Add unit and integration tests for VexCandidateEmitter and SmartDiff repositories
- Implemented comprehensive unit tests for VexCandidateEmitter to validate candidate emission logic based on various scenarios including absent and present APIs, confidence thresholds, and rate limiting. - Added integration tests for SmartDiff PostgreSQL repositories, covering snapshot storage and retrieval, candidate storage, and material risk change handling. - Ensured tests validate correct behavior for storing, retrieving, and querying snapshots and candidates, including edge cases and expected outcomes.
This commit is contained in:
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,433 @@
|
||||
Here’s a clean way to **measure and report scanner accuracy without letting one metric hide weaknesses**: track precision/recall (and AUC) separately for three evidence tiers: **Imported**, **Executed**, and **Tainted→Sink**. This mirrors how risk truly escalates in Python/JS‑style ecosystems.
|
||||
|
||||
### Why tiers?
|
||||
|
||||
* **Imported**: vuln in a dep that’s present (lots of noise).
|
||||
* **Executed**: code/deps actually run on typical paths (fewer FPs).
|
||||
* **Tainted→Sink**: user‑controlled data reaches a sensitive sink (highest signal).
|
||||
|
||||
### Minimal spec to implement now
|
||||
|
||||
**Ground‑truth corpus design**
|
||||
|
||||
* Label each finding as: `tier ∈ {imported, executed, tainted_sink}`, `true_label ∈ {TP,FN}`; store model confidence `p∈[0,1]`.
|
||||
* Keep language tags (py, js, ts), package manager, and scenario (web API, cli, job).
|
||||
|
||||
**DB schema (add to test analytics db)**
|
||||
|
||||
* `gt_sample(id, repo, commit, lang, scenario)`
|
||||
* `gt_finding(id, sample_id, vuln_id, tier, truth, score, rule, scanner_version, created_at)`
|
||||
* `gt_split(sample_id, split ∈ {train,dev,test})`
|
||||
|
||||
**Metrics to publish (all stratified by tier)**
|
||||
|
||||
* Precision@K (e.g., top‑100), Recall@K
|
||||
* PR‑AUC, ROC‑AUC (only if calibrated)
|
||||
* Latency p50/p95 from “scan start → first evidence”
|
||||
* Coverage: % of samples with any signal in that tier
|
||||
|
||||
**Reporting layout (one chart per tier)**
|
||||
|
||||
* PR curve + table: `Precision, Recall, F1, PR‑AUC, N(findings), N(samples)`
|
||||
* Error buckets: top 5 false‑positive rules, top 5 false‑negative patterns
|
||||
|
||||
**Evaluation protocol**
|
||||
|
||||
1. Freeze a **toy but diverse corpus** (50–200 repos) with deterministic fixture data and replay scripts.
|
||||
2. For each release candidate:
|
||||
|
||||
* Run scanner with fixed flags and feeds.
|
||||
* Emit per‑finding scores; map each to a tier with your reachability engine.
|
||||
* Join to ground truth; compute metrics **per tier** and **overall**.
|
||||
3. Fail the build if any of:
|
||||
|
||||
* PR‑AUC(imported) drops >2%, or PR‑AUC(executed/tainted_sink) drops >1%.
|
||||
* FP rate in `tainted_sink` > 5% at operating point Recall ≥ 0.7.
|
||||
|
||||
**How to classify tiers (deterministic rules)**
|
||||
|
||||
* `imported`: package appears in lockfile/SBOM and is reachable in graph.
|
||||
* `executed`: function/module reached by dynamic trace, coverage, or proven path in static call graph used by entrypoints.
|
||||
* `tainted_sink`: taint source → sanitizers → sink path proven, with sink taxonomy (eval, exec, SQL, SSRF, deserialization, XXE, command, path traversal).
|
||||
|
||||
**Developer checklist (Stella Ops naming)**
|
||||
|
||||
* Scanner.Worker: emit `evidence_tier` and `score` on each finding.
|
||||
* Excititor (VEX): include `tier` in statements; allow policy per‑tier thresholds.
|
||||
* Concelier (feeds): tag advisories with sink classes when available to help tier mapping.
|
||||
* Scheduler/Notify: gate alerts on **tiered** thresholds (e.g., page only on `tainted_sink` at Recall‑target op‑point).
|
||||
* Router dashboards: three small PR curves + trend sparklines; hover shows last 5 FP causes.
|
||||
|
||||
**Quick JSON result shape**
|
||||
|
||||
```json
|
||||
{
|
||||
"finding_id": "…",
|
||||
"vuln_id": "CVE-2024-12345",
|
||||
"rule": "py.sql.injection.param_concat",
|
||||
"evidence_tier": "tainted_sink",
|
||||
"score": 0.87,
|
||||
"reachability": { "entrypoint": "app.py:main", "path_len": 5, "sanitizers": ["escape_sql"] }
|
||||
}
|
||||
```
|
||||
|
||||
**Operational point selection**
|
||||
|
||||
* Choose op‑points per tier by maximizing F1 or fixing Recall targets:
|
||||
|
||||
* imported: Recall 0.60
|
||||
* executed: Recall 0.70
|
||||
* tainted_sink: Recall 0.80
|
||||
Then record **per‑tier precision at those recalls** each release.
|
||||
|
||||
**Why this prevents metric gaming**
|
||||
|
||||
* A model can’t inflate “overall precision” by over‑penalizing noisy imported findings: you still have to show gains in **executed** and **tainted_sink** curves, where it matters.
|
||||
|
||||
If you want, I can draft a tiny sample corpus template (folders + labels) and a one‑file evaluator that outputs the three PR curves and a markdown summary ready for your CI artifact.
|
||||
What you are trying to solve is this:
|
||||
|
||||
If you measure “scanner accuracy” as one overall precision/recall number, you can *accidentally* optimize the wrong thing. A scanner can look “better” by getting quieter on the easy/noisy tier (dependencies merely present) while getting worse on the tier that actually matters (user-data reaching a dangerous sink). Tiered accuracy prevents that failure mode and gives you a clean product contract:
|
||||
|
||||
* **Imported** = “it exists in the artifact” (high volume, high noise)
|
||||
* **Executed** = “it actually runs on real entrypoints” (materially more useful)
|
||||
* **Tainted→Sink** = “user-controlled input reaches a sensitive sink” (highest signal, most actionable)
|
||||
|
||||
This is not just analytics. It drives:
|
||||
|
||||
* alerting (page only on tainted→sink),
|
||||
* UX (show the *reason* a vuln matters),
|
||||
* policy/lattice merges (VEX decisions should not collapse tiers),
|
||||
* engineering priorities (don’t let “imported” improvements hide “tainted→sink” regressions).
|
||||
|
||||
Below is a concrete StellaOps implementation plan (aligned to your architecture rules: **lattice algorithms run in `scanner.webservice`**, Concelier/Excititor **preserve prune source**, Postgres is SoR, Valkey only ephemeral).
