save progress
This commit is contained in:
@@ -0,0 +1,395 @@
|
||||
# Reachability Drift Detection
|
||||
|
||||
**Date**: 2025-12-17
|
||||
**Status**: ANALYZED - Ready for Implementation Planning
|
||||
**Related Advisories**:
|
||||
- 14-Dec-2025 - Smart-Diff Technical Reference
|
||||
- 14-Dec-2025 - Reachability Analysis Technical Reference
|
||||
|
||||
---
|
||||
|
||||
## 1. EXECUTIVE SUMMARY
|
||||
|
||||
This advisory proposes extending StellaOps' Smart-Diff capabilities to detect **reachability drift** - changes in whether vulnerable code paths are reachable from application entry points between container image versions.
|
||||
|
||||
**Core Insight**: Raw diffs don't equal risk. Most changed lines don't matter for exploitability. Reachability drift detection fuses **call-stack reachability graphs** with **Smart-Diff metadata** to flag only paths that went from **unreachable to reachable** (or vice-versa), tied to **SBOM components** and **VEX statements**.
|
||||
|
||||
---
|
||||
|
||||
## 2. GAP ANALYSIS vs EXISTING INFRASTRUCTURE
|
||||
|
||||
### 2.1 What Already Exists (Leverage Points)
|
||||
|
||||
| Component | Location | Status |
|
||||
|-----------|----------|--------|
|
||||
| `MaterialRiskChangeDetector` | `Scanner.SmartDiff.Detection` | DONE - R1-R4 rules |
|
||||
| `VexCandidateEmitter` | `Scanner.SmartDiff.Detection` | DONE - Absent API detection |
|
||||
| `ReachabilityGateBridge` | `Scanner.SmartDiff.Detection` | DONE - Lattice to 3-bit |
|
||||
| `ReachabilitySignal` | `Signals.Contracts` | DONE - Call path model |
|
||||
| `ReachabilityLatticeState` | `Signals.Contracts.Evidence` | DONE - 5-state enum |
|
||||
| `CallPath`, `CallPathNode` | `Signals.Contracts.Evidence` | DONE - Path representation |
|
||||
| `ReachabilityEvidenceChain` | `Signals.Contracts.Evidence` | DONE - Proof chain |
|
||||
| `vex.graph_nodes/edges` | DB Schema | DONE - Graph storage |
|
||||
| `scanner.risk_state_snapshots` | DB Schema | DONE - State storage |
|
||||
| `scanner.material_risk_changes` | DB Schema | DONE - Change storage |
|
||||
| `FnDriftCalculator` | `Scanner.Core.Drift` | DONE - Classification drift |
|
||||
| `SarifOutputGenerator` | `Scanner.SmartDiff.Output` | DONE - CI output |
|
||||
| Reachability Benchmark | `bench/reachability-benchmark/` | DONE - Ground truth cases |
|
||||
| Language Analyzers | `Scanner.Analyzers.Lang.*` | PARTIAL - Package detection, limited call graph |
|
||||
|
||||
### 2.2 What's Missing (New Implementation Required)
|
||||
|
||||
| Component | Advisory Ref | Gap Description |
|
||||
|-----------|-------------|-----------------|
|
||||
| **Call Graph Extractor (.NET)** | §7 C# Roslyn | No MSBuildWorkspace/Roslyn analysis exists |
|
||||
| **Call Graph Extractor (Go)** | §7 Go SSA | No golang.org/x/tools/go/ssa integration |
|
||||
| **Call Graph Extractor (Java)** | §7 | No Soot/WALA integration |
|
||||
| **Call Graph Extractor (Node)** | §7 | No @babel/traverse integration |
|
||||
| **`scanner.code_changes` table** | §4 Smart-Diff | AST-level diff facts not persisted |
|
||||
| **Drift Cause Explainer** | §6 Timeline | No causal attribution on path nodes |
|
||||
| **Path Viewer UI** | §UX | No Angular component for call path visualization |
|
||||
| **Cross-scan Function-level Drift** | §6 | State drift exists, function-level doesn't |
|
||||
| **Entrypoint Discovery (per-framework)** | §3 | Limited beyond package.json/manifest parsing |
|
||||
|
||||
### 2.3 Terminology Mapping
|
||||
|
||||
| Advisory Term | StellaOps Equivalent | Notes |
|
||||
|--------------|---------------------|-------|
|
||||
| `commit_sha` | `scan_id` | StellaOps is image-centric, not commit-centric |
|
||||
| `call_node` | `vex.graph_nodes` | Existing schema, extend don't duplicate |
|
||||
| `call_edge` | `vex.graph_edges` | Existing schema |
|
||||
| `reachability_drift` | `scanner.material_risk_changes` | Add `cause`, `path_nodes` columns |
|
||||
| Risk Drift | Material Risk Change | Existing term is more precise |
|
||||
| Router, Signals | Signals module only | Router module is not implemented |
|
||||
|
||||
---
|
||||
|
||||
## 3. RECOMMENDED IMPLEMENTATION PATH
|
||||
|
||||
### 3.1 What to Ship (Delta from Current State)
|
||||
|
||||
```
|
||||
NEW TABLES:
|
||||
├── scanner.code_changes # AST-level diff facts
|
||||
└── scanner.call_graph_snapshots # Per-scan call graph cache
|
||||
|
||||
NEW COLUMNS:
|
||||
├── scanner.material_risk_changes.cause # TEXT - "guard_removed", "new_route", etc.
|
||||
├── scanner.material_risk_changes.path_nodes # JSONB - Compressed path representation
|
||||
└── scanner.material_risk_changes.base_scan_id # UUID - For cross-scan comparison
|
||||
|
||||
NEW SERVICES:
|
||||
├── CallGraphExtractor.DotNet # Roslyn-based for .NET projects
|
||||
├── CallGraphExtractor.Node # AST-based for Node.js
|
||||
├── DriftCauseExplainer # Attribute causes to code changes
|
||||
└── PathCompressor # Compress paths for storage/UI
|
||||
|
||||
NEW UI:
|
||||
└── PathViewerComponent # Angular component for call path visualization
|
||||
```
|
||||
|
||||
### 3.2 What NOT to Ship (Avoid Duplication)
|
||||
|
||||
- **Don't create `call_node`/`call_edge` tables** - Use existing `vex.graph_nodes`/`vex.graph_edges`
|
||||
- **Don't add `commit_sha` columns** - Use `scan_id` consistently
|
||||
- **Don't build React components** - Angular v17 is the stack
|
||||
|
||||
### 3.3 Use Valkey for Graph Caching
|
||||
|
||||
Valkey is already integrated in `Router.Gateway.RateLimit`. Use it for:
|
||||
- **Call graph snapshot caching** - Fast cross-instance lookups
|
||||
- **Reachability result caching** - Avoid recomputation
|
||||
- **Key pattern**: `stella:callgraph:{scan_id}:{lang}:{digest}`
|
||||
|
||||
```yaml
|
||||
# Configuration pattern (align with existing Router rate limiting)
|
||||
reachability:
|
||||
valkey_connection: "localhost:6379"
|
||||
valkey_bucket: "stella-reachability"
|
||||
cache_ttl_hours: 24
|
||||
circuit_breaker:
|
||||
failure_threshold: 5
|
||||
timeout_seconds: 30
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 4. TECHNICAL DESIGN
|
||||
|
||||
### 4.1 Call Graph Extraction Model
|
||||
|
||||
```csharp
|
||||
/// <summary>
|
||||
/// Per-scan call graph snapshot for drift comparison.
|
||||
/// </summary>
|
||||
public sealed record CallGraphSnapshot
|
||||
{
|
||||
public required string ScanId { get; init; }
|
||||
public required string GraphDigest { get; init; } // Content hash
|
||||
public required string Language { get; init; }
|
||||
public required DateTimeOffset ExtractedAt { get; init; }
|
||||
public required ImmutableArray<CallGraphNode> Nodes { get; init; }
|
||||
public required ImmutableArray<CallGraphEdge> Edges { get; init; }
|
||||
public required ImmutableArray<string> EntrypointIds { get; init; }
|
||||
}
|
||||
|
||||
public sealed record CallGraphNode
|
||||
{
|
||||
public required string NodeId { get; init; } // Stable identifier
|
||||
public required string Symbol { get; init; } // Fully qualified name
|
||||
public required string File { get; init; }
|
||||
public required int Line { get; init; }
|
||||
public required string Package { get; init; }
|
||||
public required string Visibility { get; init; } // public/internal/private
|
||||
public required bool IsEntrypoint { get; init; }
|
||||
public required bool IsSink { get; init; }
|
||||
public string? SinkCategory { get; init; } // CMD_EXEC, SQL_RAW, etc.
|
||||
}
|
||||
|
||||
public sealed record CallGraphEdge
|
||||
{
|
||||
public required string SourceId { get; init; }
|
||||
public required string TargetId { get; init; }
|
||||
public required string CallKind { get; init; } // direct/virtual/delegate
|
||||
}
|
||||
```
|
||||
|
||||
### 4.2 Code Change Facts Model
|
||||
|
||||
```csharp
|
||||
/// <summary>
|
||||
/// AST-level code change facts from Smart-Diff.
|
||||
/// </summary>
|
||||
public sealed record CodeChangeFact
|
||||
{
|
||||
public required string ScanId { get; init; }
|
||||
public required string File { get; init; }
|
||||
public required string Symbol { get; init; }
|
||||
public required CodeChangeKind Kind { get; init; }
|
||||
public required JsonDocument Details { get; init; }
|
||||
}
|
||||
|
||||
public enum CodeChangeKind
|
||||
{
|
||||
Added,
|
||||
Removed,
|
||||
SignatureChanged,
|
||||
GuardChanged, // Boolean condition around call modified
|
||||
DependencyChanged, // Callee package/version changed
|
||||
VisibilityChanged // public<->internal<->private
|
||||
}
|
||||
```
|
||||
|
||||
### 4.3 Drift Cause Attribution
|
||||
|
||||
```csharp
|
||||
/// <summary>
|
||||
/// Explains why a reachability flip occurred.
|
||||
/// </summary>
|
||||
public sealed class DriftCauseExplainer
|
||||
{
|
||||
public DriftCause Explain(
|
||||
CallGraphSnapshot baseGraph,
|
||||
CallGraphSnapshot headGraph,
|
||||
string sinkSymbol,
|
||||
IReadOnlyList<CodeChangeFact> codeChanges)
|
||||
{
|
||||
// Find shortest path to sink in head graph
|
||||
var path = ShortestPath(headGraph.EntrypointIds, sinkSymbol, headGraph);
|
||||
if (path is null)
|
||||
return DriftCause.Unknown;
|
||||
|
||||
// Check each node on path for code changes
|
||||
foreach (var nodeId in path.NodeIds)
|
||||
{
|
||||
var node = headGraph.Nodes.First(n => n.NodeId == nodeId);
|
||||
var change = codeChanges.FirstOrDefault(c => c.Symbol == node.Symbol);
|
||||
|
||||
if (change is not null)
|
||||
{
|
||||
return change.Kind switch
|
||||
{
|
||||
CodeChangeKind.GuardChanged => DriftCause.GuardRemoved(node.Symbol, node.File, node.Line),
|
||||
CodeChangeKind.Added => DriftCause.NewPublicRoute(node.Symbol),
|
||||
CodeChangeKind.VisibilityChanged => DriftCause.VisibilityEscalated(node.Symbol),
|
||||
CodeChangeKind.DependencyChanged => DriftCause.DepUpgraded(change.Details),
|
||||
_ => DriftCause.CodeModified(node.Symbol)
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
return DriftCause.Unknown;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 4.4 Database Schema Extensions
|
||||
|
||||
```sql
|
||||
-- New table: Code change facts from AST-level Smart-Diff
|
||||
CREATE TABLE scanner.code_changes (
|
||||
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
|
||||
tenant_id UUID NOT NULL,
|
||||
scan_id TEXT NOT NULL,
|
||||
file TEXT NOT NULL,
|
||||
symbol TEXT NOT NULL,
|
||||
change_kind TEXT NOT NULL, -- added|removed|signature|guard|dep|visibility
|
||||
details JSONB,
|
||||
detected_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
|
||||
CONSTRAINT code_changes_unique UNIQUE (tenant_id, scan_id, file, symbol)
|
||||
);
|
||||
|
||||
CREATE INDEX idx_code_changes_scan ON scanner.code_changes(scan_id);
|
||||
CREATE INDEX idx_code_changes_symbol ON scanner.code_changes(symbol);
|
||||
|
||||
-- New table: Per-scan call graph snapshots (compressed)
|
||||
CREATE TABLE scanner.call_graph_snapshots (
|
||||
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
|
||||
tenant_id UUID NOT NULL,
|
||||
scan_id TEXT NOT NULL,
|
||||
language TEXT NOT NULL,
|
||||
graph_digest TEXT NOT NULL, -- Content hash for dedup
|
||||
node_count INT NOT NULL,
|
||||
edge_count INT NOT NULL,
|
||||
entrypoint_count INT NOT NULL,
|
||||
extracted_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
|
||||
cas_uri TEXT NOT NULL, -- Reference to CAS for full graph
|
||||
|
||||
CONSTRAINT call_graph_snapshots_unique UNIQUE (tenant_id, scan_id, language)
|
||||
);
|
||||
|
||||
CREATE INDEX idx_call_graph_snapshots_digest ON scanner.call_graph_snapshots(graph_digest);
|
||||
|
||||
-- Extend existing material_risk_changes table
|
||||
ALTER TABLE scanner.material_risk_changes
|
||||
ADD COLUMN IF NOT EXISTS cause TEXT,
|
||||
ADD COLUMN IF NOT EXISTS path_nodes JSONB,
|
||||
ADD COLUMN IF NOT EXISTS base_scan_id TEXT;
|
||||
|
||||
CREATE INDEX IF NOT EXISTS idx_material_risk_changes_cause
|
||||
ON scanner.material_risk_changes(cause) WHERE cause IS NOT NULL;
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 5. UI DESIGN
|
||||
|
||||
### 5.1 Risk Drift Card (PR/Commit View)
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────────────────────────────────────┐
|
||||
│ RISK DRIFT ▼ │
|
||||
├─────────────────────────────────────────────────────────────────────┤
|
||||
│ +3 new reachable paths -2 mitigated paths │
|
||||
│ │
|
||||
│ ┌─ NEW REACHABLE ──────────────────────────────────────────────┐ │
|
||||
│ │ POST /payments → PaymentsController.Capture → ... → │ │
|
||||
│ │ crypto.Verify(legacy) │ │
|
||||
│ │ │ │
|
||||
│ │ [pkg:payments@1.8.2] [CVE-2024-1234] [EPSS 0.72] [VEX:affected]│ │
|
||||
│ │ │ │
|
||||
│ │ Cause: guard removed in AuthFilter.cs:42 │ │
|
||||
│ │ │ │
|
||||
│ │ [View Path] [Quarantine Route] [Pin Version] [Add Exception] │ │
|
||||
│ └───────────────────────────────────────────────────────────────┘ │
|
||||
│ │
|
||||
│ ┌─ MITIGATED ──────────────────────────────────────────────────┐ │
|
||||
│ │ GET /admin → AdminController.Execute → ... → cmd.Run │ │
|
||||
│ │ │ │
|
||||
│ │ [pkg:admin@2.0.0] [CVE-2024-5678] [VEX:not_affected] │ │
|
||||
│ │ │ │
|
||||
│ │ Reason: Vulnerable API removed in upgrade │ │
|
||||
│ └───────────────────────────────────────────────────────────────┘ │
|
||||
└─────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
### 5.2 Path Viewer Component
|
||||
|
||||
```
|
||||
┌─────────────────────────────────────────────────────────────────────┐
|
||||
│ CALL PATH: POST /payments → crypto.Verify(legacy) [Collapse] │
|
||||
├─────────────────────────────────────────────────────────────────────┤
|
||||
│ │
|
||||
│ ○ POST /payments [ENTRYPOINT] │
|
||||
│ │ PaymentsController.cs:45 │
|
||||
│ │ │
|
||||
│ ├──○ PaymentsController.Capture() │
|
||||
│ │ │ PaymentsController.cs:89 │
|
||||
│ │ │ │
|
||||
│ │ ├──○ PaymentService.ProcessPayment() │
|
||||
│ │ │ │ PaymentService.cs:156 │
|
||||
│ │ │ │ │
|
||||
│ │ │ ├──● CryptoHelper.Verify() ← GUARD REMOVED │
|
||||
│ │ │ │ │ CryptoHelper.cs:42 [Changed: AuthFilter removed] │
|
||||
│ │ │ │ │ │
|
||||
│ │ │ │ └──◆ crypto.Verify(legacy) [VULNERABLE SINK] │
|
||||
│ │ │ │ pkg:crypto@1.2.3 │
|
||||
│ │ │ │ CVE-2024-1234 (CVSS 9.8) │
|
||||
│ │
|
||||
│ Legend: ○ Node ● Changed ◆ Sink ─ Call │
|
||||
└─────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 6. POLICY INTEGRATION
|
||||
|
||||
### 6.1 CI Gate Behavior
|
||||
|
||||
```yaml
|
||||
# Policy wiring for drift detection
|
||||
smart_diff:
|
||||
gates:
|
||||
# Fail PR when new reachable paths to affected sinks
|
||||
- condition: "delta_reachable > 0 AND vex_status IN ['affected', 'under_investigation']"
|
||||
action: block
|
||||
message: "New reachable paths to vulnerable sinks detected"
|
||||
|
||||
# Warn when new paths to any sink
|
||||
- condition: "delta_reachable > 0"
|
||||
action: warn
|
||||
message: "New reachable paths detected - review recommended"
|
||||
|
||||
# Auto-mitigate when VEX confirms not_affected
|
||||
- condition: "vex_status == 'not_affected' AND vex_justification IN ['component_not_present', 'fix_applied']"
|
||||
action: allow
|
||||
auto_mitigate: true
|
||||
```
|
||||
|
||||
### 6.2 Exit Codes
|
||||
|
||||
| Code | Meaning |
|
||||
|------|---------|
|
||||
| 0 | Success, no material drift |
|
||||
| 1 | Success, material drift found (info) |
|
||||
| 2 | Success, hardening regression detected |
|
||||
| 3 | Success, new KEV reachable |
|
||||
| 10+ | Errors |
|
||||
|
||||
---
|
||||
|
||||
## 7. SPRINT STRUCTURE
|
||||
|
||||
### 7.1 Master Sprint: SPRINT_3600_0001_0001
|
||||
|
||||
**Topic**: Reachability Drift Detection
|
||||
**Dependencies**: SPRINT_3500 (Smart-Diff) - COMPLETE
|
||||
|
||||
### 7.2 Sub-Sprints
|
||||
|
||||
| ID | Topic | Priority | Effort | Dependencies |
|
||||
|----|-------|----------|--------|--------------|
|
||||
| SPRINT_3600_0002_0001 | Call Graph Infrastructure | P0 | Large | Master |
|
||||
| SPRINT_3600_0003_0001 | Drift Detection Engine | P0 | Medium | 3600.2 |
|
||||
| SPRINT_3600_0004_0001 | UI and Evidence Chain | P1 | Medium | 3600.3 |
|
||||
|
||||
---
|
||||
|
||||
## 8. REFERENCES
|
||||
|
||||
- `docs/product-advisories/14-Dec-2025 - Smart-Diff Technical Reference.md`
|
||||
- `docs/product-advisories/14-Dec-2025 - Reachability Analysis Technical Reference.md`
|
||||
- `docs/implplan/SPRINT_3500_0001_0001_smart_diff_master.md`
|
||||
- `docs/reachability/lattice.md`
|
||||
- `bench/reachability-benchmark/README.md`
|
||||
@@ -0,0 +1,751 @@
|
||||
Here’s a practical, first‑time‑friendly blueprint for making your security workflow both **explainable** and **provable**—from triage to approval.
|
||||
|
||||
# Explainable triage UX (what & why)
|
||||
|
||||
Show every risk score with the minimum evidence a responder needs to trust it:
|
||||
|
||||
* **Reachable path:** the concrete call‑chain (or network path) proving the vuln is actually hit.
|
||||
* **Entrypoint boundary:** the external surface (HTTP route, CLI verb, cron, message topic) that leads to that path.
|
||||
* **VEX status:** the exploitability decision (Affected/Not Affected/Under Investigation/Fixed) with rationale.
|
||||
* **Last‑seen timestamp:** when this evidence was last observed/generated.
|
||||
|
||||
## UI pattern (compact, 1‑click expand)
|
||||
|
||||
* **Row (collapsed):** `Score 72 • CVE‑2024‑12345 • service: api-gateway • package: x.y.z`
|
||||
* **Expand panel (evidence):**
|
||||
|
||||
* **Path:** `POST /billing/charge → BillingController.Pay() → StripeClient.Create()`
|
||||
* **Boundary:** `Ingress: /billing/charge (JWT: required, scope: payments:write)`
|
||||
* **VEX:** `Not Affected (runtime guard strips untrusted input before sink)`
|
||||
* **Last seen:** `2025‑12‑18T09:22Z` (scan: sbomer#c1a2, policy run: lattice#9f0d)
|
||||
* **Actions:** “Open proof bundle”, “Re-run check”, “Create exception (time‑boxed)”
|
||||
|
||||
## Data contract (what the panel needs)
|
||||
|
||||
```json
|
||||
{
|
||||
"finding_id": "f-7b3c",
|
||||
"cve": "CVE-2024-12345",
|
||||
"component": {"name": "stripe-sdk", "version": "6.1.2"},
|
||||
"reachable_path": [
|
||||
"HTTP POST /billing/charge",
|
||||
"BillingController.Pay",
|
||||
"StripeClient.Create"
|
||||
],
|
||||
"entrypoint": {"type":"http","route":"/billing/charge","auth":"jwt:payments:write"},
|
||||
"vex": {"status":"not_affected","justification":"runtime_sanitizer_blocks_sink","timestamp":"2025-12-18T09:22:00Z"},
|
||||
"last_seen":"2025-12-18T09:22:00Z",
|
||||
"attestation_refs": ["sha256:…sbom", "sha256:…vex", "sha256:…policy"]
|
||||
}
|
||||
```
|
||||
|
||||
# Evidence‑linked approvals (what & why)
|
||||
|
||||
Make “Approve to ship” contingent on **verifiable proof**, not screenshots:
|
||||
|
||||
* **Chain** must exist and be machine‑verifiable: **SBOM → VEX → policy decision**.
|
||||
* Use **in‑toto/DSSE** attestations or **SLSA provenance** so each link has a signature, subject digest, and predicate.
|
||||
* **Gate** merges/deploys only when the chain validates.
|
||||
|
||||
## Pipeline gate (simple policy)
|
||||
|
||||
* Require:
|
||||
|
||||
1. **SBOM attestation** referencing the exact image digest
|
||||
2. **VEX attestation** covering all listed components (or explicit allow‑gaps)
|
||||
3. **Policy decision attestation** (e.g., “risk ≤ threshold AND all reachable vulns = Not Affected/Fixed”)
|
||||
|
||||
### Minimal decision attestation (DSSE envelope → JSON payload)
|
||||
|
||||
```json
|
||||
{
|
||||
"predicateType": "stella/policy-decision@v1",
|
||||
"subject": [{"name":"registry/org/app","digest":{"sha256":"<image-digest>"}}],
|
||||
"predicate": {
|
||||
"policy": "risk_threshold<=75 && reachable_vulns.all(v => v.vex in ['not_affected','fixed'])",
|
||||
"inputs": {
|
||||
"sbom_ref": "sha256:<sbom>",
|
||||
"vex_ref": "sha256:<vex>"
|
||||
},
|
||||
"result": {"allowed": true, "score": 61, "exemptions":[]},
|
||||
"evidence_refs": ["sha256:<reachability-proof-bundle>"],
|
||||
"run_at": "2025-12-18T09:23:11Z"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
# How this lands in your product (concrete moves)
|
||||
|
||||
* **Backend:** add `/findings/:id/evidence` (returns the contract above) + `/approvals/:artifact/attestations`.
|
||||
* **Storage:** keep **proof bundles** (graphs, call stacks, logs) as content‑addressed blobs; store DSSE envelopes alongside.
|
||||
* **UI:** one list → expandable rows; chips for VEX status; “Open proof” shows the call graph and boundary in 1 view.
