feat: add entropy policy banner and policy gate indicator components
Some checks failed
Docs CI / lint-and-preview (push) Has been cancelled
Some checks failed
Docs CI / lint-and-preview (push) Has been cancelled
- Implemented EntropyPolicyBannerComponent with configuration for entropy policies, including thresholds, current scores, and mitigation steps. - Created PolicyGateIndicatorComponent to display the status of policy gates, including passed, failed, and warning gates, with detailed views for determinism and entropy gates. - Added HTML and SCSS for both components to ensure proper styling and layout. - Introduced computed properties and signals for reactive state management in Angular. - Included remediation hints and actions for user interaction within the policy gate indicator.
This commit is contained in:
@@ -0,0 +1,684 @@
|
||||
Here’s a practical, first‑time‑friendly guide to using VEX in Stella Ops, plus a concrete .NET pattern you can drop in today.
|
||||
|
||||
---
|
||||
|
||||
# VEX in a nutshell
|
||||
|
||||
* **VEX (Vulnerability Exploitability eXchange)**: a small JSON document that says whether specific CVEs *actually* affect a product/version.
|
||||
* **OpenVEX**: SBOM‑agnostic; references products/components directly (URIs, PURLs, hashes). Great for canonical internal models.
|
||||
* **CycloneDX VEX / SPDX VEX**: tie VEX statements closely to a specific SBOM instance (component BOM ref IDs). Great when the BOM is your source of truth.
|
||||
|
||||
**Our strategy:**
|
||||
|
||||
* **Store VEX separately** from SBOMs (deterministic, easier air‑gap bundling).
|
||||
* **Link by strong references** (PURLs + content hashes + optional SBOM component IDs).
|
||||
* **Translate on ingest** between OpenVEX ↔ CycloneDX VEX as needed so downstream tools stay happy.
|
||||
|
||||
---
|
||||
|
||||
# Translation model (OpenVEX ↔ CycloneDX VEX)
|
||||
|
||||
1. **Identity mapping**
|
||||
|
||||
* Prefer **PURL** for packages; fallback to **SHA256 (or SHA512)** of artifact; optionally include **SBOM `bom-ref`** if known.
|
||||
2. **Product scope**
|
||||
|
||||
* OpenVEX “product” → CycloneDX `affects` with `bom-ref` (if available) or a synthetic ref derived from PURL/hash.
|
||||
3. **Status mapping**
|
||||
|
||||
* `affected | not_affected | under_investigation | fixed` map 1:1.
|
||||
* Keep **timestamps**, **justification**, **impact statement**, and **origin**.
|
||||
4. **Evidence**
|
||||
|
||||
* Preserve links to advisories, commits, tests; attach as CycloneDX `analysis/evidence` notes (or OpenVEX `metadata/notes`).
|
||||
|
||||
**Collision rules (deterministic):**
|
||||
|
||||
* New statement wins if:
|
||||
|
||||
* Newer `timestamp` **and**
|
||||
* Higher **provenance trust** (signed by vendor/Authority) or equal with a lexicographic tiebreak (issuer keyID).
|
||||
|
||||
---
|
||||
|
||||
# Storage model (MongoDB‑friendly)
|
||||
|
||||
* **Collections**
|
||||
|
||||
* `vex.documents` – one doc per VEX file (OpenVEX or CycloneDX VEX).
|
||||
* `vex.statements` – *flattened*, one per (product/component, vuln).
|
||||
* `artifacts` – canonical component index (PURL, hashes, optional SBOM refs).
|
||||
* **Reference keys**
|
||||
|
||||
* `artifactKey = purl || sha256 || (groupId:name:version for .NET/NuGet)`
|
||||
* `vulnKey = cveId || ghsaId || internalId`
|
||||
* **Deterministic IDs**
|
||||
|
||||
* `_id = sha256(canonicalize(statement-json-without-signature))`
|
||||
* **Signatures**
|
||||
|
||||
* Keep DSSE/Sigstore envelopes in `vex.documents.signatures[]` for audit & replay.
|
||||
|
||||
---
|
||||
|
||||
# Air‑gap bundling
|
||||
|
||||
Package **SBOMs + VEX + artifacts index + trust roots** as a single tarball:
|
||||
|
||||
```
|
||||
/bundle/
|
||||
sboms/*.json
|
||||
vex/*.json # OpenVEX & CycloneDX VEX allowed
|
||||
index/artifacts.jsonl # purl, hashes, bom-ref map
|
||||
trust/rekor.merkle.roots
|
||||
trust/fulcio.certs.pem
|
||||
trust/keys/*.pub
|
||||
manifest.json # content list + sha256 + issuedAt
|
||||
```
|
||||
|
||||
* **Deterministic replay:** re‑ingest is pure function of bundle bytes → identical DB state.
|
||||
|
||||
---
|
||||
|
||||
# .NET 10 implementation (C#) – deterministic ingestion
|
||||
|
||||
### Core models
|
||||
|
||||
```csharp
|
||||
public record ArtifactRef(
|
||||
string? Purl,
|
||||
string? Sha256,
|
||||
string? BomRef);
|
||||
|
||||
public enum VexStatus { Affected, NotAffected, UnderInvestigation, Fixed }
|
||||
|
||||
public record VexStatement(
|
||||
string StatementId, // sha256 of canonical payload
|
||||
ArtifactRef Artifact,
|
||||
string VulnId, // e.g., "CVE-2024-1234"
|
||||
VexStatus Status,
|
||||
string? Justification,
|
||||
string? ImpactStatement,
|
||||
DateTimeOffset Timestamp,
|
||||
string IssuerKeyId, // from DSSE/Signing
|
||||
int ProvenanceScore); // Authority policy
|
||||
```
|
||||
|
||||
### Canonicalizer (stable order, no env fields)
|
||||
|
||||
```csharp
|
||||
static string Canonicalize(VexStatement s)
|
||||
{
|
||||
var payload = new {
|
||||
artifact = new { s.Artifact.Purl, s.Artifact.Sha256, s.Artifact.BomRef },
|
||||
vulnId = s.VulnId,
|
||||
status = s.Status.ToString(),
|
||||
justification = s.Justification,
|
||||
impact = s.ImpactStatement,
|
||||
timestamp = s.Timestamp.UtcDateTime
|
||||
};
|
||||
// Use System.Text.Json with deterministic ordering
|
||||
var opts = new System.Text.Json.JsonSerializerOptions {
|
||||
WriteIndented = false
|
||||
};
|
||||
string json = System.Text.Json.JsonSerializer.Serialize(payload, opts);
|
||||
// Normalize unicode + newline
|
||||
json = json.Normalize(NormalizationForm.FormKC).Replace("\r\n","\n");
|
||||
return json;
|
||||
}
|
||||
|
||||
static string Sha256(string s)
|
||||
{
|
||||
using var sha = System.Security.Cryptography.SHA256.Create();
|
||||
var bytes = sha.ComputeHash(System.Text.Encoding.UTF8.GetBytes(s));
|
||||
return Convert.ToHexString(bytes).ToLowerInvariant();
|
||||
}
|
||||
```
|
||||
|
||||
### Ingest pipeline
|
||||
|
||||
```csharp
|
||||
public sealed class VexIngestor
|
||||
{
|
||||
readonly IVexParser _parser; // OpenVEX & CycloneDX adapters
|
||||
readonly IArtifactIndex _artifacts;
|
||||
readonly IVexRepo _repo; // Mongo-backed
|
||||
readonly IPolicy _policy; // tie-break rules
|
||||
|
||||
public async Task IngestAsync(Stream vexJson, SignatureEnvelope? sig)
|
||||
{
|
||||
var doc = await _parser.ParseAsync(vexJson); // yields normalized statements
|
||||
var issuer = sig?.KeyId ?? "unknown";
|
||||
foreach (var st in doc.Statements)
|
||||
{
|
||||
var canon = Canonicalize(st);
|
||||
var id = Sha256(canon);
|
||||
var withMeta = st with {
|
||||
StatementId = id,
|
||||
IssuerKeyId = issuer,
|
||||
ProvenanceScore = _policy.Score(sig, st)
|
||||
};
|
||||
|
||||
// Upsert artifact (purl/hash/bomRef)
|
||||
await _artifacts.UpsertAsync(withMeta.Artifact);
|
||||
|
||||
// Deterministic merge
|
||||
var existing = await _repo.GetAsync(id)
|
||||
?? await _repo.FindByKeysAsync(withMeta.Artifact, st.VulnId);
|
||||
if (existing is null || _policy.IsNewerAndStronger(existing, withMeta))
|
||||
await _repo.UpsertAsync(withMeta);
|
||||
}
|
||||
|
||||
if (sig is not null) await _repo.AttachSignatureAsync(doc.DocumentId, sig);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Parsers (adapters)
|
||||
|
||||
* `OpenVexParser` – reads OpenVEX; emits `VexStatement` with `ArtifactRef(PURL/hash)`
|
||||
* `CycloneDxVexParser` – resolves `bom-ref` → look up PURL/hash via `IArtifactIndex` (if SBOM present); if not, store bom‑ref and mark artifact unresolved for later backfill.
|
||||
|
||||
---
|
||||
|
||||
# Why this works for Stella Ops
|
||||
|
||||
* **SBOM‑agnostic core** (OpenVEX‑first) maps cleanly to your MongoDB canonical stores and `.NET 10` services.
|
||||
* **SBOM‑aware edges** (CycloneDX VEX) are still supported via adapters and `bom-ref` backfill.
|
||||
* **Deterministic everything**: canonical JSON → SHA256 IDs → reproducible merges → perfect for audits and offline environments.
|
||||
* **Air‑gap ready**: single bundle with trust roots, replayable on any node.
|
||||
|
||||
---
|
||||
|
||||
# Next steps (plug‑and‑play)
|
||||
|
||||
1. Implement the two parsers (`OpenVexParser`, `CycloneDxVexParser`).
|
||||
2. Add the repo/index interfaces to your `StellaOps.Vexer` service:
|
||||
|
||||
* `IVexRepo` (Mongo collections `vex.documents`, `vex.statements`)
|
||||
* `IArtifactIndex` (your canonical PURL/hash map)
|
||||
3. Wire `Policy` to Authority to score signatures and apply tie‑breaks.
|
||||
4. Add a `bundle ingest` CLI: `vexer ingest /bundle/manifest.json`.
|
||||
5. Expose GraphQL (HotChocolate) queries:
|
||||
|
||||
* `vexStatements(artifactKey, vulnId)`, `vexStatus(artifactKey)`, `evidence(...)`.
|
||||
|
||||
If you want, I can generate the exact Mongo schemas, HotChocolate types, and a minimal test bundle to validate the ingest end‑to‑end.
|
||||
Below is a complete, developer-ready implementation plan for the **VEX ingestion, translation, canonicalization, storage, and merge-policy pipeline** inside **Stella Ops.Vexer**, aligned with your architecture, deterministic requirements, MongoDB model, DSSE/Authority workflow, and `.NET 10` standards.
|
||||
|
||||
This is structured so an average developer can follow it step-by-step without ambiguity.
|
||||
It is broken into phases, each with clear tasks, acceptance criteria, failure modes, interfaces, and code pointers.
|
||||
|
||||
---
|
||||
|
||||
# Stella Ops.Vexer
|
||||
|
||||
## Full Implementation Plan (Developer-Executable)
|
||||
|
||||
---
|
||||
|
||||
# 1. Core Objectives
|
||||
|
||||
Develop a deterministic, replayable, SBOM-agnostic but SBOM-compatible VEX subsystem supporting:
|
||||
|
||||
* OpenVEX and CycloneDX VEX ingestion.
|
||||
* Canonicalization → SHA-256 identity.
|
||||
* Cross-linking to artifacts (purl, hash, bom-ref).
|
||||
* Merge policies driven by Authority trust/lattice rules.
|
||||
* Complete offline reproducibility.
|
||||
* MongoDB canonical storage.
|
||||
* Exposed through gRPC/REST/GraphQL.
|
||||
|
||||
---
|
||||
|
||||
# 2. Module Structure (to be implemented)
|
||||
|
||||
```
|
||||
src/StellaOps.Vexer/
|
||||
Application/
|
||||
Commands/
|
||||
Queries/
|
||||
Ingest/
|
||||
Translation/
|
||||
Merge/
|
||||
Policies/
|
||||
Domain/
|
||||
Entities/
|
||||
ValueObjects/
|
||||
Services/
|
||||
Infrastructure/
|
||||
Mongo/
|
||||
AuthorityClient/
|
||||
Hashing/
|
||||
Signature/
|
||||
BlobStore/
|
||||
Presentation/
|
||||
GraphQL/
|
||||
REST/
|
||||
gRPC/
|
||||
```
|
||||
|
||||
Every subfolder must compile in strict mode (treat warnings as errors).
|
||||
|
||||
---
|
||||
|
||||
# 3. Data Model (MongoDB)
|
||||
|
||||
## 3.1 `vex.statements` collection
|
||||
|
||||
Document schema:
|
||||
|
||||
```json
|
||||
{
|
||||
"_id": "sha256(canonical-json)",
|
||||
"artifact": {
|
||||
"purl": "pkg:nuget/... or null",
|
||||
"sha256": "hex or null",
|
||||
"bomRef": "optional ref",
|
||||
"resolved": true | false
|
||||
},
|
||||
"vulnId": "CVE-XXXX-YYYY",
|
||||
"status": "affected | not_affected | under_investigation | fixed",
|
||||
"justification": "...",
|
||||
"impact": "...",
|
||||
"timestamp": "2024-01-01T12:34:56Z",
|
||||
"issuerKeyId": "FULCIO-KEY-ID",
|
||||
"provenanceScore": 0–100,
|
||||
"documentId": "UUID of vex.documents entry",
|
||||
"sourceFormat": "openvex|cyclonedx",
|
||||
"createdAt": "...",
|
||||
"updatedAt": "..."
|
||||
}
|
||||
```
|
||||
|
||||
## 3.2 `vex.documents` collection
|
||||
|
||||
```
|
||||
{
|
||||
"_id": "<uuid>",
|
||||
"format": "openvex|cyclonedx",
|
||||
"rawBlobId": "<blob-id in blobstore>",
|
||||
"signatures": [
|
||||
{
|
||||
"type": "dsse",
|
||||
"verified": true,
|
||||
"issuerKeyId": "F-123...",
|
||||
"timestamp": "...",
|
||||
"bundleEvidence": {...}
|
||||
}
|
||||
],
|
||||
"ingestedAt": "...",
|
||||
"statementIds": ["sha256-1", "sha256-2", ...]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# 4. Components to Implement
|
||||
|
||||
## 4.1 Parsing Layer
|
||||
|
||||
### Interfaces
|
||||
|
||||
```csharp
|
||||
public interface IVexParser
|
||||
{
|
||||
ValueTask<ParsedVexDocument> ParseAsync(Stream jsonStream);
|
||||
}
|
||||
|
||||
public sealed record ParsedVexDocument(
|
||||
string DocumentId,
|
||||
string Format,
|
||||
IReadOnlyList<ParsedVexStatement> Statements);
|
||||
```
|
||||
|
||||
### Tasks
|
||||
|
||||
1. Implement `OpenVexParser`.
|
||||
|
||||
* Use System.Text.Json source generators.
|
||||
* Validate OpenVEX schema version.
|
||||
* Extract product → component mapping.
|
||||
* Map to internal `ArtifactRef`.
|
||||
|
||||
2. Implement `CycloneDxVexParser`.
|
||||
|
||||
* Support 1.5+ “vex” extension.
|
||||
* bom-ref resolution through `IArtifactIndex`.
|
||||
* Mark unresolved `bom-ref` but store them.
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Both parsers produce identical internal representation of statements.
|
||||
* Unknown fields must not corrupt canonicalization.
|
||||
* 100% deterministic mapping for same input.
|
||||
|
||||
---
|
||||
|
||||
## 4.2 Canonicalizer
|
||||
|
||||
Implement deterministic ordering, UTF-8 normalization, stable JSON.
|
||||
|
||||
### Tasks
|
||||
|
||||
1. Create `Canonicalizer` class.
|
||||
2. Apply:
|
||||
|
||||
* Property order: artifact, vulnId, status, justification, impact, timestamp.
|
||||
* Remove optional metadata (issuerKeyId, provenance).
|
||||
* Normalize Unicode → NFKC.
|
||||
* Replace CRLF → LF.
|
||||
3. Generate SHA-256.
|
||||
|
||||
### Interface
|
||||
|
||||
```csharp
|
||||
public interface IVexCanonicalizer
|
||||
{
|
||||
string Canonicalize(VexStatement s);
|
||||
string ComputeId(string canonicalJson);
|
||||
}
|
||||
```
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Hash identical on all OS, time, locale, machines.
|
||||
* Replaying the same bundle yields same `_id`.
|
||||
|
||||
---
|
||||
|
||||
## 4.3 Authority / Signature Verification
|
||||
|
||||
### Tasks
|
||||
|
||||
1. Implement DSSE envelope reader.
|
||||
2. Integrate Authority client:
|
||||
|
||||
* Verify certificate chain (Fulcio/GOST/eIDAS etc).
|
||||
* Obtain trust lattice score.
|
||||
* Produce `ProvenanceScore`: int.
|
||||
|
||||
### Interface
|
||||
|
||||
```csharp
|
||||
public interface ISignatureVerifier
|
||||
{
|
||||
ValueTask<SignatureVerificationResult> VerifyAsync(Stream payload, Stream envelope);
|
||||
}
|
||||
```
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* If verification fails → Vexer stores document but flags signature invalid.
|
||||
* Scores map to priority in merge policy.
|
||||
|
||||
---
|
||||
|
||||
## 4.4 Merge Policies
|
||||
|
||||
### Implement Default Policy
|
||||
|
||||
1. Newer timestamp wins.
|
||||
2. If timestamps equal:
|
||||
|
||||
* Higher provenance score wins.
|
||||
* If both equal, lexicographically smaller issuerKeyId wins.
|
||||
|
||||
### Interface
|
||||
|
||||
```csharp
|
||||
public interface IVexMergePolicy
|
||||
{
|
||||
bool ShouldReplace(VexStatement existing, VexStatement incoming);
|
||||
}
|
||||
```
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Merge decisions reproducible.
|
||||
* Deterministic ordering even when values equal.
|
||||
|
||||
---
|
||||
|
||||
## 4.5 Ingestion Pipeline
|
||||
|
||||
### Steps
|
||||
|
||||
1. Accept `multipart/form-data` or referenced blob ID.
|
||||
2. Parse via correct parser.
|
||||
3. Verify signature (optional).
|
||||
4. For each statement:
|
||||
|
||||
* Canonicalize.
|
||||
* Compute `_id`.
|
||||
* Upsert artifact into `artifacts` (via `IArtifactIndex`).
|
||||
* Resolve bom-ref (if CycloneDX).
|
||||
* Existing statement? Apply merge policy.
|
||||
* Insert or update.
|
||||
5. Create `vex.documents` entry.
|
||||
|
||||
### Class
|
||||
|
||||
`VexIngestService`
|
||||
|
||||
### Required Methods
|
||||
|
||||
```csharp
|
||||
public Task<IngestResult> IngestAsync(VexIngestRequest request);
|
||||
```
|
||||
|
||||
### Acceptance Tests
|
||||
|
||||
* Idempotent: ingesting same VEX repeated → DB unchanged.
|
||||
* Deterministic under concurrency.
|
||||
* Air-gap replay produces identical DB state.
|
||||
|
||||
---
|
||||
|
||||
## 4.6 Translation Layer
|
||||
|
||||
### Implement two converters:
|
||||
|
||||
* `OpenVexToCycloneDxTranslator`
|
||||
* `CycloneDxToOpenVexTranslator`
|
||||
|
||||
### Rules
|
||||
|
||||
* Prefer PURL → hash → synthetic bom-ref.
|
||||
* Single VEX statement → one CycloneDX “analysis” entry.
|
||||
* Preserve justification, impact, notes.
