docs.snyk.io][28]) | Dismissed / auto-dismissed alerts are *not* shown by default (`is:open` filter); you must explicitly filter for closed / auto-dismissed alerts. ([GitHub Docs][29]) | When VEX is supplied, non-affected/fixed statuses are filtered out; suppressed entries are generally not shown unless you adjust filters/output. Some edge-cases exist around `.trivyignore.yaml` behavior. ([Trivy][27]) | Grype hides suppressed matches unless `--show-suppressed` is set; community discussions explicitly argue for “suppressed hidden by default” across all formats. ([artifacthub.io][30]) | Suppressed / excluded issues are hidden from normal risk views and searches and only visible via explicit filters or suppression APIs. ([pan.dev][24]) |
|
||||
| **Known pain points** | Fragmented semantics: Snyk Code vs OSS/Container vs IaC handle ignores differently; ignores are not global across ingest types. ([docs.snyk.io][31]) | Dismissal is per-tool: Dependabot rules don’t govern CodeQL and vice-versa; no VEX; you must build cross-tool policy on top. | Some rough edges reported around `.trivyignore.yaml` and SARIF vs exit-code behavior; VEX support is powerful but still labeled experimental in docs. ([GitHub][32]) | VEX support for certain source types (e.g., some directory + SBOM combos) has had bugs; suppressed entries disappear by default unless you remember `--show-suppressed`. ([GitHub][33]) | No VEX, and suppression semantics may diverge across CSPM/AppSec/Compute; complexity of RQL and multiple modules can make suppression strategy opaque without good governance. ([Palo Alto Networks][5]) |
|
||||
|
||||
---
|
||||
|
||||
## 3. Audit & export primitives
|
||||
|
||||
| Dimension | Snyk | GitHub Advanced Security | Aqua / Trivy | Anchore / Grype (Anchore Enterprise) | Prisma Cloud |
|
||||
| ------------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Built-in UI exports** | Reporting UI lets you export reports as PDF and table data as CSV; you can also download CSV from several report views. ([docs.snyk.io][34]) | UI is mostly “view only”; some security overview exports are available, but reports are usually built via API or marketplace actions (e.g., PDF report GitHub Action). ([GitHub Docs][35]) | Aqua Platform provides CSV exports and API integrations for vulnerability reports; on-prem deployments can export “user policy data, vulnerability data and system settings data.” ([Aqua][36]) | SBOM/Vulnerability views have an **Export CSV** button; the Reports service aggregates via GraphQL into CSV/JSON from pre-built templates and dashboards. ([docs.anchore.com][37]) | Vulnerability Explorer and scan reports allow CSV export; code-build issues can be exported with filters as CSV from the AppSec UI. ([docs.prismacloud.io][16]) |
|
||||
| **Machine-readable exports / APIs** | REST Issues API; Export API (GA) to create CSV exports via async jobs; SBOM CLI (`snyk sbom`) for CycloneDX/SPDX; audit log export for user actions. ([docs.snyk.io][38]) | SARIF input/output; REST & GraphQL APIs for code scanning & Dependabot; many third-party actions to transform alerts into PDFs/CSVs or send to other systems. ([GitHub Docs][11]) | Trivy outputs JSON, SARIF, CycloneDX, SPDX, SPDX-JSON, GitHub formats; these can be uploaded into GHAS or other platforms. Aqua exposes vulnerability data via API. ([Trivy][39]) | Grype outputs JSON, table, CycloneDX, SARIF, plus Go-template based CSV; Anchore Enterprise exposes APIs for vulnerabilities, policies, and reports. ([Chainguard Academy][4]) | CSPM/AppSec APIs: `vulnerabilities/search` (JSON) and `.../search/download` (GZIP CSV) for RQL queries; broader Prisma Cloud API for automation/integration. ([pan.dev][40]) |
|
||||
| **VEX / “authoritative statement” export** | No native VEX export; at best you can export SBOMs and issues and post-process into VEX with external tooling. ([Snyk][26]) | None. Vendors can publish VEX separately, but GHAS doesn’t emit VEX. | Trivy consumes VEX but does not itself author VEX; Aqua operates VEX Hub as a central repository of vendor VEX documents rather than as a generator. ([Trivy][27]) | Anchore Enterprise 5.22/5.23 is currently the most “productized” VEX exporter: OpenVEX and CycloneDX VEX including annotations, PURLs, metadata about the scanned image. ([docs.anchore.com][41]) | No VEX export; risk posture is expressed via internal policies, not standardized exploitability statements. |
|
||||
| **Suppression / ignore audit** | Ignored issues can be exported by filtering for “Ignored” in Reporting and downloading CSV; APIs expose ignore reasons; audit log export records user actions such as ignoring issues. ([docs.snyk.io][42]) | Code scanning dismissal requests are full audit records (who requested, who approved, reason, timestamps). Dependabot dismissal comments & auto-dismissed alerts are queryable via GraphQL/REST and UI filters. ([GitHub Docs][43]) | Auditability is repo-driven: `.trivyignore`/VEX/rego live in version control; Aqua’s own reporting/APIs can include current vulnerability state but do not (publicly) expose a dedicated VEX change log. ([aquasecurity.github.io][19]) | Annotations are first-class objects, controlled via RBAC and exportable as OpenVEX/CycloneDX VEX; this effectively *is* an audit log of “why we suppressed or downgraded this CVE” over time. ([docs.anchore.com][23]) | Suppression justification APIs provide a structured record of why and where policies are suppressed; combined with CSV/API exports of vulns, this gives a workable audit trail for regulators. ([pan.dev][24]) |
|
||||
|
||||
---
|
||||
|
||||
## 4. What this suggests for StellaOps UX & data-model
|
||||
|
||||
### Patterns worth copying
|
||||
|
||||
1. **Data-flow & path-level “evidence” as the default detail view**
|
||||
|
||||
* Snyk Code’s taint-flow UI and GitHub’s “Show paths” for CodeQL alerts make a single issue *explain itself* without leaving the tool. ([docs.snyk.io][1])
|
||||
* For StellaOps:
|
||||
|
||||
* For code: provide a path graph (source → sanitizers → sinks) with line-level jumps.
|
||||
* For SBOM/containers: mirror Snyk’s Project Issue Paths & Grype/Syft by showing a dependency path or image-layer path for each CVE.
|
||||
|
||||
2. **VEX-first suppression semantics**
|
||||
|
||||
* Trivy and Grype treat VEX as the *canonical* suppression mechanism; statuses like `not_affected` / `fixed` hide findings by default, with CLI flags to show suppressed. ([Trivy][27])
|
||||
* Anchore Enterprise adds a full annotation workflow and emits OpenVEX/CycloneDX VEX as the authoritative vendor statement. ([docs.anchore.com][23])
|
||||
* For StellaOps: make VEX status the **single source of truth** for suppression across all modules, and always be able to reconstruct a proof tree: SBOM → vuln → VEX statement → policy decision.
|
||||
|
||||
3. **Rich suppression metadata with explicit justification & expiry**
|
||||
|
||||
* Snyk captures reason + expiry; GitHub uses structured reasons + free-form comment; Prisma provides a dedicated suppression-justification API. ([docs.snyk.io][17])
|
||||
* For StellaOps: require a reason taxonomy + free-text + optional “proof link” (e.g., internal ticket, upstream vendor VEX) for any “Not Affected” or “Won’t Fix,” and store that as part of the public proof spine.
|
||||
|
||||
4. **Strong export & API stories for regulators**
|
||||
|
||||
* Snyk’s Export API, Anchore’s Reports service, and Prisma’s RQL+CSV APIs give customers reliable machine-readable exports for audits and custom BI. ([updates.snyk.io][44])
|
||||
* Anchore’s CycloneDX VEX export is the best current model for “signable, portable, regulator-friendly” proofs. ([Security Boulevard][45])
|
||||
* For StellaOps:
|
||||
|
||||
* Treat CSV/JSON/SBOM/VEX exports as *first-class* features, not add-ons.
|
||||
* Tie them to deterministic scan manifests and graph revision IDs (your “trust algebra” backbone) so an auditor can replay any historical report.
|
||||
|
||||
5. **Repo-local suppression files as “policy as code”**
|
||||
|
||||
* `.snyk`, `.trivyignore`, Rego policies, and VEX docs living alongside source are proven patterns for reproducible suppression. ([docs.snyk.io][46])
|
||||
* For StellaOps: mirror this with a small set of declarative files (`stellaops.vexmap.yaml`, `trust-lattice.yaml`) that your engine and UI both honor.
|
||||
|
||||
### Patterns to deliberately avoid
|
||||
|
||||
1. **Fragmented ignore semantics by scan type**
|
||||
|
||||
* Snyk’s different behavior across Code vs OSS vs Container vs IaC (e.g., `.snyk` not honored for Snyk Code) is a recurring source of confusion. ([docs.snyk.io][31])
|
||||
* For StellaOps: a single suppression model (VEX+policy) must apply consistently whether the evidence came from SAST, SBOM, container scan, or runtime telemetry.
|
||||
|
||||
2. **Making suppressed issues effectively invisible**
|
||||
|
||||
* Grype and GitHub both hide suppressed/dismissed issues by default and require extra flags/filters to see them. ([artifacthub.io][30])
|
||||
* For StellaOps:
|
||||
|
||||
* Default UI for any artifact should show a small, always-visible “suppressed” counter with a click-through view.
|
||||
* Every export format should have an option to include suppressed entries with their VEX status and reasoning.
|
||||
|
||||
3. **Lack of a standard “authoritative statement” artifact**
|
||||
|
||||
* Snyk, GitHub, Prisma Cloud all rely on internal notions of suppression and policy without emitting a standardized VEX or equivalent artifact. ([Snyk][26])
|
||||
* For StellaOps: your “Proof-of-Integrity Graph” and VEX exports should be the primary way vendors and customers communicate risk, not just internal UI states.
|
||||
|
||||
4. **Over-reliance on informal text for serious decisions**
|
||||
|
||||
* Many tools lean heavily on free-form comments (GitHub dismissal comments, Snyk ignore reasons) without tying them to structured policies or verifiable upstream evidence. ([GitHub Docs][22])
|
||||
* For StellaOps: keep free text, but anchor it in structured fields (VEX status, justification category, linked upstream VEX/SBOM, ticket ID) and make these queryable across the entire system.
|
||||
|
||||
If you want, next step can be a **StellaOps UX spec** that maps each of these rows to concrete screens and micro-interactions (e.g., “Finding details drawer,” “Suppression dialog,” “Export / attest dialog”) so your .NET/Angular team has something they can implement directly.
|
||||
|
||||
[1]: https://docs.snyk.io/scan-with-snyk/snyk-code/manage-code-vulnerabilities/breakdown-of-code-analysis?utm_source=chatgpt.com "Breakdown of Code analysis"
|
||||
[2]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/about-code-scanning-alerts?utm_source=chatgpt.com "About code scanning alerts"
|
||||
[3]: https://trivy.dev/docs/v0.56/scanner/misconfiguration/?utm_source=chatgpt.com "Misconfiguration Scanning"
|
||||
[4]: https://edu.chainguard.dev/chainguard/chainguard-images/staying-secure/working-with-scanners/grype-tutorial/?utm_source=chatgpt.com "Using Grype to Scan Software Artifacts"
|
||||
[5]: https://www.paloaltonetworks.com/prisma/cloud/cloud-code-security?utm_source=chatgpt.com "Cloud Code Security"
|
||||
[6]: https://docs.snyk.io/snyk-api/api-endpoints-index-and-tips/project-issue-paths-api-endpoints?utm_source=chatgpt.com "Project issue paths API endpoints"
|
||||
[7]: https://docs.github.com/en/code-security/dependabot/dependabot-alerts/viewing-and-updating-dependabot-alerts?utm_source=chatgpt.com "Viewing and updating Dependabot alerts"
|
||||
[8]: https://github.com/aquasecurity/trivy?utm_source=chatgpt.com "aquasecurity/trivy: Find vulnerabilities, misconfigurations, ..."
|
||||
[9]: https://docs.prismacloud.io/en/compute-edition/32/admin-guide/vulnerability-management/scan-reports?utm_source=chatgpt.com "Vulnerability Scan Reports - Prisma Cloud Documentation"
|
||||
[10]: https://docs.snyk.io/developer-tools/snyk-cli/commands/sbom?utm_source=chatgpt.com "SBOM"
|
||||
[11]: https://docs.github.com/en/code-security/code-scanning/integrating-with-code-scanning/sarif-support-for-code-scanning?utm_source=chatgpt.com "SARIF support for code scanning"
|
||||
[12]: https://edu.chainguard.dev/chainguard/chainguard-images/staying-secure/working-with-scanners/trivy-tutorial/?utm_source=chatgpt.com "Using Trivy to Scan Software Artifacts"
|
||||
[13]: https://docs.anchore.com/current/docs/?utm_source=chatgpt.com "Anchore Enterprise Documentation"
|
||||
[14]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues/consistent-ignores-for-snyk-code?utm_source=chatgpt.com "Consistent Ignores for Snyk Code"
|
||||
[15]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/assessing-code-scanning-alerts-for-your-repository?utm_source=chatgpt.com "Assessing code scanning alerts for your repository"
|
||||
[16]: https://docs.prismacloud.io/en/enterprise-edition/content-collections/runtime-security/vulnerability-management/vulnerability-explorer?utm_source=chatgpt.com "Vulnerability Explorer - Prisma Cloud Documentation"
|
||||
[17]: https://docs.snyk.io/developer-tools/snyk-cli/commands/ignore?utm_source=chatgpt.com "Ignore | Snyk User Docs"
|
||||
[18]: https://docs.github.com/en/code-security/code-scanning/managing-code-scanning-alerts/resolving-code-scanning-alerts?utm_source=chatgpt.com "Resolving code scanning alerts"
|
||||
[19]: https://aquasecurity.github.io/trivy-operator/v0.13.2/docs/vulnerability-scanning/trivy/?utm_source=chatgpt.com "Trivy Scanner - Trivy Operator - Aqua Security"
|
||||
[20]: https://github.com/anchore/grype?utm_source=chatgpt.com "anchore/grype: A vulnerability scanner for container ..."
|
||||
[21]: https://docs.prismacloud.io/en/enterprise-edition/content-collections/application-security/risk-management/monitor-and-manage-code-build/suppress-code-issues?utm_source=chatgpt.com "Suppress Code Issues - Prisma Cloud Documentation"
|
||||
[22]: https://docs.github.com/en/rest/code-scanning/code-scanning?utm_source=chatgpt.com "REST API endpoints for code scanning"
|
||||
[23]: https://docs.anchore.com/current/docs/vulnerability_management/vuln_annotations/?utm_source=chatgpt.com "Vulnerability Annotations and VEX"
|
||||
[24]: https://pan.dev/prisma-cloud/api/code/get-suppressions-justifications/?utm_source=chatgpt.com "Get Suppressions Justifications by Policy ID and Query ..."
|
||||
[25]: https://snyk.io/blog/ignoring-vulnerabilities-with-snyk/?utm_source=chatgpt.com "Ignoring vulnerabilities with Snyk"
|
||||
[26]: https://snyk.io/blog/advancing-sbom-standards-snyk-spdx/?utm_source=chatgpt.com "Advancing SBOM standards: Snyk and SPDX"
|
||||
[27]: https://trivy.dev/docs/v0.50/supply-chain/vex/?utm_source=chatgpt.com "VEX"
|
||||
[28]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues?utm_source=chatgpt.com "Ignore issues | Snyk User Docs"
|
||||
[29]: https://docs.github.com/en/code-security/dependabot/dependabot-auto-triage-rules/managing-automatically-dismissed-alerts?utm_source=chatgpt.com "Managing automatically dismissed alerts - Dependabot"
|
||||
[30]: https://artifacthub.io/packages/container/grype/grype?utm_source=chatgpt.com "grype latest · wagoodman@gmail.com/grype"
|
||||
[31]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/ignore-issues/exclude-files-and-ignore-issues-faqs?utm_source=chatgpt.com "Exclude files and ignore issues FAQs"
|
||||
[32]: https://github.com/aquasecurity/trivy/discussions/7974?utm_source=chatgpt.com ".trivyignore.yaml not allow to ignore multiple vulnerabilities ..."
|
||||
[33]: https://github.com/anchore/grype/issues/2471?utm_source=chatgpt.com "Support using VEX documents with directory scans and ..."
|
||||
[34]: https://docs.snyk.io/manage-risk/reporting?utm_source=chatgpt.com "Reporting | Snyk User Docs"
|
||||
[35]: https://docs.github.com/en/code-security/security-overview/filtering-alerts-in-security-overview?utm_source=chatgpt.com "Filtering alerts in security overview"
|
||||
[36]: https://www.aquasec.com/blog/container-vulnerability-management-best-practices/?utm_source=chatgpt.com "Cloud Native Security Best Practices: Vulnerability Management"
|
||||
[37]: https://docs.anchore.com/current/docs/sbom_management/?utm_source=chatgpt.com "SBOM Management"
|
||||
[38]: https://docs.snyk.io/snyk-api/using-specific-snyk-apis/issues-list-issues-for-a-package?utm_source=chatgpt.com "Issues: List issues for a package"
|
||||
[39]: https://trivy.dev/docs/latest/configuration/reporting/?utm_source=chatgpt.com "Reporting"
|
||||
[40]: https://pan.dev/prisma-cloud/api/cspm/vulnerabilities-search-api/?utm_source=chatgpt.com "Get Vulnerabilities by RQL | Develop with Palo Alto Networks"
|
||||
[41]: https://docs.anchore.com/current/docs/release_notes/enterprise/5220/?utm_source=chatgpt.com "Anchore Enterprise Release Notes - Version 5.22.0"
|
||||
[42]: https://docs.snyk.io/manage-risk/reporting/available-snyk-reports?utm_source=chatgpt.com "Available Snyk reports | Snyk User Docs"
|
||||
[43]: https://docs.github.com/en/enterprise-cloud%40latest/rest/code-scanning/alert-dismissal-requests?utm_source=chatgpt.com "REST API endpoints for code scanning alert dismissal ..."
|
||||
[44]: https://updates.snyk.io/export-api-ga-release-321290/?utm_source=chatgpt.com "Export API GA Release"
|
||||
[45]: https://securityboulevard.com/2025/11/anchore-enterprise-5-23-cyclonedx-vex-and-vdr-support/?utm_source=chatgpt.com "Anchore Enterprise 5.23: CycloneDX VEX and VDR Support"
|
||||
[46]: https://docs.snyk.io/manage-risk/policies/the-.snyk-file?utm_source=chatgpt.com "The .snyk file | Snyk User Docs"
|
||||
|
||||
I’ll treat this as a concrete UX blueprint your .NET/Angular team can build against, centered on three pillars:
|
||||
|
||||
1. Evidence views (how a single finding “explains itself”)
|
||||
2. Suppression/VEX (how risk decisions are captured)
|
||||
3. Audit/export (how you prove those decisions later)
|
||||
|
||||
---
|
||||
|
||||
## 1. Design principles specific to StellaOps
|
||||
|
||||
1. **Graph-first:** Every view is anchored to a graph snapshot ID from your trust algebra / proof engine. Users always know “which build / which graph revision” they’re looking at.
|
||||
2. **Single suppression model:** One suppression semantics layer (VEX + policy) across code, SBOM, containers, and runtime.
|
||||
3. **Evidence before opinion:** Detail views always show raw evidence (paths, SBOM lines, runtime traces) before risk ratings, policies, or comments.
|
||||
4. **Audit-ready by default:** Any action that changes risk posture automatically leaves a machine-readable trail that can be exported.
|
||||
|
||||
---
|
||||
|
||||
## 2. Core information architecture
|
||||
|
||||
Primary entities in the UX (mirroring your backend):
|
||||
|
||||
* **Organization / Workspace**
|
||||
* **Application / Service**
|
||||
* **Artifact**
|
||||
|
||||
* Build (commit, tag, CI run)
|
||||
* Container image
|
||||
* Binary / package
|
||||
* SBOM document
|
||||
* **Scan Result**
|
||||
|
||||
* Scanner type (SAST, SCA, container, SBOM-only, IaC, runtime)
|
||||
* Graph snapshot ID
|
||||
* **Finding**
|
||||
|
||||
* Vulnerability (CVE, GHSA, etc.)
|
||||
* Misconfiguration / policy violation
|
||||
* Supply-chain anomaly
|
||||
* **Evidence**
|
||||
|
||||
* Code path(s)
|
||||
* Dependency path(s)
|
||||
* SBOM node(s)
|
||||
* Runtime event(s)
|
||||
* **VEX Statement**
|
||||
|
||||
* Status (`affected`, `not_affected`, `fixed`, `under_investigation`, etc.)
|
||||
* Justification (standardized + free text)
|
||||
* **Suppression Decision**
|
||||
|
||||
* “Suppressed by VEX”, “De-prioritized by policy”, “Won’t fix”, etc.
|
||||
* **Export Job / Proof Bundle**
|
||||
* **Audit Event**
|
||||
|
||||
* Who, what, when, against which graph snapshot
|
||||
|
||||
The UI should surface these without drowning the user in jargon: names can be friendlier but map cleanly to this model.
|
||||
|
||||
---
|
||||
|
||||
## 3. UX spec by primary flows
|
||||
|
||||
### 3.1 Landing: Inventory & posture overview
|
||||
|
||||
**Screen: “Inventory & Risk Overview”**
|
||||
|
||||
Purpose: Secure default entry point for security engineers and auditors.
|
||||
|
||||
Layout:
|
||||
|
||||
* **Header bar**
|
||||
|
||||
* Org selector
|
||||
* Global search (by application, artifact, CVE, VEX ID, SBOM component)
|
||||
* “Exports & Proofs” shortcut
|
||||
* User menu
|
||||
|
||||
* **Left nav (primary)**
|
||||
|
||||
* Inventory
|
||||
* Findings
|
||||
* VEX & Policies
|
||||
* Exports & Proofs
|
||||
* Settings
|
||||
|
||||
* **Main content: 3 panels**
|
||||
|
||||
1. **Applications list**
|
||||
|
||||
* Columns: Name, Owner, #Artifacts, Open findings, Suppressed findings, Last build, Risk score.
|
||||
* Row click → Application view.
|
||||
2. **Top risks**
|
||||
|
||||
* Cards: “Critical vulns”, “Unsigned artifacts”, “Unknown SBOM coverage”, each showing counts and a “View findings” link (pre-filtered).
|
||||
3. **Compliance viewpoint**
|
||||
|
||||
* Tabs: “Operational”, “Regulatory”, “Attestations”.
|
||||
* Simple status indicators per framework (e.g., SLSA level, NIST SSDF coverage) if you support that.
|
||||
|
||||
Micro-interactions:
|
||||
|
||||
* Clicking any numeric count (e.g., “12 suppressed”) opens a pre-filtered Findings list.
|
||||
* Hover tooltip on risk counts shows breakdown by source (SAST vs SBOM vs runtime).
|
||||
|
||||
---
|
||||
|
||||
### 3.2 Application & artifact detail: evidence-centric view
|
||||
|
||||
**Screen: “Application detail”**
|
||||
|
||||
Purpose: Navigate from high level risk to specific artifacts and findings.
|
||||
|
||||
Layout:
|
||||
|
||||
* Tabs: Overview | Artifacts | Findings | SBOM graph | History
|
||||
|
||||
**Overview tab:**
|
||||
|
||||
* Top: Application summary (owners, repos, deployment targets).
|
||||
* Middle: Tiles for “Latest build”, “Prod artifacts”, “SBOM coverage”.
|
||||
* Bottom: “Recent decisions” timeline (suppression, VEX updates, exports).
|
||||
|
||||
**Artifacts tab:**
|
||||
|
||||
* Table with:
|
||||
|
||||
* Artifact type (image, binary, SBOM-only)
|
||||
* Identifier (tag/digest, CI job ID)
|
||||
* Environment (dev, staging, prod)
|
||||
* Graph snapshot ID
|
||||
* Findings (open / suppressed chips)
|
||||
* Last scanned
|
||||
|
||||
Selecting a row opens **Artifact detail**.
|
||||
|
||||
---
|
||||
|
||||
### 3.3 Artifact detail & Finding details drawer
|
||||
|
||||
**Screen: “Artifact detail”**
|
||||
|
||||
Layout:
|
||||
|
||||
* Header:
|
||||
|
||||
* Artifact identity (name, version/tag, digest)
|
||||
* Environment badges
|
||||
* Graph snapshot ID with “Copy” control
|
||||
* Primary actions: “Download SBOM”, “Export proof bundle”
|
||||
|
||||
* Sub-tabs:
|
||||
|
||||
* Findings
|
||||
* Evidence graph
|
||||
* SBOM tree
|
||||
* History
|
||||
|
||||
**Findings sub-tab**
|
||||
|
||||
* Filters on left:
|
||||
|
||||
* Severity, status (Open / Suppressed / Only suppressed), source (SAST/SBOM/container/runtime), VEX status, CWE/CVE.
|
||||
* Table in center:
|
||||
|
||||
* Columns: Severity, Type, ID (CVE-XXXX-XXXX), Component/Code location, Status (Open/Suppressed), VEX status, Last updated.
|
||||
* Row click opens a **Finding details drawer** sliding from the right.
|
||||
|
||||
**Finding details drawer (core evidence UX)**
|
||||
|
||||
This is the primary place where “evidence explains itself.”
|
||||
|
||||
Structure:
|
||||
|
||||
1. **Header area**
|
||||
|
||||
* Title: “CVE-2023-XXXX in `openssl`”
|
||||
* Badges: severity, status (Open / Suppressed by VEX), VEX status (`not_affected`, `fixed`, etc.)
|
||||
* Scope indicator: where this finding appears (e.g., “1 artifact (this), 3 environments, 2 images”).
|
||||
|
||||
2. **Tabs within drawer**
|
||||
|
||||
* **Evidence** (default)
|
||||
|
||||
* Section: “Where this comes from”
|
||||
|
||||
* Scanner source, scan timestamp, graph snapshot ID.
|
||||
* Section: “Code path” (for SAST)
|
||||
|
||||
* A vertical list of steps: `source` → `propagation` → `sink`.
|
||||
* Clicking a step shows code snippet with line highlighting.
|
||||
* “Open in Git” and “Open in IDE (deeplink)” actions.
|
||||
* Section: “Dependency path” (for SCA / SBOM)
|
||||
|
||||
* Path view: `app -> module -> transitive dependency -> vulnerable package`.
|
||||
* Option to switch between “tree view” and “collapsed chain”.
|
||||
* Section: “Runtime signals” (if available)
|
||||
|
||||
* Call-site frequency, exploit attempts, telemetry tags.
|
||||
|
||||
* **Impact & reach**
|
||||
|
||||
* A small graph panel: how many artifacts, environments, and applications share this finding.
|
||||
* Link: “View all affected artifacts” → filtered Findings view.
|
||||
|
||||
* **VEX & decisions**
|
||||
|
||||
* Shows current VEX statements attached:
|
||||
|
||||
* Table: Status, Justification (standardized), Source (vendor vs internal), Effective scope (artifact / app / org), Last changed by.
|
||||
* Shows local suppression decisions beyond VEX (e.g., “De-prioritized due to compensating controls”).
|
||||
* Primary action: “Update status / Add VEX decision”.
|
||||
|
||||
* **History**
|
||||
|
||||
* Timeline of events for this finding:
|
||||
|
||||
* Detected
|
||||
* VEX attached/updated
|
||||
* Suppression added/edited
|
||||
* Exported in bundles (with links)
|
||||
* Each item shows user, timestamp, and delta.
|
||||
|
||||
Micro-interactions:
|
||||
|
||||
* The drawer should support deep-linking: URL reflects `artifactId + findingId + snapshotId`.
|
||||
* Keyboard: `Esc` closes drawer, `←` / `→` cycles findings in the table.
|
||||
|
||||
---
|
||||
|
||||
## 4. Suppression & VEX UX
|
||||
|
||||
Goal: one consistent model across all scan types, anchored in VEX semantics.
|
||||
|
||||
### 4.1 “Update status / Add VEX decision” dialog
|
||||
|
||||
Entry points:
|
||||
|
||||
* From Finding details drawer > “VEX & decisions” tab > primary button.
|
||||
* Bulk selection from Findings table > “Update status”.
|
||||
|
||||
Dialog steps (single modal with progressive disclosure):
|
||||
|
||||
1. **Select decision type**
|
||||
|
||||
Radio options:
|
||||
|
||||
* “System is affected”
|
||||
|
||||
* Sub-options: `under_investigation`, `affected_no_fix_available`, `affected_fix_available`.
|
||||
* “System is *not* affected”
|
||||
|
||||
* Sub-options (justification): `vulnerable_code_not_present`, `vulnerable_code_not_in_execute_path`, `vulnerable_configuration_not_present`, `inline_mitigation_applied`, `other`.
|
||||
* “Fixed”
|
||||
|
||||
* Sub-options: `fixed_in_this_version`, `fixed_in_downstream`, `fixed_by_vendor`.
|
||||
* “Won’t fix / accepted risk”
|
||||
|
||||
* Sub-options: `business_acceptance`, `low_likelihood`, `temporary_exception`.
|
||||
|
||||
2. **Scope definition**
|
||||
|
||||
Checkboxes + selectors:
|
||||
|
||||
* Scope:
|
||||
|
||||
* [x] This artifact only
|
||||
* [ ] All artifacts of this application
|
||||
* [ ] All artifacts in this org with the same component & version
|
||||
* For each, display a short estimate: “This will apply to 3 artifacts (click to preview).”
|
||||
|
||||
3. **Metadata**
|
||||
|
||||
* Required:
|
||||
|
||||
* Justification category (if not chosen above).
|
||||
* Free-text “Reason / supporting evidence” (min length e.g., 20 characters).
|
||||
* Optional:
|
||||
|
||||
* Expiry date (for temporary exceptions).
|
||||
* Link to ticket / document (URL).
|
||||
* Attach external VEX file ID or reference (if you’ve ingested vendor VEX).
|
||||
|
||||
4. **Output preview**
|
||||
|
||||
A read-only JSON-like preview of the VEX statement(s) to be generated, with a friendly label: “These statements will be added to the proof graph for snapshot XYZ.”