|
||||
* **CLI/API:** `stella verify image:<digest> --require sbom,vex,decision` returns a signed summary; pipelines fail on non‑zero.
|
||||
* **Metrics:**
|
||||
|
||||
* **% changes with complete attestations** (target ≥95%)
|
||||
* **TTFE (time‑to‑first‑evidence)** from alert → panel open (target ≤30s)
|
||||
* **Post‑deploy reversions** due to missing proof (trend to zero)
|
||||
|
||||
# Starter acceptance checklist
|
||||
|
||||
* [ ] Every risk row expands to path, boundary, VEX, last‑seen in <300 ms.
|
||||
* [ ] “Approve” button disabled until SBOM+VEX+Decision attestations validate for the **exact artifact digest**.
|
||||
* [ ] One‑click “Show DSSE chain” renders the three envelopes with subject digests and signers.
|
||||
* [ ] Audit log captures who approved, which digests, and which evidence hashes.
|
||||
|
||||
If you want, I can turn this into ready‑to‑drop **.NET 10** endpoints + a small React panel with mocked data so your team can wire it up fast.
|
||||
Below is a “build‑it” guide for Stella Ops that goes past the concept level: concrete services, schemas, pipelines, signing/storage choices, UI components, and the exact invariants you should enforce so triage is **explainable** and approvals are **provably evidence‑linked**.
|
||||
|
||||
---
|
||||
|
||||
## 1) Start with the invariants (the rules your system must never violate)
|
||||
|
||||
If you implement nothing else, implement these invariants—they’re what make the UX trustworthy and the approvals auditable.
|
||||
|
||||
### Artifact anchoring invariant
|
||||
|
||||
Every finding, every piece of evidence, and every approval must be anchored to an immutable **subject digest** (e.g., container image digest `sha256:…`, binary SHA, or SBOM digest).
|
||||
|
||||
* No “latest tag” approvals.
|
||||
* No “approve commit” without mapping to the built artifact digest.
|
||||
|
||||
### Evidence closure invariant
|
||||
|
||||
A policy decision is only valid if it references **exactly** the evidence it used:
|
||||
|
||||
* `inputs.sbom_ref`
|
||||
* `inputs.vex_ref`
|
||||
* `inputs.reachability_ref` (optional but recommended)
|
||||
* `inputs.scan_ref` (optional)
|
||||
* and any config/IaC refs used for boundary/exposure.
|
||||
|
||||
### Signature chain invariant
|
||||
|
||||
Evidence is only admissible if it is:
|
||||
|
||||
1. structured (machine readable),
|
||||
2. signed (DSSE/in‑toto),
|
||||
3. verifiable (trusted identity/keys),
|
||||
4. retrievable by digest.
|
||||
|
||||
DSSE is specifically designed to authenticate both the message and its type (payload type) and avoid canonicalization pitfalls. ([GitHub][1])
|
||||
|
||||
### Staleness invariant
|
||||
|
||||
Evidence must have:
|
||||
|
||||
* `last_seen` and `expires_at` (or TTL),
|
||||
* a “stale evidence” behavior in policy (deny or degrade score).
|
||||
|
||||
---
|
||||
|
||||
## 2) Choose the canonical formats and where you’ll store “proof”
|
||||
|
||||
### Attestation envelope: DSSE + in‑toto Statement
|
||||
|
||||
Use:
|
||||
|
||||
* **in‑toto Attestation Framework** “Statement” as the payload model (“subject + predicateType + predicate”). ([GitHub][2])
|
||||
* Wrap it in **DSSE** for signing. ([GitHub][1])
|
||||
* If you use Sigstore bundles, the DSSE envelope is expected to carry an in‑toto statement and uses `payloadType` like `application/vnd.in-toto+json`. ([Sigstore][3])
|
||||
|
||||
### SBOM format: CycloneDX or SPDX
|
||||
|
||||
* SPDX is an ISO/IEC standard and has v3.0 and v2.3 lines in the ecosystem. ([spdx.dev][4])
|
||||
* CycloneDX is an ECMA standard (ECMA‑424) and widely used for application security contexts. ([GitHub][5])
|
||||
|
||||
Pick one as **your canonical** (internally), but ingest both.
|
||||
|
||||
### VEX format: OpenVEX (practical) + map to “classic” VEX statuses
|
||||
|
||||
VEX’s value is triage noise reduction: vendors can assert whether a product is affected, fixed, under investigation, or not affected. ([NTIA][6])
|
||||
OpenVEX is a minimal, embeddable implementation of VEX intended for interoperability. ([GitHub][7])
|
||||
|
||||
### Where to store proof: OCI registry referrers
|
||||
|
||||
Use OCI “subject/referrers” so proofs travel with the artifact:
|
||||
|
||||
* OCI 1.1 introduces an explicit `subject` field and referrers graph for signatures/attestations/SBOMs. ([opencontainers.org][8])
|
||||
* ORAS documentation explains linking artifacts via `subject`. ([Oras][9])
|
||||
* Microsoft docs show `oras attach … --artifact-type …` patterns (works across registries that support referrers). ([Microsoft Learn][10])
|
||||
|
||||
---
|
||||
|
||||
## 3) System architecture (services + data flow)
|
||||
|
||||
### Services (minimum set)
|
||||
|
||||
1. **Ingestor**
|
||||
|
||||
* Pulls scanner outputs (SCA/SAST/IaC), SBOM, runtime signals.
|
||||
2. **Evidence Builder**
|
||||
|
||||
* Computes reachability, entrypoints, boundary/auth context, score explanation.
|
||||
3. **Attestation Service**
|
||||
|
||||
* Creates in‑toto statements, wraps DSSE, signs (cosign/KMS), stores to registry.
|
||||
4. **Policy Engine**
|
||||
|
||||
* Evaluates allow/deny + reason codes, emits signed decision attestation.
|
||||
* Use OPA/Rego for maintainable declarative policies. ([openpolicyagent.org][11])
|
||||
5. **Stella Ops API**
|
||||
|
||||
* Serves findings + evidence panels to the UI (fast, cached).
|
||||
6. **UI**
|
||||
|
||||
* Explainable triage panel + chain viewer + approve button.
|
||||
|
||||
### Event flow (artifact‑centric)
|
||||
|
||||
1. Build produces `image@sha256:X`
|
||||
2. Generate SBOM → sign + attach
|
||||
3. Run vuln scan → sign + attach (optional but useful)
|
||||
4. Evidence Builder creates:
|
||||
|
||||
* reachability proof
|
||||
* boundary proof
|
||||
* vex doc (or imports vendor VEX + adds your context)
|
||||
5. Policy engine evaluates → emits “decision attestation”
|
||||
6. UI shows explainable triage + “approve” gating
|
||||
|
||||
---
|
||||
|
||||
## 4) Data model (the exact objects you need)
|
||||
|
||||
### Core IDs you should standardize
|
||||
|
||||
* `subject_digest`: `sha256:<image digest>`
|
||||
* `subject_name`: `registry/org/app`
|
||||
* `finding_key`: `(subject_digest, detector, cve, component_purl, location)` stable hash
|
||||
* `component_purl`: package URL (PURL) canonical component identifier
|
||||
|
||||
### Tables (Postgres suggested)
|
||||
|
||||
**artifacts**
|
||||
|
||||
* `id (uuid)`
|
||||
* `name`
|
||||
* `digest` (unique)
|
||||
* `created_at`
|
||||
|
||||
**findings**
|
||||
|
||||
* `id (uuid)`
|
||||
* `artifact_digest`
|
||||
* `cve`
|
||||
* `component_purl`
|
||||
* `severity`
|
||||
* `raw_score`
|
||||
* `risk_score`
|
||||
* `status` (open/triaged/accepted/fixed)
|
||||
* `first_seen`, `last_seen`
|
||||
|
||||
**evidence**
|
||||
|
||||
* `id (uuid)`
|
||||
* `finding_id`
|
||||
* `kind` (reachable_path | boundary | score_explain | vex | ...)
|
||||
* `payload_json` (jsonb, small)
|
||||
* `blob_ref` (content-addressed URI for big payloads)
|
||||
* `last_seen`
|
||||
* `expires_at`
|
||||
* `confidence` (0–1)
|
||||
* `source_attestation_digest` (nullable)
|
||||
|
||||
**attestations**
|
||||
|
||||
* `id (uuid)`
|
||||
* `artifact_digest`
|
||||
* `predicate_type`
|
||||
* `attestation_digest` (sha256 of DSSE envelope)
|
||||
* `signer_identity` (OIDC subject / cert identity)
|
||||
* `issued_at`
|
||||
* `registry_ref` (where attached)
|
||||
|
||||
**approvals**
|
||||
|
||||
* `id (uuid)`
|
||||
* `artifact_digest`
|
||||
* `decision_attestation_digest`
|
||||
* `approver`
|
||||
* `approved_at`
|
||||
* `expires_at`
|
||||
* `reason`
|
||||
|
||||
---
|
||||
|
||||
## 5) Explainable triage: how to compute the “Path + Boundary + VEX + Last‑seen”
|
||||
|
||||
### 5.1 Reachable path proof (call chain / flow)
|
||||
|
||||
You need a uniform reachability result type:
|
||||
|
||||
* `reachable = true` with an explicit path
|
||||
* `reachable = false` with justification (e.g., symbol absent, dead code)
|
||||
* `reachable = unknown` with reason (insufficient symbols, dynamic dispatch)
|
||||
|
||||
**Implementation strategy**
|
||||
|
||||
1. **Symbol mapping**: map CVE → vulnerable symbols/functions/classes
|
||||
|
||||
* Use one or more:
|
||||
|
||||
* vendor advisory → patched functions
|
||||
* diff mining (commit that fixes CVE) to extract changed symbols
|
||||
* curated mapping in your DB for high volume CVEs
|
||||
2. **Program graph extraction** at build time:
|
||||
|
||||
* Produce a call graph or dependency graph per language.
|
||||
* Store as compact adjacency list (or protobuf) keyed by `subject_digest`.
|
||||
3. **Entrypoint discovery**:
|
||||
|
||||
* HTTP routes (framework metadata)
|
||||
* gRPC service methods
|
||||
* queue/stream consumers
|
||||
* cron/CLI handlers
|
||||
4. **Path search**:
|
||||
|
||||
* BFS/DFS from entrypoints to vulnerable symbols.
|
||||
* Record the shortest path + top‑K alternatives.
|
||||
5. **Proof bundle**:
|
||||
|
||||
* path nodes with stable IDs
|
||||
* file hashes + line ranges (no raw source required)
|
||||
* tool version + config hash
|
||||
* graph digest
|
||||
|
||||
**Reachability evidence JSON (UI‑friendly)**
|
||||
|
||||
```json
|
||||
{
|
||||
"kind": "reachable_path",
|
||||
"result": "reachable",
|
||||
"confidence": 0.86,
|
||||
"entrypoints": [
|
||||
{"type":"http","route":"POST /billing/charge","auth":"jwt:payments:write"}
|
||||
],
|
||||
"paths": [{
|
||||
"path_id": "p-1",
|
||||
"steps": [
|
||||
{"node":"BillingController.Pay","file_hash":"sha256:aaa","lines":[41,88]},
|
||||
{"node":"StripeClient.Create","file_hash":"sha256:bbb","lines":[10,52]},
|
||||
{"node":"stripe-sdk.vulnFn","symbol":"stripe-sdk::parseWebhook","evidence":"symbol-match"}
|
||||
]
|
||||
}],
|
||||
"graph": {"digest":"sha256:callgraph...", "format":"stella-callgraph-v1"},
|
||||
"last_seen": "2025-12-18T09:22:00Z",
|
||||
"expires_at": "2025-12-25T09:22:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
**UI rule:** never show “reachable” without a concrete, replayable path ID.
|
||||
|
||||
---
|
||||
|
||||
### 5.2 Boundary proof (the “why this is exposed” part)
|
||||
|
||||
Boundary proof answers: “Even if reachable, who can trigger it?”
|
||||
|
||||
**Data sources**
|
||||
|
||||
* Kubernetes ingress/service (exposure)
|
||||
* API gateway routes and auth policies
|
||||
* service mesh auth (mTLS, JWT)
|
||||
* IAM policies (for cloud events)
|
||||
* network policies (deny/allow)
|
||||
|
||||
**Boundary evidence schema**
|
||||
|
||||
```json
|
||||
{
|
||||
"kind": "boundary",
|
||||
"surface": {"type":"http","route":"POST /billing/charge"},
|
||||
"exposure": {"internet": true, "ports":[443]},
|
||||
"auth": {
|
||||
"mechanism":"jwt",
|
||||
"required_scopes":["payments:write"],
|
||||
"audience":"billing-api"
|
||||
},
|
||||
"rate_limits": {"enabled": true, "rps": 20},
|
||||
"controls": [
|
||||
{"type":"waf","status":"enabled"},
|
||||
{"type":"input_validation","status":"enabled","location":"BillingController.Pay"}
|
||||
],
|
||||
"last_seen": "2025-12-18T09:22:00Z",
|
||||
"confidence": 0.74
|
||||
}
|
||||
```
|
||||
|
||||
**How to build it**
|
||||
|
||||
* Create a “Surface Extractor” plugin per environment:
|
||||
|
||||
* `k8s-extractor`: reads ingress + service + annotations
|
||||
* `gateway-extractor`: reads API gateway config
|
||||
* `iac-extractor`: parses Terraform/CloudFormation
|
||||
* Normalize into the schema above.
|
||||
|
||||
---
|
||||
|
||||
### 5.3 VEX in Stella: statuses + justifications
|
||||
|
||||
VEX statuses you should support in UI:
|
||||
|
||||
* Not affected
|
||||
* Affected
|
||||
* Fixed
|
||||
* Under investigation ([NTIA][6])
|
||||
|
||||
OpenVEX will carry the machine readable structure. ([GitHub][7])
|
||||
|
||||
**Practical approach**
|
||||
|
||||
* Treat VEX as **the decision record** for exploitability.
|
||||
* Your policy can require VEX coverage for all “reachable” high severity vulns.
|
||||
|
||||
**Rule of thumb**
|
||||
|
||||
* If `reachable=true` AND boundary shows reachable surface + auth weak → VEX defaults to `affected` until mitigations proven.
|
||||
* If `reachable=false` with high confidence and stable proof → VEX may be `not_affected`.
|
||||
|
||||
---
|
||||
|
||||
### 5.4 Explainable risk score (don’t hide the formula)
|
||||
|
||||
Make score explainability first‑class.
|
||||
|
||||
**Recommended implementation**
|
||||
|
||||
* Store risk score as an additive model:
|
||||
|
||||
* `base = CVSS normalized`
|
||||
* `+ reachability_bonus`
|
||||
* `+ exposure_bonus`
|
||||
* `+ privilege_bonus`
|
||||
* `- mitigation_discount`
|
||||
* Emit a `score_explain` evidence object:
|
||||
|
||||
```json
|
||||
{
|
||||
"kind": "score_explain",
|
||||
"risk_score": 72,
|
||||
"contributions": [
|
||||
{"factor":"cvss","value":41,"reason":"CVSS 9.8"},
|
||||
{"factor":"reachability","value":18,"reason":"reachable path p-1"},
|
||||
{"factor":"exposure","value":10,"reason":"internet-facing route"},
|
||||
{"factor":"auth","value":3,"reason":"scope required lowers impact"}
|
||||
],
|
||||
"last_seen":"2025-12-18T09:22:00Z"
|
||||
}
|
||||
```
|
||||
|
||||
**UI rule:** “Score 72” must always be clickable to a stable breakdown.
|
||||
|
||||
---
|
||||
|
||||
## 6) The UI you should build (components + interaction rules)
|
||||
|
||||
### 6.1 Findings list row (collapsed)
|
||||
|
||||
Show only what helps scanning:
|
||||
|
||||
* Score badge
|
||||
* CVE + component
|
||||
* service
|
||||
* reachability chip: Reachable / Not reachable / Unknown
|
||||
* VEX chip
|
||||
* last_seen indicator (green/yellow/red)
|
||||
|
||||
### 6.2 Evidence drawer (expanded)
|
||||
|
||||
Tabs:
|
||||
|
||||
1. **Path**
|
||||
|
||||
* show entrypoint(s)
|
||||
* render call chain (simple list first; graph view optional)
|
||||
2. **Boundary**
|
||||
|
||||
* exposure, auth, controls
|
||||
3. **VEX**
|
||||
|
||||
* status + justification + issuer identity
|
||||
4. **Score**
|
||||
|
||||
* breakdown bar/list
|
||||
5. **Proof**
|
||||
|
||||
* attestation chain viewer (SBOM → VEX → Decision)
|
||||
* “Verify locally” action
|
||||
|
||||
### 6.3 “Open proof bundle” viewer
|
||||
|
||||
Must display:
|
||||
|
||||
* subject digest
|
||||
* signer identity
|
||||
* predicate type
|
||||
* digest of proof bundle
|
||||
* last_seen + tool versions
|
||||
|
||||
**This is where trust is built:** responders can see that the evidence is signed, tied to the artifact, and recent.
|
||||
|
||||
---
|
||||
|
||||
## 7) Proof‑linked evidence: how to generate and attach attestations
|
||||
|
||||
### 7.1 Statement format: in‑toto Attestation Framework
|
||||
|
||||
in‑toto’s model is:
|
||||
|
||||
* **Subjects** (the artifact digests)
|
||||
* **Predicate type** (schema ID)
|
||||
* **Predicate** (your actual data) ([GitHub][2])
|
||||
|
||||
### 7.2 DSSE envelope
|
||||
|
||||
Wrap statements using DSSE so payload type is signed too. ([GitHub][1])
|
||||
|
||||
### 7.3 Attach to OCI image via referrers
|
||||
|
||||
OCI “subject/referrers” makes attestations discoverable from the image digest. ([opencontainers.org][8])
|
||||
ORAS provides the operational model (“attach artifacts to an image”). ([Microsoft Learn][10])
|
||||
|
||||
### 7.4 Practical signing: cosign attest + verify
|
||||
|
||||
Cosign has built‑in in‑toto attestation support and can sign custom predicates. ([Sigstore][12])
|
||||
|
||||
Typical patterns (example only; adapt to your environment):
|
||||
|
||||
```bash
|
||||
# Attach an attestation
|
||||
cosign attest --predicate reachability.json \
|
||||
--type stella/reachability/v1 \
|
||||
<image@sha256:digest>
|
||||
|
||||
# Verify attestation
|
||||
cosign verify-attestation --type stella/reachability/v1 \
|
||||
<image@sha256:digest>
|
||||
```
|
||||
|
||||
(Use keyless OIDC or KMS keys depending on your org.)
|
||||
|
||||
---
|
||||
|
||||
## 8) Define your predicate types (this is the “contract” Stella enforces)
|
||||
|
||||
You’ll want at least these predicate types:
|
||||
|
||||
1. `stella/sbom@v1`
|
||||
|
||||
* embeds CycloneDX/SPDX (or references blob digest)
|
||||
|
||||
2. `stella/vex@v1`
|
||||
|
||||
* embeds OpenVEX document or references it ([GitHub][7])
|
||||
|
||||
3. `stella/reachability@v1`
|
||||
|
||||
* the reachability evidence above
|
||||
* includes `graph.digest`, `paths`, `confidence`, `expires_at`
|
||||
|
||||
4. `stella/boundary@v1`
|
||||
|
||||
* exposure/auth proof and `last_seen`
|
||||
|
||||
5. `stella/policy-decision@v1`
|
||||
|
||||
* the gating result, references all input attestation digests
|
||||
|
||||
6. Optional: `stella/human-approval@v1`
|
||||
|
||||
* “I approve deploy of subject digest X based on decision attestation Y”
|
||||
* keep it time‑boxed
|
||||
|
||||
---
|
||||
|
||||
## 9) The policy gate (how approvals become proof‑linked)
|
||||
|
||||
### 9.1 Use OPA/Rego for the gate
|
||||
|
||||
OPA policies are written in Rego. ([openpolicyagent.org][11])
|
||||
|
||||
**Gate input** should be a single JSON document assembled from verified attestations:
|
||||
|
||||
```json
|
||||
{
|
||||
"subject": {"name":"registry/org/app","digest":"sha256:..."},
|
||||
"sbom": {...},
|
||||
"vex": {...},
|
||||
"reachability": {...},
|
||||
"boundary": {...},
|
||||
"org_policy": {"max_risk": 75, "max_age_hours": 168}
|
||||
}
|
||||
```
|
||||
|
||||
**Example Rego (deny‑by‑default)**
|
||||
|
||||
```rego
|
||||
package stella.gate
|
||||
|
||||
default allow := false
|
||||
|
||||
# deny if evidence is stale
|
||||
stale_evidence {
|
||||
now := time.now_ns()
|
||||
exp := time.parse_rfc3339_ns(input.reachability.expires_at)
|
||||
now > exp
|
||||
}
|
||||
|
||||
# deny if any high severity reachable vuln is not resolved by VEX
|
||||
unresolved_reachable[v] {
|
||||
v := input.reachability.findings[_]
|
||||
v.severity in {"critical","high"}
|
||||
v.reachable == true
|
||||
not input.vex.resolution[v.cve] in {"not_affected","fixed"}
|
||||
}
|
||||
|
||||
allow {
|
||||
input.risk_score <= input.org_policy.max_risk
|
||||
not stale_evidence
|
||||
count(unresolved_reachable) == 0
|
||||
}
|
||||
```
|
||||
|
||||
### 9.2 Emit a signed policy decision attestation
|
||||
|
||||
When OPA returns `allow=true`, emit **another attestation**:
|
||||
|
||||
* predicate includes the policy version/hash and all input refs.
|
||||
* that’s what the UI “Approve” button targets.
|
||||
|
||||
This is the “evidence‑linked approval”: approval references the signed decision, and the decision references the signed evidence.
|
||||
|
||||
---
|
||||
|
||||
## 10) “Approve” button behavior (what Stella Ops should enforce)
|
||||
|
||||
### Disabled until…
|
||||
|
||||
* subject digest known
|
||||
* SBOM attestation found + signature verified
|
||||
* VEX attestation found + signature verified
|
||||
* Decision attestation found + signature verified
|
||||
* Decision’s `inputs` digests match the actual retrieved evidence
|
||||
|
||||
### When clicked…
|
||||
|
||||
1. Stella Ops creates a `stella/human-approval@v1` statement:
|
||||
|
||||
* `subject` = artifact digest
|
||||
* `predicate.decision_ref` = decision attestation digest
|
||||
* `predicate.expires_at` = short TTL (e.g., 7–30 days)
|
||||
2. Signs it with the approver identity
|
||||
3. Attaches it to the artifact (OCI referrer)
|
||||
|
||||
### Audit view must show
|
||||
|
||||
* approver identity
|
||||
* exact artifact digest
|
||||
* exact decision attestation digest
|
||||
* timestamp and expiry
|
||||
|
||||
---
|
||||
|
||||
## 11) Implementation details that matter in production
|
||||
|
||||
### 11.1 Verification library (shared by UI backend + CI gate)
|
||||
|
||||
Write one verifier module used everywhere:
|
||||
|
||||
**Inputs**
|
||||
|
||||
* image digest
|
||||
* expected predicate types
|
||||
* trust policy (allowed identities/issuers, keyless rules, KMS keys)
|
||||
|
||||
**Steps**
|
||||
|
||||
1. Discover referrers for `image@sha256:…`
|
||||
2. Filter by `predicateType`
|
||||
3. Verify DSSE + signature + identity
|
||||
4. Validate JSON schema for predicate
|
||||
5. Check `subject.digest` matches image digest
|
||||
6. Return “verified evidence set” + “errors”
|
||||
|
||||
### 11.2 Evidence privacy
|
||||
|
||||
Reachability proofs can leak implementation details.
|
||||
|
||||
* Store file hashes, symbol names, and line ranges
|
||||
* Gate raw source behind elevated permissions
|
||||
* Provide redacted proofs by default
|
||||
|
||||
### 11.3 Evidence TTL strategy
|
||||
|
||||
* SBOM: long TTL (weeks/months) if digest immutable
|
||||
* Boundary: short TTL (hours/days) because env changes
|
||||
* Reachability: medium TTL (days/weeks) depending on code churn
|
||||
* VEX: must be renewed if boundary/reachability changes
|
||||
|
||||
### 11.4 Handling “Unknown reachability”
|
||||
|
||||
Don’t force false certainty.
