Add reference architecture and testing strategy documentation
- Created a new document for the Stella Ops Reference Architecture outlining the system's topology, trust boundaries, artifact association, and interfaces. - Developed a comprehensive Testing Strategy document detailing the importance of offline readiness, interoperability, determinism, and operational guardrails. - Introduced a README for the Testing Strategy, summarizing processing details and key concepts implemented. - Added guidance for AI agents and developers in the tests directory, including directory structure, test categories, key patterns, and rules for test development.
This commit is contained in:
Binary file not shown.
@@ -0,0 +1,81 @@
|
||||
# Archived Advisory: Mapping Evidence Within Compiled Binaries
|
||||
|
||||
**Original Advisory:** `21-Dec-2025 - Mapping Evidence Within Compiled Binaries.md`
|
||||
**Archived:** 2025-12-21
|
||||
**Status:** Converted to Implementation Plan
|
||||
|
||||
---
|
||||
|
||||
## Summary
|
||||
|
||||
This advisory proposed building a **Vulnerable Binaries Database** that enables detection of vulnerable code at the binary level, independent of package metadata.
|
||||
|
||||
## Implementation Artifacts Created
|
||||
|
||||
### Architecture Documentation
|
||||
|
||||
- `docs/modules/binaryindex/architecture.md` - Full module architecture
|
||||
- `docs/db/schemas/binaries_schema_specification.md` - Database schema
|
||||
|
||||
### Sprint Files
|
||||
|
||||
**Summary:**
|
||||
- `docs/implplan/SPRINT_6000_SUMMARY.md` - MVP roadmap overview
|
||||
|
||||
**MVP 1: Known-Build Binary Catalog (Sprint 6000.0001)**
|
||||
- `SPRINT_6000_0001_0001_binaries_schema.md` - PostgreSQL schema
|
||||
- `SPRINT_6000_0001_0002_binary_identity_service.md` - Identity extraction
|
||||
- `SPRINT_6000_0001_0003_debian_corpus_connector.md` - Debian/Ubuntu ingestion
|
||||
|
||||
**MVP 2: Patch-Aware Backport Handling (Sprint 6000.0002)**
|
||||
- `SPRINT_6000_0002_0001_fix_evidence_parser.md` - Changelog/patch parsing
|
||||
|
||||
**MVP 3: Binary Fingerprint Factory (Sprint 6000.0003)**
|
||||
- `SPRINT_6000_0003_0001_fingerprint_storage.md` - Fingerprint storage
|
||||
|
||||
**MVP 4: Scanner Integration (Sprint 6000.0004)**
|
||||
- `SPRINT_6000_0004_0001_scanner_integration.md` - Scanner.Worker integration
|
||||
|
||||
## Key Decisions
|
||||
|
||||
| Decision | Rationale |
|
||||
|----------|-----------|
|
||||
| New `BinaryIndex` module | Binary vulnerability DB is distinct concern from Scanner |
|
||||
| Build-ID as primary key | Most deterministic identifier for ELF binaries |
|
||||
| `binaries` PostgreSQL schema | Aligns with existing per-module schema pattern |
|
||||
| Three-tier lookup | Assertions → Build-ID → Fingerprints for precision |
|
||||
| Patch-aware fix index | Handles distro backports correctly |
|
||||
|
||||
## Module Structure
|
||||
|
||||
```
|
||||
src/BinaryIndex/
|
||||
├── StellaOps.BinaryIndex.WebService/
|
||||
├── StellaOps.BinaryIndex.Worker/
|
||||
├── __Libraries/
|
||||
│ ├── StellaOps.BinaryIndex.Core/
|
||||
│ ├── StellaOps.BinaryIndex.Persistence/
|
||||
│ ├── StellaOps.BinaryIndex.Corpus/
|
||||
│ ├── StellaOps.BinaryIndex.Corpus.Debian/
|
||||
│ ├── StellaOps.BinaryIndex.FixIndex/
|
||||
│ └── StellaOps.BinaryIndex.Fingerprints/
|
||||
└── __Tests/
|
||||
```
|
||||
|
||||
## Database Tables
|
||||
|
||||
| Table | Purpose |
|
||||
|-------|---------|
|
||||
| `binaries.binary_identity` | Known binary identities |
|
||||
| `binaries.binary_package_map` | Binary → package mapping |
|
||||
| `binaries.vulnerable_buildids` | Vulnerable Build-IDs |
|
||||
| `binaries.cve_fix_index` | Patch-aware fix status |
|
||||
| `binaries.vulnerable_fingerprints` | Function fingerprints |
|
||||
| `binaries.fingerprint_matches` | Scan match results |
|
||||
|
||||
## References
|
||||
|
||||
- Original advisory: This folder
|
||||
- Architecture: `docs/modules/binaryindex/architecture.md`
|
||||
- Schema: `docs/db/schemas/binaries_schema_specification.md`
|
||||
- Sprints: `docs/implplan/SPRINT_6000_*.md`
|
||||
@@ -0,0 +1,606 @@
|
||||
# CVSS and Competitive Analysis Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 29-Nov-2025 - CVSS v4.0 Momentum in Vulnerability Management
|
||||
- 30-Nov-2025 - Comparative Evidence Patterns for Stella Ops
|
||||
- 03-Dec-2025 - Next‑Gen Scanner Differentiators and Evidence Moat
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. CVSS V4.0 INTEGRATION
|
||||
|
||||
### 1.1 Requirements
|
||||
|
||||
- Vendors (NVD, GitHub, Microsoft, Snyk) shipping CVSS v4 signals
|
||||
- Awareness needed for receipt schemas, reporting, UI alignment
|
||||
|
||||
### 1.2 Determinism & Offline
|
||||
|
||||
- Keep CVSS vector parsing deterministic
|
||||
- Pin scoring library versions in receipts
|
||||
- Avoid live API dependency
|
||||
- Rely on mirrored NVD feeds or frozen samples
|
||||
|
||||
### 1.3 Schema Mapping
|
||||
|
||||
- Map impacts to receipt schemas
|
||||
- Identify UI/reporting deltas for transparency
|
||||
- Note in sprint Decisions & Risks for CVSS receipts
|
||||
|
||||
### 1.4 CVSS v4.0 MacroVector Scoring System
|
||||
|
||||
CVSS v4.0 uses a **MacroVector-based scoring system** instead of the direct formula computation used in v2/v3. The MacroVector is a 6-digit string derived from the base metrics, which maps to a precomputed score table with 486 possible combinations.
|
||||
|
||||
**MacroVector Structure**:
|
||||
```
|
||||
MacroVector = EQ1 + EQ2 + EQ3 + EQ4 + EQ5 + EQ6
|
||||
Example: "001100" -> Base Score = 8.2
|
||||
```
|
||||
|
||||
**Equivalence Classes (EQ1-EQ6)**:
|
||||
|
||||
| EQ | Metrics Used | Values | Meaning |
|
||||
|----|--------------|--------|---------|
|
||||
| EQ1 | Attack Vector + Privileges Required | 0-2 | Network reachability and auth barrier |
|
||||
| EQ2 | Attack Complexity + User Interaction | 0-1 | Attack prerequisites |
|
||||
| EQ3 | Vulnerable System CIA | 0-2 | Impact on vulnerable system |
|
||||
| EQ4 | Subsequent System CIA | 0-2 | Impact on downstream systems |
|
||||
| EQ5 | Attack Requirements | 0-1 | Preconditions needed |
|
||||
| EQ6 | Combined Impact Pattern | 0-2 | Multi-impact severity |
|
||||
|
||||
**EQ1 (Attack Vector + Privileges Required)**:
|
||||
- AV=Network + PR=None -> 0 (worst case: remote, no auth)
|
||||
- AV=Network + PR=Low/High -> 1
|
||||
- AV=Adjacent + PR=None -> 1
|
||||
- AV=Adjacent + PR=Low/High -> 2
|
||||
- AV=Local or Physical -> 2 (requires local access)
|
||||
|
||||
**EQ2 (Attack Complexity + User Interaction)**:
|
||||
- AC=Low + UI=None -> 0 (easiest to exploit)
|
||||
- AC=Low + UI=Passive/Active -> 1
|
||||
- AC=High + any UI -> 1 (harder to exploit)
|
||||
|
||||
**EQ3 (Vulnerable System CIA)**:
|
||||
- Any High in VC/VI/VA -> 0 (severe impact)
|
||||
- Any Low in VC/VI/VA -> 1 (moderate impact)
|
||||
- All None -> 2 (no impact)
|
||||
|
||||
**EQ4 (Subsequent System CIA)**:
|
||||
- Any High in SC/SI/SA -> 0 (cascading impact)
|
||||
- Any Low in SC/SI/SA -> 1
|
||||
- All None -> 2
|
||||
|
||||
**EQ5 (Attack Requirements)**:
|
||||
- AT=None -> 0 (no preconditions)
|
||||
- AT=Present -> 1 (needs specific setup)
|
||||
|
||||
**EQ6 (Combined Impact Pattern)**:
|
||||
- >=2 High impacts (vuln OR sub) -> 0 (severe multi-impact)
|
||||
- 1 High impact -> 1
|
||||
- 0 High impacts -> 2
|
||||
|
||||
**Scoring Algorithm**:
|
||||
1. Parse base metrics from vector string
|
||||
2. Compute EQ1-EQ6 from metrics
|
||||
3. Build MacroVector string: "{EQ1}{EQ2}{EQ3}{EQ4}{EQ5}{EQ6}"
|
||||
4. Lookup base score from MacroVectorLookup table
|
||||
5. Round up to nearest 0.1 (per FIRST spec)
|
||||
|
||||
**Implementation**: `src/Policy/StellaOps.Policy.Scoring/Engine/CvssV4Engine.cs:262-359`
|
||||
|
||||
### 1.5 Threat Metrics and Exploit Maturity
|
||||
|
||||
CVSS v4.0 introduces **Threat Metrics** to adjust scores based on real-world exploit intelligence. The primary metric is **Exploit Maturity (E)**, which applies a multiplier to the base score.
|
||||
|
||||
**Exploit Maturity Values**:
|
||||
|
||||
| Value | Code | Multiplier | Description |
|
||||
|-------|------|------------|-------------|
|
||||
| Attacked | A | **1.00** | Active exploitation in the wild |
|
||||
| Proof of Concept | P | **0.94** | Public PoC exists but no active exploitation |
|
||||
| Unreported | U | **0.91** | No known exploit activity |
|
||||
| Not Defined | X | 1.00 | Default (assume worst case) |
|
||||
|
||||
**Score Computation (CVSS-BT)**:
|
||||
```
|
||||
Threat Score = Base Score x Threat Multiplier
|
||||
|
||||
Example:
|
||||
Base Score = 9.1
|
||||
Exploit Maturity = Unreported (U)
|
||||
Threat Score = 9.1 x 0.91 = 8.3 (rounded up)
|
||||
```
|
||||
|
||||
**Threat Metrics in Vector String**:
|
||||
```
|
||||
CVSS:4.0/AV:N/AC:L/AT:N/PR:N/UI:N/VC:H/VI:H/VA:H/SC:N/SI:N/SA:N/E:A
|
||||
^^^
|
||||
Exploit Maturity
|
||||
```
|
||||
|
||||
**Why Threat Metrics Matter**:
|
||||
- Reduces noise: An unreported vulnerability scores ~9% lower
|
||||
- Prioritizes real threats: Actively exploited vulns maintain full score
|
||||
- Evidence-based: Integrates with KEV, EPSS, and internal threat feeds
|
||||
|
||||
**Implementation**: `src/Policy/StellaOps.Policy.Scoring/Engine/CvssV4Engine.cs:365-375`
|
||||
|
||||
### 1.6 Environmental Score Modifiers
|
||||
|
||||
**Security Requirements Multipliers**:
|
||||
|
||||
| Requirement | Low | Medium | High |
|
||||
|-------------|-----|--------|------|
|
||||
| Confidentiality (CR) | 0.5 | 1.0 | 1.5 |
|
||||
| Integrity (IR) | 0.5 | 1.0 | 1.5 |
|
||||
| Availability (AR) | 0.5 | 1.0 | 1.5 |
|
||||
|
||||
**Modified Base Metrics** (can override any base metric):
|
||||
- MAV (Modified Attack Vector)
|
||||
- MAC (Modified Attack Complexity)
|
||||
- MAT (Modified Attack Requirements)
|
||||
- MPR (Modified Privileges Required)
|
||||
- MUI (Modified User Interaction)
|
||||
- MVC/MVI/MVA (Modified Vulnerable System CIA)
|
||||
- MSC/MSI/MSA (Modified Subsequent System CIA)
|
||||
|
||||
**Score Computation (CVSS-BE)**:
|
||||
1. Apply modified metrics to base metrics (if defined)
|
||||
2. Compute modified MacroVector
|
||||
3. Lookup modified base score
|
||||
4. Multiply by average of Security Requirements
|
||||
5. Clamp to [0, 10]
|
||||
|
||||
```
|
||||
Environmental Score = Modified Base x (CR + IR + AR) / 3
|
||||
```
|
||||
|
||||
### 1.7 Supplemental Metrics (Non-Scoring)
|
||||
|
||||
CVSS v4.0 introduces supplemental metrics that provide context but **do not affect the score**:
|
||||
|
||||
| Metric | Values | Purpose |
|
||||
|--------|--------|---------|
|
||||
| Safety (S) | Negligible/Present | Safety impact (ICS/OT systems) |
|
||||
| Automatable (AU) | No/Yes | Can attack be automated? |
|
||||
| Recovery (R) | Automatic/User/Irrecoverable | System recovery difficulty |
|
||||
| Value Density (V) | Diffuse/Concentrated | Target value concentration |
|
||||
| Response Effort (RE) | Low/Moderate/High | Effort to respond |
|
||||
| Provider Urgency (U) | Clear/Green/Amber/Red | Vendor urgency rating |
|
||||
|
||||
**Use Cases**:
|
||||
- **Safety**: Critical for ICS/SCADA vulnerability prioritization
|
||||
- **Automatable**: Indicates wormable vulnerabilities
|
||||
- **Provider Urgency**: Vendor-supplied priority signal
|
||||
|
||||
## 2. SCANNER DISCREPANCIES ANALYSIS
|
||||
|
||||
### 2.1 Trivy vs Grype Comparative Study (927 images)
|
||||
|
||||
**Findings**:
|
||||
- Tools disagreed on total vulnerability counts and specific CVE IDs
|
||||
- Grype: ~603,259 vulns; Trivy: ~473,661 vulns
|
||||
- Exact match in only 9.2% of cases (80 out of 865 vulnerable images)
|
||||
- Even with same counts, specific vulnerability IDs differed
|
||||
|
||||
**Root Causes**:
|
||||
- Divergent vulnerability databases
|
||||
- Differing matching logic
|
||||
- Incomplete visibility
|
||||
|
||||
### 2.2 VEX Tools Consistency Study (2025)
|
||||
|
||||
**Tools Tested**:
|
||||
- Trivy
|
||||
- Grype
|
||||
- OWASP DepScan
|
||||
- Docker Scout
|
||||
- Snyk CLI
|
||||
- OSV-Scanner
|
||||
- Vexy
|
||||
|
||||
**Results**:
|
||||
- Low consistency/similarity across container scanners
|
||||
- DepScan: 18,680 vulns; Vexy: 191 vulns (2 orders of magnitude difference)
|
||||
- Pairwise Jaccard indices very low (near 0)
|
||||
- 4 most consistent tools shared only ~18% common vulnerabilities
|
||||
|
||||
### 2.3 Implications for StellaOps
|
||||
|
||||
**Moats Needed**:
|
||||
- Golden-fixture benchmarks (container images with known, audited vulnerabilities)
|
||||
- Deterministic, replayable scans
|
||||
- Cryptographic integrity
|
||||
- VEX/SBOM proofs
|
||||
|
||||
**Metrics**:
|
||||
- **Closure rate**: Time from flagged to confirmed exploitable
|
||||
- **Proof coverage**: % of dependencies with valid SBOM/VEX proofs
|
||||
- **Differential-closure**: Impact of database updates or policy changes on prior scan results
|
||||
|
||||
### 2.4 Deterministic Receipt System
|
||||
|
||||
Every CVSS scoring decision in StellaOps is captured in a **deterministic receipt** that enables audit-grade reproducibility.
|
||||
|
||||
**Receipt Schema**:
|
||||
```json
|
||||
{
|
||||
"receiptId": "uuid",
|
||||
"inputHash": "sha256:...",
|
||||
"baseMetrics": { ... },
|
||||
"threatMetrics": { ... },
|
||||
"environmentalMetrics": { ... },
|
||||
"supplementalMetrics": { ... },
|
||||
"scores": {
|
||||
"baseScore": 9.1,
|
||||
"threatScore": 8.3,
|
||||
"environmentalScore": null,
|
||||
"fullScore": null,
|
||||
"effectiveScore": 8.3,
|
||||
"effectiveScoreType": "threat"
|
||||
},
|
||||
"policyRef": "policy/cvss-v4-default@v1.2.0",
|
||||
"policyDigest": "sha256:...",
|
||||
"evidence": [ ... ],
|
||||
"attestationRefs": [ ... ],
|
||||
"createdAt": "2025-12-14T00:00:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
**InputHash Computation**:
|
||||
```
|
||||
inputHash = SHA256(canonicalize({
|
||||
baseMetrics,
|
||||
threatMetrics,
|
||||
environmentalMetrics,
|
||||
supplementalMetrics,
|
||||
policyRef,
|
||||
policyDigest
|
||||
}))
|
||||
```
|
||||
|
||||
**Determinism Guarantees**:
|
||||
- Same inputs -> same `inputHash` -> same scores
|
||||
- Receipts are immutable once created
|
||||
- Amendments create new receipts with `supersedes` reference
|
||||
- Optional DSSE signatures for cryptographic binding
|
||||
|
||||
**Implementation**: `src/Policy/StellaOps.Policy.Scoring/Receipts/ReceiptBuilder.cs`
|
||||
|
||||
## 3. RUNTIME REACHABILITY APPROACHES
|
||||
|
||||
### 3.1 Runtime-Aware Vulnerability Prioritization
|
||||
|
||||
**Approach**:
|
||||
- Monitor container workloads at runtime to determine which vulnerable components are actually used
|
||||
- Use eBPF-based monitors, dynamic tracers, or built-in profiling
|
||||
- Construct runtime call graph or dependency graph
|
||||
- Map vulnerabilities to code entities (functions/modules)
|
||||
- If execution trace covers entity, vulnerability is "reachable"
|
||||
|
||||
**Findings**: ~85% of critical vulns in containers are in inactive code (Sysdig)
|
||||
|
||||
### 3.2 Reachability Analysis Techniques
|
||||
|
||||
**Static**:
|
||||
- Call-graph analysis (Snyk reachability, CodeQL)
|
||||
- All possible paths
|
||||
|
||||
**Dynamic**:
|
||||
- Runtime observation (loaded modules, invoked functions)
|
||||
- Actual runtime paths
|
||||
|
||||
**Granularity Levels**:
|
||||
- Function-level (precise, limited languages: Java, .NET)
|
||||
- Package/module-level (broader, coarse)
|
||||
|
||||
**Hybrid Approach**: Combine static (all possible paths) + dynamic (actual runtime paths)
|
||||
|
||||
## 4. CONTAINER PROVENANCE & SUPPLY CHAIN
|
||||
|
||||
### 4.1 In-Toto/DSSE Framework (NDSS 2024)
|
||||
|
||||
**Purpose**:
|
||||
- Track chain of custody in software builds
|
||||
- Signed metadata (attestations) for each step
|
||||
- DSSE: Dead Simple Signing Envelope for standardized signing
|
||||
|
||||
### 4.2 Scudo System
|
||||
|
||||
**Features**:
|
||||
- Combines in-toto with Uptane
|
||||
- Verifies build process and final image
|
||||
- Full verification on client inefficient; verify upstream and trust summary
|
||||
- Client checks final signature + hash only
|
||||
|
||||
### 4.3 Supply Chain Verification
|
||||
|
||||
**Signers**:
|
||||
- Developer key signs code commit
|
||||
- CI key signs build attestation
|
||||
- Scanner key signs vulnerability attestation
|
||||
- Release key signs container image
|
||||
|
||||
**Verification Optimization**: Repository verifies in-toto attestations; client verifies final metadata only
|
||||
|
||||
## 5. VENDOR EVIDENCE PATTERNS
|
||||
|
||||
### 5.1 Snyk
|
||||
|
||||
**Evidence Handling**:
|
||||
- Runtime insights integration (Nov 2025)
|
||||
- Evolution from static-scan noise to prioritized workflow
|
||||
- Deployment context awareness
|
||||
|
||||
**VEX Support**:
|
||||
- CycloneDX VEX format
|
||||
- Reachability-aware suppression
|
||||
|
||||
### 5.2 GitHub Advanced Security
|
||||
|
||||
**Features**:
|
||||
- CodeQL for static analysis
|
||||
- Dependency graph
|
||||
- Dependabot alerts
|
||||
- Security advisories
|
||||
|
||||
**Evidence**:
|
||||
- SARIF output
|
||||
- SBOM generation (SPDX)
|
||||
|
||||
### 5.3 Aqua Security
|
||||
|
||||
**Approach**:
|
||||
- Runtime protection
|
||||
- Image scanning
|
||||
- Kubernetes security
|
||||
|
||||
**Evidence**:
|
||||
- Dynamic runtime traces
|
||||
- Network policy violations
|
||||
|
||||
### 5.4 Anchore/Grype
|
||||
|
||||
**Features**:
|
||||
- Open-source scanner
|
||||
- Policy-based compliance
|
||||
- SBOM generation
|
||||
|
||||
**Evidence**:
|
||||
- CycloneDX/SPDX SBOM
|
||||
- Vulnerability reports (JSON)
|
||||
|
||||
### 5.5 Prisma Cloud
|
||||
|
||||
**Features**:
|
||||
- Cloud-native security
|
||||
- Runtime defense
|
||||
- Compliance monitoring
|
||||
|
||||
**Evidence**:
|
||||
- Multi-cloud attestations
|
||||
- Compliance reports
|
||||
|
||||
## 6. STELLAOPS DIFFERENTIATORS
|
||||
|
||||
### 6.1 Reachability-with-Evidence
|
||||
|
||||
**Why it Matters**:
|
||||
- Snyk Container integrating runtime insights as "signal" (Nov 2025)
|
||||
- Evolution from static-scan noise to prioritized, actionable workflow
|
||||
- Deployment context: what's running, what's reachable, what's exploitable
|
||||
|
||||
**Implication**: Container security triage relies on runtime/context signals
|
||||
|
||||
### 6.2 Proof-First Architecture
|
||||
|
||||
**Advantages**:
|
||||
- Every claim backed by DSSE-signed attestations
|
||||
- Cryptographic integrity
|
||||
- Audit trail
|
||||
- Offline verification
|
||||
|
||||
### 6.3 Deterministic Scanning
|
||||
|
||||
**Advantages**:
|
||||
- Reproducible results
|
||||
- Bit-identical outputs given same inputs
|
||||
- Replay manifests
|
||||
- Golden fixture benchmarks
|
||||
|
||||
### 6.4 VEX-First Decisioning
|
||||
|
||||
**Advantages**:
|
||||
- Exploitability modeled in OpenVEX
|
||||
- Lattice logic for stable outcomes
|
||||
- Evidence-linked justifications
|
||||
|
||||
### 6.5 Offline/Air-Gap First
|
||||
|
||||
**Advantages**:
|
||||
- No hidden network dependencies
|
||||
- Bundled feeds, keys, Rekor snapshots
|
||||
- Verifiable without internet access
|
||||
|
||||
### 6.6 CVSS + KEV Risk Signal Combination
|
||||
|
||||
StellaOps combines CVSS scores with KEV (Known Exploited Vulnerabilities) data using a deterministic formula:
|
||||
|
||||
**Risk Formula**:
|
||||
```
|
||||
risk_score = clamp01((cvss / 10) + kevBonus)
|
||||
|
||||
where:
|
||||
kevBonus = 0.2 if vulnerability is in CISA KEV catalog
|
||||
kevBonus = 0.0 otherwise
|
||||
```
|
||||
|
||||
**Example Calculations**:
|
||||
|
||||
| CVSS Score | KEV Flag | Risk Score |
|
||||
|------------|----------|------------|
|
||||
| 9.0 | No | 0.90 |
|
||||
| 9.0 | Yes | 1.00 (clamped) |
|
||||
| 7.5 | No | 0.75 |
|
||||
| 7.5 | Yes | 0.95 |
|
||||
| 5.0 | No | 0.50 |
|
||||
| 5.0 | Yes | 0.70 |
|
||||
|
||||
**Rationale**:
|
||||
- KEV inclusion indicates active exploitation
|
||||
- 20% bonus prioritizes known-exploited over theoretical risks
|
||||
- Clamping prevents scores > 1.0
|
||||
- Deterministic formula enables reproducible prioritization
|
||||
|
||||
**Implementation**: `src/RiskEngine/StellaOps.RiskEngine/StellaOps.RiskEngine.Core/Providers/CvssKevProvider.cs`
|
||||
|
||||
## 7. COMPETITIVE POSITIONING
|
||||
|
||||
### 7.1 Market Segments
|
||||
|
||||
| Vendor | Strength | Weakness vs StellaOps |
|
||||
|--------|----------|----------------------|
|
||||
| Snyk | Developer experience | Less deterministic, SaaS-only |
|
||||
| Aqua | Runtime protection | Less reachability precision |
|
||||
| Anchore | Open-source, SBOM | Less proof infrastructure |
|
||||
| Prisma Cloud | Cloud-native breadth | Less offline/air-gap support |
|
||||
| GitHub | Integration with dev workflow | Less cryptographic proof chain |
|
||||
|
||||
### 7.2 StellaOps Unique Value
|
||||
|
||||
1. **Deterministic + Provable**: Bit-identical scans with cryptographic proofs
|
||||
2. **Reachability + Runtime**: Hybrid static/dynamic analysis
|
||||
3. **Offline/Sovereign**: Air-gap operation with regional crypto (FIPS/GOST/eIDAS/SM)
|
||||
4. **VEX-First**: Evidence-backed decisioning, not just alerting
|
||||
5. **AGPL-3.0**: Self-hostable, no vendor lock-in
|
||||
|
||||
## 8. MOAT METRICS
|
||||
|
||||
### 8.1 Proof Coverage
|
||||
|
||||
```
|
||||
proof_coverage = findings_with_valid_receipts / total_findings
|
||||
Target: ≥95%
|
||||
```
|
||||
|
||||
### 8.2 Closure Rate
|
||||
|
||||
```
|
||||
closure_rate = time_from_flagged_to_confirmed_exploitable
|
||||
Target: P95 < 24 hours
|
||||
```
|
||||
|
||||
### 8.3 Differential-Closure Impact
|
||||
|
||||
```
|
||||
differential_impact = findings_changed_after_db_update / total_findings
|
||||
Target: <5% (non-code changes)
|
||||
```
|
||||
|
||||
### 8.4 False Positive Reduction
|
||||
|
||||
```
|
||||
fp_reduction = (baseline_fp_rate - stella_fp_rate) / baseline_fp_rate
|
||||
Target: ≥50% vs baseline scanner
|
||||
```
|
||||
|
||||
### 8.5 Reachability Accuracy
|
||||
|
||||
```
|
||||
reachability_accuracy = correct_r0_r1_r2_r3_classifications / total_classifications
|
||||
Target: ≥90%
|
||||
```
|
||||
|
||||
## 9. COMPETITIVE INTELLIGENCE TRACKING
|
||||
|
||||
### 9.1 Feature Parity Matrix
|
||||
|
||||
| Feature | Snyk | Aqua | Anchore | Prisma | StellaOps |
|
||||
|---------|------|------|---------|--------|-----------|
|
||||
| SBOM Generation | ✓ | ✓ | ✓ | ✓ | ✓ |
|
||||
| VEX Support | ✓ | ✗ | Partial | ✗ | ✓ |
|
||||
| Reachability Analysis | ✓ | ✗ | ✗ | ✗ | ✓ |
|
||||
| Runtime Evidence | ✓ | ✓ | ✗ | ✓ | ✓ |
|
||||
| Cryptographic Proofs | ✗ | ✗ | ✗ | ✗ | ✓ |
|
||||
| Deterministic Scans | ✗ | ✗ | ✗ | ✗ | ✓ |
|
||||
| Offline/Air-Gap | ✗ | Partial | ✗ | ✗ | ✓ |
|
||||
| Regional Crypto | ✗ | ✗ | ✗ | ✗ | ✓ |
|
||||
|
||||
### 9.2 Monitoring Strategy
|
||||
|
||||
- Track vendor release notes
|
||||
- Monitor GitHub repos for feature announcements
|
||||
- Participate in security conferences
|
||||
- Engage with customer feedback
|
||||
- Update competitive matrix quarterly
|
||||
|
||||
## 10. MESSAGING FRAMEWORK
|
||||
|
||||
### 10.1 Core Message
|
||||
|
||||
"StellaOps provides deterministic, proof-backed vulnerability management with reachability analysis for offline/air-gapped environments."
|
||||
|
||||
### 10.2 Key Differentiators (Elevator Pitch)
|
||||
|
||||
1. **Deterministic**: Same inputs → same outputs, every time
|
||||
2. **Provable**: Cryptographic proof chains for every decision
|
||||
3. **Reachable**: Static + runtime analysis, not just presence
|
||||
4. **Sovereign**: Offline operation, regional crypto compliance
|
||||
5. **Open**: AGPL-3.0, self-hostable, no lock-in
|
||||
|
||||
### 10.3 Target Personas
|
||||
|
||||
- **Security Engineers**: Need proof-backed decisions for audits
|
||||
- **DevOps Teams**: Need deterministic scans in CI/CD
|
||||
- **Compliance Officers**: Need offline/air-gap for regulated environments
|
||||
- **Platform Engineers**: Need self-hostable, sovereign solution
|
||||
|
||||
## 11. BENCHMARKING PROTOCOL
|
||||
|
||||
### 11.1 Comparative Test Suite
|
||||
|
||||
**Images**:
|
||||
- 50 representative production images
|
||||
- Known vulnerabilities labeled
|
||||
- Reachability ground truth established
|
||||
|
||||
**Metrics**:
|
||||
- Precision (1 - FP rate)
|
||||
- Recall (TP / (TP + FN))
|
||||
- F1 score
|
||||
- Scan time (P50, P95)
|
||||
- Determinism (identical outputs over 10 runs)
|
||||
|
||||
### 11.2 Test Execution
|
||||
|
||||
```bash
|
||||
# Run StellaOps scan
|
||||
stellaops scan --image test-image:v1 --output stella-results.json
|
||||
|
||||
# Run competitor scans
|
||||
trivy image --format json test-image:v1 > trivy-results.json
|
||||
grype test-image:v1 -o json > grype-results.json
|
||||
snyk container test test-image:v1 --json > snyk-results.json
|
||||
|
||||
# Compare results
|
||||
stellaops benchmark compare \
|
||||
--ground-truth ground-truth.json \
|
||||
--stella stella-results.json \
|
||||
--trivy trivy-results.json \
|
||||
--grype grype-results.json \
|
||||
--snyk snyk-results.json
|
||||
```
|
||||
|
||||
### 11.3 Results Publication
|
||||
|
||||
- Publish benchmarks quarterly
|
||||
- Open-source test images and ground truth
|
||||
- Invite community contributions
|
||||
- Document methodology transparently
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,817 @@
|
||||
# Determinism and Reproducibility Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 07-Dec-2025 - Designing Deterministic Vulnerability Scores
|
||||
- 12-Dec-2025 - Designing a Deterministic Vulnerability Scoring Matrix
|
||||
- 12-Dec-2025 - Replay Fidelity as a Proof Metric
|
||||
- 01-Dec-2025 - Benchmarks for a Testable Security Moat
|
||||
- 02-Dec-2025 - Benchmarking a Testable Security Moat
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. SCORE FORMULA (BASIS POINTS)
|
||||
|
||||
**Total Score:**
|
||||
```
|
||||
riskScore = (wB*B + wR*R + wE*E + wP*P) / 10000
|
||||
```
|
||||
|
||||
**Default Weights (basis points, sum = 10000):**
|
||||
- `wB=1000` (10%) - Base Severity
|
||||
- `wR=4500` (45%) - Reachability
|
||||
- `wE=3000` (30%) - Evidence
|
||||
- `wP=1500` (15%) - Provenance
|
||||
|
||||
## 2. SUBSCORE DEFINITIONS (0-100 integers)
|
||||
|
||||
### 2.1 BaseSeverity (B)
|
||||
|
||||
```
|
||||
B = round(CVSS * 10) // CVSS 0.0-10.0 → 0-100
|
||||
```
|
||||
|
||||
### 2.2 Reachability (R)
|
||||
|
||||
Hop Buckets:
|
||||
```
|
||||
0-2 hops: 100
|
||||
3 hops: 85
|
||||
4 hops: 70
|
||||
5 hops: 55
|
||||
6 hops: 45
|
||||
7 hops: 35
|
||||
8+ hops: 20
|
||||
unreachable: 0
|
||||
```
|
||||
|
||||
Gate Multipliers (in basis points):
|
||||
```
|
||||
behind feature flag: ×7000
|
||||
auth required: ×8000
|
||||
admin only: ×8500
|
||||
non-default config: ×7500
|
||||
```
|
||||
|
||||
Final R:
|
||||
```
|
||||
R = bucketScore * gateMultiplier / 10000
|
||||
```
|
||||
|
||||
### 2.3 Evidence (E)
|
||||
|
||||
Points:
|
||||
```
|
||||
runtime trace: +60
|
||||
DAST/integration test: +30
|
||||
SAST precise sink: +20
|
||||
SCA presence only: +10
|
||||
```
|
||||
|
||||
Freshness Multiplier (basis points):
|
||||
```
|
||||
≤ 7 days: ×10000
|
||||
≤ 30 days: ×9000
|
||||
≤ 90 days: ×7500
|
||||
≤ 180 days: ×6000
|
||||
≤ 365 days: ×4000
|
||||
> 365 days: ×2000
|
||||
```
|
||||
|
||||
Final E:
|
||||
```
|
||||
E = min(100, sum(points)) * freshness / 10000
|
||||
```
|
||||
|
||||
### 2.4 Provenance (P)
|
||||
|
||||
```
|
||||
unsigned/unknown: 0
|
||||
signed image: 30
|
||||
signed + SBOM hash-linked: 60
|
||||
signed + SBOM + DSSE attestations: 80
|
||||
above + reproducible build match: 100
|
||||
```
|
||||
|
||||
## 3. SCORE POLICY YAML SCHEMA
|
||||
|
||||
```yaml
|
||||
policyVersion: score.v1
|
||||
weightsBps:
|
||||
baseSeverity: 1000
|
||||
reachability: 4500
|
||||
evidence: 3000
|
||||
provenance: 1500
|
||||
|
||||
reachability:
|
||||
hopBuckets:
|
||||
- { maxHops: 2, score: 100 }
|
||||
- { maxHops: 3, score: 85 }
|
||||
- { maxHops: 4, score: 70 }
|
||||
- { maxHops: 5, score: 55 }
|
||||
- { maxHops: 6, score: 45 }
|
||||
- { maxHops: 7, score: 35 }
|
||||
- { maxHops: 9999, score: 20 }
|
||||
unreachableScore: 0
|
||||
gateMultipliersBps:
|
||||
featureFlag: 7000
|
||||
authRequired: 8000
|
||||
adminOnly: 8500
|
||||
nonDefaultConfig: 7500
|
||||
|
||||
evidence:
|
||||
points:
|
||||
runtime: 60
|
||||
dast: 30
|
||||
sast: 20
|
||||
sca: 10
|
||||
freshnessBuckets:
|
||||
- { maxAgeDays: 7, multiplierBps: 10000 }
|
||||
- { maxAgeDays: 30, multiplierBps: 9000 }
|
||||
- { maxAgeDays: 90, multiplierBps: 7500 }
|
||||
- { maxAgeDays: 180, multiplierBps: 6000 }
|
||||
- { maxAgeDays: 365, multiplierBps: 4000 }
|
||||
- { maxAgeDays: 99999, multiplierBps: 2000 }
|
||||
|
||||
provenance:
|
||||
levels:
|
||||
unsigned: 0
|
||||
signed: 30
|
||||
signedWithSbom: 60
|
||||
signedWithSbomAndAttestations: 80
|
||||
reproducible: 100
|
||||
|
||||
overrides:
|
||||
- name: knownExploitedAndReachable
|
||||
when:
|
||||
flags:
|
||||
knownExploited: true
|
||||
minReachability: 70
|
||||
setScore: 95
|
||||
|
||||
- name: unreachableAndOnlySca
|
||||
when:
|
||||
maxReachability: 0
|
||||
maxEvidence: 10
|
||||
clampMaxScore: 25
|
||||
```
|
||||
|
||||
## 4. SCORE DATA CONTRACTS
|
||||
|
||||
### 4.1 ScoreInput
|
||||
|
||||
```json
|
||||
{
|
||||
"asOf": "2025-12-14T10:20:30Z",
|
||||
"policyVersion": "score.v1",
|
||||
"reachabilityDigest": "sha256:...",
|
||||
"evidenceDigest": "sha256:...",
|
||||
"provenanceDigest": "sha256:...",
|
||||
"baseSeverityDigest": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 ScoreResult
|
||||
|
||||
```json
|
||||
{
|
||||
"scoreId": "score_...",
|
||||
"riskScore": 73,
|
||||
"subscores": {
|
||||
"baseSeverity": 75,
|
||||
"reachability": 85,
|
||||
"evidence": 60,
|
||||
"provenance": 60
|
||||
},
|
||||
"cvss": {
|
||||
"v": "3.1",
|
||||
"base": 7.5,
|
||||
"environmental": 5.3,
|
||||
"vector": "CVSS:3.1/AV:N/AC:L/..."
|
||||
},
|
||||
"inputsRef": ["evidence_sha256:...", "env_sha256:..."],
|
||||
"policyVersion": "score.v1",
|
||||
"policyDigest": "sha256:...",
|
||||
"engineVersion": "stella-scorer@1.8.2",
|
||||
"computedAt": "2025-12-09T10:20:30Z",
|
||||
"resultDigest": "sha256:...",
|
||||
"explain": [
|
||||
{"factor": "reachability", "value": 85, "reason": "3 hops from HTTP endpoint"},
|
||||
{"factor": "evidence", "value": 60, "reason": "Runtime trace (60pts), 20 days old (×90%)"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 4.3 ReachabilityReport
|
||||
|
||||
```json
|
||||
{
|
||||
"artifactDigest": "sha256:...",
|
||||
"graphDigest": "sha256:...",
|
||||
"vulnId": "CVE-2024-1234",
|
||||
"vulnerableSymbol": "org.example.VulnClass.vulnMethod",
|
||||
"entrypoints": ["POST /api/upload"],
|
||||
"shortestPath": {
|
||||
"hops": 3,
|
||||
"nodes": [
|
||||
{"symbol": "UploadController.handleUpload", "file": "Controller.cs", "line": 42},
|
||||
{"symbol": "ProcessorService.process", "file": "Service.cs", "line": 18},
|
||||
{"symbol": "org.example.VulnClass.vulnMethod", "file": null, "line": null}
|
||||
]
|
||||
},
|
||||
"gates": [
|
||||
{"type": "authRequired", "detail": "Requires JWT token"},
|
||||
{"type": "featureFlag", "detail": "FEATURE_UPLOAD_V2=true"}
|
||||
],
|
||||
"computedAt": "2025-12-14T10:15:30Z",
|
||||
"toolVersion": "reachability-analyzer@2.1.0"
|
||||
}
|
||||
```
|
||||
|
||||
### 4.4 EvidenceBundle
|
||||
|
||||
```json
|
||||
{
|
||||
"evidenceId": "sha256:...",
|
||||
"artifactDigest": "sha256:...",
|
||||
"vulnId": "CVE-2024-1234",
|
||||
"type": "RUNTIME",
|
||||
"tool": "runtime-tracer@1.0.0",
|
||||
"timestamp": "2025-12-10T14:30:00Z",
|
||||
"confidence": 95,
|
||||
"subject": "org.example.VulnClass.vulnMethod",
|
||||
"payloadDigest": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
### 4.5 ProvenanceReport
|
||||
|
||||
```json
|
||||
{
|
||||
"artifactDigest": "sha256:...",
|
||||
"signatureChecks": [
|
||||
{"signer": "CI-KEY-1", "algorithm": "ECDSA-P256", "result": "VALID"}
|
||||
],
|
||||
"sbomDigest": "sha256:...",
|
||||
"sbomType": "cyclonedx-1.6",
|
||||
"attestations": ["sha256:...", "sha256:..."],
|
||||
"transparencyLogRefs": ["rekor://..."],
|
||||
"reproducibleMatch": true,
|
||||
"computedAt": "2025-12-14T10:15:30Z",
|
||||
"toolVersion": "provenance-verifier@1.0.0"
|
||||
}
|
||||
```
|
||||
|
||||
## 5. DETERMINISM CONSTRAINTS
|
||||
|
||||
### 5.1 Fixed-Point Math
|
||||
|
||||
- Use integer basis points (100% = 10,000 bps)
|
||||
- No floating point in scoring math
|
||||
- Round only at final display
|
||||
|
||||
### 5.2 Canonical Serialization
|
||||
|
||||
- RFC-style canonical JSON (JCS)
|
||||
- Sort keys and arrays deterministically
|
||||
- Stable ordering for explanation lists by `(factorId, contributingObjectDigest)`
|
||||
|
||||
### 5.3 Time Handling
|
||||
|
||||
- No implicit time
|
||||
- `asOf` is explicit input
|
||||
- Freshness = `asOf - evidence.timestamp`
|
||||
- Use monotonic time internally
|
||||
|
||||
## 6. FIDELITY METRICS
|
||||
|
||||
### 6.1 Bitwise Fidelity (BF)
|
||||
|
||||
```
|
||||
BF = identical_outputs / total_replays
|
||||
Target: ≥ 0.98
|
||||
```
|
||||
|
||||
### 6.2 Semantic Fidelity (SF)
|
||||
|
||||
- Normalized object comparison (same packages, versions, CVEs, severities, verdicts)
|
||||
- Allows formatting differences
|
||||
|
||||
### 6.3 Policy Fidelity (PF)
|
||||
|
||||
- Final policy decision (pass/fail + reason codes) matches
|
||||
|
||||
## 7. SCAN MANIFEST SCHEMA
|
||||
|
||||
```json
|
||||
{
|
||||
"manifest_version": "1.0",
|
||||
"scan_id": "scan_123",
|
||||
"created_at": "2025-12-12T10:15:30Z",
|
||||
|
||||
"input": {
|
||||
"type": "oci_image",
|
||||
"image_ref": "registry/app@sha256:...",
|
||||
"layers": ["sha256:...", "sha256:..."],
|
||||
"source_provenance": {"repo_sha": "abc123", "build_id": "ci-999"}
|
||||
},
|
||||
|
||||
"scanner": {
|
||||
"engine": "stella",
|
||||
"scanner_image_digest": "sha256:...",
|
||||
"scanner_version": "2025.12.0",
|
||||
"config_digest": "sha256:...",
|
||||
"flags": ["--deep", "--vex"]
|
||||
},
|
||||
|
||||
"feeds": {
|
||||
"vuln_feed_bundle_digest": "sha256:...",
|
||||
"license_db_digest": "sha256:..."
|
||||
},
|
||||
|
||||
"policy": {
|
||||
"policy_bundle_digest": "sha256:...",
|
||||
"policy_set": "prod-default"
|
||||
},
|
||||
|
||||
"environment": {
|
||||
"arch": "amd64",
|
||||
"os": "linux",
|
||||
"tz": "UTC",
|
||||
"locale": "C",
|
||||
"network": "disabled",
|
||||
"clock_mode": "frozen",
|
||||
"clock_value": "2025-12-12T10:15:30Z"
|
||||
},
|
||||
|
||||
"normalization": {
|
||||
"canonicalizer_version": "1.2.0",
|
||||
"sbom_schema": "cyclonedx-1.6",
|
||||
"vex_schema": "cyclonedx-vex-1.0"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 8. MISMATCH CLASSIFICATION TAXONOMY
|
||||
|
||||
```
|
||||
- Feed drift
|
||||
- Policy drift
|
||||
- Runtime drift
|
||||
- Scanner drift
|
||||
- Nondeterminism (ordering, concurrency, RNG, time-based logic)
|
||||
- External IO
|
||||
```
|
||||
|
||||
## 9. POSTGRESQL SCHEMA
|
||||
|
||||
```sql
|
||||
CREATE TABLE scan_manifest (
|
||||
manifest_id UUID PRIMARY KEY,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
|
||||
artifact_digest TEXT NOT NULL,
|
||||
feeds_merkle_root TEXT NOT NULL,
|
||||
engine_build_hash TEXT NOT NULL,
|
||||
policy_lattice_hash TEXT NOT NULL,
|
||||
|
||||
ruleset_hash TEXT NOT NULL,
|
||||
config_flags JSONB NOT NULL,
|
||||
|
||||
environment_fingerprint JSONB NOT NULL,
|
||||
|
||||
raw_manifest JSONB NOT NULL,
|
||||
raw_manifest_sha256 TEXT NOT NULL
|
||||
);
|
||||
|
||||
CREATE TABLE scan_execution (
|
||||
execution_id UUID PRIMARY KEY,
|
||||
manifest_id UUID NOT NULL REFERENCES scan_manifest(manifest_id) ON DELETE CASCADE,
|
||||
|
||||
started_at TIMESTAMPTZ NOT NULL,
|
||||
finished_at TIMESTAMPTZ NOT NULL,
|
||||
|
||||
t_ingest_ms INT NOT NULL,
|
||||
t_analyze_ms INT NOT NULL,
|
||||
t_reachability_ms INT NOT NULL,
|
||||
t_vex_ms INT NOT NULL,
|
||||
t_sign_ms INT NOT NULL,
|
||||
t_publish_ms INT NOT NULL,
|
||||
|
||||
proof_bundle_sha256 TEXT NOT NULL,
|
||||
findings_sha256 TEXT NOT NULL,
|
||||
vex_bundle_sha256 TEXT NOT NULL,
|
||||
|
||||
replay_mode BOOLEAN NOT NULL DEFAULT FALSE
|
||||
);
|
||||
|
||||
CREATE TABLE classification_history (
|
||||
id BIGSERIAL PRIMARY KEY,
|
||||
artifact_digest TEXT NOT NULL,
|
||||
manifest_id UUID NOT NULL REFERENCES scan_manifest(manifest_id) ON DELETE CASCADE,
|
||||
execution_id UUID NOT NULL REFERENCES scan_execution(execution_id) ON DELETE CASCADE,
|
||||
|
||||
previous_status TEXT NOT NULL,
|
||||
new_status TEXT NOT NULL,
|
||||
cause TEXT NOT NULL,
|
||||
|
||||
changed_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
|
||||
);
|
||||
|
||||
CREATE VIEW scan_tte AS
|
||||
SELECT
|
||||
execution_id,
|
||||
manifest_id,
|
||||
(finished_at - started_at) AS tte_interval
|
||||
FROM scan_execution;
|
||||
|
||||
CREATE MATERIALIZED VIEW fn_drift_stats AS
|
||||
SELECT
|
||||
date_trunc('day', changed_at) AS day_bucket,
|
||||
COUNT(*) FILTER (WHERE new_status = 'affected') AS affected_count,
|
||||
COUNT(*) AS total_reclassified,
|
||||
ROUND(
|
||||
(COUNT(*) FILTER (WHERE new_status = 'affected')::numeric /
|
||||
NULLIF(COUNT(*), 0)) * 100, 4
|
||||
) AS drift_percent
|
||||
FROM classification_history
|
||||
GROUP BY 1;
|
||||
```
|
||||
|
||||
## 10. C# CANONICAL DATA STRUCTURES
|
||||
|
||||
```csharp
|
||||
public sealed record CanonicalScanManifest
|
||||
{
|
||||
public required string ArtifactDigest { get; init; }
|
||||
public required string FeedsMerkleRoot { get; init; }
|
||||
public required string EngineBuildHash { get; init; }
|
||||
public required string PolicyLatticeHash { get; init; }
|
||||
public required string RulesetHash { get; init; }
|
||||
|
||||
public required IReadOnlyDictionary<string, string> ConfigFlags { get; init; }
|
||||
public required EnvironmentFingerprint Environment { get; init; }
|
||||
}
|
||||
|
||||
public sealed record EnvironmentFingerprint
|
||||
{
|
||||
public required string CpuModel { get; init; }
|
||||
public required string RuntimeVersion { get; init; }
|
||||
public required string Os { get; init; }
|
||||
public required IReadOnlyDictionary<string, string> Extra { get; init; }
|
||||
}
|
||||
|
||||
public sealed record ScanExecutionMetrics
|
||||
{
|
||||
public required int IngestMs { get; init; }
|
||||
public required int AnalyzeMs { get; init; }
|
||||
public required int ReachabilityMs { get; init; }
|
||||
public required int VexMs { get; init; }
|
||||
public required int SignMs { get; init; }
|
||||
public required int PublishMs { get; init; }
|
||||
}
|
||||
```
|
||||
|
||||
## 11. CANONICALIZATION IMPLEMENTATION
|
||||
|
||||
```csharp
|
||||
internal static class CanonicalJson
|
||||
{
|
||||
private static readonly JsonSerializerOptions Options = new()
|
||||
{
|
||||
WriteIndented = false,
|
||||
PropertyNamingPolicy = JsonNamingPolicy.CamelCase
|
||||
};
|
||||
|
||||
public static string Serialize(object obj)
|
||||
{
|
||||
using var stream = new MemoryStream();
|
||||
using (var writer = new Utf8JsonWriter(stream, new JsonWriterOptions
|
||||
{
|
||||
Indented = false,
|
||||
SkipValidation = false
|
||||
}))
|
||||
{
|
||||
JsonSerializer.Serialize(writer, obj, obj.GetType(), Options);
|
||||
}
|
||||
|
||||
var bytes = stream.ToArray();
|
||||
var canonical = JsonCanonicalizer.Canonicalize(bytes);
|
||||
|
||||
return canonical;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 11.1 Full Canonical JSON with Sorted Keys
|
||||
|
||||
> **Added**: 2025-12-17 from "Building a Deeper Moat Beyond Reachability" advisory
|
||||
|
||||
```csharp
|
||||
using System.Security.Cryptography;
|
||||
using System.Text;
|
||||
using System.Text.Json;
|
||||
|
||||
public static class CanonJson
|
||||
{
|
||||
public static byte[] Canonicalize<T>(T obj)
|
||||
{
|
||||
var json = JsonSerializer.SerializeToUtf8Bytes(obj, new JsonSerializerOptions
|
||||
{
|
||||
WriteIndented = false,
|
||||
PropertyNamingPolicy = JsonNamingPolicy.CamelCase
|
||||
});
|
||||
|
||||
using var doc = JsonDocument.Parse(json);
|
||||
using var ms = new MemoryStream();
|
||||
using var writer = new Utf8JsonWriter(ms, new JsonWriterOptions { Indented = false });
|
||||
|
||||
WriteElementSorted(doc.RootElement, writer);
|
||||
writer.Flush();
|
||||
return ms.ToArray();
|
||||
}
|
||||
|
||||
private static void WriteElementSorted(JsonElement el, Utf8JsonWriter w)
|
||||
{
|
||||
switch (el.ValueKind)
|
||||
{
|
||||
case JsonValueKind.Object:
|
||||
w.WriteStartObject();
|
||||
foreach (var prop in el.EnumerateObject().OrderBy(p => p.Name, StringComparer.Ordinal))
|
||||
{
|
||||
w.WritePropertyName(prop.Name);
|
||||
WriteElementSorted(prop.Value, w);
|
||||
}
|
||||
w.WriteEndObject();
|
||||
break;
|
||||
|
||||
case JsonValueKind.Array:
|
||||
w.WriteStartArray();
|
||||
foreach (var item in el.EnumerateArray())
|
||||
WriteElementSorted(item, w);
|
||||
w.WriteEndArray();
|
||||
break;
|
||||
|
||||
default:
|
||||
el.WriteTo(w);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
public static string Sha256Hex(ReadOnlySpan<byte> bytes)
|
||||
=> Convert.ToHexString(SHA256.HashData(bytes)).ToLowerInvariant();
|
||||
}
|
||||
```
|
||||
|
||||
## 11.2 SCORE PROOF LEDGER
|
||||
|
||||
> **Added**: 2025-12-17 from "Building a Deeper Moat Beyond Reachability" advisory
|
||||
|
||||
The Score Proof Ledger provides an append-only trail of scoring decisions with per-node hashing.
|
||||
|
||||
### Proof Node Types
|
||||
|
||||
```csharp
|
||||
public enum ProofNodeKind { Input, Transform, Delta, Score }
|
||||
|
||||
public sealed record ProofNode(
|
||||
string Id,
|
||||
ProofNodeKind Kind,
|
||||
string RuleId,
|
||||
string[] ParentIds,
|
||||
string[] EvidenceRefs, // digests / refs inside bundle
|
||||
double Delta, // 0 for non-Delta nodes
|
||||
double Total, // running total at this node
|
||||
string Actor, // module name
|
||||
DateTimeOffset TsUtc,
|
||||
byte[] Seed,
|
||||
string NodeHash // sha256 over canonical node (excluding NodeHash)
|
||||
);
|
||||
```
|
||||
|
||||
### Proof Hashing
|
||||
|
||||
```csharp
|
||||
public static class ProofHashing
|
||||
{
|
||||
public static ProofNode WithHash(ProofNode n)
|
||||
{
|
||||
var canonical = CanonJson.Canonicalize(new
|
||||
{
|
||||
n.Id, n.Kind, n.RuleId, n.ParentIds, n.EvidenceRefs, n.Delta, n.Total,
|
||||
n.Actor, n.TsUtc, Seed = Convert.ToBase64String(n.Seed)
|
||||
});
|
||||
|
||||
return n with { NodeHash = "sha256:" + CanonJson.Sha256Hex(canonical) };
|
||||
}
|
||||
|
||||
public static string ComputeRootHash(IEnumerable<ProofNode> nodesInOrder)
|
||||
{
|
||||
// Deterministic: root hash over canonical JSON array of node hashes in order.
|
||||
var arr = nodesInOrder.Select(n => n.NodeHash).ToArray();
|
||||
var bytes = CanonJson.Canonicalize(arr);
|
||||
return "sha256:" + CanonJson.Sha256Hex(bytes);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Minimal Ledger
|
||||
|
||||
```csharp
|
||||
public sealed class ProofLedger
|
||||
{
|
||||
private readonly List<ProofNode> _nodes = new();
|
||||
public IReadOnlyList<ProofNode> Nodes => _nodes;
|
||||
|
||||
public void Append(ProofNode node)
|
||||
{
|
||||
_nodes.Add(ProofHashing.WithHash(node));
|
||||
}
|
||||
|
||||
public string RootHash() => ProofHashing.ComputeRootHash(_nodes);
|
||||
}
|
||||
```
|
||||
|
||||
### Score Replay Invariant
|
||||
|
||||
The score replay must produce identical ledger root hashes given:
|
||||
- Same manifest (artifact, snapshots, policy)
|
||||
- Same seed
|
||||
- Same timestamp (or frozen clock)
|
||||
|
||||
```csharp
|
||||
public class DeterminismTests
|
||||
{
|
||||
[Fact]
|
||||
public void Score_Replay_IsBitIdentical()
|
||||
{
|
||||
var seed = Enumerable.Repeat((byte)7, 32).ToArray();
|
||||
var inputs = new ScoreInputs(9.0, 0.50, false, ReachabilityClass.Unknown, new("enforced","ro"));
|
||||
|
||||
var (s1, l1) = RiskScoring.Score(inputs, "scanA", seed, DateTimeOffset.Parse("2025-01-01T00:00:00Z"));
|
||||
var (s2, l2) = RiskScoring.Score(inputs, "scanA", seed, DateTimeOffset.Parse("2025-01-01T00:00:00Z"));
|
||||
|
||||
Assert.Equal(s1, s2, 10);
|
||||
Assert.Equal(l1.RootHash(), l2.RootHash());
|
||||
Assert.True(l1.Nodes.Zip(l2.Nodes).All(z => z.First.NodeHash == z.Second.NodeHash));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 12. REPLAY RUNNER
|
||||
|
||||
```csharp
|
||||
public static class ReplayRunner
|
||||
{
|
||||
public static ReplayResult Replay(Guid manifestId, IScannerEngine engine)
|
||||
{
|
||||
var manifest = ManifestRepository.Load(manifestId);
|
||||
var canonical = CanonicalJson.Serialize(manifest.RawObject);
|
||||
var canonicalHash = Sha256(canonical);
|
||||
|
||||
if (canonicalHash != manifest.RawManifestSHA256)
|
||||
throw new InvalidOperationException("Manifest integrity violation.");
|
||||
|
||||
using var feeds = FeedSnapshotResolver.Open(manifest.FeedsMerkleRoot);
|
||||
|
||||
var exec = engine.Scan(new ScanRequest
|
||||
{
|
||||
ArtifactDigest = manifest.ArtifactDigest,
|
||||
Feeds = feeds,
|
||||
LatticeHash = manifest.PolicyLatticeHash,
|
||||
EngineBuildHash = manifest.EngineBuildHash,
|
||||
CanonicalManifest = canonical
|
||||
});
|
||||
|
||||
return new ReplayResult(
|
||||
exec.FindingsHash == manifest.FindingsSHA256,
|
||||
exec.VexBundleHash == manifest.VexBundleSHA256,
|
||||
exec.ProofBundleHash == manifest.ProofBundleSHA256,
|
||||
exec
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 13. BENCHMARK METRICS
|
||||
|
||||
### 13.1 Time-to-Evidence (TTE)
|
||||
|
||||
**Definition:**
|
||||
```
|
||||
TTE = t(proof_ready) – t(artifact_ingested)
|
||||
```
|
||||
|
||||
**Targets:**
|
||||
- P50 < 2m for typical containers (≤ 500 MB)
|
||||
- P95 < 5m including cold-start/offline-bundle mode
|
||||
|
||||
**Stage Breakdown:**
|
||||
- t_ingest_ms
|
||||
- t_analyze_ms
|
||||
- t_reachability_ms
|
||||
- t_vex_ms
|
||||
- t_sign_ms
|
||||
- t_publish_ms
|
||||
|
||||
### 13.2 False-Negative Drift Rate (FN-DRIFT)
|
||||
|
||||
**Definition (rolling 30d window):**
|
||||
```
|
||||
FN-Drift = (# artifacts re-classified from {unaffected/unknown} → affected) / (total artifacts re-evaluated)
|
||||
```
|
||||
|
||||
**Stratification:**
|
||||
- feed delta
|
||||
- rule delta
|
||||
- lattice/policy delta
|
||||
- reachability delta
|
||||
|
||||
**Targets:**
|
||||
- Engine-caused FN-Drift ≈ 0
|
||||
- Feed-caused FN-Drift: faster is better
|
||||
|
||||
### 13.3 Deterministic Reproducibility
|
||||
|
||||
**Proof Object:**
|
||||
```json
|
||||
{
|
||||
"artifact_digest": "sha256:...",
|
||||
"scan_manifest_hash": "sha256:...",
|
||||
"feeds_merkle_root": "sha256:...",
|
||||
"engine_build_hash": "sha256:...",
|
||||
"policy_lattice_hash": "sha256:...",
|
||||
"findings_sha256": "sha256:...",
|
||||
"vex_bundle_sha256": "sha256:...",
|
||||
"proof_bundle_sha256": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
**Metric:**
|
||||
```
|
||||
Repro rate = identical_outputs / total_replays
|
||||
Target: 100%
|
||||
```
|
||||
|
||||
### 13.4 Detection Metrics
|
||||
|
||||
```
|
||||
true_positive_count (TP)
|
||||
false_positive_count (FP)
|
||||
false_negative_count (FN)
|
||||
|
||||
precision = TP / (TP + FP)
|
||||
recall = TP / (TP + FN)
|
||||
|
||||
fp_reduction = (baseline_fp_rate - stella_fp_rate) / baseline_fp_rate
|
||||
```
|
||||
|
||||
### 13.5 Proof Coverage
|
||||
|
||||
```
|
||||
proof_coverage_all = findings_with_valid_receipts / total_findings
|
||||
|
||||
proof_coverage_vex = vex_items_with_valid_receipts / total_vex_items
|
||||
|
||||
proof_coverage_reachable = reachable_findings_with_proofs / total_reachable_findings
|
||||
```
|
||||
|
||||
## 14. SLO THRESHOLDS
|
||||
|
||||
**Fidelity:**
|
||||
- BF ≥ 0.98 (general)
|
||||
- BF ≥ 0.95 (regulated projects)
|
||||
- PF ≈ 1.0 (unless policy changed intentionally)
|
||||
|
||||
**Alerts:**
|
||||
- BF drops ≥2% week-over-week → warn
|
||||
- BF < 0.90 overall → page/block release
|
||||
- Regulated BF < 0.95 → page/block release
|
||||
|
||||
## 15. DETERMINISTIC PACKAGING (BUNDLES)
|
||||
|
||||
Determinism applies to *packaging*, not only algorithms.
|
||||
|
||||
Rules for proof bundles and offline kits:
|
||||
- Prefer `tar` with deterministic ordering; avoid formats that inject timestamps by default.
|
||||
- Canonical file order: lexicographic path sort; include an `index.json` listing files and their digests in the same order.
|
||||
- Normalize file metadata: fixed uid/gid, fixed mtime, stable permissions; record the chosen policy in the manifest.
|
||||
- Compression must be reproducible (fixed level/settings; no embedded timestamps).
|
||||
- Bundle hash is computed over the canonical archive bytes and must be DSSE-signed.
|
||||
|
||||
## 16. BENCHMARK HARNESS (MOAT METRICS)
|
||||
|
||||
Use the repo benchmark harness as the single place where moat metrics are measured and enforced:
|
||||
- Harness root: `bench/README.md` (layout, verifiers, comparison tools).
|
||||
- Evidence contracts: `docs/benchmarks/vex-evidence-playbook.md` and `docs/replay/DETERMINISTIC_REPLAY.md`.
|
||||
|
||||
Developer rules:
|
||||
- No feature touching scans/policy/proofs ships without at least one benchmark scenario or an extension of an existing one.
|
||||
- If golden outputs change intentionally, record a short “why” note (which metric improved, which contract changed) and keep artifacts deterministic.
|
||||
- Bench runs must record and validate `graphRevisionId` and per-verdict receipts (see `docs/product-advisories/14-Dec-2025 - Proof and Evidence Chain Technical Reference.md`).