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Round-trip OpenVEX → CycloneDX → OpenVEX produces equal canonical hashes (except format markers).
|
||||
|
||||
---
|
||||
|
||||
## 4.7 Artifact Index Backfill
|
||||
|
||||
### Reason
|
||||
|
||||
CycloneDX VEX may refer to bom-refs not yet known at ingestion.
|
||||
|
||||
### Tasks
|
||||
|
||||
1. Store unresolved artifacts.
|
||||
2. Create background `BackfillWorker`:
|
||||
|
||||
* Watches `sboms.documents` ingestion events.
|
||||
* Matches bom-refs.
|
||||
* Updates statements with resolved PURL/hashes.
|
||||
* Recomputes canonical JSON + SHA-256 (new version stored as new ID).
|
||||
3. Marks old unresolved statement as superseded.
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Backfilling is monotonic: no overwriting original.
|
||||
* Deterministic after backfill: same SBOM yields same final ID.
|
||||
|
||||
---
|
||||
|
||||
## 4.8 Bundle Ingestion (Air-Gap Mode)
|
||||
|
||||
### Structure
|
||||
|
||||
```
|
||||
bundle/
|
||||
sboms/*.json
|
||||
vex/*.json
|
||||
index/artifacts.jsonl
|
||||
trust/*
|
||||
manifest.json
|
||||
```
|
||||
|
||||
### Tasks
|
||||
|
||||
1. Implement `BundleIngestService`.
|
||||
2. Stages:
|
||||
|
||||
* Validate manifest + hashes.
|
||||
* Import trust roots (local only).
|
||||
* Ingest SBOMs first.
|
||||
* Ingest VEX documents.
|
||||
3. Reproduce same IDs on all nodes.
|
||||
|
||||
### Acceptance Criteria
|
||||
|
||||
* Byte-identical bundle → byte-identical DB.
|
||||
* Works offline completely.
|
||||
|
||||
---
|
||||
|
||||
# 5. Interfaces for GraphQL/REST/gRPC
|
||||
|
||||
Expose:
|
||||
|
||||
## Queries
|
||||
|
||||
* `vexStatement(id)`
|
||||
* `vexStatementsByArtifact(purl/hash)`
|
||||
* `vexStatus(purl)` → latest merged status
|
||||
* `vexDocument(id)`
|
||||
* `affectedComponents(vulnId)`
|
||||
|
||||
## Mutations
|
||||
|
||||
* `ingestVexDocument`
|
||||
* `translateVex(format)`
|
||||
* `exportVexDocument(id, targetFormat)`
|
||||
* `replayBundle(bundleId)`
|
||||
|
||||
All responses must include deterministic IDs.
|
||||
|
||||
---
|
||||
|
||||
# 6. Detailed Developer Tasks by Sprint
|
||||
|
||||
## Sprint 1: Foundation
|
||||
|
||||
1. Create solution structure.
|
||||
2. Add Mongo DB contexts.
|
||||
3. Implement data entities.
|
||||
4. Implement hashing + canonicalizer.
|
||||
5. Implement IVexParser interface.
|
||||
|
||||
## Sprint 2: Parsers
|
||||
|
||||
1. Implement OpenVexParser.
|
||||
2. Implement CycloneDxParser.
|
||||
3. Develop strong unit tests for JSON normalization.
|
||||
|
||||
## Sprint 3: Signature & Authority
|
||||
|
||||
1. DSSE envelope reader.
|
||||
2. Call Authority to verify signatures.
|
||||
3. Produce provenance scores.
|
||||
|
||||
## Sprint 4: Merge Policy Engine
|
||||
|
||||
1. Implement deterministic lattice merge.
|
||||
2. Unit tests: 20+ collision scenarios.
|
||||
|
||||
## Sprint 5: Ingestion Pipeline
|
||||
|
||||
1. Implement ingest service end-to-end.
|
||||
2. Insert/update logic.
|
||||
3. Add GraphQL endpoints.
|
||||
|
||||
## Sprint 6: Translation Layer
|
||||
|
||||
1. OpenVEX↔CycloneDX converter.
|
||||
2. Tests for round-trip.
|
||||
|
||||
## Sprint 7: Backfill System
|
||||
|
||||
1. Bom-ref resolver worker.
|
||||
2. Rehashing logic for updated artifacts.
|
||||
3. Events linking SBOM ingestion to backfill.
|
||||
|
||||
## Sprint 8: Air-Gap Bundle
|
||||
|
||||
1. BundleIngestService.
|
||||
2. Manifest verification.
|
||||
3. Trust root local loading.
|
||||
|
||||
## Sprint 9: Hardening
|
||||
|
||||
1. Fuzz parsers.
|
||||
2. Deterministic stress tests.
|
||||
3. Concurrency validation.
|
||||
4. Storage compaction.
|
||||
|
||||
---
|
||||
|
||||
# 7. Failure Handling Matrix
|
||||
|
||||
| Failure | Action | Logged? | Retries |
|
||||
| ------------------- | -------------------------------------- | ------- | ------- |
|
||||
| Invalid JSON | Reject document | Yes | 0 |
|
||||
| Invalid schema | Reject | Yes | 0 |
|
||||
| Signature invalid | Store document, mark signature invalid | Yes | 0 |
|
||||
| Artifact unresolved | Store unresolved, enqueue backfill | Yes | 3 |
|
||||
| Merge conflict | Apply policy | Yes | 0 |
|
||||
| Canonical mismatch | Hard fail | Yes | 0 |
|
||||
|
||||
---
|
||||
|
||||
# 8. Developer Unit Test Checklist
|
||||
|
||||
### must have tests for:
|
||||
|
||||
* Canonicalization stability (100 samples).
|
||||
* Identical input twice → identical `_id`.
|
||||
* Parsing OpenVEX with multi-product definitions.
|
||||
* Parsing CycloneDX with missing bom-refs.
|
||||
* Merge policy tie-breakers.
|
||||
* Air-gap replay reproducibility.
|
||||
* Translation equivalence.
|
||||
|
||||
---
|
||||
|
||||
# 9. Deliverables for Developers
|
||||
|
||||
They must produce:
|
||||
|
||||
1. Interfaces + DTOs + document schemas.
|
||||
2. Canonicalizer with 100% deterministic output.
|
||||
3. Two production-grade parsers.
|
||||
4. Signature verification pipeline.
|
||||
5. Merge policies aligned with Authority trust model.
|
||||
6. End-to-end ingestion service.
|
||||
7. Translation layer.
|
||||
8. Backfill worker.
|
||||
9. Air-gap bundle script + service.
|
||||
10. GraphQL APIs.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can next produce:
|
||||
|
||||
* A full **developer handbook** (60–90 pages).
|
||||
* Full **technical architecture ADRs**.
|
||||
* A concrete **scaffold** with compiles-clean `.NET 10` project.
|
||||
* Complete **test suite specification**.
|
||||
* A **README.md** for new joiners.
|
||||
@@ -0,0 +1,754 @@
|
||||
Here’s a practical way to make a cross‑platform, hash‑stable JSON “fingerprint” for things like a `graph_revision_id`, so your hashes don’t change between OS/locale settings.
|
||||
|
||||
---
|
||||
|
||||
### What “canonical JSON” means (in plain terms)
|
||||
|
||||
* **Deterministic order:** Always write object properties in a fixed order (e.g., lexicographic).
|
||||
* **Stable numbers:** Serialize numbers the same way everywhere (no locale, no extra zeros).
|
||||
* **Normalized text:** Normalize all strings to Unicode **NFC** so accented/combined characters don’t vary.
|
||||
* **Consistent bytes:** Encode as **UTF‑8** with **LF** (`\n`) newlines only.
|
||||
|
||||
These ideas match the JSON Canonicalization Scheme (RFC 8785)—use it as your north star for stable hashing.
|
||||
|
||||
---
|
||||
|
||||
### Drop‑in C# helper (targets .NET 8/10)
|
||||
|
||||
This gives you a canonical UTF‑8 byte[] and a SHA‑256 hex hash. It:
|
||||
|
||||
* Recursively sorts object properties,
|
||||
* Emits numbers with invariant formatting,
|
||||
* Normalizes all string values to **NFC**,
|
||||
* Uses `\n` endings,
|
||||
* Produces a SHA‑256 for `graph_revision_id`.
|
||||
|
||||
```csharp
|
||||
using System;
|
||||
using System.Buffers.Text;
|
||||
using System.Collections.Generic;
|
||||
using System.Globalization;
|
||||
using System.Linq;
|
||||
using System.Security.Cryptography;
|
||||
using System.Text;
|
||||
using System.Text.Json;
|
||||
using System.Text.Json.Nodes;
|
||||
using System.Text.Unicode;
|
||||
|
||||
public static class CanonJson
|
||||
{
|
||||
// Entry point: produce canonical UTF-8 bytes
|
||||
public static byte[] ToCanonicalUtf8(object? value)
|
||||
{
|
||||
// 1) Serialize once to JsonNode to work with types safely
|
||||
var initialJson = JsonSerializer.SerializeToNode(
|
||||
value,
|
||||
new JsonSerializerOptions
|
||||
{
|
||||
NumberHandling = JsonNumberHandling.AllowReadingFromString,
|
||||
Encoder = System.Text.Encodings.Web.JavaScriptEncoder.UnsafeRelaxedJsonEscaping // we will control escaping
|
||||
});
|
||||
|
||||
// 2) Canonicalize (sort keys, normalize strings, normalize numbers)
|
||||
var canonNode = CanonicalizeNode(initialJson);
|
||||
|
||||
// 3) Write in a deterministic manner
|
||||
var sb = new StringBuilder(4096);
|
||||
WriteCanonical(canonNode!, sb);
|
||||
|
||||
// 4) Ensure LF only
|
||||
var lf = sb.ToString().Replace("\r\n", "\n").Replace("\r", "\n");
|
||||
|
||||
// 5) UTF-8 bytes
|
||||
return Encoding.UTF8.GetBytes(lf);
|
||||
}
|
||||
|
||||
// Convenience: compute SHA-256 hex for graph_revision_id
|
||||
public static string ComputeGraphRevisionId(object? value)
|
||||
{
|
||||
var bytes = ToCanonicalUtf8(value);
|
||||
using var sha = SHA256.Create();
|
||||
var hash = sha.ComputeHash(bytes);
|
||||
var sb = new StringBuilder(hash.Length * 2);
|
||||
foreach (var b in hash) sb.Append(b.ToString("x2"));
|
||||
return sb.ToString();
|
||||
}
|
||||
|
||||
// --- Internals ---
|
||||
|
||||
private static JsonNode? CanonicalizeNode(JsonNode? node)
|
||||
{
|
||||
if (node is null) return null;
|
||||
|
||||
switch (node)
|
||||
{
|
||||
case JsonValue v:
|
||||
if (v.TryGetValue<string>(out var s))
|
||||
{
|
||||
// Normalize strings to NFC
|
||||
var nfc = s.Normalize(NormalizationForm.FormC);
|
||||
return JsonValue.Create(nfc);
|
||||
}
|
||||
if (v.TryGetValue<double>(out var d))
|
||||
{
|
||||
// RFC-like minimal form: Invariant, no thousand sep; handle -0 => 0
|
||||
if (d == 0) d = 0; // squash -0
|
||||
return JsonValue.Create(d);
|
||||
}
|
||||
if (v.TryGetValue<long>(out var l))
|
||||
{
|
||||
return JsonValue.Create(l);
|
||||
}
|
||||
// Fallback keep as-is
|
||||
return v;
|
||||
|
||||
case JsonArray arr:
|
||||
var outArr = new JsonArray();
|
||||
foreach (var elem in arr)
|
||||
outArr.Add(CanonicalizeNode(elem));
|
||||
return outArr;
|
||||
|
||||
case JsonObject obj:
|
||||
// Sort keys lexicographically (RFC 8785 uses code unit order)
|
||||
var sorted = new JsonObject();
|
||||
foreach (var kvp in obj.OrderBy(k => k.Key, StringComparer.Ordinal))
|
||||
sorted[kvp.Key] = CanonicalizeNode(kvp.Value);
|
||||
return sorted;
|
||||
|
||||
default:
|
||||
return node;
|
||||
}
|
||||
}
|
||||
|
||||
// Deterministic writer matching our canonical rules
|
||||
private static void WriteCanonical(JsonNode node, StringBuilder sb)
|
||||
{
|
||||
switch (node)
|
||||
{
|
||||
case JsonObject obj:
|
||||
sb.Append('{');
|
||||
bool first = true;
|
||||
foreach (var kvp in obj)
|
||||
{
|
||||
if (!first) sb.Append(',');
|
||||
first = false;
|
||||
WriteString(kvp.Key, sb); // property name
|
||||
sb.Append(':');
|
||||
WriteCanonical(kvp.Value!, sb);
|
||||
}
|
||||
sb.Append('}');
|
||||
break;
|
||||
|
||||
case JsonArray arr:
|
||||
sb.Append('[');
|
||||
for (int i = 0; i < arr.Count; i++)
|
||||
{
|
||||
if (i > 0) sb.Append(',');
|
||||
WriteCanonical(arr[i]!, sb);
|
||||
}
|
||||
sb.Append(']');
|
||||
break;
|
||||
|
||||
case JsonValue val:
|
||||
if (val.TryGetValue<string>(out var s))
|
||||
{
|
||||
WriteString(s, sb);
|
||||
}
|
||||
else if (val.TryGetValue<long>(out var l))
|
||||
{
|
||||
sb.Append(l.ToString(CultureInfo.InvariantCulture));
|
||||
}
|
||||
else if (val.TryGetValue<double>(out var d))
|
||||
{
|
||||
// Minimal form close to RFC 8785 guidance:
|
||||
// - No NaN/Infinity in JSON
|
||||
// - Invariant culture, trim trailing zeros and dot
|
||||
if (double.IsNaN(d) || double.IsInfinity(d))
|
||||
throw new InvalidOperationException("Non-finite numbers are not valid in canonical JSON.");
|
||||
if (d == 0) d = 0; // squash -0
|
||||
var sNum = d.ToString("G17", CultureInfo.InvariantCulture);
|
||||
// Trim redundant zeros in exponentless decimals
|
||||
if (sNum.Contains('.') && !sNum.Contains("e") && !sNum.Contains("E"))
|
||||
{
|
||||
sNum = sNum.TrimEnd('0').TrimEnd('.');
|
||||
}
|
||||
sb.Append(sNum);
|
||||
}
|
||||
else
|
||||
{
|
||||
// bool / null
|
||||
if (val.TryGetValue<bool>(out var b))
|
||||
sb.Append(b ? "true" : "false");
|
||||
else
|
||||
sb.Append("null");
|
||||
}
|
||||
break;
|
||||
|
||||
default:
|
||||
sb.Append("null");
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
private static void WriteString(string s, StringBuilder sb)
|
||||
{
|
||||
sb.Append('"');
|
||||
foreach (var ch in s)
|
||||
{
|
||||
switch (ch)
|
||||
{
|
||||
case '\"': sb.Append("\\\""); break;
|
||||
case '\\': sb.Append("\\\\"); break;
|
||||
case '\b': sb.Append("\\b"); break;
|
||||
case '\f': sb.Append("\\f"); break;
|
||||
case '\n': sb.Append("\\n"); break;
|
||||
case '\r': sb.Append("\\r"); break;
|
||||
case '\t': sb.Append("\\t"); break;
|
||||
default:
|
||||
if (char.IsControl(ch))
|
||||
{
|
||||
sb.Append("\\u");
|
||||
sb.Append(((int)ch).ToString("x4"));
|
||||
}
|
||||
else
|
||||
{
|
||||
sb.Append(ch);
|
||||
}
|
||||
break;
|
||||
}
|
||||
}
|
||||
sb.Append('"');
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Usage in your code (e.g., Stella Ops):**
|
||||
|
||||
```csharp
|
||||
var payload = new {
|
||||
graphId = "core-vuln-edges",
|
||||
version = 3,
|
||||
edges = new[]{ new { from = "pkg:nuget/Newtonsoft.Json@13.0.3", to = "pkg:nuget/System.Text.Json@8.0.4" } },
|
||||
meta = new { generatedAt = DateTime.UtcNow.ToString("yyyy-MM-ddTHH:mm:ssZ") }
|
||||
};
|
||||
|
||||
// Canonical bytes (UTF-8 + LF) for storage/attestation:
|
||||
var canon = CanonJson.ToCanonicalUtf8(payload);
|
||||
|
||||
// Stable revision id (SHA-256 hex):
|
||||
var graphRevisionId = CanonJson.ComputeGraphRevisionId(payload);
|
||||
Console.WriteLine(graphRevisionId);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Operational tips
|
||||
|
||||
* **Freeze locales:** Always run with `CultureInfo.InvariantCulture` when formatting numbers/dates before they hit JSON.
|
||||
* **Reject non‑finite numbers:** Don’t allow `NaN`/`Infinity`—they’re not valid JSON and will break canonicalization.
|
||||
* **One writer, everywhere:** Use this same helper in CI, build agents, and runtime so the hash never drifts.
|
||||
* **Record the scheme:** Store the **canonicalization version** (e.g., `canon_v="JCS‑like v1"`) alongside the hash to allow future upgrades without breaking verification.
|
||||
|
||||
If you want, I can adapt this to stream very large JSONs (avoid `JsonNode`) or emit a **DSSE**/in‑toto style envelope with the canonical bytes as the payload for your attestation chain.
|
||||
Here’s a concrete, step‑by‑step implementation plan you can hand to the devs so they know exactly what to build and how it all fits together.
|
||||
|
||||
I’ll break it into phases:
|
||||
|
||||
1. **Design & scope**
|
||||
2. **Canonical JSON library**
|
||||
3. **Graph canonicalization & `graph_revision_id` calculation**
|
||||
4. **Tooling, tests & cross‑platform verification**
|
||||
5. **Integration & rollout**
|
||||
|
||||
---
|
||||
|
||||
## 1. Design & scope
|
||||
|
||||
### 1.1. Goals
|
||||
|
||||
* Produce a **stable, cross‑platform hash** (e.g. SHA‑256) from JSON content.
|
||||
* This hash becomes your **`graph_revision_id`** for supply‑chain graphs.
|
||||
* Hash **must not change** due to:
|
||||
|
||||
* OS differences (Windows/Linux/macOS)
|
||||
* Locale differences
|
||||
* Whitespace/property order differences
|
||||
* Unicode normalization issues (e.g. accented chars)
|
||||
|
||||
### 1.2. Canonicalization strategy (what devs should implement)
|
||||
|
||||
You’ll use **two levels of canonicalization**:
|
||||
|
||||
1. **Domain-level canonicalization (graph)**
|
||||
Make sure semantically equivalent graphs always serialize to the same in‑memory structure:
|
||||
|
||||
* Sort arrays (e.g. nodes, edges) in a deterministic way (ID, then type, etc.).
|
||||
* Remove / ignore non-semantic or unstable fields (timestamps, debug info, transient IDs).
|
||||
2. **Encoding-level canonicalization (JSON)**
|
||||
Convert that normalized object into **canonical JSON**:
|
||||
|
||||
* Object keys sorted lexicographically (`StringComparer.Ordinal`).
|
||||
* Strings normalized to **Unicode NFC**.
|
||||
* Numbers formatted with **InvariantCulture**, no locale effects.
|
||||
* No NaN/Infinity (reject or map them before hashing).
|
||||
* UTF‑8 output with **LF (`\n`) only**.
|
||||
|
||||
You already have a C# canonical JSON helper from me; this plan is about turning it into a production-ready component and wiring it through the system.
|
||||
|
||||
---
|
||||
|
||||
## 2. Canonical JSON library
|
||||
|
||||
**Owner:** backend platform team
|
||||
**Deliverable:** `StellaOps.CanonicalJson` (or similar) shared library
|
||||
|
||||
### 2.1. Project setup
|
||||
|
||||
* Create a **.NET class library**:
|
||||
|
||||
* `src/StellaOps.CanonicalJson/StellaOps.CanonicalJson.csproj`
|
||||
* Target same framework as your services (e.g. `net8.0`).
|
||||
* Add reference to `System.Text.Json`.
|
||||
|
||||
### 2.2. Public API design
|
||||
|
||||
In `CanonicalJson.cs` (or `CanonJson.cs`):
|
||||
|
||||
```csharp
|
||||
namespace StellaOps.CanonicalJson;
|
||||
|
||||
public static class CanonJson
|
||||
{
|
||||
// Version of your canonicalization algorithm (important for future changes)
|
||||
public const string CanonicalizationVersion = "canon-json-v1";
|
||||
|
||||
public static byte[] ToCanonicalUtf8<T>(T value);
|
||||
|
||||
public static string ToCanonicalString<T>(T value);
|
||||
|
||||
public static byte[] ComputeSha256<T>(T value);
|
||||
|
||||
public static string ComputeSha256Hex<T>(T value);
|
||||
}
|
||||
```
|
||||
|
||||
**Behavioral requirements:**
|
||||
|
||||
* `ToCanonicalUtf8`:
|
||||
|
||||
* Serializes input to a `JsonNode`.
|
||||
* Applies canonicalization rules (sort keys, normalize strings, normalize numbers).
|
||||
* Writes minimal JSON with:
|
||||
|
||||
* No extra spaces.
|
||||
* Keys in lexicographic order.
|
||||
* UTF‑8 bytes and LF newlines only.
|
||||
* `ComputeSha256Hex`:
|
||||
|
||||
* Uses `ToCanonicalUtf8` and computes SHA‑256.
|
||||
* Returns lower‑case hex string.
|
||||
|
||||
### 2.3. Canonicalization rules (dev checklist)
|
||||
|
||||
**Objects (`JsonObject`):**
|
||||
|
||||
* Sort keys using `StringComparer.Ordinal`.
|
||||
* Recursively canonicalize child nodes.
|
||||
|
||||
**Arrays (`JsonArray`):**
|
||||
|
||||
* Preserve order as given by caller.
|
||||
*(The “graph canonicalization” step will make sure this order is semantically stable before JSON.)*
|
||||
|
||||
**Strings:**
|
||||
|
||||
* Normalize to **NFC**:
|
||||
|
||||
```csharp
|
||||
var normalized = original.Normalize(NormalizationForm.FormC);
|
||||
```
|
||||
* When writing JSON:
|
||||
|
||||
* Escape `"`, `\`, control characters (`< 0x20`) using `\uXXXX` format.
|
||||
* Use `\n`, `\r`, `\t`, `\b`, `\f` for standard escapes.
|
||||
|
||||
**Numbers:**
|
||||
|
||||
* Support at least `long`, `double`, `decimal`.
|
||||
* Use **InvariantCulture**:
|
||||
|
||||
```csharp
|
||||
someNumber.ToString("G17", CultureInfo.InvariantCulture);
|
||||
```
|
||||
* Normalize `-0` to `0`.
|
||||
* No grouping separators, no locale decimals.
|
||||
* Reject `NaN`, `+Infinity`, `-Infinity` with a clear exception.
|
||||
|
||||
**Booleans & null:**
|
||||
|
||||
* Emit `true`, `false`, `null` (lowercase).
|
||||
|
||||
**Newlines:**
|
||||
|
||||
* Ensure final string has only `\n`:
|
||||
|
||||
```csharp
|
||||
json = json.Replace("\r\n", "\n").Replace("\r", "\n");
|
||||
```
|
||||
|
||||
### 2.4. Error handling & logging
|
||||
|
||||
* Throw a **custom exception** for unsupported content:
|
||||
|
||||
* `CanonicalJsonException : Exception`.
|
||||
* Example triggers:
|
||||
|
||||
* Non‑finite numbers (NaN/Infinity).
|
||||
* Types that can’t be represented in JSON.
|
||||
* Log the path to the field where canonicalization failed (for debugging).
|
||||
|
||||
---
|
||||
|
||||
## 3. Graph canonicalization & `graph_revision_id`
|
||||
|
||||
This is where the library gets used and where the semantics of the graph are defined.