|
||||
This makes the model transparent to power users.
|
||||
|
||||
On submit:
|
||||
|
||||
* Show a small toast: “Status updated · VEX statement anchored to snapshot [ID] · Undo” (undo limited to a short window).
|
||||
* The Finding row and drawer update immediately (status badges, history timeline).
|
||||
|
||||
### 4.2 Bulk suppression & policy overlay
|
||||
|
||||
**Screen: “VEX & Policies”**
|
||||
|
||||
Tabs:
|
||||
|
||||
1. **VEX statements**
|
||||
|
||||
* Table: VEX ID, CVE/ID, Status, Scope, Created by, Last updated, Source (vendor/internal).
|
||||
* Filters: status, scope, target (component, application, artifact).
|
||||
* Bulk actions: Export VEX (OpenVEX / CycloneDX VEX), disable / supersede.
|
||||
|
||||
2. **Policies**
|
||||
|
||||
* Declarative rules like: “Treat `vulnerable_code_not_present` from vendor X as authoritative” or “Do not auto-suppress based on `inline_mitigation_applied` without internal confirmation.”
|
||||
* This expresses how raw VEX translates into “suppressed” vs “needs review” in the UI.
|
||||
|
||||
UX pattern:
|
||||
|
||||
* Each VEX row includes a small indicator: `S` (suppresses findings under current policy) or `R` (requires review).
|
||||
* Clicking a row opens a side drawer with:
|
||||
|
||||
* Statements content (normalized).
|
||||
* Affected findings count.
|
||||
* Policy evaluation result (“This statement currently suppresses 47 findings”).
|
||||
|
||||
---
|
||||
|
||||
## 5. Findings list: global “inbox” for risk
|
||||
|
||||
**Screen: “Findings”**
|
||||
|
||||
This is the cross-application queue, similar to Snyk’s project list + GitHub’s security tab, but with VEX semantics.
|
||||
|
||||
Layout:
|
||||
|
||||
* Filters on the left:
|
||||
|
||||
* Application / artifact
|
||||
* Severity
|
||||
* Status (Open / Suppressed / Only suppressed / Needs review)
|
||||
* VEX status
|
||||
* Source (SAST, SBOM, container, runtime)
|
||||
* Table in center:
|
||||
|
||||
* Columns: Severity, ID, Application, Artifact, Status, VEX status, “Decision owner” (user or team), Age.
|
||||
* Top bar:
|
||||
|
||||
* “Assign to…” for workflow
|
||||
* “Update status / Add VEX decision” for bulk
|
||||
* “Export current view” (CSV/JSON)
|
||||
|
||||
Micro-interactions:
|
||||
|
||||
* “Status” column clearly distinguishes:
|
||||
|
||||
* Open (no VEX)
|
||||
* Open (VEX says `affected`)
|
||||
* Suppressed (VEX says `not_affected` / `fixed`)
|
||||
* Suppressed (policy exception: “Won’t fix”)
|
||||
* Hover on “Suppressed” shows a tooltip with the justification and who made the decision.
|
||||
|
||||
---
|
||||
|
||||
## 6. Audit & export / Proof bundles
|
||||
|
||||
### 6.1 Exports list
|
||||
|
||||
**Screen: “Exports & Proofs”**
|
||||
|
||||
Purpose: centralized, auditable place for generating and revisiting proofs.
|
||||
|
||||
Layout:
|
||||
|
||||
* Top actions:
|
||||
|
||||
* “New export / proof bundle”
|
||||
* Filters: type (CSV, JSON, SBOM, VEX, composite bundle), created by, status.
|
||||
|
||||
* Table:
|
||||
|
||||
* Name / description
|
||||
* Type (e.g., “OpenVEX for app ‘payments’”, “Proof bundle for prod rollout 2025-03-01”)
|
||||
* Scope (org / app / artifact / snapshot range)
|
||||
* Includes suppressed? (Yes/No)
|
||||
* Status (Complete / Failed)
|
||||
* Created by, Created at
|
||||
* Download button
|
||||
|
||||
### 6.2 “New export / proof bundle” flow
|
||||
|
||||
1. **What do you need?**
|
||||
|
||||
Choices:
|
||||
|
||||
* SBOM export (CycloneDX/SPDX)
|
||||
* VEX export (OpenVEX / CycloneDX VEX)
|
||||
* Findings export (CSV / JSON)
|
||||
* Proof bundle (zip containing SBOM + VEX + findings + manifest)
|
||||
|
||||
2. **Scope**
|
||||
|
||||
* Radio:
|
||||
|
||||
* A single artifact (picker)
|
||||
* All artifacts of an application (picker)
|
||||
* Entire org, limited by:
|
||||
|
||||
* Time window (from..to)
|
||||
* Environments (prod only / all)
|
||||
* Optional: choose graph snapshot(s) (latest vs explicit ID).
|
||||
|
||||
3. **Options**
|
||||
|
||||
* Include suppressed findings:
|
||||
|
||||
* [x] Yes, include them, with reasons
|
||||
* [ ] No, only unresolved
|
||||
* Mask sensitive fields? (e.g., repository URLs)
|
||||
* Include audit log excerpt:
|
||||
|
||||
* [x] VEX & suppression decisions
|
||||
* [ ] All user actions
|
||||
|
||||
4. **Review & create**
|
||||
|
||||
* Show a summary:
|
||||
|
||||
* N artifacts, M findings, K VEX statements.
|
||||
* Button: “Create export”.
|
||||
|
||||
Once complete:
|
||||
|
||||
* Row in the table is updated with a download button.
|
||||
* Clicking a row opens an **Export detail drawer**:
|
||||
|
||||
* Manifest preview (JSON-like).
|
||||
* Link to the associated graph snapshot IDs.
|
||||
* Embedded notice that “Regulators can verify this bundle by validating manifest signature and graph snapshot hash” (if you sign them).
|
||||
|
||||
Micro-interaction:
|
||||
|
||||
* For artifacts and applications, the Artifact detail and Application detail pages should have contextual buttons:
|
||||
|
||||
* “Export SBOM”
|
||||
* “Export VEX”
|
||||
* “Download proof bundle”
|
||||
|
||||
These open the same export dialog pre-populated with the relevant scope.
|
||||
|
||||
---
|
||||
|
||||
## 7. History & audit trail UX
|
||||
|
||||
Audit must be first-class, not buried.
|
||||
|
||||
**Pattern: Timeline component**
|
||||
|
||||
Used in:
|
||||
|
||||
* Application > History
|
||||
* Artifact > History
|
||||
* Finding > History
|
||||
* VEX statement > History
|
||||
* Export > Details
|
||||
|
||||
Timeline item shape:
|
||||
|
||||
* Icon (type of action: scan, decision, export)
|
||||
* Title (short, human readable)
|
||||
* Metadata:
|
||||
|
||||
* User
|
||||
* Timestamp
|
||||
* Graph snapshot ID
|
||||
* Detail:
|
||||
|
||||
* Before/after summary (e.g., “VEX status: `affected` → `not_affected`”)
|
||||
|
||||
Filters:
|
||||
|
||||
* By actor (user / system)
|
||||
* By action type (scan, VEX change, suppression, export, policy change)
|
||||
* By time range
|
||||
|
||||
Long-term: this timeline can become your “forensic report” generator.
|
||||
|
||||
---
|
||||
|
||||
## 8. Role-based slices
|
||||
|
||||
You can keep a single UX codebase but offer different “home” experiences per role.
|
||||
|
||||
1. **Security engineer**
|
||||
|
||||
* Default landing: “Findings” with open & needs-review filters.
|
||||
* Emphasis on Evidence & VEX decisions.
|
||||
* Quick actions: create VEX, adjust policies.
|
||||
|
||||
2. **Developer**
|
||||
|
||||
* Default landing: “My assignments” (subset of Findings where they’re the owner).
|
||||
* Simplified VEX dialog:
|
||||
|
||||
* Emphasis on “Fixed in commit X” and “Provide more evidence” rather than full-blown VEX authoring.
|
||||
* Tight links to repo/IDE.
|
||||
|
||||
3. **Auditor / Compliance**
|
||||
|
||||
* Default landing: “Exports & Proofs”.
|
||||
* Views oriented around applications and time windows, not individual findings.
|
||||
* Read-only access to VEX & policies; can request evidence rather than editing it.
|
||||
|
||||
Role behavior is enforced by RBAC, but the UX is guided by ship-ready presets.
|
||||
|
||||
---
|
||||
|
||||
## 9. Implementation checklist for your .NET/Angular team
|
||||
|
||||
To make this action-ready:
|
||||
|
||||
1. **Routes / pages**
|
||||
|
||||
* `/inventory`
|
||||
* `/applications/:appId`
|
||||
* `/artifacts/:artifactId`
|
||||
* `/findings`
|
||||
* `/vex`
|
||||
* `/exports`
|
||||
* `/settings`
|
||||
|
||||
2. **Core reusable components**
|
||||
|
||||
* Graph snapshot badge (with copy & deeplink).
|
||||
* Findings table (configurable columns, selection).
|
||||
* Finding details drawer (tabs: Evidence / Impact / VEX & decisions / History).
|
||||
* VEX status badge.
|
||||
* Timeline component.
|
||||
* Export job dialog & list.
|
||||
|
||||
3. **API contracts to align with UX**
|
||||
|
||||
* `GET /artifacts/:id/findings?snapshot=...`
|
||||
* `GET /findings/:id?includeEvidence=true`
|
||||
* `POST /vex/statements` (supports scoped statements).
|
||||
* `GET /vex/statements?filters...`
|
||||
* `POST /exports` + `GET /exports/:id`
|
||||
* `GET /audit?scopeType=&scopeId=&range=...`
|
||||
|
||||
4. **Deep-linking**
|
||||
|
||||
* URLs should embed at least `snapshotId` for deterministic views:
|
||||
|
||||
* `/artifacts/:artifactId/findings/:findingId?snapshot=:snapshotId`
|
||||
|
||||
5. **Telemetry for UX refinement**
|
||||
|
||||
* Track frequency of:
|
||||
|
||||
* Evidence tab switches (Code vs Dependency vs Runtime).
|
||||
* VEX edits per finding.
|
||||
* Export jobs by type.
|
||||
* Use this to prioritize which evidence views to optimize first.
|
||||
|
||||
---
|
||||
|
||||
If you want a next step, I can translate this into:
|
||||
|
||||
* A low-fidelity screen map (per route, per component), or
|
||||
* An example JSON schema for VEX statements + proof bundles that matches the UI’s expectations,
|
||||
|
||||
so your backend and frontend teams can converge on a single contract.
|
||||
@@ -0,0 +1,722 @@
|
||||
I thought you might appreciate a quick reality-check of public evidence backing up five concrete test cases you could drop into the StellaOps acceptance suite **today** — each rooted in a real issue or behavior in the ecosystem.
|
||||
|
||||
---
|
||||
|
||||
## 🔎 Recent public incidents & tests matching your list
|
||||
|
||||
### • Credential-leak via Grype JSON output
|
||||
|
||||
* CVE-2025-65965 / GHSA-6gxw-85q2-q646 allows registry credentials to be written unsanitized into `--output json=…`. ([GitHub][1])
|
||||
* Affects grype 0.68.0–0.104.0; patched in 0.104.1. ([GitHub][2])
|
||||
* Workaround: avoid JSON file output or upgrade. ([GitHub][1])
|
||||
|
||||
**Implication for StellaOps**: run Grype with credentials + JSON output + scan the JSON for secrets; the test catches the leak.
|
||||
|
||||
---
|
||||
|
||||
### • Air-gap / old DB schema issues with Trivy
|
||||
|
||||
* `--skip-db-update` supports offline mode. ([Trivy][3])
|
||||
* Using an old/offline DB with mismatched schema errors out instead of falling back. ([GitHub][4])
|
||||
|
||||
**Implication**: capture that deterministic failure (old DB + skip update) or document the exit code as part of offline gating.
|
||||
|
||||
---
|
||||
|
||||
### • SBOM mismatch between native binary vs container builds (Syft + friends)
|
||||
|
||||
* Mixing SBOM sources (Syft vs Trivy) yields wildly different vulnerability counts when fed into Grype. ([GitHub][5])
|
||||
|
||||
**Implication**: compare SBOMs from native builds and containers for the same artifact (digests, component counts) to detect provenance divergence.
|
||||
|
||||
---
|
||||
|
||||
### • Inconsistent vulnerability detection across Grype versions
|
||||
|
||||
* The same SBOM under Grype v0.87.0 reported multiple critical+high findings; newer versions reported none. ([GitHub][6])
|
||||
|
||||
**Implication**: ingest a stable SBOM/VEX set under multiple DB/scanner versions to detect regressions or nondeterministic outputs.
|
||||
|
||||
---
|
||||
|
||||
## ✅ Publicly verified vs speculative
|
||||
|
||||
| ✅ Publicly verified | ⚠️ Needs controlled testing / assumption-driven |
|
||||
| ------------------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Credential leak in Grype JSON output (CVE-2025-65965) ([GitHub][2]) | Exact SBOM-digest parity divergence between native & container Syft runs (no formal bug yet) |
|
||||
| Trivy offline DB schema error ([Trivy][3]) | Custom CVSS/VEX sorting in patched grype-dbs or Snyk workarounds (not publicly reproducible) |
|
||||
| Grype version divergence on the same SBOM ([GitHub][6]) | VEX evidence mappings from tools like Snyk - plausible but not documented reproducibly |
|
||||
|
||||
---
|
||||
|
||||
## 🎯 Why this matters for StellaOps
|
||||
|
||||
Your goals are deterministic, audit-ready SBOM + VEX pipelines. These public incidents show how fragile tooling can be. Embedding the above tests ensures reliability and reproducibility even under credential leaks, offline scans, or DB/schema churn.
|
||||
|
||||
Want a bash/pseudo spec for all five cases (commands + assertions)? I can drop it into your repo as a starting point.
|
||||
|
||||
[1]: https://github.com/anchore/grype/security/advisories/GHSA-6gxw-85q2-q646?utm_source=chatgpt.com "Credential disclosure vulnerability in Grype JSON output"
|
||||
[2]: https://github.com/advisories/GHSA-6gxw-85q2-q646?utm_source=chatgpt.com "Grype has a credential disclosure vulnerability in its JSON ..."
|
||||
[3]: https://trivy.dev/docs/v0.55/guide/advanced/air-gap/?utm_source=chatgpt.com "Advanced Network Scenarios"
|
||||
[4]: https://github.com/aquasecurity/trivy/discussions/4838?utm_source=chatgpt.com "trivy offline-db · aquasecurity trivy · Discussion #4838"
|
||||
[5]: https://github.com/aquasecurity/trivy/discussions/6325?utm_source=chatgpt.com "and of those detected Trivy sometimes does not report a ..."
|
||||
[6]: https://github.com/anchore/grype/issues/2628?utm_source=chatgpt.com "Grype false negatives in versions v0.88.0 and later leading ..."
|
||||
|
||||
Here’s a concrete package of **guidelines + five acceptance test specs** for StellaOps implementors, based on the incidents and behaviors we walked through (Grype leak, Trivy offline DB, Syft parity, grype-db / VEX, Snyk exploit maturity).
|
||||
|
||||
I’ll keep it tool/framework‑agnostic so you can drop this into whatever test runner you’re using.
|
||||
|
||||
---
|
||||
|
||||
## 1. Implementation guidelines for StellaOps integrators
|
||||
|
||||
These are the “rules of the road” that every new scanner / SBOM / VEX adapter in StellaOps should follow.
|
||||
|
||||
### 1.1. Test layering
|
||||
|
||||
For each external tool (Grype, Trivy, Syft, Snyk, …) you should have:
|
||||
|
||||
1. **Unit tests**
|
||||
|
||||
* Validate argument construction, environment variables, and parsing of raw tool output.
|
||||
2. **Adapter integration tests**
|
||||
|
||||
* Run the real tool (or a pinned container image) on small deterministic fixtures.
|
||||
3. **Acceptance tests (this doc)**
|
||||
|
||||
* Cross-tool workflows and critical invariants: secrets, determinism, offline behavior, VEX mapping.
|
||||
4. **Golden outputs**
|
||||
|
||||
* For key paths, store canonical JSON/CSAF/CycloneDX outputs as fixtures and diff against them.
|
||||
|
||||
Each new adapter should add at least one test in each layer.
|
||||
|
||||
---
|
||||
|
||||
### 1.2. Determinism & reproducibility
|
||||
|
||||
**Rule:** *Same inputs (artifact, SBOM, VEX, tool versions) → bit‑for‑bit identical StellaOps results.*
|
||||
|
||||
Guidelines:
|
||||
|
||||
* Pin external tool versions in tests (`GRYPE_VERSION`, `TRIVY_VERSION`, `SYFT_VERSION`, `SNYK_CLI_VERSION`).
|
||||
* Pin vulnerability DB snapshots (e.g. `GRYPE_DB_SNAPSHOT_ID`, `TRIVY_DB_DIR`).
|
||||
* Persist the “scan context” alongside results: scanner version, db snapshot id, SBOM hash, VEX hash.
|
||||
* For sorted outputs, define and test a **stable global sort order**:
|
||||
|
||||
* e.g. `effectiveSeverity DESC, exploitEvidence DESC, vulnerabilityId ASC`.
|
||||
|
||||
---
|
||||
|
||||
### 1.3. Secrets and logs
|
||||
|
||||
Recent issues show scanners can leak sensitive data to JSON or logs:
|
||||
|
||||
* **Grype**: versions v0.68.0–v0.104.0 could embed registry credentials in JSON output files when invoked with `--file` or `--output json=<file>` and credentials are configured. ([GitLab Advisory Database][1])
|
||||
* **Trivy / Snyk**: both have had edge cases where DB/CLI errors or debug logs printed sensitive info. ([Trivy][2])
|
||||
|
||||
Guidelines:
|
||||
|
||||
* **Never** enable DEBUG/TRACE logging for third‑party tools in production mode.
|
||||
* **Never** use scanner options that write JSON reports directly to disk unless you control the path and sanitize.
|
||||
* Treat logs and raw reports as **untrusted**: run them through secret‑scanning / redaction before persistence.
|
||||
* Build tests that use **fake-but-realistic secrets** (e.g. `stella_USER_123`, `stella_PASS_456`) and assert they never appear in:
|
||||
|
||||
* DB rows
|
||||
* API responses
|
||||
* UI
|
||||
* Stored raw reports
|
||||
|
||||
---
|
||||
|
||||
### 1.4. Offline / air‑gapped behavior
|
||||
|
||||
Trivy’s offline mode is a good example of fragile behavior:
|
||||
|
||||
* Using an old offline DB with `--skip-db-update` can produce fatal “old schema” errors like
|
||||
`The local DB has an old schema version… --skip-update cannot be specified with the old DB schema`. ([GitHub][3])
|
||||
* Air‑gap workflows require explicit flags like `--skip-db-update` and `--skip-java-db-update`. ([aquasecurity.github.io][4])
|
||||
|
||||
Guidelines:
|
||||
|
||||
* All scanner adapters must have an **explicit offline mode** flag / config.
|
||||
* In offline mode:
|
||||
|
||||
* Do **not** attempt any network DB updates.
|
||||
* Treat **DB schema mismatch / “old DB schema”** as a *hard* scanner infrastructure error, *not* “zero vulns”.
|
||||
* Surface offline issues as **typed StellaOps errors**, e.g. `ScannerDatabaseOutOfDate`, `ScannerFirstRunNoDB`.
|
||||
|
||||
---
|
||||
|
||||
### 1.5. External metadata → internal model
|
||||
|
||||
Different tools carry different metadata:
|
||||
|
||||
* CVSS v2/v3/v3.1/v4.0 (score & vectors).
|
||||
* GHSA vs CVE vs SNYK‑IDs.
|
||||
* Snyk’s `exploitMaturity` field (e.g. `no-known-exploit`, `proof-of-concept`, `mature`, `no-data`). ([Postman][5])
|
||||
|
||||
Guidelines:
|
||||
|
||||
* Normalize all of these into **one internal vulnerability model**:
|
||||
|
||||
* `primaryId` (CVE, GHSA, Snyk ID, etc.)
|
||||
* `aliases[]`
|
||||
* `cvss[]` (list of metrics with `version`, `baseScore`, `baseSeverity`)
|
||||
* `exploitEvidence` (internal enum derived from `exploitMaturity`, EPSS, etc.)
|
||||
* Define **deterministic merge rules** when multiple sources describe the same vuln (CVE+GHSA+SNYK).
|
||||
|
||||
---
|
||||
|
||||
### 1.6. Contract & fixture hygiene
|
||||
|
||||
* Prefer **static fixtures** over dynamic network calls in tests.
|
||||
* Version every fixture with a semantic name and version, e.g.
|
||||
`fixtures/grype/2025-credential-leak-v1.json`.
|
||||
* When you change parsers or normalizers, add a new version of the fixture, but **keep the old one** to guard regressions.
|
||||
|
||||
---
|
||||
|
||||
## 2. Acceptance test specs (for implementors)
|
||||
|
||||
Below are five concrete test cases you can add to a `tests/acceptance/` suite.
|
||||
|
||||
I’ll name them `STELLA-ACC-00X` so you can turn them into tickets if you want.
|
||||
|
||||
---
|
||||
|
||||
### STELLA-ACC-001 — Grype JSON credential leak guard
|
||||
|
||||
**Goal**
|
||||
Guarantee that StellaOps never stores or exposes registry credentials even if:
|
||||
|
||||
* Grype itself is (or becomes) vulnerable, or
|
||||
* A user uploads a raw Grype JSON report that contains creds.
|
||||
|
||||
This is directly motivated by CVE‑2025‑65965 / GHSA‑6gxw‑85q2‑q646. ([GitLab Advisory Database][1])
|
||||
|
||||
---
|
||||
|
||||
#### 001A – Adapter CLI usage (no unsafe flags)
|
||||
|
||||
**Invariant**
|
||||
|
||||
> The Grype adapter must *never* use `--file` or `--output json=<file>` — only `--output json` to stdout.
|
||||
|
||||
**Setup**
|
||||
|
||||
* Replace `grype` in PATH with a small wrapper script that:
|
||||
|
||||
* Records argv and env to a temp file.
|
||||
* Exits 0 after printing a minimal fake JSON vulnerability report to stdout.
|
||||
|
||||
**Steps**
|
||||
|
||||
1. Run a standard StellaOps Grype‑based scan through the adapter on a dummy image/SBOM.
|
||||
2. After completion, read the temp “spy” file written by the wrapper.
|
||||
|
||||
**Assertions**
|
||||
|
||||
* The recorded arguments **do not** contain:
|
||||
|
||||
* `--file`
|
||||
* `--output json=`
|
||||
* There is exactly one `--output` argument and its value is `json`.
|
||||
|
||||
> This test is purely about **command construction**; it never calls the real Grype binary.
|
||||
|
||||
---
|
||||
|
||||
#### 001B – Ingestion of JSON with embedded creds
|
||||
|
||||
**Invariant**
|
||||
|
||||
> If a Grype JSON report contains credentials, StellaOps must either reject it or scrub credentials before storage/exposure.
|
||||
|
||||
**Fixture**
|
||||
|
||||
* `fixtures/grype/credential-leak.json`, modeled roughly like the CVE report:
|
||||
|
||||
* Include a fake Docker config snippet Grype might accidentally embed, e.g.:
|
||||
|
||||
```json
|
||||
{
|
||||
"config": {
|
||||
"auths": {
|
||||
"registry.example.com": {
|
||||
"username": "stella_USER_123",
|
||||
"password": "stella_PASS_456"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* Plus one small vulnerability record so the ingestion pipeline runs normally.
|
||||
|
||||
**Steps**
|
||||
|
||||
1. Use a test helper to ingest the fixture as if it were Grype output:
|
||||
|
||||
* e.g. `stellaIngestGrypeReport("credential-leak.json")`.
|
||||
2. Fetch the stored scan result via:
|
||||
|
||||
* direct DB access, or
|
||||
* StellaOps internal API.
|
||||
|
||||
**Assertions**
|
||||
|
||||
* Nowhere in:
|
||||
|
||||
* stored raw report blobs,
|
||||
* normalized vulnerability records,
|
||||
* metadata tables,
|
||||
* logs captured by the test runner,
|
||||
|
||||
should the substrings `stella_USER_123` or `stella_PASS_456` appear.
|
||||
* The ingestion should:
|
||||
|
||||
* either succeed and **omit/sanitize** the auth section,
|
||||
* or fail with a **clear, typed error** like `ReportContainsSensitiveSecrets`.
|
||||
|
||||
**Implementation guidelines**
|
||||
|
||||
* Implement a **secret scrubber** that runs on:
|
||||
|
||||
* any external JSON you store,
|
||||
* any logs when a scanner fails verbosely.
|
||||
* Add a generic helper assertion in your test framework:
|
||||
|
||||
* `assertNoSecrets(ScanResult, ["stella_USER_123", "stella_PASS_456"])`.
|
||||
|
||||
---
|
||||
|
||||
### STELLA-ACC-002 — Syft SBOM manifest digest parity (native vs container)
|
||||
|
||||
**Goal**
|
||||
Ensure StellaOps produces the same **artifact identity** (image digest / manifest digest / tags) when SBOMs are generated:
|
||||
|
||||
* By Syft installed natively on the host vs
|
||||
* By Syft run as a container image.
|
||||
|
||||
This is about keeping VEX, rescan, and historical analysis aligned even if environments differ.
|
||||
|
||||
---
|
||||
|
||||
#### Setup
|
||||
|
||||
1. Build a small deterministic test image:
|
||||
|
||||
```bash
|
||||
docker build -t stella/parity-image:1.0 tests/fixtures/images/parity-image
|
||||
```
|
||||
|
||||
2. Make both Syft variants available:
|
||||
|
||||
* Native binary: `syft` on PATH.
|
||||
* Container image: `anchore/syft:<pinned-version>` already pulled into your local registry/cache.
|
||||
|
||||
3. Decide where you store canonical SBOMs in the pipeline, e.g. under `Scan.artifactIdentity`.
|
||||
|
||||
---
|
||||
|
||||
#### Steps
|
||||
|
||||
1. **Generate SBOM with native Syft**
|
||||
|
||||
```bash
|
||||
syft packages --scope Squashed stella/parity-image:1.0 -o json > sbom-native.json
|
||||
```
|
||||
|
||||
2. **Generate SBOM with containerized Syft**
|
||||
|
||||
```bash
|
||||
docker run --rm \
|
||||
-v /var/run/docker.sock:/var/run/docker.sock \
|
||||
anchore/syft:<pinned-version> \
|
||||
packages --scope Squashed stella/parity-image:1.0 -o json \
|
||||
> sbom-container.json
|
||||
```
|
||||
|
||||
3. Import each SBOM into StellaOps as if they were separate scans:
|
||||
|
||||
* `scanNative = stellaIngestSBOM("sbom-native.json")`
|
||||
* `scanContainer = stellaIngestSBOM("sbom-container.json")`
|
||||
|
||||
4. Extract the normalized artifact identity:
|
||||
|
||||
* `scanNative.artifactId`
|
||||
* `scanNative.imageDigest`
|
||||
* `scanNative.manifestDigest`
|
||||
* `scanContainer.*` same fields.
|
||||
|
||||
---
|
||||
|
||||
#### Assertions
|
||||
|
||||
* `scanNative.artifactId == scanContainer.artifactId`
|
||||
* `scanNative.imageDigest == scanContainer.imageDigest`
|
||||
* If you track manifest digest separately:
|
||||
`scanNative.manifestDigest == scanContainer.manifestDigest`
|
||||
* Optional: for extra paranoia, assert that the **set of package coordinates** is identical (ignoring ordering).
|
||||
|
||||
**Implementation guidelines**
|
||||
|
||||
* Don’t trust SBOM metadata blindly; if Syft metadata differs, compute a **canonical image ID** using:
|
||||
|
||||
* container runtime inspect,
|
||||
* or an independent digest calculator.
|
||||
* Store artifact IDs in a **single, normalized format** across all scanners and SBOM sources.
|
||||
|
||||
---
|
||||
|
||||
### STELLA-ACC-003 — Trivy air‑gapped DB schema / skip behavior
|
||||
|
||||
**Goal**
|
||||
In offline mode, Trivy DB schema mismatches must produce a clear, typed failure in StellaOps — never silently “0 vulns”.
|
||||
|
||||
Trivy shows specific messages for old DB schema when combined with `--skip-update/--skip-db-update`. ([GitHub][3])
|
||||
|
||||
---
|
||||
|
||||
#### Fixtures
|
||||
|
||||
1. `tests/fixtures/trivy/db-old/`
|
||||
|
||||
* A Trivy DB with `metadata.json` `Version: 1` where your pinned Trivy version expects `Version: 2` or greater.
|
||||
* You can:
|
||||
|
||||
* download an old offline DB archive, or
|
||||
* copy a modern DB and manually set `"Version": 1` in `metadata.json` for test purposes.
|
||||
2. `tests/fixtures/trivy/db-new/`
|
||||
|
||||
* A DB snapshot matching the current Trivy version (pass case).
|
||||
|
||||
---
|
||||
|
||||
#### 003A – Old schema + `--skip-db-update` gives typed error
|
||||
|
||||
**Steps**
|
||||
|
||||
1. Configure the Trivy adapter for offline scan:
|
||||
|
||||
* `TRIVY_CACHE_DIR = tests/fixtures/trivy/db-old`
|
||||
* Add `--skip-db-update` (or `--skip-update` depending on your adapter) to the CLI args.
|
||||
|
||||
2. Run a StellaOps scan using Trivy on a small test image.
|
||||
|
||||
3. Capture:
|
||||
|
||||
* Trivy exit code.
|
||||
* Stdout/stderr.
|
||||
* StellaOps internal `ScanRun` / job status.
|
||||
|
||||
**Assertions**
|
||||
|
||||
* Trivy exits non‑zero.
|
||||
* Stderr contains both:
|
||||
|
||||
* `"The local DB has an old schema version"` and
|
||||
* `"--skip-update cannot be specified with the old DB schema"` (or localized equivalent). ([GitHub][3])
|
||||
* StellaOps marks the scan as **failed with error type** `ScannerDatabaseOutOfDate` (or equivalent internal enum).