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,474 @@
|
||||
# Developer Onboarding Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 01-Dec-2025 - Common Developers guides
|
||||
- 29-Nov-2025 - StellaOps – Mid-Level .NET Onboarding (Quick Start)
|
||||
- 30-Nov-2025 - Implementor Guidelines for Stella Ops
|
||||
- 30-Nov-2025 - Standup Sprint Kickstarters
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
**Revision**: 1.1 (Corrected to match actual implementation)
|
||||
|
||||
---
|
||||
|
||||
## 0. WHERE TO START (IN-REPO)
|
||||
|
||||
- `docs/README.md` (doc map and module dossiers)
|
||||
- `docs/07_HIGH_LEVEL_ARCHITECTURE.md` (end-to-end system model)
|
||||
- `docs/18_CODING_STANDARDS.md` (C# conventions, repo rules, gates)
|
||||
- `docs/19_TEST_SUITE_OVERVIEW.md` (test layers, CI expectations)
|
||||
- `docs/technical/development/README.md` (developer tooling and workflows)
|
||||
- `docs/10_PLUGIN_SDK_GUIDE.md` (plugin SDK + packaging)
|
||||
- `LICENSE` (AGPL-3.0-or-later obligations)
|
||||
|
||||
## 1. CORE ENGINEERING PRINCIPLES
|
||||
|
||||
- **SOLID First**: Interface and dependency inversion required
|
||||
- **100-line File Rule**: Files >100 lines must be split/refactored
|
||||
- **Contracts vs Runtime**: Public DTOs/interfaces in `*.Contracts` projects
|
||||
- **Single Composition Root**: DI wiring in `StellaOps.Web/Program.cs` and plugin `IDependencyInjectionRoutine`
|
||||
- **No Service Locator**: Constructor injection only
|
||||
- **Fail-fast Startup**: Validate configuration before web host starts
|
||||
- **Hot-load Compatibility**: Avoid static singletons that survive plugin unload
|
||||
|
||||
### 1.1 Product Non-Negotiables
|
||||
|
||||
- **Determinism first**: stable ordering + canonicalization; no hidden clocks/entropy in core algorithms
|
||||
- **Offline-first**: no silent network dependency; every workflow has an offline/mirrored path
|
||||
- **Evidence over UI**: the API + signed artifacts must fully explain what the UI shows
|
||||
- **Contracts are contracts**: version schemas; add fields with defaults; never silently change semantics
|
||||
- **Golden fixtures required**: any change to scanning/policy/proofs must be covered by deterministic fixtures + replay tests
|
||||
- **Respect service boundaries**: do not re-implement scanner/policy logic in downstream services or UI
|
||||
|
||||
## 2. REPOSITORY LAYOUT RULES
|
||||
|
||||
- No "Module" folders or nested solution hierarchies
|
||||
- Tests mirror `src/` structure 1:1
|
||||
- No test code in production projects
|
||||
- Feature folder layout: `Scan/ScanService.cs`, `Scan/ScanController.cs`
|
||||
|
||||
## 3. NAMING & STYLE CONVENTIONS
|
||||
|
||||
### 3.1 Namespaces & Files
|
||||
|
||||
- **Namespaces**: File-scoped, `StellaOps.*`
|
||||
- **Classes/records**: PascalCase
|
||||
- **Interfaces**: `I` prefix (`IScannerRunner`)
|
||||
- **Private fields**: `_camelCase` (with leading underscore, standard C# convention)
|
||||
- **Constants**: `PascalCase` (standard C# convention, e.g., `MaxRetries`)
|
||||
- **Async methods**: End with `Async`
|
||||
|
||||
### 3.2 Usings
|
||||
|
||||
- Outside namespace
|
||||
- Sorted
|
||||
- No wildcards
|
||||
|
||||
## 4. C# FEATURE USAGE
|
||||
|
||||
- Nullable reference types enabled
|
||||
- Use `record` for immutable DTOs
|
||||
- Prefer pattern matching over long `switch` cascades
|
||||
- `Span`/`Memory` only when measured as necessary
|
||||
- Use `await foreach` instead of manual iterator loops
|
||||
|
||||
## 5. DI POLICY
|
||||
|
||||
### 5.1 Composition Root
|
||||
|
||||
- **One composition root** per process
|
||||
- Plugins contribute via `[ServiceBinding]` attribute or `IDependencyInjectionRoutine` implementations
|
||||
- Default lifetime: **scoped**
|
||||
- Singletons only for stateless, thread-safe helpers
|
||||
- Never use service locator or manually build nested service providers
|
||||
|
||||
### 5.2 Service Binding Attributes
|
||||
|
||||
```csharp
|
||||
[ServiceBinding(typeof(IMyContract), ServiceLifetime.Scoped)]
|
||||
public class MyService : IMyContract
|
||||
{
|
||||
// Implementation
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Advanced DI Configuration
|
||||
|
||||
```csharp
|
||||
public class MyPluginDependencyInjectionRoutine : IDependencyInjectionRoutine
|
||||
{
|
||||
public IServiceCollection Register(IServiceCollection services, IConfiguration configuration)
|
||||
{
|
||||
services.AddScoped<IMyContract, MyService>();
|
||||
services.Configure<MyOptions>(configuration.GetSection("MyPlugin"));
|
||||
return services;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 6. ASYNC & THREADING
|
||||
|
||||
- All I/O is async; avoid `.Result` / `.Wait()`
|
||||
- Library code uses `ConfigureAwait(false)`
|
||||
- Control concurrency with channels or `Parallel.ForEachAsync`
|
||||
|
||||
## 7. TEST LAYERS
|
||||
|
||||
- **Unit**: xUnit with FluentAssertions
|
||||
- **Property-based**: FsCheck (for fuzz testing in Attestor module)
|
||||
- **Integration**: API with Testcontainers (PostgreSQL)
|
||||
- **Contracts**: OpenAPI validation with Spectral
|
||||
- **Frontend**: Karma/Jasmine (unit), Playwright (e2e), Lighthouse CI (performance/a11y)
|
||||
- **Non-functional**: Dependency/license scanning, SBOM reproducibility, Axe accessibility audits
|
||||
|
||||
## 8. QUALITY GATES
|
||||
|
||||
- API unit test coverage ≥ ~85%
|
||||
- API P95 latency ≤ ~120ms
|
||||
- Δ-SBOM warm scan P95 ≤ ~5s
|
||||
- Lighthouse perf ≥ ~90, a11y ≥ ~95
|
||||
|
||||
## 9. PLUGIN SYSTEM
|
||||
|
||||
### 9.1 Plugin Templates
|
||||
|
||||
```bash
|
||||
# Install templates
|
||||
dotnet new install ./templates
|
||||
|
||||
# Create a connector plugin
|
||||
dotnet new stellaops-plugin-connector -n MyCompany.AcmeConnector
|
||||
|
||||
# Create a scheduled job plugin
|
||||
dotnet new stellaops-plugin-scheduler -n MyCompany.CleanupJob
|
||||
```
|
||||
|
||||
### 9.2 Plugin Publishing
|
||||
|
||||
- Publish signed artifacts to `<Module>.PluginBinaries/<MyPlugin>/`
|
||||
- Backend verifies Cosign signature when `EnforceSignatureVerification` is enabled
|
||||
- Enforces `[StellaPluginVersion]` compatibility when `HostVersion` is configured
|
||||
- Loads plugins in isolated `AssemblyLoadContext`s
|
||||
|
||||
### 9.3 Plugin Signing
|
||||
|
||||
```bash
|
||||
dotnet publish -c Release -o out
|
||||
cosign sign --key $COSIGN_KEY out/StellaOps.Plugin.MyConnector.dll
|
||||
```
|
||||
|
||||
### 9.4 Plugin Version Attribute
|
||||
|
||||
```csharp
|
||||
// In AssemblyInfo.cs or any file
|
||||
[assembly: StellaPluginVersion("1.0.0", MinimumHostVersion = "1.0.0")]
|
||||
```
|
||||
|
||||
## 10. POLICY DSL (stella-dsl@1)
|
||||
|
||||
### 10.1 Goals
|
||||
|
||||
- Deterministic
|
||||
- Declarative
|
||||
- Explainable
|
||||
- Offline-friendly
|
||||
- Reachability-aware
|
||||
|
||||
### 10.2 Structure
|
||||
|
||||
- One `policy` block per `.stella` file
|
||||
- Contains: `metadata`, `profile` blocks, `rule` blocks, optional `settings`
|
||||
|
||||
### 10.3 Context Namespaces
|
||||
|
||||
- `sbom`
|
||||
- `advisory`
|
||||
- `vex`
|
||||
- `env`
|
||||
- `telemetry`
|
||||
- `secret`
|
||||
- `profile.*`
|
||||
|
||||
### 10.4 Helpers
|
||||
|
||||
- `normalize_cvss`
|
||||
- `risk_score`
|
||||
- `vex.any`
|
||||
- `vex.latest`
|
||||
- `sbom.any_component`
|
||||
- `exists`
|
||||
- `coalesce`
|
||||
|
||||
### 10.5 Rules
|
||||
|
||||
- Always include clear `because` when changing `status` or `severity`
|
||||
- Avoid catch-all suppressions (`when true` + `status := "suppressed"`)
|
||||
- Use `stella policy lint/compile/simulate` in CI
|
||||
- Test in sealed (offline) mode
|
||||
|
||||
## 11. PR CHECKLIST
|
||||
|
||||
1. Use **Conventional Commit** prefixes (`feat:`, `fix:`, `docs:`)
|
||||
2. Run `dotnet format` and `dotnet test` (both must be green)
|
||||
3. Keep files within 100-line guideline
|
||||
4. Update XML-doc comments for new public API
|
||||
5. Update docs and JSON schema for contract changes
|
||||
6. Ensure analyzers and CI jobs pass
|
||||
|
||||
## 12. ONBOARDING DETERMINISM REQUIREMENTS
|
||||
|
||||
- Use fixed seeds and pinned toolchain versions
|
||||
- Avoid live network calls; prefer cached feeds/mirrors
|
||||
- Note mirror paths in examples
|
||||
|
||||
## 13. SPRINT READINESS CHECKLIST
|
||||
|
||||
- Scanner regressions verification
|
||||
- Postgres slice validation
|
||||
- DSSE/Rekor sweep complete
|
||||
- Pin tool versions in scripts
|
||||
|
||||
## 14. MODULE-SPECIFIC GUIDANCE
|
||||
|
||||
### 14.1 Scanner Module
|
||||
|
||||
- Reachability algorithms only in Scanner.WebService
|
||||
- Cache lazy and keyed by deterministic inputs
|
||||
- Output includes explicit evidence pointers
|
||||
- UI endpoints expose reachability state in structured form
|
||||
|
||||
### 14.2 Authority Module
|
||||
|
||||
- Trust roots: pinned via out-of-band distribution
|
||||
- Key rotation: maintain version history in trust store
|
||||
- Revocation: maintain revoked_keys list in trust anchors
|
||||
|
||||
### 14.3 Excititor (VEX) Module
|
||||
|
||||
- VEX schema includes pointers to all upstream artifacts
|
||||
- No duplication of SBOM/scan content inside VEX
|
||||
- DSSE used as standard envelope type
|
||||
|
||||
### 14.4 Policy Module
|
||||
|
||||
- Facts and policies serialized separately
|
||||
- Lattice code in allowed services only
|
||||
- Merge strategies named and versioned
|
||||
- Artifacts record which lattice algorithm used
|
||||
|
||||
### 14.5 SbomService Module
|
||||
|
||||
> Note: This module is implemented as `src/SbomService/` in the codebase.
|
||||
|
||||
- Emit SPDX 3.0.1 and CycloneDX 1.6 with stable ordering and deterministic IDs
|
||||
- Persist raw bytes + canonical form; hash canonical bytes for digest binding
|
||||
- Produce DSSE attestations for SBOM linkage and generation provenance
|
||||
|
||||
### 14.6 Concelier Feed Handling
|
||||
|
||||
> Note: Feed handling is implemented within the Concelier module via connectors in `src/Concelier/__Libraries/`.
|
||||
|
||||
- Treat every feed import as a versioned snapshot (URI + time + content hashes)
|
||||
- Support deterministic export/import for offline bundles
|
||||
- Imports are idempotent (same snapshot digest is a no-op)
|
||||
|
||||
### 14.7 Concelier Module
|
||||
|
||||
- Never mutate evidence; attach business context and build views only
|
||||
- Never re-implement scanner/policy risk logic; consume signed decisions + proofs
|
||||
|
||||
### 14.8 UI / Console
|
||||
|
||||
- UI is an explainer and navigator; the evidence chain must be retrievable via API and export
|
||||
- Any UI state must be reproducible from persisted evidence + graph revision identifiers
|
||||
|
||||
### 14.9 Zastava / Advisory AI
|
||||
|
||||
- AI consumes evidence graph IDs/digests; it is never a source of truth for vulnerability states
|
||||
- Pipelines must never pass/fail based on AI text; enforcement is always policy + lattice + evidence
|
||||
- Any AI output must reference evidence IDs and remain optional/offline-safe
|
||||
|
||||
## 15. COMMON PITFALLS & SOLUTIONS
|
||||
|
||||
### 15.1 Avoid
|
||||
|
||||
- ❌ Service Locator pattern
|
||||
- ❌ Static mutable state
|
||||
- ❌ Async void (except event handlers)
|
||||
- ❌ Blocking on async code (.Result, .Wait())
|
||||
- ❌ Non-deterministic ordering
|
||||
- ❌ Hard-coded timestamps
|
||||
- ❌ Environment variables in core algorithms
|
||||
|
||||
### 15.2 Prefer
|
||||
|
||||
- ✅ Constructor injection
|
||||
- ✅ Immutable data structures
|
||||
- ✅ async Task
|
||||
- ✅ await or Task.Run for CPU-bound work
|
||||
- ✅ Stable sorting with explicit comparers
|
||||
- ✅ Explicit `asOf` parameters
|
||||
- ✅ Configuration objects passed as parameters
|
||||
|
||||
## 16. DEBUGGING WORKFLOW
|
||||
|
||||
### 16.1 Local Development
|
||||
|
||||
```bash
|
||||
# Run all services
|
||||
docker-compose up -d
|
||||
|
||||
# Run specific service
|
||||
dotnet run --project src/Scanner/StellaOps.Scanner.WebService
|
||||
|
||||
# Attach debugger
|
||||
# Use VS Code launch.json or Visual Studio F5
|
||||
```
|
||||
|
||||
### 16.2 Log Correlation
|
||||
|
||||
```csharp
|
||||
// Note: Private fields use _camelCase convention
|
||||
using var activity = Activity.Current;
|
||||
activity?.SetTag("scan.id", _scanId);
|
||||
_logger.LogInformation("Processing scan {ScanId}", _scanId);
|
||||
```
|
||||
|
||||
### 16.3 OpenTelemetry
|
||||
|
||||
```csharp
|
||||
services.AddOpenTelemetry()
|
||||
.WithTracing(builder => builder
|
||||
.AddAspNetCoreInstrumentation()
|
||||
.AddNpgsql()
|
||||
.AddOtlpExporter());
|
||||
```
|
||||
|
||||
## 17. PERFORMANCE OPTIMIZATION
|
||||
|
||||
### 17.1 Database
|
||||
|
||||
- Use indexes for hot queries
|
||||
- Batch inserts/updates
|
||||
- Use `COPY` for bulk data
|
||||
- Avoid N+1 queries
|
||||
|
||||
### 17.2 Memory
|
||||
|
||||
- Use `Span<T>` for hot paths
|
||||
- Pool large objects
|
||||
- Dispose `IDisposable` promptly
|
||||
- Profile with dotMemory
|
||||
|
||||
### 17.3 Caching
|
||||
|
||||
- Cache deterministically (keyed by input hashes)
|
||||
- Use distributed cache (Valkey/Redis) for shared state
|
||||
- TTL appropriate to data volatility
|
||||
|
||||
## 18. SECURITY GUIDELINES
|
||||
|
||||
### 18.1 Input Validation
|
||||
|
||||
- Validate all user inputs
|
||||
- Use allowlists, not denylists
|
||||
- Sanitize for SQL, XSS, path traversal
|
||||
|
||||
### 18.2 Authentication & Authorization
|
||||
|
||||
- Never roll your own crypto
|
||||
- Use standard protocols (OAuth2, OIDC)
|
||||
- Implement principle of least privilege
|
||||
|
||||
### 18.3 Secrets Management
|
||||
|
||||
- Never commit secrets
|
||||
- Use environment variables or KMS
|
||||
- Rotate credentials regularly
|
||||
|
||||
## 19. DOCUMENTATION STANDARDS
|
||||
|
||||
### 19.1 XML Documentation
|
||||
|
||||
```csharp
|
||||
/// <summary>
|
||||
/// Scans the specified artifact for vulnerabilities.
|
||||
/// </summary>
|
||||
/// <param name="artifactId">The artifact identifier.</param>
|
||||
/// <param name="ct">Cancellation token.</param>
|
||||
/// <returns>Scan results with reachability analysis.</returns>
|
||||
/// <exception cref="ArgumentNullException">If artifactId is null.</exception>
|
||||
public Task<ScanResult> ScanAsync(string artifactId, CancellationToken ct);
|
||||
```
|
||||
|
||||
### 19.2 Architecture Decision Records (ADRs)
|
||||
|
||||
```markdown
|
||||
# ADR-XXX: Title
|
||||
|
||||
## Status
|
||||
Proposed | Accepted | Deprecated | Superseded
|
||||
|
||||
## Context
|
||||
What is the issue?
|
||||
|
||||
## Decision
|
||||
What did we decide?
|
||||
|
||||
## Consequences
|
||||
What are the implications?
|
||||
```
|
||||
|
||||
## 20. CI/CD INTEGRATION
|
||||
|
||||
### 20.1 Build Pipeline
|
||||
|
||||
```yaml
|
||||
stages:
|
||||
- restore
|
||||
- build
|
||||
- test
|
||||
- analyze
|
||||
- package
|
||||
- deploy
|
||||
```
|
||||
|
||||
### 20.2 Required Checks
|
||||
|
||||
- Unit tests pass
|
||||
- Integration tests pass
|
||||
- Code coverage ≥85%
|
||||
- No high/critical vulnerabilities
|
||||
- SBOM generated
|
||||
- Determinism tests pass
|
||||
|
||||
## 21. MIGRATION GUIDE
|
||||
|
||||
### 21.1 From .NET 8 to .NET 10
|
||||
|
||||
- Update `<TargetFramework>net10.0</TargetFramework>`
|
||||
- Review breaking changes
|
||||
- Update NuGet packages
|
||||
- Test thoroughly
|
||||
|
||||
### 21.2 Database Migrations
|
||||
|
||||
```bash
|
||||
# Create migration
|
||||
dotnet ef migrations add MigrationName -p src/Module -s src/WebService
|
||||
|
||||
# Apply migration
|
||||
dotnet ef database update -p src/Module -s src/WebService
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.1
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
|
||||
## Revision History
|
||||
|
||||
| Version | Date | Changes |
|
||||
|---------|------|---------|
|
||||
| 1.1 | 2025-12-14 | Corrected naming conventions (`_camelCase` for fields, `PascalCase` for constants), updated DI interface name to `IDependencyInjectionRoutine`, corrected test frameworks (PostgreSQL not Mongo/Redis, Karma/Jasmine not Jest), added plugin templates and version attribute documentation, clarified module names (SbomService, Concelier feed handling) |
|
||||
| 1.0 | 2025-12-14 | Initial consolidated reference |
|
||||
@@ -0,0 +1,441 @@
|
||||
# Offline and Air-Gap Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 01-Dec-2025 - DSSE‑Signed Offline Scanner Updates
|
||||
- 07-Dec-2025 - Reliable Air‑Gap Verification Workflows
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 0. AIR-GAP PRE-SEED CHECKLIST (GOLDEN INPUTS)
|
||||
|
||||
Before you can verify or ingest anything offline, the air-gap must be pre-seeded with:
|
||||
|
||||
- **Root of trust**
|
||||
- Vendor/org public keys (and chains if using Fulcio-like PKI)
|
||||
- Pinned transparency log root(s) for the offline log/mirror
|
||||
- **Policy bundle**
|
||||
- Verification policies (Cosign/in-toto rules, allow/deny lists)
|
||||
- Lattice rules for VEX merge/precedence
|
||||
- Toolchain manifest with hash-pinned binaries (cosign/oras/jq/scanner, etc.)
|
||||
- **Evidence bundle**
|
||||
- SBOMs (CycloneDX/SPDX), DSSE-wrapped attestations (provenance/VEX/SLSA)
|
||||
- Optional: frozen vendor feeds/VEX snapshots (as content-addressed inputs)
|
||||
- **Offline log snapshot**
|
||||
- Signed checkpoint/tree head and entry pack (leaves + proofs) for every receipt you rely on
|
||||
|
||||
Ship bundles on signed, write-once media (or equivalent operational controls) and keep chain-of-custody receipts alongside the bundle manifest.
|
||||
|
||||
## 1. OFFLINE UPDATE BUNDLE STRUCTURE
|
||||
|
||||
### 1.1 Directory Layout
|
||||
|
||||
```
|
||||
/bundle-2025-12-14/
|
||||
manifest.json # version, created_at, entries[], sha256s
|
||||
payload.tar.zst # actual DB/indices/feeds
|
||||
payload.tar.zst.sha256
|
||||
statement.dsse.json # DSSE-wrapped statement over payload hash
|
||||
rekor-receipt.json # Rekor v2 inclusion/verification material
|
||||
```
|
||||
|
||||
### 1.2 Manifest Schema
|
||||
|
||||
**manifest.json**:
|
||||
```json
|
||||
{
|
||||
"version": "string",
|
||||
"created_at": "UTC ISO-8601",
|
||||
"entries": [{"name": "string", "sha256": "string", "size": int}],
|
||||
"payload_sha256": "string"
|
||||
}
|
||||
```
|
||||
|
||||
### 1.3 DSSE Predicate Schema
|
||||
|
||||
**statement.dsse.json payload**:
|
||||
```json
|
||||
{
|
||||
"payloadType": "application/vnd.in-toto+json",
|
||||
"payload": {
|
||||
"subject": {
|
||||
"name": "stella-ops-offline-kit-<DATE>.tgz",
|
||||
"digest": {"sha256": "string"}
|
||||
},
|
||||
"predicateType": "https://stella-ops.org/attestations/offline-update/1",
|
||||
"predicate": {
|
||||
"offline_manifest_sha256": "string",
|
||||
"feeds": [{"name": "string", "snapshot_date": "UTC ISO-8601", "archive_digest": "string"}],
|
||||
"builder": "string",
|
||||
"created_at": "UTC ISO-8601",
|
||||
"oukit_channel": "edge|stable|fips-profile"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 1.4 Rekor Receipt Schema
|
||||
|
||||
**rekor-receipt.json**:
|
||||
```json
|
||||
{
|
||||
"uuid": "string",
|
||||
"logIndex": int,
|
||||
"rootHash": "string",
|
||||
"hashes": ["string"],
|
||||
"checkpoint": "string"
|
||||
}
|
||||
```
|
||||
|
||||
## 2. VERIFICATION SEQUENCE
|
||||
|
||||
### 2.1 Offline Kit Import Steps
|
||||
|
||||
```
|
||||
1. Validate Cosign signature of tarball
|
||||
2. Validate offline-manifest.json with JWS signature
|
||||
3. Verify file digests for all entries (including /attestations/*)
|
||||
4. Verify DSSE:
|
||||
- Call StellaOps.Attestor.Verify with:
|
||||
- offline-update.dsse.json
|
||||
- offline-update.rekor.json
|
||||
- local Rekor log snapshot/segment
|
||||
- Ensure payload digest matches kit tarball + manifest digests
|
||||
5. Only after all checks pass:
|
||||
- Swap Scanner's feed pointer to new snapshot
|
||||
- Emit audit event (kit filename, tarball digest, DSSE digest, Rekor UUID + log index)
|
||||
```
|
||||
|
||||
### 2.2 Activation Acceptance Rules
|
||||
|
||||
- Trust root: pinned publisher public keys (out-of-band rotation)
|
||||
- Monotonicity: only activate if `manifest.version > current.version`
|
||||
- Rollback/testing: allow an explicit force-activate path for emergency validation, but record it as a non-monotonic override in state + audit logs
|
||||
- Atomic switch: unpack → validate → symlink flip (`db/staging/` → `db/active/`)
|
||||
- Quarantine on failure: move to `updates/quarantine/` with reason code
|
||||
|
||||
## 3. OFFLINE DIRECTORY LAYOUT
|
||||
|
||||
```
|
||||
/evidence/
|
||||
keys/
|
||||
roots/ # root/intermediate certs, PGP pubkeys
|
||||
identities/ # per-vendor public keys
|
||||
tlog-root/ # hashed/pinned tlog root(s)
|
||||
policy/
|
||||
verify-policy.yaml
|
||||
lattice-rules.yaml
|
||||
sboms/ # *.cdx.json, *.spdx.json
|
||||
attestations/ # *.intoto.jsonl.dsig (DSSE)
|
||||
tlog/
|
||||
checkpoint.sig # signed tree head
|
||||
entries/ # *.jsonl (Merkle leaves) + proofs
|
||||
tools/
|
||||
cosign-<ver> (sha256)
|
||||
oras-<ver> (sha256)
|
||||
jq-<ver> (sha256)
|
||||
scanner-<ver> (sha256)
|
||||
```
|
||||
|
||||
## 4. OFFLINE VERIFICATION POLICY SCHEMA
|
||||
|
||||
```yaml
|
||||
keys:
|
||||
- ./evidence/keys/identities/vendor_A.pub
|
||||
- ./evidence/keys/identities/your_authority.pub
|
||||
tlog:
|
||||
mode: "offline"
|
||||
checkpoint: "./evidence/tlog/checkpoint.sig"
|
||||
entry_pack: "./evidence/tlog/entries"
|
||||
attestations:
|
||||
required:
|
||||
- type: slsa-provenance
|
||||
- type: cyclonedx-sbom
|
||||
optional:
|
||||
- type: vex
|
||||
constraints:
|
||||
subjects:
|
||||
alg: "sha256"
|
||||
certs:
|
||||
allowed_issuers:
|
||||
- "https://fulcio.offline"
|
||||
allow_expired_if_timepinned: true
|
||||
```
|
||||
|
||||
### 4.1 Offline Keyring Usage (Cosign / in-toto)
|
||||
|
||||
Cosign-style verification must not require any online CA, Rekor fetch, or DNS lookups. Use pinned keys and (when applicable) an offline Rekor mirror snapshot.
|
||||
|
||||
```bash
|
||||
# Verify a DSSE attestation using a locally pinned key (no network assumptions)
|
||||
COSIGN_EXPERIMENTAL=1 cosign verify-attestation \
|
||||
--key ./evidence/keys/identities/vendor_A.pub \
|
||||
--policy ./evidence/policy/verify-policy.yaml \
|
||||
<artifact-digest-or-ref>
|
||||
```
|
||||
|
||||
```bash
|
||||
# in-toto offline verification (layout + local keys)
|
||||
in-toto-verify \
|
||||
--layout ./evidence/attestations/layout.root.json \
|
||||
--layout-keys ./evidence/keys/identities/vendor_A.pub \
|
||||
--products <artifact-file>
|
||||
```
|
||||
|
||||
## 5. DETERMINISTIC EVIDENCE RECONCILIATION ALGORITHM
|
||||
|
||||
```
|
||||
1. Index artifacts by immutable digest
|
||||
2. For each artifact digest:
|
||||
- Collect SBOM nodes from canonical SBOM files
|
||||
- Collect attestations (provenance, VEX, SLSA, signatures)
|
||||
- Validate each attestation (sig + tlog inclusion proof)
|
||||
3. Normalize all docs (stable sort, strip non-essential timestamps, lowercase URIs)
|
||||
4. Apply lattice rules (precedence: vendor > maintainer > 3rd-party)
|
||||
5. Emit `evidence-graph.json` (stable node/edge order) + `evidence-graph.sha256` + DSSE signature
|
||||
```
|
||||
|
||||
## 6. OFFLINE FLOW OPERATIONAL STEPS
|
||||
|
||||
```
|
||||
1. Import bundle (mount WORM media read-only)
|
||||
2. Verify tools (hash + signature) before execution
|
||||
3. Verify tlog checkpoint
|
||||
4. Verify each inclusion proof
|
||||
5. Verify attestations (keyring + policy)
|
||||
6. Ingest SBOMs (canonicalize + hash)
|
||||
7. Reconcile (apply lattice rules → evidence graph)
|
||||
8. Record run: write `run.manifest` with input/policy/tool/output hashes; DSSE-sign with Authority key
|
||||
```
|
||||
|
||||
## 7. SCANNER CONFIG SURFACE
|
||||
|
||||
### 7.1 Offline Kit Configuration
|
||||
|
||||
```yaml
|
||||
scanner:
|
||||
offlineKit:
|
||||
requireDsse: true # fail import if DSSE/Rekor verification fails
|
||||
rekorOfflineMode: true # use local snapshots only
|
||||
attestationVerifier: https://attestor.internal
|
||||
trustAnchors:
|
||||
- anchorId: "UUID"
|
||||
purlPattern: "pkg:npm/*"
|
||||
allowedKeyids: ["key1", "key2"]
|
||||
```
|
||||
|
||||
### 7.2 DSSE/Rekor Failure Handling
|
||||
|
||||
**DSSE/Rekor fail, Cosign + manifest OK**:
|
||||
- Keep old feeds active
|
||||
- Mark import as failed; surface ProblemDetails error via API/UI
|
||||
- Log structured fields: `rekorUuid`, `attestationDigest`, `offlineKitHash`, `failureReason`
|
||||
|
||||
**Config flag to soften during rollout**:
|
||||
- When `requireDsse=false`: treat DSSE/Rekor failure as warning; allow import with alerts
|
||||
|
||||
## 8. SBOM INGESTION DETERMINISTIC FLOW
|
||||
|
||||
```bash
|
||||
# 1. Normalize SBOMs to canonical form
|
||||
jq -S . sboms/app.cdx.json > sboms/_canon/app.cdx.json
|
||||
|
||||
# 2. Validate schemas (vendored validators)
|
||||
|
||||
# 3. Hash-pin canonical files and record in manifest.lock
|
||||
sha256sum sboms/_canon/*.json > manifest.lock
|
||||
|
||||
# 4. Import to DB with idempotent keys: (artifactDigest, sbomHash)
|
||||
```
|
||||
|
||||
## 9. OFFLINE REKOR MIRROR VERIFICATION
|
||||
|
||||
### 9.1 File-Ledger Pattern
|
||||
|
||||
- Keep `tlog/checkpoint.sig` (signed tree head) + `tlog/entries/*.jsonl` (leaves + proofs)
|
||||
|
||||
### 9.2 Verification Steps
|
||||
|
||||
```
|
||||
1. Recompute Merkle root from entries
|
||||
2. Check matches `checkpoint.sig` (after verifying signature with tlog root key)
|
||||
3. For each attestation:
|
||||
- Verify UUID/digest appears in entry pack
|
||||
- Verify inclusion proof resolves
|
||||
```
|
||||
|
||||
## 10. METRICS & OBSERVABILITY
|
||||
|
||||
### 10.1 Offline Kit Metrics (Prometheus)
|
||||
|
||||
```
|
||||
offlinekit_import_total{status="success|failed_dsse|failed_rekor|failed_cosign"}
|
||||
offlinekit_attestation_verify_latency_seconds (histogram)
|
||||
attestor_rekor_success_total
|
||||
attestor_rekor_retry_total
|
||||
rekor_inclusion_latency
|
||||
```
|
||||
|
||||
### 10.2 Structured Logging Fields
|
||||
|
||||
```
|
||||
rekorUuid
|
||||
attestationDigest
|
||||
offlineKitHash
|
||||
failureReason
|
||||
kitFilename
|
||||
tarballDigest
|
||||
dsseStatementDigest
|
||||
rekorLogIndex
|
||||
```
|
||||
|
||||
## 11. ERROR HANDLING
|
||||
|
||||
### 11.1 Import Failure Modes
|
||||
|
||||
| Failure Type | Action | Audit Event |
|
||||
|--------------|--------|-------------|
|
||||
| Cosign signature invalid | Reject, quarantine | `IMPORT_FAILED_COSIGN` |
|
||||
| Manifest signature invalid | Reject, quarantine | `IMPORT_FAILED_MANIFEST` |
|
||||
| DSSE verification failed | Reject (if requireDsse=true) | `IMPORT_FAILED_DSSE` |
|
||||
| Rekor inclusion failed | Reject (if requireDsse=true) | `IMPORT_FAILED_REKOR` |
|
||||
| Digest mismatch | Reject, quarantine | `IMPORT_FAILED_DIGEST` |
|
||||
| Version not monotonic | Reject | `IMPORT_FAILED_VERSION` |
|
||||
|
||||
### 11.2 Reason Codes (structured logs/metrics)
|
||||
|
||||
Use stable, machine-readable reason codes in logs/metrics and in `ProblemDetails` payloads:
|
||||
- `HASH_MISMATCH`
|
||||
- `SIG_FAIL_COSIGN`
|
||||
- `SIG_FAIL_MANIFEST`
|
||||
- `DSSE_VERIFY_FAIL`
|
||||
- `REKOR_VERIFY_FAIL`
|
||||
- `SELFTEST_FAIL`
|
||||
- `VERSION_NON_MONOTONIC`
|
||||
- `POLICY_DENY`
|
||||
|
||||
### 11.3 Quarantine Structure
|
||||
|
||||
```
|
||||
/updates/quarantine/<timestamp>-<reason>/
|
||||
bundle.tar.zst
|
||||
manifest.json
|
||||
verification.log
|
||||
failure-reason.txt
|
||||
```
|
||||
|
||||
## 12. CLI COMMANDS
|
||||
|
||||
### 12.1 Offline Kit Import
|
||||
|
||||
```bash
|
||||
stellaops offline import \
|
||||
--bundle ./bundle-2025-12-14.tar.zst \
|
||||
--verify-dsse \
|
||||
--verify-rekor \
|
||||
--trust-root /evidence/keys/roots/stella-root.pub
|
||||
```
|
||||
|
||||
```bash
|
||||
# Emergency testing only (records a non-monotonic override in the audit trail)
|
||||
stellaops offline import \
|
||||
--bundle ./bundle-2025-12-07.tar.zst \
|
||||
--verify-dsse \
|
||||
--verify-rekor \
|
||||
--trust-root /evidence/keys/roots/stella-root.pub \
|
||||
--force-activate
|
||||
```
|
||||
|
||||
### 12.2 Offline Kit Status
|
||||
|
||||
```bash
|
||||
stellaops offline status
|
||||
# Output:
|
||||
# Active kit: bundle-2025-12-14
|
||||
# Kit digest: sha256:abc123...
|
||||
# Activated at: 2025-12-14T10:00:00Z
|
||||
# DSSE verified: true
|
||||
# Rekor verified: true
|
||||
```
|
||||
|
||||
### 12.3 Offline Verification
|
||||
|
||||
```bash
|
||||
stellaops verify offline \
|
||||
--evidence-dir /evidence \
|
||||
--artifact sha256:def456... \
|
||||
--policy verify-policy.yaml
|
||||
```
|
||||
|
||||
## 13. AUDIT TRAIL
|
||||
|
||||
### 13.1 Audit Event Schema
|
||||
|
||||
```json
|
||||
{
|
||||
"eventId": "uuid",
|
||||
"eventType": "OFFLINE_KIT_IMPORTED",
|
||||
"timestamp": "2025-12-14T10:00:00Z",
|
||||
"actor": "system",
|
||||
"details": {
|
||||
"kitFilename": "bundle-2025-12-14.tar.zst",
|
||||
"tarballDigest": "sha256:...",
|
||||
"dsseStatementDigest": "sha256:...",
|
||||
"rekorUuid": "...",
|
||||
"rekorLogIndex": 12345,
|
||||
"previousKitVersion": "bundle-2025-12-07",
|
||||
"newKitVersion": "bundle-2025-12-14"
|
||||
},
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### 13.2 Audit Log Storage
|
||||
|
||||
```sql
|
||||
CREATE TABLE offline_kit_audit (
|
||||
event_id UUID PRIMARY KEY,
|
||||
event_type TEXT NOT NULL,
|
||||
timestamp TIMESTAMPTZ NOT NULL,
|
||||
actor TEXT NOT NULL,
|
||||
details JSONB NOT NULL,
|
||||
result TEXT NOT NULL
|
||||
);
|
||||
|
||||
CREATE INDEX idx_offline_kit_audit_ts ON offline_kit_audit(timestamp DESC);
|
||||
CREATE INDEX idx_offline_kit_audit_type ON offline_kit_audit(event_type);
|
||||
```
|
||||
|
||||
## 14. SECURITY CONSIDERATIONS
|
||||
|
||||
### 14.1 Key Management
|
||||
|
||||
- Trust roots: pinned via out-of-band distribution
|
||||
- Key rotation: maintain version history in trust store
|
||||
- Revocation: maintain revoked_keys list in trust anchors
|
||||
|
||||
### 14.2 Integrity Guarantees
|
||||
|
||||
- All bundles content-addressed
|
||||
- Manifest integrity via signature
|
||||
- DSSE envelope integrity via signature
|
||||
- Rekor inclusion proof integrity via Merkle tree
|
||||
|
||||
### 14.3 Air-Gap Boundaries
|
||||
|
||||
**Allowed**:
|
||||
- Local file system reads (read-only mount)
|
||||
- Local tool execution (verified binaries)
|
||||
- Local database writes (staged)
|
||||
|
||||
**Forbidden**:
|
||||
- Network egress
|
||||
- DNS lookups
|
||||
- NTP synchronization (use frozen clock)
|
||||
- External API calls
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,577 @@
|
||||
# PostgreSQL Patterns Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 01-Dec-2025 - PostgreSQL Patterns for Each StellaOps Module
|
||||
- 14-Dec-2025 - Evaluate PostgreSQL vs MongoDB for StellaOps
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 0. POSTGRESQL VS MONGODB (DECISION RULE)
|
||||
|
||||
Default posture:
|
||||
- **System of record**: PostgreSQL (JSONB-first, per-module schema isolation).
|
||||
- **Queues & coordination**: PostgreSQL (`SKIP LOCKED`, advisory locks when needed).
|
||||
- **Cache/acceleration only**: Valkey/Redis (ephemeral).
|
||||
- **MongoDB**: only when you have a *clear* need for very large, read-optimized snapshot workloads (e.g., extremely large historical graphs), and you can regenerate those snapshots deterministically from the Postgres source-of-truth.
|
||||
|
||||
When MongoDB is justified:
|
||||
- Interactive exploration over hundreds of millions of nodes/edges where denormalized reads beat relational joins.
|
||||
- Snapshot cadence is batchy (hourly/daily) and you can re-emit snapshots deterministically.
|
||||
- You need to isolate read spikes from transactional control-plane writes.
|
||||
|
||||
## 1. MODULE-SCHEMA MAPPING
|
||||
|
||||
| Module | Schema | Primary Tables |
|
||||
|--------|--------|----------------|
|
||||
| Authority | `authority` | `user`, `role`, `grant`, `oauth_client`, `oauth_token`, `audit_log` |
|
||||
| Routing | `routing` | `feature_flag`, `instance`, `rate_limit_config` |
|
||||
| VEX | `vex` | `vuln_fact`, `package`, `vex_decision`, `mv_triage_queue` |
|
||||
| Unknowns | `unknowns` | `unknown` (bitemporal) |
|
||||
| Artifact | `artifact` | `artifact`, `signature`, `tag` |
|
||||
| Core | `core` | `outbox` |
|
||||
|
||||
## 2. CORE POSTGRESQL CONVENTIONS
|
||||
|
||||
### 2.1 Required Columns (All Tables)
|
||||
|
||||
```sql
|
||||
id uuid primary key default gen_random_uuid()
|
||||
tenant_id uuid not null
|
||||
created_at timestamptz not null default now()
|
||||
updated_at timestamptz not null default now()
|
||||
```
|
||||
|
||||
### 2.2 Multi-Tenancy RLS Pattern
|
||||
|
||||
```sql
|
||||
alter table <table> enable row level security;
|
||||
|
||||
create policy p_<table>_tenant on <table>
|
||||
for all using (tenant_id = current_setting('app.tenant_id')::uuid);
|
||||
```
|
||||
|
||||
### 2.3 Session Configuration (Set Per Request)
|
||||
|
||||
```sql
|
||||
select set_config('app.user_id', '<uuid>', false);
|
||||
select set_config('app.tenant_id', '<uuid>', false);
|
||||
select set_config('app.roles', 'role1,role2', false);
|
||||
```
|
||||
|
||||
## 3. TABLE TAXONOMY AND PATTERNS
|
||||
|
||||
### 3.1 Source-of-Truth (SOR) Tables
|
||||
|
||||
```sql
|
||||
create table <module>.<entity> (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
external_id uuid,
|
||||
content_hash bytea not null,
|
||||
doc jsonb not null,
|
||||
schema_version int not null,
|
||||
created_at timestamptz not null default now(),
|
||||
supersedes_id bigint null
|
||||
);
|
||||
|
||||
create unique index on <entity>(tenant_id, content_hash);
|
||||
```
|
||||
|
||||
### 3.2 JSONB Facts + Relational Decisions
|
||||
|
||||
**Facts (Immutable)**:
|
||||
```sql
|
||||
create table vex.vuln_fact (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
source text not null,
|
||||
external_id text,
|
||||
payload jsonb not null,
|
||||
schema_version int not null,
|
||||
received_at timestamptz not null default now()
|
||||
);
|
||||
```
|
||||
|
||||
**Decisions (Relational)**:
|
||||
```sql
|
||||
create table vex.vex_decision (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
package_id uuid not null,
|
||||
vuln_id text not null,
|
||||
status text check (status in ('not_affected','affected','fixed','under_investigation')),
|
||||
rationale text,
|
||||
proof_ref text,
|
||||
decided_by uuid,
|
||||
decided_at timestamptz not null default now(),
|
||||
unique (tenant_id, package_id, vuln_id)
|
||||
);
|
||||
```
|
||||
|
||||
### 3.3 Queue Pattern (SKIP LOCKED)
|
||||
|
||||
```sql
|
||||
create table job_queue (
|
||||
id bigserial primary key,
|
||||
tenant_id uuid,
|
||||
kind text not null,
|
||||
payload jsonb not null,
|
||||
run_after timestamptz default now(),
|
||||
attempts int default 0,
|
||||
locked_at timestamptz,
|
||||
locked_by text
|
||||
);
|
||||
|
||||
create index ix_job_ready
|
||||
on job_queue(kind, run_after, id)
|
||||
where locked_at is null;
|
||||
|
||||
-- Claim job
|
||||
with cte as (
|
||||
select id from job_queue
|
||||
where kind = $1
|
||||
and run_after <= now()
|
||||
and locked_at is null
|
||||
order by id
|
||||
for update skip locked
|
||||
limit 1
|
||||
)
|
||||
update job_queue j
|
||||
set locked_at = now(), locked_by = $2
|
||||
from cte
|
||||
where j.id = cte.id
|
||||
returning j.*;
|
||||
```
|
||||
|
||||
### 3.3.1 Advisory Locks (coordination / idempotency guards)
|
||||
|
||||
Use advisory locks for per-tenant singleton work or "at-most-once" critical sections (do not hold them while doing long-running work):
|
||||
|
||||
```sql
|
||||
-- Acquire (per tenant, per artifact) for the duration of the transaction
|
||||
select pg_try_advisory_xact_lock(hashtextextended('recalc:' || $1 || ':' || $2, 0));
|
||||
```
|
||||
|
||||
### 3.3.2 LISTEN/NOTIFY (nudge, not a durable queue)
|
||||
|
||||
Use `LISTEN/NOTIFY` to wake workers quickly after inserting work into a durable table:
|
||||
|
||||
```sql
|
||||
notify stella_scan, json_build_object('purl', $1, 'priority', 5)::text;
|
||||
```
|
||||
|
||||
### 3.4 Temporal Pattern (Unknowns)
|
||||
|
||||
```sql
|
||||
create table unknowns.unknown (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
subject_hash text not null,
|
||||
kind text not null,
|
||||
context jsonb not null,
|
||||
valid_from timestamptz not null default now(),
|
||||
valid_to timestamptz,
|
||||
sys_from timestamptz not null default now(),
|
||||
sys_to timestamptz,
|
||||
created_at timestamptz not null default now()
|
||||
);
|
||||
|
||||
create unique index unknown_one_open_per_subject
|
||||
on unknowns.unknown (tenant_id, subject_hash, kind)
|
||||
where valid_to is null;
|
||||
|
||||
create view unknowns.current as
|
||||
select * from unknowns.unknown
|
||||
where valid_to is null;
|
||||
```
|
||||
|
||||
### 3.5 Audit Log Pattern
|
||||
|
||||
```sql
|
||||
create table authority.audit_log (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
actor_id uuid,
|
||||
action text not null,
|
||||
entity_type text not null,
|
||||
entity_id uuid,
|
||||
at timestamptz not null default now(),
|
||||
diff jsonb not null
|
||||
);
|
||||
```
|
||||
|
||||
### 3.6 Outbox Pattern (Exactly-Once Side Effects)
|
||||
|
||||
```sql
|
||||
create table core.outbox (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid,
|
||||
aggregate_type text not null,
|
||||
aggregate_id uuid,
|
||||
topic text not null,
|
||||
payload jsonb not null,
|
||||
created_at timestamptz not null default now(),
|
||||
dispatched_at timestamptz,
|
||||
dispatch_attempts int not null default 0,
|
||||
error text
|
||||
);
|
||||
```
|
||||
|
||||
## 4. JSONB WITH GENERATED COLUMNS
|
||||
|
||||
```sql
|
||||
create table sbom_document (
|
||||
id bigserial primary key,
|
||||
tenant_id uuid not null,
|
||||
artifact_purl text not null,
|
||||
content_hash bytea not null,
|
||||
doc jsonb not null,
|
||||
created_at timestamptz not null default now(),
|
||||
|
||||
-- hot keys as generated columns
|
||||
bom_format text generated always as ((doc->>'bomFormat')) stored,
|
||||
spec_version text generated always as ((doc->>'specVersion')) stored
|
||||
);
|
||||
|
||||
create unique index ux_sbom_doc_hash on sbom_document(tenant_id, content_hash);
|
||||
create index ix_sbom_doc_tenant_artifact on sbom_document(tenant_id, artifact_purl, created_at desc);
|
||||
create index ix_sbom_doc_json_gin on sbom_document using gin (doc jsonb_path_ops);
|
||||
create index ix_sbom_doc_bomformat on sbom_document(tenant_id, bom_format);
|
||||
```
|
||||
|
||||
## 5. MATERIALIZED VIEWS FOR HOT READS
|
||||
|
||||
```sql
|
||||
create materialized view mv_artifact_risk as
|
||||
select tenant_id, artifact_purl, max(score) as risk_score
|
||||
from open_findings
|
||||
group by tenant_id, artifact_purl;
|
||||
|
||||
create unique index ux_mv_artifact_risk
|
||||
on mv_artifact_risk(tenant_id, artifact_purl);
|
||||
|
||||
-- Refresh
|
||||
refresh materialized view concurrently mv_artifact_risk;
|
||||
```
|
||||
|
||||
## 6. PARTITIONING (TIME-BASED EVENTS)
|
||||
|
||||
```sql
|
||||
create table scan_run_event (
|
||||
tenant_id uuid not null,
|
||||
scan_run_id bigint not null,
|
||||
occurred_at timestamptz not null,
|
||||
event_type text not null,
|
||||
payload jsonb not null
|
||||
) partition by range (occurred_at);
|
||||
|
||||
create index brin_scan_events_time
|
||||
on scan_run_event using brin (occurred_at);
|
||||
```
|
||||
|
||||
## 7. INDEX PATTERNS
|
||||
|
||||
| Use Case | Index Pattern |
|
||||
|----------|---------------|
|
||||
| Tenant-scoped queries | `INDEX(tenant_id, ...)` |
|
||||
| Latest version lookup | `INDEX(tenant_id, artifact_purl, created_at DESC)` |
|
||||
| Queue readiness | `INDEX(kind, run_after, id) WHERE locked_at IS NULL` |
|
||||
| JSONB containment | `INDEX USING GIN (doc jsonb_path_ops)` |
|
||||
| JSONB key lookup | `INDEX((doc->>'key'))` |
|
||||
| Time-series scan | `INDEX USING BRIN (occurred_at)` |
|
||||
|
||||
## 8. PERFORMANCE REQUIREMENTS
|
||||
|
||||
### 8.1 Query Performance Standards
|
||||
|
||||
**Required per PR**:
|
||||
- Provide SQL query + intended parameters
|
||||
- Provide `EXPLAIN (ANALYZE, BUFFERS)` from staging-sized dataset
|
||||
- Identify serving index(es)
|
||||
- Confirm row estimates not wildly wrong
|
||||
- Confirm tenant-scoped and uses tenant-leading index
|
||||
|
||||
### 8.2 Index Performance Standards
|
||||
|
||||
| Pattern | Requirement |
|
||||
|---------|-------------|
|
||||
| Tenant queries | `INDEX(tenant_id, ...)` leading column |
|
||||
| Sort ordering | Index must end with `ORDER BY` column + direction |
|
||||
| Queue claims | Partial index `WHERE locked_at IS NULL` |
|
||||
| Time-series | BRIN index on timestamp columns for partitioned tables |
|
||||
| JSONB containment | GIN `jsonb_path_ops` for `@>` queries |
|
||||
|
||||
### 8.3 General Performance Rules
|
||||
|
||||
- Every hot query must have an index story
|
||||
- Write path stays simple: prefer append-only versioning
|
||||
- Multi-tenant explicit: all core tables include `tenant_id`
|
||||
- Derived data modeled as projection tables or materialized views
|
||||
- Idempotency enforced in DB: unique keys for imports/jobs/results
|
||||
|
||||
### 8.4 Materialized Views vs Projection Tables
|
||||
|
||||
Materialized views are acceptable when:
|
||||
- You can refresh them deterministically at a defined cadence (owned by a specific worker/job).
|
||||
- You can afford full refresh cost, or the dataset is bounded.
|
||||
- You provide a unique index to enable `REFRESH MATERIALIZED VIEW CONCURRENTLY`.
|
||||
|
||||
Prefer projection tables when:
|
||||
- You need incremental updates (on import/scan completion).
|
||||
- You need deterministic point-in-time snapshots per scan manifest (replay/audit).
|
||||
- Refresh cost would scale with the entire dataset on every change.
|
||||
|
||||
Checklist:
|
||||
- Every derived read model declares: owner, refresh cadence/trigger, retention, and idempotency key.
|
||||
- No UI/API endpoint depends on a heavy non-materialized view for hot paths.
|
||||
|
||||
### 8.5 Queue + Outbox Rules (avoid deadlocks)
|
||||
|
||||
Queue claim rules:
|
||||
- Claim in a short transaction (commit immediately after lock acquisition).
|
||||
- Do work outside the transaction.
|
||||
- On failure: increment attempts, compute backoff into `run_after`, and release locks.
|
||||
- Define a DLQ condition (`attempts > N`) that is queryable and observable.
|
||||
|
||||
Outbox dispatch rules:
|
||||
- Dispatch is idempotent (consumer must tolerate duplicates).
|
||||
- The dispatcher writes a stable delivery attempt record (`dispatched_at`, `dispatch_attempts`, `error`).
|
||||
|
||||
### 8.6 Migration Safety Rules
|
||||
|
||||
- Create/drop indexes concurrently on large tables (`CREATE INDEX CONCURRENTLY`, `DROP INDEX CONCURRENTLY`).
|
||||
- Add `NOT NULL` in stages: add nullable column → backfill in batches → enforce constraint → then add default (if needed).
|
||||
- Avoid long-running `ALTER TABLE` on high-volume tables without a lock plan.
|
||||
|
||||
### 8.7 Definition of Done (new table/view)
|
||||
|
||||
A PR adding a table/view is incomplete unless it includes:
|
||||
- Table classification (SoR / projection / queue / event).
|
||||
- Primary key + idempotency unique key.
|
||||
- Tenant scoping strategy (and RLS policy when applicable).
|
||||
- Index plan mapped to the top 1–3 query patterns (include `EXPLAIN (ANALYZE, BUFFERS)` output).
|
||||
- Retention plan (partitioning and drop policy for high-volume tables).
|
||||
- Refresh/update plan for derived models (owner + cadence).
|
||||
|
||||
## 9. FEATURE FLAG SCHEMA
|
||||
|
||||
```sql
|
||||
create table routing.feature_flag (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
key text not null,
|
||||
rules jsonb not null,
|
||||
version int not null default 1,
|
||||
is_enabled boolean not null default true,
|
||||
created_at timestamptz not null default now(),
|
||||
updated_at timestamptz not null default now(),
|
||||
unique (tenant_id, key)
|
||||
);
|
||||
|
||||
create table routing.feature_flag_history (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
feature_flag_id uuid not null,
|
||||
tenant_id uuid not null,
|
||||
key text not null,
|
||||
rules jsonb not null,
|
||||
version int not null,
|
||||
changed_at timestamptz not null default now(),
|
||||
changed_by uuid
|
||||
);
|
||||
```
|
||||
|
||||
**Redis Cache Pattern**:
|
||||
```
|
||||
SETEX flag:{key}:{version} <ttl> <json>
|
||||
```
|
||||
|
||||
## 10. RATE LIMIT CONFIGURATION
|
||||
|
||||
```sql
|
||||
create table routing.rate_limit_config (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
key text not null,
|
||||
limit_per_interval int not null,
|
||||
interval_seconds int not null,
|
||||
created_at timestamptz not null default now(),
|
||||
updated_at timestamptz not null default now(),
|
||||
unique (tenant_id, key)
|
||||
);
|
||||
```
|
||||
|
||||
**Redis Counter Pattern**:
|
||||
```
|
||||
INCR rl:{bucket}:{window}
|
||||
```
|
||||
|
||||
## 11. INSTANCE REGISTRY
|
||||
|
||||
```sql
|
||||
create table routing.instance (
|
||||
id uuid primary key default gen_random_uuid(),
|
||||
tenant_id uuid not null,
|
||||
instance_key text not null,
|
||||
domain text not null,
|
||||
last_heartbeat timestamptz not null default now(),
|
||||
status text not null check (status in ('active','draining','offline')),
|
||||
created_at timestamptz not null default now(),
|
||||
updated_at timestamptz not null default now(),
|
||||
unique (tenant_id, instance_key),
|
||||
unique (tenant_id, domain)
|
||||
);
|
||||
```
|
||||
|
||||
## 12. MIGRATION PATTERNS
|
||||
|
||||
### 12.1 Schema Versioning
|
||||
|
||||
```sql
|
||||
create table core.schema_version (
|
||||
module text primary key,
|
||||
version int not null,
|
||||
applied_at timestamptz not null default now(),
|
||||
migration_hash text not null
|
||||
);
|
||||
```
|
||||
|
||||
### 12.2 Migration Script Template
|
||||
|
||||
```sql
|
||||
-- Migration: <module>_v<version>_<description>
|
||||
-- Dependencies: <module>_v<previous_version>
|
||||
|
||||
begin;
|
||||
|
||||
-- Schema changes
|
||||
create table if not exists <module>.<table> (...);
|
||||
|
||||
-- Data migrations (if needed)
|
||||
|
||||
-- Update version
|
||||
insert into core.schema_version (module, version, migration_hash)
|
||||
values ('<module>', <version>, '<hash>')
|
||||
on conflict (module) do update
|
||||
set version = excluded.version,
|
||||
applied_at = now(),
|
||||
migration_hash = excluded.migration_hash;
|
||||
|
||||
commit;
|
||||
```
|
||||
|
||||
## 13. CONNECTION POOLING
|
||||
|
||||
### 13.1 Recommended Settings
|
||||
|
||||
```yaml
|
||||
database:
|
||||
host: postgres.local
|
||||
port: 5432
|
||||
database: stellaops
|
||||
username: stellaops_app
|
||||
password: <from secrets>
|
||||
pool:
|
||||
min_size: 5
|
||||
max_size: 20
|
||||
connection_timeout: 5000 # ms
|
||||
idle_timeout: 600000 # ms (10 min)
|
||||
max_lifetime: 1800000 # ms (30 min)
|
||||
```
|
||||
|
||||
### 13.2 .NET Configuration
|
||||
|
||||
```csharp
|
||||
services.AddNpgsqlDataSource(connectionString, builder =>
|
||||
{
|
||||
builder.MaxConnections = 20;
|
||||
builder.MinConnections = 5;
|
||||
builder.ConnectionIdleLifetime = TimeSpan.FromMinutes(10);
|
||||
builder.ConnectionLifetime = TimeSpan.FromMinutes(30);
|
||||
});
|
||||
```
|
||||
|
||||
## 14. MONITORING & OBSERVABILITY
|
||||
|
||||
### 14.1 Essential Metrics
|
||||
|
||||
```
|
||||
postgres_connections_active
|
||||
postgres_connections_idle
|
||||
postgres_transaction_duration_seconds
|
||||
postgres_query_duration_seconds
|
||||
postgres_cache_hit_ratio
|
||||
postgres_table_size_bytes
|
||||
postgres_index_size_bytes
|
||||
postgres_slow_queries_total
|
||||
```
|
||||
|
||||
### 14.2 Query Performance Monitoring
|
||||
|
||||
```sql
|
||||
-- Enable pg_stat_statements
|
||||
create extension if not exists pg_stat_statements;
|
||||
|
||||
-- Top 10 slowest queries
|
||||
select
|
||||
substring(query, 1, 100) as query_snippet,
|
||||
calls,
|
||||
total_exec_time / 1000 as total_time_sec,
|
||||
mean_exec_time as mean_time_ms,
|
||||
max_exec_time as max_time_ms
|
||||
from pg_stat_statements
|
||||
order by total_exec_time desc
|
||||
limit 10;
|
||||
```
|
||||
|
||||
## 15. BACKUP & RECOVERY
|
||||
|
||||
### 15.1 Backup Strategy
|
||||
|
||||
- **Point-in-time recovery (PITR)**: Enabled via WAL archiving
|
||||
- **Daily full backups**: Automated via `pg_basebackup`
|
||||
- **Retention**: 30 days for compliance
|
||||
- **Testing**: Monthly restore drills
|
||||
|
||||
### 15.2 Backup Commands
|
||||
|
||||
```bash
|
||||
# Full backup
|
||||
pg_basebackup -h postgres.local -D /backup/$(date +%Y%m%d) -Ft -z -P
|
||||
|
||||
# WAL archiving (postgresql.conf)
|
||||
# archive_mode = on
|
||||
# archive_command = 'cp %p /archive/%f'
|
||||
```
|
||||
|
||||
## 16. SECURITY BEST PRACTICES
|
||||
|
||||
### 16.1 Access Control
|
||||
|
||||
- Use RLS for multi-tenancy isolation
|
||||
- Grant minimal privileges per role
|
||||
- Separate read-only and read-write users
|
||||
- Use connection pooler with separate credentials
|
||||
|
||||
### 16.2 Encryption
|
||||
|
||||
- TLS for connections: `sslmode=require`
|
||||
- Transparent data encryption (TDE) for data at rest
|
||||
- Encrypted backups
|
||||
|
||||
### 16.3 Audit Logging
|
||||
|
||||
```sql
|
||||
-- Enable audit logging
|
||||
create extension if not exists pgaudit;
|
||||
|
||||
-- Configure audit (postgresql.conf)
|
||||
-- pgaudit.log = 'write, ddl'
|
||||
-- pgaudit.log_catalog = off
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,291 @@
|
||||
# Rekor Integration Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 30-Nov-2025 - Rekor Receipt Checklist for Stella Ops
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. REQUIREMENTS
|
||||
|
||||
- Rekor receipts must be deterministic, tenant-scoped, and verifiable offline
|
||||
- For Authority/Sbomer/Vexer flows
|
||||
- Field-level ownership map for receipts and bundles
|
||||
- Offline verifier expectations
|
||||
- Mirror snapshot rules
|
||||
- DSSE/receipt schema pointers
|
||||
|
||||
## 2. DETERMINISM & OFFLINE
|
||||
|
||||
- Bundle TSA/time anchors with receipts
|
||||
- Prefer mirror snapshots
|
||||
- Avoid live log fetches in examples
|
||||
|
||||
## 3. DELIVERABLES
|
||||
|
||||
- Schema draft
|
||||
- Offline verifier stub
|
||||
- Module dossier updates
|
||||
|
||||
## 4. REKOR ENTRY STRUCTURE
|
||||
|
||||
```json
|
||||
{
|
||||
"dsseSha256": "sha256:...",
|
||||
"rekor": {
|
||||
"uuid": "...",
|
||||
"logIndex": 12345,
|
||||
"logId": "...",
|
||||
"integratedTime": 1733736000,
|
||||
"inclusionProof": {
|
||||
"rootHash": "...",
|
||||
"hashes": ["...", "..."],
|
||||
"checkpoint": "..."