|
||||
|
||||
**Owner:** team that owns your supply‑chain graph model / graph ingestion.
|
||||
**Deliverables:**
|
||||
|
||||
* Domain-specific canonicalization for graphs.
|
||||
* Stable `graph_revision_id` computation integrated into services.
|
||||
|
||||
### 3.1. Define what goes into the hash
|
||||
|
||||
Create a short **spec document** (internal) that answers:
|
||||
|
||||
1. **What object is being hashed?**
|
||||
|
||||
* For example:
|
||||
|
||||
```json
|
||||
{
|
||||
"graphId": "core-vuln-edges",
|
||||
"schemaVersion": "3",
|
||||
"nodes": [...],
|
||||
"edges": [...],
|
||||
"metadata": {
|
||||
"source": "scanner-x",
|
||||
"epoch": 1732730885
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
2. **Which fields are included vs excluded?**
|
||||
|
||||
* Include:
|
||||
|
||||
* Graph identity (ID, schema version).
|
||||
* Nodes (with stable key set).
|
||||
* Edges (with stable key set).
|
||||
* Exclude or **normalize**:
|
||||
|
||||
* Raw timestamps of ingestion.
|
||||
* Non-deterministic IDs (if they’re not part of graph semantics).
|
||||
* Any environment‑specific details.
|
||||
|
||||
3. **Versioning:**
|
||||
|
||||
* Add:
|
||||
|
||||
* `canonicalizationVersion` (from `CanonJson.CanonicalizationVersion`).
|
||||
* `graphHashSchemaVersion` (separate from graph schema version).
|
||||
|
||||
Example JSON passed into `CanonJson`:
|
||||
|
||||
```json
|
||||
{
|
||||
"graphId": "...",
|
||||
"graphSchemaVersion": "3",
|
||||
"graphHashSchemaVersion": "1",
|
||||
"canonicalizationVersion": "canon-json-v1",
|
||||
"nodes": [...],
|
||||
"edges": [...]
|
||||
}
|
||||
```
|
||||
|
||||
### 3.2. Domain-level canonicalizer
|
||||
|
||||
Create a class like `GraphCanonicalizer` in your graph domain assembly:
|
||||
|
||||
```csharp
|
||||
public interface IGraphCanonicalizer<TGraph>
|
||||
{
|
||||
object ToCanonicalGraphObject(TGraph graph);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation tasks:
|
||||
|
||||
1. **Choose a deterministic ordering for arrays:**
|
||||
|
||||
* Nodes: sort by `(nodeType, nodeId)` or `(packageUrl, version)`.
|
||||
* Edges: sort by `(from, to, edgeType)`.
|
||||
|
||||
2. **Strip / transform unstable fields:**
|
||||
|
||||
* Example: external IDs that may change but are not semantically relevant.
|
||||
* Replace `DateTime` with a normalized string format (if it must be part of the semantics).
|
||||
|
||||
3. **Output DTOs with primitive types only:**
|
||||
|
||||
* Create DTOs like:
|
||||
|
||||
```csharp
|
||||
public sealed record CanonicalNode(
|
||||
string Id,
|
||||
string Type,
|
||||
string Name,
|
||||
string? Version,
|
||||
IReadOnlyDictionary<string, string>? Attributes
|
||||
);
|
||||
```
|
||||
|
||||
* Use simple `record` types / POCOs that serialize cleanly with `System.Text.Json`.
|
||||
|
||||
4. **Combine into a single canonical graph object:**
|
||||
|
||||
```csharp
|
||||
public sealed record CanonicalGraphDto(
|
||||
string GraphId,
|
||||
string GraphSchemaVersion,
|
||||
string GraphHashSchemaVersion,
|
||||
string CanonicalizationVersion,
|
||||
IReadOnlyList<CanonicalNode> Nodes,
|
||||
IReadOnlyList<CanonicalEdge> Edges
|
||||
);
|
||||
```
|
||||
|
||||
`ToCanonicalGraphObject` returns `CanonicalGraphDto`.
|
||||
|
||||
### 3.3. `graph_revision_id` calculator
|
||||
|
||||
Add a service:
|
||||
|
||||
```csharp
|
||||
public interface IGraphRevisionCalculator<TGraph>
|
||||
{
|
||||
string CalculateRevisionId(TGraph graph);
|
||||
}
|
||||
|
||||
public sealed class GraphRevisionCalculator<TGraph> : IGraphRevisionCalculator<TGraph>
|
||||
{
|
||||
private readonly IGraphCanonicalizer<TGraph> _canonicalizer;
|
||||
|
||||
public GraphRevisionCalculator(IGraphCanonicalizer<TGraph> canonicalizer)
|
||||
{
|
||||
_canonicalizer = canonicalizer;
|
||||
}
|
||||
|
||||
public string CalculateRevisionId(TGraph graph)
|
||||
{
|
||||
var canonical = _canonicalizer.ToCanonicalGraphObject(graph);
|
||||
return CanonJson.ComputeSha256Hex(canonical);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Wire this up in DI** for all services that handle graph creation/update.
|
||||
|
||||
### 3.4. Persistence & APIs
|
||||
|
||||
1. **Database schema:**
|
||||
|
||||
* Add a `graph_revision_id` column (string, length 64) to graph tables/collections.
|
||||
* Optionally add `graph_hash_schema_version` and `canonicalization_version` columns for debugging.
|
||||
|
||||
2. **Write path:**
|
||||
|
||||
* On graph creation/update:
|
||||
|
||||
* Build the domain model.
|
||||
* Use `GraphRevisionCalculator` to get `graph_revision_id`.
|
||||
* Store it alongside the graph.
|
||||
|
||||
3. **Read path & APIs:**
|
||||
|
||||
* Ensure all relevant APIs return `graph_revision_id` for clients.
|
||||
* If you use it in attestation / DSSE payloads, include it there too.
|
||||
|
||||
---
|
||||
|
||||
## 4. Tooling, tests & cross‑platform verification
|
||||
|
||||
This is where you make sure it **actually behaves identically** on all platforms and input variations.
|
||||
|
||||
### 4.1. Unit tests for `CanonJson`
|
||||
|
||||
Create a dedicated test project: `tests/StellaOps.CanonicalJson.Tests`.
|
||||
|
||||
**Test categories & examples:**
|
||||
|
||||
1. **Property ordering:**
|
||||
|
||||
* Input 1: `{"b":1,"a":2}`
|
||||
* Input 2: `{"a":2,"b":1}`
|
||||
* Assert: `ToCanonicalString` is identical + same hash.
|
||||
|
||||
2. **Whitespace variations:**
|
||||
|
||||
* Input with lots of spaces/newlines vs compact.
|
||||
* Canonical outputs must match.
|
||||
|
||||
3. **Unicode normalization:**
|
||||
|
||||
* One string using precomposed characters.
|
||||
* Same text using combining characters.
|
||||
* Canonical output must match (NFC).
|
||||
|
||||
4. **Number formatting:**
|
||||
|
||||
* `1`, `1.0`, `1.0000000000` → must canonicalize to the same representation.
|
||||
* `-0.0` → canonicalizes to `0`.
|
||||
|
||||
5. **Booleans & null:**
|
||||
|
||||
* Check exact lowercase output: `true`, `false`, `null`.
|
||||
|
||||
6. **Error behaviors:**
|
||||
|
||||
* Try serializing `double.NaN` → expect `CanonicalJsonException`.
|
||||
|
||||
### 4.2. Integration tests for graph hashing
|
||||
|
||||
Create tests in graph service test project:
|
||||
|
||||
1. Build two graphs that are **semantically identical** but:
|
||||
|
||||
* Nodes/edges inserted in different order.
|
||||
* Fields ordered differently.
|
||||
* Different whitespace in strings (if your app might introduce such).
|
||||
|
||||
2. Assert:
|
||||
|
||||
* `CalculateRevisionId` yields the same result.
|
||||
* Canonical DTOs match expected snapshots (optional snapshot tests).
|
||||
|
||||
3. Build graphs that differ in a meaningful way (e.g., extra edge).
|
||||
|
||||
* Assert that `graph_revision_id` is different.
|
||||
|
||||
### 4.3. Cross‑platform smoke tests
|
||||
|
||||
**Goal:** Prove same hash on Windows, Linux and macOS.
|
||||
|
||||
Implementation idea:
|
||||
|
||||
1. Add a small console tool: `StellaOps.CanonicalJson.Tool`:
|
||||
|
||||
* Usage:
|
||||
`stella-canon hash graph.json`
|
||||
* Prints:
|
||||
|
||||
* Canonical JSON (optional flag).
|
||||
* SHA‑256 hex.
|
||||
|
||||
2. In CI:
|
||||
|
||||
* Run the same test JSON on:
|
||||
|
||||
* Windows runner.
|
||||
* Linux runner.
|
||||
* Assert hashes are equal (store expected in a test harness or artifact).
|
||||
|
||||
---
|
||||
|
||||
## 5. Integration into your pipelines & rollout
|
||||
|
||||
### 5.1. Where to compute `graph_revision_id`
|
||||
|
||||
Decide (and document) **one place** where the ID is authoritative, for example:
|
||||
|
||||
* After ingestion + normalization step, **before** persisting to your graph store.
|
||||
* Or in a dedicated “graph revision service” used by ingestion pipelines.
|
||||
|
||||
Implementation:
|
||||
|
||||
* Update the ingestion service:
|
||||
|
||||
1. Parse incoming data into internal graph model.
|
||||
2. Apply domain canonicalizer → `CanonicalGraphDto`.
|
||||
3. Use `GraphRevisionCalculator` → `graph_revision_id`.
|
||||
4. Persist graph + revision ID.
|
||||
|
||||
### 5.2. Migration / backfill plan
|
||||
|
||||
If you already have graphs in production:
|
||||
|
||||
1. Add new columns/fields for `graph_revision_id` (nullable).
|
||||
2. Write a migration job:
|
||||
|
||||
* Fetch existing graph.
|
||||
* Canonicalize + hash.
|
||||
* Store `graph_revision_id`.
|
||||
3. For a transition period:
|
||||
|
||||
* Accept both “old” and “new” graphs.
|
||||
* Use `graph_revision_id` where available; fall back to legacy IDs when necessary.
|
||||
4. After backfill is complete:
|
||||
|
||||
* Make `graph_revision_id` mandatory for new graphs.
|
||||
* Phase out any legacy revision logic.
|
||||
|
||||
### 5.3. Feature flag & safety
|
||||
|
||||
* Gate the use of `graph_revision_id` in high‑risk flows (e.g., attestations, policy decisions) behind a **feature flag**:
|
||||
|
||||
* `graphRevisionIdEnabled`.
|
||||
* Roll out gradually:
|
||||
|
||||
* Start in staging.
|
||||
* Then a subset of production tenants.
|
||||
* Monitor for:
|
||||
|
||||
* Unexpected changes in revision IDs on unchanged graphs.
|
||||
* Errors from `CanonicalJsonException`.
|
||||
|
||||
---
|
||||
|
||||
## 6. Documentation for developers & operators
|
||||
|
||||
Have a short internal doc (or page) with:
|
||||
|
||||
1. **Canonical JSON spec summary:**
|
||||
|
||||
* Sorting rules.
|
||||
* Unicode NFC requirement.
|
||||
* Number format rules.
|
||||
* Non‑finite numbers not allowed.
|
||||
|
||||
2. **Graph hashing spec:**
|
||||
|
||||
* Fields included in the hash.
|
||||
* Fields explicitly ignored.
|
||||
* Array ordering rules for nodes/edges.
|
||||
* Current:
|
||||
|
||||
* `graphHashSchemaVersion = "1"`
|
||||
* `CanonicalizationVersion = "canon-json-v1"`
|
||||
|
||||
3. **Examples:**
|
||||
|
||||
* Sample graph JSON input.
|
||||
* Canonical JSON output.
|
||||
* Expected SHA‑256.
|
||||
|
||||
4. **Operational guidance:**
|
||||
|
||||
* How to run the CLI tool to debug:
|
||||
|
||||
* “Why did this graph get a new `graph_revision_id`?”
|
||||
* What to do on canonicalization errors (usually indicates bad data).
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can do is: draft the **actual C# projects and folder structure** (with file names + stub code) so your team can just copy/paste the skeleton into the repo and start filling in the domain-specific bits.
|
||||
@@ -0,0 +1,775 @@
|
||||
Here’s a crisp, practical idea to harden Stella Ops: make the SBOM → VEX pipeline **deterministic and verifiable** by treating it as a series of signed, hash‑anchored state transitions—so every rebuild yields the *same* provenance envelope you can mathematically check across air‑gapped nodes.
|
||||
|
||||
---
|
||||
|
||||
### What this means (plain English)
|
||||
|
||||
* **SBOM** (what’s inside): list of packages, files, and their hashes.
|
||||
* **VEX** (what’s affected): statements like “CVE‑2024‑1234 is **not** exploitable here because X.”
|
||||
* **Deterministic**: same inputs → byte‑identical outputs, every time.
|
||||
* **Verifiable transitions**: each step (ingest → normalize → resolve → reachability → VEX) emits a signed attestation that pins its inputs/outputs by content hash.
|
||||
|
||||
---
|
||||
|
||||
### Minimal design you can drop into Stella Ops
|
||||
|
||||
1. **Canonicalize everything**
|
||||
|
||||
* Sort JSON keys, normalize whitespace/line endings.
|
||||
* Freeze timestamps by recording them only in an outer envelope (not inside payloads used for hashing).
|
||||
2. **Edge‑level attestations**
|
||||
|
||||
* For each dependency edge in the reachability graph `(nodeA → nodeB via symbol S)`, emit a tiny DSSE payload:
|
||||
|
||||
* `{edge_id, from_purl, to_purl, rule_id, witness_hashes[]}`
|
||||
* Hash is over the canonical payload; sign via DSSE (Sigstore or your Authority PKI).
|
||||
3. **Step attestations (pipeline states)**
|
||||
|
||||
* For each stage (`Sbomer`, `Scanner`, `Vexer/Excititor`, `Concelier`):
|
||||
|
||||
* Emit `predicateType`: `stellaops.dev/attestations/<stage>`
|
||||
* Include `input_digests[]`, `output_digests[]`, `parameters_digest`, `tool_version`
|
||||
* Sign with stage key; record the public key (or cert chain) in Authority.
|
||||
4. **Provenance envelope**
|
||||
|
||||
* Build a top‑level DSSE that includes:
|
||||
|
||||
* Merkle root of **all** edge attestations.
|
||||
* Merkle roots of each stage’s outputs.
|
||||
* Mapping table of `PURL ↔ build‑ID (ELF/PE/Mach‑O)` for stable identity.
|
||||
5. **Replay manifest**
|
||||
|
||||
* A single, declarative file that pins:
|
||||
|
||||
* Feeds (CPE/CVE/VEX sources + exact digests)
|
||||
* Rule/lattice versions and parameters
|
||||
* Container images + layers’ SHA256
|
||||
* Platform toggles (e.g., PQC on/off)
|
||||
* Running **replay** on this manifest must reproduce the same Merkle roots.
|
||||
6. **Air‑gap sync**
|
||||
|
||||
* Export only the envelopes + Merkle roots + public certs.
|
||||
* On the target, verify chains and recompute roots from the replay manifest—no internet required.
|
||||
|
||||
---
|
||||
|
||||
### Slim C# shapes (DTOs) for DSSE predicates
|
||||
|
||||
```csharp
|
||||
public record EdgeAttestation(
|
||||
string EdgeId,
|
||||
string FromPurl,
|
||||
string ToPurl,
|
||||
string RuleId,
|
||||
string[] WitnessHashes, // e.g., CFG slice, symbol tables, lineage JSON
|
||||
string CanonicalAlgo = "SHA256");
|
||||
|
||||
public record StepAttestation(
|
||||
string Stage, // "Sbomer" | "Scanner" | "Excititor" | "Concelier"
|
||||
string ToolVersion,
|
||||
string[] InputDigests,
|
||||
string[] OutputDigests,
|
||||
string ParametersDigest, // hash of canonicalized params
|
||||
DateTimeOffset StartedAt,
|
||||
DateTimeOffset FinishedAt);
|
||||
|
||||
public record ProvenanceEnvelope(
|
||||
string ReplayManifestDigest,
|
||||
string EdgeMerkleRoot,
|
||||
Dictionary<string,string> StageMerkleRoots, // stage -> root
|
||||
Dictionary<string,string> PurlToBuildId); // stable identity map
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Determinism checklist (quick win)
|
||||
|
||||
* Canonical JSON (stable key order) everywhere.
|
||||
* No wall‑clock timestamps inside hashed payloads.
|
||||
* Only reference inputs by digest, never by URL.
|
||||
* Lock rule sets / lattice policies by digest.
|
||||
* Normalize file paths (POSIX style) and line endings.
|
||||
* Container images by **digest**, not tags.
|
||||
|
||||
---
|
||||
|
||||
### Why it’s worth it
|
||||
|
||||
* **Auditability:** every VEX claim is backed by a verifiable graph path with signed edges.
|
||||
* **Reproducibility:** regulators (and customers) can replay your exact scan and get identical roots.
|
||||
* **Integrity at scale:** air‑gapped sites can validate without trusting your network—just the math.
|
||||
|
||||
If you want, I’ll turn this into ready‑to‑paste `.proto` contracts + a small .NET library (`StellaOps.Attestations`) with DSSE signing/verification helpers and Merkle builders.
|
||||
Got it — let’s turn that sketch into a concrete implementation plan your devs can actually execute.
|
||||
|
||||
I’ll structure this as:
|
||||
|
||||
1. **Objectives & scope**
|
||||
2. **High-level architecture**
|
||||
3. **Workstreams & milestones**
|
||||
4. **Detailed tasks per workstream**
|
||||
5. **Rollout, testing, and ops**
|
||||
|
||||
You can copy/paste this straight into a tracking system and break it into tickets.
|
||||
|
||||
---
|
||||
|
||||
## 1. Objectives & scope
|
||||
|
||||
### Primary objectives
|
||||
|
||||
* Make the **SBOM → VEX pipeline deterministic**:
|
||||
|
||||
* Same inputs (SBOM, feeds, rules, images) → **bit‑identical** provenance & VEX outputs.
|
||||
* Make the pipeline **verifiable**:
|
||||
|
||||
* Each step emits **signed attestations** with content hashes.
|
||||
* Attestations are **chainable** from raw SBOM to VEX & reports.
|
||||
* Make outputs **replayable** and **air‑gap friendly**:
|
||||
|
||||
* A single **Replay Manifest** can reconstruct pipeline outputs on another node and verify Merkle roots match.
|
||||
|
||||
### Out of scope (for this phase)
|
||||
|
||||
* New vulnerability scanning engines.
|
||||
* New UI views (beyond minimal “show provenance / verify”).
|
||||
* Key management redesign (we’ll integrate with existing Authority / PKI).
|
||||
|
||||
---
|
||||
|
||||
## 2. High-level architecture
|
||||
|
||||
### New shared library
|
||||
|
||||
**Library name (example):** `StellaOps.Attestations` (or similar)
|
||||
|
||||
Provides:
|
||||
|
||||
* Canonical serialization:
|
||||
|
||||
* Deterministic JSON encoder (stable key ordering, normalized formatting).
|
||||
* Hashing utilities:
|
||||
|
||||
* SHA‑256 (and extension point for future algorithms).
|
||||
* DSSE wrapper:
|
||||
|
||||
* `Sign(payload, keyRef)` → DSSE envelope.
|
||||
* `Verify(dsse, keyResolver)` → payload + key metadata.
|
||||
* Merkle utilities:
|
||||
|
||||
* Build Merkle trees from lists of digests.
|
||||
* DTOs:
|
||||
|
||||
* `EdgeAttestation`, `StepAttestation`, `ProvenanceEnvelope`, `ReplayManifest`.
|
||||
|
||||
### Components that will integrate the library
|
||||
|
||||
* **Sbomer** – outputs SBOM + StepAttestation.
|
||||
* **Scanner** – consumes SBOM, produces findings + StepAttestation.
|
||||
* **Excititor / Vexer** – takes findings + reachability graph → VEX + EdgeAttestations + StepAttestation.
|
||||
* **Concelier** – takes SBOM + VEX → reports + StepAttestation + ProvenanceEnvelope.
|
||||
* **Authority** – manages keys and verification (possibly separate microservice or shared module).
|
||||
|
||||
---
|
||||
|
||||
## 3. Workstreams & milestones
|
||||
|
||||
Break this into parallel workstreams:
|
||||
|
||||
1. **WS1 – Canonicalization & hashing**
|
||||
2. **WS2 – DSSE & key integration**
|
||||
3. **WS3 – Attestation schemas & Merkle envelopes**
|
||||
4. **WS4 – Pipeline integration (Sbomer, Scanner, Excititor, Concelier)**
|
||||
5. **WS5 – Replay engine & CLI**
|
||||
6. **WS6 – Verification / air‑gap support**
|
||||
7. **WS7 – Testing, observability, and rollout**
|
||||
|
||||
Each workstream below has concrete tasks + “Definition of Done” (DoD).
|
||||
|
||||
---
|
||||
|
||||
## 4. Detailed tasks per workstream
|
||||
|
||||
### WS1 – Canonicalization & hashing
|
||||
|
||||
**Goal:** A small, well-tested core that makes everything deterministic.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. **Define canonical JSON format**
|
||||
|
||||
* Decision doc:
|
||||
|
||||
* Use UTF‑8.
|
||||
* No insignificant whitespace.
|
||||
* Keys always sorted lexicographically.
|
||||
* No embedded timestamps or non-deterministic fields inside hashed payloads.
|
||||
* Implement:
|
||||
|
||||
* `CanonicalJsonSerializer.Serialize<T>(T value) : string/byte[]`.
|
||||
|
||||
2. **Define deterministic string normalization rules**
|
||||
|
||||
* Normalize line endings in any text: `\n` only.