|
||||
* **No** vulnerability records are saved for this run.
|
||||
|
||||
---
|
||||
|
||||
#### 003B – New schema + offline flags succeeds
|
||||
|
||||
**Steps**
|
||||
|
||||
1. Same as above, but:
|
||||
|
||||
* `TRIVY_CACHE_DIR = tests/fixtures/trivy/db-new`
|
||||
|
||||
2. Run the scan.
|
||||
|
||||
**Assertions**
|
||||
|
||||
* Scan succeeds.
|
||||
* A non‑empty set of vulnerabilities is stored (assuming the fixture image is intentionally vulnerable).
|
||||
* Scan metadata records:
|
||||
|
||||
* `offlineMode = true`
|
||||
* `dbSnapshotId` or a hash of `metadata.json`.
|
||||
|
||||
**Implementation guidelines**
|
||||
|
||||
* Parse known Trivy error strings into **structured error types** instead of treating all non‑zero exit codes alike.
|
||||
* Add a small helper in the adapter like:
|
||||
|
||||
```go
|
||||
func classifyTrivyError(stderr string, exitCode int) ScannerErrorType
|
||||
```
|
||||
|
||||
and unit test it with copies of real Trivy messages from docs/issues.
|
||||
|
||||
---
|
||||
|
||||
### STELLA-ACC-004 — grype‑db / CVSS & VEX sorting determinism
|
||||
|
||||
**Goal**
|
||||
Guarantee that StellaOps:
|
||||
|
||||
1. Merges and prioritizes CVSS metrics (v2/v3/v3.1/4.0) deterministically, and
|
||||
2. Produces a stable, reproducible vulnerability ordering after applying VEX.
|
||||
|
||||
This protects you from “randomly reshuffled” critical lists when DBs update or scanners add new metrics.
|
||||
|
||||
---
|
||||
|
||||
#### Fixture
|
||||
|
||||
`fixtures/grype/cvss-vex-sorting.json`:
|
||||
|
||||
* Single artifact with three vulnerabilities on the same package:
|
||||
|
||||
1. `CVE-2020-AAAA`
|
||||
|
||||
* CVSS v2: 7.5 (High)
|
||||
* CVSS v3.1: 5.0 (Medium)
|
||||
2. `CVE-2021-BBBB`
|
||||
|
||||
* CVSS v3.1: 8.0 (High)
|
||||
3. `GHSA-xxxx-yyyy-zzzz`
|
||||
|
||||
* Alias of `CVE-2021-BBBB` but only v2 score 5.0 (Medium)
|
||||
|
||||
* A companion VEX document (CycloneDX VEX or CSAF) that:
|
||||
|
||||
* Marks `CVE-2020-AAAA` as `not_affected` for the specific version.
|
||||
* Leaves `CVE-2021-BBBB` as `affected`.
|
||||
|
||||
You don’t need real IDs; you just need consistent internal expectations.
|
||||
|
||||
---
|
||||
|
||||
#### Steps
|
||||
|
||||
1. Ingest the Grype report and the VEX document together via StellaOps, producing `scanId`.
|
||||
|
||||
2. Fetch the normalized vulnerability list for that artifact:
|
||||
|
||||
* e.g. `GET /artifacts/{id}/vulnerabilities?scan={scanId}` or similar internal call.
|
||||
|
||||
3. Map it to a simplified view inside the test:
|
||||
|
||||
```json
|
||||
[
|
||||
{ "id": "CVE-2020-AAAA", "effectiveSeverity": "...", "status": "..."},
|
||||
{ "id": "CVE-2021-BBBB", "effectiveSeverity": "...", "status": "..."},
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### Assertions
|
||||
|
||||
* **Deduplication**:
|
||||
|
||||
* `GHSA-xxxx-yyyy-zzzz` is **merged** into the same logical vuln as `CVE-2021-BBBB` (i.e. appears once with aliases including both IDs).
|
||||
|
||||
* **CVSS selection**:
|
||||
|
||||
* For `CVE-2020-AAAA`, `effectiveSeverity` is based on:
|
||||
|
||||
* v3.1 over v2 if present, else highest base score.
|
||||
* For `CVE-2021-BBBB`, `effectiveSeverity` is “High” (from v3.1 8.0).
|
||||
|
||||
* **VEX impact**:
|
||||
|
||||
* `CVE-2020-AAAA` is marked as `NOT_AFFECTED` (or your internal equivalent) and should:
|
||||
|
||||
* either be excluded from the default list, or
|
||||
* appear but clearly flagged as `not_affected`.
|
||||
|
||||
* **Sorting**:
|
||||
|
||||
* The vulnerability list is ordered stably, e.g.:
|
||||
|
||||
1. `CVE-2021-BBBB` (High, affected)
|
||||
2. `CVE-2020-AAAA` (Medium, not_affected) — if you show not_affected entries.
|
||||
|
||||
* **Reproducibility**:
|
||||
|
||||
* Running the same test multiple times yields identical JSON for:
|
||||
|
||||
* the vulnerability list (after sorting),
|
||||
* the computed `effectiveSeverity` values.
|
||||
|
||||
**Implementation guidelines**
|
||||
|
||||
* Implement explicit merge logic for per‑vuln metrics:
|
||||
|
||||
```text
|
||||
1. Prefer CVSS v3.1 > 3.0 > 2.0 when computing effectiveSeverity.
|
||||
2. If multiple metrics of same version exist, pick highest baseScore.
|
||||
3. When multiple sources (NVD, GHSA, vendor) disagree on baseSeverity,
|
||||
define your precedence and test it.
|
||||
```
|
||||
|
||||
* Keep VEX application deterministic:
|
||||
|
||||
* apply VEX status before sorting,
|
||||
* optionally remove `not_affected` entries from the “default” list, but still store them.
|
||||
|
||||
---
|
||||
|
||||
### STELLA-ACC-005 — Snyk exploit‑maturity → VEX evidence mapping
|
||||
|
||||
**Goal**
|
||||
Map Snyk’s `exploitMaturity` metadata into a standardized StellaOps “exploit evidence” / VEX semantic and make this mapping deterministic and testable.
|
||||
|
||||
Snyk’s APIs and webhooks expose an `exploitMaturity` field (e.g. `no-known-exploit`, `proof-of-concept`, etc.). ([Postman][5])
|
||||
|
||||
---
|
||||
|
||||
#### Fixture
|
||||
|
||||
`fixtures/snyk/exploit-maturity.json`:
|
||||
|
||||
* Mimic a Snyk test/report response with at least four issues, one per value:
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"id": "SNYK-JS-AAA-1",
|
||||
"issueType": "vuln",
|
||||
"severity": "high",
|
||||
"issueData": {
|
||||
"exploitMaturity": "no-known-exploit",
|
||||
"cvssScore": 7.5
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "SNYK-JS-BBB-2",
|
||||
"issueData": {
|
||||
"exploitMaturity": "proof-of-concept",
|
||||
"cvssScore": 7.5
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "SNYK-JS-CCC-3",
|
||||
"issueData": {
|
||||
"exploitMaturity": "mature",
|
||||
"cvssScore": 5.0
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "SNYK-JS-DDD-4",
|
||||
"issueData": {
|
||||
"exploitMaturity": "no-data",
|
||||
"cvssScore": 9.0
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
(Names/IDs don’t matter; internal mapping does.)
|
||||
|
||||
---
|
||||
|
||||
#### Internal mapping (proposed)
|
||||
|
||||
Define a StellaOps enum, e.g. `ExploitEvidence`:
|
||||
|
||||
* `EXPLOIT_NONE` ← `no-known-exploit`
|
||||
* `EXPLOIT_POC` ← `proof-of-concept`
|
||||
* `EXPLOIT_WIDESPREAD` ← `mature`
|
||||
* `EXPLOIT_UNKNOWN` ← `no-data` or missing
|
||||
|
||||
And define how this influences risk (e.g. by factors or direct overrides).
|
||||
|
||||
---
|
||||
|
||||
#### Steps
|
||||
|
||||
1. Ingest the Snyk fixture as a Snyk scan for a dummy project/image.
|
||||
2. Fetch normalized vulnerabilities from StellaOps for that scan.
|
||||
|
||||
In the test, map each vuln to:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "SNYK-JS-AAA-1",
|
||||
"exploitEvidence": "...",
|
||||
"effectiveSeverity": "..."
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
#### Assertions
|
||||
|
||||
* Mapping:
|
||||
|
||||
* `SNYK-JS-AAA-1` → `exploitEvidence == EXPLOIT_NONE`
|
||||
* `SNYK-JS-BBB-2` → `exploitEvidence == EXPLOIT_POC`
|
||||
* `SNYK-JS-CCC-3` → `exploitEvidence == EXPLOIT_WIDESPREAD`
|
||||
* `SNYK-JS-DDD-4` → `exploitEvidence == EXPLOIT_UNKNOWN`
|
||||
|
||||
* Risk impact (example; adjust to your policy):
|
||||
|
||||
* For equal CVSS, rows with `EXPLOIT_WIDESPREAD` or `EXPLOIT_POC` must rank **above** `EXPLOIT_NONE` in any prioritized listing (e.g. patch queue).
|
||||
* A high CVSS (9.0) with `EXPLOIT_UNKNOWN` must not be treated as lower risk than a lower CVSS with `EXPLOIT_WIDESPREAD` unless your policy explicitly says so.
|
||||
|
||||
Your sorting rule might look like:
|
||||
|
||||
```text
|
||||
ORDER BY
|
||||
exploitEvidenceRank DESC, -- WIDESPREAD > POC > UNKNOWN > NONE
|
||||
cvssBaseScore DESC,
|
||||
vulnerabilityId ASC
|
||||
```
|
||||
|
||||
and the test should assert on the resulting order.
|
||||
|
||||
* Any Snyk issue missing `exploitMaturity` explicitly is treated as `EXPLOIT_UNKNOWN`, not silently defaulted to `EXPLOIT_NONE`.
|
||||
|
||||
**Implementation guidelines**
|
||||
|
||||
* Centralize the mapping in a single function and unit test it:
|
||||
|
||||
```ts
|
||||
function mapSnykExploitMaturity(value: string | null): ExploitEvidence
|
||||
```
|
||||
|
||||
* If you emit VEX (CycloneDX/CSAF) from StellaOps, propagate the internal `ExploitEvidence` into the appropriate field (e.g. as part of justification or additional evidence object) and add a small test that round‑trips this.
|
||||
|
||||
---
|
||||
|
||||
## 3. How to use this as an implementor checklist
|
||||
|
||||
When you add or modify StellaOps integrations, treat this as a living checklist:
|
||||
|
||||
1. **Touching Grype?**
|
||||
|
||||
* Ensure `STELLA-ACC-001` still passes.
|
||||
2. **Touching SBOM ingestion / artifact identity?**
|
||||
|
||||
* Run `STELLA-ACC-002`.
|
||||
3. **Touching Trivy adapter or offline mode?**
|
||||
|
||||
* Run `STELLA-ACC-003`.
|
||||
4. **Changing vulnerability normalization / severity logic?**
|
||||
|
||||
* Run `STELLA-ACC-004` and `STELLA-ACC-005`.
|
||||
5. **Adding a new scanner?**
|
||||
|
||||
* Clone these patterns:
|
||||
|
||||
* one **secret-leak** test,
|
||||
* one **offline / DB drift** test (if relevant),
|
||||
* one **identity parity** or **determinism** test,
|
||||
* one **metadata‑mapping** test (like exploit maturity).
|
||||
|
||||
If you want, next step I can help you translate these into a concrete test skeleton (e.g. Gherkin scenarios or Jest/Go test functions) for the language you’re using in StellaOps.
|
||||
|
||||
[1]: https://advisories.gitlab.com/pkg/golang/github.com/anchore/grype/CVE-2025-65965/?utm_source=chatgpt.com "Grype has a credential disclosure vulnerability in its JSON ..."
|
||||
[2]: https://trivy.dev/docs/latest/references/troubleshooting/?utm_source=chatgpt.com "Troubleshooting"
|
||||
[3]: https://github.com/aquasecurity/trivy-db/issues/186?utm_source=chatgpt.com "trivy-db latest Version has an old schema · Issue #186"
|
||||
[4]: https://aquasecurity.github.io/trivy/v0.37/docs/advanced/air-gap/?utm_source=chatgpt.com "Air-Gapped Environment"
|
||||
[5]: https://www.postman.com/api-evangelist/snyk/collection/mppgu5u/snyk-api?utm_source=chatgpt.com "Snyk API | Get Started"
|
||||
@@ -0,0 +1,328 @@
|
||||
Here’s a compact, diagram‑first blueprint that shows how to turn a CycloneDX SBOM into signed, replay‑safe proofs across DSSE/in‑toto, Rekor v2 (tile‑backed) receipts, and VEX—plus how to run this with the public instance or fully offline.
|
||||
|
||||
---
|
||||
|
||||
## 1) Mental model (one line per hop)
|
||||
|
||||
```
|
||||
[SBOM: CycloneDX JSON]
|
||||
└─(wrap as DSSE payload; predicate = CycloneDX)
|
||||
└─(optional: in‑toto statement for context)
|
||||
└─(sign → cosign/fulcio or your own CA)
|
||||
└─(log entry → Rekor v2 / tiles)
|
||||
└─(checkpoint + inclusion proof + receipt)
|
||||
└─(VEX attestation references SBOM/log)
|
||||
└─(Authority anchors/keys + policies)
|
||||
```
|
||||
|
||||
* **CycloneDX SBOM** is your canonical inventory. ([cyclonedx.org][1])
|
||||
* **DSSE** provides a minimal, standard signing envelope; in‑toto statements add supply‑chain context. ([JFrog][2])
|
||||
* **Rekor v2** stores a hash of your attestation in a **tile‑backed transparency log** and returns **checkpoint + inclusion proof** (small, verifiable). ([Sigstore Blog][3])
|
||||
* **VEX** conveys exploitability (e.g., “not affected”) and should reference the SBOM and, ideally, the Rekor receipt. ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 2) Exact capture points (what to store)
|
||||
|
||||
* **SBOM artifact**: `sbom.cdx.json` (canonicalized bytes + SHA256). ([cyclonedx.org][1])
|
||||
* **DSSE envelope** over SBOM (or in‑toto statement whose predicate is CycloneDX): keep the full JSON + signature. ([JFrog][2])
|
||||
* **Rekor v2 receipt**:
|
||||
|
||||
* **Checkpoint** (signed tree head)
|
||||
* **Inclusion proof** (audit path)
|
||||
* **Entry leaf hash / UUID**
|
||||
Persist these with your build to enable offline verification. ([Sigstore Blog][3])
|
||||
* **VEX attestation** (CycloneDX VEX): include references (by digest/URI) to the **SBOM** and the **Rekor entry/receipt** used for the SBOM attestation. ([cyclonedx.org][4])
|
||||
* **Authority anchors**: publish the verifying keys (or TUF‑root if using Sigstore public good), plus your policy describing accepted issuers and algorithms. ([Sigstore][5])
|
||||
|
||||
---
|
||||
|
||||
## 3) Field‑level linkage (IDs you’ll wire together)
|
||||
|
||||
* **`subject.digest`** in DSSE/in‑toto ↔ **SBOM SHA256**. ([OpenSSF][6])
|
||||
* **Rekor entry** ↔ **DSSE envelope digest** (leaf/UUID recorded in receipt). ([GitHub][7])
|
||||
* **VEX `affects` / `analysis`** entries ↔ **components in SBOM** (use purl/coordinates) and include **`evidence`/`justification`** with **Rekor proof URI**. ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 4) Verification flow (online or air‑gapped)
|
||||
|
||||
**Online (public good):**
|
||||
|
||||
1. Verify DSSE signature against accepted keys/issuers. ([Sigstore][5])
|
||||
2. Verify Rekor **checkpoint signature** and **inclusion proof** for the logged DSSE digest. ([Go Packages][8])
|
||||
3. Validate VEX against the same SBOM digest (and optionally that its own attestation is also logged). ([cyclonedx.org][4])
|
||||
|
||||
**Air‑gapped / sovereign:**
|
||||
|
||||
* Mirror/export **Rekor tiles + checkpoints** on a courier medium; keep receipts small by shipping only tiles covering the ranges you need.
|
||||
* Run **self‑hosted Rekor v2** or a **local tile cache**; verifiers check **checkpoint signatures** and **consistency proofs** exactly the same way. ([Sigstore Blog][3])
|
||||
|
||||
---
|
||||
|
||||
## 5) Public instance vs self‑hosted (decision notes)
|
||||
|
||||
* **Public**: zero‑ops, audited community infra; you still archive receipts with your releases. ([Sigstore][5])
|
||||
* **Self‑hosted Rekor v2 (tiles)**: cheaper/simpler than v1, tile export makes **offline kits** practical; publish your **root keys** as organization anchors. ([Sigstore Blog][3])
|
||||
|
||||
---
|
||||
|
||||
## 6) Minimal CLI recipe (illustrative)
|
||||
|
||||
* Generate SBOM → wrap → attest → log → emit receipt:
|
||||
|
||||
* Create CycloneDX JSON; compute digest. ([cyclonedx.org][1])
|
||||
* Create **DSSE** or **in‑toto** attestation for the SBOM; sign (cosign or your CA). ([JFrog][2])
|
||||
* Submit to **Rekor v2**; store **checkpoint + inclusion proof + UUID** with the build. ([Sigstore Blog][3])
|
||||
* Emit **VEX** referencing the SBOM digest **and** the Rekor entry (URI/UUID). ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
## 7) Developer guardrails (to keep proofs replay‑safe)
|
||||
|
||||
* **Canonical bytes only** (stable JSON ordering/whitespace) before hashing/signing. ([JFrog][2])
|
||||
* **Pin algorithms** (e.g., SHA‑256 + key types) in policy; reject drift. ([Sigstore][5])
|
||||
* **Always persist**: SBOM, DSSE envelope, Rekor receipt, VEX, and your **accepted‑keys manifest** with version. ([Sigstore Blog][3])
|
||||
* **Test offline**: verification must pass using only tiles + receipts you ship. ([Go Packages][9])
|
||||
|
||||
---
|
||||
|
||||
## 8) Optional niceties
|
||||
|
||||
* Gate deployments on “image must have **signed SBOM** (attestation)”. Sigstore Policy Controller example exists. ([Stackable Documentation][10])
|
||||
* Track CVE status via **CycloneDX VEX** in your UI (“affected/not affected” with evidence links to Rekor). ([cyclonedx.org][4])
|
||||
|
||||
---
|
||||
|
||||
If you want, I can turn this into a **Stella Ops** diagram + drop‑in `docs/blueprints/sbom‑to‑vex‑rekor.md` with exact JSON stubs for: DSSE envelope, in‑toto statement, Rekor receipt example, and a CycloneDX VEX snippet wired to the receipt.
|
||||
|
||||
[1]: https://cyclonedx.org/specification/overview/?utm_source=chatgpt.com "Specification Overview"
|
||||
[2]: https://jfrog.com/blog/introducing-dsse-attestation-online-decoder/?utm_source=chatgpt.com "Introducing the DSSE Attestation Online Decoder"
|
||||
[3]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[4]: https://cyclonedx.org/capabilities/vex/?utm_source=chatgpt.com "Vulnerability Exploitability eXchange (VEX)"
|
||||
[5]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
[6]: https://openssf.org/blog/2024/06/26/a-deep-dive-into-sbomit-and-attestations/?utm_source=chatgpt.com "A Deep Dive into SBOMit and Attestations"
|
||||
[7]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[8]: https://pkg.go.dev/github.com/sigstore/rekor-tiles/v2/pkg/verify?utm_source=chatgpt.com "verify package - github.com/sigstore/rekor-tiles/v2/pkg/verify"
|
||||
[9]: https://pkg.go.dev/github.com/sigstore/rekor-tiles?utm_source=chatgpt.com "rekor-tiles module - github.com/sigstore/rekor-tiles"
|
||||
[10]: https://docs.stackable.tech/home/stable/guides/viewing-and-verifying-sboms/?utm_source=chatgpt.com "Viewing and verifying SBOMs of the Stackable Data Platform"
|
||||
|
||||
These guidelines are meant for people implementing or extending Stella Ops: core maintainers, external contributors, plug-in authors, and teams wiring Stella Ops into CI/CD and offline environments. They sit under the published docs (SRS, architecture, release playbook, etc.) and try to translate those into a practical checklist. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
---
|
||||
|
||||
## 1. Anchor yourself in the canonical docs
|
||||
|
||||
Before writing code or designing a new module:
|
||||
|
||||
* **Treat the SRS as the contract.** Any feature must trace back to a requirement (or add a new one via ADR + docs). Don’t ship behavior that contradicts quota rules, SBOM formats, NFRs, or API shapes defined there. ([Gitea: Git with a cup of tea][1])
|
||||
* **Respect the existing architecture split**: backend API, CLI, Zastava agent, internal registry, web UI, plug-ins. Don’t blur responsibilities (e.g., don’t make the UI talk directly to Redis). ([Gitea: Git with a cup of tea][1])
|
||||
* **Keep docs and code in lock-step.** If you change an endpoint, CLI flag, plug-in contract, or quota behavior, update the corresponding doc page / module dossier before merge. ([Stella Ops][2])
|
||||
|
||||
Think of the docs (`docs/`, `modules/`, ADRs) as **source of truth**; code is the implementation detail.
|
||||
|
||||
---
|
||||
|
||||
## 2. Core principles you must preserve
|
||||
|
||||
### 2.1 SBOM-first & VEX-first
|
||||
|
||||
Stella Ops exists to be an **SBOM-first, VEX-policy-driven container security platform**. ([Stella Ops][3])
|
||||
|
||||
Implementor rules:
|
||||
|
||||
* **SBOMs are the system of record.** All new scanners, checks, and policies should operate on SBOMs (Trivy JSON, SPDX JSON, CycloneDX JSON) rather than ad-hoc image inspections. ([Gitea: Git with a cup of tea][1])
|
||||
* **VEX/OpenVEX is how you express exploitability.** Any feature that mutates “this thing is risky / safe” must do so via VEX-style statements (statuses like *affected*, *not affected*, *fixed*, *under investigation* + justification), not bespoke flags. ([cyclonedx.org][4])
|
||||
|
||||
### 2.2 Deterministic & replayable
|
||||
|
||||
Docs and the release playbook emphasise **deterministic replay**: given the same SBOM + advisory snapshot + policies, you must get the same verdict, even months later. ([Stella Ops][2])
|
||||
|
||||
* No hidden network calls that change behavior over time. If you need remote data, it must be:
|
||||
* Snapshotted and imported via the Offline Update Kit (OUK), or
|
||||
* Explicitly modeled as a versioned input in a replay manifest. ([Gitea: Git with a cup of tea][5])
|
||||
* Avoid nondeterminism: no reliance on wall-clock time (except where specified, e.g., quotas), random IDs in hashes, or unordered iteration when serializing JSON.
|
||||
|
||||
### 2.3 Offline-first & sovereign
|
||||
|
||||
Stella Ops must run **fully offline** with all dependencies vendored or mirrored, and allow **bring-your-own trust roots, vulnerability sources, and crypto profiles**. ([Gitea: Git with a cup of tea][6])
|
||||
|
||||
* Any new integration (scanner, advisory feed, trust store) **MUST have an offline path**:
|
||||
* Downloaded + signed into OUK, or
|
||||
* Mirrored into the internal registry / DB.
|
||||
* Never hard-code URLs to cloud services in core paths. Gate optional online behavior behind explicit config flags, default-off.
|
||||
|
||||
### 2.4 Performance, quotas, and transparency
|
||||
|
||||
The SRS sets **P95 ≤ 5 s cold, ≤ 1 s warm** and a quota of `{{quota_token}}` scans per token/day with explicit `/quota` APIs and UI banners. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
Implementor rules:
|
||||
|
||||
* Any change that touches scanning or advisory evaluation must:
|
||||
* Preserve P95 targets under the reference hardware profile.
|
||||
* Not add hidden throttling—only the documented soft quota mechanisms. ([Gitea: Git with a cup of tea][1])
|
||||
* If you introduce heavier logic (e.g., new reachability analysis), consider:
|
||||
* Pre-computation in background jobs.
|
||||
* Caching keyed by SBOM digest + advisory snapshot ID.
|
||||
|
||||
### 2.5 Security & SLSA alignment
|
||||
|
||||
The release guide already aims at **SLSA ≥ 2, targeting level 3**, with provenance via BuildKit and signed artefacts. ([Gitea: Git with a cup of tea][5])
|
||||
|
||||
Implementation rules:
|
||||
|
||||
* All new build artefacts (containers, Helm charts, OUK tarballs, plug-ins) **MUST**:
|
||||
* Have SBOMs attached.
|
||||
* Be signed (Cosign or equivalent).
|
||||
* Be compatible with future Rekor logging. ([Gitea: Git with a cup of tea][5])
|
||||
* Inter-service comms **MUST** use TLS or localhost sockets as per NFRs. ([Gitea: Git with a cup of tea][1])
|
||||
* Zero telemetry by default. Any metrics must be Prometheus-style, local, and opt-in for anything that could leak sensitive data. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
---
|
||||
|
||||
## 3. Cross-cutting implementation guidelines
|
||||
|
||||
### 3.1 APIs, CLI, and schemas
|
||||
|
||||
* **Respect existing API semantics.** `/scan`, `/layers/missing`, `/quota`, `/policy/*`, `/plugins` are canonical; new endpoints must follow the same patterns (Bearer auth, quota flags, clear error codes). ([Gitea: Git with a cup of tea][1])
|
||||
* **Keep CLI and API mirrors in sync.** If `stella scan` gains a flag, the `/scan` API should gain a corresponding field (or vice versa); update the API & CLI Reference doc. ([Stella Ops][2])
|
||||
* **Evolve schemas via versioned contracts.** Any change to SBOM or VEX-related internal schemas must add fields compatibly; never repurpose a field’s meaning silently.
|
||||
|
||||
### 3.2 Data and storage
|
||||
|
||||
* Use Mongo for durable state and Redis for caches as per SRS assumptions; don’t introduce new stateful infrastructure lightly. ([Gitea: Git with a cup of tea][1])
|
||||
* All cache keys must be explicitly invalidated when:
|
||||
* OUK updates are applied.
|
||||
* Policies, advisories, or SBOM parsing rules change. ([Gitea: Git with a cup of tea][5])
|
||||
|
||||
### 3.3 Observability
|
||||
|
||||
* For every new long-running operation or critical decision path:
|
||||
* Export Prometheus metrics (latency, error counts, queue depth where relevant).
|
||||
* Emit structured audit events where user-visible risk changes (e.g., VEX status flips, OUK updates). ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
---
|
||||
|
||||
## 4. Supply-chain evidence: SBOM → SLSA → DSSE → Rekor → VEX
|
||||
|
||||
This is where prior work on SBOM/DSSE/Rekor/VEX connects directly to Stella Ops’ roadmap. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
### 4.1 SBOM handling
|
||||
|
||||
* **Ingestion:** Implement parsers for Trivy JSON, SPDX JSON, and CycloneDX JSON, and always auto-detect when `sbomType` is omitted. ([Gitea: Git with a cup of tea][1])
|
||||
* **Generation:** When building images or plug-ins:
|
||||
* Use `StellaOps.SBOMBuilder` or equivalent to produce at least SPDX and one additional format.
|
||||
* Attach SBOMs as OCI artefacts and label images accordingly. ([Gitea: Git with a cup of tea][5])
|
||||
* **Delta SBOM:** Any new builder or scanner must preserve the delta-SBOM contract: compute layer digests, ask `/layers/missing`, generate SBOM only for missing layers, and hit the 1 s P95 warm scan target. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
### 4.2 SLSA provenance and DSSE
|
||||
|
||||
* **Per-SBOM provenance:** For each generated SBOM, produce SLSA-compliant provenance describing builder, sources, inputs, and environment (Build L1+ at minimum, aiming for L2/L3 over time). ([SLSA][7])
|
||||
* **DSSE envelopes:** Wrap SBOMs and provenance in DSSE envelopes signed with the active crypto profile (Cosign keypair, HSM, or regional provider). ([Sigstore][8])
|
||||
* **Deterministic hashing:** Always hash canonicalized JSON bytes (stable ordering, no insignificant whitespace) so proofs remain stable no matter the emitter.
|
||||
|
||||
### 4.3 Rekor integration (local mirror, future public)
|
||||
|
||||
* **Local Rekor mirror first.** Implement the TODO from FR-REKOR-1 and the release playbook: run a Rekor v2 (tile-backed) instance inside the sovereign environment and submit DSSE/SBOM digests there. ([Gitea: Git with a cup of tea][1])
|
||||
* **Receipts & proofs:**
|
||||
* Capture Rekor receipts: checkpoint, inclusion proof, and leaf hash/UUID.
|
||||
* Store them alongside scan results and in replay manifests so they can be verified fully offline. ([Sigstore][8])
|
||||
* **Offline kits & tiles:** When OUKs are built, include:
|
||||
* The minimal Rekor tile ranges and recent checkpoints needed to verify new entries.
|
||||
* A verification job that proves entries are included/consistent before publishing the OUK. ([Gitea: Git with a cup of tea][5])
|
||||
|
||||
### 4.4 VEX / OpenVEX
|
||||
|
||||
* **Use VEX for exploitability, not ad-hoc flags.** Represent vulnerability status with VEX, ideally OpenVEX (format-agnostic) plus CycloneDX-embedded VEX where useful. ([cyclonedx.org][4])
|
||||
* **Meet CISA minimum fields:** Ensure VEX documents include:
|
||||
* Document metadata (ID, version, author, timestamps),
|
||||
* Statement metadata (IDs, timestamps),
|
||||
* Product + vulnerability identifiers, and
|
||||
* Status + justification/impact, following the CISA “Minimum Requirements for VEX” and CycloneDX mappings. ([Medium][9])
|
||||
* **Link everything:**
|
||||
* Each VEX statement must reference the SBOM component via BOM-ref/purl and the product/version it applies to.