|
||||
|
||||
---
|
||||
|
||||
## 1) Product contract: what “tier” means in StellaOps
|
||||
|
||||
### 1.1 Tier assignment rule (single source of truth)
|
||||
|
||||
**Owner:** `StellaOps.Scanner.WebService`
|
||||
**Input:** raw findings + evidence objects from workers (deps, callgraph, trace, taint paths)
|
||||
**Output:** `evidence_tier` on each normalized finding (plus an evidence summary)
|
||||
|
||||
**Tier precedence (highest wins):**
|
||||
|
||||
1. `tainted_sink`
|
||||
2. `executed`
|
||||
3. `imported`
|
||||
|
||||
**Deterministic mapping rule:**
|
||||
|
||||
* `imported` if SBOM/lockfile indicates package/component present AND vuln applies to that component.
|
||||
* `executed` if reachability engine can prove reachable from declared entrypoints (static) OR runtime trace/coverage proves execution.
|
||||
* `tainted_sink` if taint engine proves source→(optional sanitizer)→sink path with sink taxonomy.
|
||||
|
||||
### 1.2 Evidence objects (the “why”)
|
||||
|
||||
Workers emit *evidence primitives*; webservice merges + tiers them:
|
||||
|
||||
* `DependencyEvidence { purl, version, lockfile_path }`
|
||||
* `ReachabilityEvidence { entrypoint, call_path[], confidence }`
|
||||
* `TaintEvidence { source, sink, sanitizers[], dataflow_path[], confidence }`
|
||||
|
||||
---
|
||||
|
||||
## 2) Data model in Postgres (system of record)
|
||||
|
||||
Create a dedicated schema `eval` for ground truth + computed metrics (keeps it separate from production scans but queryable by the UI).
|
||||
|
||||
### 2.1 Tables (minimal but complete)
|
||||
|
||||
```sql
|
||||
create schema if not exists eval;
|
||||
|
||||
-- A “sample” = one repo/fixture scenario you scan deterministically
|
||||
create table eval.sample (
|
||||
sample_id uuid primary key,
|
||||
name text not null,
|
||||
repo_path text not null, -- local path in your corpus checkout
|
||||
commit_sha text null,
|
||||
language text not null, -- py/js/ts/java/dotnet/mixed
|
||||
scenario text not null, -- webapi/cli/job/lib
|
||||
entrypoints jsonb not null, -- array of entrypoint descriptors
|
||||
created_at timestamptz not null default now()
|
||||
);
|
||||
|
||||
-- Expected truth for a sample
|
||||
create table eval.expected_finding (
|
||||
expected_id uuid primary key,
|
||||
sample_id uuid not null references eval.sample(sample_id) on delete cascade,
|
||||
vuln_key text not null, -- your canonical vuln key (see 2.2)
|
||||
tier text not null check (tier in ('imported','executed','tainted_sink')),
|
||||
rule_key text null, -- optional: expected rule family
|
||||
location_hint text null, -- e.g. file:line or package
|
||||
sink_class text null, -- sql/command/ssrf/deser/eval/path/etc
|
||||
notes text null
|
||||
);
|
||||
|
||||
-- One evaluation run (tied to exact versions + snapshots)
|
||||
create table eval.run (
|
||||
eval_run_id uuid primary key,
|
||||
scanner_version text not null,
|
||||
rules_hash text not null,
|
||||
concelier_snapshot_hash text not null, -- feed snapshot / advisory set hash
|
||||
replay_manifest_hash text not null,
|
||||
started_at timestamptz not null default now(),
|
||||
finished_at timestamptz null
|
||||
);
|
||||
|
||||
-- Observed results captured from a scan run over the corpus
|
||||
create table eval.observed_finding (
|
||||
observed_id uuid primary key,
|
||||
eval_run_id uuid not null references eval.run(eval_run_id) on delete cascade,
|
||||
sample_id uuid not null references eval.sample(sample_id) on delete cascade,
|
||||
vuln_key text not null,
|
||||
tier text not null check (tier in ('imported','executed','tainted_sink')),
|
||||
score double precision not null, -- 0..1
|
||||
rule_key text not null,
|
||||
evidence jsonb not null, -- summarized evidence blob
|
||||
first_signal_ms int not null -- TTFS-like metric for this finding
|
||||
);
|
||||
|
||||
-- Computed metrics, per tier and operating point
|
||||
create table eval.metrics (
|
||||
eval_run_id uuid not null references eval.run(eval_run_id) on delete cascade,
|
||||
tier text not null check (tier in ('imported','executed','tainted_sink')),
|
||||
op_point text not null, -- e.g. "recall>=0.80" or "threshold=0.72"
|
||||
precision double precision not null,
|
||||
recall double precision not null,
|
||||
f1 double precision not null,
|
||||
pr_auc double precision not null,
|
||||
latency_p50_ms int not null,
|
||||
latency_p95_ms int not null,
|
||||
n_expected int not null,
|
||||
n_observed int not null,
|
||||
primary key (eval_run_id, tier, op_point)
|
||||
);
|
||||
```
|
||||
|
||||
### 2.2 Canonical vuln key (avoid mismatches)
|
||||
|
||||
Define a single canonical key for matching expected↔observed:
|
||||
|
||||
* For dependency vulns: `purl + advisory_id` (or `purl + cve` if available).
|
||||
* For code-pattern vulns: `rule_family + stable fingerprint` (e.g., `sink_class + file + normalized AST span`).
|
||||
|
||||
You need this to stop “matching hell” from destroying the usefulness of metrics.
|
||||
|
||||
---
|
||||
|
||||
## 3) Corpus format (how developers add truth samples)
|
||||
|
||||
Create `/corpus/` repo (or folder) with strict structure:
|
||||
|
||||
```
|
||||
/corpus/
|
||||
/samples/
|
||||
/py_sql_injection_001/
|
||||
sample.yml
|
||||
app.py
|
||||
requirements.txt
|
||||
expected.json
|
||||
/js_ssrf_002/
|
||||
sample.yml
|
||||
index.js
|
||||
package-lock.json
|
||||
expected.json
|
||||
replay-manifest.yml # pins concelier snapshot, rules hash, analyzers
|
||||
tools/
|
||||
run-scan.ps1
|
||||
run-scan.sh
|
||||
```
|
||||
|
||||
**`sample.yml`** includes:
|
||||
|
||||
* language, scenario, entrypoints,
|
||||
* how to run/build (if needed),
|
||||
* “golden” command line for deterministic scanning.
|
||||
|
||||
**`expected.json`** is a list of expected findings with `vuln_key`, `tier`, optional `sink_class`.
|
||||
|
||||
---
|
||||
|
||||
## 4) Pipeline changes in StellaOps (where code changes go)
|
||||
|
||||
### 4.1 Scanner workers: emit evidence primitives (no tiering here)
|
||||
|
||||
**Modules:**
|
||||
|
||||
* `StellaOps.Scanner.Worker.DotNet`
|
||||
* `StellaOps.Scanner.Worker.Python`
|
||||
* `StellaOps.Scanner.Worker.Node`
|
||||
* `StellaOps.Scanner.Worker.Java`
|
||||
|
||||
**Change:**
|
||||
|
||||
* Every raw finding must include:
|
||||
|
||||
* `vuln_key`
|
||||
* `rule_key`
|
||||
* `score` (even if coarse at first)
|
||||
* `evidence[]` primitives (dependency / reachability / taint as available)
|
||||
* `first_signal_ms` (time from scan start to first evidence emitted for that finding)
|
||||
|
||||
Workers do **not** decide tiers. They only report what they saw.