|
||||
* Normalize paths:
|
||||
|
||||
* Use POSIX style `/`.
|
||||
* Remove trailing slashes (except root).
|
||||
* Normalize numeric formatting:
|
||||
|
||||
* No scientific notation.
|
||||
* Fixed decimal rules, if relevant.
|
||||
|
||||
3. **Implement hashing helper**
|
||||
|
||||
* `Digest` type:
|
||||
|
||||
```csharp
|
||||
public record Digest(string Algorithm, string Value); // Algorithm = "SHA256"
|
||||
```
|
||||
* `Hashing.ComputeDigest(byte[] data) : Digest`.
|
||||
* `Hashing.ComputeDigestCanonical<T>(T value) : Digest` (serialize canonically then hash).
|
||||
|
||||
4. **Add unit tests & golden files**
|
||||
|
||||
* Golden tests:
|
||||
|
||||
* Same input object → same canonical JSON & digest, regardless of property order, culture, runtime.
|
||||
* Hash of JSON must match pre‑computed values (store `.golden` files in repo).
|
||||
* Edge cases:
|
||||
|
||||
* Unicode strings.
|
||||
* Nested objects.
|
||||
* Arrays with different order (order preserved, but ensure same input → same output).
|
||||
|
||||
#### DoD
|
||||
|
||||
* Canonical serializer & hashing utilities available in `StellaOps.Attestations`.
|
||||
* Test suite with >95% coverage for serializer + hashing.
|
||||
* Simple CLI or test harness:
|
||||
|
||||
* `stella-attest dump-canonical <json>` → prints canonical JSON & digest.
|
||||
|
||||
---
|
||||
|
||||
### WS2 – DSSE & key integration
|
||||
|
||||
**Goal:** Standardize how we sign and verify attestations.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. **Select DSSE representation**
|
||||
|
||||
* Use JSON DSSE envelope:
|
||||
|
||||
```json
|
||||
{
|
||||
"payloadType": "stellaops.dev/attestation/edge@v1",
|
||||
"payload": "<base64 of canonical JSON>",
|
||||
"signatures": [{ "keyid": "...", "sig": "..." }]
|
||||
}
|
||||
```
|
||||
|
||||
2. **Implement DSSE API in library**
|
||||
|
||||
* Interfaces:
|
||||
|
||||
```csharp
|
||||
public interface ISigner {
|
||||
Task<Signature> SignAsync(byte[] payload, string keyRef);
|
||||
}
|
||||
|
||||
public interface IVerifier {
|
||||
Task<VerificationResult> VerifyAsync(Envelope envelope);
|
||||
}
|
||||
```
|
||||
* Helpers:
|
||||
|
||||
* `Dsse.CreateEnvelope(payloadType, canonicalPayloadBytes, signer, keyRef)`.
|
||||
* `Dsse.VerifyEnvelope(envelope, verifier)`.
|
||||
|
||||
3. **Integrate with Authority / PKI**
|
||||
|
||||
* Add `AuthoritySigner` / `AuthorityVerifier` implementations:
|
||||
|
||||
* `keyRef` is an ID understood by Authority (service name, stage name, or explicit key ID).
|
||||
* Ensure we can:
|
||||
|
||||
* Request signing of arbitrary bytes.
|
||||
* Resolve the public key used to sign.
|
||||
|
||||
4. **Key usage conventions**
|
||||
|
||||
* Define mapping:
|
||||
|
||||
* `sbomer` key.
|
||||
* `scanner` key.
|
||||
* `excititor` key.
|
||||
* `concelier` key.
|
||||
* Optional: use distinct keys per environment (dev/stage/prod) but **include environment** in attestation metadata.
|
||||
|
||||
5. **Tests**
|
||||
|
||||
* Round-trip: sign then verify sample payloads.
|
||||
* Negative tests:
|
||||
|
||||
* Tampered payload → verification fails.
|
||||
* Tampered signatures → verification fails.
|
||||
|
||||
#### DoD
|
||||
|
||||
* DSSE envelope creation/verification implemented and tested.
|
||||
* Authority integration with mock/fake for unit tests.
|
||||
* Documentation for developers:
|
||||
|
||||
* “How to emit an attestation: 5‑line example.”
|
||||
|
||||
---
|
||||
|
||||
### WS3 – Attestation schemas & Merkle envelopes
|
||||
|
||||
**Goal:** Standardize the data models for all attestations and envelopes.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. **Define EdgeAttestation schema**
|
||||
|
||||
Fields (concrete draft):
|
||||
|
||||
```csharp
|
||||
public record EdgeAttestation(
|
||||
string EdgeId, // deterministic ID
|
||||
string FromPurl, // e.g. pkg:maven/...
|
||||
string ToPurl,
|
||||
string? FromSymbol, // optional (symbol, API, entry point)
|
||||
string? ToSymbol,
|
||||
string RuleId, // which reachability rule fired
|
||||
Digest[] WitnessDigests, // digests of evidence payloads
|
||||
string CanonicalAlgo = "SHA256"
|
||||
);
|
||||
```
|
||||
|
||||
* `EdgeId` convention (document in ADR):
|
||||
|
||||
* E.g. `sha256(fromPurl + "→" + toPurl + "|" + ruleId + "|" + fromSymbol + "|" + toSymbol)` (before hashing, canonicalize strings).
|
||||
|
||||
2. **Define StepAttestation schema**
|
||||
|
||||
```csharp
|
||||
public record StepAttestation(
|
||||
string Stage, // "Sbomer" | "Scanner" | ...
|
||||
string ToolVersion,
|
||||
Digest[] InputDigests, // SBOM digest, feed digests, image digests
|
||||
Digest[] OutputDigests, // outputs of this stage
|
||||
Digest ParametersDigest, // hash of canonicalized params (flags, rule sets, etc.)
|
||||
DateTimeOffset StartedAt,
|
||||
DateTimeOffset FinishedAt,
|
||||
string Environment, // dev/stage/prod/airgap
|
||||
string NodeId // machine or logical node name
|
||||
);
|
||||
```
|
||||
|
||||
* Note: `StartedAt` / `FinishedAt` are **not** included in any hashed payload used for determinism; they’re OK as metadata but not part of Merkle roots.
|
||||
|
||||
3. **Define ProvenanceEnvelope schema**
|
||||
|
||||
```csharp
|
||||
public record ProvenanceEnvelope(
|
||||
Digest ReplayManifestDigest,
|
||||
Digest EdgeMerkleRoot,
|
||||
Dictionary<string, Digest> StageMerkleRoots, // stage -> root digest
|
||||
Dictionary<string, string> PurlToBuildId // PURL -> build-id string
|
||||
);
|
||||
```
|
||||
|
||||
4. **Define ReplayManifest schema**
|
||||
|
||||
```csharp
|
||||
public record ReplayManifest(
|
||||
string PipelineVersion,
|
||||
Digest SbomDigest,
|
||||
Digest[] FeedDigests, // CVE, CPE, VEX sources
|
||||
Digest[] RuleSetDigests, // reachability + policy rules
|
||||
Digest[] ContainerImageDigests,
|
||||
string[] PlatformToggles // e.g. ["pqc=on", "mode=strict"]
|
||||
);
|
||||
```
|
||||
|
||||
5. **Implement Merkle utilities**
|
||||
|
||||
* Provide:
|
||||
|
||||
* `Digest Merkle.BuildRoot(IEnumerable<Digest> leaves)`.
|
||||
* Deterministic rules:
|
||||
|
||||
* Sort leaves by `Value` (digest hex string) before building.
|
||||
* If odd number of leaves, duplicate last leaf or define explicit strategy and document it.
|
||||
* Tie into:
|
||||
|
||||
* Edges → `EdgeMerkleRoot`.
|
||||
* Per stage attestation list → stage‑specific root.
|
||||
|
||||
6. **Schema documentation**
|
||||
|
||||
* Markdown/ADR file:
|
||||
|
||||
* Field definitions.
|
||||
* Which fields are hashed vs. metadata only.
|
||||
* How `EdgeId`, Merkle roots, and PURL→BuildId mapping are generated.
|
||||
|
||||
#### DoD
|
||||
|
||||
* DTOs implemented in shared library.
|
||||
* Merkle root builder implemented and tested.
|
||||
* Schema documented and shared across teams.
|
||||
|
||||
---
|
||||
|
||||
### WS4 – Pipeline integration
|
||||
|
||||
**Goal:** Each stage emits StepAttestations and (for reachability) EdgeAttestations, and Concelier emits ProvenanceEnvelope.
|
||||
|
||||
We’ll do this stage by stage.
|
||||
|
||||
#### WS4.A – Sbomer integration
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Identify **SBOM hash**:
|
||||
|
||||
* After generating SBOM, serialize canonically and compute `Digest`.
|
||||
2. Collect **inputs**:
|
||||
|
||||
* Input sources digests (e.g., image digests, source artifact digests).
|
||||
3. Collect **parameters**:
|
||||
|
||||
* All relevant configuration into a `SbomerParams` object:
|
||||
|
||||
* E.g. `scanDepth`, `excludedPaths`, `sbomFormat`.
|
||||
* Canonicalize and compute `ParametersDigest`.
|
||||
4. Emit **StepAttestation**:
|
||||
|
||||
* Create DTO.
|
||||
* Canonicalize & hash for Merkle tree use.
|
||||
* Wrap in DSSE envelope with `payloadType = "stellaops.dev/attestation/step@v1"`.
|
||||
* Store envelope:
|
||||
|
||||
* Append to standard location (e.g. `<artifact-root>/attestations/sbomer-step.dsse.json`).
|
||||
5. Add config flag:
|
||||
|
||||
* `--emit-attestations` (default: off initially, later: on by default).
|
||||
|
||||
#### WS4.B – Scanner integration
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Take SBOM digest as an **InputDigest**.
|
||||
2. Collect feed digests:
|
||||
|
||||
* Each CVE/CPE/VEX feed file → canonical hash.
|
||||
3. Compute `ScannerParams` digest:
|
||||
|
||||
* E.g. `severityThreshold`, `downloaderOptions`, `scanMode`.
|
||||
4. Emit **StepAttestation** (same pattern as Sbomer).
|
||||
5. Tag scanner outputs:
|
||||
|
||||
* The vulnerability findings file(s) should be content‑addressable (filename includes digest or store meta manifest mapping).
|
||||
|
||||
#### WS4.C – Excititor/Vexer integration
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Integrate reachability graph emission:
|
||||
|
||||
* From final graph, **generate EdgeAttestations**:
|
||||
|
||||
* One per edge `(from, to, rule)`.
|
||||
* For each edge, compute witness digests:
|
||||
|
||||
* E.g. serialized CFG slice, symbol table snippet, call chain.
|
||||
* Those witness artifacts should be stored under canonical paths:
|
||||
|
||||
* `<artifact-root>/witnesses/<edge-id>/<witness-type>.json`.
|
||||
2. Canonicalize & hash each EdgeAttestation.
|
||||
3. Build **Merkle root** over all edge attestation digests.
|
||||
4. Emit **Excititor StepAttestation**:
|
||||
|
||||
* Inputs: SBOM, scanner findings, feeds, rule sets.
|
||||
* Outputs: VEX document(s), EdgeMerkleRoot digest.
|
||||
* Params: reachability flags, rule definitions digest.
|
||||
5. Store:
|
||||
|
||||
* Edge attestations:
|
||||
|
||||
* Either:
|
||||
|
||||
* One DSSE per edge (possibly a lot of files).
|
||||
* Or a **batch file** containing a list of attestations wrapped into a single DSSE.
|
||||
* Prefer: **batch** for performance; define `EdgeAttestationBatch` DTO.
|
||||
* VEX output(s) with deterministic file naming.
|
||||
|
||||
#### WS4.D – Concelier integration
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Gather all **StepAttestations** & **EdgeMerkleRoot**:
|
||||
|
||||
* Input: references (paths) to stage outputs + their DSSE envelopes.
|
||||
2. Build `PurlToBuildId` map:
|
||||
|
||||
* For each component:
|
||||
|
||||
* Extract PURL from SBOM.
|
||||
* Extract build-id from binary metadata.
|
||||
3. Build **StageMerkleRoots**:
|
||||
|
||||
* For each stage, compute Merkle root of its StepAttestations.
|
||||
* In simplest version: 1 step attestation per stage → root is just its digest.
|
||||
4. Construct **ReplayManifest**:
|
||||
|
||||
* From final pipeline context (SBOM, feeds, rules, images, toggles).
|
||||
* Compute `ReplayManifestDigest` and store manifest file (e.g. `replay-manifest.json`).
|
||||
5. Construct **ProvenanceEnvelope**:
|
||||
|
||||
* Fill fields with digests.
|
||||
* Canonicalize and sign with Concelier key (DSSE).
|
||||
6. Store outputs:
|
||||
|
||||
* `provenance-envelope.dsse.json`.
|
||||
* `replay-manifest.json` (unsigned) + optional signed manifest.
|
||||
|
||||
#### WS4 DoD
|
||||
|
||||
* All four stages can:
|
||||
|
||||
* Emit StepAttestations (and EdgeAttestations where applicable).
|
||||
* Produce a final ProvenanceEnvelope.
|
||||
* Feature can be toggled via config.
|
||||
* Pipelines run end‑to‑end in CI with attestation emission enabled.
|
||||
|
||||
---
|
||||
|
||||
### WS5 – Replay engine & CLI
|
||||
|
||||
**Goal:** Given a ReplayManifest, re‑run the pipeline and verify that all Merkle roots and digests match.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. Implement a **Replay Orchestrator** library:
|
||||
|
||||
* Input:
|
||||
|
||||
* Path/URL to `replay-manifest.json`.
|
||||
* Responsibilities:
|
||||
|
||||
* Verify manifest’s own digest (if signed).
|
||||
* Fetch or confirm presence of:
|
||||
|
||||
* SBOM.
|
||||
* Feeds.
|
||||
* Rule sets.
|
||||
* Container images.
|
||||
* Spin up each stage with parameters reconstructed from the manifest:
|
||||
|
||||
* Ensure versions and flags match.
|
||||
* Implementation: shared orchestration code reusing existing pipeline entrypoints.
|
||||
|
||||
2. Implement **CLI tool**: `stella-attest replay`
|
||||
|
||||
* Commands:
|
||||
|
||||
* `stella-attest replay run --manifest <path> --out <dir>`.
|
||||
|
||||
* Runs pipeline and emits fresh attestations.
|
||||
* `stella-attest replay verify --manifest <path> --envelope <path> --attest-dir <dir>`:
|
||||
|
||||
* Compares:
|
||||
|
||||
* Replay Merkle roots vs. `ProvenanceEnvelope`.
|
||||
* Stage roots.
|
||||
* Edge root.
|
||||
* Emits a verification report (JSON + human-readable).
|
||||
|
||||
3. Verification logic:
|
||||
|
||||
* Steps:
|
||||
|
||||
1. Parse ProvenanceEnvelope (verify DSSE signature).
|
||||
2. Compute Merkle roots from the new replay’s attestations.
|
||||
3. Compare:
|
||||
|
||||
* `ReplayManifestDigest` in envelope vs digest of manifest used.
|
||||
* `EdgeMerkleRoot` vs recalculated root.
|
||||
* `StageMerkleRoots[stage]` vs recalculated stage roots.
|
||||
4. Output:
|
||||
|
||||
* `verified = true/false`.
|
||||
* If false, list mismatches with digests.
|
||||
|
||||
4. Tests:
|
||||
|
||||
* Replay the same pipeline on same machine → must match.
|
||||
* Replay on different machine (CI job simulating different environment) → must match.
|
||||
* Injected change in feed or rule set → deliberate mismatch detected.
|
||||
|
||||
#### DoD
|
||||
|
||||
* `stella-attest replay` works locally and in CI.
|
||||
* Documentation: “How to replay a run and verify determinism.”
|
||||
|
||||
---
|
||||
|
||||
### WS6 – Verification / air‑gap support
|
||||
|
||||
**Goal:** Allow verification in environments without outward network access.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. **Define export bundle format**
|
||||
|
||||
* Bundle includes:
|
||||
|
||||
* `provenance-envelope.dsse.json`.
|
||||
* `replay-manifest.json`.
|
||||
* All DSSE attestation files.
|
||||
* All witness artifacts (or digests only if storage is local).
|
||||
* Public key material or certificate chains needed to verify signatures.
|
||||
* Represent as:
|
||||
|
||||
* Tarball or zip: e.g. `stella-bundle-<pipeline-id>.tar.gz`.
|
||||
* Manifest file listing contents and digests.
|
||||
|
||||
2. **Implement exporter**
|
||||
|
||||
* CLI: `stella-attest export --run-id <id> --out bundle.tar.gz`.
|
||||
* Internally:
|
||||
|
||||
* Collect paths to all relevant artifacts for the run.
|
||||
* Canonicalize folder structure (e.g. `/sbom`, `/scanner`, `/vex`, `/attestations`, `/witnesses`).
|
||||
|
||||
3. **Implement offline verifier**
|
||||
|
||||
* CLI: `stella-attest verify-bundle --bundle <path>`.
|
||||
* Steps:
|
||||
|
||||
* Unpack bundle to temp dir.
|
||||
* Verify:
|
||||
|
||||
* Attestation signatures via included public keys.
|
||||
* Merkle roots and digests as in WS5.
|
||||
* Do **not** attempt network calls.
|
||||
|
||||
4. **Documentation / runbook**
|
||||
|
||||
* “How to verify a Stella Ops run in an air‑gapped environment.”
|
||||
* Include:
|
||||
|
||||
* How to move bundles (e.g. via USB, secure file transfer).
|
||||
* What to do if verification fails.
|
||||
|
||||
#### DoD
|
||||
|
||||
* Bundles can be exported from a connected environment and verified in a disconnected environment using only the bundle contents.
|
||||
|
||||
---
|
||||
|
||||
### WS7 – Testing, observability, and rollout
|
||||
|
||||
**Goal:** Make this robust, observable, and gradually enable in prod.
|
||||
|
||||
#### Tasks
|
||||
|
||||
1. **Integration tests**
|
||||
|
||||
* Full pipeline scenario:
|
||||
|
||||
* Start from known SBOM + feeds + rules.
|
||||
* Run pipeline twice and:
|
||||
|
||||
* Compare final outputs: `ProvenanceEnvelope`, VEX doc, final reports.
|
||||
* Compare digests & Merkle roots.
|
||||
* Edge cases:
|
||||
|
||||
* Different machines (simulate via CI jobs with different runners).
|
||||
* Missing or corrupted attestation file → verify that verification fails with clear error.
|
||||
|
||||
2. **Property-based tests** (optional but great)
|
||||
|
||||
* Generate random but structured SBOMs and graphs.
|
||||
* Ensure:
|
||||
|
||||
* Canonicalization is idempotent.
|
||||
* Hashing is consistent.
|
||||
* Merkle roots are stable for repeated runs.
|
||||
|
||||
3. **Observability**
|
||||
|
||||
* Add logging around:
|
||||
|
||||
* Attestation creation & signing.
|
||||
* Verification failures.
|
||||
* Replay runs.
|
||||
* Add metrics:
|
||||
|
||||
* Number of attestations per run.
|
||||
* Time spent in canonicalization / hashing / signing.
|
||||
* Verification success/fail counts.
|
||||
|
||||
4. **Rollout plan**
|
||||
|
||||
1. **Phase 0 (dev only)**:
|
||||
|
||||
* Attestation emission enabled by default in dev.
|
||||
* Verification run in CI only.
|
||||
2. **Phase 1 (staging)**:
|
||||
|
||||
* Enable dual‑path:
|
||||
|
||||
* Old behaviour + new attestations.
|
||||
* Run replay+verify in staging pipeline.
|
||||
3. **Phase 2 (production, non‑enforced)**:
|
||||
|
||||
* Enable attestation emission in prod.
|
||||
* Verification runs “side‑car” but does not block.
|
||||
4. **Phase 3 (production, enforced)**:
|
||||
|
||||
* CI/CD gates:
|
||||
|
||||
* Fails if:
|
||||
|
||||
* Signatures invalid.
|
||||
* Merkle roots mismatch.
|
||||
* Envelope/manifest missing.
|
||||
|
||||
5. **Documentation**
|
||||
|
||||
* Developer docs:
|
||||
|
||||
* “How to emit a StepAttestation from your service.”
|
||||
* “How to add new fields without breaking determinism.”
|
||||
* Operator docs:
|
||||
|
||||
* “How to run replay & verification.”
|
||||
* “How to interpret failures and debug.”
|
||||
|
||||
#### DoD
|
||||
|
||||
* All new functionality covered by automated tests.
|
||||
* Observability dashboards / alerts configured.
|
||||
* Rollout phases defined with clear criteria for moving to the next phase.
|
||||
|
||||
---
|
||||
|
||||
## 5. How to turn this into tickets
|
||||
|
||||
You can break this down roughly like:
|
||||
|
||||
* **Epic 1:** Attestation core library (WS1 + WS2 + WS3).
|
||||
* **Epic 2:** Stage integrations (WS4A–D).
|
||||
* **Epic 3:** Replay & verification tooling (WS5 + WS6).
|
||||
* **Epic 4:** Testing, observability, rollout (WS7).
|
||||
|
||||
If you want, next step I can:
|
||||
|
||||
* Turn each epic into **Jira-style stories** with acceptance criteria.
|
||||
* Or produce **sample code stubs** (interfaces + minimal implementations) matching this plan.
|
||||
@@ -0,0 +1,684 @@
|
||||
I’m sharing this because it closely aligns with your strategy for building strong supply‑chain and attestation moats — these are emerging standards you’ll want to embed into your architecture now.