|
||||
|
||||
* Mark as `unknown` and show why (missing symbols, dynamic reflection, stripped binaries)
|
||||
* Policy can treat unknown as “reachable” for critical CVEs in internet‑facing services.
|
||||
|
||||
---
|
||||
|
||||
## 12) A concrete MVP path that still delivers value
|
||||
|
||||
If you want a minimal but real first release:
|
||||
|
||||
### MVP (2–3 deliverables)
|
||||
|
||||
1. **Evidence drawer** fed by:
|
||||
|
||||
* scanner output + SBOM + a simple “entrypoint map”
|
||||
2. **VEX workflow**
|
||||
|
||||
* allow engineers to set VEX status + justification
|
||||
3. **Signed decision gating**
|
||||
|
||||
* even if reachability is heuristic, the chain is real
|
||||
|
||||
Then iterate:
|
||||
|
||||
* add reachability graphs
|
||||
* add boundary extraction from IaC/K8s
|
||||
* tighten policy (staleness, confidence thresholds)
|
||||
|
||||
---
|
||||
|
||||
## 13) Quick checklist for “done enough to trust”
|
||||
|
||||
* [ ] Every finding expands to: Path, Boundary, VEX, Score, Proof
|
||||
* [ ] Every evidence tab shows `last_seen` + confidence
|
||||
* [ ] “Verify chain” works: SBOM → VEX → Decision all signed and bound to the artifact digest
|
||||
* [ ] Approve button signs a human approval attestation tied to the decision digest
|
||||
* [ ] CI gate verifies the same chain before deploy
|
||||
|
||||
---
|
||||
|
||||
If you want, I can also drop in:
|
||||
|
||||
* a full set of JSON Schemas for `stella/*@v1` predicates,
|
||||
* a reference verifier implementation outline in .NET 10 (Minimal API + a verifier class),
|
||||
* and a sample UI component tree (React) that renders path/boundary graphs and attestation chains.
|
||||
|
||||
[1]: https://github.com/secure-systems-lab/dsse?utm_source=chatgpt.com "DSSE: Dead Simple Signing Envelope"
|
||||
[2]: https://github.com/in-toto/attestation?utm_source=chatgpt.com "in-toto Attestation Framework"
|
||||
[3]: https://docs.sigstore.dev/about/bundle/?utm_source=chatgpt.com "Sigstore Bundle Format"
|
||||
[4]: https://spdx.dev/use/specifications/?utm_source=chatgpt.com "Specifications"
|
||||
[5]: https://github.com/CycloneDX/specification?utm_source=chatgpt.com "CycloneDX/specification"
|
||||
[6]: https://www.ntia.gov/sites/default/files/publications/vex_one-page_summary_0.pdf "VEX one-page summary"
|
||||
[7]: https://github.com/openvex/spec?utm_source=chatgpt.com "OpenVEX Specification"
|
||||
[8]: https://opencontainers.org/posts/blog/2024-03-13-image-and-distribution-1-1/?utm_source=chatgpt.com "OCI Image and Distribution Specs v1.1 Releases"
|
||||
[9]: https://oras.land/docs/concepts/reftypes/?utm_source=chatgpt.com "Attached Artifacts | OCI Registry As Storage"
|
||||
[10]: https://learn.microsoft.com/en-us/azure/container-registry/container-registry-manage-artifact?utm_source=chatgpt.com "Manage OCI Artifacts and Supply Chain Artifacts with ORAS"
|
||||
[11]: https://openpolicyagent.org/docs/policy-language?utm_source=chatgpt.com "Policy Language"
|
||||
[12]: https://docs.sigstore.dev/cosign/verifying/attestation/?utm_source=chatgpt.com "In-Toto Attestations"
|
||||
@@ -0,0 +1,259 @@
|
||||
I’m sharing this because the state of modern vulnerability prioritization and supply‑chain risk tooling is rapidly shifting toward *context‑aware, evidence‑driven insights* — not just raw lists of CVEs.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Here’s what’s shaping the field:
|
||||
|
||||
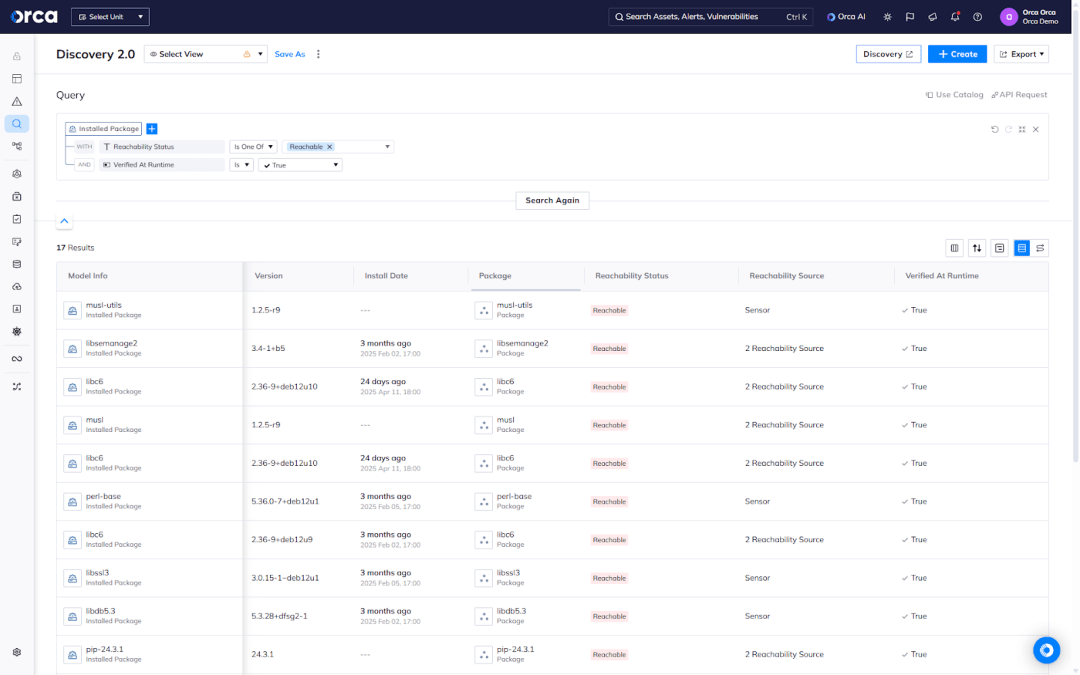
**• Reachability‑first triage is about ordering fixes by *actual call‑graph evidence*** — tools like Snyk analyze your code’s call graph to determine whether a vulnerable function is *actually reachable* from your application’s execution paths. Vulnerabilities with evidence of reachability are tagged (e.g., **REACHABLE**) so teams can focus on real exploit risk first, rather than just severity in a vacuum. This significantly reduces noise and alert fatigue by filtering out issues that can’t be invoked in context. ([Snyk User Docs][1])
|
||||
|
||||
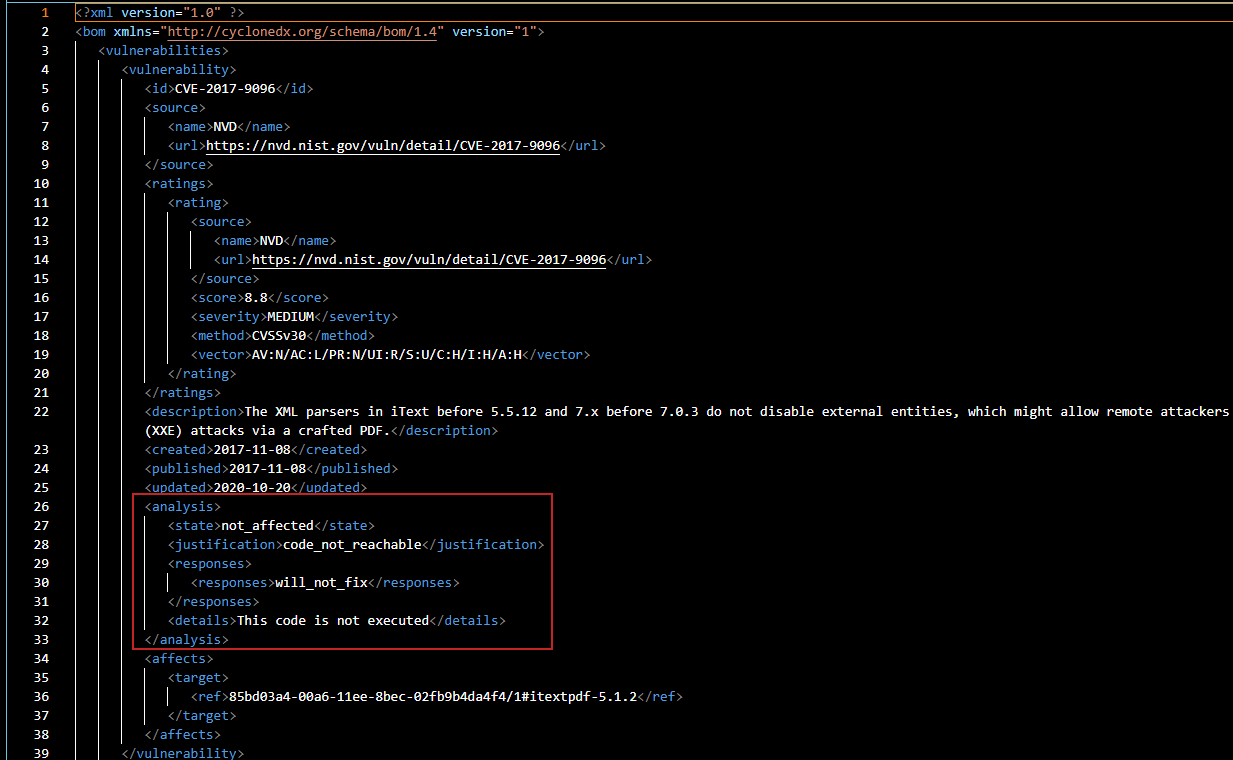
**• Inline VEX status with provenance turns static findings into contextual decisions.** *Vulnerability Exploitability eXchange (VEX)* is a structured way to annotate each finding with its *exploitability status* — like “not applicable,” “mitigated,” or “under investigation” — and attach that directly to SBOM/VEX records. Anchore Enterprise, for example, supports embedding these annotations and exporting them in both OpenVEX and CycloneDX VEX formats so downstream consumers see not just “there’s a CVE” but *what it means for your specific build or deployment*. ([Anchore][2])
|
||||
|
||||
**• OCI‑linked evidence chips (VEX attestations) bind context to images at the registry level.** Tools like Trivy can discover VEX attestations stored in OCI registries using flags like `--vex oci`. That lets scanners incorporate *pre‑existing attestations* into their vulnerability results — essentially layering registry‑attached statements about exploitability right into your scan output. ([Trivy][3])
|
||||
|
||||
Taken together, these trends illustrate a shift from *volume* (lists of vulnerabilities) to *value* (actionable, context‑specific risk insight) — especially if you’re building or evaluating risk tooling that needs to integrate call‑graph evidence, structured exploitability labels, and registry‑sourced attestations for high‑fidelity prioritization.
|
||||
|
||||
[1]: https://docs.snyk.io/manage-risk/prioritize-issues-for-fixing/reachability-analysis?utm_source=chatgpt.com "Reachability analysis"
|
||||
[2]: https://anchore.com/blog/anchore-enterprise-5-23-cyclonedx-vex-and-vdr-support/?utm_source=chatgpt.com "Anchore Enterprise 5.23: CycloneDX VEX and VDR Support"
|
||||
[3]: https://trivy.dev/docs/latest/supply-chain/vex/oci/?utm_source=chatgpt.com "Discover VEX Attestation in OCI Registry"
|
||||
Below are UX patterns that are “worth it” specifically for a VEX-first, evidence-driven scanner like Stella Ops. I’m not repeating generic “nice UI” ideas; these are interaction models that materially reduce triage time, raise trust, and turn your moats (determinism, proofs, lattice merge) into something users can feel.
|
||||
|
||||
## 1) Make “Claim → Evidence → Verdict” the core mental model
|
||||
|
||||
Every finding is a **Claim** (e.g., “CVE-X affects package Y in image Z”), backed by **Evidence** (SBOM match, symbol match, reachable path, runtime hit, vendor VEX, etc.), merged by **Semantics** (your lattice rules), producing a **Verdict** (policy outcome + signed attestation).
|
||||
|
||||
**UX consequence:** every screen should answer:
|
||||
|
||||
* What is being claimed?
|
||||
* What evidence supports it?
|
||||
* Which rule turned it into “block / allow / warn”?
|
||||
* Can I replay it identically?
|
||||
|
||||
## 2) “Risk Inbox” that behaves like an operator queue, not a report
|
||||
|
||||
Borrow the best idea from SOC tooling: a queue you can clear.
|
||||
|
||||
**List row structure (high impact):**
|
||||
|
||||
* Left: *Policy outcome* (BLOCK / WARN / PASS) as the primary indicator (not CVSS).
|
||||
* Middle: *Evidence chips* (REACHABLE, RUNTIME-SEEN, VEX-NOT-AFFECTED, ATTESTED, DIFF-NEW, etc.).
|
||||
* Right: *Blast radius* (how many artifacts/envs/services), plus “time since introduced”.
|
||||
|
||||
**Must-have filters:**
|
||||
|
||||
* “New since last release”
|
||||
* “Reachable only”
|
||||
* “Unknowns only”
|
||||
* “Policy blockers in prod”
|
||||
* “Conflicts (VEX merge disagreement)”
|
||||
* “No provenance (unsigned evidence)”
|
||||
|
||||
## 3) Delta-first everywhere (default view is “what changed”)
|
||||
|
||||
Users rarely want the full world; they want the delta relative to the last trusted point.
|
||||
|
||||
**Borrowed pattern:** PR diff mindset.
|
||||
|
||||
* Default to **Diff Lens**: “introduced / fixed / changed reachability / changed policy / changed EPSS / changed source trust”.
|
||||
* Every detail page has a “Before / After” toggle for: SBOM subgraph, reachability subgraph, VEX claims, policy trace.
|
||||
|
||||
This is one of the biggest “time saved per pixel” UX decisions you can make.
|
||||
|
||||
## 4) Evidence chips that are not decorative: click-to-proof
|
||||
|
||||
Chips should be actionable and open the exact proof.
|
||||
|
||||
Examples:
|
||||
|
||||
* **REACHABLE** → opens reachability subgraph viewer with the exact path(s) highlighted.
|
||||
* **ATTESTED** → opens DSSE/in-toto attestation viewer + signature verification status.
|
||||
* **VEX: NOT AFFECTED** → opens VEX statement with provenance + merge outcome.
|
||||
* **BINARY-MATCH** → opens mapping evidence (Build-ID / symbol / file hash) and confidence.
|
||||
|
||||
Rule: every chip either opens proof, or it doesn’t exist.
|
||||
|
||||
## 5) “Verdict Ladder” on every finding
|
||||
|
||||
A vertical ladder that shows the transformation from raw detection to final decision:
|
||||
|
||||
1. Detection source(s)
|
||||
2. Component identification (SBOM / installed / binary mapping)
|
||||
3. Applicability (platform, config flags, feature gates)
|
||||
4. Reachability (static path evidence)
|
||||
5. Runtime confirmation (if available)
|
||||
6. VEX merge & trust weighting
|
||||
7. Policy trace → final verdict
|
||||
8. Signed attestation reference (digest)
|
||||
|
||||
This turns your product from “scanner UI” into “auditor-grade reasoning UI”.
|
||||
|
||||
## 6) Reachability Explorer that is intentionally constrained
|
||||
|
||||
Reachability visualizations usually fail because they’re too generic.
|
||||
|
||||
Do this instead:
|
||||
|
||||
* Show **one shortest path** by default (operator mode).
|
||||
* Offer “show all paths” only on demand (expert mode).
|
||||
* Provide a **human-readable path narration** (“HTTP handler X → service Y → library Z → vulnerable function”) plus the reproducible anchors (file:line or symbol+offset).
|
||||
* Store and render the **subgraph evidence**, not a screenshot.
|
||||
|
||||
## 7) A “Policy Trace” panel that reads like a flight recorder
|
||||
|
||||
Borrow from OPA/rego trace concepts: show which rules fired, which evidence satisfied conditions, and where unknowns influenced outcome.
|
||||
|
||||
**UX element:** “Why blocked?” and “What would make it pass?”
|
||||
|
||||
* “Blocked because: reachable AND exploited AND no mitigation claim AND env=prod”
|
||||
* “Would pass if: VEX mitigated with evidence OR reachability unknown budget allows OR patch applied”
|
||||
|
||||
This directly enables your “risk budgets + diff-aware release gates”.
|
||||
|
||||
## 8) Unknowns are first-class, budgeted, and visual
|
||||
|
||||
Most tools hide unknowns. You want the opposite.
|
||||
|
||||
**Unknowns dashboard:**
|
||||
|
||||
* Unknown count by environment + trend.
|
||||
* Unknown categories (unmapped binaries, missing SBOM edges, unsigned VEX, stale feeds).
|
||||
* Policy thresholds (e.g., “fail if unknowns > N in prod”) with clear violation explanation.
|
||||
|
||||
**Micro-interaction:** unknowns should have a “convert to known” CTA (attach evidence, add mapping rule, import attestation, upgrade feed bundle).
|
||||
|
||||
## 9) VEX Conflict Studio: side-by-side merge with provenance
|
||||
|
||||
When two statements disagree, don’t just pick one. Show the conflict.
|
||||
|
||||
**Conflict card:**
|
||||
|
||||
* Left: Vendor VEX statement + signature/provenance
|
||||
* Right: Distro/internal statement + signature/provenance
|
||||
* Middle: lattice merge result + rule that decided it
|
||||
* Bottom: “Required evidence hook” checklist (feature flag off, config, runtime proof, etc.)
|
||||
|
||||
This makes your “Trust Algebra / Lattice Engine” tangible.
|
||||
|
||||
## 10) Exceptions as auditable objects (with TTL) integrated into triage
|
||||
|
||||
Exception UX should feel like creating a compliance-grade artifact, not clicking “ignore”.
|
||||
|
||||
**Exception form UX:**
|
||||
|
||||
* Scope selector: artifact digest(s), package range, env(s), time window
|
||||
* Required: rationale + evidence attachments
|
||||
* Optional: compensating controls (WAF, network isolation)
|
||||
* Auto-generated: signed exception attestation + audit pack link
|
||||
* Review workflow: “owner”, “approver”, “expires”, “renewal requires fresh evidence”
|
||||
|
||||
## 11) One-click “Audit Pack” export from any screen
|
||||
|
||||
Auditors don’t want screenshots; they want structured evidence.
|
||||
|
||||
From a finding/release:
|
||||
|
||||
* Included: SBOM (exact), VEX set (exact), merge rules version, policy version, reachability subgraph, signatures, feed snapshot hashes, delta verdict
|
||||
* Everything referenced by digest and replay manifest
|
||||
|
||||
UX: a single button “Generate Audit Pack”, plus “Replay locally” instructions.
|
||||
|
||||
## 12) Attestation Viewer that non-cryptographers can use
|
||||
|
||||
Most attestation UIs are unreadable. Make it layered:
|
||||
|
||||
* “Verified / Unverified” summary
|
||||
* Key identity, algorithm, timestamp
|
||||
* What was attested (subject digest, predicate type)
|
||||
* Links: “open raw DSSE JSON”, “copy digest”, “compare to current”
|
||||
|
||||
If you do crypto-sovereign modes (GOST/SM/eIDAS/FIPS), show algorithm badges and validation source.
|
||||
|
||||
## 13) Proof-of-Integrity Graph as a drill-down, not a science project
|
||||
|
||||
Graph UI should answer one question: “Can I trust this artifact lineage?”
|
||||
|
||||
Provide:
|
||||
|
||||
* A minimal lineage chain by default: Source → Build → SBOM → VEX → Scan Verdict → Deploy
|
||||
* Expand nodes on click (don’t render the whole universe)
|
||||
* Confidence meter derived from signed links and trusted issuers
|
||||
|
||||
## 14) “Remedy Plan” that is evidence-aware, not generic advice
|
||||
|
||||
Fix guidance must reflect reachability and delta:
|
||||
|
||||
* If reachable: prioritize patch/upgrade, show “patch removes reachable path” expectation
|
||||
* If not reachable: propose mitigation or deferred SLA with justification
|
||||
* Show “impact of upgrade” (packages touched, images affected, services impacted)
|
||||
* Output as a signed remediation recommendation (optional) to align with your “signed, replayable risk verdicts”
|
||||
|
||||
## 15) Fleet view as a “blast radius map”
|
||||
|
||||
Instead of listing images, show impact.
|
||||
|
||||
For any CVE or component:
|
||||
|
||||
* “Affected in prod: 3 services, 9 images”
|
||||
* “Reachable in: service A only”
|
||||
* “Blocked by policy in: env X”
|
||||
* “Deployed where: cluster/zone topology”
|
||||
|
||||
This is where your topology-aware model becomes a real UX advantage.
|
||||
|
||||
## 16) Quiet-by-design notifications with explainable suppression
|
||||
|
||||
Noise reduction must be visible and justifiable.
|
||||
|
||||
* “Suppressed because: not reachable + no exploit + already covered by exception”
|
||||
* “Unsuppressed because: delta introduced + reachable”
|
||||
* Configurable digests: daily/weekly “risk delta summary” per environment
|
||||
|
||||
## 17) “Replay” button everywhere (determinism as UX)
|
||||
|
||||
If determinism is a moat, expose it in the UI.
|
||||
|
||||
Every verdict includes:
|
||||
|
||||
* Inputs hash set (feeds, policies, rules, artifact digests)
|
||||
* “Replay this verdict” action producing the same output
|
||||
* “Compare replay to current” diff
|
||||
|
||||
This alone will differentiate Stella Ops from most scanners, because it changes trust dynamics.
|
||||
|
||||
## 18) Two modes: Operator Mode and Auditor Mode
|
||||
|
||||
Same data, different defaults:
|
||||
|
||||
* Operator: minimal, fastest path to action (shortest reachability path, top blockers, bulk triage)
|
||||
* Auditor: complete provenance, signatures, manifests, policy traces, export tools
|
||||
|
||||
A toggle at the top avoids building two products.
|
||||
|
||||
## 19) Small but lethal interaction details
|
||||
|
||||
These are easy wins that compound:
|
||||
|
||||
* Copyable digests everywhere (one-click)
|
||||
* “Pin evidence” to attach specific proof artifacts to tickets/exceptions
|
||||
* “Open in context” links (jump from vulnerability → impacted services → release gate)
|
||||
* Bulk actions that preserve proof (bulk mark “accepted vendor VEX” still produces an attested batch action record)
|
||||
|
||||
## 20) Default screen: “Release Gate Summary” (not “Vulns”)
|
||||
|
||||
For real-world teams, the primary question is: “Can I ship this release?”
|
||||
|
||||
A release summary card:
|
||||
|
||||
* Delta verdict (new blockers, fixed blockers, unknowns delta)
|
||||
* Risk budget consumption
|
||||
* Required actions + owners
|
||||
* Signed gate decision output
|
||||
|
||||
This ties scanner UX directly to deployment reality.
|
||||
|
||||
If you want, I can turn these into a concrete navigation map (pages, routes, primary components) plus a UI contract for each object (Claim, Evidence, Verdict, Snapshot, Exception, Audit Pack) so your agents can implement it consistently across web + API.
|
||||
@@ -0,0 +1,124 @@
|
||||
Here’s a practical, from‑scratch blueprint for a **two‑stage reachability map** that turns low‑level runtime facts into auditable, reproducible evidence for triage and VEX decisions.
|
||||
|
||||
---
|
||||
|
||||
# What this is (plain English)
|
||||
|
||||
* **Goal:** prove (or rule out) whether a vulnerable function/package could actually run in *your* build and deployment.
|
||||
* **How:**
|
||||
|
||||
1. extract **binary‑level call targets** (what functions your program *could* call),
|
||||
2. map those targets onto **symbol graphs** (named functions/classes/modules),
|
||||
3. correlate those symbols with **SBOM components** (which package/image layer they live in),
|
||||
4. store each “slice” of reachability as a **signed attestation** so anyone can replay and verify it.