|
||||
|
||||
### 4.2 Scanner webservice: tiering + lattice merge (this is the policy brain)
|
||||
|
||||
**Module:** `StellaOps.Scanner.WebService`
|
||||
|
||||
Responsibilities:
|
||||
|
||||
* Merge evidence for the same `vuln_key` across analyzers.
|
||||
* Run reachability/taint algorithms (your lattice policy engine sits here).
|
||||
* Assign `evidence_tier` deterministically.
|
||||
* Persist normalized findings (production tables) + export to eval capture.
|
||||
|
||||
### 4.3 Concelier + Excititor (preserve prune source)
|
||||
|
||||
* Concelier stores advisory data; does not “tier” anything.
|
||||
* Excititor stores VEX statements; when it references a finding, it may *annotate* tier context, but it must preserve pruning provenance and not recompute tiers.
|
||||
|
||||
---
|
||||
|
||||
## 5) Evaluator implementation (the thing that computes tiered precision/recall)
|
||||
|
||||
### 5.1 New service/tooling
|
||||
|
||||
Create:
|
||||
|
||||
* `StellaOps.Scanner.Evaluation.Core` (library)
|
||||
* `StellaOps.Scanner.Evaluation.Cli` (dotnet tool)
|
||||
|
||||
CLI responsibilities:
|
||||
|
||||
1. Load corpus samples + expected findings into `eval.sample` / `eval.expected_finding`.
|
||||
2. Trigger scans (via Scheduler or direct Scanner API) using `replay-manifest.yml`.
|
||||
3. Capture observed findings into `eval.observed_finding`.
|
||||
4. Compute per-tier PR curve + PR-AUC + operating-point precision/recall.
|
||||
5. Write `eval.metrics` + produce Markdown/JSON artifacts for CI.
|
||||
|
||||
### 5.2 Matching algorithm (practical and robust)
|
||||
|
||||
For each `sample_id`:
|
||||
|
||||
* Group expected by `(vuln_key, tier)`.
|
||||
* Group observed by `(vuln_key, tier)`.
|
||||
* A match is “same vuln_key, same tier”.
|
||||
|
||||
* (Later enhancement: allow “higher tier” observed to satisfy a lower-tier expected only if you explicitly want that; default: **exact tier match** so you catch tier regressions.)
|
||||
|
||||
Compute:
|
||||
|
||||
* TP/FP/FN per tier.
|
||||
* PR curve by sweeping threshold over observed scores.
|
||||
* `first_signal_ms` percentiles per tier.
|
||||
|
||||
### 5.3 Operating points (so it’s not academic)
|
||||
|
||||
Pick tier-specific gates:
|
||||
|
||||
* `tainted_sink`: require Recall ≥ 0.80, minimize FP
|
||||
* `executed`: require Recall ≥ 0.70
|
||||
* `imported`: require Recall ≥ 0.60
|
||||
|
||||
Store the chosen threshold per tier per version (so you can compare apples-to-apples in regressions).
|
||||
|
||||
---
|
||||
|
||||
## 6) CI gating (how this becomes “real” engineering pressure)
|
||||
|
||||
In GitLab/Gitea pipeline:
|
||||
|
||||
1. Build scanner + webservice.
|
||||
2. Pull pinned concelier snapshot bundle (or local snapshot).
|
||||
3. Run evaluator CLI against corpus.
|
||||
4. Fail build if:
|
||||
|
||||
* `PR-AUC(tainted_sink)` drops > 1% vs baseline
|
||||
* or precision at `Recall>=0.80` drops below a floor (e.g. 0.95)
|
||||
* or `latency_p95_ms(tainted_sink)` regresses beyond a budget
|
||||
|
||||
Store baselines in repo (`/corpus/baselines/<scanner_version>.json`) to make diffs explicit.
|
||||
|
||||
---
|
||||
|
||||
## 7) UI and alerting (so tiering changes behavior)
|
||||
|
||||
### 7.1 UI
|
||||
|
||||
Add three KPI cards:
|
||||
|
||||
* Imported PR-AUC trend
|
||||
* Executed PR-AUC trend
|
||||
* Tainted→Sink PR-AUC trend
|
||||
|
||||
In the findings list:
|
||||
|
||||
* show tier badge
|
||||
* default sort: `tainted_sink` then `executed` then `imported`
|
||||
* clicking a finding shows evidence summary (entrypoint, path length, sink class)
|
||||
|
||||
### 7.2 Notify policy
|
||||
|
||||
Default policy:
|
||||
|
||||
* Page/urgent only on `tainted_sink` above a confidence threshold.
|
||||
* Create ticket on `executed`.
|
||||
* Batch report on `imported`.
|
||||
|
||||
This is the main “why”: the system stops screaming about irrelevant imports.
|
||||
|
||||
---
|
||||
|
||||
## 8) Rollout plan (phased, developer-friendly)
|
||||
|
||||
### Phase 0: Contracts (1–2 days)
|
||||
|
||||
* Define `vuln_key`, `rule_key`, evidence DTOs, tier enum.
|
||||
* Add schema `eval.*`.
|
||||
|
||||
**Done when:** scanner output can carry evidence + score; eval tables exist.
|
||||
|
||||
### Phase 1: Evidence emission + tiering (1–2 sprints)
|
||||
|
||||
* Workers emit evidence primitives.
|
||||
* Webservice assigns tier using deterministic precedence.
|
||||
|
||||
**Done when:** every finding has a tier + evidence summary.
|
||||
|
||||
### Phase 2: Corpus + evaluator (1 sprint)
|
||||
|
||||
* Build 30–50 samples (10 per tier minimum).
|
||||
* Implement evaluator CLI + metrics persistence.
|
||||
|
||||
**Done when:** CI can compute tiered metrics and output markdown report.
|
||||
|
||||
### Phase 3: Gates + UX (1 sprint)
|
||||
|
||||
* Add CI regression gates.
|
||||
* Add UI tier badge + dashboards.
|
||||
* Add Notify tier-based routing.
|
||||
|
||||
**Done when:** a regression in tainted→sink breaks CI even if imported improves.
|
||||
|
||||
### Phase 4: Scale corpus + harden matching (ongoing)
|
||||
|
||||
* Expand to 200+ samples, multi-language.
|
||||
* Add fingerprinting for code vulns to avoid brittle file/line matching.
|
||||
|
||||
---
|
||||
|
||||
## Definition of “success” (so nobody bikesheds)
|
||||
|
||||
* You can point to one release where **overall precision stayed flat** but **tainted→sink PR-AUC improved**, and CI proves you didn’t “cheat” by just silencing imported findings.