|
||||
* Where possible, attach Rekor UUIDs or bundle IDs as evidence so auditors can trace “why we claimed not-affected”. ([Gitea: Git with a cup of tea][1])
|
||||
|
||||
---
|
||||
|
||||
## 5. Plug-in and module implementors
|
||||
|
||||
Stella Ops is designed to be **open & modular**: scanner plug-ins, attestors, registry helpers, etc. ([Gitea: Git with a cup of tea][6])
|
||||
|
||||
### 5.1 Plug-in behavior
|
||||
|
||||
* **Lifecycle & safety:**
|
||||
* Plug-ins must be hot-loadable (.NET plug-ins without restarting core services).
|
||||
* Fail closed: if a plug-in crashes or times out, the verdict must be conservative or clearly marked partial. ([Gitea: Git with a cup of tea][1])
|
||||
* **Security:**
|
||||
* No network access by default; if absolutely necessary, go through a vetted HTTP client that obeys offline mode and proxy settings.
|
||||
* Validate all input from the core platform; treat SBOMs and advisory data as untrusted until parsed/validated.
|
||||
* **Observability & quotas:**
|
||||
* Export plug-in specific metrics (latency, error rate).
|
||||
* Never bypass quotas; the host decides whether a scan is allowed, not the plug-in.
|
||||
|
||||
### 5.2 New modules/services
|
||||
|
||||
If you add a new service (e.g., runtime probe, custom advisory indexer):
|
||||
|
||||
* Put the design through an ADR + “Module dossier” doc (API, data flow, failure modes).
|
||||
* Integrate into the release pipeline: lint, tests, SBOM, signing, then (future) Rekor. ([Gitea: Git with a cup of tea][5])
|
||||
* Confirm the service can run **completely offline** in a lab setup using only OUK + mirrored registries.
|
||||
|
||||
---
|
||||
|
||||
## 6. Release & CI/CD expectations for implementors
|
||||
|
||||
The Release Engineering Playbook is canon for how code becomes a signed, air-gap-friendly release. ([Gitea: Git with a cup of tea][5])
|
||||
|
||||
As an implementor:
|
||||
|
||||
* **Keep `main` always releasable.** Broken builds break the build, not the process: fix or revert quickly.
|
||||
* **Wire your changes into the pipeline:**
|
||||
* Lint and tests for any new language/area you introduce.
|
||||
* SBOM stage updated to include any new image.
|
||||
* Signing and OUK stages updated if they touch your artefacts. ([Gitea: Git with a cup of tea][5])
|
||||
* **Guard offline assumptions:** Add/keep tests that:
|
||||
* Run the full stack without Internet.
|
||||
* Verify that SBOMs, attestations, and OUK updates all validate successfully.
|
||||
|
||||
---
|
||||
|
||||
## 7. Licensing, attribution, and governance
|
||||
|
||||
Stella Ops is AGPL-3.0-or-later and the governance docs + release playbook set clear expectations. ([Stella Ops][10])
|
||||
|
||||
* **AGPL network clause:** If you run a modified Stella Ops for others over a network, you must provide the source of that exact version. Don’t introduce proprietary modules that violate this. ([Stella Ops][10])
|
||||
* **No hidden SaaS reselling:** Re-hosting as a service is disallowed without prior consent; design and documentation should not encourage “stealth SaaS” business models on top of Stella Ops. ([Gitea: Git with a cup of tea][5])
|
||||
* **Attribution:** Keep the original Stella Ops attribution in the UI and CLI, even in forks; don’t strip branding. ([Gitea: Git with a cup of tea][5])
|
||||
* **Contribution hygiene:** Ensure all MRs:
|
||||
* Use DCO / Signed-off-by trailers,
|
||||
* Include tests + docs,
|
||||
* Record significant architectural changes in ADRs and module docs. ([Gitea: Git with a cup of tea][5])
|
||||
|
||||
---
|
||||
|
||||
## 8. A practical “before you merge” checklist
|
||||
|
||||
When you’re about to merge a feature or module, you should be able to answer “yes” to:
|
||||
|
||||
1. Does this feature align with a documented requirement or ADR? ([Gitea: Git with a cup of tea][1])
|
||||
2. Does it preserve offline-first behavior and deterministic replay?
|
||||
3. Does it operate on SBOMs as the source of truth and, if relevant, express exploitability via VEX/OpenVEX? ([Gitea: Git with a cup of tea][1])
|
||||
4. Are provenance, DSSE attestations, and (where implemented) Rekor receipts generated or at least planned? ([Gitea: Git with a cup of tea][5])
|
||||
5. Are performance, quotas, and Prometheus metrics respected? ([Gitea: Git with a cup of tea][1])
|
||||
6. Are SBOMs, signatures, and licensing for any new dependencies in order? ([Gitea: Git with a cup of tea][5])
|
||||
7. Are docs updated (API/CLI reference, module dossier, or user guide where appropriate)? ([Stella Ops][2])
|
||||
|
||||
If you want, I can next turn this into a short `docs/dev/implementor-guidelines.md` skeleton you can drop straight into the repo.
|
||||
|
||||
[1]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/10212d67c0dfa0dd849fd798c24502b773664749/docs/05_SYSTEM_REQUIREMENTS_SPEC.md "git.stella-ops.org/05_SYSTEM_REQUIREMENTS_SPEC.md at 10212d67c0dfa0dd849fd798c24502b773664749 - git.stella-ops.org - Gitea: Git with a cup of tea"
|
||||
[2]: https://stella-ops.org/docs/ "Stella Ops – Open • Sovereign • Modular container security"
|
||||
[3]: https://stella-ops.org/ "Stella Ops – Open • Sovereign • Modular container security"
|
||||
[4]: https://cyclonedx.org/capabilities/vex/ "Vulnerability Exploitability eXchange (VEX) | CycloneDX"
|
||||
[5]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/raw/commit/d0c95cf32874e5b2fe5a7b5fac15cd52f17022b1/docs/13_RELEASE_ENGINEERING_PLAYBOOK.md "git.stella-ops.org"
|
||||
[6]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/a77eb92feeafb9d0dfc75507a01f9c659db19b08/docs/02_WHY.md "git.stella-ops.org/02_WHY.md at a77eb92feeafb9d0dfc75507a01f9c659db19b08 - git.stella-ops.org - Gitea: Git with a cup of tea"
|
||||
[7]: https://slsa.dev/spec/v1.0/levels "SLSA • Security levels"
|
||||
[8]: https://docs.sigstore.dev/logging/overview/ "Rekor - Sigstore"
|
||||
[9]: https://medium.com/@interlynkblog/implementing-minimum-requirements-for-vex-622f073c2f74 "Implementing Minimum Requirements for VEX | by Interlynk | Medium"
|
||||
[10]: https://stella-ops.org/license/ "Stella Ops – Signed Reachability · Deterministic Replay · Sovereign Crypto"
|
||||
@@ -0,0 +1,582 @@
|
||||
I thought you might want a sharper picture of what’s out there — and what’s credible — for building a compact “golden set” of redistributable fixtures to drop into StellaOps’ deterministic reachability benchmark. Here’s a quick breakdown of the main external benchmark sources that map closely to your list, and what you’d get from integrating them.
|
||||
|
||||
---
|
||||
|
||||
## 🔎 Key benchmark suites & what they bring
|
||||
|
||||
### **SV-COMP (C reachability / verification tasks)**
|
||||
|
||||
* SV-COMP is the canonical benchmark for software verification tools, providing curated C programs + reachability specs (safety, mem-safety, overflow, termination). ([SV-COMP][1])
|
||||
* Tasks are published via tagged git releases (e.g., `svcomp25`), so you can reproducibly fetch exact sources and property definitions.
|
||||
* These tasks give deterministic ground truth about reachability/unreachability.
|
||||
|
||||
**Why it matters for StellaOps:** plug in real-world-like C code + formal specs.
|
||||
|
||||
### **OSS-Fuzz (reproducer corpus for fuzzed bugs)**
|
||||
|
||||
* Each OSS-Fuzz issue includes a deterministic reproducer file. ([Google GitHub][2])
|
||||
* Replaying the reproducer yields the same crash if the binary & sanitizers are consistent.
|
||||
* Public corpora can become golden fixtures.
|
||||
|
||||
**Why it matters:** covers real-world bugs beyond static properties.
|
||||
|
||||
---
|
||||
|
||||
## ❌ Not perfectly covered (Tier-2 options)
|
||||
|
||||
* Juliet / OWASP / Java/Python suites lack a single authoritative, stable distribution.
|
||||
* Package snapshots (Debian/Alpine) need manual CVE + harness mapping.
|
||||
* Curated container images (Vulhub) require licensing vetting and orchestration.
|
||||
* Call-graph corpora (NYXCorpus, SWARM) have no guaranteed stable labels.
|
||||
|
||||
**Implication:** Tier-2 fixtures need frozen versions, harness engineering, and license checks.
|
||||
|
||||
---
|
||||
|
||||
## ✅ Compact “golden set” candidate
|
||||
|
||||
| # | Fixture source | Ground truth |
|
||||
|---|----------------|--------------|
|
||||
| 1 | SV-COMP ReachSafety / MemSafety / NoOverflows | C programs + formal reachability specs (no `reach_error()` calls, no overflows). |
|
||||
| 2 | OSS-Fuzz reproducer corpus (C/C++) | Deterministic crash inputs triggering CVEs. |
|
||||
| 3 | OSS-Fuzz seed corpus | Known-safe vs bug-triggering inputs for stability comparisons. |
|
||||
| 4 | Additional SV-COMP categories (Heap, Bitvector, Float) | Broader token coverage. |
|
||||
| 5 | Placeholder: Debian/Alpine package snapshots | Manual metadata + CVEs; build harnesses. |
|
||||
| 6 | Placeholder: Java/Python OWASP/Juliet-inspired fixtures | Dynamic languages coverage; custom instrumentation required. |
|
||||
| 7 | Placeholder: Curated vulnerable container images (Vulhub) | Real-world deployment exposures. |
|
||||
| 8 | Placeholder: Call-graph corpora (NYXCorpus/SWARM) | Dataflow reachability under complex graphs; requires tooling. |
|
||||
|
||||
Start with SV-COMP + OSS-Fuzz as Tier-1; add Tier-2 once harnesses & snapshots are ready.
|
||||
|
||||
---
|
||||
|
||||
## ⚠️ Watch-outs for Tier-2
|
||||
|
||||
* Corpus maintenance (OSS-Fuzz seeds can change) requires freezing sources.
|
||||
* Label ambiguity: container/Java fixtures must have precise success/failure definitions.
|
||||
* Licensing/distribution for some corpa/containers must be vetted.
|
||||
* Call-graph/dynamic cases demand instrumentation to produce deterministic labels.
|
||||
|
||||
---
|
||||
|
||||
## 🎯 Recommendation
|
||||
|
||||
Adopt a “Tier-1 Cadre” (SV-COMP + OSS-Fuzz) for deterministic ground truth. Expand Tier-2 (packages, Java/Python, containers, call graphs) as separate projects with frozen fixtures, metadata (CWE/CVE, PURLs, CycloneDX), and verified harnesses.
|
||||
|
||||
Want me to draft an 8–12 fixture “starter pack” (paths, metadata, PURLs) you can copy into StellaOps? Let me know.
|
||||
|
||||
[1]: https://sv-comp.sosy-lab.org/2025/benchmarks.php?utm_source=chatgpt.com "Benchmark Verification Tasks - SV-COMP"
|
||||
[2]: https://google.github.io/oss-fuzz/advanced-topics/reproducing/?utm_source=chatgpt.com "Reproducing OSS-Fuzz issues"
|
||||
[3]: https://github.com/google/oss-fuzz/discussions/12278?utm_source=chatgpt.com "Corpus management in OSS-Fuzz"
|
||||
Good, let’s design this as a real “v0.1 Golden Set” spec your team can implement, not just a loose starter pack.
|
||||
|
||||
I’ll give you:
|
||||
|
||||
1. Design goals and constraints
|
||||
2. Repository layout for the benchmark
|
||||
3. Fixture metadata schema (YAML)
|
||||
4. A concrete Core-10 Golden Fixture set (each with purpose & ground truth)
|
||||
5. How to wire this into StellaOps (Scanner/Sbomer/Vexer/UnknownsRegistry/Authority)
|
||||
6. A short implementation plan for your team
|
||||
|
||||
---
|
||||
|
||||
## 1. Design goals & constraints
|
||||
|
||||
Non-negotiables:
|
||||
|
||||
* **Deterministic**: same input → same graph, same verdicts, same logs; no network, no time, no randomness.
|
||||
* **Compact**: ~10 tiny fixtures, each buildable and runnable in seconds, small SBOMs.
|
||||
* **Redistributable**: avoid licensing traps by:
|
||||
|
||||
* Preferring **synthetic code** owned by you (MIT/BSD-style).
|
||||
* For “realistic” CVEs, use **fake local IDs** (e.g. `FAKE-CVE-2025-0001`) and local feeds, not NVD data.
|
||||
* **Complete chain**: every fixture ships with:
|
||||
|
||||
* Source + build recipe
|
||||
* Binary/container
|
||||
* CycloneDX SBOM
|
||||
* Local vulnerability feed entries (OSV-like or your own schema)
|
||||
* Reference VEX document (OpenVEX or CycloneDX VEX)
|
||||
* Expected graph revision ID + reachability verdicts
|
||||
* **Coverage of patterns**:
|
||||
|
||||
* Safe vs unsafe variants (Not Affected vs Affected)
|
||||
* Intra-procedural, inter-procedural, transitive dep
|
||||
* OS package vs app-level deps
|
||||
* Multi-language (C, .NET, Java, Python)
|
||||
* Containerized vs bare-metal
|
||||
|
||||
---
|
||||
|
||||
## 2. Scope of v0: Core-10 Golden Fixtures
|
||||
|
||||
Two tiers, but all small:
|
||||
|
||||
* **Core-10** (what you ship and depend on for regression):
|
||||
|
||||
* 5 native/C fixtures (classic reachability & library shape)
|
||||
* 1 .NET fixture
|
||||
* 1 Java fixture
|
||||
* 1 Python fixture
|
||||
* 2 container fixtures (OS package style)
|
||||
* **Extended-X** (optional later): fuzz-style repros, dynamic imports, concurrency, etc.
|
||||
|
||||
Below I’ll detail the Core-10 so your team can actually implement them.
|
||||
|
||||
---
|
||||
|
||||
## 3. Repository layout
|
||||
|
||||
Recommended layout inside `stella-ops` mono-repo:
|
||||
|
||||
```text
|
||||
benchmarks/
|
||||
reachability/
|
||||
golden-v0/
|
||||
fixtures/
|
||||
C-REACH-UNSAFE-001/
|
||||
C-REACH-SAFE-002/
|
||||
C-MEM-BOUNDS-003/
|
||||
C-INT-OVERFLOW-004/
|
||||
C-LIB-TRANSITIVE-005/
|
||||
CONTAINER-OSPKG-SAFE-006/
|
||||
CONTAINER-OSPKG-UNSAFE-007/
|
||||
JAVA-HTTP-UNSAFE-008/
|
||||
DOTNET-LIB-PAIR-009/
|
||||
PYTHON-IMPORT-UNSAFE-010/
|
||||
feeds/
|
||||
osv-golden.json # “FAKE-CVE-*” style vulnerabilities
|
||||
authority/
|
||||
vex-reference-index.json # mapping fixture → reference VEX + expected verdict
|
||||
README.md
|
||||
```
|
||||
|
||||
Each fixture folder:
|
||||
|
||||
```text
|
||||
fixtures/<ID>/
|
||||
src/ # source code (C, C#, Java, Python, Dockerfile...)
|
||||
build/
|
||||
Dockerfile # if containerised
|
||||
build.sh # deterministic build commands
|
||||
artifacts/
|
||||
binary/ # final exe/jar/dll/image.tar
|
||||
sbom.cdx.json # CycloneDX SBOM (canonical, normalized)
|
||||
vex.openvex.json # reference VEX verdicts
|
||||
manifest.fixture.yaml
|
||||
graph.reference.json # canonical normalized graph
|
||||
graph.reference.sha256.txt # hash = "Graph Revision ID"
|
||||
docs/
|
||||
explanation.md # human-readable root-cause + reachability explanation
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. Fixture metadata schema (`manifest.fixture.yaml`)
|
||||
|
||||
```yaml
|
||||
id: "C-REACH-UNSAFE-001"
|
||||
name: "Simple reachable error in C"
|
||||
version: "0.1.0"
|
||||
language: "c"
|
||||
domain: "native"
|
||||
category:
|
||||
- "reachability"
|
||||
- "control-flow"
|
||||
ground_truth:
|
||||
vulnerable: true
|
||||
reachable: true
|
||||
cwes: ["CWE-754"] # Improper Check for Unusual or Exceptional Conditions
|
||||
fake_cves: ["FAKE-CVE-2025-0001"]
|
||||
verdict:
|
||||
property_type: "reach_error_unreachable"
|
||||
property_holds: false
|
||||
explanation_ref: "docs/explanation.md"
|
||||
|
||||
build:
|
||||
type: "local"
|
||||
environment: "debian:12"
|
||||
commands:
|
||||
- "gcc -O0 -g -o app main.c"
|
||||
outputs:
|
||||
binary: "artifacts/binary/app"
|
||||
|
||||
run:
|
||||
command: "./artifacts/binary/app"
|
||||
args: []
|
||||
env: {}
|
||||
stdin: ""
|
||||
expected:
|
||||
exit_code: 1
|
||||
stdout_contains: ["REACH_ERROR"]
|
||||
stderr_contains: []
|
||||
# Optional coverage or traces you might add later
|
||||
coverage_file: null
|
||||
|
||||
sbom:
|
||||
path: "artifacts/sbom.cdx.json"
|
||||
format: "cyclonedx-1.5"
|
||||
|
||||
vex:
|
||||
path: "artifacts/vex.openvex.json"
|
||||
format: "openvex-0.2"
|
||||
statement_ids:
|
||||
- "vex-statement-1"
|
||||
|
||||
graph:
|
||||
reference_path: "artifacts/graph.reference.json"
|
||||
revision_id_sha256_path: "artifacts/graph.reference.sha256.txt"
|
||||
|
||||
stellaops_tags:
|
||||
difficulty: "easy"
|
||||
focus:
|
||||
- "control-flow"
|
||||
- "single-binary"
|
||||
used_by:
|
||||
- "scanner.webservice"
|
||||
- "sbomer"
|
||||
- "vexer"
|
||||
- "excititor"
|
||||
```
|
||||
|
||||
Your team can add more, but this is enough to wire the benchmark into the pipeline.
|
||||
|
||||
---
|
||||
|
||||
## 5. Core-10 Golden Fixtures (concrete proposal)
|
||||
|
||||
I’ll describe each with: purpose, pattern, what the code does, and ground truth.
|
||||
|
||||
### 5.1 `C-REACH-UNSAFE-001` – basic reachable error
|
||||
|
||||
* **Purpose**: baseline reachability detection on a tiny C program.
|
||||
* **Pattern**: single `main`, simple branch, error sink function `reach_error()`.
|
||||
* **Code shape**:
|
||||
|
||||
* `main(int argc, char** argv)` parses integer `x`.
|
||||
* If `x == 42`, it calls `reach_error()`, which prints `REACH_ERROR` and exits 1.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: `true`.
|
||||
* Reachable: `true` if run with `x=42` (you fix input in `run.args`).
|
||||
* Property: “reach_error is unreachable” → `false` (counterexample exists).
|
||||
* **Why it’s valuable**:
|
||||
|
||||
* Exercises simple control flow; used as “hello world” of deterministic reachability.
|
||||
|
||||
### 5.2 `C-REACH-SAFE-002` – safe twin of 001
|
||||
|
||||
* **Purpose**: same SBOM shape, but no reachable error, to test “Not Affected”.
|
||||
* **Pattern**: identical to 001 but with an added guard.
|
||||
* **Code shape**:
|
||||
|
||||
* For example, check `x != 42` or remove path to `reach_error()`.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: false (no call to `reach_error` at all) *or* treat it as “patched”.
|
||||
* Reachable: false.
|
||||
* Property “reach_error is unreachable” → `true`.
|
||||
* **Why**:
|
||||
|
||||
* Used to verify that graph revision is different and VEX becomes “Not Affected” for the same fake CVE (if you model it that way).
|
||||
|
||||
### 5.3 `C-MEM-BOUNDS-003` – out-of-bounds write
|
||||
|
||||
* **Purpose**: exercise memory-safety property and CWE mapping.
|
||||
* **Pattern**: fixed-size buffer + unchecked copy.
|
||||
* **Code shape**:
|
||||
|
||||
* `char buf[16];`
|
||||
* Copies `argv[1]` into `buf` with `strcpy` or manual loop without bounds check.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: true.
|
||||
* Reachable: true on any input with length > 15 (you fix a triggering arg).
|
||||
* CWEs: `["CWE-119", "CWE-120"]`.
|
||||
* **Expected run**:
|
||||
|
||||
* With ASAN or similar, exit non-zero, mention heap/buffer overflow; for determinism, you can standardize to exit code 139 and not rely on sanitizer text in tests.
|
||||
|
||||
### 5.4 `C-INT-OVERFLOW-004` – integer overflow
|
||||
|
||||
* **Purpose**: test handling of arithmetic / overflow-related vulnerabilities.
|
||||
* **Pattern**: multiplication or addition with insufficient bounds checking.
|
||||
* **Code shape**:
|
||||
|
||||
* Function `size_t alloc_size(size_t n)` that does `n * 16` without overflow checks, then allocates and writes.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: true.
|
||||
* Reachable: true with crafted large `n`.
|
||||
* CWEs: `["CWE-190", "CWE-680"]`.
|
||||
* **Why**:
|
||||
|
||||
* Lets you validate that your vulnerability feed (fake CVE) asserts “affected” on this component, and your reachability engine confirms the path.
|
||||
|
||||
### 5.5 `C-LIB-TRANSITIVE-005` – vulnerable library, unreachable in app
|
||||
|
||||
* **Purpose**: test the core SBOM→VEX story: component is vulnerable, but not used.
|
||||
* **Pattern**:
|
||||
|
||||
* `libvuln.a` with function `void do_unsafe(char* input)` containing the same OOB bug as 003.
|
||||
* `app.c` links to `libvuln` but never calls `do_unsafe()`.
|
||||
* **Code shape**:
|
||||
|
||||
* Build static library from `libvuln.c`.
|
||||
* Build `app` that uses only `do_safe()` from `libvuln.c` or that just links but doesn’t call anything from the “unsafe” TU.
|
||||
* **SBOM**:
|
||||
|
||||
* SBOM lists `component: "pkg:generic/libvuln@1.0.0"` with `fake_cves: ["FAKE-CVE-2025-0003"]`.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable component present in SBOM: yes.
|
||||
* Reachable vulnerable function: no.
|
||||
* Correct VEX: “Not Affected: vulnerable code not in execution path for this product”.
|
||||
* **Why**:
|
||||
|
||||
* Canonical demonstration of correct VEX semantics on real-world pattern: vulnerable lib, harmless usage.
|
||||
|
||||
---
|
||||
|
||||
### 5.6 `CONTAINER-OSPKG-SAFE-006` – OS package, unused binary
|
||||
|
||||
* **Purpose**: simulate vulnerable OS package installed but unused, to test image scanning vs reachability.
|
||||
* **Pattern**:
|
||||
|
||||
* Minimal container (e.g. `debian:12-slim` or `alpine:3.x`) with installed package `vuln-tool` that is never invoked by the entrypoint.
|
||||
* Your app is a trivial “hello” binary.
|
||||
* **SBOM**:
|
||||
|
||||
* OS-level components include `pkg:generic/vuln-tool@1.0.0`.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: the package is flagged by local feed.
|
||||
* Reachable: false under the specified `CMD` and test scenario.
|
||||
* VEX: “Not Affected – vulnerable code present but not invoked in product’s operational context.”
|
||||
* **Why**:
|
||||
|
||||
* Tests that StellaOps does not over-report image-level CVEs when nothing in the product’s execution profile uses them.
|
||||
|
||||
### 5.7 `CONTAINER-OSPKG-UNSAFE-007` – OS package actually used
|
||||
|
||||
* **Purpose**: same as 006 but positive case: vulnerability is reachable.
|
||||
* **Pattern**:
|
||||
|
||||
* Same base image and package.
|
||||
* Entrypoint script calls `vuln-tool` with crafted input that triggers the bug.
|
||||
* **Ground truth**:
|
||||
|
||||
* Vulnerable: true.
|
||||
* Reachable: true.
|
||||
* This should flip the VEX verdict vs 006.
|
||||
* **Why**:
|
||||
|
||||
* Verifies that your reachability engine + runtime behaviour correctly distinguish “installed but unused” from “installed and actively exploited.”
|
||||
|
||||
---
|
||||
|
||||
### 5.8 `JAVA-HTTP-UNSAFE-008` – vulnerable route in minimal Java service
|
||||
|
||||
* **Purpose**: test JVM + HTTP + transitive dep reachability.
|
||||
* **Pattern**:
|
||||
|
||||
* Small Spring Boot or JAX-RS service with:
|
||||
|
||||
* `/safe` endpoint using only safe methods.
|
||||
* `/unsafe` endpoint calling a method in `vuln-lib` that has a simple bug (e.g. path traversal or unsafe deserialization).
|
||||
* **SBOM**:
|
||||
|
||||
* Component `pkg:maven/org.stellaops/vuln-lib@1.0.0` linked to `FAKE-CVE-2025-0004`.
|
||||
* **Ground truth**:
|
||||
|
||||
* For an HTTP call to `/unsafe`, vulnerability reachable.
|
||||
* For `/safe`, not reachable.
|
||||
* **Benchmark convention**:
|
||||
|
||||
* Fixture defines `run.unsafe` and `run.safe` commands in manifest (two separate “scenarios” under one fixture ID, or two sub-cases in `manifest.fixture.yaml`).
|
||||
* **Why**:
|
||||
|
||||
* Exercises language-level dependency resolution, transitive calls, and HTTP entrypoints.
|
||||
|
||||
---
|
||||
|
||||
### 5.9 `DOTNET-LIB-PAIR-009` – .NET assembly with safe & unsafe variants
|
||||
|
||||
* **Purpose**: cover your home turf: .NET 10 / C# pipeline + SBOM & VEX.
|
||||
* **Pattern**:
|
||||
|
||||
* `Golden.Banking.Core` library with method:
|
||||
|
||||
* `public void Process(string iban)` → suspicious string parsing / regex or overflow.
|
||||
* Two apps:
|
||||
|
||||
* `Golden.Banking.App.Unsafe` that calls `Process()` with unsafe behaviour.
|
||||
* `Golden.Banking.App.Safe` that never calls `Process()` or uses a safe wrapper.
|
||||
* **SBOM**:
|
||||
|
||||
* Component `pkg:nuget/Golden.Banking.Core@1.0.0` tied to `FAKE-CVE-2025-0005`.
|
||||
* **Ground truth**:
|
||||
|
||||
* For `App.Unsafe`, vulnerability reachable.
|
||||
* For `App.Safe`, not reachable.
|
||||
* **Why**:
|
||||
|
||||
* Validates your .NET tooling (Sbomer, scanner.webservice) and that your graphs respect assembly boundaries and call sites.
|
||||
|
||||
---
|
||||
|
||||
### 5.10 `PYTHON-IMPORT-UNSAFE-010` – Python optional import pattern
|
||||
|
||||
* **Purpose**: basic coverage for dynamic / interpreted language with optional module.
|
||||
* **Pattern**:
|
||||
|
||||
* `app.py`:
|
||||
|
||||
* Imports `helper` which conditionally imports `vuln_mod` when `ENABLE_VULN=1`.
|
||||
* When enabled, calling `/unsafe` function triggers, e.g., `eval(user_input)`.
|
||||
* **SBOM**:
|
||||
|
||||
* Component `pkg:pypi/vuln-mod@1.0.0` → `FAKE-CVE-2025-0006`.
|
||||
* **Ground truth**:
|
||||
|
||||
* With `ENABLE_VULN=0`, vulnerable module not imported → unreachable.
|
||||
* With `ENABLE_VULN=1`, reachable.
|
||||
* **Why**:
|
||||
|
||||
* Simple but realistic test for environment-dependent reachability and Python support.
|
||||
|
||||
---
|
||||
|
||||
## 6. Local vulnerability feed for the Golden Set
|
||||
|
||||
To keep everything sovereign and deterministic, define a small internal OSV-like JSON feed, e.g. `benchmarks/reachability/golden-v0/feeds/osv-golden.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"vulnerabilities": [
|
||||
{
|
||||
"id": "FAKE-CVE-2025-0001",
|
||||
"summary": "Reachable error in sample C program",
|
||||
"aliases": [],
|
||||
"affected": [
|
||||
{
|
||||
"package": {
|
||||
"ecosystem": "generic",
|
||||
"name": "C-REACH-UNSAFE-001"
|
||||
},
|
||||
"ranges": [{ "type": "SEMVER", "events": [{ "introduced": "0" }] }]
|
||||
}
|
||||
],
|
||||
"database_specific": {
|
||||
"stellaops_fixture_id": "C-REACH-UNSAFE-001"
|
||||
}
|
||||
}
|
||||
// ... more FAKE-CVE defs ...
