up
This commit is contained in:
@@ -1,944 +0,0 @@
|
||||
Here’s a clean, action‑ready blueprint for a **public reachability benchmark** you can stand up quickly and grow over time.
|
||||
|
||||
# Why this matters (quick)
|
||||
|
||||
“Reachability” asks: *is a flagged vulnerability actually executable from real entry points in this codebase/container?* A public, reproducible benchmark lets you compare tools apples‑to‑apples, drive research, and keep vendors honest.
|
||||
|
||||
# What to collect (dataset design)
|
||||
|
||||
* **Projects & languages**
|
||||
|
||||
* Polyglot mix: **C/C++ (ELF/PE/Mach‑O)**, **Java/Kotlin**, **C#/.NET**, **Python**, **JavaScript/TypeScript**, **PHP**, **Go**, **Rust**.
|
||||
* For each project: small (≤5k LOC), medium (5–100k), large (100k+).
|
||||
* **Ground‑truth artifacts**
|
||||
|
||||
* **Seed CVEs** with known sinks (e.g., deserializers, command exec, SS RF) and **neutral projects** with *no* reachable path (negatives).
|
||||
* **Exploit oracles**: minimal PoCs or unit tests that (1) reach the sink and (2) toggle reachability via feature flags.
|
||||
* **Build outputs (deterministic)**
|
||||
|
||||
* **Reproducible binaries/bytecode** (strip timestamps; fixed seeds; SOURCE_DATE_EPOCH).
|
||||
* **SBOM** (CycloneDX/SPDX) + **PURLs** + **Build‑ID** (ELF .note.gnu.build‑id / PE Authentihash / Mach‑O UUID).
|
||||
* **Attestations**: in‑toto/DSSE envelopes recording toolchain versions, flags, hashes.
|
||||
* **Execution traces (for truth)**
|
||||
|
||||
* **CI traces**: call‑graph dumps from compilers/analyzers; unit‑test coverage; optional **dynamic traces** (eBPF/.NET ETW/Java Flight Recorder).
|
||||
* **Entry‑point manifests**: HTTP routes, CLI commands, cron/queue consumers.
|
||||
* **Metadata**
|
||||
|
||||
* Language, framework, package manager, compiler versions, OS/container image, optimization level, stripping info, license.
|
||||
|
||||
# How to label ground truth
|
||||
|
||||
* **Per‑vuln case**: `(component, version, sink_id)` with label **reachable / unreachable / unknown**.
|
||||
* **Evidence bundle**: pointer to (a) static call path, (b) dynamic hit (trace/coverage), or (c) rationale for negative.
|
||||
* **Confidence**: high (static+dynamic agree), medium (one source), low (heuristic only).
|
||||
|
||||
# Scoring (simple + fair)
|
||||
|
||||
* **Binary classification** on cases:
|
||||
|
||||
* Precision, Recall, F1. Report **AU‑PR** if you output probabilities.
|
||||
* **Path quality**
|
||||
|
||||
* **Explainability score (0–3)**:
|
||||
|
||||
* 0: “vuln reachable” w/o context
|
||||
* 1: names only (entry→…→sink)
|
||||
* 2: full interprocedural path w/ locations
|
||||
* 3: plus **inputs/guards** (taint/constraints, env flags)
|
||||
* **Runtime cost**
|
||||
|
||||
* Wall‑clock, peak RAM, image size; normalized by KLOC.
|
||||
* **Determinism**
|
||||
|
||||
* Re‑run variance (≤1% is “A”, 1–5% “B”, >5% “C”).
|
||||
|
||||
# Avoiding overfitting
|
||||
|
||||
* **Train/Dev/Test** splits per language; **hidden test** projects rotated quarterly.
|
||||
* **Case churn**: introduce **isomorphic variants** (rename symbols, reorder files) to punish memorization.
|
||||
* **Poisoned controls**: include decoy sinks and unreachable dead‑code traps.
|
||||
* **Submission rules**: require **attestations** of tool versions & flags; limit per‑case hints.
|
||||
|
||||
# Reference baselines (to run out‑of‑the‑box)
|
||||
|
||||
* **Snyk Code/Reachability** (JS/Java/Python, SaaS/CLI).
|
||||
* **Semgrep + Pro Engine** (rules + reachability mode).
|
||||
* **CodeQL** (multi‑lang, LGTM‑style queries).
|
||||
* **Joern** (C/C++/JVM code property graphs).
|
||||
* **angr** (binary symbolic exec; selective for native samples).
|
||||
* **Language‑specific**: pip‑audit w/ import graphs, npm with lock‑tree + route discovery, Maven + call‑graph (Soot/WALA).
|
||||
|
||||
# Submission format (one JSON per tool run)
|
||||
|
||||
```json
|
||||
{
|
||||
"tool": {"name": "YourTool", "version": "1.2.3"},
|
||||
"run": {
|
||||
"commit": "…",
|
||||
"platform": "ubuntu:24.04",
|
||||
"time_s": 182.4, "peak_mb": 3072
|
||||
},
|
||||
"cases": [
|
||||
{
|
||||
"id": "php-shop:fastjson@1.2.68:Sink#deserialize",
|
||||
"prediction": "reachable",
|
||||
"confidence": 0.88,
|
||||
"explain": {
|
||||
"entry": "POST /api/orders",
|
||||
"path": [
|
||||
"OrdersController::create",
|
||||
"Serializer::deserialize",
|
||||
"Fastjson::parseObject"
|
||||
],
|
||||
"guards": ["feature.flag.json_enabled==true"]
|
||||
}
|
||||
}
|
||||
],
|
||||
"artifacts": {
|
||||
"sbom": "sha256:…", "attestation": "sha256:…"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
# Folder layout (repo)
|
||||
|
||||
```
|
||||
/benchmark
|
||||
/cases/<lang>/<project>/<case_id>/
|
||||
case.yaml # component@version, sink, labels, evidence refs
|
||||
entrypoints.yaml # routes/CLIs/cron
|
||||
build/ # Dockerfiles, lockfiles, pinned toolchains
|
||||
outputs/ # SBOMs, binaries, traces (checksummed)
|
||||
/splits/{train,dev,test}.txt
|
||||
/schemas/{case.json,submission.json}
|
||||
/scripts/{build.sh, run_tests.sh, score.py}
|
||||
/docs/ (how-to, FAQs, T&Cs)
|
||||
```
|
||||
|
||||
# Minimal **v1** (4–6 weeks of work)
|
||||
|
||||
1. **Languages**: JS/TS, Python, Java, C (ELF).
|
||||
2. **20–30 cases**: mix of reachable/unreachable with PoC unit tests.
|
||||
3. **Deterministic builds** in containers; publish SBOM+attestations.
|
||||
4. **Scorer**: precision/recall/F1 + explainability, runtime, determinism.
|
||||
5. **Baselines**: run CodeQL + Semgrep across all; Snyk where feasible; angr for 3 native cases.
|
||||
6. **Website**: static leaderboard (per‑lang, per‑size), download links, submission guide.
|
||||
|
||||
# V2+ (quarterly)
|
||||
|
||||
* Add **.NET, PHP, Go, Rust**; broaden binary focus (PE/Mach‑O).
|
||||
* Add **dynamic traces** (eBPF/ETW/JFR) and **taint oracles**.
|
||||
* Introduce **config‑gated reachability** (feature flags, env, k8s secrets).
|
||||
* Add **dataset cards** per case (threat model, CWE, false‑positive traps).
|
||||
|
||||
# Publishing & governance
|
||||
|
||||
* License: **CC‑BY‑SA** for metadata, **source‑compatible OSS** for code, binaries under original licenses.
|
||||
* **Repro packs**: `benchmark-kit.tgz` with container recipes, hashes, and attestations.
|
||||
* **Disclosure**: CVE hygiene, responsible use, opt‑out path for upstreams.
|
||||
* **Stewards**: small TAC (you + two external reviewers) to approve new cases and adjudicate disputes.
|
||||
|
||||
# Immediate next steps (checklist)
|
||||
|
||||
* Lock the **schemas** (case + submission + attestation fields).
|
||||
* Pick 8 seed projects (2 per language tiered by size).
|
||||
* Draft 12 sink‑cases (6 reachable, 6 unreachable) with unit‑test oracles.
|
||||
* Script deterministic builds and **hash‑locked SBOMs**.
|
||||
* Implement the scorer; publish a **starter leaderboard** with 2 baselines.
|
||||
* Ship **v1 website/docs** and open submissions.
|
||||
|
||||
If you want, I can generate the repo scaffold (folders, YAML/JSON schemas, Dockerfiles, scorer script) so your team can `git clone` and start adding cases immediately.
|
||||
Cool, let’s turn the blueprint into a concrete, developer‑friendly implementation plan.
|
||||
|
||||
I’ll assume **v1 scope** is:
|
||||
|
||||
* Languages: **JavaScript/TypeScript (Node)**, **Python**, **Java**, **C (ELF)**
|
||||
* ~**20–30 cases** total (reachable/unreachable mix)
|
||||
* Baselines: **CodeQL**, **Semgrep**, maybe **Snyk** where licenses allow, and **angr** for a few native cases
|
||||
|
||||
You can expand later, but this plan is enough to get v1 shipped.
|
||||
|
||||
---
|
||||
|
||||
## 0. Overall project structure & ownership
|
||||
|
||||
**Owners**
|
||||
|
||||
* **Tech Lead** – owns architecture & final decisions
|
||||
* **Benchmark Core** – 2–3 devs building schemas, scorer, infra
|
||||
* **Language Tracks** – 1 dev per language (JS, Python, Java, C)
|
||||
* **Website/Docs** – 1 dev
|
||||
|
||||
**Repo layout (target)**
|
||||
|
||||
```text
|
||||
reachability-benchmark/
|
||||
README.md
|
||||
LICENSE
|
||||
CONTRIBUTING.md
|
||||
CODE_OF_CONDUCT.md
|
||||
|
||||
benchmark/
|
||||
cases/
|
||||
js/
|
||||
express-blog/
|
||||
case-001/
|
||||
case.yaml
|
||||
entrypoints.yaml
|
||||
build/
|
||||
Dockerfile
|
||||
build.sh
|
||||
src/ # project source (or submodule)
|
||||
tests/ # unit tests as oracles
|
||||
outputs/
|
||||
sbom.cdx.json
|
||||
binary.tar.gz
|
||||
coverage.json
|
||||
traces/ # optional dynamic traces
|
||||
py/
|
||||
flask-api/...
|
||||
java/
|
||||
spring-app/...
|
||||
c/
|
||||
httpd-like/...
|
||||
schemas/
|
||||
case.schema.yaml
|
||||
entrypoints.schema.yaml
|
||||
truth.schema.yaml
|
||||
submission.schema.json
|
||||
tools/
|
||||
scorer/
|
||||
rb_score/
|
||||
__init__.py
|
||||
cli.py
|
||||
metrics.py
|
||||
loader.py
|
||||
explainability.py
|
||||
pyproject.toml
|
||||
tests/
|
||||
build/
|
||||
build_all.py
|
||||
validate_builds.py
|
||||
|
||||
baselines/
|
||||
codeql/
|
||||
run_case.sh
|
||||
config/
|
||||
semgrep/
|
||||
run_case.sh
|
||||
rules/
|
||||
snyk/
|
||||
run_case.sh
|
||||
angr/
|
||||
run_case.sh
|
||||
|
||||
ci/
|
||||
github/
|
||||
benchmark.yml
|
||||
|
||||
website/
|
||||
# static site / leaderboard
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 1. Phase 1 – Repo & infra setup
|
||||
|
||||
### Task 1.1 – Create repository
|
||||
|
||||
**Developer:** Tech Lead
|
||||
**Deliverables:**
|
||||
|
||||
* Repo created (`reachability-benchmark` or similar)
|
||||
* `LICENSE` (e.g., Apache-2.0 or MIT)
|
||||
* Basic `README.md` describing:
|
||||
|
||||
* Purpose (public reachability benchmark)
|
||||
* High‑level design
|
||||
* v1 scope (langs, #cases)
|
||||
|
||||
### Task 1.2 – Bootstrap structure
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create directory skeleton as above (without filling everything yet).
|
||||
|
||||
Add:
|
||||
|
||||
```bash
|
||||
# benchmark/Makefile
|
||||
.PHONY: test lint build
|
||||
test:
|
||||
\tpytest benchmark/tools/scorer/tests
|
||||
|
||||
lint:
|
||||
\tblack benchmark/tools/scorer
|
||||
\tflake8 benchmark/tools/scorer
|
||||
|
||||
build:
|
||||
\tpython benchmark/tools/build/build_all.py
|
||||
```
|
||||
|
||||
### Task 1.3 – Coding standards & tooling
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
* Add `.editorconfig`, `.gitignore`, and Python tool configs (`ruff`, `black`, or `flake8`).
|
||||
* Define minimal **PR checklist** in `CONTRIBUTING.md`:
|
||||
|
||||
* Tests pass
|
||||
* Lint passes
|
||||
* New schemas have JSON schema or YAML schema and tests
|
||||
* New cases come with oracles (tests/coverage)
|
||||
|
||||
---
|
||||
|
||||
## 2. Phase 2 – Case & submission schemas
|
||||
|
||||
### Task 2.1 – Define case metadata format
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create `benchmark/schemas/case.schema.yaml` and an example `case.yaml`.
|
||||
|
||||
**Example `case.yaml`**
|
||||
|
||||
```yaml
|
||||
id: "js-express-blog:001"
|
||||
language: "javascript"
|
||||
framework: "express"
|
||||
size: "small" # small | medium | large
|
||||
component:
|
||||
name: "express-blog"
|
||||
version: "1.0.0-bench"
|
||||
vulnerability:
|
||||
cve: "CVE-XXXX-YYYY"
|
||||
cwe: "CWE-502"
|
||||
description: "Unsafe deserialization via user-controlled JSON."
|
||||
sink_id: "Deserializer::parse"
|
||||
ground_truth:
|
||||
label: "reachable" # reachable | unreachable | unknown
|
||||
confidence: "high" # high | medium | low
|
||||
evidence_files:
|
||||
- "truth.yaml"
|
||||
notes: >
|
||||
Unit test test_reachable_deserialization triggers the sink.
|
||||
build:
|
||||
dockerfile: "build/Dockerfile"
|
||||
build_script: "build/build.sh"
|
||||
output:
|
||||
artifact_path: "outputs/binary.tar.gz"
|
||||
sbom_path: "outputs/sbom.cdx.json"
|
||||
coverage_path: "outputs/coverage.json"
|
||||
traces_dir: "outputs/traces"
|
||||
environment:
|
||||
os_image: "ubuntu:24.04"
|
||||
compiler: null
|
||||
runtime:
|
||||
node: "20.11.0"
|
||||
source_date_epoch: 1730000000
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Schema validates sample `case.yaml` with a Python script:
|
||||
|
||||
* `benchmark/tools/build/validate_schema.py` using `jsonschema` or `pykwalify`.
|
||||
|
||||
---
|
||||
|
||||
### Task 2.2 – Entry points schema
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/schemas/entrypoints.schema.yaml`
|
||||
|
||||
**Example `entrypoints.yaml`**
|
||||
|
||||
```yaml
|
||||
entries:
|
||||
http:
|
||||
- id: "POST /api/posts"
|
||||
route: "/api/posts"
|
||||
method: "POST"
|
||||
handler: "PostsController.create"
|
||||
cli:
|
||||
- id: "generate-report"
|
||||
command: "node cli.js generate-report"
|
||||
description: "Generates summary report."
|
||||
scheduled:
|
||||
- id: "daily-cleanup"
|
||||
schedule: "0 3 * * *"
|
||||
handler: "CleanupJob.run"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 2.3 – Ground truth / truth schema
|
||||
|
||||
**Developer:** Benchmark Core + Language Tracks
|
||||
|
||||
`benchmark/schemas/truth.schema.yaml`
|
||||
|
||||
**Example `truth.yaml`**
|
||||
|
||||
```yaml
|
||||
id: "js-express-blog:001"
|
||||
cases:
|
||||
- sink_id: "Deserializer::parse"
|
||||
label: "reachable"
|
||||
dynamic_evidence:
|
||||
covered_by_tests:
|
||||
- "tests/test_reachable_deserialization.js::should_reach_sink"
|
||||
coverage_files:
|
||||
- "outputs/coverage.json"
|
||||
static_evidence:
|
||||
call_path:
|
||||
- "POST /api/posts"
|
||||
- "PostsController.create"
|
||||
- "PostsService.createFromJson"
|
||||
- "Deserializer.parse"
|
||||
config_conditions:
|
||||
- "process.env.FEATURE_JSON_ENABLED == 'true'"
|
||||
notes: "If FEATURE_JSON_ENABLED=false, path is unreachable."
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 2.4 – Submission schema
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/schemas/submission.schema.json`
|
||||
|
||||
**Shape**
|
||||
|
||||
```json
|
||||
{
|
||||
"tool": { "name": "YourTool", "version": "1.2.3" },
|
||||
"run": {
|
||||
"commit": "abcd1234",
|
||||
"platform": "ubuntu:24.04",
|
||||
"time_s": 182.4,
|
||||
"peak_mb": 3072
|
||||
},
|
||||
"cases": [
|
||||
{
|
||||
"id": "js-express-blog:001",
|
||||
"prediction": "reachable",
|
||||
"confidence": 0.88,
|
||||
"explain": {
|
||||
"entry": "POST /api/posts",
|
||||
"path": [
|
||||
"PostsController.create",
|
||||
"PostsService.createFromJson",
|
||||
"Deserializer.parse"
|
||||
],
|
||||
"guards": [
|
||||
"process.env.FEATURE_JSON_ENABLED === 'true'"
|
||||
]
|
||||
}
|
||||
}
|
||||
],
|
||||
"artifacts": {
|
||||
"sbom": "sha256:...",
|
||||
"attestation": "sha256:..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Write Python validation utility:
|
||||
|
||||
```bash
|
||||
python benchmark/tools/scorer/validate_submission.py submission.json
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Validation fails on missing fields / wrong enum values.
|
||||
* At least two sample submissions pass validation (e.g., “perfect” and “random baseline”).
|
||||
|
||||
---
|
||||
|
||||
## 3. Phase 3 – Reference projects & deterministic builds
|
||||
|
||||
### Task 3.1 – Select and vendor v1 projects
|
||||
|
||||
**Developer:** Tech Lead + Language Tracks
|
||||
|
||||
For each language, choose:
|
||||
|
||||
* 1 small toy app (simple web or CLI)
|
||||
* 1 medium app (more routes, multiple modules)
|
||||
* Optional: 1 large (for performance stress tests)
|
||||
|
||||
Add them under `benchmark/cases/<lang>/<project>/src/`
|
||||
(or as git submodules if you want to track upstream).
|
||||
|
||||
---
|
||||
|
||||
### Task 3.2 – Deterministic Docker build per project
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
For each project:
|
||||
|
||||
* Create `build/Dockerfile`
|
||||
* Create `build/build.sh` that:
|
||||
|
||||
* Builds the app
|
||||
* Produces artifacts
|
||||
* Generates SBOM and attestation
|
||||
|
||||
**Example `build/Dockerfile` (Node)**
|
||||
|
||||
```dockerfile
|
||||
FROM node:20.11-slim
|
||||
|
||||
ENV NODE_ENV=production
|
||||
ENV SOURCE_DATE_EPOCH=1730000000
|
||||
|
||||
WORKDIR /app
|
||||
COPY src/ /app
|
||||
COPY package.json package-lock.json /app/
|
||||
|
||||
RUN npm ci --ignore-scripts && \
|
||||
npm run build || true
|
||||
|
||||
CMD ["node", "server.js"]
|
||||
```
|
||||
|
||||
**Example `build.sh`**
|
||||
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
set -euo pipefail
|
||||
|
||||
ROOT_DIR="$(dirname "$(readlink -f "$0")")/.."
|
||||
OUT_DIR="$ROOT_DIR/outputs"
|
||||
mkdir -p "$OUT_DIR"
|
||||
|
||||
IMAGE_TAG="rb-js-express-blog:1"
|
||||
|
||||
docker build -t "$IMAGE_TAG" "$ROOT_DIR/build"
|
||||
|
||||
# Export image as tarball (binary artifact)
|
||||
docker save "$IMAGE_TAG" | gzip > "$OUT_DIR/binary.tar.gz"
|
||||
|
||||
# Generate SBOM (e.g. via syft) – can be optional stub for v1
|
||||
syft packages "docker:$IMAGE_TAG" -o cyclonedx-json > "$OUT_DIR/sbom.cdx.json"
|
||||
|
||||
# In future: generate in-toto attestations
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### Task 3.3 – Determinism checker
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`benchmark/tools/build/validate_builds.py`:
|
||||
|
||||
* For each case:
|
||||
|
||||
* Run `build.sh` twice
|
||||
* Compare hashes of `outputs/binary.tar.gz` and `outputs/sbom.cdx.json`
|
||||
* Fail if hashes differ.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* All v1 cases produce identical artifacts across two builds on CI.
|
||||
|
||||
---
|
||||
|
||||
## 4. Phase 4 – Ground truth oracles (tests & traces)
|
||||
|
||||
### Task 4.1 – Add unit/integration tests for reachable cases
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
For each **reachable** case:
|
||||
|
||||
* Add `tests/` under the project to:
|
||||
|
||||
* Start the app (if necessary)
|
||||
* Send a request/trigger that reaches the vulnerable sink
|
||||
* Assert that a sentinel side effect occurs (e.g. log or marker file) instead of real exploitation.
|
||||
|
||||
Example for Node using Jest:
|
||||
|
||||
```js
|
||||
test("should reach deserialization sink", async () => {
|
||||
const res = await request(app)
|
||||
.post("/api/posts")
|
||||
.send({ title: "x", body: '{"__proto__":{}}' });
|
||||
|
||||
expect(res.statusCode).toBe(200);
|
||||
// Sink logs "REACH_SINK" – we check log or variable
|
||||
expect(sinkWasReached()).toBe(true);
|
||||
});
|
||||
```
|
||||
|
||||
### Task 4.2 – Instrument coverage
|
||||
|
||||
**Developer:** Language Tracks
|
||||
|
||||
* For each language, pick a coverage tool:
|
||||
|
||||
* JS: `nyc` + `istanbul`
|
||||
* Python: `coverage.py`
|
||||
* Java: `jacoco`
|
||||
* C: `gcov`/`llvm-cov` (optional for v1)
|
||||
|
||||
* Ensure running tests produces `outputs/coverage.json` or `.xml` that we then convert to a simple JSON format:
|
||||
|
||||
```json
|
||||
{
|
||||
"files": {
|
||||
"src/controllers/posts.js": {
|
||||
"lines_covered": [12, 13, 14, 27],
|
||||
"lines_total": 40
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Create a small converter script if needed.
|
||||
|
||||
### Task 4.3 – Optional dynamic traces
|
||||
|
||||
If you want richer evidence:
|
||||
|
||||
* JS: add middleware that logs `(entry_id, handler, sink)` triples to `outputs/traces/traces.json`
|
||||
* Python: similar using decorators
|
||||
* C/Java: out of scope for v1 unless you want to invest extra time.
|
||||
|
||||
---
|
||||
|
||||
## 5. Phase 5 – Scoring tool (CLI)
|
||||
|
||||
### Task 5.1 – Implement `rb-score` library + CLI
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Create `benchmark/tools/scorer/rb_score/` with:
|
||||
|
||||
* `loader.py`
|
||||
|
||||
* Load all `case.yaml`, `truth.yaml` into memory.
|
||||
* Provide functions: `load_cases() -> Dict[case_id, Case]`.
|
||||
|
||||
* `metrics.py`
|
||||
|
||||
* Implement:
|
||||
|
||||
* `compute_precision_recall(truth, predictions)`
|
||||
* `compute_path_quality_score(explain_block)` (0–3)
|
||||
* `compute_runtime_stats(run_block)`
|
||||
|
||||
* `cli.py`
|
||||
|
||||
* CLI:
|
||||
|
||||
```bash
|
||||
rb-score \
|
||||
--cases-root benchmark/cases \
|
||||
--submission submissions/mytool.json \
|
||||
--output results/mytool_results.json
|
||||
```
|
||||
|
||||
**Pseudo-code for core scoring**
|
||||
|
||||
```python
|
||||
def score_submission(truth, submission):
|
||||
y_true = []
|
||||
y_pred = []
|
||||
per_case_scores = {}
|
||||
|
||||
for case in truth:
|
||||
gt = truth[case.id].label # reachable/unreachable
|
||||
pred_case = find_pred_case(submission.cases, case.id)
|
||||
pred_label = pred_case.prediction if pred_case else "unreachable"
|
||||
|
||||
y_true.append(gt == "reachable")
|
||||
y_pred.append(pred_label == "reachable")
|
||||
|
||||
explain_score = explainability(pred_case.explain if pred_case else None)
|
||||
|
||||
per_case_scores[case.id] = {
|
||||
"gt": gt,
|
||||
"pred": pred_label,
|
||||
"explainability": explain_score,
|
||||
}
|
||||
|
||||
precision, recall, f1 = compute_prf(y_true, y_pred)
|
||||
|
||||
return {
|
||||
"summary": {
|
||||
"precision": precision,
|
||||
"recall": recall,
|
||||
"f1": f1,
|
||||
"num_cases": len(truth),
|
||||
},
|
||||
"cases": per_case_scores,
|
||||
}
|
||||
```
|
||||
|
||||
### Task 5.2 – Explainability scoring rules
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
Implement `explainability(explain)`:
|
||||
|
||||
* 0 – `explain` missing or `path` empty
|
||||
* 1 – `path` present with at least 2 nodes (sink + one function)
|
||||
* 2 – `path` contains:
|
||||
|
||||
* Entry label (HTTP route/CLI id)
|
||||
* ≥3 nodes (entry → … → sink)
|
||||
* 3 – Level 2 plus `guards` list non-empty
|
||||
|
||||
Unit tests for at least 4 scenarios.
|
||||
|
||||
### Task 5.3 – Regression tests for scoring
|
||||
|
||||
Add small test fixture:
|
||||
|
||||
* Tiny synthetic benchmark: 3 cases, 2 reachable, 1 unreachable.
|
||||
* 3 submissions:
|
||||
|
||||
* Perfect
|
||||
* All reachable
|
||||
* All unreachable
|
||||
|
||||
Assertions:
|
||||
|
||||
* Perfect: `precision=1, recall=1`
|
||||
* All reachable: `recall=1, precision<1`
|
||||
* All unreachable: `precision=1 (trivially on negatives), recall=0`
|
||||
|
||||
---
|
||||
|
||||
## 6. Phase 6 – Baseline integrations
|
||||
|
||||
### Task 6.1 – Semgrep baseline
|
||||
|
||||
**Developer:** Benchmark Core (with Semgrep experience)
|
||||
|
||||
* `baselines/semgrep/run_case.sh`:
|
||||
|
||||
* Inputs: `case_id`, `cases_root`, `output_path`
|
||||
* Steps:
|
||||
|
||||
* Find `src/` for case
|
||||
* Run `semgrep --config auto` or curated rules
|
||||
* Convert Semgrep findings into benchmark submission format:
|
||||
|
||||
* Map Semgrep rules → vulnerability types → candidate sinks
|
||||
* Heuristically guess reachability (for v1, maybe always “reachable” if sink in code path)
|
||||
* Output: `output_path` JSON conforming to `submission.schema.json`.
|
||||
|
||||
### Task 6.2 – CodeQL baseline
|
||||
|
||||
* Create CodeQL databases for each project (likely via `codeql database create`).
|
||||
* Create queries targeting known sinks (e.g., `Deserialization`, `CommandInjection`).
|
||||
* `baselines/codeql/run_case.sh`:
|
||||
|
||||
* Build DB (or reuse)
|
||||
* Run queries
|
||||
* Translate results into our submission format (again as heuristic reachability).
|
||||
|
||||
### Task 6.3 – Optional Snyk / angr baselines
|
||||
|
||||
* Snyk:
|
||||
|
||||
* Use `snyk test` on the project
|
||||
* Map results to dependencies & known CVEs
|
||||
* For v1, just mark as `reachable` if Snyk reports a reachable path (if available).
|
||||
* angr:
|
||||
|
||||
* For 1–2 small C samples, configure simple analysis script.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For at least 5 cases (across languages), the baselines produce valid submission JSON.
|
||||
* `rb-score` runs and yields metrics without errors.
|
||||
|
||||
---
|
||||
|
||||
## 7. Phase 7 – CI/CD
|
||||
|
||||
### Task 7.1 – GitHub Actions workflow
|
||||
|
||||
**Developer:** Benchmark Core
|
||||
|
||||
`ci/github/benchmark.yml`:
|
||||
|
||||
Jobs:
|
||||
|
||||
1. `lint-and-test`
|
||||
|
||||
* `python -m pip install -e benchmark/tools/scorer[dev]`
|
||||
* `make lint`
|
||||
* `make test`
|
||||
|
||||
2. `build-cases`
|
||||
|
||||
* `python benchmark/tools/build/build_all.py`
|
||||
* Run `validate_builds.py`
|
||||
|
||||
3. `smoke-baselines`
|
||||
|
||||
* For 2–3 cases, run Semgrep/CodeQL wrappers and ensure they emit valid submissions.
|
||||
|
||||
### Task 7.2 – Artifact upload
|
||||
|
||||
* Upload `outputs/` tarball from `build-cases` as workflow artifacts.
|
||||
* Upload `results/*.json` from scoring runs.
|
||||
|
||||
---
|
||||
|
||||
## 8. Phase 8 – Website & leaderboard
|
||||
|
||||
### Task 8.1 – Define results JSON format
|
||||
|
||||
**Developer:** Benchmark Core + Website dev
|
||||
|
||||
`results/leaderboard.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"tools": [
|
||||
{
|
||||
"name": "Semgrep",
|
||||
"version": "1.60.0",
|
||||
"summary": {
|
||||
"precision": 0.72,
|
||||
"recall": 0.48,
|
||||
"f1": 0.58
|
||||
},
|
||||
"by_language": {
|
||||
"javascript": {"precision": 0.80, "recall": 0.50, "f1": 0.62},
|
||||
"python": {"precision": 0.65, "recall": 0.45, "f1": 0.53}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
CLI option to generate this:
|
||||
|
||||
```bash
|
||||
rb-score compare \
|
||||
--cases-root benchmark/cases \
|
||||
--submissions submissions/*.json \
|
||||
--output results/leaderboard.json
|
||||
```
|
||||
|
||||
### Task 8.2 – Static site
|
||||
|
||||
**Developer:** Website dev
|
||||
|
||||
Tech choice: any static framework (Next.js, Astro, Docusaurus, or even pure HTML+JS).
|
||||
|
||||
Pages:
|
||||
|
||||
* **Home**
|
||||
|
||||
* What is reachability?
|
||||
* Summary of benchmark
|
||||
|
||||
* **Leaderboard**
|
||||
|
||||
* Renders `leaderboard.json`
|
||||
* Filters: language, case size
|
||||
|
||||
* **Docs**
|
||||
|
||||
* How to run benchmark locally
|
||||
* How to prepare a submission
|
||||
|
||||
Add a simple script to copy `results/leaderboard.json` into `website/public/` for publishing.
|
||||
|
||||
---
|
||||
|
||||
## 9. Phase 9 – Docs, governance, and contribution flow
|
||||
|
||||
### Task 9.1 – CONTRIBUTING.md
|
||||
|
||||
Include:
|
||||
|
||||
* How to add a new case:
|
||||
|
||||
* Step‑by‑step:
|
||||
|
||||
1. Create project folder under `benchmark/cases/<lang>/<project>/case-XXX/`
|
||||
2. Add `case.yaml`, `entrypoints.yaml`, `truth.yaml`
|
||||
3. Add oracles (tests, coverage)
|
||||
4. Add deterministic `build/` assets
|
||||
5. Run local tooling:
|
||||
|
||||
* `validate_schema.py`
|
||||
* `validate_builds.py --case <id>`
|
||||
* Example PR description template.
|
||||
|
||||
### Task 9.2 – Governance doc
|
||||
|
||||
* Define **Technical Advisory Committee (TAC)** roles:
|
||||
|
||||
* Approve new cases
|
||||
* Approve schema changes
|
||||
* Manage hidden test sets (future phase)
|
||||
|
||||
* Define **release cadence**:
|
||||
|
||||
* v1.0 with public cases
|
||||
* Quarterly updates with new hidden cases.
|
||||
|
||||
---
|
||||
|
||||
## 10. Suggested milestone breakdown (for planning / sprints)
|
||||
|
||||
### Milestone 1 – Foundation (1–2 sprints)
|
||||
|
||||
* Repo scaffolding (Tasks 1.x)
|
||||
* Schemas (Tasks 2.x)
|
||||
* Two tiny toy cases (one JS, one Python) with:
|
||||
|
||||
* `case.yaml`, `entrypoints.yaml`, `truth.yaml`
|
||||
* Deterministic build
|
||||
* Basic unit tests
|
||||
* Minimal `rb-score` with:
|
||||
|
||||
* Case loading
|
||||
* Precision/recall only
|
||||
|
||||
**Exit:** You can run `rb-score` on a dummy submission for 2 cases.
|
||||
|
||||
---
|
||||
|
||||
### Milestone 2 – v1 dataset (2–3 sprints)
|
||||
|
||||
* Add ~20–30 cases across JS, Python, Java, C
|
||||
* Ground truth & coverage for each
|
||||
* Deterministic builds validated
|
||||
* Explainability scoring implemented
|
||||
* Regression tests for `rb-score`
|
||||
|
||||
**Exit:** Full scoring tool stable; dataset repeatably builds on CI.
|
||||
|
||||
---
|
||||
|
||||
### Milestone 3 – Baselines & site (1–2 sprints)
|
||||
|
||||
* Semgrep + CodeQL baselines producing valid submissions
|
||||
* CI running smoke baselines
|
||||
* `leaderboard.json` generator
|
||||
* Static website with public leaderboard and docs
|
||||
|
||||
**Exit:** Public v1 benchmark you can share with external tool authors.
|
||||
|
||||
---
|
||||
|
||||
If you tell me which stack your team prefers for the site (React, plain HTML, SSG, etc.) or which CI you’re on, I can adapt this into concrete config files (e.g., a full GitHub Actions workflow, Next.js scaffold, or exact `pyproject.toml` for `rb-score`).
|
||||
@@ -1,636 +0,0 @@
|
||||
Here’s a compact, one‑screen “CVSS v4.0 Score Receipt” you can drop into Stella Ops so every vulnerability carries its score, evidence, and policy lineage end‑to‑end.
|
||||
|
||||
---
|
||||
|
||||
# CVSS v4.0 Score Receipt (CVSS‑BTE + Supplemental)
|
||||
|
||||
**Vuln ID / Title**
|
||||
**Final CVSS v4.0 Score:** *X.Y* (CVSS‑BTE) • **Vector:** `CVSS:4.0/...`
|
||||
**Why BTE?** CVSS v4.0 is designed to combine Base with default Threat/Environmental first, then amend with real context; Supplemental adds non‑scoring context. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 1) Base Metrics (intrinsic; vendor/researcher)
|
||||
|
||||
*List each metric with chosen value + short justification + evidence link.*
|
||||
|
||||
* **Attack Vector (AV):** N | A | I | P — *reason & evidence*
|
||||
* **Attack Complexity (AC):** L | H — *reason & evidence*
|
||||
* **Attack Requirements (AT):** N | P | ? — *reason & evidence*
|
||||
* **Privileges Required (PR):** N | L | H — *reason & evidence*
|
||||
* **User Interaction (UI):** Passive | Active — *reason & evidence*
|
||||
* **Vulnerable System Impact (VC/VI/VA):** H | L | N — *reason & evidence*
|
||||
* **Subsequent System Impact (SC/SI/SA):** H | L | N — *reason & evidence*
|
||||
|
||||
> Notes: v4.0 clarifies Base, splits vulnerable vs. subsequent system impact, and refines UI (Passive/Active). ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 2) Threat Metrics (time‑varying; consumer)
|
||||
|
||||
* **Exploit Maturity (E):** Attacked | POC | Unreported | NotDefined — *intel & source*
|
||||
* **Automatable (AU):** Yes | No | ND — *tooling/observations*
|
||||
* **Provider Urgency (U):** High | Medium | Low | ND — *advisory/ref*
|
||||
|
||||
> Threat replaces the old Temporal concept and adjusts severity with real‑world exploitation context. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 3) Environmental Metrics (your environment)
|
||||
|
||||
* **Security Controls (CR/XR/AR):** Present | Partial | None — *control IDs*
|
||||
* **Criticality (S, H, L, N) of asset/service:** *business tag*
|
||||
* **Safety/Human Impact in your environment:** *if applicable*
|
||||
|
||||
> Environmental tailors the score to your environment (controls, importance). ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 4) Supplemental (non‑scoring context)
|
||||
|
||||
* **Safety, Recovery, Value‑Density, Vulnerability Response Effort, etc.:** *values + short notes*
|
||||
|
||||
> Supplemental adds context but does not change the numeric score. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 5) Evidence Ledger
|
||||
|
||||
* **Artifacts:** logs, PoCs, packet captures, SBOM slices, call‑graphs, config excerpts
|
||||
* **References:** vendor advisory, NVD/First calculator snapshot, exploit write‑ups
|
||||
* **Timestamps & hash of each evidence item** (SHA‑256)
|
||||
|
||||
> Keep a permalink to the FIRST v4.0 calculator or NVD v4 calculator capture for audit. ([FIRST][2])
|
||||
|
||||
---
|
||||
|
||||
## 6) Policy & Determinism
|
||||
|
||||
* **Scoring Policy ID:** `cvss-policy-v4.0-stellaops-YYYYMMDD`
|
||||
* **Policy Hash:** `sha256:…` (of the JSON policy used to map inputs→metrics)
|
||||
* **Scoring Engine Version:** `stellaops.scorer vX.Y.Z`
|
||||
* **Repro Inputs Hash:** DSSE envelope including evidence URIs + CVSS vector
|
||||
|
||||
> Treat the receipt as a deterministic artifact: Base with default T/E, then amended with Threat+Environmental to produce CVSS‑BTE; store policy/evidence hashes for replayable audits. ([FIRST][1])
|
||||
|
||||
---
|
||||
|
||||
## 7) History (amendments over time)
|
||||
|
||||
| Date | Changed | From → To | Reason | Link |
|
||||
| ---------- | -------- | -------------- | ------------------------ | ----------- |
|
||||
| 2025‑11‑25 | Threat:E | POC → Attacked | Active exploitation seen | *intel ref* |
|
||||
|
||||
---
|
||||
|
||||
## Minimal JSON schema (for your UI/API)
|
||||
|
||||
```json
|
||||
{
|
||||
"vulnId": "CVE-YYYY-XXXX",
|
||||
"title": "Short vuln title",
|
||||
"cvss": {
|
||||
"version": "4.0",
|
||||
"vector": "CVSS:4.0/…",
|
||||
"base": { "AV": "N", "AC": "L", "AT": "N", "PR": "N", "UI": "P", "VC": "H", "VI": "H", "VA": "H", "SC": "L", "SI": "N", "SA": "N", "justifications": { /* per-metric text + evidence URIs */ } },
|
||||
"threat": { "E": "Attacked", "AU": "Yes", "U": "High", "evidence": [/* intel links */] },
|
||||
"environmental": { "controls": { "CR": "Present", "XR": "Partial", "AR": "None" }, "criticality": "H", "notes": "…" },
|
||||
"supplemental": { "safety": "High", "recovery": "Hard", "notes": "…" },
|
||||
"finalScore": 9.1,
|
||||
"enumeration": "CVSS-BTE"
|
||||
},
|
||||
"evidence": [{ "name": "exploit_poc.md", "sha256": "…", "uri": "…" }],
|
||||
"policy": { "id": "cvss-policy-v4.0-stellaops-20251125", "sha256": "…", "engine": "stellaops.scorer 1.2.0" },
|
||||
"repro": { "dsseEnvelope": "base64…", "inputsHash": "sha256:…" },
|
||||
"history": [{ "date": "2025-11-25", "change": "Threat:E POC→Attacked", "reason": "SOC report", "ref": "…" }]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## Drop‑in UI wireframe (single screen)
|
||||
|
||||
* **Header bar:** Score badge (X.Y), “CVSS‑BTE”, vector copy button.
|
||||
* **Tabs (or stacked cards):** Base • Threat • Environmental • Supplemental • Evidence • Policy • History.
|
||||
* **Right rail:** “Recalculate with my env” (edits only Threat/Environmental), “Export receipt (JSON/PDF)”, “Open in FIRST/NVD calculator”.
|
||||
|
||||
---
|
||||
|
||||
If you want, I’ll adapt this to your Stella Ops components (DTOs, EF Core models, and a Razor/Blazor card) and wire it to your “deterministic replay” pipeline so every scan emits this receipt alongside the VEX note.
|
||||
|
||||
[1]: https://www.first.org/cvss/v4-0/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://www.first.org/cvss/calculator/4-0?utm_source=chatgpt.com "Common Vulnerability Scoring System Version 4.0 Calculator"
|
||||
Perfect, let’s turn that receipt idea into a concrete implementation plan your devs can actually build from.
|
||||
|
||||
I’ll break it into phases and responsibilities (backend, frontend, platform/DevOps), with enough detail that someone could start creating tickets from this.
|
||||
|
||||
---
|
||||
|
||||
## 0. Align on Scope & Definitions
|
||||
|
||||
**Goal:** For every vulnerability in Stella Ops, store and display a **CVSS v4.0 CVSS‑BTE score receipt** that is:
|
||||
|
||||
* Deterministic & reproducible (policy + inputs → same score).
|
||||
* Evidenced (links + hashes of artifacts).
|
||||
* Auditable over time (history of amendments).
|
||||
* Friendly to both **vendor/base** and **consumer/threat/env** workflows.
|
||||
|
||||
**Key concepts to lock in with the team (no coding yet):**
|
||||
|
||||
* **Primary object**: `CvssScoreReceipt` attached to a `Vulnerability`.
|
||||
* **Canonical score** = **CVSS‑BTE** (Base + Threat + Environmental).