|
||||
* On-call noise drops because paging is tier-gated.
|
||||
* TTFS p95 for tainted→sink stays within a budget you set (e.g., <30s on corpus and <N seconds on real images).
|
||||
|
||||
If you want, I can also give you:
|
||||
|
||||
* a concrete DTO set (`FindingEnvelope`, `EvidenceUnion`, etc.) in C#/.NET 10,
|
||||
* and a skeleton `StellaOps.Scanner.Evaluation.Cli` command layout (`import-corpus`, `run`, `compute`, `report`) that your agents can start coding immediately.
|
||||
@@ -0,0 +1,648 @@
|
||||
I’m sharing this because integrating **real‑world exploit likelihood into your vulnerability workflow sharpens triage decisions far beyond static severity alone.**
|
||||
|
||||
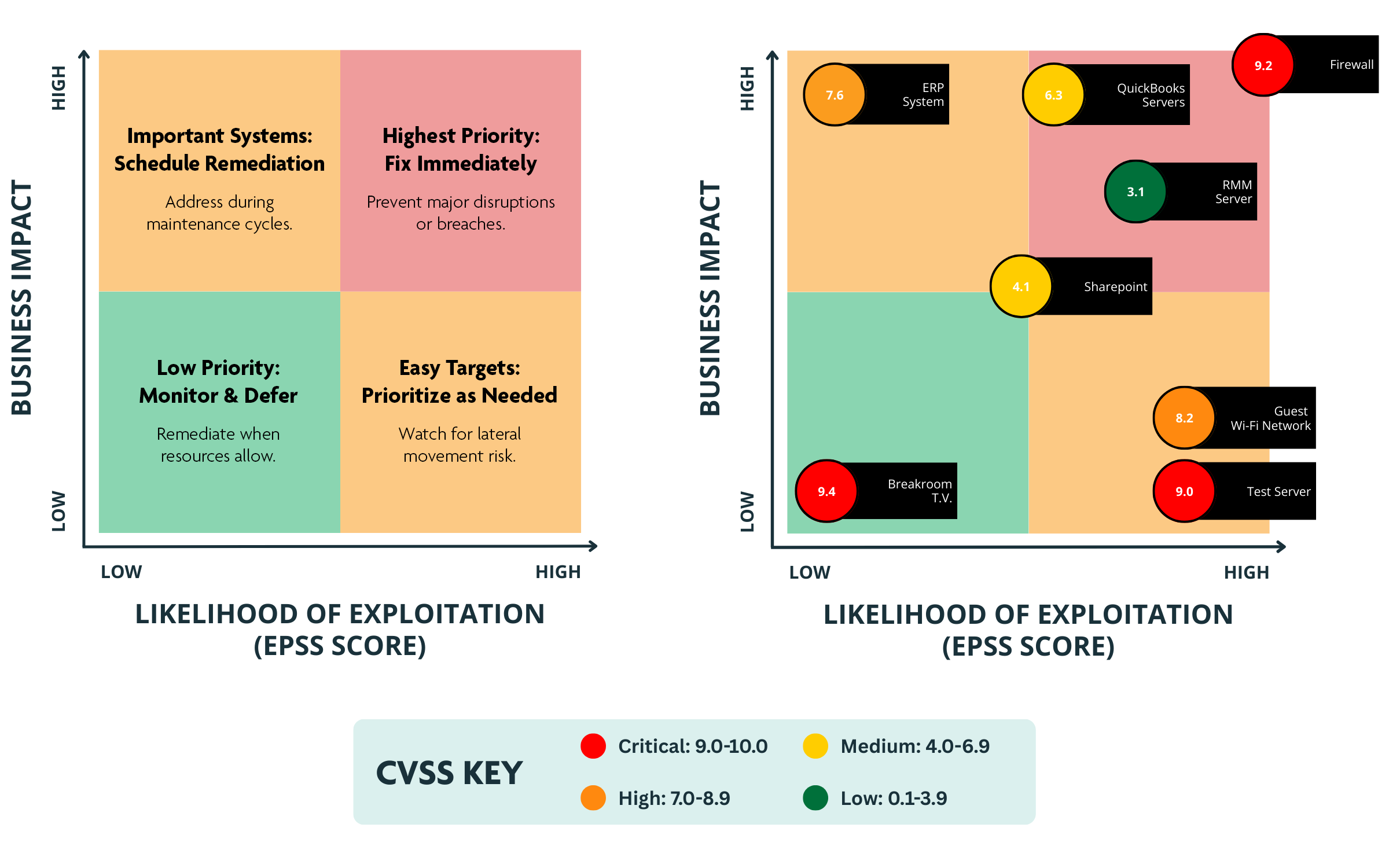
EPSS (Exploit Prediction Scoring System) is a **probabilistic model** that estimates the *likelihood* a given CVE will be exploited in the wild over the next ~30 days, producing a score from **0 to 1** you can treat as a live probability. ([FIRST][1])
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
• **CVSS v4** gives you a deterministic measurement of *severity* (impact + exploitability traits) on a 0–10 scale. ([Wikipedia][2])
|
||||
• **EPSS** gives you a dynamic, **data‑driven probability of exploitation** (0–1) updated as threat data flows in. ([FIRST][3])
|
||||
|
||||
Because CVSS doesn’t reflect *actual threat activity*, combining it with EPSS lets you identify vulnerabilities that are *both serious and likely to be exploited* — rather than just theoretically dangerous. ([Intruder][4])
|
||||
|
||||
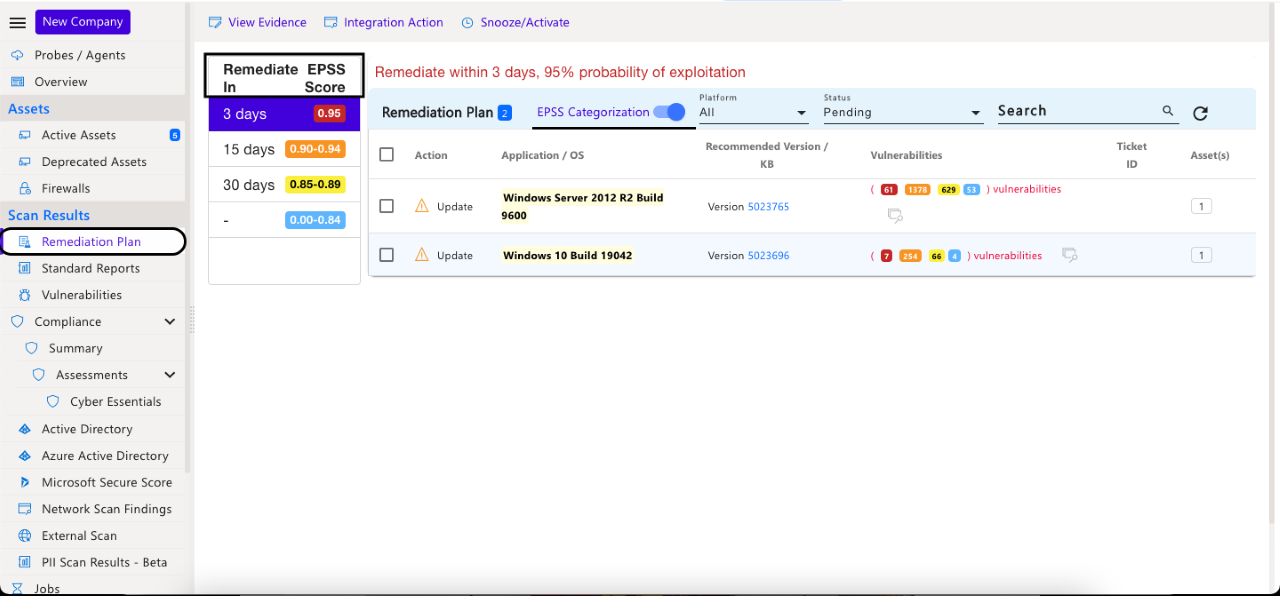
For automated platforms (like Stella Ops), treating **EPSS updates as event triggers** makes sense: fresh exploit probability changes can drive workflows such as scheduler alerts, notifications, and enrichment of vulnerability records — giving your pipeline *live risk context* to act on. (Industry best practice is to feed EPSS into prioritization alongside severity and threat intelligence.) ([Microsoft Tech Community][5])
|
||||
|
||||
If you build your triage chain around **probabilistic trust ranges rather than static buckets**, you reduce noise and focus effort where attackers are most likely to strike next.