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Scanner/Feedser in “golden mode” should:
|
||||
|
||||
* Use **only** this feed.
|
||||
* Produce deterministic, closed-world graphs and VEX decisions.
|
||||
|
||||
---
|
||||
|
||||
## 7. Integration hooks with StellaOps
|
||||
|
||||
Make sure each module has a clear use of the golden set:
|
||||
|
||||
* **Scanner.Webservice**
|
||||
|
||||
* Input: SBOM + local feed for a fixture.
|
||||
* Output: canonical graph JSON and SHA-256 revision.
|
||||
* For each fixture, compare produced `revision_id` against `graph.reference.sha256.txt`.
|
||||
* **Sbomer**
|
||||
|
||||
* Rebuilds SBOM from source/binaries and compares it to `artifacts/sbom.cdx.json`.
|
||||
* Fails test if SBOMs differ in canonicalized form.
|
||||
* **Vexer / Excititor**
|
||||
|
||||
* Ingests graph + local feed and produces VEX.
|
||||
* Compare resulting VEX to `artifacts/vex.openvex.json`.
|
||||
* **UnknownsRegistry**
|
||||
|
||||
* For v0 you can keep unknowns minimal, but:
|
||||
|
||||
* At least one fixture (e.g. Python or container) can contain a “deliberately un-PURL-able” file to confirm it enters Unknowns with expected half-life.
|
||||
* **Authority**
|
||||
|
||||
* Signs the reference artifacts:
|
||||
|
||||
* SBOM
|
||||
* Graph
|
||||
* VEX
|
||||
* Ensures deterministic attestation for the golden set (you can later publish these as public reference proofs).
|
||||
|
||||
---
|
||||
|
||||
## 8. Implementation plan for your team
|
||||
|
||||
You can drop this straight into a ticket or doc.
|
||||
|
||||
1. **Scaffold repo structure**
|
||||
|
||||
* Create `benchmarks/reachability/golden-v0/...` layout as above.
|
||||
* Add a top-level `README.md` describing goals and usage.
|
||||
|
||||
2. **Implement the 10 fixtures**
|
||||
|
||||
* Each fixture: write minimal code, build scripts, and `manifest.fixture.yaml`.
|
||||
* Keep code tiny (1–3 files) and deterministic (no network, no randomness, no wall time).
|
||||
|
||||
3. **Generate SBOMs**
|
||||
|
||||
* Use your Sbomer for each artifact.
|
||||
* Normalize / canonicalize SBOMs and commit them as `artifacts/sbom.cdx.json`.
|
||||
|
||||
4. **Define FAKE-CVE feed**
|
||||
|
||||
* Create `feeds/osv-golden.json` with 1–2 entries per fixture.
|
||||
* Map each entry to PURLs used in SBOMs.
|
||||
|
||||
5. **Produce reference graphs**
|
||||
|
||||
* Run Scanner in “golden mode” on each fixture’s SBOM + feed.
|
||||
* Normalize graphs (sorted JSON, deterministic formatting).
|
||||
* Compute SHA-256 → store in `graph.reference.sha256.txt`.
|
||||
|
||||
6. **Produce reference VEX documents**
|
||||
|
||||
* Run Vexer / Excititor with graphs + feed.
|
||||
* Manually review results, edit as needed.
|
||||
* Save final accepted VEX as `artifacts/vex.openvex.json`.
|
||||
|
||||
7. **Write explanations**
|
||||
|
||||
* For each fixture, add `docs/explanation.md`:
|
||||
|
||||
* 5–10 lines explaining root cause, path, and why affected / not affected.
|
||||
|
||||
8. **Wire into CI**
|
||||
|
||||
* Add a `GoldenReachabilityTests` job that:
|
||||
|
||||
* Builds all fixtures.
|
||||
* Regenerates SBOM, graph, and VEX.
|
||||
* Compares against reference artifacts.
|
||||
* Fail CI if any fixture drifts.
|
||||
|
||||
9. **Expose as a developer command**
|
||||
|
||||
* Add a CLI command, e.g.:
|
||||
|
||||
* `stellaops bench reachability --fixture C-REACH-UNSAFE-001`
|
||||
* So developers can locally re-run single fixtures during development.
|
||||
|
||||
---
|
||||
|
||||
If you want, next step I can:
|
||||
|
||||
* Take 2–3 of these fixtures (for example `C-REACH-UNSAFE-001`, `C-LIB-TRANSITIVE-005`, and `DOTNET-LIB-PAIR-009`) and draft **actual code sketches + full `manifest.fixture.yaml`** so your devs can literally copy-paste and start implementing.
|
||||
@@ -0,0 +1,409 @@
|
||||
Here’s a practical, Stella Ops–ready checklist for **what a Rekor v2 “receipt” must capture**, plus metadata for air-gapped delivery and deterministic re-verification—mapped to the module that must own each field and why it matters.
|
||||
|
||||
*(Quick background: Sigstore’s Rekor v2 is GA and uses a redesigned, cheaper-to-run transparency log; clients (cosign v2.6+) and bundle format are updated. Receipts/inclusion proofs + bundles enable offline verification and replay.)* ([Sigstore Blog][1])
|
||||
|
||||
---
|
||||
|
||||
# Must-have (atomic, required)
|
||||
|
||||
* **tlog URL (authority endpoint)** → **Authority**
|
||||
Ensures we’re verifying against the exact Rekor instance (public or private mirror). Needed to fetch/validate inclusion proofs and checkpoints. ([Sigstore Blog][1])
|
||||
|
||||
* **Rekor log public key (or key ID/fingerprint)** → **Authority**
|
||||
Trust root for verifying Signed Tree Heads (STHs)/checkpoints and inclusion proofs. Store pinned key for 2025 Rekor v2 (and rotation support). ([Sigstore Blog][1])
|
||||
|
||||
* **Log checkpoint at verification time (STH digest + tree size + timestamp)** → **Scheduler**
|
||||
Proves append-only consistency window used during verification; enables later consistency proofs. ([Sigstore Blog][2])
|
||||
|
||||
* **Entry locator (UUID and/or log index)** → **Sbomer**
|
||||
Stable handle to the exact log entry for the artifact’s signature/attestation. ([Chainguard Academy][3])
|
||||
|
||||
* **Inclusion proof (audit path/merkle hashes)** → **Authority**
|
||||
Cryptographic proof that the entry is included in the log corresponding to the checkpoint. ([Sigstore][4])
|
||||
|
||||
* **Sigstore Bundle (embedded signature/attestation + verification material)** → **Sbomer**
|
||||
Persist the **Sigstore bundle** emitted by clients (cosign, sigstore-python). It carries the DSSE envelope, certs, TSA timestamp, and (when applicable) transparency details for offline replay. ([Sigstore][5])
|
||||
|
||||
* **Fulcio certificate chain (PEM, short-lived)** → **Authority**
|
||||
Needed to validate keyless identities tied to OIDC claims; keep chain alongside bundle for air-gap. ([Sigstore][6])
|
||||
|
||||
* **Subject digest(s) (e.g., image/artifact SHA-256)** → **Sbomer**
|
||||
Binds the receipt to the exact bits we verified; required to re-prove later. ([OpenSSF][7])
|
||||
|
||||
* **Verification policy hash (the policy used at verify time)** → **Vexer**
|
||||
Pin the exact policy (rules, identity matchers, Rekor requirement) so future re-checks are deterministic. ([OKD Documentation][8])
|
||||
|
||||
---
|
||||
|
||||
# Nice-to-have (repro, forensics, air-gap)
|
||||
|
||||
* **TUF snapshot/version for Rekor/Fulcio bundles** → **Authority**
|
||||
Records which distributed metadata set was trusted when verifying (key rotations, URL rollout timing). ([Sigstore Blog][1])
|
||||
|
||||
* **Client + version (cosign/sigstore-python), verify flags** → **Scheduler**
|
||||
Replays the same client logic/version; helpful when formats/behaviors change across releases. ([Sigstore Blog][1])
|
||||
|
||||
* **Identity claims summary** → **Authority**
|
||||
Compact snapshot (issuer, subject/email, SANs) for audit trails without re-parsing certs. ([Sigstore][6])
|
||||
|
||||
* **Timestamp Authority (TSA) evidence (token/counter-signature)** → **Authority**
|
||||
Anchors signing time within cert validity; crucial for keyless flows. ([OpenSSF][7])
|
||||
|
||||
* **Local mirror info** → **Feedser/Concelier**
|
||||
Mirror URL, sync height/tree size, mirror key for proving private mirror consistency with public instance. ([OpenSSF][9])
|
||||
|
||||
* **Repro inputs hash: policy + trust bundle + Rekor key + toolchain** → **Vexer**
|
||||
One hash to assert the exact verifier environment used.
|
||||
|
||||
* **Attestation payload digest + size (DSSE/intoto)** → **Sbomer**
|
||||
Guard vs payload truncation and size pitfalls. ([GitHub][10])
|
||||
|
||||
* **Monitor evidence: last consistency check** → **Scheduler**
|
||||
Records proof the log remained consistent between checkpoints. ([Sigstore Blog][2])
|
||||
|
||||
---
|
||||
|
||||
# Ownership map
|
||||
|
||||
* **Authority**: Rekor URL/pkey, Fulcio chain/TSA/TUF refs, inclusion proofs, checkpoints, identity summaries.
|
||||
* **Sbomer**: bundle blob, entry UUID/index, subject digests, attestation digests/sizes.
|
||||
* **Vexer (Excititor)**: policy hash, repro hash, uses Authority/Sbomer data for verdicts.
|
||||
* **Feedser/Concelier**: mirror URLs/heights, provenance of snapshots.
|
||||
* **Scheduler**: client versions/flags, timestamps, monitor checks.
|
||||
* **UnknownsRegistry**: tracks missing receipt elements or unverifiable fields for follow-up.
|
||||
|
||||
---
|
||||
|
||||
# Storage conventions
|
||||
|
||||
* **Receipt document**: `application/json` with canonical field order + normalized encodings (PEM → base64 DER) + explicit bytes hash (CID/sha256).
|
||||
* **Bundle storage**: keep raw Sigstore bundle plus a normalized copy for indexing. ([Sigstore][5])
|
||||
* **Proof linkage**: store `checkpoint_hash`, `inclusion_proof_hash`, and `bundle_hash` so Vexer can verify all before marking “Verified”.
|
||||
|
||||
---
|
||||
|
||||
# Air-gapped delivery flow
|
||||
|
||||
1. **Seed trust**: ship Rekor public key, Fulcio bundle, TSA root, pinned checkpoint. ([Sigstore Blog][1])
|
||||
2. **Ship artefact**: Sbomer writes bundle; Authority adds proofs; Scheduler stamps tooling metadata.
|
||||
3. **Verify offline**: Vexer checks DSSE, Fulcio chain, TSA time, and inclusion proof against pinned data.
|
||||
4. **Mirror**: Feedser syncs private Rekor mirror; consistency proofs keep it honest. ([OpenSSF][9])
|
||||
|
||||
---
|
||||
|
||||
# Minimal JSON schema (starter)
|
||||
|
||||
```json
|
||||
{
|
||||
"tlog": {
|
||||
"url":"https://rekor.sigstore.dev",
|
||||
"publicKey":{"type":"pem","fingerprint":"…"},
|
||||
"checkpoint":{"treeSize":123456,"signedNote":"base64","timestamp":"2025-10-10T12:34:56Z"},
|
||||
"entry":{"uuid":"…","logIndex":987654},
|
||||
"inclusionProof":{"hashAlgo":"SHA256","auditPath":["…","…"]}
|
||||
},
|
||||
"bundle":{"mediaType":"application/vnd.dev.sigstore.bundle+json;version=…","blob":"base64","digest":"sha256:…"},
|
||||
"subject":[{"name":"registry/org/app@sha256:…","digest":"sha256:…"}],
|
||||
"fulcio":{"chainPem":["-----BEGIN CERTIFICATE-----…"]},
|
||||
"tsa":{"rootPem":"-----BEGIN CERTIFICATE-----…","tokenDigest":"sha256:…"},
|
||||
"policy":{"id":"vexer-policy-v1","sha256":"…"},
|
||||
"tooling":{"client":"cosign","version":"v2.6.0","flags":["--bundle","--rekor-url=…"]},
|
||||
"monitor":{"fromTreeSize":120000,"toTreeSize":123456,"consistencyProof":"sha256:…"},
|
||||
"provenance":{"tufSnapshot":"…","mirror":{"url":"https://rekor.mirror.local","treeSize":123456,"publicKey":"…"}}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
If you want, I’ll turn this into `docs/security/receipts.md` plus a C# POCO/EF Core entity so Authority/Sbomer/Vexer can plumb it straight into the data model.
|
||||
|
||||
[1]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[2]: https://blog.sigstore.dev/using-rekor-monitor/?utm_source=chatgpt.com "Using rekor-monitor to Scan Your Transparency Logs"
|
||||
[3]: https://edu.chainguard.dev/open-source/sigstore/rekor/an-introduction-to-rekor/?utm_source=chatgpt.com "An Introduction to Rekor"
|
||||
[4]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
[5]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[6]: https://docs.sigstore.dev/about/overview/?utm_source=chatgpt.com "Sigstore: Overview"
|
||||
[7]: https://openssf.org/blog/2024/05/24/introducing-artifact-attestations-now-in-public-beta/?utm_source=chatgpt.com "Introducing Artifact Attestations—Now in Public Beta"
|
||||
[8]: https://docs.okd.io/latest/nodes/nodes-sigstore-using.html?utm_source=chatgpt.com "Manage secure signatures with sigstore | Nodes | OKD 4"
|
||||
[9]: https://openssf.org/blog/2025/10/15/announcing-the-sigstore-transparency-log-research-dataset/?utm_source=chatgpt.com "Announcing the Sigstore Transparency Log Research ..."
|
||||
[10]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
|
||||
|
||||
Here’s a practical set of guidelines you can use as a north star when **implementing StellaOps**—both for *platform owners/operators* and for *teams building or extending StellaOps modules*.
|
||||
|
||||
I’ll structure this as:
|
||||
|
||||
1. Cross‑cutting principles (what must never be broken)
|
||||
2. A phased implementation roadmap
|
||||
3. Guidelines by concern (auth, data, CI, observability, offline, security)
|
||||
4. Short checklists you can literally paste into your runbooks
|
||||
|
||||
---
|
||||
|
||||
## 1. Cross‑cutting principles
|
||||
|
||||
These are baked into the official StellaOps docs and should guide every implementation decision.([Gitea: Git with a cup of tea][1])
|
||||
|
||||
**1.1 Determinism & replay first**
|
||||
|
||||
* All “facts” (SBOMs, advisories, VEX, reachability, logs) must be **replayable**:
|
||||
|
||||
* Stable JSON key ordering, UTC ISO‑8601 timestamps, content‑addressed bundles, deterministic hashing.
|
||||
* Avoid wall‑clock or “now()” in evaluation paths; Policy Engine and analyzers should be deterministic for the same inputs.([Gitea: Git with a cup of tea][1])
|
||||
* When in doubt: add a hash or bundle and make it verifiable rather than adding a mutable flag.
|
||||
|
||||
**1.2 Aggregation‑Only ingestion**
|
||||
|
||||
* **Concelier** and **Excititor** are *aggregation‑only*:
|
||||
|
||||
* They ingest, normalise, enrich with provenance and linksets, and write immutable `advisory_raw` / `vex_raw` docs.([Gitea: Git with a cup of tea][2])
|
||||
* They **must not** compute severity, consensus, suppressions, risk scores, or merges—that belongs to Policy Engine and downstream overlays.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
**1.3 Thin gateway, smart services**
|
||||
|
||||
* Gateway (or API edge) is **proxy only**:
|
||||
|
||||
* AuthN/AuthZ, DPoP verification, scope enforcement, routing.
|
||||
* No policy overlays, no business logic, no joining evidence there—those live in Policy Engine & domain services.([Gitea: Git with a cup of tea][3])
|
||||
|
||||
**1.4 Offline‑first & sovereignty**
|
||||
|
||||
* Assume **air‑gapped or intermittently connected** operation:
|
||||
|
||||
* Design for offline bundles, mirrors, and “kit” updates instead of live internet calls.
|
||||
* BYO trust roots, regional crypto (FIPS/eIDAS/SM/etc.), and Rekor v2 mirroring are first‑class, not afterthoughts.([Gitea: Git with a cup of tea][1])
|
||||
|
||||
**1.5 Modular responsibility boundaries**
|
||||
|
||||
From the module cheat sheet: each service has a crisp responsibility; implementations should respect that split.([Gitea: Git with a cup of tea][1])
|
||||
|
||||
* **Authority** – identity, tokens (OpToks), DPoP/mTLS, audit.
|
||||
* **Scanner (Web + Worker)** – SBOM generation, analysis, replay bundles.
|
||||
* **Signer & Attestor** – DSSE signing, PoE enforcement, Rekor v2 anchoring.
|
||||
* **Concelier & Excititor** – raw advisory & VEX ingest (Aggregation‑Only Contract).
|
||||
* **Policy Engine & Scheduler** – joins, overlays, scheduling remediation work.
|
||||
* **Notify, Export Center, UI, CLI, Zastava, Registry Token Service, Graph** – UX, notifications, exports, runtime admission, tokens, graph views.
|
||||
|
||||
When you’re “implementing StellaOps,” you’re plugging into this map—don’t blur the boundaries.
|
||||
|
||||
---
|
||||
|
||||
## 2. Phased implementation roadmap
|
||||
|
||||
Use this as a sequence for a *new* installation. It’s compatible with the official high‑level architecture, quickstart, and platform overview docs.([Gitea: Git with a cup of tea][4])
|
||||
|
||||
### Phase 0 – Plan environments & infra
|
||||
|
||||
* Decide on **envs**: at minimum `dev`, `staging`, `prod`. For regulated/orgs, add `airgap‑preprod`.
|
||||
* Stand up shared data plane per cluster:
|
||||
|
||||
* MongoDB (canonical store, jobs, overlays).([Gitea: Git with a cup of tea][1])
|
||||
* MinIO or RustFS/object storage for CAS and replay bundles.([Gitea: Git with a cup of tea][4])
|
||||
* Queue backend (Redis Streams / NATS / RabbitMQ).([Gitea: Git with a cup of tea][4])
|
||||
* Telemetry stack (logs, metrics, traces) per `docs/modules/telemetry/architecture.md`.([Gitea: Git with a cup of tea][2])
|
||||
* For `dev`, you can lean on the **docker‑compose skeleton** in the high‑level architecture doc; for `staging/prod`, translate that to Kubernetes with the same service graph.([Gitea: Git with a cup of tea][4])
|
||||
|
||||
### Phase 1 – Core control plane: Authority, Gateway, Licensing
|
||||
|
||||
* Deploy **StellaOps.Authority** with its plugin configuration under `etc/authority.plugins/*.yaml`.([Gitea: Git with a cup of tea][5])
|
||||
* Wire Authority to your IdP or use the Standard plugin for local users, observing:
|
||||
|
||||
* Strong password policies + Argon2id hashing (see cryptography updates).([Gitea: Git with a cup of tea][6])
|
||||
* Short‑lived OpToks, DPoP keypairs in OS keychains, no long‑lived bearer tokens.([Gitea: Git with a cup of tea][7])
|
||||
* Introduce an **API Gateway** that:
|
||||
|
||||
* Verifies JWT + DPoP, enforces scopes, and forwards to backend services.([Gitea: Git with a cup of tea][3])
|
||||
* Connect to the **Licensing Service** (`www.stella-ops.org`) to obtain Proof‑of‑Entitlement (PoE) for attesting installations, or deliberately run in throttled community mode.([Gitea: Git with a cup of tea][4])
|
||||
|
||||
### Phase 2 – Scanning & attestation path
|
||||
|
||||
* Deploy:
|
||||
|
||||
* `StellaOps.Scanner.WebService` and `StellaOps.Scanner.Worker`.
|
||||
* `StellaOps.Signer` and `StellaOps.Attestor` plus Fulcio/Rekor v2 (or mirror).([Gitea: Git with a cup of tea][4])
|
||||
* Install **stella CLI** for operators/CI:
|
||||
|
||||
* Native AOT binaries, config via `config.yaml` & env vars like `STELLAOPS_AUTHORITY`, `STELLAOPS_SCANNER_URL`, etc.([Gitea: Git with a cup of tea][7])
|
||||
* Enable Buildx SBOM generation via `StellaOps.Scanner.Sbomer.BuildXPlugin`.([Gitea: Git with a cup of tea][8])
|
||||
* Validate with the official quickstart:
|
||||
|
||||
* `stella auth login` (device‑code) → `stella scan image ... --sbom-type cyclonedx-json`.([Gitea: Git with a cup of tea][9])
|
||||
|
||||
### Phase 3 – Evidence graph & policy
|
||||
|
||||
* Add **Concelier** and **Excititor**:
|
||||
|
||||
* Configure connectors for upstream feeds (NVD, distro advisories, GHSA, OSV, vendor VEX, etc.).([Gitea: Git with a cup of tea][1])
|
||||
* Ensure AOC guards (`StellaOps.Aoc`) and Mongo validators are enabled so `advisory_raw` / `vex_raw` are immutable and compliant.([Gitea: Git with a cup of tea][2])
|
||||
* Deploy **Policy Engine** and **Scheduler**:
|
||||
|
||||
* Policy Engine joins SBOM inventory with raw advisories/VEX, produces `effective_finding_*` collections, and exposes simulation APIs.([Gitea: Git with a cup of tea][1])
|
||||
* Scheduler watches change streams and impact windows, driving re‑scans and policy re‑evaluation.([Gitea: Git with a cup of tea][1])
|
||||
* Bring up **Notify** for email/chat hooks based on policy events.([Gitea: Git with a cup of tea][1])
|
||||
|
||||
### Phase 4 – UX, exports, runtime
|
||||
|
||||
* Deploy **UI** (Angular SPA) and its backend, **Export Center**, and **Registry Token Service**, then **Zastava** (runtime admission / posture).([Gitea: Git with a cup of tea][1])
|
||||
* Add **Offline Kit / Export** profiles so you can produce offline bundles for air‑gapped clusters.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
You don’t have to do all phases at once; but don’t violate the dependencies in the high‑level diagram (e.g., don’t run Attestor without Authority & Rekor, don’t run Policy without AOC‑compliant ingest).([Gitea: Git with a cup of tea][4])
|
||||
|
||||
---
|
||||
|
||||
## 3. Guidelines by concern
|
||||
|
||||
### 3.1 Identity, auth, and RBAC
|
||||
|
||||
**Use Authority for everything**
|
||||
|
||||
* All services and the CLI should authenticate via **StellaOps.Authority** using OpToks (short‑lived JWTs) bound to DPoP or mTLS.([Gitea: Git with a cup of tea][1])
|
||||
* Scopes are your main guardrail:
|
||||
|
||||
* Ingestion: `advisory:ingest`, `vex:ingest`.
|
||||
* Read: `advisory:read`, `vex:read`, `findings:read`.
|
||||
* Overlay writes: `effective:write` – **Policy Engine only**.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
**Separate human vs machine identities**
|
||||
|
||||
* Humans:
|
||||
|
||||
* Use `auth login --device-code`, with scopes limited to what UI/CLI needs (`scanner.read`, `policy.read`, etc.).([Gitea: Git with a cup of tea][7])
|
||||
* CI/automation:
|
||||
|
||||
* Use client‑credentials, service principals, and tightly scoped audiences (e.g. `scanner`, `attestor`, `export-center`).([Gitea: Git with a cup of tea][7])
|
||||
|
||||
**Authority plugin hygiene**
|
||||
|
||||
* Implement or configure IdP plugins via `IAuthorityPluginRegistrar`; validate config rigorously in `PostConfigure`.([Gitea: Git with a cup of tea][5])
|
||||
* Never store secrets in git; rely on `.local.yaml`, env vars, or mounted secret files and document which keys are mandatory.([Gitea: Git with a cup of tea][5])
|
||||
|
||||
### 3.2 Data, schemas, and AOC
|
||||
|
||||
**Raw vs derived is sacred**
|
||||
|
||||
* Raw stores:
|
||||
|
||||
* `advisory_raw` and `vex_raw` are append‑only and AOC‑guarded; only Concelier/Excititor can write there through guarded paths.([Gitea: Git with a cup of tea][2])
|
||||
* Derived:
|
||||
|
||||
* `effective_finding_*` collections are produced by Policy Engine only, using `effective:write` scope. No other service should mutate them.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
**Enforce via tooling**
|
||||
|
||||
* Enable Mongo schema validators for raw collections and overlays as per platform docs.([Gitea: Git with a cup of tea][2])
|
||||
* Use `stella aoc verify` in CI whenever ingestion schema/guards change, ensuring no violations creep in.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
**No side‑routes to Mongo**
|
||||
|
||||
* Application teams must **never** talk to Mongo directly; use module APIs (Scanner, Concelier, Excititor, Policy, Graph) as the abstraction. This keeps AOC/rules enforceable and replayable.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
### 3.3 CI/CD and developer workflows
|
||||
|
||||
**Configure the CLI predictably**
|
||||
|
||||
* Honor the CLI precedence rules: flags → env vars → config file → defaults.([Gitea: Git with a cup of tea][8])
|
||||
* Standardise envs in pipelines:
|
||||
|
||||
* `STELLAOPS_AUTHORITY`, `STELLAOPS_SCANNER_URL`, `STELLAOPS_CONCELIER_URL`, `STELLAOPS_EXCITITOR_URL`, etc.([Gitea: Git with a cup of tea][8])
|
||||
|
||||
**SBOMs at build time**
|
||||
|
||||
* Prefer the **Buildx plugin** (Sbomer) for SBOM generation:
|
||||
|
||||
* `buildx install` → `buildx build` wrapper injects `--attest=type=sbom,generator=stellaops/sbom-indexer`.([Gitea: Git with a cup of tea][8])
|
||||
* If Buildx isn’t available, fall back to post‑build `stella scan image` with a visible warning in CI.([Gitea: Git with a cup of tea][8])
|
||||
|
||||
**Use exit codes & JSON for gating**
|
||||
|
||||
* In CI, run in `--json` mode and gate on CLI exit codes:
|
||||
|
||||
* `0` = success, `2` = policy fail, `3` = verification fail, `4` = auth error, etc.([Gitea: Git with a cup of tea][8])
|
||||
* Use Policy preview APIs (`/policy/preview`) to test the effect of new policies before promoting them to production.([Gitea: Git with a cup of tea][10])
|
||||
|
||||
### 3.4 Observability & SRE
|
||||
|
||||
**Standard metrics & logs**
|
||||
|
||||
* Emit and dashboard at least:
|
||||
|
||||
* `ingestion_write_total`, `aoc_violation_total{code}`, `ingestion_latency_seconds`.([Gitea: Git with a cup of tea][2])
|
||||
* Scan & policy latencies, queue depths, worker failures, OpTok issuance/error counts.([Gitea: Git with a cup of tea][4])
|
||||
* Use structured logs with `traceId`, `tenant`, `source.vendor`, `content_hash` as correlation dimensions.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
**Adopt the platform SLO hints**
|
||||
|
||||
* Take the latency and throughput targets from the high‑level architecture as initial SLOs:
|
||||
|
||||
* P95 build‑time ≤ 3–5 s on warmed images, policy+VEX ≤ 500 ms for 5k components, etc.([Gitea: Git with a cup of tea][4])
|
||||
|
||||
### 3.5 Offline & air‑gapped operation
|
||||
|
||||
**Treat offline sites as first‑class**
|
||||
|
||||
* Use **Offline Kits**:
|
||||
|
||||
* Bundle raw Mongo snapshots for `advisory_raw`/`vex_raw`, guard configs, verifier binaries, and replay bundles.([Gitea: Git with a cup of tea][2])
|
||||
* For air‑gapped clusters:
|
||||
|
||||
* Deploy the same service graph (Authority, Scanner, Concelier, Excititor, Policy, etc.), seeded via Offline Kits and Export Center exports.([Gitea: Git with a cup of tea][2])
|
||||
* Practice DR:
|
||||
|
||||
* Test restore-from‑snapshot → replay change streams → re‑validate AOC compliance per the platform overview.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
### 3.6 Security & crypto
|
||||
|
||||
**Centralise signing logic**
|
||||
|
||||
* Let **Signer** own all DSSE signing and **Attestor** own Rekor v2 anchoring:
|
||||
|
||||
* Clients/CI must never sign directly; they request signed bundles from Signer using PoE‑validated entitlements.([Gitea: Git with a cup of tea][1])
|
||||
* Use KMS/HSM backed key material where possible; use the CLI KMS verbs (`kms export/import`) for local key workflows in line with the CLI architecture.([Gitea: Git with a cup of tea][7])
|
||||
|
||||
**Defensive defaults**
|
||||
|
||||
* Enforce rate limiting, sender constraints, and safe crypto providers as described in Authority & crypto docs.([Gitea: Git with a cup of tea][6])
|
||||
* Never bypass `IAuthorityTokenStore` when revoking or mutating identities; supply machine‑friendly `revokedReason` codes so revocation bundles are deterministic.([Gitea: Git with a cup of tea][5])
|
||||
|
||||
### 3.7 Governance & change management
|
||||
|
||||
* Follow the **DevOps governance rules**:
|
||||
|
||||
* Gateway stays thin, ingestion is AOC‑only, Graph replaces older platforms, and rules are versioned in `docs/devops/contracts-and-rules.md`.([Gitea: Git with a cup of tea][3])
|
||||
* Treat architecture docs (`07_HIGH_LEVEL_ARCHITECTURE.md`, `platform/architecture-overview.md`, module dossiers) as **source of truth**; when behavior changes, update docs + sprint files, not just code.([Gitea: Git with a cup of tea][4])
|
||||
|
||||
---
|
||||
|
||||
## 4. Short checklists
|
||||
|
||||
You can paste these into your internal docs or tickets.
|
||||
|
||||
### 4.1 “Ready for first prod scan?” checklist
|
||||
|
||||
* [ ] Authority running with hardened defaults and backed by persistent Mongo.([Gitea: Git with a cup of tea][1])
|
||||
* [ ] Gateway verifies JWT + DPoP and enforces basic scopes.([Gitea: Git with a cup of tea][3])
|
||||
* [ ] Mongo, MinIO/RustFS, and queue backend deployed and monitored.([Gitea: Git with a cup of tea][4])
|
||||
* [ ] Scanner Web + Worker healthy; basic `/health` and `/ready` endpoints pass.([Gitea: Git with a cup of tea][1])
|
||||
* [ ] Signer, Attestor, Fulcio, Rekor v2 reachable; test DSSE signing + inclusion proof.([Gitea: Git with a cup of tea][4])
|
||||
* [ ] CLI installed; `stella auth login` and `stella scan image` succeed against a test image in `dev`.([Gitea: Git with a cup of tea][9])
|
||||
|
||||
### 4.2 “AOC compliant ingestion?” checklist
|
||||
|
||||
* [ ] `StellaOps.Aoc` guard wired into all Concelier/Excititor write paths.([Gitea: Git with a cup of tea][2])
|
||||
* [ ] Mongo validators enabled for `advisory_raw` and `vex_raw`.([Gitea: Git with a cup of tea][2])
|
||||
* [ ] Policy Engine is the only holder of `effective:write` scope.([Gitea: Git with a cup of tea][2])
|
||||
* [ ] `stella aoc verify` job added to CI for ingestion schema changes.([Gitea: Git with a cup of tea][2])
|
||||
|
||||
---
|
||||
|
||||
If you tell me your role (platform owner vs module implementer vs CI owner) and environment shape (Kubernetes/Compose, air‑gapped or not), I can turn these into a much more concrete “day‑1/day‑2” runbook or a set of internal ADRs.