|
||||
* **Base** usually from vendor/researcher; Threat + Environmental from Stella Ops / customer context.
|
||||
* **Supplemental** metrics: stored but **not part of numeric score**.
|
||||
* **Policy**: machine-readable config (e.g., JSON) that defines how you map questionnaire/inputs → CVSS metrics.
|
||||
|
||||
Deliverable: 2–3 page internal spec summarizing above for devs + PMs.
|
||||
|
||||
---
|
||||
|
||||
## 1. Data Model Design
|
||||
|
||||
### 1.1 Core Entities
|
||||
|
||||
*Model names are illustrative; adapt to your stack.*
|
||||
|
||||
**Vulnerability**
|
||||
|
||||
* `id`
|
||||
* `externalId` (e.g. CVE)
|
||||
* `title`
|
||||
* `description`
|
||||
* `currentCvssReceiptId` (FK → `CvssScoreReceipt`)
|
||||
|
||||
**CvssScoreReceipt**
|
||||
|
||||
* `id`
|
||||
* `vulnerabilityId` (FK)
|
||||
* `version` (e.g. `"4.0"`)
|
||||
* `enumeration` (e.g. `"CVSS-BTE"`)
|
||||
* `vectorString` (full v4.0 vector)
|
||||
* `finalScore` (numeric, 0.0–10.0)
|
||||
* `baseScore` (derived or duplicate for convenience)
|
||||
* `threatScore` (optional interim)
|
||||
* `environmentalScore` (optional interim)
|
||||
* `createdAt`
|
||||
* `createdByUserId`
|
||||
* `policyId` (FK → `CvssPolicy`)
|
||||
* `policyHash` (sha256 of policy JSON)
|
||||
* `inputsHash` (sha256 of normalized scoring inputs)
|
||||
* `dsseEnvelope` (optional text/blob if you implement full DSSE)
|
||||
* `metadata` (JSON for any extras you want)
|
||||
|
||||
**BaseMetrics (v4.0)**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `AV`, `AC`, `AT`, `PR`, `UI`
|
||||
* `VC`, `VI`, `VA`, `SC`, `SI`, `SA`
|
||||
* `justifications` (JSON object keyed by metric)
|
||||
|
||||
* e.g. `{ "AV": { "reason": "...", "evidenceIds": ["..."] }, ... }`
|
||||
|
||||
**ThreatMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `E` (Exploit Maturity)
|
||||
* `AU` (Automatable)
|
||||
* `U` (Provider/Consumer Urgency)
|
||||
* `evidence` (JSON: list of intel references)
|
||||
|
||||
**EnvironmentalMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* `CR`, `XR`, `AR` (controls)
|
||||
* `criticality` (S/H/L/N or your internal enum)
|
||||
* `notes` (text/JSON)
|
||||
|
||||
**SupplementalMetrics**
|
||||
|
||||
* `id`, `receiptId` (FK)
|
||||
* Fields you care about, e.g.:
|
||||
|
||||
* `safetyImpact`
|
||||
* `recoveryEffort`
|
||||
* `valueDensity`
|
||||
* `vulnerabilityResponseEffort`
|
||||
* `notes`
|
||||
|
||||
**EvidenceItem**
|
||||
|
||||
* `id`
|
||||
* `receiptId` (FK)
|
||||
* `name` (e.g. `"exploit_poc.md"`)
|
||||
* `uri` (link into your blob store, S3, etc.)
|
||||
* `sha256`
|
||||
* `type` (log, pcap, exploit, advisory, config, etc.)
|
||||
* `createdAt`
|
||||
* `createdBy`
|
||||
|
||||
**CvssPolicy**
|
||||
|
||||
* `id` (e.g. `cvss-policy-v4.0-stellaops-20251125`)
|
||||
* `name`
|
||||
* `version`
|
||||
* `engineVersion` (e.g. `stellaops.scorer 1.2.0`)
|
||||
* `policyJson` (JSON)
|
||||
* `sha256` (policy hash)
|
||||
* `active` (bool)
|
||||
* `validFrom`, `validTo` (optional)
|
||||
|
||||
**ReceiptHistoryEntry**
|
||||
|
||||
* `id`
|
||||
* `receiptId` (FK)
|
||||
* `date`
|
||||
* `changedField` (e.g. `"Threat.E"`)
|
||||
* `oldValue`
|
||||
* `newValue`
|
||||
* `reason`
|
||||
* `referenceUri` (link to ticket / intel)
|
||||
* `changedByUserId`
|
||||
|
||||
---
|
||||
|
||||
## 2. Backend Implementation Plan
|
||||
|
||||
### 2.1 Scoring Engine
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Create a `CvssV4Engine` module/package** with:
|
||||
|
||||
* `parseVector(string): CvssVector`
|
||||
* `computeBaseScore(metrics: BaseMetrics): number`
|
||||
* `computeThreatAdjustedScore(base: number, threat: ThreatMetrics): number`
|
||||
* `computeEnvironmentalAdjustedScore(threatAdjusted: number, env: EnvironmentalMetrics): number`
|
||||
* `buildVector(metrics: BaseMetrics & ThreatMetrics & EnvironmentalMetrics): string`
|
||||
2. Implement **CVSS v4.0 math** exactly per spec (rounding rules, minimums, etc.).
|
||||
3. Add **unit tests** for all official sample vectors + your own edge cases.
|
||||
|
||||
**Deliverables:**
|
||||
|
||||
* Test suite `CvssV4EngineTests` with:
|
||||
|
||||
* Known test vectors (from spec or FIRST calculator)
|
||||
* Edge cases: missing threat/env, zero-impact vulnerabilities, etc.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Receipt Construction Pipeline
|
||||
|
||||
Define a canonical function in backend:
|
||||
|
||||
```pseudo
|
||||
function createReceipt(vulnId, input, policyId, userId):
|
||||
policy = loadPolicy(policyId)
|
||||
normalizedInput = applyPolicy(input, policy) // map UI questionnaire → CVSS metrics
|
||||
|
||||
base = normalizedInput.baseMetrics
|
||||
threat = normalizedInput.threatMetrics
|
||||
env = normalizedInput.environmentalMetrics
|
||||
supplemental = normalizedInput.supplemental
|
||||
|
||||
// Score
|
||||
baseScore = CvssV4Engine.computeBaseScore(base)
|
||||
threatScore = CvssV4Engine.computeThreatAdjustedScore(baseScore, threat)
|
||||
finalScore = CvssV4Engine.computeEnvironmentalAdjustedScore(threatScore, env)
|
||||
|
||||
// Vector
|
||||
vector = CvssV4Engine.buildVector({base, threat, env})
|
||||
|
||||
// Hashes
|
||||
inputsHash = sha256(serializeForHashing({ base, threat, env, supplemental, evidenceRefs: input.evidenceIds }))
|
||||
policyHash = policy.sha256
|
||||
dsseEnvelope = buildDSSEEnvelope({ vulnId, base, threat, env, supplemental, policyId, policyHash, inputsHash })
|
||||
|
||||
// Persist entities in transaction
|
||||
receipt = saveCvssScoreReceipt(...)
|
||||
saveBaseMetrics(receipt.id, base)
|
||||
saveThreatMetrics(receipt.id, threat)
|
||||
saveEnvironmentalMetrics(receipt.id, env)
|
||||
saveSupplementalMetrics(receipt.id, supplemental)
|
||||
linkEvidence(receipt.id, input.evidenceItems)
|
||||
|
||||
updateVulnerabilityCurrentReceipt(vulnId, receipt.id)
|
||||
|
||||
return receipt
|
||||
```
|
||||
|
||||
**Important implementation details:**
|
||||
|
||||
* **`serializeForHashing`**: define a stable ordering and normalization (sorted keys, no whitespace sensitivity, canonical enums) so hashes are truly deterministic.
|
||||
* Use **transactions** so partial writes never leave `Vulnerability` pointing to incomplete receipts.
|
||||
* Ensure **idempotency**: if same `inputsHash + policyHash` already exists for that vuln, you can either:
|
||||
|
||||
* return existing receipt, or
|
||||
* create a new one but mark it as a duplicate-of; choose one rule and document it.
|
||||
|
||||
---
|
||||
|
||||
### 2.3 APIs
|
||||
|
||||
Design REST/GraphQL endpoints (adapt names to your style):
|
||||
|
||||
**Read:**
|
||||
|
||||
* `GET /vulnerabilities/{id}/cvss-receipt`
|
||||
|
||||
* Returns full receipt with nested metrics, evidence, policy metadata, history.
|
||||
* `GET /vulnerabilities/{id}/cvss-receipts`
|
||||
|
||||
* List historical receipts/versions.
|
||||
|
||||
**Create / Update:**
|
||||
|
||||
* `POST /vulnerabilities/{id}/cvss-receipt`
|
||||
|
||||
* Body: CVSS input payload (not raw metrics) + policyId.
|
||||
* Backend applies policy → metrics, computes scores, stores receipt.
|
||||
* `POST /vulnerabilities/{id}/cvss-receipt/recalculate`
|
||||
|
||||
* Optional: allows updating **only Threat + Environmental** while preserving Base.
|
||||
|
||||
**Evidence:**
|
||||
|
||||
* `POST /cvss-receipts/{receiptId}/evidence`
|
||||
|
||||
* Upload/link evidence artifacts, compute sha256, associate with receipt.
|
||||
* (Or integrate with your existing evidence/attachments service and only store references.)
|
||||
|
||||
**Policy:**
|
||||
|
||||
* `GET /cvss-policies`
|
||||
* `GET /cvss-policies/{id}`
|
||||
|
||||
**History:**
|
||||
|
||||
* `GET /cvss-receipts/{receiptId}/history`
|
||||
|
||||
Add auth/authorization:
|
||||
|
||||
* Only certain roles can **change Base**.
|
||||
* Different roles can **change Threat/Env**.
|
||||
* Audit logs for each change.
|
||||
|
||||
---
|
||||
|
||||
### 2.4 Integration with Existing Pipelines
|
||||
|
||||
**Automatic creation paths:**
|
||||
|
||||
1. **Scanner import path**
|
||||
|
||||
* When new vulnerability is imported with vendor CVSS v4:
|
||||
|
||||
* Parse vendor vector → BaseMetrics.
|
||||
* Use your default policy to set Threat/Env to “NotDefined”.
|
||||
* Generate initial receipt (tag as `source = "vendor"`).
|
||||
|
||||
2. **Manual analyst scoring**
|
||||
|
||||
* Analyst opens Vuln in Stella Ops UI.
|
||||
* Fills out guided form.
|
||||
* Frontend calls `POST /vulnerabilities/{id}/cvss-receipt`.
|
||||
|
||||
3. **Customer-specific Environmental scoring**
|
||||
|
||||
* Per-tenant policy stored in `CvssPolicy`.
|
||||
* Receipts store that policyId; calculating environment-specific scores uses those controls/criticality.
|
||||
|
||||
---
|
||||
|
||||
## 3. Frontend / UI Implementation Plan
|
||||
|
||||
### 3.1 Main “CVSS Score Receipt” Panel
|
||||
|
||||
Single screen/card with sections (tabs or accordions):
|
||||
|
||||
1. **Header**
|
||||
|
||||
* Large score badge: `finalScore` (e.g. 9.1).
|
||||
* Label: `CVSS v4.0 (CVSS‑BTE)`.
|
||||
* Color-coded severity (Low/Med/High/Critical).
|
||||
* Copy-to-clipboard for vector string.
|
||||
* Show Base/Threat/Env sub-scores if you choose to expose.
|
||||
|
||||
2. **Base Metrics Section**
|
||||
|
||||
* Table or form-like display:
|
||||
|
||||
* Each metric: value, short textual description, collapsed justification with “View more”.
|
||||
* Example row:
|
||||
|
||||
* **Attack Vector (AV)**: Network
|
||||
|
||||
* “The vulnerability is exploitable over the internet. PoC requires only TCP connectivity to port 443.”
|
||||
* Evidence chips: `exploit_poc.md`, `nginx_error.log.gz`.
|
||||
|
||||
3. **Threat Metrics Section**
|
||||
|
||||
* Radio/select controls for Exploit Maturity, Automatable, Urgency.
|
||||
* “Intel references” list (URLs or evidence items).
|
||||
* If the user edits these and clicks **Save**, frontend:
|
||||
|
||||
* Builds Threat input payload.
|
||||
* Calls `POST /vulnerabilities/{id}/cvss-receipt/recalculate` with updated threat/env only.
|
||||
* Shows new score & appends a `ReceiptHistoryEntry`.
|
||||
|
||||
4. **Environmental Section**
|
||||
|
||||
* Controls selection: Present / Partial / None.
|
||||
* Business criticality picker.
|
||||
* Contextual notes.
|
||||
* Same recalc flow as Threat.
|
||||
|
||||
5. **Supplemental Section**
|
||||
|
||||
* Non-scoring fields with clear label: “Does not affect numeric score, for context only”.
|
||||
|
||||
6. **Evidence Section**
|
||||
|
||||
* List of evidence items with:
|
||||
|
||||
* Name, type, hash, link.
|
||||
* “Attach evidence” button → upload / select existing artifact.
|
||||
|
||||
7. **Policy & Determinism Section**
|
||||
|
||||
* Display:
|
||||
|
||||
* Policy ID + hash.
|
||||
* Scoring engine version.
|
||||
* Inputs hash.
|
||||
* DSSE status (valid / not verified).
|
||||
* Button: **“Download receipt (JSON)”** – uses the JSON schema you already drafted.
|
||||
* Optional: **“Open in external calculator”** with vector appended as query parameter.
|
||||
|
||||
8. **History Section**
|
||||
|
||||
* Timeline of changes:
|
||||
|
||||
* Date, who, what changed (e.g. `Threat.E: POC → Attacked`).
|
||||
* Reason + link.
|
||||
|
||||
### 3.2 UX Considerations
|
||||
|
||||
* **Guardrails:**
|
||||
|
||||
* Editing Base metrics: show “This should match vendor or research data. Changing Base will alter historical comparability.”
|
||||
* Display last updated time & user for each metrics block.
|
||||
* **Permissions:**
|
||||
|
||||
* Disable inputs if user does not have edit rights; still show receipts read-only.
|
||||
* **Error Handling:**
|
||||
|
||||
* Show vector parse or scoring errors clearly, with a reference to policy/engine version.
|
||||
* **Accessibility:**
|
||||
|
||||
* High contrast for severity badges and clear iconography.
|
||||
|
||||
---
|
||||
|
||||
## 4. JSON Schema & Contracts
|
||||
|
||||
You already have a draft JSON; turn it into a formal schema (OpenAPI / JSON Schema) so backend + frontend are in sync.
|
||||
|
||||
Example top-level shape (high-level, not full code):
|
||||
|
||||
```json
|
||||
{
|
||||
"vulnId": "CVE-YYYY-XXXX",
|
||||
"title": "Short vuln title",
|
||||
"cvss": {
|
||||
"version": "4.0",
|
||||
"enumeration": "CVSS-BTE",
|
||||
"vector": "CVSS:4.0/...",
|
||||
"finalScore": 9.1,
|
||||
"baseScore": 8.7,
|
||||
"threatScore": 9.0,
|
||||
"environmentalScore": 9.1,
|
||||
"base": {
|
||||
"AV": "N", "AC": "L", "AT": "N", "PR": "N", "UI": "P",
|
||||
"VC": "H", "VI": "H", "VA": "H",
|
||||
"SC": "L", "SI": "N", "SA": "N",
|
||||
"justifications": {
|
||||
"AV": { "reason": "reachable over internet", "evidence": ["ev1"] }
|
||||
}
|
||||
},
|
||||
"threat": { "E": "Attacked", "AU": "Yes", "U": "High" },
|
||||
"environmental": { "controls": { "CR": "Present", "XR": "Partial", "AR": "None" }, "criticality": "H" },
|
||||
"supplemental": { "safety": "High", "recovery": "Hard" }
|
||||
},
|
||||
"evidence": [
|
||||
{ "id": "ev1", "name": "exploit_poc.md", "uri": "...", "sha256": "..." }
|
||||
],
|
||||
"policy": {
|
||||
"id": "cvss-policy-v4.0-stellaops-20251125",
|
||||
"sha256": "...",
|
||||
"engine": "stellaops.scorer 1.2.0"
|
||||
},
|
||||
"repro": {
|
||||
"dsseEnvelope": "base64...",
|
||||
"inputsHash": "sha256:..."
|
||||
},
|
||||
"history": [
|
||||
{ "date": "2025-11-25", "change": "Threat.E POC→Attacked", "reason": "SOC report", "ref": "..." }
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Back-end team: publish this via OpenAPI and keep it versioned.
|
||||
|
||||
---
|
||||
|
||||
## 5. Security, Integrity & Compliance
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Evidence Integrity**
|
||||
|
||||
* Enforce sha256 on every evidence item.
|
||||
* Optionally re-hash blob in background and store `verifiedAt` timestamp.
|
||||
|
||||
2. **Immutability**
|
||||
|
||||
* Decide which parts of a receipt are immutable:
|
||||
|
||||
* Typically: Base metrics, evidence links, policy references.
|
||||
* Threat/Env may change by creating **new receipts** or new “versions” of the same receipt.
|
||||
* Consider:
|
||||
|
||||
* “Current receipt” pointer on Vulnerability.
|
||||
* All receipts are read-only after creation; changes create new receipt + history entry.
|
||||
|
||||
3. **Audit Logging**
|
||||
|
||||
* Log who changed what (especially Threat/Env).
|
||||
* Store reference to ticket / change request.
|
||||
|
||||
4. **Access Control**
|
||||
|
||||
* RBAC: e.g. `ROLE_SEC_ENGINEER` can set Base; `ROLE_CUSTOMER_ANALYST` can set Env; `ROLE_VIEWER` read-only.
|
||||
|
||||
---
|
||||
|
||||
## 6. Testing Strategy
|
||||
|
||||
**Unit Tests**
|
||||
|
||||
* `CvssV4EngineTests` – coverage of:
|
||||
|
||||
* Vector parsing/serialization.
|
||||
* Calculations for B, BT, BTE.
|
||||
* `ReceiptBuilderTests` – determinism:
|
||||
|
||||
* Same inputs + policy → same score + same hashes.
|
||||
* Different policyId → different policyHash, different DSSE, even if metrics identical.
|
||||
|
||||
**Integration Tests**
|
||||
|
||||
* End-to-end:
|
||||
|
||||
* Create vulnerability → create receipt with Base only → update Threat → update Env.
|
||||
* Vendor CVSS import path.
|
||||
* Permission tests:
|
||||
|
||||
* Ensure unauthorized edits are blocked.
|
||||
|
||||
**UI Tests**
|
||||
|
||||
* Snapshot tests for the card layout.
|
||||
* Behavior: changing Threat slider updates preview score.
|
||||
* Accessibility checks (ARIA, focus order).
|
||||
|
||||
---
|
||||
|
||||
## 7. Rollout Plan
|
||||
|
||||
1. **Phase 1 – Backend Foundations**
|
||||
|
||||
* Implement data model + migrations.
|
||||
* Implement scoring engine + policies.
|
||||
* Implement REST/GraphQL endpoints (feature-flagged).
|
||||
2. **Phase 2 – UI MVP**
|
||||
|
||||
* Render read-only receipts for a subset of vulnerabilities.
|
||||
* Internal dogfood with security team.
|
||||
3. **Phase 3 – Editing & Recalc**
|
||||
|
||||
* Enable Threat/Env editing.
|
||||
* Wire evidence upload.
|
||||
* Activate history tracking.
|
||||
4. **Phase 4 – Vendor Integration + Tenants**
|
||||
|
||||
* Map scanner imports → initial Base receipts.
|
||||
* Tenant-specific Environmental policies.
|
||||
5. **Phase 5 – Hardening**
|
||||
|
||||
* Performance tests (bulk listing of vulnerabilities with receipts).
|
||||
* Security review of evidence and hash handling.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can turn this into:
|
||||
|
||||
* A set of Jira/Linear epics + tickets, or
|
||||
* A stack-specific design (for example: .NET + EF Core models + Razor components, or Node + TypeScript + React components) with concrete code skeletons.
|
||||
@@ -1,563 +0,0 @@
|
||||
Here’s a crisp, ready‑to‑use rule for VEX hygiene that will save you pain in audits and customer reviews—and make Stella Ops look rock‑solid.
|
||||
|
||||
# Adopt a strict “`not_affected` only with proof” policy
|
||||
|
||||
**What it means (plain English):**
|
||||
Only mark a vulnerability as `not_affected` if you can *prove* the vulnerable code can’t run in your product under defined conditions—then record that proof (scope, entry points, limits) inside a VEX bundle.
|
||||
|
||||
## The non‑negotiables
|
||||
|
||||
* **Audit coverage:**
|
||||
You must enumerate the reachable entry points you audited (e.g., exported handlers, CLI verbs, HTTP routes, scheduled jobs, init hooks). State their *limits* (versions, build flags, feature toggles, container args, config profiles).
|
||||
* **VEX justification required:**
|
||||
Use a concrete justification (OpenVEX/CISA style), e.g.:
|
||||
|
||||
* `vulnerable_code_not_in_execute_path`
|
||||
* `component_not_present`
|
||||
* `vulnerable_code_cannot_be_controlled_by_adversary`
|
||||
* `inline_mitigation_already_in_place`
|
||||
* **Impact or constraint statement:**
|
||||
Explain *why* it’s safe given your product’s execution model: sandboxing, dead code elimination, policy blocks, feature gates, OS hardening, container seccomp/AppArmor, etc.
|
||||
* **VEX proof bundle:**
|
||||
Store the evidence alongside the VEX: call‑graph slices, reachability reports, config snapshots, build args, lattice/policy decisions, test traces, and hashes of the exact artifacts (SBOM + attestation refs). This is what makes the claim stand up in an audit six months later.
|
||||
|
||||
## Minimal OpenVEX example (drop‑in)
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "urn:stellaops:vex:2025-11-25:svc-api:log4j:2.14.1",
|
||||
"author": "Stella Ops Authority",
|
||||
"role": "vex"
|
||||
},
|
||||
"statements": [
|
||||
{
|
||||
"vulnerability": "CVE-2021-44228",
|
||||
"products": ["pkg:maven/com.acme/svc-api@1.7.3?type=jar"],
|
||||
"status": "not_affected",
|
||||
"justification": "vulnerable_code_not_in_execute_path",
|
||||
"impact_statement": "Log4j JNDI classes excluded at build; no logger bridge; JVM flags `-Dlog4j2.formatMsgNoLookups=true` enforced by container entrypoint.",
|
||||
"analysis": {
|
||||
"entry_points_audited": [
|
||||
"com.acme.api.HttpServer#routes",
|
||||
"com.acme.jobs.Cron#run",
|
||||
"Main#init"
|
||||
],
|
||||
"limits": {
|
||||
"image_digest": "sha256:…",
|
||||
"config_profile": "prod",
|
||||
"args": ["--no-dynamic-plugins"],
|
||||
"seccomp": "stellaops-baseline-v3"
|
||||
},
|
||||
"evidence_refs": [
|
||||
"dsse:sha256:…/reachability.json",
|
||||
"dsse:sha256:…/build-args.att",
|
||||
"dsse:sha256:…/policy-lattice.proof"
|
||||
]
|
||||
},
|
||||
"timestamp": "2025-11-25T00:00:00Z"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Fast checklist (use this on every `not_affected`)
|
||||
|
||||
* [ ] Define product + artifact by immutable IDs (PURL + digest).
|
||||
* [ ] List **audited entry points** and **execution limits**.
|
||||
* [ ] Declare **status** = `not_affected` with a **justification** from the allowed set.
|
||||
* [ ] Add a short **impact/why‑safe** sentence.
|
||||
* [ ] Attach **evidence**: call graph, configs, policies, build args, test traces.
|
||||
* [ ] Sign the VEX (DSSE/In‑Toto), link it to the SBOM attestation.
|
||||
* [ ] Version and keep the proof bundle with your release.
|
||||
|
||||
## When to use an exception (temporary VEX)
|
||||
|
||||
If you can prove non‑reachability **only under a temporary constraint** (e.g., feature flag off while a permanent fix lands), emit a **time‑boxed exception** VEX:
|
||||
|
||||
* Add `constraints.expires` and the required control (e.g., `feature_flag=Off`, `policy=BlockJNDI`).
|
||||
* Schedule an auto‑recheck on expiry; flip to `affected` if the constraint lapses.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate a Stella Ops‑flavored VEX template and a tiny “proof bundle” schema (JSON) so your devs can drop it into the pipeline and your documentators can copy‑paste the rationale blocks.
|
||||
Cool, let’s turn that policy into something your devs can actually follow day‑to‑day.
|
||||
|
||||
Below is a concrete implementation plan you can drop into an internal RFC / Notion page and wire into your pipelines.
|
||||
|
||||
---
|
||||
|
||||
## 0. What we’re implementing (for context)
|
||||
|
||||
**Goal:** At Stella Ops, you can only mark a vulnerability as `not_affected` if:
|
||||
|
||||
1. You’ve **audited specific entry points** under clearly documented limits (version, build flags, config, container image).
|
||||
2. You’ve captured **evidence** and **rationale** in a VEX statement + proof bundle.
|
||||
3. The VEX is **validated, signed, and shipped** with the artifact.
|
||||
|
||||
We’ll standardize on **OpenVEX** with a small extension (`analysis` section) for developer‑friendly evidence.
|
||||
|
||||
---
|
||||
|
||||
## 1. Repo & artifact layout (week 1)
|
||||
|
||||
### 1.1. Create a standard security layout
|
||||
|
||||
In each service repo:
|
||||
|
||||
```text
|
||||
/security/
|
||||
vex/
|
||||
openvex.json # aggregate VEX doc (generated/curated)
|
||||
statements/ # one file per CVE (optional, if you like)
|
||||
proofs/
|
||||
CVE-YYYY-NNNN/
|
||||
reachability.json
|
||||
configs/
|
||||
tests/
|
||||
notes.md
|
||||
schemas/
|
||||
openvex.schema.json # JSON schema with Stella extensions
|
||||
```
|
||||
|
||||
**Developer guidance:**
|
||||
|
||||
* If you touch anything related to a vulnerability decision, you **edit `security/vex/` and `security/proofs/` in the same PR**.
|
||||
|
||||
---
|
||||
|
||||
## 2. Define the VEX schema & allowed justifications (week 1)
|
||||
|
||||
### 2.1. Fix the format & fields
|
||||
|
||||
You’ve already chosen OpenVEX, so formalize the required extras:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"vulnerability": "CVE-2021-44228",
|
||||
"products": ["pkg:maven/com.acme/svc-api@1.7.3?type=jar"],
|
||||
"status": "not_affected",
|
||||
"justification": "vulnerable_code_not_in_execute_path",
|
||||
"impact_statement": "…",
|
||||
"analysis": {
|
||||
"entry_points_audited": [
|
||||
"com.acme.api.HttpServer#routes",
|
||||
"com.acme.jobs.Cron#run",
|
||||
"Main#init"
|
||||
],
|
||||
"limits": {
|
||||
"image_digest": "sha256:…",
|
||||
"config_profile": "prod",
|
||||
"args": ["--no-dynamic-plugins"],
|
||||
"seccomp": "stellaops-baseline-v3"
|
||||
},
|
||||
"evidence_refs": [
|
||||
"dsse:sha256:…/reachability.json",
|
||||
"dsse:sha256:…/build-args.att",
|
||||
"dsse:sha256:…/policy-lattice.proof"
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Action items:**
|
||||
|
||||
* Write a **JSON schema** for the `analysis` block (required for `not_affected`):
|
||||
|
||||
* `entry_points_audited`: non‑empty array of strings.
|
||||
* `limits`: object with at least one of `image_digest`, `config_profile`, `args`, `seccomp`, `feature_flags`.
|
||||
* `evidence_refs`: non‑empty array of strings.
|
||||
* Commit this as `security/schemas/openvex.schema.json`.
|
||||
|
||||
### 2.2. Fix the allowed `justification` values
|
||||
|
||||
Publish an internal list, e.g.:
|
||||
|
||||
* `vulnerable_code_not_in_execute_path`
|
||||
* `component_not_present`
|
||||
* `vulnerable_code_cannot_be_controlled_by_adversary`
|
||||
* `inline_mitigation_already_in_place`
|
||||
* `protected_by_environment` (e.g., mandatory sandbox, read‑only FS)
|
||||
|
||||
**Rule:** any `not_affected` must pick one of these. Any new justification needs security team approval.
|
||||
|
||||
---
|
||||
|
||||
## 3. Developer process for handling a new vuln (week 2)
|
||||
|
||||
This is the **“how to act”** guide devs follow when a CVE pops up in scanners or customer reports.
|
||||
|
||||
### 3.1. Decision flow
|
||||
|
||||
1. **Is the vulnerable component actually present?**
|
||||
|
||||
* If no → `status: not_affected`, `justification: component_not_present`.
|
||||
Still fill out `products`, `impact_statement` (explain why it’s not present: different version, module excluded, etc.).
|
||||
2. **If present: analyze reachability.**
|
||||
|
||||
* Identify **entry points** of the service:
|
||||
|
||||
* HTTP routes, gRPC methods, message consumers, CLI commands, cron jobs, startup hooks.
|
||||
* Check:
|
||||
|
||||
* Is the vulnerable path reachable from any of these?
|
||||
* Is it blocked by configuration / feature flags / sandboxing?
|
||||
3. **If reachable or unclear → treat as `affected`.**
|
||||
|
||||
* Plan a patch, workaround, or runtime mitigation.
|
||||
4. **If not reachable & you can argue that clearly → `not_affected` with proof.**
|
||||
|
||||
* Fill in:
|
||||
|
||||
* `entry_points_audited`
|
||||
* `limits`
|
||||
* `evidence_refs`
|
||||
* `impact_statement` (“why safe”)
|
||||
|
||||
### 3.2. Developer checklist (drop this into your docs)
|
||||
|
||||
> **Stella Ops `not_affected` checklist**
|
||||
>
|
||||
> For any CVE you mark as `not_affected`:
|
||||
>
|
||||
> 1. **Identify product + artifact**
|
||||
>
|
||||
> * [ ] PURL (package URL)
|
||||
> * [ ] Image digest / binary hash
|
||||
> 2. **Audit execution**
|
||||
>
|
||||
> * [ ] List entry points you reviewed
|
||||
> * [ ] Note the limits (config profile, feature flags, container args, sandbox)
|
||||
> 3. **Collect evidence**
|
||||
>
|
||||
> * [ ] Reachability analysis (manual or tool report)
|
||||
> * [ ] Config snapshot (YAML, env vars, Helm values)
|
||||
> * [ ] Tests or traces (if applicable)
|
||||
> 4. **Write VEX statement**
|
||||
>
|
||||
> * [ ] `status = not_affected`
|
||||
> * [ ] `justification` from allowed list
|
||||
> * [ ] `impact_statement` explains “why safe”
|
||||
> * [ ] `analysis.entry_points_audited`, `analysis.limits`, `analysis.evidence_refs`
|
||||
> 5. **Wire into repo**
|
||||
>
|
||||
> * [ ] Proofs stored under `security/proofs/CVE-…/`
|
||||
> * [ ] VEX updated under `security/vex/`
|
||||
> 6. **Request review**
|
||||
>
|
||||
> * [ ] Security reviewer approved in PR
|
||||
|
||||
---
|
||||
|
||||
## 4. Automation & tooling for devs (week 2–3)
|
||||
|
||||
Make it easy to “do the right thing” with a small CLI and CI jobs.
|
||||
|
||||
### 4.1. Add a small `vexctl` helper
|
||||
|
||||
Language doesn’t matter—Python is fine. Rough sketch:
|
||||
|
||||
```python
|
||||
#!/usr/bin/env python3
|
||||
import json
|
||||
from pathlib import Path
|
||||
from datetime import datetime
|
||||
|
||||
VEX_PATH = Path("security/vex/openvex.json")
|
||||
|
||||
def load_vex():
|
||||
if VEX_PATH.exists():
|
||||
return json.loads(VEX_PATH.read_text())
|
||||
return {"document": {}, "statements": []}
|
||||
|
||||
def save_vex(data):
|
||||
VEX_PATH.write_text(json.dumps(data, indent=2, sort_keys=True))
|
||||
|
||||
def add_statement():
|
||||
cve = input("CVE ID (e.g. CVE-2025-1234): ").strip()
|
||||
product = input("Product PURL: ").strip()
|
||||
status = input("Status [affected/not_affected/fixed]: ").strip()
|
||||
justification = None
|
||||
analysis = None
|
||||
|
||||
if status == "not_affected":
|
||||
justification = input("Justification (from allowed list): ").strip()
|
||||
entry_points = input("Entry points (comma-separated): ").split(",")
|
||||
limits_profile = input("Config profile (e.g. prod/stage): ").strip()
|
||||
image_digest = input("Image digest (optional): ").strip()
|
||||
evidence = input("Evidence refs (comma-separated): ").split(",")
|
||||
|
||||
analysis = {
|
||||
"entry_points_audited": [e.strip() for e in entry_points if e.strip()],
|
||||
"limits": {
|
||||
"config_profile": limits_profile or None,
|
||||
"image_digest": image_digest or None
|
||||
},
|
||||
"evidence_refs": [e.strip() for e in evidence if e.strip()]
|
||||
}
|
||||
|
||||
impact = input("Impact / why safe (short text): ").strip()
|
||||
|
||||
vex = load_vex()
|
||||
vex.setdefault("document", {})
|
||||
vex.setdefault("statements", [])
|
||||
stmt = {
|
||||
"vulnerability": cve,
|
||||
"products": [product],
|
||||
"status": status,
|
||||
"impact_statement": impact,
|
||||
"timestamp": datetime.utcnow().isoformat() + "Z"
|
||||
}
|
||||
if justification:
|
||||
stmt["justification"] = justification
|
||||
if analysis:
|
||||
stmt["analysis"] = analysis
|
||||
|
||||
vex["statements"].append(stmt)
|
||||
save_vex(vex)
|
||||
print(f"Added VEX statement for {cve}")
|
||||
|
||||
if __name__ == "__main__":
|
||||
add_statement()
|
||||
```
|
||||
|
||||
**Dev UX:** run:
|
||||
|
||||
```bash
|
||||
./tools/vexctl add
|
||||
```
|
||||
|
||||
and follow prompts instead of hand‑editing JSON.
|
||||
|
||||
### 4.2. Schema validation in CI
|
||||
|
||||
Add a CI job (GitHub Actions example) that:
|
||||
|
||||
1. Installs `jsonschema`.
|
||||
2. Validates `security/vex/openvex.json` against `security/schemas/openvex.schema.json`.
|
||||
3. Fails if:
|
||||
|
||||
* any `not_affected` statement lacks `analysis.*` fields, or
|
||||
* `justification` is not in the allowed list.
|
||||
|
||||
```yaml
|
||||
name: VEX validation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
paths:
|
||||
- "security/vex/**"
|
||||
- "security/schemas/**"
|
||||
|
||||
jobs:
|
||||
validate-vex:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.12"
|
||||
|
||||
- name: Install deps
|
||||
run: pip install jsonschema
|
||||
|
||||
- name: Validate OpenVEX
|
||||
run: |
|
||||
python tools/validate_vex.py
|
||||
```
|
||||
|
||||
Example `validate_vex.py` core logic:
|
||||
|
||||
```python
|
||||
import json
|
||||
from jsonschema import validate, ValidationError
|
||||
from pathlib import Path
|
||||
import sys
|
||||
|
||||
schema = json.loads(Path("security/schemas/openvex.schema.json").read_text())
|
||||
vex = json.loads(Path("security/vex/openvex.json").read_text())
|
||||
|
||||
try:
|
||||
validate(instance=vex, schema=schema)
|
||||
except ValidationError as e:
|
||||
print("VEX schema validation failed:", e, file=sys.stderr)
|
||||
sys.exit(1)
|
||||
|
||||
ALLOWED_JUSTIFICATIONS = {
|
||||
"vulnerable_code_not_in_execute_path",
|
||||
"component_not_present",
|
||||
"vulnerable_code_cannot_be_controlled_by_adversary",
|
||||
"inline_mitigation_already_in_place",
|
||||
"protected_by_environment",
|
||||
}
|
||||
|
||||
for stmt in vex.get("statements", []):
|
||||
if stmt.get("status") == "not_affected":
|
||||
just = stmt.get("justification")
|
||||
if just not in ALLOWED_JUSTIFICATIONS:
|
||||
print(f"Invalid justification '{just}' in statement {stmt.get('vulnerability')}")
|
||||
sys.exit(1)
|
||||
|
||||
analysis = stmt.get("analysis") or {}
|
||||
missing = []
|
||||
if not analysis.get("entry_points_audited"):
|
||||
missing.append("analysis.entry_points_audited")
|
||||
if not analysis.get("limits"):
|
||||
missing.append("analysis.limits")
|
||||
if not analysis.get("evidence_refs"):
|
||||
missing.append("analysis.evidence_refs")
|
||||
|
||||
if missing:
|
||||
print(
|
||||
f"'not_affected' for {stmt.get('vulnerability')} missing fields: {', '.join(missing)}"
|
||||
)
|
||||
sys.exit(1)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. Signing & publishing VEX + proof bundles (week 3)
|
||||
|
||||
### 5.1. Signing
|
||||
|
||||
Pick a signing mechanism (e.g., DSSE + cosign/in‑toto), but keep the dev‑visible rules simple:
|
||||
|
||||
* CI step:
|
||||
|
||||
1. Build artifact (image/binary).
|
||||
2. Generate/update SBOM.
|
||||
3. Validate VEX.
|
||||
4. **Sign**:
|
||||
|
||||
* The artifact.
|
||||
* The SBOM.
|
||||
* The VEX document.
|
||||
|
||||
Enforce **KMS‑backed keys** controlled by the security team.
|
||||
|
||||
### 5.2. Publishing layout
|
||||
|
||||
Decide a canonical layout in your artifact registry / S3:
|
||||
|
||||
```text
|
||||
artifacts/
|
||||
svc-api/
|
||||
1.7.3/
|
||||
image.tar
|
||||
sbom.spdx.json
|
||||
vex.openvex.json
|
||||
proofs/
|
||||
CVE-2025-1234/
|
||||
reachability.json
|
||||
configs/
|
||||
tests/
|
||||
```
|
||||
|
||||
Link evidence by digest (`evidence_refs`) so you can prove exactly what you audited.
|
||||
|
||||
---
|
||||
|
||||
## 6. PR / review policy (week 3–4)
|
||||
|
||||
### 6.1. Add a PR checklist item
|
||||
|
||||
In your PR template:
|
||||
|
||||
```md
|
||||
### Security / VEX
|
||||
|
||||
- [ ] If this PR **changes how we handle a known CVE** or marks one as `not_affected`, I have:
|
||||
- [ ] Updated `security/vex/openvex.json`
|
||||
- [ ] Added/updated proof bundle under `security/proofs/`
|
||||
- [ ] Ran `./tools/vexctl` and CI VEX validation locally
|
||||
```
|
||||
|
||||
### 6.2. Require security reviewer for `not_affected` changes
|
||||
|
||||
Add a CODEOWNERS entry:
|
||||
|
||||
```text
|
||||
/security/vex/* @stellaops-security-team
|
||||
/security/proofs/* @stellaops-security-team
|
||||
```
|
||||
|
||||
* Any PR touching these paths must be approved by security.
|
||||
|
||||
---
|
||||
|
||||
## 7. Handling temporary exceptions (time‑boxed VEX)
|
||||
|
||||
Sometimes you’re only safe because of a **temporary constraint** (e.g., feature flag off until patch). For those:
|
||||
|
||||
1. Add a `constraints` block:
|
||||
|
||||
```json
|
||||
"constraints": {
|
||||
"control": "feature_flag",
|
||||
"name": "ENABLE_UNSAFE_PLUGIN_API",
|
||||
"required_value": "false",
|
||||
"expires": "2025-12-31T23:59:59Z"
|
||||
}
|
||||
```
|
||||
|
||||
2. Add a scheduled job (e.g., weekly) that:
|
||||
|
||||
* Parses VEX.
|
||||
* Finds any `constraints.expires < now()`.
|
||||
* Opens an issue or fails a synthetic CI job: “Constraint expired: reevaluate CVE‑2025‑1234”.
|
||||
|
||||
Dev guidance: **do not** treat time‑boxed exceptions as permanent; they must be re‑reviewed or turned into `affected` + mitigation.
|
||||
|
||||
---
|
||||
|
||||
## 8. Rollout plan by week
|
||||
|
||||
You can present this timeline internally:
|
||||
|
||||
* **Week 1**
|
||||
|
||||
* Finalize OpenVEX + `analysis` schema.
|
||||
* Create `security/` layout in 1–2 key services.
|
||||
* Publish allowed `justification` list + written policy.
|
||||
|
||||
* **Week 2**
|
||||
|
||||
* Implement `vexctl` helper.
|
||||
* Add CI validation job.
|
||||
* Pilot with one real CVE decision; walk through full proof bundle creation.
|
||||
|
||||
* **Week 3**
|
||||
|
||||
* Add signing + publishing steps for SBOM and VEX.
|
||||
* Wire artifact registry layout, link VEX + proofs per release.
|
||||
|
||||
* **Week 4**
|
||||
|
||||
* Enforce CODEOWNERS + PR checklist across all services.
|
||||
* Enable scheduled checks for expiring constraints.
|
||||
* Run internal training (30–45 min) walking through:
|
||||
|
||||
* “Bad VEX” (hand‑wavy, no entry points) vs
|
||||
* “Good VEX” (clear scope, evidence, limits).
|
||||
|
||||
---
|
||||
|
||||
## 9. What you can hand to devs right now
|
||||
|
||||
If you want, you can literally paste these as separate internal docs:
|
||||
|
||||
* **“How to mark a CVE as not_affected at Stella Ops”**
|
||||
|
||||
* Copy section 3 (decision flow + checklist) and the VEX snippet.
|
||||
* **“VEX technical reference for developers”**
|
||||
|
||||
* Copy sections 1–2–4 (structure, schema, CLI, CI validation).
|
||||
* **“VEX operations runbook”**
|
||||
|
||||
* Copy sections 5–7 (signing, publishing, exceptions).
|
||||
|
||||
---
|
||||
|
||||
If you tell me which CI system you use (GitHub Actions, GitLab CI, Circle, etc.) and your primary stack (Java, Go, Node, etc.), I can turn this into exact job configs and maybe a more tailored `vexctl` CLI for your environment.
|
||||
@@ -1,590 +0,0 @@
|
||||
I’m sharing this because it highlights important recent developments with Rekor — and how its new v2 rollout and behavior with DSSE change what you need to watch out for when building attestations (for example in your StellaOps architecture).