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 5. REKOR CLIENT INTERFACE
|
||||
|
||||
```csharp
|
||||
public interface IRekorClient
|
||||
{
|
||||
Task<RekorEntry> SubmitDsseAsync(
|
||||
DsseEnvelope envelope,
|
||||
CancellationToken ct = default
|
||||
);
|
||||
|
||||
Task<bool> VerifyInclusionAsync(
|
||||
RekorEntry entry,
|
||||
byte[] payloadDigest,
|
||||
byte[] rekorPublicKey,
|
||||
CancellationToken ct = default
|
||||
);
|
||||
}
|
||||
|
||||
public record RekorEntry(
|
||||
string Uuid,
|
||||
long LogIndex,
|
||||
string LogId,
|
||||
long IntegratedTime,
|
||||
InclusionProof Proof
|
||||
);
|
||||
|
||||
public record InclusionProof(
|
||||
string RootHash,
|
||||
string[] Hashes,
|
||||
string Checkpoint
|
||||
);
|
||||
```
|
||||
|
||||
## 6. CLI VERIFICATION
|
||||
|
||||
### 6.1 Rekor CLI Commands
|
||||
|
||||
```bash
|
||||
rekor-cli verify --rekor_server https://rekor.sigstore.dev \
|
||||
--signature artifact.sig \
|
||||
--public-key cosign.pub \
|
||||
--artifact artifact.bin
|
||||
```
|
||||
|
||||
### 6.2 Persistence per Entry
|
||||
|
||||
- Rekor UUID
|
||||
- Log index
|
||||
- Integrated time
|
||||
- Inclusion proof data
|
||||
|
||||
## 7. OFFLINE REKOR MIRROR
|
||||
|
||||
### 7.1 Mirror Structure
|
||||
|
||||
```
|
||||
/evidence/tlog/
|
||||
checkpoint.sig # signed tree head
|
||||
entries/ # *.jsonl (Merkle leaves) + proofs
|
||||
```
|
||||
|
||||
### 7.2 Verification Steps
|
||||
|
||||
```
|
||||
1. Recompute Merkle root from entries
|
||||
2. Check matches `checkpoint.sig` (after verifying signature with tlog root key)
|
||||
3. For each attestation:
|
||||
- Verify UUID/digest appears in entry pack
|
||||
- Verify inclusion proof resolves
|
||||
```
|
||||
|
||||
## 8. REKOR STORAGE SCHEMA
|
||||
|
||||
```sql
|
||||
CREATE TABLE rekor_entries (
|
||||
dsse_sha256 VARCHAR(64) PRIMARY KEY,
|
||||
log_index BIGINT NOT NULL,
|
||||
log_id TEXT NOT NULL,
|
||||
integrated_time BIGINT NOT NULL,
|
||||
inclusion_proof JSONB NOT NULL,
|
||||
created_at TIMESTAMPTZ DEFAULT NOW()
|
||||
);
|
||||
|
||||
CREATE INDEX idx_rekor_log_index ON rekor_entries(log_index);
|
||||
CREATE INDEX idx_rekor_integrated_time ON rekor_entries(integrated_time);
|
||||
```
|
||||
|
||||
## 9. REKOR FAILURE HANDLING
|
||||
|
||||
### 9.1 Rekor Unavailable
|
||||
|
||||
```
|
||||
If Rekor unavailable:
|
||||
- Store DSSE envelope locally
|
||||
- Queue for retry
|
||||
- Mark proof chain as "rekorStatus: pending"
|
||||
- Internal-only until Rekor sync succeeds
|
||||
- Flag in verification results
|
||||
```
|
||||
|
||||
### 9.2 Rekor Verification Failed
|
||||
|
||||
```
|
||||
If verification fails:
|
||||
- Log error with structured fields (rekorUuid, dsseDigest, failureReason)
|
||||
- Mark envelope as "rekor_verification_failed"
|
||||
- Do not accept as valid proof
|
||||
- Alert security team
|
||||
```
|
||||
|
||||
## 10. INTEGRATION POINTS
|
||||
|
||||
### 10.1 Authority Module
|
||||
|
||||
- Submit signed attestations to Rekor
|
||||
- Store receipts with DSSE envelopes
|
||||
- Verify inclusion proofs on retrieval
|
||||
|
||||
### 10.2 Sbomer Module
|
||||
|
||||
- Submit SBOM attestations to Rekor
|
||||
- Link Rekor UUID to SBOM entries
|
||||
|
||||
### 10.3 Vexer Module
|
||||
|
||||
- Submit VEX statements to Rekor
|
||||
- Store receipts with VEX decisions
|
||||
|
||||
## 11. METRICS & OBSERVABILITY
|
||||
|
||||
```
|
||||
rekor_submit_total{status="success|failed"}
|
||||
rekor_submit_latency_seconds
|
||||
rekor_verify_total{result="pass|fail"}
|
||||
rekor_verify_latency_seconds
|
||||
rekor_queue_depth (pending submissions)
|
||||
rekor_retry_attempts_total
|
||||
```
|
||||
|
||||
## 12. CONFIGURATION
|
||||
|
||||
```yaml
|
||||
rekor:
|
||||
server_url: https://rekor.sigstore.dev
|
||||
public_key_path: /etc/stellaops/rekor-pub.pem
|
||||
offline_mode: false
|
||||
retry:
|
||||
max_attempts: 3
|
||||
initial_delay_ms: 1000
|
||||
max_delay_ms: 10000
|
||||
timeout_seconds: 30
|
||||
```
|
||||
|
||||
## 13. OFFLINE BUNDLE INTEGRATION
|
||||
|
||||
### 13.1 Rekor Receipt in Offline Kit
|
||||
|
||||
**rekor-receipt.json**:
|
||||
```json
|
||||
{
|
||||
"uuid": "string",
|
||||
"logIndex": int,
|
||||
"rootHash": "string",
|
||||
"hashes": ["string"],
|
||||
"checkpoint": "string"
|
||||
}
|
||||
```
|
||||
|
||||
### 13.2 Offline Verification
|
||||
|
||||
```
|
||||
1. Load Rekor public key from offline bundle
|
||||
2. Verify checkpoint signature
|
||||
3. Recompute Merkle root from inclusion proof
|
||||
4. Verify root hash matches checkpoint
|
||||
5. Verify DSSE envelope hash appears in proof
|
||||
```
|
||||
|
||||
## 14. SECURITY CONSIDERATIONS
|
||||
|
||||
### 14.1 Trust Model
|
||||
|
||||
- Rekor provides transparency, not trust
|
||||
- Trust derives from key verification
|
||||
- Inclusion proof demonstrates timestamp
|
||||
- Does not prove correctness of content
|
||||
|
||||
### 14.2 Key Pinning
|
||||
|
||||
- Pin Rekor public key via out-of-band distribution
|
||||
- Verify checkpoint signatures before trusting
|
||||
- Maintain key version history
|
||||
|
||||
### 14.3 Replay Protection
|
||||
|
||||
- Use integrated_time to detect backdated entries
|
||||
- Compare with local clock (within reasonable skew)
|
||||
- Alert on time anomalies
|
||||
|
||||
## 15. TESTING REQUIREMENTS
|
||||
|
||||
### 15.1 Integration Tests
|
||||
|
||||
- Submit DSSE to Rekor (staging)
|
||||
- Verify inclusion proof
|
||||
- Offline verification with mirror
|
||||
- Retry on failure
|
||||
- Timeout handling
|
||||
|
||||
### 15.2 Failure Scenarios
|
||||
|
||||
- Rekor unavailable
|
||||
- Network timeout
|
||||
- Invalid inclusion proof
|
||||
- Signature verification failure
|
||||
- Malformed response
|
||||
|
||||
## 16. OPERATIONAL PROCEDURES
|
||||
|
||||
### 16.1 Rekor Mirror Sync
|
||||
|
||||
```bash
|
||||
# Download latest checkpoint
|
||||
curl https://rekor.sigstore.dev/api/v1/log/checkpoint > checkpoint.sig
|
||||
|
||||
# Verify checkpoint signature
|
||||
rekor-cli verify --checkpoint checkpoint.sig --public-key rekor-pub.pem
|
||||
|
||||
# Sync entries since last update
|
||||
rekor-cli sync --since <last_log_index> --output ./entries/
|
||||
```
|
||||
|
||||
### 16.2 Monitoring
|
||||
|
||||
- Alert on Rekor submission failures >1% over 5 minutes
|
||||
- Alert on verification failures >0.1% over 5 minutes
|
||||
- Alert on queue depth >1000 for >10 minutes
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,281 @@
|
||||
# Smart-Diff Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 09-Dec-2025 - Smart‑Diff and Provenance‑Rich Binaries
|
||||
- 12-Dec-2025 - Smart‑Diff Detects Meaningful Risk Shifts
|
||||
- 13-Dec-2025 - Smart‑Diff - Defining Meaningful Risk Change
|
||||
- 05-Dec-2025 - Design Notes on Smart‑Diff and Call‑Stack Analysis
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. SMART-DIFF PREDICATE SCHEMA
|
||||
|
||||
```json
|
||||
{
|
||||
"predicateType": "stellaops.dev/predicates/smart-diff@v1",
|
||||
"predicate": {
|
||||
"baseImage": {"name":"...", "digest":"sha256:..."},
|
||||
"targetImage": {"name":"...", "digest":"sha256:..."},
|
||||
"diff": {
|
||||
"filesAdded": [...],
|
||||
"filesRemoved": [...],
|
||||
"filesChanged": [{"path":"...", "hunks":[...]}],
|
||||
"packagesChanged": [{"name":"openssl","from":"1.1.1u","to":"3.0.14"}]
|
||||
},
|
||||
"context": {
|
||||
"entrypoint":["/app/start"],
|
||||
"env":{"FEATURE_X":"true"},
|
||||
"user":{"uid":1001,"caps":["NET_BIND_SERVICE"]}
|
||||
},
|
||||
"reachabilityGate": {"reachable":true,"configActivated":true,"runningUser":false,"class":6},
|
||||
"scanner": {"name":"StellaOps.Scanner","version":"...","ruleset":"reachability-2025.12"}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 2. REACHABILITY GATE (3-BIT SEVERITY)
|
||||
|
||||
**Data Model:**
|
||||
```csharp
|
||||
public sealed record ReachabilityGate(
|
||||
bool? Reachable, // true / false / null for unknown
|
||||
bool? ConfigActivated,
|
||||
bool? RunningUser,
|
||||
int Class, // 0..7 derived from the bits when all known
|
||||
string Rationale // short explanation, human-readable
|
||||
);
|
||||
```
|
||||
|
||||
**Class Computation:** 0-7 based on 3 binary gates (reachable, config-activated, running user)
|
||||
|
||||
**Unknown Handling:**
|
||||
- Never silently treat `null` as `false` or `true`
|
||||
- If any bit is `null`, set `Class = -1` or compute from known bits only
|
||||
|
||||
## 3. DELTA DATA STRUCTURES
|
||||
|
||||
```csharp
|
||||
// Delta.Packages
|
||||
{
|
||||
added[],
|
||||
removed[],
|
||||
changed[{name, fromVer, toVer}]
|
||||
}
|
||||
|
||||
// Delta.Layers
|
||||
{
|
||||
changed[{path, fromHash, toHash, licenseDelta}]
|
||||
}
|
||||
|
||||
// Delta.Functions
|
||||
{
|
||||
added[],
|
||||
removed[],
|
||||
changed[{symbol, file, signatureHashFrom, signatureHashTo}]
|
||||
}
|
||||
|
||||
// PatchDelta
|
||||
{
|
||||
addedSymbols[],
|
||||
removedSymbols[],
|
||||
changedSignatures[]
|
||||
}
|
||||
```
|
||||
|
||||
## 4. SMART-DIFF ALGORITHMS
|
||||
|
||||
**Core Diff Computation:**
|
||||
```pseudo
|
||||
prev = load_snapshot(t-1)
|
||||
curr = load_snapshot(t)
|
||||
|
||||
Δ.pkg = diff_packages(prev.lock, curr.lock)
|
||||
Δ.layers= diff_layers(prev.sbom, curr.sbom)
|
||||
Δ.funcs = diff_cfg(prev.cfgIndex, curr.cfgIndex)
|
||||
|
||||
scope = union(
|
||||
impact_of(Δ.pkg.changed),
|
||||
impact_of_files(Δ.layers.changed),
|
||||
reachability_of(Δ.funcs.changed)
|
||||
)
|
||||
|
||||
for f in scope.functions:
|
||||
rescore(f)
|
||||
|
||||
for v in impacted_vulns(scope):
|
||||
annotate(v, patch_delta(Δ))
|
||||
link_evidence(v, dsse_attestation(), proof_links())
|
||||
|
||||
for v in previously_flagged where vulnerable_apis_now_absent(v, curr):
|
||||
emit_vex_candidate(v, status="not_affected", rationale="API not present", evidence=proof_links())
|
||||
```
|
||||
|
||||
## 5. MATERIAL RISK CHANGE DETECTION RULES
|
||||
|
||||
**FindingKey:**
|
||||
```
|
||||
FindingKey = (component_purl, component_version, cve_id)
|
||||
```
|
||||
|
||||
**RiskState Fields:**
|
||||
- `reachable: bool | unknown`
|
||||
- `vex_status: enum` (AFFECTED | NOT_AFFECTED | FIXED | UNDER_INVESTIGATION | UNKNOWN)
|
||||
- `in_affected_range: bool | unknown`
|
||||
- `kev: bool`
|
||||
- `epss_score: float | null`
|
||||
- `policy_flags: set<string>`
|
||||
- `evidence_links: list<EvidenceLink>`
|
||||
|
||||
**Rule R1: Reachability Flip**
|
||||
- `reachable` changes: `false → true` (risk ↑) or `true → false` (risk ↓)
|
||||
|
||||
**Rule R2: VEX Status Flip**
|
||||
- Meaningful changes: `AFFECTED ↔ NOT_AFFECTED`, `UNDER_INVESTIGATION → NOT_AFFECTED`
|
||||
|
||||
**Rule R3: Affected Range Boundary**
|
||||
- `in_affected_range` flips: `false → true` or `true → false`
|
||||
|
||||
**Rule R4: Intelligence/Policy Flip**
|
||||
- `kev` changes `false → true`
|
||||
- `epss_score` crosses configured threshold
|
||||
- `policy_flag` changes severity (warn → block)
|
||||
|
||||
## 6. SUPPRESSION RULES
|
||||
|
||||
**Suppression Conditions (ALL must apply):**
|
||||
1. `reachable == false`
|
||||
2. `vex_status == NOT_AFFECTED`
|
||||
3. `kev == false`
|
||||
4. No policy override
|
||||
|
||||
**Patch Churn Suppression:**
|
||||
- If version changes AND `in_affected_range` remains false in both AND no KEV/policy flip → suppress
|
||||
|
||||
## 7. CALL-STACK ANALYSIS
|
||||
|
||||
**C# Roslyn Skeleton:**
|
||||
```csharp
|
||||
public static class SmartDiff
|
||||
{
|
||||
public static async Task<HashSet<string>> ReachableSinks(string solutionPath, string[] entrypoints, string[] sinks)
|
||||
{
|
||||
var workspace = MSBuild.MSBuildWorkspace.Create();
|
||||
var solution = await workspace.OpenSolutionAsync(solutionPath);
|
||||
var index = new HashSet<string>();
|
||||
|
||||
foreach (var proj in solution.Projects)
|
||||
{
|
||||
var comp = await proj.GetCompilationAsync();
|
||||
if (comp is null) continue;
|
||||
|
||||
var epSymbols = comp.GlobalNamespace.GetMembers().SelectMany(Descend)
|
||||
.OfType<IMethodSymbol>().Where(m => entrypoints.Contains(m.ToDisplayString())).ToList();
|
||||
var sinkSymbols = comp.GlobalNamespace.GetMembers().SelectMany(Descend)
|
||||
.OfType<IMethodSymbol>().Where(m => sinks.Contains(m.ToDisplayString())).ToList();
|
||||
|
||||
foreach (var ep in epSymbols)
|
||||
foreach (var sink in sinkSymbols)
|
||||
{
|
||||
var refs = await SymbolFinder.FindReferencesAsync(sink, solution);
|
||||
if (refs.SelectMany(r => r.Locations).Any())
|
||||
index.Add($"{ep.ToDisplayString()} -> {sink.ToDisplayString()}");
|
||||
}
|
||||
}
|
||||
return index;
|
||||
|
||||
static IEnumerable<ISymbol> Descend(INamespaceOrTypeSymbol sym)
|
||||
{
|
||||
foreach (var m in sym.GetMembers())
|
||||
{
|
||||
yield return m;
|
||||
if (m is INamespaceOrTypeSymbol nt)
|
||||
foreach (var x in Descend(nt)) yield return x;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Go SSA Skeleton:**
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"golang.org/x/tools/go/callgraph/cha"
|
||||
"golang.org/x/tools/go/packages"
|
||||
"golang.org/x/tools/go/ssa"
|
||||
)
|
||||
|
||||
func main() {
|
||||
cfg := &packages.Config{Mode: packages.LoadAllSyntax, Tests: false}
|
||||
pkgs, _ := packages.Load(cfg, "./...")
|
||||
prog, pkgsSSA := ssa.NewProgram(pkgs[0].Fset, ssa.BuilderMode(0))
|
||||
for _, p := range pkgsSSA { prog.CreatePackage(p, p.Syntax, p.TypesInfo, true) }
|
||||
prog.Build()
|
||||
|
||||
cg := cha.CallGraph(prog)
|
||||
fmt.Println("nodes:", len(cg.Nodes))
|
||||
}
|
||||
```
|
||||
|
||||
## 8. SINK TAXONOMY
|
||||
|
||||
```yaml
|
||||
sinks:
|
||||
- CMD_EXEC
|
||||
- UNSAFE_DESER
|
||||
- SQL_RAW
|
||||
- SSRF
|
||||
- FILE_WRITE
|
||||
- PATH_TRAVERSAL
|
||||
- TEMPLATE_INJECTION
|
||||
- CRYPTO_WEAK
|
||||
- AUTHZ_BYPASS
|
||||
```
|
||||
|
||||
## 9. POLICY SCORING FORMULA
|
||||
|
||||
**Priority Score:**
|
||||
```
|
||||
score =
|
||||
+ 1000 if new.kev
|
||||
+ 500 if new.reachable
|
||||
+ 200 if reason includes RANGE_FLIP to affected
|
||||
+ 150 if VEX_FLIP to AFFECTED
|
||||
+ 0..100 based on EPSS (epss * 100)
|
||||
+ policy weight: +300 if decision BLOCK, +100 if WARN
|
||||
```
|
||||
|
||||
## 10. PROVENANCE-RICH BINARIES (BINARY SCA + PROVENANCE + SARIF)
|
||||
|
||||
Smart-Diff becomes materially stronger when it can reason about *binary-level* deltas (symbols/sections/hardening), not only package versions.
|
||||
|
||||
Required extractors (deterministic):
|
||||
- ELF/PE/Mach-O headers, sections, imports/exports, build-id, rpaths
|
||||
- Symbol tables (public + demangled), string tables, debug info pointers (DWARF/PDB when present)
|
||||
- Compiler/linker fingerprints (e.g., `.comment`, PE version info, toolchain IDs)
|
||||
- Per-section and per-function rolling hashes (stable across identical bytes)
|
||||
- Optional: Bloom filter for symbol presence proofs (binary digest + filter digest)
|
||||
|
||||
Provenance capture (per binary):
|
||||
- Compiler name/version, target triple, LTO mode, linker name/version
|
||||
- Hardening flags (PIE/RELRO/CFGuard/CET/FORTIFY, stack protector)
|
||||
- Link inputs (libraries + order) and build materials (git commit, dependency lock digests)
|
||||
|
||||
Attestation output:
|
||||
- Emit a DSSE-wrapped in-toto statement per binary (SLSA provenance compatible) with subject = binary sha256.
|
||||
|
||||
CI output (developer-facing):
|
||||
- Emit SARIF 2.1.0 (`tool`: `StellaOps.BinarySCA`) so binary findings and hardening regressions can surface in code scanning.
|
||||
- Each SARIF result references the binary digest, symbol/section, and the attestation digest(s) needed to verify the claim.
|
||||
|
||||
Smart-Diff linkage rule:
|
||||
- When a binary changes, map file delta → binary digest delta → symbol delta → impacted sinks/vulns, then re-score only the impacted scope.
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,465 @@
|
||||
# Testing and Quality Guardrails Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 29-Nov-2025 - Acceptance Tests Pack and Guardrails
|
||||
- 29-Nov-2025 - SCA Failure Catalogue for StellaOps Tests
|
||||
- 30-Nov-2025 - Ecosystem Reality Test Cases for StellaOps
|
||||
- 14-Dec-2025 - Create a small ground‑truth corpus
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. ACCEPTANCE TEST PACK SCHEMA
|
||||
|
||||
### 1.1 Required Artifacts (MVP for DONE)
|
||||
|
||||
- Advisory summary under `docs/process/`
|
||||
- Checklist stub referencing AT1–AT10
|
||||
- Fixture pack path: `tests/acceptance/packs/guardrails/` (no network)
|
||||
- Links into sprint tracker (`SPRINT_0300_0001_0001_documentation_process.md`)
|
||||
|
||||
### 1.2 Determinism & Offline
|
||||
|
||||
- Freeze scanner/db versions; record in `inputs.lock`
|
||||
- All fixtures reproducible from seeds
|
||||
- Include DSSE envelopes for pack manifests
|
||||
|
||||
## 2. SCA FAILURE CATALOGUE (FC1-FC10)
|
||||
|
||||
### 2.1 Required Artifacts
|
||||
|
||||
- Catalogue plus fixture pack root: `tests/fixtures/sca/catalogue/`
|
||||
- Sprint Execution Log entry when published
|
||||
|
||||
### 2.2 Fixture Requirements
|
||||
|
||||
- Pin scanner versions and feeds
|
||||
- Include `inputs.lock` and DSSE manifest per case
|
||||
- Normalize results (ordering, casing) for stable comparisons
|
||||
|
||||
## 3. ECOSYSTEM REALITY TEST CASES (ET1-ET10)
|
||||
|
||||
**Fixture Path**: `tests/fixtures/sca/catalogue/`
|
||||
|
||||
**Requirements**:
|
||||
- Map each incident to acceptance tests and fixture paths
|
||||
- Pin tool versions and feeds; no live network
|
||||
- Populate fixtures and acceptance specs
|
||||
|
||||
## 4. GROUND-TRUTH CORPUS SCHEMA
|
||||
|
||||
### 4.1 Service Structure
|
||||
|
||||
Each service under `/toys/svc-XX-<name>/`:
|
||||
|
||||
```
|
||||
app/
|
||||
infra/ # Dockerfile, compose, network policy
|
||||
tests/ # positive + negative reachability tests
|
||||
labels.yaml # ground truth
|
||||
evidence/ # generated by tests (trace, tags, manifests)
|
||||
fix/ # minimal patch proving remediation
|
||||
```
|
||||
|
||||
### 4.2 labels.yaml Schema
|
||||
|
||||
```yaml
|
||||
service: svc-01-password-reset
|
||||
vulns:
|
||||
- id: V1
|
||||
cve: CVE-2022-XXXXX
|
||||
type: dep_runtime|dep_build|code|config|os_pkg|supply_chain
|
||||
package: string
|
||||
version: string
|
||||
reachable: true|false
|
||||
reachability_level: R0|R1|R2|R3|R4
|
||||
entrypoint: string # route:/reset, topic:jobs, cli:command
|
||||
preconditions: [string] # flags/env/auth
|
||||
path_tags: [string]
|
||||
proof:
|
||||
artifacts: [string]
|
||||
tags: [string]
|
||||
fix:
|
||||
type: upgrade|config|code
|
||||
patch_path: string
|
||||
expected_delta: string
|
||||
negative_proof: string # if unreachable
|
||||
```
|
||||
|
||||
### 4.3 Reachability Tiers
|
||||
|
||||
- **R0 Present**: component exists in SBOM, not imported/loaded
|
||||
- **R1 Loaded**: imported/linked/initialized, no executed path
|
||||
- **R2 Executed**: vulnerable function executed (deterministic trace)
|
||||
- **R3 Tainted execution**: execution with externally influenced input
|
||||
- **R4 Exploitable**: controlled, non-harmful PoC (optional)
|
||||
|
||||
### 4.4 Evidence Requirements per Tier
|
||||
|
||||
- **R0**: SBOM + file hash/package metadata
|
||||
- **R1**: runtime startup logs or module load trace tag
|
||||
- **R2**: callsite tag + stack trace snippet
|
||||
- **R3**: R2 + taint marker showing external data reached call
|
||||
- **R4**: only if safe/necessary; non-weaponized, sandboxed
|
||||
|
||||
### 4.5 Canonical Tag Format
|
||||
|
||||
```
|
||||
TAG:route:<method> <path>
|
||||
TAG:topic:<name>
|
||||
TAG:call:<sink>
|
||||
TAG:taint:<boundary>
|
||||
TAG:flag:<name>=<value>
|
||||
```
|
||||
|
||||
### 4.6 Evidence Artifact Schema
|
||||
|
||||
**evidence/trace.json**:
|
||||
```json
|
||||
{
|
||||
"ts": "UTC ISO-8601",
|
||||
"corr": "correlation-id",
|
||||
"tags": ["TAG:route:POST /reset", "TAG:taint:http.body.email", "TAG:call:Crypto.MD5"]
|
||||
}
|
||||
```
|
||||
|
||||
### 4.7 Evidence Manifest
|
||||
|
||||
**evidence/manifest.json**:
|
||||
```json
|
||||
{
|
||||
"git_sha": "string",
|
||||
"image_digest": "string",
|
||||
"tool_versions": {"scanner": "string", "db": "string"},
|
||||
"timestamps": {"started_at": "UTC ISO-8601", "completed_at": "UTC ISO-8601"},
|
||||
"evidence_hashes": {"trace.json": "sha256:...", "tags.log": "sha256:..."}
|
||||
}
|
||||
```
|
||||
|
||||
## 5. CORE TEST METRICS
|
||||
|
||||
| Metric | Definition |
|
||||
|--------|------------|
|
||||
| Recall (by class) | % of labeled vulns detected (runtime deps, OS pkgs, code, config) |
|
||||
| Precision | 1 - false positive rate |
|
||||
| Reachability accuracy | % correct R0/R1/R2/R3 classifications |
|
||||
| Overreach | Predicted reachable but labeled R0/R1 |
|
||||
| Underreach | Labeled R2/R3 but predicted non-reachable |
|
||||
| TTFS | Time-to-first-signal (first evidence-backed blocking issue) |
|
||||
| Fix validation | % of applied fixes producing expected delta |
|
||||
|
||||
## 6. TEST QUALITY GATES (CI ENFORCEMENT THRESHOLDS)
|
||||
|
||||
```yaml
|
||||
thresholds:
|
||||
runtime_dependency_recall: >= 0.95
|
||||
unreachable_false_positives: <= 0.05
|
||||
reachability_underreport: <= 0.10
|
||||
ttfs_regression: <= +10% vs main
|
||||
fix_validation_pass_rate: 100%
|
||||
```
|
||||
|
||||
## 7. SERVICE DEFINITION OF DONE
|
||||
|
||||
A service PR is DONE only if it includes:
|
||||
|
||||
- [ ] `labels.yaml` validated by `schemas/labels.schema.json`
|
||||
- [ ] Docker build reproducible (digest pinned, lockfiles committed)
|
||||
- [ ] Positive tests generating evidence proving reachability tiers
|
||||
- [ ] Negative tests proving "unreachable" claims
|
||||
- [ ] `fix/` patch removing/mitigating weakness with measurable delta
|
||||
- [ ] `evidence/manifest.json` capturing tool versions, git sha, image digest, timestamps, evidence hashes
|
||||
|
||||
## 8. REVIEWER REJECTION CRITERIA
|
||||
|
||||
Reject PR if any fail:
|
||||
|
||||
- [ ] Labels complete, schema-valid, stable IDs preserved
|
||||
- [ ] Proof artifacts deterministic and generated by tests
|
||||
- [ ] Reachability tier justified and matches evidence
|
||||
- [ ] Unreachable claims have negative proofs
|
||||
- [ ] Docker build uses pinned digests + committed lockfiles
|
||||
- [ ] `fix/` produces measurable delta without new unlabeled issues
|
||||
- [ ] No network egress required; tests hermetic
|
||||
|
||||
## 9. TEST HARNESS PATTERNS
|
||||
|
||||
### 9.1 xUnit Test Template
|
||||
|
||||
```csharp
|
||||
public class ReachabilityAcceptanceTests : IClassFixture<PostgresFixture>
|
||||
{
|
||||
private readonly PostgresFixture _db;
|
||||
|
||||
public ReachabilityAcceptanceTests(PostgresFixture db)
|
||||
{
|
||||
_db = db;
|
||||
}
|
||||
|
||||
[Theory]
|
||||
[InlineData("svc-01-password-reset", "V1", ReachabilityLevel.R2)]
|
||||
[InlineData("svc-02-file-upload", "V1", ReachabilityLevel.R0)]
|
||||
public async Task VerifyReachabilityClassification(
|
||||
string serviceId,
|
||||
string vulnId,
|
||||
ReachabilityLevel expectedLevel)
|
||||
{
|
||||
// Arrange
|
||||
var labels = await LoadLabels($"toys/{serviceId}/labels.yaml");
|
||||
var expectedVuln = labels.Vulns.First(v => v.Id == vulnId);
|
||||
|
||||
// Act
|
||||
var result = await _scanner.ScanAsync(serviceId);
|
||||
var actualVuln = result.Findings.First(f => f.VulnId == vulnId);
|
||||
|
||||
// Assert
|
||||
Assert.Equal(expectedLevel, actualVuln.ReachabilityLevel);
|
||||
Assert.NotEmpty(actualVuln.Evidence);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 9.2 Testcontainers Pattern
|
||||
|
||||
```csharp
|
||||
public class PostgresFixture : IAsyncLifetime
|
||||
{
|
||||
private PostgreSqlContainer? _container;
|
||||
public string ConnectionString { get; private set; } = null!;
|
||||
|
||||
public async Task InitializeAsync()
|
||||
{
|
||||
_container = new PostgreSqlBuilder()
|
||||
.WithImage("postgres:16-alpine")
|
||||
.WithDatabase("stellaops_test")
|
||||
.WithUsername("test")
|
||||
.WithPassword("test")
|
||||
.Build();
|
||||
|
||||
await _container.StartAsync();
|
||||
ConnectionString = _container.GetConnectionString();
|
||||
|
||||
// Run migrations
|
||||
await RunMigrations(ConnectionString);
|
||||
}
|
||||
|
||||
public async Task DisposeAsync()
|
||||
{
|
||||
if (_container != null)
|
||||
await _container.DisposeAsync();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 10. FIXTURE ORGANIZATION
|
||||
|
||||
```
|
||||
tests/
|
||||
fixtures/
|
||||
sca/
|
||||
catalogue/
|
||||
FC001_openssl_version_range/
|
||||
inputs.lock
|
||||
sbom.cdx.json
|
||||
expected_findings.json
|
||||
dsse_manifest.json
|
||||
acceptance/
|
||||
packs/
|
||||
guardrails/
|
||||
AT001_reachability_present/
|
||||
AT002_reachability_loaded/
|
||||
AT003_reachability_executed/
|
||||
micro/
|
||||
motion/
|
||||
error/
|
||||
offline/
|
||||
toys/
|
||||
svc-01-password-reset/
|
||||
app/
|
||||
infra/
|
||||
tests/
|
||||
labels.yaml
|
||||
evidence/
|
||||
fix/
|
||||
```
|
||||
|
||||
## 11. DETERMINISTIC TEST REQUIREMENTS
|
||||
|
||||
### 11.1 Time Handling
|
||||
|
||||
- Freeze timers to `2025-12-04T12:00:00Z` in stories/e2e
|
||||
- Use `FakeTimeProvider` in .NET tests
|
||||
- Playwright: `useFakeTimers`
|
||||
|
||||
### 11.2 Random Number Generation
|
||||
|
||||
- Seed RNG with `0x5EED2025` unless scenario-specific
|
||||
- Never use `Random()` without explicit seed
|
||||
|
||||
### 11.3 Network Isolation
|
||||
|
||||
- No network calls in test execution
|
||||
- Offline assets bundled
|
||||
- Testcontainers for external dependencies
|
||||
- Mock external APIs
|
||||
|
||||
### 11.4 Snapshot Testing
|
||||
|
||||
- All fixtures stored under `tests/fixtures/`
|
||||
- Golden outputs checked into git
|
||||
- Stable ordering for arrays/objects
|
||||
- Strip volatile fields (timestamps, UUIDs) unless semantic
|
||||
|
||||
## 12. COVERAGE REQUIREMENTS
|
||||
|
||||
### 12.1 Unit Tests
|
||||
|
||||
- **Target**: ≥85% line coverage for core modules
|
||||
- **Critical paths**: 100% coverage required
|
||||
- **Exceptions**: UI glue code, generated code
|
||||
|
||||
### 12.2 Integration Tests
|
||||
|
||||
- **Database operations**: All repositories tested with Testcontainers
|
||||
- **API endpoints**: All endpoints tested with WebApplicationFactory
|
||||
- **External integrations**: Mocked or stubbed
|
||||
|
||||
### 12.3 End-to-End Tests
|
||||
|
||||
- **Critical workflows**: User registration → scan → triage → decision
|
||||
- **Happy paths**: All major features
|
||||
- **Error paths**: Authentication failures, network errors, data validation
|
||||
|
||||
## 13. PERFORMANCE TESTING
|
||||
|
||||
### 13.1 Benchmark Tests
|
||||
|
||||
```csharp
|
||||
[MemoryDiagnoser]
|
||||
public class ScannerBenchmarks
|
||||
{
|
||||
[Benchmark]
|
||||
public async Task ScanMediumImage()
|
||||
{
|
||||
// 100k LOC .NET service
|
||||
await _scanner.ScanAsync("medium-service");
|
||||
}
|
||||
|
||||
[Benchmark]
|
||||
public async Task ComputeReachability()
|
||||
{
|
||||
await _reachability.ComputeAsync(_testGraph);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 13.2 Performance Targets
|
||||
|
||||
| Operation | Target |
|
||||
|-----------|--------|
|
||||
| Medium service scan | < 2 minutes |
|
||||
| Reachability compute | < 30 seconds |
|
||||
| Query GET finding | < 200ms p95 |
|
||||
| SBOM ingestion | < 5 seconds |
|
||||
|
||||
## 14. MUTATION TESTING
|
||||
|
||||
### 14.1 Stryker Configuration
|
||||
|
||||
```json
|
||||
{
|
||||
"stryker-config": {
|
||||
"mutate": [
|
||||
"src/**/*.cs",
|
||||
"!src/**/*.Designer.cs",
|
||||
"!src/**/Migrations/**"
|
||||
],
|
||||
"test-runner": "dotnet",
|
||||
"threshold-high": 90,
|
||||
"threshold-low": 70,
|
||||
"threshold-break": 60
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 14.2 Mutation Score Targets
|
||||
|
||||
- **Critical modules**: ≥90%
|
||||
- **Standard modules**: ≥70%
|
||||
- **Break build**: <60%
|
||||
|
||||
## 15. SECURITY TESTING
|
||||
|
||||
### 15.1 OWASP Top 10 Coverage
|
||||
|
||||
- [ ] SQL Injection
|
||||
- [ ] XSS (Cross-Site Scripting)
|
||||
- [ ] CSRF (Cross-Site Request Forgery)
|
||||
- [ ] Authentication bypasses
|
||||
- [ ] Authorization bypasses
|
||||
- [ ] Sensitive data exposure
|
||||
- [ ] XML External Entities (XXE)
|
||||
- [ ] Broken Access Control
|
||||
- [ ] Security Misconfiguration
|
||||
- [ ] Insecure Deserialization
|
||||
|
||||
### 15.2 Dependency Scanning
|
||||
|
||||
```bash
|
||||
# SBOM generation
|
||||
dotnet sbom-tool generate -b ./bin -bc ./src -pn StellaOps -pv 1.0.0
|
||||
|
||||
# Vulnerability scanning
|
||||
dotnet list package --vulnerable --include-transitive
|
||||
```
|
||||
|
||||
## 16. CI/CD INTEGRATION
|
||||
|
||||
### 16.1 GitHub Actions Workflow
|
||||
|
||||
```yaml
|
||||
name: Test
|
||||
|
||||
on: [push, pull_request]
|
||||
|
||||
jobs:
|
||||
test:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- uses: actions/setup-dotnet@v4
|
||||
with:
|
||||
dotnet-version: '10.0.x'
|
||||
- name: Restore dependencies
|
||||
run: dotnet restore
|
||||
- name: Build
|
||||
run: dotnet build --no-restore
|
||||
- name: Test
|
||||
run: dotnet test --no-build --verbosity normal --collect:"XPlat Code Coverage"
|
||||
- name: Upload coverage
|
||||
uses: codecov/codecov-action@v4
|
||||
```
|
||||
|
||||
### 16.2 Quality Gates
|
||||
|
||||
- All tests pass
|
||||
- Coverage ≥85%
|
||||
- No high/critical vulnerabilities
|
||||
- Mutation score ≥70%
|
||||
- Performance regressions <10%
|
||||
|
||||
## 17. BENCH HARNESSES (SIGNED, REPRODUCIBLE METRICS)
|
||||
|
||||
Use the repo bench harness for moat-grade, reproducible comparisons and audit kits:
|
||||
- Harness root: `bench/README.md`
|
||||
- Signed finding bundles + verifiers live under `bench/findings/` and `bench/tools/`
|
||||
- Baseline comparisons and rollups live under `bench/results/`
|
||||
|
||||
Guardrail:
|
||||
- Any change to scanning/policy/proof logic must be covered by at least one deterministic bench scenario (or an extension of an existing one).
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,470 @@
|
||||
# Triage and Unknowns Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 30-Nov-2025 - Unknowns Decay & Triage Heuristics
|
||||
- 14-Dec-2025 - Dissect triage and evidence workflows
|
||||
- 04-Dec-2025 - Ranking Unknowns in Reachability Graphs
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. EVIDENCE-FIRST PRINCIPLES
|
||||
|
||||
1. **Evidence before detail**: Opening alert shows best available evidence immediately
|
||||
2. **Fast first signal**: UI renders credible "first signal" quickly
|
||||
3. **Determinism reduces hesitation**: Sorting, graphs, diffs stable across refreshes
|
||||
4. **Offline by design**: If evidence exists locally, render without network
|
||||
5. **Audit-ready by default**: Every decision reproducible, attributable, exportable
|
||||
|
||||
## 2. MINIMAL EVIDENCE BUNDLE (PER FINDING)
|
||||
|
||||
1. **Reachability proof**: Function-level path or package-level import chain
|
||||
2. **Call-stack snippet**: 5–10 frames around sink/source with file:line anchors
|
||||
3. **Provenance**: Attestation/DSSE + build ancestry (image → layer → artifact → commit)
|
||||
4. **VEX/CSAF status**: affected/not-affected/under-investigation + reason
|
||||
5. **Diff**: SBOM or VEX delta since last scan (smart-diff)
|
||||
6. **Graph revision + receipt**: `graphRevisionId` plus the signed verdict receipt linking to upstream evidence (DSSE/Rekor when available)
|
||||
|
||||
## 3. KPIS
|
||||
|
||||
### 3.1 TTFS (Time-to-First-Signal)
|
||||
|
||||
**Definition**: p50/p95 from alert creation to first rendered evidence
|
||||
|
||||
**Target**: p95 < 1.5s (with 100ms RTT, 1% loss)
|
||||
|
||||
### 3.2 Clicks-to-Closure
|
||||
|
||||
**Definition**: Median interactions per decision type
|
||||
|
||||
**Target**: median < 6 clicks
|
||||
|
||||
### 3.3 Evidence Completeness Score
|
||||
|
||||
**Definition**: 0–4 (reachability, call-stack, provenance, VEX present)
|
||||
|
||||
**Target**: ≥90% of decisions include all evidence + reason + replay token
|
||||
|
||||
### 3.4 Offline Friendliness
|
||||
|
||||
**Definition**: % evidence resolvable with no network
|
||||
|
||||
**Target**: ≥95% with local bundle
|
||||
|
||||
### 3.5 Audit Log Completeness
|
||||
|
||||
**Requirement**: Every decision has evidence hash set, actor, policy context, replay token
|
||||
|
||||
## 4. KEYBOARD SHORTCUTS
|
||||
|
||||
- `J`: Jump to first incomplete evidence pane
|
||||
- `Y`: Copy DSSE (attestation block or Rekor entry ref)
|
||||
- `R`: Toggle reachability view (path list ↔ compact graph ↔ textual proof)
|
||||
- `/`: Search within graph (node/func/package)
|
||||
- `S`: Deterministic sort (reachability→severity→age→component)
|
||||
- `A`, `N`, `U`: Quick VEX set (Affected / Not-affected / Under-investigation)
|
||||
- `?`: Keyboard help overlay
|
||||
|
||||
## 5. UX FLOW
|
||||
|
||||
### 5.1 Alert Row
|
||||
|
||||
- TTFS timer
|
||||
- Reachability badge
|
||||
- Decision state
|
||||
- Diff-dot
|
||||
|
||||
### 5.2 Open Alert → Evidence Tab (Not Details)
|
||||
|
||||
**Top strip**: 3 proof pills (Reachability ✓ / Call-stack ✓ / Provenance ✓)
|
||||
|
||||
Click to expand inline
|
||||
|
||||
### 5.3 Decision Drawer (Pinned Right)
|
||||
|
||||
- VEX/CSAF radio (A/N/U)
|
||||
- Reason presets → "Record decision"
|
||||
- Audit-ready summary (hashes, timestamps, policy)
|
||||
|
||||
### 5.4 Diff Tab
|
||||
|
||||
SBOM/VEX delta, grouped by "meaningful risk shift"
|
||||
|
||||
### 5.5 Activity Tab
|
||||
|
||||
Immutable audit log; export as signed bundle
|
||||
|
||||
## 6. GRAPH PERFORMANCE (LARGE CALL GRAPHS)
|
||||
|
||||
### 6.1 Minimal-Latency Snapshots
|
||||
|
||||
- Pre-render static PNG/SVG thumbnails server-side
|
||||
|
||||
### 6.2 Progressive Neighborhood Expansion
|
||||
|
||||
- Load 1-hop first, expand on demand
|
||||
- First TTFS < 500ms
|
||||
|
||||
### 6.3 Stable Node Ordering
|
||||
|
||||
- Deterministic layout with consistent anchors
|
||||
|
||||
### 6.4 Chunked Graph Edges
|
||||
|
||||
- Capped fan-out
|
||||
- Collapse identical library paths into reachability macro-edge
|
||||
|
||||
**Targets**:
|
||||
- Preview < 300ms
|
||||
- Interactive hydration < 2.0s for large graphs
|
||||
|
||||
## 7. OFFLINE DESIGN
|
||||
|
||||
### 7.1 Local Evidence Cache
|
||||
|
||||
Store (SBOM slices, path proofs, DSSE attestations, compiled call-stacks) in signed bundle beside SARIF/VEX
|
||||
|
||||
### 7.2 Deferred Enrichment
|
||||
|
||||
Mark fields needing internet; queue background "enricher" when network returns
|
||||
|
||||
### 7.3 Predictable Fallbacks
|
||||
|
||||
Show embedded DSSE + "verification pending" if provenance server missing
|
||||
|
||||
## 8. AUDIT & REPLAY
|
||||
|
||||
### 8.1 Deterministic Replay Token
|
||||
|
||||
```
|
||||
replay_token = hash(feed_manifests + rules + lattice_policy + inputs)
|
||||
```
|
||||
|
||||
### 8.2 One-Click "Reproduce"
|
||||
|
||||
CLI snippet pinned to exact versions and policies
|
||||
|
||||
### 8.3 Evidence Hash-Set
|
||||
|
||||
Content-address each proof artifact; audit entry stores hashes + signer
|
||||
|
||||
## 9. TELEMETRY IMPLEMENTATION
|
||||
|
||||
```typescript
|
||||
ttfs.start → (alert creation)
|
||||
ttfs.signal → (first evidence card paint)
|
||||
close.clicks → (decision recorded)
|
||||
```
|
||||
|
||||
Log evidence bitset (reach, stack, prov, vex) at decision time
|
||||
|
||||
## 10. API REQUIREMENTS
|
||||
|
||||
### 10.1 Endpoints
|
||||
|
||||
```
|
||||
GET /alerts?filters… → list view
|
||||
GET /alerts/{id}/evidence → evidence payload (reachability, call stack, provenance, hashes)
|
||||
POST /alerts/{id}/decisions → record decision event (append-only)
|
||||
GET /alerts/{id}/audit → audit timeline
|
||||
GET /alerts/{id}/diff?baseline=… → SBOM/VEX diff
|
||||
GET /bundles/{id}, POST /bundles/verify → offline bundle download/verify
|
||||
```
|
||||
|
||||
### 10.2 Evidence Payload Schema
|
||||
|
||||
```json
|
||||
{
|
||||
"alert_id": "a123",
|
||||
"reachability": { "status": "available|loading|unavailable|error", "hash": "sha256:…", "proof": {...} },
|
||||
"callstack": { "status": "...", "hash": "...", "frames": [...] },
|
||||
"provenance": { "status": "...", "hash": "...", "dsse": {...} },
|
||||
"vex": { "status": "...", "current": {...}, "history": [...] },
|
||||
"hashes": ["sha256:…", ...]
|
||||
}
|
||||
```
|
||||
|
||||
**Guidelines**:
|
||||
- Deterministic ordering for arrays and nodes
|
||||
- Explicit `status` per evidence section
|
||||
- Include `hash` per artifact
|
||||
|
||||
## 11. DECISION EVENT SCHEMA
|
||||
|
||||
Store per decision:
|
||||
|
||||
- `alert_id`, `artifact_id` (image digest/commit hash)
|
||||
- `actor_id`, `timestamp`
|
||||
- `decision_status` (Affected/Not affected/Under investigation)
|
||||
- `reason_code` (preset) + `reason_text`
|
||||
- `evidence_hashes[]` (content-addressed)
|
||||
- `policy_context` (ruleset version, policy id)
|
||||
- `replay_token` (hash of inputs)
|
||||
|
||||
## 12. OFFLINE BUNDLE FORMAT
|
||||
|
||||
Single file (`.stella.bundle.tgz`) containing:
|
||||
|
||||
- Alert metadata snapshot
|
||||
- Evidence artifacts (reachability proofs, call stacks, provenance attestations)
|
||||
- SBOM slice(s) for diffs
|
||||
- VEX decision history
|
||||
- Manifest with content hashes
|
||||
- **Must be signed and verifiable**
|
||||
|
||||
## 13. PERFORMANCE BUDGETS
|
||||
|
||||
- **TTFS**: <200ms skeleton, <500ms first evidence pill, <1.5s p95 full evidence
|
||||
- **Graph**: Preview <300ms, interactive <2.0s
|
||||
- **Interaction response**: ≤100ms
|
||||
- **Animation frame budget**: 16ms avg / 50ms p95
|
||||
- **Keyboard coverage**: ≥90% of triage actions
|
||||
- **Offline replay**: 100% of decisions re-render from bundle
|
||||
|
||||
## 14. ERROR HANDLING
|
||||
|
||||
Never show empty states without explanation. Distinguish:
|
||||
|
||||
- "not computed yet"
|
||||
- "not possible due to missing inputs"
|
||||
- "blocked by permissions"
|
||||
- "offline—enrichment pending"
|
||||
- "verification failed"
|
||||
|
||||
## 15. RBAC
|
||||
|
||||
Gate:
|
||||
- Viewing provenance attestations
|
||||
- Recording decisions
|
||||
- Exporting audit bundles
|
||||
|
||||
All decision events immutable; corrections are new events (append-only)
|
||||
|
||||
## 16. UNKNOWNS DECAY & TRIAGE HEURISTICS
|
||||
|
||||
### 16.1 Problem
|
||||
|
||||
Stale "unknown" findings create noise; need deterministic decay and triage rules
|
||||
|
||||
### 16.2 Requirements
|
||||
|
||||
- Confidence decay card
|
||||
- Triage queue UI
|
||||
- Export artifacts for planning
|
||||
|
||||
### 16.3 Determinism
|
||||
|
||||
- Decay windows and thresholds must be deterministic
|
||||
- Exports reproducible without live dependencies
|
||||
|
||||
### 16.4 Decay Logic
|
||||
|
||||
**Decay Windows**: Define time-based decay windows
|
||||
|
||||
**Thresholds**: Set confidence thresholds for promotion/demotion
|
||||
|
||||
**UI/Export Snapshot Expectations**: Deterministic decay logic description
|
||||
|
||||
## 17. UNKNOWNS RANKING ALGORITHM
|
||||
|
||||
### 17.1 Score Formula
|
||||
|
||||
```
|
||||
Score = clamp01(
|
||||
wP·P + # Popularity impact
|
||||
wE·E + # Exploit consequence potential
|
||||
wU·U + # Uncertainty density
|
||||
wC·C + # Graph centrality
|
||||
wS·S # Evidence staleness
|
||||
)
|
||||
```
|
||||
|
||||
### 17.2 Default Weights
|
||||
|
||||
```
|
||||
wP = 0.25 (deployment impact)
|
||||
wE = 0.25 (potential consequence)
|
||||
wU = 0.25 (uncertainty density)
|
||||
wC = 0.15 (graph centrality)
|
||||
wS = 0.10 (evidence staleness)
|
||||
```
|
||||
|
||||
### 17.3 Heuristics
|
||||
|
||||
```
|
||||
P = min(1, log10(1 + deployments)/log10(1 + 100))
|
||||
U = sum of flags, capped at 1.0:
|
||||
+0.30 if no provenance anchor
|
||||
+0.25 if version_range
|
||||
+0.20 if conflicting_feeds
|
||||
+0.15 if missing_vector
|
||||
+0.10 if unreachable source advisory
|
||||
S = min(1, age_days / 14)
|
||||
```
|
||||
|
||||
### 17.4 Band Assignment
|
||||
|
||||
```
|
||||
Score ≥ 0.70 → HOT (immediate rescan + VEX escalation)
|
||||
0.40 ≤ Score < 0.70 → WARM (scheduled rescan 12-72h)
|
||||
Score < 0.40 → COLD (weekly batch)
|
||||
```
|
||||
|
||||
### 17.5 Alternative: Blast Radius + Containment Model
|
||||
|
||||
> **Added**: 2025-12-17 from "Building a Deeper Moat Beyond Reachability" advisory
|
||||
|
||||
An alternative ranking model that incorporates blast radius and runtime containment signals:
|
||||
|
||||
**Unknown reasons tracked**:
|
||||
- missing VEX for a CVE/component
|
||||
- version provenance uncertain
|
||||
- ambiguous indirect call edge for reachability
|
||||
- packed/stripped binary blocking symbolization
|
||||
|
||||
**Rank factors (weighted)**:
|
||||
- **Blast radius**: transitive dependents, runtime privilege, exposure surface (net-facing? in container PID 1?)
|
||||
- **Evidence scarcity**: how many critical facts are missing?
|
||||
- **Exploit pressure**: EPSS percentile (if available), KEV presence
|
||||
- **Containment signals**: sandboxing, seccomp, read-only FS, eBPF/LSM denies observed
|
||||
|
||||
**Data Model**:
|
||||
|
||||
```csharp
|
||||
public sealed record UnknownItem(
|
||||
string Id,
|
||||
string ArtifactDigest,
|
||||
string ArtifactPurl,
|
||||
string[] Reasons,
|
||||
BlastRadius BlastRadius,
|
||||
double EvidenceScarcity,
|
||||
ExploitPressure ExploitPressure,
|
||||
ContainmentSignals Containment,
|
||||
double Score, // 0..1
|
||||
string ProofRef // path inside proof bundle
|
||||
);
|
||||
|
||||
public sealed record BlastRadius(int Dependents, bool NetFacing, string Privilege);
|
||||
public sealed record ExploitPressure(double? Epss, bool Kev);
|
||||
public sealed record ContainmentSignals(string Seccomp, string Fs);
|
||||
```
|
||||
|
||||
**Ranking Function**:
|
||||
|
||||
```csharp
|
||||
public static class UnknownRanker
|
||||
{
|
||||
public static double Rank(BlastRadius b, double scarcity, ExploitPressure ep, ContainmentSignals c)
|
||||
{
|
||||
var dependents01 = Math.Clamp(b.Dependents / 50.0, 0, 1);
|
||||
var net = b.NetFacing ? 0.5 : 0.0;
|
||||
var priv = string.Equals(b.Privilege, "root", StringComparison.OrdinalIgnoreCase) ? 0.5 : 0.0;
|
||||
var blast = Math.Clamp((dependents01 + net + priv) / 2.0, 0, 1);
|
||||
|
||||
var epss01 = ep.Epss is null ? 0.35 : Math.Clamp(ep.Epss.Value, 0, 1);
|
||||
var kev = ep.Kev ? 0.30 : 0.0;
|
||||
var pressure = Math.Clamp(epss01 + kev, 0, 1);
|
||||
|
||||
var containment = 0.0;
|
||||
if (string.Equals(c.Seccomp, "enforced", StringComparison.OrdinalIgnoreCase)) containment -= 0.10;
|
||||
if (string.Equals(c.Fs, "ro", StringComparison.OrdinalIgnoreCase)) containment -= 0.10;
|
||||
|
||||
return Math.Clamp(0.60 * blast + 0.30 * scarcity + 0.30 * pressure + containment, 0, 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**JSON Schema**:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "unk_...",
|
||||
"artifactPurl": "pkg:...",
|
||||
"reasons": ["missing_vex", "ambiguous_indirect_call"],
|
||||
"blastRadius": { "dependents": 42, "privilege": "root", "netFacing": true },
|
||||
"evidenceScarcity": 0.7,
|
||||
"exploitPressure": { "epss": 0.83, "kev": false },
|
||||
"containment": { "seccomp": "enforced", "fs": "ro" },
|
||||
"score": 0.66,
|
||||
"proofRef": "proofs/unk_.../tree.cbor"
|
||||
}
|
||||
|
||||
## 18. UNKNOWNS DATABASE SCHEMA
|
||||
|
||||
```sql
|
||||
CREATE TABLE unknowns (
|
||||
unknown_id uuid PRIMARY KEY,
|
||||
pkg_id text,
|
||||
pkg_version text,
|
||||
digest_anchor bytea,
|
||||
unknown_flags jsonb,
|
||||
popularity_p float,
|
||||
potential_e float,
|
||||
uncertainty_u float,
|
||||
centrality_c float,
|
||||
staleness_s float,
|
||||
score float,
|
||||
band text CHECK(band IN ('HOT','WARM','COLD')),
|
||||
graph_slice_hash bytea,
|
||||
evidence_set_hash bytea,
|
||||
normalization_trace jsonb,
|
||||
callgraph_attempt_hash bytea,
|
||||
created_at timestamptz,
|
||||
updated_at timestamptz
|
||||
);
|
||||
|
||||
CREATE TABLE deploy_refs (
|
||||
pkg_id text,
|
||||
image_id text,
|
||||
env text,
|
||||
first_seen timestamptz,
|
||||
last_seen timestamptz
|
||||
);
|
||||
|
||||
CREATE TABLE graph_metrics (
|
||||
pkg_id text PRIMARY KEY,
|
||||
degree_c float,
|
||||
betweenness_c float,
|
||||
last_calc_at timestamptz
|
||||
);
|
||||
```
|
||||
|
||||
## 19. TRIAGE QUEUE UI
|
||||
|
||||
### 19.1 Queue Views
|
||||
|
||||
- **HOT**: Red badge, sort by score desc
|
||||
- **WARM**: Yellow badge, sort by score desc
|
||||
- **COLD**: Gray badge, sort by age asc
|
||||
|
||||
### 19.2 Bulk Actions
|
||||
|
||||
- Mark as reviewed
|
||||
- Escalate to HOT
|
||||
- Suppress (with reason)
|
||||
- Export selected
|
||||
|
||||
### 19.3 Filters
|
||||
|
||||
- By band
|
||||
- By package
|
||||
- By environment
|
||||
- By date range
|
||||
|
||||
## 20. DECISION WORKFLOW CHECKLIST
|
||||
|
||||
For any triage decision:
|
||||
|
||||
- [ ] Evidence reviewed (reachability, call-stack, provenance, VEX)
|
||||
- [ ] Decision status selected (A/N/U)
|
||||
- [ ] Reason provided (preset or custom)
|
||||
- [ ] Replay token generated
|
||||
- [ ] Evidence hashes captured
|
||||
- [ ] Audit event recorded
|
||||
- [ ] Decision immutable (append-only)
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,724 @@
|
||||
# UX and Time-to-Evidence Technical Reference
|
||||
|
||||
**Source Advisories**:
|
||||
- 01-Dec-2025 - Tracking UX Health with Time‑to‑Evidence
|
||||
- 12-Dec-2025 - Measure UX Efficiency Through TTFS
|
||||
- 13-Dec-2025 - Define a north star metric for TTFS
|
||||
- 14-Dec-2025 - Add a dedicated "first_signal" event
|
||||
- 04-Dec-2025 - Designing Traceable Evidence in Security UX
|
||||
- 05-Dec-2025 - Designing Triage UX That Stays Quiet on Purpose
|
||||
- 30-Nov-2025 - UI Micro-Interactions for StellaOps
|
||||
- 11-Dec-2025 - Stella DevOps UX Implementation Guide
|
||||
|
||||
**Last Updated**: 2025-12-14
|
||||
|
||||
---
|
||||
|
||||
## 1. PERFORMANCE TARGETS & SLOS
|
||||
|
||||
### 1.1 Time-to-Evidence (TTE)
|
||||
|
||||
**Definition**: `TTE = t_first_proof_rendered − t_open_finding`
|
||||
|
||||
**Primary SLO**: P95 ≤ 15s (stretch: P99 ≤ 30s)
|
||||
|
||||
**Guardrail**: P50 < 3s
|
||||
|
||||
**By proof type**:
|
||||
- Simple proof (SBOM row): P95 ≤ 5s
|
||||
- Complex proof (reachability graph): P95 ≤ 15s
|
||||
|
||||
**Backend budget**: 12s backend + 3s UI/render margin = 15s P95
|
||||
|
||||
**Query performance**: O(log n) on indexed columns
|
||||
|
||||
### 1.2 Time-to-First-Signal (TTFS)
|
||||
|
||||
**Definition**: Time from user action/CI start → first meaningful signal rendered/logged
|
||||
|
||||
**Primary SLO**: P50 < 2s, P95 < 5s (all surfaces: UI, CLI, CI)
|
||||
|
||||
**Warm path**: P50 < 700ms, P95 < 2500ms
|
||||
|
||||
**Cold path**: P95 ≤ 4000ms
|
||||
|
||||
**Component budgets**:
|
||||
- Frontend: ≤150ms (skeleton + last known state)
|
||||
- Edge/API: ≤250ms (signal frame fast path from cache)
|
||||
- Core services: ≤500–1500ms (pre-indexed failures, warm summaries)
|
||||
- Slow work: async (scan, lattice merge, provenance)
|
||||
|
||||
### 1.3 General UX Performance
|
||||
|
||||
- **Interaction response**: ≤100ms
|
||||
- **Animation frame budget**: 16ms avg / 50ms P95
|
||||
- **LCP placeholder**: shown immediately
|
||||
- **Layout shift**: <0.05
|
||||
- **Motion durations**: 80/140/200/260/320ms
|
||||
- **Reduced-motion**: 0-80ms clamp
|
||||
|
||||
### 1.4 Cache Performance
|
||||
|
||||
- **Cache-hit response**: P95 ≤ 250ms
|
||||
- **Cold response**: P95 ≤ 500ms
|
||||
- **Endpoint error rate**: < 0.1% under expected concurrency
|
||||
|
||||
## 2. METRICS DEFINITIONS & FORMULAS
|
||||
|
||||
### 2.1 TTE Metrics
|
||||
|
||||
```typescript
|
||||
// Core TTE calculation
|
||||
tte_ms = proof_rendered.timestamp - finding_open.timestamp
|
||||
|
||||
// Dimensions
|
||||
{
|
||||
tenant: string,
|
||||
finding_id: string,
|
||||
proof_kind: 'sbom' | 'reachability' | 'vex',
|
||||
source: 'local' | 'remote' | 'cache',
|
||||
page: string
|
||||
}
|
||||
```
|
||||
|
||||
**SQL Rollup (hourly)**:
|
||||
```sql
|
||||
SELECT
|
||||
proof_kind,
|
||||
percentile_cont(0.95) WITHIN GROUP (ORDER BY tte_ms) AS p95_ms
|
||||
FROM tte_events
|
||||
WHERE ts >= now() - interval '1 hour'
|
||||
GROUP BY proof_kind;
|
||||
```
|
||||
|
||||
### 2.2 TTFS Metrics
|
||||
|
||||
```typescript
|
||||
// Core TTFS calculation
|
||||
ttfs_ms = signal_rendered.timestamp - start.timestamp
|
||||
|
||||
// Dimensions
|
||||
{
|
||||
surface: 'ui' | 'cli' | 'ci',
|
||||
cache_hit: boolean,
|
||||
signal_source: 'snapshot' | 'cold_start' | 'failure_index',
|
||||
kind: string,
|
||||
repo_size_bucket: string,
|
||||
provider: string,
|
||||
branch: string,
|
||||
run_type: 'PR' | 'main',
|
||||
network_state: string
|
||||
}
|
||||
```
|
||||
|
||||
### 2.3 Secondary Metrics
|
||||
|
||||
- **Open→Action time**: Time from opening run to first user action
|
||||
- **Bounce rate**: Close page within 10s without interaction
|
||||
- **MTTR proxy**: Time from failure to first rerun or fix commit
|
||||
- **Signal availability rate**: % of run views showing first signal within 3s
|
||||
- **Signal accuracy score**: Engineer confirms "helpful vs not" (sampled)
|
||||
- **Extractor failure rate**: Parsing errors / missing mappings / timeouts
|
||||
|
||||
### 2.4 DORA Metrics
|
||||
|
||||
- **Deployment Frequency**: Deploys per day/week
|
||||
- **Lead Time for Changes**: Commit → deployment completion
|
||||
- **Change Failure Rate**: Failed deployments / total deployments
|
||||
- **Time to Restore**: Incident start → resolution
|
||||
|
||||
### 2.5 Quality Metrics
|
||||
|
||||
- **Error budget burn**: Minutes over target per day
|
||||
- **Top regressions**: Last 7 days vs prior 7
|
||||
- **Extraction failure rate**: < 1% for sampled runs
|
||||
|
||||
## 3. EVENT SCHEMAS
|
||||
|
||||
### 3.1 TTE Events
|
||||
|
||||
**finding_open**:
|
||||
```typescript
|
||||
{
|
||||
event: 'finding_open',
|
||||
findingId: string,
|
||||
tenantId: string,
|
||||
userId: string,
|
||||
userRole: 'admin' | 'dev' | 'triager',
|
||||
entryPoint: 'list' | 'search' | 'notification' | 'deep_link',
|
||||
uiVersion: string,
|
||||
buildSha: string,
|
||||
t: number // performance.now()
|
||||
}
|
||||
```
|
||||
|
||||
**proof_rendered**:
|
||||
```typescript
|
||||
{
|
||||
event: 'proof_rendered',
|
||||
findingId: string,
|
||||
proofKind: 'sbom' | 'reachability' | 'vex' | 'logs' | 'other',
|
||||
source: 'local_cache' | 'backend_api' | '3rd_party',
|
||||
proofHeight: number, // pixel offset from top
|
||||
t: number // performance.now()
|
||||
}
|
||||
```
|
||||
|
||||
### 3.2 TTFS Events
|
||||
|
||||
**ttfs_start**:
|
||||
```typescript
|
||||
{
|
||||
event: 'ttfs_start',
|
||||
runId: string,
|
||||
surface: 'ui' | 'cli' | 'ci',
|
||||
provider: string,
|
||||
repo: string,
|
||||
branch: string,
|
||||
runType: 'PR' | 'main',
|
||||
device: string,
|
||||
release: string,
|
||||
networkState: string,
|
||||
t: number
|
||||
}
|
||||
```
|
||||
|
||||
**ttfs_signal_rendered**:
|
||||
```typescript
|
||||
{
|
||||
event: 'ttfs_signal_rendered',
|
||||
runId: string,
|
||||
surface: 'ui' | 'cli' | 'ci',
|
||||
cacheHit: boolean,
|
||||
signalSource: 'snapshot' | 'cold_start' | 'failure_index',
|
||||
kind: string,
|
||||
t: number
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3 FirstSignal Event Contract
|
||||
|
||||
```typescript
|
||||
interface FirstSignal {
|
||||
version: '1.0',
|
||||
signalId: string,
|
||||
jobId: string,
|
||||
timestamp: string, // ISO-8601
|
||||
kind: 'queued' | 'started' | 'phase' | 'blocked' | 'failed' | 'succeeded' | 'canceled' | 'unavailable',
|
||||
phase: 'resolve' | 'fetch' | 'restore' | 'analyze' | 'policy' | 'report' | 'unknown',
|
||||
scope: {
|
||||
type: 'repo' | 'image' | 'artifact',
|
||||
id: string
|
||||
},
|
||||
summary: string,
|
||||
etaSeconds?: number,
|
||||
lastKnownOutcome?: {
|
||||
signatureId: string,
|
||||
errorCode: string,
|
||||
token: string,
|
||||
excerpt: string,
|
||||
confidence: 'low' | 'medium' | 'high',
|
||||
firstSeenAt: string,
|
||||
hitCount: number
|
||||
},
|
||||
nextActions?: Array<{
|
||||
type: 'open_logs' | 'open_job' | 'docs' | 'retry' | 'cli_command',
|
||||
label: string,
|
||||
target: string
|
||||
}>,
|
||||
diagnostics: {
|
||||
cacheHit: boolean,
|
||||
source: 'snapshot' | 'failure_index' | 'cold_start',
|
||||
correlationId: string
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 3.4 UI Telemetry Schema
|
||||
|
||||
**ui.micro.* events**:
|
||||
```typescript
|
||||
{
|
||||
version: string,
|
||||
tenant: string,
|
||||
surface: string,
|
||||
component: string,
|
||||
action: string,
|
||||
latency_ms: number,
|
||||
outcome: string,
|
||||
reduced_motion: boolean,
|
||||
offline_mode: boolean,
|
||||
error_code?: string
|
||||
}
|
||||
```
|
||||
*Schema location*: `docs/modules/ui/telemetry/ui-micro.schema.json`
|
||||
|
||||
## 4. API CONTRACTS
|
||||
|
||||
### 4.1 First Signal Endpoint
|
||||
|
||||
**GET** `/api/runs/{runId}/first-signal`
|
||||
|
||||
**Headers**:
|
||||
- `If-None-Match: W/"..."` (supported)
|
||||
|
||||
**Response**:
|
||||
```json
|
||||
{
|
||||
"runId": "123",
|
||||
"firstSignal": {
|
||||
"type": "stage_failed",
|
||||
"stage": "build",
|
||||
"step": "dotnet restore",
|
||||
"message": "401 Unauthorized: token expired",
|
||||
"at": "2025-12-11T09:22:31Z",
|
||||
"artifact": {
|
||||
"kind": "log",
|
||||
"range": { "start": 1880, "end": 1896 }
|
||||
}
|
||||
},
|
||||
"summaryEtag": "W/\"a1b2c3\""
|
||||
}
|
||||
```
|
||||
|
||||
**Status codes**:
|
||||
- `200`: Full first signal object
|
||||
- `304`: Not modified
|
||||
- `404`: Run not found
|
||||
- `204`: Run exists but signal not available yet
|
||||
|
||||
**Response headers**:
|
||||
- `ETag`
|
||||
- `Cache-Control`
|
||||
- `X-Correlation-Id`
|
||||
- `Cache-Status: hit|miss|bypass`
|
||||
|
||||
### 4.2 Summary Endpoint
|
||||
|
||||
**GET** `/api/runs/{runId}/summary`
|
||||
|
||||
Returns: Status, first failing stage/job, timestamps, blocking policies, artifact counts
|
||||
|
||||
### 4.3 SSE Events Endpoint
|
||||
|
||||
**GET** `/api/runs/{runId}/events` (Server-Sent Events)
|
||||
|
||||
**Event payloads**:
|
||||
- `status` (kind+phase+message)
|
||||
- `hint` (token+errorCode+confidence)
|
||||
- `policy` (blocked + policyId)
|
||||
- `complete` (terminal)
|
||||
|
||||
## 5. FRONTEND PATTERNS & COMPONENT SPECIFICATIONS
|
||||
|
||||
### 5.1 UI Contract (Evidence First)
|
||||
|
||||
**Above the fold**:
|
||||
- Always show compact **Proof panel** first (not hidden behind tabs)
|
||||
- **Skeletons over spinners**: Reserve space; render partial proof as ready
|
||||
- **Plain text copy affordance**: "Copy SBOM line / path" button next to proof
|
||||
- **Defer non-proof widgets**: CVSS badges, remediation prose, charts load *after* proof
|
||||
- **Empty-state truth**: "No proof available yet" + loader for *that* proof type only