|
||||
|
||||
---
|
||||
|
||||
# Stage A — Binary → Symbol graph
|
||||
|
||||
* **Inputs:** built artifacts (ELF/COFF/Mach‑O), debug symbols (when available), stripped bins, and language runtimes.
|
||||
* **Process (per artifact):**
|
||||
|
||||
* Parse binaries (headers, sections, symbol tables, relocations).
|
||||
* Recover call edges:
|
||||
|
||||
* Direct calls: disassemble; record `caller -> callee`.
|
||||
* Indirect calls: resolve via PLT/IAT/vtables; fall back to conservative points‑to sets.
|
||||
* Dynamic loading: log `dlopen/LoadLibrary` + exported symbol usage heuristics.
|
||||
* Normalize to **Symbol Graph**: nodes = `{binary, symbol, addr, hash}`, edges = `CALLS`.
|
||||
* **Outputs:** `symbol-graph.jsonl` (+ compact binary form), content‑addressed by hash.
|
||||
|
||||
# Stage B — Symbol graph ↔ SBOM components
|
||||
|
||||
* **Inputs:** CycloneDX/SPDX SBOM for the image/build; file→component mapping (path→pkg).
|
||||
* **Process:**
|
||||
|
||||
* For each symbol: derive file path (or Build‑ID) → map to SBOM component/version/layer.
|
||||
* Build **Component Reachability Graph**:
|
||||
|
||||
* nodes = `{component@version}`, edges = “component provides symbol X used by Y”.
|
||||
* annotate with file hashes, Build‑IDs, container layer digests.
|
||||
* **Outputs:** `reachability-slices/COMPONENT@VERSION.slice.json` (per impacted component).
|
||||
|
||||
# Attestable “slice” (the evidence object)
|
||||
|
||||
Each slice is a minimal proof unit answering: *“This vulnerable symbol is (or isn’t) on a feasible path at runtime in build X.”*
|
||||
|
||||
* **Contents:**
|
||||
|
||||
* Scan manifest (tool versions, ruleset hashes, feed versions).
|
||||
* Inputs digests (binaries, SBOM, container layers).
|
||||
* The subgraph (only nodes/edges needed).
|
||||
* Query + result (e.g., “is `openssl:EVP_PKEY_decrypt` reachable from any exported entrypoint?”).
|
||||
* **Format:** DSSE + in‑toto statement, stored as OCI artifact or file; **deterministic** (same inputs → same bytes).
|
||||
|
||||
# Triage flow (how it helps today)
|
||||
|
||||
* Given CVE → map to symbols/functions → check reachability slice:
|
||||
|
||||
* **Reachable path found:** mark “affected (reachable)”, include call chain and components; raise priority.
|
||||
* **No path / gated by feature flag:** mark “not affected (unreachable/mitigated)”, with proof chain.
|
||||
* **Unknowns present:** fail‑safe policy (e.g., “unknowns > N → block prod”) with explicit unknown edges listed.
|
||||
|
||||
# Minimal data model (JSON hints)
|
||||
|
||||
* `Symbol`: `{ id, name, demangled, addr, file_sha256, build_id }`
|
||||
* `Edge`: `{ src_symbol_id, dst_symbol_id, kind: "direct"|"plt"|"indirect" }`
|
||||
* `Mapping`: `{ file_sha256|build_id -> component_purl, layer_digest, path }`
|
||||
* `Slice`: `{ inputs:{…}, query:{…}, subgraph:{symbols:[…],edges:[…]}, verdict:"reachable"|"unreachable"|"unknown" }`
|
||||
|
||||
# Determinism & replay
|
||||
|
||||
* Pin **everything**: disassembler version, rules, demangler options, container digests, SBOM doc hash, symbolization flags.
|
||||
* Emit a **Scan Manifest** with content hashes; store alongside slices.
|
||||
* Provide a `replay` command that re‑hydrates inputs and re‑computes the slice; byte‑for‑byte match required.
|
||||
|
||||
# Where this plugs into Stella Ops (suggested modules)
|
||||
|
||||
* **Sbomer**: component/file mapping & SBOM import.
|
||||
* **Scanner.webservice**: binary parse & call‑graph extraction (keep lattice/policy elsewhere per your rule).
|
||||
* **Vexer/Policy Engine**: consume slices as evidence for “affected/not‑affected” claims.
|
||||
* **Attestor/Authority**: sign DSSE/in‑toto statements; push to OCI.
|
||||
* **Timeline/Notify**: surface verdict deltas over time, link to slices.
|
||||
|
||||
# Guardrails & fallbacks
|
||||
|
||||
* If stripped binaries: prefer Build‑ID + external symbol servers; else conservative over‑approx (mark unknown).
|
||||
* For JIT/dynamic plugins: capture runtime traces (eBPF/ETW) and merge as **observed edges** with timestamps.
|
||||
* Mixed‑lang stacks: unify by file hash + symbol name mangling rules per toolchain.
|
||||
|
||||
# Quick implementation plan (6 sprints)
|
||||
|
||||
1. **Binary ingest**: ELF/PE/Mach‑O parsing, Build‑ID hashing, symbol tables, PLT/IAT resolution.
|
||||
2. **Call‑edge recovery**: direct calls, basic indirect resolution, slice extractor by entrypoint.
|
||||
3. **SBOM mapping**: file→component map, layer digests, purl normalization.
|
||||
4. **Evidence format**: DSSE/in‑toto schema, deterministic manifests, OCI storage.
|
||||
5. **Queries & policies**: “is‑reachable?” API, unknowns budget, feature‑flag conditions, VEX plumbing.
|
||||
6. **Runtime merge**: optional eBPF/ETW traces → annotate edges, produce “observed‑path” slices.
|
||||
|
||||
# Lightweight APIs (sketch)
|
||||
|
||||
* `POST /reachability/query { cve, symbols[], entrypoints[], policy } -> slice+verdict`
|
||||
* `GET /slice/{digest}` -> attested slice
|
||||
* `POST /replay { slice_digest }` -> match | mismatch (with diff)
|
||||
|
||||
# Small example (CVE → symbol mapping)
|
||||
|
||||
* `CVE‑XXXX‑YYYY` → advisory lists function `foo_decrypt` in `libfoo.so`
|
||||
* We resolve `libfoo.so` Build‑ID in image, find symbols that match demangled name, build call paths from service entrypoints; if path exists, slice is “reachable” with 3–7 hop chain; otherwise “unreachable” with reasons (no import, stripped at link‑time, dead code eliminated, or gated by `FEATURE_X=false`).
|
||||
|
||||
# Costs (rough, for planning inside Stella Ops)
|
||||
|
||||
* **Core parsing & graph**: 3–4 engineer‑weeks
|
||||
* **Indirect calls & heuristics**: +3–5 weeks
|
||||
* **SBOM mapping & layers**: 2 weeks
|
||||
* **Attestations & OCI storage**: 1–2 weeks
|
||||
* **Policy/VEX integration & UI surfacing**: 2–3 weeks
|
||||
* **Runtime trace merge (optional)**: 2–4 weeks
|
||||
*(Parallelizable; add 25–40% for hardening/tests.)*
|
||||
|
||||
If you want, I can turn this into:
|
||||
|
||||
* a concrete **.NET 10 service skeleton** (endpoints + data contracts),
|
||||
* a **DSSE/in‑toto schema** for the slice, and
|
||||
* a **dev checklist** for deterministic builds and replay harness.
|
||||
@@ -0,0 +1,104 @@
|
||||
Here’s a simple, big‑picture primer on how a modern, verifiable supply‑chain security platform fits together—and what each part does—before we get into the practical wiring and artifacts.
|
||||
|
||||
---
|
||||
|
||||
# Topology & trust boundaries (plain‑English)
|
||||
|
||||
Think of the system as four layers, each with a clear job and a cryptographic handshake between them:
|
||||
|
||||
1. **Edge** (where users & CI/CD touch the system)
|
||||
|
||||
* **StellaRouter / UI** receive requests, authenticate users/agents (OAuth2/OIDC), and fan them into the control plane.
|
||||
* Trust boundary: everything from the outside must present signed credentials/attestations before it’s allowed deeper.
|
||||
|
||||
2. **Control Plane** (brains & policy)
|
||||
|
||||
* **Scheduler**: queues and routes work (scan this image, verify that build, recompute reachability, etc.).
|
||||
* **Policy Engine**: evaluates SBOMs, VEX, and signals against policies (“ship/block/defer”) and produces **signed, replayable verdicts**.
|
||||
* **Authority**: key custody & identity (who can sign what).
|
||||
* **Attestor**: issues DSSE/in‑toto attestations for scans, verdicts, and exports.
|
||||
* **Timeline / Notify**: immutable audit log + notifications.
|
||||
* Trust boundary: only evidence and identities blessed here can influence decisions.
|
||||
|
||||
3. **Evidence Plane** (facts, not opinions)
|
||||
|
||||
* **Sbomer**: builds SBOMs from images/binaries/source (CycloneDX 1.6 / SPDX 3.0.1).
|
||||
* **Excititor**: runs scanners/executors (code, binary, OS, language deps, “what’s installed” on hosts).
|
||||
* **Concelier**: correlates advisories, VEX claims, reachability, EPSS, exploit telemetry.
|
||||
* **Reachability / Signals**: computes “is the vulnerable code actually reachable here?” plus runtime/infra signals.
|
||||
* Trust boundary: raw evidence is tamper‑evident and separately signed; opinions live in policy/verdicts, not here.
|
||||
|
||||
4. **Data Plane** (do the heavy lifting)
|
||||
|
||||
* Horizontal workers/scanners that pull tasks, do the compute, and emit artifacts and attestations.
|
||||
* Trust boundary: workers are isolated per tenant; outputs are always tied to inputs via cryptographic subjects.
|
||||
|
||||
---
|
||||
|
||||
# Artifact association & tenant isolation (why OCI referrers matter)
|
||||
|
||||
* Every image/artifact becomes a **subject** in the registry.
|
||||
* SBOMs, VEX, reachability slices, and verdicts are published as **OCI referrers** that point back to that subject (no guessing or loose coupling).
|
||||
* This lets you attach **multiple, versioned, signed facts** to the same build without altering the image itself.
|
||||
* Tenants stay cryptographically separate: different keys, different trust roots, different namespaces.
|
||||
|
||||
---
|
||||
|
||||
# Interfaces, dataflows & provenance hooks (what flows where)
|
||||
|
||||
* **Workers emit**:
|
||||
|
||||
* **SBOMs** in CycloneDX 1.6 and/or SPDX 3.0.1.
|
||||
* **VEX claims** (affected/not‑affected, under‑investigation, fixed).
|
||||
* **Reachability subgraphs** (the minimal “slice” proving a vuln is or isn’t callable in this build).
|
||||
* All wrapped as **DSSE/in‑toto attestations** and **attached via OCI referrers** to the image digest.
|
||||
* **Policy Engine**:
|
||||
|
||||
* Ingests SBOM/VEX/reachability/signals, applies rules, and emits a **signed verdict** (OCI‑attached).
|
||||
* Verdicts are **replayable**: same inputs → same output, with the exact inputs hashed and referenced.
|
||||
* **Timeline**:
|
||||
|
||||
* Stores an **audit‑ready record** of who ran what, with which inputs, producing which attestations and verdicts.
|
||||
|
||||
---
|
||||
|
||||
# Why this design helps in real life
|
||||
|
||||
* **Audits become trivial**: point an auditor at the image digest; they can fetch all linked SBOMs/VEX/attestations/verdicts and replay the decision.
|
||||
* **Noise collapses**: reachability + VEX + policy means you block only what matters for *this* build in *this* environment.
|
||||
* **Multi‑tenant safety**: each customer’s artifacts and keys are isolated; strong boundaries reduce blast radius.
|
||||
* **No vendor lock‑in**: OCI referrers and open schemas (CycloneDX/SPDX/in‑toto/DSSE) let you interoperate.
|
||||
|
||||
---
|
||||
|
||||
# Minimal “starter” policy you can adopt Day‑1
|
||||
|
||||
* **Gate** on any CVE with reachability=“reachable” AND severity ≥ High, unless a trusted VEX source says “not affected” with required evidence hooks (e.g., feature flag off, code path pruned).
|
||||
* **Fail on unknowns** above a threshold (e.g., >N packages with missing metadata).
|
||||
* **Require** signed SBOM + signed verdict for prod deploys; store both in Timeline.
|
||||
|
||||
---
|
||||
|
||||
# Quick glossary
|
||||
|
||||
* **SBOM**: Software Bill of Materials (what’s inside).
|
||||
* **VEX**: Vulnerability Exploitability eXchange (is a CVE actually relevant?).
|
||||
* **Reachability**: graph proof that vulnerable code is (not) callable.
|
||||
* **DSSE / in‑toto**: standardized ways to sign and describe supply‑chain steps and their outputs.
|
||||
* **OCI referrers**: a registry mechanism to hang related artifacts (SBOMs, attestations, verdicts) off an image digest.
|
||||
|
||||
---
|
||||
|
||||
# A tiny wiring sketch
|
||||
|
||||
```
|
||||
User/CI → Router/UI → Scheduler ─→ Workers (Sbomer/Excititor)
|
||||
│ │
|
||||
│ └─→ emit SBOM/VEX/reachability (DSSE, OCI-referrers)
|
||||
│
|
||||
Policy Engine ──→ signed verdict (OCI-referrer)
|
||||
│
|
||||
Timeline/Notify (immutable audit, alerts)
|
||||
```
|
||||
|
||||
If you want, I can turn this into a one‑pager architecture card, plus a checklist your PMs/engineers can use to validate each trust boundary and artifact flow in your Stella Ops setup.
|
||||
@@ -0,0 +1,565 @@
|
||||
Here’s a compact, practical plan to harden Stella Ops around **offline‑ready security evidence and deterministic verdicts**, with just enough background so it all clicks.
|
||||
|
||||
---
|
||||
|
||||
# Why this matters (quick primer)
|
||||
|
||||
* **Air‑gapped/offline**: Many customers can’t reach public feeds or registries. Your scanners, SBOM tooling, and attestations must work with **pre‑synced bundles** and prove what data they used.
|
||||
* **Interoperability**: Teams mix tools (Syft/Grype/Trivy, cosign, CycloneDX/SPDX). Your CI should **round‑trip** SBOMs and attestations end‑to‑end and prove that downstream consumers (e.g., Grype) can load them.
|
||||
* **Determinism**: Auditors expect **“same inputs → same verdict.”** Capture inputs, policies, and feed hashes so a verdict is exactly reproducible later.
|
||||
* **Operational guardrails**: Shipping gates should fail early on **unknowns** and apply **backpressure** gracefully when load spikes.
|
||||
|
||||
---
|
||||
|
||||
# E2E test themes to add (what to build)
|
||||
|
||||
1. **Air‑gapped operation e2e**
|
||||
|
||||
* Package “offline bundle” (vuln feeds, package catalogs, policy/lattice rules, certs, keys).
|
||||
* Run scans (containers, OS, language deps, binaries) **without network**.
|
||||
* Assert: SBOMs generated, attestations signed/verified, verdicts emitted.
|
||||
* Evidence: manifest of bundle contents + hashes in the run log.
|
||||
|
||||
2. **Interop round‑trips (SBOM ⇄ attestation ⇄ scanner)**
|
||||
|
||||
* Produce SBOM (CycloneDX 1.6 and SPDX 3.0.1) with Syft.
|
||||
* Create **DSSE/cosign** attestation for that SBOM.
|
||||
* Verify consumer tools:
|
||||
|
||||
* **Grype** scans **from SBOM** (no image pull) and respects attestations.
|
||||
* Verdict references the exact SBOM digest and attestation chain.
|
||||
* Assert: consumers load, validate, and produce identical findings vs direct scan.
|
||||
|
||||
3. **Replayability (delta‑verdicts + strict replay)**
|
||||
|
||||
* Store input set: artifact digest(s), SBOM digests, policy version, feed digests, lattice rules, tool versions.
|
||||
* Re‑run later; assert **byte‑identical verdict** and same “delta‑verdict” when inputs unchanged.
|
||||
|
||||
4. **Unknowns‑budget policy gates**
|
||||
|
||||
* Inject controlled “unknown” conditions (missing CPE mapping, unresolved package source, unparsed distro).
|
||||
* Gate: **fail build if unknowns > budget** (e.g., prod=0, staging≤N).
|
||||
* Assert: UI, CLI, and attestation all record unknown counts and gate decision.
|
||||
|
||||
5. **Attestation round‑trip & validation**
|
||||
|
||||
* Produce: build‑provenance (in‑toto/DSSE), SBOM attest, VEX attest, final **verdict attest**.
|
||||
* Verify: signature (cosign), certificate chain, time‑stamping, Rekor‑style (or mirror) inclusion when online; cached proofs when offline.
|
||||
* Assert: each attestation is linked in the verdict’s evidence index.
|
||||
|
||||
6. **Router backpressure chaos (HTTP 429/503 + Retry‑After)**
|
||||
|
||||
* Load tests that trigger per‑instance and per‑environment limits.
|
||||
* Assert: clients back off per **Retry‑After**, queues drain, no data loss, latencies bounded; UI shows throttling reason.
|
||||
|
||||
7. **UI reducer tests for reachability & VEX chips**
|
||||
|
||||
* Component tests: large SBOM graphs, focused **reachability subgraphs**, and VEX status chips (affected/not‑affected/under‑investigation).
|
||||
* Assert: stable rendering under 50k+ nodes; interactions remain <200 ms.
|
||||
|
||||
---
|
||||
|
||||
# Next‑week checklist (do these now)
|
||||
|
||||
1. **Delta‑verdict replay tests**: golden corpus; lock tool+feed versions; assert bit‑for‑bit verdict.
|
||||
2. **Unknowns‑budget gates in CI**: policy + failing examples; surface in PR checks and UI.
|
||||
3. **SBOM attestation round‑trip**: Syft → cosign attest → Grype consume‑from‑SBOM; verify signatures & digests.
|
||||
4. **Router backpressure chaos**: scripted spike; verify 429/503 + Retry‑After handling and metrics.
|
||||
5. **UI reducer tests**: reachability graph snapshots; VEX chip states; regression suite.
|
||||
|
||||
---
|
||||
|
||||
# Minimal artifacts to standardize (so tests are boring—good!)
|
||||
|
||||
* **Offline bundle spec**: `bundle.json` with content digests (feeds, policies, keys).
|
||||
* **Evidence manifest**: machine‑readable index linking verdict → SBOM digest → attestation IDs → tool versions.
|
||||
* **Delta‑verdict schema**: captures before/after graph deltas, rule evals, and final gate result.
|
||||
* **Unknowns taxonomy**: codes (e.g., `PKG_SOURCE_UNKNOWN`, `CPE_AMBIG`) with severities and budgets.
|
||||
|
||||
---
|
||||
|
||||
# CI wiring (quick sketch)
|
||||
|
||||
* **Jobs**: `offline-e2e`, `interop-e2e`, `replayable-verdicts`, `unknowns-gate`, `router-chaos`, `ui-reducers`.
|
||||
* **Matrix**: {Debian/Alpine/RHEL‑like} × {amd64/arm64} × {CycloneDX/SPDX}.
|
||||
* **Cache discipline**: pin tool versions, vendor feeds to content‑addressed store.
|
||||
|
||||
---
|
||||
|
||||
# Fast success criteria (green = done)
|
||||
|
||||
* Can run **full scan + attest + verify** with **no network**.
|
||||
* Re‑running a fixed input set yields **identical verdict**.
|
||||
* Grype (from SBOM) matches image scan results within tolerance.
|
||||
* Builds auto‑fail when **unknowns budget exceeded**.
|
||||
* Router under burst emits **correct Retry‑After** and recovers cleanly.
|
||||
* UI handles huge graphs; VEX chips never desync from evidence.
|
||||
|
||||
If you want, I’ll turn this into GitLab/Gitea pipeline YAML + a tiny sample repo (image, SBOM, policies, and goldens) so your team can plug‑and‑play.
|
||||
Below is a complete, end-to-end testing strategy for Stella Ops that turns your moats (offline readiness, deterministic replayable verdicts, lattice/policy decisioning, attestation provenance, unknowns budgets, router backpressure, UI reachability evidence) into continuously verified guarantees.
|
||||
|
||||
---
|
||||
|
||||
## 1) Non-negotiable test principles
|
||||
|
||||
### 1.1 Determinism as a testable contract
|
||||
|
||||
A scan/verdict is *deterministic* iff **same inputs → byte-identical outputs** across time and machines (within defined tolerances like timestamps captured as evidence, not embedded in payload order).
|
||||
|
||||
**Determinism controls (must be enforced by tests):**
|
||||
|
||||
* Canonical JSON (stable key order, stable array ordering where semantically unordered).
|
||||
* Stable sorting for:
|
||||
|
||||
* packages/components
|
||||
* vulnerabilities
|
||||
* edges in graphs
|
||||
* evidence lists
|
||||
* Time is an *input*, never implicit:
|
||||
|
||||
* stamp times in a dedicated evidence field; never affect hashing/verdict evaluation.
|
||||
* PRNG uses explicit seed; seed stored in run manifest.
|
||||
* Tool versions + feed digests + policy versions are inputs.
|
||||
* Locale/encoding invariants: UTF-8 everywhere; invariant culture in .NET.
|
||||
|
||||
### 1.2 Offline by default
|
||||
|
||||
Every CI job (except explicitly tagged “online”) runs with **no egress**.
|
||||
|
||||
* Offline bundle is mandatory input for scanning.
|
||||
* Any attempted network call fails the test (proves air-gap compliance).
|
||||
|
||||
### 1.3 Evidence-first validation
|
||||
|
||||
No assertion is “verdict == pass” without verifying the chain of evidence:
|
||||
|
||||
* verdict references SBOM digest(s)
|
||||
* SBOM references artifact digest(s)
|
||||
* VEX claims reference vulnerabilities + components + reachability evidence
|
||||
* attestations verify cryptographically and chain to configured roots.
|
||||
|
||||
### 1.4 Interop is required, not “nice to have”
|
||||
|
||||
Stella Ops must round-trip with:
|
||||
|
||||
* SBOM: CycloneDX 1.6 and SPDX 3.0.1
|
||||
* Attestation: DSSE / in-toto style envelopes, cosign-compatible flows
|
||||
* Consumer scanners: at least Grype from SBOM; ideally Trivy as cross-check
|
||||
|
||||
Interop tests are treated as “compatibility contracts” and block releases.
|
||||
|
||||
### 1.5 Architectural boundary enforcement (your standing rule)
|
||||
|
||||
* Lattice/policy merge algorithms run **in `scanner.webservice`**.
|
||||
* `Concelier` and `Excitors` must “preserve prune source”.
|
||||
This is enforced with tests that detect forbidden behavior (see §6.2).
|
||||
|
||||
---
|
||||
|
||||
## 2) The test portfolio (what kinds of tests exist)
|
||||
|
||||
Think “coverage by risk”, not “coverage by lines”.
|
||||
|
||||
### 2.1 Test layers and what they prove
|
||||
|
||||
1. **Unit tests** (fast, deterministic)
|
||||
|
||||
* Canonicalization, hashing, semantic version range ops
|
||||
* Graph delta algorithms
|
||||
* Policy rule evaluation primitives
|
||||
* Unknowns taxonomy + budgeting math
|
||||
* Evidence index assembly
|
||||
|
||||
2. **Property-based tests** (FsCheck)
|
||||
|
||||
* “Reordering inputs does not change verdict hash”
|
||||
* “Graph merge is associative/commutative where policy declares it”
|
||||
* “Unknowns budgets always monotonic with missing evidence”
|
||||
* Parser robustness: arbitrary JSON for SBOM/VEX envelopes never crashes
|
||||
|
||||
3. **Component tests** (service + Postgres; optional Valkey)
|
||||
|
||||
* `scanner.webservice` lattice merge and replay
|
||||
* Feed loader and cache behavior (offline feeds)
|
||||
* Router backpressure decision logic
|
||||
* Attestation verification modules
|
||||
|
||||
4. **Contract tests** (API compatibility)
|
||||
|
||||
* OpenAPI/JSON schema compatibility for public endpoints
|
||||
* Evidence manifest schema backward compatibility
|
||||
* OCI artifact layout compatibility (attestation attachments)
|
||||
|
||||
5. **Integration tests** (multi-service)
|
||||
|
||||
* Router → scanner.webservice → attestor → storage
|
||||
* Offline bundle import/export
|
||||
* Knowledge snapshot “time travel” replay pipeline
|
||||
|
||||
6. **End-to-end tests** (realistic flows)
|
||||
|
||||
* scan an image → generate SBOM → produce attestations → decision verdict → UI evidence extraction
|
||||
* interop consumers load SBOM and confirm findings parity
|
||||
|
||||
7. **Non-functional tests**
|
||||
|
||||
* Performance & scale (throughput, memory, large SBOM graphs)
|
||||
* Chaos/fault injection (DB restarts, queue spikes, 429/503 backpressure)
|
||||
* Security tests (fuzzers, decompression bomb defense, signature bypass resistance)
|
||||
|
||||
---
|
||||
|
||||
## 3) Hermetic test harness (how tests run)
|
||||
|
||||
### 3.1 Standard test profiles
|
||||
|
||||
You already decided: **Postgres is system-of-record**, **Valkey is ephemeral**.