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 🚨 What changed with Rekor v2
|
||||
|
||||
* Rekor v2 is now GA: it moves to a tile‑backed transparency log backend (via the module rekor‑tiles), which simplifies maintenance and lowers infrastructure cost. ([blog.sigstore.dev][1])
|
||||
* The global publicly‑distributed instance now supports only two entry types: `hashedrekord` (for artifacts) and `dsse` (for attestations). Many previously supported entry types — e.g. `intoto`, `rekord`, `helm`, `rfc3161`, etc. — have been removed. ([blog.sigstore.dev][1])
|
||||
* The log is now sharded: instead of a single growing Merkle tree, multiple “shards” (trees) are used. This supports better scaling, simpler rotation/maintenance, and easier querying by tree shard + identifier. ([Sigstore][2])
|
||||
|
||||
### ⚠️ Why this matters for attestations, and common pitfalls
|
||||
|
||||
* Historically, when using DSSE or in‑toto style attestations submitted to Rekor (or via Cosign), the **entire attestation payload** had to be uploaded to Rekor. That becomes problematic when payloads are large. There’s a reported case where a 130 MB attestation was rejected due to size. ([GitHub][3])
|
||||
* The public instance of Rekor historically had a relatively small attestation size limit (on the order of 100 KB) for uploads. ([GitHub][4])
|
||||
* Because Rekor v2 no longer supports many entry types and simplifies the log types, you no longer have fallback for some of the older attestation/storage formats if they don’t fit DSSE/hashedrekord constraints. ([blog.sigstore.dev][1])
|
||||
|
||||
### ✅ What you must design for — and pragmatic workarounds
|
||||
|
||||
Given your StellaOps architecture goals (deterministic builds, reproducible scans, large SBOMs/metadata, private/off‑air‑gap compliance), here’s what you should consider:
|
||||
|
||||
* **Plan for payload-size constraints**: don’t assume arbitrary large attestations will be accepted. Keep attestation payloads small — ideally put large blobs (e.g. full SBOMs, large metadata) **outside** DSSE and store them elsewhere (artifact storage, internal logs, blob store) with the attestation only embedding a hash or reference.
|
||||
* **Use “private logs” / self‑hosted Rekor** if you anticipate large payloads — public instance limits make heavy payload uploads impractical. Running your own instance gives you control over size limits and resource allocation. ([GitHub][4])
|
||||
* **Chunking / sharding**: For large metadata blobs, consider splitting (“sharding”) or chunking the data into smaller pieces, each with its own DSSE/hashed‑rekord entry, then reference or re‑assemble externally. This avoids hitting size limits while maintaining inclusion proofs.
|
||||
* **Build idempotent re‑submit logic**: Because DSSE/hashed‑rekord entries are the only supported types, and large payloads may fail, your pipelines (e.g. StellaOps) should handle retries, partial submits, and ensure idempotence — so re‑submits don’t create inconsistent or duplicate entries.
|
||||
* **Persist full attestations outside Rekor**: Since Rekor v2 dropped many types and doesn’t store full arbitrary blobs necessarily, ensure that the “source of truth” for large metadata remains under your control (e.g. in your internal storage), with Rekor only storing minimal hashed attestations.
|
||||
|
||||
### 🎯 What this means for StellaOps
|
||||
|
||||
For your “Proof‑of‑Integrity Graph” + “offline bundle + replayable scans” vision — this means you should treat Rekor (especially public) as a *lightweight ledger for proofs*, not as a full-blown metadata store. In practice:
|
||||
|
||||
* Use Rekor for auditing, signature/inclusion proofs, and “commit‑to‑hash” attestations.
|
||||
* Store full SBOMs, VEX data, scan metadata, large build/context blobs externally.
|
||||
* Build your log‑sharding, replay, and artifact‑reference logic to survive Rekor’s constraints.
|
||||
* For air‑gapped workflows, consider a private Rekor or alternative internal log that mirrors the public transparency‑log guarantees but under your control.
|
||||
|
||||
If you like — I can pull up **real‑world examples** of organizations that already adapted to Rekor v2’s DSSE constraints (with chunking, private logs, hybrid storage) — could help shape StellaOps resilience strategy.
|
||||
|
||||
[1]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[2]: https://docs.sigstore.dev/logging/sharding/?utm_source=chatgpt.com "Sharding"
|
||||
[3]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
[4]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
Here’s a concrete, developer‑friendly implementation plan you can hand to the team. I’ll assume the context is “StellaOps + Sigstore/Rekor v2 + DSSE + air‑gapped support”.
|
||||
|
||||
---
|
||||
|
||||
## 0. Shared context & constraints (what devs should keep in mind)
|
||||
|
||||
**Key facts (summarized):**
|
||||
|
||||
* Rekor v2 keeps only **two** entry types: `hashedrekord` (artifact signatures) and `dsse` (attestations). Older types (`intoto`, `rekord`, etc.) are gone. ([Sigstore Blog][1])
|
||||
* The **public** Rekor instance enforces a ~**100KB attestation size limit** per upload; bigger payloads must use your **own Rekor instance** instead. ([GitHub][2])
|
||||
* For DSSE entries, Rekor **does not store the full payload**; it stores hashes and verification material. Users are expected to persist the attestations alongside artifacts in their own storage. ([Go Packages][3])
|
||||
* People have already hit problems where ~130MB attestations were rejected by Rekor, showing that “just upload the whole SBOM/provenance” is not sustainable. ([GitHub][4])
|
||||
* Sigstore’s **bundle** format is the canonical way to ship DSSE + tlog metadata around as a single JSON object (very useful for offline/air‑gapped replay). ([Sigstore][5])
|
||||
|
||||
**Guiding principles for the implementation:**
|
||||
|
||||
1. **Rekor is a ledger, not a blob store.** We log *proofs* (hashes, inclusion proofs), not big documents.
|
||||
2. **Attestation payloads live in our storage** (object store / DB).
|
||||
3. **All Rekor interaction goes through one abstraction** so we can easily switch public/private/none.
|
||||
4. **Everything is idempotent and replayable** (important for retries and air‑gapped exports).
|
||||
|
||||
---
|
||||
|
||||
## 1. High‑level architecture
|
||||
|
||||
### 1.1 Components
|
||||
|
||||
1. **Attestation Builder library (in CI/build tools)**
|
||||
|
||||
* Used by build pipelines / scanners / SBOM generators.
|
||||
* Responsibilities:
|
||||
|
||||
* Collect artifact metadata (digest, build info, SBOM, scan results).
|
||||
* Call Attestation API (below) with **semantic info** and raw payload(s).
|
||||
|
||||
2. **Attestation Service (core backend microservice)**
|
||||
|
||||
* Single entry‑point for creating and managing attestations.
|
||||
* Responsibilities:
|
||||
|
||||
* Normalize incoming metadata.
|
||||
* Store large payload(s) in object store.
|
||||
* Construct **small DSSE envelope** (payload = manifest / summary, not giant blob).
|
||||
* Persist attestation records & payload manifests in DB.
|
||||
* Enqueue log‑submission jobs for:
|
||||
|
||||
* Public Rekor v2
|
||||
* Private Rekor v2 (optional)
|
||||
* Internal event log (DB/Kafka)
|
||||
* Produce **Sigstore bundles** for offline use.
|
||||
|
||||
3. **Log Writer / Rekor Client Worker(s)**
|
||||
|
||||
* Background workers consuming submission jobs.
|
||||
* Responsibilities:
|
||||
|
||||
* Submit `dsse` (and optionally `hashedrekord`) entries to configured Rekor instances.
|
||||
* Handle retries with backoff.
|
||||
* Guarantee idempotency (no duplicate entries, no inconsistent state).
|
||||
* Update DB with Rekor log index/uuid and status.
|
||||
|
||||
4. **Offline Bundle Exporter (CLI or API)**
|
||||
|
||||
* Runs in air‑gapped cluster.
|
||||
* Responsibilities:
|
||||
|
||||
* Periodically export “new” attestations + bundles since last export.
|
||||
* Materialize data as tar/zip with:
|
||||
|
||||
* Sigstore bundles (JSON)
|
||||
* Chunk manifests
|
||||
* Large payload chunks (optional, depending on policy).
|
||||
|
||||
5. **Offline Replay Service (connected environment)**
|
||||
|
||||
* Runs where internet access and public Rekor are available.
|
||||
* Responsibilities:
|
||||
|
||||
* Read offline bundles from incoming location.
|
||||
* Replay to:
|
||||
|
||||
* Public Rekor
|
||||
* Cloud storage
|
||||
* Internal observability
|
||||
* Write updated status back (e.g., via a status file or callback).
|
||||
|
||||
6. **Config & Policy Layer**
|
||||
|
||||
* Central (e.g. YAML, env, config DB).
|
||||
* Controls:
|
||||
|
||||
* Which logs to use: `public_rekor`, `private_rekor`, `internal_only`.
|
||||
* Size thresholds (DSSE payload limit, chunk size).
|
||||
* Retry/backoff policy.
|
||||
* Air‑gapped mode toggles.
|
||||
|
||||
---
|
||||
|
||||
## 2. Data model (DB + storage)
|
||||
|
||||
Use whatever DB you have (Postgres is fine). Here’s a suggested schema, adapt as needed.
|
||||
|
||||
### 2.1 Core tables
|
||||
|
||||
**`attestations`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| ------------------------ | ----------- | ----------------------------------------- |
|
||||
| `id` | UUID (PK) | Internal identifier |
|
||||
| `subject_digest` | text | e.g., `sha256:<hex>` of build artifact |
|
||||
| `subject_uri` | text | Optional URI (image ref, file path, etc.) |
|
||||
| `predicate_type` | text | e.g. `https://slsa.dev/provenance/v1` |
|
||||
| `payload_schema_version` | text | Version of our manifest schema |
|
||||
| `dsse_envelope_digest` | text | `sha256` of DSSE envelope |
|
||||
| `bundle_location` | text | URL/path to Sigstore bundle (if cached) |
|
||||
| `created_at` | timestamptz | Creation time |
|
||||
| `created_by` | text | Origin (pipeline id, service name) |
|
||||
| `metadata` | jsonb | Extra labels / tags |
|
||||
|
||||
**`payload_manifests`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------- | ------------------------------------------------- |
|
||||
| `attestation_id` (FK) | UUID | Link to `attestations.id` |
|
||||
| `total_size_bytes` | bigint | Size of the *full* logical payload |
|
||||
| `chunk_count` | int | Number of chunks |
|
||||
| `root_digest` | text | Digest of full payload or Merkle root over chunks |
|
||||
| `manifest_json` | jsonb | The JSON we sign in the DSSE payload |
|
||||
| `created_at` | timestamptz | |
|
||||
|
||||
**`payload_chunks`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------------------------- | ---------------------- |
|
||||
| `attestation_id` (FK) | UUID | |
|
||||
| `chunk_index` | int | 0‑based index |
|
||||
| `chunk_digest` | text | sha256 of this chunk |
|
||||
| `size_bytes` | bigint | Size of chunk |
|
||||
| `storage_uri` | text | `s3://…` or equivalent |
|
||||
| PRIMARY KEY | (attestation_id, chunk_index) | Ensures uniqueness |
|
||||
|
||||
**`log_submissions`**
|
||||
|
||||
| Column | Type | Description |
|
||||
| --------------------- | ----------- | --------------------------------------------------------- |
|
||||
| `id` | UUID (PK) | |
|
||||
| `attestation_id` (FK) | UUID | |
|
||||
| `target` | text | `public_rekor`, `private_rekor`, `internal` |
|
||||
| `submission_key` | text | Idempotency key (see below) |
|
||||
| `state` | text | `pending`, `in_progress`, `succeeded`, `failed_permanent` |
|
||||
| `attempt_count` | int | For retries |
|
||||
| `last_error` | text | Last error message |
|
||||
| `rekor_log_index` | bigint | If applicable |
|
||||
| `rekor_log_id` | text | Log ID (tree ID / key ID) |
|
||||
| `created_at` | timestamptz | |
|
||||
| `updated_at` | timestamptz | |
|
||||
|
||||
Add a **unique index** on `(target, submission_key)` to guarantee idempotency.
|
||||
|
||||
---
|
||||
|
||||
## 3. DSSE payload design (how to avoid size limits)
|
||||
|
||||
### 3.1 Manifest‑based DSSE instead of giant payloads
|
||||
|
||||
Instead of DSSE‑signing the **entire SBOM/provenance blob** (which hits Rekor’s 100KB limit), we sign a **manifest** describing where the payload lives and how to verify it.
|
||||
|
||||
**Example manifest JSON** (payload of DSSE, small):
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "stellaops.manifest.v1",
|
||||
"subject": {
|
||||
"uri": "registry.example.com/app@sha256:abcd...",
|
||||
"digest": "sha256:abcd..."
|
||||
},
|
||||
"payload": {
|
||||
"type": "sbom.spdx+json",
|
||||
"rootDigest": "sha256:deadbeef...",
|
||||
"totalSize": 73400320,
|
||||
"chunkCount": 12
|
||||
},
|
||||
"chunks": [
|
||||
{
|
||||
"index": 0,
|
||||
"digest": "sha256:1111...",
|
||||
"size": 6291456
|
||||
},
|
||||
{
|
||||
"index": 1,
|
||||
"digest": "sha256:2222...",
|
||||
"size": 6291456
|
||||
}
|
||||
// ...
|
||||
],
|
||||
"storagePolicy": {
|
||||
"backend": "s3",
|
||||
"bucket": "stellaops-attestations",
|
||||
"pathPrefix": "sboms/app/abcd..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
* This JSON is small enough to **fit under 100KB** even with lots of chunks, so the DSSE envelope stays small.
|
||||
* Full SBOM/scan results live in your object store; Rekor logs the DSSE envelope hash.
|
||||
|
||||
### 3.2 Chunking logic (Attestation Service)
|
||||
|
||||
Config values (can be env vars):
|
||||
|
||||
* `CHUNK_SIZE_BYTES` = e.g. 5–10 MiB
|
||||
* `MAX_DSSE_PAYLOAD_BYTES` = e.g. 70 KiB (keeping margin under Rekor 100KB limit)
|
||||
* `MAX_CHUNK_COUNT` = safety guard
|
||||
|
||||
Algorithm:
|
||||
|
||||
1. Receive raw payload bytes (SBOM / provenance / scan results).
|
||||
2. Compute full `root_digest = sha256(payload_bytes)` (or Merkle root if you want more advanced verification).
|
||||
3. If `len(payload_bytes) <= SMALL_PAYLOAD_THRESHOLD` (e.g. 64 KB):
|
||||
|
||||
* Skip chunking.
|
||||
* Store payload as single object.
|
||||
* Manifest can optionally omit `chunks` and just record one object.
|
||||
4. If larger:
|
||||
|
||||
* Split into fixed‑size chunks (except last).
|
||||
* For each chunk:
|
||||
|
||||
* Compute `chunk_digest`.
|
||||
* Upload chunk to object store path derived from `root_digest` + `chunk_index`.
|
||||
* Insert `payload_chunks` rows.
|
||||
5. Build manifest JSON with:
|
||||
|
||||
* `version`
|
||||
* `subject`
|
||||
* `payload` block
|
||||
* `chunks[]` (no URIs if you don’t want to leak details; the URIs can be derived by clients).
|
||||
6. Check serialized manifest size ≤ `MAX_DSSE_PAYLOAD_BYTES`. If not:
|
||||
|
||||
* Option A: increase chunk size so you have fewer chunks.
|
||||
* Option B: move chunk list to a secondary “chunk index” document and sign only its root digest.
|
||||
7. DSSE‑sign manifest JSON.
|
||||
8. Persist DSSE envelope digest + manifest in DB.
|
||||
|
||||
---
|
||||
|
||||
## 4. Rekor integration & idempotency
|
||||
|
||||
### 4.1 Rekor client abstraction
|
||||
|
||||
Implement an interface like:
|
||||
|
||||
```ts
|
||||
interface TransparencyLogClient {
|
||||
submitDsseEnvelope(params: {
|
||||
dsseEnvelope: Buffer; // JSON bytes
|
||||
subjectDigest: string;
|
||||
predicateType: string;
|
||||
}): Promise<{
|
||||
logIndex: number;
|
||||
logId: string;
|
||||
entryUuid: string;
|
||||
}>;
|
||||
}
|
||||
```
|
||||
|
||||
Provide implementations:
|
||||
|
||||
* `PublicRekorClient` (points at `https://rekor.sigstore.dev` or v2 equivalent).
|
||||
* `PrivateRekorClient` (your own Rekor v2 cluster).
|
||||
* `NullClient` (for internal‑only mode).
|
||||
|
||||
Use official API semantics from Rekor OpenAPI / SDKs where possible. ([Sigstore][6])
|
||||
|
||||
### 4.2 Submission jobs & idempotency
|
||||
|
||||
**Submission key design:**
|
||||
|
||||
```text
|
||||
submission_key = sha256(
|
||||
"dsse" + "|" +
|
||||
rekor_base_url + "|" +
|
||||
dsse_envelope_digest
|
||||
)
|
||||
```
|
||||
|
||||
Workflow in the worker:
|
||||
|
||||
1. Worker fetches `log_submissions` with `state = 'pending'` or due for retry.
|
||||
2. Set `state = 'in_progress'` (optimistic update).
|
||||
3. Call `client.submitDsseEnvelope`.
|
||||
4. If success:
|
||||
|
||||
* Update `state = 'succeeded'`, set `rekor_log_index`, `rekor_log_id`.
|
||||
5. If Rekor indicates “already exists” (or returns same logIndex for same envelope):
|
||||
|
||||
* Treat as success, update `state = 'succeeded'`.
|
||||
6. On network/5xx errors:
|
||||
|
||||
* Increment `attempt_count`.
|
||||
* If `attempt_count < MAX_RETRIES`: schedule retry with backoff.
|
||||
* Else: `state = 'failed_permanent'`, keep `last_error`.
|
||||
|
||||
DB constraint: `UNIQUE(target, submission_key)` ensures we don’t create conflicting jobs.
|
||||
|
||||
---
|
||||
|
||||
## 5. Attestation Service API design
|
||||
|
||||
### 5.1 Create attestation (build/scan pipeline → Attestation Service)
|
||||
|
||||
**`POST /v1/attestations`**
|
||||
|
||||
**Request body (example):**
|
||||
|
||||
```json
|
||||
{
|
||||
"subject": {
|
||||
"uri": "registry.example.com/app@sha256:abcd...",
|
||||
"digest": "sha256:abcd..."
|
||||
},
|
||||
"payloadType": "sbom.spdx+json",
|
||||
"payload": {
|
||||
"encoding": "base64",
|
||||
"data": "<base64-encoded-sbom-or-scan>"
|
||||
},
|
||||
"predicateType": "https://slsa.dev/provenance/v1",
|
||||
"logTargets": ["internal", "private_rekor", "public_rekor"],
|
||||
"airgappedMode": false,
|
||||
"labels": {
|
||||
"team": "payments",
|
||||
"env": "prod"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Server behavior:**
|
||||
|
||||
1. Validate subject & payload.
|
||||
2. Chunk payload as per rules (section 3).
|
||||
3. Store payload chunks.
|
||||
4. Build manifest JSON & DSSE envelope.
|
||||
5. Insert `attestations`, `payload_manifests`, `payload_chunks`.
|
||||
6. For each `logTargets`:
|
||||
|
||||
* Insert `log_submissions` row with `state = 'pending'`.
|
||||
7. Optionally construct Sigstore bundle representing:
|
||||
|
||||
* DSSE envelope
|
||||
* Transparency log entry (when available) — for async, you can fill this later.
|
||||
8. Return `202 Accepted` with resource URL:
|
||||
|
||||
```json
|
||||
{
|
||||
"attestationId": "1f4b3d...",
|
||||
"status": "pending_logs",
|
||||
"subjectDigest": "sha256:abcd...",
|
||||
"logTargets": ["internal", "private_rekor", "public_rekor"],
|
||||
"links": {
|
||||
"self": "/v1/attestations/1f4b3d...",
|
||||
"bundle": "/v1/attestations/1f4b3d.../bundle"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Get attestation status
|
||||
|
||||
**`GET /v1/attestations/{id}`**
|
||||
|
||||
Returns:
|
||||
|
||||
```json
|
||||
{
|
||||
"attestationId": "1f4b3d...",
|
||||
"subjectDigest": "sha256:abcd...",
|
||||
"predicateType": "https://slsa.dev/provenance/v1",
|
||||
"logs": {
|
||||
"internal": {
|
||||
"state": "succeeded"
|
||||
},
|
||||
"private_rekor": {
|
||||
"state": "succeeded",
|
||||
"logIndex": 1234,
|
||||
"logId": "..."
|
||||
},
|
||||
"public_rekor": {
|
||||
"state": "pending",
|
||||
"lastError": null
|
||||
}
|
||||
},
|
||||
"createdAt": "2025-11-27T12:34:56Z"
|
||||
}
|
||||
```
|
||||
|
||||
### 5.3 Get bundle
|
||||
|
||||
**`GET /v1/attestations/{id}/bundle`**
|
||||
|
||||
* Returns a **Sigstore bundle JSON** that:
|
||||
|
||||
* Contains either:
|
||||
|
||||
* Only the DSSE + identity + certificate chain (if logs not yet written).
|
||||
* Or DSSE + log entries (`hashedrekord` / `dsse` entries) for whichever logs are ready. ([Sigstore][5])
|
||||
|
||||
* This is what air‑gapped exports and verifiers consume.
|
||||
|
||||
---
|
||||
|
||||
## 6. Air‑gapped workflows
|
||||
|
||||
### 6.1 In the air‑gapped environment
|
||||
|
||||
* Attestation Service runs in “air‑gapped mode”:
|
||||
|
||||
* `logTargets` typically = `["internal", "private_rekor"]`.
|
||||
* No direct public Rekor.
|
||||
|
||||
* **Offline Exporter CLI**:
|
||||
|
||||
```bash
|
||||
stellaops-offline-export \
|
||||
--since-id <last_exported_attestation_id> \
|
||||
--output offline-bundle-<timestamp>.tar.gz
|
||||
```
|
||||
|
||||
* Exporter logic:
|
||||
|
||||
1. Query DB for new `attestations` > `since-id`.
|
||||
2. For each attestation:
|
||||
|
||||
* Fetch DSSE envelope.
|
||||
* Fetch current log statuses (private rekor, internal).
|
||||
* Build or reuse Sigstore bundle JSON.
|
||||
* Optionally include payload chunks and/or original payload.
|
||||
3. Write them into a tarball with structure like:
|
||||
|
||||
```
|
||||
/attestations/<id>/bundle.json
|
||||
/attestations/<id>/chunks/chunk-0000.bin
|
||||
...
|
||||
/meta/export-metadata.json
|
||||
```
|
||||
|
||||
### 6.2 In the connected environment
|
||||
|
||||
* **Replay Service**:
|
||||
|
||||
```bash
|
||||
stellaops-offline-replay \
|
||||
--input offline-bundle-<timestamp>.tar.gz \
|
||||
--public-rekor-url https://rekor.sigstore.dev
|
||||
```
|
||||
|
||||
* Replay logic:
|
||||
|
||||
1. Read each `/attestations/<id>/bundle.json`.
|
||||
2. If `public_rekor` entry not present:
|
||||
|
||||
* Extract DSSE envelope from bundle.
|
||||
* Call Attestation Service “import & log” endpoint or directly call PublicRekorClient.
|
||||
* Build new updated bundle (with public tlog entry).
|
||||
3. Emit an updated `result.json` for each attestation (so you can sync status back to original environment if needed).
|
||||
|
||||
---
|
||||
|
||||
## 7. Observability & ops
|
||||
|
||||
### 7.1 Metrics
|
||||
|
||||
Have devs expose at least:
|
||||
|
||||
* `rekor_submit_requests_total{target, outcome}`
|
||||
* `rekor_submit_latency_seconds{target}` (histogram)
|
||||
* `log_submissions_in_queue{target}`
|
||||
* `attestations_total{predicateType}`
|
||||
* `attestation_payload_bytes{bucket}` (distribution of payload sizes)
|
||||
|
||||
### 7.2 Logging
|
||||
|
||||
* Log at **info**:
|
||||
|
||||
* Attestation created (subject digest, predicateType, manifest version).
|
||||
* Log submission succeeded (target, logIndex, logId).
|
||||
* Log at **warn/error**:
|
||||
|
||||
* Any permanent failure.
|
||||
* Any time DSSE payload nearly exceeds size threshold (to catch misconfig).
|
||||
|
||||
### 7.3 Feature flags
|
||||
|
||||
* `FEATURE_REKOR_PUBLIC_ENABLED`
|
||||
* `FEATURE_REKOR_PRIVATE_ENABLED`
|
||||
* `FEATURE_OFFLINE_EXPORT_ENABLED`
|
||||
* `FEATURE_CHUNKING_ENABLED` (to allow rolling rollout)
|
||||
|
||||
---
|
||||
|
||||
## 8. Concrete work breakdown for developers
|
||||
|
||||
You can basically drop this as a backlog outline:
|
||||
|
||||
1. **Domain model & storage**
|
||||
|
||||
* [ ] Implement DB migrations for `attestations`, `payload_manifests`, `payload_chunks`, `log_submissions`.
|
||||
* [ ] Implement object storage abstraction and content‑addressable layout for chunks.
|
||||
2. **Attestation Service skeleton**
|
||||
|
||||
* [ ] Implement `POST /v1/attestations` with basic validation.
|
||||
* [ ] Implement manifest building and DSSE envelope creation (no Rekor yet).
|
||||
* [ ] Persist records in DB.
|
||||
3. **Chunking & manifest logic**
|
||||
|
||||
* [ ] Implement chunker with thresholds & tests (small vs large).
|
||||
* [ ] Implement manifest JSON builder.
|
||||
* [ ] Ensure DSSE payload size is under configurable limit.
|
||||
4. **Rekor client & log submissions**
|
||||
|
||||
* [ ] Implement `TransparencyLogClient` interface + Public/Private implementations.
|
||||
* [ ] Implement `log_submissions` worker (queue + backoff + idempotency).
|
||||
* [ ] Wire worker into service config and deployment.
|
||||
5. **Sigstore bundle support**
|
||||
|
||||
* [ ] Implement bundle builder given DSSE envelope + log metadata.
|
||||
* [ ] Add `GET /v1/attestations/{id}/bundle`.
|
||||
6. **Offline export & replay**
|
||||
|
||||
* [ ] Implement Exporter CLI (queries DB, packages bundles and chunks).
|
||||
* [ ] Implement Replay CLI/service (reads tarball, logs to public Rekor).
|
||||
* [ ] Document operator workflow for moving tarballs between environments.
|
||||
7. **Observability & docs**
|
||||
|
||||
* [ ] Add metrics, logs, and dashboards.
|
||||
* [ ] Write verification docs: “How to fetch manifest, verify DSSE, reconstruct payload, and check Rekor.”
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can do is: take this and turn it into a more strict format your devs might already use (e.g. Jira epics + stories, or a design doc template with headers like “Motivation, Alternatives, Risks, Rollout Plan”).
|
||||
|
||||
[1]: https://blog.sigstore.dev/rekor-v2-ga/?utm_source=chatgpt.com "Rekor v2 GA - Cheaper to run, simpler to maintain"
|
||||
[2]: https://github.com/sigstore/rekor?utm_source=chatgpt.com "sigstore/rekor: Software Supply Chain Transparency Log"
|
||||
[3]: https://pkg.go.dev/github.com/sigstore/rekor/pkg/types/dsse?utm_source=chatgpt.com "dsse package - github.com/sigstore/rekor/pkg/types/dsse"
|
||||
[4]: https://github.com/sigstore/cosign/issues/3599?utm_source=chatgpt.com "Attestations require uploading entire payload to rekor #3599"
|
||||
[5]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[6]: https://docs.sigstore.dev/logging/overview/?utm_source=chatgpt.com "Rekor"
|
||||
@@ -1,886 +0,0 @@
|
||||
Here’s a concrete, low‑lift way to boost Stella Ops’s visibility and prove your “deterministic, replayable” moat: publish a **sanitized subset of reachability graphs** as a public benchmark that others can run and score identically.
|
||||
|
||||
### What this is (plain English)
|
||||
|
||||
* You release a small, carefully scrubbed set of **packages + SBOMs + VEX + call‑graphs** (source & binaries) with **ground‑truth reachability labels** for a curated list of CVEs.
|
||||
* You also ship a **deterministic scoring harness** (container + manifest) so anyone can reproduce the exact scores, byte‑for‑byte.
|
||||
|
||||
### Why it helps
|
||||
|
||||
* **Proof of determinism:** identical inputs → identical graphs → identical scores.
|
||||
* **Research magnet:** gives labs and tool vendors a neutral yardstick; you become “the” benchmark steward.
|
||||
* **Biz impact:** easy demo for buyers; lets you publish leaderboards and whitepapers.
|
||||
|
||||
### Scope (MVP dataset)
|
||||
|
||||
* **Languages:** PHP, JS, Python, plus **binary** (ELF/PE/Mach‑O) mini-cases.
|
||||
* **Units:** 20–30 packages total; 3–6 CVEs per language; 4–6 binary cases (static & dynamically‑linked).
|
||||
* **Artifacts per unit:**
|
||||
|
||||
* Package tarball(s) or container image digest
|
||||
* SBOM (CycloneDX 1.6 + SPDX 3.0.1)
|
||||
* VEX (known‑exploited, not‑affected, under‑investigation)
|
||||
* **Call graph** (normalized JSON)
|
||||
* **Ground truth**: list of vulnerable entrypoints/edges considered *reachable*
|
||||
* **Determinism manifest**: feed URLs + rule hashes + container digests + tool versions
|
||||
|
||||
### Data model (keep it simple)
|
||||
|
||||
* `dataset.json`: index of cases with content‑addressed URIs (sha256)
|
||||
* `sbom/`, `vex/`, `graphs/`, `truth/` folders mirroring the index
|
||||
* `manifest.lock.json`: DSSE‑signed record of:
|
||||
|
||||
* feeder rules, lattice policies, normalizers (name + version + hash)
|
||||
* container image digests for each step (scanner/cartographer/normalizer)
|
||||
* timestamp + signer (Stella Ops Authority)
|
||||
|
||||
### Scoring harness (deterministic)
|
||||
|
||||
* One Docker image: `stellaops/benchmark-harness:<tag>`
|
||||
* Inputs: dataset root + `manifest.lock.json`
|
||||
* Outputs:
|
||||
|
||||
* `scores.json` (precision/recall/F1, per‑case and macro)
|
||||
* `replay-proof.txt` (hashes of every artifact used)
|
||||
* **No network** mode (offline‑first). Fails closed if any hash mismatches.
|
||||
|
||||
### Metrics (clear + auditable)
|
||||
|
||||
* Per case: TP/FP/FN for **reachable** functions (or edges), plus optional **sink‑reach** verification.
|
||||
* Aggregates: micro/macro F1; “Determinism Index” (stddev of repeated runs must be 0).
|
||||
* **Repro test:** the harness re‑runs N=3 and asserts identical outputs (hash compare).
|
||||
|
||||
### Sanitization & legal
|
||||
|
||||
* Strip any proprietary code/data; prefer OSS with permissive licenses.
|
||||
* Replace real package registries with **local mirrors** and pin digests.
|
||||
* Publish under **CC‑BY‑4.0** (data) + **Apache‑2.0** (harness). Add a simple **contributor license agreement** for external case submissions.
|
||||
|
||||
### Baselines to include (neutral + useful)
|
||||
|
||||
* “Naïve reachable” (all functions in package)
|
||||
* “Imports‑only” (entrypoints that match import graph)
|
||||
* “Call‑depth‑2” (bounded traversal)
|
||||
* **Your** graph engine run with **frozen rules** from the manifest (as a reference, not a claim of SOTA)
|
||||
|
||||
### Repository layout (public)
|
||||
|
||||
```
|
||||
stellaops-reachability-benchmark/
|
||||
dataset/
|
||||
dataset.json
|
||||
sbom/...
|
||||
vex/...
|
||||
graphs/...
|
||||
truth/...
|
||||
manifest.lock.json (DSSE-signed)
|
||||
harness/
|
||||
Dockerfile
|
||||
runner.py (CLI)
|
||||
schema/ (JSON Schemas for graphs, truth, scores)
|
||||
docs/
|
||||
HOWTO.md (5-min run)
|
||||
CONTRIBUTING.md
|
||||
SANITIZATION.md
|
||||
LICENSES/
|
||||
```
|
||||
|
||||
### Docs your team can ship in a day
|
||||
|
||||
* **HOWTO.md:** `docker run -v $PWD/dataset:/d -v $PWD/out:/o stellaops/benchmark-harness score /d /o`
|
||||
* **SCHEMA.md:** JSON Schemas for graph and truth (keep fields minimal: `nodes`, `edges`, `purls`, `sinks`, `evidence`).
|
||||
* **REPRODUCIBILITY.md:** explains DSSE signatures, lockfile, and offline run.
|
||||
* **LIMITATIONS.md:** clarifies scope (no dynamic runtime traces in v1, etc.).
|
||||
|
||||
### Governance (lightweight)
|
||||
|
||||
* **Versioned releases:** `v0.1`, `v0.2` with changelogs.
|
||||
* **Submission gate:** PR template + CI that:
|
||||
|
||||
* validates schemas
|
||||
* checks hashes match lockfile
|
||||
* re‑scores and compares to contributor’s score
|
||||
* **Leaderboard cadence:** monthly markdown table regenerated by CI.
|
||||
|
||||
### Launch plan (2‑week sprint)
|
||||
|
||||
* **Day 1–2:** pick cases; finalize schemas; write SANITIZATION.md.
|
||||
* **Day 3–5:** build harness image; implement deterministic runner; freeze `manifest.lock.json`.
|
||||
* **Day 6–8:** produce ground truth; run baselines; generate initial scores.
|
||||
* **Day 9–10:** docs + website README; record a 2‑minute demo GIF.
|
||||
* **Day 11–12:** legal review + licenses; create issue labels (“good first case”).
|
||||
* **Day 13–14:** publish, post on GitHub + LinkedIn; invite Semgrep/Snyk/OSS‑Fuzz folks to submit cases.
|
||||
|
||||
### Nice‑to‑have (but easy)
|
||||
|
||||
* **JSON Schema** for ground‑truth edges so academics can auto‑ingest.
|
||||
* **Small “unknowns” registry** example to show how you annotate unresolved symbols without breaking determinism.
|
||||
* **Binary mini‑lab**: stripped vs non‑stripped ELF pair to show your patch‑oracle technique in action (truth labels reflect oracle result).
|
||||
|
||||
If you want, I can draft the repo skeleton (folders, placeholder JSON Schemas, a sample `manifest.lock.json`, and a minimal `runner.py` CLI) so you can drop it straight into GitHub.
|
||||
Got you — let’s turn that high‑level idea into something your devs can actually pick up and ship.
|
||||
|
||||
Below is a **concrete implementation plan** for the *StellaOps Reachability Benchmark* repo: directory structure, components, tasks, and acceptance criteria. You can drop this straight into a ticketing system as epics → stories.
|
||||
|
||||
---
|
||||
|
||||
## 0. Tech assumptions (adjust if needed)
|
||||
|
||||
To be specific, I’ll assume:
|
||||
|
||||
* **Repo**: `stellaops-reachability-benchmark`
|
||||
* **Harness language**: Python 3.11+
|
||||
* **Packaging**: Docker image for the harness
|
||||
* **Schemas**: JSON Schema (Draft 2020–12)
|
||||
* **CI**: GitHub Actions
|
||||
|
||||
If your stack differs, you can still reuse the structure and acceptance criteria.
|
||||
|
||||
---
|
||||
|
||||
## 1. Repo skeleton & project bootstrap
|
||||
|
||||
**Goal:** Create a minimal but fully wired repo.
|
||||
|
||||
### Tasks
|
||||
|
||||
1. **Create skeleton**
|
||||
|
||||
* Structure:
|
||||
|
||||
```text
|
||||
stellaops-reachability-benchmark/
|
||||
dataset/
|
||||
dataset.json
|
||||
sbom/
|
||||
vex/
|
||||
graphs/
|
||||
truth/
|
||||
packages/
|
||||
manifest.lock.json # initially stub
|
||||
harness/
|
||||
reachbench/
|
||||
__init__.py
|
||||
cli.py
|
||||
dataset_loader.py
|
||||
schemas/
|
||||
graph.schema.json
|
||||
truth.schema.json
|
||||
dataset.schema.json
|
||||
scores.schema.json
|
||||
tests/
|
||||
docs/
|
||||
HOWTO.md
|
||||
SCHEMA.md
|
||||
REPRODUCIBILITY.md
|
||||
LIMITATIONS.md
|
||||
SANITIZATION.md
|
||||
.github/
|
||||
workflows/
|
||||
ci.yml
|
||||
pyproject.toml
|
||||
README.md
|
||||
LICENSE
|
||||
Dockerfile
|
||||
```
|
||||
|
||||
2. **Bootstrap Python project**
|
||||
|
||||
* `pyproject.toml` with:
|
||||
|
||||
* `reachbench` package
|
||||
* deps: `jsonschema`, `click` or `typer`, `pyyaml`, `pytest`
|
||||
* `harness/tests/` with a dummy test to ensure CI is green.
|
||||
|
||||
3. **Dockerfile**
|
||||
|
||||
* Minimal, pinned versions:
|
||||
|
||||
```Dockerfile
|
||||
FROM python:3.11-slim
|
||||
WORKDIR /app
|
||||
COPY . .
|
||||
RUN pip install --no-cache-dir .
|
||||
ENTRYPOINT ["reachbench"]
|
||||
```
|
||||
|
||||
4. **CI basic pipeline (`.github/workflows/ci.yml`)**
|
||||
|
||||
* Jobs:
|
||||
|
||||
* `lint` (e.g., `ruff` or `flake8` if you want)
|
||||
* `test` (pytest)
|
||||
* `build-docker` (just to ensure Dockerfile stays valid)
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `pip install .` works locally.
|
||||
* `reachbench --help` prints CLI help (even if commands are stubs).
|
||||
* CI passes on main branch.
|
||||
|
||||
---
|
||||
|
||||
## 2. Dataset & schema definitions
|
||||
|
||||
**Goal:** Define all JSON formats and enforce them.
|
||||
|
||||
### 2.1 Define dataset index format (`dataset/dataset.json`)
|
||||
|
||||
**File:** `dataset/dataset.json`
|
||||
|
||||
**Example:**
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"cases": [
|
||||
{
|
||||
"id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"language": "php",
|
||||
"kind": "source", // "source" | "binary" | "container"
|
||||
"cves": ["CVE-2023-12345"],
|
||||
"artifacts": {
|
||||
"package": {
|
||||
"path": "packages/php/wordpress-5.8.tar.gz",
|
||||
"sha256": "…"
|
||||
},
|
||||
"sbom": {
|
||||
"path": "sbom/php/wordpress-5.8.cdx.json",
|
||||
"format": "cyclonedx-1.6",
|
||||
"sha256": "…"
|
||||
},
|
||||
"vex": {
|
||||
"path": "vex/php/wordpress-5.8.vex.json",
|
||||
"format": "csaf-2.0",
|
||||
"sha256": "…"
|
||||
},
|
||||
"graph": {
|
||||
"path": "graphs/php/wordpress-5.8.graph.json",
|
||||
"schema": "graph.schema.json",
|
||||
"sha256": "…"
|
||||
},
|
||||
"truth": {
|
||||
"path": "truth/php/wordpress-5.8.truth.json",
|
||||
"schema": "truth.schema.json",
|
||||
"sha256": "…"
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 2.2 Define **truth schema** (`harness/reachbench/schemas/truth.schema.json`)
|
||||
|
||||
**Model (conceptual):**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"vulnerable_components": [
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"symbol_kind": "function", // "function" | "method" | "binary_symbol"
|
||||
"status": "reachable", // "reachable" | "not_reachable"
|
||||
"reachable_from": [
|
||||
{
|
||||
"entrypoint_id": "web:GET:/foo",
|
||||
"notes": "HTTP route /foo"
|
||||
}
|
||||
],
|
||||
"evidence": "manual-analysis" // or "unit-test", "patch-oracle"
|
||||
}
|
||||
],
|
||||
"non_vulnerable_components": [
|
||||
{
|
||||
"symbol": "wp_safe_function",
|
||||
"symbol_kind": "function",
|
||||
"status": "not_reachable",
|
||||
"evidence": "manual-analysis"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Tasks**
|
||||
|
||||
* Implement JSON Schema capturing:
|
||||
|
||||
* required fields: `case_id`, `vulnerable_components`
|
||||
* allowed enums for `symbol_kind`, `status`, `evidence`
|
||||
* Add unit tests that:
|
||||
|
||||
* validate a valid truth file
|
||||
* fail on various broken ones (missing `case_id`, unknown `status`, etc.)
|
||||
|
||||
### 2.3 Define **graph schema** (`harness/reachbench/schemas/graph.schema.json`)
|
||||
|
||||
**Model (conceptual):**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"language": "php",
|
||||
"nodes": [
|
||||
{
|
||||
"id": "func:wp_ajax_nopriv_some_vuln",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"kind": "function",
|
||||
"purl": "pkg:composer/wordpress/wordpress@5.8"
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"from": "func:wp_ajax_nopriv_some_vuln",
|
||||
"to": "func:wpdb_query",
|
||||
"kind": "call"
|
||||
}
|
||||
],
|
||||
"entrypoints": [
|
||||
{
|
||||
"id": "web:GET:/foo",
|
||||
"symbol": "some_controller",
|
||||
"kind": "http_route"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
**Tasks**
|
||||
|
||||
* JSON Schema with:
|
||||
|
||||
* `nodes[]` (id, symbol, kind, optional purl)
|
||||
* `edges[]` (`from`, `to`, `kind`)
|
||||
* `entrypoints[]` (id, symbol, kind)
|
||||
* Tests: verify a valid graph; invalid ones (missing `id`, unknown `kind`) are rejected.