|
||||
|
||||
### 5.2 Progressive Rendering Pattern
|
||||
|
||||
**Immediate render**:
|
||||
1. Title, status badge, pipeline metadata (run id, commit, branch)
|
||||
2. Skeleton for details area
|
||||
|
||||
**First signal fetch**:
|
||||
3. Render `FirstSignalCard` immediately when available
|
||||
4. Fire telemetry event when card is in DOM and visible
|
||||
|
||||
**Lazy-load**:
|
||||
5. Stage graph
|
||||
6. Full logs viewer
|
||||
7. Artifacts list
|
||||
8. Security findings
|
||||
9. Trends, flaky tests, etc.
|
||||
|
||||
### 5.3 Component Specifications
|
||||
|
||||
#### FirstSignalCard Component
|
||||
- Standalone, minimal dependencies
|
||||
- Shows: summary + at least one next action button (Open job/logs)
|
||||
- Updates in-place on deltas from SSE
|
||||
- Falls back to polling when SSE fails
|
||||
|
||||
#### EvidencePanel Component
|
||||
```typescript
|
||||
interface EvidencePanel {
|
||||
tabs: ['SBOM', 'Reachability', 'VEX', 'Logs', 'Other'],
|
||||
firstProofType: ProofKind,
|
||||
copyEnabled: boolean,
|
||||
emptyStateMessage?: string
|
||||
}
|
||||
```
|
||||
|
||||
#### ProofSpine Component
|
||||
- Displays: `graphRevisionId`, bundle hashes (SBOM/VEX/proof), receipt digest, and Rekor details (when present)
|
||||
- Copy affordances: copy `graphRevisionId`, `proofBundleId`, and receipt digest in one click
|
||||
- Verification status: `Verified` | `Unverified` | `Failed verification` | `Expired/Outdated`
|
||||
- "Verify locally" copy button with exact commands
|
||||
|
||||
### 5.4 Prefetch Strategy
|
||||
|
||||
From runs list view:
|
||||
- Use `IntersectionObserver` to prefetch summaries/first signals for items in viewport
|
||||
- Store results in in-memory cache (`Map<runId, FirstSignal>`)
|
||||
- Respect ETag to avoid redundant payloads
|
||||
|
||||
## 6. TELEMETRY REQUIREMENTS
|
||||
|
||||
### 6.1 Client-Side Telemetry
|
||||
|
||||
**Frontend events**:
|
||||
```typescript
|
||||
// On route enter
|
||||
metrics.emit('finding_open', { findingId, t: performance.now() });
|
||||
|
||||
// When first proof node/line hits DOM
|
||||
metrics.emit('proof_rendered', { findingId, proofKind, t: performance.now() });
|
||||
```
|
||||
|
||||
**Sampling**:
|
||||
- **Staging**: 100%
|
||||
- **Production**: ≥25% of sessions (ideal: 100%)
|
||||
|
||||
**Clock handling**:
|
||||
- Use `performance.now()` for TTE (monotonic within tab)
|
||||
- Don't mix backend clocks into TTE calculation
|
||||
|
||||
### 6.2 Backend Telemetry
|
||||
|
||||
**Endpoint metrics**:
|
||||
- `signal_endpoint_latency_ms`
|
||||
- `signal_payload_bytes`
|
||||
- `signal_error_rate`
|
||||
|
||||
**Server-side timing logs** (debug-level):
|
||||
- Cache read time
|
||||
- DB read time
|
||||
- Cold path time
|
||||
|
||||
**Tracing**:
|
||||
- Correlation ID propagated in:
|
||||
- API response header
|
||||
- Worker logs
|
||||
- Events
|
||||
|
||||
### 6.3 Dashboard Requirements
|
||||
|
||||
**Core widgets**:
|
||||
1. TTE distribution (P50/P90/P95/P99) per day, split by proof_kind
|
||||
2. TTE by page/surface (list→detail, deep links, bookmarks)
|
||||
3. TTE by user segment (new vs power users, roles)
|
||||
4. Error budget: "Minutes over SLO per day"
|
||||
5. Correlation: TTE vs session length, TTE vs "clicked ignore/snooze"
|
||||
|
||||
**Operational panels**:
|
||||
- Update granularity: Real-time or ≤15 min
|
||||
- Retention: ≥90 days
|
||||
- Breakdowns: backend_region, build_version
|
||||
|
||||
**TTFS dashboards**:
|
||||
- By surface (ui/cli/ci)
|
||||
- Cache hit rate
|
||||
- Endpoint latency percentiles
|
||||
- Repo size bucket
|
||||
- Kind/phase
|
||||
|
||||
**Alerts**:
|
||||
- Page when `p95(ttfs_ms) > 5000` for 5 mins
|
||||
- Page when `signal_endpoint_error_rate > 1%`
|
||||
- Alert when **P95 TTE > 15s** for 15 minutes
|
||||
|
||||
## 7. DATABASE SCHEMAS
|
||||
|
||||
### 7.1 TTE Events Table
|
||||
|
||||
```sql
|
||||
CREATE TABLE tte_events (
|
||||
id SERIAL PRIMARY KEY,
|
||||
ts TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
tenant TEXT NOT NULL,
|
||||
finding_id TEXT NOT NULL,
|
||||
proof_kind TEXT NOT NULL,
|
||||
source TEXT NOT NULL,
|
||||
tte_ms INT NOT NULL,
|
||||
page TEXT,
|
||||
user_role TEXT
|
||||
);
|
||||
|
||||
CREATE INDEX ON tte_events (ts DESC);
|
||||
CREATE INDEX ON tte_events (proof_kind, ts DESC);
|
||||
```
|
||||
|
||||
### 7.2 First Signal Snapshots
|
||||
|
||||
```sql
|
||||
CREATE TABLE first_signal_snapshots (
|
||||
job_id TEXT PRIMARY KEY,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
updated_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
kind TEXT NOT NULL,
|
||||
phase TEXT NOT NULL,
|
||||
summary TEXT NOT NULL,
|
||||
eta_seconds INT NULL,
|
||||
payload_json JSONB NOT NULL
|
||||
);
|
||||
|
||||
CREATE INDEX ON first_signal_snapshots (updated_at DESC);
|
||||
```
|
||||
|
||||
### 7.3 Failure Signatures
|
||||
|
||||
```sql
|
||||
CREATE TABLE failure_signatures (
|
||||
signature_id TEXT PRIMARY KEY,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
updated_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
scope_type TEXT NOT NULL,
|
||||
scope_id TEXT NOT NULL,
|
||||
toolchain_hash TEXT NOT NULL,
|
||||
error_code TEXT NULL,
|
||||
token TEXT NOT NULL,
|
||||
excerpt TEXT NULL,
|
||||
confidence TEXT NOT NULL,
|
||||
first_seen_at TIMESTAMPTZ NOT NULL,
|
||||
last_seen_at TIMESTAMPTZ NOT NULL,
|
||||
hit_count INT NOT NULL DEFAULT 1
|
||||
);
|
||||
|
||||
CREATE INDEX ON failure_signatures (scope_type, scope_id, toolchain_hash);
|
||||
CREATE INDEX ON failure_signatures (token);
|
||||
```
|
||||
|
||||
## 8. MOTION & ANIMATION TOKENS
|
||||
|
||||
### 8.1 Duration Tokens
|
||||
|
||||
| Token | Value | Use Case |
|
||||
|-------|-------|----------|
|
||||
| `duration-xs` | 80ms | Quick hover, focus |
|
||||
| `duration-sm` | 140ms | Button press, small transitions |
|
||||
| `duration-md` | 200ms | Modal open/close, panel slide |
|
||||
| `duration-lg` | 260ms | Page transitions |
|
||||
| `duration-xl` | 320ms | Complex animations |
|
||||
|
||||
**Reduced-motion override**: Clamp all to 0-80ms
|
||||
|
||||
### 8.2 Easing Tokens
|
||||
|
||||
- `standard`: Default transition
|
||||
- `decel`: Element entering (start fast, slow down)
|
||||
- `accel`: Element exiting (slow start, speed up)
|
||||
- `emphasized`: Important state changes
|
||||
|
||||
### 8.3 Distance Scales
|
||||
|
||||
- `XS`: 4px
|
||||
- `SM`: 8px
|
||||
- `MD`: 16px
|
||||
- `LG`: 24px
|
||||
- `XL`: 32px
|
||||
|
||||
**Location**: `src/Web/StellaOps.Web/src/styles/tokens/motion.{ts,scss}`
|
||||
|
||||
## 9. ACCESSIBILITY REQUIREMENTS
|
||||
|
||||
### 9.1 WCAG 2.1 AA Compliance
|
||||
|
||||
- Focus order: logical and consistent
|
||||
- Keyboard: all interactive elements accessible
|
||||
- Contrast:
|
||||
- Text: ≥ 4.5:1
|
||||
- UI elements: ≥ 3:1
|
||||
- Reduced motion: honored via `prefers-reduced-motion`
|
||||
- Status messaging: `aria-live=polite` for updates
|
||||
|
||||
### 9.2 Reduced-Motion Rules
|
||||
|
||||
When `prefers-reduced-motion: reduce`:
|
||||
- Durations clamp to 0-80ms
|
||||
- Disable parallax/auto-animations
|
||||
- Focus/hover states remain visible
|
||||
- No animated GIF/Lottie autoplay
|
||||
|
||||
### 9.3 Screen Reader Support
|
||||
|
||||
- **Undo window**: 8s with keyboard focus and `aria-live=polite`
|
||||
- **Loading states**: Announce state changes
|
||||
- **Error messages**: Informative, not generic
|
||||
|
||||
## 10. EVIDENCE & PROOF SPECIFICATIONS
|
||||
|
||||
### 10.1 Evidence Bundle Minimum Requirements
|
||||
|
||||
**Component presence**:
|
||||
- SBOM fragment (SPDX/CycloneDX) with component identity and provenance
|
||||
- Signed attestation for SBOM artifact
|
||||
|
||||
**Vulnerability match**:
|
||||
- Matching rule details (CPE/purl/range) + scanner identity/version
|
||||
- Signed vulnerability report attestation
|
||||
|
||||
**Reachable vulnerability**:
|
||||
- Call path: entrypoint → frames → vulnerable symbol
|
||||
- Hash/digest of call graph slice (tamper-evident)
|
||||
- Tool info + limitations (reflection/dynamic dispatch uncertainty)
|
||||
|
||||
**Not affected via VEX**:
|
||||
- VEX statement (OpenVEX/CSAF) + signer
|
||||
- Justification for `not_affected`
|
||||
- Align to CISA minimum requirements
|
||||
|
||||
**Gate decision**:
|
||||
- Input digests (SBOM digest, scan attestation digests, VEX doc digests)
|
||||
- Policy version + rule ID
|
||||
- Deterministic **decision hash** over (policy + input digests)
|
||||
|
||||
### 10.2 Evidence Object Structure
|
||||
|
||||
```typescript
|
||||
interface Evidence {
|
||||
sbom_snippet_attestation: DSSEEnvelope,
|
||||
reachability_proof: {
|
||||
entrypoint: string,
|
||||
frames: CallFrame[],
|
||||
file_hashes: string[],
|
||||
graph_digest: string
|
||||
},
|
||||
attestation_chain: DSSESummary[],
|
||||
transparency_receipt: {
|
||||
logIndex: number,
|
||||
uuid: string,
|
||||
inclusionProof: string,
|
||||
checkpoint: string
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 10.3 Proof Panel Requirements
|
||||
|
||||
**Four artifacts**:
|
||||
1. **SBOM snippet (signed)**: DSSE attestation, verify with cosign
|
||||
2. **Call-stack slice**: Entrypoint → vulnerable symbol, status pill (`Reachable`, `Potentially reachable`, `Unreachable`)
|
||||
3. **Attestation chain**: DSSE envelope summary, verification status, "Verify locally" command
|
||||
4. **Transparency receipt**: Rekor inclusion proof, "Verify inclusion" command
|
||||
|
||||
**One-click export**:
|
||||
- "Export Evidence (.tar.gz)" bundling: SBOM slice, call-stack JSON, DSSE attestation, Rekor proof JSON
|
||||
|
||||
## 11. CONFIGURATION & FEATURE FLAGS
|
||||
|
||||
### 11.1 TTFS Feature Flags
|
||||
|
||||
```yaml
|
||||
ttfs:
|
||||
first_signal_enabled: true # Default ON in staging
|
||||
cache_enabled: true
|
||||
failure_index_enabled: true
|
||||
sse_enabled: true
|
||||
policy_preeval_enabled: true
|
||||
```
|
||||
|
||||
### 11.2 Cache Configuration
|
||||
|
||||
```yaml
|
||||
cache:
|
||||
backend: valkey | postgres | none # TTFS_CACHE_BACKEND
|
||||
ttl_seconds: 86400 # TTFS_CACHE_TTL_SECONDS
|
||||
key_pattern: "signal:job:{jobId}"
|
||||
```
|
||||
|
||||
### 11.3 Air-Gapped Profile
|
||||
|
||||
- Skip Valkey; use Postgres-only
|
||||
- Use `first_signal_snapshots` table
|
||||
- NOTIFY/LISTEN for streaming updates
|
||||
|
||||
## 12. TESTING REQUIREMENTS
|
||||
|
||||
### 12.1 Acceptance Criteria (TTE)
|
||||
|
||||
- [ ] First paint shows real proof snippet (not summary)
|
||||
- [ ] "Copy proof" button works within 1 click
|
||||
- [ ] TTE P95 in staging ≤ 10s; in prod ≤ 15s
|
||||
- [ ] If proof missing, explicit empty-state + retry path
|
||||
- [ ] Telemetry sampled ≥ 50% of sessions (or 100% for internal)
|
||||
|
||||
### 12.2 Acceptance Tests (TTFS)
|
||||
|
||||
- Run with early fail → first signal < 1s, shows exact command + exit code
|
||||
- Run with policy gate fail → rule name + fix hint visible first
|
||||
- Offline/slow network → cached summary still renders actionable hint
|
||||
|
||||
### 12.3 Determinism Requirements
|
||||
|
||||
- Freeze timers to `2025-12-04T12:00:00Z` in stories/e2e
|
||||
- Seed RNG with `0x5EED2025` unless scenario-specific
|
||||
- All fixtures stored under `tests/fixtures/micro/`
|
||||
- No network calls; offline assets bundled
|
||||
- Playwright runs with `--disable-animations` and reduced-motion emulation
|
||||
|
||||
### 12.4 Load Tests
|
||||
|
||||
`/jobs/{id}/signal`:
|
||||
- Cache-hit P95 ≤ 250ms
|
||||
- Cold path P95 ≤ 500ms
|
||||
- Error rate < 0.1% under expected concurrency
|
||||
|
||||
## 13. REDACTION & SECURITY
|
||||
|
||||
### 13.1 Excerpt Redaction Rules
|
||||
|
||||
- Strip: bearer tokens, API keys, access tokens, private URLs
|
||||
- Cap excerpt length: 240 chars
|
||||
- Normalize whitespace
|
||||
- Never include excerpts in telemetry attributes
|
||||
|
||||
### 13.2 Tenant Isolation
|
||||
|
||||
Cache keys include tenant boundary:
|
||||
```
|
||||
tenant:{tenantId}:signal:job:{jobId}
|
||||
```
|
||||
|
||||
Failure signatures looked up within same tenant only.
|
||||
|
||||
### 13.3 Secret Scanning
|
||||
|
||||
Runtime guardrails:
|
||||
- If excerpt contains forbidden patterns → replace with "[redacted]"
|
||||
- Security review sign-off required for snapshot + signature + telemetry
|
||||
|
||||
## 14. LOCALIZATION
|
||||
|
||||
### 14.1 Micro-Copy Requirements
|
||||
|
||||
- Keys and ICU messages for micro-interaction copy
|
||||
- Defaults: EN
|
||||
- Fallbacks present
|
||||
- No hard-coded strings in components
|
||||
- i18n extraction shows zero TODO keys
|
||||
|
||||
### 14.2 Snapshot Verification
|
||||
|
||||
Verify translated skeleton/error/undo copy in snapshots.
|
||||
|
||||
## 15. DELIVERABLES MAP
|
||||
|
||||
| Category | Location | Description |
|
||||
|----------|----------|-------------|
|
||||
| Motion tokens | `src/Web/StellaOps.Web/src/styles/tokens/motion.{ts,scss}` | Duration, easing, distance scales + reduced-motion overrides |
|
||||
| Storybook stories | `apps/storybook/src/stories/micro/*` | Slow, error, offline, reduced-motion, undo flows |
|
||||
| Playwright suite | `tests/e2e/micro-interactions.spec.ts` | MI2/MI3/MI4/MI8 coverage |
|
||||
| Telemetry schema | `docs/modules/ui/telemetry/ui-micro.schema.json` | Event schema + validators |
|
||||
| Component map | `docs/modules/ui/micro-interactions-map.md` | Components → interaction type → token usage |
|
||||
| Fixtures | `tests/fixtures/micro/` | Deterministic test fixtures |
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL ≥16, Angular v17
|
||||
@@ -0,0 +1,97 @@
|
||||
# MOAT Gap Closure Archive Manifest
|
||||
|
||||
**Archive Date**: 2025-12-21
|
||||
**Archive Reason**: Product advisories processed and implementation gaps identified
|
||||
|
||||
---
|
||||
|
||||
## Summary
|
||||
|
||||
This archive contains 12 MOAT (Market-Oriented Architecture Transformation) product advisories that were analyzed against the StellaOps codebase. After thorough source code exploration, the implementation coverage was assessed at **~92%**.
|
||||
|
||||
---
|
||||
|
||||
## Implementation Coverage
|
||||
|
||||
| Advisory Topic | Coverage | Notes |
|
||||
|---------------|----------|-------|
|
||||
| CVSS and Competitive Analysis | 100% | Full CVSS v4 engine, all attack complexity metrics |
|
||||
| Determinism and Reproducibility | 100% | Stable ordering, hash chains, replayTokens, NDJSON |
|
||||
| Developer Onboarding | 100% | AGENTS.md files, CLAUDE.md, module dossiers |
|
||||
| Offline and Air-Gap | 100% | Bundle system, egress allowlists, offline sources |
|
||||
| PostgreSQL Patterns | 100% | RLS, tenant isolation, schema per module |
|
||||
| Proof and Evidence Chain | 100% | ProofSpine, DSSE envelopes, hash chaining |
|
||||
| Reachability Analysis | 100% | CallGraphAnalyzer, AttackPathScorer, CodePathResult |
|
||||
| Rekor Integration | 100% | RekorClient, transparency log publishing |
|
||||
| Smart-Diff | 100% | MaterialRiskChangeDetector, hash-based diffing |
|
||||
| Testing and Quality Guardrails | 100% | Testcontainers, benchmarks, truth schemas |
|
||||
| UX and Time-to-Evidence | 100% | EvidencePanel, keyboard shortcuts, motion tokens |
|
||||
| Triage and Unknowns | 75% | UnknownRanker exists, missing decay/containment |
|
||||
|
||||
**Overall**: ~92% implementation coverage
|
||||
|
||||
---
|
||||
|
||||
## Identified Gaps & Sprint References
|
||||
|
||||
Three implementation gaps were identified and documented in sprints:
|
||||
|
||||
### Gap 1: Decay Algorithm (Sprint 4000.0001.0001)
|
||||
- **File**: `docs/implplan/SPRINT_4000_0001_0001_unknowns_decay_algorithm.md`
|
||||
- **Scope**: Add time-based decay factor to UnknownRanker
|
||||
- **Story Points**: 15
|
||||
- **Working Directory**: `src/Policy/__Libraries/StellaOps.Policy.Unknowns/`
|
||||
|
||||
### Gap 2: BlastRadius & Containment (Sprint 4000.0001.0002)
|
||||
- **File**: `docs/implplan/SPRINT_4000_0001_0002_unknowns_blast_radius_containment.md`
|
||||
- **Scope**: Add BlastRadius and ContainmentSignals to ranking
|
||||
- **Story Points**: 19
|
||||
- **Working Directory**: `src/Policy/__Libraries/StellaOps.Policy.Unknowns/`
|
||||
|
||||
### Gap 3: EPSS Feed Connector (Sprint 4000.0002.0001)
|
||||
- **File**: `docs/implplan/SPRINT_4000_0002_0001_epss_feed_connector.md`
|
||||
- **Scope**: Create Concelier connector for orchestrated EPSS ingestion
|
||||
- **Story Points**: 22
|
||||
- **Working Directory**: `src/Concelier/__Libraries/StellaOps.Concelier.Connector.Epss/`
|
||||
|
||||
**Total Gap Closure Effort**: 56 story points
|
||||
|
||||
---
|
||||
|
||||
## Archived Files (12)
|
||||
|
||||
1. `14-Dec-2025 - CVSS and Competitive Analysis Technical Reference.md`
|
||||
2. `14-Dec-2025 - Determinism and Reproducibility Technical Reference.md`
|
||||
3. `14-Dec-2025 - Developer Onboarding Technical Reference.md`
|
||||
4. `14-Dec-2025 - Offline and Air-Gap Technical Reference.md`
|
||||
5. `14-Dec-2025 - PostgreSQL Patterns Technical Reference.md`
|
||||
6. `14-Dec-2025 - Proof and Evidence Chain Technical Reference.md`
|
||||
7. `14-Dec-2025 - Reachability Analysis Technical Reference.md`
|
||||
8. `14-Dec-2025 - Rekor Integration Technical Reference.md`
|
||||
9. `14-Dec-2025 - Smart-Diff Technical Reference.md`
|
||||
10. `14-Dec-2025 - Testing and Quality Guardrails Technical Reference.md`
|
||||
11. `14-Dec-2025 - Triage and Unknowns Technical Reference.md`
|
||||
12. `14-Dec-2025 - UX and Time-to-Evidence Technical Reference.md`
|
||||
|
||||
---
|
||||
|
||||
## Key Discoveries
|
||||
|
||||
Features that were discovered to exist with different naming than expected:
|
||||
|
||||
| Expected | Actual Implementation |
|
||||
|----------|----------------------|
|
||||
| FipsProfile, GostProfile, SmProfile | ComplianceProfiles (unified) |
|
||||
| FindingsLedger.HashChain | Exists in FindingsSnapshot with replayTokens |
|
||||
| Benchmark suite | Exists in `__Benchmarks/` directories |
|
||||
| EvidencePanel | Exists in Web UI with motion tokens |
|
||||
|
||||
---
|
||||
|
||||
## Post-Closure Target
|
||||
|
||||
After completing the three gap-closure sprints:
|
||||
- Implementation coverage: **95%+**
|
||||
- All advisory requirements addressed
|
||||
- Triage/Unknowns module fully featured
|
||||
|
||||
@@ -0,0 +1,366 @@
|
||||
|
||||
# A. Executive directive (send as-is to both PM + Dev)
|
||||
|
||||
1. **A “Release” is not an SBOM or a scan report. A Release is a “Security State Snapshot.”**
|
||||
|
||||
* A snapshot is a **versioned, content-addressed bundle** containing:
|
||||
|
||||
* SBOM graph (canonical form, hashed)
|
||||
* Reachability graph (canonical form, hashed)
|
||||
* VEX claim set (canonical form, hashed)
|
||||
* Policies + rule versions used (hashed)
|
||||
* Data-feed identifiers used (hashed)
|
||||
* Toolchain versions (hashed)
|
||||
|
||||
2. **Diff is a product primitive, not a UI feature.**
|
||||
|
||||
* “Diff” must exist as a stable API and artifact, not a one-off report.
|
||||
* Every comparison produces a **Delta object** (machine-readable) and a **Delta Verdict attestation** (signed).
|
||||
|
||||
3. **The CI/CD gate should never ask “how many CVEs?”**
|
||||
|
||||
* It should ask: **“What materially changed in exploitable risk since the last approved baseline?”**
|
||||
* The Delta Verdict must be deterministically reproducible given the same snapshots and policy.
|
||||
|
||||
4. **Every Delta Verdict must be portable and auditable.**
|
||||
|
||||
* It must be a signed attestation that can be stored with the build artifact (OCI attach) and replayed offline.
|
||||
|
||||
---
|
||||
|
||||
# B. Product Management directions
|
||||
|
||||
## B1) Define the product concept: “Security Delta as the unit of governance”
|
||||
|
||||
**Position the capability as change-control for software risk**, not as “a scanner with comparisons.”
|
||||
|
||||
### Primary user stories (MVP)
|
||||
|
||||
1. **Release Manager / Security Engineer**
|
||||
|
||||
* “Compare the candidate build to the last approved build and explain *what changed* in exploitable risk.”
|
||||
2. **CI Pipeline Owner**
|
||||
|
||||
* “Fail the build only for *new* reachable high-risk exposures (or policy-defined deltas), not for unchanged legacy issues.”
|
||||
3. **Auditor / Compliance**
|
||||
|
||||
* “Show a signed delta verdict with evidence references proving why this release passed.”
|
||||
|
||||
### MVP “Delta Verdict” policy questions to support
|
||||
|
||||
* Are there **new reachable vulnerabilities** introduced?
|
||||
* Did any **previously unreachable vulnerability become reachable**?
|
||||
* Are there **new affected VEX states** (e.g., NOT_AFFECTED → AFFECTED)?
|
||||
* Are there **new Unknowns** above a threshold?
|
||||
* Is the **net exploitable surface** increased beyond policy budget?
|
||||
|
||||
## B2) Define the baseline selection rules (product-critical)
|
||||
|
||||
Diff is meaningless without a baseline contract. Product must specify baseline selection as a first-class choice.
|
||||
|
||||
Minimum baseline modes:
|
||||
|
||||
* **Previous build in the same pipeline**
|
||||
* **Last “approved” snapshot** (from an approval gate)
|
||||
* **Last deployed in environment X** (optional later, but roadmap it)
|
||||
|
||||
Acceptance criteria:
|
||||
|
||||
* The delta object must always contain:
|
||||
|
||||
* `baseline_snapshot_digest`
|
||||
* `target_snapshot_digest`
|
||||
* `baseline_selection_method` and identifiers
|
||||
|
||||
## B3) Define the delta taxonomy (what your product “knows” how to talk about)
|
||||
|
||||
Avoid “diffing findings lists.” You need consistent delta categories.
|
||||
|
||||
Minimum taxonomy:
|
||||
|
||||
1. **SBOM deltas**
|
||||
|
||||
* Component added/removed
|
||||
* Component version change
|
||||
* Dependency edge change (graph-level)
|
||||
2. **VEX deltas**
|
||||
|
||||
* Claim added/removed
|
||||
* Status change (e.g., under_investigation → fixed)
|
||||
* Justification/evidence change (optional MVP)
|
||||
3. **Reachability deltas**
|
||||
|
||||
* New reachable vulnerable symbol(s)
|
||||
* Removed reachability
|
||||
* Entry point changes
|
||||
4. **Decision deltas**
|
||||
|
||||
* Policy outcome changed (PASS → FAIL)
|
||||
* Explanation changed (drivers of decision)
|
||||
|
||||
PM deliverable:
|
||||
|
||||
* A one-page **Delta Taxonomy Spec** that becomes the canonical list used across API, UI, and attestations.
|
||||
|
||||
## B4) Define what “signed delta verdict” means in product terms
|
||||
|
||||
A delta verdict is not a PDF.
|
||||
|
||||
It is:
|
||||
|
||||
* A deterministic JSON payload
|
||||
* Wrapped in a signature envelope (DSSE)
|
||||
* Attached to the artifact (OCI attach)
|
||||
* Includes pointers (hash references) to evidence graphs
|
||||
|
||||
PM must define:
|
||||
|
||||
* Where customers can view it (UI + CLI)
|
||||
* Where it lives (artifact registry + Stella store)
|
||||
* How it is consumed (policy gate, audit export)
|
||||
|
||||
## B5) PM success metrics (must be measurable)
|
||||
|
||||
* % of releases gated by delta verdict
|
||||
* Mean time to explain “why failed”
|
||||
* Reduction in “unchanged legacy vuln” false gating
|
||||
* Reproducibility rate: same inputs → same verdict (target: 100%)
|
||||
|
||||
---
|
||||
|
||||
# C. Development Management directions
|
||||
|
||||
## C1) Architecture: treat Snapshot and Delta as immutable, content-addressed objects
|
||||
|
||||
You need four core services/modules:
|
||||
|
||||
1. **Canonicalization + Hashing**
|
||||
|
||||
* Deterministic serialization (stable field ordering, normalized IDs)
|
||||
* Content addressing: every graph and claim set gets a digest
|
||||
|
||||
2. **Snapshot Store (Ledger)**
|
||||
|
||||
* Store snapshots keyed by digest
|
||||
* Store relationships: artifact → snapshot, snapshot → predecessor(s)
|
||||
* Must support offline export/import later (design now)
|
||||
|
||||
3. **Diff Engine**
|
||||
|
||||
* Inputs: `baseline_snapshot_digest`, `target_snapshot_digest`
|
||||
* Outputs:
|
||||
|
||||
* `delta_object` (structured)
|
||||
* `delta_summary` (human-friendly)
|
||||
* Must be deterministic and testable with golden fixtures
|
||||
|
||||
4. **Verdict Engine + Attestation Writer**
|
||||
|
||||
* Evaluate policies against delta
|
||||
* Produce `delta_verdict`
|
||||
* Wrap as DSSE / in-toto-style statement (or your chosen predicate type)
|
||||
* Sign and optionally attach to OCI artifact
|
||||
|
||||
## C2) Data model (minimum viable schemas)
|
||||
|
||||
### Snapshot (conceptual fields)
|
||||
|
||||
* `snapshot_id` (digest)
|
||||
* `artifact_ref` (e.g., image digest)
|
||||
* `sbom_graph_digest`
|
||||
* `reachability_graph_digest`
|
||||
* `vex_claimset_digest`
|
||||
* `policy_bundle_digest`
|
||||
* `feed_snapshot_digest`
|
||||
* `toolchain_digest`
|
||||
* `created_at`
|
||||
|
||||
### Delta object (conceptual fields)
|
||||
|
||||
* `delta_id` (digest)
|
||||
* `baseline_snapshot_digest`
|
||||
* `target_snapshot_digest`
|
||||
* `sbom_delta` (structured)
|
||||
* `reachability_delta` (structured)
|
||||
* `vex_delta` (structured)
|
||||
* `unknowns_delta` (structured)
|
||||
* `derived_risk_delta` (structured)
|
||||
* `created_at`
|
||||
|
||||
### Delta verdict attestation (must include)
|
||||
|
||||
* Subjects: artifact digest(s)
|
||||
* Baseline snapshot digest + Target snapshot digest
|
||||
* Policy bundle digest
|
||||
* Verdict enum: PASS/WARN/FAIL
|
||||
* Drivers: references to delta nodes (hash pointers)
|
||||
* Signature metadata
|
||||
|
||||
## C3) Determinism requirements (non-negotiable)
|
||||
|
||||
Development must implement:
|
||||
|
||||
* **Canonical ID scheme** for components and graph nodes
|
||||
(example: package URL + version + supplier + qualifiers, then hashed)
|
||||
* Stable sorting for node/edge lists
|
||||
* Stable normalization of timestamps (do not include wall-clock in hash inputs unless explicitly policy-relevant)
|
||||
* A “replay test harness”:
|
||||
|
||||
* Given the same inputs, byte-for-byte identical snapshot/delta/verdict
|
||||
|
||||
Definition of Done:
|
||||
|
||||
* Golden test vectors for snapshots and deltas checked into repo
|
||||
* Deterministic hashing tests in CI
|
||||
|
||||
## C4) Graph diff design (how to do it without drowning in noise)
|
||||
|
||||
### SBOM graph diff (MVP)
|
||||
|
||||
Implement:
|
||||
|
||||
* Node set delta: added/removed/changed nodes (by stable node ID)
|
||||
* Edge set delta: added/removed edges (dependency relations)
|
||||
* A “noise suppressor” layer:
|
||||
|
||||
* ignore ordering differences
|
||||
* ignore metadata-only changes unless policy enables
|
||||
|
||||
Output should identify:
|
||||
|
||||
* “What changed?” (added/removed/upgraded/downgraded)
|
||||
* “Why it matters?” (ties to vulnerability & reachability where available)
|
||||
|
||||
### VEX claimset diff (MVP)
|
||||
|
||||
Implement:
|
||||
|
||||
* Keyed by `(product/artifact scope, component ID, vulnerability ID)`
|
||||
* Delta types:
|
||||
|
||||
* claim added/removed
|
||||
* status changed
|
||||
* justification changed (optional later)
|
||||
|
||||
### Reachability diff (incremental approach)
|
||||
|
||||
MVP can start narrow:
|
||||
|
||||
* Support one or two ecosystems initially (e.g., Java + Maven, or Go modules)
|
||||
* Represent reachability as:
|
||||
|
||||
* `entrypoint → function/symbol → vulnerable symbol`
|
||||
* Diff should highlight:
|
||||
|
||||
* Newly reachable vulnerable symbols
|
||||
* Removed reachability
|
||||
|
||||
Important: even if reachability is initially partial, the diff model must support it cleanly (unknowns must exist).
|
||||
|
||||
## C5) Policy evaluation must run on delta, not on raw findings
|
||||
|
||||
Define a policy DSL contract like:
|
||||
|
||||
* `fail_if new_reachable_critical > 0`
|
||||
* `warn_if new_unknowns > 10`
|
||||
* `fail_if vex_status_regressed == true`
|
||||
* `pass_if no_net_increase_exploitable_surface == true`
|
||||
|
||||
Engineering directive:
|
||||
|
||||
* Policies must reference **delta fields**, not scanner-specific output.
|
||||
* Keep the policy evaluation pure and deterministic.
|
||||
|
||||
## C6) Signing and attachment (implementation-level)
|
||||
|
||||
Minimum requirements:
|
||||
|
||||
* Support signing delta verdict as a DSSE envelope with a stable predicate type.
|
||||
* Support:
|
||||
|
||||
* keyless signing (optional)
|
||||
* customer-managed keys (enterprise)
|
||||
* Attach to OCI artifact as an attestation (where possible), and store in Stella ledger for retrieval.
|
||||
|
||||
Definition of Done:
|
||||
|
||||
* A CI workflow can:
|
||||
|
||||
1. create snapshots
|
||||
2. compute delta
|
||||
3. produce signed delta verdict
|
||||
4. verify signature and gate
|
||||
|
||||
---
|
||||
|
||||
# D. Roadmap (sequenced to deliver value early without painting into a corner)
|
||||
|
||||
## Phase 1: “Snapshot + SBOM Diff + Delta Verdict”
|
||||
|
||||
* Version SBOM graphs
|
||||
* Diff SBOM graphs
|
||||
* Produce delta verdict based on SBOM delta + vulnerability delta (even before reachability)
|
||||
* Signed delta verdict artifact exists
|
||||
|
||||
Output:
|
||||
|
||||
* Baseline/target selection
|
||||
* Delta taxonomy v1
|
||||
* Signed delta verdict v1
|
||||
|
||||
## Phase 2: “VEX claimsets and VEX deltas”
|
||||
|
||||
* Ingest OpenVEX/CycloneDX/CSAF
|
||||
* Store canonical claimsets per snapshot
|
||||
* Diff claimsets and incorporate into delta verdict
|
||||
|
||||
Output:
|
||||
|
||||
* “VEX status regression” gating works deterministically
|
||||
|
||||
## Phase 3: “Reachability graphs and reachability deltas”
|
||||
|
||||
* Start with one ecosystem
|
||||
* Generate reachability evidence
|
||||
* Diff reachability and incorporate into verdict
|
||||
|
||||
Output:
|
||||
|
||||
* “new reachable critical” becomes the primary gate
|
||||
|
||||
## Phase 4: “Offline replay bundle”
|
||||
|
||||
* Export/import snapshot + feed snapshot + policy bundle
|
||||
* Replay delta verdict identically in air-gapped environment
|
||||
|
||||
---
|
||||
|
||||
# E. Acceptance criteria checklist (use this as a release gate for your own feature)
|
||||
|
||||
A feature is not done until:
|
||||
|
||||
1. **Snapshot is content-addressed** and immutable.
|
||||
2. **Delta is content-addressed** and immutable.
|
||||
3. Delta shows:
|
||||
|
||||
* SBOM delta
|
||||
* VEX delta (when enabled)
|
||||
* Reachability delta (when enabled)
|
||||
* Unknowns delta
|
||||
4. **Delta verdict is signed** and verification is automated.
|
||||
5. **Replay test**: given same baseline/target snapshots + policy bundle, verdict is identical byte-for-byte.
|
||||
6. The product answers, clearly:
|
||||
|
||||
* What changed?
|
||||
* Why does it matter?
|
||||
* Why is the verdict pass/fail?
|
||||
* What evidence supports this?
|
||||
|
||||
---
|
||||
|
||||
# F. What to tell your teams to avoid (common failure modes)
|
||||
|
||||
* Do **not** ship “diff” as a UI compare of two scan outputs.
|
||||
* Do **not** make reachability an unstructured “note” field; it must be a graph with stable IDs.
|
||||
* Do **not** allow non-deterministic inputs into verdict hashes (timestamps, random IDs, nondeterministic ordering).
|
||||
* Do **not** treat VEX as “ignore rules” only; treat it as a claimset with provenance and merge semantics (even if merge comes later).
|
||||
@@ -0,0 +1,234 @@
|
||||
## 1) Define the product primitive (non-negotiable)
|
||||
|
||||
### Directive (shared)
|
||||
|
||||
**The product’s primary output is not “findings.” It is a “Risk Verdict Attestation” (RVA).**
|
||||
Everything else (SBOMs, CVEs, VEX, reachability, reports) is *supporting evidence* referenced by the RVA.
|
||||
|
||||
### What “first-class artifact” means in practice
|
||||
|
||||
1. **The verdict is an OCI artifact “referrer” attached to a specific image/artifact digest** via OCI 1.1 `subject` and discoverable via the referrers API. ([opencontainers.org][1])
|
||||
2. **The verdict is cryptographically signed** (at least one supported signing pathway).
|
||||
|
||||
* DSSE is a standard approach for signing attestations, and cosign supports creating/verifying in‑toto attestations signed with DSSE. ([Sigstore][2])
|
||||
* Notation is a widely deployed approach for signing/verifying OCI artifacts in enterprise environments. ([Microsoft Learn][3])
|
||||
|
||||
---
|
||||
|
||||
## 2) Directions for Product Managers (PM)
|
||||
|
||||
### A. Write the “Risk Verdict Attestation v1” product contract
|
||||
|
||||
**Deliverable:** A one-page contract + schema that product and customers can treat as an API.
|
||||
|
||||
Minimum fields the contract must standardize:
|
||||
|
||||
* **Subject binding:** exact OCI digest, repo/name, platform (if applicable)
|
||||
* **Verdict:** `PASS | FAIL | PASS_WITH_EXCEPTIONS | INDETERMINATE`
|
||||
* **Policy reference:** policy ID, policy digest, policy version, enforcement mode
|
||||
* **Knowledge snapshot reference:** snapshot ID + digest (see replay semantics below)
|
||||
* **Evidence references:** digests/pointers for SBOM, VEX inputs, vuln feed snapshot, reachability proof(s), config snapshot, and unknowns summary
|
||||
* **Reason codes:** stable machine-readable codes (`RISK.CVE.REACHABLE`, `RISK.VEX.NOT_AFFECTED`, `RISK.UNKNOWN.INPUT_MISSING`, etc.)
|
||||
* **Human explanation stub:** short rationale text plus links/IDs for deeper evidence
|
||||
|
||||
**Key PM rule:** the contract must be **stable and versioned**, with explicit deprecation rules. If you can’t maintain compatibility, ship a new version (v2), don’t silently mutate v1.
|
||||
|
||||
Why: OCI referrers create long-lived metadata chains. Breaking them is a customer trust failure.
|
||||
|
||||
### B. Define strict replay semantics as a product requirement (not “nice to have”)
|
||||
|
||||
PM must specify what “same inputs” means. At minimum, inputs include:
|
||||
|
||||
* artifact digest (subject)
|
||||
* policy bundle digest
|
||||
* vulnerability dataset snapshot digest(s)
|
||||
* VEX bundle digest(s)
|
||||
* SBOM digest(s) or SBOM generation recipe digest
|
||||
* scoring rules version/digest
|
||||
* engine version
|
||||
* reachability configuration version/digest (if enabled)
|
||||
|
||||
**Product acceptance criterion:**
|
||||
When a user re-runs evaluation in “replay mode” using the same knowledge snapshot and policy digest, the **verdict and reason codes must match** (byte-for-byte identical predicate is ideal; if not, the deterministic portion must match exactly).
|
||||
|
||||
OCI 1.1 and ORAS guidance also implies you should avoid shoving large evidence into annotations; store large evidence as blobs and reference by digest. ([opencontainers.org][1])
|
||||
|
||||
### C. Make “auditor evidence extraction” a first-order user journey
|
||||
|
||||
Define the auditor journey as a separate persona:
|
||||
|
||||
* Auditor wants: “Prove why you blocked/allowed artifact X at time Y.”
|
||||
* They should be able to:
|
||||
|
||||
1. Verify the signature chain
|
||||
2. Extract the decision + evidence package
|
||||
3. Replay the evaluation
|
||||
4. Produce a human-readable report without bespoke consulting
|
||||
|
||||
**PM feature requirements (v1)**
|
||||
|
||||
* `explain` experience that outputs:
|
||||
|
||||
* decision summary
|
||||
* policy used
|
||||
* evidence references and hashes
|
||||
* top N reasons (with stable codes)
|
||||
* unknowns and assumptions
|
||||
* `export-audit-package` experience:
|
||||
|
||||
* exports a ZIP (or OCI bundle) containing the RVA, its referenced evidence artifacts, and a machine-readable manifest listing all digests
|
||||
* `verify` experience:
|
||||
|
||||
* verifies signature + policy expectations (who is trusted to sign; which predicate type(s) are acceptable)
|
||||
|
||||
Cosign explicitly supports creating/verifying in‑toto attestations (DSSE-signed) and even validating custom predicates against policy languages like Rego/CUE—this is a strong PM anchor for ecosystem interoperability. ([Sigstore][2])
|
||||
|
||||
---
|
||||
|
||||
## 3) Directions for Development Managers (Dev/Eng)
|
||||
|
||||
### A. Implement OCI attachment correctly (artifact, referrer, fallback)
|
||||
|
||||
**Engineering decisions:**
|
||||
|
||||
1. Store RVA as an OCI artifact manifest with:
|
||||
|
||||
* `artifactType` set to your verdict media type
|
||||
* `subject` pointing to the exact image/artifact digest being evaluated
|
||||
OCI 1.1 introduced these fields for associating metadata artifacts and retrieving them via the referrers API. ([opencontainers.org][1])
|
||||
2. Support discovery via:
|
||||
|
||||
* Referrers API (`GET /v2/<name>/referrers/<digest>`) when registry supports it
|
||||
* **Fallback “tagged index” strategy** for registries that don’t support referrers (OCI 1.1 guidance calls out a fallback tag approach and client responsibilities). ([opencontainers.org][1])
|
||||
|
||||
**Dev acceptance tests**
|
||||
|
||||
* Push subject image → push RVA artifact with `subject` → query referrers → RVA appears.
|
||||
* On a registry without referrers support: fallback retrieval still works.
|
||||
|
||||
### B. Use a standard attestation envelope and signing flow
|
||||
|
||||
For attestations, the lowest friction pathway is:
|
||||
|
||||
* in‑toto Statement + DSSE envelope
|
||||
* Sign/verify using cosign-compatible workflows (so customers can verify without you) ([Sigstore][2])
|
||||
|
||||
DSSE matters because it:
|
||||
|
||||
* authenticates message + type
|
||||
* avoids canonicalization pitfalls
|
||||
* supports arbitrary encodings ([GitHub][4])
|
||||
|
||||
**Engineering rule:** the signed payload must include enough data to replay and audit (policy + knowledge snapshot digests), but avoid embedding huge evidence blobs directly.
|
||||
|
||||
### C. Build determinism into the evaluation core (not bolted on)
|
||||
|
||||
**“Same inputs → same verdict” is a software architecture constraint.**
|
||||
It fails if any of these are non-deterministic:
|
||||
|
||||
* fetching “latest” vulnerability DB at runtime
|
||||
* unstable iteration order (maps/hashes)
|
||||
* timestamps included as decision inputs
|
||||
* concurrency races changing aggregation order
|
||||
* floating point scoring without canonical rounding
|
||||
|
||||
**Engineering requirements**
|
||||
|
||||
1. Create a **Knowledge Snapshot** object (content-addressed):
|
||||
|
||||
* a manifest listing every dataset input by digest and version
|
||||
2. The evaluation function becomes:
|
||||
|
||||
* `Verdict = Evaluate(subject_digest, policy_digest, knowledge_snapshot_digest, engine_version, options_digest)`
|
||||
3. The RVA must embed those digests so replay is possible offline.
|
||||
|
||||
**Dev acceptance tests**
|
||||
|
||||
* Run Evaluate twice with same snapshot/policy → verdict + reason codes identical.
|
||||
* Run Evaluate with one dataset changed (snapshot digest differs) → RVA must reflect changed snapshot digest.
|
||||
|
||||
### D. Treat “evidence” as a graph of content-addressed artifacts
|
||||
|
||||
Implement evidence storage with these rules:
|
||||
|
||||
* Large evidence artifacts are stored as OCI blobs/artifacts (SBOM, VEX bundle, reachability proof graph, config snapshot).
|
||||
* RVA references evidence by digest and type.
|
||||
* “Explain” traverses this graph and renders:
|
||||
|
||||
* a machine-readable explanation JSON
|
||||
* a human-readable report
|
||||
|
||||
ORAS guidance highlights artifact typing via `artifactType` in OCI 1.1 and suggests keeping manifests manageable; don’t overload annotations. ([oras.land][5])
|
||||
|
||||
### E. Provide a verification and policy enforcement path
|
||||
|
||||
You want customers to be able to enforce “only run artifacts with an approved RVA predicate.”
|
||||
|
||||
Two practical patterns:
|
||||
|
||||
* **Cosign verification of attestations** (customers can do `verify-attestation` and validate predicate structure; cosign supports validating attestations with policy languages like Rego/CUE). ([Sigstore][2])
|
||||
* **Notation signatures** for organizations that standardize on Notary/Notation for OCI signing/verification workflows. ([Microsoft Learn][3])
|
||||
|
||||
Engineering should not hard-code one choice; implement an abstraction:
|
||||
|
||||
* signing backend: `cosign/DSSE` first
|
||||
* optional: notation signature over the RVA artifact for environments that require it
|
||||
|
||||
---
|
||||
|
||||
## 4) Minimal “v1” spec by example (what your teams should build)
|
||||
|
||||
### A. OCI artifact requirements (registry-facing)
|
||||
|
||||
* artifact is discoverable as a referrer via `subject` linkage and `artifactType` classification (OCI 1.1). ([opencontainers.org][1])
|
||||
|
||||
### B. Attestation payload structure (contract-facing)
|
||||
|
||||
In code terms (illustrative only), build on the in‑toto Statement model:
|
||||
|
||||
```json
|
||||
{
|
||||
"_type": "https://in-toto.io/Statement/v0.1",
|
||||
"subject": [
|
||||
{
|
||||
"name": "oci://registry.example.com/team/app",
|
||||
"digest": { "sha256": "<SUBJECT_DIGEST>" }
|
||||
}
|
||||
],
|
||||
"predicateType": "https://stellaops.dev/attestations/risk-verdict/v1",
|
||||
"predicate": {
|
||||
"verdict": "FAIL",
|
||||
"reasonCodes": ["RISK.CVE.REACHABLE", "RISK.POLICY.THRESHOLD_EXCEEDED"],
|
||||
"policy": { "id": "prod-gate", "digest": "sha256:<POLICY_DIGEST>" },
|
||||
"knowledgeSnapshot": { "id": "ks-2025-12-19", "digest": "sha256:<KS_DIGEST>" },
|
||||
"evidence": {
|
||||
"sbom": { "digest": "sha256:<SBOM_DIGEST>", "format": "cyclonedx-json" },
|
||||
"vexBundle": { "digest": "sha256:<VEX_DIGEST>", "format": "openvex" },
|
||||
"vulnData": { "digest": "sha256:<VULN_FEEDS_DIGEST>" },
|
||||
"reachability": { "digest": "sha256:<REACH_PROOF_DIGEST>" },
|
||||
"unknowns": { "count": 2, "digest": "sha256:<UNKNOWNS_DIGEST>" }
|
||||
},
|
||||
"engine": { "name": "stella-eval", "version": "1.3.0" }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Cosign supports creating and verifying in‑toto attestations (DSSE-signed), which is exactly the interoperability you want for customer-side verification. ([Sigstore][2])
|
||||
|
||||
---
|
||||
|
||||
## 5) Definition of Done (use this to align PM/Eng and prevent scope drift)
|
||||
|
||||
### v1 must satisfy all of the following:
|
||||
|
||||
1. **OCI-attached:** RVA is stored as an OCI artifact referrer to the subject digest and discoverable (referrers API + fallback mode). ([opencontainers.org][1])
|
||||
2. **Signed:** RVA can be verified by a standard toolchain (cosign at minimum). ([Sigstore][2])
|
||||
3. **Replayable:** Given the embedded policy + knowledge snapshot digests, the evaluation can be replayed and produces the same verdict + reason codes.
|
||||
4. **Auditor extractable:** One command produces an audit package containing:
|
||||
|
||||
* RVA attestation
|
||||
* policy bundle
|
||||
* knowledge snapshot manifest
|
||||
* referenced evidence artifacts
|
||||
* an “explanation report” rendering the decision
|
||||
5. **Stable contract:** predicate schema is versioned and validated (strict JSON schema checks; backwards compatibility rules).
|
||||
@@ -0,0 +1,463 @@
|
||||
## Outcome you are shipping
|
||||
|
||||
A deterministic “claim resolution” capability that takes:
|
||||
|
||||
* Multiple **claims** about the same vulnerability (vendor VEX, distro VEX, internal assessments, scanner inferences),
|
||||
* A **policy** describing trust and merge semantics,
|
||||
* A set of **evidence artifacts** (SBOM, config snapshots, reachability proofs, etc.),
|
||||
|
||||
…and produces a **single resolved status** per vulnerability/component/artifact **with an explainable trail**:
|
||||
|
||||
* Which claims applied and why
|
||||
* Which were rejected and why
|
||||
* What evidence was required and whether it was satisfied
|
||||
* What policy rules triggered the resolution outcome
|
||||
|
||||
This replaces naive precedence like `vendor > distro > internal`.
|
||||
|
||||
---
|
||||
|
||||
# Directions for Product Managers
|
||||
|
||||
## 1) Write the PRD around “claims resolution,” not “VEX support”
|
||||
|
||||
The customer outcome is not “we ingest VEX.” It is:
|
||||
|
||||
* “We can *safely* accept ‘not affected’ without hiding risk.”
|
||||
* “We can prove, to auditors and change control, why a CVE was downgraded.”
|
||||
* “We can consistently resolve conflicts between issuer statements.”
|
||||
|
||||
### Non-negotiable product properties
|
||||
|
||||
* **Deterministic**: same inputs → same resolved outcome
|
||||
* **Explainable**: a human can trace the decision path
|
||||
* **Guardrailed**: a “safe” resolution requires evidence, not just a statement
|
||||
|
||||
---
|
||||
|
||||
## 2) Define the core objects (these drive everything)
|
||||
|
||||
In the PRD, define these three objects explicitly:
|
||||
|
||||
### A) Claim (normalized)
|
||||
|
||||
A “claim” is any statement about vulnerability applicability to an artifact/component, regardless of source format.
|
||||
|
||||
Minimum fields:
|
||||
|
||||
* `vuln_id` (CVE/GHSA/etc.)
|
||||
* `subject` (component identity; ideally package + version + digest/purl)
|
||||
* `target` (the thing we’re evaluating: image, repo build, runtime instance)
|
||||
* `status` (affected / not_affected / fixed / under_investigation / unknown)
|
||||
* `justification` (human/machine reason)
|
||||
* `issuer` (who said it; plus verification state)
|
||||
* `scope` (what it applies to; versions, ranges, products)
|
||||
* `timestamp` (when produced)
|
||||
* `references` (links/IDs to evidence or external material)
|
||||
|
||||
### B) Evidence
|
||||
|
||||
A typed artifact that can satisfy a requirement.
|
||||
|
||||
Examples (not exhaustive):
|
||||
|
||||
* `config_snapshot` (e.g., Helm values, env var map, feature flag export)
|
||||
* `sbom_presence_or_absence` (SBOM proof that component is/ isn’t present)
|
||||
* `reachability_proof` (call-path evidence from entrypoint to vulnerable symbol)
|
||||
* `symbol_absence` (binary inspection shows symbol/function not present)
|
||||
* `patch_presence` (artifact includes backport / fixed build)
|
||||
* `manual_attestation` (human-reviewed attestation with reviewer identity + scope)
|
||||
|
||||
Each evidence item must have:
|
||||
|
||||
* `type`
|
||||
* `collector` (tool/provider)
|
||||
* `inputs_hash` and `output_hash`
|
||||
* `scope` (what artifact/environment it applies to)
|
||||
* `confidence` (optional but recommended)
|
||||
* `expires_at` / `valid_for` (for config/runtime evidence)
|
||||
|
||||
### C) Policy
|
||||
|
||||
A policy describes:
|
||||
|
||||
* **Trust rules** (how much to trust whom, under which conditions)
|
||||
* **Merge semantics** (how to resolve conflicts)
|
||||
* **Evidence requirements** (what must be present to accept certain claims)
|
||||
|
||||
---
|
||||
|
||||
## 3) Ship “policy-controlled merge semantics” as a configuration schema first
|
||||
|
||||
Do not start with a fully general policy language. You need a small, explicit schema that makes behavior predictable.
|
||||
|
||||
PM deliverable: a policy spec with these sections:
|
||||
|
||||
1. **Issuer trust**
|
||||
|
||||
* weights by issuer category (vendor/distro/internal/scanner)
|
||||
* optional constraints (must be signed, must match product ownership, must be within time window)
|
||||
2. **Applicability rules**
|
||||
|
||||
* what constitutes a match to artifact/component (range semantics, digest match priority)
|
||||
3. **Evidence requirements**
|
||||
|
||||
* per status + per justification: what evidence types are required
|
||||
4. **Conflict resolution strategy**
|
||||
|
||||
* conservative vs weighted vs most-specific
|
||||
* explicit guardrails (never accept “safe” without evidence)
|
||||
5. **Override rules**
|
||||
|
||||
* when internal can override vendor (and what evidence is required to do so)
|
||||
* environment-specific policies (prod vs dev)
|
||||
|
||||
---
|
||||
|
||||
## 4) Make “evidence hooks” a first-class user workflow
|
||||
|
||||
You are explicitly shipping the ability to say:
|
||||
|
||||
> “This is not affected **because** feature flag X is off.”
|
||||
|
||||
That requires:
|
||||
|
||||
* a way to **provide or discover** feature flag state, and
|
||||
* a way to **bind** that flag to the vulnerable surface
|
||||
|
||||
PM must specify: what does the user do to assert that?
|
||||
|
||||
Minimum viable workflow:
|
||||
|
||||
* User attaches a `config_snapshot` (or system captures it)
|
||||
* User provides a “binding” to the vulnerable module/function:
|
||||
|
||||
* either automatic (later) or manual (first release)
|
||||
* e.g., `flag X gates module Y` with references (file path, code reference, runbook)
|
||||
|
||||
This “binding” itself becomes evidence.
|
||||
|
||||
---
|
||||
|
||||
## 5) Define acceptance criteria as decision trace tests
|
||||
|
||||
PM should write acceptance criteria as “given claims + policy + evidence → resolved outcome + trace”.
|
||||
|
||||
You need at least these canonical tests:
|
||||
|
||||
1. **Distro backport vs vendor version logic conflict**
|
||||
|
||||
* Vendor says affected (by version range)
|
||||
* Distro says fixed (backport)
|
||||
* Policy says: in distro context, distro claim can override vendor if patch evidence exists
|
||||
* Outcome: fixed, with trace proving why
|
||||
|
||||
2. **Internal ‘feature flag off’ downgrade**
|
||||
|
||||
* Vendor says affected
|
||||
* Internal says not_affected because flag off
|
||||
* Evidence: config snapshot + flag→module binding
|
||||
* Outcome: not_affected **only for that environment context**, with trace
|
||||
|
||||
3. **Evidence missing**
|
||||
|
||||
* Internal says not_affected because “code not reachable”
|
||||
* No reachability evidence present
|
||||
* Outcome: unknown or affected (policy-dependent), but **not “not_affected”**
|
||||
|
||||
4. **Conflicting “safe” claims**
|
||||
|
||||
* Vendor says not_affected (reason A)
|
||||
* Internal says affected (reason B) with strong evidence
|
||||
* Outcome follows merge strategy, and trace must show why.
|
||||
|
||||
---
|
||||
|
||||
## 6) Package it as an “Explainable Resolution” feature
|
||||
|
||||
UI/UX requirements PM must specify:
|
||||
|
||||
* A “Resolved Status” view per vuln/component showing:
|
||||
|
||||
* contributing claims (ranked)
|
||||
* rejected claims (with reason)
|
||||
* evidence required vs evidence present
|
||||
* the policy clauses triggered (line-level references)
|
||||
* A policy editor can be CLI/JSON first; UI later, but explainability cannot wait.
|
||||
|
||||
---
|
||||
|
||||
# Directions for Development Managers
|
||||
|
||||
## 1) Implement as three services/modules with strict interfaces
|
||||
|
||||
### Module A: Claim Normalization
|
||||
|
||||
* Inputs: OpenVEX / CycloneDX VEX / CSAF / internal annotations / scanner hints
|
||||
* Output: canonical `Claim` objects
|
||||
|
||||
Rules:
|
||||
|
||||
* Canonicalize IDs (normalize CVE formats, normalize package coordinates)
|
||||
* Preserve provenance: issuer identity, signature metadata, timestamps, original document hash
|
||||
|
||||
### Module B: Evidence Providers (plugin boundary)
|
||||
|
||||
* Provide an interface like:
|
||||
|
||||
```
|
||||
evaluate_evidence(context, claim) -> EvidenceEvaluation
|
||||
```
|
||||
|
||||
Where `EvidenceEvaluation` returns:
|
||||
|
||||
* required evidence types for this claim (from policy)
|
||||
* found evidence items (from store/providers)
|
||||
* satisfied / not satisfied
|
||||
* explanation strings
|
||||
* confidence
|
||||
|
||||
Start with 3 providers:
|
||||
|
||||
1. SBOM provider (presence/absence)
|
||||
2. Config provider (feature flags/config snapshot ingestion)
|
||||
3. Reachability provider (even if initially limited or stubbed, it must exist as a typed hook)
|
||||
|
||||
### Module C: Merge & Resolution Engine
|
||||
|
||||
* Inputs: set of claims + policy + evidence evaluations + context
|
||||
* Output: `ResolvedDecision`
|
||||
|
||||
A `ResolvedDecision` must include:
|
||||
|
||||
* final status
|
||||
* selected “winning” claim(s)
|
||||
* all considered claims
|
||||
* evidence satisfaction summary
|
||||
* applied policy rule IDs
|
||||
* deterministic ordering keys/hashes
|
||||
|
||||
---
|
||||
|
||||
## 2) Define the evaluation context (this avoids foot-guns)
|
||||
|
||||
The resolved outcome must be context-aware.
|
||||
|
||||
Create an immutable `EvaluationContext` object, containing:
|
||||
|
||||
* artifact identity (image digest / build digest / SBOM hash)
|
||||
* environment identity (prod/stage/dev; cluster; region)
|
||||
* config snapshot ID
|
||||
* time (evaluation timestamp)
|
||||
* policy version hash
|
||||
|
||||
This is how you support: “not affected because feature flag off” in prod but not in dev.
|
||||
|
||||
---
|
||||
|
||||
## 3) Merge semantics: implement scoring + guardrails, not precedence
|
||||
|
||||
You need a deterministic function. One workable approach:
|
||||
|
||||
### Step 1: compute statement strength
|
||||
|
||||
For each claim:
|
||||
|
||||
* `trust_weight` from policy (issuer + scope + signature requirements)
|
||||
* `evidence_factor` (1.0 if requirements satisfied; <1 or 0 if not)
|
||||
* `specificity_factor` (exact digest match > exact version > range)
|
||||
* `freshness_factor` (optional; policy-defined)
|
||||
* `applicability` must be true or claim is excluded
|
||||
|
||||
Compute:
|
||||
|
||||
```
|
||||
support = trust_weight * evidence_factor * specificity_factor * freshness_factor
|
||||
```
|
||||
|
||||
### Step 2: apply merge strategy (policy-controlled)
|
||||
|
||||
Ship at least two strategies:
|
||||
|
||||
1. **Conservative default**
|
||||
|
||||
* If any “unsafe” claim (affected/under_investigation) has support above threshold, it wins
|
||||
* A “safe” claim (not_affected/fixed) can override only if:
|
||||
|
||||
* it has equal/higher support + delta, AND
|
||||
* its evidence requirements are satisfied
|
||||
|
||||
2. **Evidence-weighted**
|
||||
|
||||
* Highest support wins, but safe statuses have a hard evidence gate
|
||||
|
||||
### Step 3: apply guardrails
|
||||
|
||||
Hard guardrail to prevent bad outcomes:
|
||||
|
||||
* **Never emit a safe status unless evidence requirements for that safe claim are satisfied.**
|
||||
* If a safe claim lacks evidence, downgrade the safe claim to “unsupported” and do not allow it to win.
|
||||
|
||||
This single rule is what makes your system materially different from “VEX as suppression.”
|
||||
|
||||
---
|
||||
|
||||
## 4) Evidence hooks: treat them as typed contracts, not strings
|
||||
|
||||
For “feature flag off,” implement it as a structured evidence requirement.
|
||||
|
||||
Example evidence requirement for a “safe because feature flag off” claim:
|
||||
|
||||
* Required evidence types:
|
||||
|
||||
* `config_snapshot`
|
||||
* `flag_binding` (the mapping “flag X gates vulnerable surface Y”)
|
||||
|
||||
Implementation:
|
||||
|
||||
* Config provider can parse:
|
||||
|
||||
* Helm values / env var sets / feature flag exports
|
||||
* Store them as normalized key/value with hashes
|
||||
* Binding evidence can start as manual JSON that references:
|
||||
|
||||
* repo path / module / function group
|
||||
* a link to code ownership / runbook
|
||||
* optional test evidence
|
||||
|
||||
Later you can automate binding via static analysis, but do not block shipping on that.
|
||||
|
||||
---
|
||||
|
||||
## 5) Determinism requirements (engineering non-negotiables)
|
||||
|
||||
Development manager should enforce:
|
||||
|
||||
* stable sorting of claims by canonical key
|
||||
* stable tie-breakers (e.g., issuer ID, timestamp, claim hash)
|
||||
* no nondeterministic external calls during evaluation (or they must be snapshot-based)
|
||||
* every evaluation produces:
|
||||
|
||||
* `input_bundle_hash` (claims + evidence + policy + context)
|
||||
* `decision_hash`
|
||||
|
||||
This is the foundation for replayability and audits.
|
||||
|
||||
---
|
||||
|
||||
## 6) Storage model: store raw inputs and canonical forms
|
||||
|
||||
Minimum stores:
|
||||
|
||||
* Raw documents (original VEX/CSAF/etc.) keyed by content hash
|
||||
* Canonical claims keyed by claim hash
|
||||
* Evidence items keyed by evidence hash and scoped by context
|
||||
* Policy versions keyed by policy hash
|
||||
* Resolutions keyed by (context, vuln_id, subject) with decision hash
|
||||
|
||||
---
|
||||
|
||||
## 7) “Definition of done” checklist for engineering
|
||||
|
||||
You are done when:
|
||||
|
||||
1. You can ingest at least two formats into canonical claims (pick OpenVEX + CycloneDX VEX first).
|
||||
2. You can configure issuer trust and evidence requirements in a policy file.
|
||||
3. You can resolve conflicts deterministically.
|
||||
4. You can attach a config snapshot and produce:
|
||||
|
||||
* `not_affected because feature flag off` **only when evidence satisfied**
|
||||
5. The system produces a decision trace with:
|
||||
|
||||
* applied policy rules
|
||||
* evidence satisfaction
|
||||
* selected/rejected claims and reasons
|
||||
6. Golden test vectors exist for the acceptance scenarios listed above.
|
||||
|
||||
---
|
||||
|
||||
# A concrete example policy (schema-first, no full DSL required)
|
||||
|
||||
```yaml
|
||||
version: 1
|
||||
|
||||
trust:
|
||||
issuers:
|
||||
- match: {category: vendor}
|
||||
weight: 70
|
||||
require_signature: true
|
||||
- match: {category: distro}
|
||||
weight: 75
|
||||
require_signature: true
|
||||
- match: {category: internal}
|
||||
weight: 85
|
||||
require_signature: false
|
||||
- match: {category: scanner}
|
||||
weight: 40
|
||||
|
||||
evidence_requirements:
|
||||
safe_status_requires_evidence: true
|
||||
|
||||
rules:
|
||||
- when:
|
||||
status: not_affected
|
||||
reason: feature_flag_off
|
||||
require: [config_snapshot, flag_binding]
|
||||
|
||||
- when:
|
||||
status: not_affected
|
||||
reason: component_not_present
|
||||
require: [sbom_absence]
|
||||
|
||||
- when:
|
||||
status: not_affected
|
||||
reason: not_reachable
|
||||
require: [reachability_proof]
|
||||
|
||||
merge:
|
||||
strategy: conservative
|
||||
unsafe_wins_threshold: 50
|
||||
safe_override_delta: 10
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# A concrete example output trace (what auditors and engineers must see)
|
||||
|
||||
```json
|
||||
{
|
||||
"vuln_id": "CVE-XXXX-YYYY",
|
||||
"subject": "pkg:maven/org.example/foo@1.2.3",
|
||||
"context": {
|
||||
"artifact_digest": "sha256:...",
|
||||
"environment": "prod",
|
||||
"policy_hash": "sha256:..."