|
||||
|
||||
[1]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/raw/commit/56c687253fbacabc25d8e1944f4fd43cb8dcef9c/AGENTS.md "git.stella-ops.org"
|
||||
[2]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/61f963fd52cd4d6bb2f86afc5a82eac04c04b00e/docs/modules/platform/architecture-overview.md?utm_source=chatgpt.com "StellaOps Architecture Overview (Sprint 19)"
|
||||
[3]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/raw/commit/13e4b53dda1575ba46c6188c794fd465ec6fdeec/docs/devops/contracts-and-rules.md?utm_source=chatgpt.com "Raw - Stella Ops"
|
||||
[4]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/efc4f5f761d1b77c370c7d34d3dd58f786fad617/docs/07_HIGH_LEVEL_ARCHITECTURE.md?utm_source=chatgpt.com "git.stella-ops.org/07_HIGH_LEVEL_ARCHITECTURE.md at ..."
|
||||
[5]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/8da4e12a90fd82f6b2ec870bb73e0499b4ff6343/docs/dev/31_AUTHORITY_PLUGIN_DEVELOPER_GUIDE.md?utm_source=chatgpt.com "Authority Plug-in Developer Guide - Stella Ops"
|
||||
[6]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/commits/commit/2e89a92d92387b49a0ce17333fcbaf17f00389e3/docs/07_HIGH_LEVEL_ARCHITECTURE.md?utm_source=chatgpt.com "8 Commits - Stella Ops"
|
||||
[7]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/240e8ff25ddf0f3385b817c30c26a24bff2e5730/docs/modules/cli/architecture.md?utm_source=chatgpt.com "git.stella-ops.org/architecture.md at ..."
|
||||
[8]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/commit/e2672ba968a7bd2c935cbc4cb572b383b15c8b07?files=docs%2FARCHITECTURE_CLI.md&utm_source=chatgpt.com "Rewrite architecture docs and add Vexer connector template ..."
|
||||
[9]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org/src/commit/48702191bed7d66b8e29929a8fad4ecdb40b9490/docs/quickstart.md?utm_source=chatgpt.com "Quickstart – First Scan in Five Minutes - Stella Ops"
|
||||
[10]: https://git.stella-ops.org/stella-ops.org/git.stella-ops.org?utm_source=chatgpt.com "stella-ops.org/git.stella-ops.org - git.stella-ops.org - Stella Ops"
|
||||
@@ -0,0 +1,861 @@
|
||||
Here’s a crisp, no-drama standup plan with three small wins that unblock bigger work. Background first, then exact tasks you can ship in a day.
|
||||
|
||||
---
|
||||
|
||||
# 1) Scanner post-mortem → 2 reproducible regressions
|
||||
|
||||
**Why:** Post-mortems sprawl. Two bullet-proof repros turn theories into fixable tickets.
|
||||
|
||||
**Task today**
|
||||
|
||||
* Pick the two highest-impact failure modes (e.g., wrong reachability verdict; missed OSV/CVE due to parser).
|
||||
* For each, produce a 1-command repro script (Docker image + SBOM fixture) and an **expected vs actual** JSON artifact.
|
||||
* Store under `tests/scanner/regressions/<case-id>/` with `README.md` and `make test` target.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* CI job `Scanner-Regression` runs both and fails deterministically if behavior regresses.
|
||||
|
||||
---
|
||||
|
||||
# 2) Mongo→Postgres slice prototype (pick one)
|
||||
|
||||
**Why:** A focused end-to-end slice beats a giant migration plan.
|
||||
|
||||
**Candidates**
|
||||
|
||||
* `Authority.Tokens` (licensing/entitlements)
|
||||
* `Scheduler.Jobs` (enqueued/executed metadata)
|
||||
* `VEX.Verdicts` (append-only history)
|
||||
|
||||
**Task today**
|
||||
|
||||
* Draft minimal DDL in `db/pg/migrations/0001_<slice>.sql` and EF Core model.
|
||||
* Add writer + reader paths behind `I<Slice>Store`; toggle backend using `STORE_BACKEND=Mongo|Postgres`.
|
||||
* Compose a data-parity test: write N records → read from both stores → byte-compare normalized JSON.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Service boots with `STORE_BACKEND=Postgres`, parity test passes locally, migration cleanly creates/drops the slice.
|
||||
|
||||
---
|
||||
|
||||
# 3) DSSE + Rekor attestation batch sweep
|
||||
|
||||
**Plain English:** sign DSSE envelopes, submit to Rekor, and size batches until failures appear.
|
||||
|
||||
**Task today**
|
||||
|
||||
* Choose an artifact type (e.g., `scanner-report.json`).
|
||||
* Implement a tiny CLI/script that signs K reports into DSSE, submits to Rekor/mirror, and logs latency + bytes + success.
|
||||
* Sweep K in {1,5,10,25,50}, output CSV under `experiments/dsse_rekor/`.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Deliver plot/table with recommended batch size and failure threshold (e.g., “use 10; >25 implies 8% retries”).
|
||||
|
||||
---
|
||||
|
||||
## Suggested assignments (1-day scope)
|
||||
|
||||
* **Alex** → #1 repros
|
||||
* **Mira** → #2 PG slice (Authority.Tokens)
|
||||
* **Petar** → #3 DSSE/Rekor sweep
|
||||
|
||||
## Ready-to-copy tickets
|
||||
|
||||
* **SCN-201:** “Create 2 deterministic regression tests for Scanner failures” (include folder layout + CI target).
|
||||
* **DB-301:** “Prototype Postgres backend for Authority.Tokens with parity test and feature flag.”
|
||||
* **SEC-411:** “Run DSSE+Rekor batch sweep for scanner reports; publish CSV and default threshold.”
|
||||
|
||||
If you want, I can generate the folders, Makefiles, EF Core stubs, and DSSE/Rekor sweep script next.
|
||||
Good, this helps narrow the scope. I’ll go point by point and then expand #3.
|
||||
|
||||
---
|
||||
|
||||
## 1) How these fit into Stella Ops, concretely
|
||||
|
||||
Think in terms of your core promises / moats:
|
||||
|
||||
* Deterministic, replayable scans
|
||||
* Verifiable SBOM → VEX chain with proofs
|
||||
* Future-proof data layout (Mongo + “recognized” SQL)
|
||||
* Proof-of-integrity / Rekor-style transparency
|
||||
|
||||
The three tasks line up like this:
|
||||
|
||||
### Task 1: Scanner post-mortem → 2 reproducible test cases
|
||||
|
||||
**Where it lives:** `scanner.webservice` + your test suite.
|
||||
|
||||
**Why it matters for Stella Ops:**
|
||||
|
||||
* Your brand is: “we don’t silently miss things; if we ever do, it becomes a test forever”.
|
||||
* Each “failure mode” becomes a **fixture** that:
|
||||
|
||||
* feeds into reachability heuristics,
|
||||
* is later used by Vexer/Excititor to show “we’ve seen this pattern in the wild and we handle it”.
|
||||
|
||||
It’s not random QA; it’s the foundation for your **“golden reachability dataset”** idea from the other branch. Every time you study a competitor miss or your own miss, it turns into:
|
||||
|
||||
* “Golden fixture #NN – known tricky case, guarded forever by CI”.
|
||||
|
||||
So this is directly supporting:
|
||||
|
||||
* Deterministic scanner behavior
|
||||
* Trust Algebra Studio later being able to say: “policy X passes all N golden fixtures”.
|
||||
|
||||
Very practical outcome: it gives your devs a **concrete target** instead of a vague “scanner is sometimes wrong”.
|
||||
|
||||
---
|
||||
|
||||
### Task 2: Postgres without migration: why and how
|
||||
|
||||
You’re right: there is no migration today, only **shape-finding**.
|
||||
|
||||
You said earlier: “conversion, not migration” and “we use PostgreSQL mainly because of recognition”. That can be turned into something useful now, without over-engineering:
|
||||
|
||||
**Goal in this phase**
|
||||
|
||||
* Define **one** slice of data model in Postgres that:
|
||||
|
||||
* is understandable to auditors / integrators,
|
||||
* is stable enough that, if you later decide to “convert” Mongo → PG, you already know how it should look,
|
||||
* forces you to create a clean abstraction (`IWhateverStore`) rather than hard-wiring Mongo into every service.
|
||||
|
||||
So instead of “migration plan”, think:
|
||||
|
||||
> “We are prototyping a **Postgres-friendly façade** for one core concept, behind an interface.”
|
||||
|
||||
Example: `Authority.Tokens` or `Scheduler.Jobs`.
|
||||
|
||||
* You keep Mongo as the actual source of truth for now.
|
||||
* You add a minimal Postgres model in EF Core.
|
||||
* You add a parity test (write/read in both backends, compare).
|
||||
* You wire a feature flag like `STORE_BACKEND=Mongo|Postgres` so you can switch environments on/off.
|
||||
|
||||
This gives you:
|
||||
|
||||
* Early signal about “does this data model work in SQL?”
|
||||
* A future-proof seam where “conversion” can happen when the product stabilizes.
|
||||
* Something that looks familiar to enterprise customers (“yes, we have Postgres, here is the schema”).
|
||||
|
||||
No migration script, no DMS, just **learning and shaping**.
|
||||
|
||||
If you prefer, you can drop the CI parity test and only keep:
|
||||
|
||||
* Interface
|
||||
* Two implementations
|
||||
* A simple console test or integration test
|
||||
|
||||
to keep ceremony minimal while still forcing a clean boundary.
|
||||
|
||||
---
|
||||
|
||||
## 3) DSSE + Rekor attestation experiment: deeper elaboration
|
||||
|
||||
I’ll treat this as: “Explain what exactly my team should build and why it matters to Stella Ops.”
|
||||
|
||||
### 3.1. Why you care at all
|
||||
|
||||
This task supports at least three of your moats:
|
||||
|
||||
* **Deterministic replayable scans**
|
||||
The DSSE envelope + Rekor entry is a cryptographic “receipt” for a given scan + SBOM + VEX result.
|
||||
* **Proof-of-Integrity Graph / Proof-Market Ledger**
|
||||
If you later build your own Rekor mirror or “Proof-Market Ledger”, you need to know real batch sizes and behavior now.
|
||||
* **Crypto-sovereign readiness**
|
||||
Eventually you want GOST / SM / PQC signatures; this small experiment tells you how your stack behaves with any signature scheme you plug in later.
|
||||
|
||||
So we’re doing **one focused measurement**:
|
||||
|
||||
> For *one* type of attestation, find the smallest batch size that:
|
||||
>
|
||||
> * keeps latency acceptable,
|
||||
> * doesn’t cause excessive timeouts or retries,
|
||||
> * doesn’t make envelopes so large they become awkward.
|
||||
|
||||
This becomes your **default configuration** for Scanner → Attestation → Rekor in all future designs.
|
||||
|
||||
---
|
||||
|
||||
### 3.2. What exactly to build
|
||||
|
||||
Propose a tiny .NET 10 console tool, e.g.:
|
||||
|
||||
`src/Experiments/StellaOps.Attest.Bench/StellaOps.Attest.Bench.csproj`
|
||||
|
||||
Binary: `stella-attest-bench`
|
||||
|
||||
**Inputs**
|
||||
|
||||
* A directory with scanner reports, e.g.: `artifacts/scanner-reports/*.json`
|
||||
* Rekor endpoint and credentials (or test/mirror instance)
|
||||
* Batch sizes to sweep: e.g. `1,5,10,25,50`
|
||||
|
||||
**CLI sketch**
|
||||
|
||||
```bash
|
||||
stella-attest-bench \
|
||||
--reports-dir ./artifacts/scanner-reports \
|
||||
--rekor-url https://rekor.stella.local \
|
||||
--batch-sizes 1,5,10,25,50 \
|
||||
--out ./experiments/dsse_rekor/results.csv
|
||||
```
|
||||
|
||||
**What each run does**
|
||||
|
||||
For each batch size `K`:
|
||||
|
||||
1. Take `K` reports from the directory.
|
||||
2. For each report:
|
||||
|
||||
* Wrap into a DSSE envelope:
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.stellaops.scanner-report+json",
|
||||
"payload": "<base64(report.json)>",
|
||||
"signatures": [
|
||||
{
|
||||
"keyid": "authority-key-1",
|
||||
"sig": "<base64(signature-by-key-1)>"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
* Measure size of the envelope in bytes.
|
||||
3. Submit the `K` envelopes to Rekor:
|
||||
|
||||
* Either one by one, or if your client API supports it, in a single batch call.
|
||||
* Record:
|
||||
|
||||
* start timestamp
|
||||
* end timestamp
|
||||
* status (success / failure / retry count)
|
||||
4. Append a row to `results.csv`:
|
||||
|
||||
```csv
|
||||
timestamp,batch_size,envelopes_count,total_bytes,avg_bytes,latency_ms,successes,failures,retries
|
||||
2025-11-30T14:02:00Z,10,10,123456,12345.6,820,10,0,0
|
||||
```
|
||||
|
||||
You can enrich it later with HTTP codes, Rekor log index, etc., but this is enough to choose a default.
|
||||
|
||||
---
|
||||
|
||||
### 3.3. Minimal internal structure
|
||||
|
||||
Rough C# layout (no full code, just architecture so devs don’t wander):
|
||||
|
||||
```csharp
|
||||
// Program.cs
|
||||
// - Parse args
|
||||
// - Build IServiceProvider
|
||||
// - Resolve and run BenchRunner
|
||||
|
||||
public sealed class BenchConfig
|
||||
{
|
||||
public string ReportsDirectory { get; init; } = default!;
|
||||
public Uri RekorUrl { get; init; } = default!;
|
||||
public int[] BatchSizes { get; init; } = Array.Empty<int>();
|
||||
public string OutputCsvPath { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed class BenchRunner
|
||||
{
|
||||
private readonly IDsseSigner _signer;
|
||||
private readonly IRekorClient _rekor;
|
||||
private readonly IResultsSink _sink;
|
||||
|
||||
public async Task RunAsync(BenchConfig config, CancellationToken ct);
|
||||
}
|
||||
|
||||
// IDsseSigner: wraps "payload" (report json bytes) -> DSSE envelope bytes
|
||||
// IRekorClient: envelope bytes -> result (success/fail, latency, retries)
|
||||
// IResultsSink: append rows to CSV
|
||||
```
|
||||
|
||||
Later, `IDsseSigner` and `IRekorClient` can be reused inside a proper `StellaOps.Attest` library that the Scanner or Scheduler use.
|
||||
|
||||
---
|
||||
|
||||
### 3.4. What “done” looks like in a way that matters to Stella Ops
|
||||
|
||||
Not just “we have a toy”. You want a **decision** out of this:
|
||||
|
||||
* `DEFAULT_DSSE_BATCH_SIZE = 10`
|
||||
* “For this Rekor setup, we observe:
|
||||
|
||||
* ≤10: 100 % success, latency ~X ms
|
||||
* 25: occasional retries
|
||||
* 50: frequent 5xx / timeouts; not recommended”
|
||||
|
||||
You then:
|
||||
|
||||
* Write this into a short markdown note, e.g.
|
||||
`docs/attestation/dsse-rekor-batch-sizing.md`
|
||||
* Use it when designing:
|
||||
|
||||
* Scanner → “Attestation job” messages (avoid pushing >10 envelopes at once),
|
||||
* The future “Proof-Market Ledger” so it doesn’t assume unbounded batches,
|
||||
* Air-gap mirror behavior (“we queue up batches of 10 before syncing”).
|
||||
|
||||
So the outcome is a **concrete configuration default and a constraint** that all future modules respect.
|
||||
|
||||
---
|
||||
|
||||
### If you want to simplify further
|
||||
|
||||
If this still feels too heavy for current prototyping speed, the absolute minimum to keep the value:
|
||||
|
||||
* Hardcode 2 batch sizes: `1` and `10`.
|
||||
* Only measure:
|
||||
|
||||
* latency
|
||||
* success/fail
|
||||
* Print results to stdout instead of CSV.
|
||||
|
||||
The key is: **one small executable experiment** that turns “DSSE + Rekor is cool” into “our default batch size is X for environment Y”.
|
||||
|
||||
---
|
||||
|
||||
If you tell me which module names you want to standardize on for this (e.g. `StellaOps.Attest`, `StellaOps.Experiments`, etc.), I can sketch exact folder names, namespaces, and even a first `.csproj` + `Program.cs` your dev can paste in.
|
||||
I’ll rewrite all three as tight internal guidelines you can drop into `docs/dev/`. Think of each as something you can hand to a new engineer and say: “Follow this exactly.”
|
||||
|
||||
---
|
||||
|
||||
## G1 · Scanner regression fixtures
|
||||
|
||||
**File:** `docs/dev/scanner-regressions.md`
|
||||
**Applies to:** `scanner.webservice` and any libraries it uses.
|
||||
|
||||
### 1. Purpose
|
||||
|
||||
Any serious scanner failure must become a deterministic regression fixture. Over time this becomes Stella Ops’ “golden dataset” for reachability and correctness.
|
||||
|
||||
Outcomes:
|
||||
|
||||
* Bugs don’t repeat silently.
|
||||
* Heuristics and future policies are validated against the same corpus.
|
||||
* Post‑mortems always end with a guardrail in CI.
|
||||
|
||||
### 2. When to create a regression fixture
|
||||
|
||||
Create a fixture when all three hold:
|
||||
|
||||
1. The bug affects at least one of:
|
||||
|
||||
* Severity ≥ Medium
|
||||
* High‑volume ecosystems (OS packages, Java, Python, Node, container base images)
|
||||
* Core behaviors (reachability, deduplication, suppression, parser correctness)
|
||||
2. The behavior is reproducible from static inputs (image, SBOM, or manifests).
|
||||
3. The expected correct behavior is agreed by at least one more engineer on the scanner team.
|
||||
|
||||
If in doubt: add the fixture. It is cheap, and it strengthens the golden corpus.
|
||||
|
||||
### 3. Directory structure & naming
|
||||
|
||||
Test project:
|
||||
|
||||
```text
|
||||
tests/
|
||||
StellaOps.Scanner.RegressionTests/
|
||||
Regression/
|
||||
SCN-0001-missed-cve-in-layer/
|
||||
SCN-0002-wrong-reachability/
|
||||
...
|
||||
```
|
||||
|
||||
Fixture layout (example):
|
||||
|
||||
```text
|
||||
SCN-0001-missed-cve-in-layer/
|
||||
input/
|
||||
image.sbom.json # or image.tar, etc.
|
||||
config.json # scanner flags, if needed
|
||||
expected/
|
||||
findings.json # canonical expected findings
|
||||
case.metadata.json # machine-readable description
|
||||
case.md # short human narrative
|
||||
```
|
||||
|
||||
`case.metadata.json` schema:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "SCN-0001",
|
||||
"title": "Missed CVE-2025-12345 in lower layer",
|
||||
"kind": "vulnerability-missed",
|
||||
"source": "internal-postmortem",
|
||||
"severity": "high",
|
||||
"tags": [
|
||||
"reachability",
|
||||
"language:java",
|
||||
"package:log4j"
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
`case.md` should answer:
|
||||
|
||||
* What failed?
|
||||
* Why this case is representative / important?
|
||||
* What is the correct expected behavior?
|
||||
|
||||
### 4. Test harness rules
|
||||
|
||||
Global rules for all regression tests:
|
||||
|
||||
* No network access (fixtures must be fully self‑contained).
|
||||
* No time‑dependent logic (use fixed timestamps if necessary).
|
||||
* No nondeterministic behavior (seed any randomness).
|
||||
|
||||
Comparison rules:
|
||||
|
||||
* Normalize scanner output before comparison:
|
||||
|
||||
* Sort arrays (e.g. findings).
|
||||
* Remove volatile fields (generated IDs, timestamps, internal debug metadata).
|
||||
* Compare canonical JSON (e.g. string equality on normalized JSON).
|
||||
|
||||
Implementation sketch (xUnit):
|
||||
|
||||
```csharp
|
||||
public class GoldenRegressionTests
|
||||
{
|
||||
[Theory]
|
||||
[MemberData(nameof(RegressionSuite.LoadCases), MemberType = typeof(RegressionSuite))]
|
||||
public async Task Scanner_matches_expected_findings(RegressionCase @case)
|
||||
{
|
||||
var actual = await ScannerTestHost.RunAsync(@case.InputDirectory);
|
||||
|
||||
var expectedJson = File.ReadAllText(@case.ExpectedFindingsPath);
|
||||
|
||||
var normalizedActual = FindingsNormalizer.Normalize(actual);
|
||||
var normalizedExpected = FindingsNormalizer.Normalize(expectedJson);
|
||||
|
||||
Assert.Equal(normalizedExpected, normalizedActual);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5. How to add a new regression case
|
||||
|
||||
Checklist for developers:
|
||||
|
||||
1. **Reproduce the bug** using local dev tools.
|
||||
2. **Minimize the input**:
|
||||
|
||||
* Prefer a trimmed SBOM or minimal image over full customer artifacts.
|
||||
* Remove sensitive data; use synthetic equivalents if needed.
|
||||
3. **Create folder** under `Regression/SCN-XXXX-short-slug/`.
|
||||
4. Populate:
|
||||
|
||||
* `input/` with all needed inputs (SBOMs, manifests, config).
|
||||
* `expected/findings.json` with the correct canonical output (not the buggy one).
|
||||
* `case.metadata.json` and `case.md`.
|
||||
5. **Run tests** locally:
|
||||
`dotnet test tests/StellaOps.Scanner.RegressionTests`
|
||||
6. Fix the scanner behavior (if not already fixed).
|
||||
7. Ensure tests fail without the fix and pass with it.
|
||||
8. Open PR with:
|
||||
|
||||
* Fixture directory.
|
||||
* Scanner fix.
|
||||
* Any harness adjustments.
|
||||
|
||||
### 6. CI integration & “done” definition
|
||||
|
||||
* CI job `Scanner-Regression` runs in PR validation and main.
|
||||
* A regression case is “live” when:
|
||||
|
||||
* It’s present under `Regression/`.
|
||||
* It is picked up by the harness.
|
||||
* CI fails if the behavior regresses.
|
||||
|
||||
---
|
||||
|
||||
## G2 · Postgres slice prototype (shape‑finding, no migration)
|
||||
|
||||
**File:** `docs/dev/authority-store-backends.md`
|
||||
**Applies to:** Authority (or similar) services that currently use Mongo.
|
||||
|
||||
### 1. Purpose
|
||||
|
||||
This is not data migration. It is about:
|
||||
|
||||
* Designing a clean storage interface.
|
||||
* Prototyping a Postgres‑friendly schema for one bounded slice (e.g. `Authority.Tokens`).
|
||||
* Being able to run the service with either Mongo or Postgres behind the same interface.
|
||||
|
||||
This supports future “conversion” and enterprise expectations (“we speak Postgres”) without blocking current prototyping speed.
|
||||
|
||||
### 2. Scope & constraints
|
||||
|
||||
* Scope: one slice only (e.g. tokens, jobs, or VEX verdicts).
|
||||
* Mongo remains the operational source of truth for now.
|
||||
* Postgres path is opt‑in via configuration.
|
||||
* No backward migration or synchronization logic.
|
||||
|
||||
### 3. Repository layout
|
||||
|
||||
Example for `Authority.Tokens`:
|
||||
|
||||
```text
|
||||
src/
|
||||
StellaOps.Authority/
|
||||
Domain/
|
||||
Token.cs
|
||||
TokenId.cs
|
||||
...
|
||||
Stores/
|
||||
ITokenStore.cs
|
||||
MongoTokenStore.cs
|
||||
PostgresTokenStore.cs
|
||||
Persistence/
|
||||
AuthorityPgDbContext.cs
|
||||
Migrations/
|
||||
0001_AuthTokens_Init.sql
|
||||
docs/
|
||||
dev/
|
||||
authority-store-backends.md
|
||||
```
|
||||
|
||||
### 4. Store interface design
|
||||
|
||||
Guidelines:
|
||||
|
||||
* Keep the interface narrow and domain‑centric.
|
||||
* Do not leak Mongo or SQL constructs.
|
||||
|
||||
Example:
|
||||
|
||||
```csharp
|
||||
public interface ITokenStore
|
||||
{
|
||||
Task<Token?> GetByIdAsync(TokenId id, CancellationToken ct = default);
|
||||
Task<IReadOnlyList<Token>> GetByOwnerAsync(PrincipalId ownerId, CancellationToken ct = default);
|
||||
Task SaveAsync(Token token, CancellationToken ct = default);
|
||||
Task RevokeAsync(TokenId id, RevocationReason reason, CancellationToken ct = default);
|
||||
}
|
||||
```
|
||||
|
||||
Both `MongoTokenStore` and `PostgresTokenStore` must implement this contract.
|
||||
|
||||
### 5. Postgres schema guidelines
|
||||
|
||||
Principles:
|
||||
|
||||
* Use schemas per bounded context, e.g. `authority`.
|
||||
* Choose stable primary keys (`uuid` or `bigint`), not composite keys unless necessary.
|
||||
* Index only for known access patterns.
|
||||
|
||||
Example DDL:
|
||||
|
||||
```sql
|
||||
CREATE SCHEMA IF NOT EXISTS authority;
|
||||
|
||||
CREATE TABLE IF NOT EXISTS authority.tokens (
|
||||
id uuid PRIMARY KEY,
|
||||
owner_id uuid NOT NULL,
|
||||
kind text NOT NULL,
|
||||
issued_at_utc timestamptz NOT NULL,
|
||||
expires_at_utc timestamptz NULL,
|
||||
is_revoked boolean NOT NULL DEFAULT false,
|
||||
revoked_at_utc timestamptz NULL,
|
||||
revoked_reason text NULL,
|
||||
payload_json jsonb NOT NULL,
|
||||
created_at_utc timestamptz NOT NULL DEFAULT now(),
|
||||
updated_at_utc timestamptz NOT NULL DEFAULT now()
|
||||
);
|
||||
|
||||
CREATE INDEX IF NOT EXISTS ix_tokens_owner_id
|
||||
ON authority.tokens (owner_id);
|
||||
|
||||
CREATE INDEX IF NOT EXISTS ix_tokens_kind
|
||||
ON authority.tokens (kind);
|
||||
```
|
||||
|
||||
EF Core:
|
||||
|
||||
* Map with `ToTable("tokens", "authority")`.
|
||||
* Use owned types or value converters for `payload_json`.
|
||||
|
||||
### 6. Configuration & feature flag
|
||||
|
||||
Configuration:
|
||||
|
||||
```jsonc
|
||||
// appsettings.json
|
||||
{
|
||||
"Authority": {
|
||||
"StoreBackend": "Mongo", // or "Postgres"
|
||||
"Postgres": {
|
||||
"ConnectionString": "Host=...;Database=stella;..."
|
||||
},
|
||||
"Mongo": {
|
||||
"ConnectionString": "...",
|
||||
"Database": "stella_authority"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Environment override:
|
||||
|
||||
* `AUTHORITY_STORE_BACKEND=Postgres`
|
||||
|
||||
DI wiring:
|
||||
|
||||
```csharp
|
||||
services.AddSingleton<ITokenStore>(sp =>
|
||||
{
|
||||
var cfg = sp.GetRequiredService<IOptions<AuthorityOptions>>().Value;
|
||||
return cfg.StoreBackend switch
|
||||
{
|
||||
"Postgres" => new PostgresTokenStore(
|
||||
sp.GetRequiredService<AuthorityPgDbContext>()),
|
||||
"Mongo" => new MongoTokenStore(
|
||||
sp.GetRequiredService<IMongoDatabase>()),
|
||||
_ => throw new InvalidOperationException("Unknown store backend")
|
||||
};
|
||||
});
|
||||
```
|
||||
|
||||
### 7. Minimal parity / sanity checks
|
||||
|
||||
Given you are still prototyping, keep this light.
|
||||
|
||||
Recommended:
|
||||
|
||||
* A single test or console harness that:
|
||||
|
||||
* Creates a small set of `Token` objects.
|
||||
* Writes via Mongo and via Postgres.
|
||||
* Reads back from each and compares a JSON representation of the domain object (ignoring DB‑specific metadata).
|
||||
|
||||
This is not full data migration testing; it is a smoke check that both backends honor the same domain contract.
|
||||
|
||||
### 8. “Done” definition for the first slice
|
||||
|
||||
For the chosen slice (e.g. `Authority.Tokens`):
|
||||
|
||||
* `ITokenStore` exists, with Mongo and Postgres implementations.
|
||||
* A Postgres DbContext and first migration are present and runnable.
|
||||
* The service starts cleanly with `StoreBackend=Postgres` against an empty DB.
|
||||
* There is at least one automated or scripted sanity check that both backends behave equivalently for typical operations.
|
||||
* This is documented in `docs/dev/authority-store-backends.md`:
|
||||
|
||||
* How to switch backends.
|
||||
* Current state: “Postgres is experimental; Mongo is default.”
|
||||
|
||||
---
|
||||
|
||||
## G3 · DSSE + Rekor batch‑size experiment
|
||||
|
||||
**File:** `docs/attestation/dsse-rekor-batch-sizing.md`
|
||||
**Applies to:** Attestation / integrity pipeline for scanner reports.
|
||||
|
||||
### 1. Purpose
|
||||
|
||||
Determine a concrete default batch size for DSSE envelopes submitted to Rekor, balancing:
|
||||
|
||||
* Reliability (few or no failures / retries).
|
||||
* Latency (per batch).
|
||||
* Envelope size (practical for transport and logging).
|
||||
|
||||
Outcome: a hard configuration value, e.g. `DefaultDsseRekorBatchSize = 10`, backed by measurement.
|
||||
|
||||
### 2. Scope
|
||||
|
||||
* Artifact type: scanner report (e.g. `scanner-report.json`).
|
||||
* Environment: your current Rekor endpoint (or mirror), not production critical path.
|
||||
* One small experiment tool, later reusable by attestation services.