|
||||
|
||||
### 2.4 Dataset index schema (`dataset.schema.json`)
|
||||
|
||||
* JSON Schema describing `dataset.json` (version string, cases array).
|
||||
* Tests: validate the example dataset file.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* Running a simple script (will be `reachbench validate-dataset`) validates all JSON files in `dataset/` against schemas without errors.
|
||||
* CI fails if any dataset JSON is invalid.
|
||||
|
||||
---
|
||||
|
||||
## 3. Lockfile & determinism manifest
|
||||
|
||||
**Goal:** Implement `manifest.lock.json` generation and verification.
|
||||
|
||||
### 3.1 Lockfile structure
|
||||
|
||||
**File:** `dataset/manifest.lock.json`
|
||||
|
||||
**Example:**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"created_at": "2025-01-15T12:00:00Z",
|
||||
"dataset": {
|
||||
"root": "dataset/",
|
||||
"sha256": "…",
|
||||
"cases": {
|
||||
"php-wordpress-5.8-cve-2023-12345": {
|
||||
"sha256": "…"
|
||||
}
|
||||
}
|
||||
},
|
||||
"tools": {
|
||||
"graph_normalizer": {
|
||||
"name": "stellaops-graph-normalizer",
|
||||
"version": "1.2.3",
|
||||
"sha256": "…"
|
||||
}
|
||||
},
|
||||
"containers": {
|
||||
"scanner_image": "ghcr.io/stellaops/scanner@sha256:…",
|
||||
"normalizer_image": "ghcr.io/stellaops/normalizer@sha256:…"
|
||||
},
|
||||
"signatures": [
|
||||
{
|
||||
"type": "dsse",
|
||||
"key_id": "stellaops-benchmark-key-1",
|
||||
"signature": "base64-encoded-blob"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
*(Signatures can be optional in v1 – but structure should be there.)*
|
||||
|
||||
### 3.2 `lockfile.py` module
|
||||
|
||||
**File:** `harness/reachbench/lockfile.py`
|
||||
|
||||
**Responsibilities**
|
||||
|
||||
* Compute deterministic SHA-256 digest of:
|
||||
|
||||
* each case’s artifacts (path → hash from `dataset.json`)
|
||||
* entire `dataset/` tree (sorted traversal)
|
||||
* Generate new `manifest.lock.json`:
|
||||
|
||||
* `version` (hard-coded constant)
|
||||
* `created_at` (UTC ISO8601)
|
||||
* `dataset` section with case hashes
|
||||
* Verification:
|
||||
|
||||
* `verify_lockfile(dataset_root, lockfile_path)`:
|
||||
|
||||
* recompute hashes
|
||||
* compare to `lockfile.dataset`
|
||||
* return boolean + list of mismatches
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. Implement canonical hashing:
|
||||
|
||||
* For text JSON files: normalize with:
|
||||
|
||||
* sort keys
|
||||
* no whitespace
|
||||
* UTF‑8 encoding
|
||||
* For binaries (packages): raw bytes.
|
||||
2. Implement `compute_dataset_hashes(dataset_root)`:
|
||||
|
||||
* Returns `{"cases": {...}, "root_sha256": "…"}`.
|
||||
3. Implement `write_lockfile(...)` and `verify_lockfile(...)`.
|
||||
4. Tests:
|
||||
|
||||
* Two calls with same dataset produce identical lockfile (order of `cases` keys normalized).
|
||||
* Changing any artifact file changes the root hash and causes verify to fail.
|
||||
|
||||
### 3.3 CLI commands
|
||||
|
||||
Add to `cli.py`:
|
||||
|
||||
* `reachbench compute-lockfile --dataset-root ./dataset --out ./dataset/manifest.lock.json`
|
||||
* `reachbench verify-lockfile --dataset-root ./dataset --lockfile ./dataset/manifest.lock.json`
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `reachbench compute-lockfile` generates a stable file (byte-for-byte identical across runs).
|
||||
* `reachbench verify-lockfile` exits with:
|
||||
|
||||
* code 0 if matches
|
||||
* non-zero if mismatch (plus human-readable diff).
|
||||
|
||||
---
|
||||
|
||||
## 4. Scoring harness CLI
|
||||
|
||||
**Goal:** Deterministically score participant results against ground truth.
|
||||
|
||||
### 4.1 Result format (participant output)
|
||||
|
||||
**Expectation:**
|
||||
|
||||
Participants provide `results/` with one JSON per case:
|
||||
|
||||
```text
|
||||
results/
|
||||
php-wordpress-5.8-cve-2023-12345.json
|
||||
js-express-4.17-cve-2022-9999.json
|
||||
```
|
||||
|
||||
**Result file example:**
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"tool_name": "my-reachability-analyzer",
|
||||
"tool_version": "1.0.0",
|
||||
"predictions": [
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_ajax_nopriv_some_vuln",
|
||||
"symbol_kind": "function",
|
||||
"status": "reachable"
|
||||
},
|
||||
{
|
||||
"cve": "CVE-2023-12345",
|
||||
"symbol": "wp_safe_function",
|
||||
"symbol_kind": "function",
|
||||
"status": "not_reachable"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 Scoring model
|
||||
|
||||
* Treat scoring as classification over `(cve, symbol)` pairs.
|
||||
* For each case:
|
||||
|
||||
* Truth positives: all `vulnerable_components` with `status == "reachable"`.
|
||||
* Truth negatives: everything marked `not_reachable` (optional in v1).
|
||||
* Predictions: all entries with `status == "reachable"`.
|
||||
* Compute:
|
||||
|
||||
* `TP`: predicted reachable & truth reachable.
|
||||
* `FP`: predicted reachable but truth says not reachable / unknown.
|
||||
* `FN`: truth reachable but not predicted reachable.
|
||||
* Metrics:
|
||||
|
||||
* Precision, Recall, F1 per case.
|
||||
* Macro-averaged metrics across all cases.
|
||||
|
||||
### 4.3 Implementation (`scoring.py`)
|
||||
|
||||
**File:** `harness/reachbench/scoring.py`
|
||||
|
||||
**Functions:**
|
||||
|
||||
* `load_truth(case_truth_path) -> TruthModel`
|
||||
|
||||
* `load_predictions(predictions_path) -> PredictionModel`
|
||||
|
||||
* `compute_case_metrics(truth, preds) -> dict`
|
||||
|
||||
* returns:
|
||||
|
||||
```python
|
||||
{
|
||||
"case_id": str,
|
||||
"tp": int,
|
||||
"fp": int,
|
||||
"fn": int,
|
||||
"precision": float,
|
||||
"recall": float,
|
||||
"f1": float
|
||||
}
|
||||
```
|
||||
|
||||
* `aggregate_metrics(case_metrics_list) -> dict`
|
||||
|
||||
* `macro_precision`, `macro_recall`, `macro_f1`, `num_cases`.
|
||||
|
||||
### 4.4 CLI: `score`
|
||||
|
||||
**Signature:**
|
||||
|
||||
```bash
|
||||
reachbench score \
|
||||
--dataset-root ./dataset \
|
||||
--results-root ./results \
|
||||
--lockfile ./dataset/manifest.lock.json \
|
||||
--out ./out/scores.json \
|
||||
[--cases php-*] \
|
||||
[--repeat 3]
|
||||
```
|
||||
|
||||
**Behavior:**
|
||||
|
||||
1. **Verify lockfile** (fail closed if mismatch).
|
||||
|
||||
2. Load `dataset.json`, filter cases if `--cases` is set (glob).
|
||||
|
||||
3. For each case:
|
||||
|
||||
* Load truth file (and validate schema).
|
||||
* Locate results file (`<case_id>.json`) under `results-root`:
|
||||
|
||||
* If missing, treat as all FN (or mark case as “no submission”).
|
||||
* Load and validate predictions (include a JSON Schema: `results.schema.json`).
|
||||
* Compute per-case metrics.
|
||||
|
||||
4. Aggregate metrics.
|
||||
|
||||
5. Write `scores.json`:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"version": "0.1.0",
|
||||
"dataset_version": "0.1.0",
|
||||
"generated_at": "2025-01-15T12:34:56Z",
|
||||
"macro_precision": 0.92,
|
||||
"macro_recall": 0.88,
|
||||
"macro_f1": 0.90,
|
||||
"cases": [
|
||||
{
|
||||
"case_id": "php-wordpress-5.8-cve-2023-12345",
|
||||
"tp": 10,
|
||||
"fp": 1,
|
||||
"fn": 2,
|
||||
"precision": 0.91,
|
||||
"recall": 0.83,
|
||||
"f1": 0.87
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
6. **Determinism check**:
|
||||
|
||||
* If `--repeat N` given:
|
||||
|
||||
* Re-run scoring in-memory N times.
|
||||
* Compare resulting JSON strings (canonicalized via sorted keys).
|
||||
* If any differ, exit non-zero with message (“non-deterministic scoring detected”).
|
||||
|
||||
### 4.5 Offline-only mode
|
||||
|
||||
* In `cli.py`, early check:
|
||||
|
||||
```python
|
||||
if os.getenv("REACHBENCH_OFFLINE_ONLY", "1") == "1":
|
||||
# Verify no outbound network: by policy, just ensure we never call any net libs.
|
||||
# (In v1, simply avoid adding any such calls.)
|
||||
```
|
||||
|
||||
* Document that harness must not reach out to the internet.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* Given a small artificial dataset with 2–3 cases and handcrafted results, `reachbench score` produces expected metrics (assert via tests).
|
||||
* Running `reachbench score --repeat 3` produces identical `scores.json` across runs.
|
||||
* Missing results files are handled gracefully (but clearly documented).
|
||||
|
||||
---
|
||||
|
||||
## 5. Baseline implementations
|
||||
|
||||
**Goal:** Provide in-repo baselines that use only the provided graphs (no extra tooling).
|
||||
|
||||
### 5.1 Baseline types
|
||||
|
||||
1. **Naïve reachable**: all symbols in the vulnerable package are considered reachable.
|
||||
2. **Imports-only**: reachable = any symbol that:
|
||||
|
||||
* appears in the graph AND
|
||||
* is reachable from any entrypoint by a single edge OR name match.
|
||||
3. **Call-depth-2**:
|
||||
|
||||
* From each entrypoint, traverse up to depth 2 along `call` edges.
|
||||
* Anything at depth ≤ 2 is considered reachable.
|
||||
|
||||
### 5.2 Implementation
|
||||
|
||||
**File:** `harness/reachbench/baselines.py`
|
||||
|
||||
* `baseline_naive(graph, truth) -> PredictionModel`
|
||||
* `baseline_imports_only(graph, truth) -> PredictionModel`
|
||||
* `baseline_call_depth_2(graph, truth) -> PredictionModel`
|
||||
|
||||
**CLI:**
|
||||
|
||||
```bash
|
||||
reachbench run-baseline \
|
||||
--dataset-root ./dataset \
|
||||
--baseline naive|imports|depth2 \
|
||||
--out ./results-baseline-<baseline>/
|
||||
```
|
||||
|
||||
Behavior:
|
||||
|
||||
* For each case:
|
||||
|
||||
* Load graph.
|
||||
* Generate predictions per baseline.
|
||||
* Write result file `results-baseline-<baseline>/<case_id>.json`.
|
||||
|
||||
### 5.3 Tests
|
||||
|
||||
* Tiny synthetic dataset in `harness/tests/data/`:
|
||||
|
||||
* 1–2 cases with simple graphs.
|
||||
* Known expectations for each baseline (TP/FP/FN counts).
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* `reachbench run-baseline --baseline naive` runs end-to-end and outputs results files.
|
||||
* `reachbench score` on baseline results produces stable scores.
|
||||
* Tests validate baseline behavior on synthetic cases.
|
||||
|
||||
---
|
||||
|
||||
## 6. Dataset validation & tooling
|
||||
|
||||
**Goal:** One command to validate everything (schemas, hashes, internal consistency).
|
||||
|
||||
### CLI: `validate-dataset`
|
||||
|
||||
```bash
|
||||
reachbench validate-dataset \
|
||||
--dataset-root ./dataset \
|
||||
[--lockfile ./dataset/manifest.lock.json]
|
||||
```
|
||||
|
||||
**Checks:**
|
||||
|
||||
1. `dataset.json` conforms to `dataset.schema.json`.
|
||||
2. For each case:
|
||||
|
||||
* all artifact paths exist
|
||||
* `graph` file passes `graph.schema.json`
|
||||
* `truth` file passes `truth.schema.json`
|
||||
3. Optional: verify lockfile if provided.
|
||||
|
||||
**Implementation:**
|
||||
|
||||
* `dataset_loader.py`:
|
||||
|
||||
* `load_dataset_index(path) -> DatasetIndex`
|
||||
* `iter_cases(dataset_index)` yields case objects.
|
||||
* `validate_case(case, dataset_root) -> list[str]` (list of error messages).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Broken paths / invalid JSON produce a clear error message and non-zero exit code.
|
||||
* CI job calls `reachbench validate-dataset` on every push.
|
||||
|
||||
---
|
||||
|
||||
## 7. Documentation
|
||||
|
||||
**Goal:** Make it trivial for outsiders to use the benchmark.
|
||||
|
||||
### 7.1 `README.md`
|
||||
|
||||
* Overview:
|
||||
|
||||
* What the benchmark is.
|
||||
* What it measures (reachability precision/recall).
|
||||
* Quickstart:
|
||||
|
||||
```bash
|
||||
git clone ...
|
||||
cd stellaops-reachability-benchmark
|
||||
|
||||
# Validate dataset
|
||||
reachbench validate-dataset --dataset-root ./dataset
|
||||
|
||||
# Run baselines
|
||||
reachbench run-baseline --baseline naive --dataset-root ./dataset --out ./results-naive
|
||||
|
||||
# Score baselines
|
||||
reachbench score --dataset-root ./dataset --results-root ./results-naive --out ./out/naive-scores.json
|
||||
```
|
||||
|
||||
### 7.2 `docs/HOWTO.md`
|
||||
|
||||
* Step-by-step:
|
||||
|
||||
* Installing harness.
|
||||
* Running your own tool on the dataset.
|
||||
* Formatting your `results/`.
|
||||
* Running `reachbench score`.
|
||||
* Interpreting `scores.json`.
|
||||
|
||||
### 7.3 `docs/SCHEMA.md`
|
||||
|
||||
* Human-readable description of:
|
||||
|
||||
* `graph` JSON
|
||||
* `truth` JSON
|
||||
* `results` JSON
|
||||
* `scores` JSON
|
||||
* Link to actual JSON Schemas.
|
||||
|
||||
### 7.4 `docs/REPRODUCIBILITY.md`
|
||||
|
||||
* Explain:
|
||||
|
||||
* lockfile design
|
||||
* hashing rules
|
||||
* deterministic scoring and `--repeat` flag
|
||||
* how to verify you’re using the exact same dataset.
|
||||
|
||||
### 7.5 `docs/SANITIZATION.md`
|
||||
|
||||
* Rules for adding new cases:
|
||||
|
||||
* Only use OSS or properly licensed code.
|
||||
* Strip secrets / proprietary paths / user data.
|
||||
* How to confirm nothing sensitive is in package tarballs.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* A new engineer (or external user) can go from zero to “I ran the baseline and got scores” by following docs only.
|
||||
* All example commands work as written.
|
||||
|
||||
---
|
||||
|
||||
## 8. CI/CD details
|
||||
|
||||
**Goal:** Keep repo healthy and ensure determinism.
|
||||
|
||||
### CI jobs (GitHub Actions)
|
||||
|
||||
1. **`lint`**
|
||||
|
||||
* Run `ruff` / `flake8` (your choice).
|
||||
2. **`test`**
|
||||
|
||||
* Run `pytest`.
|
||||
3. **`validate-dataset`**
|
||||
|
||||
* Run `reachbench validate-dataset --dataset-root ./dataset`.
|
||||
4. **`determinism`**
|
||||
|
||||
* Small workflow step:
|
||||
|
||||
* Run `reachbench score` on a tiny test dataset with `--repeat 3`.
|
||||
* Assert success.
|
||||
5. **`docker-build`**
|
||||
|
||||
* `docker build` the harness image.
|
||||
|
||||
### Acceptance criteria
|
||||
|
||||
* All jobs green on main.
|
||||
* PRs show failing status if schemas or determinism break.
|
||||
|
||||
---
|
||||
|
||||
## 9. Rough “epics → stories” breakdown
|
||||
|
||||
You can paste roughly like this into Jira/Linear:
|
||||
|
||||
1. **Epic: Repo bootstrap & CI**
|
||||
|
||||
* Story: Create repo skeleton & Python project
|
||||
* Story: Add Dockerfile & basic CI (lint + tests)
|
||||
|
||||
2. **Epic: Schemas & dataset plumbing**
|
||||
|
||||
* Story: Implement `truth.schema.json` + tests
|
||||
* Story: Implement `graph.schema.json` + tests
|
||||
* Story: Implement `dataset.schema.json` + tests
|
||||
* Story: Implement `validate-dataset` CLI
|
||||
|
||||
3. **Epic: Lockfile & determinism**
|
||||
|
||||
* Story: Implement lockfile computation + verification
|
||||
* Story: Add `compute-lockfile` & `verify-lockfile` CLI
|
||||
* Story: Add determinism checks in CI
|
||||
|
||||
4. **Epic: Scoring harness**
|
||||
|
||||
* Story: Define results format + `results.schema.json`
|
||||
* Story: Implement scoring logic (`scoring.py`)
|
||||
* Story: Implement `score` CLI with `--repeat`
|
||||
* Story: Add unit tests for metrics
|
||||
|
||||
5. **Epic: Baselines**
|
||||
|
||||
* Story: Implement naive baseline
|
||||
* Story: Implement imports-only baseline
|
||||
* Story: Implement depth-2 baseline
|
||||
* Story: Add `run-baseline` CLI + tests
|
||||
|
||||
6. **Epic: Documentation & polish**
|
||||
|
||||
* Story: Write README + HOWTO
|
||||
* Story: Write SCHEMA / REPRODUCIBILITY / SANITIZATION docs
|
||||
* Story: Final repo cleanup & examples
|
||||
|
||||
---
|
||||
|
||||
If you tell me your preferred language and CI, I can also rewrite this into exact tickets and even starter code for `cli.py` and a couple of schemas.
|
||||
@@ -1,654 +0,0 @@
|
||||
Here’s a small but high‑impact product tweak: **add an immutable `graph_revision_id` to every call‑graph page and API link**, so any result is citeable and reproducible across time.
|
||||
|
||||
---
|
||||
|
||||
### Why it matters (quick)
|
||||
|
||||
* **Auditability:** you can prove *which* graph produced a finding.
|
||||
* **Reproducibility:** reruns that change paths won’t “move the goalposts.”
|
||||
* **Support & docs:** screenshots/links in tickets point to an exact graph state.
|
||||
|
||||
### What to add
|
||||
|
||||
* **Stable anchor in all URLs:**
|
||||
`https://…/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
`https://…/api/graphs/{graph_id}/nodes?rev={graph_revision_id}`
|
||||
* **Opaque, content‑addressed ID:** e.g., `graph_revision_id = blake3( sorted_edges + cfg + tool_versions + dataset_hashes )`.
|
||||
* **First‑class fields:** store `graph_id` (logical lineage), `graph_revision_id` (immutable), `parent_revision_id` (if derived), `created_at`, `provenance` (feed hashes, toolchain).
|
||||
* **UI surfacing:** show a copy‑button “Rev: 8f2d…c9” on graph pages and in the “Share” dialog.
|
||||
* **Diff affordance:** when `?rev=A` and `?rev=B` are both present, offer “Compare paths (A↔B).”
|
||||
|
||||
### Minimal API contract (suggested)
|
||||
|
||||
* `GET /api/graphs/{graph_id}` → latest + `latest_revision_id`
|
||||
* `GET /api/graphs/{graph_id}/revisions/{graph_revision_id}` → immutable snapshot
|
||||
* `GET /api/graphs/{graph_id}/nodes?rev=…` and `/edges?rev=…`
|
||||
* `POST /api/graphs/{graph_id}/pin` with `{ graph_revision_id }` to mark “official”
|
||||
* HTTP `Link` header on all responses:
|
||||
`Link: <…/graphs/{graph_id}/revisions/{graph_revision_id}>; rel="version"`
|
||||
|
||||
### How to compute the revision id (deterministic)
|
||||
|
||||
* Inputs (all normalized): sorted node/edge sets; build config; tool+model versions; input artifacts (SBOM/VEX/feed) **by hash**; environment knobs (feature flags).
|
||||
* Serialization: canonical JSON (UTF‑8, ordered keys).
|
||||
* Hash: BLAKE3/sha256 → base58/hex (shortened in UI, full in API).
|
||||
* Store alongside a manifest (so you can replay the graph later).
|
||||
|
||||
### Guardrails
|
||||
|
||||
* **Never reuse an ID** if any input bit differs.
|
||||
* **Do not** make it guessable from business data (avoid leaking repo names, paths).
|
||||
* **Break glass:** if a bad graph must be purged, keep the ID tombstoned (410 Gone) so references don’t silently change.
|
||||
|
||||
### Stella Ops touches (concrete)
|
||||
|
||||
* **Authority**: add `GraphRevisionManifest` (feeds, lattice/policy versions, scanners, in‑toto/DSSE attestations).
|
||||
* **Scanner/Vexer**: emit deterministic manifests and hand them to Authority for id derivation.
|
||||
* **Ledger**: record `(graph_id, graph_revision_id, manifest_hash, signatures)`; expose audit query by `graph_revision_id`.
|
||||
* **Docs & Support**: “Attach your `graph_revision_id`” line in issue templates.
|
||||
|
||||
### Tiny UX copy
|
||||
|
||||
* On graph page header: `Rev 8f2d…c9` • **Copy** • **Compare** • **Pin**
|
||||
* Share dialog: “This link freezes today’s state. New runs get a different rev.”
|
||||
|
||||
If you want, I can draft the DB table, the manifest JSON schema, and the exact URL/router changes for your .NET 10 services next.
|
||||
Cool, let’s turn this into something your engineers can actually pick up and implement.
|
||||
|
||||
Below is a concrete implementation plan broken down by phases, services, and tickets, with suggested data models, APIs, and tests.
|
||||
|
||||
---
|
||||
|
||||
## 0. Definitions (shared across teams)
|
||||
|
||||
* **Graph ID (`graph_id`)** – Logical identifier for a call graph lineage (e.g., “the call graph for build X of repo Y”).
|
||||
* **Graph Revision ID (`graph_revision_id`)** – Immutable identifier for a specific snapshot of that graph, derived from a manifest (content-addressed hash).
|
||||
* **Parent Revision ID (`parent_revision_id`)** – Previous revision in the lineage (if any).
|
||||
* **Manifest** – Canonical JSON blob that describes *everything* that could affect graph structure or results:
|
||||
|
||||
* Nodes & edges
|
||||
* Input feeds and their hashes (SBOM, VEX, scanner output, etc.)
|
||||
* config/policies/feature flags
|
||||
* tool + version (scanner, vexer, authority)
|
||||
|
||||
---
|
||||
|
||||
## 1. High-Level Architecture Changes
|
||||
|
||||
1. **Introduce `graph_revision_id` as a first-class concept** in:
|
||||
|
||||
* Graph storage / Authority
|
||||
* Ledger / audit
|
||||
* Backend APIs serving call graphs
|
||||
2. **Derive `graph_revision_id` deterministically** from a manifest via a cryptographic hash.
|
||||
3. **Expose revision in all graph-related URLs & APIs**:
|
||||
|
||||
* UI: `…/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
* API: `…/api/graphs/{graph_id}/revisions/{graph_revision_id}`
|
||||
4. **Ensure immutability**: once a revision exists, it can never be updated in-place—only superseded by new revisions.
|
||||
|
||||
---
|
||||
|
||||
## 2. Backend: Data Model & Storage
|
||||
|
||||
### 2.1. Authority (graph source of truth)
|
||||
|
||||
**Goal:** Model graphs and revisions explicitly.
|
||||
|
||||
**New / updated tables (example in SQL-ish form):**
|
||||
|
||||
1. **Graphs (logical entity)**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graphs (
|
||||
id UUID PRIMARY KEY,
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
latest_revision_id VARCHAR(128) NULL, -- FK into graph_revisions.id
|
||||
label TEXT NULL, -- optional human label
|
||||
metadata JSONB NULL
|
||||
);
|
||||
```
|
||||
|
||||
2. **Graph Revisions (immutable snapshots)**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graph_revisions (
|
||||
id VARCHAR(128) PRIMARY KEY, -- graph_revision_id (hash)
|
||||
graph_id UUID NOT NULL REFERENCES graphs(id),
|
||||
parent_revision_id VARCHAR(128) NULL REFERENCES graph_revisions(id),
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
manifest JSONB NOT NULL, -- canonical manifest
|
||||
provenance JSONB NOT NULL, -- tool versions, etc.
|
||||
is_pinned BOOLEAN NOT NULL DEFAULT FALSE,
|
||||
pinned_by UUID NULL, -- user id
|
||||
pinned_at TIMESTAMPTZ NULL
|
||||
);
|
||||
CREATE INDEX idx_graph_revisions_graph_id ON graph_revisions(graph_id);
|
||||
```
|
||||
|
||||
3. **Call Graph Data (if separate)**
|
||||
If you store nodes/edges in separate tables, add a foreign key to `graph_revision_id`:
|
||||
|
||||
```sql
|
||||
ALTER TABLE call_graph_nodes
|
||||
ADD COLUMN graph_revision_id VARCHAR(128) NULL;
|
||||
|
||||
ALTER TABLE call_graph_edges
|
||||
ADD COLUMN graph_revision_id VARCHAR(128) NULL;
|
||||
```
|
||||
|
||||
> **Rule:** Nodes/edges for a revision are **never mutated**; a new revision means new rows.
|
||||
|
||||
---
|
||||
|
||||
### 2.2. Ledger (audit trail)
|
||||
|
||||
**Goal:** Every revision gets a ledger record for auditability.
|
||||
|
||||
**Table change or new table:**
|
||||
|
||||
```sql
|
||||
CREATE TABLE graph_revision_ledger (
|
||||
id BIGSERIAL PRIMARY KEY,
|
||||
graph_revision_id VARCHAR(128) NOT NULL,
|
||||
graph_id UUID NOT NULL,
|
||||
manifest_hash VARCHAR(128) NOT NULL,
|
||||
manifest_digest_algo TEXT NOT NULL, -- e.g., "BLAKE3"
|
||||
authority_signature BYTEA NULL, -- optional
|
||||
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
|
||||
);
|
||||
CREATE INDEX idx_grl_revision ON graph_revision_ledger(graph_revision_id);
|
||||
```
|
||||
|
||||
Ledger ingestion happens **after** a revision is stored in Authority, but **before** it is exposed as “current” in the UI.
|
||||
|
||||
---
|
||||
|
||||
## 3. Backend: Revision Hashing & Manifest
|
||||
|
||||
### 3.1. Define the manifest schema
|
||||
|
||||
Create a spec (e.g., JSON Schema) used by Scanner/Vexer/Authority.
|
||||
|
||||
**Example structure:**
|
||||
|
||||
```json
|
||||
{
|
||||
"graph": {
|
||||
"graph_id": "uuid",
|
||||
"generator": {
|
||||
"tool_name": "scanner",
|
||||
"tool_version": "1.4.2",
|
||||
"run_id": "some-run-id"
|
||||
}
|
||||
},
|
||||
"inputs": {
|
||||
"sbom_hash": "sha256:…",
|
||||
"vex_hash": "sha256:…",
|
||||
"repos": [
|
||||
{
|
||||
"name": "repo-a",
|
||||
"commit": "abc123",
|
||||
"tree_hash": "sha1:…"
|
||||
}
|
||||
]
|
||||
},
|
||||
"config": {
|
||||
"policy_version": "2024-10-01",
|
||||
"feature_flags": {
|
||||
"new_vex_engine": true
|
||||
}
|
||||
},
|
||||
"graph_content": {
|
||||
"nodes": [
|
||||
// nodes in canonical sorted order
|
||||
],
|
||||
"edges": [
|
||||
// edges in canonical sorted order
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Key requirements:**
|
||||
|
||||
* All lists that affect the graph (`nodes`, `edges`, `repos`, etc.) must be **sorted deterministically**.
|
||||
* Keys must be **stable** (no environment-dependent keys, no random IDs).
|
||||
* All hashes of input artifacts must be included (not raw content).
|
||||
|
||||
### 3.2. Hash computation
|
||||
|
||||
Language-agnostic algorithm:
|
||||
|
||||
1. Normalize manifest to **canonical JSON**:
|
||||
|
||||
* UTF-8
|
||||
* Sorted keys
|
||||
* No extra whitespace
|
||||
2. Hash the bytes using a cryptographic hash (BLAKE3 or SHA-256).
|
||||
3. Encode as hex or base58 string.
|
||||
|
||||
**Pseudocode:**
|
||||
|
||||
```pseudo
|
||||
function compute_graph_revision_id(manifest):
|
||||
canonical_json = canonical_json_encode(manifest) // sorted keys
|
||||
digest_bytes = BLAKE3(canonical_json)
|
||||
digest_hex = hex_encode(digest_bytes)
|
||||
return "grv_" + digest_hex[0:40] // prefix + shorten for UI
|
||||
```
|
||||
|
||||
**Ticket:** Implement `GraphRevisionIdGenerator` library (shared):
|
||||
|
||||
* `Compute(manifest) -> graph_revision_id`
|
||||
* `ValidateFormat(graph_revision_id) -> bool`
|
||||
|
||||
Make this a **shared library** across Scanner, Vexer, Authority to avoid divergence.
|
||||
|
||||
---
|
||||
|
||||
## 4. Backend: APIs
|
||||
|
||||
### 4.1. Graphs & revisions REST API
|
||||
|
||||
**New endpoints (example):**
|
||||
|
||||
1. **Get latest graph revision**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"latest_revision_id": "grv_8f2d…c9",
|
||||
"created_at": "…",
|
||||
"metadata": { … }
|
||||
}
|
||||
```
|
||||
|
||||
2. **List revisions for a graph**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/revisions
|
||||
Query: ?page=1&pageSize=20
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"items": [
|
||||
{
|
||||
"graph_revision_id": "grv_8f2d…c9",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": null,
|
||||
"is_pinned": true
|
||||
},
|
||||
{
|
||||
"graph_revision_id": "grv_3a1b…e4",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": "grv_8f2d…c9",
|
||||
"is_pinned": false
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. **Get a specific revision (snapshot)**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/revisions/{graph_revision_id}
|
||||
Response:
|
||||
{
|
||||
"graph_id": "…",
|
||||
"graph_revision_id": "…",
|
||||
"created_at": "…",
|
||||
"parent_revision_id": null,
|
||||
"manifest": { … }, // optional: maybe not full content if large
|
||||
"provenance": { … }
|
||||
}
|
||||
```
|
||||
|
||||
4. **Get nodes/edges for a revision**
|
||||
|
||||
```http
|
||||
GET /api/graphs/{graph_id}/nodes?rev={graph_revision_id}
|
||||
GET /api/graphs/{graph_id}/edges?rev={graph_revision_id}
|
||||
```
|
||||
|
||||
Behavior:
|
||||
|
||||
* If `rev` is **omitted**, return the **latest_revision_id** for that `graph_id`.
|
||||
* If `rev` is **invalid or unknown**, return `404` (not fallback).
|
||||
|
||||
5. **Pin/unpin a revision (optional for v1)**
|
||||
|
||||
```http
|
||||
POST /api/graphs/{graph_id}/pin
|
||||
Body: { "graph_revision_id": "…" }
|
||||
|
||||
DELETE /api/graphs/{graph_id}/pin
|
||||
Body: { "graph_revision_id": "…" }
|
||||
```
|
||||
|
||||
### 4.2. Backward compatibility
|
||||
|
||||
* Existing endpoints like `GET /api/graphs/{graph_id}/nodes` should:
|
||||
|
||||
* Continue working with no `rev` param.
|
||||
* Internally resolve to `latest_revision_id`.
|
||||
* For old records with no revision:
|
||||
|
||||
* Create a synthetic manifest from current stored data.
|
||||
* Compute a `graph_revision_id`.
|
||||
* Store it and set `latest_revision_id` on the `graphs` row.
|
||||
|
||||
---
|
||||
|
||||
## 5. Scanner / Vexer / Upstream Pipelines
|
||||
|
||||
**Goal:** At the end of a graph build, they produce a manifest and a `graph_revision_id`.
|
||||
|
||||
### 5.1. Responsibilities
|
||||
|
||||
1. **Scanner/Vexer**:
|
||||
|
||||
* Gather:
|
||||
|
||||
* Tool name/version
|
||||
* Input artifact hashes
|
||||
* Feature flags / config
|
||||
* Graph nodes/edges
|
||||
* Construct manifest (according to schema).
|
||||
* Compute `graph_revision_id` using shared library.
|
||||
* Send manifest + revision ID to Authority via an internal API (e.g., `POST /internal/graph-build-complete`).
|
||||
|
||||
2. **Authority**:
|
||||
|
||||
* Idempotently upsert:
|
||||
|
||||
* `graphs` (if new `graph_id`)
|
||||
* `graph_revisions` row (if `graph_revision_id` not yet present)
|
||||
* nodes/edges rows keyed by `graph_revision_id`.
|
||||
* Update `graphs.latest_revision_id` to the new revision.
|
||||
|
||||
### 5.2. Internal API (Authority)
|
||||
|
||||
```http
|
||||
POST /internal/graphs/{graph_id}/revisions
|
||||
Body:
|
||||
{
|
||||
"graph_revision_id": "…",
|
||||
"parent_revision_id": "…", // optional
|
||||
"manifest": { … },
|
||||
"provenance": { … },
|
||||
"nodes": [ … ],
|
||||
"edges": [ … ]
|
||||
}
|
||||
Response: 201 Created (or 200 if idempotent)
|
||||
```
|
||||
|
||||
**Rules:**
|
||||
|
||||
* If `graph_revision_id` already exists for that `graph_id` with identical `manifest_hash`, treat as **idempotent**.
|
||||
* If `graph_revision_id` exists but manifest hash differs → log and reject (bug in hashing).
|
||||
|
||||
---
|
||||
|
||||
## 6. Frontend / UX Changes
|
||||
|
||||
Assuming a SPA (React/Vue/etc.), we’ll treat these as tasks.
|
||||
|
||||
### 6.1. URL & routing
|
||||
|
||||
* **New canonical URL format** for graph UI:
|
||||
|
||||
* Latest: `/graphs/{graph_id}`
|
||||
* Specific revision: `/graphs/{graph_id}?rev={graph_revision_id}`
|
||||
|
||||
* Router:
|
||||
|
||||
* Parse `rev` query param.
|
||||
* If present, call `GET /api/graphs/{graph_id}/nodes?rev=…`.
|
||||
* If not present, call same endpoint but without `rev` → backend returns latest.
|
||||
|
||||
### 6.2. Displaying revision info
|
||||
|
||||
* In graph page header:
|
||||
|
||||
* Show truncated revision:
|
||||
|
||||
* `Rev: 8f2d…c9`
|
||||
* Buttons:
|
||||
|
||||
* **Copy** → Copies full `graph_revision_id`.
|
||||
* **Share** → Copies full URL with `?rev=…`.
|
||||
* Optional chip if pinned: `Pinned`.
|
||||
|
||||
**Example data model (TS):**
|
||||
|
||||
```ts
|
||||
type GraphRevisionSummary = {
|
||||
graphId: string;
|
||||
graphRevisionId: string;
|
||||
createdAt: string;
|
||||
parentRevisionId?: string | null;
|
||||
isPinned: boolean;
|
||||
};
|
||||
```
|
||||
|
||||
### 6.3. Revision list panel (optional but useful)
|
||||
|
||||
* Add a side panel or tab: “Revisions”.
|
||||
* Fetch from `GET /api/graphs/{graph_id}/revisions`.
|
||||
* Clicking a revision:
|
||||
|
||||
* Navigates to same page with `?rev={graph_revision_id}`.
|
||||
* Preserves other UI state where reasonable.
|
||||
|
||||
### 6.4. Diff view (nice-to-have, can be v2)
|
||||
|
||||
* UX: “Compare with…” button in header.
|
||||
|
||||
* Opens dialog to pick a second revision.
|
||||
* Backend: add a diff endpoint later, or compute diff client-side from node/edge lists if feasible.
|
||||
|
||||
---
|
||||
|
||||
## 7. Migration Plan
|
||||
|
||||
### 7.1. Phase 1 – Schema & read-path ready
|
||||
|
||||
1. **Add DB columns/tables**:
|
||||
|
||||
* `graphs`, `graph_revisions`, `graph_revision_ledger`.
|
||||
* `graph_revision_id` column to `call_graph_nodes` / `call_graph_edges`.
|
||||
2. **Deploy with no behavior changes**:
|
||||
|
||||
* Default `graph_revision_id` columns NULL.
|
||||
* Existing APIs continue to work.
|
||||
|
||||
### 7.2. Phase 2 – Backfill existing graphs
|
||||
|
||||
1. Write a **backfill job**:
|
||||
|
||||
* For each distinct existing graph:
|
||||
|
||||
* Build a manifest from existing stored data.
|
||||
* Compute `graph_revision_id`.
|
||||
* Insert into `graphs` & `graph_revisions`.
|
||||
* Update nodes/edges for that graph to set `graph_revision_id`.
|
||||
* Set `graphs.latest_revision_id`.
|
||||
|
||||
2. Log any graphs that can’t be backfilled (corrupt data, etc.) for manual review.
|
||||
|
||||
3. After backfill:
|
||||
|
||||
* Add **NOT NULL** constraint on `graph_revision_id` for nodes/edges (if practical).
|
||||
* Ensure all public APIs can fetch revisions without changes from clients.
|
||||
|
||||
### 7.3. Phase 3 – Wire up new pipelines
|
||||
|
||||
1. Update Scanner/Vexer to construct manifests and compute revision IDs.
|
||||
2. Update Authority to accept `/internal/graphs/{graph_id}/revisions`.
|
||||
3. Gradually roll out:
|
||||
|
||||
* Feature flag: `graphRevisionIdFromPipeline`.
|
||||
* For flagged runs, use the new pipeline; for others, fall back to old + synthetic revision.
|
||||
|
||||
### 7.4. Phase 4 – Frontend rollout
|
||||
|
||||
1. Update UI to:
|
||||
|
||||
* Read `rev` from URL (but not required).
|
||||
* Show `Rev` in header.
|
||||
* Use revision-aware endpoints.
|
||||
2. Once stable:
|
||||
|
||||
* Update “Share” actions to always include `?rev=…`.
|
||||
|
||||
---
|
||||
|
||||
## 8. Testing Strategy
|
||||
|
||||
### 8.1. Unit tests
|
||||
|
||||
* **Hashing library**:
|
||||
|
||||
* Same manifest → same `graph_revision_id`.
|
||||
* Different node ordering → same `graph_revision_id`.
|
||||
* Tiny manifest change → different `graph_revision_id`.
|
||||
* **Authority service**:
|
||||
|
||||
* Creating a revision stores `graph_revisions` + nodes/edges with matching `graph_revision_id`.
|
||||
* Duplicate revision (same id + manifest) is idempotent.
|
||||
* Conflicting manifest with same `graph_revision_id` is rejected.
|
||||
|
||||
### 8.2. Integration tests
|
||||
|
||||
* Scenario: “Create graph → view in UI”
|
||||
|
||||
* Pipeline produces manifest & revision.
|
||||
* Authority persists revision.
|
||||
* Ledger logs event.
|
||||
* UI shows matching `graph_revision_id`.
|
||||
* Scenario: “Stable permalinks”
|
||||
|
||||
* Capture a link with `?rev=…`.
|
||||
* Rerun pipeline (new revision).
|
||||
* Old link still shows original nodes/edges.
|
||||
|
||||
### 8.3. Migration tests
|
||||
|
||||
* On a sanitized snapshot:
|
||||
|
||||
* Run migration & backfill.
|
||||
* Spot-check:
|
||||
|
||||
* Each `graph_id` has exactly one `latest_revision_id`.
|
||||
* Node/edge counts before and after match.
|
||||
* Manually recompute hash for a few graphs and compare to stored `graph_revision_id`.
|
||||
|
||||
---
|
||||
|
||||
## 9. Security & Compliance Considerations
|
||||
|
||||
* **Immutability guarantee**:
|
||||
|
||||
* Don’t allow updates to `graph_revisions.manifest`.
|
||||
* Any change must happen by creating a new revision.
|
||||
* **Tombstoning** (for rare delete cases):
|
||||
|
||||
* If you must “remove” a bad graph, mark revision as `tombstoned` in an additional column and return `410 Gone` for that `graph_revision_id`.
|
||||
* Never reuse that ID.
|
||||
* **Access control**:
|
||||
|
||||
* Ensure revision APIs use the same ACLs as existing graph APIs.
|
||||
* Don’t leak manifests to users not allowed to see underlying artifacts.
|
||||
|
||||
---
|
||||
|
||||
## 10. Concrete Ticket Breakdown (example)
|
||||
|
||||
You can copy/paste this into your tracker and tweak.
|
||||
|
||||
1. **BE-01** – Add `graphs` and `graph_revisions` tables
|
||||
|
||||
* AC:
|
||||
|
||||
* Tables exist with fields above.
|
||||
* Migrations run cleanly in staging.
|
||||
|
||||
2. **BE-02** – Add `graph_revision_id` to nodes/edges tables
|
||||
|
||||
* AC:
|
||||
|
||||
* Column added, nullable.
|
||||
* No runtime errors in staging.