|
||||
},
|
||||
"resolved_status": "not_affected",
|
||||
"because": [
|
||||
{
|
||||
"winning_claim": "claim_hash_abc",
|
||||
"reason": "feature_flag_off",
|
||||
"evidence_required": ["config_snapshot", "flag_binding"],
|
||||
"evidence_present": ["ev_hash_1", "ev_hash_2"],
|
||||
"policy_rules_applied": ["trust.issuers[internal]", "evidence.rules[0]", "merge.safe_override_delta"]
|
||||
}
|
||||
],
|
||||
"claims_considered": [
|
||||
{"issuer": "vendor", "status": "affected", "support": 62, "accepted": false, "rejection_reason": "overridden_by_higher_support_safe_claim_with_satisfied_evidence"},
|
||||
{"issuer": "internal", "status": "not_affected", "support": 78, "accepted": true, "evidence_satisfied": true}
|
||||
],
|
||||
"decision_hash": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## The two strategic pitfalls to explicitly avoid
|
||||
|
||||
1. **“Trust precedence” as the merge mechanism**
|
||||
|
||||
* It will fail immediately on backports, forks, downstream patches, and environment-specific mitigations.
|
||||
2. **Allowing “safe” without evidence**
|
||||
|
||||
* That turns VEX into a suppression system and will collapse trust in the product.
|
||||
@@ -0,0 +1,338 @@
|
||||
## Executive directive
|
||||
|
||||
Build **Reachability as Evidence**, not as a UI feature.
|
||||
|
||||
Every reachability conclusion must produce a **portable, signed, replayable evidence bundle** that answers:
|
||||
|
||||
1. **What vulnerable code unit is being discussed?** (symbol/method/function + version)
|
||||
2. **What entrypoint is assumed?** (HTTP handler, RPC method, CLI, scheduled job, etc.)
|
||||
3. **What is the witness?** (a call-path subgraph, not a screenshot)
|
||||
4. **What assumptions/gates apply?** (config flags, feature toggles, runtime wiring)
|
||||
5. **Can a third party reproduce it?** (same inputs → same evidence hash)
|
||||
|
||||
This must work for **source** and **post-build artifacts**.
|
||||
|
||||
---
|
||||
|
||||
# Directions for Product Managers
|
||||
|
||||
## 1) Define the product contract in one page
|
||||
|
||||
### Capability name
|
||||
**Proof‑carrying reachability**.
|
||||
|
||||
### Contract
|
||||
Given an artifact (source or built) and a vulnerability mapping, Stella Ops outputs:
|
||||
|
||||
- **Reachability verdict:** `REACHABLE | NOT_PROVEN_REACHABLE | INCONCLUSIVE`
|
||||
- **Witness evidence:** a minimal **reachability subgraph** + one or more witness paths
|
||||
- **Reproducibility bundle:** all inputs and toolchain metadata needed to replay
|
||||
- **Attestation:** signed statement tied to the artifact digest
|
||||
|
||||
### Important language choice
|
||||
Avoid claiming “unreachable” unless you can prove non-reachability under a formally sound model.
|
||||
|
||||
- Use **NOT_PROVEN_REACHABLE** for “no path found under current analysis + assumptions.”
|
||||
- Use **INCONCLUSIVE** when analysis cannot be performed reliably (missing symbols, obfuscation, unsupported language, dynamic dispatch uncertainty, etc.).
|
||||
|
||||
This is essential for credibility and audit use.
|
||||
|
||||
---
|
||||
|
||||
## 2) Anchor personas and top workflows
|
||||
|
||||
### Primary personas
|
||||
- Security governance / AppSec: wants fewer false positives and defensible prioritization.
|
||||
- Compliance/audit: wants evidence and replayability.
|
||||
- Engineering teams: wants specific call paths and what to change.
|
||||
|
||||
### Top workflows (must support in MVP)
|
||||
1. **CI gate with signed verdict**
|
||||
- “Block release if any `REACHABLE` high severity is present OR if `INCONCLUSIVE` exceeds threshold.”
|
||||
2. **Audit replay**
|
||||
- “Reproduce the reachability proof for artifact digest X using snapshot Y.”
|
||||
3. **Release delta**
|
||||
- “Show what reachability changed between release A and B.”
|
||||
|
||||
---
|
||||
|
||||
## 3) Minimum viable scope: pick targets that make “post-build” real early
|
||||
|
||||
To satisfy “source and post-build artifacts” without biting off ELF-level complexity first:
|
||||
|
||||
### MVP artifact types (recommended)
|
||||
- **Source repository** for 1–2 languages with mature static IR
|
||||
- **Post-build intermediate artifacts** that retain symbol structure:
|
||||
- Java `.jar/.class`
|
||||
- .NET assemblies
|
||||
- Python wheels (bytecode)
|
||||
- Node bundles with sourcemaps (optional)
|
||||
|
||||
These give you “post-build” support where call graphs are tractable.
|
||||
|
||||
### Defer for later phases
|
||||
- Native ELF/Mach-O deep reachability (harder due to stripping, inlining, indirect calls, dynamic loading)
|
||||
- Highly dynamic languages without strong type info, unless you accept “witness-only” semantics
|
||||
|
||||
Your differentiator is proof portability and determinism, not “supports every binary on day one.”
|
||||
|
||||
---
|
||||
|
||||
## 4) Product requirements: what “proof-carrying” means in requirements language
|
||||
|
||||
### Functional requirements
|
||||
- Output must include a **reachability subgraph**:
|
||||
- Nodes = code units (function/method) with stable IDs
|
||||
- Edges = call or dispatch edges with type annotations
|
||||
- Must include at least one **witness path** from entrypoint to vulnerable node when `REACHABLE`
|
||||
- Output must be **artifact-tied**:
|
||||
- Evidence must reference artifact digest(s) (source commit, build artifact digest, container image digest)
|
||||
- Output must be **attestable**:
|
||||
- Produce a signed attestation (DSSE/in-toto style) attached to the artifact digest
|
||||
- Output must be **replayable**:
|
||||
- Provide a “replay recipe” (analyzer versions, configs, vulnerability mapping version, and input digests)
|
||||
|
||||
### Non-functional requirements
|
||||
- Deterministic: repeated runs on same inputs produce identical evidence hash
|
||||
- Size-bounded: subgraph evidence must be bounded (e.g., path-based extraction + limited context)
|
||||
- Privacy-controllable:
|
||||
- Support a mode that avoids embedding raw source content (store pointers/hashes instead)
|
||||
- Verifiable offline:
|
||||
- Verification and replay must work air-gapped given the snapshot bundle
|
||||
|
||||
---
|
||||
|
||||
## 5) Acceptance criteria (use as Definition of Done)
|
||||
|
||||
A feature is “done” only when:
|
||||
|
||||
1. **Verifier can validate** the attestation signature and confirm the evidence hash matches content.
|
||||
2. A second machine can **reproduce the same evidence hash** given the replay bundle.
|
||||
3. Evidence includes at least one witness path for `REACHABLE`.
|
||||
4. Evidence includes explicit assumptions/gates; absence of gating is recorded as an assumption (e.g., “config unknown”).
|
||||
5. Evidence is **linked to the precise artifact digest** being deployed/scanned.
|
||||
|
||||
---
|
||||
|
||||
## 6) Product packaging decisions that create switching cost
|
||||
|
||||
These are product decisions that turn engineering into moat:
|
||||
|
||||
- **Make “reachability proof” an exportable object**, not just a UI view.
|
||||
- Provide an API: `GET /findings/{id}/proof` returning canonical evidence.
|
||||
- Support policy gates on:
|
||||
- `verdict`
|
||||
- `confidence`
|
||||
- `assumption_count`
|
||||
- `inconclusive_reasons`
|
||||
- Make “proof replay” a one-command workflow in CLI.
|
||||
|
||||
---
|
||||
|
||||
# Directions for Development Managers
|
||||
|
||||
## 1) Architecture: build a “proof pipeline” with strict boundaries
|
||||
|
||||
Implement as composable modules with stable interfaces:
|
||||
|
||||
1. **Artifact Resolver**
|
||||
- Inputs: repo URL/commit, build artifact path, container image digest
|
||||
- Output: normalized “artifact record” with digests and metadata
|
||||
|
||||
2. **Graph Builder (language-specific adapters)**
|
||||
- Inputs: artifact record
|
||||
- Output: canonical **Program Graph**
|
||||
- Nodes: code units
|
||||
- Edges: calls/dispatch
|
||||
- Optional: config gates, dependency edges
|
||||
|
||||
3. **Vulnerability-to-Code Mapper**
|
||||
- Inputs: vulnerability record (CVE), package coordinates, symbol metadata (if available)
|
||||
- Output: vulnerable node set + mapping confidence
|
||||
|
||||
4. **Entrypoint Modeler**
|
||||
- Inputs: artifact + runtime context (framework detection, routing tables, main methods)
|
||||
- Output: entrypoint node set with types (HTTP, RPC, CLI, cron)
|
||||
|
||||
5. **Reachability Engine**
|
||||
- Inputs: graph + entrypoints + vulnerable nodes + constraints
|
||||
- Output: witness paths + minimal subgraph extraction
|
||||
|
||||
6. **Evidence Canonicalizer**
|
||||
- Inputs: witness paths + subgraph + metadata
|
||||
- Output: canonical JSON (stable ordering, stable IDs), plus content hash
|
||||
|
||||
7. **Attestor**
|
||||
- Inputs: evidence hash + artifact digest
|
||||
- Output: signed attestation object (OCI attachable)
|
||||
|
||||
8. **Verifier (separate component)**
|
||||
- Must validate signatures + evidence integrity independently of generator
|
||||
|
||||
Critical: generator and verifier must be decoupled to preserve trust.
|
||||
|
||||
---
|
||||
|
||||
## 2) Evidence model: what to store (and how to keep it stable)
|
||||
|
||||
### Node identity must be stable across runs
|
||||
Define a canonical NodeID scheme:
|
||||
|
||||
- Source node ID:
|
||||
- `{language}:{repo_digest}:{symbol_signature}:{optional_source_location_hash}`
|
||||
- Post-build node ID:
|
||||
- `{language}:{artifact_digest}:{symbol_signature}:{optional_offset_or_token}`
|
||||
|
||||
Avoid raw file paths or non-deterministic compiler offsets as primary IDs unless normalized.
|
||||
|
||||
### Edge identity
|
||||
`{caller_node_id} -> {callee_node_id} : {edge_type}`
|
||||
Edge types matter (direct call, virtual dispatch, reflection, dynamic import, etc.)
|
||||
|
||||
### Subgraph extraction rule
|
||||
Store:
|
||||
- All nodes/edges on at least one witness path (or k witness paths)
|
||||
- Plus bounded context:
|
||||
- 1–2 hop neighborhood around the vulnerable node and entrypoint
|
||||
- routing edges (HTTP route → handler) where applicable
|
||||
|
||||
This makes the proof compact and audit-friendly.
|
||||
|
||||
### Canonicalization requirements
|
||||
- Stable sorting of nodes and edges
|
||||
- Canonical JSON serialization (no map-order nondeterminism)
|
||||
- Explicit analyzer version + config included in evidence
|
||||
- Hash everything that influences results
|
||||
|
||||
---
|
||||
|
||||
## 3) Determinism and reproducibility: engineering guardrails
|
||||
|
||||
### Deterministic computation
|
||||
- Avoid parallel graph traversal that yields nondeterministic order without canonical sorting
|
||||
- If using concurrency, collect results and sort deterministically before emitting
|
||||
|
||||
### Repro bundle (“time travel”)
|
||||
Persist, as digests:
|
||||
- Analyzer container/image digest
|
||||
- Analyzer config hash
|
||||
- Vulnerability mapping dataset version hash
|
||||
- Artifact digest(s)
|
||||
- Graph builder version hash
|
||||
|
||||
A replay must be possible without “calling home.”
|
||||
|
||||
### Golden tests
|
||||
Create fixtures where:
|
||||
- Same input graph + mapping → exact evidence hash
|
||||
- Regression test for canonicalization changes (version the schema intentionally)
|
||||
|
||||
---
|
||||
|
||||
## 4) Attestation format and verification
|
||||
|
||||
### Attestation contents (minimum)
|
||||
- Subject: artifact digest (image digest / build artifact digest)
|
||||
- Predicate: reachability evidence hash + metadata
|
||||
- Predicate type: `reachability` (custom) with versioning
|
||||
|
||||
### Verification requirements
|
||||
- Verification must run offline
|
||||
- It must validate:
|
||||
1) signature
|
||||
2) subject digest binding
|
||||
3) evidence hash matches serialized evidence
|
||||
|
||||
### Storage model
|
||||
Use content-addressable storage keyed by evidence hash.
|
||||
Attestation references the hash; evidence stored separately or embedded (size tradeoff).
|
||||
|
||||
---
|
||||
|
||||
## 5) Source + post-build support: engineering plan
|
||||
|
||||
### Unifying principle
|
||||
Both sources produce the same canonical Program Graph abstraction.
|
||||
|
||||
#### Source analyzers produce:
|
||||
- Function/method nodes using language signatures
|
||||
- Edges from static analysis IR
|
||||
|
||||
#### Post-build analyzers produce:
|
||||
- Nodes from bytecode/assembly symbol tables (where available)
|
||||
- Edges from bytecode call instructions / metadata
|
||||
|
||||
### Practical sequencing (recommended)
|
||||
1. Implement one source language adapter (fastest to prove model)
|
||||
2. Implement one post-build adapter where symbols are rich (e.g., Java bytecode)
|
||||
3. Ensure evidence schema and attestation workflow works identically for both
|
||||
4. Expand to more ecosystems once the proof pipeline is stable
|
||||
|
||||
---
|
||||
|
||||
## 6) Operational constraints (performance, size, security)
|
||||
|
||||
### Performance
|
||||
- Cache program graphs per artifact digest
|
||||
- Cache vulnerability-to-code mapping per package/version
|
||||
- Compute reachability on-demand per vulnerability, but reuse graphs
|
||||
|
||||
### Evidence size
|
||||
- Limit witness paths (e.g., up to N shortest paths)
|
||||
- Prefer “witness + bounded neighborhood” over exporting full call graph
|
||||
|
||||
### Security and privacy
|
||||
- Provide a “redacted proof mode”
|
||||
- include symbol hashes instead of raw names if needed
|
||||
- store source locations as hashes/pointers
|
||||
- Never embed raw source code unless explicitly enabled
|
||||
|
||||
---
|
||||
|
||||
## 7) Definition of Done for the engineering team
|
||||
|
||||
A milestone is complete when you can demonstrate:
|
||||
|
||||
1. Generate a reachability proof for a known vulnerable code unit with a witness path.
|
||||
2. Serialize a canonical evidence subgraph and compute a stable hash.
|
||||
3. Sign the attestation bound to the artifact digest.
|
||||
4. Verify the attestation on a clean machine (offline).
|
||||
5. Replay the analysis from the replay bundle and reproduce the same evidence hash.
|
||||
|
||||
---
|
||||
|
||||
# Concrete artifact example (for alignment)
|
||||
|
||||
A reachability evidence object should look structurally like:
|
||||
|
||||
- `subject`: artifact digest(s)
|
||||
- `claim`:
|
||||
- `verdict`: REACHABLE / NOT_PROVEN_REACHABLE / INCONCLUSIVE
|
||||
- `entrypoints`: list of NodeIDs
|
||||
- `vulnerable_nodes`: list of NodeIDs
|
||||
- `witness_paths`: list of paths (each path = ordered NodeIDs)
|
||||
- `subgraph`:
|
||||
- `nodes`: list with stable IDs + metadata
|
||||
- `edges`: list with stable ordering + edge types
|
||||
- `assumptions`:
|
||||
- gating conditions, unresolved dynamic dispatch notes, etc.
|
||||
- `tooling`:
|
||||
- analyzer name/version/digest
|
||||
- config hash
|
||||
- mapping dataset hash
|
||||
- `hashes`:
|
||||
- evidence content hash
|
||||
- schema version
|
||||
|
||||
Then wrap and sign it as an attestation tied to the artifact digest.
|
||||
|
||||
---
|
||||
|
||||
## The one decision you should force early
|
||||
|
||||
Decide (and document) whether your semantics are:
|
||||
|
||||
- **Witness-based** (“REACHABLE only if we can produce a witness path”), and
|
||||
- **Conservative on negative claims** (“NOT_PROVEN_REACHABLE” is not “unreachable”).
|
||||
|
||||
This single decision will keep the system honest, reduce legal/audit risk, and prevent the product from drifting into hand-wavy “trust us” scoring.
|
||||
@@ -0,0 +1,268 @@
|
||||
## 1) Product direction: make “Unknowns” a first-class risk primitive
|
||||
|
||||
### Non‑negotiable product principles
|
||||
|
||||
1. **Unknowns are not suppressed findings**
|
||||
|
||||
* They are a distinct state with distinct governance.
|
||||
2. **Unknowns must be policy-addressable**
|
||||
|
||||
* If policy cannot block or allow them explicitly, the feature is incomplete.
|
||||
3. **Unknowns must be attested**
|
||||
|
||||
* Every signed decision must carry “what we don’t know” in a machine-readable way.
|
||||
4. **Unknowns must be default-on**
|
||||
|
||||
* Users may adjust thresholds, but they must not be able to “turn off unknown tracking.”
|
||||
|
||||
### Definition: what counts as an “unknown”
|
||||
|
||||
PMs must ensure that “unknown” is not vague. Define **reason-coded unknowns**, for example:
|
||||
|
||||
* **U-RCH**: Reachability unknown (call path indeterminate)
|
||||
* **U-ID**: Component identity unknown (ambiguous package / missing digest / unresolved PURL)
|
||||
* **U-PROV**: Provenance unknown (cannot map binary → source/build)
|
||||
* **U-VEX**: VEX conflict or missing applicability statement
|
||||
* **U-FEED**: Knowledge source missing (offline feed gaps, mirror stale)
|
||||
* **U-CONFIG**: Config/runtime gate unknown (feature flag not observable)
|
||||
* **U-ANALYZER**: Analyzer limitation (language/framework unsupported)
|
||||
|
||||
Each unknown must have:
|
||||
|
||||
* `reason_code` (one of a stable enum)
|
||||
* `scope` (component, binary, symbol, package, image, repo)
|
||||
* `evidence_refs` (what we inspected)
|
||||
* `assumptions` (what would need to be true/false)
|
||||
* `remediation_hint` (how to reduce unknown)
|
||||
|
||||
**Acceptance criterion:** every unknown surfaced to users can be traced to a reason code and remediation hint.
|
||||
|
||||
---
|
||||
|
||||
## 2) Policy direction: “unknown budgets” must be enforceable and environment-aware
|
||||
|
||||
### Policy model requirements
|
||||
|
||||
Policy must support:
|
||||
|
||||
* Thresholds by environment (dev/test/stage/prod)
|
||||
* Thresholds by unknown type (reachability vs provenance vs feed, etc.)
|
||||
* Severity weighting (e.g., unknown on internet-facing service is worse)
|
||||
* Exception workflow (time-bound, owner-bound)
|
||||
* Deterministic evaluation (same inputs → same result)
|
||||
|
||||
### Recommended default policy posture (ship as opinionated defaults)
|
||||
|
||||
These defaults are intentionally strict in prod:
|
||||
|
||||
**Prod (default)**
|
||||
|
||||
* `unknown_reachable == 0` (fail build/deploy)
|
||||
* `unknown_provenance == 0` (fail)
|
||||
* `unknown_total <= 3` (fail if exceeded)
|
||||
* `unknown_feed == 0` (fail; “we didn’t have data” is unacceptable for prod)
|
||||
|
||||
**Stage**
|
||||
|
||||
* `unknown_reachable <= 1`
|
||||
* `unknown_provenance <= 1`
|
||||
* `unknown_total <= 10`
|
||||
|
||||
**Dev**
|
||||
|
||||
* Never hard fail by default; warn + ticket/PR annotation
|
||||
* Still compute unknowns and show trendlines (so teams see drift)
|
||||
|
||||
### Exception policy (required to avoid “disable unknowns” pressure)
|
||||
|
||||
Implement **explicit exceptions** rather than toggles:
|
||||
|
||||
* Exception must include: `owner`, `expiry`, `justification`, `scope`, `risk_ack`
|
||||
* Exception must be emitted into attestations and reports (“this passed with exception X”).
|
||||
|
||||
**Acceptance criterion:** there is no “turn off unknowns” knob; only thresholds and expiring exceptions.
|
||||
|
||||
---
|
||||
|
||||
## 3) Reporting direction: unknowns must be visible, triaged, and trendable
|
||||
|
||||
### Required reporting surfaces
|
||||
|
||||
1. **Release / PR report**
|
||||
|
||||
* Unknown summary at top:
|
||||
|
||||
* total unknowns
|
||||
* unknowns by reason code
|
||||
* unknowns blocking policy vs not
|
||||
* “What changed?” vs previous baseline (unknown delta)
|
||||
2. **Dashboard (portfolio view)**
|
||||
|
||||
* Unknowns over time
|
||||
* Top teams/services by unknown count
|
||||
* Top unknown causes (reason codes)
|
||||
3. **Operational triage view**
|
||||
|
||||
* “Unknown queue” sortable by:
|
||||
|
||||
* environment impact (prod/stage)
|
||||
* exposure class (internet-facing/internal)
|
||||
* reason code
|
||||
* last-seen time
|
||||
* owner
|
||||
|
||||
### Reporting should drive action, not anxiety
|
||||
|
||||
Every unknown row must include:
|
||||
|
||||
* Why it’s unknown (reason code + short explanation)
|
||||
* What evidence is missing
|
||||
* How to reduce unknown (concrete steps)
|
||||
* Expected effect (e.g., “adding debug symbols will likely reduce U-RCH by ~X”)
|
||||
|
||||
**Key PM instruction:** treat unknowns like an **SLO**. Teams should be able to commit to “unknowns in prod must trend to zero.”
|
||||
|
||||
---
|
||||
|
||||
## 4) Attestations direction: unknowns must be cryptographically bound to decisions
|
||||
|
||||
Every signed decision/attestation must include an “unknowns summary” section.
|
||||
|
||||
### Attestation requirements
|
||||
|
||||
Include at minimum:
|
||||
|
||||
* `unknown_total`
|
||||
* `unknown_by_reason_code` (map of reason→count)
|
||||
* `unknown_blocking_count`
|
||||
* `unknown_details_digest` (hash of the full list if too large)
|
||||
* `policy_thresholds_applied` (the exact thresholds used)
|
||||
* `exceptions_applied` (IDs + expiries)
|
||||
* `knowledge_snapshot_id` (feeds/policy bundle hash if you support offline snapshots)
|
||||
|
||||
**Why this matters:** if you sign a “pass,” you must also sign what you *didn’t know* at the time. Otherwise the signature is not audit-grade.
|
||||
|
||||
**Acceptance criterion:** any downstream verifier can reject a signed “pass” based solely on unknown fields (e.g., “reject if unknown_reachable>0 in prod”).
|
||||
|
||||
---
|
||||
|
||||
## 5) Development direction: implement unknown propagation as a first-class data flow
|
||||
|
||||
### Core engineering tasks (must be done in this order)
|
||||
|
||||
#### A. Define the canonical “Tri-state” evaluation type
|
||||
|
||||
For any security claim, the evaluator must return:
|
||||
|
||||
* `TRUE` (evidence supports)
|
||||
* `FALSE` (evidence refutes)
|
||||
* `UNKNOWN` (insufficient evidence)
|
||||
|
||||
Do not represent unknown as nulls or missing fields. It must be explicit.
|
||||
|
||||
#### B. Build the unknown aggregator and reason-code framework
|
||||
|
||||
* A single aggregation layer computes:
|
||||
|
||||
* unknown counts per scope
|
||||
* unknown counts per reason code
|
||||
* unknown “blockers” based on policy
|
||||
* This must be deterministic and stable (no random ordering, stable IDs).
|
||||
|
||||
#### C. Ensure analyzers emit unknowns instead of silently failing
|
||||
|
||||
Any analyzer that cannot conclude must emit:
|
||||
|
||||
* `UNKNOWN` + reason code + evidence pointers
|
||||
Examples:
|
||||
* call graph incomplete → `U-RCH`
|
||||
* stripped binary cannot map symbols → `U-PROV`
|
||||
* unsupported language → `U-ANALYZER`
|
||||
|
||||
#### D. Provide “reduce unknown” instrumentation hooks
|
||||
|
||||
Attach remediation metadata:
|
||||
|
||||
* “add build flags …”
|
||||
* “upload debug symbols …”
|
||||
* “enable source mapping …”
|
||||
* “mirror feeds …”
|
||||
|
||||
This is how you prevent user backlash.
|
||||
|
||||
---
|
||||
|
||||
## 6) Make it default rather than optional: rollout plan without breaking adoption
|
||||
|
||||
### Phase 1: compute + display (no blocking)
|
||||
|
||||
* Unknowns computed for all scans
|
||||
* Reports show unknown budgets and what would have failed in prod
|
||||
* Collect baseline metrics for 2–4 weeks of typical usage
|
||||
|
||||
### Phase 2: soft gating
|
||||
|
||||
* In prod-like pipelines: fail only on `unknown_reachable > 0`
|
||||
* Everything else warns + requires owner acknowledgement
|
||||
|
||||
### Phase 3: full policy enforcement
|
||||
|
||||
* Enforce default thresholds
|
||||
* Exceptions require expiry and are visible in attestations
|
||||
|
||||
### Phase 4: governance integration
|
||||
|
||||
* Unknowns become part of:
|
||||
|
||||
* release readiness checks
|
||||
* quarterly risk reviews
|
||||
* vendor compliance audits
|
||||
|
||||
**Dev Manager instruction:** invest in tooling that reduces unknowns early (symbol capture, provenance mapping, better analyzers). Otherwise “unknown gating” becomes politically unsustainable.
|
||||
|
||||
---
|
||||
|
||||
## 7) “Definition of Done” checklist for PMs and Dev Managers
|
||||
|
||||
### PM DoD
|
||||
|
||||
* [ ] Unknowns are explicitly defined with stable reason codes
|
||||
* [ ] Policy can fail on unknowns with environment-scoped thresholds
|
||||
* [ ] Reports show unknown deltas and remediation guidance
|
||||
* [ ] Exceptions are time-bound and appear everywhere (UI + API + attestations)
|
||||
* [ ] Unknowns cannot be disabled; only thresholds/exceptions are configurable
|
||||
|
||||
### Engineering DoD
|
||||
|
||||
* [ ] Tri-state evaluation implemented end-to-end
|
||||
* [ ] Analyzer failures never disappear; they become unknowns
|
||||
* [ ] Unknown aggregation is deterministic and reproducible
|
||||
* [ ] Signed attestation includes unknown summary + policy thresholds + exceptions
|
||||
* [ ] CI/CD integration can enforce “fail if unknowns > N in prod”
|
||||
|
||||
---
|
||||
|
||||
## 8) Concrete policy examples you can standardize internally
|
||||
|
||||
### Minimal policy (prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_provenance > 0`
|
||||
|
||||
### Balanced policy (prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_provenance > 0`
|
||||
* OR `unknown_total > 3`
|
||||
|
||||
### Risk-sensitive policy (internet-facing prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_total > 1`
|
||||
* OR any unknown affects a component with known remotely-exploitable CVEs
|
||||
@@ -0,0 +1,299 @@
|
||||
## 1) Anchor the differentiator in one sentence everyone repeats
|
||||
|
||||
**Positioning invariant:**
|
||||
Stella Ops does not “consume VEX to suppress findings.” Stella Ops **verifies who made the claim, scores how much to trust it, deterministically applies it to a decision, and emits a signed, replayable verdict**.
|
||||
|
||||
Everything you ship should make that sentence more true.
|
||||
|
||||
---
|
||||
|
||||
## 2) Shared vocabulary PMs/DMs must standardize
|
||||
|
||||
If you don’t align on these, you’ll ship features that look similar to competitors but do not compound into a moat.
|
||||
|
||||
### Core objects
|
||||
- **VEX source**: a distribution channel and issuer identity (e.g., vendor feed, distro feed, OCI-attached attestation).
|
||||
- **Issuer identity**: cryptographic identity used to sign/attest the VEX (key/cert/OIDC identity), not a string.
|
||||
- **VEX statement**: one claim about one vulnerability status for one or more products; common statuses include *Not Affected, Affected, Fixed, Under Investigation* (terminology varies by format). citeturn6view1turn10view0
|
||||
- **Verification result**: cryptographic + semantic verification facts about a VEX document/source.
|
||||
- **Trust score**: deterministic numeric/ranked evaluation of the source and/or statement quality.
|
||||
- **Decision**: a policy outcome (pass/fail/needs-review) for a specific artifact or release.
|
||||
- **Attestation**: signed statement bound to an artifact (e.g., OCI artifact) that captures decision + evidence.
|
||||
- **Knowledge snapshot**: frozen set of inputs (VEX docs, keys, policies, vulnerability DB versions, scoring code version) required for deterministic replay.
|
||||
|
||||
---
|
||||
|
||||
## 3) Product Manager guidelines
|
||||
|
||||
### 3.1 Treat “VEX source onboarding” as a first-class product workflow
|
||||
Your differentiator collapses if VEX is just “upload a file.”
|
||||
|
||||
**PM requirements:**
|
||||
1. **VEX Source Registry UI/API**
|
||||
- Add/edit a source: URL/feed/OCI pattern, update cadence, expected issuer(s), allowed formats.
|
||||
- Define trust policy per source (thresholds, allowed statuses, expiry, overrides).
|
||||
2. **Issuer enrollment & key lifecycle**
|
||||
- Capture: issuer identity, trust anchor, rotation, revocation/deny-list, “break-glass disable.”
|
||||
3. **Operational status**
|
||||
- Source health: last fetch, last verified doc, signature failures, schema failures, drift.
|
||||
|
||||
**Why it matters:** customers will only operationalize VEX at scale if they can **govern it like a dependency feed**, not like a manual exception list.
|
||||
|
||||
### 3.2 Make “verification” visible, not implied
|
||||
If users can’t see it, they won’t trust it—and auditors won’t accept it.
|
||||
|
||||
**Minimum UX per VEX document/statement:**
|
||||
- Verification status: **Verified / Unverified / Failed**
|
||||
- Issuer identity: who signed it (and via what trust anchor)
|
||||
- Format + schema validation status (OpenVEX JSON schema exists and is explicitly recommended for validation). citeturn10view0
|
||||
- Freshness: timestamp, last updated
|
||||
- Product mapping coverage: “X of Y products matched to SBOM/components”
|
||||
|
||||
### 3.3 Provide “trust score explanations” as a primary UI primitive
|
||||
Trust scoring must not feel like a magic number.
|
||||
|
||||
**UX requirement:** every trust score shows a **breakdown** (e.g., Identity 30/30, Authority 20/25, Freshness 8/10, Evidence quality 6/10…).
|
||||
|
||||
This is both:
|
||||
- a user adoption requirement (security teams will challenge it), and
|
||||
- a moat hardener (competitors rarely expose scoring mechanics).
|
||||
|
||||
### 3.4 Define policy experiences that force deterministic coupling
|
||||
You are not building a “VEX viewer.” You are building **decisioning**.
|
||||
|
||||
Policies must allow:
|
||||
- “Accept VEX only if verified AND trust score ≥ threshold”
|
||||
- “Accept Not Affected only if justification/impact statement exists”
|
||||
- “If conflicting VEX exists, resolve by trust-weighted precedence”
|
||||
- “For unverified VEX, treat status as Under Investigation (or Unknown), not Not Affected”
|
||||
|
||||
This aligns with CSAF’s VEX profile expectation that *known_not_affected* should have an impact statement (machine-readable flag or human-readable justification). citeturn1view1
|
||||
|
||||
### 3.5 Ship “audit export” as a product feature, not a report
|
||||
Auditors want to know:
|
||||
- which VEX claims were applied,
|
||||
- who asserted them,
|
||||
- what trust policy allowed them,
|
||||
- and what was the resulting decision.
|
||||
|
||||
ENISA’s SBOM guidance explicitly emphasizes “historical snapshots” and “evidence chain integrity” as success criteria for SBOM/VEX integration programs. citeturn8view0
|
||||
|
||||
So your product needs:
|
||||
- exportable evidence bundles (machine-readable)
|
||||
- signed verdicts linked to the artifact
|
||||
- replay semantics (“recompute this exact decision later”)
|
||||
|
||||
### 3.6 MVP scoping: start with sources that prove the model
|
||||
For early product proof, prioritize sources that:
|
||||
- are official,
|
||||
- have consistent structure,
|
||||
- publish frequently,
|
||||
- contain configuration nuance.
|
||||
|
||||
Example: Ubuntu publishes VEX following OpenVEX, emphasizing exploitability in specific configurations and providing official distribution points (tarball + GitHub). citeturn9view0turn6view0
|
||||
|
||||
This gives you a clean first dataset for verification/trust scoring behaviors.
|
||||
|
||||
---
|
||||
|
||||
## 4) Development Manager guidelines
|
||||
|
||||
### 4.1 Architect it as a pipeline with hard boundaries
|
||||
Do not mix verification, scoring, and decisioning in one component. You need isolatable, testable stages.
|
||||
|
||||
**Recommended pipeline stages:**
|
||||
1. **Ingest**
|
||||
- Fetch from registry/OCI
|
||||
- Deduplicate by content hash
|
||||
2. **Parse & normalize**
|
||||
- Convert OpenVEX / CSAF VEX / CycloneDX VEX into a **canonical internal VEX model**
|
||||
- Note: OpenVEX explicitly calls out that CycloneDX VEX uses different status/justification labels and may need translation. citeturn10view0
|
||||
3. **Verify (cryptographic + semantic)**
|
||||
4. **Trust score (pure function)**
|
||||
5. **Conflict resolve**
|
||||
6. **Decision**
|
||||
7. **Attest + persist snapshot**
|
||||
|
||||
### 4.2 Verification must include both cryptography and semantics
|
||||
|
||||
#### Cryptographic verification (minimum bar)
|
||||
- Verify signature/attestation against expected issuer identity.
|
||||
- Validate certificate/identity chains per customer trust anchors.
|
||||
- Support OCI-attached artifacts and “signature-of-signature” patterns (Sigstore describes countersigning: signature artifacts can themselves be signed). citeturn1view3
|
||||
|
||||
#### Semantic verification (equally important)
|
||||
- Schema validation (OpenVEX provides JSON schema guidance). citeturn10view0
|
||||
- Vulnerability identifier validity (CVE/aliases)
|
||||
- Product reference validity (e.g., purl)
|
||||
- Statement completeness rules:
|
||||
- “Not affected” must include rationale; CSAF VEX profile requires an impact statement for known_not_affected in flags or threats. citeturn1view1
|
||||
- Cross-check the statement scope to known SBOM/components:
|
||||
- If the VEX references products that do not exist in the artifact SBOM, the claim should not affect the decision (or should reduce trust sharply).
|
||||
|
||||
### 4.3 Trust scoring must be deterministic by construction
|
||||
If trust scoring varies between runs, you cannot produce replayable, attestable decisions.
|
||||
|
||||
**Rules for determinism:**
|
||||
- Trust score is a **pure function** of:
|
||||
- VEX document hash
|
||||
- verification result
|
||||
- source configuration (immutable version)
|
||||
- scoring algorithm version
|
||||
- evaluation timestamp (explicit input, included in snapshot)
|
||||
- Never call external services during scoring unless responses are captured and hashed into the snapshot.
|
||||
|
||||
### 4.4 Implement two trust concepts: Source Trust and Statement Quality
|
||||
Do not overload one score to do everything.
|
||||
|
||||
- **Source Trust**: “how much do we trust the issuer/channel?”
|
||||
- **Statement Quality**: “how well-formed, specific, justified is this statement?”
|
||||
|
||||
You can then combine them:
|
||||
`TrustScore = f(SourceTrust, StatementQuality, Freshness, TrackRecord)`
|
||||
|
||||
### 4.5 Conflict resolution must be policy-driven, not hard-coded
|
||||
Conflicting VEX is inevitable:
|
||||
- vendor vs distro
|
||||
- older vs newer
|
||||
- internal vs external
|
||||
|
||||
Resolve via:
|
||||
- deterministic precedence rules configured per tenant
|
||||
- trust-weighted tie-breakers
|
||||
- “newer statement wins” only when issuer is the same or within the same trust class
|
||||
|
||||
### 4.6 Store VEX and decision inputs as content-addressed artifacts
|
||||
If you want replayability, you must be able to reconstruct the “world state.”
|
||||
|
||||
**Persist:**
|
||||
- VEX docs (by digest)
|
||||
- verification artifacts (signature bundles, cert chains)
|
||||
- normalized VEX statements (canonical form)
|
||||
- trust score + breakdown + algorithm version
|
||||
- policy bundle + version
|
||||
- vulnerability DB snapshot identifiers
|
||||
- decision output + evidence pointers
|
||||
|
||||
---
|
||||
|
||||
## 5) A practical trust scoring rubric you can hand to teams
|
||||
|
||||
Use a 0–100 score with defined buckets. The weights below are a starting point; what matters is consistency and explainability.
|
||||
|
||||
### 5.1 Source Trust (0–60)
|
||||
1. **Issuer identity verified (0–25)**
|
||||
- 0 if unsigned/unverifiable
|
||||
- 25 if signature verified to a known trust anchor
|
||||
2. **Issuer authority alignment (0–20)**
|
||||
- 20 if issuer is the product supplier/distro maintainer for that component set
|
||||
- lower if third party / aggregator
|
||||
3. **Distribution integrity (0–15)**
|
||||
- extra credit if the VEX is distributed as an attestation bound to an artifact and/or uses auditable signature patterns (e.g., countersigning). citeturn1view3turn10view0
|
||||
|
||||
### 5.2 Statement Quality (0–40)
|
||||
1. **Scope specificity (0–15)**
|
||||
- exact product IDs (purl), versions, architectures, etc.
|
||||
2. **Justification/impact present and structured (0–15)**
|
||||
- CSAF VEX expects impact statement for known_not_affected; Ubuntu maps “not_affected” to justifications like `vulnerable_code_not_present`. citeturn1view1turn9view0
|
||||
3. **Freshness (0–10)**
|
||||
- based on statement/document timestamps (explicitly hashed into snapshot)
|
||||
|
||||
### Score buckets
|
||||
- **90–100**: Verified + authoritative + high-quality → eligible for gating
|
||||
- **70–89**: Verified but weaker evidence/scope → eligible with policy constraints
|
||||
- **40–69**: Mixed/partial trust → informational, not gating by default
|
||||
- **0–39**: Unverified/low quality → do not affect decisions
|
||||
|
||||
---
|
||||
|
||||
## 6) Tight coupling to deterministic decisioning: what “coupling” means in practice
|
||||
|
||||
### 6.1 VEX must be an input to the same deterministic evaluation engine that produces the verdict
|
||||
Do not build “VEX handling” as a sidecar that produces annotations.
|
||||
|
||||
**Decision engine inputs must include:**
|
||||
- SBOM / component graph
|
||||
- vulnerability findings
|
||||
- normalized VEX statements
|
||||
- verification results + trust scores
|
||||
- tenant policy bundle
|
||||
- evaluation timestamp + snapshot identifiers
|
||||
|
||||
The engine output must include:
|
||||
- final status per vulnerability (affected/not affected/fixed/under investigation/unknown)
|
||||
- **why** (evidence pointers)
|
||||
- the policy rule(s) that caused it
|
||||
|
||||
### 6.2 Default posture: fail-safe, not fail-open
|
||||
Recommended defaults:
|
||||
- **Unverified VEX never suppresses vulnerabilities.**
|
||||
- Trust score below threshold never suppresses.
|
||||
- “Not affected” without justification/impact statement never suppresses.
|
||||
|
||||
This is aligned with CSAF VEX expectations and avoids the easiest suppression attack vector. citeturn1view1
|
||||
|
||||
### 6.3 Make uncertainty explicit
|
||||
If VEX conflicts or is low trust, your decisioning must produce explicit states like:
|
||||
- “Unknown (insufficient trusted VEX)”
|
||||
- “Under Investigation”
|
||||
|
||||
That is consistent with common VEX status vocabulary and avoids false certainty. citeturn6view1turn9view0
|
||||
|
||||
---
|
||||
|
||||
## 7) Tight coupling to attestations: what to attest, when, and why
|
||||
|
||||
### 7.1 Attest **decisions**, not just documents
|
||||
Competitors already sign SBOMs. Your moat is signing the **verdict** with the evidence chain.
|
||||
|
||||
Each signed verdict should bind:
|
||||
- subject artifact digest (container/image/package)
|
||||
- decision output (pass/fail/etc.)
|
||||
- hashes of:
|
||||
- VEX docs used
|
||||
- verification artifacts
|
||||
- trust scoring breakdown
|
||||
- policy bundle
|
||||
- vulnerability DB snapshot identifiers
|
||||
|
||||
### 7.2 Make attestations replayable
|
||||
Your attestation must contain enough references (digests) that the system can:
|
||||
- re-run the decision in an air-gapped environment
|
||||
- obtain the same outputs
|
||||
|
||||
This aligns with “historical snapshots” / “evidence chain integrity” expectations in modern SBOM programs. citeturn8view0
|
||||
|
||||
### 7.3 Provide two attestations (recommended)
|
||||
1. **VEX intake attestation** (optional but powerful)
|
||||
- “We ingested and verified this VEX doc from issuer X under policy Y.”
|
||||
2. **Risk verdict attestation** (core differentiator)
|
||||
- “Given SBOM, vulnerabilities, verified VEX, and policy snapshot, the artifact is acceptable/unacceptable.”
|
||||
|
||||
Sigstore’s countersigning concept illustrates that you can add layers of trust over artifacts/signatures; your verdict is the enterprise-grade layer. citeturn1view3
|
||||
|
||||
---
|
||||
|
||||
## 8) “Definition of Done” checklists (use in roadmaps)
|
||||
|
||||
### PM DoD for VEX Trust (ship criteria)
|
||||
- A customer can onboard a VEX source and see issuer identity + verification state.
|
||||
- Trust score exists with a visible breakdown and policy thresholds.
|
||||
- Policies can gate on trust score + verification.
|
||||
- Audit export: per release, show which VEX claims affected the final decision.
|
||||
|
||||
### DM DoD for Deterministic + Attestable
|
||||
- Same inputs → identical trust score and decision (golden tests).
|
||||
- All inputs content-addressed and captured in a snapshot bundle.
|
||||
- Attestation includes digests of all relevant inputs and a decision summary.
|
||||
- No network dependency at evaluation time unless recorded in snapshot.
|
||||
|
||||
---
|
||||
|
||||
## 9) Metrics that prove you differentiated
|
||||
|
||||
Track these from the first pilot:
|
||||
1. **% of decisions backed by verified VEX** (not just present)
|
||||
2. **% of “not affected” outcomes with cryptographic verification + justification**
|
||||
3. **Replay success rate** (recompute verdict from snapshot)
|
||||
4. **Time-to-audit** (minutes to produce evidence chain for a release)
|
||||
5. **False suppression rate** (should be effectively zero with fail-safe defaults)
|
||||
@@ -0,0 +1,268 @@
|
||||
## 1) Product direction: make “Unknowns” a first-class risk primitive
|
||||
|
||||
### Non‑negotiable product principles
|
||||
|
||||
1. **Unknowns are not suppressed findings**
|
||||
|
||||
* They are a distinct state with distinct governance.
|
||||
2. **Unknowns must be policy-addressable**
|
||||
|
||||
* If policy cannot block or allow them explicitly, the feature is incomplete.
|
||||
3. **Unknowns must be attested**
|
||||
|
||||
* Every signed decision must carry “what we don’t know” in a machine-readable way.
|
||||
4. **Unknowns must be default-on**
|
||||
|
||||
* Users may adjust thresholds, but they must not be able to “turn off unknown tracking.”
|
||||
|
||||
### Definition: what counts as an “unknown”
|
||||
|
||||
PMs must ensure that “unknown” is not vague. Define **reason-coded unknowns**, for example:
|
||||
|
||||
* **U-RCH**: Reachability unknown (call path indeterminate)
|
||||
* **U-ID**: Component identity unknown (ambiguous package / missing digest / unresolved PURL)
|
||||
* **U-PROV**: Provenance unknown (cannot map binary → source/build)
|
||||
* **U-VEX**: VEX conflict or missing applicability statement
|
||||
* **U-FEED**: Knowledge source missing (offline feed gaps, mirror stale)
|
||||
* **U-CONFIG**: Config/runtime gate unknown (feature flag not observable)
|
||||
* **U-ANALYZER**: Analyzer limitation (language/framework unsupported)
|
||||
|
||||
Each unknown must have:
|
||||
|
||||
* `reason_code` (one of a stable enum)
|
||||
* `scope` (component, binary, symbol, package, image, repo)
|
||||
* `evidence_refs` (what we inspected)
|
||||
* `assumptions` (what would need to be true/false)
|
||||
* `remediation_hint` (how to reduce unknown)
|
||||
|
||||
**Acceptance criterion:** every unknown surfaced to users can be traced to a reason code and remediation hint.
|
||||
|
||||
---
|
||||
|
||||
## 2) Policy direction: “unknown budgets” must be enforceable and environment-aware
|
||||
|
||||
### Policy model requirements
|
||||
|
||||
Policy must support:
|
||||
|
||||
* Thresholds by environment (dev/test/stage/prod)
|
||||
* Thresholds by unknown type (reachability vs provenance vs feed, etc.)
|
||||
* Severity weighting (e.g., unknown on internet-facing service is worse)
|
||||
* Exception workflow (time-bound, owner-bound)
|
||||
* Deterministic evaluation (same inputs → same result)
|
||||
|
||||
### Recommended default policy posture (ship as opinionated defaults)
|
||||
|
||||
These defaults are intentionally strict in prod:
|
||||
|
||||
**Prod (default)**
|
||||
|
||||
* `unknown_reachable == 0` (fail build/deploy)
|
||||
* `unknown_provenance == 0` (fail)
|
||||
* `unknown_total <= 3` (fail if exceeded)
|
||||
* `unknown_feed == 0` (fail; “we didn’t have data” is unacceptable for prod)
|
||||
|
||||
**Stage**
|
||||
|
||||
* `unknown_reachable <= 1`
|
||||
* `unknown_provenance <= 1`
|
||||
* `unknown_total <= 10`
|
||||
|
||||
**Dev**
|
||||
|
||||
* Never hard fail by default; warn + ticket/PR annotation
|
||||
* Still compute unknowns and show trendlines (so teams see drift)
|
||||
|
||||
### Exception policy (required to avoid “disable unknowns” pressure)
|
||||
|
||||
Implement **explicit exceptions** rather than toggles:
|
||||
|
||||
* Exception must include: `owner`, `expiry`, `justification`, `scope`, `risk_ack`
|
||||
* Exception must be emitted into attestations and reports (“this passed with exception X”).
|
||||
|
||||
**Acceptance criterion:** there is no “turn off unknowns” knob; only thresholds and expiring exceptions.
|
||||
|
||||
---
|
||||
|
||||
## 3) Reporting direction: unknowns must be visible, triaged, and trendable
|
||||
|
||||
### Required reporting surfaces
|
||||
|
||||
1. **Release / PR report**
|
||||
|
||||
* Unknown summary at top:
|
||||
|
||||
* total unknowns
|
||||
* unknowns by reason code
|
||||
* unknowns blocking policy vs not
|
||||
* “What changed?” vs previous baseline (unknown delta)
|
||||
2. **Dashboard (portfolio view)**
|
||||
|
||||
* Unknowns over time
|
||||
* Top teams/services by unknown count
|
||||
* Top unknown causes (reason codes)
|
||||
3. **Operational triage view**
|
||||
|
||||
* “Unknown queue” sortable by:
|
||||
|
||||
* environment impact (prod/stage)
|
||||
* exposure class (internet-facing/internal)
|
||||
* reason code
|
||||
* last-seen time
|
||||
* owner
|
||||
|
||||
### Reporting should drive action, not anxiety
|
||||
|
||||
Every unknown row must include:
|
||||
|
||||
* Why it’s unknown (reason code + short explanation)
|
||||
* What evidence is missing
|
||||
* How to reduce unknown (concrete steps)
|
||||
* Expected effect (e.g., “adding debug symbols will likely reduce U-RCH by ~X”)
|
||||
|
||||
**Key PM instruction:** treat unknowns like an **SLO**. Teams should be able to commit to “unknowns in prod must trend to zero.”
|
||||
|
||||
---
|
||||
|
||||
## 4) Attestations direction: unknowns must be cryptographically bound to decisions
|
||||
|
||||
Every signed decision/attestation must include an “unknowns summary” section.
|
||||
|
||||
### Attestation requirements
|
||||
|
||||
Include at minimum:
|
||||
|
||||
* `unknown_total`
|
||||
* `unknown_by_reason_code` (map of reason→count)
|
||||
* `unknown_blocking_count`
|
||||
* `unknown_details_digest` (hash of the full list if too large)
|
||||
* `policy_thresholds_applied` (the exact thresholds used)
|
||||
* `exceptions_applied` (IDs + expiries)
|
||||
* `knowledge_snapshot_id` (feeds/policy bundle hash if you support offline snapshots)
|
||||
|
||||
**Why this matters:** if you sign a “pass,” you must also sign what you *didn’t know* at the time. Otherwise the signature is not audit-grade.
|
||||
|
||||
**Acceptance criterion:** any downstream verifier can reject a signed “pass” based solely on unknown fields (e.g., “reject if unknown_reachable>0 in prod”).
|
||||
|
||||
---
|
||||
|
||||
## 5) Development direction: implement unknown propagation as a first-class data flow
|
||||
|
||||
### Core engineering tasks (must be done in this order)
|
||||
|
||||
#### A. Define the canonical “Tri-state” evaluation type
|
||||
|
||||
For any security claim, the evaluator must return:
|
||||
|
||||
* `TRUE` (evidence supports)
|
||||
* `FALSE` (evidence refutes)
|
||||
* `UNKNOWN` (insufficient evidence)
|
||||
|
||||
Do not represent unknown as nulls or missing fields. It must be explicit.
|
||||
|
||||
#### B. Build the unknown aggregator and reason-code framework
|
||||
|
||||
* A single aggregation layer computes:
|
||||
|
||||
* unknown counts per scope
|
||||
* unknown counts per reason code
|
||||
* unknown “blockers” based on policy
|
||||
* This must be deterministic and stable (no random ordering, stable IDs).
|
||||
|
||||
#### C. Ensure analyzers emit unknowns instead of silently failing
|
||||
|
||||
Any analyzer that cannot conclude must emit:
|
||||
|
||||
* `UNKNOWN` + reason code + evidence pointers
|
||||
Examples:
|
||||
* call graph incomplete → `U-RCH`
|
||||
* stripped binary cannot map symbols → `U-PROV`
|
||||
* unsupported language → `U-ANALYZER`
|
||||
|
||||
#### D. Provide “reduce unknown” instrumentation hooks
|
||||
|
||||
Attach remediation metadata:
|
||||
|
||||
* “add build flags …”
|
||||
* “upload debug symbols …”
|
||||
* “enable source mapping …”
|
||||
* “mirror feeds …”
|
||||
|
||||
This is how you prevent user backlash.
|
||||
|
||||
---
|
||||
|
||||
## 6) Make it default rather than optional: rollout plan without breaking adoption
|
||||
|
||||
### Phase 1: compute + display (no blocking)
|
||||
|
||||
* Unknowns computed for all scans
|
||||
* Reports show unknown budgets and what would have failed in prod
|
||||
* Collect baseline metrics for 2–4 weeks of typical usage
|
||||
|
||||
### Phase 2: soft gating
|
||||
|
||||
* In prod-like pipelines: fail only on `unknown_reachable > 0`
|
||||
* Everything else warns + requires owner acknowledgement
|
||||
|
||||
### Phase 3: full policy enforcement
|
||||
|
||||
* Enforce default thresholds
|
||||
* Exceptions require expiry and are visible in attestations
|
||||
|
||||
### Phase 4: governance integration
|
||||
|
||||
* Unknowns become part of:
|
||||
|
||||
* release readiness checks
|
||||
* quarterly risk reviews
|
||||
* vendor compliance audits
|
||||
|
||||
**Dev Manager instruction:** invest in tooling that reduces unknowns early (symbol capture, provenance mapping, better analyzers). Otherwise “unknown gating” becomes politically unsustainable.
|
||||
|
||||
---
|
||||
|
||||
## 7) “Definition of Done” checklist for PMs and Dev Managers
|
||||
|
||||
### PM DoD
|
||||
|
||||
* [ ] Unknowns are explicitly defined with stable reason codes
|
||||
* [ ] Policy can fail on unknowns with environment-scoped thresholds
|
||||
* [ ] Reports show unknown deltas and remediation guidance
|
||||
* [ ] Exceptions are time-bound and appear everywhere (UI + API + attestations)
|
||||
* [ ] Unknowns cannot be disabled; only thresholds/exceptions are configurable
|
||||
|
||||
### Engineering DoD
|
||||
|
||||
* [ ] Tri-state evaluation implemented end-to-end
|
||||
* [ ] Analyzer failures never disappear; they become unknowns
|
||||
* [ ] Unknown aggregation is deterministic and reproducible
|
||||
* [ ] Signed attestation includes unknown summary + policy thresholds + exceptions
|
||||
* [ ] CI/CD integration can enforce “fail if unknowns > N in prod”
|
||||
|
||||
---
|
||||
|
||||
## 8) Concrete policy examples you can standardize internally
|
||||
|
||||
### Minimal policy (prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_provenance > 0`
|
||||
|
||||
### Balanced policy (prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_provenance > 0`
|
||||
* OR `unknown_total > 3`
|
||||
|
||||
### Risk-sensitive policy (internet-facing prod)
|
||||
|
||||
* Block deploy if:
|
||||
|
||||
* `unknown_reachable > 0`
|
||||
* OR `unknown_total > 1`
|
||||
* OR any unknown affects a component with known remotely-exploitable CVEs
|
||||
@@ -0,0 +1,469 @@
|
||||
Below are implementation-grade guidelines for Stella Ops Product Managers (PMs) and Development Managers (Eng Managers / Tech Leads) for two tightly coupled capabilities:
|
||||
|
||||
1. **Exception management as auditable objects** (not suppression files)
|
||||
2. **Audit packs** (exportable, verifiable evidence bundles for releases and environments)
|
||||
|
||||
The intent is to make these capabilities:
|
||||
|
||||
* operationally useful (reduce friction in CI/CD and runtime governance),
|
||||
* defensible in audits (tamper-evident, attributable, time-bounded), and
|
||||
* consistent with Stella Ops’ positioning around determinism, evidence, and replayability.
|
||||
|
||||
---
|
||||
|
||||
# 1. Shared objectives and boundaries
|
||||
|
||||
## 1.1 Objectives
|
||||
|
||||
These two capabilities must jointly enable:
|
||||
|
||||
* **Risk decisions are explicit**: Every “ignore/suppress/waive” is a governed decision with an owner and expiry.
|
||||
* **Decisions are replayable**: If an auditor asks “why did you ship this on date X?”, Stella Ops can reproduce the decision using the same policy + evidence + knowledge snapshot.
|
||||
* **Decisions are exportable and verifiable**: Audit packs include the minimum necessary artifacts and a manifest that allows independent verification of integrity and completeness.
|
||||
* **Operational friction is reduced**: Teams can ship safely with controlled exceptions, rather than ad-hoc suppressions, while retaining accountability.
|
||||
|
||||
## 1.2 Out of scope (explicitly)
|
||||
|
||||
Avoid scope creep early. The following are out of scope for v1 unless mandated by a target customer:
|
||||
|
||||
* Full GRC mapping to specific frameworks (you can *support evidence*; don’t claim compliance).
|
||||
* Fully automated approvals based on HR org charts.
|
||||
* Multi-year archival systems (start with retention, export, and immutable event logs).
|
||||
* A “ticketing system replacement.” Integrate with ticketing; don’t rebuild it.
|
||||
|
||||
---
|
||||
|
||||
# 2. Shared design principles (non-negotiables)
|
||||
|
||||
These principles apply to both Exception Objects and Audit Packs:
|
||||
|
||||
1. **Attribution**: every action has an authenticated actor identity (human or service), a timestamp, and a reason.
|
||||
2. **Immutability of history**: edits are new versions/events; never rewrite history in place.
|
||||
3. **Least privilege scope**: exceptions must be as narrow as possible (artifact digest over tag; component purl over “any”; environment constraints).
|
||||
4. **Time-bounded risk**: exceptions must expire. “Permanent ignore” is a governance smell.
|
||||
5. **Deterministic evaluation**: given the same policy + snapshot + exceptions + inputs, the outcome is stable and reproducible.
|
||||
6. **Separation of concerns**:
|
||||
|
||||
* Exception store = governed decisions.
|
||||
* Scanner = evidence producer.
|
||||
* Policy engine = deterministic evaluator.
|
||||
* Audit packer = exporter/assembler/verifier.
|
||||
|
||||
---
|
||||
|
||||
# 3. Exception management as auditable objects
|
||||
|
||||
## 3.1 What an “Exception Object” is
|
||||
|
||||
An Exception Object is a structured, versioned record that modifies evaluation behavior *in a controlled manner*, while leaving the underlying findings intact.
|
||||
|
||||
It is not:
|
||||
|
||||
* a local `.ignore` file,
|
||||
* a hidden suppression rule,
|
||||
* a UI-only toggle,
|
||||
* a vendor-specific “ignore list” with no audit trail.
|
||||
|
||||
### Exception types you should support (minimum set)
|
||||
|
||||
PMs should start with these canonical types:
|
||||
|
||||
1. **Vulnerability exception**
|
||||
|
||||
* suppress/waive a specific vulnerability finding (e.g., CVE/CWE) under defined scope.
|
||||
2. **Policy exception**
|
||||
|
||||
* allow a policy rule to be bypassed under defined scope (e.g., “allow unsigned artifact for dev namespace”).
|
||||
3. **Unknown-state exception** (if Stella models unknowns)
|
||||
|
||||
* allow a release despite unresolved unknowns, with explicit risk acceptance.
|
||||
4. **Component exception**
|
||||
|
||||
* allow/deny a component/package/version across a domain, again with explicit scope and expiry.
|
||||
|
||||
## 3.2 Required fields and schema guidelines
|
||||
|
||||
PMs: mandate these fields; Eng: enforce them at API and storage level.
|
||||
|
||||
### Required fields (v1)
|
||||
|
||||
* **exception_id** (stable identifier)
|
||||
* **version** (monotonic; or event-sourced)
|
||||
* **status**: proposed | approved | active | expired | revoked
|
||||
* **owner** (accountable person/team)
|
||||
* **requester** (who initiated)
|
||||
* **approver(s)** (who approved; may be empty for dev environments depending on policy)
|
||||
* **created_at / updated_at / approved_at / expires_at**
|
||||
* **scope** (see below)
|
||||
* **reason_code** (taxonomy)
|
||||
* **rationale** (free text, required)
|
||||
* **evidence_refs** (optional in v1 but strongly recommended)
|
||||
* **risk_acceptance** (explicit boolean or structured “risk accepted” block)
|
||||
* **links** (ticket ID, PR, incident, vendor advisory reference) – optional but useful
|
||||
* **audit_log_refs** (implicit if event-sourced)
|
||||
|
||||
### Scope model (critical to defensibility)
|
||||
|
||||
Scope must be structured and narrowable. Provide scope dimensions such as:
|
||||
|
||||
* **Artifact scope**: image digest, SBOM digest, build provenance digest (preferred)
|
||||
(Avoid tags as primary scope unless paired with immutability constraints.)
|
||||
* **Component scope**: purl + version range + ecosystem
|
||||
* **Vulnerability scope**: CVE ID(s), GHSA, internal ID; optionally path/function/symbol constraints
|
||||
* **Environment scope**: cluster/namespace, runtime env (dev/stage/prod), repository, project, tenant
|
||||
* **Time scope**: expires_at (required), optional “valid_from”
|
||||
|
||||
PM guideline: default UI and API should encourage digest-based scope and warn on broad scopes.
|
||||
|
||||
## 3.3 Reason codes (taxonomy)
|
||||
|
||||
Reason codes are a moat because they enable governance analytics and policy automation.
|
||||
|
||||
Minimum suggested taxonomy:
|
||||
|
||||
* **FALSE_POSITIVE** (with evidence expectations)
|
||||
* **NOT_REACHABLE** (reachable proof preferred)
|
||||
* **NOT_AFFECTED** (VEX-backed preferred)
|
||||
* **BACKPORT_FIXED** (package/distro evidence preferred)
|
||||
* **COMPENSATING_CONTROL** (link to control evidence)
|
||||
* **RISK_ACCEPTED** (explicit sign-off)
|
||||
* **TEMPORARY_WORKAROUND** (link to mitigation plan)
|
||||
* **VENDOR_PENDING** (under investigation)
|
||||
* **BUSINESS_EXCEPTION** (rare; requires stronger approval)
|
||||
|
||||
PM guideline: reason codes must be selectable and reportable; do not allow “Other” as the default.
|
||||
|
||||
## 3.4 Evidence attachments
|
||||
|
||||
Exceptions should evolve from “justification-only” to “justification + evidence.”
|
||||
|
||||
Evidence references can point to:
|
||||
|
||||
* VEX statements (OpenVEX/CycloneDX VEX)
|
||||
* reachability proof fragments (call-path subgraph, symbol references)
|
||||
* distro advisories / patch references
|
||||
* internal change tickets / mitigation PRs
|
||||
* runtime mitigations
|
||||
|
||||
Eng guideline: store evidence as references with integrity checks (hash/digest). For v2+, store evidence bundles as content-addressed blobs.
|
||||
|
||||
## 3.5 Lifecycle and workflows
|
||||
|
||||
### Lifecycle states and transitions
|
||||
|
||||
* **Proposed** → **Approved** → **Active** → (**Expired** or **Revoked**)
|
||||
* **Renewal** should create a **new version** (never extend an old record silently).
|
||||
|
||||
### Approvals
|
||||
|
||||
PM guideline:
|
||||
|
||||
* At least two approval modes:
|
||||
|
||||
1. **Self-approved** (allowed only for dev/experimental scopes)
|
||||
2. **Two-person review** (required for prod or broad scope)
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Enforce approval rules via policy config (not hard-coded).
|
||||
* Record every approval action with actor identity and timestamp.
|
||||
|
||||
### Expiry enforcement
|
||||
|
||||
Non-negotiable:
|
||||
|
||||
* Expired exceptions must stop applying automatically.
|
||||
* Renewals require an explicit action and new audit trail.
|
||||
|
||||
## 3.6 Evaluation semantics (how exceptions affect results)
|
||||
|
||||
This is where most products become non-auditable. You need deterministic, explicit rules.
|
||||
|
||||
PM guideline: define precedence clearly:
|
||||
|
||||
* Policy engine evaluates baseline findings → applies exceptions → produces verdict.
|
||||
* Exceptions never delete underlying findings; they alter the *decision outcome* and annotate the reasoning.
|
||||
|
||||
Eng guideline: exception application must be:
|
||||
|
||||
* **Deterministic** (stable ordering rules)
|
||||
* **Transparent** (verdict includes “exception applied: exception_id, reason_code, scope match explanation”)
|
||||
* **Scoped** (match explanation must state which scope dimensions matched)
|
||||
|
||||
## 3.7 Auditability requirements
|
||||
|
||||
Exception management must be audit-ready by construction.
|
||||
|
||||
Minimum requirements:
|
||||
|
||||
* **Append-only event log** for create/approve/revoke/expire/renew actions
|
||||
* **Versioning**: every change results in a new version or event
|
||||
* **Tamper-evidence**: hash chain events or sign event batches
|
||||
* **Retention**: define retention policy and export strategy
|
||||
|
||||
PM guideline: auditors will ask “who approved,” “why,” “when,” “what scope,” and “what changed since.” Design the UX and exports to answer those in minutes.
|
||||
|
||||
## 3.8 UX guidelines
|
||||
|
||||
Key UX flows:
|
||||
|
||||
* **Create exception from a finding** (pre-fill CVE/component/artifact scope)
|
||||
* **Preview impact** (“this will suppress 37 findings across 12 images; are you sure?”)
|
||||
* **Expiry visibility** (countdown, alerts, renewal prompts)
|
||||
* **Audit trail view** (who did what, with diffs between versions)
|
||||
* **Search and filters** by owner, reason, expiry window, scope breadth, environment
|
||||
|
||||
UX anti-patterns to forbid:
|
||||
|
||||
* “Ignore all vulnerabilities in this image” with one click
|
||||
* Silent suppressions without owner/expiry
|
||||
* Exceptions created without linking to scope and reason
|
||||
|
||||
## 3.9 Product acceptance criteria (PM-owned)
|
||||
|
||||
A feature is not “done” until:
|
||||
|
||||
* Every exception has owner, expiry, reason code, scope.
|
||||
* Exception history is immutable and exportable.
|
||||
* Policy outcomes show applied exceptions and why.
|
||||
* Expiry is enforced automatically.
|
||||
* A user can answer: “What exceptions were active for this release?” within 2 minutes.
|
||||
|
||||
---
|
||||
|
||||
# 4. Audit packs
|
||||
|
||||
## 4.1 What an audit pack is
|
||||
|
||||
An Audit Pack is a **portable, verifiable bundle** that answers:
|
||||
|
||||
* What was evaluated? (artifacts, versions, identities)
|
||||
* Under what policies? (policy version/config)
|
||||
* Using what knowledge state? (vuln DB snapshot, VEX inputs)
|
||||
* What exceptions were applied? (IDs, owners, rationales)
|
||||
* What was the decision and why? (verdict + evidence pointers)
|
||||
* What changed since the last release? (optional diff summary)
|
||||
|
||||
PM guideline: treat the Audit Pack as a product deliverable, not an export button.
|
||||
|
||||
## 4.2 Pack structure (recommended)
|
||||
|
||||
Use a predictable, documented layout. Example:
|
||||
|
||||
* `manifest.json`
|
||||
|
||||
* pack_id, generated_at, generator_version
|
||||
* hashes/digests of every included file
|
||||
* signing info (optional in v1; recommended soon)
|
||||
* `inputs/`
|
||||
|
||||
* artifact identifiers (digests), repo references (optional)
|
||||
* SBOM(s) (CycloneDX/SPDX)
|
||||
* `vex/`
|
||||
|
||||
* VEX docs used + any VEX produced
|
||||
* `policy/`
|
||||
|
||||
* policy bundle used (versioned)
|
||||
* evaluation settings
|
||||
* `exceptions/`
|
||||
|
||||
* all exceptions relevant to the evaluated scope
|
||||
* plus event logs / versions
|
||||
* `findings/`
|
||||
|
||||
* normalized findings list
|
||||
* reachability evidence fragments if applicable
|
||||
* `verdict/`
|
||||
|
||||
* final decision object
|
||||
* explanation summary
|
||||
* signed attestation (if supported)
|
||||
* `diff/` (optional)
|
||||
|
||||
* delta from prior baseline (what changed materially)
|
||||
|
||||
## 4.3 Formats: human and machine
|
||||
|
||||
You need both:
|
||||
|
||||
* **Machine-readable** (JSON + standard SBOM/VEX formats) for verification and automation
|
||||
* **Human-readable** summary (HTML or PDF) for auditors and leadership
|
||||
|
||||
PM guideline: machine artifacts are the source of truth. Human docs are derived views.