|
||||
|
||||
[1]: https://www.first.org/epss/?utm_source=chatgpt.com "Exploit Prediction Scoring System (EPSS)"
|
||||
[2]: https://en.wikipedia.org/wiki/Common_Vulnerability_Scoring_System?utm_source=chatgpt.com "Common Vulnerability Scoring System"
|
||||
[3]: https://www.first.org/epss/data_stats?utm_source=chatgpt.com "Exploit Prediction Scoring System (EPSS)"
|
||||
[4]: https://www.intruder.io/blog/epss-vs-cvss?utm_source=chatgpt.com "EPSS vs. CVSS: What's The Best Approach To Vulnerability ..."
|
||||
[5]: https://techcommunity.microsoft.com/blog/vulnerability-management/supporting-cvss-v4-score-for-cve-for-enhanced-vulnerability-assessment/4391439?utm_source=chatgpt.com "Supporting CVSS V4 score for CVE for Enhanced ..."
|
||||
To build an **EPSS database from first principles**, think of it as a **time-series enrichment layer over CVEs**, not a standalone vulnerability catalog. EPSS does not replace CVE/NVD; it annotates it with *probabilistic exploit likelihood* that changes daily.
|
||||
|
||||
Below is a **clean, production-grade blueprint**, aligned with how Stella Ops should treat it.
|
||||
|
||||
---
|
||||
|
||||
## 1. What EPSS actually gives you (ground truth)
|
||||
|
||||
EPSS is published by FIRST as **daily snapshots**, not events.
|
||||
|
||||
Each record is essentially:
|
||||
|
||||
* `cve_id`
|
||||
* `epss_score` (0.00000–1.00000)
|
||||
* `percentile` (rank vs all CVEs)
|
||||
* `date` (model run date)
|
||||
|
||||
No descriptions, no severity, no metadata.
|
||||
|
||||
**Key implication:**
|
||||
Your EPSS database must be **append-only time-series**, not “latest-only”.
|
||||
|
||||
---
|
||||
|
||||
## 2. Authoritative data source
|
||||
|
||||
FIRST publishes **two canonical feeds**:
|
||||
|
||||
1. **Daily CSV** (full snapshot, ~200k CVEs)
|
||||
2. **Daily JSON** (same content, heavier)
|
||||
|
||||
Best practice:
|
||||
|
||||
* Use **CSV for bulk ingestion**
|
||||
* Use **JSON only for debugging or spot checks**
|
||||
|
||||
You do **not** train EPSS yourself unless you want to replicate FIRST’s ML pipeline (not recommended).
|
||||
|
||||
---
|
||||
|
||||
## 3. Minimal EPSS schema (PostgreSQL-first)
|
||||
|
||||
### Core table (append-only)
|
||||
|
||||
```sql
|
||||
CREATE TABLE epss_scores (
|
||||
cve_id TEXT NOT NULL,
|
||||
score DOUBLE PRECISION NOT NULL,
|
||||
percentile DOUBLE PRECISION NOT NULL,
|
||||
model_date DATE NOT NULL,
|
||||
ingested_at TIMESTAMPTZ NOT NULL DEFAULT now(),
|
||||
PRIMARY KEY (cve_id, model_date)
|
||||
);
|
||||
```
|
||||
|
||||
### Indexes that matter
|
||||
|
||||
```sql
|
||||
CREATE INDEX idx_epss_date ON epss_scores (model_date);
|
||||
CREATE INDEX idx_epss_score ON epss_scores (score DESC);
|
||||
CREATE INDEX idx_epss_cve_latest
|
||||
ON epss_scores (cve_id, model_date DESC);
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. “Latest view” (never store latest as truth)
|
||||
|
||||
Create a **deterministic view**, not a table:
|
||||
|
||||
```sql
|
||||
CREATE VIEW epss_latest AS
|
||||
SELECT DISTINCT ON (cve_id)
|
||||
cve_id,
|
||||
score,
|
||||
percentile,
|
||||
model_date
|
||||
FROM epss_scores
|
||||
ORDER BY cve_id, model_date DESC;
|
||||
```
|
||||
|
||||
This preserves:
|
||||
|
||||
* Auditability
|
||||
* Replayability
|
||||
* Backtesting
|
||||
|
||||
---
|
||||
|
||||
## 5. Ingestion pipeline (daily, deterministic)
|
||||
|
||||
### Step-by-step
|
||||
|
||||
1. **Scheduler triggers daily EPSS fetch**
|
||||
2. Download CSV for `YYYY-MM-DD`
|
||||
3. Validate:
|
||||
|
||||
* row count sanity
|
||||
* score ∈ [0,1]
|
||||
* monotonic percentile
|
||||
4. Bulk insert with `COPY`
|
||||
5. Emit **“epss.updated” event**
|
||||
|
||||
### Failure handling
|
||||
|
||||
* If feed missing → **no delete**
|
||||
* If partial → **reject entire day**
|
||||
* If duplicate day → **idempotent ignore**
|
||||
|
||||
---
|
||||
|
||||
## 6. Event model inside Stella Ops
|
||||
|
||||
Treat EPSS as **risk signal**, not vulnerability data.