|
||||
|
||||
3. **BE-03** – Implement `GraphRevisionIdGenerator` library
|
||||
|
||||
* AC:
|
||||
|
||||
* Given a manifest, returns deterministic ID.
|
||||
* Unit tests cover ordering, minimal changes.
|
||||
|
||||
4. **BE-04** – Implement `/internal/graphs/{graph_id}/revisions` in Authority
|
||||
|
||||
* AC:
|
||||
|
||||
* Stores new revision + nodes/edges.
|
||||
* Idempotent on duplicate revisions.
|
||||
|
||||
5. **BE-05** – Implement public revision APIs
|
||||
|
||||
* AC:
|
||||
|
||||
* Endpoints in §4.1 available with Swagger.
|
||||
* `rev` query param supported.
|
||||
* Default behavior returns latest revision.
|
||||
|
||||
6. **BE-06** – Backfill existing graphs into `graph_revisions`
|
||||
|
||||
* AC:
|
||||
|
||||
* All existing graphs have `latest_revision_id`.
|
||||
* Nodes/edges linked to a `graph_revision_id`.
|
||||
* Metrics & logs generated for failures.
|
||||
|
||||
7. **BE-07** – Ledger integration for revisions
|
||||
|
||||
* AC:
|
||||
|
||||
* Each new revision creates a ledger entry.
|
||||
* Query by `graph_revision_id` works.
|
||||
|
||||
8. **PIPE-01** – Scanner/Vexer manifest construction
|
||||
|
||||
* AC:
|
||||
|
||||
* Manifest includes all required fields.
|
||||
* Values verified against Authority for a sample run.
|
||||
|
||||
9. **PIPE-02** – Scanner/Vexer computes `graph_revision_id` and calls Authority
|
||||
|
||||
* AC:
|
||||
|
||||
* End-to-end pipeline run produces a new `graph_revision_id`.
|
||||
* Authority stores it and sets as latest.
|
||||
|
||||
10. **FE-01** – UI supports `?rev=` param and displays revision
|
||||
|
||||
* AC:
|
||||
|
||||
* When URL has `rev`, UI loads that revision.
|
||||
* When no `rev`, loads latest.
|
||||
* Rev appears in header with copy/share.
|
||||
|
||||
11. **FE-02** – Revision list UI (optional)
|
||||
|
||||
* AC:
|
||||
|
||||
* Revision panel lists revisions.
|
||||
* Click navigates to appropriate `?rev=`.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next help you turn this into a very explicit design doc (with diagrams and exact JSON examples) or into ready-to-paste migration scripts / TypeScript interfaces tailored to your actual stack.
|
||||
@@ -1,696 +0,0 @@
|
||||
Here are some key developments in the software‑supply‑chain and vulnerability‑scoring world that you’ll want on your radar.
|
||||
|
||||
---
|
||||
|
||||
## 1. CVSS v4.0 – traceable scoring with richer context
|
||||
|
||||
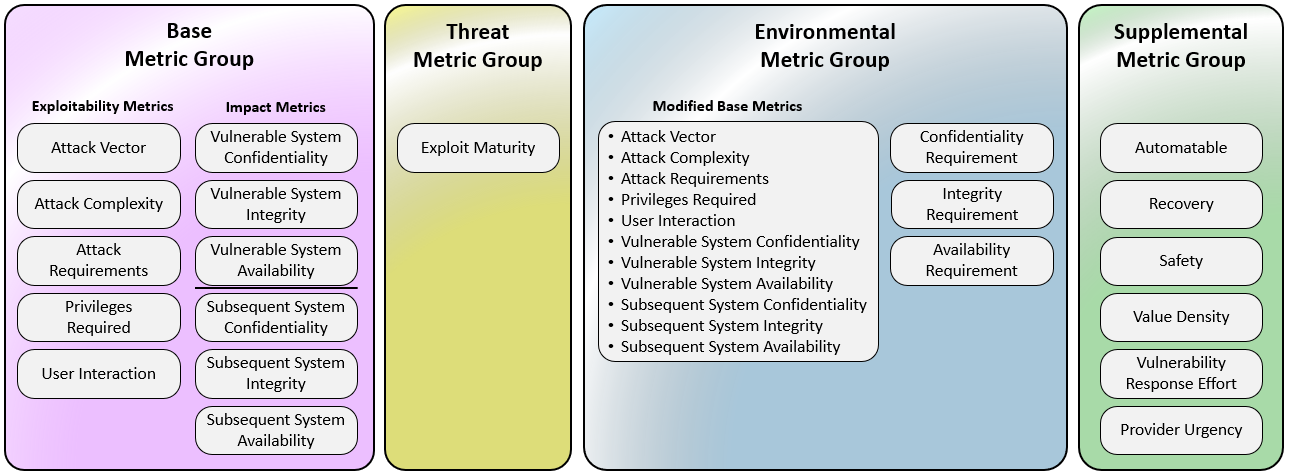
|
||||
|
||||
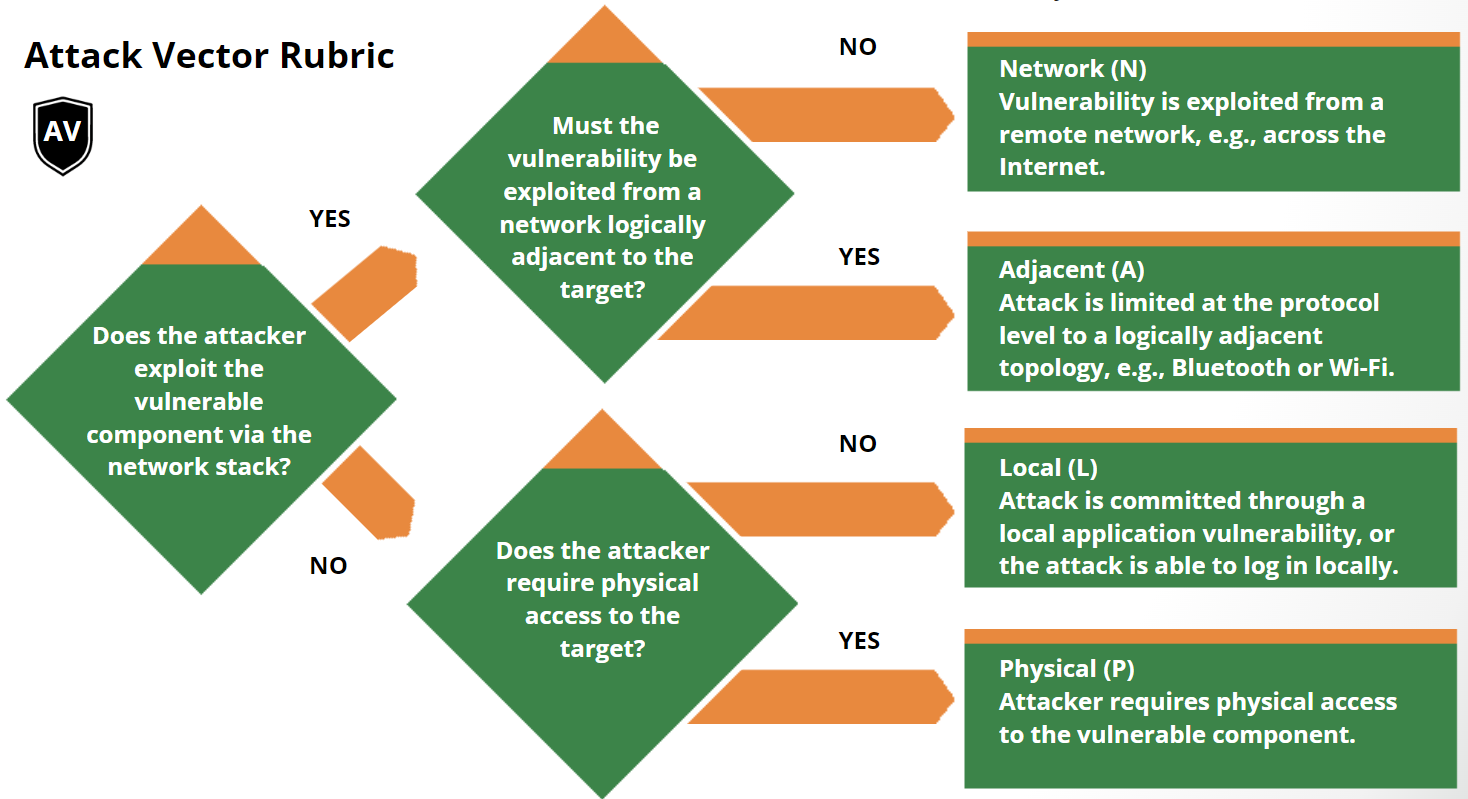
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
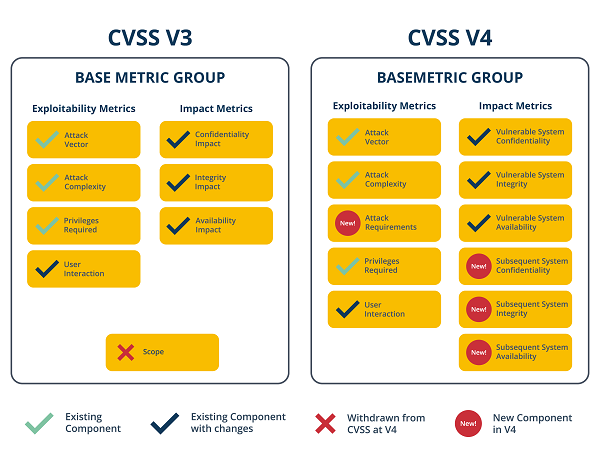
|
||||
|
||||
* CVSS v4.0 was officially released by FIRST (Forum of Incident Response & Security Teams) on **November 1, 2023**. ([first.org][1])
|
||||
* The specification now clearly divides metrics into four groups: Base, Threat, Environmental, and Supplemental. ([first.org][1])
|
||||
* The National Vulnerability Database (NVD) has added support for CVSS v4.0 — meaning newer vulnerability records can carry v4‑style scores, vector strings and search filters. ([NVD][2])
|
||||
* What’s new/tangible: better granularity, explicit “Attack Requirements” and richer metadata to better reflect real‑world contextual risk. ([Seemplicity][3])
|
||||
* Why this matters: Enables more traceable evidence of how a score was derived (which metrics used, what context), supporting auditing, prioritisation and transparency.
|
||||
|
||||
**Take‑away for your world**: If you’re leveraging vulnerability scanning, SBOM enrichment or compliance workflows (given your interest in SBOM/VEX/provenance), then moving to or supporting CVSS v4.0 ensures you have stronger traceability and richer scoring context that maps into policy, audit and remediation workflows.
|
||||
|
||||
---
|
||||
|
||||
## 2. CycloneDX v1.7 – SBOM/VEX/provenance with cryptographic & IP transparency
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
* Version 1.7 of the SBOM standard from OWASP Foundation (CycloneDX) launched on **October 21, 2025**. ([CycloneDX][4])
|
||||
* Key enhancements: *Cryptography Bill of Materials (CBOM)* support (listing algorithm families, elliptic curves, etc) and *structured citations* (who provided component info, how, when) to improve provenance. ([CycloneDX][4])
|
||||
* Provenance use‑cases: The spec enables declaring supplier/author/publisher metadata, component origin, external references. ([CycloneDX][5])
|
||||
* Broadening scope: CycloneDX now supports not just SBOM (software), but hardware BOMs (HBOM), machine learning BOMs, cryptographic BOMs (CBOM) and supports VEX/attestation use‑cases. ([openssf.org][6])
|
||||
* Why this matters: For your StellaOps architecture (with a strong emphasis on provenance, deterministic scans, trust‑frameworks) CycloneDX v1.7 provides native standard support for deeper audit‑ready evidence, cryptographic algorithm visibility (which matters for crypto‑sovereign readiness) and formal attestations/citations in the BOM.
|
||||
|
||||
**Take‑away**: Aligning your SBOM/VEX/provenance stack (e.g., scanner.webservice) to output CycloneDX v1.7‑compliant artifacts means you jump ahead in terms of traceability, auditability and future‑proofing (crypto and IP).
|
||||
|
||||
---
|
||||
|
||||
## 3. SLSA v1.2 Release Candidate 2 – supply‑chain build provenance standard
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
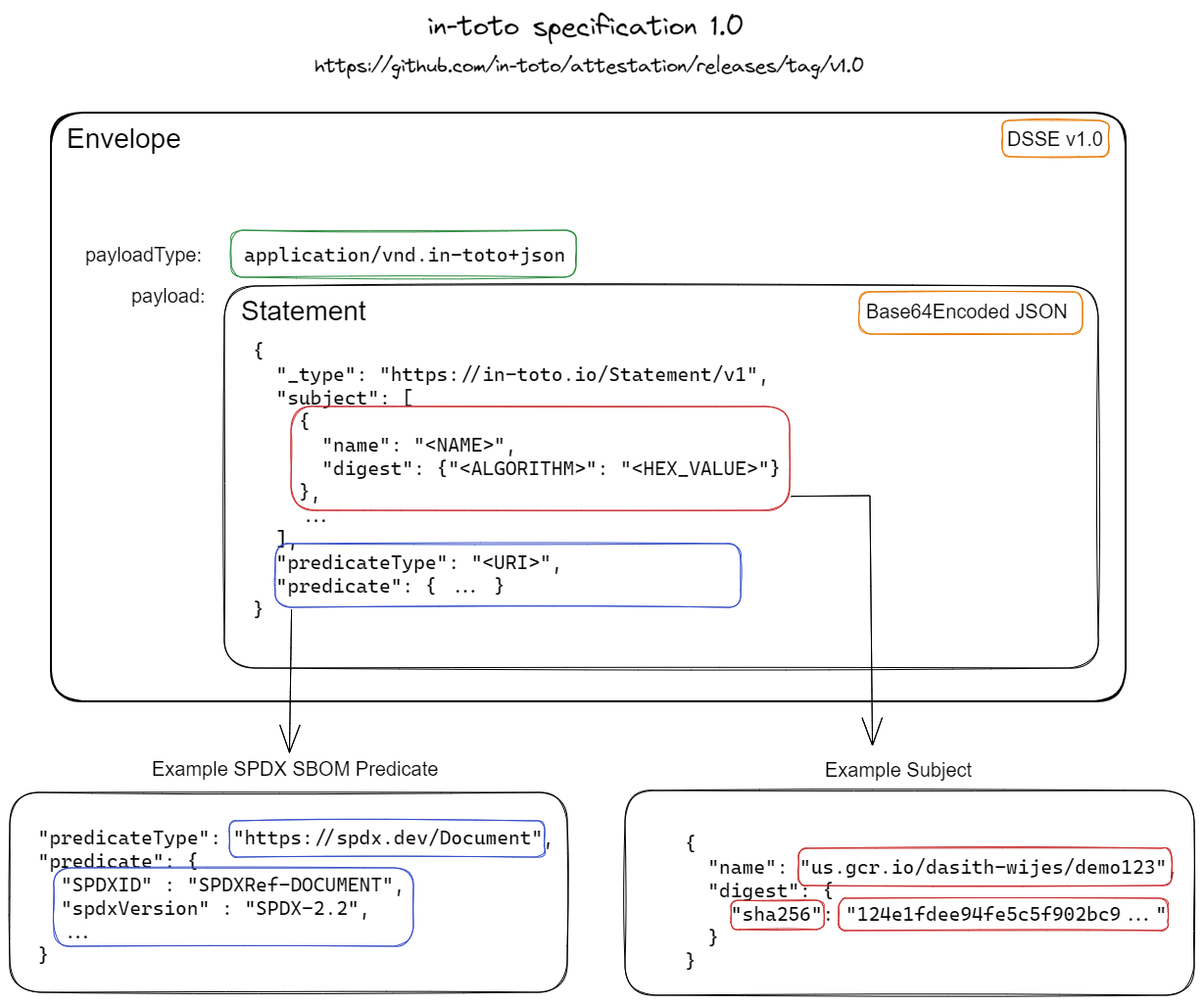
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
* On **November 10, 2025**, the Open Source Security Foundation (via the SLSA community) announced RC2 of SLSA v1.2, open for public comment until November 24, 2025. ([SLSA][7])
|
||||
* What’s new: Introduction of a *Source Track* (in addition to the Build Track) to capture source control provenance, distributed provenance, artifact attestations. ([SLSA][7])
|
||||
* Specification clarifies provenance/attestation formats, how builds should be produced, distributed, verified. ([SLSA][8])
|
||||
* Why this matters: SLSA gives you a standard framework for “I can trace this binary back to the code, the build system, the signer, the provenance chain,” which aligns directly with your strategic moats around deterministic replayable scans, proof‑of‑integrity graph, and attestations.
|
||||
|
||||
**Take‑away**: If you integrate SLSA v1.2 (once finalised) into StellaOps, you gain an industry‑recognised standard for build provenance and attestation, complementing your SBOM/VEX and CVSS code bases.
|
||||
|
||||
---
|
||||
|
||||
### Why I’m sharing this with you
|
||||
|
||||
Given your interest in cryptographic‑sovereign readiness, deterministic scanning, provenance and audit‑grade supply‑chain tooling (your StellaOps moat list), this trifecta (CVSS v4.0 + CycloneDX v1.7 + SLSA v1.2) represents the major standards you need to converge on. They each address different layers: vulnerability scoring, component provenance and build/trust chain assurance. Aligning all three will give you a strong governance and tooling stack.
|
||||
|
||||
If you like, I can pull together a detailed gap‑analysis table (your current architecture versus what these standards demand) and propose roadmap steps for StellaOps to adopt them.
|
||||
|
||||
[1]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://nvd.nist.gov/general/news/cvss-v4-0-official-support?utm_source=chatgpt.com "CVSS v4.0 Official Support - NVD"
|
||||
[3]: https://seemplicity.io/blog/decoding-cvss-4-clarified-base-metrics/?utm_source=chatgpt.com "Decoding CVSS 4.0: Clarified Base Metrics"
|
||||
[4]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[5]: https://cyclonedx.org/use-cases/provenance/?utm_source=chatgpt.com "Security Use Case: Provenance"
|
||||
[6]: https://openssf.org/blog/2025/10/22/sboms-in-the-era-of-the-cra-toward-a-unified-and-actionable-framework/?utm_source=chatgpt.com "Global Alignment on SBOM Standards: How the EU Cyber ..."
|
||||
[7]: https://slsa.dev/blog/2025/11/slsa-v1.2-rc2?utm_source=chatgpt.com "Announcing SLSA v1.2 Release Candidate 2"
|
||||
[8]: https://slsa.dev/spec/v1.2-rc2/?utm_source=chatgpt.com "SLSA specification"
|
||||
Cool, let’s turn all that standards talk into something your engineers can actually build against.
|
||||
|
||||
Below is a concrete implementation plan, broken into 3 workstreams, each with phases, tasks and clear acceptance criteria:
|
||||
|
||||
* **A — CVSS v4.0 integration (scoring & evidence)**
|
||||
* **B — CycloneDX 1.7 SBOM/CBOM + provenance**
|
||||
* **C — SLSA 1.2 (build + source provenance)**
|
||||
* **X — Cross‑cutting (APIs, UX, docs, rollout)**
|
||||
|
||||
I’ll assume you have:
|
||||
|
||||
* A scanner / ingestion pipeline,
|
||||
* A central data model (DB or graph),
|
||||
* An API + UI layer (StellaOps console or similar),
|
||||
* CI/CD on GitHub/GitLab/whatever.
|
||||
|
||||
---
|
||||
|
||||
## A. CVSS v4.0 integration
|
||||
|
||||
**Goal:** Your platform can ingest, calculate, store and expose CVSS v4.0 scores and vectors alongside (or instead of) v3.x, using the official FIRST spec and NVD data. ([FIRST][1])
|
||||
|
||||
### A1. Foundations & decisions
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Pick canonical CVSSv4 library or implementation**
|
||||
|
||||
* Evaluate existing OSS libraries for your main language(s), or plan an internal one based directly on FIRST’s spec (Base, Threat, Environmental, Supplemental groups).
|
||||
* Decide:
|
||||
|
||||
* Supported metric groups (Base only vs. Base+Threat+Environmental+Supplemental).
|
||||
* Which groups your UI will expose/edit vs. read-only from upstream feeds.
|
||||
|
||||
2. **Versioning strategy**
|
||||
|
||||
* Decide how to represent CVSS v3.0/v3.1/v4.0 in your DB:
|
||||
|
||||
* `vulnerability_scores` table with `version`, `vector`, `base_score`, `environmental_score`, `temporal_score`, `severity_band`.
|
||||
* Define precedence rules: if both v3.1 and v4.0 exist, which one your “headline” severity uses.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Tech design doc reviewed & approved.
|
||||
* Decision on library vs. custom implementation recorded.
|
||||
* DB schema migration plan ready.
|
||||
|
||||
---
|
||||
|
||||
### A2. Data model & storage
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **DB schema changes**
|
||||
|
||||
* Add a `cvss_scores` table or expand the existing vulnerability table, e.g.:
|
||||
|
||||
```text
|
||||
cvss_scores
|
||||
id (PK)
|
||||
vuln_id (FK)
|
||||
source (enum: NVD, scanner, manual)
|
||||
version (enum: 2.0, 3.0, 3.1, 4.0)
|
||||
vector (string)
|
||||
base_score (float)
|
||||
temporal_score (float, nullable)
|
||||
environmental_score (float, nullable)
|
||||
severity (enum: NONE/LOW/MEDIUM/HIGH/CRITICAL)
|
||||
metrics_json (JSONB) // raw metrics for traceability
|
||||
created_at / updated_at
|
||||
```
|
||||
|
||||
2. **Traceable evidence**
|
||||
|
||||
* Store:
|
||||
|
||||
* Raw CVSS vector string (e.g. `CVSS:4.0/AV:N/...(etc)`).
|
||||
* Parsed metrics as JSON for audit (show “why” a score is what it is).
|
||||
* Optional: add `calculated_by` + `calculated_at` for your internal scoring runs.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Migrations applied in dev.
|
||||
* Read/write repository functions implemented and unit‑tested.
|
||||
|
||||
---
|
||||
|
||||
### A3. Ingestion & calculation
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **NVD / external feeds**
|
||||
|
||||
* Update your NVD ingestion to read CVSS v4.0 when present in JSON `metrics` fields. ([NVD][2])
|
||||
* Map NVD → internal `cvss_scores` model.
|
||||
|
||||
2. **Local CVSSv4 calculator service**
|
||||
|
||||
* Implement a service (or module) that:
|
||||
|
||||
* Accepts metric values (Base/Threat/Environmental/Supplemental).
|
||||
* Produces:
|
||||
|
||||
* Canonical vector.
|
||||
* Base/Threat/Environmental scores.
|
||||
* Severity band.
|
||||
* Make this callable by:
|
||||
|
||||
* Scanner engine (calculating scores for private vulns).
|
||||
* UI (recalculate button).
|
||||
* API (for automated clients).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a set of reference vectors from FIRST, your calculator returns exact expected scores.
|
||||
* NVD ingestion for a sample of CVEs produces v4 scores in your DB.
|
||||
|
||||
---
|
||||
|
||||
### A4. UI & API
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **API**
|
||||
|
||||
* Extend vulnerability API payload with:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "CVE-2024-XXXX",
|
||||
"cvss": [
|
||||
{
|
||||
"version": "4.0",
|
||||
"source": "NVD",
|
||||
"vector": "CVSS:4.0/AV:N/...",
|
||||
"base_score": 8.3,
|
||||
"severity": "HIGH",
|
||||
"metrics": { "...": "..." }
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
* Add filters: `cvss.version`, `cvss.min_score`, `cvss.severity`.
|
||||
|
||||
2. **UI**
|
||||
|
||||
* On vulnerability detail:
|
||||
|
||||
* Show v3.x and v4.0 side-by-side.
|
||||
* Expandable panel with metric breakdown and “explain my score” text.
|
||||
* On list views:
|
||||
|
||||
* Support sorting & filtering by v4.0 base score & severity.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Frontend can render v4.0 vectors and scores.
|
||||
* QA can filter vulnerabilities using v4 metrics via API and UI.
|
||||
|
||||
---
|
||||
|
||||
### A5. Migration & rollout
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Backfill**
|
||||
|
||||
* For all stored vulnerabilities where metrics exist:
|
||||
|
||||
* If v4 not present but inputs available, compute v4.
|
||||
* Store both historical (v3.x) and new v4 for comparison.
|
||||
|
||||
2. **Feature flag / rollout**
|
||||
|
||||
* Introduce feature flag `cvss_v4_enabled` per tenant or environment.
|
||||
* Run A/B comparison internally before enabling for all users.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Backfill job runs successfully on staging data.
|
||||
* Rollout plan + rollback strategy documented.
|
||||
|
||||
---
|
||||
|
||||
## B. CycloneDX 1.7 SBOM/CBOM + provenance
|
||||
|
||||
CycloneDX 1.7 is now the current spec; it adds things like a Cryptography BOM (CBOM) and structured citations/provenance to strengthen trust and traceability. ([CycloneDX][3])
|
||||
|
||||
### B1. Decide scope & generators
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Select BOM formats & languages**
|
||||
|
||||
* JSON as your primary format (`application/vnd.cyclonedx+json`). ([CycloneDX][4])
|
||||
* Components you’ll cover:
|
||||
|
||||
* Application BOMs (packages, containers).
|
||||
* Optional: infrastructure (IaC, images).
|
||||
* Optional: CBOM for crypto usage.
|
||||
|
||||
2. **Choose or implement generators**
|
||||
|
||||
* For each ecosystem (e.g., Maven, NPM, PyPI, containers), choose:
|
||||
|
||||
* Existing tools (`cyclonedx-maven-plugin`, `cyclonedx-npm`, etc).
|
||||
* Or central generator using lockfiles/manifests.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Matrix of ecosystems → generator tool finalized.
|
||||
* POC shows valid CycloneDX 1.7 JSON BOM for one representative project.
|
||||
|
||||
---
|
||||
|
||||
### B2. Schema alignment & validation
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Model updates**
|
||||
|
||||
* Extend your internal SBOM model to include:
|
||||
|
||||
* `spec_version: "1.7"`
|
||||
* `bomFormat: "CycloneDX"`
|
||||
* `serialNumber` (UUID/URI).
|
||||
* `metadata.tools` (how BOM was produced).
|
||||
* `properties`, `licenses`, `crypto` (for CBOM).
|
||||
* For provenance:
|
||||
|
||||
* `metadata.authors`, `metadata.manufacture`, `metadata.supplier`.
|
||||
* `components[x].evidence` and `components[x].properties` for evidence & citations. ([CycloneDX][5])
|
||||
|
||||
2. **Validation pipeline**
|
||||
|
||||
* Integrate the official CycloneDX JSON schema validation step into:
|
||||
|
||||
* CI (for projects generating BOMs).
|
||||
* Your ingestion path (reject/flag invalid BOMs).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Any BOM produced must pass CycloneDX 1.7 JSON schema validation in CI.
|
||||
* Ingestion rejects malformed BOMs with clear error messages.
|
||||
|
||||
---
|
||||
|
||||
### B3. Provenance & citations in BOMs
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Define provenance policy**
|
||||
|
||||
* Minimal set for every BOM:
|
||||
|
||||
* Author (CI system / team).
|
||||
* Build pipeline ID, commit, repo URL.
|
||||
* Build time.
|
||||
* Extended:
|
||||
|
||||
* `externalReferences` for:
|
||||
|
||||
* Build logs.
|
||||
* SLSA attestations.
|
||||
* Security reports (e.g., scanner runs).
|
||||
|
||||
2. **Implement metadata injection**
|
||||
|
||||
* In your CI templates:
|
||||
|
||||
* Capture build info (commit SHA, pipeline ID, creator, environment).
|
||||
* Add it into CycloneDX `metadata` and `properties`.
|
||||
* For evidence:
|
||||
|
||||
* Use `components[x].evidence` to reference where a component was detected (e.g., file paths, manifest lines).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For any BOM, engineers can trace:
|
||||
|
||||
* WHO built it.
|
||||
* WHEN it was built.
|
||||
* WHICH repo/commit/pipeline it came from.
|
||||
|
||||
---
|
||||
|
||||
### B4. CBOM (Cryptography BOM) support (optional but powerful)
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Crypto inventory**
|
||||
|
||||
* Scanner enhancement:
|
||||
|
||||
* Detect crypto libraries & primitives used (e.g., OpenSSL, bcrypt, TLS versions).
|
||||
* Map them into CycloneDX CBOM structures in `crypto` sections (per spec).
|
||||
|
||||
2. **Policy hooks**
|
||||
|
||||
* Define policy checks:
|
||||
|
||||
* “Disallow SHA-1,”
|
||||
* “Warn on RSA < 2048 bits,”
|
||||
* “Flag non-FIPS-approved algorithms.”
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* From a BOM, you can list all cryptographic algorithms and libraries used in an application.
|
||||
* At least one simple crypto policy implemented (e.g., SHA-1 usage alert).
|
||||
|
||||
---
|
||||
|
||||
### B5. Ingestion, correlation & UI
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Ingestion service**
|
||||
|
||||
* API endpoint: `POST /sboms` accepting CycloneDX 1.7 JSON.
|
||||
* Store:
|
||||
|
||||
* Raw BOM (for evidence).
|
||||
* Normalized component graph (packages, relationships).
|
||||
* Link BOM to:
|
||||
|
||||
* Repo/project.
|
||||
* Build (from SLSA provenance).
|
||||
* Deployed asset.
|
||||
|
||||
2. **Correlation**
|
||||
|
||||
* Join SBOM components with:
|
||||
|
||||
* Vulnerability data (CVE/CWE/CPE/PURL).
|
||||
* Crypto policy results.
|
||||
* Maintain “asset → BOM → components → vulnerabilities” graph.
|
||||
|
||||
3. **UI**
|
||||
|
||||
* For any service/image:
|
||||
|
||||
* Show latest BOM metadata (CycloneDX version, timestamp).
|
||||
* Component list with vulnerability badges.
|
||||
* Crypto tab (if CBOM enabled).
|
||||
* Provenance tab (author, build pipeline, SLSA attestation links).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given an SBOM upload, the UI shows:
|
||||
|
||||
* Components.
|
||||
* Associated vulnerabilities.
|
||||
* Provenance metadata.
|
||||
* API consumers can fetch SBOM + correlated risk in a single call.
|
||||
|
||||
---
|
||||
|
||||
## C. SLSA 1.2 build + source provenance
|
||||
|
||||
SLSA 1.2 (final) introduces a **Source Track** in addition to the Build Track, defining levels and attestation formats for both source control and build provenance. ([SLSA][6])
|
||||
|
||||
### C1. Target SLSA levels & scope
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Choose target levels**
|
||||
|
||||
* For each critical product:
|
||||
|
||||
* Pick Build Track level (e.g., target L2 now, L3 later).
|
||||
* Pick Source Track level (e.g., L1 for all, L2 for sensitive repos).
|
||||
|
||||
2. **Repo inventory**
|
||||
|
||||
* Classify repos by risk:
|
||||
|
||||
* Critical (agents, scanners, control-plane).
|
||||
* Important (integrations).
|
||||
* Low‑risk (internal tools).
|
||||
* Map target SLSA levels accordingly.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For every repo, there is an explicit target SLSA Build + Source level.
|
||||
* Gap analysis doc exists (current vs target).
|
||||
|
||||
---
|
||||
|
||||
### C2. Build provenance in CI/CD
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Attestation generation**
|
||||
|
||||
* For each CI pipeline:
|
||||
|
||||
* Use SLSA-compatible builders or tooling (e.g., `slsa-github-generator`, `slsa-framework` actions, Tekton Chains, etc.) to produce **build provenance attestations** in SLSA 1.2 format.
|
||||
* Attestation content includes:
|
||||
|
||||
* Builder identity.
|
||||
* Build inputs (commit, repo, config).
|
||||
* Build parameters.
|
||||
* Produced artifacts (digest, image tags).
|
||||
|
||||
2. **Signing & storage**
|
||||
|
||||
* Sign attestations (Sigstore/cosign or equivalent).
|
||||
* Store:
|
||||
|
||||
* In an OCI registry (as artifacts).
|
||||
* Or in a dedicated provenance store.
|
||||
* Expose pointer to attestation in:
|
||||
|
||||
* BOM (`externalReferences`).
|
||||
* Your StellaOps metadata.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For any built artifact (image/binary), you can retrieve a SLSA attestation proving:
|
||||
|
||||
* What source it came from.
|
||||
* Which builder ran.
|
||||
* What steps were executed.
|
||||
|
||||
---
|
||||
|
||||
### C3. Source Track controls
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Source provenance**
|
||||
|
||||
* Implement controls to support SLSA Source Track:
|
||||
|
||||
* Enforce protected branches.
|
||||
* Require code review (e.g., 2 reviewers) for main branches.
|
||||
* Require signed commits for critical repos.
|
||||
* Log:
|
||||
|
||||
* Author, reviewers, branch, PR ID, merge SHA.
|
||||
|
||||
2. **Source attestation**
|
||||
|
||||
* For each release:
|
||||
|
||||
* Generate **source attestations** capturing:
|
||||
|
||||
* Repo URL and commit.
|
||||
* Review status.
|
||||
* Policy compliance (review count, checks passing).
|
||||
* Link these to build attestations (Source → Build provenance chain).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* For a release, you can prove:
|
||||
|
||||
* Which reviews happened.
|
||||
* Which branch strategy was followed.
|
||||
* That policies were met at merge time.
|
||||
|
||||
---
|
||||
|
||||
### C4. Verification & policy in StellaOps
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Verifier service**
|
||||
|
||||
* Implement a service that:
|
||||
|
||||
* Fetches SLSA attestations (source + build).
|
||||
* Verifies signatures and integrity.
|
||||
* Evaluates them against policies:
|
||||
|
||||
* “Artifact must have SLSA Build L2 attestation from trusted builders.”
|
||||
* “Critical services must have Source L2 attestation (review, branch protections).”
|
||||
|
||||
2. **Runtime & deployment gates**
|
||||
|
||||
* Integrate verification into:
|
||||
|
||||
* Admission controller (Kubernetes or deployment gate).
|
||||
* CI release stage (block promotion if SLSA requirements not met).
|
||||
|
||||
3. **UI**
|
||||
|
||||
* On artifact/service detail page:
|
||||
|
||||
* Surface SLSA level achieved (per track).
|
||||
* Status (pass/fail).
|
||||
* Drill-down view of attestation evidence (who built, when, from where).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* A deployment can be blocked (in a test env) when SLSA requirements are not satisfied.
|
||||
* Operators can visually see SLSA status for an artifact/service.
|
||||
|
||||
---
|
||||
|
||||
## X. Cross‑cutting: APIs, UX, docs, rollout
|
||||
|
||||
### X1. Unified data model & APIs
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Graph relationships**
|
||||
|
||||
* Model the relationship:
|
||||
|
||||
* **Source repo** → **SLSA Source attestation**
|
||||
→ **Build attestation** → **Artifact**
|
||||
→ **SBOM (CycloneDX 1.7)** → **Components**
|
||||
→ **Vulnerabilities (CVSS v4)**.
|
||||
|
||||
2. **Graph queries**
|
||||
|
||||
* Build API endpoints for:
|
||||
|
||||
* “Given a CVE, show all affected artifacts and their SLSA + BOM evidence.”
|
||||
* “Given an artifact, show its full provenance chain and risk posture.”
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* At least 2 end‑to‑end queries work:
|
||||
|
||||
* CVE → impacted assets with scores + provenance.
|
||||
* Artifact → SBOM + vulnerabilities + SLSA + crypto posture.
|
||||
|
||||
---
|
||||
|
||||
### X2. Observability & auditing
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Audit logs**
|
||||
|
||||
* Log:
|
||||
|
||||
* BOM uploads and generators.
|
||||
* SLSA attestation creation/verification.
|
||||
* CVSS recalculations (who/what triggered them).
|
||||
|
||||
2. **Metrics**
|
||||
|
||||
* Track:
|
||||
|
||||
* % of builds with valid SLSA attestations.
|
||||
* % artifacts with CycloneDX 1.7 BOMs.
|
||||
* % vulns with v4 scores.
|
||||
* Expose dashboards (Prometheus/Grafana or similar).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Dashboards exist showing coverage for:
|
||||
|
||||
* CVSSv4 adoption.
|
||||
* CycloneDX 1.7 coverage.
|
||||
* SLSA coverage.
|
||||
|
||||
---
|
||||
|
||||
### X3. Documentation & developer experience
|
||||
|
||||
**Tasks**
|
||||
|
||||
1. **Developer playbooks**
|
||||
|
||||
* Short, repo‑friendly docs:
|
||||
|
||||
* “How to enable CycloneDX BOM generation in this repo.”
|
||||
* “How to ensure your service reaches SLSA Build L2.”
|
||||
* “How to interpret CVSS v4 in StellaOps.”
|
||||
|
||||
2. **Templates**
|
||||
|
||||
* CI templates:
|
||||
|
||||
* `bom-enabled-pipeline.yaml`
|
||||
* `slsa-enabled-pipeline.yaml`
|
||||
* Code snippets:
|
||||
|
||||
* API examples for pushing SBOMs.
|
||||
* API examples for querying risk posture.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* A new project can:
|
||||
|
||||
* Copy a CI template.
|
||||
* Produce a validated CycloneDX 1.7 BOM.
|
||||
* Generate SLSA attestations.
|
||||
* Show up correctly in StellaOps with CVSS v4 scoring.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can:
|
||||
|
||||
* Turn this into a **Jira-ready epic + stories breakdown**, or
|
||||
* Draft concrete **API schemas (OpenAPI/JSON)** for SBOM ingestion, CVSS scoring, and SLSA attestation verification.
|
||||
|
||||
[1]: https://www.first.org/cvss/specification-document?utm_source=chatgpt.com "CVSS v4.0 Specification Document"
|
||||
[2]: https://nvd.nist.gov/general/news/cvss-v4-0-official-support?utm_source=chatgpt.com "CVSS v4.0 Official Support - NVD"
|
||||
[3]: https://cyclonedx.org/news/cyclonedx-v1.7-released/?utm_source=chatgpt.com "CycloneDX v1.7 Delivers Advanced Cryptography, ..."
|
||||
[4]: https://cyclonedx.org/specification/overview/?utm_source=chatgpt.com "Specification Overview"
|
||||
[5]: https://cyclonedx.org/docs/latest?utm_source=chatgpt.com "CycloneDX v1.7 JSON Reference"
|
||||
[6]: https://slsa.dev/spec/v1.2/?utm_source=chatgpt.com "SLSA specification"
|
||||
@@ -1,913 +0,0 @@
|
||||
Here’s a clear, SBOM‑first blueprint you can drop into Stella Ops without extra context.
|
||||
|
||||
---
|
||||
|
||||
# SBOM‑first spine (with attestations) — the short, practical version
|
||||
|
||||

|
||||
|
||||
## Why this matters (plain English)
|
||||
|
||||
* **SBOMs** (CycloneDX/SPDX) = a complete parts list of your software.
|
||||
* **Attestations** (in‑toto + DSSE) = tamper‑evident receipts proving *who did what, to which artifact, when, and how*.
|
||||
* **Determinism** = if you re‑scan tomorrow, you get the same result for the same inputs.
|
||||
* **Explainability** = every risk decision links back to evidence you can show to auditors/customers.
|
||||
|
||||
---
|
||||
|
||||
## Core pipeline (modules & responsibilities)
|
||||
|
||||
1. **Scan (Scanner)**
|
||||
|
||||
* Inputs: container image / dir / repo.
|
||||
* Outputs: raw facts (packages, files, symbols), and a **Scan‑Evidence** attestation (DSSE‑wrapped in‑toto statement).
|
||||
* Must support offline feeds (bundle CVE/NVD/OSV/vendor advisories).
|
||||
|
||||
2. **Sbomer**
|
||||
|
||||
* Normalizes raw facts → **canonical SBOM** (CycloneDX or SPDX) with:
|
||||
|
||||
* PURLs, license info, checksums, build‑IDs (ELF/PE/Mach‑O), source locations.
|
||||
* Emits **SBOM‑Produced** attestation linking SBOM ↔ image digest.
|
||||
|
||||
3. **Authority**
|
||||
|
||||
* Verifies every attestation chain (Sigstore/keys; PQ-ready option later).
|
||||
* Stamps **Policy‑Verified** attestation (who approved, policy hash, inputs).
|
||||
* Persists **trust‑log**: signatures, cert chains, Rekor‑like index (mirrorable offline).
|
||||
|
||||
4. **Graph Store (Canonical Graph)**
|
||||
|
||||
* Ingests SBOM, vulnerabilities, reachability facts, VEX statements.
|
||||
* Preserves **evidence links** (edge predicates: “found‑by”, “reachable‑via”, “proven‑by”).
|
||||
* Enables **deterministic replay** (snapshot manifests: feeds+rules+hashes).
|
||||
|
||||
---
|
||||
|
||||
## Stable APIs (keep these boundaries sharp)
|
||||
|
||||
* **/scan** → start scan; returns Evidence ID + attestation ref.
|
||||
* **/sbom** → get canonical SBOM (by image digest or Evidence ID).
|
||||
* **/attest** → submit/fetch attestations; verify chain; returns trust‑proof.
|
||||
* **/vex‑gate** → policy decision: *allow / warn / block* with proof bundle.
|
||||
* **/diff** → SBOM↔SBOM + SBOM↔runtime diffs (see below).
|
||||
* **/unknowns** → create/list/resolve Unknowns (signals needing human/vendor input).
|
||||
|
||||
Design notes:
|
||||
|
||||
* All responses include `decision`, `explanation`, `evidence[]`, `hashes`, `clock`.
|
||||
* Support **air‑gap**: all endpoints operate on local bundles (ZIP/TAR with SBOM+attestations+feeds).
|
||||
|
||||
---
|
||||
|
||||
## Determinism & “Unknowns” (noise‑killer loop)
|
||||
|
||||
**Smart diffs**
|
||||
|
||||
* **SBOM↔SBOM**: detect added/removed/changed components (by PURL+version+hash).
|
||||
* **SBOM↔runtime**: prove reachability (e.g., symbol/function use, loaded libs, process maps).
|
||||
* Score only on **provable** paths; gate on **VEX** (vendor/exploitability statements).
|
||||
|
||||
**Unknowns handler**
|
||||
|
||||
* Any unresolved signal (ambiguous CVE mapping, stripped binary, unverified vendor VEX) → **Unknowns** queue:
|
||||
|
||||
* SLA, owner, evidence snapshot, audit trail.
|
||||
* State machine: `new → triage → vendor‑query → verified → closed`.
|
||||
* Every VEX or vendor reply becomes an attestation; decisions re‑evaluated deterministically.
|
||||
|
||||
---
|
||||
|
||||
## What to store (so you can explain every decision)
|
||||
|
||||
* **Artifacts**: image digest, SBOM hash, feed versions, rule set hash.
|
||||
* **Proofs**: DSSE envelopes, signatures, certs, inclusion proofs (Rekor‑style).
|
||||
* **Predicates (edges)**:
|
||||
|
||||
* `contains(component)`, `vulnerable_to(cve)`, `reachable_via(callgraph|runtime)`,
|
||||
* `overridden_by(vex)`, `verified_by(authority)`, `derived_from(scan-evidence)`.
|
||||
* **Why‑strings**: human‑readable proof trails (1–3 sentences) output with every decision.
|
||||
|
||||
---
|
||||
|
||||
## Minimal policies that work on day 1
|
||||
|
||||
* **Block** only when: `vuln.severity ≥ High` AND `reachable == true` AND `no VEX allows`.
|
||||
* **Warn** when: `High/Critical` but `reachable == unknown` → route to Unknowns with SLA.
|
||||
* **Allow** when: `Low/Medium` OR VEX says `not_affected` (trusted signer + policy).
|
||||
|
||||
---
|
||||
|
||||
## Offline/air‑gap bundle format (zip)
|
||||
|
||||
```
|
||||
/bundle/
|
||||
feeds/ (NVD, OSV, vendor) + manifest.json (hashes, timestamps)
|
||||
sboms/ imageDigest.json
|
||||
attestations/ *.jsonl (DSSE)
|
||||
proofs/ rekor/ merkle.json
|
||||
policy/ lattice.json
|
||||
replay/ inputs.lock (content‑hashes of everything above)
|
||||
```
|
||||
|
||||
* Every API accepts `?bundle=/path/to/bundle.zip`.
|
||||
* **Replay**: `inputs.lock` guarantees deterministic re‑evaluation.
|
||||
|
||||
---
|
||||
|
||||
## .NET 10 implementation sketch (pragmatic)
|
||||
|
||||
* **Contracts**: `StellaOps.Contracts.*` (Scan, Attest, VexGate, Diff, Unknowns).
|
||||
* **Attestations**: `StellaOps.Attest.Dsse` (IEnvelope, IStatement<TPredicate>); pluggable crypto (FIPS/GOST/SM/PQ).
|
||||
* **SBOM**: `StellaOps.Sbom` (CycloneDX/SPDX models + mappers; PURL utilities).
|
||||
* **Graph**: `StellaOps.Graph` (EF Core 9/10 over Mongo/Postgres; edge predicates as enums + JSON evidence).
|
||||
* **Policy/Lattice**: `StellaOps.Policy.Lattice` (pure functions over graph snapshots; produce Decision+Why).
|
||||
* **Unknowns**: `StellaOps.Unknowns` (aggregate root; SLA timers; audit events).
|
||||
* **CLI**: `stella scan|sbom|attest|vex-gate|diff|unknowns` with `--bundle`.
|
||||
|
||||
Key patterns:
|
||||
|
||||
* All public methods return `(Result<T> value, Proof proof)`.
|
||||
* Hash everything (inputs, rules, feeds) and bake into `Proof`.
|
||||
* Emit DSSE envelopes at each hop; verify on ingest; never trust unauthenticated input.
|
||||
|
||||
---
|
||||
|
||||
## Next steps (week‑one checklist)
|
||||
|
||||
* Define JSON schemas for: **Decision** (with Why+Proof), **Unknown**, **DiffResult**.
|
||||
* Stand up **/scan**, **/sbom**, **/attest**, **/vex‑gate** skeletons returning mock Proofs.
|
||||
* Implement **SBOM↔SBOM diff** (PURL+version+hash) and wire to **/diff**.
|
||||
* Create **bundle.zip** reader/writer + `inputs.lock`.
|
||||
* Add **Authority.Verify()** with DSSE verification + trust‑store.
|
||||
* Ship a basic **policy.lattice.json** (3 rules above) and e2e test: image → allow/block with proofs.