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Ensure the pack can be generated **offline**.
|
||||
* Ensure deterministic outputs where feasible (stable ordering, consistent serialization).
|
||||
|
||||
## 4.4 Integrity and verification
|
||||
|
||||
At minimum:
|
||||
|
||||
* `manifest.json` includes a digest for each file.
|
||||
* Provide a `stella verify-pack` CLI that checks:
|
||||
|
||||
* manifest integrity
|
||||
* file hashes
|
||||
* schema versions
|
||||
* optional signature verification
|
||||
|
||||
For v2:
|
||||
|
||||
* Sign the manifest (and/or the verdict) using your standard attestation mechanism.
|
||||
|
||||
## 4.5 Confidentiality and redaction
|
||||
|
||||
Audit packs often include sensitive data (paths, internal package names, repo URLs).
|
||||
|
||||
PM guideline:
|
||||
|
||||
* Provide **redaction profiles**:
|
||||
|
||||
* external auditor pack (minimal identifiers)
|
||||
* internal audit pack (full detail)
|
||||
* Provide encryption options (password/recipient keys) if packs leave the environment.
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Redaction must be deterministic and declarative (policy-based).
|
||||
* Pack generation must not leak secrets from raw scan logs.
|
||||
|
||||
## 4.6 Pack generation workflow
|
||||
|
||||
Key product flows:
|
||||
|
||||
* Generate pack for:
|
||||
|
||||
* a specific artifact digest
|
||||
* a release (set of digests)
|
||||
* an environment snapshot (e.g., cluster inventory)
|
||||
* a date range (for audit period)
|
||||
* Trigger sources:
|
||||
|
||||
* UI
|
||||
* API
|
||||
* CI pipeline step
|
||||
|
||||
Engineering:
|
||||
|
||||
* Treat pack generation as an async job (queue + status endpoint).
|
||||
* Cache pack components when inputs are identical (avoid repeated work).
|
||||
|
||||
## 4.7 What must be included (minimum viable audit pack)
|
||||
|
||||
PMs should enforce that v1 includes:
|
||||
|
||||
* Artifact identity
|
||||
* SBOM(s) or component inventory
|
||||
* Findings list (normalized)
|
||||
* Policy bundle reference + policy content
|
||||
* Exceptions applied (full object + version info)
|
||||
* Final verdict + explanation summary
|
||||
* Integrity manifest with file hashes
|
||||
|
||||
Add these when available (v1.5+):
|
||||
|
||||
* VEX inputs and outputs
|
||||
* Knowledge snapshot references
|
||||
* Reachability evidence fragments
|
||||
* Diff summary vs prior release
|
||||
|
||||
## 4.8 Product acceptance criteria (PM-owned)
|
||||
|
||||
Audit Packs are not “done” until:
|
||||
|
||||
* A third party can validate the pack contents haven’t been altered (hash verification).
|
||||
* The pack answers “why did this pass/fail?” including exceptions applied.
|
||||
* Packs can be generated without external network calls (air-gap friendly).
|
||||
* Packs support redaction profiles.
|
||||
* Pack schema is versioned and backward compatible.
|
||||
|
||||
---
|
||||
|
||||
# 5. Cross-cutting: roles, responsibilities, and delivery checkpoints
|
||||
|
||||
## 5.1 Responsibilities
|
||||
|
||||
**Product Manager**
|
||||
|
||||
* Define exception types and required fields
|
||||
* Define reason code taxonomy and governance policies
|
||||
* Define approval rules by environment and scope breadth
|
||||
* Define audit pack templates, profiles, and export targets
|
||||
* Own acceptance criteria and audit usability testing
|
||||
|
||||
**Development Manager / Tech Lead**
|
||||
|
||||
* Own event model (immutability, versioning, retention)
|
||||
* Own policy evaluation semantics and determinism guarantees
|
||||
* Own integrity and signing design (manifest hashes, optional signatures)
|
||||
* Own performance and scalability targets (pack generation and query latency)
|
||||
* Own secure storage and access controls (RBAC, tenant isolation)
|
||||
|
||||
## 5.2 Deliverables checklist (for each capability)
|
||||
|
||||
For “Exception Objects”:
|
||||
|
||||
* PRD + threat model (abuse cases: blanket waivers, privilege escalation)
|
||||
* Schema spec + versioning policy
|
||||
* API endpoints + RBAC model
|
||||
* UI flows + audit trail UI
|
||||
* Policy engine semantics + test vectors
|
||||
* Metrics dashboards
|
||||
|
||||
For “Audit Packs”:
|
||||
|
||||
* Pack schema spec + folder layout
|
||||
* Manifest + hash verification rules
|
||||
* Generator service + async job API
|
||||
* Redaction profiles + tests
|
||||
* Verifier CLI + documentation
|
||||
* Performance benchmarks + caching strategy
|
||||
|
||||
---
|
||||
|
||||
# 6. Common failure modes to actively prevent
|
||||
|
||||
1. **Exceptions become suppressions again**
|
||||
If you allow exceptions without expiry/owner or without audit trail, you’ve rebuilt “ignore lists.”
|
||||
|
||||
2. **Over-broad scopes by default**
|
||||
If “all repos/all images” is easy, you will accumulate permanent waivers and lose credibility.
|
||||
|
||||
3. **No deterministic semantics**
|
||||
If the same artifact can pass/fail depending on evaluation order or transient feed updates, auditors will distrust outputs.
|
||||
|
||||
4. **Audit packs that are reports, not evidence**
|
||||
A PDF without machine-verifiable artifacts is not an audit pack—it’s a slide.
|
||||
|
||||
5. **No renewal discipline**
|
||||
If renewals are frictionless and don’t require re-justification, exceptions never die.
|
||||
|
||||
---
|
||||
|
||||
# 7. Recommended phased rollout (to manage build cost)
|
||||
|
||||
**Phase 1: Governance basics**
|
||||
|
||||
* Exception object schema + lifecycle + expiry enforcement
|
||||
* Create-from-finding UX
|
||||
* Audit pack v1 (SBOM/inventory + findings + policy + exceptions + manifest)
|
||||
|
||||
**Phase 2: Evidence binding**
|
||||
|
||||
* Evidence refs on exceptions (VEX, reachability fragments)
|
||||
* Pack includes VEX inputs/outputs and knowledge snapshot identifiers
|
||||
|
||||
**Phase 3: Verifiable trust**
|
||||
|
||||
* Signed verdicts and/or signed pack manifests
|
||||
* Verifier tooling and deterministic replay hooks
|
||||
|
||||
---
|
||||
|
||||
If you want, I can convert the above into two artifacts your teams can execute against immediately:
|
||||
|
||||
1. A concise **PRD template** (sections + required decisions) for Exceptions and Audit Packs
|
||||
2. A **technical spec outline** (schema definitions, endpoints, state machines, and acceptance test vectors)
|
||||
@@ -0,0 +1,556 @@
|
||||
## Guidelines for Product and Development Managers: Signed, Replayable Risk Verdicts
|
||||
|
||||
### Purpose
|
||||
|
||||
Signed, replayable risk verdicts are the Stella Ops mechanism for producing a **cryptographically verifiable, audit‑ready decision** about an artifact (container image, VM image, filesystem snapshot, SBOM, etc.) that can be **recomputed later to the same result** using the same inputs (“time-travel replay”).
|
||||
|
||||
This capability is not “scan output with a signature.” It is a **decision artifact** that becomes the unit of governance in CI/CD, registry admission, and audits.
|
||||
|
||||
---
|
||||
|
||||
# 1) Shared definitions and non-negotiables
|
||||
|
||||
## 1.1 Definitions
|
||||
|
||||
**Risk verdict**
|
||||
A structured decision: *Pass / Fail / Warn / Needs‑Review* (or similar), produced by a deterministic evaluator under a specific policy and knowledge state.
|
||||
|
||||
**Signed**
|
||||
The verdict is wrapped in a tamper‑evident envelope (e.g., DSSE/in‑toto statement) and signed using an organization-approved trust model (key-based, keyless, or offline CA).
|
||||
|
||||
**Replayable**
|
||||
Given the same:
|
||||
|
||||
* target artifact identity
|
||||
* SBOM (or derivation method)
|
||||
* vulnerability and advisory knowledge state
|
||||
* VEX inputs
|
||||
* policy bundle
|
||||
* evaluator version
|
||||
…Stella Ops can **re-evaluate and reproduce the same verdict** and provide evidence equivalence.
|
||||
|
||||
> Critical nuance: replayability is about *result equivalence*. Byte‑for‑byte equality is ideal but not always required if signatures/metadata necessarily vary. If byte‑for‑byte is a goal, you must strictly control timestamps, ordering, and serialization.
|
||||
|
||||
---
|
||||
|
||||
## 1.2 Non-negotiables (what must be true in v1)
|
||||
|
||||
1. **Verdicts are bound to immutable artifact identity**
|
||||
|
||||
* Container image: digest (sha256:…)
|
||||
* SBOM: content digest
|
||||
* File tree: merkle root digest, or equivalent
|
||||
|
||||
2. **Verdicts are deterministic**
|
||||
|
||||
* No “current time” dependence in scoring
|
||||
* No non-deterministic ordering of findings
|
||||
* No implicit network calls during evaluation
|
||||
|
||||
3. **Verdicts are explainable**
|
||||
|
||||
* Every deny/block decision must cite the policy clause and evidence pointers that triggered it.
|
||||
|
||||
4. **Verdicts are verifiable**
|
||||
|
||||
* Independent verification toolchain exists (CLI/library) that validates signature and checks referenced evidence integrity.
|
||||
|
||||
5. **Knowledge state is pinned**
|
||||
|
||||
* The verdict references a “knowledge snapshot” (vuln feeds, advisories, VEX set) by digest/ID, not “latest.”
|
||||
|
||||
---
|
||||
|
||||
## 1.3 Explicit non-goals (avoid scope traps)
|
||||
|
||||
* Building a full CNAPP runtime protection product as part of verdicting.
|
||||
* Implementing “all possible attestation standards.” Pick one canonical representation; support others via adapters.
|
||||
* Solving global revocation and key lifecycle for every ecosystem on day one; define a minimum viable trust model per deployment mode.
|
||||
|
||||
---
|
||||
|
||||
# 2) Product Management Guidelines
|
||||
|
||||
## 2.1 Position the verdict as the primary product artifact
|
||||
|
||||
**PM rule:** if a workflow does not end in a verdict artifact, it is not part of this moat.
|
||||
|
||||
Examples:
|
||||
|
||||
* CI pipeline step produces `VERDICT.attestation` attached to the OCI artifact.
|
||||
* Registry admission checks for a valid verdict attestation meeting policy.
|
||||
* Audit export bundles the verdict plus referenced evidence.
|
||||
|
||||
**Avoid:** “scan reports” as the goal. Reports are views; the verdict is the object.
|
||||
|
||||
---
|
||||
|
||||
## 2.2 Define the core personas and success outcomes
|
||||
|
||||
Minimum personas:
|
||||
|
||||
1. **Release/Platform Engineering**
|
||||
|
||||
* Needs automated gates, reproducibility, and low friction.
|
||||
2. **Security Engineering / AppSec**
|
||||
|
||||
* Needs evidence, explainability, and exception workflows.
|
||||
3. **Audit / Compliance**
|
||||
|
||||
* Needs replay, provenance, and a defensible trail.
|
||||
|
||||
Define “first value” for each:
|
||||
|
||||
* Release engineer: gate merges/releases without re-running scans.
|
||||
* Security engineer: investigate a deny decision with evidence pointers in minutes.
|
||||
* Auditor: replay a verdict months later using the same knowledge snapshot.
|
||||
|
||||
---
|
||||
|
||||
## 2.3 Product requirements (expressed as “shall” statements)
|
||||
|
||||
### 2.3.1 Verdict content requirements
|
||||
|
||||
A verdict SHALL contain:
|
||||
|
||||
* **Subject**: immutable artifact reference (digest, type, locator)
|
||||
* **Decision**: pass/fail/warn/etc.
|
||||
* **Policy binding**: policy bundle ID + version + digest
|
||||
* **Knowledge snapshot binding**: snapshot IDs/digests for vuln feed and VEX set
|
||||
* **Evaluator binding**: evaluator name/version + schema version
|
||||
* **Rationale summary**: stable short explanation (human-readable)
|
||||
* **Findings references**: pointers to detailed findings/evidence (content-addressed)
|
||||
* **Unknowns state**: explicit unknown counts and categories
|
||||
|
||||
### 2.3.2 Replay requirements
|
||||
|
||||
The product SHALL support:
|
||||
|
||||
* Re-evaluating the same subject under the same policy+knowledge snapshot
|
||||
* Proving equivalence of inputs used in the original verdict
|
||||
* Producing a “replay report” that states:
|
||||
|
||||
* replay succeeded and matched
|
||||
* or replay failed and why (e.g., missing evidence, policy changed)
|
||||
|
||||
### 2.3.3 UX requirements
|
||||
|
||||
UI/UX SHALL:
|
||||
|
||||
* Show verdict status clearly (Pass/Fail/…)
|
||||
* Display:
|
||||
|
||||
* policy clause(s) responsible
|
||||
* top evidence pointers
|
||||
* knowledge snapshot ID
|
||||
* signature trust status (who signed, chain validity)
|
||||
* Provide “Replay” as an action (even if replay happens offline, the UX must guide it)
|
||||
|
||||
---
|
||||
|
||||
## 2.4 Product taxonomy: separate “verdicts” from “evaluations” from “attestations”
|
||||
|
||||
This is where many products get confused. Your terminology must remain strict:
|
||||
|
||||
* **Evaluation**: internal computation that produces decision + findings.
|
||||
* **Verdict**: the stable, canonical decision payload (the thing being signed).
|
||||
* **Attestation**: the signed envelope binding the verdict to cryptographic identity.
|
||||
|
||||
PMs must enforce this vocabulary in PRDs, UI labels, and docs.
|
||||
|
||||
---
|
||||
|
||||
## 2.5 Policy model guidelines for verdicting
|
||||
|
||||
Verdicting depends on policy discipline.
|
||||
|
||||
PM rules:
|
||||
|
||||
* Policy must be **versioned** and **content-addressed**.
|
||||
* Policies must be **pure functions** of declared inputs:
|
||||
|
||||
* SBOM graph
|
||||
* VEX claims
|
||||
* vulnerability data
|
||||
* reachability evidence (if present)
|
||||
* environment assertions (if present)
|
||||
* Policies must produce:
|
||||
|
||||
* a decision
|
||||
* plus a minimal explanation graph (policy rule ID → evidence IDs)
|
||||
|
||||
Avoid “freeform scripts” early. You need determinism and auditability.
|
||||
|
||||
---
|
||||
|
||||
## 2.6 Exceptions are part of the verdict product, not an afterthought
|
||||
|
||||
PM requirement:
|
||||
|
||||
* Exceptions must be first-class objects with:
|
||||
|
||||
* scope (exact artifact/component range)
|
||||
* owner
|
||||
* justification
|
||||
* expiry
|
||||
* required evidence (optional but strongly recommended)
|
||||
|
||||
And verdict logic must:
|
||||
|
||||
* record that an exception was applied
|
||||
* include exception IDs in the verdict evidence graph
|
||||
* make exception usage visible in UI and audit pack exports
|
||||
|
||||
---
|
||||
|
||||
## 2.7 Success metrics (PM-owned)
|
||||
|
||||
Choose metrics that reflect the moat:
|
||||
|
||||
* **Replay success rate**: % of verdicts that can be replayed after N days.
|
||||
* **Policy determinism incidents**: number of non-deterministic evaluation bugs.
|
||||
* **Audit cycle time**: time to satisfy an audit evidence request for a release.
|
||||
* **Noise**: # of manual suppressions/overrides per 100 releases (should drop).
|
||||
* **Gate adoption**: % of releases gated by verdict attestations (not reports).
|
||||
|
||||
---
|
||||
|
||||
# 3) Development Management Guidelines
|
||||
|
||||
## 3.1 Architecture principles (engineering tenets)
|
||||
|
||||
### Tenet A: Determinism-first evaluation
|
||||
|
||||
Engineering SHALL ensure evaluation is deterministic across:
|
||||
|
||||
* OS and architecture differences (as much as feasible)
|
||||
* concurrency scheduling
|
||||
* non-ordered data structures
|
||||
|
||||
Practical rules:
|
||||
|
||||
* Never iterate over maps/hashes without sorting keys.
|
||||
* Canonicalize output ordering (findings sorted by stable tuple: (component_id, cve_id, path, rule_id)).
|
||||
* Keep “generated at” timestamps out of the signed payload; if needed, place them in an unsigned wrapper or separate metadata field excluded from signature.
|
||||
|
||||
### Tenet B: Content-address everything
|
||||
|
||||
All significant inputs/outputs should have content digests:
|
||||
|
||||
* SBOM digest
|
||||
* policy digest
|
||||
* knowledge snapshot digest
|
||||
* evidence bundle digest
|
||||
* verdict digest
|
||||
|
||||
This makes replay and integrity checks possible.
|
||||
|
||||
### Tenet C: No hidden network
|
||||
|
||||
During evaluation, the engine must not fetch “latest” anything.
|
||||
Network is allowed only in:
|
||||
|
||||
* snapshot acquisition phase
|
||||
* artifact retrieval phase
|
||||
* attestation publication phase
|
||||
…and each must be explicitly logged and pinned.
|
||||
|
||||
---
|
||||
|
||||
## 3.2 Canonical verdict schema and serialization rules
|
||||
|
||||
**Engineering guideline:** pick a canonical serialization and stick to it.
|
||||
|
||||
Options:
|
||||
|
||||
* Canonical JSON (JCS or equivalent)
|
||||
* CBOR with deterministic encoding
|
||||
|
||||
Rules:
|
||||
|
||||
* Define a **schema version** and strict validation.
|
||||
* Make field names stable; avoid “optional” fields that appear/disappear nondeterministically.
|
||||
* Ensure numeric formatting is stable (no float drift; prefer integers or rational representation).
|
||||
* Always include empty arrays if required for stability, or exclude consistently by schema rule.
|
||||
|
||||
---
|
||||
|
||||
## 3.3 Suggested verdict payload (illustrative)
|
||||
|
||||
This is not a mandate—use it as a baseline structure.
|
||||
|
||||
```json
|
||||
{
|
||||
"schema_version": "1.0",
|
||||
"subject": {
|
||||
"type": "oci-image",
|
||||
"name": "registry.example.com/app/service",
|
||||
"digest": "sha256:…",
|
||||
"platform": "linux/amd64"
|
||||
},
|
||||
"evaluation": {
|
||||
"evaluator": "stella-eval",
|
||||
"evaluator_version": "0.9.0",
|
||||
"policy": {
|
||||
"id": "prod-default",
|
||||
"version": "2025.12.1",
|
||||
"digest": "sha256:…"
|
||||
},
|
||||
"knowledge_snapshot": {
|
||||
"vuln_db_digest": "sha256:…",
|
||||
"advisory_digest": "sha256:…",
|
||||
"vex_set_digest": "sha256:…"
|
||||
}
|
||||
},
|
||||
"decision": {
|
||||
"status": "fail",
|
||||
"score": 87,
|
||||
"reasons": [
|
||||
{ "rule_id": "RISK.CRITICAL.REACHABLE", "evidence_ref": "sha256:…" }
|
||||
],
|
||||
"unknowns": {
|
||||
"unknown_reachable": 2,
|
||||
"unknown_unreachable": 0
|
||||
}
|
||||
},
|
||||
"evidence": {
|
||||
"sbom_digest": "sha256:…",
|
||||
"finding_bundle_digest": "sha256:…",
|
||||
"inputs_manifest_digest": "sha256:…"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Then wrap this payload in your chosen attestation envelope and sign it.
|
||||
|
||||
---
|
||||
|
||||
## 3.4 Attestation format and storage guidelines
|
||||
|
||||
Development managers must enforce a consistent publishing model:
|
||||
|
||||
1. **Envelope**
|
||||
|
||||
* Prefer DSSE/in-toto style envelope because it:
|
||||
|
||||
* standardizes signing
|
||||
* supports multiple signature schemes
|
||||
* is widely adopted in supply chain ecosystems
|
||||
|
||||
2. **Attachment**
|
||||
|
||||
* OCI artifacts should carry verdicts as referrers/attachments to the subject digest (preferred).
|
||||
* For non-OCI targets, store in an internal ledger keyed by the subject digest/ID.
|
||||
|
||||
3. **Verification**
|
||||
|
||||
* Provide:
|
||||
|
||||
* `stella verify <artifact>` → checks signature and integrity references
|
||||
* `stella replay <verdict>` → re-run evaluation from snapshots and compare
|
||||
|
||||
4. **Transparency / logs**
|
||||
|
||||
* Optional in v1, but plan for:
|
||||
|
||||
* transparency log (public or private) to strengthen auditability
|
||||
* offline alternatives for air-gapped customers
|
||||
|
||||
---
|
||||
|
||||
## 3.5 Knowledge snapshot engineering requirements
|
||||
|
||||
A “snapshot” must be an immutable bundle, ideally content-addressed:
|
||||
|
||||
Snapshot includes:
|
||||
|
||||
* vulnerability database at a specific point
|
||||
* advisory sources (OS distro advisories)
|
||||
* VEX statement set(s)
|
||||
* any enrichment signals that influence scoring
|
||||
|
||||
Rules:
|
||||
|
||||
* Snapshot resolution must be explicit: “use snapshot digest X”
|
||||
* Must support export/import for air-gapped deployments
|
||||
* Must record source provenance and ingestion timestamps (timestamps may be excluded from signed payload if they cause nondeterminism; store them in snapshot metadata)
|
||||
|
||||
---
|
||||
|
||||
## 3.6 Replay engine requirements
|
||||
|
||||
Replay is not “re-run scan and hope it matches.”
|
||||
|
||||
Replay must:
|
||||
|
||||
* retrieve the exact subject (or confirm it via digest)
|
||||
* retrieve the exact SBOM (or deterministically re-generate it from the subject in a defined way)
|
||||
* load exact policy bundle by digest
|
||||
* load exact knowledge snapshot by digest
|
||||
* run evaluator version pinned in verdict (or enforce a compatibility mapping)
|
||||
* produce:
|
||||
|
||||
* verdict-equivalence result
|
||||
* a delta explanation if mismatch occurs
|
||||
|
||||
Engineering rule: replay must fail loudly and specifically when inputs are missing.
|
||||
|
||||
---
|
||||
|
||||
## 3.7 Testing strategy (required)
|
||||
|
||||
Deterministic systems require “golden” testing.
|
||||
|
||||
Minimum tests:
|
||||
|
||||
1. **Golden verdict tests**
|
||||
|
||||
* Fixed artifact + fixed snapshots + fixed policy
|
||||
* Expected verdict output must match exactly
|
||||
|
||||
2. **Cross-platform determinism tests**
|
||||
|
||||
* Run same evaluation on different machines/containers and compare outputs
|
||||
|
||||
3. **Mutation tests for determinism**
|
||||
|
||||
* Randomize ordering of internal collections; output should remain unchanged
|
||||
|
||||
4. **Replay regression tests**
|
||||
|
||||
* Store verdict + snapshots and replay after code changes to ensure compatibility guarantees hold
|
||||
|
||||
---
|
||||
|
||||
## 3.8 Versioning and backward compatibility guidelines
|
||||
|
||||
This is essential to prevent “replay breaks after upgrades.”
|
||||
|
||||
Rules:
|
||||
|
||||
* **Verdict schema version** changes must be rare and carefully managed.
|
||||
* Maintain a compatibility matrix:
|
||||
|
||||
* evaluator vX can replay verdict schema vY
|
||||
* If you must evolve logic, do so by:
|
||||
|
||||
* bumping evaluator version
|
||||
* preserving older evaluators in a compatibility mode (containerized evaluators are often easiest)
|
||||
|
||||
---
|
||||
|
||||
## 3.9 Security and key management guidelines
|
||||
|
||||
Development managers must ensure:
|
||||
|
||||
* Signing keys are managed via:
|
||||
|
||||
* KMS/HSM (enterprise)
|
||||
* keyless (OIDC-based) where acceptable
|
||||
* offline keys for air-gapped
|
||||
|
||||
* Verification trust policy is explicit:
|
||||
|
||||
* which identities are trusted to sign verdicts
|
||||
* which policies are accepted
|
||||
* whether transparency is required
|
||||
* how to handle revocation/rotation
|
||||
|
||||
* Separate “can sign” from “can publish”
|
||||
|
||||
* Signing should be restricted; publishing may be broader.
|
||||
|
||||
---
|
||||
|
||||
# 4) Operational workflow requirements (cross-functional)
|
||||
|
||||
## 4.1 CI gate flow
|
||||
|
||||
* Build artifact
|
||||
* Produce SBOM deterministically (or record SBOM digest if generated elsewhere)
|
||||
* Evaluate → produce verdict payload
|
||||
* Sign verdict → publish attestation attached to artifact
|
||||
* Gate decision uses verification of:
|
||||
|
||||
* signature validity
|
||||
* policy compliance
|
||||
* snapshot integrity
|
||||
|
||||
## 4.2 Registry / admission flow
|
||||
|
||||
* Admission controller checks for a valid, trusted verdict attestation
|
||||
* Optionally requires:
|
||||
|
||||
* verdict not older than X snapshot age (this is policy)
|
||||
* no expired exceptions
|
||||
* replay not required (replay is for audits; admission is fast-path)
|
||||
|
||||
## 4.3 Audit flow
|
||||
|
||||
* Export “audit pack”:
|
||||
|
||||
* verdict + signature chain
|
||||
* policy bundle
|
||||
* knowledge snapshot
|
||||
* referenced evidence bundles
|
||||
* Auditor (or internal team) runs `verify` and optionally `replay`
|
||||
|
||||
---
|
||||
|
||||
# 5) Common failure modes to avoid
|
||||
|
||||
1. **Signing “findings” instead of a decision**
|
||||
|
||||
* Leads to unbounded payload growth and weak governance semantics.
|
||||
|
||||
2. **Using “latest” feeds during evaluation**
|
||||
|
||||
* Breaks replayability immediately.
|
||||
|
||||
3. **Embedding timestamps in signed payload**
|
||||
|
||||
* Eliminates deterministic byte-level reproducibility.
|
||||
|
||||
4. **Letting the UI become the source of truth**
|
||||
|
||||
* The verdict artifact must be the authority; UI is a view.
|
||||
|
||||
5. **No clear separation between: evidence store, snapshot store, verdict store**
|
||||
|
||||
* Creates coupling and makes offline operations painful.
|
||||
|
||||
---
|
||||
|
||||
# 6) Definition of Done checklist (use this to gate release)
|
||||
|
||||
A feature increment for signed, replayable verdicts is “done” only if:
|
||||
|
||||
* [ ] Verdict binds to immutable subject digest
|
||||
* [ ] Verdict includes policy digest/version and knowledge snapshot digests
|
||||
* [ ] Verdict is signed and verifiable via CLI
|
||||
* [ ] Verification works offline (given exported artifacts)
|
||||
* [ ] Replay works with stored snapshots and produces match/mismatch output with reasons
|
||||
* [ ] Determinism tests pass (golden + mutation + cross-platform)
|
||||
* [ ] UI displays signer identity, policy, snapshot IDs, and rule→evidence links
|
||||
* [ ] Exceptions (if implemented) are recorded in verdict and enforced deterministically
|
||||
|
||||
---
|
||||
|
||||
## Optional: Recommended implementation sequence (keeps risk down)
|
||||
|
||||
1. Canonical verdict schema + deterministic evaluator skeleton
|
||||
2. Signing + verification CLI
|
||||
3. Snapshot bundle format + pinned evaluation
|
||||
4. Replay tool + golden tests
|
||||
5. OCI attachment publishing + registry/admission integration
|
||||
6. Evidence bundles + UI explainability
|
||||
7. Exceptions + audit pack export
|
||||
|
||||
---
|
||||
|
||||
If you want this turned into a formal internal PRD template, I can format it as:
|
||||
|
||||
* “Product requirements” (MUST/SHOULD/COULD)
|
||||
* “Engineering requirements” (interfaces + invariants + test plan)
|
||||
* “Security model” (trust roots, signing identities, verification policy)
|
||||
* “Acceptance criteria” for an MVP and for GA
|
||||
@@ -0,0 +1,462 @@
|
||||
Below are internal guidelines for Stella Ops Product Managers and Development Managers for the capability: **Knowledge Snapshots / Time‑Travel Replay**. This is written as an implementable operating standard (not a concept note).
|
||||
|
||||
---
|
||||
|
||||
# Knowledge Snapshots / Time‑Travel Replay
|
||||
|
||||
## Product and Engineering Guidelines for Stella Ops
|
||||
|
||||
## 1) Purpose and value proposition
|
||||
|
||||
### What this capability must achieve
|
||||
|
||||
Enable Stella Ops to **reproduce any historical risk decision** (scan result, policy evaluation, verdict) **deterministically**, using a **cryptographically bound snapshot** of the exact knowledge inputs that were available at the time the decision was made.
|
||||
|
||||
### Why customers pay for it
|
||||
|
||||
This capability is primarily purchased for:
|
||||
|
||||
* **Auditability**: “Show me what you knew, when you knew it, and why the system decided pass/fail.”
|
||||
* **Incident response**: reproduce prior posture using historical feeds/VEX/policies and explain deltas.
|
||||
* **Air‑gapped / regulated environments**: deterministic, offline decisioning with attested knowledge state.
|
||||
* **Change control**: prove whether a decision changed due to code change vs knowledge change.
|
||||
|
||||
### Core product promise
|
||||
|
||||
For a given artifact and snapshot:
|
||||
|
||||
* **Same inputs → same outputs** (verdict, scores, findings, evidence pointers), or Stella Ops must clearly declare the precise exceptions.
|
||||
|
||||
---
|
||||
|
||||
## 2) Definitions (PMs and engineers must align on these)
|
||||
|
||||
### Knowledge input
|
||||
|
||||
Any external or semi-external information that can influence the outcome:
|
||||
|
||||
* vulnerability databases and advisories (any source)
|
||||
* exploit-intel signals
|
||||
* VEX statements (OpenVEX, CSAF, CycloneDX VEX, etc.)
|
||||
* SBOM ingestion logic and parsing rules
|
||||
* package identification rules (including distro/backport logic)
|
||||
* policy content and policy engine version
|
||||
* scoring rules (including weights and thresholds)
|
||||
* trust anchors and signature verification policy
|
||||
* plugin versions and enabled capabilities
|
||||
* configuration defaults and overrides that change analysis
|
||||
|
||||
### Knowledge Snapshot
|
||||
|
||||
A **sealed record** of:
|
||||
|
||||
1. **References** (which inputs were used), and
|
||||
2. **Content** (the exact bytes used), and
|
||||
3. **Execution contract** (the evaluator and ruleset versions)
|
||||
|
||||
### Time‑Travel Replay
|
||||
|
||||
Re-running evaluation of an artifact **using only** the snapshot content and the recorded execution contract, producing the same decision and explainability artifacts.
|
||||
|
||||
---
|
||||
|
||||
## 3) Product principles (non‑negotiables)
|
||||
|
||||
1. **Determinism is a product requirement**, not an engineering detail.
|
||||
2. **Snapshots are first‑class artifacts** with explicit lifecycle (create, verify, export/import, retain, expire).
|
||||
3. **The snapshot is cryptographically bound** to outcomes and evidence (tamper-evident chain).
|
||||
4. **Replays must be possible offline** (when the snapshot includes content) and must fail clearly when not possible.
|
||||
5. **Minimal surprise**: the UI must explain when a verdict changed due to “knowledge drift” vs “artifact drift.”
|
||||
6. **Scalability by content addressing**: the platform must deduplicate knowledge content aggressively.
|
||||
7. **Backward compatibility**: old snapshots must remain replayable within a documented support window.
|
||||
|
||||
---
|
||||
|
||||
## 4) Scope boundaries (what this is not)
|
||||
|
||||
### Non-goals (explicitly out of scope for v1 unless approved)
|
||||
|
||||
* Reconstructing *external internet state* beyond what is recorded (no “fetch historical CVE state from the web”).
|
||||
* Guaranteeing replay across major engine rewrites without a compatibility plan.
|
||||
* Storing sensitive proprietary customer code in snapshots (unless explicitly enabled).
|
||||
* Replaying “live runtime signals” unless those signals were captured into the snapshot at decision time.
|
||||
|
||||
---
|
||||
|
||||
## 5) Personas and use cases (PM guidance)
|
||||
|
||||
### Primary personas
|
||||
|
||||
* **Security Governance / GRC**: needs audit packs, controls evidence, deterministic history.
|
||||
* **Incident response / AppSec lead**: needs “what changed and why” quickly.
|
||||
* **Platform engineering / DevOps**: needs reproducible CI gates and air‑gap workflows.
|
||||
* **Procurement / regulated customers**: needs proof of process and defensible attestations.
|
||||
|
||||
### Must-support use cases
|
||||
|
||||
1. **Replay a past release gate decision** in a new environment (including offline) and get identical outcome.
|
||||
2. **Explain drift**: “This build fails today but passed last month—why?”
|
||||
3. **Air‑gap export/import**: create snapshots in connected environment, import to disconnected one.
|
||||
4. **Audit bundle generation**: export snapshot + verdict(s) + evidence pointers.
|
||||
|
||||
---
|
||||
|
||||
## 6) Functional requirements (PM “must/should” list)
|
||||
|
||||
### Must
|
||||
|
||||
* **Snapshot creation** for every material evaluation (or for every “decision object” chosen by configuration).
|
||||
* **Snapshot manifest** containing:
|
||||
|
||||
* unique snapshot ID (content-addressed)
|
||||
* list of knowledge sources with hashes/digests
|
||||
* policy IDs and exact policy content hashes
|
||||
* engine version and plugin versions
|
||||
* timestamp and clock source metadata
|
||||
* trust anchor set hash and verification policy hash
|
||||
* **Snapshot sealing**:
|
||||
|
||||
* snapshot manifest is signed
|
||||
* signed link from verdict → snapshot ID
|
||||
* **Replay**:
|
||||
|
||||
* re-evaluate using only snapshot inputs
|
||||
* output must match prior results (or emit a deterministic mismatch report)
|
||||
* **Export/import**:
|
||||
|
||||
* portable bundle format
|
||||
* import verifies integrity and signatures before allowing use
|
||||
* **Retention controls**:
|
||||
|
||||
* configurable retention windows and storage quotas
|
||||
* deduplication and garbage collection
|
||||
|
||||
### Should
|
||||
|
||||
* **Partial snapshots** (reference-only) vs **full snapshots** (content included), with explicit replay guarantees.
|
||||
* **Diff views**: compare two snapshots and highlight what knowledge changed.
|
||||
* **Multi-snapshot replay**: run “as-of snapshot A” and “as-of snapshot B” to show drift impact.
|
||||
|
||||
### Could
|
||||
|
||||
* Snapshot “federation” for large orgs (mirrors/replication with policy controls).
|
||||
* Snapshot “pinning” to releases or environments as a governance policy.
|
||||
|
||||
---
|
||||
|
||||
## 7) UX and workflow guidelines (PM + Eng)
|
||||
|
||||
### UI must communicate three states clearly
|
||||
|
||||
1. **Reproducible offline**: snapshot includes all required content.
|
||||
2. **Reproducible with access**: snapshot references external sources that must be available.
|
||||
3. **Not reproducible**: missing content or unsupported evaluator version.
|
||||
|
||||
### Required UI objects
|
||||
|
||||
* **Snapshot Details page**
|
||||
|
||||
* snapshot ID and signature status
|
||||
* list of knowledge sources (name, version/epoch, digest, size)
|
||||
* policy bundle version, scoring rules version
|
||||
* trust anchors + verification policy digest
|
||||
* replay status: “verified reproducible / reproducible / not reproducible”
|
||||
* **Verdict page**
|
||||
|
||||
* links to snapshot(s)
|
||||
* “replay now” action
|
||||
* “compare to latest knowledge” action
|
||||
|
||||
### UX guardrails
|
||||
|
||||
* Never show “pass/fail” without also showing:
|
||||
|
||||
* snapshot ID
|
||||
* policy ID/version
|
||||
* verification status
|
||||
* When results differ on replay, show:
|
||||
|
||||
* exact mismatch class (engine mismatch, missing data, nondeterminism, corrupted snapshot)
|
||||
* what input changed (if known)
|
||||
* remediation steps
|
||||
|
||||
---
|
||||
|
||||
## 8) Data model and format guidelines (Development Managers)
|
||||
|
||||
### Canonical objects (recommended minimum set)
|
||||
|
||||
* **KnowledgeSnapshotManifest (KSM)**
|
||||
* **KnowledgeBlob** (content-addressed bytes)
|
||||
* **KnowledgeSourceDescriptor**
|
||||
* **PolicyBundle**
|
||||
* **TrustBundle**
|
||||
* **Verdict** (signed decision artifact)
|
||||
* **ReplayReport** (records replay result and mismatches)
|
||||
|
||||
### Content addressing
|
||||
|
||||
* Use a stable hash (e.g., SHA‑256) for:
|
||||
|
||||
* each knowledge blob
|
||||
* manifest
|
||||
* policy bundle
|
||||
* trust bundle
|
||||
* Snapshot ID should be derived from manifest digest.
|
||||
|
||||
### Example manifest shape (illustrative)
|
||||
|
||||
```json
|
||||
{
|
||||
"snapshot_id": "ksm:sha256:…",
|
||||
"created_at": "2025-12-19T10:15:30Z",
|
||||
"engine": { "name": "stella-evaluator", "version": "1.7.0", "build": "…"},
|
||||
"plugins": [
|
||||
{ "name": "pkg-id", "version": "2.3.1", "digest": "sha256:…" }
|
||||
],
|
||||
"policy": { "bundle_id": "pol:sha256:…", "digest": "sha256:…" },
|
||||
"scoring": { "ruleset_id": "score:sha256:…", "digest": "sha256:…" },
|
||||
"trust": { "bundle_id": "trust:sha256:…", "digest": "sha256:…" },
|
||||
"sources": [
|
||||
{
|
||||
"name": "nvd",
|
||||
"epoch": "2025-12-18",
|
||||
"kind": "vuln_feed",
|
||||
"content_digest": "sha256:…",
|
||||
"licenses": ["…"],
|
||||
"origin": { "uri": "…", "retrieved_at": "…" }
|
||||
},
|
||||
{
|
||||
"name": "customer-vex",
|
||||
"kind": "vex",
|
||||
"content_digest": "sha256:…"
|
||||
}
|
||||
],
|
||||
"environment": {
|
||||
"determinism_profile": "strict",
|
||||
"timezone": "UTC",
|
||||
"normalization": { "line_endings": "LF", "sort_order": "canonical" }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Versioning rules
|
||||
|
||||
* Every object is immutable once written.
|
||||
* Changes create new digests; never mutate in place.
|
||||
* Support schema evolution via:
|
||||
|
||||
* `schema_version`
|
||||
* strict validation + migration tooling
|
||||
* Keep manifests small; store large data as blobs.
|
||||
|
||||
---
|
||||
|
||||
## 9) Determinism contract (Engineering must enforce)
|
||||
|
||||
### Determinism requirements
|
||||
|
||||
* Stable ordering: sort inputs and outputs canonically.
|
||||
* Stable timestamps: timestamps may exist but must not change computed scores/verdict.
|
||||
* Stable randomization: no RNG; if unavoidable, fixed seed recorded in snapshot.
|
||||
* Stable parsers: parser versions are pinned by digest; parsing must be deterministic.
|
||||
|
||||
### Allowed nondeterminism (if any) must be explicit
|
||||
|
||||
If you must allow nondeterminism, it must be:
|
||||
|
||||
* documented,
|
||||
* surfaced in UI,
|
||||
* included in replay report as “non-deterministic factor,”
|
||||
* and excluded from the signed decision if it affects pass/fail.
|
||||
|
||||
---
|
||||
|
||||
## 10) Security model (Development Managers)
|
||||
|
||||
### Threats this feature must address
|
||||
|
||||
* Feed poisoning (tampered vulnerability data)
|
||||
* Time-of-check/time-of-use drift (same artifact evaluated against moving feeds)
|
||||
* Replay manipulation (swap snapshot content)
|
||||
* “Policy drift hiding” (claiming old decision used different policies)
|
||||
* Signature bypass (trust anchors altered)
|
||||
|
||||
### Controls required
|
||||
|
||||
* Sign manifests and verdicts.
|
||||
* Bind verdict → snapshot ID → policy bundle hash → trust bundle hash.
|
||||
* Verify on every import and on every replay invocation.
|
||||
* Audit log:
|
||||
|
||||
* snapshot created
|
||||
* snapshot imported
|
||||
* replay executed
|
||||
* verification failures
|
||||
|
||||
### Key handling
|
||||
|
||||
* Decide and document:
|
||||
|
||||
* who signs snapshots/verdicts (service keys vs tenant keys)
|
||||
* rotation policy
|
||||
* revocation/compromise handling
|
||||
* Avoid designing cryptography from scratch; use well-established signing formats and separation of duties.
|
||||
|
||||
---
|
||||
|
||||
## 11) Offline / air‑gapped requirements
|
||||
|
||||
### Snapshot levels (PM packaging guideline)
|
||||
|
||||
Offer explicit snapshot types with clear guarantees:
|
||||
|
||||
* **Level A: Reference-only snapshot**
|
||||
|
||||
* stores hashes + source descriptors
|
||||
* replay requires access to original sources
|
||||
* **Level B: Portable snapshot**
|
||||
|
||||
* includes blobs necessary for replay
|
||||
* replay works offline
|
||||
* **Level C: Sealed portable snapshot**
|
||||
|
||||
* portable + signed + includes trust anchors
|
||||
* replay works offline and can be verified independently
|
||||
|
||||
Do not market air‑gap support without specifying which level is provided.
|
||||
|
||||
---
|
||||
|
||||
## 12) Performance and storage guidelines
|
||||
|
||||
### Principles
|
||||
|
||||
* Content-address knowledge blobs to maximize deduplication.
|
||||
* Separate “hot” knowledge (recent epochs) from cold storage.
|
||||
* Support snapshot compaction and garbage collection.
|
||||
|
||||
### Operational requirements
|
||||
|
||||
* Retention policies per tenant/project/environment.
|
||||
* Quotas and alerting when snapshot storage approaches limits.
|
||||
* Export bundles should be chunked/streamable for large feeds.
|
||||
|
||||
---
|
||||
|
||||
## 13) Testing and acceptance criteria
|
||||
|
||||
### Required test categories
|
||||
|
||||
1. **Golden replay tests**
|
||||
|
||||
* same artifact + same snapshot → identical outputs
|
||||
2. **Corruption tests**
|
||||
|
||||
* bit flips in blobs/manifests are detected and rejected
|
||||
3. **Version skew tests**
|
||||
|
||||
* old snapshot + new engine should either replay deterministically or fail with a clear incompatibility report
|
||||
4. **Air‑gap tests**
|
||||
|
||||
* export → import → replay without network access
|
||||
5. **Diff accuracy tests**
|
||||
|
||||
* compare snapshots and ensure the diff identifies actual knowledge changes, not noise
|
||||
|
||||
### Definition of Done (DoD) for the feature
|
||||
|
||||
* Snapshots are created automatically according to policy.
|
||||
* Snapshots can be exported and imported with verified integrity.
|
||||
* Replay produces matching verdicts for a representative corpus.
|
||||
* UI exposes snapshot provenance and replay status.
|
||||
* Audit log records snapshot lifecycle events.
|
||||
* Clear failure modes exist (missing blobs, incompatible engine, signature failure).
|
||||
|
||||
---
|
||||
|
||||
## 14) Metrics (PM ownership)
|
||||
|
||||
Track metrics that prove this is a moat, not a checkbox.
|
||||
|
||||
### Core KPIs
|
||||
|
||||
* **Replay success rate** (strict determinism)
|
||||
* **Time to explain drift** (median time from “why changed” to root cause)
|
||||
* **% verdicts with sealed portable snapshots**
|
||||
* **Audit effort reduction** (customer-reported or measured via workflow steps)
|
||||
* **Storage efficiency** (dedup ratio; bytes per snapshot over time)
|
||||
|
||||
### Guardrail metrics
|
||||
|
||||
* Snapshot creation latency impact on CI
|
||||
* Snapshot storage growth per tenant
|
||||
* Verification failure rates
|
||||
|
||||
---
|
||||
|
||||
## 15) Common failure modes (what to prevent)
|
||||
|
||||
1. Treating snapshots as “metadata only” and still claiming replayability.
|
||||
2. Allowing “latest feed fetch” during replay (breaks the promise).
|
||||
3. Not pinning parser/policy/scoring versions—causes silent drift.
|
||||
4. Missing clear UX around replay limitations and failure reasons.
|
||||
5. Overcapturing sensitive inputs (privacy and customer trust risk).
|
||||
6. Underinvesting in dedup/retention (cost blowups).
|
||||
|
||||
---
|
||||
|
||||
## 16) Management checklists
|
||||
|
||||
### PM checklist (before commitment)
|
||||
|
||||
* Precisely define “replay” guarantee level (A/B/C) for each SKU/environment.
|
||||
* Define which inputs are in scope (feeds, VEX, policies, trust bundles, plugins).
|
||||
* Define customer-facing workflows:
|
||||
|
||||
* “replay now”
|
||||
* “compare to latest”
|
||||
* “export for audit / air-gap”
|
||||
* Confirm governance outcomes:
|
||||
|
||||
* audit pack integration
|
||||
* exception linkage
|
||||
* release gate linkage
|
||||
|
||||
### Development Manager checklist (before build)
|
||||
|
||||
* Establish canonical schemas and versioning plan.
|
||||
* Establish content-addressed storage + dedup plan.
|
||||
* Establish signing and trust anchor strategy.
|
||||
* Establish deterministic evaluation contract and test harness.
|
||||
* Establish import/export packaging and verification.
|
||||
* Establish retention, quotas, and GC.
|
||||
|
||||
---
|
||||
|
||||
## 17) Minimal phased delivery (recommended)
|
||||
|
||||
**Phase 1: Reference snapshot + verdict binding**
|
||||
|
||||
* Record source descriptors + hashes, policy/scoring/trust digests.
|
||||
* Bind snapshot ID into verdict artifacts.
|
||||
|
||||
**Phase 2: Portable snapshots**
|
||||
|
||||
* Store knowledge blobs locally with dedup.
|
||||
* Export/import with integrity verification.
|
||||
|
||||
**Phase 3: Sealed portable snapshots + replay tooling**
|
||||
|
||||
* Sign snapshots.
|
||||
* Deterministic replay pipeline + replay report.
|
||||
* UI surfacing and audit logs.
|
||||
|
||||
**Phase 4: Snapshot diff + drift explainability**
|
||||
|
||||
* Compare snapshots.
|
||||
* Attribute decision drift to knowledge changes vs artifact changes.
|
||||
|
||||
---
|
||||
|
||||
If you want this turned into an internal PRD template, I can rewrite it into a structured PRD format with: objectives, user stories, functional requirements, non-functional requirements, security/compliance, dependencies, risks, and acceptance tests—ready for Jira/Linear epics and engineering design review.
|
||||
@@ -0,0 +1,497 @@
|
||||
## Stella Ops Guidelines
|
||||
|
||||
### Risk Budgets and Diff-Aware Release Gates
|
||||
|
||||
**Audience:** Product Managers (PMs) and Development Managers (DMs)
|
||||
**Applies to:** All customer-impacting software and configuration changes shipped by Stella Ops (code, infrastructure-as-code, runtime config, feature flags, data migrations, dependency upgrades).
|
||||
|
||||
---
|
||||
|
||||
## 1) What we are optimizing for
|
||||
|
||||
Stella Ops ships quickly **without** letting change-driven incidents, security regressions, or data integrity failures become the hidden cost of “speed.”
|
||||
|
||||
These guidelines enforce two linked controls:
|
||||
|
||||
1. **Risk Budgets** — a quantitative “capacity to take risk” that prevents reliability and trust from being silently depleted.
|
||||
2. **Diff-Aware Release Gates** — release checks whose strictness scales with *what changed* (the diff), not with generic process.
|
||||
|
||||
Together they let us move fast on low-risk diffs and slow down only when the change warrants it.
|
||||
|
||||
---
|
||||
|
||||
## 2) Non-negotiable principles
|
||||
|
||||
1. **All changes are risk-bearing** (even “small” diffs). We quantify and route them accordingly.
|
||||
2. **Risk is managed at the product/service boundary** (each service has its own budget and gating profile).
|
||||
3. **Automation first, approvals last**. Humans review what automation cannot reliably verify.
|
||||
4. **Blast radius is a first-class variable**. A safe rollout beats a perfect code review.
|
||||
5. **Exceptions are allowed but never free**. Every bypass is logged, justified, and paid back via budget reduction and follow-up controls.
|
||||
|
||||
---
|
||||
|
||||
## 3) Definitions
|
||||
|
||||
### 3.1 Risk Budget (what it is)
|
||||
|
||||
A **Risk Budget** is the amount of change-risk a product/service is allowed to take over a defined window (typically a sprint or month) **without increasing the probability of customer harm beyond the agreed tolerance**.
|
||||
|
||||
It is a management control, not a theoretical score.
|
||||
|
||||
### 3.2 Risk Budget vs. Error Budget (important distinction)
|
||||
|
||||
* **Error Budget** (classic SRE): backward-looking tolerance for *actual* unreliability vs. SLO.
|
||||
* **Risk Budget** (this policy): forward-looking tolerance for *change risk* before shipping.
|
||||
|
||||
They interact:
|
||||
|
||||
* If error budget is burned (service is unstable), risk budget is automatically constrained.
|
||||
* If risk budget is low, release gates tighten by policy.
|
||||
|
||||
### 3.3 Diff-aware release gates (what it is)
|
||||
|
||||
A **release gate** is a set of required checks (tests, scans, reviews, rollout controls) that must pass before a change can progress.
|
||||
**Diff-aware** means the gate level is determined by:
|
||||
|
||||
* what changed (diff classification),
|
||||
* where it changed (criticality),
|
||||
* how it ships (blast radius controls),
|
||||
* and current operational context (incidents, SLO health, budget remaining).
|
||||
|
||||
---
|
||||
|
||||
## 4) Roles and accountability
|
||||
|
||||
### Product Manager (PM) — accountable for risk appetite
|
||||
|
||||
PM responsibilities:
|
||||
|
||||
* Define product-level risk tolerance with stakeholders (customer impact tolerance, regulatory constraints).
|
||||
* Approve the **Risk Budget Policy settings** for their product/service tier (criticality level, default gates).
|
||||
* Prioritize reliability work when budgets are constrained.
|
||||
* Own customer communications for degraded service or risk-driven release deferrals.
|
||||
|
||||
### Development Manager (DM) — accountable for enforcement and engineering hygiene
|
||||
|
||||
DM responsibilities:
|
||||
|
||||
* Ensure pipelines implement diff classification and enforce gates.
|
||||
* Ensure tests, telemetry, rollout mechanisms, and rollback procedures exist and are maintained.
|
||||
* Ensure “exceptions” process is real (logged, postmortemed, paid back).
|
||||
* Own staffing/rotation decisions to ensure safe releases (on-call readiness, release captains).
|
||||
|
||||
### Shared responsibilities
|
||||
|
||||
PM + DM jointly:
|
||||
|
||||
* Review risk budget status weekly.
|
||||
* Resolve trade-offs: feature velocity vs. reliability/security work.
|
||||
* Approve gate profile changes (tighten/loosen) based on evidence.
|
||||
|
||||
---
|
||||
|
||||
## 5) Risk Budgets
|
||||
|
||||
### 5.1 Establish service tiers (criticality)
|
||||
|
||||
Each service/product component must be assigned a **Criticality Tier**:
|
||||
|
||||
* **Tier 0 – Internal only** (no external customers; low business impact)
|
||||
* **Tier 1 – Customer-facing non-critical** (degradation tolerated; limited blast radius)
|
||||
* **Tier 2 – Customer-facing critical** (core workflows; meaningful revenue/trust impact)
|
||||
* **Tier 3 – Safety/financial/data-critical** (payments, auth, permissions, PII, regulated workflows)
|
||||
|
||||
Tier drives default budgets and minimum gates.
|
||||
|
||||
### 5.2 Choose a budget window and units
|
||||
|
||||
**Window:** default to **monthly** with weekly tracking; optionally sprint-based if release cadence is sprint-coupled.
|
||||
**Units:** use **Risk Points (RP)** — consumed by each change. (Do not overcomplicate at first; tune with data.)
|
||||
|
||||
Recommended initial monthly budgets (adjust after 2–3 cycles with evidence):
|
||||
|
||||
* Tier 0: 300 RP/month
|
||||
* Tier 1: 200 RP/month
|
||||
* Tier 2: 120 RP/month
|
||||
* Tier 3: 80 RP/month
|
||||
|
||||
> Interpretation: Tier 3 ships fewer “risky” changes; it can still ship frequently, but changes must be decomposed into low-risk diffs and shipped with strong controls.
|
||||
|
||||
### 5.3 Risk Point scoring (how changes consume budget)
|
||||
|
||||
Every change gets a **Release Risk Score (RRS)** in RP.
|
||||
|
||||
A practical baseline model:
|
||||
|
||||
**RRS = Base(criticality) + Diff Risk + Operational Context – Mitigations**
|
||||
|
||||
**Base (criticality):**
|
||||
|
||||
* Tier 0: +1
|
||||
* Tier 1: +3
|
||||
* Tier 2: +6
|
||||
* Tier 3: +10
|
||||
|
||||
**Diff Risk (additive):**
|
||||
|
||||
* +1: docs, comments, non-executed code paths, telemetry-only additions
|
||||
* +3: UI changes, non-core logic changes, refactors with high test coverage
|
||||
* +6: API contract changes, dependency upgrades, medium-complexity logic in a core path
|
||||
* +10: database schema migrations, auth/permission logic, data retention/PII handling
|
||||
* +15: infra/networking changes, encryption/key handling, payment flows, queue semantics changes
|
||||
|
||||
**Operational Context (additive):**
|
||||
|
||||
* +5: service currently in incident or had Sev1/Sev2 in last 7 days
|
||||
* +3: error budget < 50% remaining
|
||||
* +2: on-call load high (paging above normal baseline)
|
||||
* +5: release during restricted windows (holidays/freeze) via exception
|
||||
|
||||
**Mitigations (subtract):**
|
||||
|
||||
* –3: feature flag with staged rollout + instant kill switch verified
|
||||
* –3: canary + automated health gates + rollback tested in last 30 days
|
||||
* –2: high-confidence integration coverage for touched components
|
||||
* –2: no data migration OR backward-compatible migration with proven rollback
|
||||
* –2: change isolated behind permission boundary / limited cohort
|
||||
|
||||
**Minimum RRS floor:** never below 1 RP.
|
||||
|
||||
DM is responsible for making sure the pipeline can calculate a *default* RRS automatically and require humans only for edge cases.
|
||||
|
||||
### 5.4 Budget operating rules
|
||||
|
||||
**Budget ledger:** Maintain a per-service ledger:
|
||||
|
||||
* Budget allocated for the window
|
||||
* RP consumed per release
|
||||
* RP remaining
|
||||
* Trendline (projected depletion date)
|
||||
* Exceptions (break-glass releases)
|
||||
|
||||
**Control thresholds:**
|
||||
|
||||
* **Green (≥60% remaining):** normal operation
|
||||
* **Yellow (30–59%):** additional caution; gates tighten by 1 level for medium/high-risk diffs
|
||||
* **Red (<30%):** freeze high-risk diffs; allow only low-risk changes or reliability/security work
|
||||
* **Exhausted (≤0%):** releases restricted to incident fixes, security fixes, and rollback-only, with tightened gates and explicit sign-off
|
||||
|
||||
### 5.5 What to do when budget is low (expected behavior)
|
||||
|
||||
When Yellow/Red:
|
||||
|
||||
* PM shifts roadmap execution toward:
|
||||
|
||||
* reliability work, defect burn-down,
|
||||
* decomposing large changes into smaller, reversible diffs,
|
||||
* reducing scope of risky features.
|
||||
* DM enforces:
|
||||
|
||||
* smaller diffs,
|
||||
* increased feature flagging,
|
||||
* staged rollout requirements,
|
||||
* improved test/observability coverage.
|
||||
|
||||
Budget constraints are a signal, not a punishment.
|
||||
|
||||
### 5.6 Budget replenishment and incentives
|
||||
|
||||
Budgets replenish on the window boundary, but we also allow **earned capacity**:
|
||||
|
||||
* If a service improves change failure rate and MTTR for 2 consecutive windows, it may earn:
|
||||
|
||||
* +10–20% budget increase **or**
|
||||
* one gate level relaxation for specific change categories
|
||||
|
||||
This must be evidence-driven (metrics, not opinions).
|
||||
|
||||
---
|
||||
|
||||
## 6) Diff-Aware Release Gates
|
||||
|
||||
### 6.1 Diff classification (what the pipeline must detect)
|
||||
|
||||
At minimum, automatically classify diffs into these categories:
|
||||
|
||||
**Code scope**
|
||||
|
||||
* Executable code vs docs-only
|
||||
* Core vs non-core modules (define module ownership boundaries)
|
||||
* Hot paths (latency-sensitive), correctness-sensitive paths
|
||||
|
||||
**Data scope**
|
||||
|
||||
* Schema migration (additive vs breaking)
|
||||
* Backfill jobs / batch jobs
|
||||
* Data model changes impacting downstream consumers
|
||||
* PII / regulated data touchpoints
|
||||
|
||||
**Security scope**
|
||||
|
||||
* Authn/authz logic
|
||||
* Permission checks
|
||||
* Secrets, key handling, encryption changes
|
||||
* Dependency changes with known CVEs
|
||||
|
||||
**Infra scope**
|
||||
|
||||
* IaC changes, networking, load balancer, DNS, autoscaling
|
||||
* Runtime config changes (feature flags, limits, thresholds)
|
||||
* Queue/topic changes, retention settings
|
||||
|
||||
**Interface scope**
|
||||
|
||||
* Public API contract changes
|
||||
* Backward compatibility of payloads/events
|
||||
* Client version dependency
|
||||
|
||||
### 6.2 Gate levels
|
||||
|
||||
Define **Gate Levels G0–G4**. The pipeline assigns one based on diff + context + budget.
|
||||
|
||||
#### G0 — No-risk / administrative
|
||||
|
||||
Use for:
|
||||
|
||||
* docs-only, comments-only, non-functional metadata
|
||||
|
||||
Requirements:
|
||||
|
||||
* Lint/format checks
|
||||
* Basic CI pass (build)
|
||||
|
||||
#### G1 — Low risk
|
||||
|
||||
Use for:
|
||||
|
||||
* small, localized code changes with strong unit coverage
|
||||
* non-core UI changes
|
||||
* telemetry additions (no removal)
|
||||
|
||||
Requirements:
|
||||
|
||||
* All automated unit tests
|
||||
* Static analysis/linting
|
||||
* 1 peer review (code owner not required if outside critical modules)
|
||||
* Automated deploy to staging
|
||||
* Post-deploy smoke checks
|
||||
|
||||
#### G2 — Moderate risk
|
||||
|
||||
Use for:
|
||||
|
||||
* moderate logic changes in customer-facing paths
|
||||
* dependency upgrades
|
||||
* API changes that are backward compatible
|
||||
* config changes affecting behavior
|
||||
|
||||
Requirements:
|
||||
|
||||
* G1 +
|
||||
* Integration tests relevant to impacted modules
|
||||
* Code owner review for touched modules
|
||||
* Feature flag required if customer impact possible
|
||||
* Staged rollout: canary or small cohort
|
||||
* Rollback plan documented in PR
|
||||
|
||||
#### G3 — High risk
|
||||
|
||||
Use for:
|
||||
|
||||
* schema migrations
|
||||
* auth/permission changes
|
||||
* core business logic in critical flows
|
||||
* infra changes affecting availability
|
||||
* non-trivial concurrency/queue semantics changes
|
||||
|
||||
Requirements:
|
||||
|
||||
* G2 +
|
||||
* Security scan + dependency audit (must pass, exceptions logged)
|
||||
* Migration plan (forward + rollback) reviewed
|
||||
* Load/performance checks if in hot path
|
||||
* Observability: new/updated dashboards/alerts for the change
|
||||
* Release captain / on-call sign-off (someone accountable live)
|
||||
* Progressive delivery with automatic health gates (error rate/latency)
|
||||
|
||||
#### G4 — Very high risk / safety-critical / budget-constrained releases
|
||||
|
||||
Use for:
|
||||
|
||||
* Tier 3 critical systems with low budget remaining
|
||||
* changes during freeze windows via exception
|
||||
* broad blast radius changes (platform-wide)
|
||||
* remediation after major incident where recurrence risk is high
|
||||
|
||||
Requirements:
|
||||
|
||||
* G3 +
|
||||
* Formal risk review (PM+DM+Security/SRE) in writing
|
||||
* Explicit rollback rehearsal or prior proven rollback path
|
||||
* Extended canary period with success criteria and abort criteria
|
||||
* Customer comms plan if impact is plausible
|
||||
* Post-release verification checklist executed and logged
|
||||
|
||||
### 6.3 Gate selection logic (policy)
|
||||
|
||||
Default rule:
|
||||
|
||||
1. Compute **RRS** (Risk Points) from diff + context.
|
||||
2. Map RRS to default gate:
|
||||
|
||||
* 1–5 RP → G1
|
||||
* 6–12 RP → G2
|
||||
* 13–20 RP → G3
|
||||
* 21+ RP → G4
|
||||
3. Apply modifiers:
|
||||
|
||||
* If **budget Yellow**: escalate one gate for changes ≥ G2
|
||||
* If **budget Red**: escalate one gate for changes ≥ G1 and block high-risk categories unless exception
|
||||
* If active incident or error budget severely degraded: block non-fix releases by default
|
||||
|
||||
DM must ensure the pipeline enforces this mapping automatically.