|
||||
|
||||
Define two mandatory execution profiles in CI:
|
||||
|
||||
1. **Default**: Postgres + Valkey
|
||||
2. **Air-gapped minimal**: Postgres only
|
||||
|
||||
Both must pass.
|
||||
|
||||
### 3.2 Environment isolation
|
||||
|
||||
* Containers started with **no network** unless a test explicitly declares “online”.
|
||||
* For Kubernetes e2e: apply a default-deny egress NetworkPolicy.
|
||||
|
||||
### 3.3 Golden corpora repository (your “truth set”)
|
||||
|
||||
Create a versioned `stellaops-test-corpus/` containing:
|
||||
|
||||
* container images (or image tarballs) pinned by digest
|
||||
* SBOM expected outputs (CycloneDX + SPDX)
|
||||
* VEX examples (vendor/distro/internal)
|
||||
* vulnerability feed snapshots (pinned digests)
|
||||
* policies + lattice rules + unknown budgets
|
||||
* expected verdicts + delta verdicts
|
||||
* reachability subgraphs as evidence
|
||||
* negative fixtures: malformed SPDX, corrupted DSSE, missing digests, unsupported distros
|
||||
|
||||
Every corpus item includes a **Run Manifest** (see §4).
|
||||
|
||||
### 3.4 Artifact retention in CI
|
||||
|
||||
Every failing integration/e2e test uploads:
|
||||
|
||||
* run manifest
|
||||
* offline bundle manifest + hashes
|
||||
* logs (structured)
|
||||
* produced SBOMs
|
||||
* attestations
|
||||
* verdict + delta verdict
|
||||
* evidence index
|
||||
|
||||
This turns failures into audit-grade reproductions.
|
||||
|
||||
---
|
||||
|
||||
## 4) Core artifacts that tests must validate
|
||||
|
||||
### 4.1 Run Manifest (replay key)
|
||||
|
||||
A scan run is defined by:
|
||||
|
||||
* artifact digests (image/config/layers, or binary hash)
|
||||
* SBOM digests produced/consumed
|
||||
* vuln feed snapshot digest(s)
|
||||
* policy version + lattice rules digest
|
||||
* tool versions (scanner, parsers, reachability engine)
|
||||
* crypto profile (roots, key IDs, algorithm set)
|
||||
* environment profile (postgres-only vs postgres+valkey)
|
||||
* seed + canonicalization version
|
||||
|
||||
**Test invariant:** re-running the same manifest produces **byte-identical verdict** and **same evidence references**.
|
||||
|
||||
### 4.2 Offline Bundle Manifest
|
||||
|
||||
Bundle includes:
|
||||
|
||||
* feeds + indexes
|
||||
* policies + lattice rule sets
|
||||
* trust roots, intermediate CAs, timestamp roots (as needed)
|
||||
* crypto provider modules (for sovereign readiness)
|
||||
* optional: Rekor mirror snapshot / inclusion proofs cache
|
||||
|
||||
**Test invariant:** offline scan is blocked if bundle is missing required parts; error is explicit and counts as “unknown” only where policy says so.
|
||||
|
||||
### 4.3 Evidence Index
|
||||
|
||||
The verdict is not the product; the product is verdict + evidence graph:
|
||||
|
||||
* pointers to SBOM, VEX, reachability proofs, attestations
|
||||
* their digests and verification status
|
||||
* unknowns list with codes + remediation hints
|
||||
|
||||
**Test invariant:** every “not affected” claim has required evidence hooks per policy (“because feature flag off” etc.), otherwise becomes unknown/fail.
|
||||
|
||||
---
|
||||
|
||||
## 5) Required E2E flows (minimum set)
|
||||
|
||||
These are your release blockers.
|
||||
|
||||
### Flow A: Air-gapped scan and verdict
|
||||
|
||||
* Inputs: image tarball + offline bundle
|
||||
* Network: disabled
|
||||
* Output: SBOM (CycloneDX + SPDX), attestations, verdict
|
||||
* Assertions:
|
||||
|
||||
* no network calls occurred
|
||||
* verdict references bundle digest + feed snapshot digest
|
||||
* unknowns within budget
|
||||
* evidence index complete
|
||||
|
||||
### Flow B: SBOM interop round-trip
|
||||
|
||||
* Produce SBOM via your pipeline
|
||||
* Attach SBOM attestation (DSSE/cosign format)
|
||||
* Consumer (Grype-from-SBOM) reads SBOM and produces findings
|
||||
* Assertions:
|
||||
|
||||
* consumer can parse SBOM
|
||||
* findings parity within defined tolerance
|
||||
* verdict references exact SBOM digest used by consumer
|
||||
|
||||
### Flow C: Deterministic replay
|
||||
|
||||
* Run scan → store run manifest + outputs
|
||||
* Run again from same manifest
|
||||
* Assertions:
|
||||
|
||||
* verdict bytes identical
|
||||
* evidence index identical (except allowed “execution metadata” section)
|
||||
* delta verdict is “empty delta”
|
||||
|
||||
### Flow D: Diff-aware delta verdict (smart-diff)
|
||||
|
||||
* Two versions of same image with controlled change (one dependency bump)
|
||||
* Assertions:
|
||||
|
||||
* delta verdict contains only changed nodes/edges
|
||||
* risk budget computation based on delta matches expected
|
||||
* signed delta verdict validates and is OCI-attached
|
||||
|
||||
### Flow E: Unknowns budget gates
|
||||
|
||||
* Inject unknowns (unmapped package, missing distro metadata, ambiguous CPE)
|
||||
* Policy:
|
||||
|
||||
* prod budget = 0
|
||||
* staging budget = N
|
||||
* Assertions:
|
||||
|
||||
* prod fails, staging passes
|
||||
* unknowns appear in attestation and UI evidence
|
||||
|
||||
### Flow F: Router backpressure under burst
|
||||
|
||||
* Spike requests to a single router instance + environment bucket
|
||||
* Assertions:
|
||||
|
||||
* 429/503 with Retry-After emitted correctly
|
||||
* clients backoff; no request loss
|
||||
* metrics expose throttling reasons
|
||||
|
||||
### Flow G: Evidence export (“audit pack”)
|
||||
|
||||
* Run scan
|
||||
* Export a sealed audit pack (bundle + run manifest + evidence + verdict)
|
||||
* Import elsewhere (clean environment)
|
||||
* Assertions:
|
||||
|
||||
* replay produces identical verdict
|
||||
* signatures verify under imported trust roots
|
||||
|
||||
---
|
||||
|
||||
## 6) Module-specific test requirements
|
||||
|
||||
### 6.1 `scanner.webservice` (lattice + policy decisioning)
|
||||
|
||||
Must have:
|
||||
|
||||
* unit tests for lattice merge algebra
|
||||
* property tests: declared commutativity/associativity/idempotency
|
||||
* integration tests that merge vendor/distro/internal VEX and confirm precedence rules are policy-driven
|
||||
|
||||
**Critical invariant tests:**
|
||||
|
||||
* “Vendor > distro > internal” must be demonstrably *configurable*, and wrong merges must fail deterministically.
|
||||
|
||||
### 6.2 Boundary enforcement: Concelier & Excitors preserve prune source
|
||||
|
||||
Add a “behavioral boundary suite”:
|
||||
|
||||
* instrument events/telemetry that records where merges happened
|
||||
* feed in conflicting VEX claims and assert:
|
||||
|
||||
* Concelier/Excitors do not resolve conflicts; they retain provenance and “prune source”
|
||||
* only `scanner.webservice` produces the final merged semantics
|
||||
|
||||
If Concelier/Excitors output a resolved claim, the test fails.
|
||||
|
||||
### 6.3 `Router` backpressure and DPoP/nonce rate limiting
|
||||
|
||||
* deterministic unit tests for token bucket math
|
||||
* time-controlled tests (virtual clock)
|
||||
* integration tests with Valkey + Postgres-only fallbacks
|
||||
* chaos tests: Valkey down → router degrades gracefully (local per-instance limiter still works)
|
||||
|
||||
### 6.4 Storage (Postgres) + Valkey accelerator
|
||||
|
||||
* migration tests: schema upgrades forward/backward in CI
|
||||
* replay tests: Postgres-only profile yields same verdict bytes
|
||||
* consistency tests: Valkey cache misses never change decision outcomes, only latency
|
||||
|
||||
### 6.5 UI evidence rendering
|
||||
|
||||
* reducer snapshot tests for:
|
||||
|
||||
* reachability subgraph rendering (large graphs)
|
||||
* VEX chip states: affected/not-affected/under-investigation/unknown
|
||||
* performance budgets:
|
||||
|
||||
* large graph render under threshold (define and enforce)
|
||||
* contract tests against evidence index schema
|
||||
|
||||
---
|
||||
|
||||
## 7) Non-functional test program
|
||||
|
||||
### 7.1 Performance and scale tests
|
||||
|
||||
Define standard workloads:
|
||||
|
||||
* small image (200 packages)
|
||||
* medium (2k packages)
|
||||
* large (20k+ packages)
|
||||
* “monorepo container” worst case (50k+ nodes graph)
|
||||
|
||||
Metrics collected:
|
||||
|
||||
* p50/p95/p99 scan time
|
||||
* memory peak
|
||||
* DB write volume
|
||||
* evidence pack size
|
||||
* router throughput + throttle rate
|
||||
|
||||
Add regression gates:
|
||||
|
||||
* no more than X% slowdown in p95 vs baseline
|
||||
* no more than Y% growth in evidence pack size for unchanged inputs
|
||||
|
||||
### 7.2 Chaos and reliability
|
||||
|
||||
Run chaos suites weekly/nightly:
|
||||
|
||||
* kill scanner during run → resume/retry semantics deterministic
|
||||
* restart Postgres mid-run → job fails with explicit retryable state
|
||||
* corrupt offline bundle file → fails with typed error, not crash
|
||||
* burst router + slow downstream → confirms backpressure not meltdown
|
||||
|
||||
### 7.3 Security robustness tests
|
||||
|
||||
* fuzz parsers: SPDX, CycloneDX, VEX, DSSE envelopes
|
||||
* zip/tar bomb defenses (artifact ingestion)
|
||||
* signature bypass attempts:
|
||||
|
||||
* mismatched digest
|
||||
* altered payload with valid signature on different content
|
||||
* wrong root chain
|
||||
* SSRF defense: any URL fields in SBOM/VEX are treated as data, never fetched in offline mode
|
||||
|
||||
---
|
||||
|
||||
## 8) CI/CD gating rules (what blocks a release)
|
||||
|
||||
Release candidate is blocked if any of these fail:
|
||||
|
||||
1. All mandatory E2E flows (§5) pass in both profiles:
|
||||
|
||||
* Postgres-only
|
||||
* Postgres+Valkey
|
||||
|
||||
2. Deterministic replay suite:
|
||||
|
||||
* zero non-deterministic diffs in verdict bytes
|
||||
* allowed diff list is explicit and reviewed
|
||||
|
||||
3. Interop suite:
|
||||
|
||||
* CycloneDX 1.6 and SPDX 3.0.1 round-trips succeed
|
||||
* consumer scanner compatibility tests pass
|
||||
|
||||
4. Risk budgets + unknowns budgets:
|
||||
|
||||
* must pass on corpus, and no regressions against baseline
|
||||
|
||||
5. Backpressure correctness:
|
||||
|
||||
* Retry-After compliance and throttle metrics validated
|
||||
|
||||
6. Performance regression budgets:
|
||||
|
||||
* no breach of p95/memory budgets on standard workloads
|
||||
|
||||
7. Flakiness threshold:
|
||||
|
||||
* if a test flakes more than N times per week, it is quarantined *and* release is blocked until a deterministic root cause is established (quarantine is allowed only for non-blocking suites, never for §5 flows)
|
||||
|
||||
---
|
||||
|
||||
## 9) Implementation blueprint (how to build this test program)
|
||||
|
||||
### Phase 0: Harness and corpus
|
||||
|
||||
* Stand up test harness: docker compose + Testcontainers (.NET xUnit)
|
||||
* Create corpus repo with 10–20 curated artifacts
|
||||
* Implement run manifest + evidence index capture in all tests
|
||||
|
||||
### Phase 1: Determinism and replay
|
||||
|
||||
* canonicalization utilities + golden verdict bytes
|
||||
* replay runner that loads manifest and replays end-to-end
|
||||
* add property-based tests for ordering and merge invariants
|
||||
|
||||
### Phase 2: Offline e2e + interop
|
||||
|
||||
* offline bundle builder + strict “no egress” enforcement
|
||||
* SBOM attestation round-trip + consumer parsing suite
|
||||
|
||||
### Phase 3: Unknowns budgets + delta verdict
|
||||
|
||||
* unknown taxonomy everywhere (UI + attestations)
|
||||
* delta verdict generation and signing
|
||||
* diff-aware release gates
|
||||
|
||||
### Phase 4: Backpressure + chaos + performance
|
||||
|
||||
* router throttle chaos suite
|
||||
* scale tests with standard workloads and baselines
|
||||
|
||||
### Phase 5: Audit packs + time-travel snapshots
|
||||
|
||||
* sealed export/import
|
||||
* one-command replay for auditors
|
||||
|
||||
---
|
||||
|
||||
## 10) What you should standardize immediately
|
||||
|
||||
If you do only three things, do these:
|
||||
|
||||
1. **Run Manifest** as first-class test artifact
|
||||
2. **Golden corpus** that pins all digests (feeds, policies, images, expected outputs)
|
||||
3. **“No egress” default** in CI with explicit opt-in for online tests
|
||||
|
||||
Everything else becomes far easier once these are in place.
|
||||
|
||||
---
|
||||
|
||||
If you want, I can also produce a concrete repository layout and CI job matrix (xUnit categories, docker compose profiles, artifact retention conventions, and baseline benchmark scripts) that matches .NET 10 conventions and your Postgres/Valkey profiles.
|
||||
@@ -0,0 +1,469 @@
|
||||
Below are implementation-grade guidelines for Stella Ops Product Managers (PMs) and Development Managers (Eng Managers / Tech Leads) for two tightly coupled capabilities:
|
||||
|
||||
1. **Exception management as auditable objects** (not suppression files)
|
||||
2. **Audit packs** (exportable, verifiable evidence bundles for releases and environments)
|
||||
|
||||
The intent is to make these capabilities:
|
||||
|
||||
* operationally useful (reduce friction in CI/CD and runtime governance),
|
||||
* defensible in audits (tamper-evident, attributable, time-bounded), and
|
||||
* consistent with Stella Ops’ positioning around determinism, evidence, and replayability.
|
||||
|
||||
---
|
||||
|
||||
# 1. Shared objectives and boundaries
|
||||
|
||||
## 1.1 Objectives
|
||||
|
||||
These two capabilities must jointly enable:
|
||||
|
||||
* **Risk decisions are explicit**: Every “ignore/suppress/waive” is a governed decision with an owner and expiry.
|
||||
* **Decisions are replayable**: If an auditor asks “why did you ship this on date X?”, Stella Ops can reproduce the decision using the same policy + evidence + knowledge snapshot.
|
||||
* **Decisions are exportable and verifiable**: Audit packs include the minimum necessary artifacts and a manifest that allows independent verification of integrity and completeness.
|
||||
* **Operational friction is reduced**: Teams can ship safely with controlled exceptions, rather than ad-hoc suppressions, while retaining accountability.
|
||||
|
||||
## 1.2 Out of scope (explicitly)
|
||||
|
||||
Avoid scope creep early. The following are out of scope for v1 unless mandated by a target customer:
|
||||
|
||||
* Full GRC mapping to specific frameworks (you can *support evidence*; don’t claim compliance).
|
||||
* Fully automated approvals based on HR org charts.
|
||||
* Multi-year archival systems (start with retention, export, and immutable event logs).
|
||||
* A “ticketing system replacement.” Integrate with ticketing; don’t rebuild it.
|
||||
|
||||
---
|
||||
|
||||
# 2. Shared design principles (non-negotiables)
|
||||
|
||||
These principles apply to both Exception Objects and Audit Packs:
|
||||
|
||||
1. **Attribution**: every action has an authenticated actor identity (human or service), a timestamp, and a reason.
|
||||
2. **Immutability of history**: edits are new versions/events; never rewrite history in place.
|
||||
3. **Least privilege scope**: exceptions must be as narrow as possible (artifact digest over tag; component purl over “any”; environment constraints).
|
||||
4. **Time-bounded risk**: exceptions must expire. “Permanent ignore” is a governance smell.
|
||||
5. **Deterministic evaluation**: given the same policy + snapshot + exceptions + inputs, the outcome is stable and reproducible.
|
||||
6. **Separation of concerns**:
|
||||
|
||||
* Exception store = governed decisions.
|
||||
* Scanner = evidence producer.
|
||||
* Policy engine = deterministic evaluator.
|
||||
* Audit packer = exporter/assembler/verifier.
|
||||
|
||||
---
|
||||
|
||||
# 3. Exception management as auditable objects
|
||||
|
||||
## 3.1 What an “Exception Object” is
|
||||
|
||||
An Exception Object is a structured, versioned record that modifies evaluation behavior *in a controlled manner*, while leaving the underlying findings intact.
|
||||
|
||||
It is not:
|
||||
|
||||
* a local `.ignore` file,
|
||||
* a hidden suppression rule,
|
||||
* a UI-only toggle,
|
||||
* a vendor-specific “ignore list” with no audit trail.
|
||||
|
||||
### Exception types you should support (minimum set)
|
||||
|
||||
PMs should start with these canonical types:
|
||||
|
||||
1. **Vulnerability exception**
|
||||
|
||||
* suppress/waive a specific vulnerability finding (e.g., CVE/CWE) under defined scope.
|
||||
2. **Policy exception**
|
||||
|
||||
* allow a policy rule to be bypassed under defined scope (e.g., “allow unsigned artifact for dev namespace”).
|
||||
3. **Unknown-state exception** (if Stella models unknowns)
|
||||
|
||||
* allow a release despite unresolved unknowns, with explicit risk acceptance.
|
||||
4. **Component exception**
|
||||
|
||||
* allow/deny a component/package/version across a domain, again with explicit scope and expiry.
|
||||
|
||||
## 3.2 Required fields and schema guidelines
|
||||
|
||||
PMs: mandate these fields; Eng: enforce them at API and storage level.
|
||||
|
||||
### Required fields (v1)
|
||||
|
||||
* **exception_id** (stable identifier)
|
||||
* **version** (monotonic; or event-sourced)
|
||||
* **status**: proposed | approved | active | expired | revoked
|
||||
* **owner** (accountable person/team)
|
||||
* **requester** (who initiated)
|
||||
* **approver(s)** (who approved; may be empty for dev environments depending on policy)
|
||||
* **created_at / updated_at / approved_at / expires_at**
|
||||
* **scope** (see below)
|
||||
* **reason_code** (taxonomy)
|
||||
* **rationale** (free text, required)
|
||||
* **evidence_refs** (optional in v1 but strongly recommended)
|
||||
* **risk_acceptance** (explicit boolean or structured “risk accepted” block)
|
||||
* **links** (ticket ID, PR, incident, vendor advisory reference) – optional but useful
|
||||
* **audit_log_refs** (implicit if event-sourced)
|
||||
|
||||
### Scope model (critical to defensibility)
|
||||
|
||||
Scope must be structured and narrowable. Provide scope dimensions such as:
|
||||
|
||||
* **Artifact scope**: image digest, SBOM digest, build provenance digest (preferred)
|
||||
(Avoid tags as primary scope unless paired with immutability constraints.)
|
||||
* **Component scope**: purl + version range + ecosystem
|
||||
* **Vulnerability scope**: CVE ID(s), GHSA, internal ID; optionally path/function/symbol constraints
|
||||
* **Environment scope**: cluster/namespace, runtime env (dev/stage/prod), repository, project, tenant
|
||||
* **Time scope**: expires_at (required), optional “valid_from”
|
||||
|
||||
PM guideline: default UI and API should encourage digest-based scope and warn on broad scopes.
|
||||
|
||||
## 3.3 Reason codes (taxonomy)
|
||||
|
||||
Reason codes are a moat because they enable governance analytics and policy automation.
|
||||
|
||||
Minimum suggested taxonomy:
|
||||
|
||||
* **FALSE_POSITIVE** (with evidence expectations)
|
||||
* **NOT_REACHABLE** (reachable proof preferred)
|
||||
* **NOT_AFFECTED** (VEX-backed preferred)
|
||||
* **BACKPORT_FIXED** (package/distro evidence preferred)
|
||||
* **COMPENSATING_CONTROL** (link to control evidence)
|
||||
* **RISK_ACCEPTED** (explicit sign-off)
|
||||
* **TEMPORARY_WORKAROUND** (link to mitigation plan)
|
||||
* **VENDOR_PENDING** (under investigation)
|
||||
* **BUSINESS_EXCEPTION** (rare; requires stronger approval)
|
||||
|
||||
PM guideline: reason codes must be selectable and reportable; do not allow “Other” as the default.
|
||||
|
||||
## 3.4 Evidence attachments
|
||||
|
||||
Exceptions should evolve from “justification-only” to “justification + evidence.”
|
||||
|
||||
Evidence references can point to:
|
||||
|
||||
* VEX statements (OpenVEX/CycloneDX VEX)
|
||||
* reachability proof fragments (call-path subgraph, symbol references)
|
||||
* distro advisories / patch references
|
||||
* internal change tickets / mitigation PRs
|
||||
* runtime mitigations
|
||||
|
||||
Eng guideline: store evidence as references with integrity checks (hash/digest). For v2+, store evidence bundles as content-addressed blobs.
|
||||
|
||||
## 3.5 Lifecycle and workflows
|
||||
|
||||
### Lifecycle states and transitions
|
||||
|
||||
* **Proposed** → **Approved** → **Active** → (**Expired** or **Revoked**)
|
||||
* **Renewal** should create a **new version** (never extend an old record silently).
|
||||
|
||||
### Approvals
|
||||
|
||||
PM guideline:
|
||||
|
||||
* At least two approval modes:
|
||||
|
||||
1. **Self-approved** (allowed only for dev/experimental scopes)
|
||||
2. **Two-person review** (required for prod or broad scope)
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Enforce approval rules via policy config (not hard-coded).
|
||||
* Record every approval action with actor identity and timestamp.
|
||||
|
||||
### Expiry enforcement
|
||||
|
||||
Non-negotiable:
|
||||
|
||||
* Expired exceptions must stop applying automatically.
|
||||
* Renewals require an explicit action and new audit trail.
|
||||
|
||||
## 3.6 Evaluation semantics (how exceptions affect results)
|
||||
|
||||
This is where most products become non-auditable. You need deterministic, explicit rules.
|
||||
|
||||
PM guideline: define precedence clearly:
|
||||
|
||||
* Policy engine evaluates baseline findings → applies exceptions → produces verdict.
|
||||
* Exceptions never delete underlying findings; they alter the *decision outcome* and annotate the reasoning.
|
||||
|
||||
Eng guideline: exception application must be:
|
||||
|
||||
* **Deterministic** (stable ordering rules)
|
||||
* **Transparent** (verdict includes “exception applied: exception_id, reason_code, scope match explanation”)
|
||||
* **Scoped** (match explanation must state which scope dimensions matched)
|
||||
|
||||
## 3.7 Auditability requirements
|
||||
|
||||
Exception management must be audit-ready by construction.