|
||||
|
||||
### 3. Project structure
|
||||
|
||||
```text
|
||||
src/
|
||||
Experiments/
|
||||
StellaOps.Attest.Bench/
|
||||
Program.cs
|
||||
BenchConfig.cs
|
||||
BenchRunner.cs
|
||||
DsseSigner.cs
|
||||
RekorClient.cs
|
||||
ResultsCsvSink.cs
|
||||
experiments/
|
||||
dsse_rekor/
|
||||
results.csv
|
||||
docs/
|
||||
attestation/
|
||||
dsse-rekor-batch-sizing.md
|
||||
```
|
||||
|
||||
### 4. CLI contract
|
||||
|
||||
Binary: `stella-attest-bench`
|
||||
|
||||
Example usage:
|
||||
|
||||
```bash
|
||||
stella-attest-bench \
|
||||
--reports-dir ./artifacts/scanner-reports \
|
||||
--rekor-url https://rekor.lab.stella \
|
||||
--batch-sizes 1,5,10,25,50 \
|
||||
--out ./experiments/dsse_rekor/results.csv \
|
||||
--max-retries 3 \
|
||||
--timeout-ms 10000
|
||||
```
|
||||
|
||||
Required flags:
|
||||
|
||||
* `--reports-dir`
|
||||
* `--rekor-url`
|
||||
* `--batch-sizes`
|
||||
* `--out`
|
||||
|
||||
Optional:
|
||||
|
||||
* `--max-retries` (default 3)
|
||||
* `--timeout-ms` (default 10000 ms)
|
||||
|
||||
### 5. Implementation guidelines
|
||||
|
||||
Core config:
|
||||
|
||||
```csharp
|
||||
public sealed class BenchConfig
|
||||
{
|
||||
public string ReportsDirectory { get; init; } = default!;
|
||||
public Uri RekorUrl { get; init; } = default!;
|
||||
public int[] BatchSizes { get; init; } = Array.Empty<int>();
|
||||
public string OutputCsvPath { get; init; } = default!;
|
||||
public int MaxRetries { get; init; } = 3;
|
||||
public int TimeoutMs { get; init; } = 10_000;
|
||||
}
|
||||
```
|
||||
|
||||
Interfaces:
|
||||
|
||||
```csharp
|
||||
public interface IDsseSigner
|
||||
{
|
||||
byte[] WrapAndSign(byte[] payload, string payloadType);
|
||||
}
|
||||
|
||||
public interface IRekorClient
|
||||
{
|
||||
Task<RekorSubmitResult> SubmitAsync(
|
||||
IReadOnlyList<byte[]> envelopes,
|
||||
CancellationToken ct);
|
||||
}
|
||||
|
||||
public interface IResultsSink
|
||||
{
|
||||
Task AppendAsync(BatchMeasurement measurement, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
Measurement model:
|
||||
|
||||
```csharp
|
||||
public sealed class BatchMeasurement
|
||||
{
|
||||
public DateTime TimestampUtc { get; init; }
|
||||
public int BatchSize { get; init; }
|
||||
public int EnvelopeCount { get; init; }
|
||||
public long TotalBytes { get; init; }
|
||||
public double AverageBytes { get; init; }
|
||||
public long LatencyMs { get; init; }
|
||||
public int SuccessCount { get; init; }
|
||||
public int FailureCount { get; init; }
|
||||
public int RetryCount { get; init; }
|
||||
}
|
||||
```
|
||||
|
||||
Runner outline:
|
||||
|
||||
1. Enumerate report files in `ReportsDirectory` (e.g. `*.json`).
|
||||
2. For each `batchSize`:
|
||||
|
||||
* Select up to `batchSize` reports.
|
||||
* For each report:
|
||||
|
||||
* Read bytes.
|
||||
* Call `IDsseSigner.WrapAndSign` with payload type
|
||||
`application/vnd.stellaops.scanner-report+json`.
|
||||
* Track envelope sizes.
|
||||
* Start stopwatch.
|
||||
* Submit via `IRekorClient.SubmitAsync` with retry logic honoring `MaxRetries` and `TimeoutMs`.
|
||||
* Record latency, successes, failures, retries.
|
||||
* Write one `BatchMeasurement` row to `results.csv`.
|
||||
|
||||
CSV headers:
|
||||
|
||||
```csv
|
||||
timestamp_utc,batch_size,envelopes_count,total_bytes,avg_bytes,latency_ms,successes,failures,retries
|
||||
```
|
||||
|
||||
Signer:
|
||||
|
||||
* For the experiment, use a local dev key (e.g. Ed25519).
|
||||
* Make signing deterministic (no random salts that affect envelope size unexpectedly).
|
||||
|
||||
Rekor client:
|
||||
|
||||
* For this experiment, you only need “accepted or not” plus HTTP status codes; inclusion proof verification is out of scope.
|
||||
|
||||
### 6. How to run and interpret
|
||||
|
||||
Execution steps:
|
||||
|
||||
1. Prepare a folder with representative scanner reports:
|
||||
|
||||
* At least 20–30 reports from different images, to approximate typical size variance.
|
||||
2. Ensure the Rekor environment is reachable and not rate‑limited.
|
||||
3. Run the tool with a sweep like `1,5,10,25,50`.
|
||||
4. Inspect `results.csv`:
|
||||
|
||||
* For each batch size, look at:
|
||||
|
||||
* Average latency.
|
||||
* Any non‑zero failures or elevated retry counts.
|
||||
* Total and average bytes per envelope.
|
||||
|
||||
Decision rules:
|
||||
|
||||
* Pick the largest batch size that:
|
||||
|
||||
* Shows 0 failures and acceptable retry counts across multiple runs.
|
||||
* Keeps latency in a reasonable budget for your pipeline (e.g. under a few seconds per batch).
|
||||
* Define:
|
||||
|
||||
* `DefaultBatchSize` = chosen safe value.
|
||||
* `HardMaxBatchSize` = first size where failures or unacceptable latency appear.
|
||||
|
||||
Document in `docs/attestation/dsse-rekor-batch-sizing.md`:
|
||||
|
||||
* Environment details (Rekor version, hardware, network).
|
||||
* Brief description of report corpus.
|
||||
* A summarized table from `results.csv`.
|
||||
* The chosen `DefaultBatchSize` and `HardMaxBatchSize` with a clear statement:
|
||||
|
||||
* “All production attestation jobs must respect this default and must not exceed the hard max without a new measurement.”
|
||||
|
||||
### 7. “Done” definition
|
||||
|
||||
The experiment is “done” when:
|
||||
|
||||
* `StellaOps.Attest.Bench` builds and runs with the specified CLI.
|
||||
* It produces a `results.csv` with one row per `(run, batch_size)` combination.
|
||||
* There is a written default:
|
||||
|
||||
* `DefaultDsseRekorBatchSize = X`
|
||||
* plus rationale in `dsse-rekor-batch-sizing.md`.
|
||||
* Future attestation designs (e.g. scanner → ledger pipeline) are required to use that default unless they explicitly update the experiment and the document.
|
||||
|
||||
---
|
||||
|
||||
If you want, next step can be: convert each of these into actual files (including a minimal `csproj` and `Program.cs` for the bench tool) so your team can copy‑paste and start implementing.
|
||||
@@ -0,0 +1,497 @@
|
||||
Here are **three tightly scoped UI micro-interactions** you can drop into the next front-end sprint. Each maps to a single Angular task and reinforces StellaOps’ auditability, low-noise VEX gating, and evidence provenance for both air-gapped and online users.
|
||||
|
||||
---
|
||||
|
||||
# 1) Audit Trail “Why am I seeing this?” (per-row expandable reason)
|
||||
|
||||
**Goal:** Make every verdict/action explainable at a glance.
|
||||
|
||||
* **User flow:** In Tables (Findings, Components, Policies), each row shows a tiny “ⓘ Why?” chip. Clicking expands an inline panel with the explanation capsule (policy that fired, rule hash, data inputs, and the deterministic graph revision ID).
|
||||
* **Angular task:**
|
||||
* Add `ReasonCapsuleComponent` (standalone) with inputs: `policyName`, `ruleId`, `graphRevisionId`, `inputsDigest`, `timestamp`, `actor`.
|
||||
* Drop it into tables via `*ngTemplateOutlet` so no table refactor.
|
||||
* Keyboard accessible (Enter/Space toggles).
|
||||
* **Backend contract (read-only):** `GET /api/audit/reasons/:verdictId` →
|
||||
```json
|
||||
{
|
||||
"policy":"Default VEX Merge",
|
||||
"ruleId":"vex.merge.R12",
|
||||
"graphRevisionId":"grv_2025-11-18T12:03Z_b3e1",
|
||||
"inputsDigest":"sha256:…",
|
||||
"actor":"Vexer",
|
||||
"ts":"2025-11-18T12:03:22Z"
|
||||
}
|
||||
```
|
||||
* **Acceptance criteria:**
|
||||
* Toggle persists open/closed per row in URL state (`?open=rid1,rid3`).
|
||||
* Copy-to-clipboard for `graphRevisionId`.
|
||||
* Works in offline bundle (served from local API).
|
||||
|
||||
---
|
||||
|
||||
# 2) Low-noise VEX Gate (inline, gated action with 3 evidence tiers)
|
||||
|
||||
**Goal:** Reduce false prompts and only block when evidence is meaningful.
|
||||
|
||||
* **User flow:** On risky actions (promote image, approve import), the primary button morphs into a **VEX Gate**: a small dropdown right-aligned to the button label showing **Green/Amber/Red** status with the top blocking reason. Clicking opens a concise sheet (not a modal) with the minimal evidence set, and a single “Proceed anyway” path if policy allows.
|
||||
* **Angular task:**
|
||||
* Create `VexGateButtonDirective` that decorates existing `<button>` to append status chip + sheet host.
|
||||
* Create `VexEvidenceSheetComponent` that renders: top finding, reachability hint, last vendor VEX statement, and policy clause that blocks/allows.
|
||||
* **Backend contract:** `POST /api/vex/gate` with `{artifactId, action}` →
|
||||
```json
|
||||
{
|
||||
"tier":"amber",
|
||||
"reason":"Reachable CVE with pending vendor statement",
|
||||
"policyClause":"gates.required.vendor_vex==true",
|
||||
"allowBypass":true,
|
||||
"expires":"2025-12-31T00:00:00Z"
|
||||
}
|
||||
```
|
||||
* **Acceptance criteria:**
|
||||
* Button aria-label reflects state (“Promote — VEX Amber”).
|
||||
* Gate sheet loads <300ms cached; falls back to last known cache if offline.
|
||||
* “Proceed anyway” requires typed confirmation only when `allowBypass=true` and logs an audit event.
|
||||
|
||||
---
|
||||
|
||||
# 3) Evidence Provenance Chip (DSSE/receipt capture w/ one-tap export)
|
||||
|
||||
**Goal:** Make provenance obvious and exportable for audits.
|
||||
|
||||
* **User flow:** Wherever we render an SBOM, VEX, or Attestation, show a **Provenance chip** (`Signed • Verified • Logged`) with an overflow menu: **View DSSE**, **View Rekor/Receipt**, **Export bundle (.tar.zst)**. In air-gap mode, the “Logged” badge swaps to “Queued” with a tooltip.
|
||||
* **Angular task:**
|
||||
* `ProvenanceChipComponent` with inputs: `sigStatus`, `dsseDigest`, `rekorInclusion`, `queued`.
|
||||
* `ProvenanceDialogComponent` to show DSSE envelope (pretty-printed), inclusion proof (Merkle path), and copy buttons.
|
||||
* **Backend contract:**
|
||||
* `GET /api/provenance/:artifactId` → DSSE envelope + receipt (or offline queue record).
|
||||
* `POST /api/provenance/export` → streams `application/zstd` containing: envelope, payload, receipt, local trust anchors.
|
||||
* **Acceptance criteria:**
|
||||
* Chip states: `Unsigned`, `Signed`, `Verified`, `Verified+Logged`; offline shows `Signed+Queued`.
|
||||
* Export under 5s for 10MB payloads; filename includes `graphRevisionId`.
|
||||
* All views work with no internet; if Rekor unreachable, show last cached receipt with “not recently synced” hint.
|
||||
|
||||
---
|
||||
|
||||
## Dev notes (quick drop-in)
|
||||
|
||||
* **Module placement:** `apps/console/src/app/shared/micro/…` (standalone components, tree-shakable).
|
||||
* **Theme:** Consume existing Tailwind tokens; no new colors (use semantic classes).
|
||||
* **Testing:**
|
||||
* Unit: input contracts + a11y snapshot.
|
||||
* E2E: Cypress happy path per interaction (open/close, bypass, export).
|
||||
* **Telemetry/Audit:** Emit a single `ui_event` per interaction with `graphRevisionId`, `policyClause`, `artifactId`.
|
||||
* **Offline kits:** All three rely only on local API; Rekor calls are optional/cached.
|
||||
|
||||
If you want, I can turn this into three Jira tickets (with checklists) and a PR scaffold (`ng g component` stubs + sample mocks) so your team can start today.
|
||||
Here’s a **v0.1 “StellaOps UX Guidelines”** you can hand to your UX devs and iterate on. I’ll keep it concrete and opinionated, tuned to your world: SBOMs, evidence, attestations, VEX, online + air‑gap.
|
||||
|
||||
---
|
||||
|
||||
## 0. Who these guidelines are for
|
||||
|
||||
These guidelines are for people who:
|
||||
|
||||
* Build UI in Angular for the StellaOps console
|
||||
* Design workflows around **evidence, SBOMs, VEX, and policy decisions**
|
||||
* Need to keep **high‑assurance users** (security, compliance, infra) happy without drowning them in noise
|
||||
|
||||
Whenever in doubt: **opt for clarity, traceability, and low noise**.
|
||||
|
||||
---
|
||||
|
||||
## 1. Core StellaOps UX Principles
|
||||
|
||||
These are the “north star” rules. Every screen and interaction should support them:
|
||||
|
||||
1. **Everything is explainable**
|
||||
|
||||
* Every verdict, badge, and gating decision must have an explicit “why” nearby.
|
||||
* Implement via the *Reason Capsule* (“Why am I seeing this?” expanders) on rows, cards, and actions.
|
||||
|
||||
2. **Evidence in one hop**
|
||||
|
||||
* The user should never click more than **once** from a verdict to the underlying evidence (SBOM, attestation, DSSE, log receipt).
|
||||
* Use: side panel / drawer or inline expansion instead of forcing navigation to a separate page.
|
||||
|
||||
3. **Noise is a bug**
|
||||
|
||||
* Prompts, warnings, and banners are **exceptions**, not the default.
|
||||
* High-severity blocking states must be rare, justified, and explicitly tied to a policy clause.
|
||||
|
||||
4. **Deterministic, not magical**
|
||||
|
||||
* If something is inferred or uncertain, label it clearly (“Inferred reachability”, “Heuristic match”).
|
||||
* Never present a guess as a fact.
|
||||
|
||||
5. **Safe by default, reversible when possible**
|
||||
|
||||
* Default to the safer path (e.g., “Block promotion” if in doubt).
|
||||
* If a potentially risky override is allowed, make it:
|
||||
|
||||
* Explicit
|
||||
* Audited
|
||||
* Slightly “hard” (typed confirmation, not just a single click)
|
||||
|
||||
6. **Online and air‑gapped parity**
|
||||
|
||||
* The same mental model must work whether online or air‑gapped.
|
||||
* When external services are unavailable, show **degraded but honest** states (“Verified + Queued” vs “Verified + Logged”).
|
||||
|
||||
7. **Fast for experts**
|
||||
|
||||
* Keyboard accessible, dense data tables, predictable shortcuts.
|
||||
* Avoid wizards for frequent tasks; use in-place controls and drawers instead.
|
||||
|
||||
---
|
||||
|
||||
## 2. Domain model in the UI (what users should always see)
|
||||
|
||||
Make these concepts feel consistent across all screens:
|
||||
|
||||
* **Artifact**: image, package, or component.
|
||||
* **Evidence**: SBOMs, attestations, VEX docs, logs, receipts, scans.
|
||||
* **Policy**: the rules that drive decisions.
|
||||
* **Verdict / Status**: “Allowed / Blocked / Needs Review / Unknown”.
|
||||
* **Graph Revision ID**: the immutable “snapshot ID” of the decision state.
|
||||
* **Audit Event**: who did what, when, and based on which graph revision.
|
||||
|
||||
**Guideline:** Any place the user sees a **verdict or action**, they should also see:
|
||||
|
||||
* The **policy** that drove it
|
||||
* The **graph revision ID**
|
||||
* A one-click path to **evidence** and **audit trail**
|
||||
|
||||
Our 3 micro‑interactions (Reason Capsule, VEX Gate, Provenance Chip) exist to make this easy.
|
||||
|
||||
---
|
||||
|
||||
## 3. Core Interaction Patterns
|
||||
|
||||
### 3.1 Reason Capsule: “Why am I seeing this?”
|
||||
|
||||
Used in tables, lists, and detail views.
|
||||
|
||||
**Where to place**
|
||||
|
||||
* In tables: right side of each row as a small chip or icon: `ⓘ Why?`
|
||||
* In cards/detail headers: as a text link: “Why this verdict?”
|
||||
|
||||
**Behavior**
|
||||
|
||||
* Click/Enter/Space toggles an **inline expansion** under the row or section.
|
||||
* Show:
|
||||
|
||||
* Policy name (with pill: e.g., `Policy: Default VEX Merge`)
|
||||
* Rule ID (e.g., `vex.merge.R12`)
|
||||
* Graph revision ID (copyable)
|
||||
* Key inputs (SBOM digest, VEX source, relevant CVE IDs)
|
||||
* Actor (“Vexer”, “User override: [alice@example.com](mailto:alice@example.com)”)
|
||||
* Timestamp
|
||||
|
||||
**UX rules**
|
||||
|
||||
* Keep it **3–5 lines** max by default; use “Show more” for full detail.
|
||||
* Always lead with a **plain-language sentence**:
|
||||
|
||||
* “This artifact is blocked because policy ‘Prod Promotion’ requires a vendor VEX statement for reachable critical CVEs.”
|
||||
* Include a **copy-to-clipboard** affordance for graphRevisionId.
|
||||
* Remember accessibility:
|
||||
|
||||
* `aria-expanded` reflects state
|
||||
* The expander is focusable and operable via keyboard
|
||||
|
||||
---
|
||||
|
||||
### 3.2 VEX Gate: Gated primary actions
|
||||
|
||||
Used on high-impact actions: promote image, approve import, mark as compliant, etc.
|
||||
|
||||
**Pattern**
|
||||
|
||||
* Primary button is enhanced by a **VEX status chip**:
|
||||
|
||||
* Label pattern: `Promote` + `VEX: Green/Amber/Red` chip.
|
||||
* Clicking the chip or a small caret opens a **compact sheet** anchored to the button.
|
||||
* The sheet shows:
|
||||
|
||||
* Tier: `Green` (no blocking issues), `Amber` (warning), `Red` (blocking)
|
||||
* Top reason in plain language
|
||||
* Policy clause that applies
|
||||
* Minimal evidence summary: 1–2 key findings, last vendor VEX statement, reachability
|
||||
* Whether bypass is allowed and what it implies
|
||||
|
||||
**Noise rules**
|
||||
|
||||
* Don’t show a blocking **modal** unless absolutely necessary:
|
||||
|
||||
* Prefer anchored sheets or drawers that don’t break context.
|
||||
* Only require **typed confirmation** if:
|
||||
|
||||
* Tier is `Red` **and**
|
||||
* Policy explicitly allows bypass
|
||||
|
||||
**Copy guidelines**
|
||||
|
||||
* Green:
|
||||
|
||||
* “No blocking VEX findings for this artifact under ‘Prod Promotion’ policy.”
|
||||
* Amber:
|
||||
|
||||
* “Found reachable CVE with pending vendor VEX. Policy allows promotion with review.”
|
||||
* Red:
|
||||
|
||||
* “Blocking: reachable critical CVE without compensating VEX or mitigation documented.”
|
||||
|
||||
**Offline/air‑gapped**
|
||||
|
||||
* If gate info is coming from cache:
|
||||
|
||||
* Label: “Based on last local evaluation (not recently synced).”
|
||||
* The action should still be possible if the **policy** says so, even when external VEX feeds are offline.
|
||||
|
||||
---
|
||||
|
||||
### 3.3 Provenance Chip: Attestations, DSSE, receipts
|
||||
|
||||
Appears next to any evidence object (SBOM, attestation, VEX doc) and on artifact details.
|
||||
|
||||
**States**
|
||||
|
||||
Use a small chip with an icon + label:
|
||||
|
||||
* `Unsigned`
|
||||
* `Signed`
|
||||
* `Signed • Verified`
|
||||
* `Signed • Verified • Logged`
|
||||
* Offline variant: `Signed • Verified • Queued`
|
||||
|
||||
**Behavior**
|
||||
|
||||
* Clicking opens a **Provenance dialog**:
|
||||
|
||||
* DSSE envelope (structured view with collapsing sections)
|
||||
* Subject digest(s)
|
||||
* Inclusion proof / log receipt (if online)
|
||||
* Trust anchor summary (what keys were trusted)
|
||||
* Export CTA for full bundle
|
||||
|
||||
**Rules**
|
||||
|
||||
* The chip state must **never lie**. If Rekor (or similar) is unreachable:
|
||||
|
||||
* Show last known receipt + “not recently synced” note.
|
||||
* Export action:
|
||||
|
||||
* Single button: “Export provenance bundle (.tar.zst)”
|
||||
* Filename should include artifactId and graphRevisionId.
|
||||
|
||||
---
|
||||
|
||||
## 4. Layout & Information Density
|
||||
|
||||
### 4.1 Tables and lists
|
||||
|
||||
* Default to **tables** for any list of artifacts, findings, or evidence.
|
||||
* Per row:
|
||||
|
||||
* Left side: identity (name, version, image tag)
|
||||
* Middle: key status chips (severity, policy verdicts, provenance state)
|
||||
* Right: row actions + Reason Capsule
|
||||
|
||||
**Column order guideline**
|
||||
|
||||
1. Artifact / Evidence identifier
|
||||
2. Primary status (Allowed/Blocked/Needs Review)
|
||||
3. Severity / Risk
|
||||
4. Provenance status
|
||||
5. Last updated / source
|
||||
6. Actions + “Why?”
|
||||
|
||||
Avoid more than **7 columns** at once; beyond that, use:
|
||||
|
||||
* Column visibility toggles
|
||||
* A compact “More details” drawer
|
||||
|
||||
### 4.2 Detail views (artifact / policy / evidence)
|
||||
|
||||
Use a **two-pane layout**:
|
||||
|
||||
* Left: core summary; main actions; VEX Gate button
|
||||
* Right: tabs or sections: `Evidence`, `Policies`, `Audit trail`
|
||||
|
||||
In the summary header:
|
||||
|
||||
* Show:
|
||||
|
||||
* Artifact identity
|
||||
* Primary verdict
|
||||
* Graph revision ID
|
||||
* Provenance chip
|
||||
* Provide the **one-tap path** to:
|
||||
|
||||
* Policy explanation (Reason Capsule)
|
||||
* Provenance dialog
|
||||
|
||||
---
|
||||
|
||||
## 5. Copy & Microcopy Guidelines
|
||||
|
||||
Your users are experts; don’t over-simplify. But also don’t write walls of text.
|
||||
|
||||
### 5.1 Tone
|
||||
|
||||
* Neutral, precise, never blamey.
|
||||
* Prefer “This artifact is blocked because…” over “You can’t do this because…”.
|
||||
* Avoid overloaded acronyms unless they are **core to the domain** (SBOM, VEX, CVE are fine).
|
||||
|
||||
### 5.2 Phrase patterns
|
||||
|
||||
**Verdicts**
|
||||
|
||||
* “Allowed by policy ‘X’.”
|
||||
* “Blocked by policy ‘X’ (rule R12: requires vendor VEX for critical CVEs).”
|
||||
* “Needs review: incomplete evidence for ‘X’.”
|
||||
|
||||
**Uncertainty**
|
||||
|
||||
* “Inferred reachable based on call graph analysis.”
|
||||
* “Vendor VEX statement not found in local cache.”
|
||||
|
||||
**Offline**
|
||||
|
||||
* “Using cached results from 2025‑11‑29. External logs not reachable.”
|
||||
|
||||
**Overrides**
|
||||
|
||||
* “Override applied by [alice@example.com](mailto:alice@example.com) on 2025‑11‑18: promotion allowed despite Red VEX gate.”
|
||||
|
||||
### 5.3 Don’ts
|
||||
|
||||
* Don’t use “Unknown error”. Always say **what** failed (e.g., “Failed to fetch Rekor receipt: TLS handshake error”).
|
||||
* Don’t just show raw IDs without labels (e.g., “grv_...” → always “Graph revision: grv_...”).
|
||||
* Don’t hide **policy names**; they are how users think about business intent.
|
||||
|
||||
---
|
||||
|
||||
## 6. States: Loading, Errors, Offline, Edge Cases
|
||||
|
||||
### 6.1 Loading
|
||||
|
||||
* For tables: use **skeleton rows**, not giant spinners.
|
||||
* For buttons with gates:
|
||||
|
||||
* Show inline “Checking VEX…” with a subtle spinner in the chip area only.
|
||||
* Maximum loading time before showing a message: ~2–3 seconds; after that, show:
|
||||
|
||||
* “Still evaluating VEX; you can proceed with last known result from 2025‑11‑18, or wait.”
|
||||
|
||||
### 6.2 Error states
|
||||
|
||||
For any failed fetch related to:
|
||||
|
||||
* Provenance
|
||||
* Log receipts
|
||||
* Policy evaluation
|
||||
|
||||
…show:
|
||||
|
||||
* A neutral banner in the relevant area:
|
||||
|
||||
* “Could not refresh provenance from log. Using last known verification from 2025‑11‑10.”
|
||||
* A clear fallback behavior:
|
||||
|
||||
* Block or proceed according to **policy**, not “best guess”.
|
||||
|
||||
### 6.3 Offline & Air‑gapped
|
||||
|
||||
**Golden rule:** Never pretend to be online when you’re not.
|
||||
|
||||
* Make offline clearly visible but not screaming:
|
||||
|
||||
* Small badge in the header: `Air-gapped mode` or `Offline mode`
|
||||
* Provenance chip:
|
||||
|
||||
* Use the `Queued` variant when receipts haven’t been synced.
|
||||
* Export path:
|
||||
|
||||
* Always work without internet (local export).
|
||||
|
||||
---
|
||||
|
||||
## 7. Accessibility & Keyboard Support
|
||||
|
||||
Your users will live in this tool; keyboard and a11y aren’t nice-to-haves.
|
||||
|
||||
**Minimums**
|
||||
|
||||
* All interactive chips (Reason Capsule, Provenance Chip, VEX Gate) must:
|
||||
|
||||
* Be reachable via Tab
|
||||
* Be clickable via Enter / Space
|
||||
* Have descriptive `aria-label`s (e.g., “Explain verdict for artifact nginx:1.24.0”)
|
||||
* Use **visible focus outlines** that fit your design tokens.
|
||||
* Do not rely solely on color:
|
||||
|
||||
* VEX tiers need both color and text (`Green`, `Amber`, `Red`).
|
||||
|
||||
---
|
||||
|
||||
## 8. Implementation Handshake (Design ⇄ Dev)
|
||||
|
||||
A simple workflow you can standardize on:
|
||||
|
||||
1. **Design defines the pattern**
|
||||
|
||||
* For each reusable micro‑interaction (Reason Capsule, VEX Gate, Provenance Chip), the designer:
|
||||
|
||||
* Specifies inputs/props
|
||||
* Lists states (default, loading, error, offline)
|
||||
* Provides content examples
|
||||
|
||||
2. **Dev builds a standalone Angular component**
|
||||
|
||||
* One component per pattern:
|
||||
|
||||
* `ReasonCapsuleComponent`
|
||||
* `VexGateButtonDirective + VexEvidenceSheetComponent`
|
||||
* `ProvenanceChipComponent + ProvenanceDialogComponent`
|
||||
* All styling via shared tokens (no hard‑coded colors).
|
||||
|
||||
3. **Shared acceptance criteria**
|
||||
|
||||
* Each pattern must have:
|
||||
|
||||
* a11y behavior defined
|
||||
* Loading and error behavior defined
|
||||
* At least one **offline** scenario defined
|
||||
* E2E check:
|
||||
|
||||
* Can a user go from a verdict to:
|
||||
|
||||
1. Why it happened,
|
||||
2. Evidence that supports it,
|
||||
3. Audit record of who acted
|
||||
…in **≤ 2 clicks**?
|
||||
|
||||
---
|
||||
|
||||
## 9. Quick “Do This, Not That” Cheat Sheet
|
||||
|
||||
* **Do:** Show `Blocked • Why?` → inline explanation → evidence link
|
||||
**Don’t:** Show just `Blocked` with no context.
|
||||
|
||||
* **Do:** Attach VEX Gate logic to existing primary buttons as a small extension.
|
||||
**Don’t:** Introduce a separate, second “Check VEX” action the user has to remember.
|
||||
|
||||
* **Do:** Use small chips for provenance state (`Signed • Verified • Logged`).
|
||||
**Don’t:** Hide signature/log info in a separate “Advanced” tab.
|
||||
|
||||
* **Do:** Be honest about offline/cached states.
|
||||
**Don’t:** Fake a “Verified + Logged” status when the log sync actually failed.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can also turn this into:
|
||||
|
||||
* A one-page **“UX checklist per screen”** your devs can run through before shipping, and
|
||||
* Concrete Angular interface definitions for each of the shared components so design/dev are literally talking about the same props.
|
||||
@@ -0,0 +1,716 @@
|
||||
Here’s a compact, low-friction way to tame “unknowns” in Stella Ops without boiling the ocean: two heuristics you can prototype this week—each yields one clear artifact you can show in the UI and wire into the next planning cycle.
|
||||
|
||||
---
|
||||
|
||||
# 1) Decaying Confidence (Half-Life) for Unknown Reachability
|
||||
|
||||
**Idea:** every “unknown” reachability/verdict starts with a confidence score that **decays over time** (exponential half-life). If no new evidence arrives, confidence naturally drifts toward “needs refresh,” preventing stale assumptions from lingering.