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* The exact C# interfaces/classes (namespaces + DTOs),
|
||||
* JSON Schemas for Decision/Proof/Unknowns,
|
||||
* A seed `bundle.zip` layout with fake data for local e2e.
|
||||
Cool, let’s turn that blueprint into something your devs can actually build from.
|
||||
|
||||
Below is a detailed, opinionated implementation plan you can paste into an engineering doc and assign as epics / tickets.
|
||||
|
||||
---
|
||||
|
||||
## 0. Solution layout (concrete)
|
||||
|
||||
**Repo structure**
|
||||
|
||||
```text
|
||||
/stella-ops
|
||||
/src
|
||||
StellaOps.Contracts // DTOs, API contracts, JSON schemas
|
||||
StellaOps.Domain // Core domain types (ArtifactId, Proof, Decision, etc.)
|
||||
StellaOps.Attest // DSSE envelopes, in-toto statements, signing/verification
|
||||
StellaOps.Sbom // SBOM models + normalization
|
||||
StellaOps.Graph // Graph store, entities, queries
|
||||
StellaOps.Policy // Policy engine (lattice evaluation)
|
||||
StellaOps.WebApi // HTTP APIs: /scan, /sbom, /attest, /vex-gate, /diff, /unknowns
|
||||
StellaOps.Cli // `stella` CLI, offline bundles
|
||||
/tests
|
||||
StellaOps.Tests.Unit
|
||||
StellaOps.Tests.Integration
|
||||
StellaOps.Tests.E2E
|
||||
```
|
||||
|
||||
**Baseline tech assumptions**
|
||||
|
||||
* Runtime: .NET (8+; you can call it “.NET 10” in your roadmap).
|
||||
* API: ASP.NET Core minimal APIs.
|
||||
* DB: Postgres (via EF Core) for graph + unknowns + metadata.
|
||||
* Storage: local filesystem / S3-compatible for bundle zips, scanner DB caches.
|
||||
* External scanners: Trivy / Grype / Syft (invoked via CLI with deterministic config).
|
||||
|
||||
---
|
||||
|
||||
## 1. Core domain & shared contracts (Phase 1)
|
||||
|
||||
**Goal:** Have a stable core domain + contracts that all teams can build against.
|
||||
|
||||
### 1.1 Core domain types (`StellaOps.Domain`)
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public readonly record struct Digest(string Algorithm, string Value); // e.g. ("sha256", "abcd...")
|
||||
public readonly record struct ArtifactRef(string Kind, string Value);
|
||||
// Kind: "container-image", "file", "package", "sbom", etc.
|
||||
|
||||
public readonly record struct EvidenceId(Guid Value);
|
||||
public readonly record struct AttestationId(Guid Value);
|
||||
|
||||
public enum PredicateType
|
||||
{
|
||||
ScanEvidence,
|
||||
SbomProduced,
|
||||
PolicyVerified,
|
||||
VulnerabilityFinding,
|
||||
ReachabilityFinding,
|
||||
VexStatement
|
||||
}
|
||||
|
||||
public sealed class Proof
|
||||
{
|
||||
public string ProofId { get; init; } = default!;
|
||||
public Digest InputsLock { get; init; } = default!; // hash of feeds+rules+sbom bundle
|
||||
public DateTimeOffset EvaluatedAt { get; init; }
|
||||
public IReadOnlyList<string> EvidenceIds { get; init; } = Array.Empty<string>();
|
||||
public IReadOnlyDictionary<string,string> Meta { get; init; } = new Dictionary<string,string>();
|
||||
}
|
||||
```
|
||||
|
||||
### 1.2 Attestation model (`StellaOps.Attest`)
|
||||
|
||||
Implement DSSE + in‑toto abstractions:
|
||||
|
||||
```csharp
|
||||
public sealed class DsseEnvelope
|
||||
{
|
||||
public string PayloadType { get; init; } = default!;
|
||||
public string Payload { get; init; } = default!; // base64url(JSON)
|
||||
public IReadOnlyList<DsseSignature> Signatures { get; init; } = Array.Empty<DsseSignature>();
|
||||
}
|
||||
|
||||
public sealed class DsseSignature
|
||||
{
|
||||
public string KeyId { get; init; } = default!;
|
||||
public string Sig { get; init; } = default!; // base64url
|
||||
}
|
||||
|
||||
public interface IStatement<out TPredicate>
|
||||
{
|
||||
string Type { get; } // in-toto type URI
|
||||
string PredicateType { get; } // URI or enum -> string
|
||||
TPredicate Predicate { get; }
|
||||
string Subject { get; } // e.g., image digest
|
||||
}
|
||||
```
|
||||
|
||||
Attestation services:
|
||||
|
||||
```csharp
|
||||
public interface IAttestationSigner
|
||||
{
|
||||
Task<DsseEnvelope> SignAsync<TPredicate>(IStatement<TPredicate> statement, CancellationToken ct);
|
||||
}
|
||||
|
||||
public interface IAttestationVerifier
|
||||
{
|
||||
Task VerifyAsync(DsseEnvelope envelope, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
### 1.3 Decision & VEX-gate contracts (`StellaOps.Contracts`)
|
||||
|
||||
```csharp
|
||||
public enum GateDecisionKind
|
||||
{
|
||||
Allow,
|
||||
Warn,
|
||||
Block
|
||||
}
|
||||
|
||||
public sealed class GateDecision
|
||||
{
|
||||
public GateDecisionKind Decision { get; init; }
|
||||
public string Reason { get; init; } = default!; // short human-readable
|
||||
public Proof Proof { get; init; } = default!;
|
||||
public IReadOnlyList<string> Evidence { get; init; } = Array.Empty<string>(); // EvidenceIds / AttestationIds
|
||||
}
|
||||
|
||||
public sealed class VexGateRequest
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; }
|
||||
public string? Environment { get; init; } // "prod", "staging", cluster id, etc.
|
||||
public string? BundlePath { get; init; } // optional offline bundle path
|
||||
}
|
||||
```
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Shared projects compile.
|
||||
* No service references each other directly (only via Contracts + Domain).
|
||||
* Example test that serializes/deserializes GateDecision and DsseEnvelope using System.Text.Json.
|
||||
|
||||
---
|
||||
|
||||
## 2. SBOM pipeline (Scanner → Sbomer) (Phase 2)
|
||||
|
||||
**Goal:** For a container image, produce a canonical SBOM + attestation deterministically.
|
||||
|
||||
### 2.1 Scanner integration (`StellaOps.WebApi` + `StellaOps.Cli`)
|
||||
|
||||
#### API contract (`/scan`)
|
||||
|
||||
```csharp
|
||||
public sealed class ScanRequest
|
||||
{
|
||||
public string SourceType { get; init; } = default!; // "container-image" | "directory" | "git-repo"
|
||||
public string Locator { get; init; } = default!; // e.g. "registry/myapp:1.2.3"
|
||||
public bool IncludeFiles { get; init; } = true;
|
||||
public bool IncludeLicenses { get; init; } = true;
|
||||
public string? BundlePath { get; init; } // for offline data
|
||||
}
|
||||
|
||||
public sealed class ScanResponse
|
||||
{
|
||||
public EvidenceId EvidenceId { get; init; }
|
||||
public AttestationId AttestationId { get; init; }
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
}
|
||||
```
|
||||
|
||||
#### Implementation steps
|
||||
|
||||
1. **Scanner abstraction**
|
||||
|
||||
```csharp
|
||||
public interface IArtifactScanner
|
||||
{
|
||||
Task<ScanResult> ScanAsync(ScanRequest request, CancellationToken ct);
|
||||
}
|
||||
|
||||
public sealed class ScanResult
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public IReadOnlyList<DiscoveredPackage> Packages { get; init; } = Array.Empty<DiscoveredPackage>();
|
||||
public IReadOnlyList<DiscoveredFile> Files { get; init; } = Array.Empty<DiscoveredFile>();
|
||||
}
|
||||
```
|
||||
|
||||
2. **CLI wrapper** (Trivy/Grype/Syft):
|
||||
|
||||
* Implement `SyftScanner : IArtifactScanner`:
|
||||
|
||||
* Invoke external CLI with fixed flags.
|
||||
* Use JSON output mode.
|
||||
* Resolve CLI path from config.
|
||||
* Ensure deterministic:
|
||||
|
||||
* Disable auto-updating DB.
|
||||
* Use a local DB path versioned and optionally included into bundle.
|
||||
* Write parsing code Syft → `ScanResult`.
|
||||
* Add retry & clear error mapping (timeout, auth error, network error).
|
||||
|
||||
3. **/scan endpoint**
|
||||
|
||||
* Validate request.
|
||||
* Call `IArtifactScanner.ScanAsync`.
|
||||
* Build a `ScanEvidence` predicate:
|
||||
|
||||
```csharp
|
||||
public sealed class ScanEvidencePredicate
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public DateTimeOffset ScannedAt { get; init; }
|
||||
public string ScannerName { get; init; } = default!;
|
||||
public string ScannerVersion { get; init; } = default!;
|
||||
public IReadOnlyList<DiscoveredPackage> Packages { get; init; } = Array.Empty<DiscoveredPackage>();
|
||||
}
|
||||
```
|
||||
|
||||
* Build in‑toto statement for predicate.
|
||||
* Call `IAttestationSigner.SignAsync`, persist:
|
||||
|
||||
* Raw envelope to `attestations` table.
|
||||
* Map to `EvidenceId` + `AttestationId`.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a fixed image and fixed scanner DB, repeated `/scan` calls produce identical:
|
||||
|
||||
* `ScanResult` (up to ordering).
|
||||
* `ScanEvidence` payload.
|
||||
* `InputsLock` proof hash (once implemented).
|
||||
* E2E test: run scan on a small public image in CI using a pre-bundled scanner DB.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Sbomer (`StellaOps.Sbom` + `/sbom`)
|
||||
|
||||
**Goal:** Normalize `ScanResult` into a canonical SBOM (CycloneDX/SPDX) + emit SBOM attestation.
|
||||
|
||||
#### Models
|
||||
|
||||
Create neutral SBOM model (internal):
|
||||
|
||||
```csharp
|
||||
public sealed class CanonicalComponent
|
||||
{
|
||||
public string Name { get; init; } = default!;
|
||||
public string Version { get; init; } = default!;
|
||||
public string Purl { get; init; } = default!;
|
||||
public string? License { get; init; }
|
||||
public Digest Digest { get; init; } = default!;
|
||||
public string? SourceLocation { get; init; } // file path, layer info
|
||||
}
|
||||
|
||||
public sealed class CanonicalSbom
|
||||
{
|
||||
public string SbomId { get; init; } = default!;
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public Digest ArtifactDigest { get; init; } = default!;
|
||||
public IReadOnlyList<CanonicalComponent> Components { get; init; } = Array.Empty<CanonicalComponent>();
|
||||
public DateTimeOffset CreatedAt { get; init; }
|
||||
public string Format { get; init; } = "CycloneDX-JSON-1.5"; // default
|
||||
}
|
||||
```
|
||||
|
||||
#### Sbomer service
|
||||
|
||||
```csharp
|
||||
public interface ISbomer
|
||||
{
|
||||
CanonicalSbom FromScan(ScanResult scan);
|
||||
string ToCycloneDxJson(CanonicalSbom sbom);
|
||||
string ToSpdxJson(CanonicalSbom sbom);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation details:
|
||||
|
||||
* Map OS/deps to PURLs (use existing PURL libs or implement minimal helpers).
|
||||
* Stable ordering:
|
||||
|
||||
* Sort components by `Purl` then `Version` before serialization.
|
||||
* Hash the SBOM JSON → `Digest` (e.g., `Digest("sha256", "...")`).
|
||||
|
||||
#### SBOM attestation & `/sbom` endpoint
|
||||
|
||||
* For an `ArtifactRef` (or `ScanEvidence` EvidenceId):
|
||||
|
||||
1. Fetch latest `ScanResult` from DB.
|
||||
2. Call `ISbomer.FromScan`.
|
||||
3. Serialize to CycloneDX.
|
||||
4. Emit `SbomProduced` predicate & DSSE envelope.
|
||||
5. Persist SBOM JSON blob & link to artifact.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Same `ScanResult` always produces bit-identical SBOM JSON.
|
||||
* Unit tests verifying:
|
||||
|
||||
* PURL mapping correctness.
|
||||
* Stable ordering.
|
||||
* `/sbom` endpoint can:
|
||||
|
||||
* Build SBOM from scan.
|
||||
* Return existing SBOM if already generated (idempotence).
|
||||
|
||||
---
|
||||
|
||||
## 3. Attestation Authority & trust log (Phase 3)
|
||||
|
||||
**Goal:** Verify all attestations, store them with a trust log, and produce `PolicyVerified` attestations.
|
||||
|
||||
### 3.1 Authority service (`StellaOps.Attest` + `StellaOps.WebApi`)
|
||||
|
||||
Key interfaces:
|
||||
|
||||
```csharp
|
||||
public interface IAuthority
|
||||
{
|
||||
Task<AttestationId> RecordAsync(DsseEnvelope envelope, CancellationToken ct);
|
||||
Task<Proof> VerifyChainAsync(ArtifactRef artifact, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation steps:
|
||||
|
||||
1. **Attestations store**
|
||||
|
||||
* Table `attestations`:
|
||||
|
||||
* `id` (AttestationId, PK)
|
||||
* `artifact_kind` / `artifact_value`
|
||||
* `predicate_type` (enum)
|
||||
* `payload_type`
|
||||
* `payload_hash`
|
||||
* `envelope_json`
|
||||
* `created_at`
|
||||
* `signer_keyid`
|
||||
* Table `trust_log`:
|
||||
|
||||
* `id`
|
||||
* `attestation_id`
|
||||
* `status` (verified / failed / pending)
|
||||
* `reason`
|
||||
* `verified_at`
|
||||
* `verification_data_json` (cert chain, Rekor log index, etc.)
|
||||
|
||||
2. **Verification pipeline**
|
||||
|
||||
* Implement `IAttestationVerifier.VerifyAsync`:
|
||||
|
||||
* Check envelope integrity (no duplicate signatures, required fields).
|
||||
* Verify crypto signature (keys from configuration store or Sigstore if you integrate later).
|
||||
* `IAuthority.RecordAsync`:
|
||||
|
||||
* Verify envelope.
|
||||
* Save to `attestations`.
|
||||
* Add entry to `trust_log`.
|
||||
* `VerifyChainAsync`:
|
||||
|
||||
* For a given `ArtifactRef`:
|
||||
|
||||
* Load all attestations for that artifact.
|
||||
* Ensure each is `status=verified`.
|
||||
* Compute `InputsLock` = hash of:
|
||||
|
||||
* Sorted predicate payloads.
|
||||
* Feeds manifest.
|
||||
* Policy rules.
|
||||
* Return `Proof`.
|
||||
|
||||
### 3.2 `/attest` API
|
||||
|
||||
* **POST /attest**: submit DSSE envelope (for external tools).
|
||||
* **GET /attest?artifact=`...`**: list attestations + trust status.
|
||||
* **GET /attest/{id}/proof**: return verification proof (including InputsLock).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Invalid signatures rejected.
|
||||
* Tampering test: alter a byte in envelope JSON → verification fails.
|
||||
* `VerifyChainAsync` returns same `Proof.InputsLock` for identical sets of inputs.
|
||||
|
||||
---
|
||||
|
||||
## 4. Graph Store & Policy engine (Phase 4)
|
||||
|
||||
**Goal:** Store SBOM, vulnerabilities, reachability, VEX, and query them to make deterministic VEX-gate decisions.
|
||||
|
||||
### 4.1 Graph model (`StellaOps.Graph`)
|
||||
|
||||
Tables (simplified):
|
||||
|
||||
* `artifacts`:
|
||||
|
||||
* `id` (PK), `kind`, `value`, `digest_algorithm`, `digest_value`
|
||||
* `components`:
|
||||
|
||||
* `id`, `purl`, `name`, `version`, `license`, `digest_algorithm`, `digest_value`
|
||||
* `vulnerabilities`:
|
||||
|
||||
* `id`, `cve_id`, `severity`, `source` (NVD/OSV/vendor), `data_json`
|
||||
* `vex_statements`:
|
||||
|
||||
* `id`, `cve_id`, `component_purl`, `status` (`not_affected`, `affected`, etc.), `source`, `data_json`
|
||||
* `edges`:
|
||||
|
||||
* `id`, `from_kind`, `from_id`, `to_kind`, `to_id`, `relation` (enum), `evidence_id`, `data_json`
|
||||
|
||||
Example `relation` values:
|
||||
|
||||
* `artifact_contains_component`
|
||||
* `component_vulnerable_to`
|
||||
* `component_reachable_via`
|
||||
* `vulnerability_overridden_by_vex`
|
||||
* `artifact_scanned_by`
|
||||
* `decision_verified_by`
|
||||
|
||||
Graph access abstraction:
|
||||
|
||||
```csharp
|
||||
public interface IGraphRepository
|
||||
{
|
||||
Task UpsertSbomAsync(CanonicalSbom sbom, EvidenceId evidenceId, CancellationToken ct);
|
||||
Task ApplyVulnerabilityFactsAsync(IEnumerable<VulnerabilityFact> facts, CancellationToken ct);
|
||||
Task ApplyReachabilityFactsAsync(IEnumerable<ReachabilityFact> facts, CancellationToken ct);
|
||||
Task ApplyVexStatementsAsync(IEnumerable<VexStatement> vexStatements, CancellationToken ct);
|
||||
|
||||
Task<ArtifactGraphSnapshot> GetSnapshotAsync(ArtifactRef artifact, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
`ArtifactGraphSnapshot` is an in-memory projection used by the policy engine.
|
||||
|
||||
### 4.2 Policy engine (`StellaOps.Policy`)
|
||||
|
||||
Policy lattice (minimal version):
|
||||
|
||||
```csharp
|
||||
public enum RiskState
|
||||
{
|
||||
Clean,
|
||||
VulnerableNotReachable,
|
||||
VulnerableReachable,
|
||||
Unknown
|
||||
}
|
||||
|
||||
public sealed class PolicyEvaluationContext
|
||||
{
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public ArtifactGraphSnapshot Snapshot { get; init; } = default!;
|
||||
public IReadOnlyDictionary<string,string>? Environment { get; init; }
|
||||
}
|
||||
|
||||
public interface IPolicyEngine
|
||||
{
|
||||
GateDecision Evaluate(PolicyEvaluationContext context);
|
||||
}
|
||||
```
|
||||
|
||||
Default policy logic:
|
||||
|
||||
1. For each vulnerability affecting a component in the artifact:
|
||||
|
||||
* Check for VEX:
|
||||
|
||||
* If trusted VEX says `not_affected` → ignore.
|
||||
* Check reachability:
|
||||
|
||||
* If proven reachable → mark as `VulnerableReachable`.
|
||||
* If proven not reachable → `VulnerableNotReachable`.
|
||||
* If unknown → `Unknown`.
|
||||
|
||||
2. Aggregate:
|
||||
|
||||
* If any `Critical/High` in `VulnerableReachable` → `Block`.
|
||||
* Else if any `Critical/High` in `Unknown` → `Warn` and log Unknowns.
|
||||
* Else → `Allow`.
|
||||
|
||||
### 4.3 `/vex-gate` endpoint
|
||||
|
||||
Implementation:
|
||||
|
||||
* Resolve `ArtifactRef`.
|
||||
* Build `ArtifactGraphSnapshot` using `IGraphRepository.GetSnapshotAsync`.
|
||||
* Call `IPolicyEngine.Evaluate`.
|
||||
* Request `IAuthority.VerifyChainAsync` → `Proof`.
|
||||
* Emit `PolicyVerified` attestation for this decision.
|
||||
* Return `GateDecision` + `Proof`.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given a fixture DB snapshot, calling `/vex-gate` twice yields identical decisions & proof IDs.
|
||||
* Policy behavior matches the rule text:
|
||||
|
||||
* Regression test that modifies severity or reachability → correct decision changes.
|
||||
|
||||
---
|
||||
|
||||
## 5. Diffs & Unknowns workflow (Phase 5)
|
||||
|
||||
### 5.1 Diff engine (`/diff`)
|
||||
|
||||
Contracts:
|
||||
|
||||
```csharp
|
||||
public sealed class DiffRequest
|
||||
{
|
||||
public string Kind { get; init; } = default!; // "sbom-sbom" | "sbom-runtime"
|
||||
public string LeftId { get; init; } = default!;
|
||||
public string RightId { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed class DiffComponentChange
|
||||
{
|
||||
public string Purl { get; init; } = default!;
|
||||
public string ChangeType { get; init; } = default!; // "added" | "removed" | "changed"
|
||||
public string? OldVersion { get; init; }
|
||||
public string? NewVersion { get; init; }
|
||||
}
|
||||
|
||||
public sealed class DiffResponse
|
||||
{
|
||||
public IReadOnlyList<DiffComponentChange> Components { get; init; } = Array.Empty<DiffComponentChange>();
|
||||
}
|
||||
```
|
||||
|
||||
Implementation:
|
||||
|
||||
* SBOM↔SBOM: compare `CanonicalSbom.Components` by PURL (+ version).
|
||||
* SBOM↔runtime:
|
||||
|
||||
* Input runtime snapshot (`process maps`, `loaded libs`, etc.) from agents.
|
||||
* Map runtime libs to PURLs.
|
||||
* Determine reachable components from runtime usage → `ReachabilityFact`s into graph.
|
||||
|
||||
### 5.2 Unknowns module (`/unknowns`)
|
||||
|
||||
Data model:
|
||||
|
||||
```csharp
|
||||
public enum UnknownState
|
||||
{
|
||||
New,
|
||||
Triage,
|
||||
VendorQuery,
|
||||
Verified,
|
||||
Closed
|
||||
}
|
||||
|
||||
public sealed class Unknown
|
||||
{
|
||||
public Guid Id { get; init; }
|
||||
public ArtifactRef Artifact { get; init; } = default!;
|
||||
public string Type { get; init; } = default!; // "vuln-mapping", "reachability", "vex-trust"
|
||||
public string Subject { get; init; } = default!; // e.g., "CVE-2024-XXXX / purl:pkg:..."
|
||||
public UnknownState State { get; set; }
|
||||
public DateTimeOffset CreatedAt { get; init; }
|
||||
public DateTimeOffset? SlaDeadline { get; set; }
|
||||
public string? Owner { get; set; }
|
||||
public string EvidenceJson { get; init; } = default!; // serialized proof / edges
|
||||
public string? ResolutionNotes { get; set; }
|
||||
}
|
||||
```
|
||||
|
||||
API:
|
||||
|
||||
* `GET /unknowns`: filter by state, artifact, owner.
|
||||
* `POST /unknowns`: create manual unknown.
|
||||
* `PATCH /unknowns/{id}`: update state, owner, notes.
|
||||
|
||||
Integration:
|
||||
|
||||
* Policy engine:
|
||||
|
||||
* For any `Unknown` risk state, auto-create Unknown with SLA if not already present.
|
||||
* When Unknown resolves (e.g., vendor VEX added), re-run policy evaluation for affected artifact(s).
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* When `VulnerableReachability` is `Unknown`, `/vex-gate` both:
|
||||
|
||||
* Returns `Warn`.
|
||||
* Creates an Unknown row.
|
||||
* Transitioning Unknown to `Verified` triggers re-evaluation (integration test).
|
||||
|
||||
---
|
||||
|
||||
## 6. Offline / air‑gapped bundles (Phase 6)
|
||||
|
||||
**Goal:** Everything works on a single machine with no network.
|
||||
|
||||
### 6.1 Bundle format & IO (`StellaOps.Cli` + `StellaOps.WebApi`)
|
||||
|
||||
Directory structure inside ZIP:
|
||||
|
||||
```text
|
||||
/bundle/
|
||||
feeds/
|
||||
manifest.json // hashes, timestamps for NVD, OSV, vendor feeds
|
||||
nvd.json
|
||||
osv.json
|
||||
vendor-*.json
|
||||
sboms/
|
||||
{artifactDigest}.json
|
||||
attestations/
|
||||
*.jsonl // one DSSE envelope per line
|
||||
proofs/
|
||||
rekor/
|
||||
merkle.json
|
||||
policy/
|
||||
lattice.json // serialized rules / thresholds
|
||||
replay/
|
||||
inputs.lock // hash & metadata of all of the above
|
||||
```
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public interface IBundleReader
|
||||
{
|
||||
Task<Bundle> ReadAsync(string path, CancellationToken ct);
|
||||
}
|
||||
|
||||
public interface IBundleWriter
|
||||
{
|
||||
Task WriteAsync(Bundle bundle, string path, CancellationToken ct);
|
||||
}
|
||||
```
|
||||
|
||||
`Bundle` holds strongly-typed representations of the manifest, SBOMs, attestations, proofs, etc.
|
||||
|
||||
### 6.2 CLI commands
|
||||
|
||||
* `stella scan --image registry/app:1.2.3 --out bundle.zip`
|
||||
|
||||
* Runs scan + sbom locally.
|
||||
* Writes bundle with:
|
||||
|
||||
* SBOM.
|
||||
* Scan + Sbom attestations.
|
||||
* Feeds manifest.
|
||||
* `stella vex-gate --bundle bundle.zip`
|
||||
|
||||
* Loads bundle.
|
||||
* Runs policy engine locally.
|
||||
* Prints `Allow/Warn/Block` + proof summary.
|
||||
|
||||
**Acceptance criteria**
|
||||
|
||||
* Given the same `bundle.zip`, `stella vex-gate` on different machines produces identical decisions and proof hashes.
|
||||
* `/vex-gate?bundle=/path/to/bundle.zip` in API uses same BundleReader and yields same output as CLI.
|
||||
|
||||
---
|
||||
|
||||
## 7. Testing & quality plan
|
||||
|
||||
### 7.1 Unit tests
|
||||
|
||||
* Domain & Contracts:
|
||||
|
||||
* Serialization roundtrip for all DTOs.
|
||||
* Attest:
|
||||
|
||||
* DSSE encode/decode.
|
||||
* Signature verification with test key pair.
|
||||
* Sbom:
|
||||
|
||||
* Known `ScanResult` → expected SBOM JSON snapshot.
|
||||
* Policy:
|
||||
|
||||
* Table-driven tests:
|
||||
|
||||
* Cases: {severity, reachable, hasVex} → {Allow/Warn/Block}.
|
||||
|
||||
### 7.2 Integration tests
|
||||
|
||||
* Scanner:
|
||||
|
||||
* Use a tiny test image with known components.
|
||||
* Graph + Policy:
|
||||
|
||||
* Seed DB with:
|
||||
|
||||
* 1 artifact, 2 components, 1 vuln, 1 VEX, 1 reachability fact.
|
||||
* Assert that `/vex-gate` returns expected decision.
|
||||
|
||||
### 7.3 E2E scenario
|
||||
|
||||
Single test flow:
|
||||
|
||||
1. `POST /scan` → EvidenceId.
|
||||
2. `POST /sbom` → SBOM + SbomProduced attestation.
|
||||
3. Load dummy vulnerability feed → `ApplyVulnerabilityFactsAsync`.
|
||||
4. `POST /vex-gate` → Block (no VEX).
|
||||
5. Add VEX statement → `ApplyVexStatementsAsync`.
|
||||
6. `POST /vex-gate` → Allow.
|
||||
|
||||
Assertions:
|
||||
|
||||
* All decisions contain `Proof` with non-empty `InputsLock`.
|
||||
* `InputsLock` is identical between runs with unchanged inputs.
|
||||
|
||||
---
|
||||
|
||||
## 8. Concrete backlog (you can paste into Jira)
|
||||
|
||||
### Epic 1 – Foundations
|
||||
|
||||
* Task: Create solution & project skeleton.
|
||||
* Task: Implement core domain types (`Digest`, `ArtifactRef`, `EvidenceId`, `Proof`).
|
||||
* Task: Implement DSSE envelope + JSON serialization.
|
||||
* Task: Implement basic `IAttestationSigner` with local key pair.
|
||||
* Task: Define `GateDecision` & `VexGateRequest` contracts.
|
||||
|
||||
### Epic 2 – Scanner & Sbomer
|
||||
|
||||
* Task: Implement `IArtifactScanner` + `SyftScanner`.
|
||||
* Task: Implement `/scan` endpoint + attestation.
|
||||
* Task: Implement `ISbomer` & canonical SBOM model.
|
||||
* Task: Implement `/sbom` endpoint + SbomProduced attestation.
|
||||
* Task: Snapshot tests for SBOM determinism.
|
||||
|
||||
### Epic 3 – Authority & Trust log
|
||||
|
||||
* Task: Design `attestations` & `trust_log` tables (EF Core migrations).
|
||||
* Task: Implement `IAuthority.RecordAsync` + `VerifyChainAsync`.
|
||||
* Task: Implement `/attest` endpoints.
|
||||
* Task: Add proof generation (`InputsLock` hashing).
|
||||
|
||||
### Epic 4 – Graph & Policy
|
||||
|
||||
* Task: Create graph schema (`artifacts`, `components`, `vulnerabilities`, `edges`, `vex_statements`).
|
||||
* Task: Implement `IGraphRepository.UpsertSbomAsync`.
|
||||
* Task: Ingest vulnerability feed (NVD/OSV) into graph facts.
|
||||
* Task: Implement minimal `IPolicyEngine` with rules.
|
||||
* Task: Implement `/vex-gate` endpoint.
|
||||
|
||||
### Epic 5 – Diff & Unknowns
|
||||
|
||||
* Task: Implement SBOM↔SBOM diff logic + `/diff`.
|
||||
* Task: Create `unknowns` table + API.
|
||||
* Task: Wire policy engine to auto-create Unknowns.
|
||||
* Task: Add re-evaluation when Unknown state changes.
|
||||
|
||||
### Epic 6 – Offline bundles & CLI
|
||||
|
||||
* Task: Implement `BundleReader` / `BundleWriter`.
|
||||
* Task: Implement `stella scan` and `stella vex-gate`.
|
||||
* Task: Add `?bundle=` parameter support in APIs.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Turn this into actual C# interface files (ready to drop into your repo), or
|
||||
* Produce a JSON OpenAPI sketch for `/scan`, `/sbom`, `/attest`, `/vex-gate`, `/diff`, `/unknowns`.
|
||||
@@ -1,747 +0,0 @@
|
||||
Here’s a compact, practical way to add an **explanation graph** that traces every vulnerability verdict back to raw evidence—so auditors can verify results without trusting an LLM.
|
||||
|
||||
---
|
||||
|
||||
# What it is (in one line)
|
||||
|
||||
A small, immutable graph that connects a **verdict** → to **reasoning steps** → to **raw evidence** (source scan records, binary symbol/build‑ID matches, external advisories/feeds), with cryptographic hashes so anyone can replay/verify it.
|
||||
|
||||
---
|
||||
|
||||
# Minimal data model (vendor‑neutral)
|
||||
|
||||
```json
|
||||
{
|
||||
"explanationGraph": {
|
||||
"scanId": "uuid",
|
||||
"artifact": {
|
||||
"purl": "pkg:docker/redis@7.2.4",
|
||||
"digest": "sha256:…",
|
||||
"buildId": "elf:abcd…|pe:…|macho:…"
|
||||
},
|
||||
"verdicts": [
|
||||
{
|
||||
"verdictId": "uuid",
|
||||
"cve": "CVE-2024-XXXX",
|
||||
"status": "affected|not_affected|under_investigation",
|
||||
"policy": "vex/lattice:v1",
|
||||
"reasoning": [
|
||||
{"stepId":"s1","type":"callgraph.reachable","evidenceRef":"e1"},
|
||||
{"stepId":"s2","type":"version.match","evidenceRef":"e2"},
|
||||
{"stepId":"s3","type":"vendor.vex.override","evidenceRef":"e3"}
|
||||
],
|
||||
"provenance": {
|
||||
"scanner": "StellaOps.Scanner@1.3.0",
|
||||
"rulesHash": "sha256:…",
|
||||
"time": "2025-11-25T12:34:56Z",
|
||||
"attestation": "dsse:…"
|
||||
}
|
||||
}
|
||||
],
|
||||
"evidence": [
|
||||
{
|
||||
"evidenceId":"e1",
|
||||
"kind":"binary.callgraph",
|
||||
"hash":"sha256:…",
|
||||
"summary":"main -> libssl!EVP_* path present",
|
||||
"blobPointer":"ipfs://… | file://… | s3://…"
|
||||
},
|
||||
{
|
||||
"evidenceId":"e2",
|
||||
"kind":"source.scan",
|
||||
"hash":"sha256:…",
|
||||
"summary":"Detected libssl 3.0.14 via SONAME + build‑id",
|
||||
"blobPointer":"…"
|
||||
},
|
||||
{
|
||||
"evidenceId":"e3",
|
||||
"kind":"external.feed",
|
||||
"hash":"sha256:…",
|
||||
"summary":"Vendor VEX: CVE not reachable when FIPS mode enabled",
|
||||
"blobPointer":"…",
|
||||
"externalRef":{"type":"advisory","id":"VEX-ACME-2025-001","url":"…"}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
# How it works (flow)
|
||||
|
||||
* **Collect** raw artifacts: scanner findings, binary symbol matches (Build‑ID / PDB / dSYM), SBOM components, external feeds (NVD, vendor VEX).
|
||||
* **Normalize** to evidence nodes (immutable blobs with content hash + pointer).
|
||||
* **Reason** via small, deterministic rules (your lattice/policy). Each rule emits a *reasoning step* that points to evidence.
|
||||
* **Emit a verdict** with status + full chain of steps.
|
||||
* **Seal** with DSSE/Sigstore (or your offline signer) so the whole graph is replayable.
|
||||
|
||||
---
|
||||
|
||||
# Why this helps (auditable AI)
|
||||
|
||||
* **No black box**: every “affected/not affected” claim links to verifiable bytes.
|
||||
* **Deterministic**: same inputs + rules = same verdict (hashes prove it).
|
||||
* **Reproducible for clients/regulators**: export graph + blobs, they replay locally.
|
||||
* **LLM‑optional**: you can add LLM explanations as *non‑authoritative* annotations; the verdict remains policy‑driven.
|
||||
|
||||
---
|
||||
|
||||
# C# drop‑in (Stella Ops style)
|
||||
|
||||
```csharp
|
||||
public record EvidenceNode(
|
||||
string EvidenceId, string Kind, string Hash, string Summary, string BlobPointer,
|
||||
ExternalRef? ExternalRef = null);
|
||||
|
||||
public record ReasoningStep(string StepId, string Type, string EvidenceRef);
|
||||
|
||||
public record Verdict(
|
||||
string VerdictId, string Cve, string Status, string Policy,
|
||||
IReadOnlyList<ReasoningStep> Reasoning, Provenance Provenance);
|
||||
|
||||
public record Provenance(string Scanner, string RulesHash, DateTimeOffset Time, string Attestation);
|
||||
|
||||
public record ExplanationGraph(
|
||||
Guid ScanId, Artifact Artifact,
|
||||
IReadOnlyList<Verdict> Verdicts, IReadOnlyList<EvidenceNode> Evidence);
|
||||
|
||||
public record Artifact(string Purl, string Digest, string BuildId);
|
||||
```
|
||||
|
||||
* Persist as immutable documents (Mongo collection `explanations`).
|
||||
* Store large evidence blobs in object storage; keep `hash` + `blobPointer` in Mongo.
|
||||
* Sign the serialized graph (DSSE) and store the signature alongside.
|
||||
|
||||
---
|
||||
|
||||
# UI (compact “trace” panel)
|
||||
|
||||
* **Top line:** CVE → Status chip (Affected / Not affected / Needs review).
|
||||
* **Three tabs:** *Evidence*, *Reasoning*, *Provenance*.
|
||||
* **One‑click export:** “Download Replay Bundle (.zip)” → JSON graph + evidence blobs + verify script.
|
||||
* **Badge:** “Deterministic ✓” when rulesHash + inputs resolve to prior signature.
|
||||
|
||||
---
|
||||
|
||||
# Ops & replay
|
||||
|
||||
* Bundle a tiny CLI: `stellaops-explain verify graph.json --evidence ./blobs/`.
|
||||
* Verification checks: all hashes match, DSSE signature valid, rulesHash known, verdict derivable from steps.
|
||||
|
||||
---
|
||||
|
||||
# Where to start (1‑week sprint)
|
||||
|
||||
* Day 1–2: Model + Mongo collections + signer service.
|
||||
* Day 3: Scanner adapters emit `EvidenceNode` records; policy engine emits `ReasoningStep`.
|
||||
* Day 4: Verdict assembly + DSSE signing + export bundle.
|
||||
* Day 5: Minimal UI trace panel + CLI verifier.
|
||||
|
||||
If you want, I can generate the Mongo schemas, a DSSE signing helper, and the React/Angular trace panel stub next.
|
||||
Here’s a concrete implementation plan you can hand to your developers so they’re not guessing what to build.
|
||||
|
||||
I’ll break it down by **phases**, and inside each phase I’ll call out **owner**, **deliverables**, and **acceptance criteria**.
|
||||
|
||||
---
|
||||
|
||||
## Phase 0 – Scope & decisions (½ day)
|
||||
|
||||
**Goal:** Lock in the “rules of the game” so nobody bikesheds later.
|
||||
|
||||
**Decisions to confirm (write in a short ADR):**
|
||||
|
||||
1. **Canonical representation & hashing**
|
||||
|
||||
* Format for hashing: **canonical JSON** (stable property ordering, UTF‑8, no whitespace).
|
||||
* Algorithm: **SHA‑256** for:
|
||||
|
||||
* `ExplanationGraph` document
|
||||
* each `EvidenceNode`
|
||||
* Hash scope:
|
||||
|
||||
* `evidence.hash` = hash of the raw evidence blob (or canonical subset if huge)
|
||||
* `graphHash` = hash of the entire explanation graph document (minus signature).