|
||||
|
||||
### Event emitted
|
||||
|
||||
```json
|
||||
{
|
||||
"event": "epss.updated",
|
||||
"model_date": "2025-12-16",
|
||||
"cve_count": 231417,
|
||||
"delta_summary": {
|
||||
"new_high_risk": 312,
|
||||
"significant_jumps": 87
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 7. How EPSS propagates in Stella Ops
|
||||
|
||||
**Correct chain (your architecture):**
|
||||
|
||||
```
|
||||
Scheduler
|
||||
→ EPSS Ingest Worker
|
||||
→ Notify
|
||||
→ Concealer
|
||||
→ Excititor
|
||||
```
|
||||
|
||||
### What happens downstream
|
||||
|
||||
* **Concelier**
|
||||
|
||||
* Enrich existing vulnerability facts
|
||||
* Never overwrite CVSS or VEX
|
||||
* **Excititor**
|
||||
|
||||
* Re-evaluate policy thresholds
|
||||
* Trigger alerts only if:
|
||||
|
||||
* EPSS crosses trust boundary
|
||||
* OR delta > configured threshold
|
||||
|
||||
---
|
||||
|
||||
## 8. Trust-lattice integration (important)
|
||||
|
||||
Do **not** treat EPSS as severity.
|
||||
|
||||
Correct interpretation:
|
||||
|
||||
| Signal | Nature |
|
||||
| --------------- | -------------------- |
|
||||
| CVSS v4 | Deterministic impact |
|
||||
| EPSS | Probabilistic threat |
|
||||
| VEX | Vendor intent |
|
||||
| Runtime context | Actual exposure |
|
||||
|
||||
**Rule:**
|
||||
EPSS only *modulates confidence*, never asserts truth.
|
||||
|
||||
Example lattice rule:
|
||||
|
||||
```
|
||||
IF CVSS >= 8.0
|
||||
AND EPSS >= 0.35
|
||||
AND runtime_exposed = true
|
||||
→ elevate to “Immediate Attention”
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 9. Retention policy
|
||||
|
||||
Recommended:
|
||||
|
||||
* Keep **all EPSS history** (storage is cheap)
|
||||
* Allow optional roll-up:
|
||||
|
||||
* weekly averages
|
||||
* max-delta windows
|
||||
|
||||
Never delete raw data.
|
||||
|
||||
---
|
||||
|
||||
## 10. What not to do (common mistakes)
|
||||
|
||||
* ❌ Storing only latest EPSS
|
||||
* ❌ Mixing EPSS into CVE table
|
||||
* ❌ Treating EPSS as severity
|
||||
* ❌ Triggering alerts on every daily fluctuation
|
||||
* ❌ Recomputing EPSS internally
|
||||
|
||||
---
|
||||
|
||||
## 11. Minimal MVP checklist
|
||||
|
||||
* [x] Append-only table
|
||||
* [x] Latest view
|
||||
* [x] Daily scheduler job
|
||||
* [x] Delta detection
|
||||
* [x] Event emission
|
||||
* [x] Policy-driven alerting
|
||||
|
||||
---
|
||||
|
||||
### Bottom line
|
||||
|
||||
An EPSS database is **not a vulnerability database**.
|
||||
It is a **probabilistic signal ledger** that feeds your trust calculus.
|
||||
|
||||
If you want, next I can:
|
||||
|
||||
* Provide **.NET ingestion code**
|
||||
* Design **delta-based alert thresholds**
|
||||
* Map EPSS → **Trust Algebra Studio** rules
|
||||
* Show how to **replay historical EPSS for audits**
|
||||
Below is a **full implementation + usage plan** for **EPSS v4 (published starting 2025-03-17)** in Stella Ops, designed for your existing components (**Scheduler WebService**, **Notify WebService**, **Concelier**, **Excititor**, **Scanner.WebService**) and consistent with your architectural rules (Postgres system of record; Valkey optional ephemeral accelerator; lattice logic stays in Scanner.WebService).
|
||||
|
||||
EPSS facts you should treat as authoritative:
|
||||
|
||||
* EPSS is a **daily** probability score in **[0..1]** with a **percentile**, per CVE. ([first.org][1])
|
||||
* FIRST provides **daily CSV .gz snapshots** at `https://epss.empiricalsecurity.com/epss_scores-YYYY-mm-dd.csv.gz`. ([first.org][1])
|
||||
* FIRST also provides a REST API base `https://api.first.org/data/v1/epss` with filters and `scope=time-series`. ([first.org][2])
|
||||
* The daily files include (at least since v2) a leading `#` comment with **model version + publish date**, and FIRST explicitly notes the v4 publishing start date. ([first.org][1])
|
||||
|
||||
---
|
||||
|
||||
## 1) Product scope (what Stella Ops must deliver)
|
||||
|
||||
### 1.1 Functional capabilities
|
||||
|
||||
1. **Ingest EPSS daily snapshot** (online) + **manual import** (air-gapped bundle).
|
||||
2. Store **immutable history** (time series) and maintain a **fast “current projection”**.
|
||||
3. Enrich:
|
||||
|
||||
* **New scans** (attach EPSS at scan time as immutable evidence).
|
||||
* **Existing findings** (attach latest EPSS for “live triage” without breaking replay).
|
||||
4. Trigger downstream events:
|
||||
|
||||
* `epss.updated` (daily)
|
||||
* `vuln.priority.changed` (only when band/threshold changes)
|
||||
5. UI/UX:
|
||||
|
||||
* Show EPSS score + percentile + trend (delta).
|
||||
* Filters and sort by exploit likelihood and changes.
|
||||
6. Policy hooks (but **calculation lives in Scanner.WebService**):
|
||||
|
||||
* Risk priority uses EPSS as a probabilistic factor, not “severity”.
|
||||
|
||||
### 1.2 Non-functional requirements
|
||||
|
||||
* **Deterministic replay**: every scan stores the EPSS snapshot reference used (model_date + import_run_id + hash).
|
||||
* **Idempotent ingestion**: safe to re-run for same date.
|
||||
* **Performance**: daily ingest of ~300k rows should be seconds-to-low-minutes; query path must be fast.
|
||||
* **Auditability**: retain raw provenance: source URL, hashes, model version tag.
|
||||
* **Deployment profiles**:
|
||||
|
||||
* Default: Postgres + Valkey (optional)
|
||||
* Air-gapped minimal: Postgres only (manual import)
|
||||
|
||||
---
|
||||
|
||||
## 2) Data architecture (Postgres as source of truth)
|
||||
|
||||
### 2.1 Tables (recommended minimum set)
|
||||
|
||||
#### A) Import runs (provenance)
|
||||
|
||||
```sql
|
||||
CREATE TABLE epss_import_runs (
|
||||
import_run_id UUID PRIMARY KEY,
|
||||
model_date DATE NOT NULL,
|
||||
source_uri TEXT NOT NULL,
|
||||
retrieved_at TIMESTAMPTZ NOT NULL,
|
||||
file_sha256 TEXT NOT NULL,
|
||||
decompressed_sha256 TEXT NULL,
|
||||
row_count INT NOT NULL,
|
||||
model_version_tag TEXT NULL, -- e.g. v2025.03.14 (from leading # comment)
|
||||
published_date DATE NULL, -- from leading # comment if present
|
||||
status TEXT NOT NULL, -- SUCCEEDED / FAILED
|
||||
error TEXT NULL,
|
||||
UNIQUE (model_date)
|
||||
);
|
||||
```
|
||||
|
||||
#### B) Immutable daily scores (time series)
|
||||
|
||||
Partition by month (recommended):
|
||||
|
||||
```sql
|
||||
CREATE TABLE epss_scores (
|
||||
model_date DATE NOT NULL,
|
||||
cve_id TEXT NOT NULL,
|
||||
epss_score DOUBLE PRECISION NOT NULL,
|
||||
percentile DOUBLE PRECISION NOT NULL,
|
||||
import_run_id UUID NOT NULL REFERENCES epss_import_runs(import_run_id),
|
||||
PRIMARY KEY (model_date, cve_id)
|
||||
) PARTITION BY RANGE (model_date);
|
||||
```
|
||||
|
||||
Create monthly partitions via migration helper.