|
||||
|
||||
**Why it helps (plain English):** unknowns don’t stay “probably fine” forever—this makes them self-expiring, so triage resurfaces them at the right time instead of only when something breaks.
|
||||
|
||||
**Minimal data model (UnknownsRegistry):**
|
||||
|
||||
```json
|
||||
{
|
||||
"unknown_id": "URN:unknown:pkg/npm/lodash:4.17.21:CVE-2021-23337:reachability",
|
||||
"subject_ref": { "type": "package", "purl": "pkg:npm/lodash@4.17.21" },
|
||||
"vuln_id": "CVE-2021-23337",
|
||||
"dimension": "reachability",
|
||||
"confidence": { "value": 0.78, "method": "half_life", "t0": "2025-11-29T12:00:00Z", "half_life_days": 14 },
|
||||
"evidence": [{ "kind": "static_scan_hint", "hash": "…" }],
|
||||
"next_review_at": "2025-12-06T12:00:00Z",
|
||||
"status": "unknown"
|
||||
}
|
||||
```
|
||||
|
||||
**Update rule (per tick or on read):**
|
||||
|
||||
* `confidence_now = confidence_t0 * 0.5^(Δdays / half_life_days)`
|
||||
* When `confidence_now < threshold_low` → flag for human review (see Queue below).
|
||||
* When fresh evidence arrives → reset `t0`, optionally raise confidence.
|
||||
|
||||
**One UI artifact:**
|
||||
A **“Confidence Decay Card”** on each unknown, showing:
|
||||
|
||||
* sparkline of decay over time,
|
||||
* next review ETA,
|
||||
* button “Refresh with latest evidence” (re-run reachability probes).
|
||||
|
||||
**One ops hook (planning):**
|
||||
Export a **daily CSV/JSON of unknowns whose confidence crossed threshold** to feed the triage board.
|
||||
|
||||
---
|
||||
|
||||
# 2) Human-Review Queue for High-Impact Unknowns
|
||||
|
||||
**Idea:** only a subset of unknowns deserve people time. Auto-rank them by potential blast radius + decayed confidence.
|
||||
|
||||
**Triage score (simple, transparent):**
|
||||
`triage_score = impact_score * (1 - confidence_now)`
|
||||
|
||||
* `impact_score` (0–1): runtime exposure, privilege, prevalence, SLA tier.
|
||||
* `confidence_now`: from heuristic #1.
|
||||
|
||||
**Queue item schema (artifact to display & act on):**
|
||||
|
||||
```json
|
||||
{
|
||||
"queue_item_id": "TRIAGE:unknown:…",
|
||||
"unknown_id": "URN:unknown:…",
|
||||
"triage_score": 0.74,
|
||||
"impact_factors": { "runtime_presence": true, "privilege": "high", "fleet_prevalence": 0.62, "sla_tier": "gold" },
|
||||
"confidence_now": 0.28,
|
||||
"assigned_to": "unassigned",
|
||||
"due_by": "2025-12-02T17:00:00Z",
|
||||
"actions": [
|
||||
{ "type": "collect_runtime_trace", "cost": "low" },
|
||||
{ "type": "symbolic_slice_probe", "cost": "medium" },
|
||||
{ "type": "vendor_VEX_request", "cost": "low" }
|
||||
],
|
||||
"audit": [{ "at": "2025-11-29T12:05:00Z", "who": "system", "what": "enqueued: threshold_low crossed" }]
|
||||
}
|
||||
```
|
||||
|
||||
**One UI artifact:**
|
||||
A **“High-Impact Unknowns” queue view** sorted by `triage_score`, showing:
|
||||
|
||||
* pill tags for impact factors,
|
||||
* inline actions (Assign, Probe, Add Evidence, Mark Resolved),
|
||||
* SLO badge showing `due_by`.
|
||||
|
||||
**One ops hook (planning):**
|
||||
Pull top N items by `triage_score` at sprint start. Each resolved item must attach new evidence or a documented “Not Affected” rationale so the next decay cycle begins from stronger assumptions.
|
||||
|
||||
---
|
||||
|
||||
## Wiring into Stella Ops quickly (dev notes)
|
||||
|
||||
* **Storage:** add `UnknownsRegistry` collection/table; compute decay on read to avoid cron churn.
|
||||
* **Thresholds:** start with `half_life_days = 14`, `threshold_low = 0.35`; tune later.
|
||||
* **Impact scoring:** begin with simple weights in config (runtime_presence=0.4, privilege=0.3, prevalence=0.2, SLA=0.1).
|
||||
* **APIs:**
|
||||
* `GET /unknowns?stale=true` (confidence < threshold)
|
||||
* `POST /triage/enqueue` (system-owned)
|
||||
* `POST /unknowns/{id}/evidence` (resets t0, recomputes next_review_at)
|
||||
* **Events:** emit `UnknownConfidenceCrossedLow` → `TriageItemCreated`.
|
||||
|
||||
---
|
||||
|
||||
## What you’ll have after a 1–2 day spike
|
||||
|
||||
* A decay card on each unknown + a simple, sortable triage queue.
|
||||
* A daily export artifact to drive planning.
|
||||
* A clear, auditable path from “we’re unsure” → “we gathered evidence” → “we’re confident (for now).”
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* the C# POCOs/EF mappings,
|
||||
* a minimal Controller set,
|
||||
* Angular components (card + queue table),
|
||||
* and seed data + an evaluator that computes `confidence_now` and `triage_score` from config.
|
||||
Cool, let’s turn those two sketchy heuristics into something you can actually ship and iterate on in Stella Ops.
|
||||
|
||||
I’ll go deeper on:
|
||||
|
||||
1. Decaying confidence as a proper first‑class concept
|
||||
2. The triage queue and workflow around “unknowns”
|
||||
3. A lightweight “unknown budget” / guardrail layer
|
||||
4. Concrete implementation sketches (data models, formulas, pseudo‑code)
|
||||
5. How this feeds planning & metrics
|
||||
|
||||
---
|
||||
|
||||
## 1) Decaying Confidence: From Idea to Mechanism
|
||||
|
||||
### 1.1 What “confidence” actually means
|
||||
|
||||
To keep semantics crisp, define **confidence** as:
|
||||
|
||||
> “How fresh and well‑supported our knowledge is about this vulnerability in this subject along this dimension (reachability, exploitability, etc.).”
|
||||
|
||||
* `1.0` = Recently assessed with strong evidence
|
||||
* `0.0` = We basically haven’t looked / our info is ancient
|
||||
|
||||
This works for **unknown**, **known‑affected**, and **known‑not‑affected**; decay is about **knowledge freshness**, not the verdict itself.
|
||||
|
||||
For unknowns, confidence will usually be low and decaying → that’s what pushes them into the queue.
|
||||
|
||||
### 1.2 Data model v2 (UnknownsRegistry)
|
||||
|
||||
Extend the earlier object a bit:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"unknown_id": "URN:unknown:pkg/npm/lodash:4.17.21:CVE-2021-23337:reachability",
|
||||
|
||||
"subject_ref": {
|
||||
"type": "package", // package | service | container | host | cluster
|
||||
"purl": "pkg:npm/lodash@4.17.21",
|
||||
"service_id": "checkout-api",
|
||||
"env": "prod" // prod | staging | dev
|
||||
},
|
||||
|
||||
"vuln_id": "CVE-2021-23337",
|
||||
"dimension": "reachability", // reachability | exploitability | fix_validity | other
|
||||
|
||||
"state": "unknown", // unknown | known_affected | known_not_affected | ignored
|
||||
"unknown_cause": "tooling_gap", // data_missing | vendor_silent | tooling_gap | conflicting_evidence
|
||||
|
||||
"confidence": {
|
||||
"value": 0.62, // computed on read
|
||||
"method": "half_life",
|
||||
"t0": "2025-11-29T12:00:00Z",
|
||||
"value_at_t0": 0.9,
|
||||
"half_life_days": 14,
|
||||
"threshold_low": 0.35,
|
||||
"threshold_high": 0.75
|
||||
},
|
||||
|
||||
"impact": {
|
||||
"runtime_presence": true,
|
||||
"internet_exposed": true,
|
||||
"privilege_level": "high",
|
||||
"data_sensitivity": "pii", // none | internal | pii | financial
|
||||
"fleet_prevalence": 0.62, // fraction of services using this
|
||||
"sla_tier": "gold" // bronze | silver | gold
|
||||
},
|
||||
|
||||
"next_review_at": "2025-12-06T12:00:00Z",
|
||||
"owner": "team-checkout",
|
||||
"created_at": "2025-11-29T12:00:00Z",
|
||||
"updated_at": "2025-11-29T12:00:00Z",
|
||||
|
||||
"evidence": [
|
||||
{
|
||||
"kind": "static_scan_hint",
|
||||
"summary": "No direct call from public handler to vulnerable sink found.",
|
||||
"created_at": "2025-11-29T12:00:00Z",
|
||||
"link": "https://stellaops/ui/evidence/123"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Key points:
|
||||
|
||||
* `unknown_cause` helps you slice unknowns by “why do we not know?” (lack of data vs tooling vs vendor).
|
||||
* `impact` is embedded here so triage scoring can be local without joining a ton of tables.
|
||||
* `half_life_days` can be **per dimension & per environment**, e.g.:
|
||||
|
||||
* prod + reachability → 7 days
|
||||
* staging + fix_validity → 30 days
|
||||
|
||||
### 1.3 Decay math & scheduling
|
||||
|
||||
Use exponential decay:
|
||||
|
||||
```text
|
||||
confidence(t) = value_at_t0 * 0.5^(Δdays / half_life_days)
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
* `Δdays = (now - t0) in days`
|
||||
|
||||
On write (when you update or create the record), you:
|
||||
|
||||
1. Compute `value_now` from any previous state.
|
||||
2. Apply bump/delta based on new evidence (bounded by 0..1).
|
||||
3. Set `value_at_t0 = value_now_after_bump`, `t0 = now`.
|
||||
4. Precompute `next_review_at` = when `confidence(t)` will cross `threshold_low`.
|
||||
|
||||
Pseudo‑code for step 4:
|
||||
|
||||
```csharp
|
||||
double DaysUntilThreshold(double valueAtT0, double threshold, double halfLifeDays)
|
||||
{
|
||||
if (valueAtT0 <= threshold) return 0;
|
||||
|
||||
// threshold = valueAtT0 * 0.5^(Δ/halfLife)
|
||||
// Δ = halfLife * log(threshold/valueAtT0) / log(0.5)
|
||||
return halfLifeDays * Math.Log(threshold / valueAtT0) / Math.Log(0.5);
|
||||
}
|
||||
```
|
||||
|
||||
Then:
|
||||
|
||||
```csharp
|
||||
var days = DaysUntilThreshold(valueAtT0, thresholdLow, halfLifeDays);
|
||||
nextReviewAt = now.AddDays(days);
|
||||
```
|
||||
|
||||
**Important:** this gives you a **cheap query** to build the queue:
|
||||
|
||||
```sql
|
||||
SELECT * FROM UnknownsRegistry
|
||||
WHERE state = 'unknown'
|
||||
AND next_review_at <= now();
|
||||
```
|
||||
|
||||
No cron‑based bulk recomputation necessary.
|
||||
|
||||
### 1.4 Events that bump confidence
|
||||
|
||||
Any new evidence should “refresh” knowledge and adjust confidence:
|
||||
|
||||
Examples:
|
||||
|
||||
* **Runtime traces showing the vulnerable function never called in a hot path**
|
||||
→ bump reachability confidence up moderately (e.g. +0.2, capped at 0.9).
|
||||
|
||||
* **Symbolic or fuzzing probe explicitly drives execution into the vulnerable code**
|
||||
→ flip `state = known_affected`, set confidence close to 1.0 with longer half‑life.
|
||||
|
||||
* **Vendor VEX: NOT AFFECTED**
|
||||
→ flip `state = known_not_affected`, long half‑life (60–90 days), high confidence.
|
||||
|
||||
* **New major release, infra changes, or new internet exposure**
|
||||
→ degrade confidence (e.g. −0.3) because architecture changed.
|
||||
|
||||
Implement this as a simple rules table:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"on_evidence": [
|
||||
{
|
||||
"when": { "kind": "runtime_trace", "result": "no_calls_observed" },
|
||||
"dimension": "reachability",
|
||||
"delta_confidence": +0.2,
|
||||
"half_life_days": 14
|
||||
},
|
||||
{
|
||||
"when": { "kind": "runtime_trace", "result": "calls_into_vuln" },
|
||||
"dimension": "reachability",
|
||||
"set_state": "known_affected",
|
||||
"set_confidence": 0.95,
|
||||
"half_life_days": 21
|
||||
},
|
||||
{
|
||||
"when": { "kind": "vendor_vex", "result": "not_affected" },
|
||||
"set_state": "known_not_affected",
|
||||
"set_confidence": 0.98,
|
||||
"half_life_days": 60
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 1.5 UI for decaying confidence
|
||||
|
||||
On the **Unknown Detail page**, you can show:
|
||||
|
||||
* **Confidence chip**:
|
||||
|
||||
* “Knowledge freshness: 0.28 (stale)” with a color gradient.
|
||||
* **Decay sparkline**: small chart showing confidence over the last 30 days.
|
||||
* **Next review**: “Next review recommended by Dec 2, 2025 (in 3 days)”
|
||||
* **Evidence stack**: timeline of evidence events with icons (static scan, runtime, vendor, etc.).
|
||||
* **Actions area**: “Refresh now → Trigger runtime probe / request VEX / open Jira”.
|
||||
|
||||
All of that makes the heuristic feel concrete and gives engineers a mental model:
|
||||
“this is decaying; here’s when we revisit; here’s how to add evidence.”
|
||||
|
||||
---
|
||||
|
||||
## 2) Triage Queue for High‑Impact Unknowns: Making It Useful
|
||||
|
||||
The goal: **reduce an ocean of unknowns to a small, actionable queue** that:
|
||||
|
||||
* Is **ranked by risk**, not noise
|
||||
* Has clear **owners and due dates**
|
||||
* Plugs cleanly into teams’ existing planning
|
||||
|
||||
### 2.1 Impact scoring, more formally
|
||||
|
||||
Define a normalized **impact score** `I` between 0 and 1:
|
||||
|
||||
```text
|
||||
I = w_env * EnvExposure
|
||||
+ w_data * DataSensitivity
|
||||
+ w_prevalence * Prevalence
|
||||
+ w_sla * SlaCriticality
|
||||
+ w_cvss * CvssSeverity
|
||||
```
|
||||
|
||||
Where each factor is also 0–1:
|
||||
|
||||
* `EnvExposure`:
|
||||
|
||||
* prod + internet_exposed → 1.0
|
||||
* prod + internal only → 0.7
|
||||
* non‑prod → 0.3
|
||||
|
||||
* `DataSensitivity`:
|
||||
|
||||
* none → 0.0, internal → 0.3, pii → 0.7, financial/health → 1.0
|
||||
|
||||
* `Prevalence`:
|
||||
|
||||
* fraction of services/assets affected (0..1)
|
||||
|
||||
* `SlaCriticality`:
|
||||
|
||||
* bronze → 0.3, silver → 0.6, gold → 1.0
|
||||
|
||||
* `CvssSeverity`:
|
||||
|
||||
* use CVSS normalized to 0..1 if you have it, otherwise approximate from “critical/high/med/low”.
|
||||
|
||||
Weights `w_*` configurable, e.g.:
|
||||
|
||||
```text
|
||||
w_env = 0.3
|
||||
w_data = 0.25
|
||||
w_prevalence = 0.15
|
||||
w_sla = 0.15
|
||||
w_cvss = 0.15
|
||||
```
|
||||
|
||||
These can live in a tenant‑level config.
|
||||
|
||||
### 2.2 Triage score
|
||||
|
||||
You already had the core idea:
|
||||
|
||||
```text
|
||||
triage_score = Impact * (1 - ConfidenceNow)
|
||||
```
|
||||
|
||||
You can enrich this slightly with recency:
|
||||
|
||||
```text
|
||||
RecencyBoost = min(1.2, 1.0 + DaysSinceCreated / 30 * 0.2)
|
||||
triage_score = Impact * (1 - ConfidenceNow) * RecencyBoost
|
||||
```
|
||||
|
||||
So very old unknowns with low confidence get a slight bump to avoid being buried forever.
|
||||
|
||||
### 2.3 Queue item lifecycle
|
||||
|
||||
Represent queue items as a simple workflow:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"queue_item_id": "TRIAGE:unknown:…",
|
||||
"unknown_id": "URN:unknown:…",
|
||||
"triage_score": 0.81,
|
||||
"status": "open", // open | in_progress | blocked | resolved | wont_fix
|
||||
"reason_blocked": null,
|
||||
"owner_team": "team-checkout",
|
||||
"assigned_to": "alice",
|
||||
"created_at": "2025-11-29T12:05:00Z",
|
||||
"due_by": "2025-12-02T17:00:00Z",
|
||||
|
||||
"required_outcome": "add_evidence_or_verdict", // tasks that actually change state
|
||||
"suggested_actions": [
|
||||
{ "type": "collect_runtime_trace", "cost": "low" },
|
||||
{ "type": "symbolic_slice_probe", "cost": "medium" },
|
||||
{ "type": "vendor_VEX_request", "cost": "low" }
|
||||
],
|
||||
|
||||
"audit": [
|
||||
{
|
||||
"at": "2025-11-29T12:05:00Z",
|
||||
"who": "system",
|
||||
"what": "enqueued: confidence below threshold_low; I=0.9, C=0.21"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Rules:
|
||||
|
||||
* Queue item is (re)created automatically when unknown’s `next_review_at <= now` **and** impact above a minimum threshold.
|
||||
* When an engineer **adds evidence** or changes `state` on the underlying unknown, the system:
|
||||
|
||||
* Recomputes confidence, impact, triage_score
|
||||
* Closes the queue item if confidence now > `threshold_high` or state != unknown
|
||||
* You can allow **re‑open** if it decays again later.
|
||||
|
||||
### 2.4 Queue UI & ops hooks
|
||||
|
||||
In UI, the **“High‑Impact Unknowns”** view shows:
|
||||
|
||||
Columns:
|
||||
|
||||
* Unknown (vuln + subject)
|
||||
* State (always “unknown” here, but future‑proof)
|
||||
* Impact badge (Low/Med/High/Critical)
|
||||
* Confidence chip
|
||||
* Triage score (sortable)
|
||||
* Owner team
|
||||
* Due by
|
||||
* Quick actions
|
||||
|
||||
Interactions:
|
||||
|
||||
* Default filter: `impact >= High` AND `env = prod`
|
||||
* Per‑team view: filter owner_team = “team‑X”
|
||||
* Bulk ops: “Assign top 10 to me”, “Open Jira for selected” etc.
|
||||
|
||||
Ops hooks:
|
||||
|
||||
* **Daily digest** to each team: “You have 5 high‑impact unknowns due this week.”
|
||||
* **Planning export**: per sprint, each team looks at “Top N unknowns by triage_score” and picks some into the sprint.
|
||||
* **SLO integration**: if team’s “unknown budget” (see below) is overrun, they must schedule unknown work.
|
||||
|
||||
### 2.5 Example: one unknown from signal to closure
|
||||
|
||||
1. New CVE hits; SBOM says `checkout-api` uses affected library.
|
||||
|
||||
* Unknown created with:
|
||||
|
||||
* Impact ≈ 0.9 (prod, internet, PII, critical CVE)
|
||||
* Confidence = 0.4 (all we know is “it exists”).
|
||||
* `triage_score ≈ 0.9 * (1 - 0.4) = 0.54` → high enough to enqueue.
|
||||
|
||||
2. Engineer collects runtime trace, sees no calls to vulnerable path under normal traffic.
|
||||
|
||||
* Evidence added, confidence bumped to 0.75, half‑life 14 days.
|
||||
* Queue item auto‑resolves if your `threshold_high` is 0.7.
|
||||
|
||||
3. Two months later, architecture changes, service gets a new public endpoint.
|
||||
|
||||
* Deployment event triggers an automatic “degrade confidence” rule (−0.2), sets new `t0` and shorter half‑life.
|
||||
* `next_review_at` moves closer; unknown re‑enters queue later.
|
||||
|
||||
This gives you **continuously updating risk** without manual spreadsheets.
|
||||
|
||||
---
|
||||
|
||||
## 3) Unknown Budget & Guardrails (Optional but Powerful)
|
||||
|
||||
To connect this to leadership/SRE conversations, define an **“unknown budget”** per service/team:
|
||||
|
||||
> A target maximum risk mass of unknowns we’re willing to tolerate.
|
||||
|
||||
### 3.1 Per‑unknown “risk units”
|
||||
|
||||
For each unknown, define:
|
||||
|
||||
```text
|
||||
risk_units = Impact * (1 - ConfidenceNow)
|
||||
```
|
||||
|
||||
(It’s literally the triage score, but aggregated differently.)
|
||||
|
||||
Per team or service:
|
||||
|
||||
```text
|
||||
unknown_risk_budget = sum(risk_units for that team/service)
|
||||
```
|
||||
|
||||
You can then set **guardrails**, e.g.:
|
||||
|
||||
* Gold‑tier service: budget ≤ 5.0
|
||||
* Silver: ≤ 15.0
|
||||
* Bronze: ≤ 30.0
|
||||
|
||||
### 3.2 Guardrail behaviors
|
||||
|
||||
If a team exceeds its budget:
|
||||
|
||||
* Show warnings in the Stella Ops UI on the service details page.
|
||||
* Add a banner in the high‑impact queue: “Unknown budget exceeded by 3.2 units.”
|
||||
* Optional: feed into deployment checks:
|
||||
|
||||
* Above 2× budget → require security approval before prod deploy.
|
||||
* Above 1× budget → must plan unknown work in next sprint.
|
||||
|
||||
This ties the heuristics to behavior change without being draconian.
|
||||
|
||||
---
|
||||
|
||||
## 4) Implementation Sketch (API & Code)
|
||||
|
||||
### 4.1 C# model sketch
|
||||
|
||||
```csharp
|
||||
public enum UnknownState { Unknown, KnownAffected, KnownNotAffected, Ignored }
|
||||
|
||||
public sealed class UnknownRecord
|
||||
{
|
||||
public string Id { get; set; } = default!;
|
||||
|
||||
public string SubjectType { get; set; } = default!; // "package", "service", ...
|
||||
public string? Purl { get; set; }
|
||||
public string? ServiceId { get; set; }
|
||||
public string Env { get; set; } = "prod";
|
||||
|
||||
public string? VulnId { get; set; } // CVE, GHSA, etc.
|
||||
public string Dimension { get; set; } = "reachability";
|
||||
public UnknownState State { get; set; } = UnknownState.Unknown;
|
||||
public string UnknownCause { get; set; } = "data_missing";
|
||||
|
||||
// Confidence fields persisted
|
||||
public double ConfidenceValueAtT0 { get; set; }
|
||||
public DateTimeOffset ConfidenceT0 { get; set; }
|
||||
public double HalfLifeDays { get; set; }
|
||||
public double ThresholdLow { get; set; }
|
||||
public double ThresholdHigh { get; set; }
|
||||
public DateTimeOffset NextReviewAt { get; set; }
|
||||
|
||||
// Impact factors
|
||||
public bool RuntimePresence { get; set; }
|
||||
public bool InternetExposed { get; set; }
|
||||
public string PrivilegeLevel { get; set; } = "low";
|
||||
public string DataSensitivity { get; set; } = "none";
|
||||
public double FleetPrevalence { get; set; }
|
||||
public string SlaTier { get; set; } = "bronze";
|
||||
|
||||
// Ownership & audit
|
||||
public string OwnerTeam { get; set; } = default!;
|
||||
public DateTimeOffset CreatedAt { get; set; }
|
||||
public DateTimeOffset UpdatedAt { get; set; }
|
||||
}
|
||||
```
|
||||
|
||||
Helper to compute `ConfidenceNow`:
|
||||
|
||||
```csharp
|
||||
public static class ConfidenceCalculator
|
||||
{
|
||||
public static double ComputeNow(UnknownRecord r, DateTimeOffset now)
|
||||
{
|
||||
var deltaDays = (now - r.ConfidenceT0).TotalDays;
|
||||
if (deltaDays <= 0) return Clamp01(r.ConfidenceValueAtT0);
|
||||
|
||||
var factor = Math.Pow(0.5, deltaDays / r.HalfLifeDays);
|
||||
return Clamp01(r.ConfidenceValueAtT0 * factor);
|
||||
}
|
||||
|
||||
public static (double valueAtT0, DateTimeOffset t0, DateTimeOffset nextReviewAt)
|
||||
ApplyEvidence(UnknownRecord r, double deltaConfidence, double? newHalfLifeDays, DateTimeOffset now)
|
||||
{
|
||||
var current = ComputeNow(r, now);
|
||||
var updated = Clamp01(current + deltaConfidence);
|
||||
var halfLife = newHalfLifeDays ?? r.HalfLifeDays;
|
||||
|
||||
var daysToThreshold = DaysUntilThreshold(updated, r.ThresholdLow, halfLife);
|
||||
var nextReview = now.AddDays(daysToThreshold);
|
||||
|
||||
return (updated, now, nextReview);
|
||||
}
|
||||
|
||||
private static double DaysUntilThreshold(double valueAtT0, double threshold, double halfLifeDays)
|
||||
{
|
||||
if (valueAtT0 <= threshold) return 0;
|
||||
return halfLifeDays * Math.Log(threshold / valueAtT0) / Math.Log(0.5);
|
||||
}
|
||||
|
||||
private static double Clamp01(double v) => v < 0 ? 0 : (v > 1 ? 1 : v);
|
||||
}
|
||||
```
|
||||
|
||||
Queue scoring:
|
||||
|
||||
```csharp
|
||||
public sealed class TriageConfig
|
||||
{
|
||||
public double WEnv { get; set; } = 0.3;
|
||||
public double WData { get; set; } = 0.25;
|
||||
public double WPrev { get; set; } = 0.15;
|
||||
public double WSla { get; set; } = 0.15;
|
||||
public double WCvss { get; set; } = 0.15;
|
||||
|
||||
public double MinImpactForQueue { get; set; } = 0.4;
|
||||
public double MaxRecencyBoost { get; set; } = 1.2;
|
||||
}
|
||||
|
||||
public static class TriageScorer
|
||||
{
|
||||
public static double ComputeImpact(UnknownRecord r, double cvssNorm, TriageConfig cfg)
|
||||
{
|
||||
var env = r.Env == "prod"
|
||||
? (r.InternetExposed ? 1.0 : 0.7)
|
||||
: 0.3;
|
||||
|
||||
var data = r.DataSensitivity switch
|
||||
{
|
||||
"none" => 0.0,
|
||||
"internal" => 0.3,
|
||||
"pii" => 0.7,
|
||||
"financial" => 1.0,
|
||||
_ => 0.3
|
||||
};
|
||||
|
||||
var sla = r.SlaTier switch
|
||||
{
|
||||
"bronze" => 0.3,
|
||||
"silver" => 0.6,
|
||||
"gold" => 1.0,
|
||||
_ => 0.3
|
||||
};
|
||||
|
||||
var prev = Math.Max(0, Math.Min(1, r.FleetPrevalence));
|
||||
|
||||
return cfg.WEnv * env
|
||||
+ cfg.WData * data
|
||||
+ cfg.WPrev * prev
|
||||
+ cfg.WSla * sla
|
||||
+ cfg.WCvss * cvssNorm;
|
||||
}
|
||||
|
||||
public static double ComputeTriageScore(
|
||||
UnknownRecord r,
|
||||
double cvssNorm,
|
||||
DateTimeOffset now,
|
||||
DateTimeOffset createdAt,
|
||||
TriageConfig cfg)
|
||||
{
|
||||
var impact = ComputeImpact(r, cvssNorm, cfg);
|
||||
var confidence = ConfidenceCalculator.ComputeNow(r, now);
|
||||
|
||||
if (impact < cfg.MinImpactForQueue) return 0;
|
||||
|
||||
var ageDays = (now - createdAt).TotalDays;
|
||||
var recencyBoost = Math.Min(cfg.MaxRecencyBoost, 1.0 + (ageDays / 30.0) * 0.2);
|
||||
|
||||
return impact * (1 - confidence) * recencyBoost;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
This is all straightforward to wire into your existing C#/Angular stack.
|
||||
|
||||
---
|
||||
|
||||
## 5) How This Feeds Planning & Metrics
|
||||
|
||||
Once this is live, you get a bunch of useful knobs for product and leadership:
|
||||
|
||||
### 5.1 Per‑team dashboards
|
||||
|
||||
For each team/service, show:
|
||||
|
||||
* **Unknown count** (total & by dimension)
|
||||
* **Unknown risk budget** (current vs target)
|
||||
* **Distribution of confidence** (e.g., histogram buckets: 0–0.25, 0.25–0.5, etc.)
|
||||
* **Average age of unknowns**
|
||||
* **Queue throughput**:
|
||||
|
||||
* # of unknowns investigated this sprint
|
||||
* Average time from `enqueued → evidence added/ verdict`
|
||||
|
||||
These tell you if teams are actually burning down epistemic risk or just tagging things.
|
||||
|
||||
### 5.2 Process metrics to tune heuristics
|
||||
|
||||
Every quarter, look at:
|
||||
|
||||
* How many unknowns **re‑enter the queue** because decay hits threshold?
|
||||
* For unknowns that later become **known‑affected incidents**, what were their triage scores?
|
||||
|
||||
* If many “incident‑causing unknowns” had low triage scores, adjust weights.
|
||||
* Are teams routinely ignoring certain impact factors (e.g., low data sensitivity)?
|
||||
|
||||
* Maybe reduce weight or adjust scoring.
|
||||
|
||||
Because the heuristics are **explicit and simple**, you can iterate: tweak half‑lives and weights, observe effect on queue size and incident correlation.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can sketch:
|
||||
|
||||
* A REST API surface (`GET /unknowns`, `GET /unknowns/triage`, `POST /unknowns/{id}/evidence`)
|
||||
* Or specific Angular components for the **Confidence Decay Card** and **High‑Impact Unknowns** table, wired to these models.
|
||||
Reference in New Issue
Block a user