|
||||
|
||||
Minimum requirements:
|
||||
|
||||
* **Append-only event log** for create/approve/revoke/expire/renew actions
|
||||
* **Versioning**: every change results in a new version or event
|
||||
* **Tamper-evidence**: hash chain events or sign event batches
|
||||
* **Retention**: define retention policy and export strategy
|
||||
|
||||
PM guideline: auditors will ask “who approved,” “why,” “when,” “what scope,” and “what changed since.” Design the UX and exports to answer those in minutes.
|
||||
|
||||
## 3.8 UX guidelines
|
||||
|
||||
Key UX flows:
|
||||
|
||||
* **Create exception from a finding** (pre-fill CVE/component/artifact scope)
|
||||
* **Preview impact** (“this will suppress 37 findings across 12 images; are you sure?”)
|
||||
* **Expiry visibility** (countdown, alerts, renewal prompts)
|
||||
* **Audit trail view** (who did what, with diffs between versions)
|
||||
* **Search and filters** by owner, reason, expiry window, scope breadth, environment
|
||||
|
||||
UX anti-patterns to forbid:
|
||||
|
||||
* “Ignore all vulnerabilities in this image” with one click
|
||||
* Silent suppressions without owner/expiry
|
||||
* Exceptions created without linking to scope and reason
|
||||
|
||||
## 3.9 Product acceptance criteria (PM-owned)
|
||||
|
||||
A feature is not “done” until:
|
||||
|
||||
* Every exception has owner, expiry, reason code, scope.
|
||||
* Exception history is immutable and exportable.
|
||||
* Policy outcomes show applied exceptions and why.
|
||||
* Expiry is enforced automatically.
|
||||
* A user can answer: “What exceptions were active for this release?” within 2 minutes.
|
||||
|
||||
---
|
||||
|
||||
# 4. Audit packs
|
||||
|
||||
## 4.1 What an audit pack is
|
||||
|
||||
An Audit Pack is a **portable, verifiable bundle** that answers:
|
||||
|
||||
* What was evaluated? (artifacts, versions, identities)
|
||||
* Under what policies? (policy version/config)
|
||||
* Using what knowledge state? (vuln DB snapshot, VEX inputs)
|
||||
* What exceptions were applied? (IDs, owners, rationales)
|
||||
* What was the decision and why? (verdict + evidence pointers)
|
||||
* What changed since the last release? (optional diff summary)
|
||||
|
||||
PM guideline: treat the Audit Pack as a product deliverable, not an export button.
|
||||
|
||||
## 4.2 Pack structure (recommended)
|
||||
|
||||
Use a predictable, documented layout. Example:
|
||||
|
||||
* `manifest.json`
|
||||
|
||||
* pack_id, generated_at, generator_version
|
||||
* hashes/digests of every included file
|
||||
* signing info (optional in v1; recommended soon)
|
||||
* `inputs/`
|
||||
|
||||
* artifact identifiers (digests), repo references (optional)
|
||||
* SBOM(s) (CycloneDX/SPDX)
|
||||
* `vex/`
|
||||
|
||||
* VEX docs used + any VEX produced
|
||||
* `policy/`
|
||||
|
||||
* policy bundle used (versioned)
|
||||
* evaluation settings
|
||||
* `exceptions/`
|
||||
|
||||
* all exceptions relevant to the evaluated scope
|
||||
* plus event logs / versions
|
||||
* `findings/`
|
||||
|
||||
* normalized findings list
|
||||
* reachability evidence fragments if applicable
|
||||
* `verdict/`
|
||||
|
||||
* final decision object
|
||||
* explanation summary
|
||||
* signed attestation (if supported)
|
||||
* `diff/` (optional)
|
||||
|
||||
* delta from prior baseline (what changed materially)
|
||||
|
||||
## 4.3 Formats: human and machine
|
||||
|
||||
You need both:
|
||||
|
||||
* **Machine-readable** (JSON + standard SBOM/VEX formats) for verification and automation
|
||||
* **Human-readable** summary (HTML or PDF) for auditors and leadership
|
||||
|
||||
PM guideline: machine artifacts are the source of truth. Human docs are derived views.
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Ensure the pack can be generated **offline**.
|
||||
* Ensure deterministic outputs where feasible (stable ordering, consistent serialization).
|
||||
|
||||
## 4.4 Integrity and verification
|
||||
|
||||
At minimum:
|
||||
|
||||
* `manifest.json` includes a digest for each file.
|
||||
* Provide a `stella verify-pack` CLI that checks:
|
||||
|
||||
* manifest integrity
|
||||
* file hashes
|
||||
* schema versions
|
||||
* optional signature verification
|
||||
|
||||
For v2:
|
||||
|
||||
* Sign the manifest (and/or the verdict) using your standard attestation mechanism.
|
||||
|
||||
## 4.5 Confidentiality and redaction
|
||||
|
||||
Audit packs often include sensitive data (paths, internal package names, repo URLs).
|
||||
|
||||
PM guideline:
|
||||
|
||||
* Provide **redaction profiles**:
|
||||
|
||||
* external auditor pack (minimal identifiers)
|
||||
* internal audit pack (full detail)
|
||||
* Provide encryption options (password/recipient keys) if packs leave the environment.
|
||||
|
||||
Eng guideline:
|
||||
|
||||
* Redaction must be deterministic and declarative (policy-based).
|
||||
* Pack generation must not leak secrets from raw scan logs.
|
||||
|
||||
## 4.6 Pack generation workflow
|
||||
|
||||
Key product flows:
|
||||
|
||||
* Generate pack for:
|
||||
|
||||
* a specific artifact digest
|
||||
* a release (set of digests)
|
||||
* an environment snapshot (e.g., cluster inventory)
|
||||
* a date range (for audit period)
|
||||
* Trigger sources:
|
||||
|
||||
* UI
|
||||
* API
|
||||
* CI pipeline step
|
||||
|
||||
Engineering:
|
||||
|
||||
* Treat pack generation as an async job (queue + status endpoint).
|
||||
* Cache pack components when inputs are identical (avoid repeated work).
|
||||
|
||||
## 4.7 What must be included (minimum viable audit pack)
|
||||
|
||||
PMs should enforce that v1 includes:
|
||||
|
||||
* Artifact identity
|
||||
* SBOM(s) or component inventory
|
||||
* Findings list (normalized)
|
||||
* Policy bundle reference + policy content
|
||||
* Exceptions applied (full object + version info)
|
||||
* Final verdict + explanation summary
|
||||
* Integrity manifest with file hashes
|
||||
|
||||
Add these when available (v1.5+):
|
||||
|
||||
* VEX inputs and outputs
|
||||
* Knowledge snapshot references
|
||||
* Reachability evidence fragments
|
||||
* Diff summary vs prior release
|
||||
|
||||
## 4.8 Product acceptance criteria (PM-owned)
|
||||
|
||||
Audit Packs are not “done” until:
|
||||
|
||||
* A third party can validate the pack contents haven’t been altered (hash verification).
|
||||
* The pack answers “why did this pass/fail?” including exceptions applied.
|
||||
* Packs can be generated without external network calls (air-gap friendly).
|
||||
* Packs support redaction profiles.
|
||||
* Pack schema is versioned and backward compatible.
|
||||
|
||||
---
|
||||
|
||||
# 5. Cross-cutting: roles, responsibilities, and delivery checkpoints
|
||||
|
||||
## 5.1 Responsibilities
|
||||
|
||||
**Product Manager**
|
||||
|
||||
* Define exception types and required fields
|
||||
* Define reason code taxonomy and governance policies
|
||||
* Define approval rules by environment and scope breadth
|
||||
* Define audit pack templates, profiles, and export targets
|
||||
* Own acceptance criteria and audit usability testing
|
||||
|
||||
**Development Manager / Tech Lead**
|
||||
|
||||
* Own event model (immutability, versioning, retention)
|
||||
* Own policy evaluation semantics and determinism guarantees
|
||||
* Own integrity and signing design (manifest hashes, optional signatures)
|
||||
* Own performance and scalability targets (pack generation and query latency)
|
||||
* Own secure storage and access controls (RBAC, tenant isolation)
|
||||
|
||||
## 5.2 Deliverables checklist (for each capability)
|
||||
|
||||
For “Exception Objects”:
|
||||
|
||||
* PRD + threat model (abuse cases: blanket waivers, privilege escalation)
|
||||
* Schema spec + versioning policy
|
||||
* API endpoints + RBAC model
|
||||
* UI flows + audit trail UI
|
||||
* Policy engine semantics + test vectors
|
||||
* Metrics dashboards
|
||||
|
||||
For “Audit Packs”:
|
||||
|
||||
* Pack schema spec + folder layout
|
||||
* Manifest + hash verification rules
|
||||
* Generator service + async job API
|
||||
* Redaction profiles + tests
|
||||
* Verifier CLI + documentation
|
||||
* Performance benchmarks + caching strategy
|
||||
|
||||
---
|
||||
|
||||
# 6. Common failure modes to actively prevent
|
||||
|
||||
1. **Exceptions become suppressions again**
|
||||
If you allow exceptions without expiry/owner or without audit trail, you’ve rebuilt “ignore lists.”
|
||||
|
||||
2. **Over-broad scopes by default**
|
||||
If “all repos/all images” is easy, you will accumulate permanent waivers and lose credibility.
|
||||
|
||||
3. **No deterministic semantics**
|
||||
If the same artifact can pass/fail depending on evaluation order or transient feed updates, auditors will distrust outputs.
|
||||
|
||||
4. **Audit packs that are reports, not evidence**
|
||||
A PDF without machine-verifiable artifacts is not an audit pack—it’s a slide.
|
||||
|
||||
5. **No renewal discipline**
|
||||
If renewals are frictionless and don’t require re-justification, exceptions never die.
|
||||
|
||||
---
|
||||
|
||||
# 7. Recommended phased rollout (to manage build cost)
|
||||
|
||||
**Phase 1: Governance basics**
|
||||
|
||||
* Exception object schema + lifecycle + expiry enforcement
|
||||
* Create-from-finding UX
|
||||
* Audit pack v1 (SBOM/inventory + findings + policy + exceptions + manifest)
|
||||
|
||||
**Phase 2: Evidence binding**
|
||||
|
||||
* Evidence refs on exceptions (VEX, reachability fragments)
|
||||
* Pack includes VEX inputs/outputs and knowledge snapshot identifiers
|
||||
|
||||
**Phase 3: Verifiable trust**
|
||||
|
||||
* Signed verdicts and/or signed pack manifests
|
||||
* Verifier tooling and deterministic replay hooks
|
||||
|
||||
---
|
||||
|
||||
If you want, I can convert the above into two artifacts your teams can execute against immediately:
|
||||
|
||||
1. A concise **PRD template** (sections + required decisions) for Exceptions and Audit Packs
|
||||
2. A **technical spec outline** (schema definitions, endpoints, state machines, and acceptance test vectors)
|
||||
@@ -0,0 +1,556 @@
|
||||
## Guidelines for Product and Development Managers: Signed, Replayable Risk Verdicts
|
||||
|
||||
### Purpose
|
||||
|
||||
Signed, replayable risk verdicts are the Stella Ops mechanism for producing a **cryptographically verifiable, audit‑ready decision** about an artifact (container image, VM image, filesystem snapshot, SBOM, etc.) that can be **recomputed later to the same result** using the same inputs (“time-travel replay”).
|
||||
|
||||
This capability is not “scan output with a signature.” It is a **decision artifact** that becomes the unit of governance in CI/CD, registry admission, and audits.
|
||||
|
||||
---
|
||||
|
||||
# 1) Shared definitions and non-negotiables
|
||||
|
||||
## 1.1 Definitions
|
||||
|
||||
**Risk verdict**
|
||||
A structured decision: *Pass / Fail / Warn / Needs‑Review* (or similar), produced by a deterministic evaluator under a specific policy and knowledge state.
|
||||
|
||||
**Signed**
|
||||
The verdict is wrapped in a tamper‑evident envelope (e.g., DSSE/in‑toto statement) and signed using an organization-approved trust model (key-based, keyless, or offline CA).
|
||||
|
||||
**Replayable**
|
||||
Given the same:
|
||||
|
||||
* target artifact identity
|
||||
* SBOM (or derivation method)
|
||||
* vulnerability and advisory knowledge state
|
||||
* VEX inputs
|
||||
* policy bundle
|
||||
* evaluator version
|
||||
…Stella Ops can **re-evaluate and reproduce the same verdict** and provide evidence equivalence.
|
||||
|
||||
> Critical nuance: replayability is about *result equivalence*. Byte‑for‑byte equality is ideal but not always required if signatures/metadata necessarily vary. If byte‑for‑byte is a goal, you must strictly control timestamps, ordering, and serialization.
|
||||
|
||||
---
|
||||
|
||||
## 1.2 Non-negotiables (what must be true in v1)
|
||||
|
||||
1. **Verdicts are bound to immutable artifact identity**
|
||||
|
||||
* Container image: digest (sha256:…)
|
||||
* SBOM: content digest
|
||||
* File tree: merkle root digest, or equivalent
|
||||
|
||||
2. **Verdicts are deterministic**
|
||||
|
||||
* No “current time” dependence in scoring
|
||||
* No non-deterministic ordering of findings
|
||||
* No implicit network calls during evaluation
|
||||
|
||||
3. **Verdicts are explainable**
|
||||
|
||||
* Every deny/block decision must cite the policy clause and evidence pointers that triggered it.
|
||||
|
||||
4. **Verdicts are verifiable**
|
||||
|
||||
* Independent verification toolchain exists (CLI/library) that validates signature and checks referenced evidence integrity.
|
||||
|
||||
5. **Knowledge state is pinned**
|
||||
|
||||
* The verdict references a “knowledge snapshot” (vuln feeds, advisories, VEX set) by digest/ID, not “latest.”
|
||||
|
||||
---
|
||||
|
||||
## 1.3 Explicit non-goals (avoid scope traps)
|
||||
|
||||
* Building a full CNAPP runtime protection product as part of verdicting.
|
||||
* Implementing “all possible attestation standards.” Pick one canonical representation; support others via adapters.
|
||||
* Solving global revocation and key lifecycle for every ecosystem on day one; define a minimum viable trust model per deployment mode.
|
||||
|
||||
---
|
||||
|
||||
# 2) Product Management Guidelines
|
||||
|
||||
## 2.1 Position the verdict as the primary product artifact
|
||||
|
||||
**PM rule:** if a workflow does not end in a verdict artifact, it is not part of this moat.
|
||||
|
||||
Examples:
|
||||
|
||||
* CI pipeline step produces `VERDICT.attestation` attached to the OCI artifact.
|
||||
* Registry admission checks for a valid verdict attestation meeting policy.
|
||||
* Audit export bundles the verdict plus referenced evidence.
|
||||
|
||||
**Avoid:** “scan reports” as the goal. Reports are views; the verdict is the object.
|
||||
|
||||
---
|
||||
|
||||
## 2.2 Define the core personas and success outcomes
|
||||
|
||||
Minimum personas:
|
||||
|
||||
1. **Release/Platform Engineering**
|
||||
|
||||
* Needs automated gates, reproducibility, and low friction.
|
||||
2. **Security Engineering / AppSec**
|
||||
|
||||
* Needs evidence, explainability, and exception workflows.
|
||||
3. **Audit / Compliance**
|
||||
|
||||
* Needs replay, provenance, and a defensible trail.
|
||||
|
||||
Define “first value” for each:
|
||||
|
||||
* Release engineer: gate merges/releases without re-running scans.
|
||||
* Security engineer: investigate a deny decision with evidence pointers in minutes.
|
||||
* Auditor: replay a verdict months later using the same knowledge snapshot.
|
||||
|
||||
---
|
||||
|
||||
## 2.3 Product requirements (expressed as “shall” statements)
|
||||
|
||||
### 2.3.1 Verdict content requirements
|
||||
|
||||
A verdict SHALL contain:
|
||||
|
||||
* **Subject**: immutable artifact reference (digest, type, locator)
|
||||
* **Decision**: pass/fail/warn/etc.
|
||||
* **Policy binding**: policy bundle ID + version + digest
|
||||
* **Knowledge snapshot binding**: snapshot IDs/digests for vuln feed and VEX set
|
||||
* **Evaluator binding**: evaluator name/version + schema version
|
||||
* **Rationale summary**: stable short explanation (human-readable)
|
||||
* **Findings references**: pointers to detailed findings/evidence (content-addressed)
|
||||
* **Unknowns state**: explicit unknown counts and categories
|
||||
|
||||
### 2.3.2 Replay requirements
|
||||
|
||||
The product SHALL support:
|
||||
|
||||
* Re-evaluating the same subject under the same policy+knowledge snapshot
|
||||
* Proving equivalence of inputs used in the original verdict
|
||||
* Producing a “replay report” that states:
|
||||
|
||||
* replay succeeded and matched
|
||||
* or replay failed and why (e.g., missing evidence, policy changed)
|
||||
|
||||
### 2.3.3 UX requirements
|
||||
|
||||
UI/UX SHALL:
|
||||
|
||||
* Show verdict status clearly (Pass/Fail/…)
|
||||
* Display:
|
||||
|
||||
* policy clause(s) responsible
|
||||
* top evidence pointers
|
||||
* knowledge snapshot ID
|
||||
* signature trust status (who signed, chain validity)
|
||||
* Provide “Replay” as an action (even if replay happens offline, the UX must guide it)
|
||||
|
||||
---
|
||||
|
||||
## 2.4 Product taxonomy: separate “verdicts” from “evaluations” from “attestations”
|
||||
|
||||
This is where many products get confused. Your terminology must remain strict:
|
||||
|
||||
* **Evaluation**: internal computation that produces decision + findings.
|
||||
* **Verdict**: the stable, canonical decision payload (the thing being signed).
|
||||
* **Attestation**: the signed envelope binding the verdict to cryptographic identity.
|
||||
|
||||
PMs must enforce this vocabulary in PRDs, UI labels, and docs.
|
||||
|
||||
---
|
||||
|
||||
## 2.5 Policy model guidelines for verdicting
|
||||
|
||||
Verdicting depends on policy discipline.
|
||||
|
||||
PM rules:
|
||||
|
||||
* Policy must be **versioned** and **content-addressed**.
|
||||
* Policies must be **pure functions** of declared inputs:
|
||||
|
||||
* SBOM graph
|
||||
* VEX claims
|
||||
* vulnerability data
|
||||
* reachability evidence (if present)
|
||||
* environment assertions (if present)
|
||||
* Policies must produce:
|
||||
|
||||
* a decision
|
||||
* plus a minimal explanation graph (policy rule ID → evidence IDs)
|
||||
|
||||
Avoid “freeform scripts” early. You need determinism and auditability.
|
||||
|
||||
---
|
||||
|
||||
## 2.6 Exceptions are part of the verdict product, not an afterthought
|
||||
|
||||
PM requirement:
|
||||
|
||||
* Exceptions must be first-class objects with:
|
||||
|
||||
* scope (exact artifact/component range)
|
||||
* owner
|
||||
* justification
|
||||
* expiry
|
||||
* required evidence (optional but strongly recommended)
|
||||
|
||||
And verdict logic must:
|
||||
|
||||
* record that an exception was applied
|
||||
* include exception IDs in the verdict evidence graph
|
||||
* make exception usage visible in UI and audit pack exports
|
||||
|
||||
---
|
||||
|
||||
## 2.7 Success metrics (PM-owned)
|
||||
|
||||
Choose metrics that reflect the moat:
|
||||
|
||||
* **Replay success rate**: % of verdicts that can be replayed after N days.
|
||||
* **Policy determinism incidents**: number of non-deterministic evaluation bugs.
|
||||
* **Audit cycle time**: time to satisfy an audit evidence request for a release.
|
||||
* **Noise**: # of manual suppressions/overrides per 100 releases (should drop).
|
||||
* **Gate adoption**: % of releases gated by verdict attestations (not reports).
|
||||
|
||||
---
|
||||
|
||||
# 3) Development Management Guidelines
|
||||
|
||||
## 3.1 Architecture principles (engineering tenets)
|
||||
|
||||
### Tenet A: Determinism-first evaluation
|
||||
|
||||
Engineering SHALL ensure evaluation is deterministic across:
|
||||
|
||||
* OS and architecture differences (as much as feasible)
|
||||
* concurrency scheduling
|
||||
* non-ordered data structures
|
||||
|
||||
Practical rules:
|
||||
|
||||
* Never iterate over maps/hashes without sorting keys.
|
||||
* Canonicalize output ordering (findings sorted by stable tuple: (component_id, cve_id, path, rule_id)).
|
||||
* Keep “generated at” timestamps out of the signed payload; if needed, place them in an unsigned wrapper or separate metadata field excluded from signature.
|
||||
|
||||
### Tenet B: Content-address everything
|
||||
|
||||
All significant inputs/outputs should have content digests:
|
||||
|
||||
* SBOM digest
|
||||
* policy digest
|
||||
* knowledge snapshot digest
|
||||
* evidence bundle digest
|
||||
* verdict digest
|
||||
|
||||
This makes replay and integrity checks possible.
|
||||
|
||||
### Tenet C: No hidden network
|
||||
|
||||
During evaluation, the engine must not fetch “latest” anything.
|
||||
Network is allowed only in:
|
||||
|
||||
* snapshot acquisition phase
|
||||
* artifact retrieval phase
|
||||
* attestation publication phase
|
||||
…and each must be explicitly logged and pinned.
|
||||
|
||||
---
|
||||
|
||||
## 3.2 Canonical verdict schema and serialization rules
|
||||
|
||||
**Engineering guideline:** pick a canonical serialization and stick to it.
|
||||
|
||||
Options:
|
||||
|
||||
* Canonical JSON (JCS or equivalent)
|
||||
* CBOR with deterministic encoding
|
||||
|
||||
Rules:
|
||||
|
||||
* Define a **schema version** and strict validation.
|
||||
* Make field names stable; avoid “optional” fields that appear/disappear nondeterministically.
|
||||
* Ensure numeric formatting is stable (no float drift; prefer integers or rational representation).
|
||||
* Always include empty arrays if required for stability, or exclude consistently by schema rule.
|
||||
|
||||
---
|
||||
|
||||
## 3.3 Suggested verdict payload (illustrative)
|
||||
|
||||
This is not a mandate—use it as a baseline structure.
|
||||
|
||||
```json
|
||||
{
|
||||
"schema_version": "1.0",
|
||||
"subject": {
|
||||
"type": "oci-image",
|
||||
"name": "registry.example.com/app/service",
|
||||
"digest": "sha256:…",
|
||||
"platform": "linux/amd64"
|
||||
},
|
||||
"evaluation": {
|
||||
"evaluator": "stella-eval",
|
||||
"evaluator_version": "0.9.0",
|
||||
"policy": {
|
||||
"id": "prod-default",
|
||||
"version": "2025.12.1",
|
||||
"digest": "sha256:…"
|
||||
},
|
||||
"knowledge_snapshot": {
|
||||
"vuln_db_digest": "sha256:…",
|
||||
"advisory_digest": "sha256:…",
|
||||
"vex_set_digest": "sha256:…"
|
||||
}
|
||||
},
|
||||
"decision": {
|
||||
"status": "fail",
|
||||
"score": 87,
|
||||
"reasons": [
|
||||
{ "rule_id": "RISK.CRITICAL.REACHABLE", "evidence_ref": "sha256:…" }
|
||||
],
|
||||
"unknowns": {
|
||||
"unknown_reachable": 2,
|
||||
"unknown_unreachable": 0
|
||||
}
|
||||
},
|
||||
"evidence": {
|
||||
"sbom_digest": "sha256:…",
|
||||
"finding_bundle_digest": "sha256:…",
|
||||
"inputs_manifest_digest": "sha256:…"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Then wrap this payload in your chosen attestation envelope and sign it.