|
||||
|
||||
#### C) Current projection (fast lookup)
|
||||
|
||||
```sql
|
||||
CREATE TABLE epss_current (
|
||||
cve_id TEXT PRIMARY KEY,
|
||||
epss_score DOUBLE PRECISION NOT NULL,
|
||||
percentile DOUBLE PRECISION NOT NULL,
|
||||
model_date DATE NOT NULL,
|
||||
import_run_id UUID NOT NULL
|
||||
);
|
||||
|
||||
CREATE INDEX idx_epss_current_score_desc ON epss_current (epss_score DESC);
|
||||
CREATE INDEX idx_epss_current_percentile_desc ON epss_current (percentile DESC);
|
||||
```
|
||||
|
||||
#### D) Changes (delta) to drive enrichment + notifications
|
||||
|
||||
```sql
|
||||
CREATE TABLE epss_changes (
|
||||
model_date DATE NOT NULL,
|
||||
cve_id TEXT NOT NULL,
|
||||
old_score DOUBLE PRECISION NULL,
|
||||
new_score DOUBLE PRECISION NOT NULL,
|
||||
delta_score DOUBLE PRECISION NULL,
|
||||
old_percentile DOUBLE PRECISION NULL,
|
||||
new_percentile DOUBLE PRECISION NOT NULL,
|
||||
flags INT NOT NULL, -- bitmask: NEW_SCORED, CROSSED_HIGH, BIG_JUMP, etc
|
||||
PRIMARY KEY (model_date, cve_id)
|
||||
) PARTITION BY RANGE (model_date);
|
||||
```
|
||||
|
||||
### 2.2 Why “current projection” is necessary
|
||||
|
||||
EPSS is daily; your scan/UI paths need **O(1) latest lookup**. Keeping `epss_current` avoids expensive “latest per cve” queries across huge time-series.
|
||||
|
||||
---
|
||||
|
||||
## 3) Service responsibilities and event flow
|
||||
|
||||
### 3.1 Scheduler.WebService (or Scheduler.Worker)
|
||||
|
||||
* Owns the **schedule**: daily EPSS import job.
|
||||
* Emits a durable job command (Postgres outbox) to Concelier worker.
|
||||
|
||||
Job types:
|
||||
|
||||
* `epss.ingest(date=YYYY-MM-DD, source=online|bundle)`
|
||||
* `epss.backfill(date_from, date_to)` (optional)
|
||||
|
||||
### 3.2 Concelier (ingestion + enrichment, “preserve/prune source” compliant)
|
||||
|
||||
Concelier does **not** compute lattice/risk. It:
|
||||
|
||||
* Downloads/imports EPSS snapshot.
|
||||
* Stores raw facts + provenance.
|
||||
* Computes **delta** for changed CVEs.
|
||||
* Updates `epss_current`.
|
||||
* Triggers downstream enrichment jobs for impacted vulnerability instances.
|
||||
|
||||
Produces outbox events:
|
||||
|
||||
* `epss.updated` (always after successful ingest)
|
||||
* `epss.failed` (on failure)
|
||||
* `vuln.priority.changed` (after enrichment, only when a band changes)
|
||||
|
||||
### 3.3 Scanner.WebService (risk evaluation lives here)
|
||||
|
||||
On scan:
|
||||
|
||||
* pulls `epss_current` for the CVEs in the scan (bulk query).
|
||||
* stores immutable evidence:
|
||||
|
||||
* `epss_score_at_scan`
|
||||
* `epss_percentile_at_scan`
|
||||
* `epss_model_date_at_scan`
|
||||
* `epss_import_run_id_at_scan`
|
||||
* computes *derived* risk (your lattice/scoring) using EPSS as an input factor.
|
||||
|
||||
### 3.4 Notify.WebService
|
||||
|
||||
Subscribes to:
|
||||
|
||||
* `epss.updated`
|
||||
* `vuln.priority.changed`
|
||||
* sends:
|
||||
|
||||
* Slack/email/webhook/in-app notifications (your channels)
|
||||
|
||||
### 3.5 Excititor (VEX workflow assist)
|
||||
|
||||
EPSS does not change VEX truth. Excititor may:
|
||||
|
||||
* create a “**VEX requested / vendor attention**” task when:
|
||||
|
||||
* EPSS is high AND vulnerability affects shipped artifact AND VEX missing/unknown
|
||||
No lattice math here; only task generation.
|
||||
|
||||
---
|
||||
|
||||
## 4) Ingestion design (online + air-gapped)
|
||||
|
||||
### 4.1 Preferred source: daily CSV snapshot
|
||||
|
||||
Use FIRST’s documented daily snapshot URL pattern. ([first.org][1])
|
||||
|
||||
Pipeline for date D:
|
||||
|
||||
1. Download `epss_scores-D.csv.gz`.
|
||||
2. Decompress stream.
|
||||
3. Parse:
|
||||
|
||||
* Skip leading `# ...` comment line; capture model tag and publish date if present. ([first.org][1])
|
||||
* Parse CSV header fields `cve, epss, percentile`. ([first.org][1])
|
||||
4. Bulk load into **TEMP staging**.
|
||||
5. In one DB transaction:
|
||||
|
||||
* insert `epss_import_runs`
|
||||
* insert into partition `epss_scores`
|
||||
* compute `epss_changes` by comparing staging vs `epss_current`
|
||||
* upsert `epss_current`
|
||||
* enqueue outbox `epss.updated`
|
||||
6. Commit.
|
||||
|
||||
### 4.2 Air-gapped bundle import
|
||||
|
||||
Accept a local file + manifest:
|
||||
|
||||
* `epss_scores-YYYY-mm-dd.csv.gz`
|
||||
* `manifest.json` containing: sha256, source attribution, retrieval timestamp, optional DSSE signature.
|
||||
|
||||
Concelier runs the same ingest pipeline, but source_uri becomes `bundle://…`.
|
||||
|
||||
---
|
||||
|
||||
## 5) Enrichment rules (existing + new scans) without breaking determinism
|
||||
|
||||
### 5.1 New scan findings (immutable)
|
||||
|
||||
Store EPSS “as-of” scan time:
|
||||
|
||||
* This supports replay audits even if EPSS changes later.