|
||||
|
||||

|
||||
|
||||
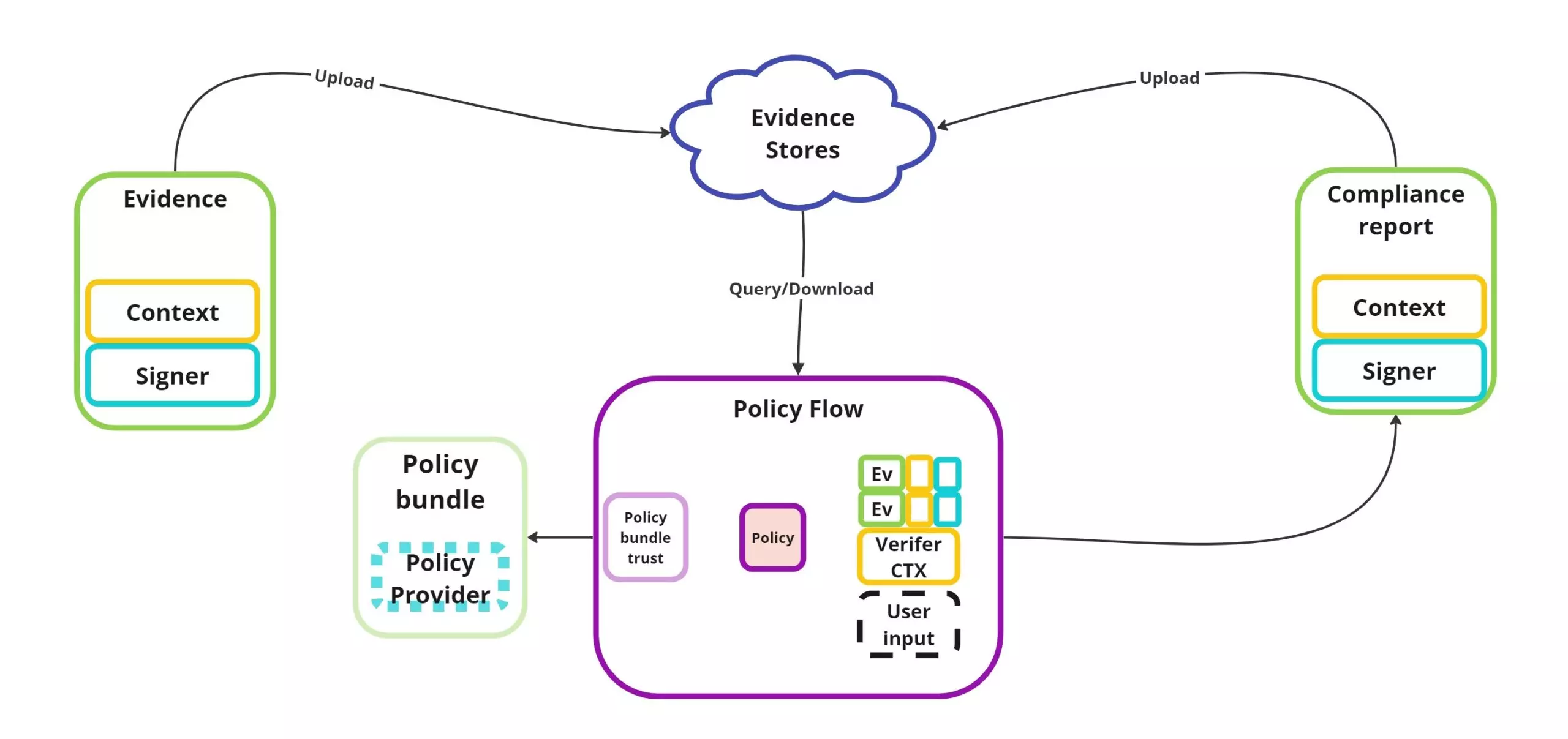
|
||||
|
||||
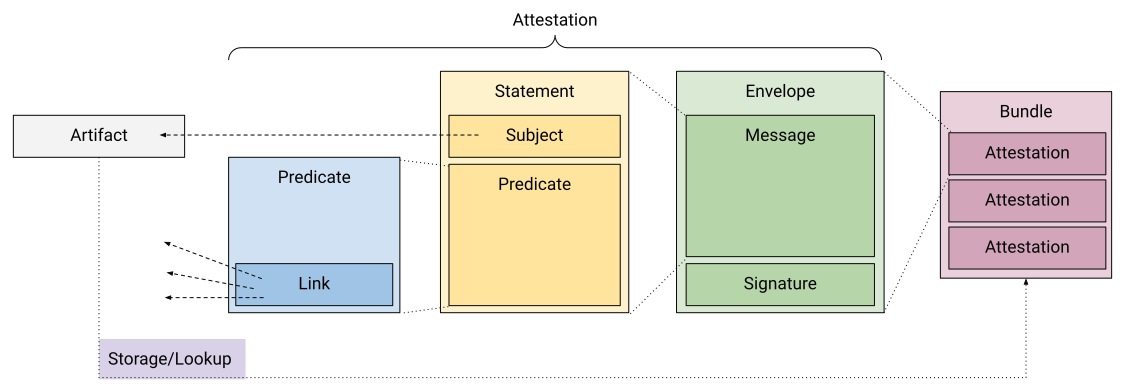
|
||||
|
||||
### DSSE + in‑toto: The event‑spine
|
||||
|
||||
* The Dead Simple Signing Envelope (DSSE) spec defines a minimal JSON envelope for signing arbitrary data — “transparent transport for signed statements”. ([GitHub][1])
|
||||
* The in‑toto Attestation model builds on DSSE as the envelope, with a statement + predicate about the artifact (e.g., build/cohort metadata). ([Legit Security][2])
|
||||
* In your architecture: using DSSE‑signed in‑toto attestations across Scanner → Sbomer → Vexer → Scorer → Attestor gives you a unified “event spine” of provenance and attestations.
|
||||
* That means every step emits a signed statement, verifiable, linking tooling. Helps achieve deterministic replayability and audit‑integrity.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
### CycloneDX v1.7: SBOM + cryptography assurance
|
||||
|
||||
* Version 1.7 of CycloneDX was released October 21, 2025 and introduces **advanced cryptography, data‑provenance transparency, and IP visibility** for the software supply chain. ([CycloneDX][3])
|
||||
* It introduces a “Cryptography Registry” to standardize naming / classification of crypto algorithms in BOMs — relevant for PQC readiness, global cryptographic standards like GOST/SM, etc. ([CycloneDX][4])
|
||||
* If you emit SBOMs in CycloneDX v1.7 format (and include CBOM/crypto details), you’re aligning with modern supply‑chain trust expectations — satisfying your moat #1 (crypto‑sovereign readiness) and #2 (deterministic manifests).
|
||||
|
||||

|
||||
|
||||
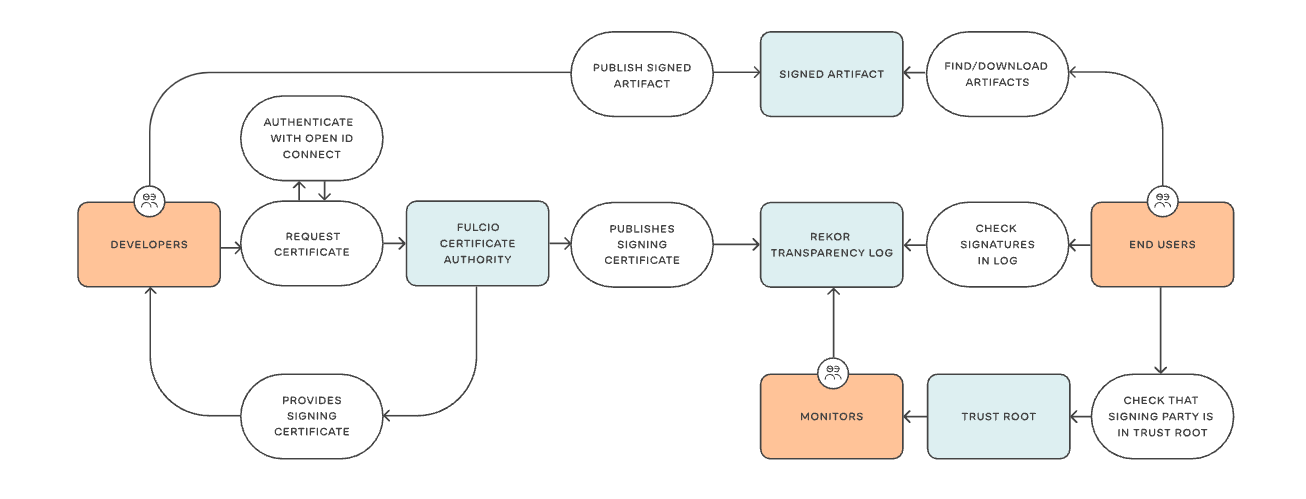
|
||||
|
||||

|
||||
|
||||
### Sigstore Rekor v2: Logging the provenance chain
|
||||
|
||||
* Rekor v2 reached GA on October 10 2025; the redesign introduces a “tile‑backed transparency log implementation” to simplify ops and reduce costs. ([Sigstore Blog][5])
|
||||
* Rekor supports auditing of signing events, monitors to verify append‑only consistency, and log inclusion proofs. ([Sigstore][6])
|
||||
* By bundling your provenance/SBOM/VEX/scores and recording those in Rekor v2, you’re closing your chain of custody with immutable log entries — supports your “Proof‑of‑Integrity Graph” moat (point #4).
|
||||
|
||||
### Why this matters for your architecture
|
||||
|
||||
* With each scan or stage (Scanner → Sbomer → Vexer → Scorer → Attestor) producing a DSSE‑signed in‑toto statement, you have a canonical spine of events.
|
||||
* Emitting SBOMs in CycloneDX v1.7 ensures you not only list components but crypto metadata, attestation pointers, and versions ready for future‑proofing.
|
||||
* Recording all artifacts (attestations, SBOM, VEX, scores) into Rekor v2 gives you external public verifiability and auditability — minimal trust surface, maximal transparency.
|
||||
* These standards map directly to several of your moats: crypto‑sovereign readiness, deterministic replayable scans, provenance graphs, trust‑ledger.
|
||||
|
||||
If you like, I can pull together **mappings** of your internal modules (Scanner, Sbomer, Vexer, etc) to these standards and provide a **reference implementation skeleton** in .NET 10 (you indicated you’re working with that).
|
||||
|
||||
[1]: https://github.com/secure-systems-lab/dsse?utm_source=chatgpt.com "secure-systems-lab/dsse - Dead Simple Signing Envelope"
|
||||
[2]: https://www.legitsecurity.com/blog/slsa-provenance-blog-series-part-1-what-is-software-attestation?utm_source=chatgpt.com "SLSA Provenance Blog Series, Part 1: What Is Software ..."
|
||||
[3]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[4]: https://cyclonedx.org/registry/cryptography/?utm_source=chatgpt.com "Cryptography Registry"
|
||||
[5]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[6]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
Got it — let’s turn your vision into something devs can actually build against.
|
||||
|
||||
Below is a **concrete implementation plan** you can paste into an internal doc / ticketing system and refine into epics & stories.
|
||||
|
||||
---
|
||||
|
||||
## 0. Assumptions & Target End‑State
|
||||
|
||||
**Assumptions**
|
||||
|
||||
* Services: `Scanner → Sbomer → Vexer → Scorer → Attestor` (plus shared infra).
|
||||
* Language: .NET (8/10) for your services.
|
||||
* You want:
|
||||
|
||||
* **DSSE‑signed in‑toto attestations** as the event “spine”. ([GitHub][1])
|
||||
* **CycloneDX 1.7 SBOM + VEX** for inventory + exploitability. ([CycloneDX][2])
|
||||
* **Rekor v2** as the transparency log, with Sigstore bundles for offline verification. ([Sigstore Blog][3])
|
||||
|
||||
**Target picture**
|
||||
|
||||
For every artifact *A* (image / binary / model):
|
||||
|
||||
1. Each stage emits a **DSSE‑signed in‑toto attestation**:
|
||||
|
||||
* Scanner → scan predicate
|
||||
* Sbomer → CycloneDX 1.7 SBOM predicate
|
||||
* Vexer → VEX predicate
|
||||
* Scorer → score predicate
|
||||
* Attestor → final decision predicate
|
||||
|
||||
2. Each attestation is:
|
||||
|
||||
* Signed with your keys or Sigstore keyless.
|
||||
* Logged to Rekor (v2) and optionally packaged into a Sigstore bundle.
|
||||
|
||||
3. A consumer can:
|
||||
|
||||
* Fetch all attestations for *A*, verify signatures + Rekor proofs, read SBOM/VEX, and understand the score.
|
||||
|
||||
The rest of this plan is: **how to get there step‑by‑step.**
|
||||
|
||||
---
|
||||
|
||||
## 1. Core Data Contracts (Must Be Done First)
|
||||
|
||||
### 1.1 Define the canonical envelope and statement
|
||||
|
||||
**Standards to follow**
|
||||
|
||||
* **DSSE Envelope** from secure‑systems‑lab (`envelope.proto`). ([GitHub][1])
|
||||
* **In‑toto Attestation “Statement”** model (subject + predicateType + predicate). ([SLSA][4])
|
||||
|
||||
**Deliverable: internal spec**
|
||||
|
||||
Create a short internal spec (Markdown) for developers:
|
||||
|
||||
* `ArtifactIdentity`
|
||||
|
||||
* `algorithm`: `sha256` | `sha512` | etc.
|
||||
* `digest`: hex string.
|
||||
* Optional: `name`, `version`, `buildPipelineId`.
|
||||
|
||||
* `InTotoStatement<TPredicate>`
|
||||
|
||||
* `type`: fixed: `https://in-toto.io/Statement/v1`
|
||||
* `subject`: list of `ArtifactIdentity`.
|
||||
* `predicateType`: string (URL-ish).
|
||||
* `predicate`: generic JSON (stage‑specific payload).
|
||||
|
||||
* `DsseEnvelope`
|
||||
|
||||
* `payloadType`: e.g. `application/vnd.in-toto+json`
|
||||
* `payload`: base64 of the JSON `InTotoStatement`.
|
||||
* `signatures[]`: `{ keyid, sig }`.
|
||||
|
||||
### 1.2 Implement the .NET representation
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Generate DSSE envelope types**
|
||||
|
||||
* Use `envelope.proto` from DSSE repo and generate C# types; or reuse the Grafeas `Envelope` class which is explicitly aligned with DSSE. ([Google Cloud][5])
|
||||
* Project: `Attestations.Core`.
|
||||
|
||||
2. **Define generic Statement & Predicate types**
|
||||
|
||||
In `Attestations.Core`:
|
||||
|
||||
```csharp
|
||||
public record ArtifactIdentity(string Algorithm, string Digest, string? Name = null, string? Version = null);
|
||||
|
||||
public record InTotoStatement<TPredicate>(
|
||||
string _Type,
|
||||
IReadOnlyList<ArtifactIdentity> Subject,
|
||||
string PredicateType,
|
||||
TPredicate Predicate
|
||||
);
|
||||
|
||||
public record DsseSignature(string KeyId, byte[] Sig);
|
||||
|
||||
public record DsseEnvelope(
|
||||
string PayloadType,
|
||||
byte[] Payload,
|
||||
IReadOnlyList<DsseSignature> Signatures
|
||||
);
|
||||
```
|
||||
|
||||
3. **Define predicate contracts for each stage**
|
||||
|
||||
Example:
|
||||
|
||||
```csharp
|
||||
public static class PredicateTypes
|
||||
{
|
||||
public const string ScanV1 = "https://example.com/attestations/scan/v1";
|
||||
public const string SbomV1 = "https://example.com/attestations/sbom/cyclonedx-1.7";
|
||||
public const string VexV1 = "https://example.com/attestations/vex/cyclonedx";
|
||||
public const string ScoreV1 = "https://example.com/attestations/score/v1";
|
||||
public const string VerdictV1= "https://example.com/attestations/verdict/v1";
|
||||
}
|
||||
```
|
||||
|
||||
Then define concrete predicates:
|
||||
|
||||
* `ScanPredicateV1`
|
||||
* `SbomPredicateV1` (likely mostly a pointer to a CycloneDX doc)
|
||||
* `VexPredicateV1` (pointer to VEX doc + summary)
|
||||
* `ScorePredicateV1`
|
||||
* `VerdictPredicateV1` (attest/deny + reasoning)
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* All services share a single `Attestations.Core` library.
|
||||
* There is a test that serializes + deserializes `InTotoStatement` and `DsseEnvelope` and matches the JSON format expected by in‑toto tooling.
|
||||
|
||||
---
|
||||
|
||||
## 2. Signing & Key Management Layer
|
||||
|
||||
### 2.1 Abstraction: decouple from crypto choice
|
||||
|
||||
Create an internal package: `Attestations.Signing`.
|
||||
|
||||
```csharp
|
||||
public interface IArtifactSigner
|
||||
{
|
||||
Task<DsseEnvelope> SignStatementAsync<TPredicate>(
|
||||
InTotoStatement<TPredicate> statement,
|
||||
CancellationToken ct = default);
|
||||
}
|
||||
|
||||
public interface IArtifactVerifier
|
||||
{
|
||||
Task VerifyAsync(DsseEnvelope envelope, CancellationToken ct = default);
|
||||
}
|
||||
```
|
||||
|
||||
Backends to implement:
|
||||
|
||||
1. **KMS‑backed signer** (e.g., AWS KMS, GCP KMS, Azure Key Vault).
|
||||
2. **Sigstore keyless / cosign integration**:
|
||||
|
||||
* For now you can wrap the **cosign CLI**, which already understands in‑toto attestations and Rekor. ([Sigstore][6])
|
||||
* Later, replace with a native HTTP client against Sigstore services.
|
||||
|
||||
### 2.2 Key & algorithm strategy
|
||||
|
||||
* Default: **ECDSA P‑256** or **Ed25519** keys, stored in KMS.
|
||||
* Wrap all usage via `IArtifactSigner`/`IArtifactVerifier`.
|
||||
* Keep room for **PQC migration** by never letting services call crypto APIs directly; only use the abstraction.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* CLI or small test harness that:
|
||||
|
||||
* Creates a dummy `InTotoStatement`,
|
||||
* Signs it via `IArtifactSigner`,
|
||||
* Verifies via `IArtifactVerifier`,
|
||||
* Fails verification if payload is tampered.
|
||||
|
||||
---
|
||||
|
||||
## 3. Service‑by‑Service Integration
|
||||
|
||||
For each component we’ll define **inputs → behavior → attestation output**.
|
||||
|
||||
### 3.1 Scanner
|
||||
|
||||
**Goal**
|
||||
For each artifact, emit a **scan attestation** with normalized findings.
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Extend Scanner to normalize findings to a canonical model:
|
||||
|
||||
* Vulnerability id (CVE / GHSA / etc).
|
||||
* Affected package (`purl`, version).
|
||||
* Severity, source (NVD, OSV, etc).
|
||||
|
||||
2. Define `ScanPredicateV1`:
|
||||
|
||||
```csharp
|
||||
public record ScanPredicateV1(
|
||||
string ScannerName,
|
||||
string ScannerVersion,
|
||||
DateTimeOffset ScanTime,
|
||||
string ScanConfigurationId,
|
||||
IReadOnlyList<ScanFinding> Findings
|
||||
);
|
||||
```
|
||||
|
||||
3. After each scan completes:
|
||||
|
||||
* Build `ArtifactIdentity` from the artifact digest.
|
||||
* Build `InTotoStatement<ScanPredicateV1>` with `PredicateTypes.ScanV1`.
|
||||
* Call `IArtifactSigner.SignStatementAsync`.
|
||||
* Save `DsseEnvelope` to an **Attestation Store** (see section 5).
|
||||
* Publish an event `scan.attestation.created` on your message bus with the attestation id.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Every scan results in a stored DSSE envelope with `ScanV1` predicate.
|
||||
* A consumer service can query by artifact digest and get all scan attestations.
|
||||
|
||||
---
|
||||
|
||||
### 3.2 Sbomer (CycloneDX 1.7)
|
||||
|
||||
**Goal**
|
||||
Generate **CycloneDX 1.7 SBOMs** and attest to them.
|
||||
|
||||
CycloneDX provides a .NET library and tools for producing and consuming SBOMs. ([GitHub][7])
|
||||
CycloneDX 1.7 adds cryptography registry, data‑provenance and IP transparency. ([CycloneDX][2])
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Add CycloneDX .NET library
|
||||
|
||||
* NuGet: `CycloneDX.Core` (and optional `CycloneDX.Utils`). ([NuGet][8])
|
||||
|
||||
2. SBOM generation process
|
||||
|
||||
* Input: artifact digest + build metadata (e.g., manifest, lock file).
|
||||
* Generate a **CycloneDX 1.7 SBOM**:
|
||||
|
||||
* Fill `metadata.component`, `bomRef`, and dependency graph.
|
||||
* Include crypto material using the **Cryptography Registry** (algorithms, key sizes, modes) when relevant. ([CycloneDX][9])
|
||||
* Include data provenance (tool name/version, timestamp).
|
||||
|
||||
3. Storage
|
||||
|
||||
* Store SBOM documents (JSON) in object storage: `sboms/{artifactDigest}/cyclonedx-1.7.json`.
|
||||
* Index them in the Attestation DB (see 5).
|
||||
|
||||
4. `SbomPredicateV1`
|
||||
|
||||
```csharp
|
||||
public record SbomPredicateV1(
|
||||
string Format, // "CycloneDX"
|
||||
string Version, // "1.7"
|
||||
Uri Location, // URL to the SBOM blob
|
||||
string? HashAlgorithm,
|
||||
string? HashDigest // hash of the SBOM document itself
|
||||
);
|
||||
```
|
||||
|
||||
5. After SBOM generation:
|
||||
|
||||
* Create statement with `PredicateTypes.SbomV1`.
|
||||
* Sign via `IArtifactSigner`.
|
||||
* Store DSSE envelope + publish `sbom.attestation.created`.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* For any scanned artifact, you can fetch:
|
||||
|
||||
* A CycloneDX 1.7 SBOM, and
|
||||
* A DSSE‑signed in‑toto SBOM attestation pointing to it.
|
||||
|
||||
---
|
||||
|
||||
### 3.3 Vexer (CycloneDX VEX / CSAF)
|
||||
|
||||
**Goal**
|
||||
Turn “raw vulnerability findings” into **VEX documents** that say whether each vulnerability is exploitable, using CycloneDX VEX representation. ([CycloneDX][10])
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Model VEX status mapping
|
||||
|
||||
* Example statuses: `affected`, `not_affected`, `fixed`, `under_investigation`.
|
||||
* Derive rules from:
|
||||
|
||||
* Reachability analysis, config, feature usage.
|
||||
* Business logic (e.g., vulnerability only affects optional module not shipped).
|
||||
|
||||
2. Generate VEX docs
|
||||
|
||||
* Use the same CycloneDX .NET library to emit **CycloneDX VEX** documents.
|
||||
* Store them: `vex/{artifactDigest}/cyclonedx-vex.json`.
|
||||
|
||||
3. `VexPredicateV1`
|
||||
|
||||
```csharp
|
||||
public record VexPredicateV1(
|
||||
string Format, // "CycloneDX-VEX"
|
||||
string Version,
|
||||
Uri Location,
|
||||
string? HashAlgorithm,
|
||||
string? HashDigest,
|
||||
int TotalVulnerabilities,
|
||||
int ExploitableVulnerabilities
|
||||
);
|
||||
```
|
||||
|
||||
4. After VEX generation:
|
||||
|
||||
* Build statement with `PredicateTypes.VexV1`.
|
||||
* Sign, store, publish `vex.attestation.created`.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* For an artifact with scan results, there is a VEX doc and attestation that:
|
||||
|
||||
* Marks each vulnerability with exploitability status.
|
||||
* Can be consumed by `Scorer` to prioritize risk.
|
||||
|
||||
---
|
||||
|
||||
### 3.4 Scorer
|
||||
|
||||
**Goal**
|
||||
Compute a **trust/risk score** based on SBOM + VEX + other signals, and attest to it.