|
||||
|
||||
---
|
||||
|
||||
## 3.4 Attestation format and storage guidelines
|
||||
|
||||
Development managers must enforce a consistent publishing model:
|
||||
|
||||
1. **Envelope**
|
||||
|
||||
* Prefer DSSE/in-toto style envelope because it:
|
||||
|
||||
* standardizes signing
|
||||
* supports multiple signature schemes
|
||||
* is widely adopted in supply chain ecosystems
|
||||
|
||||
2. **Attachment**
|
||||
|
||||
* OCI artifacts should carry verdicts as referrers/attachments to the subject digest (preferred).
|
||||
* For non-OCI targets, store in an internal ledger keyed by the subject digest/ID.
|
||||
|
||||
3. **Verification**
|
||||
|
||||
* Provide:
|
||||
|
||||
* `stella verify <artifact>` → checks signature and integrity references
|
||||
* `stella replay <verdict>` → re-run evaluation from snapshots and compare
|
||||
|
||||
4. **Transparency / logs**
|
||||
|
||||
* Optional in v1, but plan for:
|
||||
|
||||
* transparency log (public or private) to strengthen auditability
|
||||
* offline alternatives for air-gapped customers
|
||||
|
||||
---
|
||||
|
||||
## 3.5 Knowledge snapshot engineering requirements
|
||||
|
||||
A “snapshot” must be an immutable bundle, ideally content-addressed:
|
||||
|
||||
Snapshot includes:
|
||||
|
||||
* vulnerability database at a specific point
|
||||
* advisory sources (OS distro advisories)
|
||||
* VEX statement set(s)
|
||||
* any enrichment signals that influence scoring
|
||||
|
||||
Rules:
|
||||
|
||||
* Snapshot resolution must be explicit: “use snapshot digest X”
|
||||
* Must support export/import for air-gapped deployments
|
||||
* Must record source provenance and ingestion timestamps (timestamps may be excluded from signed payload if they cause nondeterminism; store them in snapshot metadata)
|
||||
|
||||
---
|
||||
|
||||
## 3.6 Replay engine requirements
|
||||
|
||||
Replay is not “re-run scan and hope it matches.”
|
||||
|
||||
Replay must:
|
||||
|
||||
* retrieve the exact subject (or confirm it via digest)
|
||||
* retrieve the exact SBOM (or deterministically re-generate it from the subject in a defined way)
|
||||
* load exact policy bundle by digest
|
||||
* load exact knowledge snapshot by digest
|
||||
* run evaluator version pinned in verdict (or enforce a compatibility mapping)
|
||||
* produce:
|
||||
|
||||
* verdict-equivalence result
|
||||
* a delta explanation if mismatch occurs
|
||||
|
||||
Engineering rule: replay must fail loudly and specifically when inputs are missing.
|
||||
|
||||
---
|
||||
|
||||
## 3.7 Testing strategy (required)
|
||||
|
||||
Deterministic systems require “golden” testing.
|
||||
|
||||
Minimum tests:
|
||||
|
||||
1. **Golden verdict tests**
|
||||
|
||||
* Fixed artifact + fixed snapshots + fixed policy
|
||||
* Expected verdict output must match exactly
|
||||
|
||||
2. **Cross-platform determinism tests**
|
||||
|
||||
* Run same evaluation on different machines/containers and compare outputs
|
||||
|
||||
3. **Mutation tests for determinism**
|
||||
|
||||
* Randomize ordering of internal collections; output should remain unchanged
|
||||
|
||||
4. **Replay regression tests**
|
||||
|
||||
* Store verdict + snapshots and replay after code changes to ensure compatibility guarantees hold
|
||||
|
||||
---
|
||||
|
||||
## 3.8 Versioning and backward compatibility guidelines
|
||||
|
||||
This is essential to prevent “replay breaks after upgrades.”
|
||||
|
||||
Rules:
|
||||
|
||||
* **Verdict schema version** changes must be rare and carefully managed.
|
||||
* Maintain a compatibility matrix:
|
||||
|
||||
* evaluator vX can replay verdict schema vY
|
||||
* If you must evolve logic, do so by:
|
||||
|
||||
* bumping evaluator version
|
||||
* preserving older evaluators in a compatibility mode (containerized evaluators are often easiest)
|
||||
|
||||
---
|
||||
|
||||
## 3.9 Security and key management guidelines
|
||||
|
||||
Development managers must ensure:
|
||||
|
||||
* Signing keys are managed via:
|
||||
|
||||
* KMS/HSM (enterprise)
|
||||
* keyless (OIDC-based) where acceptable
|
||||
* offline keys for air-gapped
|
||||
|
||||
* Verification trust policy is explicit:
|
||||
|
||||
* which identities are trusted to sign verdicts
|
||||
* which policies are accepted
|
||||
* whether transparency is required
|
||||
* how to handle revocation/rotation
|
||||
|
||||
* Separate “can sign” from “can publish”
|
||||
|
||||
* Signing should be restricted; publishing may be broader.
|
||||
|
||||
---
|
||||
|
||||
# 4) Operational workflow requirements (cross-functional)
|
||||
|
||||
## 4.1 CI gate flow
|
||||
|
||||
* Build artifact
|
||||
* Produce SBOM deterministically (or record SBOM digest if generated elsewhere)
|
||||
* Evaluate → produce verdict payload
|
||||
* Sign verdict → publish attestation attached to artifact
|
||||
* Gate decision uses verification of:
|
||||
|
||||
* signature validity
|
||||
* policy compliance
|
||||
* snapshot integrity
|
||||
|
||||
## 4.2 Registry / admission flow
|
||||
|
||||
* Admission controller checks for a valid, trusted verdict attestation
|
||||
* Optionally requires:
|
||||
|
||||
* verdict not older than X snapshot age (this is policy)
|
||||
* no expired exceptions
|
||||
* replay not required (replay is for audits; admission is fast-path)
|
||||
|
||||
## 4.3 Audit flow
|
||||
|
||||
* Export “audit pack”:
|
||||
|
||||
* verdict + signature chain
|
||||
* policy bundle
|
||||
* knowledge snapshot
|
||||
* referenced evidence bundles
|
||||
* Auditor (or internal team) runs `verify` and optionally `replay`
|
||||
|
||||
---
|
||||
|
||||
# 5) Common failure modes to avoid
|
||||
|
||||
1. **Signing “findings” instead of a decision**
|
||||
|
||||
* Leads to unbounded payload growth and weak governance semantics.
|
||||
|
||||
2. **Using “latest” feeds during evaluation**
|
||||
|
||||
* Breaks replayability immediately.
|
||||
|
||||
3. **Embedding timestamps in signed payload**
|
||||
|
||||
* Eliminates deterministic byte-level reproducibility.
|
||||
|
||||
4. **Letting the UI become the source of truth**
|
||||
|
||||
* The verdict artifact must be the authority; UI is a view.
|
||||
|
||||
5. **No clear separation between: evidence store, snapshot store, verdict store**
|
||||
|
||||
* Creates coupling and makes offline operations painful.
|
||||
|
||||
---
|
||||
|
||||
# 6) Definition of Done checklist (use this to gate release)
|
||||
|
||||
A feature increment for signed, replayable verdicts is “done” only if:
|
||||
|
||||
* [ ] Verdict binds to immutable subject digest
|
||||
* [ ] Verdict includes policy digest/version and knowledge snapshot digests
|
||||
* [ ] Verdict is signed and verifiable via CLI
|
||||
* [ ] Verification works offline (given exported artifacts)
|
||||
* [ ] Replay works with stored snapshots and produces match/mismatch output with reasons
|
||||
* [ ] Determinism tests pass (golden + mutation + cross-platform)
|
||||
* [ ] UI displays signer identity, policy, snapshot IDs, and rule→evidence links
|
||||
* [ ] Exceptions (if implemented) are recorded in verdict and enforced deterministically
|
||||
|
||||
---
|
||||
|
||||
## Optional: Recommended implementation sequence (keeps risk down)
|
||||
|
||||
1. Canonical verdict schema + deterministic evaluator skeleton
|
||||
2. Signing + verification CLI
|
||||
3. Snapshot bundle format + pinned evaluation
|
||||
4. Replay tool + golden tests
|
||||
5. OCI attachment publishing + registry/admission integration
|
||||
6. Evidence bundles + UI explainability
|
||||
7. Exceptions + audit pack export
|
||||
|
||||
---
|
||||
|
||||
If you want this turned into a formal internal PRD template, I can format it as:
|
||||
|
||||
* “Product requirements” (MUST/SHOULD/COULD)
|
||||
* “Engineering requirements” (interfaces + invariants + test plan)
|
||||
* “Security model” (trust roots, signing identities, verification policy)
|
||||
* “Acceptance criteria” for an MVP and for GA
|
||||
@@ -0,0 +1,462 @@
|
||||
Below are internal guidelines for Stella Ops Product Managers and Development Managers for the capability: **Knowledge Snapshots / Time‑Travel Replay**. This is written as an implementable operating standard (not a concept note).
|
||||
|
||||
---
|
||||
|
||||
# Knowledge Snapshots / Time‑Travel Replay
|
||||
|
||||
## Product and Engineering Guidelines for Stella Ops
|
||||
|
||||
## 1) Purpose and value proposition
|
||||
|
||||
### What this capability must achieve
|
||||
|
||||
Enable Stella Ops to **reproduce any historical risk decision** (scan result, policy evaluation, verdict) **deterministically**, using a **cryptographically bound snapshot** of the exact knowledge inputs that were available at the time the decision was made.
|
||||
|
||||
### Why customers pay for it
|
||||
|
||||
This capability is primarily purchased for:
|
||||
|
||||
* **Auditability**: “Show me what you knew, when you knew it, and why the system decided pass/fail.”
|
||||
* **Incident response**: reproduce prior posture using historical feeds/VEX/policies and explain deltas.
|
||||
* **Air‑gapped / regulated environments**: deterministic, offline decisioning with attested knowledge state.
|
||||
* **Change control**: prove whether a decision changed due to code change vs knowledge change.
|
||||
|
||||
### Core product promise
|
||||
|
||||
For a given artifact and snapshot:
|
||||
|
||||
* **Same inputs → same outputs** (verdict, scores, findings, evidence pointers), or Stella Ops must clearly declare the precise exceptions.
|
||||
|
||||
---
|
||||
|
||||
## 2) Definitions (PMs and engineers must align on these)
|
||||
|
||||
### Knowledge input
|
||||
|
||||
Any external or semi-external information that can influence the outcome:
|
||||
|
||||
* vulnerability databases and advisories (any source)
|
||||
* exploit-intel signals
|
||||
* VEX statements (OpenVEX, CSAF, CycloneDX VEX, etc.)
|
||||
* SBOM ingestion logic and parsing rules
|
||||
* package identification rules (including distro/backport logic)
|
||||
* policy content and policy engine version
|
||||
* scoring rules (including weights and thresholds)
|
||||
* trust anchors and signature verification policy
|
||||
* plugin versions and enabled capabilities
|
||||
* configuration defaults and overrides that change analysis
|
||||
|
||||
### Knowledge Snapshot
|
||||
|
||||
A **sealed record** of:
|
||||
|
||||
1. **References** (which inputs were used), and
|
||||
2. **Content** (the exact bytes used), and
|
||||
3. **Execution contract** (the evaluator and ruleset versions)
|
||||
|
||||
### Time‑Travel Replay
|
||||
|
||||
Re-running evaluation of an artifact **using only** the snapshot content and the recorded execution contract, producing the same decision and explainability artifacts.
|
||||
|
||||
---
|
||||
|
||||
## 3) Product principles (non‑negotiables)
|
||||
|
||||
1. **Determinism is a product requirement**, not an engineering detail.
|
||||
2. **Snapshots are first‑class artifacts** with explicit lifecycle (create, verify, export/import, retain, expire).
|
||||
3. **The snapshot is cryptographically bound** to outcomes and evidence (tamper-evident chain).
|
||||
4. **Replays must be possible offline** (when the snapshot includes content) and must fail clearly when not possible.
|
||||
5. **Minimal surprise**: the UI must explain when a verdict changed due to “knowledge drift” vs “artifact drift.”
|
||||
6. **Scalability by content addressing**: the platform must deduplicate knowledge content aggressively.
|
||||
7. **Backward compatibility**: old snapshots must remain replayable within a documented support window.
|
||||
|
||||
---
|
||||
|
||||
## 4) Scope boundaries (what this is not)
|
||||
|
||||
### Non-goals (explicitly out of scope for v1 unless approved)
|
||||
|
||||
* Reconstructing *external internet state* beyond what is recorded (no “fetch historical CVE state from the web”).
|
||||
* Guaranteeing replay across major engine rewrites without a compatibility plan.
|
||||
* Storing sensitive proprietary customer code in snapshots (unless explicitly enabled).
|
||||
* Replaying “live runtime signals” unless those signals were captured into the snapshot at decision time.
|
||||
|
||||
---
|
||||
|
||||
## 5) Personas and use cases (PM guidance)
|
||||
|
||||
### Primary personas
|
||||
|
||||
* **Security Governance / GRC**: needs audit packs, controls evidence, deterministic history.
|
||||
* **Incident response / AppSec lead**: needs “what changed and why” quickly.
|
||||
* **Platform engineering / DevOps**: needs reproducible CI gates and air‑gap workflows.
|
||||
* **Procurement / regulated customers**: needs proof of process and defensible attestations.
|
||||
|
||||
### Must-support use cases
|
||||
|
||||
1. **Replay a past release gate decision** in a new environment (including offline) and get identical outcome.
|
||||
2. **Explain drift**: “This build fails today but passed last month—why?”
|
||||
3. **Air‑gap export/import**: create snapshots in connected environment, import to disconnected one.
|
||||
4. **Audit bundle generation**: export snapshot + verdict(s) + evidence pointers.
|
||||
|
||||
---
|
||||
|
||||
## 6) Functional requirements (PM “must/should” list)
|
||||
|
||||
### Must
|
||||
|
||||
* **Snapshot creation** for every material evaluation (or for every “decision object” chosen by configuration).
|
||||
* **Snapshot manifest** containing:
|
||||
|
||||
* unique snapshot ID (content-addressed)
|
||||
* list of knowledge sources with hashes/digests
|
||||
* policy IDs and exact policy content hashes
|
||||
* engine version and plugin versions
|
||||
* timestamp and clock source metadata
|
||||
* trust anchor set hash and verification policy hash
|
||||
* **Snapshot sealing**:
|
||||
|
||||
* snapshot manifest is signed
|
||||
* signed link from verdict → snapshot ID
|
||||
* **Replay**:
|
||||
|
||||
* re-evaluate using only snapshot inputs
|
||||
* output must match prior results (or emit a deterministic mismatch report)
|
||||
* **Export/import**:
|
||||
|
||||
* portable bundle format
|
||||
* import verifies integrity and signatures before allowing use
|
||||
* **Retention controls**:
|
||||
|
||||
* configurable retention windows and storage quotas
|
||||
* deduplication and garbage collection
|
||||
|
||||
### Should
|
||||
|
||||
* **Partial snapshots** (reference-only) vs **full snapshots** (content included), with explicit replay guarantees.
|
||||
* **Diff views**: compare two snapshots and highlight what knowledge changed.
|
||||
* **Multi-snapshot replay**: run “as-of snapshot A” and “as-of snapshot B” to show drift impact.
|
||||
|
||||
### Could
|
||||
|
||||
* Snapshot “federation” for large orgs (mirrors/replication with policy controls).
|
||||
* Snapshot “pinning” to releases or environments as a governance policy.
|
||||
|
||||
---
|
||||
|
||||
## 7) UX and workflow guidelines (PM + Eng)
|
||||
|
||||
### UI must communicate three states clearly
|
||||
|
||||
1. **Reproducible offline**: snapshot includes all required content.
|
||||
2. **Reproducible with access**: snapshot references external sources that must be available.
|
||||
3. **Not reproducible**: missing content or unsupported evaluator version.
|
||||
|
||||
### Required UI objects
|
||||
|
||||
* **Snapshot Details page**
|
||||
|
||||
* snapshot ID and signature status
|
||||
* list of knowledge sources (name, version/epoch, digest, size)
|
||||
* policy bundle version, scoring rules version
|
||||
* trust anchors + verification policy digest
|
||||
* replay status: “verified reproducible / reproducible / not reproducible”
|
||||
* **Verdict page**
|
||||
|
||||
* links to snapshot(s)
|
||||
* “replay now” action
|
||||
* “compare to latest knowledge” action
|
||||
|
||||
### UX guardrails
|
||||
|
||||
* Never show “pass/fail” without also showing:
|
||||
|
||||
* snapshot ID
|
||||
* policy ID/version
|
||||
* verification status
|
||||
* When results differ on replay, show:
|
||||
|
||||
* exact mismatch class (engine mismatch, missing data, nondeterminism, corrupted snapshot)
|
||||
* what input changed (if known)
|
||||
* remediation steps
|
||||
|
||||
---
|
||||
|
||||
## 8) Data model and format guidelines (Development Managers)
|
||||
|
||||
### Canonical objects (recommended minimum set)
|
||||
|
||||
* **KnowledgeSnapshotManifest (KSM)**
|
||||
* **KnowledgeBlob** (content-addressed bytes)
|
||||
* **KnowledgeSourceDescriptor**
|
||||
* **PolicyBundle**
|
||||
* **TrustBundle**
|
||||
* **Verdict** (signed decision artifact)
|
||||
* **ReplayReport** (records replay result and mismatches)
|
||||
|
||||
### Content addressing
|
||||
|
||||
* Use a stable hash (e.g., SHA‑256) for:
|
||||
|
||||
* each knowledge blob
|
||||
* manifest
|
||||
* policy bundle
|
||||
* trust bundle
|
||||
* Snapshot ID should be derived from manifest digest.
|
||||
|
||||
### Example manifest shape (illustrative)
|
||||
|
||||
```json
|
||||
{
|
||||
"snapshot_id": "ksm:sha256:…",
|
||||
"created_at": "2025-12-19T10:15:30Z",
|
||||
"engine": { "name": "stella-evaluator", "version": "1.7.0", "build": "…"},
|
||||
"plugins": [
|
||||
{ "name": "pkg-id", "version": "2.3.1", "digest": "sha256:…" }
|
||||
],
|
||||
"policy": { "bundle_id": "pol:sha256:…", "digest": "sha256:…" },
|
||||
"scoring": { "ruleset_id": "score:sha256:…", "digest": "sha256:…" },
|
||||
"trust": { "bundle_id": "trust:sha256:…", "digest": "sha256:…" },
|
||||
"sources": [
|
||||
{
|
||||
"name": "nvd",
|
||||
"epoch": "2025-12-18",
|
||||
"kind": "vuln_feed",
|
||||
"content_digest": "sha256:…",
|
||||
"licenses": ["…"],
|
||||
"origin": { "uri": "…", "retrieved_at": "…" }
|
||||
},
|
||||
{
|
||||
"name": "customer-vex",
|
||||
"kind": "vex",
|
||||
"content_digest": "sha256:…"
|
||||
}
|
||||
],
|
||||
"environment": {
|
||||
"determinism_profile": "strict",
|
||||
"timezone": "UTC",
|
||||
"normalization": { "line_endings": "LF", "sort_order": "canonical" }
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Versioning rules
|
||||
|
||||
* Every object is immutable once written.
|
||||
* Changes create new digests; never mutate in place.
|
||||
* Support schema evolution via:
|
||||
|
||||
* `schema_version`
|
||||
* strict validation + migration tooling
|
||||
* Keep manifests small; store large data as blobs.
|
||||
|
||||
---
|
||||
|
||||
## 9) Determinism contract (Engineering must enforce)
|
||||
|
||||
### Determinism requirements
|
||||
|
||||
* Stable ordering: sort inputs and outputs canonically.
|
||||
* Stable timestamps: timestamps may exist but must not change computed scores/verdict.
|
||||
* Stable randomization: no RNG; if unavoidable, fixed seed recorded in snapshot.
|
||||
* Stable parsers: parser versions are pinned by digest; parsing must be deterministic.
|
||||
|
||||
### Allowed nondeterminism (if any) must be explicit
|
||||
|
||||
If you must allow nondeterminism, it must be:
|
||||
|
||||
* documented,
|
||||
* surfaced in UI,
|
||||
* included in replay report as “non-deterministic factor,”
|
||||
* and excluded from the signed decision if it affects pass/fail.
|
||||
|
||||
---
|
||||
|
||||
## 10) Security model (Development Managers)
|
||||
|
||||
### Threats this feature must address
|
||||
|
||||
* Feed poisoning (tampered vulnerability data)
|
||||
* Time-of-check/time-of-use drift (same artifact evaluated against moving feeds)
|
||||
* Replay manipulation (swap snapshot content)
|
||||
* “Policy drift hiding” (claiming old decision used different policies)
|
||||
* Signature bypass (trust anchors altered)
|
||||
|
||||
### Controls required
|
||||
|
||||
* Sign manifests and verdicts.
|
||||
* Bind verdict → snapshot ID → policy bundle hash → trust bundle hash.
|
||||
* Verify on every import and on every replay invocation.
|
||||
* Audit log:
|
||||
|
||||
* snapshot created
|
||||
* snapshot imported
|
||||
* replay executed
|
||||
* verification failures
|
||||
|
||||
### Key handling
|
||||
|
||||
* Decide and document:
|
||||
|
||||
* who signs snapshots/verdicts (service keys vs tenant keys)
|
||||
* rotation policy
|
||||
* revocation/compromise handling
|
||||
* Avoid designing cryptography from scratch; use well-established signing formats and separation of duties.
|
||||
|
||||
---
|
||||
|
||||
## 11) Offline / air‑gapped requirements
|
||||
|
||||
### Snapshot levels (PM packaging guideline)
|
||||
|
||||
Offer explicit snapshot types with clear guarantees:
|
||||
|
||||
* **Level A: Reference-only snapshot**
|
||||
|
||||
* stores hashes + source descriptors
|
||||
* replay requires access to original sources
|
||||
* **Level B: Portable snapshot**
|
||||
|
||||
* includes blobs necessary for replay
|
||||
* replay works offline
|
||||
* **Level C: Sealed portable snapshot**
|
||||
|
||||
* portable + signed + includes trust anchors
|
||||
* replay works offline and can be verified independently
|
||||
|
||||
Do not market air‑gap support without specifying which level is provided.
|
||||
|
||||
---
|
||||
|
||||
## 12) Performance and storage guidelines
|
||||
|
||||
### Principles
|
||||
|
||||
* Content-address knowledge blobs to maximize deduplication.
|
||||
* Separate “hot” knowledge (recent epochs) from cold storage.
|
||||
* Support snapshot compaction and garbage collection.
|
||||
|
||||
### Operational requirements
|
||||
|
||||
* Retention policies per tenant/project/environment.
|
||||
* Quotas and alerting when snapshot storage approaches limits.
|
||||
* Export bundles should be chunked/streamable for large feeds.
|
||||
|
||||
---
|
||||
|
||||
## 13) Testing and acceptance criteria
|
||||
|
||||
### Required test categories
|
||||
|
||||
1. **Golden replay tests**
|
||||
|
||||
* same artifact + same snapshot → identical outputs
|
||||
2. **Corruption tests**
|
||||
|
||||
* bit flips in blobs/manifests are detected and rejected
|
||||
3. **Version skew tests**
|
||||
|
||||
* old snapshot + new engine should either replay deterministically or fail with a clear incompatibility report
|
||||
4. **Air‑gap tests**
|
||||
|
||||
* export → import → replay without network access
|
||||
5. **Diff accuracy tests**
|
||||
|
||||
* compare snapshots and ensure the diff identifies actual knowledge changes, not noise
|
||||
|
||||
### Definition of Done (DoD) for the feature
|
||||
|
||||
* Snapshots are created automatically according to policy.
|
||||
* Snapshots can be exported and imported with verified integrity.
|
||||
* Replay produces matching verdicts for a representative corpus.
|
||||
* UI exposes snapshot provenance and replay status.
|
||||
* Audit log records snapshot lifecycle events.
|
||||
* Clear failure modes exist (missing blobs, incompatible engine, signature failure).
|
||||
|
||||
---
|
||||
|
||||
## 14) Metrics (PM ownership)
|
||||
|
||||
Track metrics that prove this is a moat, not a checkbox.