|
||||
|
||||
### 5.2 Existing findings (live triage)
|
||||
|
||||
Maintain a mutable “current EPSS” on vulnerability instances (or a join at query time):
|
||||
|
||||
* Concelier updates only the **triage projection**, never the immutable scan evidence.
|
||||
|
||||
Recommended pattern:
|
||||
|
||||
* `scan_finding_evidence` → immutable EPSS-at-scan
|
||||
* `vuln_instance_triage` (or columns on instance) → current EPSS + band
|
||||
|
||||
### 5.3 Efficient targeting using epss_changes
|
||||
|
||||
On `epss.updated(D)` Concelier:
|
||||
|
||||
1. Reads `epss_changes` for D where flags indicate “material change”.
|
||||
2. Finds impacted vulnerability instances by CVE.
|
||||
3. Updates only those.
|
||||
4. Emits `vuln.priority.changed` only if band/threshold crossed.
|
||||
|
||||
---
|
||||
|
||||
## 6) Notification policy (defaults you can ship)
|
||||
|
||||
Define configurable thresholds:
|
||||
|
||||
* `HighPercentile = 0.95` (top 5%)
|
||||
* `HighScore = 0.50` (probability threshold)
|
||||
* `BigJumpDelta = 0.10` (meaningful daily change)
|
||||
|
||||
Notification triggers:
|
||||
|
||||
1. **Newly scored** CVE appears in your inventory AND `percentile >= HighPercentile`
|
||||
2. Existing CVE in inventory **crosses above** HighPercentile or HighScore
|
||||
3. Delta jump above BigJumpDelta AND CVE is present in runtime-exposed assets
|
||||
|
||||
All thresholds must be org-configurable.
|
||||
|
||||
---
|
||||
|
||||
## 7) API + UI surfaces
|
||||
|
||||
### 7.1 Internal API (your services)
|
||||
|
||||
Endpoints (example):
|
||||
|
||||
* `GET /epss/current?cve=CVE-…&cve=CVE-…`
|
||||
* `GET /epss/history?cve=CVE-…&days=180`
|
||||
* `GET /epss/top?order=epss&limit=100`
|
||||
* `GET /epss/changes?date=YYYY-MM-DD&flags=…`
|
||||
|
||||
### 7.2 UI requirements
|
||||
|
||||
For each vulnerability instance:
|
||||
|
||||
* EPSS score + percentile
|
||||
* Model date
|
||||
* Trend: delta vs previous scan date or vs yesterday
|
||||
* Filter chips:
|
||||
|
||||
* “High EPSS”
|
||||
* “Rising EPSS”
|
||||
* “High CVSS + High EPSS”
|
||||
* Evidence panel:
|
||||
|
||||
* shows EPSS-at-scan and current EPSS side-by-side
|
||||
|
||||
Add attribution footer in UI per FIRST usage expectations. ([first.org][3])
|
||||
|
||||
---
|
||||
|
||||
## 8) Reference implementation skeleton (.NET 10)
|
||||
|
||||
### 8.1 Concelier Worker: `EpssIngestJob`
|
||||
|
||||
Core steps (streamed, low memory):
|
||||
|
||||
* `HttpClient` → download `.gz`
|
||||
* `GZipStream` → `StreamReader`
|
||||
* parse comment line `# …`
|
||||
* parse CSV rows and `COPY` into TEMP table using `NpgsqlBinaryImporter`
|
||||
|
||||
Pseudo-structure:
|
||||
|
||||
* `IEpssSource` (online vs bundle)
|
||||
* `EpssCsvStreamParser` (yields rows)
|
||||
* `EpssRepository.IngestAsync(modelDate, rows, header, hashes, ct)`
|
||||
* `OutboxPublisher.EnqueueAsync(new EpssUpdatedEvent(...))`
|
||||
|
||||
### 8.2 Scanner.WebService: `IEpssProvider`
|
||||
|
||||
* `GetCurrentAsync(IEnumerable<string> cves)`:
|
||||
|
||||
* single SQL call: `SELECT ... FROM epss_current WHERE cve_id = ANY(@cves)`
|
||||
* optional Valkey cache:
|
||||
|
||||
* only as a read-through cache; never required for correctness.
|
||||
|
||||
---
|
||||
|
||||
## 9) Test plan (must be implemented, not optional)
|
||||
|
||||
### 9.1 Unit tests
|
||||
|
||||
* CSV parsing:
|
||||
|
||||
* handles leading `#` comment
|
||||
* handles missing/extra whitespace
|
||||
* rejects invalid scores outside [0,1]
|
||||
* delta flags:
|
||||
|
||||
* new-scored
|
||||
* crossing thresholds
|
||||
* big jump
|
||||
|
||||
### 9.2 Integration tests (Testcontainers)
|
||||
|
||||
* ingest a small `.csv.gz` fixture into Postgres
|
||||
* verify:
|
||||
|
||||
* epss_import_runs inserted
|
||||
* epss_scores inserted (partition correct)
|
||||
* epss_current upserted
|
||||
* epss_changes correct
|
||||
* outbox has `epss.updated`
|
||||
|
||||
### 9.3 Performance tests
|
||||
|
||||
* ingest synthetic 310k rows (close to current scale) ([first.org][1])
|
||||
* budgets:
|
||||
|
||||
* parse+copy under defined SLA
|
||||
* peak memory bounded
|
||||
* concurrency:
|
||||
|
||||
* ensure two ingests cannot both claim same model_date (unique constraint)
|
||||
|
||||
---
|
||||
|
||||
## 10) Implementation rollout plan (what your agents should build in order)
|
||||
|
||||
1. **DB migrations**: tables + partitions + indexes.
|
||||
2. **Concelier ingestion job**: online download + bundle import + provenance + outbox event.
|
||||
3. **epss_current + epss_changes projection**: delta computation and flags.
|
||||
4. **Scanner.WebService integration**: attach EPSS-at-scan evidence + bulk lookup API.
|
||||
5. **Concelier enrichment job**: update triage projections for impacted vuln instances.
|
||||
6. **Notify**: subscribe to `vuln.priority.changed` and send notifications.
|
||||
7. **UI**: EPSS fields, filters, trend, evidence panel.
|
||||
8. **Backfill tool** (optional): last 180 days (or configurable) via daily CSV URLs.
|
||||
9. **Ops runbook**: schedules, manual re-run, air-gap import procedure.
|
||||
|
||||
---
|
||||
|
||||
If you want this to be directly executable by your agents, tell me which repo layout you want to target (paths/module names), and I will convert the above into:
|
||||
|
||||
* exact **SQL migration files**,
|
||||
* concrete **C# .NET 10 code** for ingestion + repository + outbox,
|
||||
* and a **TASKS.md** breakdown with acceptance criteria per component.
|
||||
|
||||
[1]: https://www.first.org/epss/data_stats "Exploit Prediction Scoring System (EPSS)"
|
||||
[2]: https://www.first.org/epss/api "Exploit Prediction Scoring System (EPSS)"
|
||||
[3]: https://www.first.org/epss/ "Exploit Prediction Scoring System (EPSS)"
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user