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Scoring model v1
|
||||
|
||||
* Inputs:
|
||||
|
||||
* Count of exploitable vulns by severity.
|
||||
* Presence/absence of required attestations (scan, sbom, vex).
|
||||
* Age of last scan.
|
||||
* Output:
|
||||
|
||||
* `RiskScore` (0–100 or letter grade).
|
||||
* `RiskTier` (“low”, “medium”, “high”).
|
||||
* Reasons (top 3 contributors).
|
||||
|
||||
2. `ScorePredicateV1`
|
||||
|
||||
```csharp
|
||||
public record ScorePredicateV1(
|
||||
double Score,
|
||||
string Tier,
|
||||
DateTimeOffset CalculatedAt,
|
||||
IReadOnlyList<string> Reasons
|
||||
);
|
||||
```
|
||||
|
||||
3. When triggered (new VEX or SBOM):
|
||||
|
||||
* Recompute score for the artifact.
|
||||
* Create attestation, sign, store, publish `score.attestation.created`.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* A consumer can call “/artifacts/{digest}/score” and:
|
||||
|
||||
* Verify the DSSE envelope,
|
||||
* Read a deterministic `ScorePredicateV1`.
|
||||
|
||||
---
|
||||
|
||||
### 3.5 Attestor (Final Verdict + Rekor integration)
|
||||
|
||||
**Goal**
|
||||
Emit the **final verdict attestation** and push evidences to Rekor / Sigstore bundle.
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. `VerdictPredicateV1`
|
||||
|
||||
```csharp
|
||||
public record VerdictPredicateV1(
|
||||
string Decision, // "allow" | "deny" | "quarantine"
|
||||
string PolicyVersion,
|
||||
DateTimeOffset DecidedAt,
|
||||
IReadOnlyList<string> Reasons,
|
||||
string? RequestedBy,
|
||||
string? Environment // "prod", "staging", etc.
|
||||
);
|
||||
```
|
||||
|
||||
2. Policy evaluation:
|
||||
|
||||
* Input: all attestations for artifact (scan, sbom, vex, score).
|
||||
* Apply policy (e.g., “no critical exploitable vulns”, “score ≥ 70”).
|
||||
* Produce `allow` / `deny`.
|
||||
|
||||
3. Rekor integration (v2‑ready)
|
||||
|
||||
* Rekor provides an HTTP API and CLI for recording signed metadata. ([Sigstore][11])
|
||||
* Rekor v2 uses a modern tile‑backed log for better cost/ops (you don’t need details, just that the API remains similar). ([Sigstore Blog][3])
|
||||
|
||||
**Implementation options:**
|
||||
|
||||
* **Option A: CLI wrapper**
|
||||
|
||||
* Use `rekor-cli` via a sidecar container.
|
||||
* Call `rekor-cli upload` with the DSSE payload or Sigstore bundle.
|
||||
* **Option B: Native HTTP client**
|
||||
|
||||
* Generate client from Rekor OpenAPI in .NET.
|
||||
* Implement:
|
||||
|
||||
```csharp
|
||||
public interface IRekorClient
|
||||
{
|
||||
Task<RekorEntryRef> UploadDsseAsync(DsseEnvelope envelope, CancellationToken ct);
|
||||
}
|
||||
|
||||
public record RekorEntryRef(
|
||||
string Uuid,
|
||||
long LogIndex,
|
||||
byte[] SignedEntryTimestamp);
|
||||
```
|
||||
|
||||
4. Sigstore bundle support
|
||||
|
||||
* A **Sigstore bundle** packages:
|
||||
|
||||
* Verification material (cert, Rekor SET, timestamps),
|
||||
* Signature content (DSSE envelope). ([Sigstore][12])
|
||||
* You can:
|
||||
|
||||
* Store bundles alongside DSSE envelopes: `bundles/{artifactDigest}/{stage}.json`.
|
||||
* Expose them in an API for offline verification.
|
||||
|
||||
5. After producing final verdict:
|
||||
|
||||
* Sign verdict statement.
|
||||
* Upload verdict attestation (and optionally previous key attestations) to Rekor.
|
||||
* Store Rekor entry ref (`uuid`, `index`, `SET`) in DB.
|
||||
* Publish `verdict.attestation.created`.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* For a given artifact, you can:
|
||||
|
||||
* Retrieve a verdict DSSE envelope.
|
||||
* Verify its signature and Rekor inclusion.
|
||||
* Optionally retrieve a Sigstore bundle for fully offline verification.
|
||||
|
||||
---
|
||||
|
||||
## 4. Attestation Store & Data Model
|
||||
|
||||
Create an **“Attestation Service”** that all others depend on for reading/writing.
|
||||
|
||||
### 4.1 Database schema (simplified)
|
||||
|
||||
Relational schema example:
|
||||
|
||||
* `artifacts`
|
||||
|
||||
* `id` (PK)
|
||||
* `algorithm`
|
||||
* `digest`
|
||||
* `name`
|
||||
* `version`
|
||||
|
||||
* `attestations`
|
||||
|
||||
* `id` (PK)
|
||||
* `artifact_id` (FK)
|
||||
* `stage` (`scan`, `sbom`, `vex`, `score`, `verdict`)
|
||||
* `predicate_type`
|
||||
* `dsse_envelope_json`
|
||||
* `created_at`
|
||||
* `signer_key_id`
|
||||
|
||||
* `rekor_entries`
|
||||
|
||||
* `id` (PK)
|
||||
* `attestation_id` (FK)
|
||||
* `uuid`
|
||||
* `log_index`
|
||||
* `signed_entry_timestamp` (bytea)
|
||||
|
||||
* `sboms`
|
||||
|
||||
* `id`
|
||||
* `artifact_id`
|
||||
* `format` (CycloneDX)
|
||||
* `version` (1.7)
|
||||
* `location`
|
||||
* `hash_algorithm`
|
||||
* `hash_digest`
|
||||
|
||||
* `vex_documents`
|
||||
|
||||
* `id`
|
||||
* `artifact_id`
|
||||
* `format`
|
||||
* `version`
|
||||
* `location`
|
||||
* `hash_algorithm`
|
||||
* `hash_digest`
|
||||
|
||||
### 4.2 Attestation Service API
|
||||
|
||||
Provide a REST/gRPC API:
|
||||
|
||||
* `GET /artifacts/{algo}:{digest}/attestations`
|
||||
* `GET /artestations/{id}`
|
||||
* `GET /artifacts/{algo}:{digest}/sbom`
|
||||
* `GET /artifacts/{algo}:{digest}/vex`
|
||||
* `GET /artifacts/{algo}:{digest}/score`
|
||||
* `GET /artifacts/{algo}:{digest}/bundle` (optional, Sigstore bundle)
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* All other services call Attestation Service instead of touching the DB directly.
|
||||
* You can fetch the full “attestation chain” for a given artifact from one place.
|
||||
|
||||
---
|
||||
|
||||
## 5. Observability & QA
|
||||
|
||||
### 5.1 Metrics
|
||||
|
||||
For each service:
|
||||
|
||||
* `attestations_emitted_total{stage}`
|
||||
* `attestation_sign_errors_total{stage}`
|
||||
* `rekor_upload_errors_total`
|
||||
* `attestation_verification_failures_total`
|
||||
|
||||
### 5.2 Tests
|
||||
|
||||
1. **Contract tests**
|
||||
|
||||
* JSON produced for `InTotoStatement` and `DsseEnvelope` is validated by:
|
||||
|
||||
* in‑toto reference tooling.
|
||||
* DSSE reference implementations. ([GitHub][1])
|
||||
|
||||
2. **End‑to‑end flow**
|
||||
|
||||
* Seed a mini pipeline with a test artifact:
|
||||
|
||||
* Build → Scan → SBOM → VEX → Score → Verdict.
|
||||
* Use an external verifier (e.g., cosign, in‑toto attestation verifier) to:
|
||||
|
||||
* Verify DSSE signatures.
|
||||
* Verify Rekor entries and/or Sigstore bundles. ([Sigstore][6])
|
||||
|
||||
3. **Failure scenarios**
|
||||
|
||||
* Corrupt payload (verification must fail).
|
||||
* Missing VEX (policy should deny or fall back to stricter rules).
|
||||
* Rekor offline (system should continue but mark entries as “not logged”).
|
||||
|
||||
---
|
||||
|
||||
## 6. Phased Rollout Plan (High‑Level)
|
||||
|
||||
You can translate this into epics:
|
||||
|
||||
1. **Epic 1 – Core Attestation Platform**
|
||||
|
||||
* Implement `Attestations.Core` & `Attestations.Signing`.
|
||||
* Implement Attestation Service + DB schema.
|
||||
* Build small CLI / test harness.
|
||||
|
||||
2. **Epic 2 – Scanner Integration**
|
||||
|
||||
* Normalize findings.
|
||||
* Emit scan attestations only (no SBOM/VEX yet).
|
||||
|
||||
3. **Epic 3 – CycloneDX SBOMs**
|
||||
|
||||
* Integrate CycloneDX .NET library.
|
||||
* Generate 1.7 SBOMs for each artifact.
|
||||
* Emit SBOM attestations.
|
||||
|
||||
4. **Epic 4 – VEXer**
|
||||
|
||||
* Implement VEX derivation logic + CycloneDX VEX docs.
|
||||
* Emit VEX attestations.
|
||||
|
||||
5. **Epic 5 – Scorer & Policy**
|
||||
|
||||
* Implement scoring model v1.
|
||||
* Implement policy engine.
|
||||
* Emit Score + Verdict attestations.
|
||||
|
||||
6. **Epic 6 – Rekor & Bundles**
|
||||
|
||||
* Stand up Rekor (or integrate with public instance).
|
||||
* Implement Rekor client and Sigstore bundle support.
|
||||
* Wire Attestor to log final (and optionally intermediate) attestations.
|
||||
|
||||
7. **Epic 7 – UX & Docs**
|
||||
|
||||
* Build UI (or CLI) to visualize:
|
||||
|
||||
* Artifact → SBOM → VEX → Score → Verdict.
|
||||
* Document how other teams integrate (what events to listen to, which APIs to call).
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Turn this into **Jira‑style epics & stories** with acceptance criteria; or
|
||||
* Draft the actual **C# interfaces** and a project structure (`src/Attestations.Core`, `src/Attestations.Signing`, services, etc.).
|
||||
|
||||
[1]: https://github.com/secure-systems-lab/dsse?utm_source=chatgpt.com "secure-systems-lab/dsse - Dead Simple Signing Envelope"
|
||||
[2]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[3]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[4]: https://slsa.dev/blog/2023/05/in-toto-and-slsa?utm_source=chatgpt.com "in-toto and SLSA"
|
||||
[5]: https://cloud.google.com/dotnet/docs/reference/Grafeas.V1/latest/Grafeas.V1.Envelope?utm_source=chatgpt.com "Grafeas v1 API - Class Envelope (3.10.0) | .NET client library"
|
||||
[6]: https://docs.sigstore.dev/cosign/verifying/attestation/?utm_source=chatgpt.com "In-Toto Attestations"
|
||||
[7]: https://github.com/CycloneDX/cyclonedx-dotnet-library?utm_source=chatgpt.com "NET library to consume and produce CycloneDX Software ..."
|
||||
[8]: https://www.nuget.org/packages/CycloneDX.Core/?utm_source=chatgpt.com "CycloneDX.Core 10.0.1"
|
||||
[9]: https://cyclonedx.org/registry/cryptography/?utm_source=chatgpt.com "Cryptography Registry"
|
||||
[10]: https://cyclonedx.org/capabilities/vex/?utm_source=chatgpt.com "Vulnerability Exploitability eXchange (VEX)"
|
||||
[11]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
[12]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
@@ -0,0 +1,19 @@
|
||||
Here’s a quick sizing rule of thumb for Sigstore attestations so you don’t hit Rekor limits.
|
||||
|
||||
* **Base64 bloat:** DSSE wraps your JSON statement and then Base64‑encodes it. Base64 turns every 3 bytes into 4, so size ≈ `ceil(P/3)*4` (about **+33–37%** on top of your raw JSON). ([Stack Overflow][1])
|
||||
* **DSSE envelope fields:** Expect a small extra overhead for JSON keys like `payloadType`, `payload`, and `signatures` (and the signature itself). Sigstore’s bundle/DSSE examples show the structure used. ([Sigstore][2])
|
||||
* **Public Rekor cap:** The **public Rekor instance rejects uploads over 100 KB**. If your DSSE (after Base64 + JSON fields) exceeds that, shard/split the attestation or run your own Rekor. ([GitHub][3])
|
||||
* **Reality check:** Teams routinely run into size errors when large statements are uploaded—the whole DSSE payload is sent to Rekor during verification/ingest. ([GitHub][4])
|
||||
|
||||
### Practical guidance
|
||||
|
||||
* Keep a **single attestation well under ~70–80 KB raw JSON** if it will be wrapped+Base64’d (gives headroom for signatures/keys).
|
||||
* Prefer **compact JSON** (no whitespace), **short key names**, and **avoid huge embedded fields** (e.g., trim SBOM evidence or link it by digest/URI).
|
||||
* For big evidence sets, publish **multiple attestations** (logical shards) or **self‑host Rekor**. ([GitHub][3])
|
||||
|
||||
If you want, I can add a tiny calculator snippet that takes your payload bytes and estimates the final DSSE+Base64 size vs. the 100 KB limit.
|
||||
|
||||
[1]: https://stackoverflow.com/questions/4715415/base64-what-is-the-worst-possible-increase-in-space-usage?utm_source=chatgpt.com "Base64: What is the worst possible increase in space usage?"
|
||||
[2]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[3]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[4]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
@@ -0,0 +1,766 @@
|
||||
Here’s a quick, practical heads‑up on publishing attestations to Sigstore/Rekor without pain, plus a drop‑in pattern you can adapt today.
|
||||
|
||||
---
|
||||
|
||||
## Why this matters (plain English)
|
||||
|
||||
* **Rekor** is a public transparency log for your build proofs.
|
||||
* **DSSE attestations** (e.g., in‑toto, SLSA) are uploaded **in full**—not streamed—so big blobs hit **payload limits** and fail.
|
||||
* Thousands of tiny attestations also hurt you: **API overhead, retries, and throttling** skyrocket.
|
||||
|
||||
The sweet spot: **chunk your evidence sensibly**, keep each DSSE envelope small enough for Rekor, and add **retry + resume** so partial batches don’t nuke your whole publish step.
|
||||
|
||||
---
|
||||
|
||||
## Design rules of thumb
|
||||
|
||||
* **Target envelope size:** keep each DSSE (base64‑encoded) comfortably **< 1–2 MB** (tunable per your CI).
|
||||
* **Shard by artifact + section:** e.g., split SBOMs by package namespace, split provenance by step/log segments, split test evidence by suite.
|
||||
* **Stable chunking keys:** deterministic chunk IDs (e.g., `artifactDigest + section + seqNo`) so retries can **idempotently** re‑publish.
|
||||
* **Batch with backoff:** publish N envelopes, exponential backoff on 429/5xx, **resume from last success**.
|
||||
* **Record mapping:** keep a **local index**: `chunkId → rekorUUID`, so you can later reconstruct the full evidence set.
|
||||
* **Verify before delete:** only discard local chunk files **after** Rekor inclusion proof is verified.
|
||||
* **Observability:** metrics for envelopes/s, bytes/s, retry count, and final inclusion rate.
|
||||
|
||||
---
|
||||
|
||||
## Minimal workflow (pseudo)
|
||||
|
||||
1. **Produce evidence** → split into chunks
|
||||
2. **Wrap each chunk in DSSE** (sign once per chunk)
|
||||
3. **Publish to Rekor** with retry + idempotency
|
||||
4. **Store rekor UUID + inclusion proof**
|
||||
5. **Emit a manifest** that lists all chunk IDs for downstream recomposition
|
||||
|
||||
---
|
||||
|
||||
## C# sketch (fits .NET 10 style)
|
||||
|
||||
```csharp
|
||||
public sealed record ChunkRef(string Artifact, string Section, int Part, string ChunkId);
|
||||
public sealed record PublishResult(ChunkRef Ref, string RekorUuid, string InclusionHash);
|
||||
|
||||
public interface IChunker {
|
||||
IEnumerable<(ChunkRef Ref, ReadOnlyMemory<byte> Payload)> Split(ArtifactEvidence evidence, int targetBytes);
|
||||
}
|
||||
|
||||
public interface IDsseSigner {
|
||||
// Returns serialized DSSE envelope (JSON) ready to upload
|
||||
byte[] Sign(ReadOnlySpan<byte> payload, string payloadType);
|
||||
}
|
||||
|
||||
public interface IRekorClient {
|
||||
// Idempotent publish: returns existing UUID if duplicate body digest
|
||||
Task<(string uuid, string inclusionHash)> UploadAsync(ReadOnlySpan<byte> dsseEnvelope, CancellationToken ct);
|
||||
}
|
||||
|
||||
public sealed class Publisher {
|
||||
private readonly IChunker _chunker;
|
||||
private readonly IDsseSigner _signer;
|
||||
private readonly IRekorClient _rekor;
|
||||
private readonly ICheckpointStore _store; // chunkId -> (uuid, inclusionHash)
|
||||
|
||||
public Publisher(IChunker c, IDsseSigner s, IRekorClient r, ICheckpointStore st) =>
|
||||
(_chunker, _signer, _rekor, _store) = (c, s, r, st);
|
||||
|
||||
public async IAsyncEnumerable<PublishResult> PublishAsync(
|
||||
ArtifactEvidence ev, int targetBytes, string payloadType,
|
||||
[System.Runtime.CompilerServices.EnumeratorCancellation] CancellationToken ct = default)
|
||||
{
|
||||
foreach (var (refInfo, chunk) in _chunker.Split(ev, targetBytes)) {
|
||||
if (_store.TryGet(refInfo.ChunkId, out var cached)) {
|
||||
yield return new PublishResult(refInfo, cached.uuid, cached.inclusionHash);
|
||||
continue;
|
||||
}
|
||||
|
||||
var envelope = _signer.Sign(chunk.Span, payloadType);
|
||||
|
||||
// retry with jitter/backoff
|
||||
var delay = TimeSpan.FromMilliseconds(200);
|
||||
for (int attempt = 1; ; attempt++) {
|
||||
try {
|
||||
var (uuid, incl) = await _rekor.UploadAsync(envelope, ct);
|
||||
_store.Put(refInfo.ChunkId, uuid, incl);
|
||||
yield return new PublishResult(refInfo, uuid, incl);
|
||||
break;
|
||||
} catch (TransientHttpException) when (attempt < 6) {
|
||||
await Task.Delay(delay + TimeSpan.FromMilliseconds(Random.Shared.Next(0, 250)), ct);
|
||||
delay = TimeSpan.FromMilliseconds(Math.Min(delay.TotalMilliseconds * 2, 5000));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Notes:**
|
||||
|
||||
* Implement `IChunker` so splits are **deterministic** (e.g., package groups of an SBOM or line‑bounded log slices).
|
||||
* Make `IRekorClient.UploadAsync` **idempotent** by hashing the DSSE envelope and using Rekor’s response on duplicates.
|
||||
* `ICheckpointStore` can be a local SQLite/JSON file in CI artifacts; export it with your build.
|
||||
|
||||
---
|
||||
|
||||
## What to chunk (practical presets)
|
||||
|
||||
* **SBOM (CycloneDX/SPDX):** per dependency namespace/layer; keep each file ~300–800 KB before DSSE.
|
||||
* **Provenance (in‑toto/SLSA):** one DSSE per build step or per 10–50 KB of logs/evidence.
|
||||
* **Test proofs:** group per suite; avoid single mega‑JUnit JSONs.
|
||||
|
||||
---
|
||||
|
||||
## “Done” checklist
|
||||
|
||||
* [ ] Envelopes consistently under your Rekor size ceiling (leave 30–40% headroom).
|
||||
* [ ] Idempotent retry with resume (no duplicate spam).
|
||||
* [ ] Local index mapping `chunkId → rekorUUID` stored in CI artifacts.