|
||||
|
||||
2. **Signing**
|
||||
|
||||
* Format: **DSSE envelope** (`payloadType = "stellaops/explanation-graph@v1"`).
|
||||
* Key management: use existing **offline signing key** or Sigstore‑style keyless if already in org.
|
||||
* Signature attached as:
|
||||
|
||||
* `provenance.attestation` field inside each verdict **and**
|
||||
* stored in a separate `explanation_signatures` collection or S3 path for replay.
|
||||
|
||||
3. **Storage**
|
||||
|
||||
* Metadata: **MongoDB** collection `explanation_graphs`.
|
||||
* Evidence blobs:
|
||||
|
||||
* S3 (or compatible) bucket `stella-explanations/` with layout:
|
||||
|
||||
* `evidence/{evidenceId}` or `evidence/{hash}`.
|
||||
|
||||
4. **ID formats**
|
||||
|
||||
* `scanId`: UUID (string).
|
||||
* `verdictId`, `evidenceId`, `stepId`: UUID (string).
|
||||
* `buildId`: reuse existing convention (`elf:<buildid>`, `pe:<guid>`, `macho:<uuid>`).
|
||||
|
||||
**Deliverable:** 1–2 page ADR in repo (`/docs/adr/000-explanation-graph.md`).
|
||||
|
||||
---
|
||||
|
||||
## Phase 1 – Domain model & persistence (backend)
|
||||
|
||||
**Owner:** Backend
|
||||
|
||||
### 1.1. Define core C# domain models
|
||||
|
||||
Place in `StellaOps.Explanations` project or equivalent:
|
||||
|
||||
```csharp
|
||||
public record ArtifactRef(
|
||||
string Purl,
|
||||
string Digest,
|
||||
string BuildId);
|
||||
|
||||
public record ExternalRef(
|
||||
string Type, // "advisory", "vex", "nvd", etc.
|
||||
string Id,
|
||||
string Url);
|
||||
|
||||
public record EvidenceNode(
|
||||
string EvidenceId,
|
||||
string Kind, // "binary.callgraph", "source.scan", "external.feed", ...
|
||||
string Hash, // sha256 of blob
|
||||
string Summary,
|
||||
string BlobPointer, // s3://..., file://..., ipfs://...
|
||||
ExternalRef? ExternalRef = null);
|
||||
|
||||
public record ReasoningStep(
|
||||
string StepId,
|
||||
string Type, // "callgraph.reachable", "version.match", ...
|
||||
string EvidenceRef); // EvidenceId
|
||||
|
||||
public record Provenance(
|
||||
string Scanner,
|
||||
string RulesHash, // hash of rules/policy bundle used
|
||||
DateTimeOffset Time,
|
||||
string Attestation); // DSSE envelope (base64 or JSON)
|
||||
|
||||
public record Verdict(
|
||||
string VerdictId,
|
||||
string Cve,
|
||||
string Status, // "affected", "not_affected", "under_investigation"
|
||||
string Policy, // e.g. "vex.lattice:v1"
|
||||
IReadOnlyList<ReasoningStep> Reasoning,
|
||||
Provenance Provenance);
|
||||
|
||||
public record ExplanationGraph(
|
||||
Guid ScanId,
|
||||
ArtifactRef Artifact,
|
||||
IReadOnlyList<Verdict> Verdicts,
|
||||
IReadOnlyList<EvidenceNode> Evidence,
|
||||
string GraphHash); // sha256 of canonical JSON
|
||||
```
|
||||
|
||||
### 1.2. MongoDB schema
|
||||
|
||||
Collection: `explanation_graphs`
|
||||
|
||||
Document shape:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"_id": "scanId:artifactDigest", // composite key or just ObjectId + separate fields
|
||||
"scanId": "uuid",
|
||||
"artifact": {
|
||||
"purl": "pkg:docker/redis@7.2.4",
|
||||
"digest": "sha256:...",
|
||||
"buildId": "elf:abcd..."
|
||||
},
|
||||
"verdicts": [ /* Verdict[] */ ],
|
||||
"evidence": [ /* EvidenceNode[] */ ],
|
||||
"graphHash": "sha256:..."
|
||||
}
|
||||
```
|
||||
|
||||
**Indexes:**
|
||||
|
||||
* `{ scanId: 1 }`
|
||||
* `{ "artifact.digest": 1 }`
|
||||
* `{ "verdicts.cve": 1, "artifact.digest": 1 }` (compound)
|
||||
* Optional: TTL or archiving mechanism if you don’t want to keep these forever.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* You can serialize/deserialize `ExplanationGraph` to Mongo without loss.
|
||||
* Indexes exist and queries by `scanId`, `artifact.digest`, and `(digest + CVE)` are efficient.
|
||||
|
||||
---
|
||||
|
||||
## Phase 2 – Evidence ingestion plumbing
|
||||
|
||||
**Goal:** Make every relevant raw fact show up as an `EvidenceNode`.
|
||||
|
||||
**Owner:** Backend scanner team
|
||||
|
||||
### 2.1. Evidence factory service
|
||||
|
||||
Create `IEvidenceService`:
|
||||
|
||||
```csharp
|
||||
public interface IEvidenceService
|
||||
{
|
||||
Task<EvidenceNode> StoreBinaryCallgraphAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
byte[] callgraphBytes,
|
||||
string summary,
|
||||
ExternalRef? externalRef = null);
|
||||
|
||||
Task<EvidenceNode> StoreSourceScanAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
byte[] scanResultJson,
|
||||
string summary);
|
||||
|
||||
Task<EvidenceNode> StoreExternalFeedAsync(
|
||||
Guid scanId,
|
||||
ExternalRef externalRef,
|
||||
byte[] rawPayload,
|
||||
string summary);
|
||||
}
|
||||
```
|
||||
|
||||
Implementation tasks:
|
||||
|
||||
1. **Hash computation**
|
||||
|
||||
* Compute SHA‑256 over raw bytes.
|
||||
* Prefer a helper:
|
||||
|
||||
```csharp
|
||||
public static string Sha256Hex(ReadOnlySpan<byte> data) { ... }
|
||||
```
|
||||
|
||||
2. **Blob storage**
|
||||
|
||||
* S3 key format, e.g.: `explanations/{scanId}/{evidenceId}`.
|
||||
* `BlobPointer` string = `s3://stella-explanations/explanations/{scanId}/{evidenceId}`.
|
||||
|
||||
3. **EvidenceNode creation**
|
||||
|
||||
* Generate `evidenceId = Guid.NewGuid().ToString("N")`.
|
||||
* Populate `kind`, `hash`, `summary`, `blobPointer`, `externalRef`.
|
||||
|
||||
4. **Graph assembly contract**
|
||||
|
||||
* Evidence service **does not** write to Mongo.
|
||||
* It only uploads blobs and returns `EvidenceNode` objects.
|
||||
* The **ExplanationGraphBuilder** (next phase) collects them.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Given a callgraph binary, a corresponding `EvidenceNode` is returned with:
|
||||
|
||||
* hash matching the blob (verified in tests),
|
||||
* blob present in S3,
|
||||
* summary populated.
|
||||
|
||||
---
|
||||
|
||||
## Phase 3 – Reasoning & policy integration
|
||||
|
||||
**Goal:** Instrument your existing VEX / lattice policy engine to emit deterministic **reasoning steps** instead of just a boolean status.
|
||||
|
||||
**Owner:** Policy / rules engine team
|
||||
|
||||
### 3.1. Expose rule evaluation trace
|
||||
|
||||
Assume you already have something like:
|
||||
|
||||
```csharp
|
||||
VulnerabilityStatus Evaluate(ArtifactRef artifact, string cve, Findings findings);
|
||||
```
|
||||
|
||||
Extend it to:
|
||||
|
||||
```csharp
|
||||
public sealed class RuleEvaluationTrace
|
||||
{
|
||||
public string StepType { get; init; } // e.g. "version.match"
|
||||
public string RuleId { get; init; } // "rule:openssl:versionFromElf"
|
||||
public string Description { get; init; } // human-readable explanation
|
||||
public string EvidenceKind { get; init; } // to match with EvidenceService
|
||||
public object EvidencePayload { get; init; } // callgraph bytes, json, etc.
|
||||
}
|
||||
|
||||
public sealed class EvaluationResult
|
||||
{
|
||||
public string Status { get; init; } // "affected", etc.
|
||||
public IReadOnlyList<RuleEvaluationTrace> Trace { get; init; }
|
||||
}
|
||||
```
|
||||
|
||||
New API:
|
||||
|
||||
```csharp
|
||||
EvaluationResult EvaluateWithTrace(
|
||||
ArtifactRef artifact, string cve, Findings findings);
|
||||
```
|
||||
|
||||
### 3.2. From trace to ReasoningStep + EvidenceNode
|
||||
|
||||
Create `ExplanationGraphBuilder`:
|
||||
|
||||
```csharp
|
||||
public interface IExplanationGraphBuilder
|
||||
{
|
||||
Task<ExplanationGraph> BuildAsync(
|
||||
Guid scanId,
|
||||
ArtifactRef artifact,
|
||||
IReadOnlyList<CveFinding> cveFindings,
|
||||
string scannerName);
|
||||
}
|
||||
```
|
||||
|
||||
Internal algorithm for each `CveFinding`:
|
||||
|
||||
1. Call `EvaluateWithTrace(artifact, cve, finding)` to get `EvaluationResult`.
|
||||
2. For each `RuleEvaluationTrace`:
|
||||
|
||||
* Use `EvidenceService` with appropriate method based on `EvidenceKind`.
|
||||
* Get back an `EvidenceNode` with `evidenceId`.
|
||||
* Create `ReasoningStep`:
|
||||
|
||||
* `StepId = Guid.NewGuid()`
|
||||
* `Type = trace.StepType`
|
||||
* `EvidenceRef = evidenceNode.EvidenceId`
|
||||
3. Assemble `Verdict`:
|
||||
|
||||
```csharp
|
||||
var verdict = new Verdict(
|
||||
verdictId: Guid.NewGuid().ToString("N"),
|
||||
cve: finding.Cve,
|
||||
status: result.Status,
|
||||
policy: "vex.lattice:v1",
|
||||
reasoning: steps,
|
||||
provenance: new Provenance(
|
||||
scanner: scannerName,
|
||||
rulesHash: rulesBundleHash,
|
||||
time: DateTimeOffset.UtcNow,
|
||||
attestation: "" // set in Phase 4
|
||||
)
|
||||
);
|
||||
```
|
||||
|
||||
4. Collect:
|
||||
|
||||
* all `EvidenceNode`s (dedupe by `hash` to avoid duplicates).
|
||||
* all `Verdict`s.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Given deterministic inputs (scan + rules bundle hash), repeated runs produce:
|
||||
|
||||
* same sequence of `ReasoningStep` types,
|
||||
* same set of `EvidenceNode.hash` values,
|
||||
* same `status`.
|
||||
|
||||
---
|
||||
|
||||
## Phase 4 – Graph hashing & DSSE signing
|
||||
|
||||
**Owner:** Security / platform
|
||||
|
||||
### 4.1. Canonical JSON for hash
|
||||
|
||||
Implement:
|
||||
|
||||
```csharp
|
||||
public static class ExplanationGraphSerializer
|
||||
{
|
||||
public static string ToCanonicalJson(ExplanationGraph graph)
|
||||
{
|
||||
// no graphHash, no attestation in this step
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Key requirements:
|
||||
|
||||
* Consistent property ordering (e.g. alphabetical).
|
||||
* No extra whitespace.
|
||||
* UTF‑8 encoding.
|
||||
* Primitive formatting options fixed (e.g. date as ISO 8601 with `Z`).
|
||||
|
||||
### 4.2. Hash and sign
|
||||
|
||||
Before persisting:
|
||||
|
||||
```csharp
|
||||
var graphWithoutHash = graph with { GraphHash = "" };
|
||||
var canonicalJson = ExplanationGraphSerializer.ToCanonicalJson(graphWithoutHash);
|
||||
var graphHash = Sha256Hex(Encoding.UTF8.GetBytes(canonicalJson));
|
||||
|
||||
// sign DSSE envelope
|
||||
var envelope = dsseSigner.Sign(
|
||||
payloadType: "stellaops/explanation-graph@v1",
|
||||
payload: Encoding.UTF8.GetBytes(canonicalJson)
|
||||
);
|
||||
|
||||
// attach
|
||||
var signedVerdicts = graph.Verdicts
|
||||
.Select(v => v with
|
||||
{
|
||||
Provenance = v.Provenance with { Attestation = envelope.ToJson() }
|
||||
})
|
||||
.ToList();
|
||||
|
||||
var finalGraph = graph with
|
||||
{
|
||||
GraphHash = $"sha256:{graphHash}",
|
||||
Verdicts = signedVerdicts
|
||||
};
|
||||
```
|
||||
|
||||
Then write `finalGraph` to Mongo.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Recomputing `graphHash` from Mongo document (zeroing `graphHash` and `attestation`) matches stored value.
|
||||
* Verifying DSSE signature with the public key succeeds.
|
||||
|
||||
---
|
||||
|
||||
## Phase 5 – Backend APIs & export bundle
|
||||
|
||||
**Owner:** Backend / API
|
||||
|
||||
### 5.1. Read APIs
|
||||
|
||||
Add endpoints (REST-ish):
|
||||
|
||||
1. **Get graph for scan-artifact**
|
||||
|
||||
`GET /explanations/scans/{scanId}/artifacts/{digest}`
|
||||
|
||||
* Returns entire `ExplanationGraph` JSON.
|
||||
|
||||
2. **Get single verdict**
|
||||
|
||||
`GET /explanations/scans/{scanId}/artifacts/{digest}/cves/{cve}`
|
||||
|
||||
* Returns `Verdict` + its subset of `EvidenceNode`s.
|
||||
|
||||
3. **Search by CVE**
|
||||
|
||||
`GET /explanations/search?cve=CVE-2024-XXXX&digest=sha256:...`
|
||||
|
||||
* Returns list of `(scanId, artifact, verdictId)`.
|
||||
|
||||
### 5.2. Export replay bundle
|
||||
|
||||
`POST /explanations/{scanId}/{digest}/export`
|
||||
|
||||
Implementation:
|
||||
|
||||
* Create a temporary directory.
|
||||
* Write:
|
||||
|
||||
* `graph.json` → `ExplanationGraph` as stored.
|
||||
* `signature.json` → DSSE envelope alone (optional).
|
||||
* Evidence blobs:
|
||||
|
||||
* For each `EvidenceNode`:
|
||||
|
||||
* Download from S3 and store as `evidence/{evidenceId}`.
|
||||
* Zip the folder: `explanation-{scanId}-{shortDigest}.zip`.
|
||||
* Stream as download.
|
||||
|
||||
### 5.3. CLI verifier
|
||||
|
||||
Small .NET / Go CLI:
|
||||
|
||||
Commands:
|
||||
|
||||
```bash
|
||||
stellaops-explain verify graph.json --evidence ./evidence
|
||||
```
|
||||
|
||||
Verification steps:
|
||||
|
||||
1. Load `graph.json`, parse to `ExplanationGraph`.
|
||||
2. Strip `graphHash` & `attestation`, re‑serialize canonical JSON.
|
||||
3. Recompute SHA‑256 and compare to `graphHash`.
|
||||
4. Verify DSSE envelope with public key.
|
||||
5. For each `EvidenceNode`:
|
||||
|
||||
* Read file `./evidence/{evidenceId}`.
|
||||
* Recompute hash and compare with `evidence.hash`.
|
||||
|
||||
Exit with non‑zero code if anything fails; print a short summary.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* Export bundle round‑trips: `verify` passes on an exported zip.
|
||||
* APIs documented in OpenAPI / Swagger.
|
||||
|
||||
---
|
||||
|
||||
## Phase 6 – UI: Explanation trace panel
|
||||
|
||||
**Owner:** Frontend
|
||||
|
||||
### 6.1. API integration
|
||||
|
||||
New calls in frontend client:
|
||||
|
||||
* `GET /explanations/scans/{scanId}/artifacts/{digest}`
|
||||
* Optionally `GET /explanations/.../cves/{cve}` if you want lazy loading per CVE.
|
||||
|
||||
### 6.2. Component UX
|
||||
|
||||
On the “vulnerability detail” view:
|
||||
|
||||
* Add **“Explanation”** tab with three sections:
|
||||
|
||||
1. **Verdict summary**
|
||||
|
||||
* Badge: `Affected` / `Not affected` / `Under investigation`.
|
||||
* Text: `Derived using policy {policy}, rules hash {rulesHash[..8]}.`
|
||||
|
||||
2. **Reasoning timeline**
|
||||
|
||||
* Vertical list of `ReasoningStep`s:
|
||||
|
||||
* Icon per type (e.g. “flow” icon for `callgraph.reachable`).
|
||||
* Title = `Type` (humanized).
|
||||
* Click to expand underlying `EvidenceNode.summary`.
|
||||
* Optional “View raw evidence” link (downloads blob via S3 signed URL).
|
||||
|
||||
3. **Provenance**
|
||||
|
||||
* Show:
|
||||
|
||||
* `scanner`
|
||||
* `rulesHash`
|
||||
* `time`
|
||||
* “Attested ✓” if DSSE verifies on the backend (or pre‑computed).
|
||||
|
||||
4. **Export**
|
||||
|
||||
* Button: “Download replay bundle (.zip)”
|
||||
* Calls export endpoint and triggers browser download.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* For any CVE in UI, a user can:
|
||||
|
||||
* See why it is (not) affected in at most 2 clicks.
|
||||
* Download a replay bundle via the UI.
|
||||
|
||||
---
|
||||
|
||||
## Phase 7 – Testing strategy
|
||||
|
||||
**Owner:** QA + all devs
|
||||
|
||||
### 7.1. Unit tests
|
||||
|
||||
* EvidenceService:
|
||||
|
||||
* Hash matches blob contents.
|
||||
* BlobPointer formats are as expected.
|
||||
* ExplanationGraphBuilder:
|
||||
|
||||
* Given fixed test input, the resulting graph JSON matches golden file.
|
||||
* Serializer:
|
||||
|
||||
* Canonical JSON is stable under property reordering in the code.
|
||||
|
||||
### 7.2. Integration tests
|
||||
|
||||
* End‑to‑end fake scan:
|
||||
|
||||
* Simulate scanner output + rules.
|
||||
* Build graph → persist → fetch via API.
|
||||
* Run CLI verify on exported bundle in CI.
|
||||
|
||||
### 7.3. Security tests
|
||||
|
||||
* Signature tampering:
|
||||
|
||||
* Modify `graph.json` in exported bundle; `verify` must fail.
|
||||
* Evidence tampering:
|
||||
|
||||
* Modify an evidence file; `verify` must fail.
|
||||
|
||||
---
|
||||
|
||||
## Phase 8 – Rollout
|
||||
|
||||
**Owner:** PM / Tech lead
|
||||
|
||||
1. **Feature flag**
|
||||
|
||||
* Start with explanation graph generation behind a flag for:
|
||||
|
||||
* subset of scanners,
|
||||
* subset of tenants.
|
||||
|
||||
2. **Backfill (optional)**
|
||||
|
||||
* If useful, run a one‑off job that:
|
||||
|
||||
* Takes recent scans,
|
||||
* Rebuilds explanation graphs,
|
||||
* Stores them in Mongo.
|
||||
|
||||
3. **Docs**
|
||||
|
||||
* Short doc page for customers:
|
||||
|
||||
* “What is an Explanation Graph?”
|
||||
* “How to verify it with the CLI?”
|
||||
|
||||
---
|
||||
|
||||
## Developer checklist (TL;DR)
|
||||
|
||||
You can literally drop this into Jira as epics/tasks:
|
||||
|
||||
1. **Backend**
|
||||
|
||||
* [ ] Implement domain models (`ExplanationGraph`, `Verdict`, `EvidenceNode`, etc.).
|
||||
* [ ] Implement `IEvidenceService` + S3 integration.
|
||||
* [ ] Extend policy engine to `EvaluateWithTrace`.
|
||||
* [ ] Implement `ExplanationGraphBuilder`.
|
||||
* [ ] Implement canonical serializer, hashing, DSSE signing.
|
||||
* [ ] Implement Mongo persistence + indexes.
|
||||
* [ ] Implement REST APIs + export ZIP.
|
||||
|
||||
2. **Frontend**
|
||||
|
||||
* [ ] Wire new APIs into the vulnerability detail view.
|
||||
* [ ] Build Explanation tab (Summary / Reasoning / Provenance).
|
||||
* [ ] Implement “Download replay bundle” button.
|
||||
|
||||
3. **Tools**
|
||||
|
||||
* [ ] Implement `stellaops-explain verify` CLI.
|
||||
* [ ] Add CI test that runs verify against a sample bundle.
|
||||
|
||||
4. **QA**
|
||||
|
||||
* [ ] Golden‑file tests for graphs.
|
||||
* [ ] Signature & evidence tampering tests.
|
||||
* [ ] UI functional tests on explanations.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, next step I can turn this into:
|
||||
|
||||
* concrete **OpenAPI spec** for the new endpoints, and/or
|
||||
* a **sample `stellaops-explain verify` CLI skeleton** (C# or Go).
|
||||
@@ -1,799 +0,0 @@
|
||||
Here’s a quick win for making your vuln paths auditor‑friendly without retraining any models: **add a plain‑language `reason` to every graph edge** (why this edge exists). Think “introduced via dynamic import” or “symbol relocation via `ld`”, not jargon soup.
|
||||
|
||||
|
||||
|
||||
# Why this helps
|
||||
|
||||
* **Explains reachability** at a glance (auditors & devs can follow the story).
|
||||
* **Reduces false‑positive fights** (every hop justifies itself).
|
||||
* **Stable across languages** (no model changes, just metadata).
|
||||
|
||||
# Minimal schema change
|
||||
|
||||
Add three fields to every edge in your call/dep graph (SBOM→Reachability→Fix plan):
|
||||
|
||||
```json
|
||||
{
|
||||
"from": "pkg:pypi/requests@2.32.3#requests.sessions.Session.request",
|
||||
"to": "pkg:pypi/urllib3@2.2.3#urllib3.connectionpool.HTTPConnectionPool.urlopen",
|
||||
"via": {
|
||||
"reason": "imported via top-level module dependency",
|
||||
"evidence": [
|
||||
"import urllib3 in requests/adapters.py:12",
|
||||
"pip freeze: urllib3==2.2.3"
|
||||
],
|
||||
"provenance": {
|
||||
"detector": "StellaOps.Scanner.WebService@1.4.2",
|
||||
"rule_id": "PY-IMPORT-001",
|
||||
"confidence": "high"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Standard reason glossary (use as enum)
|
||||
|
||||
* `declared_dependency` (manifest lock/SBOM edge)
|
||||
* `static_call` (direct call site with symbol ref)
|
||||
* `dynamic_import` (e.g., `__import__`, `importlib`, `require(...)`)
|
||||
* `reflection_call` (C# `MethodInfo.Invoke`, Java reflection)
|
||||
* `plugin_discovery` (entry points, ServiceLoader, MEF)
|
||||
* `symbol_relocation` (ELF/PE/Mach‑O relocation binds)
|
||||
* `plt_got_resolution` (ELF PLT/GOT jump to symbol)
|
||||
* `ld_preload_injection` (runtime injected .so/.dll)
|
||||
* `env_config_path` (path read from env/config enables load)
|
||||
* `taint_propagation` (user input reaches sink)
|
||||
* `vendor_patch_alias` (function moved/aliased across versions)
|
||||
|
||||
# Emission rules (keep it deterministic)
|
||||
|
||||
* **One reason per edge**, short, lowercase snake_case from glossary.
|
||||
* **Up to 3 evidence strings** (file:line or binary section + symbol).
|
||||
* **Confidence**: `high|medium|low` with a single, stable rubric:
|
||||
|
||||
* high = exact symbol/call site or relocation
|
||||
* medium = heuristic import/loader path
|
||||
* low = inferred from naming or optional plugin
|
||||
|
||||
# UI/Report snippet
|
||||
|
||||
Render paths like:
|
||||
|
||||
```
|
||||
app → requests → urllib3 → OpenSSL EVP_PKEY_new_raw_private_key
|
||||
• declared_dependency (poetry.lock)
|
||||
• static_call (requests.adapters:345)
|
||||
• symbol_relocation (ELF .rela.plt: _EVP_PKEY_new_raw_private_key)
|
||||
```
|
||||
|
||||
# C# drop‑in (for your .NET 10 code)
|
||||
|
||||
Edge builder with reason/evidence:
|
||||
|
||||
```csharp
|
||||
public sealed record EdgeId(string From, string To);
|
||||
|
||||
public sealed record EdgeEvidence(
|
||||
string Reason, // enum string from glossary
|
||||
IReadOnlyList<string> Evidence, // file:line, symbol, section
|
||||
string Confidence, // high|medium|low
|
||||
string Detector, // component@version
|
||||
string RuleId // stable rule key
|
||||
);
|
||||
|
||||
public sealed record GraphEdge(EdgeId Id, EdgeEvidence Via);
|
||||
|
||||
public static class EdgeFactory
|
||||
{
|
||||
public static GraphEdge DeclaredDependency(string from, string to, string manifestPath)
|
||||
=> new(new EdgeId(from, to),
|
||||
new EdgeEvidence(
|
||||
Reason: "declared_dependency",
|
||||
Evidence: new[] { $"manifest:{manifestPath}" },
|
||||
Confidence: "high",
|
||||
Detector: "StellaOps.Scanner.WebService@1.0.0",
|
||||
RuleId: "DEP-LOCK-001"));
|
||||
|
||||
public static GraphEdge SymbolRelocation(string from, string to, string objPath, string section, string symbol)
|
||||
=> new(new EdgeId(from, to),
|
||||
new EdgeEvidence(
|
||||
Reason: "symbol_relocation",
|
||||
Evidence: new[] { $"{objPath}::{section}:{symbol}" },
|
||||
Confidence: "high",
|
||||
Detector: "StellaOps.Scanner.WebService@1.0.0",
|
||||
RuleId: "BIN-RELOC-101"));
|
||||
}
|
||||
```
|
||||
|
||||
# Integration checklist (fast path)
|
||||
|
||||
* Emit `via.reason/evidence/provenance` for **all** edges (SBOM, source, binary).
|
||||
* Validate `reason` against glossary; reject free‑text.
|
||||
* Add a “**Why this edge exists**” column in your path tables.
|
||||
* In JSON/CSV exports, keep columns: `from,to,reason,confidence,evidence0..2,rule_id`.
|
||||
* In the console, collapse evidence by default; expand on click.
|
||||
|
||||
If you want, I’ll plug this into your Stella Ops graph contracts (Concelier/Cartographer) and produce the enum + validators and a tiny renderer for your docs.
|
||||
Cool, let’s turn this into a concrete, dev‑friendly implementation plan you can actually hand to teams.
|
||||
|
||||
I’ll structure it by phases and by component (schema, producers, APIs, UI, testing, rollout) so you can slice into tickets easily.
|
||||
|
||||
---
|
||||
|
||||
## 0. Recap of what we’re building
|
||||
|
||||
**Goal:**
|
||||
Every edge in your vuln path graph (SBOM → Reachability → Fix plan) carries **machine‑readable, auditor‑friendly metadata**:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"from": "pkg:pypi/requests@2.32.3#requests.sessions.Session.request",
|
||||
"to": "pkg:pypi/urllib3@2.2.3#urllib3.connectionpool.HTTPConnectionPool.urlopen",
|
||||
"via": {
|
||||
"reason": "declared_dependency", // from a controlled enum
|
||||
"evidence": [
|
||||
"manifest:requirements.txt:3", // up to 3 short evidence strings
|
||||
"pip freeze: urllib3==2.2.3"
|
||||
],
|
||||
"provenance": {
|
||||
"detector": "StellaOps.Scanner.WebService@1.4.2",
|
||||
"rule_id": "PY-IMPORT-001",
|
||||
"confidence": "high"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Standard **reason glossary** (enum):
|
||||
|
||||
* `declared_dependency`
|
||||
* `static_call`
|
||||
* `dynamic_import`
|
||||
* `reflection_call`
|
||||
* `plugin_discovery`
|
||||
* `symbol_relocation`
|
||||
* `plt_got_resolution`
|
||||
* `ld_preload_injection`
|
||||
* `env_config_path`
|
||||
* `taint_propagation`
|
||||
* `vendor_patch_alias`
|
||||
* `unknown` (fallback only when you truly can’t do better)
|
||||
|
||||
---
|
||||
|
||||
## 1. Design & contracts (shared work for backend & frontend)
|
||||
|
||||
### 1.1 Define the canonical edge metadata types
|
||||
|
||||
**Owner:** Platform / shared lib team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. In your shared C# library (used by scanners + API), define:
|
||||
|
||||
```csharp
|
||||
public enum EdgeReason
|
||||
{
|
||||
Unknown = 0,
|
||||
DeclaredDependency,
|
||||
StaticCall,
|
||||
DynamicImport,
|
||||
ReflectionCall,
|
||||
PluginDiscovery,
|
||||
SymbolRelocation,
|
||||
PltGotResolution,
|
||||
LdPreloadInjection,
|
||||
EnvConfigPath,
|
||||
TaintPropagation,
|
||||
VendorPatchAlias
|
||||
}
|
||||
|
||||
public enum EdgeConfidence
|
||||
{
|
||||
Low = 0,
|
||||
Medium,
|
||||
High
|
||||
}
|
||||
|
||||
public sealed record EdgeProvenance(
|
||||
string Detector, // e.g., "StellaOps.Scanner.WebService@1.4.2"
|
||||
string RuleId, // e.g., "PY-IMPORT-001"
|
||||
EdgeConfidence Confidence
|
||||
);
|
||||
|
||||
public sealed record EdgeVia(
|
||||
EdgeReason Reason,
|
||||
IReadOnlyList<string> Evidence,
|
||||
EdgeProvenance Provenance
|
||||
);
|
||||
|
||||
public sealed record EdgeId(string From, string To);
|
||||
|
||||
public sealed record GraphEdge(
|
||||
EdgeId Id,
|
||||
EdgeVia Via
|
||||
);
|
||||
```
|
||||
|
||||
2. Enforce **max 3 evidence strings** via a small helper to avoid accidental spam:
|
||||
|
||||
```csharp
|
||||
public static class EdgeViaFactory
|
||||
{
|
||||
private const int MaxEvidence = 3;
|
||||
|
||||
public static EdgeVia Create(
|
||||
EdgeReason reason,
|
||||
IEnumerable<string> evidence,
|
||||
string detector,
|
||||
string ruleId,
|
||||
EdgeConfidence confidence
|
||||
)
|
||||
{
|
||||
var ev = evidence
|
||||
.Where(s => !string.IsNullOrWhiteSpace(s))
|
||||
.Take(MaxEvidence)
|
||||
.ToArray();
|
||||
|
||||
return new EdgeVia(
|
||||
Reason: reason,
|
||||
Evidence: ev,
|
||||
Provenance: new EdgeProvenance(detector, ruleId, confidence)
|
||||
);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] EdgeReason enum defined and shared in a reusable package.
|
||||
* [ ] EdgeVia and EdgeProvenance types exist and are serializable to JSON.
|
||||
* [ ] Evidence is capped to 3 entries and cannot be null (empty list allowed).
|
||||
|
||||
---
|
||||
|
||||
### 1.2 API / JSON contract
|
||||
|
||||
**Owner:** API team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Extend your existing graph edge DTO to include `via`:
|
||||
|
||||
```csharp
|
||||
public sealed record GraphEdgeDto
|
||||
{
|
||||
public string From { get; init; } = default!;
|
||||
public string To { get; init; } = default!;
|
||||
public EdgeViaDto Via { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed record EdgeViaDto
|
||||
{
|
||||
public string Reason { get; init; } = default!; // enum as string
|
||||
public string[] Evidence { get; init; } = Array.Empty<string>();
|
||||
public EdgeProvenanceDto Provenance { get; init; } = default!;
|
||||
}
|
||||
|
||||
public sealed record EdgeProvenanceDto
|
||||
{
|
||||
public string Detector { get; init; } = default!;
|
||||
public string RuleId { get; init; } = default!;
|
||||
public string Confidence { get; init; } = default!; // "high|medium|low"
|
||||
}
|
||||
```
|
||||
|
||||
2. Ensure JSON is **additive** (backward compatible):
|
||||
|
||||
* `via` is **non‑nullable** in responses from the new API version.
|
||||
* If you must keep a legacy endpoint, add **v2** endpoints that guarantee `via`.
|
||||
|
||||
3. Update OpenAPI spec:
|
||||
|
||||
* Document `via.reason` as enum string, including allowed values.
|
||||
* Document `via.provenance.detector`, `rule_id`, `confidence`.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] OpenAPI / Swagger shows `via.reason` as a string enum + description.
|
||||
* [ ] New clients can deserialize edges with `via` without custom hacks.
|
||||
* [ ] Old clients remain unaffected (either keep old endpoint or allow them to ignore `via`).
|
||||
|
||||
---
|
||||
|
||||
## 2. Producers: add reasons & evidence where edges are created
|
||||
|
||||
You likely have 3 main edge producers:
|
||||
|
||||
* SBOM / manifest / lockfile analyzers
|
||||
* Source analyzers (call graph, taint analysis)
|
||||
* Binary analyzers (ELF/PE/Mach‑O, containers)
|
||||
|
||||
Treat each as a mini‑project with identical patterns.
|
||||
|
||||
---
|
||||
|
||||
### 2.1 SBOM / manifest edges
|
||||
|
||||
**Owner:** SBOM / dep graph team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Identify all code paths that create “declared dependency” edges:
|
||||
|
||||
* Manifest → Package
|
||||
* Root module → Imported package (if you store these explicitly)
|
||||
|
||||
2. Replace plain edge construction with factory calls:
|
||||
|
||||
```csharp
|
||||
public static class EdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Sbom@1.0.0";
|
||||
|
||||
public static GraphEdge DeclaredDependency(
|
||||
string from,
|
||||
string to,
|
||||
string manifestPath,
|
||||
string? dependencySpecLine
|
||||
)
|
||||
{
|
||||
var evidence = new List<string>
|
||||
{
|
||||
$"manifest:{manifestPath}"
|
||||
};
|
||||
|
||||
if (!string.IsNullOrWhiteSpace(dependencySpecLine))
|
||||
evidence.Add($"spec:{dependencySpecLine}");
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.DeclaredDependency,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"DEP-LOCK-001",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(from, to), via);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. Make sure each SBOM/manifest edge sets:
|
||||
|
||||
* `reason = declared_dependency`
|
||||
* `confidence = high`
|
||||
* Evidence includes at least `manifest:<path>` and, if possible, line or spec snippet.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Any SBOM‑generated edge returns with `via.reason == declared_dependency`.
|
||||
* [ ] Evidence contains manifest path for ≥ 99% of SBOM edges.
|
||||
* [ ] Unit tests cover at least: normal manifest, multiple manifests, malformed manifest.
|
||||
|
||||
---
|
||||
|
||||
### 2.2 Source code call graph edges
|
||||
|
||||
**Owner:** Static analysis / call graph team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Map current edge types → reasons:
|
||||
|
||||
* Direct function/method calls → `static_call`
|
||||
* Reflection (Java/C#) → `reflection_call`
|
||||
* Dynamic imports (`__import__`, `importlib`, `require(...)`) → `dynamic_import`
|
||||
* Plugin systems (entry points, ServiceLoader, MEF) → `plugin_discovery`
|
||||
* Taint / dataflow edges (user input → sink) → `taint_propagation`
|
||||
|
||||
2. Implement helper factories:
|
||||
|
||||
```csharp
|
||||
public static class SourceEdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Source@1.0.0";
|
||||
|
||||
public static GraphEdge StaticCall(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string filePath,
|
||||
int lineNumber
|
||||
)
|
||||
{
|
||||
var evidence = new[]
|
||||
{
|
||||
$"callsite:{filePath}:{lineNumber}"
|
||||
};
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.StaticCall,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"SRC-CALL-001",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
|
||||
public static GraphEdge DynamicImport(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string filePath,
|
||||
int lineNumber
|
||||
)
|
||||
{
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.DynamicImport,
|
||||
new[] { $"importsite:{filePath}:{lineNumber}" },
|
||||
DetectorName,
|
||||
"SRC-DYNIMPORT-001",
|
||||
EdgeConfidence.Medium
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
|
||||
// Similar for ReflectionCall, PluginDiscovery, TaintPropagation...
|
||||
}
|
||||
```
|
||||
|
||||
3. Replace all direct `new GraphEdge(...)` calls in source analyzers with these factories.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Direct call edges produce `reason = static_call` with file:line evidence.
|
||||
* [ ] Reflection/dynamic import edges use correct reasons and mark `confidence = medium` (or high where you’re certain).
|
||||
* [ ] Unit tests check that for a known source file, the resulting edges contain expected `reason`, `evidence`, and `rule_id`.
|
||||
|
||||
---
|
||||
|
||||
### 2.3 Binary / container analyzers
|
||||
|
||||
**Owner:** Binary analysis / SCA team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Map binary features to reasons:
|
||||
|
||||
* Symbol relocations + PLT/GOT edges → `symbol_relocation` or `plt_got_resolution`
|
||||
* LD_PRELOAD or injection edges → `ld_preload_injection`
|
||||
|
||||
2. Implement factory:
|
||||
|
||||
```csharp
|
||||
public static class BinaryEdgeFactory
|
||||
{
|
||||
private const string DetectorName = "StellaOps.Scanner.Binary@1.0.0";
|
||||
|
||||
public static GraphEdge SymbolRelocation(
|
||||
string fromSymbol,
|
||||
string toSymbol,
|
||||
string binaryPath,
|
||||
string section,
|
||||
string relocationName
|
||||
)
|
||||
{
|
||||
var evidence = new[]
|
||||
{
|
||||
$"{binaryPath}::{section}:{relocationName}"
|
||||
};
|
||||
|
||||
var via = EdgeViaFactory.Create(
|
||||
EdgeReason.SymbolRelocation,
|
||||
evidence,
|
||||
DetectorName,
|
||||
"BIN-RELOC-101",
|
||||
EdgeConfidence.High
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(fromSymbol, toSymbol), via);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. Wire up all binary edge creation to use this.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] For a test binary with a known relocation, edges include `reason = symbol_relocation` and section/symbol in evidence.
|
||||
* [ ] No binary edge is created without `via`.
|
||||
|
||||
---
|
||||
|
||||
## 3. Storage & migrations
|
||||
|
||||
This depends on your backing store, but the pattern is similar.
|
||||
|
||||
### 3.1 Relational (SQL) example
|
||||
|
||||
**Owner:** Data / infra team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Add columns:
|
||||
|
||||
```sql
|
||||
ALTER TABLE graph_edges
|
||||
ADD COLUMN via_reason VARCHAR(64) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_evidence JSONB NOT NULL DEFAULT '[]'::jsonb,
|
||||
ADD COLUMN via_detector VARCHAR(255) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_rule_id VARCHAR(128) NOT NULL DEFAULT 'unknown',
|
||||
ADD COLUMN via_confidence VARCHAR(16) NOT NULL DEFAULT 'low';
|
||||
```
|
||||
|
||||
2. Update ORM model:
|
||||
|
||||
```csharp
|
||||
public class EdgeEntity
|
||||
{
|
||||
public string From { get; set; } = default!;
|
||||
public string To { get; set; } = default!;
|
||||
|
||||
public string ViaReason { get; set; } = "unknown";
|
||||
public string[] ViaEvidence { get; set; } = Array.Empty<string>();
|
||||
public string ViaDetector { get; set; } = "unknown";
|
||||
public string ViaRuleId { get; set; } = "unknown";
|
||||
public string ViaConfidence { get; set; } = "low";
|
||||
}
|
||||
```
|
||||
|
||||
3. Add mapping to domain `GraphEdge`:
|
||||
|
||||
```csharp
|
||||
public static GraphEdge ToDomain(this EdgeEntity e)
|
||||
{
|
||||
var via = new EdgeVia(
|
||||
Reason: Enum.TryParse<EdgeReason>(e.ViaReason, true, out var r) ? r : EdgeReason.Unknown,
|
||||
Evidence: e.ViaEvidence,
|
||||
Provenance: new EdgeProvenance(
|
||||
Detector: e.ViaDetector,
|
||||
RuleId: e.ViaRuleId,
|
||||
Confidence: Enum.TryParse<EdgeConfidence>(e.ViaConfidence, true, out var c) ? c : EdgeConfidence.Low
|
||||
)
|
||||
);
|
||||
|
||||
return new GraphEdge(new EdgeId(e.From, e.To), via);
|
||||
}
|
||||
```
|
||||
|
||||
4. **Backfill existing data** (optional but recommended):
|
||||
|
||||
* For edges with a known “type” column, map to best‑fit `reason`.
|
||||
* If you can’t infer: set `reason = unknown`, `confidence = low`, `detector = "backfill@<version>"`.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] DB migration runs cleanly in staging and prod.
|
||||
* [ ] No existing reader breaks: default values keep queries functioning.
|
||||
* [ ] Edge round‑trip (domain → DB → API JSON) retains `via` fields correctly.
|
||||
|
||||
---
|
||||
|
||||
## 4. API & service layer
|
||||
|
||||
**Owner:** API / service team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. Wire domain model → DTOs:
|
||||
|
||||
```csharp
|
||||
public static GraphEdgeDto ToDto(this GraphEdge edge)
|
||||
{
|
||||
return new GraphEdgeDto
|
||||
{
|
||||
From = edge.Id.From,
|
||||
To = edge.Id.To,
|
||||
Via = new EdgeViaDto
|
||||
{
|
||||
Reason = edge.Via.Reason.ToString().ToSnakeCaseLower(), // e.g. "static_call"
|
||||
Evidence = edge.Via.Evidence.ToArray(),
|
||||
Provenance = new EdgeProvenanceDto
|
||||
{
|
||||
Detector = edge.Via.Provenance.Detector,
|
||||
RuleId = edge.Via.Provenance.RuleId,
|
||||
Confidence = edge.Via.Provenance.Confidence.ToString().ToLowerInvariant()
|
||||
}
|
||||
}
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
2. If you accept edges via API (internal services), validate:
|
||||
|
||||
* `reason` must be one of the known values; otherwise reject or coerce to `unknown`.