|
||||
|
||||
### 6.4 “Diff-aware” also means “blast-radius aware”
|
||||
|
||||
If the diff is inherently risky, reduce risk operationally:
|
||||
|
||||
* feature flags with cohort controls
|
||||
* dark launches (ship code disabled)
|
||||
* canary deployments
|
||||
* blue/green with quick revert
|
||||
* backwards-compatible DB migrations (expand/contract pattern)
|
||||
* circuit breakers and rate limiting
|
||||
* progressive exposure by tenant / region / account segment
|
||||
|
||||
Large diffs are not “made safe” by more reviewers; they are made safe by **reversibility and containment**.
|
||||
|
||||
---
|
||||
|
||||
## 7) Exceptions (“break glass”) policy
|
||||
|
||||
Exceptions are permitted only when one of these is true:
|
||||
|
||||
* incident mitigation or customer harm prevention,
|
||||
* urgent security fix (actively exploited or high severity),
|
||||
* legal/compliance deadline.
|
||||
|
||||
**Requirements for any exception:**
|
||||
|
||||
* Recorded rationale in the PR/release ticket
|
||||
* Named approver(s): DM + on-call owner; PM for customer-impacting risk
|
||||
* Mandatory follow-up within 5 business days:
|
||||
|
||||
* post-incident or post-release review
|
||||
* remediation tasks created and prioritized
|
||||
* **Budget penalty:** subtract additional RP (e.g., +50% of the change’s RRS) to reflect unmanaged risk
|
||||
|
||||
Repeated exceptions are a governance failure and trigger gate tightening.
|
||||
|
||||
---
|
||||
|
||||
## 8) Operational metrics (what PMs and DMs must review)
|
||||
|
||||
Minimum weekly review dashboard per service:
|
||||
|
||||
* **Risk budget remaining** (RP and %)
|
||||
* **Deploy frequency**
|
||||
* **Change failure rate**
|
||||
* **MTTR**
|
||||
* **Sev1/Sev2 count** (rolling 30/90 days)
|
||||
* **SLO / error budget status**
|
||||
* **Gate compliance rate** (how often gates were bypassed)
|
||||
* **Diff size distribution** (are we shipping huge diffs?)
|
||||
* **Rollback frequency and time-to-rollback**
|
||||
|
||||
Policy expectation:
|
||||
|
||||
* If change failure rate or MTTR worsens materially over 2 windows, budgets tighten and gate mapping escalates until stability returns.
|
||||
|
||||
---
|
||||
|
||||
## 9) Practical operating cadence
|
||||
|
||||
### Weekly (PM + DM)
|
||||
|
||||
* Review budgets and trends
|
||||
* Identify upcoming high-risk releases and plan staged rollouts
|
||||
* Confirm staffing for release windows (release captain / on-call coverage)
|
||||
* Decide whether to defer, decompose, or harden changes
|
||||
|
||||
### Per release (DM-led, PM informed)
|
||||
|
||||
* Ensure correct gate level
|
||||
* Verify rollout + rollback readiness
|
||||
* Confirm monitoring/alerts exist and are watched during rollout
|
||||
* Execute post-release verification checklist
|
||||
|
||||
### Monthly (leadership)
|
||||
|
||||
* Adjust tier assignments if product criticality changed
|
||||
* Recalibrate budget numbers based on measured outcomes
|
||||
* Identify systemic causes: test gaps, observability gaps, deployment tooling gaps
|
||||
|
||||
---
|
||||
|
||||
## 10) Required templates (standardize execution)
|
||||
|
||||
### 10.1 Release Plan (required for G2+)
|
||||
|
||||
* What is changing (1–3 bullets)
|
||||
* Expected customer impact (or “none”)
|
||||
* Diff category flags (DB/auth/infra/API/etc.)
|
||||
* Rollout strategy (canary/cohort/blue-green)
|
||||
* Abort criteria (exact metrics/thresholds)
|
||||
* Rollback steps (exact commands/process)
|
||||
* Owners during rollout (names)
|
||||
|
||||
### 10.2 Migration Plan (required for schema/data changes)
|
||||
|
||||
* Migration type: additive / expand-contract / breaking (breaking is disallowed without explicit G4 approval)
|
||||
* Backfill approach and rate limits
|
||||
* Validation checks (row counts, invariants)
|
||||
* Rollback strategy (including data implications)
|
||||
|
||||
### 10.3 Post-release Verification Checklist (G1+)
|
||||
|
||||
* Smoke test results
|
||||
* Key dashboards checked (latency, error rate, saturation)
|
||||
* Alerts status
|
||||
* User-facing workflows validated (as applicable)
|
||||
* Ticket updated with outcome
|
||||
|
||||
---
|
||||
|
||||
## 11) What “good” looks like
|
||||
|
||||
* Low-risk diffs ship quickly with minimal ceremony (G0–G1).
|
||||
* High-risk diffs are decomposed and shipped progressively, not heroically.
|
||||
* Risk budgets are visible, used in planning, and treated as a real constraint.
|
||||
* Exceptions are rare and followed by concrete remediation.
|
||||
* Over time: deploy frequency stays high while change failure rate and MTTR decrease.
|
||||
|
||||
---
|
||||
|
||||
## 12) Immediate adoption checklist (first 30 days)
|
||||
|
||||
**DM deliverables**
|
||||
|
||||
* Implement diff classification in CI/CD (at least: DB/auth/infra/API/deps/config)
|
||||
* Implement automatic gate mapping and enforcement
|
||||
* Add “release plan” and “rollback plan” checks for G2+
|
||||
* Add logging for gate overrides
|
||||
|
||||
**PM deliverables**
|
||||
|
||||
* Confirm service tiering for owned areas
|
||||
* Approve initial monthly RP budgets
|
||||
* Add risk budget review to the weekly product/engineering ritual
|
||||
* Reprioritize work when budgets hit Yellow/Red (explicitly)
|
||||
|
||||
---
|
||||
|
||||
If you want, I can also provide:
|
||||
|
||||
* a concrete scoring worksheet (ready to paste into Confluence/Notion),
|
||||
* a CI/CD policy example (e.g., GitHub Actions / GitLab rules) that computes gate level from diff patterns,
|
||||
* and a one-page “Release Captain Runbook” aligned to G2–G4.
|
||||
@@ -0,0 +1,146 @@
|
||||
# MOAT Phase 2 Archive Manifest
|
||||
|
||||
**Archive Date**: 2025-12-21
|
||||
**Archive Reason**: Product advisories processed and implementation gaps identified
|
||||
**Epoch**: 4100 (MOAT Phase 2 - Governance & Replay)
|
||||
|
||||
---
|
||||
|
||||
## Summary
|
||||
|
||||
This archive contains 11 MOAT (Market-Oriented Architecture Transformation) product advisories from 19-Dec and 20-Dec 2025 that were analyzed against the StellaOps codebase. After thorough source code exploration, the implementation coverage was assessed at **~65% baseline** with sprints planned to reach **~90% target**.
|
||||
|
||||
---
|
||||
|
||||
## Gap Analysis (from 65% baseline)
|
||||
|
||||
| Area | Current | Target | Gap |
|
||||
|------|---------|--------|-----|
|
||||
| Security Snapshots & Deltas | 55% | 90% | Unified snapshot, DeltaVerdict |
|
||||
| Risk Verdict Attestations | 50% | 90% | RVA contract, OCI push |
|
||||
| VEX Claims Resolution | 80% | 95% | JSON parsing, evidence providers |
|
||||
| Unknowns First-Class | 60% | 95% | Reason codes, budgets, attestations |
|
||||
| Knowledge Snapshots | 60% | 90% | Manifest, ReplayEngine |
|
||||
| Risk Budgets & Gates | 20% | 80% | RP scoring, gate levels |
|
||||
|
||||
---
|
||||
|
||||
## Sprint Structure (10 Sprints, 169 Story Points)
|
||||
|
||||
### Batch 4100.0001: Unknowns Enhancement (40 pts)
|
||||
|
||||
| Sprint | Topic | Points | Status |
|
||||
|--------|-------|--------|--------|
|
||||
| 4100.0001.0001 | Reason-Coded Unknowns | 15 | Planned |
|
||||
| 4100.0001.0002 | Unknown Budgets & Env Thresholds | 13 | Planned |
|
||||
| 4100.0001.0003 | Unknowns in Attestations | 12 | Planned |
|
||||
|
||||
### Batch 4100.0002: Knowledge Snapshots & Replay (55 pts)
|
||||
|
||||
| Sprint | Topic | Points | Status |
|
||||
|--------|-------|--------|--------|
|
||||
| 4100.0002.0001 | Knowledge Snapshot Manifest | 18 | Planned |
|
||||
| 4100.0002.0002 | Replay Engine | 22 | Planned |
|
||||
| 4100.0002.0003 | Snapshot Export/Import | 15 | Planned |
|
||||
|
||||
### Batch 4100.0003: Risk Verdict & OCI (34 pts)
|
||||
|
||||
| Sprint | Topic | Points | Status |
|
||||
|--------|-------|--------|--------|
|
||||
| 4100.0003.0001 | Risk Verdict Attestation Contract | 16 | Planned |
|
||||
| 4100.0003.0002 | OCI Referrer Push & Discovery | 18 | Planned |
|
||||
|
||||
### Batch 4100.0004: Deltas & Gates (38 pts)
|
||||
|
||||
| Sprint | Topic | Points | Status |
|
||||
|--------|-------|--------|--------|
|
||||
| 4100.0004.0001 | Security State Delta & Verdict | 20 | Planned |
|
||||
| 4100.0004.0002 | Risk Budgets & Gate Levels | 18 | Planned |
|
||||
|
||||
---
|
||||
|
||||
## Sprint File References
|
||||
|
||||
| Sprint | File |
|
||||
|--------|------|
|
||||
| 4100.0001.0001 | `docs/implplan/SPRINT_4100_0001_0001_reason_coded_unknowns.md` |
|
||||
| 4100.0001.0002 | `docs/implplan/SPRINT_4100_0001_0002_unknown_budgets.md` |
|
||||
| 4100.0001.0003 | `docs/implplan/SPRINT_4100_0001_0003_unknowns_attestations.md` |
|
||||
| 4100.0002.0001 | `docs/implplan/SPRINT_4100_0002_0001_knowledge_snapshot_manifest.md` |
|
||||
| 4100.0002.0002 | `docs/implplan/SPRINT_4100_0002_0002_replay_engine.md` |
|
||||
| 4100.0002.0003 | `docs/implplan/SPRINT_4100_0002_0003_snapshot_export_import.md` |
|
||||
| 4100.0003.0001 | `docs/implplan/SPRINT_4100_0003_0001_risk_verdict_attestation.md` |
|
||||
| 4100.0003.0002 | `docs/implplan/SPRINT_4100_0003_0002_oci_referrer_push.md` |
|
||||
| 4100.0004.0001 | `docs/implplan/SPRINT_4100_0004_0001_security_state_delta.md` |
|
||||
| 4100.0004.0002 | `docs/implplan/SPRINT_4100_0004_0002_risk_budgets_gates.md` |
|
||||
|
||||
---
|
||||
|
||||
## Archived Files (11)
|
||||
|
||||
### 19-Dec-2025 Moat Advisories (7)
|
||||
|
||||
1. `19-Dec-2025 - Moat #1.md`
|
||||
2. `19-Dec-2025 - Moat #2.md`
|
||||
3. `19-Dec-2025 - Moat #3.md`
|
||||
4. `19-Dec-2025 - Moat #4.md`
|
||||
5. `19-Dec-2025 - Moat #5.md`
|
||||
6. `19-Dec-2025 - Moat #6.md`
|
||||
7. `19-Dec-2025 - Moat #7.md`
|
||||
|
||||
### 20-Dec-2025 Moat Explanation Advisories (4)
|
||||
|
||||
8. `20-Dec-2025 - Moat Explanation - Exception management as auditable objects.md`
|
||||
9. `20-Dec-2025 - Moat Explanation - Guidelines for Product and Development Managers - Signed, Replayable Risk Verdicts.md`
|
||||
10. `20-Dec-2025 - Moat Explanation - Knowledge Snapshots and Time-Travel Replay.md`
|
||||
11. `20-Dec-2025 - Moat Explanation - Risk Budgets and Diff-Aware Release Gates.md`
|
||||
|
||||
---
|
||||
|
||||
## Key New Concepts
|
||||
|
||||
| Concept | Description | Sprint |
|
||||
|---------|-------------|--------|
|
||||
| UnknownReasonCode | 7 reason codes: U-RCH, U-ID, U-PROV, U-VEX, U-FEED, U-CONFIG, U-ANALYZER | 4100.0001.0001 |
|
||||
| UnknownBudget | Environment-aware thresholds (prod: block, stage: warn, dev: warn_only) | 4100.0001.0002 |
|
||||
| KnowledgeSnapshotManifest | Content-addressed bundle (ksm:sha256:{hash}) | 4100.0002.0001 |
|
||||
| ReplayEngine | Time-travel replay with frozen inputs for determinism verification | 4100.0002.0002 |
|
||||
| RiskVerdictAttestation | PASS/FAIL/PASS_WITH_EXCEPTIONS/INDETERMINATE verdicts | 4100.0003.0001 |
|
||||
| OCI Referrer Push | OCI 1.1 referrers API with fallback to tagged indexes | 4100.0003.0002 |
|
||||
| SecurityStateDelta | Baseline vs target comparison with DeltaVerdict | 4100.0004.0001 |
|
||||
| GateLevel | G0-G4 diff-aware release gates with RP scoring | 4100.0004.0002 |
|
||||
|
||||
---
|
||||
|
||||
## Recommended Parallel Execution
|
||||
|
||||
```
|
||||
Phase 1: 4100.0001.0001 + 4100.0002.0001 + 4100.0003.0001 + 4100.0004.0002
|
||||
Phase 2: 4100.0001.0002 + 4100.0002.0002 + 4100.0003.0002
|
||||
Phase 3: 4100.0001.0003 + 4100.0002.0003 + 4100.0004.0001
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Success Criteria
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Reason-coded unknowns | 7 codes implemented |
|
||||
| Unknown budget tests | 5+ passing |
|
||||
| Knowledge snapshot tests | 8+ passing |
|
||||
| Replay engine golden tests | 10+ passing |
|
||||
| RVA verification tests | 6+ passing |
|
||||
| OCI push integration tests | 4+ passing |
|
||||
| Delta computation tests | 6+ passing |
|
||||
| Overall MOAT coverage | 85%+ |
|
||||
|
||||
---
|
||||
|
||||
## Post-Closure Target
|
||||
|
||||
After completing all 10 sprints:
|
||||
- Implementation coverage: **90%+**
|
||||
- All Phase 2 advisory requirements addressed
|
||||
- Full governance and replay capabilities
|
||||
- Risk budgets and gate levels operational
|
||||
@@ -0,0 +1,104 @@
|
||||
Here’s a simple, big‑picture primer on how a modern, verifiable supply‑chain security platform fits together—and what each part does—before we get into the practical wiring and artifacts.
|
||||
|
||||
---
|
||||
|
||||
# Topology & trust boundaries (plain‑English)
|
||||
|
||||
Think of the system as four layers, each with a clear job and a cryptographic handshake between them:
|
||||
|
||||
1. **Edge** (where users & CI/CD touch the system)
|
||||
|
||||
* **StellaRouter / UI** receive requests, authenticate users/agents (OAuth2/OIDC), and fan them into the control plane.
|
||||
* Trust boundary: everything from the outside must present signed credentials/attestations before it’s allowed deeper.
|
||||
|
||||
2. **Control Plane** (brains & policy)
|
||||
|
||||
* **Scheduler**: queues and routes work (scan this image, verify that build, recompute reachability, etc.).
|
||||
* **Policy Engine**: evaluates SBOMs, VEX, and signals against policies (“ship/block/defer”) and produces **signed, replayable verdicts**.
|
||||
* **Authority**: key custody & identity (who can sign what).
|
||||
* **Attestor**: issues DSSE/in‑toto attestations for scans, verdicts, and exports.
|
||||
* **Timeline / Notify**: immutable audit log + notifications.
|
||||
* Trust boundary: only evidence and identities blessed here can influence decisions.
|
||||
|
||||
3. **Evidence Plane** (facts, not opinions)
|
||||
|
||||
* **Sbomer**: builds SBOMs from images/binaries/source (CycloneDX 1.6 / SPDX 3.0.1).
|
||||
* **Excititor**: runs scanners/executors (code, binary, OS, language deps, “what’s installed” on hosts).
|
||||
* **Concelier**: correlates advisories, VEX claims, reachability, EPSS, exploit telemetry.
|
||||
* **Reachability / Signals**: computes “is the vulnerable code actually reachable here?” plus runtime/infra signals.
|
||||
* Trust boundary: raw evidence is tamper‑evident and separately signed; opinions live in policy/verdicts, not here.
|
||||
|
||||
4. **Data Plane** (do the heavy lifting)
|
||||
|
||||
* Horizontal workers/scanners that pull tasks, do the compute, and emit artifacts and attestations.
|
||||
* Trust boundary: workers are isolated per tenant; outputs are always tied to inputs via cryptographic subjects.
|
||||
|
||||
---
|
||||
|
||||
# Artifact association & tenant isolation (why OCI referrers matter)
|
||||
|
||||
* Every image/artifact becomes a **subject** in the registry.
|
||||
* SBOMs, VEX, reachability slices, and verdicts are published as **OCI referrers** that point back to that subject (no guessing or loose coupling).
|
||||
* This lets you attach **multiple, versioned, signed facts** to the same build without altering the image itself.
|
||||
* Tenants stay cryptographically separate: different keys, different trust roots, different namespaces.
|
||||
|
||||
---
|
||||
|
||||
# Interfaces, dataflows & provenance hooks (what flows where)
|
||||
|
||||
* **Workers emit**:
|
||||
|
||||
* **SBOMs** in CycloneDX 1.6 and/or SPDX 3.0.1.
|
||||
* **VEX claims** (affected/not‑affected, under‑investigation, fixed).
|
||||
* **Reachability subgraphs** (the minimal “slice” proving a vuln is or isn’t callable in this build).
|
||||
* All wrapped as **DSSE/in‑toto attestations** and **attached via OCI referrers** to the image digest.
|
||||
* **Policy Engine**:
|
||||
|
||||
* Ingests SBOM/VEX/reachability/signals, applies rules, and emits a **signed verdict** (OCI‑attached).
|
||||
* Verdicts are **replayable**: same inputs → same output, with the exact inputs hashed and referenced.
|
||||
* **Timeline**:
|
||||
|
||||
* Stores an **audit‑ready record** of who ran what, with which inputs, producing which attestations and verdicts.
|
||||
|
||||
---
|
||||
|
||||
# Why this design helps in real life
|
||||
|
||||
* **Audits become trivial**: point an auditor at the image digest; they can fetch all linked SBOMs/VEX/attestations/verdicts and replay the decision.
|
||||
* **Noise collapses**: reachability + VEX + policy means you block only what matters for *this* build in *this* environment.
|
||||
* **Multi‑tenant safety**: each customer’s artifacts and keys are isolated; strong boundaries reduce blast radius.
|
||||
* **No vendor lock‑in**: OCI referrers and open schemas (CycloneDX/SPDX/in‑toto/DSSE) let you interoperate.
|
||||
|
||||
---
|
||||
|
||||
# Minimal “starter” policy you can adopt Day‑1
|
||||
|
||||
* **Gate** on any CVE with reachability=“reachable” AND severity ≥ High, unless a trusted VEX source says “not affected” with required evidence hooks (e.g., feature flag off, code path pruned).
|
||||
* **Fail on unknowns** above a threshold (e.g., >N packages with missing metadata).
|
||||
* **Require** signed SBOM + signed verdict for prod deploys; store both in Timeline.
|
||||
|
||||
---
|
||||
|
||||
# Quick glossary
|
||||
|
||||
* **SBOM**: Software Bill of Materials (what’s inside).
|
||||
* **VEX**: Vulnerability Exploitability eXchange (is a CVE actually relevant?).
|
||||
* **Reachability**: graph proof that vulnerable code is (not) callable.
|
||||
* **DSSE / in‑toto**: standardized ways to sign and describe supply‑chain steps and their outputs.
|
||||
* **OCI referrers**: a registry mechanism to hang related artifacts (SBOMs, attestations, verdicts) off an image digest.
|
||||
|
||||
---
|
||||
|
||||
# A tiny wiring sketch
|
||||
|
||||
```
|
||||
User/CI → Router/UI → Scheduler ─→ Workers (Sbomer/Excititor)
|
||||
│ │
|
||||
│ └─→ emit SBOM/VEX/reachability (DSSE, OCI-referrers)
|
||||
│
|
||||
Policy Engine ──→ signed verdict (OCI-referrer)
|
||||
│
|
||||
Timeline/Notify (immutable audit, alerts)
|
||||
```
|
||||
|
||||
If you want, I can turn this into a one‑pager architecture card, plus a checklist your PMs/engineers can use to validate each trust boundary and artifact flow in your Stella Ops setup.
|
||||
@@ -0,0 +1,565 @@
|
||||
Here's a compact, practical plan to harden Stella Ops around **offline‑ready security evidence and deterministic verdicts**, with just enough background so it all clicks.
|
||||
|
||||
---
|
||||
|
||||
# Why this matters (quick primer)
|
||||
|
||||
* **Air‑gapped/offline**: Many customers can't reach public feeds or registries. Your scanners, SBOM tooling, and attestations must work with **pre‑synced bundles** and prove what data they used.
|
||||
* **Interoperability**: Teams mix tools (Syft/Grype/Trivy, cosign, CycloneDX/SPDX). Your CI should **round‑trip** SBOMs and attestations end‑to‑end and prove that downstream consumers (e.g., Grype) can load them.
|
||||
* **Determinism**: Auditors expect **"same inputs → same verdict."** Capture inputs, policies, and feed hashes so a verdict is exactly reproducible later.
|
||||
* **Operational guardrails**: Shipping gates should fail early on **unknowns** and apply **backpressure** gracefully when load spikes.
|
||||
|
||||
---
|
||||
|
||||
# E2E test themes to add (what to build)
|
||||
|
||||
1. **Air‑gapped operation e2e**
|
||||
|
||||
* Package "offline bundle" (vuln feeds, package catalogs, policy/lattice rules, certs, keys).
|
||||
* Run scans (containers, OS, language deps, binaries) **without network**.
|
||||
* Assert: SBOMs generated, attestations signed/verified, verdicts emitted.
|
||||
* Evidence: manifest of bundle contents + hashes in the run log.
|
||||
|
||||
2. **Interop round‑trips (SBOM ⇄ attestation ⇄ scanner)**
|
||||
|
||||
* Produce SBOM (CycloneDX 1.6 and SPDX 3.0.1) with Syft.
|
||||
* Create **DSSE/cosign** attestation for that SBOM.
|
||||
* Verify consumer tools:
|
||||
|
||||
* **Grype** scans **from SBOM** (no image pull) and respects attestations.
|
||||
* Verdict references the exact SBOM digest and attestation chain.
|
||||
* Assert: consumers load, validate, and produce identical findings vs direct scan.
|
||||
|
||||
3. **Replayability (delta‑verdicts + strict replay)**
|
||||
|
||||
* Store input set: artifact digest(s), SBOM digests, policy version, feed digests, lattice rules, tool versions.
|
||||
* Re‑run later; assert **byte‑identical verdict** and same "delta‑verdict" when inputs unchanged.
|
||||
|
||||
4. **Unknowns‑budget policy gates**
|
||||
|
||||
* Inject controlled "unknown" conditions (missing CPE mapping, unresolved package source, unparsed distro).
|
||||
* Gate: **fail build if unknowns > budget** (e.g., prod=0, staging≤N).
|
||||
* Assert: UI, CLI, and attestation all record unknown counts and gate decision.
|
||||
|
||||
5. **Attestation round‑trip & validation**
|
||||
|
||||
* Produce: build‑provenance (in‑toto/DSSE), SBOM attest, VEX attest, final **verdict attest**.
|
||||
* Verify: signature (cosign), certificate chain, time‑stamping, Rekor‑style (or mirror) inclusion when online; cached proofs when offline.
|
||||
* Assert: each attestation is linked in the verdict's evidence index.
|
||||
|
||||
6. **Router backpressure chaos (HTTP 429/503 + Retry‑After)**
|
||||
|
||||
* Load tests that trigger per‑instance and per‑environment limits.
|
||||
* Assert: clients back off per **Retry‑After**, queues drain, no data loss, latencies bounded; UI shows throttling reason.
|
||||
|
||||
7. **UI reducer tests for reachability & VEX chips**
|
||||
|
||||
* Component tests: large SBOM graphs, focused **reachability subgraphs**, and VEX status chips (affected/not‑affected/under‑investigation).
|
||||
* Assert: stable rendering under 50k+ nodes; interactions remain <200 ms.
|
||||
|
||||
---
|
||||
|
||||
# Next‑week checklist (do these now)
|
||||
|
||||
1. **Delta‑verdict replay tests**: golden corpus; lock tool+feed versions; assert bit‑for‑bit verdict.
|
||||
2. **Unknowns‑budget gates in CI**: policy + failing examples; surface in PR checks and UI.
|
||||
3. **SBOM attestation round‑trip**: Syft → cosign attest → Grype consume‑from‑SBOM; verify signatures & digests.
|
||||
4. **Router backpressure chaos**: scripted spike; verify 429/503 + Retry‑After handling and metrics.
|
||||
5. **UI reducer tests**: reachability graph snapshots; VEX chip states; regression suite.
|
||||
|
||||
---
|
||||
|
||||
# Minimal artifacts to standardize (so tests are boring—good!)
|
||||
|
||||
* **Offline bundle spec**: `bundle.json` with content digests (feeds, policies, keys).
|
||||
* **Evidence manifest**: machine‑readable index linking verdict → SBOM digest → attestation IDs → tool versions.
|
||||
* **Delta‑verdict schema**: captures before/after graph deltas, rule evals, and final gate result.
|
||||
* **Unknowns taxonomy**: codes (e.g., `PKG_SOURCE_UNKNOWN`, `CPE_AMBIG`) with severities and budgets.
|
||||
|
||||
---
|
||||
|
||||
# CI wiring (quick sketch)
|
||||
|
||||
* **Jobs**: `offline-e2e`, `interop-e2e`, `replayable-verdicts`, `unknowns-gate`, `router-chaos`, `ui-reducers`.
|
||||
* **Matrix**: {Debian/Alpine/RHEL‑like} × {amd64/arm64} × {CycloneDX/SPDX}.
|
||||
* **Cache discipline**: pin tool versions, vendor feeds to content‑addressed store.
|
||||
|
||||
---
|
||||
|
||||
# Fast success criteria (green = done)
|
||||
|
||||
* Can run **full scan + attest + verify** with **no network**.
|
||||
* Re‑running a fixed input set yields **identical verdict**.
|
||||
* Grype (from SBOM) matches image scan results within tolerance.
|
||||
* Builds auto‑fail when **unknowns budget exceeded**.
|
||||
* Router under burst emits **correct Retry‑After** and recovers cleanly.
|
||||
* UI handles huge graphs; VEX chips never desync from evidence.
|
||||
|
||||
If you want, I'll turn this into GitLab/Gitea pipeline YAML + a tiny sample repo (image, SBOM, policies, and goldens) so your team can plug‑and‑play.
|
||||
Below is a complete, end-to-end testing strategy for Stella Ops that turns your moats (offline readiness, deterministic replayable verdicts, lattice/policy decisioning, attestation provenance, unknowns budgets, router backpressure, UI reachability evidence) into continuously verified guarantees.
|
||||
|
||||
---
|
||||
|
||||
## 1) Non-negotiable test principles
|
||||
|
||||
### 1.1 Determinism as a testable contract
|
||||
|
||||
A scan/verdict is *deterministic* iff **same inputs → byte-identical outputs** across time and machines (within defined tolerances like timestamps captured as evidence, not embedded in payload order).
|
||||
|
||||
**Determinism controls (must be enforced by tests):**
|
||||
|
||||
* Canonical JSON (stable key order, stable array ordering where semantically unordered).
|
||||
* Stable sorting for:
|
||||
|
||||
* packages/components
|
||||
* vulnerabilities
|
||||
* edges in graphs
|
||||
* evidence lists
|
||||
* Time is an *input*, never implicit:
|
||||
|
||||
* stamp times in a dedicated evidence field; never affect hashing/verdict evaluation.
|
||||
* PRNG uses explicit seed; seed stored in run manifest.
|
||||
* Tool versions + feed digests + policy versions are inputs.
|
||||
* Locale/encoding invariants: UTF-8 everywhere; invariant culture in .NET.
|
||||
|
||||
### 1.2 Offline by default
|
||||
|
||||
Every CI job (except explicitly tagged "online") runs with **no egress**.
|
||||
|
||||
* Offline bundle is mandatory input for scanning.
|
||||
* Any attempted network call fails the test (proves air-gap compliance).
|
||||
|
||||
### 1.3 Evidence-first validation
|
||||
|
||||
No assertion is "verdict == pass" without verifying the chain of evidence:
|
||||
|
||||
* verdict references SBOM digest(s)
|
||||
* SBOM references artifact digest(s)
|
||||
* VEX claims reference vulnerabilities + components + reachability evidence
|
||||
* attestations verify cryptographically and chain to configured roots.
|
||||
|
||||
### 1.4 Interop is required, not "nice to have"
|
||||
|
||||
Stella Ops must round-trip with:
|
||||
|
||||
* SBOM: CycloneDX 1.6 and SPDX 3.0.1
|
||||
* Attestation: DSSE / in-toto style envelopes, cosign-compatible flows
|
||||
* Consumer scanners: at least Grype from SBOM; ideally Trivy as cross-check
|
||||
|
||||
Interop tests are treated as "compatibility contracts" and block releases.
|
||||
|
||||
### 1.5 Architectural boundary enforcement (your standing rule)
|
||||
|
||||
* Lattice/policy merge algorithms run **in `scanner.webservice`**.
|
||||
* `Concelier` and `Excitors` must "preserve prune source".
|
||||
This is enforced with tests that detect forbidden behavior (see §6.2).
|
||||
|
||||
---
|
||||
|
||||
## 2) The test portfolio (what kinds of tests exist)
|
||||
|
||||
Think "coverage by risk", not "coverage by lines".
|
||||
|
||||
### 2.1 Test layers and what they prove
|
||||
|
||||
1. **Unit tests** (fast, deterministic)
|
||||
|
||||
* Canonicalization, hashing, semantic version range ops
|
||||
* Graph delta algorithms
|
||||
* Policy rule evaluation primitives
|
||||
* Unknowns taxonomy + budgeting math
|
||||
* Evidence index assembly
|
||||
|
||||
2. **Property-based tests** (FsCheck)
|
||||
|
||||
* "Reordering inputs does not change verdict hash"
|
||||
* "Graph merge is associative/commutative where policy declares it"
|
||||
* "Unknowns budgets always monotonic with missing evidence"
|
||||
* Parser robustness: arbitrary JSON for SBOM/VEX envelopes never crashes
|
||||
|
||||
3. **Component tests** (service + Postgres; optional Valkey)
|
||||
|
||||
* `scanner.webservice` lattice merge and replay
|
||||
* Feed loader and cache behavior (offline feeds)
|
||||
* Router backpressure decision logic
|
||||
* Attestation verification modules
|
||||
|
||||
4. **Contract tests** (API compatibility)
|
||||
|
||||
* OpenAPI/JSON schema compatibility for public endpoints
|
||||
* Evidence manifest schema backward compatibility
|
||||
* OCI artifact layout compatibility (attestation attachments)
|
||||
|
||||
5. **Integration tests** (multi-service)
|
||||
|
||||
* Router → scanner.webservice → attestor → storage
|
||||
* Offline bundle import/export
|
||||
* Knowledge snapshot "time travel" replay pipeline
|
||||
|
||||
6. **End-to-end tests** (realistic flows)
|
||||
|
||||
* scan an image → generate SBOM → produce attestations → decision verdict → UI evidence extraction
|
||||
* interop consumers load SBOM and confirm findings parity
|
||||
|
||||
7. **Non-functional tests**
|
||||
|
||||
* Performance & scale (throughput, memory, large SBOM graphs)
|
||||
* Chaos/fault injection (DB restarts, queue spikes, 429/503 backpressure)
|
||||
* Security tests (fuzzers, decompression bomb defense, signature bypass resistance)
|
||||
|
||||
---
|
||||
|
||||
## 3) Hermetic test harness (how tests run)
|
||||
|
||||
### 3.1 Standard test profiles
|
||||
|
||||
You already decided: **Postgres is system-of-record**, **Valkey is ephemeral**.
|
||||
|
||||
Define two mandatory execution profiles in CI:
|
||||
|
||||
1. **Default**: Postgres + Valkey
|
||||
2. **Air-gapped minimal**: Postgres only
|
||||
|
||||
Both must pass.
|
||||
|
||||
### 3.2 Environment isolation
|
||||
|
||||
* Containers started with **no network** unless a test explicitly declares "online".
|
||||
* For Kubernetes e2e: apply a default-deny egress NetworkPolicy.
|
||||
|
||||
### 3.3 Golden corpora repository (your "truth set")
|
||||
|
||||
Create a versioned `stellaops-test-corpus/` containing:
|
||||
|
||||
* container images (or image tarballs) pinned by digest
|
||||
* SBOM expected outputs (CycloneDX + SPDX)
|
||||
* VEX examples (vendor/distro/internal)
|
||||
* vulnerability feed snapshots (pinned digests)
|
||||
* policies + lattice rules + unknown budgets
|
||||
* expected verdicts + delta verdicts
|
||||
* reachability subgraphs as evidence
|
||||
* negative fixtures: malformed SPDX, corrupted DSSE, missing digests, unsupported distros
|
||||
|
||||
Every corpus item includes a **Run Manifest** (see §4).
|
||||
|
||||
### 3.4 Artifact retention in CI
|
||||
|
||||
Every failing integration/e2e test uploads:
|
||||
|
||||
* run manifest
|
||||
* offline bundle manifest + hashes
|
||||
* logs (structured)
|
||||
* produced SBOMs
|
||||
* attestations
|
||||
* verdict + delta verdict
|
||||
* evidence index
|
||||
|
||||
This turns failures into audit-grade reproductions.
|
||||
|
||||
---
|
||||
|
||||
## 4) Core artifacts that tests must validate
|
||||
|
||||
### 4.1 Run Manifest (replay key)
|
||||
|
||||
A scan run is defined by:
|
||||
|
||||
* artifact digests (image/config/layers, or binary hash)
|
||||
* SBOM digests produced/consumed
|
||||
* vuln feed snapshot digest(s)
|
||||
* policy version + lattice rules digest
|
||||
* tool versions (scanner, parsers, reachability engine)
|
||||
* crypto profile (roots, key IDs, algorithm set)
|
||||
* environment profile (postgres-only vs postgres+valkey)
|
||||
* seed + canonicalization version
|
||||
|
||||
**Test invariant:** re-running the same manifest produces **byte-identical verdict** and **same evidence references**.
|
||||
|
||||
### 4.2 Offline Bundle Manifest
|
||||
|
||||
Bundle includes:
|
||||
|
||||
* feeds + indexes
|
||||
* policies + lattice rule sets
|
||||
* trust roots, intermediate CAs, timestamp roots (as needed)
|
||||
* crypto provider modules (for sovereign readiness)
|
||||
* optional: Rekor mirror snapshot / inclusion proofs cache
|
||||
|
||||
**Test invariant:** offline scan is blocked if bundle is missing required parts; error is explicit and counts as "unknown" only where policy says so.
|
||||
|
||||
### 4.3 Evidence Index
|
||||
|
||||
The verdict is not the product; the product is verdict + evidence graph:
|
||||
|
||||
* pointers to SBOM, VEX, reachability proofs, attestations
|
||||
* their digests and verification status
|
||||
* unknowns list with codes + remediation hints
|
||||
|
||||
**Test invariant:** every "not affected" claim has required evidence hooks per policy ("because feature flag off" etc.), otherwise becomes unknown/fail.
|
||||
|
||||
---
|
||||
|
||||
## 5) Required E2E flows (minimum set)
|
||||
|
||||
These are your release blockers.
|
||||
|
||||
### Flow A: Air-gapped scan and verdict
|
||||
|
||||
* Inputs: image tarball + offline bundle
|
||||
* Network: disabled
|
||||
* Output: SBOM (CycloneDX + SPDX), attestations, verdict
|
||||
* Assertions:
|
||||
|
||||
* no network calls occurred
|
||||
* verdict references bundle digest + feed snapshot digest
|
||||
* unknowns within budget
|
||||
* evidence index complete
|
||||
|
||||
### Flow B: SBOM interop round-trip
|
||||
|
||||
* Produce SBOM via your pipeline
|
||||
* Attach SBOM attestation (DSSE/cosign format)
|
||||
* Consumer (Grype-from-SBOM) reads SBOM and produces findings
|
||||
* Assertions:
|
||||
|
||||
* consumer can parse SBOM
|
||||
* findings parity within defined tolerance
|
||||
* verdict references exact SBOM digest used by consumer
|
||||
|
||||
### Flow C: Deterministic replay
|
||||
|
||||
* Run scan → store run manifest + outputs
|
||||
* Run again from same manifest
|
||||
* Assertions:
|
||||
|
||||
* verdict bytes identical
|
||||
* evidence index identical (except allowed "execution metadata" section)
|
||||
* delta verdict is "empty delta"
|
||||
|
||||
### Flow D: Diff-aware delta verdict (smart-diff)
|
||||
|
||||
* Two versions of same image with controlled change (one dependency bump)
|
||||
* Assertions:
|
||||
|
||||
* delta verdict contains only changed nodes/edges
|
||||
* risk budget computation based on delta matches expected
|
||||
* signed delta verdict validates and is OCI-attached
|
||||
|
||||
### Flow E: Unknowns budget gates
|
||||
|
||||
* Inject unknowns (unmapped package, missing distro metadata, ambiguous CPE)
|
||||
* Policy:
|
||||
|
||||
* prod budget = 0
|
||||
* staging budget = N
|
||||
* Assertions:
|
||||
|
||||
* prod fails, staging passes
|
||||
* unknowns appear in attestation and UI evidence
|
||||
|
||||
### Flow F: Router backpressure under burst
|
||||
|
||||
* Spike requests to a single router instance + environment bucket
|
||||
* Assertions:
|
||||
|
||||
* 429/503 with Retry-After emitted correctly
|
||||
* clients backoff; no request loss
|
||||
* metrics expose throttling reasons
|
||||
|
||||
### Flow G: Evidence export ("audit pack")
|
||||
|
||||
* Run scan
|
||||
* Export a sealed audit pack (bundle + run manifest + evidence + verdict)
|
||||
* Import elsewhere (clean environment)
|
||||
* Assertions:
|
||||
|
||||
* replay produces identical verdict
|
||||
* signatures verify under imported trust roots
|
||||
|
||||
---
|
||||
|
||||
## 6) Module-specific test requirements
|
||||
|
||||
### 6.1 `scanner.webservice` (lattice + policy decisioning)
|
||||
|
||||
Must have:
|
||||
|
||||
* unit tests for lattice merge algebra
|
||||
* property tests: declared commutativity/associativity/idempotency
|
||||
* integration tests that merge vendor/distro/internal VEX and confirm precedence rules are policy-driven
|
||||
|
||||
**Critical invariant tests:**
|
||||
|
||||
* "Vendor > distro > internal" must be demonstrably *configurable*, and wrong merges must fail deterministically.
|
||||
|
||||
### 6.2 Boundary enforcement: Concelier & Excitors preserve prune source
|
||||
|
||||
Add a "behavioral boundary suite":
|
||||
|
||||
* instrument events/telemetry that records where merges happened
|
||||
* feed in conflicting VEX claims and assert:
|
||||
|
||||
* Concelier/Excitors do not resolve conflicts; they retain provenance and "prune source"
|
||||
* only `scanner.webservice` produces the final merged semantics
|
||||
|
||||
If Concelier/Excitors output a resolved claim, the test fails.
|
||||
|
||||
### 6.3 `Router` backpressure and DPoP/nonce rate limiting
|
||||
|
||||
* deterministic unit tests for token bucket math
|
||||
* time-controlled tests (virtual clock)
|
||||
* integration tests with Valkey + Postgres-only fallbacks
|
||||
* chaos tests: Valkey down → router degrades gracefully (local per-instance limiter still works)
|
||||
|
||||
### 6.4 Storage (Postgres) + Valkey accelerator
|
||||
|
||||
* migration tests: schema upgrades forward/backward in CI
|
||||
* replay tests: Postgres-only profile yields same verdict bytes
|
||||
* consistency tests: Valkey cache misses never change decision outcomes, only latency
|
||||
|
||||
### 6.5 UI evidence rendering
|
||||
|
||||
* reducer snapshot tests for:
|
||||
|
||||
* reachability subgraph rendering (large graphs)
|
||||
* VEX chip states: affected/not-affected/under-investigation/unknown
|
||||
* performance budgets:
|
||||
|
||||
* large graph render under threshold (define and enforce)
|
||||
* contract tests against evidence index schema
|
||||
|
||||
---
|
||||
|
||||
## 7) Non-functional test program
|
||||
|
||||
### 7.1 Performance and scale tests
|
||||
|
||||
Define standard workloads:
|
||||
|
||||
* small image (200 packages)
|
||||
* medium (2k packages)
|
||||
* large (20k+ packages)
|
||||
* "monorepo container" worst case (50k+ nodes graph)
|
||||
|
||||
Metrics collected:
|
||||
|
||||
* p50/p95/p99 scan time
|
||||
* memory peak
|
||||
* DB write volume
|
||||
* evidence pack size
|
||||
* router throughput + throttle rate
|
||||
|
||||
Add regression gates:
|
||||
|
||||
* no more than X% slowdown in p95 vs baseline
|
||||
* no more than Y% growth in evidence pack size for unchanged inputs
|
||||
|
||||
### 7.2 Chaos and reliability
|
||||
|
||||
Run chaos suites weekly/nightly:
|
||||
|
||||
* kill scanner during run → resume/retry semantics deterministic
|
||||
* restart Postgres mid-run → job fails with explicit retryable state
|
||||
* corrupt offline bundle file → fails with typed error, not crash
|
||||
* burst router + slow downstream → confirms backpressure not meltdown
|
||||
|
||||
### 7.3 Security robustness tests
|
||||
|
||||
* fuzz parsers: SPDX, CycloneDX, VEX, DSSE envelopes
|
||||
* zip/tar bomb defenses (artifact ingestion)
|
||||
* signature bypass attempts:
|
||||
|
||||
* mismatched digest
|
||||
* altered payload with valid signature on different content
|
||||
* wrong root chain
|
||||
* SSRF defense: any URL fields in SBOM/VEX are treated as data, never fetched in offline mode
|
||||
|
||||
---
|
||||
|
||||
## 8) CI/CD gating rules (what blocks a release)
|
||||
|
||||
Release candidate is blocked if any of these fail:
|
||||
|
||||
1. All mandatory E2E flows (§5) pass in both profiles:
|
||||
|
||||
* Postgres-only
|
||||
* Postgres+Valkey
|
||||
|
||||
2. Deterministic replay suite:
|
||||
|
||||
* zero non-deterministic diffs in verdict bytes
|
||||
* allowed diff list is explicit and reviewed
|
||||
|
||||
3. Interop suite:
|
||||
|
||||
* CycloneDX 1.6 and SPDX 3.0.1 round-trips succeed
|
||||
* consumer scanner compatibility tests pass
|
||||
|
||||
4. Risk budgets + unknowns budgets:
|
||||
|
||||
* must pass on corpus, and no regressions against baseline
|
||||
|
||||
5. Backpressure correctness:
|
||||
|
||||
* Retry-After compliance and throttle metrics validated
|
||||
|
||||
6. Performance regression budgets:
|
||||
|
||||
* no breach of p95/memory budgets on standard workloads
|
||||
|
||||
7. Flakiness threshold:
|
||||
|
||||
* if a test flakes more than N times per week, it is quarantined *and* release is blocked until a deterministic root cause is established (quarantine is allowed only for non-blocking suites, never for §5 flows)
|
||||
|
||||
---
|
||||
|
||||
## 9) Implementation blueprint (how to build this test program)
|
||||
|
||||
### Phase 0: Harness and corpus
|
||||
|
||||
* Stand up test harness: docker compose + Testcontainers (.NET xUnit)
|
||||
* Create corpus repo with 10–20 curated artifacts
|
||||
* Implement run manifest + evidence index capture in all tests
|
||||
|
||||
### Phase 1: Determinism and replay
|
||||
|
||||
* canonicalization utilities + golden verdict bytes
|
||||
* replay runner that loads manifest and replays end-to-end
|
||||
* add property-based tests for ordering and merge invariants
|
||||
|
||||
### Phase 2: Offline e2e + interop
|
||||
|
||||
* offline bundle builder + strict "no egress" enforcement
|
||||
* SBOM attestation round-trip + consumer parsing suite
|
||||
|
||||
### Phase 3: Unknowns budgets + delta verdict
|
||||
|
||||
* unknown taxonomy everywhere (UI + attestations)
|
||||
* delta verdict generation and signing
|
||||
* diff-aware release gates
|
||||
|
||||
### Phase 4: Backpressure + chaos + performance
|
||||
|
||||
* router throttle chaos suite
|
||||
* scale tests with standard workloads and baselines
|
||||
|
||||
### Phase 5: Audit packs + time-travel snapshots
|
||||
|
||||
* sealed export/import
|
||||
* one-command replay for auditors
|
||||
|
||||
---
|
||||
|
||||
## 10) What you should standardize immediately
|
||||
|
||||
If you do only three things, do these:
|
||||
|
||||
1. **Run Manifest** as first-class test artifact
|
||||
2. **Golden corpus** that pins all digests (feeds, policies, images, expected outputs)
|
||||
3. **"No egress" default** in CI with explicit opt-in for online tests
|
||||
|
||||
Everything else becomes far easier once these are in place.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can also produce a concrete repository layout and CI job matrix (xUnit categories, docker compose profiles, artifact retention conventions, and baseline benchmark scripts) that matches .NET 10 conventions and your Postgres/Valkey profiles.
|
||||
@@ -0,0 +1,56 @@
|
||||
# Archived Advisory: Testing Strategy
|
||||
|
||||
**Archived**: 2025-12-21
|
||||
**Original**: `docs/product-advisories/20-Dec-2025 - Testing strategy.md`
|
||||
|
||||
## Processing Summary
|
||||
|
||||
This advisory was processed into Sprint Epic 5100 - Comprehensive Testing Strategy.
|
||||
|
||||
### Artifacts Created
|
||||
|
||||
**Sprint Files** (12 sprints, ~75 tasks):
|
||||
|
||||
| Sprint | Name | Phase |
|
||||
|--------|------|-------|
|
||||
| 5100.0001.0001 | Run Manifest Schema | Phase 0 |
|
||||
| 5100.0001.0002 | Evidence Index Schema | Phase 0 |
|
||||
| 5100.0001.0003 | Offline Bundle Manifest | Phase 0 |
|
||||
| 5100.0001.0004 | Golden Corpus Expansion | Phase 0 |
|
||||
| 5100.0002.0001 | Canonicalization Utilities | Phase 1 |
|
||||
| 5100.0002.0002 | Replay Runner Service | Phase 1 |
|
||||
| 5100.0002.0003 | Delta-Verdict Generator | Phase 1 |
|
||||
| 5100.0003.0001 | SBOM Interop Round-Trip | Phase 2 |
|
||||
| 5100.0003.0002 | No-Egress Enforcement | Phase 2 |
|
||||
| 5100.0004.0001 | Unknowns Budget CI Gates | Phase 3 |
|
||||
| 5100.0005.0001 | Router Chaos Suite | Phase 4 |
|
||||
| 5100.0006.0001 | Audit Pack Export/Import | Phase 5 |
|
||||
|
||||
**Documentation Updated**:
|
||||
- `docs/implplan/SPRINT_5100_SUMMARY.md` - Master epic summary
|
||||
- `docs/19_TEST_SUITE_OVERVIEW.md` - Test suite documentation
|
||||
- `tests/AGENTS.md` - AI agent guidance for tests directory
|
||||
|
||||
### Key Concepts Implemented
|
||||
|
||||
1. **Deterministic Replay**: Run Manifests capture all inputs for byte-identical verdict reproduction
|
||||
2. **Canonical JSON**: RFC 8785 principles for stable serialization
|
||||
3. **Evidence Index**: Linking verdicts to complete evidence chain
|
||||
4. **Air-Gap Compliance**: Network-isolated testing with `--network none`
|
||||
5. **SBOM Interoperability**: Round-trip testing with Syft, Grype, cosign
|
||||
6. **Unknowns Budget Gates**: Environment-based budget enforcement
|
||||
7. **Router Backpressure**: HTTP 429/503 with Retry-After validation
|
||||
8. **Audit Packs**: Sealed export/import for compliance verification
|
||||
|
||||
### Release Blocking Gates
|
||||
|
||||
- Replay Verification: 0 byte diff
|
||||
- Interop Suite: 95%+ findings parity
|
||||
- Offline E2E: All pass with no network
|
||||
- Unknowns Budget: Within configured limits
|
||||
- Router Retry-After: 100% compliance
|
||||
|
||||
---
|
||||
|
||||
*Processed by: Claude Code*
|
||||
*Date: 2025-12-21*
|
||||
@@ -0,0 +1,783 @@
|
||||
Below is a practical, production-grade architecture for building a **vulnerable binaries database**. I’m going to be explicit about what “such a database” can mean, because there are two materially different products:
|
||||
|
||||
1. **Known-build catalog**: “These exact shipped binaries (Build-ID / hash) are affected or fixed for CVE X.”
|
||||
2. **Binary fingerprint DB**: “Even if the binary is unpackaged / self-built, we can match vulnerable code patterns.”
|
||||
|
||||
You want both. The first gets you breadth fast; the second is the moat.
|
||||
|
||||
---
|
||||
|
||||
## 1) Core principle: treat “binary identity” as the primary key
|
||||
|
||||
For Linux ELF:
|
||||
|
||||
* Primary: `ELF Build-ID` (from `.note.gnu.build-id`)
|
||||
* Fallback: `sha256(file_bytes)`
|
||||
* Add: `sha256(.text)` and/or BLAKE3 for speed
|
||||
|
||||
This creates a stable identity that survives “package metadata lies.”
|
||||
|
||||
**BinaryKey = build_id || file_sha256**
|
||||
|
||||
---
|
||||
|
||||
## 2) High-level system diagram
|
||||
|
||||
```
|
||||
┌──────────────────────────┐
|
||||
│ Vulnerability Intel │
|
||||
│ OSV/NVD + distro advis. │
|
||||
└───────────┬──────────────┘
|
||||
│ normalize
|
||||
v
|
||||
┌──────────────────────────┐
|
||||
│ Vuln Knowledge Store │
|
||||
│ CVE↔pkg ranges, patches │
|
||||
└───────────┬──────────────┘
|
||||
│
|
||||
│
|
||||
┌───────────────────────v─────────────────────────┐
|
||||
│ Repo Snapshotter (per distro/arch/date) │
|
||||
│ - mirrors metadata + packages (+ debuginfo) │
|
||||
│ - verifies signatures │
|
||||
│ - emits signed snapshot manifest │
|
||||
└───────────┬───────────────────────────┬─────────┘
|
||||
│ │
|
||||
│ packages │ debuginfo/sources
|
||||
v v
|
||||
┌──────────────────────────┐ ┌──────────────────────────┐
|
||||
│ Package Unpacker │ │ Source/Buildinfo Mapper │
|
||||
│ - extract files │ │ - pkg→source commit/patch │
|
||||
└───────────┬──────────────┘ └───────────┬──────────────┘
|
||||
│ binaries │
|
||||
v │
|
||||
┌──────────────────────────┐ │
|
||||
│ Binary Feature Extractor │ │
|
||||
│ - Build-ID, hashes │ │
|
||||
│ - dyn deps, symbols │ │
|
||||
│ - function boundaries (opt)│ │
|
||||
└───────────┬──────────────┘ │
|
||||
│ │
|
||||
v v
|
||||
┌──────────────────────────────────────────────────┐
|
||||
│ Vulnerable Binary Classifier │
|
||||
│ Tier A: pkg/version range │
|
||||
│ Tier B: Build-ID→known shipped build │
|
||||
│ Tier C: code fingerprints (function/CFG hashes) │
|
||||
└───────────┬───────────────────────────┬──────────┘
|
||||
│ │
|
||||
v v
|
||||
┌──────────────────────────┐ ┌──────────────────────────┐
|
||||
│ Vulnerable Binary DB │ │ Evidence/Attestation DB │
|
||||
│ (indexed by BinaryKey) │ │ (signed proofs, snapshots)│
|
||||
└───────────┬──────────────┘ └───────────┬──────────────┘
|
||||
│ publish signed snapshot │
|
||||
v v
|
||||
Clients/Scanners Explainable VEX outputs
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3) Data stores you actually need
|
||||
|
||||
### A) Relational store (Postgres)
|
||||
|
||||
Use this for *indexes and joins*.
|
||||
|
||||
Key tables:
|
||||
|
||||
**`binary_identity`**
|
||||
|
||||
* `binary_key` (build_id or file_sha256) PK
|
||||
* `build_id` (nullable)
|
||||
* `file_sha256`, `text_sha256`
|
||||
* `arch`, `osabi`, `type` (ET_DYN/EXEC), `stripped`
|
||||
* `first_seen_snapshot`, `last_seen_snapshot`
|
||||
|
||||
**`binary_package_map`**
|
||||
|
||||
* `binary_key`
|
||||
* `distro`, `pkg_name`, `pkg_version_release`, `arch`
|
||||
* `file_path_in_pkg`, `snapshot_id`
|
||||
|
||||
**`snapshot_manifest`**
|
||||
|
||||
* `snapshot_id`
|
||||
* `distro`, `arch`, `timestamp`
|
||||
* `repo_metadata_digests`, `signing_key_id`, `dsse_envelope_ref`
|
||||
|
||||
**`cve_package_ranges`**
|
||||
|
||||
* `cve_id`, `ecosystem` (deb/rpm/apk), `pkg_name`
|
||||
* `vulnerable_ranges`, `fixed_ranges`
|
||||
* `advisory_ref`, `snapshot_id`
|
||||
|
||||
**`binary_vuln_assertion`**
|
||||
|
||||
* `binary_key`, `cve_id`
|
||||
* `status` ∈ {affected, not_affected, fixed, unknown}
|
||||
* `method` ∈ {range_match, buildid_catalog, fingerprint_match}
|
||||
* `confidence` (0–1)
|
||||
* `evidence_ref` (points to signed evidence)
|
||||
|
||||
### B) Object store (S3/MinIO)
|
||||
|
||||
Do not bloat Postgres with large blobs.
|
||||
|
||||
Store:
|
||||
|
||||
* extracted symbol lists, string tables
|
||||
* function hash maps
|
||||
* disassembly snippets for matched functions (small)
|
||||
* DSSE envelopes / attestations
|
||||
* optional: debug info extracts (or references to where they can be fetched)
|
||||
|
||||
### C) Optional search index (OpenSearch/Elastic)
|
||||
|
||||
If you want fast “find all binaries exporting `SSL_read`” style queries, index symbols/strings.
|
||||
|
||||
---
|
||||
|
||||
## 4) Building the database: pipelines
|
||||
|
||||
### Pipeline 1: Distro repo snapshots → Known-build catalog (breadth)
|
||||
|
||||
This is your fastest route to a “binaries DB.”
|
||||
|
||||
**Step 1 — Snapshot**
|
||||
|
||||
* Mirror repo metadata + packages for (distro, release, arch).
|
||||
* Verify signatures (APT Release.gpg, RPM signatures, APK signatures).
|
||||
* Emit **signed snapshot manifest** (DSSE) listing digests of everything mirrored.
|
||||
|
||||
**Step 2 — Extract binaries**
|
||||
For each package:
|
||||
|
||||
* unpack (deb/rpm/apk)
|
||||
* select ELF files (EXEC + shared libs)
|
||||
* compute Build-ID, file hash, `.text` hash
|
||||
* store identity + `binary_package_map`
|
||||
|
||||
**Step 3 — Assign CVE status (Tier A + Tier B)**
|
||||
|
||||
* Ingest distro advisories and/or OSV mappings into `cve_package_ranges`
|
||||
* For each `binary_package_map`, apply range checks
|
||||
* Create `binary_vuln_assertion` entries:
|
||||
|
||||
* `method=range_match` (coarse)
|
||||
* If you have a Build-ID mapping to exact shipped builds, you can tag:
|
||||
|
||||
* `method=buildid_catalog` (stronger than pure version)
|
||||
|
||||
This yields a database where a scanner can do:
|
||||
|
||||
* “Given Build-ID, tell me all CVEs per the distro snapshot.”
|
||||
|
||||
This already reduces noise because the primary key is the **binary**.
|
||||
|
||||
---
|
||||
|
||||
### Pipeline 2: Patch-aware classification (backports handled)
|
||||
|
||||
To handle “version says vulnerable but backport fixed” you must incorporate patch provenance.
|
||||
|
||||
**Step 1 — Build provenance mapping**
|
||||
Per ecosystem:
|
||||
|
||||
* Debian/Ubuntu: parse `Sources`, changelogs, (ideally) `.buildinfo`, patch series.
|
||||
* RPM distros: SRPM + changelog + patch list.
|
||||
* Alpine: APKBUILD + patches.
|
||||
|
||||
**Step 2 — CVE ↔ patch linkage**
|
||||
From advisories and patch metadata, store:
|
||||
|
||||
* “CVE fixed by patch set P in build B of pkg V-R”
|
||||
|
||||
**Step 3 — Apply to binaries**
|
||||
Instead of version-only, decide:
|
||||
|
||||
* if the **specific build** includes the patch
|
||||
* mark as `fixed` even if upstream version looks vulnerable
|
||||
|
||||
This is still not “binary-only,” but it’s much closer to truth for distros.
|
||||
|
||||
---
|
||||
|
||||
### Pipeline 3: Binary fingerprint factory (the moat)
|
||||
|
||||
This is where you become independent of packaging claims.
|
||||
|
||||
You build fingerprints at the **function/CFG level** for high-impact CVEs.
|
||||
|
||||
#### 3.1 Select targets
|
||||
|
||||
You cannot fingerprint everything. Start with:
|
||||
|
||||
* top shared libs (openssl, glibc, zlib, expat, libxml2, curl, sqlite, ncurses, etc.)
|
||||
* CVEs that are exploited in the wild / high-severity
|
||||
* CVEs where distros backport heavily (version logic is unreliable)
|
||||
|
||||
#### 3.2 Identify “changed functions” from the fix
|
||||
|
||||
Input: upstream commit/patch or distro patch.
|
||||
|
||||
Process:
|
||||
|
||||
* diff the patch
|
||||
* extract affected files + functions (tree-sitter/ctags + diff hunks)
|
||||
* list candidate functions and key basic blocks
|
||||
|
||||
#### 3.3 Build vulnerable + fixed reference binaries
|
||||
|
||||
For each (arch, toolchain profile):
|
||||
|
||||
* compile “known vulnerable” and “known fixed”
|
||||
* ensure reproducibility: record compiler version, flags, link mode
|
||||
* store provenance (DSSE) for these reference builds
|
||||
|
||||
#### 3.4 Extract robust fingerprints
|
||||
|
||||
Avoid raw byte signatures (they break across compilers).
|
||||
|
||||
Better fingerprint types, from weakest to strongest:
|
||||
|
||||
* **symbol-level**: function name + versioned symbol + library SONAME
|
||||
* **function normalized hash**:
|
||||
|
||||
* disassemble function
|
||||
* normalize:
|
||||
|
||||
* strip addresses/relocs
|
||||
* bucket registers
|
||||
* normalize immediates (where safe)
|
||||
* hash instruction sequence or basic-block sequence
|
||||
* **basic-block multiset hash**:
|
||||
|
||||
* build a set/multiset of block hashes; order-independent
|
||||
* **lightweight CFG hash**:
|
||||
|
||||
* nodes: block hashes
|
||||
* edges: control flow
|
||||
* hash canonical representation
|
||||
|
||||
Store fingerprints like:
|
||||
|
||||
**`vuln_fingerprint`**
|
||||
|
||||
* `cve_id`
|
||||
* `component` (openssl/libssl)
|
||||
* `arch`
|
||||
* `fp_type` (func_norm_hash, bb_multiset, cfg_hash)
|
||||
* `fp_value`
|
||||
* `function_hint` (name if present; else pattern)
|
||||
* `confidence`, `notes`
|
||||
* `evidence_ref` (points to reference builds + patch)
|
||||
|
||||
#### 3.5 Validate fingerprints at scale
|
||||
|
||||
This is non-negotiable.
|
||||
|
||||
Validation loop:
|
||||
|
||||
* Test against:
|
||||
|
||||
* known vulnerable builds (must match)
|
||||
* known fixed builds (must not match)
|
||||
* large “benign corpus” (estimate false positives)
|
||||
* Maintain:
|
||||
|
||||
* precision/recall metrics per fingerprint
|
||||
* confidence score
|
||||
|
||||
Only promote fingerprints to “production” when validation passes thresholds.
|
||||
|
||||
---
|
||||
|
||||
## 5) Query-time logic (how scanners use the DB)
|
||||
|
||||
Given a target binary, the scanner computes:
|
||||
|
||||
* `binary_key`
|
||||
* basic features (arch, SONAME, symbols)
|
||||
* optional function hashes (for targeted libs)
|
||||
|
||||
Then it queries in this precedence order:
|
||||
|
||||
1. **Exact match**: `binary_key` exists with explicit assertion (strong)
|
||||
2. **Build catalog**: Build-ID→known distro build→CVE mapping (strong)
|
||||
3. **Fingerprint match**: function/CFG hashes hit (strong, binary-only)
|
||||
4. **Fallback**: package range matching (weakest)
|
||||
|
||||
Return result as a signed VEX with evidence references.
|
||||
|
||||
---
|
||||
|
||||
## 6) Update model: “sealed knowledge snapshots”
|
||||
|
||||
To make this auditable and customer-friendly:
|
||||
|
||||
* Every repo snapshot is immutable and signed.
|
||||
* Every fingerprint bundle is versioned and signed.
|
||||
* Every “vulnerable binaries DB release” is a signed manifest pointing to:
|
||||
|
||||
* which repo snapshots were used
|
||||
* which advisory snapshots were used
|
||||
* which fingerprint sets were included
|
||||
|
||||
This lets you prove:
|
||||
|
||||
* what you knew
|
||||
* when you knew it
|
||||
* exactly which data drove the verdict
|
||||
|
||||
---
|
||||
|
||||
## 7) Scaling and cost control
|
||||
|
||||
Without control, fingerprinting explodes. Use these constraints:
|
||||
|
||||
* Only disassemble/hash functions for:
|
||||
|
||||
* libraries in your “hot set”
|
||||
* binaries whose package indicates relevance to a targeted CVE family
|
||||
* Deduplicate aggressively:
|
||||
|
||||
* identical `.text_sha256` ⇒ reuse extracted functions
|
||||
* identical Build-ID across paths ⇒ reuse features
|
||||
* Incremental snapshots:
|
||||
|
||||
* process only new/changed packages per snapshot
|
||||
* store “already processed digest” cache (Valkey)
|
||||
|
||||
---
|
||||
|
||||
## 8) Security and trust boundaries
|
||||
|
||||
A vulnerable binary DB is itself a high-value target. Hardening must be part of architecture:
|
||||
|
||||
* Verify upstream repo signatures before ingestion.
|
||||
* Run unpacking/extraction in sandboxes (namespaces/seccomp) because packages can be hostile.