|
||||
* [ ] Inclusion proofs verified and archived.
|
||||
* [ ] A recomposition manifest that lists all chunk IDs for auditors.
|
||||
|
||||
If you want, I can tailor this to Stella Ops (naming, namespaces, and your Rekor mirror strategy) and drop in a ready‑to‑compile module for your `.NET 10` solution.
|
||||
Cool, let’s turn that sketch into something your devs can actually pick up and build.
|
||||
|
||||
I’ll lay this out like an implementation guide: architecture, project layout, per‑component specs, config, and a suggested rollout plan.
|
||||
|
||||
---
|
||||
|
||||
## 1. Objectives & constraints
|
||||
|
||||
**Primary goals**
|
||||
|
||||
* Publish DSSE attestations into Rekor:
|
||||
|
||||
* Avoid size limits (chunking).
|
||||
* Avoid throttling (batching & retry).
|
||||
* Ensure idempotency & resumability.
|
||||
* Keep it **framework‑agnostic** inside `.NET 10` (can run in any CI).
|
||||
* Make verification/auditing easy (manifest + inclusion proofs).
|
||||
|
||||
**Non‑functional**
|
||||
|
||||
* Deterministic behavior: same inputs → same chunk IDs & envelopes.
|
||||
* Observable: metrics and logs for troubleshooting.
|
||||
* Testable: clear seams/interfaces for mocking Rekor & signing.
|
||||
|
||||
---
|
||||
|
||||
## 2. High‑level architecture
|
||||
|
||||
Core pipeline (per build / artifact):
|
||||
|
||||
1. **Evidence input** – you pass in provenance/SBOM/test data as `ArtifactEvidence`.
|
||||
2. **Chunker** – splits oversized evidence into multiple chunks with stable IDs.
|
||||
3. **DSSE Signer** – wraps each chunk in a DSSE envelope.
|
||||
4. **Rekor client** – publishes envelopes to the Rekor log with retry/backoff.
|
||||
5. **Checkpoint store** – remembers which chunks were already published.
|
||||
6. **Manifest builder** – emits a manifest mapping artifact → all Rekor entries.
|
||||
|
||||
Text diagram:
|
||||
|
||||
```text
|
||||
[ArtifactEvidence]
|
||||
|
|
||||
v
|
||||
IChunker ---> [ChunkRef + Payload] x N
|
||||
|
|
||||
v
|
||||
IDsseSigner ---> [DSSE Envelope] x N
|
||||
|
|
||||
v
|
||||
IRekorClient (with retry & backoff)
|
||||
|
|
||||
v
|
||||
ICheckpointStore <--> ManifestBuilder
|
||||
|
|
||||
v
|
||||
[attestations_manifest.json] + inclusion proofs
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. Project & namespace layout
|
||||
|
||||
Example solution layout:
|
||||
|
||||
```text
|
||||
src/
|
||||
SupplyChain.Attestations.Core/
|
||||
Chunking/
|
||||
Signing/
|
||||
Publishing/
|
||||
Models/
|
||||
Manifest/
|
||||
|
||||
SupplyChain.Attestations.Rekor/
|
||||
RekorClient/
|
||||
Models/
|
||||
|
||||
SupplyChain.Attestations.Cli/
|
||||
Program.cs
|
||||
Commands/ # e.g., publish-attestations
|
||||
|
||||
tests/
|
||||
SupplyChain.Attestations.Core.Tests/
|
||||
SupplyChain.Attestations.Rekor.Tests/
|
||||
SupplyChain.Attestations.IntegrationTests/
|
||||
```
|
||||
|
||||
You can of course rename to match your org.
|
||||
|
||||
---
|
||||
|
||||
## 4. Data models & contracts
|
||||
|
||||
### 4.1 Core domain models
|
||||
|
||||
```csharp
|
||||
public sealed record ArtifactEvidence(
|
||||
string ArtifactId, // e.g., image digest, package id, etc.
|
||||
string ArtifactType, // "container-image", "nuget-package", ...
|
||||
string ArtifactDigest, // canonical digest (sha256:...)
|
||||
IReadOnlyList<EvidenceBlob> EvidenceBlobs // SBOM, provenance, tests, etc.
|
||||
);
|
||||
|
||||
public sealed record EvidenceBlob(
|
||||
string Section, // "sbom", "provenance", "tests", "logs"
|
||||
string ContentType, // "application/json", "text/plain"
|
||||
ReadOnlyMemory<byte> Content
|
||||
);
|
||||
|
||||
public sealed record ChunkRef(
|
||||
string ArtifactId,
|
||||
string Section, // from EvidenceBlob.Section
|
||||
int Part, // 0-based index
|
||||
string ChunkId // stable identifier
|
||||
);
|
||||
```
|
||||
|
||||
**ChunkId generation rule (deterministic):**
|
||||
|
||||
```csharp
|
||||
// Pseudo:
|
||||
ChunkId = Base64Url( SHA256( $"{ArtifactDigest}|{Section}|{Part}" ) )
|
||||
```
|
||||
|
||||
Store both `ChunkRef` and hashes in the manifest so it’s reproducible.
|
||||
|
||||
### 4.2 Rekor publication result
|
||||
|
||||
```csharp
|
||||
public sealed record PublishResult(
|
||||
ChunkRef Ref,
|
||||
string RekorUuid,
|
||||
string InclusionHash, // hash used for inclusion proof
|
||||
string LogIndex // optional, if returned by Rekor
|
||||
);
|
||||
```
|
||||
|
||||
### 4.3 Manifest format
|
||||
|
||||
A single build emits `attestations_manifest.json`:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"schemaVersion": "1.0",
|
||||
"buildId": "build-2025-11-27T12:34:56Z",
|
||||
"artifact": {
|
||||
"id": "my-app@sha256:abcd...",
|
||||
"type": "container-image",
|
||||
"digest": "sha256:abcd..."
|
||||
},
|
||||
"chunks": [
|
||||
{
|
||||
"chunkId": "aBcD123...",
|
||||
"section": "sbom",
|
||||
"part": 0,
|
||||
"rekorUuid": "1234-5678-...",
|
||||
"inclusionHash": "deadbeef...",
|
||||
"logIndex": "42"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Define a C# model mirroring this and serialize with `System.Text.Json`.
|
||||
|
||||
---
|
||||
|
||||
## 5. Component‑level design
|
||||
|
||||
### 5.1 Chunker
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public sealed record ChunkingOptions(
|
||||
int TargetMaxBytes, // e.g., 800_000 bytes pre‑DSSE
|
||||
int HardMaxBytes // e.g., 1_000_000 bytes pre‑DSSE
|
||||
);
|
||||
|
||||
public interface IChunker
|
||||
{
|
||||
IEnumerable<(ChunkRef Ref, ReadOnlyMemory<byte> Payload)> Split(
|
||||
ArtifactEvidence evidence,
|
||||
ChunkingOptions options
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
**Behavior**
|
||||
|
||||
* For each `EvidenceBlob`:
|
||||
|
||||
* If `Content.Length <= TargetMaxBytes` → 1 chunk.
|
||||
* Else:
|
||||
|
||||
* Split on **logical boundaries** if possible:
|
||||
|
||||
* SBOM JSON: split by package list segments.
|
||||
* Logs: split by line boundaries.
|
||||
* Tests: split by test suite / file.
|
||||
* If not easily splittable (opaque binary), hard‑chunk by byte window.
|
||||
* Ensure **each chunk** respects `HardMaxBytes`.
|
||||
* Generate `ChunkRef.Part` sequentially (0,1,2,…) per `(ArtifactId, Section)`.
|
||||
* Generate `ChunkId` with the deterministic rule above.
|
||||
|
||||
**Implementation plan**
|
||||
|
||||
* Start with a **simple hard‑byte chunker**:
|
||||
|
||||
* Always split at `TargetMaxBytes` boundaries.
|
||||
* Add optional **format‑aware chunkers**:
|
||||
|
||||
* `SbomChunkerDecorator` – detects JSON SBOM structure and splits on package groups.
|
||||
* `LogChunkerDecorator` – splits on lines.
|
||||
* Use the decorator pattern or strategy pattern, all implementing `IChunker`.
|
||||
|
||||
---
|
||||
|
||||
### 5.2 DSSE signer
|
||||
|
||||
We abstract away how keys are managed.
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public interface IDsseSigner
|
||||
{
|
||||
// payload: raw bytes of the evidence chunk
|
||||
// payloadType: DSSE payloadType string, e.g. "application/vnd.in-toto+json"
|
||||
byte[] Sign(ReadOnlySpan<byte> payload, string payloadType);
|
||||
}
|
||||
```
|
||||
|
||||
**Responsibilities**
|
||||
|
||||
* Create DSSE envelope:
|
||||
|
||||
* `payloadType` → from config (per section or global).
|
||||
* `payload` → base64url of chunk.
|
||||
* `signatures` → one or more signatures (key ID + signature bytes).
|
||||
* Serialize to **JSON** as UTF‑8 `byte[]`.
|
||||
|
||||
**Implementation plan**
|
||||
|
||||
* Implement `KeyBasedDsseSigner`:
|
||||
|
||||
* Uses a configured private key (e.g., from a KMS, HSM, or file).
|
||||
* Accept `IDSseCryptoProvider` dependency for the actual signature primitive (RSA/ECDSA/Ed25519).
|
||||
* Keep space for future `KeylessDsseSigner` (Sigstore Fulcio/OIDC), but not required for v1.
|
||||
|
||||
**Config mapping**
|
||||
|
||||
* `payloadType` default: `"application/vnd.in-toto+json"`.
|
||||
* Allow overrides per section: e.g., SBOM vs test logs.
|
||||
|
||||
---
|
||||
|
||||
### 5.3 Rekor client
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public interface IRekorClient
|
||||
{
|
||||
Task<(string Uuid, string InclusionHash, string? LogIndex)> UploadAsync(
|
||||
ReadOnlySpan<byte> dsseEnvelope,
|
||||
CancellationToken ct = default
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
**Responsibilities**
|
||||
|
||||
* Wrap HTTP client to Rekor:
|
||||
|
||||
* Build the proper Rekor entry for DSSE (log entry with DSSE envelope).
|
||||
* Send HTTP POST to Rekor API.
|
||||
* Parse UUID and inclusion information.
|
||||
* Handle **duplicate entries**:
|
||||
|
||||
* If Rekor responds “entry already exists”, return existing UUID instead of failing.
|
||||
* Surface **clear exceptions**:
|
||||
|
||||
* `TransientHttpException` (for retryable 429/5xx).
|
||||
* `PermanentHttpException` (4xx like 400/413).
|
||||
|
||||
**Implementation plan**
|
||||
|
||||
* Implement `RekorClient` using `HttpClientFactory`.
|
||||
* Add config:
|
||||
|
||||
* `BaseUrl` (e.g., your Rekor instance).
|
||||
* `TimeoutSeconds`.
|
||||
* `MaxRequestBodyBytes` (for safety).
|
||||
|
||||
**Retry classification**
|
||||
|
||||
* Retry on:
|
||||
|
||||
* 429 (Too Many Requests).
|
||||
* 5xx (server errors).
|
||||
* Network timeouts / transient socket errors.
|
||||
* No retry on:
|
||||
|
||||
* 4xx (except 408 if you want).
|
||||
* 413 Payload Too Large (signal chunking issue).
|
||||
|
||||
---
|
||||
|
||||
### 5.4 Checkpoint store
|
||||
|
||||
Used to allow **resume** and **idempotency**.
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public sealed record CheckpointEntry(
|
||||
string ChunkId,
|
||||
string RekorUuid,
|
||||
string InclusionHash,
|
||||
string? LogIndex
|
||||
);
|
||||
|
||||
public interface ICheckpointStore
|
||||
{
|
||||
bool TryGet(string chunkId, out CheckpointEntry entry);
|
||||
void Put(CheckpointEntry entry);
|
||||
void Flush(); // to persist to disk or remote store
|
||||
}
|
||||
```
|
||||
|
||||
**Implementation plan (v1)**
|
||||
|
||||
* Use a simple **file‑based JSON** store per build:
|
||||
|
||||
* Path derived from build ID: e.g., `.attestations/checkpoints.json`.
|
||||
* Internal representation: `Dictionary<string, CheckpointEntry>`.
|
||||
* At end of run, `Flush()` writes out the file.
|
||||
* On start of run, if file exists:
|
||||
|
||||
* Load existing checkpoints → support resume.
|
||||
|
||||
**Future options**
|
||||
|
||||
* Plug in a distributed store (`ICheckpointStore` implementation backed by Redis, SQL, etc) for multi‑stage pipelines.
|
||||
|
||||
---
|
||||
|
||||
### 5.5 Publisher / Orchestrator
|
||||
|
||||
Use a slightly enhanced version of what we sketched before.
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public sealed record AttestationPublisherOptions(
|
||||
int TargetChunkBytes,
|
||||
int HardChunkBytes,
|
||||
string PayloadType,
|
||||
int MaxAttempts,
|
||||
TimeSpan InitialBackoff,
|
||||
TimeSpan MaxBackoff
|
||||
);
|
||||
|
||||
public sealed class AttestationPublisher
|
||||
{
|
||||
public AttestationPublisher(
|
||||
IChunker chunker,
|
||||
IDsseSigner signer,
|
||||
IRekorClient rekor,
|
||||
ICheckpointStore checkpointStore,
|
||||
ILogger<AttestationPublisher> logger,
|
||||
AttestationPublisherOptions options
|
||||
) { ... }
|
||||
|
||||
public async IAsyncEnumerable<PublishResult> PublishAsync(
|
||||
ArtifactEvidence evidence,
|
||||
[System.Runtime.CompilerServices.EnumeratorCancellation] CancellationToken ct = default
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
**Algorithm**
|
||||
|
||||
For each `(ChunkRef, Payload)` from `IChunker.Split`:
|
||||
|
||||
1. Check `ICheckpointStore.TryGet(ChunkId)`:
|
||||
|
||||
* If found → yield cached `PublishResult` (idempotency).
|
||||
2. Build DSSE envelope via `_signer.Sign(payload, options.PayloadType)`.
|
||||
3. Retry loop:
|
||||
|
||||
* Try `_rekor.UploadAsync(envelope, ct)`.
|
||||
* On success:
|
||||
|
||||
* Create `CheckpointEntry`, store via `_checkpointStore.Put`.
|
||||
* Yield `PublishResult`.
|
||||
* On `TransientHttpException`:
|
||||
|
||||
* If attempts ≥ `MaxAttempts` → surface as failure.
|
||||
* Else exponential backoff with jitter and repeat.
|
||||
* On `PermanentHttpException`:
|
||||
|
||||
* Log error and surface (no retry).
|
||||
|
||||
At the end of the run, call `_checkpointStore.Flush()`.
|
||||
|
||||
---
|
||||
|
||||
### 5.6 Manifest builder
|
||||
|
||||
**Responsibility**
|
||||
|
||||
Turn a set of `PublishResult` items into one manifest JSON.
|
||||
|
||||
**Interface**
|
||||
|
||||
```csharp
|
||||
public interface IManifestBuilder
|
||||
{
|
||||
AttestationManifest Build(
|
||||
ArtifactEvidence artifact,
|
||||
IReadOnlyCollection<PublishResult> results,
|
||||
string buildId,
|
||||
DateTimeOffset publishedAtUtc
|
||||
);
|
||||
}
|
||||
|
||||
public interface IManifestWriter
|
||||
{
|
||||
Task WriteAsync(AttestationManifest manifest, string path, CancellationToken ct = default);
|
||||
}
|
||||
```
|
||||
|
||||
**Implementation plan**
|
||||
|
||||
* `JsonManifestBuilder` – pure mapping from models to manifest DTO.
|
||||
* `FileSystemManifestWriter` – writes to a configurable path (e.g., `artifacts/attestations_manifest.json`).
|
||||
|
||||
---
|
||||
|
||||
## 6. Configuration & wiring
|
||||
|
||||
### 6.1 Options class
|
||||
|
||||
```csharp
|
||||
public sealed class AttestationConfig
|
||||
{
|
||||
public string RekorBaseUrl { get; init; } = "";
|
||||
public int RekorTimeoutSeconds { get; init; } = 30;
|
||||
|
||||
public int TargetChunkBytes { get; init; } = 800_000;
|
||||
public int HardChunkBytes { get; init; } = 1_000_000;
|
||||
|
||||
public string DefaultPayloadType { get; init; } = "application/vnd.in-toto+json";
|
||||
|
||||
public int MaxAttempts { get; init; } = 5;
|
||||
public int InitialBackoffMs { get; init; } = 200;
|
||||
public int MaxBackoffMs { get; init; } = 5000;
|
||||
|
||||
public string CheckpointFilePath { get; init; } = ".attestations/checkpoints.json";
|
||||
public string ManifestOutputPath { get; init; } = "attestations_manifest.json";
|
||||
}
|
||||
```
|
||||
|
||||
### 6.2 Example `appsettings.json` for CLI
|
||||
|
||||
```json
|
||||
{
|
||||
"Attestation": {
|
||||
"RekorBaseUrl": "https://rekor.example.com",
|
||||
"TargetChunkBytes": 800000,
|
||||
"HardChunkBytes": 1000000,
|
||||
"DefaultPayloadType": "application/vnd.in-toto+json",
|
||||
"MaxAttempts": 5,
|
||||
"InitialBackoffMs": 200,
|
||||
"MaxBackoffMs": 5000,
|
||||
"CheckpointFilePath": ".attestations/checkpoints.json",
|
||||
"ManifestOutputPath": "attestations_manifest.json"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Wire via `IOptions<AttestationConfig>` in your DI container.
|
||||
|
||||
---
|
||||
|
||||
## 7. Observability & logging
|
||||
|
||||
### 7.1 Metrics (suggested)
|
||||
|
||||
Expose via your monitoring stack (Prometheus, App Insights, etc.):
|
||||
|
||||
* `attestations_chunks_total` – labeled by `section`, `artifact_type`.
|
||||
* `attestations_rekor_publish_success_total` – labeled by `section`.
|
||||
* `attestations_rekor_publish_failure_total` – labeled by `section`, `failure_type` (4xx, 5xx, client_error).
|
||||
* `attestations_rekor_latency_seconds` – histogram.
|
||||
* `attestations_chunk_size_bytes` – histogram.
|
||||
|
||||
### 7.2 Logging
|
||||
|
||||
Log at **INFO**:
|
||||
|
||||
* Start/end of attestation publishing for each artifact.
|
||||
* Number of chunks per section.
|
||||
* Rekor UUID info (non‑sensitive, ok to log).
|
||||
|
||||
Log at **DEBUG**:
|
||||
|
||||
* Exact Rekor request payload sizes.
|
||||
* Retry attempts and backoff durations.
|
||||
|
||||
Log at **WARN/ERROR**:
|
||||
|
||||
* 4xx errors.
|
||||
* Exhausted retries.
|
||||
|
||||
Include correlation IDs (build ID, artifact digest, chunk ID) in structured logs.
|
||||
|
||||
---
|
||||
|
||||
## 8. Testing strategy
|
||||
|
||||
### 8.1 Unit tests
|
||||
|
||||
* `ChunkerTests`
|
||||
|
||||
* Small payload → 1 chunk.
|
||||
* Large payload → multiple chunks with no overlap and full coverage.
|
||||
* Deterministic `ChunkId` generation (same input → same IDs).
|
||||
* `DsseSignerTests`
|
||||
|
||||
* Given a fixed key and payload → DSSE envelope matches golden snapshot.
|
||||
* `RekorClientTests`
|
||||
|
||||
* Mock `HttpMessageHandler`:
|
||||
|
||||
* 200 OK -> parse UUID, inclusion hash.
|
||||
* 409 / “already exists” -> treat as success.
|
||||
* 429 & 5xx -> throw `TransientHttpException`.
|
||||
* 4xx -> throw `PermanentHttpException`.
|
||||
* `CheckpointStoreTests`
|
||||
|
||||
* Put/TryGet behavior.
|
||||
* Flush and reload from disk.
|
||||
|
||||
### 8.2 Integration tests
|
||||
|
||||
Against a **local or staging Rekor**:
|
||||
|
||||
* Publish single small attestation.
|
||||
* Publish large SBOM that must be chunked.
|
||||
* Simulate transient failure: first request 500, then 200; verify retry.
|
||||
* Restart the test mid‑flow, rerun; ensure already published chunks are skipped.
|
||||
|
||||
### 8.3 E2E in CI
|
||||
|
||||
* For a test project:
|
||||
|
||||
* Build → produce dummy SBOM/provenance.
|
||||
* Run CLI to publish attestations.
|
||||
* Archive:
|
||||
|
||||
* `attestations_manifest.json`.
|
||||
* `checkpoints.json`.
|
||||
* Optional: run a verification script that:
|
||||
|
||||
* Reads manifest.
|
||||
* Queries Rekor for each UUID and validates inclusion.
|
||||
|
||||
---
|
||||
|
||||
## 9. CI integration (example)
|
||||
|
||||
Example GitHub Actions step (adapt as needed):
|
||||
|
||||
```yaml
|
||||
- name: Publish attestations
|
||||
run: |
|
||||
dotnet SupplyChain.Attestations.Cli publish \
|
||||
--artifact-id "${{ env.IMAGE_DIGEST }}" \
|
||||
--artifact-type "container-image" \
|
||||
--sbom "build/sbom.json" \
|
||||
--provenance "build/provenance.json" \
|
||||
--tests "build/test-results.json" \
|
||||
--config "attestation.appsettings.json"
|
||||
env:
|
||||
ATTESTATION_SIGNING_KEY: ${{ secrets.ATTESTATION_SIGNING_KEY }}
|
||||
```
|
||||
|
||||
The CLI command should:
|
||||
|
||||
1. Construct `ArtifactEvidence` from the input files.
|
||||
2. Use DI to build `AttestationPublisher` and dependencies.
|
||||
3. Stream results, build manifest, write outputs.
|
||||
4. Exit non‑zero if any chunk fails to publish.
|
||||
|
||||
---
|
||||
|
||||
## 10. Implementation roadmap (dev‑oriented)
|
||||
|
||||
You can translate this into epics/stories; here’s a logical order:
|
||||
|
||||
**Epic 1 – Core models & chunking**
|
||||
|
||||
* Story 1: Define `ArtifactEvidence`, `EvidenceBlob`, `ChunkRef`, `PublishResult`.