|
||||
* `evidence` length ≤ 3.
|
||||
* Trim whitespace and limit each evidence string length (e.g. 256 chars).
|
||||
|
||||
3. Versioning:
|
||||
|
||||
* Introduce `/v2/graph/paths` (or similar) that guarantees `via`.
|
||||
* Keep `/v1/...` unchanged or mark deprecated.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Path API returns `via.reason` and `via.evidence` for all edges in new endpoints.
|
||||
* [ ] Invalid reason strings are rejected or converted to `unknown` with a log.
|
||||
* [ ] Integration tests cover full flow: repo → scanner → DB → API → JSON.
|
||||
|
||||
---
|
||||
|
||||
## 5. UI: make paths auditor‑friendly
|
||||
|
||||
**Owner:** Frontend team
|
||||
|
||||
**Tasks:**
|
||||
|
||||
1. **Path details UI**:
|
||||
|
||||
For each edge in the vulnerability path table:
|
||||
|
||||
* Show a **“Reason” column** with a small pill:
|
||||
|
||||
* `static_call` → “Static call”
|
||||
* `declared_dependency` → “Declared dependency”
|
||||
* etc.
|
||||
* Below or on hover, show **primary evidence** (first evidence string).
|
||||
|
||||
2. **Edge details panel** (drawer/modal):
|
||||
|
||||
When user clicks an edge:
|
||||
|
||||
* Show:
|
||||
|
||||
* From → To (symbols/packages)
|
||||
* Reason (with friendly description per enum)
|
||||
* Evidence list (each on its own line)
|
||||
* Detector, rule id, confidence
|
||||
|
||||
3. **Filtering & sorting (optional but powerful)**:
|
||||
|
||||
* Filter edges by `reason` (multi‑select).
|
||||
* Filter by `confidence` (e.g. show only high/medium).
|
||||
* This helps auditors quickly isolate more speculative edges.
|
||||
|
||||
4. **UX text / glossary**:
|
||||
|
||||
* Add a small “?” tooltip that links to a glossary explaining each reason type in human language.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] For a given vulnerability, the path view shows a “Reason” column per edge.
|
||||
* [ ] Clicking an edge reveals all evidence and provenance information.
|
||||
* [ ] UX has a glossary/tooltip explaining what each reason means in plain English.
|
||||
|
||||
---
|
||||
|
||||
## 6. Testing strategy
|
||||
|
||||
**Owner:** QA + each feature team
|
||||
|
||||
### 6.1 Unit tests
|
||||
|
||||
* **Factories**: verify correct mapping from input to `EdgeVia`:
|
||||
|
||||
* Reason set correctly.
|
||||
* Evidence trimmed, max 3.
|
||||
* Confidence matches rubric (high for relocations, medium for heuristic imports, etc.).
|
||||
* **Serialization**: `EdgeVia` → JSON and back.
|
||||
|
||||
### 6.2 Integration tests
|
||||
|
||||
Set up **small fixtures**:
|
||||
|
||||
1. **Simple dependency project**:
|
||||
|
||||
* Example: Python project with `requirements.txt` → `requests` → `urllib3`.
|
||||
* Expected edges:
|
||||
|
||||
* App → requests: `declared_dependency`, evidence includes `requirements.txt`.
|
||||
* requests → urllib3: `declared_dependency`, plus static call edges.
|
||||
|
||||
2. **Dynamic import case**:
|
||||
|
||||
* A module using `importlib.import_module("mod")`.
|
||||
* Ensure edge is `dynamic_import` with `confidence = medium`.
|
||||
|
||||
3. **Binary edge case**:
|
||||
|
||||
* Test ELF with known symbol relocation.
|
||||
* Ensure an edge with `reason = symbol_relocation` exists.
|
||||
|
||||
### 6.3 End‑to‑end tests
|
||||
|
||||
* Run full scan on a sample repo and:
|
||||
|
||||
* Hit path API.
|
||||
* Assert every edge has non‑null `via` fields.
|
||||
* Spot check a few known edges for exact `reason` and evidence.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Automated tests fail if any edge is emitted without `via`.
|
||||
* [ ] Coverage includes at least one example for each `EdgeReason` you support.
|
||||
|
||||
---
|
||||
|
||||
## 7. Observability, guardrails & rollout
|
||||
|
||||
### 7.1 Metrics & logging
|
||||
|
||||
**Owner:** Observability / platform
|
||||
|
||||
**Tasks:**
|
||||
|
||||
* Emit metrics:
|
||||
|
||||
* `% edges with reason != unknown`
|
||||
* Count by `reason` and `confidence`
|
||||
* Log warnings when:
|
||||
|
||||
* Edge is emitted with `reason = unknown`.
|
||||
* Evidence is empty for a non‑unknown reason.
|
||||
|
||||
**Acceptance criteria:**
|
||||
|
||||
* [ ] Dashboards showing distribution of edge reasons over time.
|
||||
* [ ] Alerts if `unknown` reason edges exceed a threshold (e.g. >5%).
|
||||
|
||||
---
|
||||
|
||||
### 7.2 Rollout plan
|
||||
|
||||
**Owner:** PM + tech leads
|
||||
|
||||
**Steps:**
|
||||
|
||||
1. **Phase 1 – Dark‑launch metadata:**
|
||||
|
||||
* Start generating & storing `via` for new scans.
|
||||
* Keep UI unchanged.
|
||||
* Monitor metrics, unknown ratio, and storage overhead.
|
||||
|
||||
2. **Phase 2 – Enable for internal users:**
|
||||
|
||||
* Toggle UI on (feature flag for internal / beta users).
|
||||
* Collect feedback from security engineers and auditors.
|
||||
|
||||
3. **Phase 3 – General availability:**
|
||||
|
||||
* Enable UI for all.
|
||||
* Update customer‑facing documentation & audit guides.
|
||||
|
||||
---
|
||||
|
||||
### 7.3 Documentation
|
||||
|
||||
**Owner:** Docs / PM
|
||||
|
||||
* Short **“Why this edge exists”** section in:
|
||||
|
||||
* Product docs (for customers).
|
||||
* Internal runbooks (for support & SEs).
|
||||
* Include:
|
||||
|
||||
* Table of reasons → human descriptions.
|
||||
* Examples of path explanations (e.g., “This edge exists because `app` declares `urllib3` in `requirements.txt` and calls it in `client.py:42`”).
|
||||
|
||||
---
|
||||
|
||||
## 8. Ready‑to‑use ticket breakdown
|
||||
|
||||
You can almost copy‑paste these into your tracker:
|
||||
|
||||
1. **Shared**: Define EdgeReason, EdgeVia & EdgeProvenance in shared library, plus EdgeViaFactory.
|
||||
2. **SBOM**: Use EdgeFactory.DeclaredDependency for all manifest‑generated edges.
|
||||
3. **Source**: Wire all callgraph edges to SourceEdgeFactory (static_call, dynamic_import, reflection_call, plugin_discovery, taint_propagation).
|
||||
4. **Binary**: Wire relocations/PLT/GOT edges to BinaryEdgeFactory (symbol_relocation, plt_got_resolution, ld_preload_injection).
|
||||
5. **Data**: Add via_* columns/properties to graph_edges storage and map to/from domain.
|
||||
6. **API**: Extend graph path DTOs to include `via`, update OpenAPI, and implement /v2 endpoints if needed.
|
||||
7. **UI**: Show edge reason, evidence, and provenance in vulnerability path screens and add filters.
|
||||
8. **Testing**: Add unit, integration, and end‑to‑end tests ensuring every edge has non‑null `via`.
|
||||
9. **Observability**: Add metrics and logs for edge reasons and unknown rates.
|
||||
10. **Docs & rollout**: Write glossary + auditor docs and plan staged rollout.
|
||||
|
||||
---
|
||||
|
||||
If you tell me a bit about your current storage (e.g., Neo4j vs SQL) and the services’ names, I can tailor this into an even more literal set of code snippets and migrations to match your stack exactly.
|
||||
@@ -1,819 +0,0 @@
|
||||
Here’s a crisp, ready‑to‑ship concept you can drop into Stella Ops: an **Unknowns Registry** that captures ambiguous scanner artifacts (stripped binaries, unverifiable packages, orphaned PURLs, missing digests) and treats them as first‑class citizens with probabilistic severity and trust‑decay—so you stay transparent without blocking delivery.
|
||||
|
||||
### What this solves (in plain terms)
|
||||
|
||||
* **No silent drops:** every “can’t verify / can’t resolve” is tracked, not discarded.
|
||||
* **Quantified risk:** unknowns still roll into a portfolio‑level risk number with confidence intervals.
|
||||
* **Trust over time:** stale unknowns get *riskier* the longer they remain unresolved.
|
||||
* **Client confidence:** visibility + trajectory (are unknowns shrinking?) becomes a maturity signal.
|
||||
|
||||
### Core data model (CycloneDX/SPDX compatible, attaches to your SBOM spine)
|
||||
|
||||
```yaml
|
||||
UnknownArtifact:
|
||||
id: urn:stella:unknowns:<uuid>
|
||||
observedAt: <RFC3339>
|
||||
origin:
|
||||
source: scanner|ingest|runtime
|
||||
feed: <name/version>
|
||||
evidence: [ filePath, containerDigest, buildId, sectionHints ]
|
||||
identifiers:
|
||||
purl?: <string> # orphan/incomplete PURL allowed
|
||||
hash?: <sha256|null> # missing digest allowed
|
||||
cpe?: <string|null>
|
||||
classification:
|
||||
type: binary|library|package|script|config|other
|
||||
reason: stripped_binary|missing_signature|no_feed_match|ambiguous_name|checksum_mismatch|other
|
||||
metrics:
|
||||
baseUnkScore: 0..1
|
||||
confidence: 0..1 # model confidence in the *score*
|
||||
trust: 0..1 # provenance trust (sig/attest, feed quality)
|
||||
decayPolicyId: <ref>
|
||||
resolution:
|
||||
status: unresolved|suppressed|mitigated|confirmed-benign|confirmed-risk
|
||||
updatedAt: <RFC3339>
|
||||
notes: <text>
|
||||
links:
|
||||
scanId: <ref>
|
||||
componentId?: <ref to SBOM component if later mapped>
|
||||
attestations?: [ dsse, in-toto, rekorRef ]
|
||||
```
|
||||
|
||||
### Scoring (simple, explainable, deterministic)
|
||||
|
||||
* **Unknown Risk (UR):**
|
||||
`UR_t = clamp( (B * (1 + A)) * D_t * (1 - T) , 0, 1 )`
|
||||
|
||||
* `B` = `baseUnkScore` (heuristics: file entropy, section hints, ELF flags, import tables, size, location)
|
||||
* `A` = **Environment Amplifier** (runtime proximity: container entrypoint? PID namespace? network caps?)
|
||||
* `T` = **Trust** (sig/attest/registry reputation/feed pedigree normalized to 0..1)
|
||||
* `D_t` = **Trust‑decay multiplier** over time `t`:
|
||||
|
||||
* Linear: `D_t = 1 + k * daysOpen` (e.g., `k = 0.01`)
|
||||
* or Exponential: `D_t = e^(λ * daysOpen)` (e.g., `λ = 0.005`)
|
||||
* **Portfolio roll‑up:** use **P90 of UR_t** across images + **sum of top‑N UR_t** to avoid dilution.
|
||||
|
||||
### Policies & SLOs
|
||||
|
||||
* **SLO:** *Unknowns burn‑down* ≤ X% week‑over‑week; *Median age* ≤ Y days.
|
||||
* **Gates:** block promotion when (a) any `UR_t ≥ 0.8`, or (b) more than `M` unknowns with age > `Z` days.
|
||||
* **Suppressions:** require justification + expiry; suppression reduces `A` but does **not** zero `D_t`.
|
||||
|
||||
### Trust‑decay policies (pluggable)
|
||||
|
||||
```yaml
|
||||
DecayPolicy:
|
||||
id: decay:default:v1
|
||||
kind: linear|exponential|custom
|
||||
params:
|
||||
k: 0.01 # linear slope per day
|
||||
cap: 2.0 # max multiplier
|
||||
```
|
||||
|
||||
### Scanner hooks (where to emit Unknowns)
|
||||
|
||||
* **Binary scan:** stripped ELF/Mach‑O/PE; missing build‑ID; abnormal sections; impossible symbol map.
|
||||
* **Package map:** PURL inferred from path without registry proof; mismatched checksum; vendor fork detected.
|
||||
* **Attestation:** DSSE missing / invalid; Sigstore chain unverifiable; Rekor entry not found.
|
||||
* **Feeds:** component seen in runtime but absent from SBOM (or vice versa).
|
||||
|
||||
### Deterministic generation (for replay/audits)
|
||||
|
||||
* Include **Unknowns** in the **Scan Manifest** (your deterministic bundle): inputs, ruleset hash, feed hashes, lattice policy version, and the exact classifier thresholds that produced `B`, `A`, `T`. That lets you replay and reproduce UR_t byte‑for‑byte during audits.
|
||||
|
||||
### API surface (StellaOps.Authority)
|
||||
|
||||
```
|
||||
POST /unknowns/ingest # bulk ingest from Scanner/Vexer
|
||||
GET /unknowns?imageDigest=… # list + filters (status, age, UR buckets)
|
||||
PATCH /unknowns/{id}/resolve # set status, add evidence, set suppression (with expiry)
|
||||
GET /unknowns/stats # burn-downs, age histograms, P90 UR_t, top-N contributors
|
||||
```
|
||||
|
||||
### UI slices (Trust Algebra Studio)
|
||||
|
||||
* **Risk ribbon:** Unknowns count, P90 UR_t, median age, trend sparkline.
|
||||
* **Aging board:** columns by age buckets; cards show reason, UR_t, `T`, decay policy, evidence.
|
||||
* **What‑if slider:** adjust `k`/`λ` and see retroactive effect on release readiness (deterministic preview).
|
||||
* **Explainability panel:** show `B`, `A`, `T`, `D_t` factors with succinct evidence (e.g., “ELF stripped; no .symtab; no Sigstore; runtime hits PID 1 → A=0.2; trust=0.1; day 17 → D=1.17”).
|
||||
|
||||
### Heuristics for `baseUnkScore (B)` (portable across ELF/PE/Mach‑O)
|
||||
|
||||
* Section/segment anomalies; entropy outliers; import tables linking to risky APIs; executable heap/stack flags.
|
||||
* Location & role (PATH proximity to entrypoint, init scripts).
|
||||
* Size/type priors (tiny droppers vs fat libs).
|
||||
* Known‑unknown patterns (packer signatures, `UPX` traces without unpack attest).
|
||||
|
||||
### Governance & reporting
|
||||
|
||||
* **Weekly Unknowns Report:** totals, burn‑down, median age, “top unresolved origins” (by registry / base image), and “time‑to‑first‑evidence.”
|
||||
* **Vendor scorecards:** if a supplier causes recurring unknowns, reflect it in **Adaptive Trust Economics**.
|
||||
|
||||
### Minimal implementation slice (2 sprints)
|
||||
|
||||
1. **Sprint A (backend + ingest):** model + tables, ingest endpoint, deterministic manifest hook, basic scoring (linear decay), list/query API, roll‑up metrics.
|
||||
2. **Sprint B (UI + policy):** Unknowns board, what‑if slider, suppress/resolve workflow w/ expiry, weekly report, policy gates in CI.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can generate:
|
||||
|
||||
* the exact **PostgreSQL schema + indices** (including age/UR materialized views),
|
||||
* **.NET 10** DTOs, handlers, and a **deterministic scoring library** with unit tests,
|
||||
* a **Grafana/ClickHouse** dashboard spec for burn‑down and P90 tracking,
|
||||
* and a one‑page client‑facing explainer your sales team can use.
|
||||
Perfect, let’s turn the concept into a concrete, dev‑ready implementation plan.
|
||||
|
||||
I’ll assume:
|
||||
|
||||
* You already have:
|
||||
|
||||
* A scanner pipeline (binaries, SBOMs, attestations)
|
||||
* A backend service (StellaOps.Authority)
|
||||
* A UI (Trust Algebra Studio)
|
||||
* Observability (OpenTelemetry, ClickHouse/Presto)
|
||||
|
||||
You can adapt naming and tech stack as needed.
|
||||
|
||||
---
|
||||
|
||||
## 0. Scope & success criteria
|
||||
|
||||
**Goals**
|
||||
|
||||
1. Persist all “unknown-ish” scanner findings (stripped binaries, unverifiable PURLs, missing digests, etc.) as first‑class entities.
|
||||
2. Compute a deterministic **Unknown Risk (UR)** per artifact and roll it up per image/application.
|
||||
3. Apply **trust‑decay** over time and expose burn‑down metrics.
|
||||
4. Provide UI workflows to triage, suppress, and resolve unknowns.
|
||||
5. Enforce release gates based on unknown risk and age.
|
||||
|
||||
**Non‑goals (for v1)**
|
||||
|
||||
* No full ML; use deterministic heuristics + tunable weights.
|
||||
* No cross‑org multi‑tenant policy — single org/single policy set.
|
||||
* No per‑developer responsibility/assignment yet (can add later).
|
||||
|
||||
---
|
||||
|
||||
## 1. Architecture & components
|
||||
|
||||
### 1.1 New/updated components
|
||||
|
||||
1. **Unknowns Registry (backend submodule)**
|
||||
|
||||
* Lives in your existing backend (e.g., `StellaOps.Authority.Unknowns`).
|
||||
* Owns DB schema, scoring logic, and API.
|
||||
|
||||
2. **Scanner integration**
|
||||
|
||||
* Extend `StellaOps.Scanner` (and/or `Vexer`) to emit “unknown” findings into the registry via HTTP or message bus.
|
||||
|
||||
3. **UI: Unknowns in Trust Algebra Studio**
|
||||
|
||||
* New section/tab: “Unknowns” under each image/app.
|
||||
* Global “Unknowns board” for portfolio view.
|
||||
|
||||
4. **Analytics & jobs**
|
||||
|
||||
* Periodic job to recompute trust‑decay & UR.
|
||||
* Weekly report generator (e.g., pushing into ClickHouse, Slack, or email).
|
||||
|
||||
---
|
||||
|
||||
## 2. Data model (DB schema)
|
||||
|
||||
Use relational DB; here’s a concrete schema you can translate into migrations.
|
||||
|
||||
### 2.1 Tables
|
||||
|
||||
#### `unknown_artifacts`
|
||||
|
||||
Represents the current state of each unknown.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `created_at` (timestamp)
|
||||
* `updated_at` (timestamp)
|
||||
* `first_observed_at` (timestamp, NOT NULL)
|
||||
* `last_observed_at` (timestamp, NOT NULL)
|
||||
* `origin_source` (enum: `scanner`, `runtime`, `ingest`)
|
||||
* `origin_feed` (text) – e.g., `binary-scanner@1.4.3`
|
||||
* `origin_scan_id` (UUID / text) – foreign key to `scan_runs` if you have it
|
||||
* `image_digest` (text, indexed) – to tie to container/image
|
||||
* `component_id` (UUID, nullable) – SBOM component when later mapped
|
||||
* `file_path` (text, nullable)
|
||||
* `build_id` (text, nullable) – ELF/Mach-O/PE build ID if any
|
||||
* `purl` (text, nullable)
|
||||
* `hash_sha256` (text, nullable)
|
||||
* `cpe` (text, nullable)
|
||||
* `classification_type` (enum: `binary`, `library`, `package`, `script`, `config`, `other`)
|
||||
* `classification_reason` (enum:
|
||||
`stripped_binary`, `missing_signature`, `no_feed_match`,
|
||||
`ambiguous_name`, `checksum_mismatch`, `other`)
|
||||
* `status` (enum:
|
||||
`unresolved`, `suppressed`, `mitigated`, `confirmed_benign`, `confirmed_risk`)
|
||||
* `status_changed_at` (timestamp)
|
||||
* `status_changed_by` (text / user-id)
|
||||
* `notes` (text)
|
||||
* `decay_policy_id` (FK → `decay_policies`)
|
||||
* `base_unk_score` (double, 0..1)
|
||||
* `env_amplifier` (double, 0..1)
|
||||
* `trust` (double, 0..1)
|
||||
* `current_decay_multiplier` (double)
|
||||
* `current_ur` (double, 0..1) – Unknown Risk at last recompute
|
||||
* `current_confidence` (double, 0..1) – confidence in `current_ur`
|
||||
* `is_deleted` (bool) – soft delete
|
||||
|
||||
**Indexes**
|
||||
|
||||
* `idx_unknown_artifacts_image_digest_status`
|
||||
* `idx_unknown_artifacts_status_created_at`
|
||||
* `idx_unknown_artifacts_current_ur`
|
||||
* `idx_unknown_artifacts_last_observed_at`
|
||||
|
||||
#### `unknown_artifact_events`
|
||||
|
||||
Append-only event log for auditable changes.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `unknown_artifact_id` (FK → `unknown_artifacts`)
|
||||
* `created_at` (timestamp)
|
||||
* `actor` (text / user-id / system)
|
||||
* `event_type` (enum:
|
||||
`created`, `reobserved`, `status_changed`, `note_added`,
|
||||
`metrics_recomputed`, `linked_component`, `suppression_applied`, `suppression_expired`)
|
||||
* `payload` (JSONB) – diff or event‑specific details
|
||||
|
||||
Index: `idx_unknown_artifact_events_artifact_id_created_at`
|
||||
|
||||
#### `decay_policies`
|
||||
|
||||
Defines how trust‑decay works.
|
||||
|
||||
* `id` (text, PK) – e.g., `decay:default:v1`
|
||||
* `kind` (enum: `linear`, `exponential`)
|
||||
* `param_k` (double, nullable) – for linear: slope
|
||||
* `param_lambda` (double, nullable) – for exponential
|
||||
* `cap` (double, default 2.0)
|
||||
* `description` (text)
|
||||
* `is_default` (bool)
|
||||
|
||||
#### `unknown_suppressions`
|
||||
|
||||
Optional; can also reuse `unknown_artifacts.status` but separate table lets you have multiple suppressions over time.
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `unknown_artifact_id` (FK)
|
||||
* `created_at` (timestamp)
|
||||
* `created_by` (text)
|
||||
* `reason` (text)
|
||||
* `expires_at` (timestamp, nullable)
|
||||
* `active` (bool)
|
||||
|
||||
Index: `idx_unknown_suppressions_artifact_active_expires_at`
|
||||
|
||||
#### `unknown_image_rollups`
|
||||
|
||||
Precomputed rollups per image (for fast dashboards/gates).
|
||||
|
||||
* `id` (UUID, PK)
|
||||
* `image_digest` (text, indexed)
|
||||
* `computed_at` (timestamp)
|
||||
* `unknown_count_total` (int)
|
||||
* `unknown_count_unresolved` (int)
|
||||
* `unknown_count_high_ur` (int) – e.g., UR ≥ 0.8
|
||||
* `p50_ur` (double)
|
||||
* `p90_ur` (double)
|
||||
* `top_n_ur_sum` (double)
|
||||
* `median_age_days` (double)
|
||||
|
||||
---
|
||||
|
||||
## 3. Scoring engine implementation
|
||||
|
||||
Create a small, deterministic scoring library so the same code can be used in:
|
||||
|
||||
* Backend ingest path (for immediate UR)
|
||||
* Batch recompute job
|
||||
* “What‑if” UI simulations (optionally via stateless API)
|
||||
|
||||
### 3.1 Data types
|
||||
|
||||
Define a core model, e.g.:
|
||||
|
||||
```ts
|
||||
type UnknownMetricsInput = {
|
||||
baseUnkScore: number; // B
|
||||
envAmplifier: number; // A
|
||||
trust: number; // T
|
||||
daysOpen: number; // t
|
||||
decayPolicy: {
|
||||
kind: "linear" | "exponential";
|
||||
k?: number;
|
||||
lambda?: number;
|
||||
cap: number;
|
||||
};
|
||||
};
|
||||
|
||||
type UnknownMetricsOutput = {
|
||||
decayMultiplier: number; // D_t
|
||||
unknownRisk: number; // UR_t
|
||||
};
|
||||
```
|
||||
|
||||
### 3.2 Algorithm
|
||||
|
||||
```ts
|
||||
function computeDecayMultiplier(
|
||||
daysOpen: number,
|
||||
policy: DecayPolicy
|
||||
): number {
|
||||
if (policy.kind === "linear") {
|
||||
const raw = 1 + (policy.k ?? 0) * daysOpen;
|
||||
return Math.min(raw, policy.cap);
|
||||
}
|
||||
if (policy.kind === "exponential") {
|
||||
const lambda = policy.lambda ?? 0;
|
||||
const raw = Math.exp(lambda * daysOpen);
|
||||
return Math.min(raw, policy.cap);
|
||||
}
|
||||
return 1;
|
||||
}
|
||||
|
||||
function computeUnknownRisk(input: UnknownMetricsInput): UnknownMetricsOutput {
|
||||
const { baseUnkScore: B, envAmplifier: A, trust: T, daysOpen, decayPolicy } = input;
|
||||
|
||||
const D_t = computeDecayMultiplier(daysOpen, decayPolicy);
|
||||
const raw = (B * (1 + A)) * D_t * (1 - T);
|
||||
|
||||
const unknownRisk = Math.max(0, Math.min(raw, 1)); // clamp 0..1
|
||||
|
||||
return { decayMultiplier: D_t, unknownRisk };
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3 Heuristics for `B`, `A`, `T`
|
||||
|
||||
Implement these as pure functions with configuration‑driven weights:
|
||||
|
||||
* `B` (base unknown score):
|
||||
|
||||
* Start from prior: by `classification_type` (binary > library > config).
|
||||
* Adjust up for:
|
||||
|
||||
* Stripped binary (no symbols, high entropy)
|
||||
* Suspicious segments (executable stack/heap)
|
||||
* Known packer signatures (UPX, etc.)
|
||||
* Adjust down for:
|
||||
|
||||
* Large, well‑known dependency path (`/usr/lib/...`)
|
||||
* Known safe signatures (if partially known).
|
||||
|
||||
* `A` (environment amplifier):
|
||||
|
||||
* +0.2 if artifact is part of container entrypoint (PID 1).
|
||||
* +0.1 if file is in a PATH dir (e.g., `/usr/local/bin`).
|
||||
* +0.1 if the runtime has network capabilities/capabilities flags.
|
||||
* Cap at 0.5 for v1.
|
||||
|
||||
* `T` (trust):
|
||||
|
||||
* Start at 0.5.
|
||||
* +0.3 if registry/signature/attestation chain verified.
|
||||
* +0.1 if source registry is “trusted vendor list”.
|
||||
* −0.3 if checksum mismatch or feed conflict.
|
||||
* Clamp 0..1.
|
||||
|
||||
Store the raw factors (`B`, `A`, `T`) on the artifact for transparency and later replays.
|
||||
|
||||
---
|
||||
|
||||
## 4. Scanner integration
|
||||
|
||||
### 4.1 Emission format (from scanner → backend)
|
||||
|
||||
Define a minimal ingestion contract (JSON over HTTP or a message):
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"scanId": "urn:scan:1234",
|
||||
"imageDigest": "sha256:abc123...",
|
||||
"observedAt": "2025-11-27T12:34:56Z",
|
||||
"unknowns": [
|
||||
{
|
||||
"externalId": "scanner-unique-id-1",
|
||||
"originSource": "scanner",
|
||||
"originFeed": "binary-scanner@1.4.3",
|
||||
"filePath": "/usr/local/bin/stripped",
|
||||
"buildId": null,
|
||||
"purl": null,
|
||||
"hashSha256": "aa...",
|
||||
"cpe": null,
|
||||
"classificationType": "binary",
|
||||
"classificationReason": "stripped_binary",
|
||||
"rawSignals": {
|
||||
"entropy": 7.4,
|
||||
"hasSymbols": false,
|
||||
"isEntrypoint": true,
|
||||
"inPathDir": true
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The backend maps `rawSignals` → `B`, `A`, `T`.
|
||||
|
||||
### 4.2 Idempotency
|
||||
|
||||
* Define uniqueness key on `(image_digest, file_path, hash_sha256)` for v1.
|
||||
* On ingest:
|
||||
|
||||
* If an artifact exists:
|
||||
|
||||
* Update `last_observed_at`.
|
||||
* Recompute age (`now - first_observed_at`) and UR.
|
||||
* Add `reobserved` event.
|
||||
* If not:
|
||||
|
||||
* Insert new row with `first_observed_at = observedAt`.
|
||||
|
||||
### 4.3 HTTP endpoint
|
||||
|
||||
`POST /internal/unknowns/ingest`
|
||||
|
||||
* Auth: internal service token.
|
||||
* Returns per‑unknown mapping to internal `id` and computed UR.
|
||||
|
||||
Error handling:
|
||||
|
||||
* If invalid payload → 400 with list of errors.
|
||||
* Partial failure: process valid unknowns, return `failedUnknowns` array with reasons.
|
||||
|
||||
---
|
||||
|
||||
## 5. Backend API for UI & CI
|
||||
|
||||
### 5.1 List unknowns
|
||||
|
||||
`GET /unknowns`
|
||||
|
||||
Query params:
|
||||
|
||||
* `imageDigest` (optional)
|
||||
* `status` (optional multi: unresolved, suppressed, etc.)
|
||||
* `minUr`, `maxUr` (optional)
|
||||
* `maxAgeDays` (optional)
|
||||
* `page`, `pageSize`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"items": [
|
||||
{
|
||||
"id": "urn:stella:unknowns:uuid",
|
||||
"imageDigest": "sha256:...",
|
||||
"filePath": "/usr/local/bin/stripped",
|
||||
"classificationType": "binary",
|
||||
"classificationReason": "stripped_binary",
|
||||
"status": "unresolved",
|
||||
"firstObservedAt": "...",
|
||||
"lastObservedAt": "...",
|
||||
"ageDays": 17,
|
||||
"baseUnkScore": 0.7,
|
||||
"envAmplifier": 0.2,
|
||||
"trust": 0.1,
|
||||
"decayPolicyId": "decay:default:v1",
|
||||
"decayMultiplier": 1.17,
|
||||
"currentUr": 0.84,
|
||||
"currentConfidence": 0.8
|
||||
}
|
||||
],
|
||||
"total": 123
|
||||
}
|
||||
```
|
||||
|
||||
### 5.2 Get single unknown + event history
|
||||
|
||||
`GET /unknowns/{id}`
|
||||
|
||||
Include:
|
||||
|
||||
* The artifact.
|
||||
* Latest metrics.
|
||||
* Recent events (with pagination).
|
||||
|
||||
### 5.3 Update status / suppression
|
||||
|
||||
`PATCH /unknowns/{id}`
|
||||
|
||||
Body options:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"status": "suppressed",
|
||||
"notes": "Reviewed; internal diagnostics binary.",
|
||||
"suppression": {
|
||||
"expiresAt": "2025-12-31T00:00:00Z"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Backend:
|
||||
|
||||
* Validates transition (cannot un‑suppress to “unresolved” without event).
|
||||
* Writes to `unknown_suppressions`.
|
||||
* Writes `status_changed` + `suppression_applied` events.
|
||||
|
||||
### 5.4 Image rollups
|
||||
|
||||
`GET /images/{imageDigest}/unknowns/summary`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"imageDigest": "sha256:...",
|
||||
"computedAt": "...",
|
||||
"unknownCountTotal": 40,
|
||||
"unknownCountUnresolved": 30,
|
||||
"unknownCountHighUr": 4,
|
||||
"p50Ur": 0.35,
|
||||
"p90Ur": 0.82,
|
||||
"topNUrSum": 2.4,
|
||||
"medianAgeDays": 9
|
||||
}
|
||||
```
|
||||
|
||||
This is what CI and UI will mostly query.
|
||||
|
||||
---
|
||||
|
||||
## 6. Trust‑decay job & rollup computation
|
||||
|
||||
### 6.1 Periodic recompute job
|
||||
|
||||
Schedule (e.g., every hour):
|
||||
|
||||
1. Fetch `unknown_artifacts` where:
|
||||
|
||||
* `status IN ('unresolved', 'suppressed', 'mitigated')`
|
||||
* `last_observed_at >= now() - interval '90 days'` (tunable)
|
||||
2. Compute `daysOpen = now() - first_observed_at`.
|
||||
3. Compute `D_t` and `UR_t` with scoring library.
|
||||
4. Update `unknown_artifacts.current_ur`, `current_decay_multiplier`.
|
||||
5. Append `metrics_recomputed` event (batch size threshold, e.g., only when UR changed > 0.01).
|
||||
|
||||
### 6.2 Rollup job
|
||||
|
||||
Every X minutes:
|
||||
|
||||
1. For each `image_digest` with active unknowns:
|
||||
|
||||
* Compute:
|
||||
|
||||
* `unknown_count_total`
|
||||
* `unknown_count_unresolved` (`status = unresolved`)
|
||||
* `unknown_count_high_ur` (UR ≥ threshold)
|
||||
* `p50` / `p90` UR (use DB percentile or compute in app)
|
||||
* `top_n_ur_sum` (sum of top 5 UR)
|
||||
* `median_age_days`
|
||||
2. Upsert into `unknown_image_rollups`.
|
||||
|
||||
---
|
||||
|
||||
## 7. CI / promotion gating
|
||||
|
||||
Expose a simple policy evaluation API for CI and deploy pipelines.
|
||||
|
||||
### 7.1 Policy definition (config)
|
||||
|
||||
Example YAML:
|
||||
|
||||
```yaml
|
||||
unknownsPolicy:
|
||||
blockIf:
|
||||
- kind: "anyUrAboveThreshold"
|
||||
threshold: 0.8
|
||||
- kind: "countAboveAge"
|
||||
maxCount: 5
|
||||
ageDays: 14
|
||||
warnIf:
|
||||
- kind: "unknownCountAbove"
|
||||
maxCount: 50
|
||||
```
|
||||
|
||||
### 7.2 Policy evaluation endpoint
|
||||
|
||||
`GET /policy/unknowns/evaluate?imageDigest=sha256:...`
|
||||
|
||||
Response:
|
||||
|
||||
```jsonc
|
||||
{
|
||||
"imageDigest": "sha256:...",
|
||||
"result": "block", // "ok" | "warn" | "block"
|
||||
"reasons": [
|
||||
{
|
||||
"kind": "anyUrAboveThreshold",
|
||||
"detail": "1 unknown with UR>=0.8 (max allowed: 0)"
|
||||
}
|
||||
],
|
||||
"summary": {
|
||||
"unknownCountUnresolved": 30,
|
||||
"p90Ur": 0.82,
|
||||
"medianAgeDays": 17
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
CI can decide to fail build/deploy based on `result`.
|
||||
|
||||
---
|
||||
|
||||
## 8. UI implementation (Trust Algebra Studio)
|
||||
|
||||
### 8.1 Image detail page: “Unknowns” tab
|
||||
|
||||
Components:
|
||||
|
||||
1. **Header metrics ribbon**
|
||||
|
||||
* Unknowns unresolved, p90 UR, median age, weekly trend sparkline.
|
||||
* Fetch from `/images/{digest}/unknowns/summary`.
|
||||
|
||||
2. **Unknowns table**
|
||||
|
||||
* Columns:
|
||||
|
||||
* Status pill
|
||||
* UR (with color + tooltip showing `B`, `A`, `T`, `D_t`)
|
||||
* Classification type/reason
|
||||
* File path
|
||||
* Age
|
||||
* Last observed
|
||||
* Filters:
|
||||
|
||||
* Status, UR range, age range, reason, type.
|
||||
|
||||
3. **Row drawer / detail panel**
|
||||
|
||||
* Show:
|
||||
|
||||
* All core fields.
|
||||
* Evidence:
|
||||
|
||||
* origin (scanner, feed, runtime)
|
||||
* raw signals (entropy, sections, etc)
|
||||
* SBOM component link (if any)
|
||||
* Timeline (events list)
|
||||
* Actions:
|
||||
|
||||
* Change status (unresolved → suppressed/mitigated/confirmed).
|
||||
* Add note.
|
||||
* Set/extend suppression expiry.
|
||||
|
||||
### 8.2 Global “Unknowns board”
|
||||
|
||||
Goals:
|
||||
|
||||
* Portfolio view; triage across many images.
|
||||
|
||||
Features:
|
||||
|
||||
* Filters by:
|
||||
|
||||
* Team/application/service
|
||||
* Time range for first observed
|
||||
* UR bucket (0–0.3, 0.3–0.6, 0.6–1)
|
||||
* Cards/rows per image:
|
||||
|
||||
* Unknown counts, p90 UR, median age.
|
||||
* Trend of unknown count (last N weeks).
|
||||
* Click through to image‑detail tab.
|
||||
|
||||
### 8.3 “What‑if” slider (optional v1.1)
|
||||
|
||||
On an image or org-level:
|
||||
|
||||
* Slider(s) to visualize effect of:
|
||||
|
||||
* `k` / `lambda` change (decay speed).
|
||||
* Trust baseline changes (simulate better attestations).
|
||||
* Implement by calling a stateless endpoint:
|
||||
|
||||
* `POST /unknowns/what-if` with:
|
||||
|
||||
* Current unknowns list IDs
|
||||
* Proposed decay policy
|
||||
* Returns recalculated URs and hypothetical gate result (but does **not** persist).
|
||||
|
||||
---
|
||||
|
||||
## 9. Observability & analytics
|
||||
|
||||
### 9.1 Metrics
|
||||
|
||||
Emit structured events/metrics (OpenTelemetry, etc.):
|
||||
|
||||
* Counters:
|
||||
|
||||
* `unknowns_ingested_total` (labels: `source`, `classification_type`, `reason`)
|
||||
* `unknowns_resolved_total` (labels: `status`)
|
||||
* Gauges:
|
||||
|
||||
* `unknowns_unresolved_count` per image/service.
|
||||
* `unknowns_p90_ur` per image/service.
|
||||
* `unknowns_median_age_days`.
|
||||
|
||||
### 9.2 Weekly report generator
|
||||
|
||||
Batch job:
|
||||
|
||||
1. Compute, per org or team:
|
||||
|
||||
* Total unknowns.
|
||||
* New unknowns this week.
|
||||
* Resolved unknowns this week.
|
||||
* Median age.
|
||||
* Top 10 images by:
|
||||
|
||||
* Highest p90 UR.
|
||||
* Largest number of long‑lived unknowns (> X days).
|
||||
2. Persist into analytics store (ClickHouse) + push into:
|
||||
|
||||
* Slack channel / email with a short plain‑text summary and link to UI.
|
||||
|
||||
---
|
||||
|
||||
## 10. Security & compliance
|
||||
|
||||
* Ensure all APIs require authentication & proper scopes:
|
||||
|
||||
* Scanner ingest: internal service token only.
|
||||
* UI APIs: user identity + RBAC (e.g., team can only see their images).
|
||||
* Audit log:
|
||||
|
||||
* `unknown_artifact_events` must be immutable and queryable by compliance teams.
|
||||
* PII:
|
||||
|
||||
* Avoid storing user PII in notes; if necessary, apply redaction.
|
||||
|
||||
---
|
||||
|
||||
## 11. Suggested delivery plan (sprints/epics)
|
||||
|
||||
### Sprint 1 – Foundations & ingest path
|
||||
|
||||
* [ ] DB migrations: `unknown_artifacts`, `unknown_artifact_events`, `decay_policies`.
|
||||
* [ ] Implement scoring library (`B`, `A`, `T`, `UR_t`, `D_t`).
|
||||
* [ ] Implement `/internal/unknowns/ingest` endpoint with idempotency.
|
||||
* [ ] Extend scanner to emit unknowns and integrate with ingest.
|
||||
* [ ] Basic `GET /unknowns?imageDigest=...` API.
|
||||
* [ ] Seed `decay:default:v1` policy.
|
||||
|
||||
**Exit criteria:** Unknowns created and UR computed from real scans; queryable via API.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 2 – Decay, rollups, and CI hook
|
||||
|
||||
* [ ] Implement periodic job to recompute decay & UR.
|
||||
* [ ] Implement rollup job + `unknown_image_rollups` table.
|
||||
* [ ] Implement `GET /images/{digest}/unknowns/summary`.
|
||||
* [ ] Implement policy evaluation endpoint for CI.
|
||||
* [ ] Wire CI to block/warn based on policy.
|
||||
|
||||
**Exit criteria:** CI gate can fail a build due to high‑risk unknowns; rollups visible via API.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 3 – UI (Unknowns tab + board)
|
||||
|
||||
* [ ] Image detail “Unknowns” tab:
|
||||
|
||||
* Metrics ribbon, table, filters.
|
||||
* Row drawer with evidence & history.
|
||||
* [ ] Global “Unknowns board” page.
|
||||
* [ ] Integrate with APIs.
|
||||
* [ ] Add basic “explainability tooltip” for UR.
|
||||
|
||||
**Exit criteria:** Security team can triage unknowns via UI; product teams can see their exposure.
|
||||
|
||||
---
|
||||
|
||||
### Sprint 4 – Suppression workflow & reporting
|
||||
|
||||
* [ ] Implement `PATCH /unknowns/{id}` + suppression rules & expiries.
|
||||
* [ ] Extend periodic jobs to auto‑expire suppressions.
|
||||
* [ ] Weekly unknowns report job → analytics + Slack/email.
|
||||
* [ ] Add “trend” sparklines and unknowns burn‑down in UI.
|
||||
|
||||
**Exit criteria:** Unknowns can be suppressed with justification; org gets weekly burn‑down trends.
|
||||
|
||||
---
|
||||
|
||||
If you’d like, I can next:
|
||||
|
||||
* Turn this into concrete tickets (Jira-style) with story points and acceptance criteria, or
|
||||
* Generate example migration scripts (SQL) and API contract files (OpenAPI snippet) that your devs can copy‑paste.
|
||||
File diff suppressed because it is too large
Load Diff
Reference in New Issue
Block a user