|
||||
* Sign:
|
||||
|
||||
* snapshot manifests
|
||||
* fingerprint sets
|
||||
* DB releases
|
||||
* Keep signing keys in an HSM/KMS.
|
||||
* Maintain provenance chain: input digests → output digests.
|
||||
|
||||
---
|
||||
|
||||
## 9) Minimal viable build plan (no wishful thinking)
|
||||
|
||||
### MVP 1: Known-build binary catalog (fast, broad)
|
||||
|
||||
* Repo snapshot + Build-ID extraction
|
||||
* CVE ranges + advisory snapshots
|
||||
* `binary_key → (pkg@ver, CVEs)` mapping
|
||||
* Signed snapshot releases
|
||||
|
||||
### MVP 2: Patch-aware backport handling (precision jump)
|
||||
|
||||
* Source/patch mapping
|
||||
* Build-specific “fixed-by-backport” logic
|
||||
|
||||
### MVP 3: Fingerprints for top components (moat)
|
||||
|
||||
* Fingerprint factory for ~20–50 “most reused” libs
|
||||
* Validation corpus + confidence scoring
|
||||
|
||||
---
|
||||
|
||||
## 10) What you can claim (and what you should not)
|
||||
|
||||
You can defensibly claim:
|
||||
|
||||
* “We can identify vulnerable **binaries** (not just packages) with verifiable evidence.”
|
||||
|
||||
You should not claim (until you have it):
|
||||
|
||||
* “We can detect every vulnerable binary on earth”
|
||||
No one can do that without unacceptable false positives/negatives.
|
||||
|
||||
---
|
||||
|
||||
If you want this aligned tightly to your Stella Ops services split (scanner webservice lattice algorithms + proof-of-integrity graph), I can map the above into:
|
||||
|
||||
* concrete microservices,
|
||||
* queue/job boundaries,
|
||||
* and the exact API surfaces (`/snapshots`, `/features`, `/fingerprints`, `/match`, `/vex`).
|
||||
To code **MVP 2 (patch-aware backport handling)** without any human triage, you need one thing in your database that most scanners do not maintain:
|
||||
|
||||
> A normalized, distro-specific index:
|
||||
> **(distro, release, source-package, CVE) → fixed-in distro version (or not-affected / wontfix / unknown), with evidence and confidence.**
|
||||
|
||||
Then every scan decision becomes a deterministic version comparison against that index, not against upstream semver.
|
||||
|
||||
Below is a concrete, buildable approach (pipelines + data model + code skeletons) that stays fully automated.
|
||||
|
||||
---
|
||||
|
||||
## 1) What MVP2 computes
|
||||
|
||||
### Output table you must build
|
||||
|
||||
**`cve_fix_index`**
|
||||
|
||||
* `distro` (e.g., debian, ubuntu, rhel, alpine)
|
||||
* `release` (e.g., bookworm, jammy, 9, 3.19)
|
||||
* `source_pkg` (not binary subpackage)
|
||||
* `cve_id`
|
||||
* `state` ∈ {`fixed`, `vulnerable`, `not_affected`, `wontfix`, `unknown`}
|
||||
* `fixed_version` (nullable; distro version string, including revision)
|
||||
* `method` ∈ {`security_feed`, `changelog`, `patch_header`, `upstream_patch_match`}
|
||||
* `confidence` (float)
|
||||
* `evidence` (JSON: references to advisory entry, changelog lines, patch names + digests)
|
||||
* `snapshot_id` (your sealed snapshot identifier)
|
||||
|
||||
### Why “source package”?
|
||||
|
||||
Security trackers and patch sets are tracked at the **source** level (e.g., `openssl`), while runtime installs are often **binary subpackages** (e.g., `libssl3`). You need a stable join:
|
||||
`binary_pkg -> source_pkg`.
|
||||
|
||||
---
|
||||
|
||||
## 2) No-human signals, in strict priority order
|
||||
|
||||
You can do this with **zero manual** work by using a tiered resolver:
|
||||
|
||||
### Tier 1 — Structured distro security feed (highest precision)
|
||||
|
||||
This is the authoritative “backport-aware” answer because it encodes:
|
||||
|
||||
* “fixed in 1.1.1n-0ubuntu2.4” (even if upstream says “fixed in 1.1.1o”)
|
||||
* “not affected” cases
|
||||
* sometimes arch-specific applicability
|
||||
|
||||
Your ingestor just parses and normalizes it.
|
||||
|
||||
### Tier 2 — Source package changelog CVE mentions
|
||||
|
||||
If a feed entry is missing/late, parse source changelog:
|
||||
|
||||
* Debian/Ubuntu: `debian/changelog`
|
||||
* RPM: `%changelog` in `.spec`
|
||||
* Alpine: `secfixes` in `APKBUILD` (often present)
|
||||
|
||||
This is surprisingly effective because maintainers often include “CVE-XXXX-YYYY” in the entry that introduced the fix.
|
||||
|
||||
### Tier 3 — Patch metadata (DEP-3 headers / patch filenames)
|
||||
|
||||
Parse patches shipped with the source package:
|
||||
|
||||
* Debian: `debian/patches/*` + `debian/patches/series`
|
||||
* RPM: patch files listed in spec / SRPM
|
||||
* Alpine: `patches/*.patch` in the aport
|
||||
|
||||
Search patch headers and filenames for CVE IDs, store patch hashes.
|
||||
|
||||
### Tier 4 — Upstream patch equivalence (optional in MVP2, strong)
|
||||
|
||||
If you can map CVE→upstream fix commit (OSV often helps), you can match canonicalized patch hunks against distro patches.
|
||||
|
||||
MVP2 can ship without Tier 4; Tier 1+2 already eliminates most backport false positives.
|
||||
|
||||
---
|
||||
|
||||
## 3) Architecture: the “Fix Index Builder” job
|
||||
|
||||
### Inputs
|
||||
|
||||
* Your sealed repo snapshot: Packages + Sources (or SRPM/aports)
|
||||
* Distro security feed snapshot (OVAL/JSON/errata tracker) for same release
|
||||
* (Optional) OSV/NVD upstream ranges for fallback only
|
||||
|
||||
### Processing graph
|
||||
|
||||
1. **Build `binary_pkg → source_pkg` map** from repo metadata
|
||||
2. **Ingest security feed** → produce `FixRecord(method=security_feed, confidence=0.95)`
|
||||
3. **For source packages in snapshot**:
|
||||
|
||||
* unpack source
|
||||
* parse changelog for CVE mentions → `FixRecord(method=changelog, confidence=0.75–0.85)`
|
||||
* parse patch headers → `FixRecord(method=patch_header, confidence=0.80–0.90)`
|
||||
4. **Merge** records into a single best record per key (distro, release, source_pkg, cve)
|
||||
5. Store into `cve_fix_index` with evidence
|
||||
6. Sign the resulting snapshot manifest
|
||||
|
||||
---
|
||||
|
||||
## 4) Merge logic (no human, deterministic)
|
||||
|
||||
You need a deterministic rule for conflicts.
|
||||
|
||||
Recommended (conservative but still precision-improving):
|
||||
|
||||
1. If any record says `not_affected` with confidence ≥ 0.9 → choose `not_affected`
|
||||
2. Else if any record says `fixed` with confidence ≥ 0.9 → choose `fixed` and `fixed_version = max_fixed_version_among_high_conf`
|
||||
3. Else if any record says `fixed` at all → choose `fixed` with best available `fixed_version`
|
||||
4. Else if any says `wontfix` → choose `wontfix`
|
||||
5. Else `unknown`
|
||||
|
||||
Additionally:
|
||||
|
||||
* Keep *all* evidence records in `evidence` so you can explain and audit.
|
||||
|
||||
---
|
||||
|
||||
## 5) Version comparison: do not reinvent it
|
||||
|
||||
Backport handling lives or dies on correct version ordering.
|
||||
|
||||
### Practical approach (recommended for ingestion + server-side decisioning)
|
||||
|
||||
Use official tooling in containerized workers:
|
||||
|
||||
* Debian/Ubuntu: `dpkg --compare-versions`
|
||||
* RPM distros: `rpmdev-vercmp` or `rpm` library
|
||||
* Alpine: `apk version -t`
|
||||
|
||||
This is reliable and avoids subtle comparator bugs.
|
||||
|
||||
If you must do it in-process, use well-tested libraries per ecosystem (but containerized official tools are the most robust).
|
||||
|
||||
---
|
||||
|
||||
## 6) Concrete code: Debian/Ubuntu changelog + patch parsing
|
||||
|
||||
This example shows **Tier 2 + Tier 3** inference for a single unpacked source tree. You would wrap this inside your snapshot processing loop.
|
||||
|
||||
### 6.1 CVE extractor
|
||||
|
||||
```python
|
||||
import re
|
||||
from pathlib import Path
|
||||
from hashlib import sha256
|
||||
|
||||
CVE_RE = re.compile(r"\bCVE-\d{4}-\d{4,7}\b")
|
||||
|
||||
def extract_cves(text: str) -> set[str]:
|
||||
return set(CVE_RE.findall(text or ""))
|
||||
```
|
||||
|
||||
### 6.2 Parse the *top* debian/changelog entry (for this version)
|
||||
|
||||
This works well because when you unpack a `.dsc` for version `V`, the top entry is for `V`.
|
||||
|
||||
```python
|
||||
def parse_debian_changelog_top_entry(src_dir: Path) -> tuple[str, set[str], dict]:
|
||||
"""
|
||||
Returns:
|
||||
version: str
|
||||
cves: set[str] found in the top entry
|
||||
evidence: dict with excerpt for explainability
|
||||
"""
|
||||
changelog_path = src_dir / "debian" / "changelog"
|
||||
if not changelog_path.exists():
|
||||
return "", set(), {}
|
||||
|
||||
lines = changelog_path.read_text(errors="replace").splitlines()
|
||||
if not lines:
|
||||
return "", set(), {}
|
||||
|
||||
# First line: "pkgname (version) distro; urgency=..."
|
||||
m = re.match(r"^[^\s]+\s+\(([^)]+)\)\s+", lines[0])
|
||||
version = m.group(1) if m else ""
|
||||
|
||||
entry_lines = [lines[0]]
|
||||
# Collect until maintainer trailer line: " -- Name <email> date"
|
||||
for line in lines[1:]:
|
||||
entry_lines.append(line)
|
||||
if line.startswith(" -- "):
|
||||
break
|
||||
|
||||
entry_text = "\n".join(entry_lines)
|
||||
cves = extract_cves(entry_text)
|
||||
|
||||
evidence = {
|
||||
"file": "debian/changelog",
|
||||
"version": version,
|
||||
"excerpt": entry_text[:2000], # store small excerpt, not whole file
|
||||
}
|
||||
return version, cves, evidence
|
||||
```
|
||||
|
||||
### 6.3 Parse CVEs from patch headers (DEP-3-ish)
|
||||
|
||||
```python
|
||||
def parse_debian_patches_for_cves(src_dir: Path) -> tuple[dict[str, list[dict]], dict]:
|
||||
"""
|
||||
Returns:
|
||||
cve_to_patches: {CVE: [ {path, sha256, header_excerpt}, ... ]}
|
||||
evidence_summary: dict
|
||||
"""
|
||||
patches_dir = src_dir / "debian" / "patches"
|
||||
if not patches_dir.exists():
|
||||
return {}, {}
|
||||
|
||||
cve_to_patches: dict[str, list[dict]] = {}
|
||||
|
||||
for patch in patches_dir.glob("*"):
|
||||
if not patch.is_file():
|
||||
continue
|
||||
# Read only first N lines to keep it cheap
|
||||
header = "\n".join(patch.read_text(errors="replace").splitlines()[:80])
|
||||
cves = extract_cves(header + "\n" + patch.name)
|
||||
if not cves:
|
||||
continue
|
||||
|
||||
digest = sha256(patch.read_bytes()).hexdigest()
|
||||
rec = {
|
||||
"path": str(patch.relative_to(src_dir)),
|
||||
"sha256": digest,
|
||||
"header_excerpt": header[:1200],
|
||||
}
|
||||
for cve in cves:
|
||||
cve_to_patches.setdefault(cve, []).append(rec)
|
||||
|
||||
evidence = {
|
||||
"dir": "debian/patches",
|
||||
"matched_cves": len(cve_to_patches),
|
||||
}
|
||||
return cve_to_patches, evidence
|
||||
```
|
||||
|
||||
### 6.4 Produce FixRecords from the source tree
|
||||
|
||||
```python
|
||||
def infer_fix_records_from_debian_source(src_dir: Path, distro: str, release: str, source_pkg: str, snapshot_id: str):
|
||||
version, changelog_cves, changelog_ev = parse_debian_changelog_top_entry(src_dir)
|
||||
cve_to_patches, patch_ev = parse_debian_patches_for_cves(src_dir)
|
||||
|
||||
records = []
|
||||
|
||||
# Changelog-based: treat CVE mentioned in top entry as fixed in this version
|
||||
for cve in changelog_cves:
|
||||
records.append({
|
||||
"distro": distro,
|
||||
"release": release,
|
||||
"source_pkg": source_pkg,
|
||||
"cve_id": cve,
|
||||
"state": "fixed",
|
||||
"fixed_version": version,
|
||||
"method": "changelog",
|
||||
"confidence": 0.80,
|
||||
"evidence": {"changelog": changelog_ev},
|
||||
"snapshot_id": snapshot_id,
|
||||
})
|
||||
|
||||
# Patch-header-based: treat CVE-tagged patches as fixed in this version
|
||||
for cve, patches in cve_to_patches.items():
|
||||
records.append({
|
||||
"distro": distro,
|
||||
"release": release,
|
||||
"source_pkg": source_pkg,
|
||||
"cve_id": cve,
|
||||
"state": "fixed",
|
||||
"fixed_version": version,
|
||||
"method": "patch_header",
|
||||
"confidence": 0.87,
|
||||
"evidence": {"patches": patches, "patch_summary": patch_ev},
|
||||
"snapshot_id": snapshot_id,
|
||||
})
|
||||
|
||||
return records
|
||||
```
|
||||
|
||||
That is the automated “patch-aware” signal generator.
|
||||
|
||||
---
|
||||
|
||||
## 7) Wiring this into your database build
|
||||
|
||||
### 7.1 Store raw evidence and merged result
|
||||
|
||||
Two-stage storage is worth it:
|
||||
|
||||
1. `cve_fix_evidence` (append-only)
|
||||
2. `cve_fix_index` (merged best record)
|
||||
|
||||
So you can:
|
||||
|
||||
* rerun merge rules
|
||||
* improve confidence scoring
|
||||
* keep auditability
|
||||
|
||||
### 7.2 Merging “fixed_version” for a CVE
|
||||
|
||||
When multiple versions mention the same CVE, you usually want the **latest** mentioning version (highest by distro comparator), because repeated mentions often indicate earlier partial fix.
|
||||
|
||||
Pseudo:
|
||||
|
||||
```python
|
||||
def choose_fixed_version(existing: str | None, candidate: str, vercmp) -> str:
|
||||
if not existing:
|
||||
return candidate
|
||||
return candidate if vercmp(candidate, existing) > 0 else existing
|
||||
```
|
||||
|
||||
Where `vercmp` calls `dpkg --compare-versions` (Debian) or equivalent for that distro.
|
||||
|
||||
---
|
||||
|
||||
## 8) Decisioning logic at scan time (what changes with MVP2)
|
||||
|
||||
Without MVP2, you likely do:
|
||||
|
||||
* upstream range check (false positives for backports)
|
||||
|
||||
With MVP2, you do:
|
||||
|
||||
1. identify `distro+release` from environment (or image base)
|
||||
2. map `binary_pkg → source_pkg`
|
||||
3. query `cve_fix_index(distro, release, source_pkg, cve)`
|
||||
4. if `state=fixed` and `pkg_version >= fixed_version` → fixed
|
||||
5. if `state=not_affected` → safe
|
||||
6. else fallback to upstream ranges
|
||||
|
||||
That single substitution removes most backport noise.
|
||||
|
||||
---
|
||||
|
||||
## 9) Practical notes so you don’t get trapped
|
||||
|
||||
### A) You must know the distro release
|
||||
|
||||
Backport reality is release-specific. The same package name/version can have different patching across releases.
|
||||
|
||||
### B) Arch-specific fixes exist
|
||||
|
||||
Your schema should allow `arch` on fix records (nullable). If the feed says “only amd64 affected,” store it.
|
||||
|
||||
### C) False positives in changelog parsing
|
||||
|
||||
Mitigation without humans:
|
||||
|
||||
* require CVE mention + security-ish verbs (“fix”, “security”, “patch”) OR presence in patch headers
|
||||
* otherwise lower confidence and let feed override
|
||||
|
||||
### D) Keep evidence small
|
||||
|
||||
Store:
|
||||
|
||||
* excerpt + patch hashes
|
||||
Not entire source tarballs.
|
||||
|
||||
---
|
||||
|
||||
## 10) Minimal “done definition” for MVP2
|
||||
|
||||
You have MVP2 when, for Debian/Ubuntu at least, you can demonstrate:
|
||||
|
||||
* A CVE that upstream marks vulnerable for version X
|
||||
* The distro backported it in X-<revision>
|
||||
* Your system classifies:
|
||||
|
||||
* `X-older_revision` as vulnerable
|
||||
* `X-newer_revision` as fixed
|
||||
* With evidence: fix feed record and/or changelog/patch proof
|
||||
|
||||
No human required.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can provide the same “Tier 2/3 inference” module for RPM (SRPM/spec parsing) and Alpine (APKBUILD `secfixes` extraction), plus the exact Postgres DDL for `cve_fix_evidence` and `cve_fix_index`, and the merge SQL.
|
||||
@@ -0,0 +1,140 @@
|
||||
# Reimagining Proof-Linked UX in Security Workflows
|
||||
|
||||
**Date**: 2025-12-16
|
||||
**Status**: PROCESSED
|
||||
**Last Updated**: 2025-12-17
|
||||
|
||||
---
|
||||
|
||||
## Overview
|
||||
|
||||
This advisory introduces a **"Narrative-First" Triage UX** paradigm for Stella Ops, designed to dramatically reduce time-to-evidence and provide cryptographically verifiable proof chains for every security decision.
|
||||
|
||||
### Core Innovation
|
||||
|
||||
**Competitor pattern (Lists-First):**
|
||||
- Big table of CVEs → filters → click into details → hunt for reachability/SBOM/VEX links scattered across tabs.
|
||||
- Weak proof chain; noisy; slow "time-to-evidence".
|
||||
|
||||
**Stella pattern (Narrative-First):**
|
||||
- Case Header answers "Can I ship?" above the fold
|
||||
- Single Evidence tab with proof-linked artifacts
|
||||
- Quiet-by-default noise controls with reversible, signed decisions
|
||||
- Smart-Diff history explaining meaningful risk changes
|
||||
|
||||
### Key Deliverables
|
||||
|
||||
This advisory has been split into formal documentation:
|
||||
|
||||
| Document | Location | Purpose |
|
||||
|----------|----------|---------|
|
||||
| **Triage UX Guide** | `docs/ux/TRIAGE_UX_GUIDE.md` | Complete UX specification |
|
||||
| **UI Reducer Spec** | `docs/ux/TRIAGE_UI_REDUCER_SPEC.md` | Angular 17 state machine |
|
||||
| **API Contract v1** | `docs/api/triage.contract.v1.md` | REST endpoint specifications |
|
||||
| **Database Schema** | `docs/db/triage_schema.sql` | PostgreSQL tables and views |
|
||||
|
||||
---
|
||||
|
||||
## Key Concepts
|
||||
|
||||
### 1. Lanes (Visibility Buckets)
|
||||
|
||||
| Lane | Description |
|
||||
|------|-------------|
|
||||
| ACTIVE | Actionable findings requiring attention |
|
||||
| BLOCKED | Findings blocking deployment |
|
||||
| NEEDS_EXCEPTION | Findings requiring exception approval |
|
||||
| MUTED_REACH | Auto-muted due to non-reachability |
|
||||
| MUTED_VEX | Auto-muted due to VEX not_affected status |
|
||||
| COMPENSATED | Muted due to compensating controls |
|
||||
|
||||
### 2. Verdicts
|
||||
|
||||
- **SHIP**: Safe to deploy
|
||||
- **BLOCK**: Deployment blocked by policy
|
||||
- **EXCEPTION**: Needs exception approval
|
||||
|
||||
### 3. Evidence Types
|
||||
|
||||
- SBOM_SLICE
|
||||
- VEX_DOC
|
||||
- PROVENANCE
|
||||
- CALLSTACK_SLICE
|
||||
- REACHABILITY_PROOF
|
||||
- REPLAY_MANIFEST
|
||||
- POLICY
|
||||
- SCAN_LOG
|
||||
|
||||
### 4. Decision Types
|
||||
|
||||
All decisions are DSSE-signed and reversible:
|
||||
- MUTE_REACH
|
||||
- MUTE_VEX
|
||||
- ACK
|
||||
- EXCEPTION
|
||||
|
||||
---
|
||||
|
||||
## Performance Targets
|
||||
|
||||
| Metric | Target |
|
||||
|--------|--------|
|
||||
| Time-to-Evidence (TTFS) | P95 ≤ 30s |
|
||||
| Mute Correctness | < 3% reversal rate |
|
||||
| Audit Coverage | > 98% complete bundles |
|
||||
|
||||
---
|
||||
|
||||
## Sprint Plan
|
||||
|
||||
See `docs/implplan/` for detailed sprint files:
|
||||
|
||||
1. **SPRINT_3700_0001_0001**: Database Schema & Migrations
|
||||
2. **SPRINT_3701_0001_0001**: Triage API Endpoints
|
||||
3. **SPRINT_3702_0001_0001**: Decision Service with DSSE Signing
|
||||
4. **SPRINT_0360_0001_0001**: Angular State Management
|
||||
5. **SPRINT_0361_0001_0001**: UI Components
|
||||
6. **SPRINT_0362_0001_0001**: Evidence Bundle Export
|
||||
|
||||
---
|
||||
|
||||
## Integration Points
|
||||
|
||||
### Services Involved
|
||||
|
||||
- `scanner.webservice`: Risk evaluation, evidence storage, API
|
||||
- `concelier`: Vuln feed aggregation (preserve prune source)
|
||||
- `excititor`: VEX merge (preserve prune source)
|
||||
- `notify.webservice`: Event emission (first_signal, risk_changed, gate_blocked)
|
||||
- `scheduler.webservice`: Re-evaluation triggers
|
||||
|
||||
### Data Flow
|
||||
|
||||
```
|
||||
concelier (feeds) ─┬─► scanner.webservice ─► triage API ─► UI
|
||||
│ ▲
|
||||
excititor (VEX) ───┘ │
|
||||
│
|
||||
scheduler (re-eval) ───────┘
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Related Documentation
|
||||
|
||||
- `docs/product-advisories/14-Dec-2025 - Proof and Evidence Chain Technical Reference.md`
|
||||
- `docs/product-advisories/14-Dec-2025 - UX and Time-to-Evidence Technical Reference.md`
|
||||
- `docs/15_UI_GUIDE.md`
|
||||
- `docs/modules/ui/architecture.md`
|
||||
|
||||
---
|
||||
|
||||
## Archive Note
|
||||
|
||||
The original content of this advisory was incorrectly populated with performance testing infrastructure content. That content has been preserved at:
|
||||
`docs/dev/performance-testing-playbook.md`
|
||||
|
||||
---
|
||||
|
||||
**Document Version**: 1.0
|
||||
**Target Platform**: .NET 10, PostgreSQL >= 16, Angular v17
|
||||
@@ -0,0 +1,259 @@
|
||||
I’m sharing this because the state of modern vulnerability prioritization and supply‑chain risk tooling is rapidly shifting toward *context‑aware, evidence‑driven insights* — not just raw lists of CVEs.
|
||||
|
||||
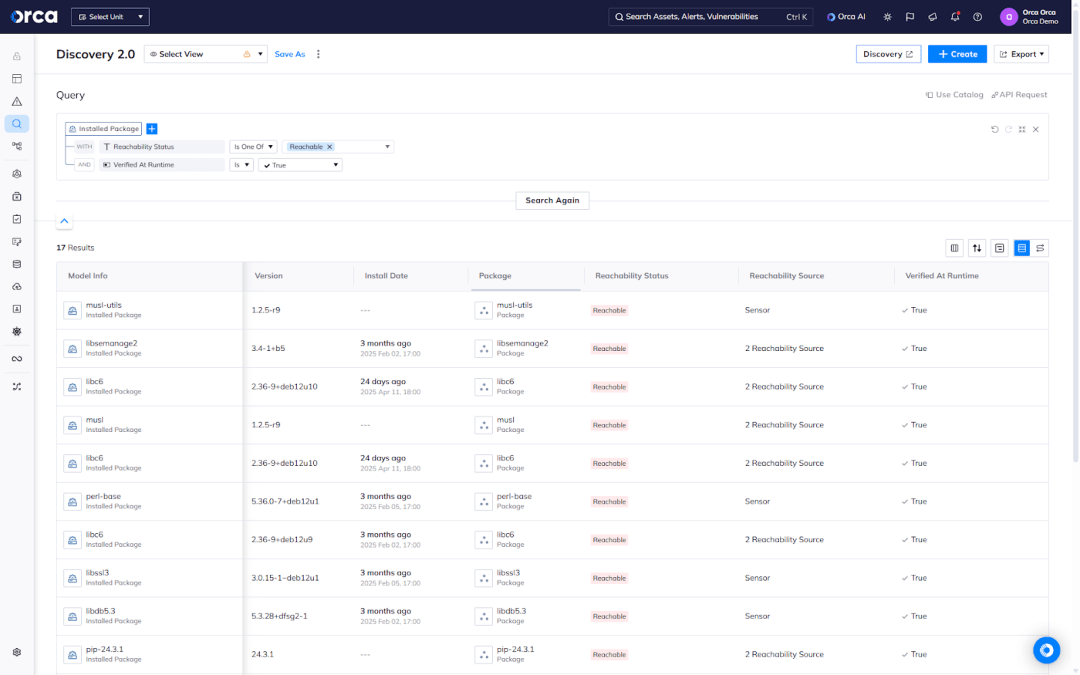
|
||||
|
||||

|
||||
|
||||
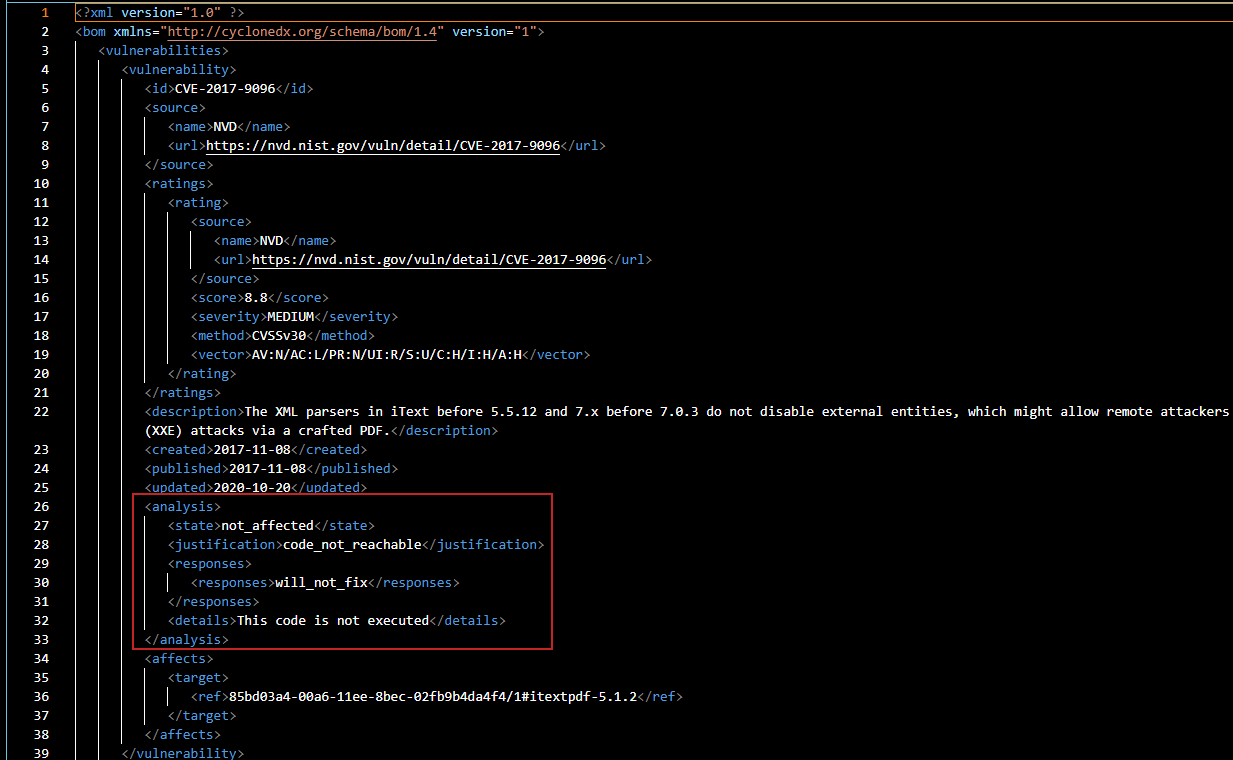
|
||||
|
||||
|
||||
|
||||
Here’s what’s shaping the field:
|
||||
|
||||
**• Reachability‑first triage is about ordering fixes by *actual call‑graph evidence*** — tools like Snyk analyze your code’s call graph to determine whether a vulnerable function is *actually reachable* from your application’s execution paths. Vulnerabilities with evidence of reachability are tagged (e.g., **REACHABLE**) so teams can focus on real exploit risk first, rather than just severity in a vacuum. This significantly reduces noise and alert fatigue by filtering out issues that can’t be invoked in context. ([Snyk User Docs][1])
|
||||
|
||||
**• Inline VEX status with provenance turns static findings into contextual decisions.** *Vulnerability Exploitability eXchange (VEX)* is a structured way to annotate each finding with its *exploitability status* — like “not applicable,” “mitigated,” or “under investigation” — and attach that directly to SBOM/VEX records. Anchore Enterprise, for example, supports embedding these annotations and exporting them in both OpenVEX and CycloneDX VEX formats so downstream consumers see not just “there’s a CVE” but *what it means for your specific build or deployment*. ([Anchore][2])
|
||||
|
||||
**• OCI‑linked evidence chips (VEX attestations) bind context to images at the registry level.** Tools like Trivy can discover VEX attestations stored in OCI registries using flags like `--vex oci`. That lets scanners incorporate *pre‑existing attestations* into their vulnerability results — essentially layering registry‑attached statements about exploitability right into your scan output. ([Trivy][3])
|
||||
|
||||
Taken together, these trends illustrate a shift from *volume* (lists of vulnerabilities) to *value* (actionable, context‑specific risk insight) — especially if you’re building or evaluating risk tooling that needs to integrate call‑graph evidence, structured exploitability labels, and registry‑sourced attestations for high‑fidelity prioritization.
|
||||
|
||||
[1]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/reachability-analysis?utm_source=chatgpt.com "Reachability analysis"
|
||||
[2]: https://anchore.com/blog/anchore-enterprise-5-23-cyclonedx-vex-and-vdr-support/?utm_source=chatgpt.com "Anchore Enterprise 5.23: CycloneDX VEX and VDR Support"
|
||||
[3]: https://trivy.dev/docs/latest/supply-chain/vex/oci/?utm_source=chatgpt.com "Discover VEX Attestation in OCI Registry"
|
||||
Below are UX patterns that are “worth it” specifically for a VEX-first, evidence-driven scanner like Stella Ops. I’m not repeating generic “nice UI” ideas; these are interaction models that materially reduce triage time, raise trust, and turn your moats (determinism, proofs, lattice merge) into something users can feel.
|
||||
|
||||
## 1) Make “Claim → Evidence → Verdict” the core mental model
|
||||
|
||||
Every finding is a **Claim** (e.g., “CVE-X affects package Y in image Z”), backed by **Evidence** (SBOM match, symbol match, reachable path, runtime hit, vendor VEX, etc.), merged by **Semantics** (your lattice rules), producing a **Verdict** (policy outcome + signed attestation).
|
||||
|
||||
**UX consequence:** every screen should answer:
|
||||
|
||||
* What is being claimed?
|
||||
* What evidence supports it?
|
||||
* Which rule turned it into “block / allow / warn”?
|
||||
* Can I replay it identically?
|
||||
|
||||
## 2) “Risk Inbox” that behaves like an operator queue, not a report
|
||||
|
||||
Borrow the best idea from SOC tooling: a queue you can clear.
|
||||
|
||||
**List row structure (high impact):**
|
||||
|
||||
* Left: *Policy outcome* (BLOCK / WARN / PASS) as the primary indicator (not CVSS).
|
||||
* Middle: *Evidence chips* (REACHABLE, RUNTIME-SEEN, VEX-NOT-AFFECTED, ATTESTED, DIFF-NEW, etc.).
|
||||
* Right: *Blast radius* (how many artifacts/envs/services), plus “time since introduced”.
|
||||
|
||||
**Must-have filters:**
|
||||
|
||||
* “New since last release”
|
||||
* “Reachable only”
|
||||
* “Unknowns only”
|
||||
* “Policy blockers in prod”
|
||||
* “Conflicts (VEX merge disagreement)”
|
||||
* “No provenance (unsigned evidence)”
|
||||
|
||||
## 3) Delta-first everywhere (default view is “what changed”)
|
||||
|
||||
Users rarely want the full world; they want the delta relative to the last trusted point.
|
||||
|
||||
**Borrowed pattern:** PR diff mindset.
|
||||
|
||||
* Default to **Diff Lens**: “introduced / fixed / changed reachability / changed policy / changed EPSS / changed source trust”.
|
||||
* Every detail page has a “Before / After” toggle for: SBOM subgraph, reachability subgraph, VEX claims, policy trace.
|
||||
|
||||
This is one of the biggest “time saved per pixel” UX decisions you can make.
|
||||
|
||||
## 4) Evidence chips that are not decorative: click-to-proof
|
||||
|
||||
Chips should be actionable and open the exact proof.
|
||||
|
||||
Examples:
|
||||
|
||||
* **REACHABLE** → opens reachability subgraph viewer with the exact path(s) highlighted.
|
||||
* **ATTESTED** → opens DSSE/in-toto attestation viewer + signature verification status.
|
||||
* **VEX: NOT AFFECTED** → opens VEX statement with provenance + merge outcome.
|
||||
* **BINARY-MATCH** → opens mapping evidence (Build-ID / symbol / file hash) and confidence.
|
||||
|
||||
Rule: every chip either opens proof, or it doesn’t exist.
|
||||
|
||||
## 5) “Verdict Ladder” on every finding
|
||||
|
||||
A vertical ladder that shows the transformation from raw detection to final decision:
|
||||
|
||||
1. Detection source(s)
|
||||
2. Component identification (SBOM / installed / binary mapping)
|
||||
3. Applicability (platform, config flags, feature gates)
|
||||
4. Reachability (static path evidence)
|
||||
5. Runtime confirmation (if available)
|
||||
6. VEX merge & trust weighting
|
||||
7. Policy trace → final verdict
|
||||
8. Signed attestation reference (digest)
|
||||
|
||||
This turns your product from “scanner UI” into “auditor-grade reasoning UI”.
|
||||
|
||||
## 6) Reachability Explorer that is intentionally constrained
|
||||
|
||||
Reachability visualizations usually fail because they’re too generic.
|
||||
|
||||
Do this instead:
|
||||
|
||||
* Show **one shortest path** by default (operator mode).
|
||||
* Offer “show all paths” only on demand (expert mode).
|
||||
* Provide a **human-readable path narration** (“HTTP handler X → service Y → library Z → vulnerable function”) plus the reproducible anchors (file:line or symbol+offset).
|
||||
* Store and render the **subgraph evidence**, not a screenshot.
|
||||
|
||||
## 7) A “Policy Trace” panel that reads like a flight recorder
|
||||
|
||||
Borrow from OPA/rego trace concepts: show which rules fired, which evidence satisfied conditions, and where unknowns influenced outcome.
|
||||
|
||||
**UX element:** “Why blocked?” and “What would make it pass?”
|
||||
|
||||
* “Blocked because: reachable AND exploited AND no mitigation claim AND env=prod”
|
||||
* “Would pass if: VEX mitigated with evidence OR reachability unknown budget allows OR patch applied”
|
||||
|
||||
This directly enables your “risk budgets + diff-aware release gates”.
|
||||
|
||||
## 8) Unknowns are first-class, budgeted, and visual
|
||||
|
||||
Most tools hide unknowns. You want the opposite.
|
||||
|
||||
**Unknowns dashboard:**
|
||||
|
||||
* Unknown count by environment + trend.
|
||||
* Unknown categories (unmapped binaries, missing SBOM edges, unsigned VEX, stale feeds).
|
||||
* Policy thresholds (e.g., “fail if unknowns > N in prod”) with clear violation explanation.
|
||||
|
||||
**Micro-interaction:** unknowns should have a “convert to known” CTA (attach evidence, add mapping rule, import attestation, upgrade feed bundle).
|
||||
|
||||
## 9) VEX Conflict Studio: side-by-side merge with provenance
|
||||
|
||||
When two statements disagree, don’t just pick one. Show the conflict.
|
||||
|
||||
**Conflict card:**
|
||||
|
||||
* Left: Vendor VEX statement + signature/provenance
|
||||
* Right: Distro/internal statement + signature/provenance
|
||||
* Middle: lattice merge result + rule that decided it
|
||||
* Bottom: “Required evidence hook” checklist (feature flag off, config, runtime proof, etc.)
|
||||
|
||||
This makes your “Trust Algebra / Lattice Engine” tangible.
|
||||
|
||||
## 10) Exceptions as auditable objects (with TTL) integrated into triage
|
||||
|
||||
Exception UX should feel like creating a compliance-grade artifact, not clicking “ignore”.
|
||||
|
||||
**Exception form UX:**
|
||||
|
||||
* Scope selector: artifact digest(s), package range, env(s), time window
|
||||
* Required: rationale + evidence attachments
|
||||
* Optional: compensating controls (WAF, network isolation)
|
||||
* Auto-generated: signed exception attestation + audit pack link
|
||||
* Review workflow: “owner”, “approver”, “expires”, “renewal requires fresh evidence”
|
||||
|
||||
## 11) One-click “Audit Pack” export from any screen
|
||||
|
||||
Auditors don’t want screenshots; they want structured evidence.
|
||||
|
||||
From a finding/release:
|
||||
|
||||
* Included: SBOM (exact), VEX set (exact), merge rules version, policy version, reachability subgraph, signatures, feed snapshot hashes, delta verdict
|
||||
* Everything referenced by digest and replay manifest
|
||||
|
||||
UX: a single button “Generate Audit Pack”, plus “Replay locally” instructions.
|
||||
|
||||
## 12) Attestation Viewer that non-cryptographers can use
|
||||
|
||||
Most attestation UIs are unreadable. Make it layered:
|
||||
|
||||
* “Verified / Unverified” summary
|
||||
* Key identity, algorithm, timestamp
|
||||
* What was attested (subject digest, predicate type)
|
||||
* Links: “open raw DSSE JSON”, “copy digest”, “compare to current”
|
||||
|
||||
If you do crypto-sovereign modes (GOST/SM/eIDAS/FIPS), show algorithm badges and validation source.
|
||||
|
||||
## 13) Proof-of-Integrity Graph as a drill-down, not a science project
|
||||
|
||||
Graph UI should answer one question: “Can I trust this artifact lineage?”
|
||||
|
||||
Provide:
|
||||
|
||||
* A minimal lineage chain by default: Source → Build → SBOM → VEX → Scan Verdict → Deploy
|
||||
* Expand nodes on click (don’t render the whole universe)
|
||||
* Confidence meter derived from signed links and trusted issuers
|
||||
|
||||
## 14) “Remedy Plan” that is evidence-aware, not generic advice
|
||||
|
||||
Fix guidance must reflect reachability and delta:
|
||||
|
||||
* If reachable: prioritize patch/upgrade, show “patch removes reachable path” expectation
|
||||
* If not reachable: propose mitigation or deferred SLA with justification
|
||||
* Show “impact of upgrade” (packages touched, images affected, services impacted)
|
||||
* Output as a signed remediation recommendation (optional) to align with your “signed, replayable risk verdicts”
|
||||
|
||||
## 15) Fleet view as a “blast radius map”
|
||||
|
||||
Instead of listing images, show impact.
|
||||
|
||||
For any CVE or component:
|
||||
|
||||
* “Affected in prod: 3 services, 9 images”
|
||||
* “Reachable in: service A only”
|
||||
* “Blocked by policy in: env X”
|
||||
* “Deployed where: cluster/zone topology”
|
||||
|
||||
This is where your topology-aware model becomes a real UX advantage.
|
||||
|
||||
## 16) Quiet-by-design notifications with explainable suppression
|
||||
|
||||
Noise reduction must be visible and justifiable.
|
||||
|
||||
* “Suppressed because: not reachable + no exploit + already covered by exception”
|
||||
* “Unsuppressed because: delta introduced + reachable”
|
||||
* Configurable digests: daily/weekly “risk delta summary” per environment
|
||||
|
||||
## 17) “Replay” button everywhere (determinism as UX)
|
||||
|
||||
If determinism is a moat, expose it in the UI.
|
||||
|
||||
Every verdict includes:
|
||||
|
||||
* Inputs hash set (feeds, policies, rules, artifact digests)
|
||||
* “Replay this verdict” action producing the same output
|
||||
* “Compare replay to current” diff
|
||||
|
||||
This alone will differentiate Stella Ops from most scanners, because it changes trust dynamics.
|
||||
|
||||
## 18) Two modes: Operator Mode and Auditor Mode
|
||||
|
||||
Same data, different defaults:
|
||||
|
||||
* Operator: minimal, fastest path to action (shortest reachability path, top blockers, bulk triage)
|
||||
* Auditor: complete provenance, signatures, manifests, policy traces, export tools
|
||||
|
||||
A toggle at the top avoids building two products.
|
||||
|
||||
## 19) Small but lethal interaction details
|
||||
|
||||
These are easy wins that compound:
|
||||
|
||||
* Copyable digests everywhere (one-click)
|
||||
* “Pin evidence” to attach specific proof artifacts to tickets/exceptions
|
||||
* “Open in context” links (jump from vulnerability → impacted services → release gate)
|
||||
* Bulk actions that preserve proof (bulk mark “accepted vendor VEX” still produces an attested batch action record)
|
||||
|
||||
## 20) Default screen: “Release Gate Summary” (not “Vulns”)
|
||||
|
||||
For real-world teams, the primary question is: “Can I ship this release?”
|
||||
|
||||
A release summary card:
|
||||
|
||||
* Delta verdict (new blockers, fixed blockers, unknowns delta)
|
||||
* Risk budget consumption
|
||||
* Required actions + owners
|
||||
* Signed gate decision output
|
||||
|
||||
This ties scanner UX directly to deployment reality.
|
||||
|
||||
If you want, I can turn these into a concrete navigation map (pages, routes, primary components) plus a UI contract for each object (Claim, Evidence, Verdict, Snapshot, Exception, Audit Pack) so your agents can implement it consistently across web + API.
|
||||
@@ -0,0 +1,556 @@
|
||||
## Guidelines for Product and Development Managers: Signed, Replayable Risk Verdicts
|
||||
|
||||
### Purpose
|
||||
|
||||
Signed, replayable risk verdicts are the Stella Ops mechanism for producing a **cryptographically verifiable, audit‑ready decision** about an artifact (container image, VM image, filesystem snapshot, SBOM, etc.) that can be **recomputed later to the same result** using the same inputs (“time-travel replay”).
|
||||
|
||||
This capability is not “scan output with a signature.” It is a **decision artifact** that becomes the unit of governance in CI/CD, registry admission, and audits.
|
||||
|
||||
---
|
||||
|
||||
# 1) Shared definitions and non-negotiables
|
||||
|
||||
## 1.1 Definitions
|
||||
|
||||
**Risk verdict**
|
||||
A structured decision: *Pass / Fail / Warn / Needs‑Review* (or similar), produced by a deterministic evaluator under a specific policy and knowledge state.
|
||||
|
||||
**Signed**
|
||||
The verdict is wrapped in a tamper‑evident envelope (e.g., DSSE/in‑toto statement) and signed using an organization-approved trust model (key-based, keyless, or offline CA).
|
||||
|
||||
**Replayable**
|
||||
Given the same:
|
||||
|
||||
* target artifact identity
|
||||
* SBOM (or derivation method)
|
||||
* vulnerability and advisory knowledge state
|
||||
* VEX inputs
|
||||
* policy bundle
|
||||
* evaluator version
|
||||
…Stella Ops can **re-evaluate and reproduce the same verdict** and provide evidence equivalence.
|
||||
|
||||
> Critical nuance: replayability is about *result equivalence*. Byte‑for‑byte equality is ideal but not always required if signatures/metadata necessarily vary. If byte‑for‑byte is a goal, you must strictly control timestamps, ordering, and serialization.
|
||||
|
||||
---
|
||||
|
||||
## 1.2 Non-negotiables (what must be true in v1)
|
||||
|
||||
1. **Verdicts are bound to immutable artifact identity**
|
||||
|
||||
* Container image: digest (sha256:…)
|
||||
* SBOM: content digest
|
||||
* File tree: merkle root digest, or equivalent
|
||||
|
||||
2. **Verdicts are deterministic**
|
||||
|
||||
* No “current time” dependence in scoring
|
||||
* No non-deterministic ordering of findings
|
||||
* No implicit network calls during evaluation
|
||||
|
||||
3. **Verdicts are explainable**
|
||||
|
||||
* Every deny/block decision must cite the policy clause and evidence pointers that triggered it.
|
||||
|
||||
4. **Verdicts are verifiable**
|
||||
|
||||
* Independent verification toolchain exists (CLI/library) that validates signature and checks referenced evidence integrity.
|
||||
|
||||
5. **Knowledge state is pinned**
|
||||
|
||||
* The verdict references a “knowledge snapshot” (vuln feeds, advisories, VEX set) by digest/ID, not “latest.”
|
||||
|
||||
---
|
||||
|
||||
## 1.3 Explicit non-goals (avoid scope traps)
|
||||
|
||||
* Building a full CNAPP runtime protection product as part of verdicting.
|
||||
* Implementing “all possible attestation standards.” Pick one canonical representation; support others via adapters.
|
||||
* Solving global revocation and key lifecycle for every ecosystem on day one; define a minimum viable trust model per deployment mode.
|
||||
|
||||
---
|
||||
|
||||
# 2) Product Management Guidelines
|
||||
|
||||
## 2.1 Position the verdict as the primary product artifact
|
||||
|
||||
**PM rule:** if a workflow does not end in a verdict artifact, it is not part of this moat.
|
||||
|
||||
Examples:
|
||||
|
||||
* CI pipeline step produces `VERDICT.attestation` attached to the OCI artifact.
|
||||
* Registry admission checks for a valid verdict attestation meeting policy.
|
||||
* Audit export bundles the verdict plus referenced evidence.
|
||||
|
||||
**Avoid:** “scan reports” as the goal. Reports are views; the verdict is the object.
|
||||
|
||||
---
|
||||
|
||||
## 2.2 Define the core personas and success outcomes
|
||||
|
||||
Minimum personas:
|
||||
|
||||
1. **Release/Platform Engineering**
|
||||
|
||||
* Needs automated gates, reproducibility, and low friction.
|
||||
2. **Security Engineering / AppSec**
|
||||
|
||||
* Needs evidence, explainability, and exception workflows.
|
||||
3. **Audit / Compliance**
|
||||
|
||||
* Needs replay, provenance, and a defensible trail.
|
||||
|
||||
Define “first value” for each:
|
||||
|
||||
* Release engineer: gate merges/releases without re-running scans.
|
||||
* Security engineer: investigate a deny decision with evidence pointers in minutes.
|
||||
* Auditor: replay a verdict months later using the same knowledge snapshot.
|
||||
|
||||
---
|
||||
|
||||
## 2.3 Product requirements (expressed as “shall” statements)
|
||||
|
||||
### 2.3.1 Verdict content requirements
|
||||
|
||||
A verdict SHALL contain:
|
||||
|
||||
* **Subject**: immutable artifact reference (digest, type, locator)
|
||||
* **Decision**: pass/fail/warn/etc.
|
||||
* **Policy binding**: policy bundle ID + version + digest
|
||||
* **Knowledge snapshot binding**: snapshot IDs/digests for vuln feed and VEX set
|
||||
* **Evaluator binding**: evaluator name/version + schema version
|
||||
* **Rationale summary**: stable short explanation (human-readable)
|
||||
* **Findings references**: pointers to detailed findings/evidence (content-addressed)
|
||||
* **Unknowns state**: explicit unknown counts and categories
|
||||
|
||||
### 2.3.2 Replay requirements
|
||||
|
||||
The product SHALL support:
|
||||
|
||||
* Re-evaluating the same subject under the same policy+knowledge snapshot
|
||||
* Proving equivalence of inputs used in the original verdict
|
||||
* Producing a “replay report” that states:
|
||||
|
||||
* replay succeeded and matched
|
||||
* or replay failed and why (e.g., missing evidence, policy changed)
|
||||
|
||||
### 2.3.3 UX requirements
|
||||
|
||||
UI/UX SHALL:
|
||||
|
||||
* Show verdict status clearly (Pass/Fail/…)
|
||||
* Display:
|
||||
|
||||
* policy clause(s) responsible
|
||||
* top evidence pointers
|
||||
* knowledge snapshot ID
|
||||
* signature trust status (who signed, chain validity)
|
||||
* Provide “Replay” as an action (even if replay happens offline, the UX must guide it)
|
||||
|
||||
---
|
||||
|
||||
## 2.4 Product taxonomy: separate “verdicts” from “evaluations” from “attestations”
|
||||
|
||||
This is where many products get confused. Your terminology must remain strict:
|
||||
|
||||
* **Evaluation**: internal computation that produces decision + findings.
|
||||
* **Verdict**: the stable, canonical decision payload (the thing being signed).
|
||||
* **Attestation**: the signed envelope binding the verdict to cryptographic identity.
|
||||
|
||||
PMs must enforce this vocabulary in PRDs, UI labels, and docs.
|
||||
|
||||
---
|
||||
|
||||
## 2.5 Policy model guidelines for verdicting
|
||||
|
||||
Verdicting depends on policy discipline.
|
||||
|
||||
PM rules:
|
||||
|
||||
* Policy must be **versioned** and **content-addressed**.
|
||||
* Policies must be **pure functions** of declared inputs:
|
||||
|
||||
* SBOM graph
|
||||
* VEX claims
|
||||
* vulnerability data
|
||||
* reachability evidence (if present)
|
||||
* environment assertions (if present)
|
||||
* Policies must produce:
|
||||
|
||||
* a decision
|
||||
* plus a minimal explanation graph (policy rule ID → evidence IDs)
|
||||
|
||||
Avoid “freeform scripts” early. You need determinism and auditability.
|
||||
|
||||
---
|
||||
|
||||
## 2.6 Exceptions are part of the verdict product, not an afterthought
|
||||
|
||||
PM requirement:
|
||||
|
||||
* Exceptions must be first-class objects with:
|
||||
|
||||
* scope (exact artifact/component range)
|
||||
* owner
|
||||
* justification
|
||||
* expiry
|
||||
* required evidence (optional but strongly recommended)
|
||||
|
||||
And verdict logic must:
|
||||
|
||||
* record that an exception was applied
|
||||
* include exception IDs in the verdict evidence graph
|
||||
* make exception usage visible in UI and audit pack exports
|
||||
|
||||
---
|
||||
|
||||
## 2.7 Success metrics (PM-owned)
|
||||
|
||||
Choose metrics that reflect the moat:
|
||||
|
||||
* **Replay success rate**: % of verdicts that can be replayed after N days.
|
||||
* **Policy determinism incidents**: number of non-deterministic evaluation bugs.
|
||||
* **Audit cycle time**: time to satisfy an audit evidence request for a release.
|
||||
* **Noise**: # of manual suppressions/overrides per 100 releases (should drop).
|
||||
* **Gate adoption**: % of releases gated by verdict attestations (not reports).
|
||||
|
||||
---
|
||||
|
||||
# 3) Development Management Guidelines
|
||||
|
||||
## 3.1 Architecture principles (engineering tenets)
|
||||
|
||||
### Tenet A: Determinism-first evaluation
|
||||
|
||||
Engineering SHALL ensure evaluation is deterministic across:
|
||||
|
||||
* OS and architecture differences (as much as feasible)
|
||||
* concurrency scheduling
|
||||
* non-ordered data structures
|
||||
|
||||
Practical rules:
|
||||
|
||||
* Never iterate over maps/hashes without sorting keys.
|
||||
* Canonicalize output ordering (findings sorted by stable tuple: (component_id, cve_id, path, rule_id)).
|
||||
* Keep “generated at” timestamps out of the signed payload; if needed, place them in an unsigned wrapper or separate metadata field excluded from signature.
|
||||
|
||||
### Tenet B: Content-address everything
|
||||
|
||||
All significant inputs/outputs should have content digests:
|
||||
|
||||
* SBOM digest
|
||||
* policy digest
|
||||
* knowledge snapshot digest
|
||||
* evidence bundle digest
|
||||
* verdict digest
|
||||
|
||||
This makes replay and integrity checks possible.
|
||||
|
||||
### Tenet C: No hidden network
|
||||
|
||||
During evaluation, the engine must not fetch “latest” anything.
|
||||
Network is allowed only in:
|
||||
|
||||
* snapshot acquisition phase
|
||||
* artifact retrieval phase
|
||||
* attestation publication phase
|
||||
…and each must be explicitly logged and pinned.
|
||||
|
||||
---
|
||||
|
||||
## 3.2 Canonical verdict schema and serialization rules
|
||||
|
||||
**Engineering guideline:** pick a canonical serialization and stick to it.
|
||||
|
||||
Options:
|
||||
|
||||
* Canonical JSON (JCS or equivalent)
|
||||
* CBOR with deterministic encoding
|
||||
|
||||
Rules:
|
||||
|
||||
* Define a **schema version** and strict validation.
|
||||
* Make field names stable; avoid “optional” fields that appear/disappear nondeterministically.
|
||||
* Ensure numeric formatting is stable (no float drift; prefer integers or rational representation).
|
||||
* Always include empty arrays if required for stability, or exclude consistently by schema rule.
|
||||
|
||||
---
|
||||
|
||||
## 3.3 Suggested verdict payload (illustrative)
|
||||
|
||||
This is not a mandate—use it as a baseline structure.
|
||||
|
||||
```json
|
||||
{
|
||||
"schema_version": "1.0",
|
||||
"subject": {
|
||||
"type": "oci-image",
|
||||
"name": "registry.example.com/app/service",
|
||||
"digest": "sha256:…",
|
||||
"platform": "linux/amd64"
|
||||
},
|
||||
"evaluation": {
|
||||
"evaluator": "stella-eval",
|
||||
"evaluator_version": "0.9.0",
|
||||
"policy": {
|
||||
"id": "prod-default",
|
||||
"version": "2025.12.1",
|
||||
"digest": "sha256:…"
|
||||
},
|
||||
"knowledge_snapshot": {
|
||||
"vuln_db_digest": "sha256:…",
|
||||
"advisory_digest": "sha256:…",
|
||||
"vex_set_digest": "sha256:…"
|
||||
}
|
||||
},
|
||||
"decision": {
|
||||
"status": "fail",
|
||||
"score": 87,
|
||||
"reasons": [
|
||||
{ "rule_id": "RISK.CRITICAL.REACHABLE", "evidence_ref": "sha256:…" }
|
||||
],
|
||||
"unknowns": {
|
||||
"unknown_reachable": 2,
|
||||
"unknown_unreachable": 0
|
||||
}
|
||||
},
|
||||
"evidence": {
|
||||
"sbom_digest": "sha256:…",
|
||||
"finding_bundle_digest": "sha256:…",
|
||||
"inputs_manifest_digest": "sha256:…"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Then wrap this payload in your chosen attestation envelope and sign it.
|
||||
|
||||
---
|
||||
|
||||
## 3.4 Attestation format and storage guidelines
|
||||
|
||||
Development managers must enforce a consistent publishing model:
|
||||
|
||||
1. **Envelope**
|
||||
|
||||
* Prefer DSSE/in-toto style envelope because it:
|
||||
|
||||
* standardizes signing
|
||||
* supports multiple signature schemes
|
||||
* is widely adopted in supply chain ecosystems
|
||||
|
||||
2. **Attachment**
|
||||
|
||||
* OCI artifacts should carry verdicts as referrers/attachments to the subject digest (preferred).
|
||||
* For non-OCI targets, store in an internal ledger keyed by the subject digest/ID.
|
||||
|
||||
3. **Verification**
|
||||
|
||||
* Provide:
|
||||
|
||||
* `stella verify <artifact>` → checks signature and integrity references
|
||||
* `stella replay <verdict>` → re-run evaluation from snapshots and compare
|
||||
|
||||
4. **Transparency / logs**
|
||||
|
||||
* Optional in v1, but plan for:
|
||||
|
||||
* transparency log (public or private) to strengthen auditability
|
||||
* offline alternatives for air-gapped customers
|
||||
|
||||
---
|
||||
|
||||
## 3.5 Knowledge snapshot engineering requirements
|
||||
|
||||
A “snapshot” must be an immutable bundle, ideally content-addressed:
|
||||
|
||||
Snapshot includes:
|
||||
|
||||
* vulnerability database at a specific point
|
||||
* advisory sources (OS distro advisories)
|
||||
* VEX statement set(s)
|
||||
* any enrichment signals that influence scoring
|
||||
|
||||
Rules:
|
||||
|
||||
* Snapshot resolution must be explicit: “use snapshot digest X”
|
||||
* Must support export/import for air-gapped deployments
|
||||
* Must record source provenance and ingestion timestamps (timestamps may be excluded from signed payload if they cause nondeterminism; store them in snapshot metadata)
|
||||
|
||||
---
|
||||
|
||||
## 3.6 Replay engine requirements
|
||||
|
||||
Replay is not “re-run scan and hope it matches.”
|
||||
|
||||
Replay must:
|
||||
|
||||
* retrieve the exact subject (or confirm it via digest)
|
||||
* retrieve the exact SBOM (or deterministically re-generate it from the subject in a defined way)
|
||||
* load exact policy bundle by digest
|
||||
* load exact knowledge snapshot by digest
|
||||
* run evaluator version pinned in verdict (or enforce a compatibility mapping)
|
||||
* produce:
|
||||
|
||||
* verdict-equivalence result
|
||||
* a delta explanation if mismatch occurs
|
||||
|
||||
Engineering rule: replay must fail loudly and specifically when inputs are missing.
|
||||
|
||||
---
|
||||
|
||||
## 3.7 Testing strategy (required)
|
||||
|
||||
Deterministic systems require “golden” testing.
|
||||
|
||||
Minimum tests:
|
||||
|
||||
1. **Golden verdict tests**
|
||||
|
||||
* Fixed artifact + fixed snapshots + fixed policy
|
||||
* Expected verdict output must match exactly
|
||||
|
||||
2. **Cross-platform determinism tests**
|
||||
|
||||
* Run same evaluation on different machines/containers and compare outputs
|
||||
|
||||
3. **Mutation tests for determinism**
|
||||
|
||||
* Randomize ordering of internal collections; output should remain unchanged
|
||||
|
||||
4. **Replay regression tests**
|
||||
|
||||
* Store verdict + snapshots and replay after code changes to ensure compatibility guarantees hold
|
||||
|
||||
---
|
||||
|
||||
## 3.8 Versioning and backward compatibility guidelines
|
||||
|
||||
This is essential to prevent “replay breaks after upgrades.”
|
||||
|
||||
Rules:
|
||||
|
||||
* **Verdict schema version** changes must be rare and carefully managed.
|
||||
* Maintain a compatibility matrix:
|
||||
|
||||
* evaluator vX can replay verdict schema vY
|
||||
* If you must evolve logic, do so by:
|
||||
|
||||
* bumping evaluator version
|
||||
* preserving older evaluators in a compatibility mode (containerized evaluators are often easiest)
|
||||
|
||||
---
|
||||
|
||||
## 3.9 Security and key management guidelines
|
||||
|
||||
Development managers must ensure:
|
||||
|
||||
* Signing keys are managed via:
|
||||
|
||||
* KMS/HSM (enterprise)
|
||||
* keyless (OIDC-based) where acceptable
|
||||
* offline keys for air-gapped
|
||||
|
||||
* Verification trust policy is explicit:
|
||||
|
||||
* which identities are trusted to sign verdicts
|
||||
* which policies are accepted
|
||||
* whether transparency is required
|
||||
* how to handle revocation/rotation
|
||||
|
||||
* Separate “can sign” from “can publish”
|
||||
|
||||
* Signing should be restricted; publishing may be broader.
|
||||
|
||||
---
|
||||
|
||||
# 4) Operational workflow requirements (cross-functional)
|
||||
|
||||
## 4.1 CI gate flow
|
||||
|
||||
* Build artifact
|
||||
* Produce SBOM deterministically (or record SBOM digest if generated elsewhere)
|
||||
* Evaluate → produce verdict payload
|
||||
* Sign verdict → publish attestation attached to artifact
|
||||
* Gate decision uses verification of:
|
||||
|
||||
* signature validity
|
||||
* policy compliance
|
||||
* snapshot integrity
|
||||
|
||||
## 4.2 Registry / admission flow
|
||||
|
||||
* Admission controller checks for a valid, trusted verdict attestation
|
||||
* Optionally requires:
|
||||
|
||||
* verdict not older than X snapshot age (this is policy)
|
||||
* no expired exceptions
|
||||
* replay not required (replay is for audits; admission is fast-path)
|
||||
|
||||
## 4.3 Audit flow
|
||||
|
||||
* Export “audit pack”:
|
||||
|
||||
* verdict + signature chain
|
||||
* policy bundle
|
||||
* knowledge snapshot
|
||||
* referenced evidence bundles
|
||||
* Auditor (or internal team) runs `verify` and optionally `replay`
|
||||
|
||||
---
|
||||
|
||||
# 5) Common failure modes to avoid
|
||||
|
||||
1. **Signing “findings” instead of a decision**
|
||||
|
||||
* Leads to unbounded payload growth and weak governance semantics.
|
||||
|
||||
2. **Using “latest” feeds during evaluation**
|
||||
|
||||
* Breaks replayability immediately.
|
||||
|
||||
3. **Embedding timestamps in signed payload**
|
||||
|
||||
* Eliminates deterministic byte-level reproducibility.
|
||||
|
||||
4. **Letting the UI become the source of truth**
|
||||
|
||||
* The verdict artifact must be the authority; UI is a view.
|
||||
|
||||
5. **No clear separation between: evidence store, snapshot store, verdict store**
|
||||
|
||||
* Creates coupling and makes offline operations painful.
|
||||
|
||||
---
|
||||
|
||||
# 6) Definition of Done checklist (use this to gate release)
|
||||
|
||||
A feature increment for signed, replayable verdicts is “done” only if:
|
||||
|
||||
* [ ] Verdict binds to immutable subject digest
|
||||
* [ ] Verdict includes policy digest/version and knowledge snapshot digests
|
||||
* [ ] Verdict is signed and verifiable via CLI
|
||||
* [ ] Verification works offline (given exported artifacts)
|
||||
* [ ] Replay works with stored snapshots and produces match/mismatch output with reasons
|
||||
* [ ] Determinism tests pass (golden + mutation + cross-platform)
|
||||
* [ ] UI displays signer identity, policy, snapshot IDs, and rule→evidence links
|
||||
* [ ] Exceptions (if implemented) are recorded in verdict and enforced deterministically
|
||||
|
||||
---
|
||||
|
||||
## Optional: Recommended implementation sequence (keeps risk down)
|
||||
|
||||
1. Canonical verdict schema + deterministic evaluator skeleton
|
||||
2. Signing + verification CLI
|
||||
3. Snapshot bundle format + pinned evaluation
|
||||
4. Replay tool + golden tests
|
||||
5. OCI attachment publishing + registry/admission integration
|
||||
6. Evidence bundles + UI explainability
|
||||
7. Exceptions + audit pack export
|
||||
|
||||
---
|
||||
|
||||
If you want this turned into a formal internal PRD template, I can format it as:
|
||||
|
||||
* “Product requirements” (MUST/SHOULD/COULD)
|
||||
* “Engineering requirements” (interfaces + invariants + test plan)
|
||||
* “Security model” (trust roots, signing identities, verification policy)
|
||||
* “Acceptance criteria” for an MVP and for GA
|
||||
Reference in New Issue
Block a user