|
||||
* Story 2: Implement `IChunker` with simple byte‑based splitter.
|
||||
* Story 3: Deterministic `ChunkId` generation + tests.
|
||||
|
||||
**Epic 2 – Signing & DSSE envelopes**
|
||||
|
||||
* Story 4: Implement `IDsseSigner` + `KeyBasedDsseSigner`.
|
||||
* Story 5: DSSE envelope serialization tests (golden snapshots).
|
||||
* Story 6: Wire in an abstract crypto provider so you can swap key sources later.
|
||||
|
||||
**Epic 3 – Rekor client**
|
||||
|
||||
* Story 7: Implement `IRekorClient` using `HttpClient`.
|
||||
* Story 8: Error classification & `TransientHttpException` / `PermanentHttpException`.
|
||||
* Story 9: Integration tests with staging/local Rekor.
|
||||
|
||||
**Epic 4 – Publisher, checkpoints, manifest**
|
||||
|
||||
* Story 10: Implement `ICheckpointStore` (file‑based JSON).
|
||||
* Story 11: Implement `AttestationPublisher` with retry/backoff.
|
||||
* Story 12: Implement `IManifestBuilder` + `IManifestWriter`.
|
||||
* Story 13: Create manifest schema and sample.
|
||||
|
||||
**Epic 5 – CLI & CI integration**
|
||||
|
||||
* Story 14: Implement CLI `publish` command.
|
||||
* Story 15: Wire config (appsettings + env overrides).
|
||||
* Story 16: Add CI job template + docs for teams.
|
||||
|
||||
**Epic 6 – Observability & hardening**
|
||||
|
||||
* Story 17: Add metrics & structured logging.
|
||||
* Story 18: Load testing with large SBOMs/logs.
|
||||
* Story 19: Final documentation: “How to add attestations to your pipeline”.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Draft the exact C# interfaces and one full concrete implementation (e.g., `FileCheckpointStore`), or
|
||||
* Write the CLI `publish` command skeleton that wires everything together.
|
||||
@@ -0,0 +1,514 @@
|
||||
Here’s a quick sizing rule of thumb for Sigstore attestations so you don’t hit Rekor limits.
|
||||
|
||||
* **Base64 bloat:** DSSE wraps your JSON statement and then Base64‑encodes it. Base64 turns every 3 bytes into 4, so size ≈ `ceil(P/3)*4` (about **+33–37%** on top of your raw JSON). ([Stack Overflow][1])
|
||||
* **DSSE envelope fields:** Expect a small extra overhead for JSON keys like `payloadType`, `payload`, and `signatures` (and the signature itself). Sigstore’s bundle/DSSE examples show the structure used. ([Sigstore][2])
|
||||
* **Public Rekor cap:** The **public Rekor instance rejects uploads over 100 KB**. If your DSSE (after Base64 + JSON fields) exceeds that, shard/split the attestation or run your own Rekor. ([GitHub][3])
|
||||
* **Reality check:** Teams routinely run into size errors when large statements are uploaded—the whole DSSE payload is sent to Rekor during verification/ingest. ([GitHub][4])
|
||||
|
||||
### Practical guidance
|
||||
|
||||
* Keep a **single attestation well under ~70–80 KB raw JSON** if it will be wrapped+Base64’d (gives headroom for signatures/keys).
|
||||
* Prefer **compact JSON** (no whitespace), **short key names**, and **avoid huge embedded fields** (e.g., trim SBOM evidence or link it by digest/URI).
|
||||
* For big evidence sets, publish **multiple attestations** (logical shards) or **self‑host Rekor**. ([GitHub][3])
|
||||
|
||||
If you want, I can add a tiny calculator snippet that takes your payload bytes and estimates the final DSSE+Base64 size vs. the 100 KB limit.
|
||||
|
||||
[1]: https://stackoverflow.com/questions/4715415/base64-what-is-the-worst-possible-increase-in-space-usage?utm_source=chatgpt.com "Base64: What is the worst possible increase in space usage?"
|
||||
[2]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[3]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[4]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
Here’s a concrete, developer‑friendly implementation plan you can hand to the team.
|
||||
|
||||
I’ll assume:
|
||||
|
||||
* You’re using **Sigstore (Fulcio + Rekor + DSSE)**.
|
||||
* You’re pushing to the **public Rekor instance**, which enforces a **100 KB per‑entry size limit**.([GitHub][1])
|
||||
* Attestations are JSON in a DSSE envelope and are produced in CI/CD.
|
||||
|
||||
You can copy this into a design doc and turn sections into tickets.
|
||||
|
||||
---
|
||||
|
||||
## 1. Goals & non‑goals
|
||||
|
||||
**Goals**
|
||||
|
||||
1. Ensure **all Rekor uploads succeed** without hitting the 100 KB limit.
|
||||
2. Provide a **deterministic pipeline**: same inputs → same set of attestations.
|
||||
3. Avoid losing security signal: large data (SBOMs, logs, etc.) should still be verifiable via references.
|
||||
|
||||
**Non‑goals**
|
||||
|
||||
* Changing Rekor itself (we’ll treat it as a black box).
|
||||
* Re‑designing your whole supply chain; we’re just changing how attestations are structured and uploaded.
|
||||
|
||||
---
|
||||
|
||||
## 2. Architecture changes (high‑level)
|
||||
|
||||
Add three core pieces:
|
||||
|
||||
1. **Attestation Builder** – constructs one or more JSON statements per artifact.
|
||||
2. **Size Guardrail & Sharder** – checks size *before* upload; splits or externalizes data if needed.
|
||||
3. **Rekor Client Wrapper** – calls Rekor, handles size errors, and reports metrics.
|
||||
|
||||
Rough flow:
|
||||
|
||||
```text
|
||||
CI job
|
||||
→ gather metadata (subject digest, build info, SBOM, test results, etc.)
|
||||
→ Attestation Builder (domain logic)
|
||||
→ Size Guardrail & Sharder (JSON + DSSE + size checks)
|
||||
→ Rekor Client Wrapper (upload + logging + metrics)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 3. Config & constants (Ticket group A)
|
||||
|
||||
**A1 – Add config**
|
||||
|
||||
* Add a configuration object / env variables:
|
||||
|
||||
```yaml
|
||||
REKOR_MAX_ENTRY_BYTES: 100000 # current public limit, but treat as configurable
|
||||
REKOR_SIZE_SAFETY_MARGIN: 0.9 # 90% of the limit as “soft” max
|
||||
ATTESTATION_JSON_SOFT_MAX: 80000 # e.g. 80 KB JSON before DSSE/base64
|
||||
```
|
||||
|
||||
* Make **`REKOR_MAX_ENTRY_BYTES`** overridable so:
|
||||
|
||||
* you can bump it for a private Rekor deployment.
|
||||
* tests can simulate different limits.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Config is available in whoever builds attestations (CI job, shared library, etc.).
|
||||
* Unit tests read these values and assert behavior around boundary values.
|
||||
|
||||
---
|
||||
|
||||
## 4. Attestation schema guidelines (Ticket group B)
|
||||
|
||||
**B1 – Define / revise schema**
|
||||
|
||||
For each statement type (e.g., SLSA, SBOM, test results):
|
||||
|
||||
* Mark **required vs optional** fields.
|
||||
* Identify **large fields**:
|
||||
|
||||
* SBOM JSON
|
||||
* long log lines
|
||||
* full dependency lists
|
||||
* coverage details
|
||||
|
||||
**Rule:**
|
||||
|
||||
> Large data should **not** be inlined; it should be stored externally and referenced by digest.
|
||||
|
||||
Add a standard “external evidence” shape:
|
||||
|
||||
```json
|
||||
{
|
||||
"externalEvidence": [
|
||||
{
|
||||
"type": "sbom-spdx-json",
|
||||
"uri": "https://artifacts.example.com/sbom/<build-id>.json",
|
||||
"digest": "sha256:abcd...",
|
||||
"sizeBytes": 123456
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**B2 – Budget fields**
|
||||
|
||||
* For each statement type, estimate typical sizes:
|
||||
|
||||
* Fixed overhead (keys, small fields).
|
||||
* Variable data (e.g., components length).
|
||||
* Document a **rule of thumb**:
|
||||
“Total JSON payload for type X should be ≤ 80 KB; otherwise we split or externalize.”
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Schema docs updated with “size budget” notes.
|
||||
* New `externalEvidence` (or equivalent) field defined and versioned.
|
||||
|
||||
---
|
||||
|
||||
## 5. Size Guardrail & Estimator (Ticket group C)
|
||||
|
||||
This is the core safety net.
|
||||
|
||||
### C1 – Implement JSON size estimator
|
||||
|
||||
Language‑agnostic idea:
|
||||
|
||||
```pseudo
|
||||
function jsonBytes(payloadObject): int {
|
||||
jsonString = JSON.stringify(payloadObject, no_whitespace)
|
||||
return length(utf8_encode(jsonString))
|
||||
}
|
||||
```
|
||||
|
||||
* Always **minify** (no pretty printing) for the final payload.
|
||||
* Use UTF‑8 byte length, not character count.
|
||||
|
||||
### C2 – DSSE + base64 size estimator
|
||||
|
||||
Instead of guessing, **actually build the envelope** before upload:
|
||||
|
||||
```pseudo
|
||||
function buildDsseEnvelope(statementJson: string, signature: bytes, keyId: string): string {
|
||||
envelope = {
|
||||
"payloadType": "application/vnd.in-toto+json",
|
||||
"payload": base64_encode(statementJson),
|
||||
"signatures": [
|
||||
{
|
||||
"sig": base64_encode(signature),
|
||||
"keyid": keyId
|
||||
}
|
||||
]
|
||||
}
|
||||
return JSON.stringify(envelope, no_whitespace)
|
||||
}
|
||||
|
||||
function envelopeBytes(envelopeJson: string): int {
|
||||
return length(utf8_encode(envelopeJson))
|
||||
}
|
||||
```
|
||||
|
||||
**Rule:** if `envelopeBytes(envelopeJson) > REKOR_MAX_ENTRY_BYTES * REKOR_SIZE_SAFETY_MARGIN`, we consider this envelope **too big** and trigger sharding / externalization logic before calling Rekor.
|
||||
|
||||
> Note: This means you temporarily sign once to measure size. That’s acceptable; signing is cheap compared to a failing Rekor upload.
|
||||
|
||||
### C3 – Guardrail function
|
||||
|
||||
```pseudo
|
||||
function ensureWithinRekorLimit(envelopeJson: string) {
|
||||
bytes = envelopeBytes(envelopeJson)
|
||||
if bytes > REKOR_MAX_ENTRY_BYTES {
|
||||
throw new OversizeAttestationError(bytes, REKOR_MAX_ENTRY_BYTES)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Utility functions for `jsonBytes`, `buildDsseEnvelope`, `envelopeBytes`, and `ensureWithinRekorLimit`.
|
||||
* Unit tests:
|
||||
|
||||
* Below limit → pass.
|
||||
* Exactly at limit → pass.
|
||||
* Above limit → throws `OversizeAttestationError`.
|
||||
|
||||
---
|
||||
|
||||
## 6. Sharding / externalization strategy (Ticket group D)
|
||||
|
||||
This is where you decide *what to do* when a statement is too big.
|
||||
|
||||
### D1 – Strategy decision
|
||||
|
||||
Implement in this order:
|
||||
|
||||
1. **Externalize big blobs** (preferred).
|
||||
2. If still too big, **shard** into multiple attestations.
|
||||
|
||||
#### 1) Externalization rules
|
||||
|
||||
Examples:
|
||||
|
||||
* SBOM:
|
||||
|
||||
* Write full SBOM to artifact store or object storage (S3, GCS, internal).
|
||||
* In attestation, keep only:
|
||||
|
||||
* URI
|
||||
* hash
|
||||
* size
|
||||
* format
|
||||
* Test logs:
|
||||
|
||||
* Keep only summary + URI to full logs.
|
||||
|
||||
Implement a helper:
|
||||
|
||||
```pseudo
|
||||
function externalizeIfLarge(fieldName, dataBytes, thresholdBytes): RefOrInline {
|
||||
if length(dataBytes) <= thresholdBytes {
|
||||
return { "inline": true, "value": dataBytes }
|
||||
} else {
|
||||
uri = uploadToArtifactStore(dataBytes)
|
||||
digest = sha256(dataBytes)
|
||||
return {
|
||||
"inline": false,
|
||||
"uri": uri,
|
||||
"digest": "sha256:" + digest
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 2) Sharding rules
|
||||
|
||||
Example for SBOM‑like data: if you have a big `components` list:
|
||||
|
||||
```pseudo
|
||||
MAX_COMPONENTS_PER_ATTESTATION = 1000 # tune this via tests
|
||||
|
||||
function shardComponents(components[]):
|
||||
chunks = chunk(components, MAX_COMPONENTS_PER_ATTESTATION)
|
||||
attestations = []
|
||||
for each chunk in chunks:
|
||||
att = baseStatement()
|
||||
att["components"] = chunk
|
||||
attestations.append(att)
|
||||
return attestations
|
||||
```
|
||||
|
||||
After sharding:
|
||||
|
||||
* Each chunk becomes its **own statement** (and its own DSSE envelope + Rekor entry).
|
||||
* Each statement should include:
|
||||
|
||||
* The same **subject (artifact digest)**.
|
||||
* A `shardId` and `shardCount`, or a `groupId` (e.g., build ID) to relate them.
|
||||
|
||||
Example:
|
||||
|
||||
```json
|
||||
{
|
||||
"_sharding": {
|
||||
"groupId": "build-1234-sbom",
|
||||
"shardIndex": 0,
|
||||
"shardCount": 3
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**D2 – Integration with size guardrail**
|
||||
|
||||
Flow:
|
||||
|
||||
1. Build full statement.
|
||||
2. If `jsonBytes(statement) <= ATTESTATION_JSON_SOFT_MAX`: use as‑is.
|
||||
3. Else:
|
||||
|
||||
* Try externalizing big fields.
|
||||
* Re‑measure JSON size.
|
||||
4. If still above `ATTESTATION_JSON_SOFT_MAX`:
|
||||
|
||||
* Apply sharding (e.g., split `components` list).
|
||||
5. For each shard:
|
||||
|
||||
* Build DSSE envelope.
|
||||
* Run `ensureWithinRekorLimit`.
|
||||
|
||||
If after sharding a single shard **still** exceeds Rekor’s limit, you must:
|
||||
|
||||
* Fail the pipeline with a **clear error**.
|
||||
* Log enough diagnostics to adjust your thresholds or schemas.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Implementation for:
|
||||
|
||||
* `externalizeIfLarge`,
|
||||
* `shardComponents` (or equivalent for your large arrays),
|
||||
* `_sharding` metadata.
|
||||
* Tests:
|
||||
|
||||
* Large SBOM → multiple attestations, each under size limit.
|
||||
* Externalization correctly moves large fields out and keeps digests.
|
||||
|
||||
---
|
||||
|
||||
## 7. Rekor client wrapper (Ticket group E)
|
||||
|
||||
### E1 – Wrap Rekor interactions
|
||||
|
||||
Create a small abstraction:
|
||||
|
||||
```pseudo
|
||||
class RekorClient {
|
||||
function uploadDsseEnvelope(envelopeJson: string): LogEntryRef {
|
||||
ensureWithinRekorLimit(envelopeJson)
|
||||
response = http.post(REKOR_URL + "/api/v1/log/entries", body=envelopeJson)
|
||||
|
||||
if response.statusCode == 201 or response.statusCode == 200:
|
||||
return parseLogEntryRef(response.body)
|
||||
else if response.statusCode == 413 or isSizeError(response.body):
|
||||
throw new RekorSizeLimitError(response.statusCode, response.body)
|
||||
else:
|
||||
throw new RekorUploadError(response.statusCode, response.body)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* The `ensureWithinRekorLimit` call should prevent most 413s.
|
||||
* `isSizeError` should inspect message strings that mention “size”, “100KB”, etc., just in case Rekor’s error handling changes.
|
||||
|
||||
### E2 – Error handling strategy
|
||||
|
||||
On `RekorSizeLimitError`:
|
||||
|
||||
* Mark the build as **failed** (or at least **non‑compliant**).
|
||||
|
||||
* Emit a structured log event:
|
||||
|
||||
```json
|
||||
{
|
||||
"event": "rekor_upload_oversize",
|
||||
"envelopeBytes": 123456,
|
||||
"rekorMaxBytes": 100000,
|
||||
"buildId": "build-1234"
|
||||
}
|
||||
```
|
||||
|
||||
* (Optional) Attach the JSON size breakdown for debugging.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Wrapper around existing Rekor client (or direct HTTP).
|
||||
* Tests for:
|
||||
|
||||
* Successful upload.
|
||||
* Simulated 413 / size error → recognized and surfaced cleanly.
|
||||
|
||||
---
|
||||
|
||||
## 8. CI/CD integration (Ticket group F)
|
||||
|
||||
### F1 – Where to run this
|
||||
|
||||
Integrate in your pipeline step that currently does signing, e.g.:
|
||||
|
||||
```text
|
||||
build → test → sign → attest → rekor-upload → deploy
|
||||
```
|
||||
|
||||
Change to:
|
||||
|
||||
```text
|
||||
build → test → sign → build-attestations (w/ size control)
|
||||
→ upload-all-attestations-to-rekor
|
||||
→ deploy
|
||||
```
|
||||
|
||||
### F2 – Multi‑entry handling
|
||||
|
||||
If sharding is used:
|
||||
|
||||
* The pipeline should treat **“all relevant attestations uploaded successfully”** as a success condition.
|
||||
* Store a manifest per build:
|
||||
|
||||
```json
|
||||
{
|
||||
"buildId": "build-1234",
|
||||
"subjectDigest": "sha256:abcd...",
|
||||
"attestationEntries": [
|
||||
{
|
||||
"type": "slsa",
|
||||
"rekorLogIndex": 123456,
|
||||
"shardIndex": 0,
|
||||
"shardCount": 1
|
||||
},
|
||||
{
|
||||
"type": "sbom",
|
||||
"rekorLogIndex": 123457,
|
||||
"shardIndex": 0,
|
||||
"shardCount": 3
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
This manifest can be stored in your artifact store and used later by verifiers.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* CI job updated.
|
||||
* Build manifest persisted.
|
||||
* Documentation updated so ops/security know where to find attestation references.
|
||||
|
||||
---
|
||||
|
||||
## 9. Verification path updates (Ticket group G)
|
||||
|
||||
If you shard or externalize, your **verifiers** need to understand that.
|
||||
|
||||
### G1 – Verify external evidence
|
||||
|
||||
* When verifying, for each `externalEvidence` entry:
|
||||
|
||||
* Fetch the blob from its URI.
|
||||
* Compute its digest.
|
||||
* Compare with the digest in the attestation.
|
||||
* Decide whether verifiers:
|
||||
|
||||
* Must fetch all external evidence (strict), or
|
||||
* Are allowed to do “metadata‑only” verification if evidence URLs look trustworthy.
|
||||
|
||||
### G2 – Verify sharded attestations
|
||||
|
||||
* Given a build ID or subject digest:
|
||||
|
||||
* Look up all Rekor entries for that subject (or use your manifest).
|
||||
* Group by `_sharding.groupId`.
|
||||
* Ensure all shards are present (`shardCount`).
|
||||
* Verify each shard’s signature and subject digest.
|
||||
|
||||
**Definition of done**
|
||||
|
||||
* Verifier code updated to:
|
||||
|
||||
* Handle `externalEvidence`.
|
||||
* Handle `_sharding` metadata.
|
||||
* Integration test:
|
||||
|
||||
* End‑to‑end: build → shard → upload → verify all shards and external evidence.
|
||||
|
||||
---
|
||||
|
||||
## 10. Observability & guardrails (Ticket group H)
|
||||
|
||||
**H1 – Metrics**
|
||||
|
||||
Add these metrics:
|
||||
|
||||
* `attestation_json_size_bytes` (per type).
|
||||
* `rekor_envelope_size_bytes` (per type).
|
||||
* Counters:
|
||||
|
||||
* `attestation_sharded_total`
|
||||
* `attestation_externalized_total`
|
||||
* `rekor_upload_oversize_total`
|
||||
|
||||
**H2 – Alerts**
|
||||
|
||||
* If `rekor_upload_oversize_total` > 0 over some window → alert.
|
||||
* If average `rekor_envelope_size_bytes` > 70–80% of limit for long → investigate schema growth.
|
||||
|
||||
---
|
||||
|
||||
## 11. Suggested ticket breakdown
|
||||
|
||||
You can cut this into roughly these tickets:
|
||||
|
||||
1. **Config & constants for Rekor size limits** (A).
|
||||
2. **Schema update: support externalEvidence + sharding metadata** (B).
|
||||
3. **Implement JSON & DSSE size estimation utilities** (C1–C3).
|
||||
4. **Implement externalization of SBOMs/logs and size‑aware builder** (D1).
|
||||
5. **Implement sharding for large arrays (e.g., components)** (D1–D2).
|
||||
6. **Wrap Rekor client with size checks and error handling** (E).
|
||||
7. **CI pipeline integration + build manifest** (F).
|
||||
8. **Verifier changes for sharding + external evidence** (G).
|
||||
9. **Metrics & alerts for attestation/Rekor sizes** (H).
|
||||
|
||||
---
|
||||
|
||||
If you tell me what language / stack you’re using (Go, Java, Python, Node, etc.), I can turn this into more concrete code snippets and even example modules.
|
||||
|
||||
[1]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
Reference in New Issue
Block a user