|
||||
|
||||
### Core KPIs
|
||||
|
||||
* **Replay success rate** (strict determinism)
|
||||
* **Time to explain drift** (median time from “why changed” to root cause)
|
||||
* **% verdicts with sealed portable snapshots**
|
||||
* **Audit effort reduction** (customer-reported or measured via workflow steps)
|
||||
* **Storage efficiency** (dedup ratio; bytes per snapshot over time)
|
||||
|
||||
### Guardrail metrics
|
||||
|
||||
* Snapshot creation latency impact on CI
|
||||
* Snapshot storage growth per tenant
|
||||
* Verification failure rates
|
||||
|
||||
---
|
||||
|
||||
## 15) Common failure modes (what to prevent)
|
||||
|
||||
1. Treating snapshots as “metadata only” and still claiming replayability.
|
||||
2. Allowing “latest feed fetch” during replay (breaks the promise).
|
||||
3. Not pinning parser/policy/scoring versions—causes silent drift.
|
||||
4. Missing clear UX around replay limitations and failure reasons.
|
||||
5. Overcapturing sensitive inputs (privacy and customer trust risk).
|
||||
6. Underinvesting in dedup/retention (cost blowups).
|
||||
|
||||
---
|
||||
|
||||
## 16) Management checklists
|
||||
|
||||
### PM checklist (before commitment)
|
||||
|
||||
* Precisely define “replay” guarantee level (A/B/C) for each SKU/environment.
|
||||
* Define which inputs are in scope (feeds, VEX, policies, trust bundles, plugins).
|
||||
* Define customer-facing workflows:
|
||||
|
||||
* “replay now”
|
||||
* “compare to latest”
|
||||
* “export for audit / air-gap”
|
||||
* Confirm governance outcomes:
|
||||
|
||||
* audit pack integration
|
||||
* exception linkage
|
||||
* release gate linkage
|
||||
|
||||
### Development Manager checklist (before build)
|
||||
|
||||
* Establish canonical schemas and versioning plan.
|
||||
* Establish content-addressed storage + dedup plan.
|
||||
* Establish signing and trust anchor strategy.
|
||||
* Establish deterministic evaluation contract and test harness.
|
||||
* Establish import/export packaging and verification.
|
||||
* Establish retention, quotas, and GC.
|
||||
|
||||
---
|
||||
|
||||
## 17) Minimal phased delivery (recommended)
|
||||
|
||||
**Phase 1: Reference snapshot + verdict binding**
|
||||
|
||||
* Record source descriptors + hashes, policy/scoring/trust digests.
|
||||
* Bind snapshot ID into verdict artifacts.
|
||||
|
||||
**Phase 2: Portable snapshots**
|
||||
|
||||
* Store knowledge blobs locally with dedup.
|
||||
* Export/import with integrity verification.
|
||||
|
||||
**Phase 3: Sealed portable snapshots + replay tooling**
|
||||
|
||||
* Sign snapshots.
|
||||
* Deterministic replay pipeline + replay report.
|
||||
* UI surfacing and audit logs.
|
||||
|
||||
**Phase 4: Snapshot diff + drift explainability**
|
||||
|
||||
* Compare snapshots.
|
||||
* Attribute decision drift to knowledge changes vs artifact changes.
|
||||
|
||||
---
|
||||
|
||||
If you want this turned into an internal PRD template, I can rewrite it into a structured PRD format with: objectives, user stories, functional requirements, non-functional requirements, security/compliance, dependencies, risks, and acceptance tests—ready for Jira/Linear epics and engineering design review.
|
||||
@@ -0,0 +1,497 @@
|
||||
## Stella Ops Guidelines
|
||||
|
||||
### Risk Budgets and Diff-Aware Release Gates
|
||||
|
||||
**Audience:** Product Managers (PMs) and Development Managers (DMs)
|
||||
**Applies to:** All customer-impacting software and configuration changes shipped by Stella Ops (code, infrastructure-as-code, runtime config, feature flags, data migrations, dependency upgrades).
|
||||
|
||||
---
|
||||
|
||||
## 1) What we are optimizing for
|
||||
|
||||
Stella Ops ships quickly **without** letting change-driven incidents, security regressions, or data integrity failures become the hidden cost of “speed.”
|
||||
|
||||
These guidelines enforce two linked controls:
|
||||
|
||||
1. **Risk Budgets** — a quantitative “capacity to take risk” that prevents reliability and trust from being silently depleted.
|
||||
2. **Diff-Aware Release Gates** — release checks whose strictness scales with *what changed* (the diff), not with generic process.
|
||||
|
||||
Together they let us move fast on low-risk diffs and slow down only when the change warrants it.
|
||||
|
||||
---
|
||||
|
||||
## 2) Non-negotiable principles
|
||||
|
||||
1. **All changes are risk-bearing** (even “small” diffs). We quantify and route them accordingly.
|
||||
2. **Risk is managed at the product/service boundary** (each service has its own budget and gating profile).
|
||||
3. **Automation first, approvals last**. Humans review what automation cannot reliably verify.
|
||||
4. **Blast radius is a first-class variable**. A safe rollout beats a perfect code review.
|
||||
5. **Exceptions are allowed but never free**. Every bypass is logged, justified, and paid back via budget reduction and follow-up controls.
|
||||
|
||||
---
|
||||
|
||||
## 3) Definitions
|
||||
|
||||
### 3.1 Risk Budget (what it is)
|
||||
|
||||
A **Risk Budget** is the amount of change-risk a product/service is allowed to take over a defined window (typically a sprint or month) **without increasing the probability of customer harm beyond the agreed tolerance**.
|
||||
|
||||
It is a management control, not a theoretical score.
|
||||
|
||||
### 3.2 Risk Budget vs. Error Budget (important distinction)
|
||||
|
||||
* **Error Budget** (classic SRE): backward-looking tolerance for *actual* unreliability vs. SLO.
|
||||
* **Risk Budget** (this policy): forward-looking tolerance for *change risk* before shipping.
|
||||
|
||||
They interact:
|
||||
|
||||
* If error budget is burned (service is unstable), risk budget is automatically constrained.
|
||||
* If risk budget is low, release gates tighten by policy.
|
||||
|
||||
### 3.3 Diff-aware release gates (what it is)
|
||||
|
||||
A **release gate** is a set of required checks (tests, scans, reviews, rollout controls) that must pass before a change can progress.
|
||||
**Diff-aware** means the gate level is determined by:
|
||||
|
||||
* what changed (diff classification),
|
||||
* where it changed (criticality),
|
||||
* how it ships (blast radius controls),
|
||||
* and current operational context (incidents, SLO health, budget remaining).
|
||||
|
||||
---
|
||||
|
||||
## 4) Roles and accountability
|
||||
|
||||
### Product Manager (PM) — accountable for risk appetite
|
||||
|
||||
PM responsibilities:
|
||||
|
||||
* Define product-level risk tolerance with stakeholders (customer impact tolerance, regulatory constraints).
|
||||
* Approve the **Risk Budget Policy settings** for their product/service tier (criticality level, default gates).
|
||||
* Prioritize reliability work when budgets are constrained.
|
||||
* Own customer communications for degraded service or risk-driven release deferrals.
|
||||
|
||||
### Development Manager (DM) — accountable for enforcement and engineering hygiene
|
||||
|
||||
DM responsibilities:
|
||||
|
||||
* Ensure pipelines implement diff classification and enforce gates.
|
||||
* Ensure tests, telemetry, rollout mechanisms, and rollback procedures exist and are maintained.
|
||||
* Ensure “exceptions” process is real (logged, postmortemed, paid back).
|
||||
* Own staffing/rotation decisions to ensure safe releases (on-call readiness, release captains).
|
||||
|
||||
### Shared responsibilities
|
||||
|
||||
PM + DM jointly:
|
||||
|
||||
* Review risk budget status weekly.
|
||||
* Resolve trade-offs: feature velocity vs. reliability/security work.
|
||||
* Approve gate profile changes (tighten/loosen) based on evidence.
|
||||
|
||||
---
|
||||
|
||||
## 5) Risk Budgets
|
||||
|
||||
### 5.1 Establish service tiers (criticality)
|
||||
|
||||
Each service/product component must be assigned a **Criticality Tier**:
|
||||
|
||||
* **Tier 0 – Internal only** (no external customers; low business impact)
|
||||
* **Tier 1 – Customer-facing non-critical** (degradation tolerated; limited blast radius)
|
||||
* **Tier 2 – Customer-facing critical** (core workflows; meaningful revenue/trust impact)
|
||||
* **Tier 3 – Safety/financial/data-critical** (payments, auth, permissions, PII, regulated workflows)
|
||||
|
||||
Tier drives default budgets and minimum gates.
|
||||
|
||||
### 5.2 Choose a budget window and units
|
||||
|
||||
**Window:** default to **monthly** with weekly tracking; optionally sprint-based if release cadence is sprint-coupled.
|
||||
**Units:** use **Risk Points (RP)** — consumed by each change. (Do not overcomplicate at first; tune with data.)
|
||||
|
||||
Recommended initial monthly budgets (adjust after 2–3 cycles with evidence):
|
||||
|
||||
* Tier 0: 300 RP/month
|
||||
* Tier 1: 200 RP/month
|
||||
* Tier 2: 120 RP/month
|
||||
* Tier 3: 80 RP/month
|
||||
|
||||
> Interpretation: Tier 3 ships fewer “risky” changes; it can still ship frequently, but changes must be decomposed into low-risk diffs and shipped with strong controls.
|
||||
|
||||
### 5.3 Risk Point scoring (how changes consume budget)
|
||||
|
||||
Every change gets a **Release Risk Score (RRS)** in RP.
|
||||
|
||||
A practical baseline model:
|
||||
|
||||
**RRS = Base(criticality) + Diff Risk + Operational Context – Mitigations**
|
||||
|
||||
**Base (criticality):**
|
||||
|
||||
* Tier 0: +1
|
||||
* Tier 1: +3
|
||||
* Tier 2: +6
|
||||
* Tier 3: +10
|
||||
|
||||
**Diff Risk (additive):**
|
||||
|
||||
* +1: docs, comments, non-executed code paths, telemetry-only additions
|
||||
* +3: UI changes, non-core logic changes, refactors with high test coverage
|
||||
* +6: API contract changes, dependency upgrades, medium-complexity logic in a core path
|
||||
* +10: database schema migrations, auth/permission logic, data retention/PII handling
|
||||
* +15: infra/networking changes, encryption/key handling, payment flows, queue semantics changes
|
||||
|
||||
**Operational Context (additive):**
|
||||
|
||||
* +5: service currently in incident or had Sev1/Sev2 in last 7 days
|
||||
* +3: error budget < 50% remaining
|
||||
* +2: on-call load high (paging above normal baseline)
|
||||
* +5: release during restricted windows (holidays/freeze) via exception
|
||||
|
||||
**Mitigations (subtract):**
|
||||
|
||||
* –3: feature flag with staged rollout + instant kill switch verified
|
||||
* –3: canary + automated health gates + rollback tested in last 30 days
|
||||
* –2: high-confidence integration coverage for touched components
|
||||
* –2: no data migration OR backward-compatible migration with proven rollback
|
||||
* –2: change isolated behind permission boundary / limited cohort
|
||||
|
||||
**Minimum RRS floor:** never below 1 RP.
|
||||
|
||||
DM is responsible for making sure the pipeline can calculate a *default* RRS automatically and require humans only for edge cases.
|
||||
|
||||
### 5.4 Budget operating rules
|
||||
|
||||
**Budget ledger:** Maintain a per-service ledger:
|
||||
|
||||
* Budget allocated for the window
|
||||
* RP consumed per release
|
||||
* RP remaining
|
||||
* Trendline (projected depletion date)
|
||||
* Exceptions (break-glass releases)
|
||||
|
||||
**Control thresholds:**
|
||||
|
||||
* **Green (≥60% remaining):** normal operation
|
||||
* **Yellow (30–59%):** additional caution; gates tighten by 1 level for medium/high-risk diffs
|
||||
* **Red (<30%):** freeze high-risk diffs; allow only low-risk changes or reliability/security work
|
||||
* **Exhausted (≤0%):** releases restricted to incident fixes, security fixes, and rollback-only, with tightened gates and explicit sign-off
|
||||
|
||||
### 5.5 What to do when budget is low (expected behavior)
|
||||
|
||||
When Yellow/Red:
|
||||
|
||||
* PM shifts roadmap execution toward:
|
||||
|
||||
* reliability work, defect burn-down,
|
||||
* decomposing large changes into smaller, reversible diffs,
|
||||
* reducing scope of risky features.
|
||||
* DM enforces:
|
||||
|
||||
* smaller diffs,
|
||||
* increased feature flagging,
|
||||
* staged rollout requirements,
|
||||
* improved test/observability coverage.
|
||||
|
||||
Budget constraints are a signal, not a punishment.
|
||||
|
||||
### 5.6 Budget replenishment and incentives
|
||||
|
||||
Budgets replenish on the window boundary, but we also allow **earned capacity**:
|
||||
|
||||
* If a service improves change failure rate and MTTR for 2 consecutive windows, it may earn:
|
||||
|
||||
* +10–20% budget increase **or**
|
||||
* one gate level relaxation for specific change categories
|
||||
|
||||
This must be evidence-driven (metrics, not opinions).
|
||||
|
||||
---
|
||||
|
||||
## 6) Diff-Aware Release Gates
|
||||
|
||||
### 6.1 Diff classification (what the pipeline must detect)
|
||||
|
||||
At minimum, automatically classify diffs into these categories:
|
||||
|
||||
**Code scope**
|
||||
|
||||
* Executable code vs docs-only
|
||||
* Core vs non-core modules (define module ownership boundaries)
|
||||
* Hot paths (latency-sensitive), correctness-sensitive paths
|
||||
|
||||
**Data scope**
|
||||
|
||||
* Schema migration (additive vs breaking)
|
||||
* Backfill jobs / batch jobs
|
||||
* Data model changes impacting downstream consumers
|
||||
* PII / regulated data touchpoints
|
||||
|
||||
**Security scope**
|
||||
|
||||
* Authn/authz logic
|
||||
* Permission checks
|
||||
* Secrets, key handling, encryption changes
|
||||
* Dependency changes with known CVEs
|
||||
|
||||
**Infra scope**
|
||||
|
||||
* IaC changes, networking, load balancer, DNS, autoscaling
|
||||
* Runtime config changes (feature flags, limits, thresholds)
|
||||
* Queue/topic changes, retention settings
|
||||
|
||||
**Interface scope**
|
||||
|
||||
* Public API contract changes
|
||||
* Backward compatibility of payloads/events
|
||||
* Client version dependency
|
||||
|
||||
### 6.2 Gate levels
|
||||
|
||||
Define **Gate Levels G0–G4**. The pipeline assigns one based on diff + context + budget.
|
||||
|
||||
#### G0 — No-risk / administrative
|
||||
|
||||
Use for:
|
||||
|
||||
* docs-only, comments-only, non-functional metadata
|
||||
|
||||
Requirements:
|
||||
|
||||
* Lint/format checks
|
||||
* Basic CI pass (build)
|
||||
|
||||
#### G1 — Low risk
|
||||
|
||||
Use for:
|
||||
|
||||
* small, localized code changes with strong unit coverage
|
||||
* non-core UI changes
|
||||
* telemetry additions (no removal)
|
||||
|
||||
Requirements:
|
||||
|
||||
* All automated unit tests
|
||||
* Static analysis/linting
|
||||
* 1 peer review (code owner not required if outside critical modules)
|
||||
* Automated deploy to staging
|
||||
* Post-deploy smoke checks
|
||||
|
||||
#### G2 — Moderate risk
|
||||
|
||||
Use for:
|
||||
|
||||
* moderate logic changes in customer-facing paths
|
||||
* dependency upgrades
|
||||
* API changes that are backward compatible
|
||||
* config changes affecting behavior
|
||||
|
||||
Requirements:
|
||||
|
||||
* G1 +
|
||||
* Integration tests relevant to impacted modules
|
||||
* Code owner review for touched modules
|
||||
* Feature flag required if customer impact possible
|
||||
* Staged rollout: canary or small cohort
|
||||
* Rollback plan documented in PR
|
||||
|
||||
#### G3 — High risk
|
||||
|
||||
Use for:
|
||||
|
||||
* schema migrations
|
||||
* auth/permission changes
|
||||
* core business logic in critical flows
|
||||
* infra changes affecting availability
|
||||
* non-trivial concurrency/queue semantics changes
|
||||
|
||||
Requirements:
|
||||
|
||||
* G2 +
|
||||
* Security scan + dependency audit (must pass, exceptions logged)
|
||||
* Migration plan (forward + rollback) reviewed
|
||||
* Load/performance checks if in hot path
|
||||
* Observability: new/updated dashboards/alerts for the change
|
||||
* Release captain / on-call sign-off (someone accountable live)
|
||||
* Progressive delivery with automatic health gates (error rate/latency)
|
||||
|
||||
#### G4 — Very high risk / safety-critical / budget-constrained releases
|
||||
|
||||
Use for:
|
||||
|
||||
* Tier 3 critical systems with low budget remaining
|
||||
* changes during freeze windows via exception
|
||||
* broad blast radius changes (platform-wide)
|
||||
* remediation after major incident where recurrence risk is high
|
||||
|
||||
Requirements:
|
||||
|
||||
* G3 +
|
||||
* Formal risk review (PM+DM+Security/SRE) in writing
|
||||
* Explicit rollback rehearsal or prior proven rollback path
|
||||
* Extended canary period with success criteria and abort criteria
|
||||
* Customer comms plan if impact is plausible
|
||||
* Post-release verification checklist executed and logged
|
||||
|
||||
### 6.3 Gate selection logic (policy)
|
||||
|
||||
Default rule:
|
||||
|
||||
1. Compute **RRS** (Risk Points) from diff + context.
|
||||
2. Map RRS to default gate:
|
||||
|
||||
* 1–5 RP → G1
|
||||
* 6–12 RP → G2
|
||||
* 13–20 RP → G3
|
||||
* 21+ RP → G4
|
||||
3. Apply modifiers:
|
||||
|
||||
* If **budget Yellow**: escalate one gate for changes ≥ G2
|
||||
* If **budget Red**: escalate one gate for changes ≥ G1 and block high-risk categories unless exception
|
||||
* If active incident or error budget severely degraded: block non-fix releases by default
|
||||
|
||||
DM must ensure the pipeline enforces this mapping automatically.
|
||||
|
||||
### 6.4 “Diff-aware” also means “blast-radius aware”
|
||||
|
||||
If the diff is inherently risky, reduce risk operationally:
|
||||
|
||||
* feature flags with cohort controls
|
||||
* dark launches (ship code disabled)
|
||||
* canary deployments
|
||||
* blue/green with quick revert
|
||||
* backwards-compatible DB migrations (expand/contract pattern)
|
||||
* circuit breakers and rate limiting
|
||||
* progressive exposure by tenant / region / account segment
|
||||
|
||||
Large diffs are not “made safe” by more reviewers; they are made safe by **reversibility and containment**.
|
||||
|
||||
---
|
||||
|
||||
## 7) Exceptions (“break glass”) policy
|
||||
|
||||
Exceptions are permitted only when one of these is true:
|
||||
|
||||
* incident mitigation or customer harm prevention,
|
||||
* urgent security fix (actively exploited or high severity),
|
||||
* legal/compliance deadline.
|
||||
|
||||
**Requirements for any exception:**
|
||||
|
||||
* Recorded rationale in the PR/release ticket
|
||||
* Named approver(s): DM + on-call owner; PM for customer-impacting risk
|
||||
* Mandatory follow-up within 5 business days:
|
||||
|
||||
* post-incident or post-release review
|
||||
* remediation tasks created and prioritized
|
||||
* **Budget penalty:** subtract additional RP (e.g., +50% of the change’s RRS) to reflect unmanaged risk
|
||||
|
||||
Repeated exceptions are a governance failure and trigger gate tightening.
|
||||
|
||||
---
|
||||
|
||||
## 8) Operational metrics (what PMs and DMs must review)
|
||||
|
||||
Minimum weekly review dashboard per service:
|
||||
|
||||
* **Risk budget remaining** (RP and %)
|
||||
* **Deploy frequency**
|
||||
* **Change failure rate**
|
||||
* **MTTR**
|
||||
* **Sev1/Sev2 count** (rolling 30/90 days)
|
||||
* **SLO / error budget status**
|
||||
* **Gate compliance rate** (how often gates were bypassed)
|
||||
* **Diff size distribution** (are we shipping huge diffs?)
|
||||
* **Rollback frequency and time-to-rollback**
|
||||
|
||||
Policy expectation:
|
||||
|
||||
* If change failure rate or MTTR worsens materially over 2 windows, budgets tighten and gate mapping escalates until stability returns.
|
||||
|
||||
---
|
||||
|
||||
## 9) Practical operating cadence
|
||||
|
||||
### Weekly (PM + DM)
|
||||
|
||||
* Review budgets and trends
|
||||
* Identify upcoming high-risk releases and plan staged rollouts
|
||||
* Confirm staffing for release windows (release captain / on-call coverage)
|
||||
* Decide whether to defer, decompose, or harden changes
|
||||
|
||||
### Per release (DM-led, PM informed)
|
||||
|
||||
* Ensure correct gate level
|
||||
* Verify rollout + rollback readiness
|
||||
* Confirm monitoring/alerts exist and are watched during rollout
|
||||
* Execute post-release verification checklist
|
||||
|
||||
### Monthly (leadership)
|
||||
|
||||
* Adjust tier assignments if product criticality changed
|
||||
* Recalibrate budget numbers based on measured outcomes
|
||||
* Identify systemic causes: test gaps, observability gaps, deployment tooling gaps
|
||||
|
||||
---
|
||||
|
||||
## 10) Required templates (standardize execution)
|
||||
|
||||
### 10.1 Release Plan (required for G2+)
|
||||
|
||||
* What is changing (1–3 bullets)
|
||||
* Expected customer impact (or “none”)
|
||||
* Diff category flags (DB/auth/infra/API/etc.)
|
||||
* Rollout strategy (canary/cohort/blue-green)
|
||||
* Abort criteria (exact metrics/thresholds)
|
||||
* Rollback steps (exact commands/process)
|
||||
* Owners during rollout (names)
|
||||
|
||||
### 10.2 Migration Plan (required for schema/data changes)
|
||||
|
||||
* Migration type: additive / expand-contract / breaking (breaking is disallowed without explicit G4 approval)
|
||||
* Backfill approach and rate limits
|
||||
* Validation checks (row counts, invariants)
|
||||
* Rollback strategy (including data implications)
|
||||
|
||||
### 10.3 Post-release Verification Checklist (G1+)
|
||||
|
||||
* Smoke test results
|
||||
* Key dashboards checked (latency, error rate, saturation)
|
||||
* Alerts status
|
||||
* User-facing workflows validated (as applicable)
|
||||
* Ticket updated with outcome
|
||||
|
||||
---
|
||||
|
||||
## 11) What “good” looks like
|
||||
|
||||
* Low-risk diffs ship quickly with minimal ceremony (G0–G1).
|
||||
* High-risk diffs are decomposed and shipped progressively, not heroically.
|
||||
* Risk budgets are visible, used in planning, and treated as a real constraint.
|
||||
* Exceptions are rare and followed by concrete remediation.
|
||||
* Over time: deploy frequency stays high while change failure rate and MTTR decrease.
|
||||
|
||||
---
|
||||
|
||||
## 12) Immediate adoption checklist (first 30 days)
|
||||
|
||||
**DM deliverables**
|
||||
|
||||
* Implement diff classification in CI/CD (at least: DB/auth/infra/API/deps/config)
|
||||
* Implement automatic gate mapping and enforcement
|
||||
* Add “release plan” and “rollback plan” checks for G2+
|
||||
* Add logging for gate overrides
|
||||
|
||||
**PM deliverables**
|
||||
|
||||
* Confirm service tiering for owned areas
|
||||
* Approve initial monthly RP budgets
|
||||
* Add risk budget review to the weekly product/engineering ritual
|
||||
* Reprioritize work when budgets hit Yellow/Red (explicitly)
|
||||
|
||||
---
|
||||
|
||||
If you want, I can also provide:
|
||||
|
||||
* a concrete scoring worksheet (ready to paste into Confluence/Notion),
|
||||
* a CI/CD policy example (e.g., GitHub Actions / GitLab rules) that computes gate level from diff patterns,
|
||||
* and a one-page “Release Captain Runbook” aligned to G2–G4.
|
||||
Reference in New Issue
Block a user